



MS-AGAN: Road Extraction via Multi-Scale Information Fusion and Asymmetric Generative Adversarial Networks from High-Resolution Remote Sensing Images under Complex Backgrounds

 , , ,
, , ,  , ,
, ,
Abstract
1. Introduction
- The current deep models have better road extraction results in open-source datasets in HRSIs (e.g., DeepGlobe dataset [47], Massachusetts dataset [17], and SpaceNet dataset [48]). However, the robustness of the models has been tested only in fine-grained road extraction tasks [32,37,44]. Open-source datasets such as the DeepGlobe and the Massachusetts datasets, which are widely employed for remotely sensed road extraction [46,49], are less subject to external interference (e.g., vegetation cover, manual annotation). However, most of these datasets cover urban areas while ignoring the vast suburban zones [50]. Yao et al. demonstrate that models that perform well on open-source clear datasets have significantly lower road extraction capabilities in complex contexts, and road disturbances have not been learned enough [51]. As a matter of fact, most of the road areas in current HRSIs have problems such as high vegetation coverage, vague images, and large road spans, as shown in Figure 1, which will directly affect road extraction performance.
- The connectivity of the extracted roads in HRSIs is influenced by misinformation from the shadows of buildings and trees, the diversity of imaging conditions, and the spectral similarity of roads with other objects. This is one of the biggest challenges in road extraction [52]. Pixel-wise supervised learning models (e.g., patch-based DCNN, FCNs, DeconvNet, etc.) pay much attention to road extraction accuracy rather than the quality of road connectivity [10], leading to fragmented results. The GAN-based approaches show the advantage in maintaining road network connectivity; nevertheless, some studies suggest that these methods have no mechanism for constructing road network topology [37,53], and the symmetric encoder and decoder structure also contributes to feature redundancy and incorporates attritional noises into road connectivity judgment [36].
- Most current road extraction approaches from HRSIs focus on accuracy, efficiency, connectivity, and completeness [3,8,54], yet there is no metric that can describe the model’s lowest error boundary that can be achieved in the road extraction process, while the metric is extremely important for the evaluation of the robustness and universality of the specified model in practical applications [54]. Completeness, correctness, and quality are common standards to measure road extraction performance [15]. Pixel accuracy (PA) and mean pixel accuracy (mPA) are widely adopted to represent model effect in pixel-level accuracy. However, there is still a gap in the literature to measure the robustness and universality of deep learning models under the worst conditions in road extraction from HRSIs.
- (1)
- In MS-AGAN, we propose an asymmetric encoder–decoder generator to address the requirement for multi-scale road extraction in HRSIs. The enhanced encoder utilizes ResNet34 as the backbone network to extract high-dimensional features, while the simplified decoder eliminates the multi-scale cascading operations in symmetric structures to reduce the impact of noises. The ASPP and multi-scale feature fusion modules are integrated into the asymmetric encoder–decoder structure to avoid feature redundancy and to enhance the capability to extract fine-grained road information at the pixel level.
- (2)
