Abstract
Recently, optical remote-sensing images have been widely applied in fields such as environmental monitoring and land cover classification. However, due to limitations in imaging equipment and other factors, low-resolution images that are unfavorable for image analysis are often obtained. Although existing image super-resolution algorithms can enhance image resolution, these algorithms are not specifically designed for the characteristics of remote-sensing images and cannot effectively recover high-resolution images. Therefore, this paper proposes a novel remote-sensing image super-resolution algorithm based on an efficient hybrid conditional diffusion model (EHC-DMSR). The algorithm applies the theory of diffusion models to remote-sensing image super-resolution. Firstly, the comprehensive features of low-resolution images are extracted through a transformer network and CNN to serve as conditions for guiding image generation. Furthermore, to constrain the diffusion model and generate more high-frequency information, a Fourier high-frequency spatial constraint is proposed to emphasize high-frequency spatial loss and optimize the reverse diffusion direction. To address the time-consuming issue of the diffusion model during the reverse diffusion process, a feature-distillation-based method is proposed to reduce the computational load of U-Net, thereby shortening the inference time without affecting the super-resolution performance. Extensive experiments on multiple test datasets demonstrated that our proposed algorithm not only achieves excellent results in quantitative evaluation metrics but also generates sharper super-resolved images with rich detailed information.
1. Introduction
Remote-sensing images are captured using optical remote-sensing imaging technologies, such as aircraft and remote-sensing satellites. These images record radiation information on the Earth’s surface and find applications in various fields, including environmental monitoring, military target recognition, and land resource exploration [1]. Accurate prediction and analysis in remote-sensing applications require high-resolution images with rich detailed information. However, the resolution of remote-sensing images is often limited by imaging equipment, and factors such as blur, downsampling, noise, and compression further reduce image quality. This results in a reduction in the image resolution and the loss of high-frequency information, which is crucial for effective analysis of the images [2]. Improving hardware equipment in remote-sensing imaging systems is an effective way to solve the problem of low resolution, but it also requires significant additional costs. Therefore, it is necessary to develop practical and cost-effective super-resolution algorithms to enhance the resolution of remote-sensing images. Super-resolution (SR) algorithms aim to improve image resolution while providing finer spatial details, thus compensating for the weaknesses of satellite images. By enhancing resolution and preserving high-frequency information in images, SR algorithms reduce the dependence on hardware upgrades, thereby improving efficiency and reducing costs [3,4].
Single-image super-resolution (SISR) is a current research hotspot in the field of computer vision [5], aiming to recover high-resolution (HR) images and rich high-frequency information from low-resolution (LR) images. The study of SISR is of great significance to both industry and academia. However, SISR is an ill-posed problem, and due to the loss of high-frequency information, the image super-resolution process involves multi-mapping from the LR to HR space, resulting in multiple solution spaces for any LR input. Existing algorithms aim to determine the correct solution from the solution space. Currently, numerous methods have been proposed for SISR, which can be categorized into three main categories: interpolation-based methods, reconstruction-based methods [6,7,8], and learning-based methods [5,9,10,11,12,13,14].
Interpolation-based methods are simple and effective algorithms for SISR. These methods increase the resolution of low-resolution images through interpolation, including nearest-neighbor interpolation, bilinear interpolation, and bicubic interpolation [1]. However, it should be noted that in these interpolation methods, high-frequency information is severely lost during the upsampling process due to the lack of external prior information. Reconstruction-based methods in super-resolution use self-information and prior knowledge of images as constraints to optimize the quality of super-resolved images [6,7,8]. Although these methods can overcome the limitations of interpolation-based methods, they require manual parameter tuning, have slow convergence speeds, and have high computational costs. Therefore, they may not be suitable for handling complex and diverse scenarios in remote-sensing image applications.
With the improvement in computer performance, the theory of deep learning has flourished in multiple application domains [15,16], and significant progress has been made in deep-neural-network-based super-resolution algorithms [1]. In contrast with the aforementioned methods, learning-based methods represent the mapping relationship between LR and HR remote-sensing images by establishing a neural network learning model. Compared with traditional methods, learning-based methods make use of a large number of LR and HR image pairs as external prior information. Deep convolutional neural networks (CNNs) have strong feature representation capabilities and faster inference speeds and can achieve end-to-end training. Researchers have proposed a series of deep-learning-based SISR algorithms based on CNNs [5,9,10,11,12,13,14], which show significant improvements in super-resolution performance compared with traditional algorithms. However, CNN-based super-resolution models still face some challenges in remote-sensing image super-resolution tasks. Most CNN models do not consider the complex textures and structures present in remote-sensing images, limiting their ability to recover high-frequency details in super-resolved images. Since the proposal of denoising diffusion probabilistic models (DDPMs) [17], DDPMs have been widely used in many natural scene reconstruction tasks, including super-resolution tasks. Subsequently, researchers have proposed methods to improve DDPMs to address existing problems based on the characteristics of image super-resolution tasks. To address the over-smoothing and mode collapse problems in previous learning-based super-resolution algorithms, Li et al. proposed a diffusion-based method for face super-resolution (SRDiff) [18], which was the first attempt to apply diffusion models to single-image super-resolution. A low-resolution image is used as a conditional input, and the Gaussian noise latent variable is gradually transformed into a super-resolution image through a Markov chain. Additionally, residual prediction was introduced to accelerate the convergence speed of the neural network during practical operations. Liu et al. proposed a detail-complementary generative diffusion model (DMDC) [2] for remote-sensing image super-resolution, which includes detailed supplementary tasks to improve the restoration ability of DMDC. The proposed model solves the problems of insufficient attention to small targets, lack of model understanding, and detail supplementation in traditional optimization models. However, the above algorithms overlook the importance of input feature conditioning and the ability to maintain details during the training process, resulting in lower-quality super-resolution remote-sensing images and longer inference times when these algorithms are applied to remote-sensing images. To address these challenges, we propose a diffusion-model-based method that leverages the powerful generative capabilities of the diffusion model to reconstruct high-resolution remote-sensing images.
In summary, the main contributions of this paper are as follows:
- This paper proposes a remote-sensing image super-resolution network based on the diffusion model. By using the comprehensive features of low-resolution images extracted with a transformer network and CNN as conditions to guide image generation, the diffusion model can fully utilize the conditional features to predict the noise data distribution and effectively recover high-resolution images from noise. The powerful generative capability of the diffusion model enables it to fully understand image information, addressing the shortcomings of previous neural-network-based remote-sensing super-resolution methods that typically fail to obtain high-fidelity detailed images at high magnifications.
- A Fourier high-frequency spatial constraint is proposed to emphasize high-frequency spatial loss and optimize the reverse diffusion direction. By emphasizing high-frequency spatial loss through the Fourier high-frequency spatial constraint, missing high-frequency information in low-resolution remote-sensing images can be restored, significantly improving the quality of remote-sensing image super-resolution. The method can generate more textured and detailed information, while reducing the diversity of the diffusion model, and produce super-resolved images that are closer to the original images, achieving precise detailed information reconstruction.
- To address the time-consuming issue in the reverse diffusion process of the diffusion model, a feature-distillation-based method is proposed that shortens the inference time without affecting the super-resolution performance.
