
Denoising Diffusion Probabilistic Feature-Based Network for Cloud Removal in Sentinel-2 Imagery

Abstract
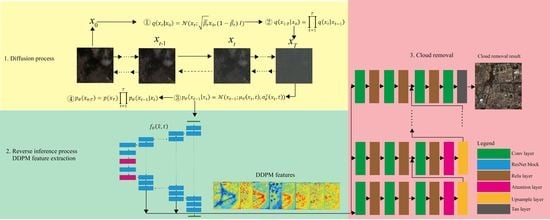
1. Introduction
- The proposed DDPM-CR network effectively retrieves missing information based on multilevel deep features, allowing for the reuse of cloud-contaminated images.
- The cloud-oriented loss function, which integrates the advantages of various loss functions, improves the performance and efficiency of network training.
2. DDPM-CR Architecture for Cloud Removal
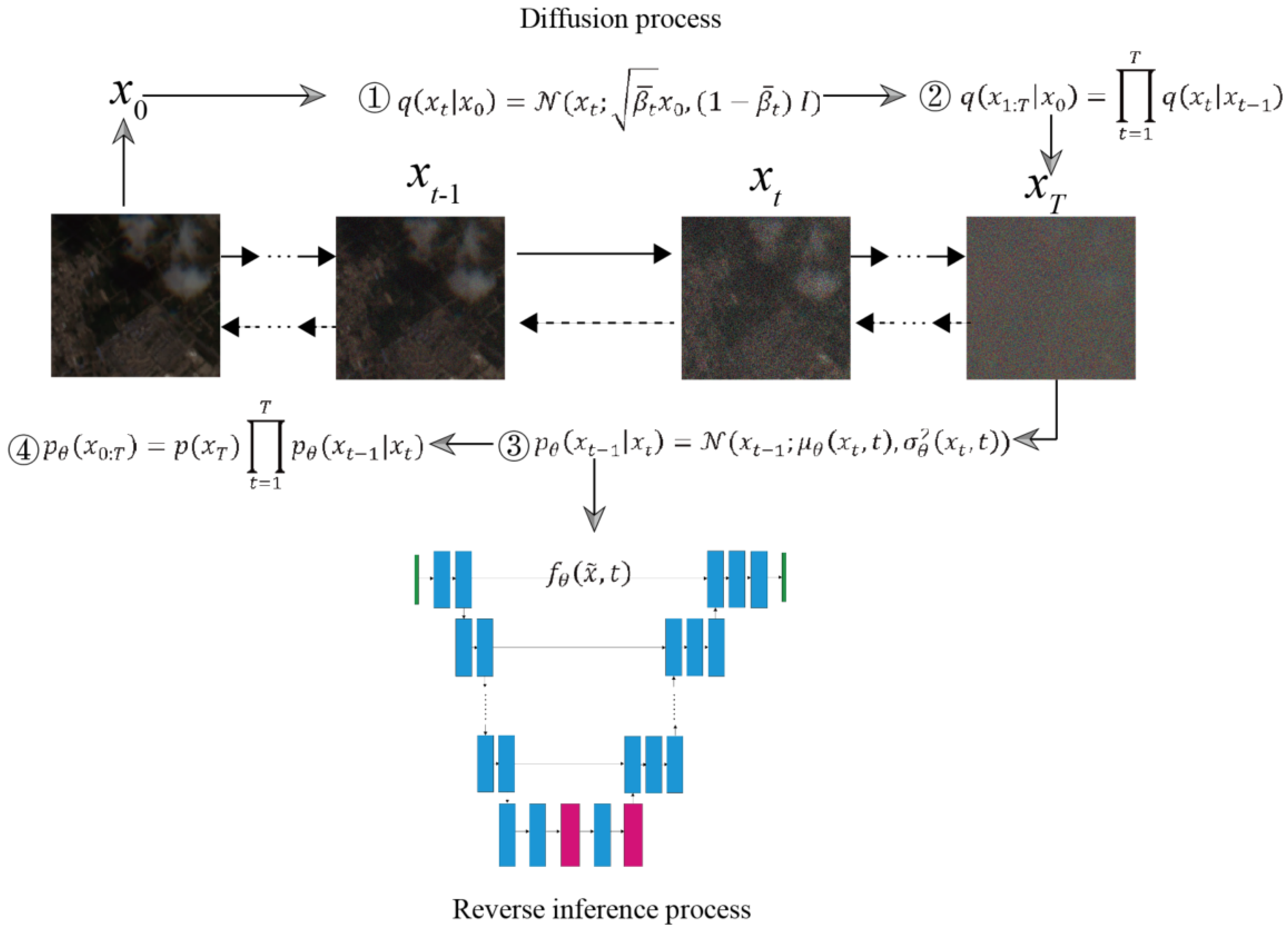
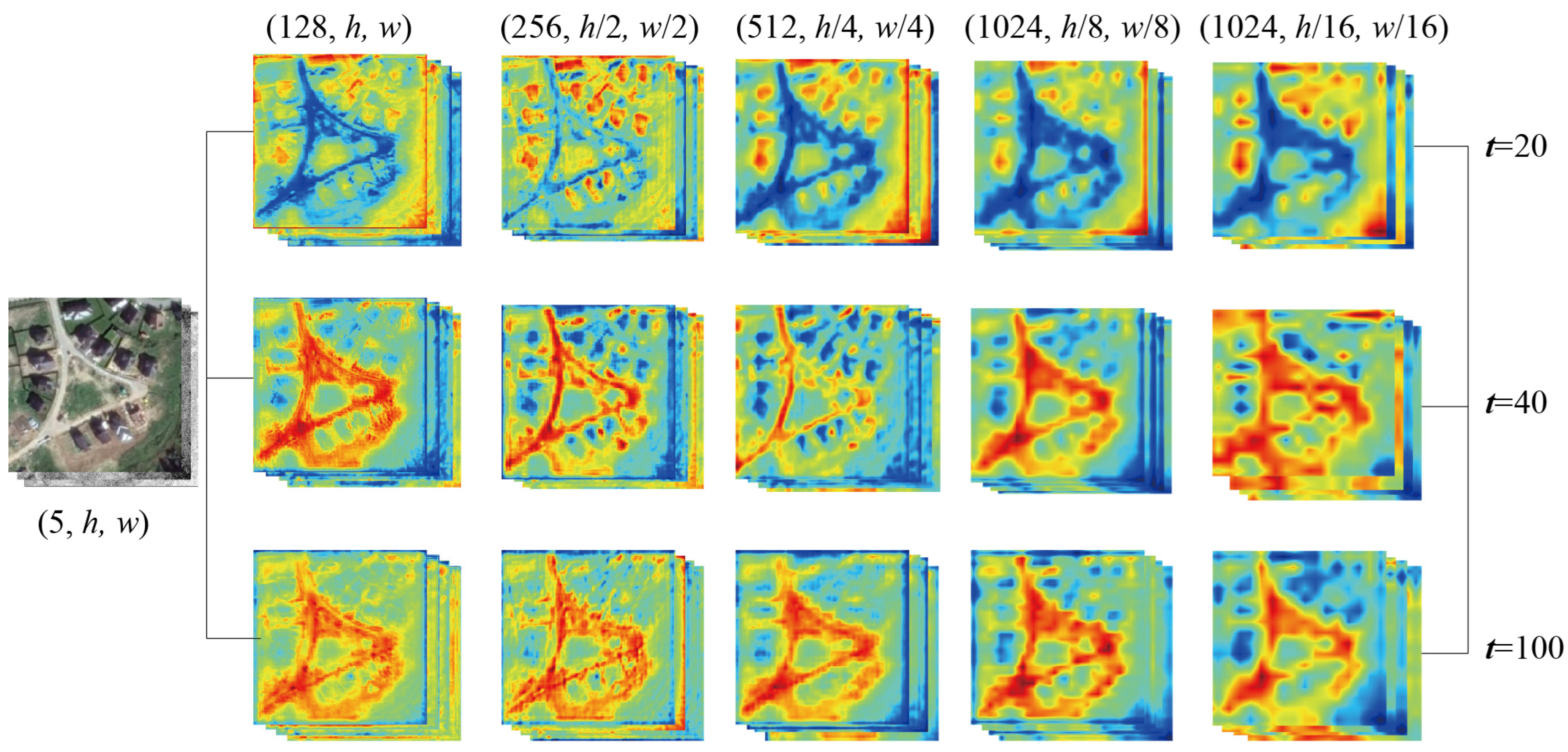
2.1. DDPM Features on Cloud Removal
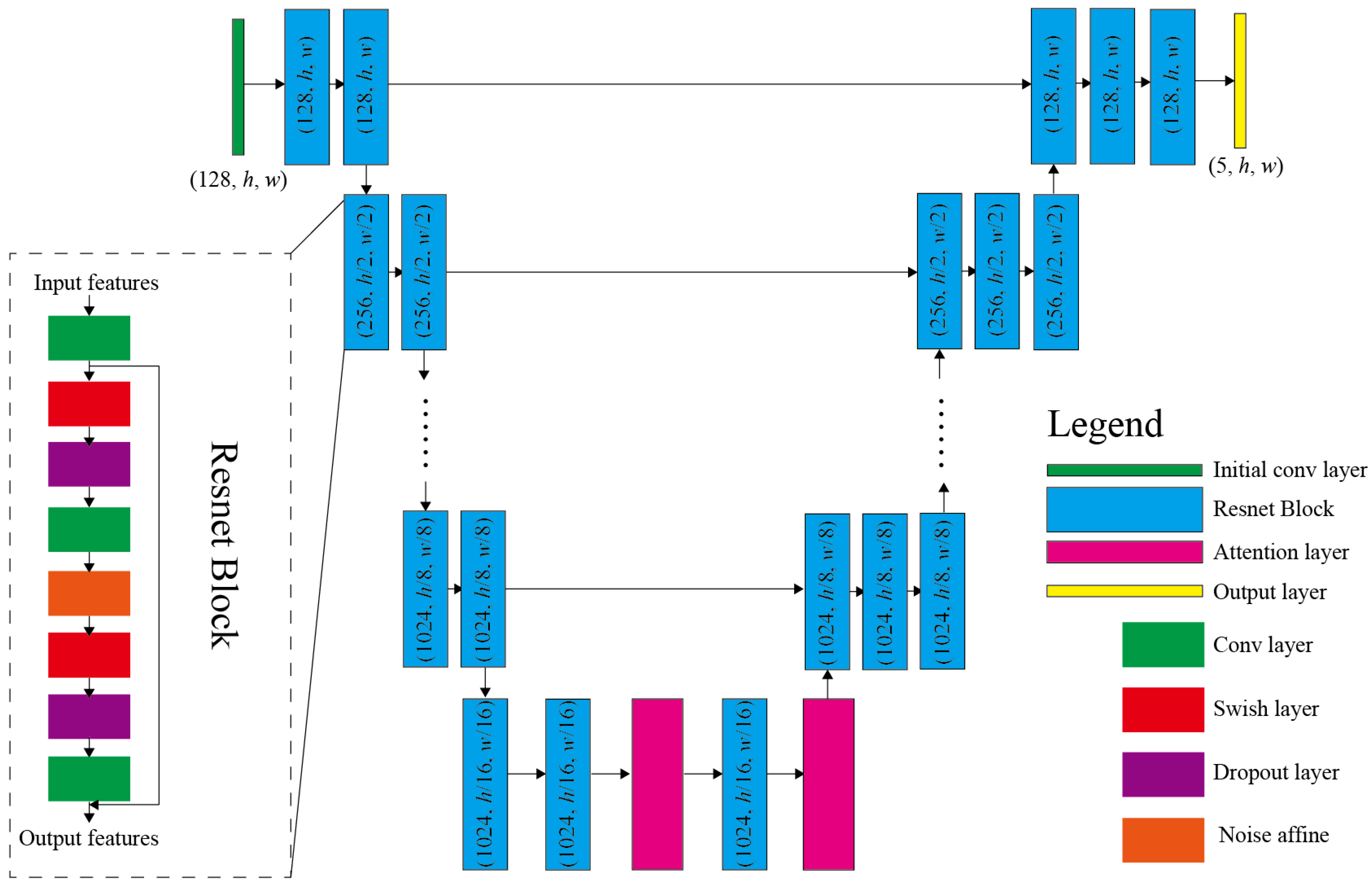
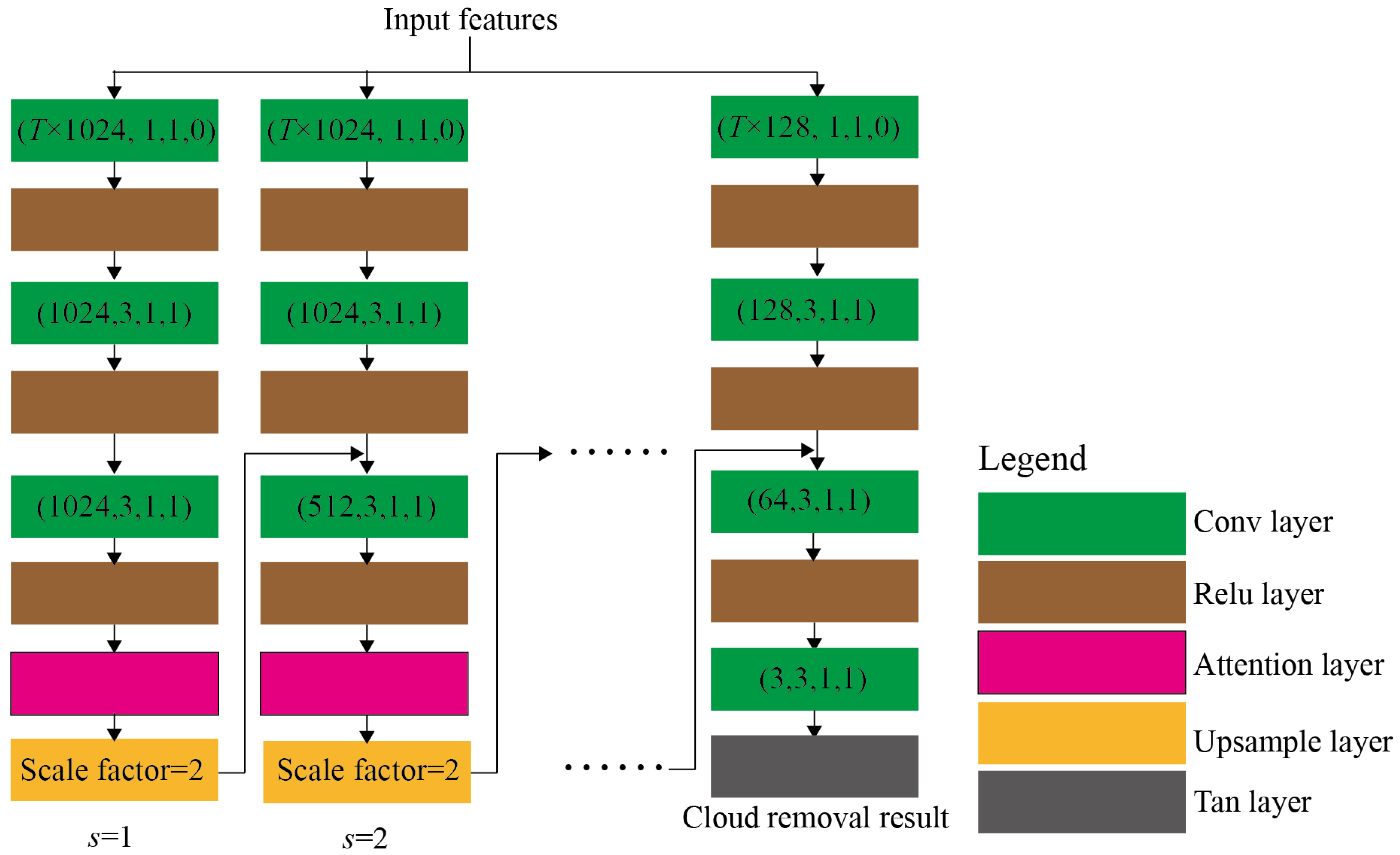
2.2. Cloud Removal Head
2.3. Cloud-Oriented Loss
2.4. Experimental Data and Training Details
- (1)
- Mean absolute error (MAE)
- (2)
- Root-mean-square error (RMSE)
- (3)
- Peak signal-to-noise ratio (PSNR)
- (4)
- Structural similarity (SSIM)
3. Experiments and Results
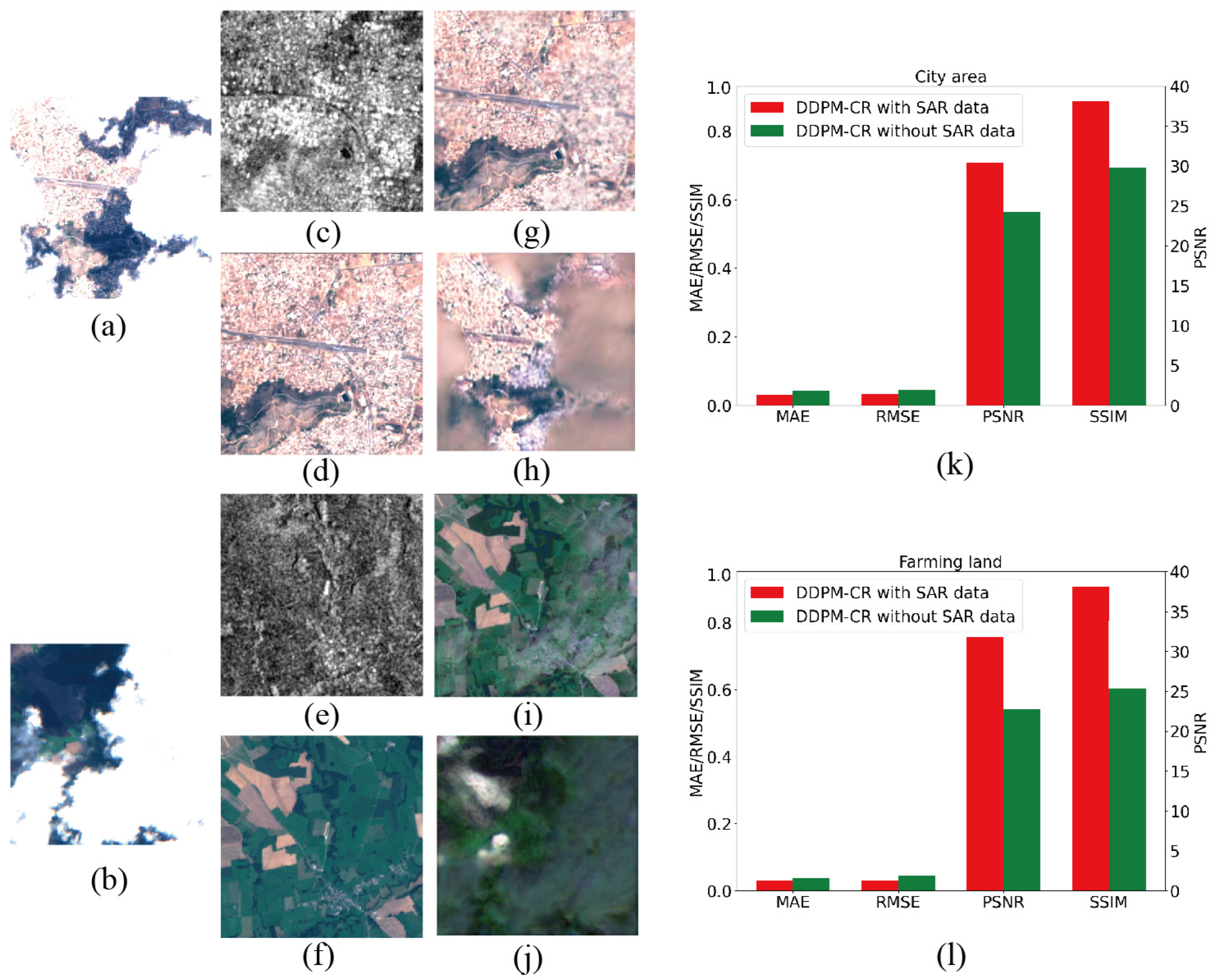
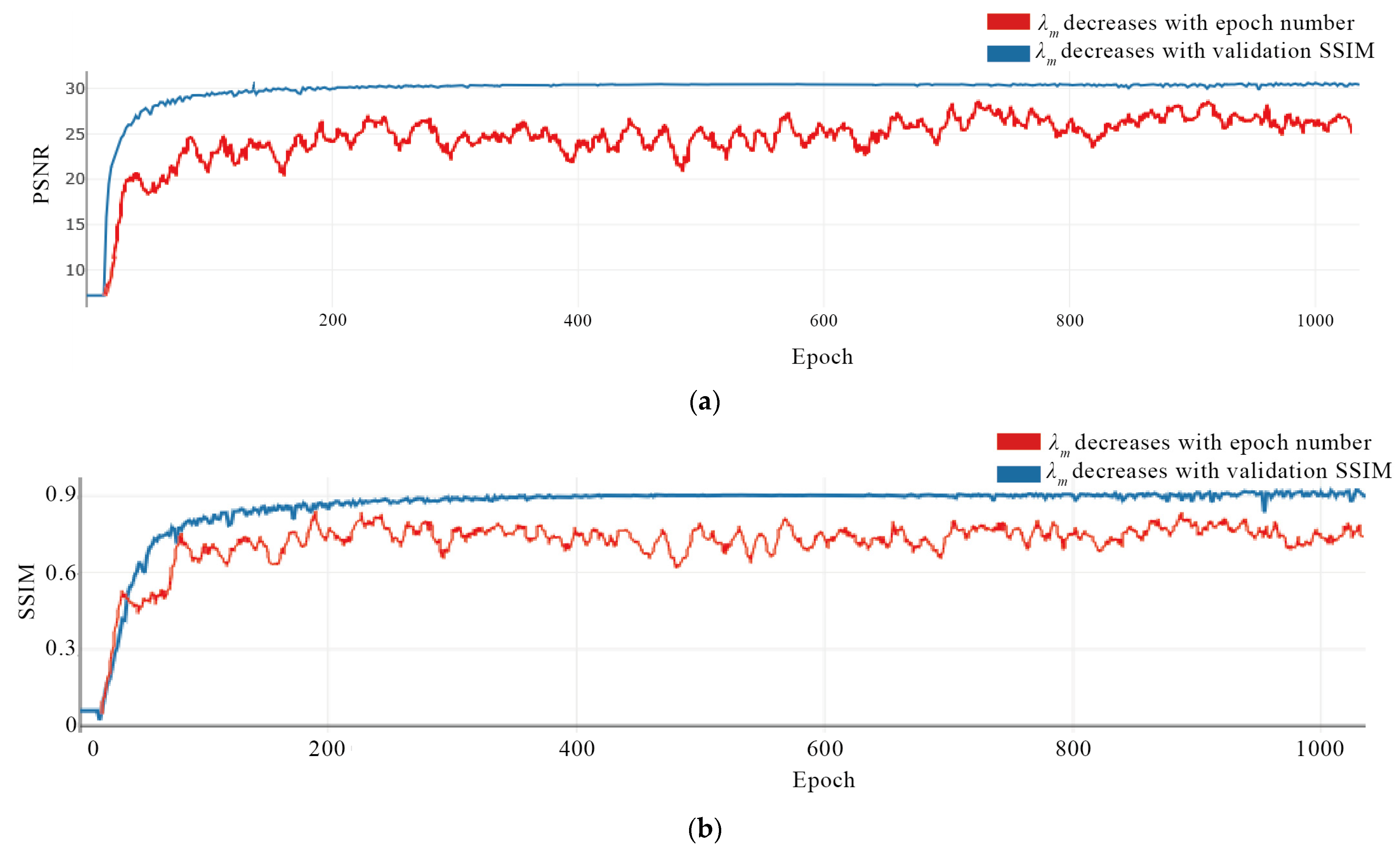
3.1. Ablation Study on SAR-Multispectral Multimodal Input Data
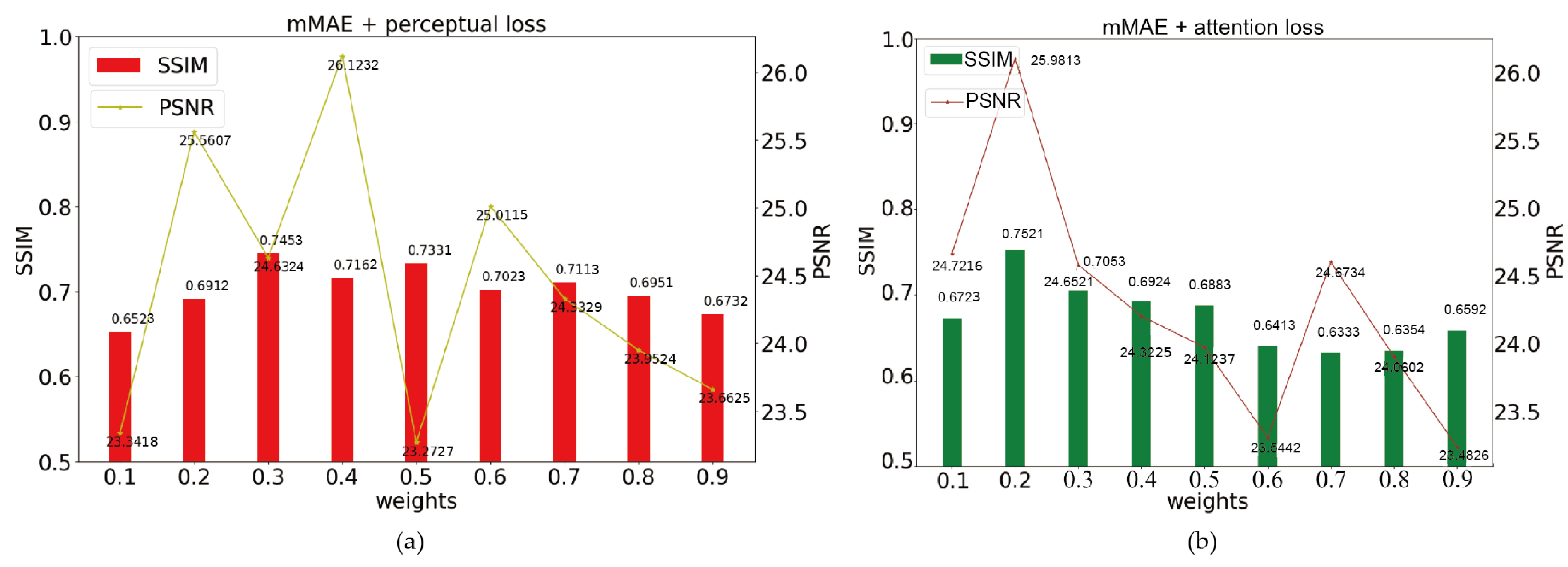
3.2. The Evaluation of Loss Functions on Cloud Removal
3.3. Comparative Experiments with Baseline Models
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Garioud, A.; Valero, S.; Giordano, S.; Mallet, C. Recurrent-based regression of Sentinel time series for continuous vegetation monitoring. Remote Sens. Environ. 2021, 263, 112419. [Google Scholar] [CrossRef]
- Yin, J.; Dong, J.; Hamm, N.A.; Li, Z.; Wang, J.; Xing, H.; Fu, P. Integrating remote sensing and geospatial big data for urban land use mapping: A review. Int. J. Appl. Earth Obs. Geoinf. 2021, 103, 102514. [Google Scholar] [CrossRef]