- The topologic features are considered in the pixel segmentation process to maintain the connectivity of the road network. A linear structural similarity loss () is introduced into the loss function of MS-AGAN, which guides MS-AGAN to generate more accurate segmentation results without auxiliary data or additional processing and to ensure that the extracted road information is more continuous and the model has stronger occlusion resistance.
- (3)
- Bayesian error rate (BER) is introduced into the field of road extraction to fairly evaluate the performance of deep models under complex backgrounds for the first time. BER determines the model’s lowest error boundary that can be achieved in road extraction from HRSIs, providing a practical metric for evaluating the universality and robustness of the models.
2. Related Works
2.1. Traditional Approaches for Road Extraction from HRSIs
2.2. Deep Learning Methods for Road Extraction from HRSIs
2.3. Road Connectivity
2.4. Evaluation Metrics
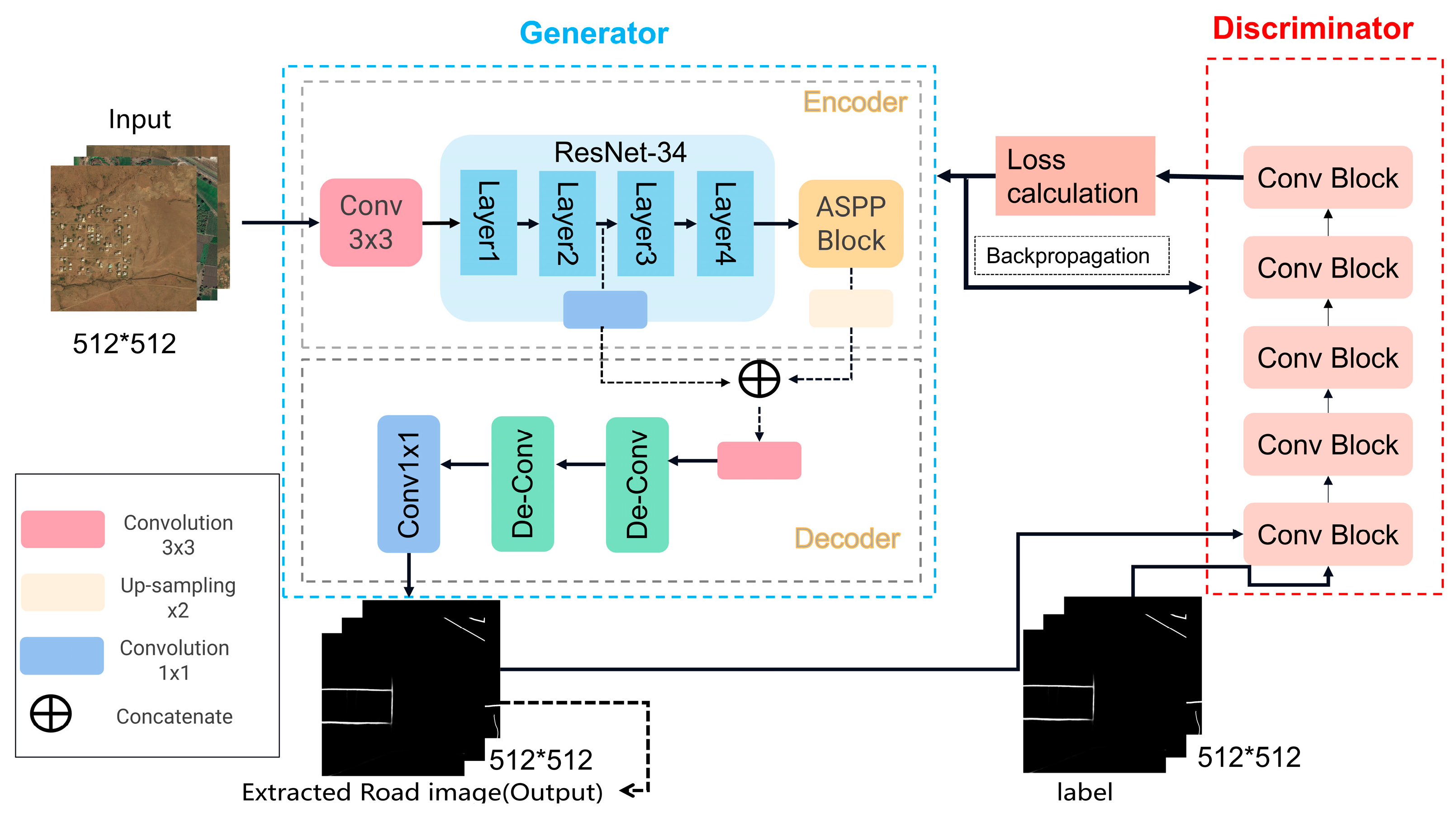
3. MS-AGAN Network
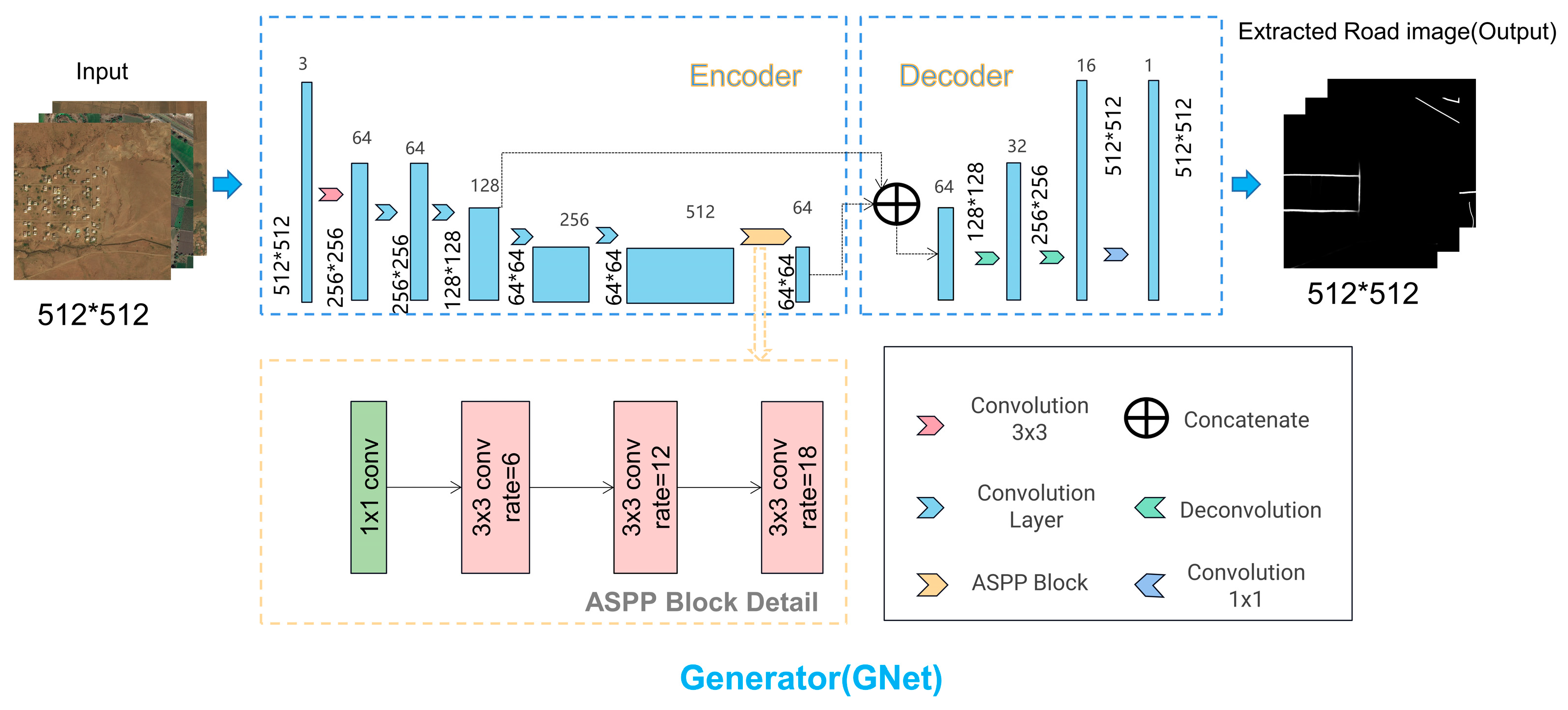
3.1. Generator GNet
3.1.1. Improved ResNet34
3.1.2. The ASPP Module
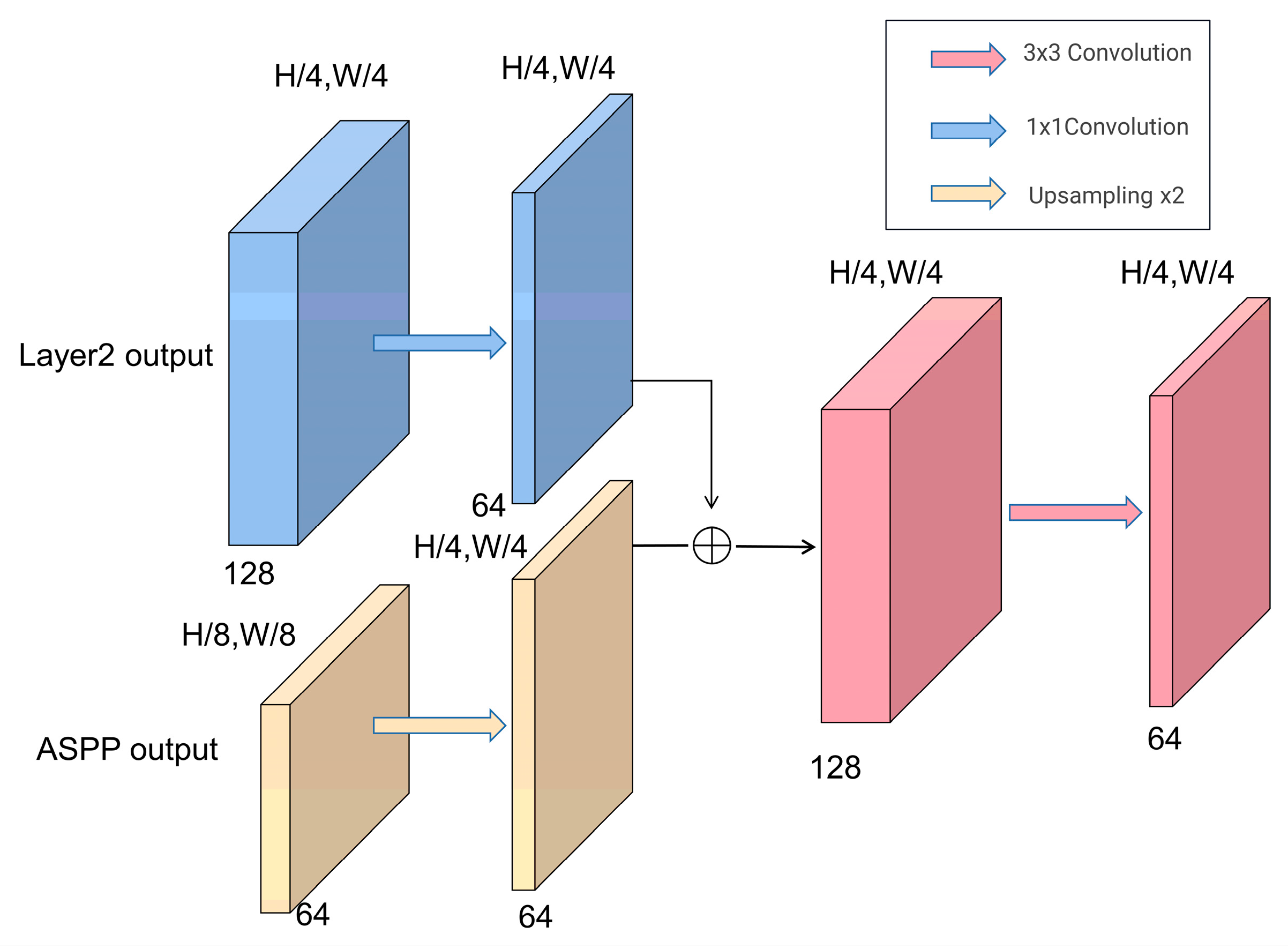
3.1.3. Decoder Structure
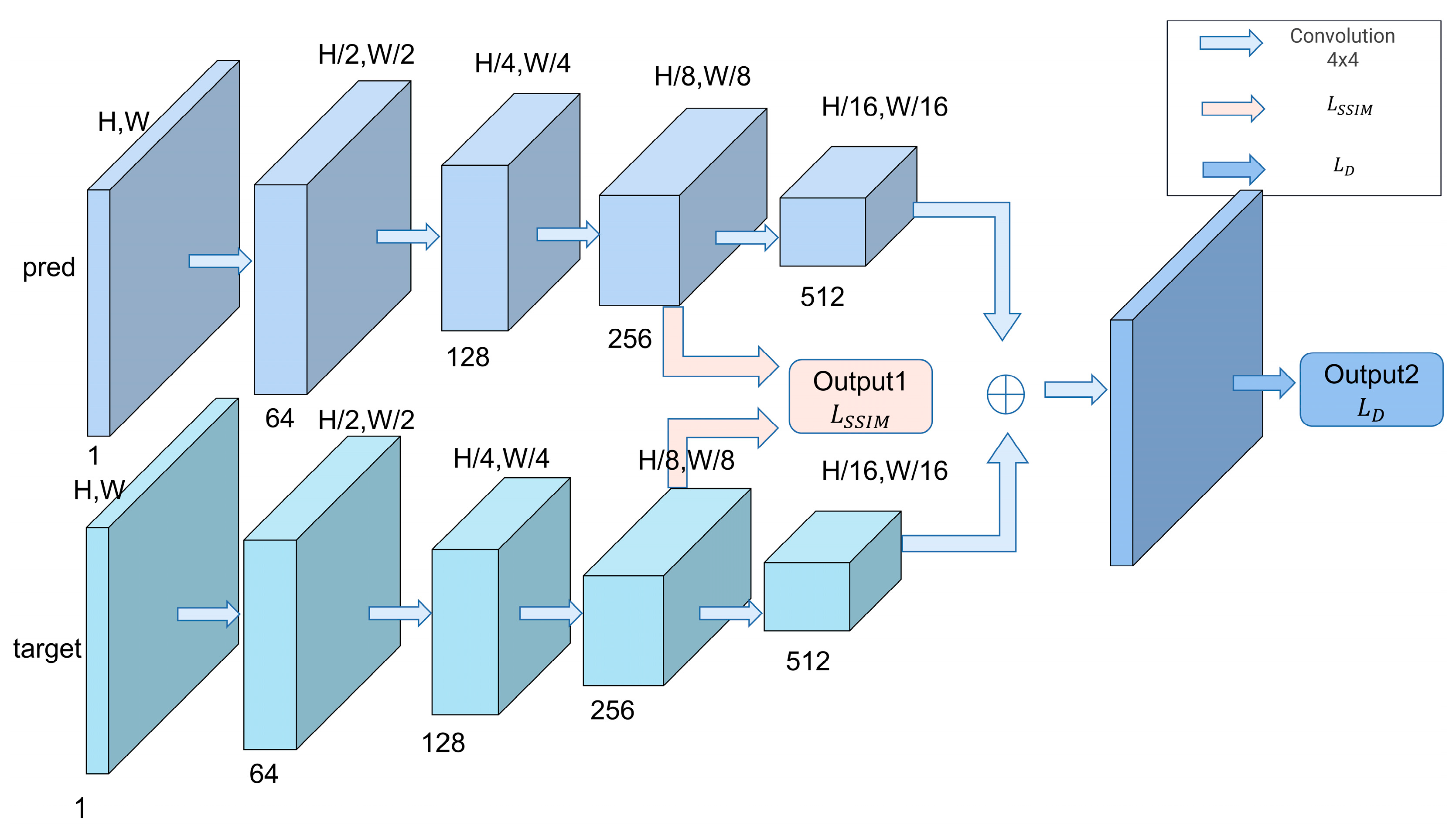
3.2. Discriminator DNet
3.3. Loss Function
3.3.1. Generation Loss Function in GNet
3.3.2. Discrimination Loss Function in DNet
3.3.3. Topologic Structure Loss
4. Experiments and Results
4.1. Datasets and Study Areas
4.1.1. DeepGlobe
4.1.2. The GF-2 Dataset of Daxing District, Beijing
4.2. Experimental Settings
4.3. Evaluation Metrics
4.4. Data Pre-Processing and Parameter Settings
4.5. Experimental Results and Evaluations
4.5.1. Performance Evaluation
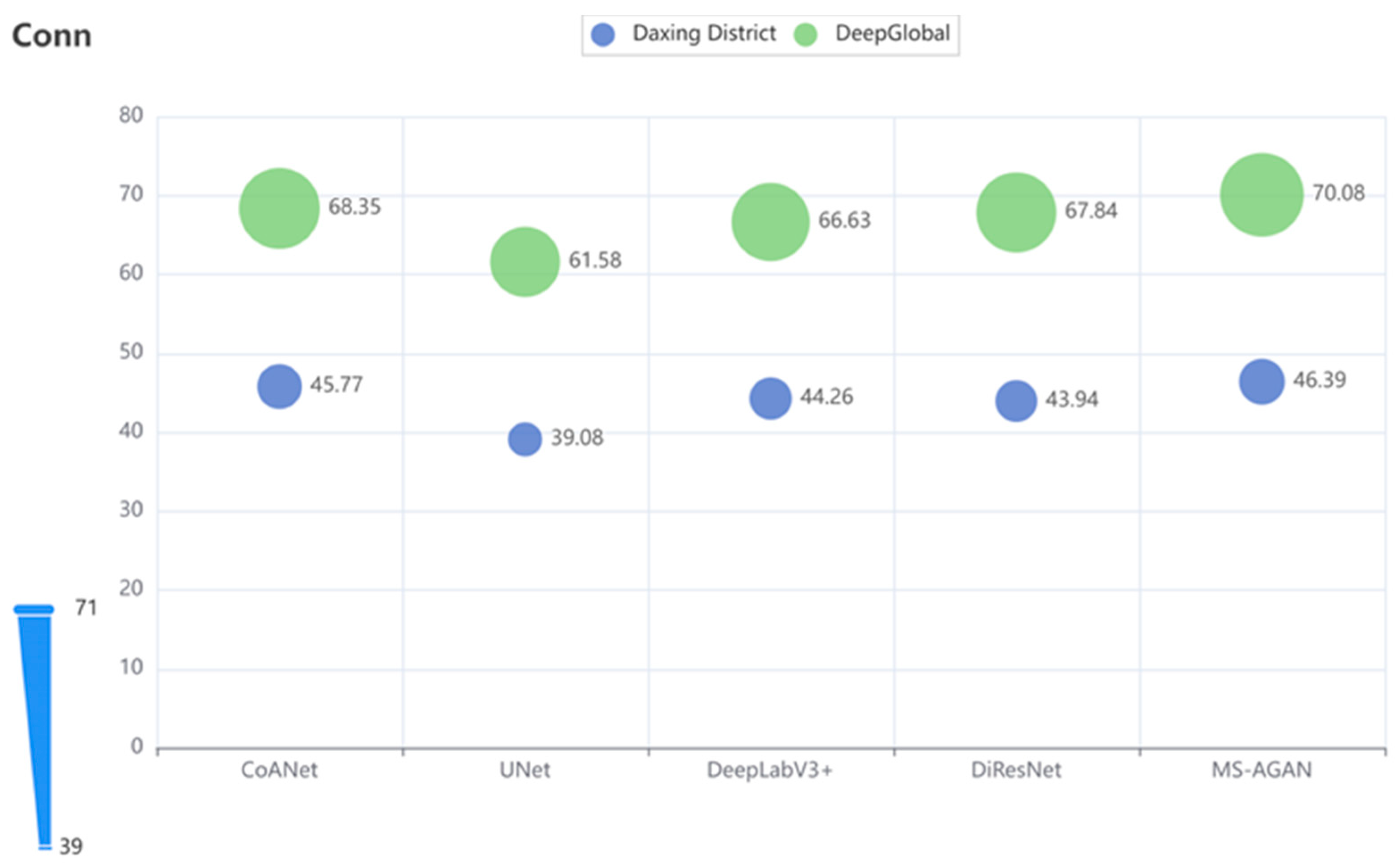
4.5.2. Evaluation of Road Connectivity
4.5.3. BER Evaluation
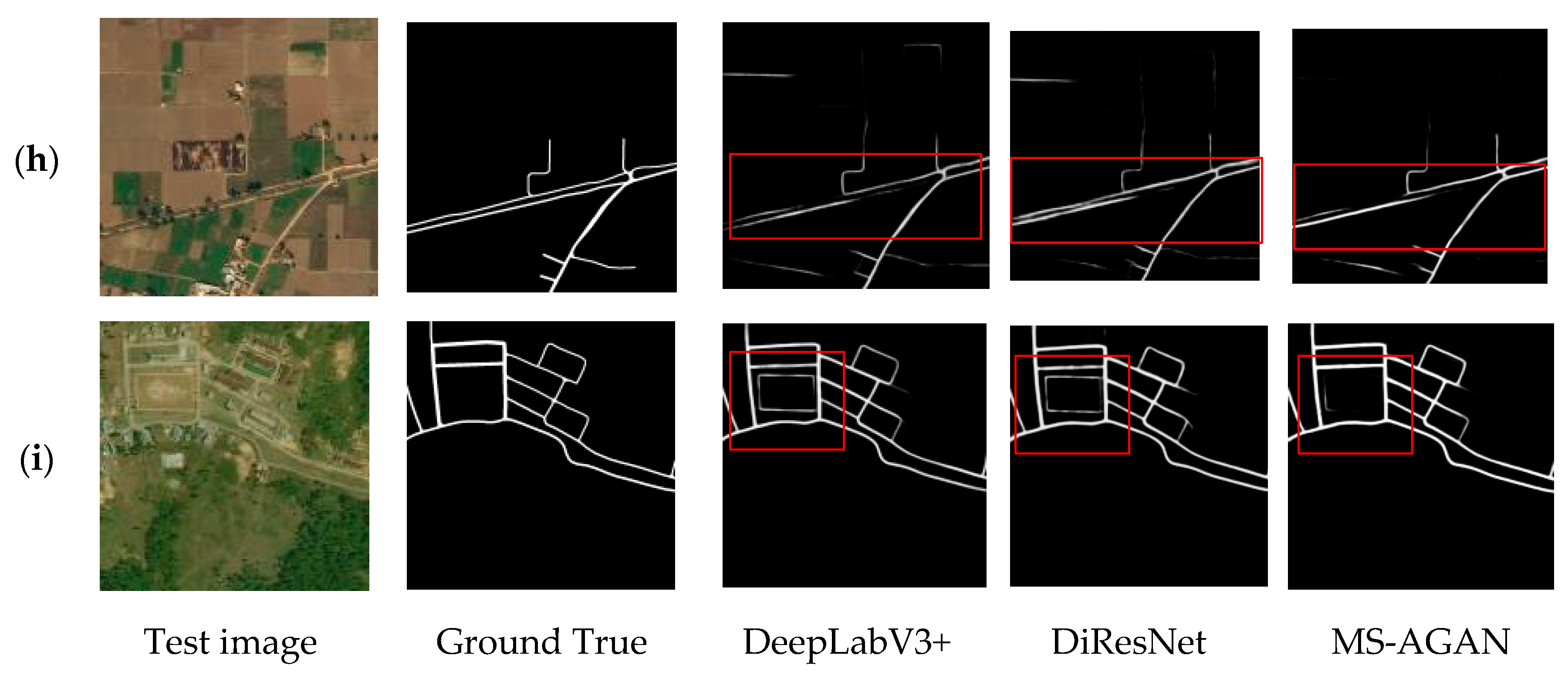
4.5.4. Qualitative Analysis
4.6. Ablation Study
4.7. Time Complexity Studies
5. Discussion and Conclusions
5.1. Discussion
5.2. Conclusions and Future Directions
Author Contributions
Funding
Conflicts of Interest
References
- Bakhtiari, H.R.R.; Abdollahi, A.; Rezaeian, H. Semi automatic road extraction from digital images. Egypt. J. Remote Sens. Space Sci. 2017, 20, 117–123. [Google Scholar] [CrossRef]
- Liu, P.; Di, L.; Du, Q.; Wang, L. Remote sensing big data: Theory, methods and applications. Remote Sens. 2018, 10, 711. [Google Scholar] [CrossRef]
- Zhou, M.; Sui, H.; Chen, S.; Wang, J.; Chen, X. BT-RoadNet: A boundary and topologically-aware neural network for road extraction from high-resolution remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2020, 168, 288–306. [Google Scholar] [CrossRef]
- Senthilnath, J.; Varia, N.; Dokania, A.; Anand, G.; Benediktsson, J.A. Deep tec: Deep transfer learning with ensemble classifier for road extraction from Uav imagery. Remote Sens. 2020, 12, 245. [Google Scholar] [CrossRef]
- Tan, Y.Q.; Gao, S.H.; Li, X.Y.; Cheng, M.M.; Ren, B. Vecroad: Point-based iterative graph exploration for road graphs extraction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8910–8918. [Google Scholar]
- Abdollahi, A.; Pradhan, B.; Alamri, A. VNet: An end-to-end fully convolutional neural network for road extraction from high-resolution remote sensing data. IEEE Access 2020, 8, 179424–179436. [Google Scholar] [CrossRef]
- Wang, Y.; Seo, J.; Jeon, T. NL-LinkNet: Toward lighter but more accurate road extraction with nonlocal operations. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Wei, Y.; Zhang, K.; Ji, S. Simultaneous Road Surface and Centerline Extraction From Large-Scale Remote Sensing Images Using CNN-Based Segmentation and Tracing. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8919–8931. [Google Scholar] [CrossRef]
- Panteras, G.; Cervone, G. Enhancing the temporal resolution of satellite-based flood extent generation using crowdsourced data for disaster monitoring. Int. J. Remote Sens. 2018, 39, 1459–1474. [Google Scholar] [CrossRef]
