
Within-Season Crop Identification by the Fusion of Spectral Time-Series Data and Historical Crop Planting Data




Abstract
:1. Introduction
2. Materials and Methods
2.1. The Proposed Fusion Method to Integrate Spectral Times-Series Data with Historical Crop Planting Data
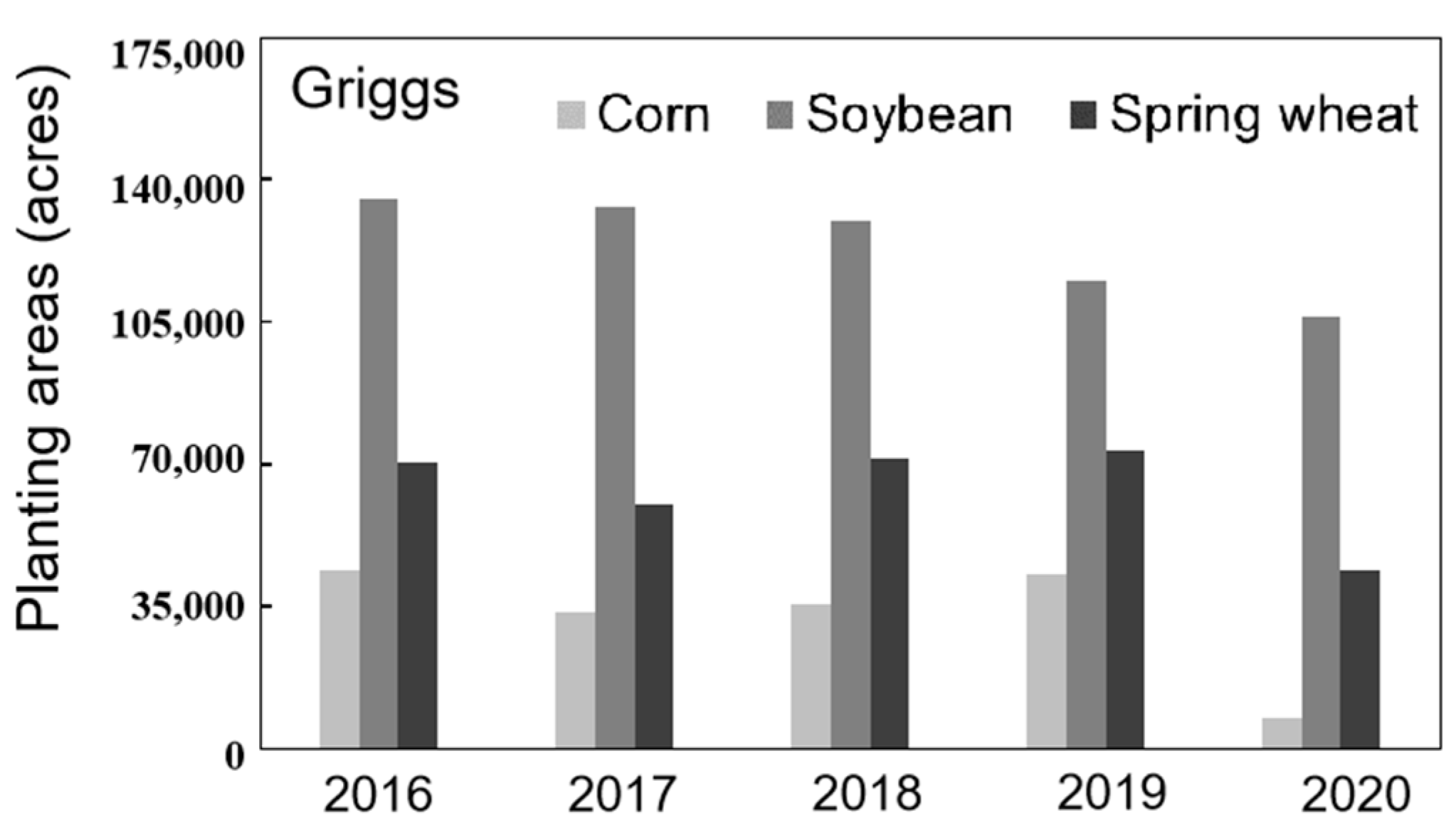
2.2. Study Area
2.3. Data and Preprocessing
2.4. Experiments
2.5. Accuracy Assessment
3. Results
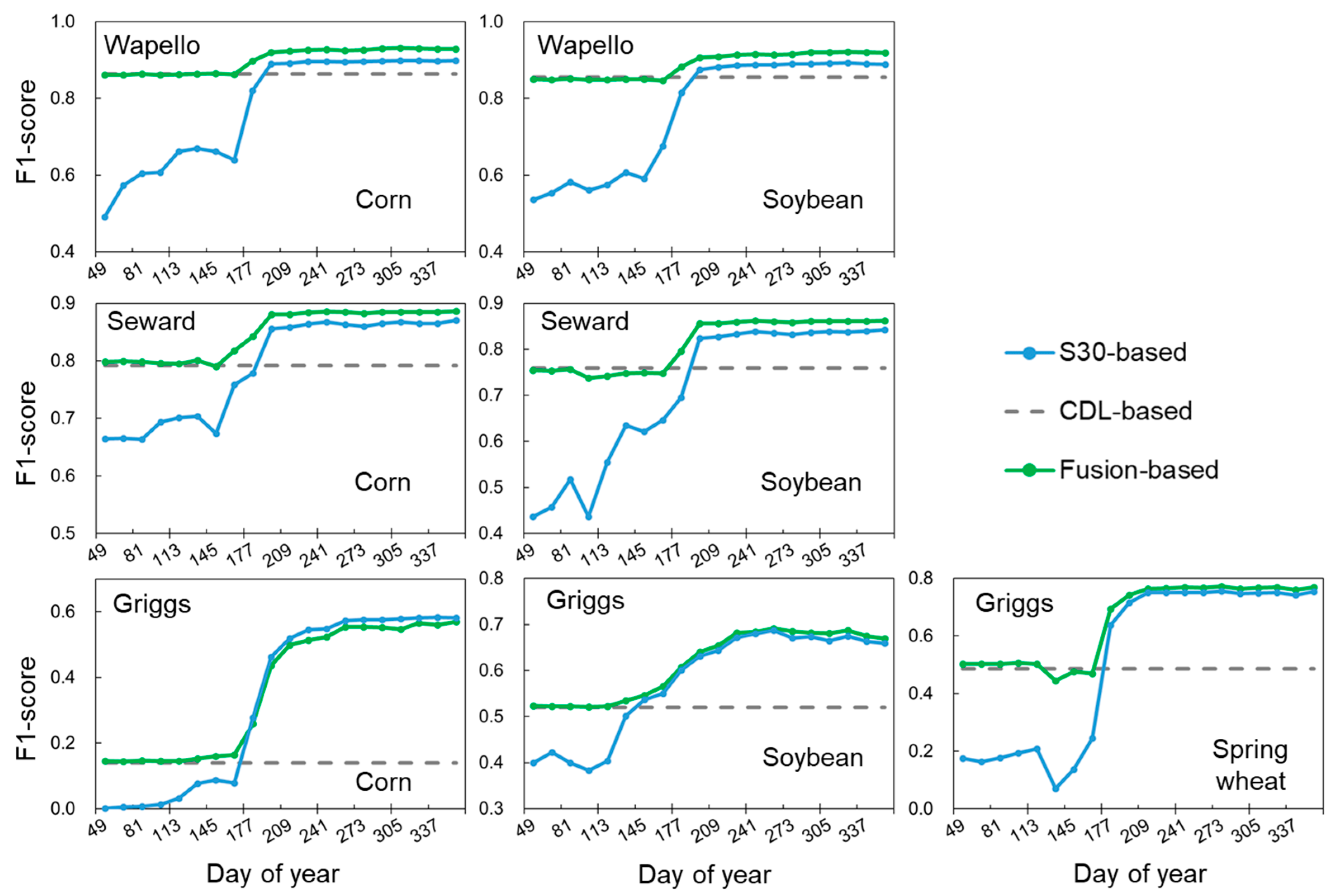
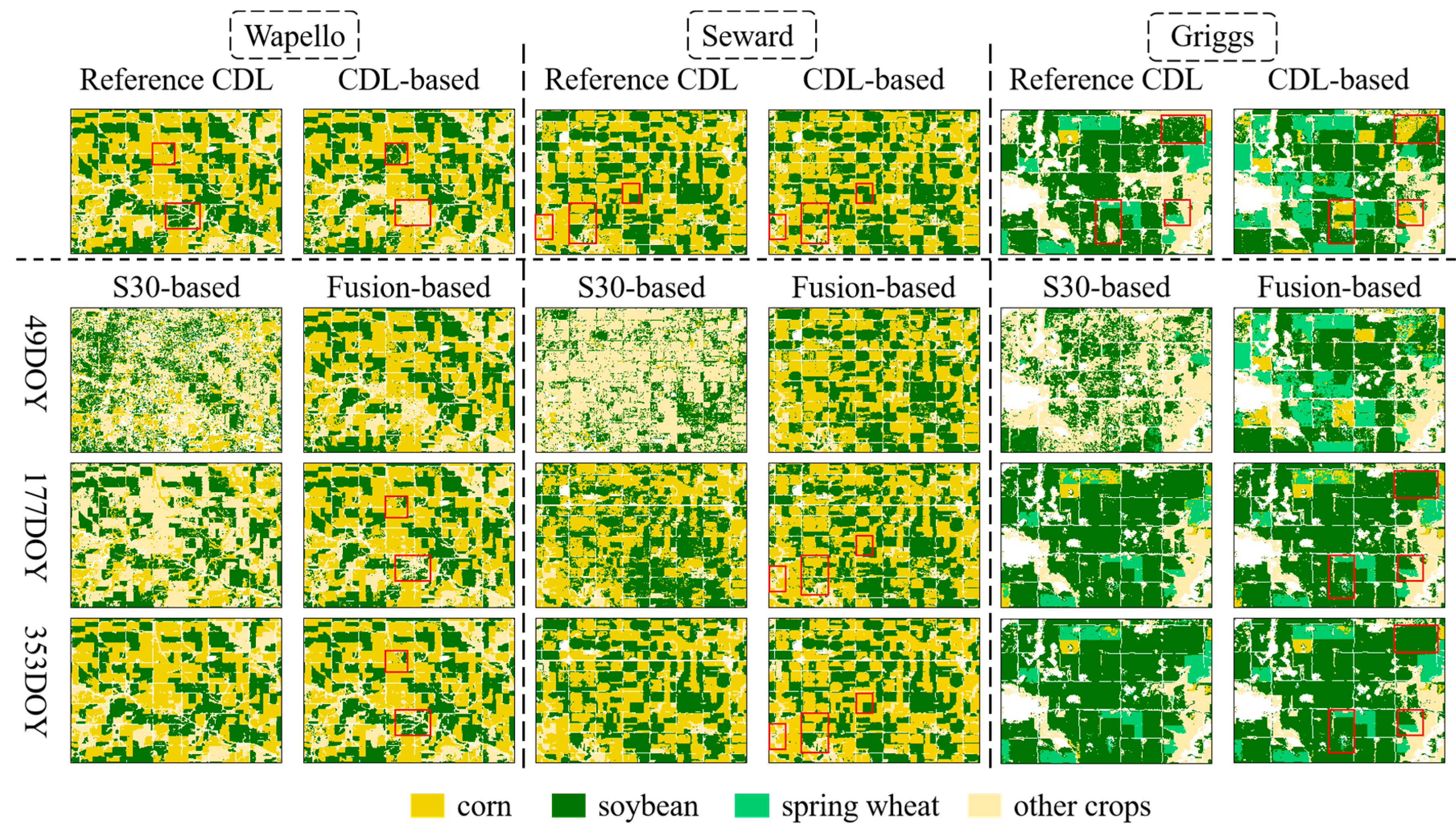
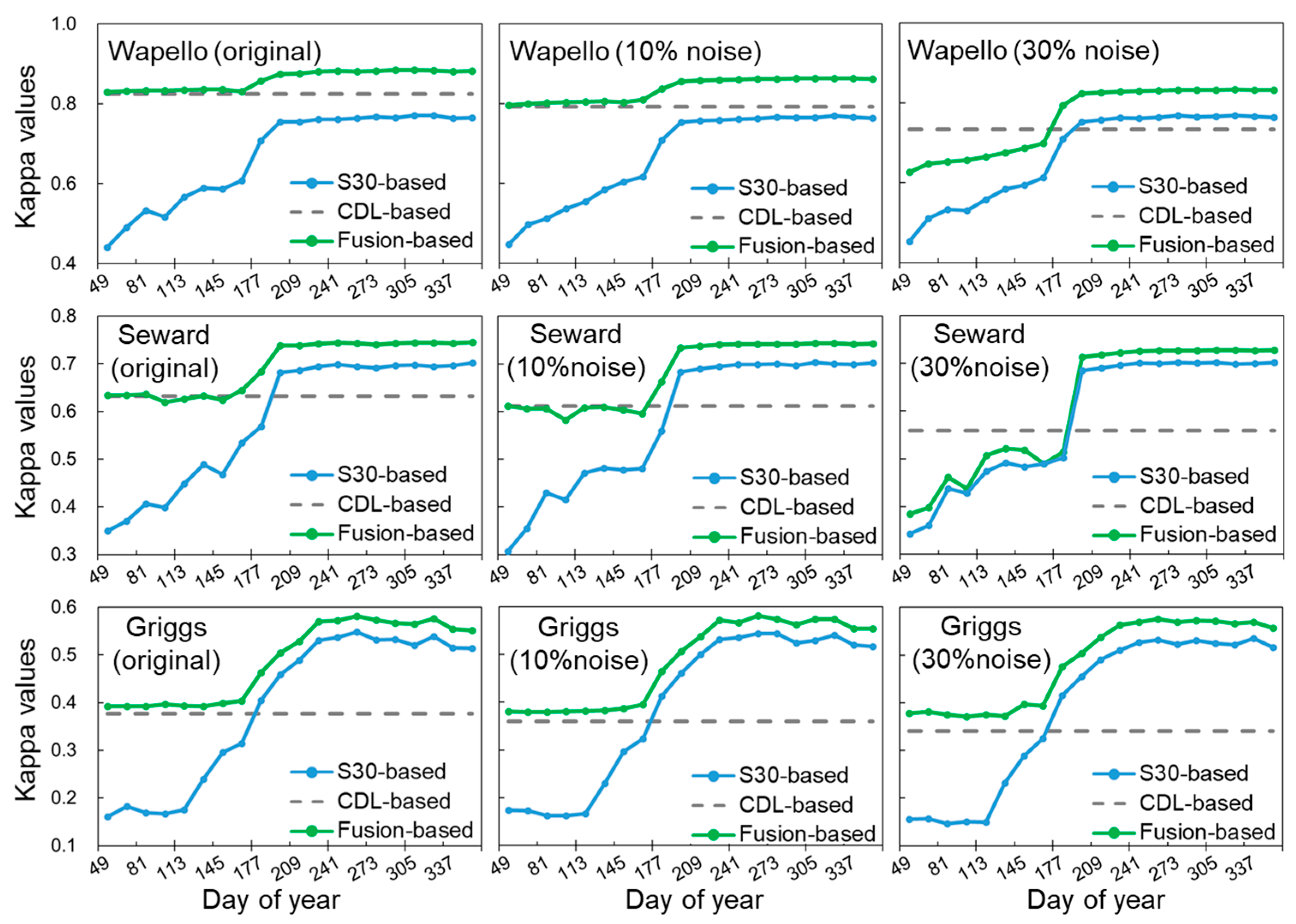
3.1. Performance of Crop Classifications as the Growing Season Progresses
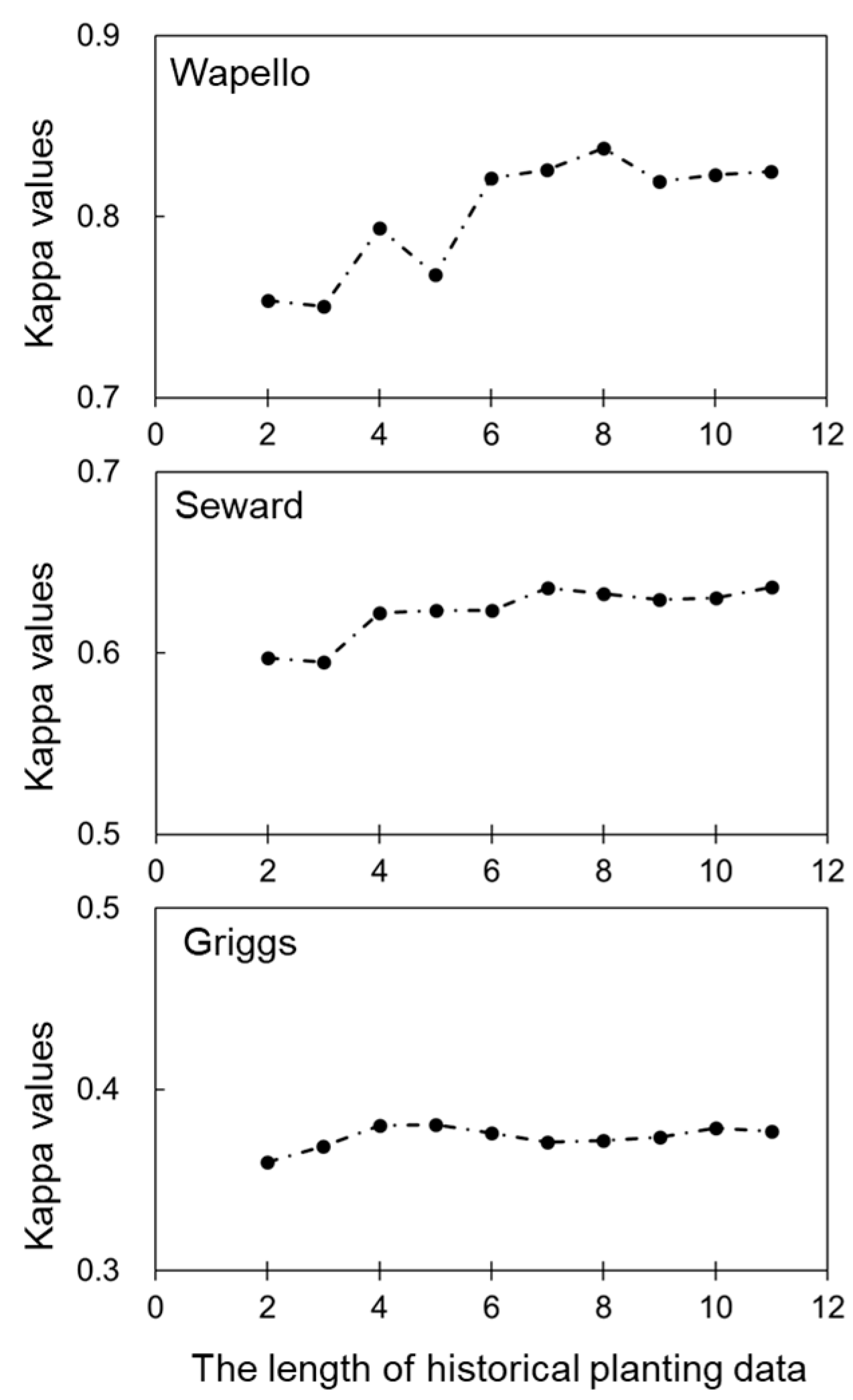
3.2. Impact of Historical Crop Planting Pattern on Pre-Season Crop Classification
3.3. Impact of Historical Crop Planting Data Errors on Crop Identification
3.4. An Application of the Fusion Method at the Sichuan Site
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gallego, J.; Carfagna, E.; Baruth, B. Accuracy, objectivity and efficiency of remote sensing for agricultural statistics. In Agricultural Survey Methods; Benedetti, R., Bee, M., Espa, G., Piersimoni, F., Eds.; John Wiley & Sons: Chichester, UK, 2010; pp. 193–211. [Google Scholar]