- Zhu, D.; Chen, T.; Wang, Z.; Niu, R. Detecting ecological spatial-temporal changes by remote sensing ecological index with local adaptability. J. Environ. Manag. 2021, 299, 113655. [Google Scholar] [CrossRef] [PubMed]
- King, M.D.; Platnick, S.; Menzel, W.P.; Ackerman, S.A.; Hubanks, P.A. Spatial and temporal distribution of clouds observed by MODIS onboard the Terra and Aqua satellites. IEEE Trans. Geosci. Remote Sens. 2013, 51, 3826–3852. [Google Scholar] [CrossRef]
- Shen, H.; Li, X.; Cheng, Q.; Zeng, C.; Yang, G.; Li, H.; Zhang, L. Missing information reconstruction of remote sensing data: A technical review. IEEE Geosci. Remote Sens. Mag. 2015, 3, 61–85. [Google Scholar] [CrossRef]
- Huang, B.; Li, Y.; Han, X.; Cui, Y.; Li, W.; Li, R. Cloud removal from optical satellite imagery with SAR imagery using sparse representation. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1046–1050. [Google Scholar] [CrossRef]
- Dong, C.; Menzel, L. Producing cloud-free MODIS snow cover products with conditional probability interpolation and meteorological data. Remote Sens. Environ. 2016, 186, 439–451. [Google Scholar] [CrossRef]
- Mendez-Rial, R.; Calvino-Cancela, M.; Martin-Herrero, J. Anisotropic inpainting of the hypercube. IEEE Geosci. Remote Sens. Lett. 2011, 9, 214–218. [Google Scholar] [CrossRef]
- Shen, H.; Zhang, L. A MAP-based algorithm for destriping and inpainting of remotely sensed images. IEEE Trans. Geosci. Remote Sens. 2008, 47, 1492–1502. [Google Scholar] [CrossRef]
- Chen, Y.; He, W.; Yokoya, N.; Huang, T.-Z. Blind cloud and cloud shadow removal of multitemporal images based on total variation regularized low-rank sparsity decomposition. ISPRS J. Photogramm. Remote Sens. 2019, 157, 93–107. [Google Scholar] [CrossRef]