- Abdollahi, A.; Pradhan, B.; Alamri, A. SC-RoadDeepNet: A New Shape and Connectivity-Preserving Road Extraction Deep Learning-Based Network from Remote Sensing Data. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Bastani, F.; He, S.; Abbar, S.; Alizadeh, M.; Balakrishnan, H.; Chawla, S.; DeWitt, D. Roadtracer: Automatic extraction of road networks from aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4720–4728. [Google Scholar]
- Abdollahi, A.; Pradhan, B.; Shukla, N.; Chakraborty, S.; Alamri, A. Deep learning approaches applied to remote sensing datasets for road extraction: A state-of-the-art review. Remote Sens. 2020, 12, 1444. [Google Scholar] [CrossRef]
- Ma, Y.; Wu, H.; Wang, L.; Huang, B.; Ranjan, R.; Zomaya, A.; Jie, W. Remote sensing big data computing: Challenges and opportunities. Future Gener. Comput. Syst. 2015, 51, 47–60. [Google Scholar] [CrossRef]
- Abdollahi, A.; Pradhan, B.; Alamri, A. RoadVecNet: A new approach for simultaneous road network segmentation and vectorization from aerial and google earth imagery in a complex urban set-up. GIScience Remote Sens. 2021, 58, 1151–1174. [Google Scholar] [CrossRef]
- Chen, Z.; Deng, L.; Luo, Y.; Li, D.; Junior, J.M.; Gonçalves, W.N.; Li, D. Road extraction in remote sensing data: A survey. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102833. [Google Scholar] [CrossRef]
- Mnih, V.; Hinton, G.E. Learning to detect roads in high-resolution aerial images. In Computer Vision—ECCV 2010; Daniilidis, K., Maragos, P., Paragios, N., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6316. [Google Scholar] [CrossRef]
- Mnih, V. Machine Learning for Aerial Image Labeling. Ph.D. Thesis, University of Toronto, Toronto, ON, Canada, 2013. [Google Scholar]
- Amit, S.N.K.B.; Aoki, Y. Disaster detection from aerial imagery with convolutional neural network. In Proceedings of the 2017 International Electronics Symposium on Knowledge Creation and Intelligent Computing (IES-KCIC), Surabaya, Indonesia, 26–27 September 2017; IEEE: New York, NY, USA, 2017; pp. 239–245. [Google Scholar]
- Pi, Y.; Nath, N.D.; Behzadan, A.H. Convolutional neural networks for object detection in aerial imagery for disaster response and recovery. Adv. Eng.Inform. 2020, 43, 101009. [Google Scholar] [CrossRef]
- Atwood, J.; Towsley, D. Diffusion-convolutional neural networks. Adv. Neural Inf. Process. Syst. 2016, 29, 2001–2009. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Chen, L.; Zhu, Q.; Xie, X.; Hu, H.; Zeng, H. Road extraction from VHR remote-sensing imagery via object segmentation constrained by Gabor features. ISPRS Int. J. Geo-Inf. 2018, 7, 362. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; pp. 3431–3440. [Google Scholar]
- Patil, D.; Jadhav, S. Road extraction techniques from remote sensing images: A review. In Innovative Data Communication Technologies and Application, Proceedings of ICIDCA 2020, Coimbatore, India, 3–4 September 2020; Springer: Berlin/Heidelberg, Germany, 2021; pp. 663–677. [Google Scholar]
- Zhang, Y.; Xia, G.; Wang, J.; Lha, D. A multiple feature fully convolutional network for road extraction from high-resolution remote sensing image over mountainous areas. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1600–1604. [Google Scholar] [CrossRef]
- Pan, D.; Zhang, M.; Zhang, B. A generic FCN-based approach for the road-network extraction from VHR remote sensing images–using openstreetmap as benchmarks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2662–2673. [Google Scholar] [CrossRef]
- Xu, Z.; Shen, Z.; Li, Y.; Xia, L.; Wang, H.; Li, S.; Jiao, S.; Lei, Y. Road extraction in mountainous regions from high-resolution images based on DSDNet and terrain optimization. Remote Sens. 2020, 13, 90. [Google Scholar] [CrossRef]