- Konduri, V.S.; Kumar, J.; Hargrove, W.W.; Hoffman, F.M.; Ganguly, A.R. Mapping crops within the growing season across the United States. Remote Sens. Environ. 2020, 251, 112048. [Google Scholar] [CrossRef]
- Boryan, C.; Yang, Z.; Mueller, R.; Craig, M. Monitoring US Agriculture: The US Department of Agriculture, National Agricultural Statistics Service, Cropland Data Layer Program. Geocarto Int. 2011, 26, 341–358. [Google Scholar] [CrossRef]
- Mueller, R.; Harris, M. Reported uses of CropScape and the national cropland data layer program. In Proceedings of the International Conference on Agricultural Statistics VI, Rio de Janeiro, Brazil, 23–25 October 2013; pp. 23–25. [Google Scholar]
- Cai, Y.P.; Guan, K.Y.; Peng, J.; Wang, S.W.; Seifert, C.; Wardlow, B.; Li, Z. A high-performance and in-season classification system of field-level crop types using time-series Landsat data and a machine learning approach. Remote Sens. Environ. 2018, 210, 35–47. [Google Scholar] [CrossRef]
- Xiao, Y.; Mignolet, C.; Mari, J.; Benoît, M. Modeling the Spatial Distribution of Cropping Systems at a Large Regional Scale: A Case of Crop Sequence Patterns in France between 1992 and 2003. In Proceedings of the 12th Congress of the European Society for Agronomy, Helsinki, Finland, 20–24 August 2012. [Google Scholar]