- Li, Y.; Li, W.; Shen, C. Removal of optically thick clouds from high-resolution satellite imagery using dictionary group learning and interdictionary nonlocal joint sparse coding. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 1870–1882. [Google Scholar] [CrossRef]
- Gladkova, I.; Grossberg, M.D.; Shahriar, F.; Bonev, G.; Romanov, P. Quantitative restoration for MODIS band 6 on Aqua. IEEE Trans. Geosci. Remote Sens. 2011, 50, 2409–2416. [Google Scholar] [CrossRef]
- Shen, H.; Li, X.; Zhang, L.; Tao, D.; Zeng, C. Compressed sensing-based inpainting of aqua moderate resolution imaging spectroradiometer band 6 using adaptive spectrum-weighted sparse Bayesian dictionary learning. IEEE Trans. Geosci. Remote Sens. 2013, 52, 894–906. [Google Scholar] [CrossRef]
- Xu, M.; Pickering, M.; Plaza, A.J.; Jia, X. Thin cloud removal based on signal transmission principles and spectral mixture analysis. IEEE Trans. Geosci. Remote Sens. 2015, 54, 1659–1669. [Google Scholar] [CrossRef]
- Li, J.; Hu, Q.; Ai, M. Haze and thin cloud removal via sphere model improved dark channel prior. IEEE Geosci. Remote Sens. Lett. 2018, 16, 472–476. [Google Scholar] [CrossRef]
- Shen, H.; Wu, J.; Cheng, Q.; Aihemaiti, M.; Zhang, C.; Li, Z. A spatiotemporal fusion based cloud removal method for remote sensing images with land cover changes. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 862–874. [Google Scholar] [CrossRef]
- Li, Z.; Shen, H.; Cheng, Q.; Li, W.; Zhang, L. Thick cloud removal in high-resolution satellite images using stepwise radiometric adjustment and residual correction. Remote Sens. 2019, 11, 1925. [Google Scholar] [CrossRef]
- Chen, J.; Jönsson, P.; Tamura, M.; Gu, Z.; Matsushita, B.; Eklundh, L. A simple method for reconstructing a high-quality NDVI time-series data set based on the Savitzky–Golay filter. Remote Sens. Environ. 2004, 91, 332–344. [Google Scholar] [CrossRef]