- Ge, Z.; Zhao, Y.; Wang, J.; Wang, D.; Si, Q. Deep feature-review transmit network of contour-enhanced road extraction from remote sensing images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Zou, W.; Feng, D. Multi-dimensional attention unet with variable size convolution group for road segmentation in remote sensing imagery. In Proceedings of the 2022 2nd Asia-Pacific Conference on Communications Technology and Computer Science (ACCTCS), Shenyang, China, 25–27 February 2022; IEEE: New York, NY, USA, 2022; pp. 328–334. [Google Scholar]
- Chen, G.; Li, C.; Wei, W.; Jing, W.; Woźniak, M.; Blažauskas, T.; Damaševičius, R. Fully Convolutional Neural Network with Augmented Atrous Spatial Pyramid Pool and Fully Connected Fusion Path for High Resolution Remote Sensing Image Segmentation. Appl. Sci. 2019, 9, 1816. [Google Scholar] [CrossRef]
- Liu, Y.; Yao, J.; Lu, X.; Xia, M.; Wang, X.; Liu, Y. Roadnet: Learning to comprehensively analyze road networks in complex urban scenes from high-resolution remotely sensed images. IEEE Trans. Geosci. Remote Sens. 2018, 57, 2043–2056. [Google Scholar] [CrossRef]
- Wang, S.; Mu, X.; Yang, D.; He, H.; Zhao, P. Road extraction from remote sensing images using the inner convolution integrated encoder-decoder network and directional conditional random fields. Remote Sens. 2021, 13, 465. [Google Scholar] [CrossRef]
- Ding, L.; Bruzzone, L. DiResNet: Direction-aware residual network for road extraction in VHR remote sensing images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 10243–10254. [Google Scholar] [CrossRef]
- Zhang, Y.; Xiong, Z.; Zang, Y.; Wang, C.; Li, J.; Li, X. Topology-aware road network extraction via multi-supervised generative adversarial networks. Remote Sens. 2019, 11, 1017. [Google Scholar] [CrossRef]
- Zhang, X.; Han, X.; Li, C.; Tang, X.; Zhou, H.; Jiao, L. Aerial Image Road Extraction Based on an Improved Generative Adversarial Network. Remote Sens. 2019, 11, 930. [Google Scholar] [CrossRef]
- Batra, A.; Singh, S.; Pang, G.; Basu, S.; Jawahar, C.V.; Paluri, M. Improved road connectivity by joint learning of orientation and segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10385–10393. [Google Scholar]
- Varia, N.; Dokania, A.; Senthilnath, J. DeepExt: A convolution neural network for road extraction using RGB images captured by UAV. In Proceedings of the 2018 IEEE Symposium Series on Computational Intelligence (SSCI), Bangalore, India, 18–21 November 2018; IEEE: New York, NY, USA, 2018; pp. 1890–1895. [Google Scholar]
- Yang, C.; Wang, Z. An ensemble Wasserstein generative adversarial network method for road extraction from high resolution remote sensing images in rural areas. IEEE Access 2020, 8, 174317–174324. [Google Scholar] [CrossRef]
- Chen, H.; Li, Z.; Wu, J.; Xiong, W.; Du, C. SemiRoadExNet: A semi-supervised network for road extraction from remote sensing imagery via adversarial learning. ISPRS J. Photogramm. Remote Sens. 2023, 198, 169–183. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention, Proceedings of the MICCAI 2015 18th International Conference, Munich, Germany, 5–9 October 2015; Part III 18; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Zhou, L.; Zhang, C.; Wu, M. D-LinkNet: LinkNet with pretrained encoder and dilated convolution for high resolution satellite imagery road extraction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 182–186. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Mei, J.; Li, R.J.; Gao, W.; Cheng, M.M. CoANet: Connectivity attention network for road extraction from satellite imagery. IEEE Trans. Image Process. 2021, 30, 8540–8552. [Google Scholar] [CrossRef] [PubMed]