- Castellazzi, M.S.; Wood, G.A.; Burgess, P.J.; Morris, J.; Conrad, K.F.; Perry, J.N. A Systematic Representation of Crop Rotations. Agric. Syst. 2008, 97, 26–33. [Google Scholar] [CrossRef]
- Le Ber, F.; Benoît, M.; Schott, C.; Mari, J.-F.; Mignolet, C. Studying Crop Sequences with CarrotAge, a HMM-Based Data Mining Software. Ecol. Model. 2006, 191, 170–185. [Google Scholar] [CrossRef]
- Osman, J.; Inglada, J.; Dejoux, J.-F. Assessment of a Markov logic model of crop rotations for early crop mapping. Comput. Electron. Agric. 2015, 113, 234–243. [Google Scholar] [CrossRef]
- Zhang, C.; Di, L.; Lin, L.; Guo, L. Machine-Learned Prediction of Annual Crop Planting in the U.S. Corn Belt Based on Historical Crop Planting Maps. Comput. Electron. Agric. 2019, 166, 104989. [Google Scholar] [CrossRef]
- Yaramasu, R.; Bandaru, V.; Pnvr, K. Pre-season crop type mapping using deep neural networks. Comput. Electron. Agric. 2020, 176, 105664. [Google Scholar] [CrossRef]
- Hu, F.; Xia, G.-S.; Hu, J.; Zhang, L. Transferring Deep Convolutional Neural Networks for the Scene Classification of High-Resolution Remote Sensing Imagery. Remote Sens. 2015, 7, 14680–14707. [Google Scholar] [CrossRef]
- Hu, Q.; Wu, W.B.; Song, Q.; Yu, Q.Y.; Yang, P.; Tang, H.J. Recent Progresses in Research of Crop Patterns Mapping by Using Remote Sensing. Sci. Agric. Sin. 2015, 48, 1900–1914. [Google Scholar]