- This paper not only tested the proposed algorithm on the commonly used RSOD [19] and UC Merced Land Use [20] remote-sensing image datasets but also verified its effectiveness on the real dataset Gaofen-2 [21]. The experimental results show that our proposed method outperforms other comparable super-resolution algorithms in both quantitative metrics and visual quality.
The rest of this paper is organized as follows. Section 2 briefly introduces the application of CNNs in remote-sensing image super-resolution and the related concepts and research progress of the diffusion model. Section 3 elaborates on our proposed remote-sensing image super-resolution method based on the efficient hybrid conditional diffusion model and the implementation details of each part. Section 4 presents a large number of experimental details and discusses the effectiveness of our proposed method. Finally, Section 5 summarizes the entire paper.
2. Related Work
2.1. Remote-Sensing Image Super-Resolution Based on CNNs
Dong et al. [5] proposed the first three-layer CNN architecture for image super-resolution, known as SRCNN. Subsequently, the emergence of residual networks [22] allowed an increase in the number of network layers, enabling deep neural networks to learn high-level features and reducing training difficulty. Based on residual networks, Kim et al. [9] proposed a 20-layer CNN for image super-resolution, called VDSR. RDN [13] developed a deep network using dense blocks that fully utilized the hierarchical features of all previous layers. Zhang et al. [11] incorporated a channel attention (CA) module into the residual structure using the SE block for inspiration, forming a very deep network called RCAN. Haris et al. [23] proposed DDBPN based on the idea of iterative upsampling and downsampling, which provides an error feedback mechanism. SRFBN [24] utilizes the hidden state in an RNN to achieve feedback for super-resolution.
Inspired by the successful application of CNNs to traditional images, more and more remote-sensing image super-resolution methods are adopting deep learning techniques and achieving good results. Lei et al. [25] proposed a local–global combined network (LGCNet) based on a CNN for remote-sensing image super-resolution. Inspired by back-projection networks, Pan et al. [26] proposed residual dense projection blocks to enhance the resolution of remote-sensing images. Gu et al. [4] drew inspiration from some emerging concepts in deep learning, such as channel attention, and proposed residual squeeze-and-excitation blocks as building blocks for super-resolution networks. To avoid overfitting and excessive parameters, Chang and Luo et al. [27] introduced bidirectional convolutional long short-term memory layers to learn feature correlations from each recursion.
Due to the ability of generative adversarial networks (GANs) to generate more visually pleasing remote-sensing super-resolution images and achieve better quantitative metrics, GANs have gradually become the backbones of super-resolution networks. Ma et al. [3] proposed a GAN-based method to enhance the resolution of remote-sensing images, called dense residual GAN (DRGAN). Specifically, DRGAN modified the loss function of the reference Wasserstein GAN to improve reconstruction accuracy and avoid gradient vanishing. Jiang et al. [28] also proposed an edge-enhancement network (EEGAN) that utilizes adversarial learning strategies for robust satellite image SR reconstruction, which is particularly good at restoring sharp edges. The diffusion model and GAN model used in this paper differ in terms of image super-resolution. The diffusion model can capture the complex statistical information of the visual world, inferring structures at higher scales than low-resolution inputs. However, GAN models often suffer from mode collapse, resulting in the generated samples lacking diversity. In addition, recent studies have shown that diffusion models based on image conditioning are superior to regression-based models in terms of image super-resolution. Therefore, diffusion models have certain advantages in image super-resolution.
2.2. Diffusion Model
As shown in Figure 1, commonly used generative models include GANs [29], variational autoencoders (VAEs) [30], and normalizing flows (NFs) [31]. Each of these generative models can generate high-quality samples, but each method has its own limitations. GAN models can be unstable during training without careful parameter tuning, and can easily suffer from mode collapse [32] and produce low-quality samples. Samples generated with a VAE with autoencoding structures can be blurry and lack detailed information. Flow-based models require a specialized architecture to construct reversible transformations.
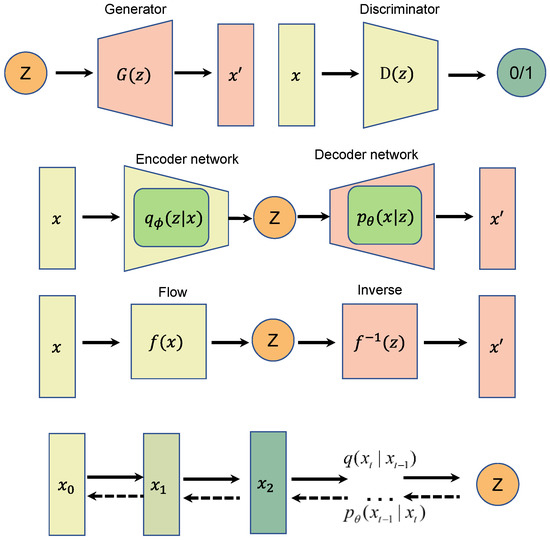
Figure 1.
Comparison between the schematic diagrams of four generative models, from top to bottom: generative adversarial network (GAN), variational autoencoder (VAE), normalizing flow (NF), and diffusion model.
The diffusion model [17,33,34] is also a generative model and is inspired by non-equilibrium thermodynamics. It defines a Markov chain with a diffusion step, gradually adding random noise to the data, and then learns the reverse diffusion process (reverse Markov diffusion chain) to construct the desired data samples from the noise. The learning process of the diffusion model is fixed, and the data dimension of the latent variables is the same as that of the original data.
In recent years, many generative models based on diffusion models have been proposed, including diffusion probability models [33], conditional score models [35], and denoising diffusion probability models (DDPM) [17]. Among them, DDPMs have been widely used in various scenarios, such as image coloring, super-resolution, inpainting, and semantic editing. In 2015, Sohl-Dickstein et al. [33] introduced the diffusion probability model, which gradually destroys the structure of the data distribution during the forward diffusion process and then restores the structure of the data by learning the reverse diffusion process to generate highly flexible and easy-to-handle data generative models. In 2020, Ho et al. [17] proposed the denoising diffusion probability model and demonstrated that the diffusion model could actually generate high-quality samples. The diffusion probability model is a parameterized Markov chain that can be trained using variational inference. The fractional generative model proposed by Song et al. [36] generates images by solving stochastic differential equations using a neural-network-estimated score function and (Refs. [17,33]) can be regarded as the discrete form of the fractional generative model. Rombach et al. [37] proposed a latent diffusion model that can significantly improve the training and sampling efficiency of denoising diffusion models without reducing the quality of the diffusion model, achieving state-of-the-art results in image patching and class-conditional image synthesis. DiffusionCLIP [38] uses the contrastive language-image pretraining (CLIP) loss and pre-trained diffusion model for text-guided image processing. ILVR [39] proposed a method to guide the DDPM generation process, which can generate high-quality images based on given reference images. CCDF [40] proposed starting from a single forward diffusion with better initialization, which can significantly reduce the number of sampling steps for reverse conditional diffusion.