- Demir, I.; Koperski, K.; Lindenbaum, D.; Pang, G.; Huang, J.; Basu, S.; Raskar, R. Deepglobe 2018: A challenge to parse the earth through satellite images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 172–181. [Google Scholar]
- Van Etten, A.; Lindenbaum, D.; Bacastow, T.M. Spacenet: A remote sensing dataset and challenge series. arXiv 2018, arXiv:1807.01232. [Google Scholar]
- Bandara, W.G.C.; Valanarasu, J.M.J.; Patel, V.M. Spin road mapper: Extracting roads from aerial images via spatial and interaction space graph reasoning for autonomous driving. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; IEEE: New York, NY, USA, 2022; pp. 343–350. [Google Scholar]
- Shamsolmoali, P.; Zareapoor, M.; Zhou, H.; Wang, R.; Yang, J. Road segmentation for remote sensing images using adversarial spatial pyramid networks. IEEE Trans. Geosci. Remote Sens. 2021, 59, 4673–4688. [Google Scholar] [CrossRef]
- Yao, X.; Yang, H.; Wu, Y.; Wu, P.; Wang, B.; Zhou, X.; Wang, S. Land use classification of the deep convolutional neural network method reducing the loss of spatial features. Sensors 2019, 19, 2792. [Google Scholar] [CrossRef]
- Li, X.; Cong, G.; Cheng, Y. Spatial transition learning on road networks with deep probabilistic models. In Proceedings of the 2020 IEEE 36th International Conference on Data Engineering (ICDE), Dallas, TX, USA, 20–24 April 2020; IEEE: New York, NY, USA, 2020; pp. 349–360. [Google Scholar]
- Zhou, M.; Sui, H.; Chen, S.; Liu, J.; Shi, W.; Chen, X. Large-scale road extraction from high-resolution remote sensing images based on a weakly-supervised structural and orientational consistency constraint network. ISPRS J. Photogramm. RemoteSens. 2022, 193, 234–251. [Google Scholar] [CrossRef]
- Zhu, Q.; Zhang, Y.; Wang, L.; Zhong, Y.; Guan, Q.; Lu, X.; Li, D. A global context-aware and batch-independent network for road extraction from VHR satellite imagery. ISPRS J. Photogramm. Remote Sens. 2021, 175, 353–365. [Google Scholar] [CrossRef]
- Alshehhi, R.; Marpu, P.R.; Wei, L.W.; Mura, M.D. Simultaneous extraction of roads and buildings in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2017, 130, 139–149. [Google Scholar] [CrossRef]
- Leninisha, S.; Vani, K. Water flow based geometric active deformable model for road network. ISPRS J. Photogramm. Remote Sens. 2015, 102, 140–147. [Google Scholar] [CrossRef]
- Courtrai, L.; Lefèvre, S. Morphological path filtering at the region scale for efficient and robust road network extraction from satellite imagery. Pattern Recogn. Lett. 2016, 83, 195–204. [Google Scholar] [CrossRef]
- Grinias, I.; Panagiotakis, C.; Tziritas, G. Mrf-based segmentation and unsupervised classification for building and road detection in peri-urban areas of high-resolution satellite images. ISPRS J. Photogramm. Remote Sens. 2016, 122, 145–166. [Google Scholar] [CrossRef]
- Zang, Y.; Wang, C.; Yu, Y.; Luo, L.; Yang, K.; Li, J. Joint enhancing filtering for road network extraction. IEEE Trans. Geosci. Remote Sens. 2017, 55, 1511–1525. [Google Scholar] [CrossRef]
- Valero, S.; Chanussot, J.; Benediktsson, J.A.; Talbot, H.; Waske, B. Advanced directional mathematical morphology for the detection of the road network in very high resolution remote sensing images. Pattern Recogn. Lett. 2010, 31, 1120–1127. [Google Scholar] [CrossRef]
- Chaudhuri, D.; Kushwaha, N.K.; Samal, A. Semi-automated road detection from high resolution satellite images by directional morphological enhancement and segmentation techniques. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 1538–1544. [Google Scholar] [CrossRef]
- Bae, Y.; Lee, W.-H.; Choi, Y.-J.; Jeon, Y.W.; Ra, J. Automatic road extraction from remote sensing images based on a normalized second derivative map. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1858–1862. [Google Scholar] [CrossRef]