- Qiu, B.; Luo, Y.; Tang, Z.; Chen, C.; Lu, D.; Huang, H.; Chen, Y.; Chen, N.; Xu, W. Winter Wheat Mapping Combining Variations before and after Estimated Heading Dates. ISPRS J. Photogramm. Remote Sens. 2017, 123, 35–46. [Google Scholar] [CrossRef]
- Xiao, X.; Boles, S.; Liu, J.; Zhuang, D.; Frolking, S.; Li, C.; Salas, W.; Moore, B. Mapping paddy rice agriculture in southern Chinausing multi-temporal MODIS images. Remote Sens. Environ. 2005, 95, 480–492. [Google Scholar] [CrossRef]
- Zang, Y.; Chen, X.; Chen, J.; Tian, Y.; Shi, Y.; Cao, X.; Cui, X. Remote Sensing Index for Mapping Canola Flowers Using MODIS Data. Remote Sens. 2020, 12, 3912. [Google Scholar] [CrossRef]
- Sulik, J.J.; Long, D.S. Spectral indices for yellow canola flowers. Int. J. Remote Sens. 2015, 36, 2751–2765. [Google Scholar] [CrossRef]
- Sulik, J.J.; Long, D.S. Spectral Considerations for Modeling Yield of Canola. Remote Sens. Environ. 2016, 184, 161–174. [Google Scholar] [CrossRef]
- Tao, J.; Wu, W.; Liu, W.; Xu, M. Exploring the Spatio-Temporal Dynamics of Winter Rape on the Middle Reaches of Yangtze River Valley Using Time-Series MODIS Data. Sustainability 2020, 12, 466. [Google Scholar] [CrossRef]