- Li, X.; Shen, H.; Zhang, L.; Zhang, H.; Yuan, Q.; Yang, G. Recovering quantitative remote sensing products contaminated by thick clouds and shadows using multitemporal dictionary learning. IEEE Trans. Geosci. Remote Sens. 2014, 52, 7086–7098. [Google Scholar] [CrossRef]
- Malek, S.; Melgani, F.; Bazi, Y.; Alajlan, N. Reconstructing cloud-contaminated multispectral images with contextualized autoencoder neural networks. IEEE Trans. Geosci. Remote Sens. 2017, 56, 2270–2282. [Google Scholar] [CrossRef]
- Zhang, Q.; Yuan, Q.; Zeng, C.; Li, X.; Wei, Y. Missing data reconstruction in remote sensing image with a unified spatial–temporal–spectral deep convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4274–4288. [Google Scholar] [CrossRef]
- Zheng, J.; Liu, X.-Y.; Wang, X. Single image cloud removal using U-Net and generative adversarial networks. IEEE Trans. Geosci. Remote Sens. 2020, 59, 6371–6385. [Google Scholar] [CrossRef]
- Xu, F.; Shi, Y.; Ebel, P.; Yu, L.; Xia, G.-S.; Yang, W.; Zhu, X.X. GLF-CR: SAR-enhanced cloud removal with global–local fusion. ISPRS J. Photogramm. Remote Sens. 2022, 192, 268–278. [Google Scholar] [CrossRef]
- Meraner, A.; Ebel, P.; Zhu, X.X.; Schmitt, M. Cloud removal in Sentinel-2 imagery using a deep residual neural network and SAR-optical data fusion. ISPRS J. Photogramm. Remote Sens. 2020, 166, 333–346. [Google Scholar] [CrossRef]
- Ji, S.; Dai, P.; Lu, M.; Zhang, Y. Simultaneous cloud detection and removal from bitemporal remote sensing images using cascade convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2020, 59, 732–748. [Google Scholar] [CrossRef]