The diffusion model has made impressive progress in the field of image generation, surpassing the performance of GANs and emerging as a new type of generative model. In addition, the diffusion model has achieved state-of-the-art results in fields such as speech synthesis tasks [34] and image translation [41]. The diffusion model obtains results from posterior probability sampling instead of using traditional end-to-end inference methods, making it able to handle various distribution changes. The trained model can be generalized to out-of-distribution (OOD) test data and has achieved impressive results, especially in solving one-to-many problems such as image super-resolution. In this study, we first used simulated noisy signals for diffusion to generate high-quality images. As shown in Figure 2, the process of using the diffusion model for image super-resolution typically includes two processes: a forward diffusion process and a reverse diffusion process. The diffusion process gradually adds Gaussian noise to an image, and the reverse diffusion process is implemented through a parameterized Markov chain. Each Markov step is modeled with a deep neural network, which can learn how to invert the forward diffusion process to approximate the true data distribution to the greatest extent possible through the variational inference optimization of the network parameters.
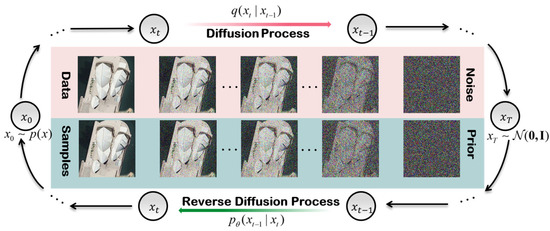
Figure 2.
The diffusion process and reverse diffusion process of the diffusion model used for image super-resolution.
3. Proposed Method
3.1. Principles of Super-Resolution Using Diffusion Model
3.1.1. Diffusion Model
The diffusion model is an important generative model in machine learning, consisting of two main processes: a forward diffusion process and a reverse diffusion process. During the diffusion stage, the image data gradually become corrupted by noise until they completely become random noise. Intuitively, the forward process continuously adds noise to the data , while the generation process continually removes noise to obtain the original data . First, the true data distribution is defined, and small Gaussian noise is gradually added during the diffusion process. Assuming that steps are taken in total, a series of noisy samples x are generated, which are latent variables with the same dimensions as the original data . The noise parameters during the diffusion process are determined by an increasing sequence of , and for convenience of calculation and formula representation, let , , where . The forward process transforms the distribution of the original data step by step into the distribution of the latent variables , which can be described using the following formula:
where
The data distribution at any given time can be calculated without the need for any iteration through the derivation of Formula (3):
where
As increases, the proportion of noise becomes larger, and the proportion of original data becomes smaller. Gaussian noise occupies a larger proportion, and the distribution of tends to . At this point, it can be considered that the diffusion process of the model has been completed.
The reverse diffusion process in the diffusion model uses a Markov chain to transform a simple Gaussian probability distribution into a complex distribution in the real data. This process transforms the distribution of the latent variables into the data distribution . Since the noise added in the forward process is very small each time, we assume that is also a Gaussian distribution. As is an unknown probability distribution, it can be fitted using a neural network. Herein, represents the parameters of the neural network.
When is set close enough to 1, approaches the standard normal distribution for all . Therefore, can be set to the standard normal distribution, i.e., . The joint probability distribution of the reverse diffusion process can be expressed using the following formula:
where
By decomposing into and noise, an approximate value for the mean can be obtained as
By setting the variance as a constant related to , the trainable parameters only exist in the mean, and the generation process can be expressed as
where denotes a neural network with the same input and output, wherein the noise predicted by the neural network at each step is used for the reverse diffusion process.
Our goal is to find the parameters that maximize the double target data distribution , as shown in Equation (9). This is achieved by adding a non-negative KL divergence term to the negative log-likelihood function of the target data distribution , which constitutes an upper bound on the negative log-likelihood.
Continuing to expand the result in the above equation yields the following:
is expressed as , and its corresponding diffusion process posterior is expressed as , where
The final loss function can be written as the root-mean-squared error between the means of the two distributions:
To simplify the expression, the following loss function is minimized during the training process:
During the inference process, the latent variable is first sampled from the standard normal distribution, and then it is sampled from it again using the formula detailed above to obtain .
where , and the iteration continues until is computed.
3.1.2. Super-Resolution-Based Diffusion Model
In the previous section, we introduced the principle of the diffusion model. Our proposed super-resolution method for remote-sensing images is also based on the T-step diffusion model, as shown in Figure 2. It mainly includes the diffusion process from left to right and the inverse diffusion process from right to left. Assuming that the distribution of high-resolution images in the given training set is , as shown in Equation (2), Gaussian noise is continuously added to a clean image during the diffusion process to produce a series of noisy images, . As the number of steps increases, the high-resolution image gradually loses its original characteristics, equivalent to an isotropic Gaussian distribution. The inverse diffusion process is the opposite of the diffusion process, as shown in Equations (5)–(7). The latent variable is gradually denoised and transformed into a high-resolution image. We use a neural network to simulate this denoising process and predict the noise added at each step in the diffusion process through the neural network, with the LR image encoding as the input condition. In practical operation, a high-resolution image is not directly used as ; rather, the residual between the high-resolution image and the image obtained by upsampling the low-resolution image is used. In the following chapters, we will introduce in detail the hybrid conditional features for low-resolution image encoding, the conditional noise predictor, as well as the training and inference processes.
3.2. Overview of Neural Network Model
3.2.1. Hybrid Conditional Features
As illustrated in Figure 3, we present the overall flowchart of our proposed hybrid conditional diffusion model for remote-sensing image super-resolution. This algorithm utilizes the diffusion model to represent the data points’ diffusion patterns in the latent space, thereby learning the underlying structure within the dataset. The neural network (U-Net) is employed to learn the reverse diffusion process, which can generate high-resolution remote-sensing images from random noise images through the reverse diffusion procedure. The three inputs to the U-Net neural network are the latent variables at time , the low-resolution image features , and the time , respectively. For detailed information regarding these three inputs, please refer to the structure of the conditional noise predictor in Figure 4. The previous diffusion models do not pay much attention to the importance of the conditional features of the low-resolution input in the diffusion model. However, these features can better guide the generation of high-resolution images in practice. Therefore, as shown in Figure 3, we designed hybrid conditional features in this paper, which include global high-level features and local visual features. The global high-level features are captured through the transformer network, while the local visual features are captured with our proposed convolutional neural network. The following sections detail the specific implementation steps of these two feature extraction methods:
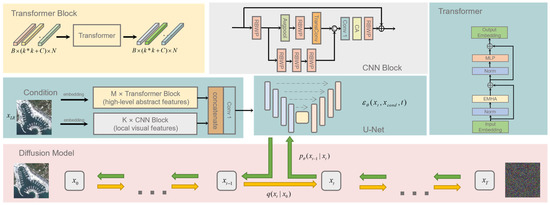
Figure 3.
The primary components of the hybrid conditional diffusion model proposed for super-resolution of remote-sensing images.
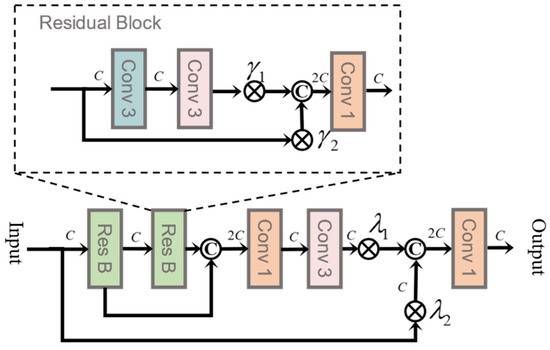
Figure 4.