- Veloso, A.; Mermoz, S.; Bouvet, A.; Le Toan, T.; Planells, M.; Dejoux, J.F.; Ceschia, E. Understanding the temporal behavior of crops using Sentinel-1 and Sentinel-2-like data for agricultural applications. Remote Sens. Environ. 2017, 199, 415–426. [Google Scholar] [CrossRef]
- Dong, J.; Xiao, X. Evolution of regional to global paddy rice mapping methods: A review. ISPRS J. Photogramm. Remote Sens. 2016, 119, 214–227. [Google Scholar] [CrossRef]
- Clauss, K.; Ottinger, M.; Leinenkugel, P.; Kuenzer, C. Estimating Rice Production in the Mekong Delta, Vietnam, Utilizing TimeSeries of Sentinel-1 SAR Data. Int. J. Appl. Earth Obs. 2018, 73, 574–585. [Google Scholar]
- Foerster, S.; Kaden, K.; Foerster, M.; Itzerott, S. Crop type mapping using spectral-temporal profiles and phenological information. Comput. Electron. Agric. 2012, 89, 30–40. [Google Scholar] [CrossRef]
- Belgiu, M.; Csillik, O. Sentinel-2 cropland mapping using pixel-based and object- based time-weighted dynamic time warpinganalysis. Remote Sens. Environ. 2018, 204, 509–523. [Google Scholar] [CrossRef]
- Dong, Q.; Chen, X.; Chen, J.; Zhang, C.; Liu, L.; Cao, X.; Zang, Y.; Zhu, X.; Cui, X. Mapping Winter Wheat in North China Using Sentinel 2A/B Data: A Method Based on Phenology-Time Weighted Dynamic Time Warping. Remote Sens. 2020, 12, 1274. [Google Scholar] [CrossRef]