- Jing, R.; Duan, F.; Lu, F.; Zhang, M.; Zhao, W. An NDVI Retrieval Method Based on a Double-Attention Recurrent Neural Network for Cloudy Regions. Remote Sens. 2022, 14, 1632. [Google Scholar] [CrossRef]
- Grohnfeldt, C.; Schmitt, M.; Zhu, X. A conditional generative adversarial network to fuse SAR and multispectral optical data for cloud removal from Sentinel-2 images. In Proceedings of the IGARSS 2018-2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 1726–1729. [Google Scholar]
- Zhao, Y.; Shen, S.; Hu, J.; Li, Y.; Pan, J. Cloud Removal Using Multimodal GAN With Adversarial Consistency Loss. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Chen, X.; Huang, Y. Memory-Oriented Unpaired Learning for Single Remote Sensing Image Dehazing. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Jing, R.; Duan, F.; Lu, F.; Zhang, M.; Zhao, W. Cloud removal for optical remote sensing imagery using the SPA-CycleGAN network. J. Appl. Remote Sens. 2022, 16, 034520. [Google Scholar] [CrossRef]
- Darbaghshahi, F.N.; Mohammadi, M.R.; Soryani, M. Cloud removal in remote sensing images using generative adversarial networks and SAR-to-optical image translation. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–9. [Google Scholar] [CrossRef]
- Kong, Y.; Liu, S.; Peng, X. Multi-Scale translation method from SAR to optical remote sensing images based on conditional generative adversarial network. Int. J. Remote Sens. 2022, 43, 2837–2860. [Google Scholar] [CrossRef]
- Fuentes Reyes, M.; Auer, S.; Merkle, N.; Henry, C.; Schmitt, M. Sar-to-optical image translation based on conditional generative adversarial networks—Optimization, opportunities and limits. Remote Sens. 2019, 11, 2067. [Google Scholar] [CrossRef]
- Saharia, C.; Ho, J.; Chan, W.; Salimans, T.; Fleet, D.J.; Norouzi, M. Image super-resolution via iterative refinement. IEEE Trans. Pattern Anal. Mach. Intell. 2022. [Google Scholar] [CrossRef]