- Wan, J.; Xie, Z.; Xu, Y.; Chen, S.; Qiu, Q. DA-RoadNet: A dual-attention network for road extraction from high resolution satellite imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 6302–6315. [Google Scholar] [CrossRef]
- Krylov, V.A.; Nelson, J.D.B. Stochastic extraction of elongated curvilinear structures with applications. IEEE Trans. Image Process. 2014, 23, 5360–5373. [Google Scholar] [CrossRef]
- Coulibaly, I.; Spiric, N.; Lepage, R. St-Jacques, Semiautomatic road extraction from VHR images based on multiscale and spectral angle in case of earthquake. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 11, 238–248. [Google Scholar] [CrossRef]
- Ziems, M.; Rottensteiner, F.; Heipke, C. Verification of road databases using multiple road models. ISPRS J. Photogramm. Remote Sens. 2017, 130, 44–62. [Google Scholar] [CrossRef]
- Alshehhi, R.; Marpu, P.R. Hierarchical graph-based segmentation for extracting road networks from high-resolution satellite images. ISPRS J. Photogramm. Remote Sens. 2017, 126, 245–260. [Google Scholar] [CrossRef]
- Movaghati, S.; Moghaddamjoo, A.; Tavakoli, A. Road extraction from satellite images using particle filtering and extended kalman filtering. IEEE Trans. Geosci. Remote Sens. 2010, 48, 2807–2817. [Google Scholar] [CrossRef]
- Wegner, J.D.; Montoya-Zegarra, J.A.; Schindler, K. A higher-order Crf model for road network extraction. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013. [Google Scholar] [CrossRef]
- Poullis, C. Tensor-cuts: A simultaneous multi-type feature extractor and classifier and its application to road extraction from satellite images. ISPRS J. Photogramm. Remote Sens. 2014, 95, 93–108. [Google Scholar] [CrossRef]
- Maboudi, M.; Amini, J.; Hahn, M.; Saati, M. Road network extraction from Vhr satellite images using context aware object feature integration and tensor voting. Remote Sens. 2016, 8, 637. [Google Scholar] [CrossRef]
- Chen, X.; Sun, Q.; Guo, W.; Qiu, C.; Yu, A. GA-Net: A geometry prior assisted neural network for road extraction. Int. J. Appl. Earth Obs. Geoinf. 2022, 114, 103004. [Google Scholar] [CrossRef]
- Yang, M.; Yuan, Y.; Liu, G. SDUNet: Road extraction via spatial enhanced and densely connected Unet. PatternRecognit. 2022, 126, 108549. [Google Scholar] [CrossRef]
- Bonafilia, D.; Gill, J.; Basu, S.; Yang, D. Building high resolution maps for humanitarian aid and development with weakly-and semi-supervised learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019; pp. 1–9. [Google Scholar]
- Wang, Z.; Tian, S. Ground object information extraction from hyperspectral remote sensing images using deep learning algorithm. Microprocess. Microsyst. 2021, 87, 104394. [Google Scholar] [CrossRef]
- Yuan, J.; Wang, D.; Wu, B.; Yan, L.; Li, R. Legion-based automatic road extraction from satellite imagery. IEEE Trans. Geosci. Remote Sens. 2011, 49, 4528–4538. [Google Scholar] [CrossRef]
- Chen, Z.; Fan, W.; Zhong, B.; Li, J.; Du, J.; Wang, C. Corse-to-fine road extraction based on local dirichlet mixture models and multiscale-high-order deep learning. IEEE Trans. Intell. Transp. Syst. 2020, 21, 4283–4293. [Google Scholar] [CrossRef]
- Wang, Q.; Gao, J.; Yuan, Y. Embedding structured contour and location prior in siamesed fully convolutional networks for road detection. IEEE Trans. Intell. Transp. Syst. 2018, 19, 230–241. [Google Scholar] [CrossRef]
- Ren, Y.; Yu, Y.; Guan, H. Da-capsunet: A dual-attention capsule U-net for road extraction from remote sensing imagery. Remote Sens. 2020, 12, 2866. [Google Scholar] [CrossRef]
- Wei, Y.; Wang, Z.; Xu, M. Road Structure Refined CNN for Road Extraction in Aerial Image. IEEE Geosci.Remote Sens. Lett. 2017, 14, 709–713. [Google Scholar] [CrossRef]