- Yi, Z.; Jia, L.; Chen, Q. Crop Classification Using Multi-Temporal Sentinel-2 Data in the Shiyang River Basin of China. Remote Sens. 2020, 12, 4052. [Google Scholar] [CrossRef]
- Zhong, L.; Hu, L.; Zhou, H. Deep Learning Based Multi-Temporal Crop Classification. Remote Sens. Environ. 2019, 221, 430–443. [Google Scholar] [CrossRef]
- Zhong, L.; Hu, L.; Zhou, H.; Tao, X. Deep learning based winter wheat mapping using statistical data as ground references in Kansas and northern Texas, US. Remote Sens. Environ. 2019, 233, 111411. [Google Scholar] [CrossRef]
- You, N.; Dong, J. Examining earliest identifiable timing of crops using all available Sentinel 1/2 imagery and Google Earth Engine. ISPRS J. Photogramm. Remote Sens. 2020, 161, 109–123. [Google Scholar] [CrossRef]
- Zaremba, W.; Sutskever, I.; Vinyals, O. Recurrent Neural Network Regularization. arXiv 2014, arXiv:1409.2329. [Google Scholar]
- Xu, J.F.; Zhu, Y.; Zhong, R.H.; Lin, Z.X.; Xu, J.L.; Jiang, H.; Huang, J.F.; Li, H.F.; Lin, T. DeepCropMapping: A multi-temporal deeplearning approach with improved spatial generalizability for dynamic corn and soybean mapping. Remote Sens. Environ. 2020, 247, 111946. [Google Scholar] [CrossRef]