Framework of the proposed residual block with parameter (RBWP).
To obtain global high-level features from a low-resolution image, we selected a transformer structure similar to that in [42] as the backbone of the feature extraction network. The transformer captures long-distance dependencies between image blocks through self-attention, enabling it to acquire high-level global visual features. As shown in Figure 3, we first embed the input low-resolution image to obtain the feature , where is the number of feature channels. We then unfold the input feature into a sequence, which can be viewed as a series of flattened feature blocks obtained by dividing the feature into small blocks. The sequence contains feature blocks, each with a dimension of , where represents the size of the feature block, is the number of channels, and is considered the length of the sequence. The serialized features are then inputted to the transformer architecture. Assuming that the input sequence to the transformer block is and the output sequence is , we then obtain
where represents the intermediate representation of features, denotes layer normalization, represents the multi-layer perceptron, and represents efficient multi-head self-attention [42].
The overall structure of the CNN we used is shown in Figure 3, which mainly consists of the residual block with parameter (RBWP) illustrated in Figure 4. The learnable parameters in RBWP can be regarded as reallocating available resources to the part with the maximum amount of information, thereby encouraging the feature extraction network to focus on useful information.
Assuming that the input of RBWP is , and represents a nonlinear mapping, RBWP can be represented with the following formula:
where denotes element-wise multiplication, and the nonlinear mapping consists of two residual blocks (Res Bs), a convolutional layer for channel reduction, and a convolutional layer for information fusion. Inside a Res B, there are two convolutional kernels and learnable parameters and . Assuming the input of the Res B is , it can be represented with the following formula:
where represents the output of the Res B, and denote the convolutional layers with and kernels, respectively, and represent the learnable parameters, denotes multiplication, and denotes the aggregation of two feature maps.
Subsequently, we concatenate the high-level global visual features and local visual features obtained from the transformer network and the CNN. After concatenation, we employ a 1 × 1 convolution operation to fuse these two sets of features. Ultimately, this serves as one of the inputs, denoted as , for the U-Net architecture.
3.2.2. Conditional Noise Predictor (U-Net)
The network architecture of our conditional noise predictor is shown in Figure 5. The network adopts the encoder–decoder structure of U-Net, which can effectively capture the details and global information in an image, is easy to train, and has a stable training process. The skip connections can help the network better learn the spatial information of the image and alleviate the problems of gradient vanishing and overfitting. The inputs of the network are the latent variable at time , the low-resolution image feature , and the time . According to Equations (15) and (16), the noise at time in the reverse diffusion process can be predicted via the well-trained conditional noise predictor , and then and can be obtained, and the next latent variable can be sampled. By repeatedly iterating, the super-resolution remote-sensing image can be obtained. The U-Net network serves as the main network of the conditional noise predictor. Firstly, the network transforms the input into feature maps using two-dimensional convolution and a Mish activation function. Then, the feature map of the LR image is fused with the feature map of and input into the U-Net main network. According to the design by Ho et al., time is encoded into using transformer sinusoidal positional encoding and embedded into the Res block through a multi-layer perceptron (MLP). The main structure of the U-Net network consists of the encoder step, middle step, and decoder step. The detailed structures of each part will be introduced below.
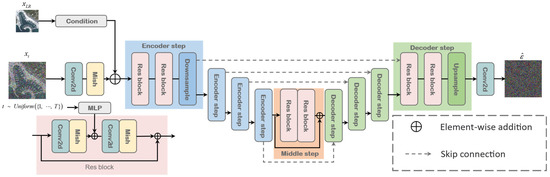
Figure 5.
The architecture of conditional noise predictor (U-Net).
As shown in Figure 5, the input of the Res block is , and represents the nonlinear mapping branch that includes a convolution and Mish activation function. The Res block can be expressed with the following equation:
where represents the output of the Res block.
Each encoder step contains two Res blocks and one downsampling block, where the downsampling block uses a 2D convolution with a stride of 2 to reduce the feature map size by a stride of 2. Let be the output of the n-th layer of the encoder, which can be expressed with the following equation:
The middle step consists of two Res blocks and residual structures, which can be formulated as
where and are the input and output of the middle step, respectively.
Each decoder step contains two Res blocks and one upsampling block, where the upsampling block uses transpose convolution to double the feature map size. Let x be the output of the n-th layer of the encoder, which can be expressed with the following equation:
where transpose denotes transpose convolution with a stride of 2 to achieve upsampling. represents the output of the (n + 1)-th layer of the decoder, and represents the output of the n-th layer of the encoder. Finally, we reconstruct the predicted noise value by applying a 2D convolution to the output of the decoder. This predicted value is then used to recover the latent variable at the next time step.
3.3. Fourier High-Frequency Spatial Constraints
The purpose of remote-sensing image super-resolution is to increase the high-frequency information in low-resolution images. How to obtain the lost high-frequency information has become the key to solving the super-resolution problem. For super-resolution methods based on diffusion models, it has been proven that adding pixel-level constraints in the reverse diffusion process of the model can guide the diffusion process [2], leading to more precise remote-sensing image super-resolution reconstruction. In order to further improve the efficiency of the model to reconstruct more detailed information and narrow the gap with high-resolution images, we propose a Fourier high-frequency spatial loss function in this paper to better enhance the lost high-frequency information restoration capability in LR images. By directly emphasizing the high-frequency content through the frequency components calculated with the fast Fourier transform (FFT) [43], the proposed loss function can generate remote-sensing super-resolution images with more detailed information and fine objects. Moreover, it provides global constraints during training rather than local pixel loss in the spatial domain. This high-frequency information greatly contributes to small target recognition and the clarity of remote-sensing images.
The Fourier transform is widely used to analyze the frequency components of signals, and it can also be applied in the field of image processing, such as for image enhancement, image compression, and image analysis [44]. The Fourier transform represents the changes in pixel brightness in an image as a series of frequencies, including their amplitudes and phases. This representation can help us better understand the content and features of the image, such as edges, textures, and shapes. As shown in Figure 6, the 2D discrete Fourier transform (DFT) is a special form of the continuous Fourier transform (CFT) that can transform digital images from the spatial domain into the frequency domain. The Fourier space consists of standard orthogonal basis functions, where complex frequency components describe the characteristics of the spectrum. It should be noted that for multi-channel images, the Fourier transform can be applied to each channel separately and then combined. This process can be represented with the following formula:
where represents the size of the image, denotes the pixel coordinates in the spatial domain, represents the pixel value, represents the coordinates of the spatial frequency in the spectrum, represents the complex frequency value, and and represent the Euler’s number and imaginary unit, respectively. Using Euler’s formula, we can obtain

Figure 6.
(a) The original image and its corresponding frequency spectrum, (b) the effect after applying a high-pass filter to the frequency spectrum, (c) the effect after applying a low-pass filter to the frequency spectrum.
The amplitude spectrum and phase spectrum of the Fourier transform are obtained via
where and are the real and imaginary parts of the Fourier transform, respectively.
Then, we can obtain the high-frequency and low-frequency features of the corresponding image.