- Wang, J.; Song, J.; Chen, M.; Yang, Z. Road network extraction: A neural-dynamic framework based on deep learning and a finite state machine. Int. J. Remote Sens. 2015, 36, 3144–3169. [Google Scholar] [CrossRef]
- Zhang, X.; Ma, W.; Li, C.; Wu, J.; Tang, X.; Jiao, L. Fully convolutional network-based ensemble method for road extraction from aerial images. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1777–1781. [Google Scholar] [CrossRef]
- Chen, D.; Zhong, Y.; Zheng, Z.; Ma, A.; Lu, X. Urban road mapping based on an end-to-end road vectorization mapping network framework. ISPRS J. Photogramm. Remote Sens. 2021, 178, 345–365. [Google Scholar] [CrossRef]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Cham, Switzerland, 2018; pp. 3–11. [Google Scholar]
- Xu, Y.; Xie, Z.; Feng, Y.; Chen, Z. Road extraction from high-resolution remote sensing imagery using deep learning. Remote Sens. 2018, 10, 1461. [Google Scholar] [CrossRef]
- Lu, X.; Zhong, Y.; Zheng, Z.; Liu, Y.; Zhao, J.; Ma, A.; Yang, J. Multi-scale and multi-task deep learning framework for automatic road extraction. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9362–9377. [Google Scholar] [CrossRef]
- Li, Y.; Xu, L.; Rao, J.; Guo, L.; Yan, Z.; Jin, S. A Y-Net deep learning method for road segmentation using high-resolution visible remote sensing images. Remote Sens. Lett. 2019, 10, 381–390. [Google Scholar] [CrossRef]
- Xie, Y.; Miao, F.; Zhou, K.; Peng, J. HsgNet: A Road Extraction Network Based on Global Perception of High-Order Spatial Information. ISPRS Int. J. Geo-Inf. 2019, 8, 571. [Google Scholar] [CrossRef]
- He, H.; Yang, D.; Wang, S.; Wang, S.; Li, Y. Road Extraction by Using Atrous Spatial Pyramid Pooling Integrated Encoder-Decoder Network and Structural Similarity Loss. Remote Sens. 2019, 11, 1015. [Google Scholar] [CrossRef]
- Shao, Z.; Zhou, Z.; Huang, X.; Zhang, Y. MRENet: Simultaneous extraction of road surface and road centerline in complex urban scenes from very high-resolution images. Remote Sens. 2021, 13, 239. [Google Scholar] [CrossRef]
- Lin, Y.; Xu, D.; Wang, N.; Shi, Z.; Chen, Q. Road extraction from very-high-resolution remote sensing images via a nested SE-Deeplab model. Remote Sens. 2020, 12, 2985. [Google Scholar] [CrossRef]
- Creswell, A.; White, T.; Dumoulin, V.; Arulkumaran, K.; Sengupta, B.; Bharath, A.A. Generative adversarial networks: An overview. IEEE Signal Process. Mag. 2018, 35, 53–65. [Google Scholar] [CrossRef]
- Chen, W.; Zhou, G.; Liu, Z.; Li, X.; Zheng, X.; Wang, L. NIGAN: A framework for mountain road extraction integrating remote sensing road-scene neighborhood probability enhancements and improved conditional generative adversarial network. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Chen, H.; Peng, S.; Du, C.; Li, J.; Wu, S. SW-GAN: Road Extraction from Remote Sensing Imagery Using Semi-Weakly Supervised Adversarial Learning. Remote Sens. 2022, 14, 4145. [Google Scholar] [CrossRef]
- Basiri, A.; Amirian, P.; Mooney, P. Using crowdsourced trajectories for automated OSM data entry approach. Sensors 2016, 16, 1510. [Google Scholar] [CrossRef] [PubMed]
- Hu, A.; Chen, S.; Wu, L.; Xie, Z.; Qiu, Q.; Xu, Y. WSGAN: An Improved Generative Adversarial Network for Remote Sensing Image Road Network Extraction by Weakly Supervised Processing. Remote Sens. 2021, 13, 2506. [Google Scholar] [CrossRef]
- Costea, D.; Marcu, A.; Slusanschi, E.; Leordeanu, M. Creating roadmaps in aerial images with generative adversarial networks and smoothing-based optimization. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 2100–2109. [Google Scholar]
- Rezaei, M.; Harmuth, K.; Gierke, W.; Kellermeier, T.; Fischer, M.; Yang, H.; Meinel, C. A Conditional Adversarial Network for Semantic Segmentation of Brain Tumor. Available online: https://arxiv.org/abs/1708.05227 (accessed on 23 June 2021).