- Johnson, D.M.; Mueller, R. Pre- and within-Season Crop Type Classification Trained with Archival Land Cover Information. Remote Sens. Environ. 2021, 264, 112576. [Google Scholar] [CrossRef]
- Zhou, P.; Shi, W.; Tian, J.; Qi, Z.; Li, B.; Hao, H.; Xu, B. Attention-based bidirectional long short-term memory networks forrelation classification. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Berlin/Heidelberg, Germany, 7–12 August 2016; pp. 207–212. [Google Scholar]
- Claverie, M.; Ju, J.; Masek, J.G.; Dungan, J.L.; Vermote, E.F.; Roger, J.-C.; Skakun, S.V.; Justice, C. The Harmonized Landsat andSentinel-2 Surface Reflectance Data Set. Remote Sens. Environ. 2018, 219, 145–161. [Google Scholar] [CrossRef]
- Gao, F.; Zhang, X. Mapping Crop Phenology in Near Real-Time Using Satellite Remote Sensing: Challenges and Opportunities. J. Remote Sens. 2021, 2021, 8379391. [Google Scholar] [CrossRef]
- USDA; National Agricultural Statistics Service. Field Crop Usual Planting and Harvesting Dates; NASS: Washington, DC, USA, 2010. [Google Scholar]
- Han, J.; Zhang, Z.; Luo, Y.; Cao, J.; Zhang, L.; Zhang, J.; Li, Z. The RapeseedMap10 database: Annual maps of rapeseed at a spatial resolution of 10 m based on multi-source data. Earth Syst. Sci. Data 2021, 13, 2857–2874. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Acquisition Method | Canola | Winter Wheat | Other Vegetation | Total |