By using the FFT to transform these two images into the frequency domain, we can obtain the high-frequency feature region in the Fourier space by applying a mask. Our idea is to calculate the loss in the high-frequency region of the Fourier space. The difference between the two vectors can be expressed as follows:
In order to more accurately represent the error, the loss function includes two parts: the amplitude loss and phase loss at the location [45], as shown in the Figure 7.
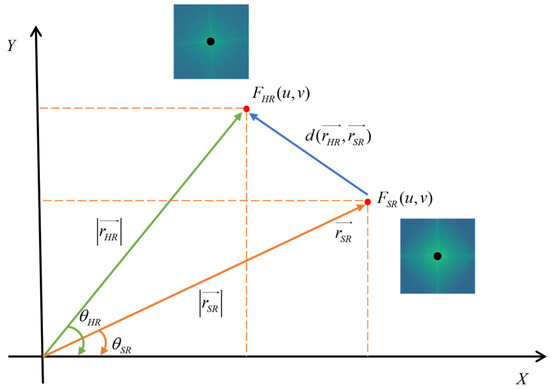
Figure 7.
Schematic diagram of the high-frequency feature loss function.
The transformation into the entire high-frequency spectrum can be represented with the following formula:
Finally, the total Fourier high-frequency spatial loss is obtained as follows:
This loss function consists of two parts: amplitude loss and the corresponding phase loss . Then, the pixel loss function is added as a constraint term to the diffusion model to generate higher-quality images. Finally, the total loss function is obtained as follows:
where and are hyperparameters used to control the weighting of the two loss functions.
3.4. Training and Inference Process
As shown in Algorithm 1, during the training phase, we first prepare the model to be trained and randomly initialize its parameters (line 1). The LR-HR image pairs are used as the training dataset (line 2), and the input low-resolution images are passed through the pre-trained hybrid feature network to obtain the low-resolution image features (line 4). Then, during training, we randomly sample an image pair from the dataset (line 6), randomly sample a time t from a uniform distribution (line 8), and calculate the latent variable at time according to the formula (line 3). Next, we feed into the noise predictor and optimize it through gradient descent (line 10).
| Algorithm 1 Training process. |
| 1: The model to be trained: |
| 2: Dataset: |
| 3: The latent variable at time t: |
| 4: Input low-resolution image features: |
| 5: Loss function: |
| 5: While not converged do |
| 6: |
| 7: |
| 8: |
| 9: Take gradient step on Loss |
| 10: |
| 11: End while |
As shown in Algorithm 2, the inference process requires steps, starting with (line 5). At this point, is sampled from a standard normal distribution (line 4), and a residual image with different levels of noise is output at each iteration (line 7). When t > 1, we sample z from a standard normal distribution , and when , it is set to 0 (line 6). Then, using the noise predictor with as input, we calculate (line 7), and serves as the final output. The super-resolution image is obtained by adding the residual image to the up-sampled low-resolution image . The intermediate images generated at each stage of the inference process in the diffusion model are presented as shown in Figure 8.
| Algorithm 2 Inference process. |
| 1: The trained model: , , |
| 2: The low-resolution image to be SR: |
| 3: Features of the low-resolution image: |
| 4: |
| 5: for do |
| 6: if , else |
| 7: |
| 8: end for |
| 9: Return |

Figure 8.
(a–f) depict the process of image reconstruction using the diffusion model, where the image on top represents , and the image at the bottom represents . (g) represents the result of the image reconstruction, where the image on top represents , and the image at the bottom represents .
3.5. Inference Acceleration of Diffusion Model
Generating a high-resolution remote-sensing image from random noise involves a reverse diffusion process that includes nearly a hundred steps. Therefore, a key challenge in using diffusion models for remote-sensing image super resolution is how to address the time cost resulting from multiple iterations. One effective method to address this issue is to use a smaller noise prediction model such as U-Net. Currently, there are many model compression methods available, including manually designing lightweight networks, pruning, quantization, neural architecture search (NAS), and knowledge distillation. Among these, knowledge distillation is a widely used and high-performing model compression method. It can transfer knowledge learned from a large teacher network to a smaller student network with minimal performance loss. The teacher network is typically a single complex network or a collection of networks with good performance and generalization ability. During the training process, the teacher network can learn mapping relationships, and the student network can improve its performance by learning the target task knowledge from the teacher network. To avoid the significant impact of distillation on the super resolution results, this paper introduced a feature distillation method [46] into the diffusion model super resolution to reduce the time cost in the reverse diffusion process.
First, we replaced the original U-Net network with a smaller U-Net network. The input and output channel numbers of each convolutional layer in the smaller U-Net network were reduced by half, while the input channel number of the input layer was kept unchanged. To address the issue of mismatched feature sizes between the smaller U-Net network and the original U-Net network, a 1 × 1 convolutional layer was applied between them. As shown in Figure 9, we defined the loss of the student model learning the intermediate hidden layer features of the teacher model as follows:
where represents the weights of the teacher model, represents the weights of the student model, represents the i-th output feature map that needs to be matched between the teacher and student networks, and is a convolutional layer function designed to address inconsistencies between the hidden layers of the teacher and student models. After passing through this convolutional layer, the output features of the student network can match the feature dimension of the teacher’s features.
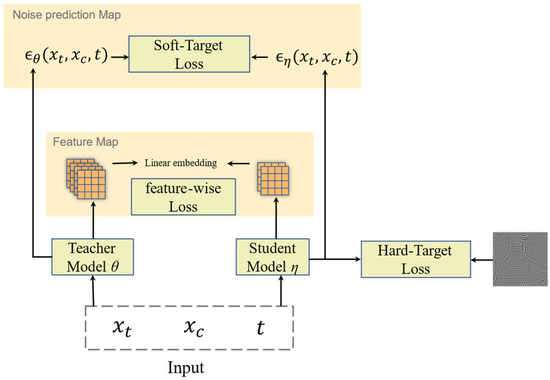
Figure 9.
The feature distillation method applied to diffusion model super resolution.
represents the difference between the output results of the student and teacher models, while represents the difference between the output and the high-resolution image target. From this, the joint loss function can be obtained.
The variables , , and represent the weight hyperparameters of the respective loss functions. These three parameters are empirically set to , , and . The process of training the student model mirrors the steps involved in training the teacher model.
4. Experiment
This section is divided with subheadings. It provides a concise and precise description of the experimental results, their interpretation, as well as the experimental conclusions that can be drawn.
4.1. Settings
4.1.1. Dataset
We used two publicly available datasets, AID [47] and RSSCN7 [48], for our training data. The RSSCN7 dataset contains 2800 remote-sensing images from seven typical scenes: grassland, forests, farmland, parking lots, residential areas, industrial areas, and rivers/lakes. Each category includes 400 images, which are sampled at four different scales. The AID dataset is a large-scale aerial image dataset that collects sample images from Google Earth. Although Google Earth images are post-processed from the raw optical aerial images to render them in RGB, there is no significant difference between them and actual optical aerial images. Therefore, the AID dataset can also be used as a training dataset for remote-sensing image super-resolution algorithms.