- Whang, J.; Delbracio, M.; Talebi, H.; Saharia, C.; Dimakis, A.G.; Milanfar, P. Deblurring via stochastic refinement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 16293–16303. [Google Scholar]
- Song, Y.; Sohl-Dickstein, J.; Kingma, D.P.; Kumar, A.; Ermon, S.; Poole, B. Score-based generative modeling through stochastic differential equations. arXiv 2020, arXiv:2011.13456. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Ramachandran, P.; Zoph, B.; Le, Q.V. Searching for activation functions. arXiv 2017, arXiv:1710.05941. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Zhai, H.; Zhang, H.; Zhang, L.; Li, P. Cloud/shadow detection based on spectral indices for multi/hyperspectral optical remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2018, 144, 235–253. [Google Scholar] [CrossRef]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 694–711. [Google Scholar]
- Drusch, M.; Del Bello, U.; Carlier, S.; Colin, O.; Fernandez, V.; Gascon, F.; Hoersch, B.; Isola, C.; Laberinti, P.; Martimort, P. Sentinel-2: ESA’s optical high-resolution mission for GMES operational services. Remote Sens. Environ. 2012, 120, 25–36. [Google Scholar] [CrossRef]
- Torres, R.; Snoeij, P.; Geudtner, D.; Bibby, D.; Davidson, M.; Attema, E.; Potin, P.; Rommen, B.; Floury, N.; Brown, M. GMES Sentinel-1 mission. Remote Sens. Environ. 2012, 120, 9–24. [Google Scholar] [CrossRef]
- Ebel, P.; Meraner, A.; Schmitt, M.; Zhu, X.X. Multisensor data fusion for cloud removal in global and all-season sentinel-2 imagery. IEEE Trans. Geosci. Remote Sens. 2020, 59, 5866–5878. [Google Scholar] [CrossRef]
- Lin, S.-S.; Shen, S.-L.; Zhou, A.; Lyu, H.-M. Sustainable development and environmental restoration in Lake Erhai, China. J. Clean. Prod. 2020, 258, 120758. [Google Scholar] [CrossRef]