|---|---|---|---|---|
| Field investigation | 110 | 151 | 93 | 354 |
| Visual interpretation | 140 | 122 | 123 | 385 |
| Total | 250 | 273 | 216 | 739 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Q.; Yang, B.; Li, L.; Liang, H.; Zhu, X.; Cao, R. Within-Season Crop Identification by the Fusion of Spectral Time-Series Data and Historical Crop Planting Data. Remote Sens. 2023, 15, 5043. https://doi.org/10.3390/rs15205043
Wang Q, Yang B, Li L, Liang H, Zhu X, Cao R. Within-Season Crop Identification by the Fusion of Spectral Time-Series Data and Historical Crop Planting Data. Remote Sensing. 2023; 15(20):5043. https://doi.org/10.3390/rs15205043
Chicago/Turabian StyleWang, Qun, Boli Yang, Luchun Li, Hongyi Liang, Xiaolin Zhu, and Ruyin Cao. 2023. "Within-Season Crop Identification by the Fusion of Spectral Time-Series Data and Historical Crop Planting Data" Remote Sensing 15, no. 20: 5043. https://doi.org/10.3390/rs15205043
APA StyleWang, Q., Yang, B., Li, L., Liang, H., Zhu, X., & Cao, R. (2023). Within-Season Crop Identification by the Fusion of Spectral Time-Series Data and Historical Crop Planting Data. Remote Sensing, 15(20), 5043. https://doi.org/10.3390/rs15205043