As shown in Figure 10, Figure 11 and Figure 12, to demonstrate the generalization capability of our proposed algorithm, we conducted experiments on two datasets, RSOD [19] and UC Merced Land Use [20], and validated our results with the real-world Gaofen-2 dataset [21]. The UC Merced Land Use dataset is a scene recognition dataset released by the Computer Vision Lab at the University of California, Merced. The images in the dataset are sourced from the United States Geological Survey (USGS) National Map Urban Area Imagery collection and include 21 categories, such as agricultural areas, airplanes, and baseball fields. The RSOD dataset is a dataset for object detection in remote-sensing images. It contains four categories of objects, including airplanes, playgrounds, overpasses, and oil drums. The dataset was released by Wuhan University in 2015 and contains a total of 976 images. The Gaofen-2 dataset [21] comes from the Gaofen-2 (GF-2) satellite, which is the first civil optical remote-sensing satellite in China with a spatial resolution of less than 1 m, carrying two cameras with a spatial resolution of 1 m (panchromatic) and 4 m (multispectral). The dataset was acquired from the satellite and has a spatial resolution of up to 0.8 m at the ground level.

Figure 10.
Display of images in different scene categories in the UC Merced Land Use test set.

Figure 11.
Display of images in different scene categories in the RSOD test set.

Figure 12.
Display of images in different scene categories in the Gaofen-2 test set.
4.1.2. Implementation Details
We propose a model consisting of a conditional noise predictor U-Net, with U-Net channels set to , as well as a transformer network and a CNN for extracting low-resolution image features, with , , and channels. The conditional noise predictor uses the Adam [49] optimization method to update model parameters, with and set to 0.9 and 0.999, respectively, and a batch size of 8. To improve the model’s stability, a series of data augmentation operations, such as rotation and flipping, were applied to the training dataset. The number of steps for the forward and reverse diffusion processes in the diffusion model were set empirically to 100, while the noise schedule and were set according to [50]. The learning rate was initially set to and decreased by a factor of 10 every 20 epochs. We performed 5 identical training and validation runs for each experiment to obtain an average result and increase the persuasiveness of the experiments. All experiments were conducted using PyTorch 1.12.1 [51] and Python 3.9, with CUDA 11.7 and CuDNN 8.2.1, on a server with an Intel Core i9-12900K CPU, 64 GB RAM, and an NVIDIA GeForce RTX 3090 GPU.
4.1.3. Evaluation Metrics
To effectively evaluate the effectiveness of the algorithm proposed in this paper, we employed several widely used objective image quality assessment methods in the super-resolution field. The details of these image quality assessment methods are provided below.
The mean square error (MSE) is used to represent the intensity of image distortion by calculating the average difference between the pixel values of the reference image and the distorted image. The MSE can be calculated using the following formula:
where represents the input image, and and denote its height and width, respectively. represents the pixel value of the image at location .
The peak signal-to-noise ratio (PSNR) of an image is a physical measure that represents the ratio of the maximum value of a signal to the maximum value of the distorted signal. PSNR is often used as a quantitative indicator for image quality enhancement. When evaluating distorted images, the PSNR can be calculated using the maximum grayscale value and the mean square error (MSE) between the distorted and reference images.
where represents the dynamic range of the pixel values, which is typically 256 for 8-bit images.
Natural images have strong inter-pixel dependencies, which form the structural information of the images. Compared with PSNR and MSE, which evaluate image quality based on pixel-level differences, SSIM can effectively measure changes in the structural information of the image. Therefore, SSIM is better suited to the human visual system (HVS). The SSIM algorithm compares images from three perspectives—luminance, contrast, and structure—and combines the results to obtain the structural similarity index (SSIM). The calculation process is as follows:
where and are the mean values of x and y, and are the variances of x and y, is the covariance of x and y, and , are two constants to avoid division by zero.
4.2. Comparisons with State-of-the-Art Algorithms
In this section, we compare the leading super-resolution algorithms for general images, including SRCNN [5], VDSR [9], SAN [12], DDBPN [23], and RDN [13], with those designed specifically for remote-sensing images, such as MHAN [10] and EEGAN [28]. The source code for these benchmark methods can be downloaded from the authors’ websites, and the relevant parameters were strictly configured according to the authors’ recommendations in their publications. We trained and tested these methods under the same conditions on the RSOD and UCMerced_Land datasets, as shown in Table 1 and Table 2. Unlike general images, remote-sensing images contain complex scenes and small targets, which may render models that perform well on general image datasets unsuitable for remote-sensing images. Our model achieved competitive results in both PSNR and SSIM metrics for different scale factors (×2, ×4, and ×8), outperforming the other methods by 1–3 points in PSNR and SSIM for ×4 and ×8 scale factors. These results suggest that our model is superior to other methods.

Table 1.
Comparison between different remote-sensing image super-resolution methods on the UCMerced_Land test dataset, with evaluation metrics including PSNR and SSIM values, at scale factors of ×2, ×4, and ×8.
Table 2.
Comparison between different remote-sensing image super-resolution methods on the RSOD test dataset, with evaluation metrics including PSNR and SSIM values, at scale factors of ×2, ×4, and ×8.
Due to significant differences in remote-sensing images across various scenes, we further tested our proposed method on remote-sensing images of different scenes to demonstrate its universality and robustness. Specifically, we conducted experiments on remote-sensing images of different types of scenes and the results, as shown in Table 3, Table 4, Table 5, Table 6, Table 7 and Table 8, indicate that our proposed method achieves competitive results on remote-sensing images of various scenes. Notably, our method performs particularly well on images of complex scenes with rich textures, such as buildings or forests, as indicated by the higher SSIM values.
Table 3.
Performance comparison between different remote-sensing image super-resolution methods on the UCMerced_Land test dataset for various scenes at scale factor of ×2, with evaluation metrics including PSNR and SSIM values.
Table 4.
Performance comparison between different remote-sensing image super-resolution methods on the RSOD test dataset for various scenes at scale factor of ×2, with evaluation metrics including PSNR and SSIM values.
Table 5.
Performance comparison between different remote-sensing image super-resolution methods on the UCMerced_Land test dataset for various scenes at scale factor of ×4, with evaluation metrics including PSNR and SSIM values.
Table 6.
Performance comparison between different remote-sensing image super-resolution methods on the RSOD test dataset for various scenes at scale factor of ×4, with evaluation metrics including PSNR and SSIM values.
Table 7.
Performance comparison between different remote-sensing image super-resolution methods on the UCMerced_Land test dataset for various scenes at scale factor of ×8, with evaluation metrics including PSNR and SSIM values.
Table 8.
Performance comparison between different remote-sensing image super-resolution methods on the RSOD test dataset for various scenes at scale factor of ×8, with evaluation metrics including PSNR and SSIM values.
Since the visual differences between various SR algorithms for a ×2 scale factor are not significant, this paper compared the visual effects of various algorithms for ×4 and ×8 scale factors, as shown in Figure 13 and Figure 14. The proposed model effectively distinguishes between roof textures and road signs, separates closely spaced individual targets, and accurately reconstructs the color information and texture details of high-resolution images, restoring most of the details (including roof details and dense trees). The generated images exhibit more intricate details and higher contrast, demonstrating that our algorithm can recover high-resolution images with rich semantic information from low-resolution images that contain minimal detailed information, without producing excessive additional information.


Figure 13.