- Liu, Q.; Gao, X.; He, L.; Lu, W. Haze removal for a single visible remote sensing image. Signal Process. 2017, 137, 33–43. [Google Scholar] [CrossRef]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Hawaii, HI, USA, 21–26 June 2017; pp. 1125–1134. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Train Samples | Validation Samples | Test Samples |
|---|---|---|---|
| SEN12MS-CR | 73,331 | 24,444 | 24,443 |
| Training Strategy | MAE | RMSE | PSNR | SSIM |
|---|---|---|---|---|
| With SAR as a complement | 0.0301 | 0.0327 | 29.7334 | 0.8943 |
| Without SAR as a complement | 0.0394 | 0.0432 | 26.3421 | 0.7334 |
| Loss Function | MAE | RMSE | PSNR | SSIM |
|---|---|---|---|---|
| Sole mMAE loss | 0.0524 | 0.0672 | 22.3123 | 0.6073 |
| mMAE + perceptual loss | 0.0396 | 0.0423 | 25.8741 | 0.7371 |
| mMAE + attention loss | 0.0458 | 0.0312 | 24.9611 | 0.7282 |
| Cloud-oriented loss | 0.0301 | 0.0327 | 29.7334 | 0.8943 |
| Model | MAE | RMSE | PSNR | SSIM |
|---|---|---|---|---|
| Wuhan | ||||
| Thin cloud | ||||
| RSdehaze | 0.0332 | 0.0504 | 25.6918 | 0.7912 |
| DSen2-CR | 0.0249 | 0.0237 | 28.4247 | 0.8581 |
| Pix2pix | 0.0274 | 0.0295 | 27.9325 | 0.8471 |
| GLF-CR | 0.0266 | 0.0302 | 28.1113 | 0.8444 |
| SPA-CycleGAN | 0.0304 | 0.0478 | 27.3222 | 0.8862 |
| DDPM-CR | 0.0229 | 0.0268 | 31.7712 | 0.9033 |
| Thick cloud | ||||
| RSdehaze | 0.4965 | 0.7748 | 17.2436 | 0.4662 |
| DSsen2-CR | 0.1542 | 0.2895 | 25.4547 | 0.6523 |
| Pix2pix | 0.2376 | 0.5781 | 18.9818 | 0.5271 |
| GLF-CR | 0.1434 | 0.2575 | 25.8633 | 0.6934 |
| SPA-CycleGAN | 0.1593 | 0.2996 | 21.6325 | 0.6951 |
| DDPM-CR | 0.1017 | 0.2148 | 26.7608 | 0.7513 |
| Erhai | ||||
| Thin cloud | ||||
| RSdehaze | 0.1022 | 0.2764 | 23.1819 | 0.5951 |
| DSen2-CR | 0.0289 | 0.0386 | 27.8712 | 0.7974 |
| Pix2pix | 0.0298 | 0.0464 | 26.9147 | 0.7862 |
| GLF-CR | 0.0277 | 0.0442 | 28.3436 | 0.8232 |
| SPA-CycleGAN | 0.0210 | 0.0311 | 28.8522 | 0.8713 |
| DDPM-CR | 0.0247 | 0.0393 | 29.8535 | 0.8924 |
| Thick cloud | ||||
| RSdehaze | 0.3471 | 0.4661 | 18.3826 | 0.4342 |
| DSen2-CR | 0.1148 | 0.1276 | 25.8511 | 0.6963 |
| Pix2pix | 0.1682 | 0.4712 | 19.2638 | 0.4871 |
| GLF-CR | 0.1265 | 0.1181 | 26.3232 | 0.7034 |
| SPA-CycleGAN | 0.0883 | 0.1775 | 23.8141 | 0.7420 |
| DDPM-CR | 0.0509 | 0.0624 | 27.5331 | 0.8131 |
| PSNR | SSIM | |||
|---|---|---|---|---|
| 0.80 | 0.15 | 0.05 | 33.4623 | 0.9223 |
| 0.75 | 0.10 | 0.15 | 32.2115 | 0.9132 |
| 0.85 | 0.05 | 0.10 | 31.7337 | 0.8562 |
| 0.80 | 0.10 | 0.10 | 29.8914 | 0.8911 |
| 0.85 | 0.00 | 0.15 | 28.5418 | 0.8741 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jing, R.; Duan, F.; Lu, F.; Zhang, M.; Zhao, W. Denoising Diffusion Probabilistic Feature-Based Network for Cloud Removal in Sentinel-2 Imagery. Remote Sens. 2023, 15, 2217. https://doi.org/10.3390/rs15092217
Jing R, Duan F, Lu F, Zhang M, Zhao W. Denoising Diffusion Probabilistic Feature-Based Network for Cloud Removal in Sentinel-2 Imagery. Remote Sensing. 2023; 15(9):2217. https://doi.org/10.3390/rs15092217
Chicago/Turabian StyleJing, Ran, Fuzhou Duan, Fengxian Lu, Miao Zhang, and Wenji Zhao. 2023. "Denoising Diffusion Probabilistic Feature-Based Network for Cloud Removal in Sentinel-2 Imagery" Remote Sensing 15, no. 9: 2217. https://doi.org/10.3390/rs15092217
APA StyleJing, R., Duan, F., Lu, F., Zhang, M., & Zhao, W. (2023). Denoising Diffusion Probabilistic Feature-Based Network for Cloud Removal in Sentinel-2 Imagery. Remote Sensing, 15(9), 2217. https://doi.org/10.3390/rs15092217