SR results at scale factor of ×4 on the test dataset [19,20] using different approaches (b–j), and (a) represents the original high-resolution image for each approach.


Figure 14.
SR results at scale factor of ×8 on the test dataset [19,20] using different approaches (b–j), and (a) represents the original high-resolution image for each approach.
Furthermore, to verify the generalization performance of our proposed algorithm and its performance on real remote-sensing datasets, we validated our algorithm on the Gaofen-2 dataset [21]. Since there is no reference image available for real datasets, we compared the different methods from the perspective of human visual perception, as shown in Figure 15 and Figure 16. Our proposed algorithm recovers images with higher contrast and sharper edges, while the results generated by other methods are blurry and lack detailed information.

Figure 15.
SR results at scale factor of ×2 on the real-world Gaofen-2 dataset [21] using different approaches (a–d). (a) Bicubic; (b) SRCNN [5]; (c) MHAN [13]; (d) Ours.


Figure 16.
SR results at scale factor of ×4 on the real-world Gaofen-2 dataset [21] using different approaches (a–d). (a) Bicubic; (b) SRCNN; (c) MHAN; (d) Ours.
4.3. Comparison between Time Consumption and Performance before and after Distillation
In this section, we analyze the effectiveness of the proposed feature distillation method through extensive experiments on the RSOD test dataset. The experimental results in Table 9 and Table 10 demonstrate that, with the same experimental configuration, the compressed U-Net model reduces the size by nearly 2 times, and the reverse diffusion time for a single image is reduced by approximately 56%. In a quantitative metrics comparison, the performance of the compressed model is only slightly inferior to that of the original model. As shown in Figure 17, the visual comparison between the compressed model and the original model reveals only minor differences that are imperceptible to the human eye. Furthermore, as shown in Table 11, we compared the inference time of our proposed algorithm with that of traditional deep-learning-based end-to-end super-resolution algorithms. It can be seen that our algorithm takes an order of magnitude more time than other algorithms. In our future work, we will address these issues by using a more efficient U-Net network and model compression methods.
Table 9.
Comparison between original model and compressed model in terms of parameters, computation, and time consumption. The size of the input image was 256 × 256 pixels, with a scale factor of ×4.
Table 10.
The comparison between quantitative results of the original model and the compressed model on the RSOD test dataset.

Figure 17.
The visual quality comparison between the original model and the compressed model with a scale factor of ×4. (a) Ground truth; (b) Bicubic; (c) Original; (d) Distillation.
Table 11.
Comparison between the time consumptions of different super-resolution algorithms during the model inference process. The size of the input image was 256 × 256 pixels, with a scale factor of ×4.
4.4. Ablation Study
In this section, we demonstrate the importance of the transformer network and CNN in the hybrid conditional feature extraction as well as the high-frequency spatial constraint in our proposed diffusion model through six ablation experiments. All experiments were conducted on the UCMerced_Land test dataset, and the quantitative metrics of PSNR and SSIM were used to evaluate the super-resolution performance. As shown in Table 12, the absence of any of the three components has a negative impact on the objective performance metrics of the generated images. Among them, the high-frequency spatial constraint plays an important role. Even when considering the other two components, the lack of high-frequency spatial constraints resulted in a decrease of approximately 0.22 dB compared with the best PSNR result.
Table 12.
This paper investigated the impact of different module combinations in the proposed hybrid conditional diffusion model on the super-resolution performance of remote-sensing images. All experiments were conducted on the UCMerced_Land test dataset.
5. Conclusions
In this paper, we proposed a diffusion-model-based framework for remote-sensing image super-resolution, named EHC-DMSR, which utilizes a hybrid conditional diffusion model architecture. The transformer network and CNN are used to extract comprehensive features from low-resolution images, which are then used as guidance in image generation. Furthermore, to constrain the diffusion fusion model and generate more high-frequency information, we proposed a Fourier high-frequency spatial constraint to emphasize high-frequency spatial loss and optimize the reverse diffusion direction. To address the time-consuming issue of the diffusion model in the reverse diffusion process, we proposed a feature-distillation-based model compression method for the diffusion model to reduce the computational load of U-Net, thereby shortening the inference time without affecting the super-resolution performance. Extensive experiments on the synthetic dataset RSOD, real dataset Gaofen-2, and large-scale experiments demonstrated that our proposed algorithm achieves excellent results in both quantitative evaluation metrics and generates clearer, more detailed super-resolution images at high scale factors compared with other advanced algorithms. Although our proposed model achieved excellent visual quality and objective evaluation scores, compared with other learning-based super-resolution algorithms, the inference time of the model is longer due to the use of a more complex transformer architecture to extract global features, which may result in wasted computational resources. In addition, the noise prediction network in our study heavily borrows the U-Net network structure from DDPM, and the influence of the noise prediction model on the diffusion model has not been explored. We hope that researchers can make improvements in the above aspects in the future to promote the practical application of diffusion models in remote-sensing image super-resolution and extend our work to more low-level vision tasks such as image restoration.
Author Contributions
Conceptualization, L.H. and Q.H.; methodology, L.H.; software, L.H.; validation, Y.Z. (Yuchen Zhao), H.L. (Hengyi Lv) and G.B.; formal analysis, Y.Z. (Yisa Zhang); writing—original draft preparation, L.H.; writing—review and editing, Y.Z. (Yuchen Zhao); visualization, Q.H.; supervision, Y.Z. (Yuchen Zhao); project administration, G.B.; funding acquisition, H.L. (Hailong Liu). All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China (62005269).
Data Availability Statement
Not applicable.
Acknowledgments
The authors thank the editors and reviewers for their hard work and valuable advice.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Wang, X.; Yi, J.; Guo, J.; Song, Y.; Lyu, J.; Xu, J.; Yan, W.; Zhao, J.; Cai, Q.; Min, H. A Review of Image Super-Resolution Approaches Based on Deep Learning and Applications in Remote Sensing. Remote Sens. 2022, 14, 5423. [Google Scholar] [CrossRef]
- Liu, J.; Yuan, Z.; Pan, Z.; Fu, Y.; Liu, L.; Lu, B. Diffusion Model with Detail Complement for Super-Resolution of Remote Sensing. Remote Sens. 2022, 14, 4834. [Google Scholar] [CrossRef]
- Ma, W.; Pan, Z.; Yuan, F.; Lei, B. Super-Resolution of Remote Sensing Images via a Dense Residual Generative Adversarial Network. Remote Sens. 2019, 11, 2578. [Google Scholar] [CrossRef]
- Gu, J.; Sun, X.; Zhang, Y.; Fu, K.; Wang, L. Deep Residual Squeeze and Excitation Network for Remote Sensing Image Super-Resolution. Remote Sens. 2019, 11, 1817. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef] [PubMed]
- Xu, Y.; Li, J.; Song, H.; Du, L.; Muhammad, T. Single-Image Super-Resolution Using Panchromatic Gradient Prior and Variational Model. Math. Probl. Eng. 2021, 2021, 9944385. [Google Scholar] [CrossRef]
- Huang, Y.; Li, J.; Gao, X.; He, L.; Lu, W. Single Image Super-Resolution via Multiple Mixture Prior Models. IEEE Trans. Image Process. 2018, 27, 5904–5917. [Google Scholar] [CrossRef] [PubMed]
- Yang, Q.; Zhang, Y.; Zhao, T.; Chen, Y. Single image super-resolution using self-optimizing mask via fractional-order gradient interpolation and reconstruction. ISA Trans. 2018, 82, 163–171. [Google Scholar] [CrossRef]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Zhang, D.; Shao, J.; Li, X.; Shen, H.T. Remote Sensing Image Super-Resolution via Mixed High-Order Attention Network. IEEE Trans. Geosci. Remote Sens. 2021, 59, 5183–5196. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Dai, T.; Cai, J.; Zhang, Y.; Xia, S.-T.; Zhang, L. Second-order attention network for single image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 11065–11074. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2472–2481. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- ElHaj, K.; Alshamsi, D.; Aldahan, A. GeoZ: A Region-Based Visualization of Clustering Algorithms. J. Geovisualization Spat. Anal. 2023, 7, 15. [Google Scholar] [CrossRef]
- Harrie, L.; Oucheikh, R.; Nilsson, Å.; Oxenstierna, A.; Cederholm, P.; Wei, L.; Richter, K.-F.; Olsson, P. Label Placement Challenges in City Wayfinding Map Production—Identification and Possible Solutions. J. Geovisualization Spat. Anal. 2022, 6, 16. [Google Scholar] [CrossRef]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. arXiv 2020, arXiv:2006.11239. [Google Scholar]
- Li, H.Y.; Yang, Y.F.; Chang, M.; Chen, S.Q.; Feng, H.J.; Xu, Z.H.; Li, Q.; Chen, Y.T. SRDiff: Single image super-resolution with diffusion probabilistic models. Neurocomputing 2022, 479, 47–59. [Google Scholar] [CrossRef]
- Long, Y.; Gong, Y.; Xiao, Z.; Liu, Q. Accurate Object Localization in Remote Sensing Images Based on Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2486–2498. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Tong, X.-Y.; Xia, G.-S.; Lu, Q.; Shen, H.; Li, S.; You, S.; Zhang, L. Land-cover classification with high-resolution remote sensing images using transferable deep models. Remote Sens. Environ. 2020, 237, 111322. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Haris, M.; Shakhnarovich, G.; Ukita, N. Deep back-projection networks for super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1664–1673. [Google Scholar]
- Li, Z.; Yang, J.; Liu, Z.; Yang, X.; Jeon, G.; Wu, W. Feedback network for image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3867–3876. [Google Scholar]
- Lei, S.; Shi, Z.; Zou, Z. Super-Resolution for Remote Sensing Images via Local–Global Combined Network. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1243–1247. [Google Scholar] [CrossRef]
- Pan, Z.; Ma, W.; Guo, J.; Lei, B. Super-resolution of single remote sensing image based on residual dense backprojection networks. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7918–7933. [Google Scholar] [CrossRef]
- Chang, Y.; Luo, B. Bidirectional Convolutional LSTM Neural Network for Remote Sensing Image Super-Resolution. Remote Sens. 2019, 11, 2333. [Google Scholar] [CrossRef]
- Jiang, K.; Wang, Z.; Yi, P.; Wang, G.; Lu, T.; Jiang, J. Edge-Enhanced GAN for Remote Sensing Image Superresolution. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5799–5812. [Google Scholar] [CrossRef]
- Creswell, A.; White, T.; Dumoulin, V.; Arulkumaran, K.; Sengupta, B.; Bharath, A.A. Generative Adversarial Networks: An Overview. IEEE Signal Process. Mag. 2018, 35, 53–65. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Rezende, D.; Mohamed, S. Variational inference with normalizing flows. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 1530–1538. [Google Scholar]
- Thanh-Tung, H.; Tran, T. Catastrophic forgetting and mode collapse in GANs. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Neural Network, Glasgow, UK, 19–24 July 2020; pp. 1–10. [Google Scholar]
- Sohl-Dickstein, J.; Weiss, E.; Maheswaranathan, N.; Ganguli, S. Deep unsupervised learning using nonequilibrium thermodynamics. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 2256–2265. [Google Scholar]
- Kong, Z.; Ping, W.; Huang, J.; Zhao, K.; Catanzaro, B. Diffwave: A versatile diffusion model for audio synthesis. arXiv 2020, arXiv:2009.09761. [Google Scholar]
- Batzolis, G.; Stanczuk, J.; Schönlieb, C.-B.; Etmann, C. Conditional image generation with score-based diffusion models. arXiv 2021, arXiv:2111.13606. [Google Scholar]
- Song, Y.; Sohl-Dickstein, J.; Kingma, D.P.; Kumar, A.; Ermon, S.; Poole, B. Score-based generative modeling through stochastic differential equations. arXiv 2020, arXiv:2011.13456. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695. [Google Scholar]
- Kim, G.; Kwon, T.; Ye, J.C. Diffusionclip: Text-guided diffusion models for robust image manipulation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 2426–2435. [Google Scholar]
- Choi, J.; Kim, S.; Jeong, Y.; Gwon, Y.; Yoon, S. Ilvr: Conditioning method for denoising diffusion probabilistic models. arXiv 2021, arXiv:2108.02938. [Google Scholar]
- Chung, H.; Sim, B.; Ye, J.C. Come-closer-diffuse-faster: Accelerating conditional diffusion models for inverse problems through stochastic contraction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12413–12422. [Google Scholar]
- Saharia, C.; Chan, W.; Chang, H.; Lee, C.; Ho, J.; Salimans, T.; Fleet, D.; Norouzi, M. Palette: Image-to-image diffusion models. In Proceedings of the ACM SIGGRAPH 2022 Conference Proceedings, Vancouver, BC, Canada, 7–11 August 2022; pp. 1–10. [Google Scholar]
- Lu, Z.; Li, J.; Liu, H.; Huang, C.; Zhang, L.; Zeng, T. Transformer for single image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 457–466. [Google Scholar]
- Brigham, E.O.; Morrow, R.E. The fast Fourier transform. IEEE Spectr. 1967, 4, 63–70. [Google Scholar] [CrossRef]
- Pandey, S.; Singh, M.P.; Pandey, V. Image transformation and compression using Fourier transformation. Int. J. Curr. Eng. Technol. 2015, 5, 1178–1182. [Google Scholar]
- Fuoli, D.; Van Gool, L.; Timofte, R. Fourier space losses for efficient perceptual image super-resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2360–2369. [Google Scholar]
- Chen, W.; Peng, L.; Huang, Y.; Jing, M.; Zeng, X. Knowledge Distillation for U-Net Based Image Denoising. In Proceedings of the 2021 IEEE 14th International Conference on ASIC (ASICON), Kunming, China, 26–29 October 2021; pp. 1–4. [Google Scholar]
- Xia, G.-S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A Benchmark Data Set for Performance Evaluation of Aerial Scene Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef]
- Zou, Q.; Ni, L.; Zhang, T.; Wang, Q. Deep Learning Based Feature Selection for Remote Sensing Scene Classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2321–2325. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Nichol, A.Q.; Dhariwal, P. Improved denoising diffusion probabilistic models. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 8162–8171. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.M.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]




















Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).