- Pan, X.; Zhao, J.; Xu, J. Conditional Generative Adversarial Network-Based Training Sample Set Improvement Model for the Semantic Segmentation of High-Resolution Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 1–17. [Google Scholar] [CrossRef]
- Shi, Q.; Liu, X.; Li, X. Road detection from remote sensing images by generative adversarial networks. IEEE Access 2017, 6, 25486–25494. [Google Scholar] [CrossRef]
- Li, X.; Wang, Y.; Zhang, L.; Liu, S.; Mei, J.; Li, Y. Topology-enhanced urban road extraction via a geographic feature-enhanced network. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8819–8830. [Google Scholar] [CrossRef]
- Laptev, I.; Mayer, H.; Lindeberg, T.; Eckstein, W.; Steger, C.; Baumgartner, A. Automatic extraction of roads from aerial images based on scale space and snakes. Mach. Vis. Appl. 2000, 12, 23–31. [Google Scholar] [CrossRef]
- Chai, D.; Forstner, W.; Lafarge, F. Recovering line-networks in images by junction-point processes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1894–1901. [Google Scholar]
- Barzohar, M.; Cooper, D.B. Automatic finding of main roads in aerial images by using geometric-stochastic models and estimation. IEEE Trans. Pattern Anal. Mach. Intell. 1996, 18, 707–721. [Google Scholar] [CrossRef]
- Wang, Y.; Zheng, Q. Recognition of roads and bridges in SAR images. Pattern Recognit. 1998, 31, 953–962. [Google Scholar] [CrossRef]
- Hong, Z.; Ming, D.; Zhou, K.; Guo, Y.; Lu, T. Road Extraction From a High Spatial Resolution Remote Sensing Image Based on Richer Convolutional Features. IEEE Access 2018, 6, 46988–47000. [Google Scholar] [CrossRef]
- Gao, L.; Wang, J.; Wang, Q.; Shi, W.; Zheng, J.; Gan, H.; Qiao, H. Road Extraction Using a Dual Attention Dilated-LinkNet Based on Satellite Images and Floating Vehicle Trajectory Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 10428–10438. [Google Scholar] [CrossRef]
- Yuan, W.; Xu, W. GapLoss: A Loss Function for Semantic Segmentation of Roads in Remote Sensing Images. Remote Sens. 2022, 14, 2422. [Google Scholar] [CrossRef]
- Máttyus, G.; Luo, W.; Urtasun, R. Deeproadmapper: Extracting road topology from aerial images. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3438–3446. [Google Scholar]
- Lian, R.; Wang, W.; Mustafa, N.; Huang, L. Road extraction methods in high-resolution remote sensing images: A comprehensive review. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5489–5507. [Google Scholar] [CrossRef]
- Cheng, G.; Wang, Y.; Xu, S.; Wang, H.; Xiang, S.; Pan, C. Automatic road detection and centerline extraction via cascaded end-to-end convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3322–3337. [Google Scholar] [CrossRef]
- Zou, H.; Yue, Y.; Li, Q.; Yeh, A.G. An improved distance metric for the interpolation of link-based traffic data using kriging: A case study of a large-scale urban road network. Int. J. Geogr. Inf. Sci. 2012, 26, 667–689. [Google Scholar] [CrossRef]
- Etten, A.V. City-scale road extraction from satellite imagery v2: Road speeds and travel times. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass, CO, USA, 1–5 May 2020; pp. 1786–1795. [Google Scholar]
- Tan, J.; Gao, M.; Yang, K.; Tan, J.; Gao, M.; Yang, K.; Duan, T. Remote sensing road extraction by road segmentation network. Appl. Sci. 2021, 11, 5050. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Zhang, C.; Wang, L.; Li, R.; Zhang, C.; Fang, S.; Duan, C.; Meng, X.; Atkinson, P.M. UNetFormer: A UNet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery. ISPRS J. Photogramm. Remote Sens. 2022, 190, 196–214. [Google Scholar] [CrossRef]
- Ge, C.; Nie, Y.; Kong, F.; Xu, X. Improving road extraction for autonomous driving using swin transformer unet. In Proceedings of the 2022 IEEE 25th International Conference on Intelligent Transportation Systems (ITSC), Macau, China, 8–12 October 2022; IEEE: New York, NY, USA, 2022; pp. 1216–1221. [Google Scholar]
- Fan, R.; Wang, Y.; Qiao, L.; Yao, R.; Han, P.; Zhang, W.; Liu, M. PT-ResNet: Perspective transformation-based residual network for semantic road image segmentation. In Proceedings of the 2019 IEEE International Conference on Imaging Systems and Techniques (IST), Abu Dhabi, United Arab Emirates, 9–10 December 2019; IEEE: New York, NY, USA, 2019; pp. 1–5. [Google Scholar]
- Wang, H.; Chen, J.; Fan, Z.; Zhang, Z.; Cai, Z.; Song, X. ST-ExpertNet: A Deep Expert Framework for Traffic Prediction. In IEEE Transactions on Knowledge and Data Engineering; IEEE: New York, NY, USA, 2022. [Google Scholar]
- Le, L.; Patterson, A.; White, M. Supervised autoencoders: Improving generalization performance with unsupervised regularizers. Adv. Neural Inf. Process. Syst. 2018, 31, 107–117. [Google Scholar]
- Ying, X. An overview of overfitting and its solutions. J. Phys. Conf. Ser. 2019, 1168, 022022. [Google Scholar] [CrossRef]
- Chen, Q.; Xue, B.; Zhang, M. Improving generalization of genetic programming for symbolic regression with angle-driven geometric semantic operators. IEEE Trans. Evol. Comput. 2018, 23, 488–502. [Google Scholar] [CrossRef]
- Koonce, B.; Koonce, B. ResNet 34. Convolutional Neural Networks with Swift for Tensorflow: Image Recognition and Dataset Categorization; Apress: Berkeley, CA, USA, 2021; pp. 51–61. [Google Scholar]
- Zhang, J.; Li, Z.; Zhang, C.; Ma, H. Stable self-attention adversarial learning for semi-supervised semantic image segmentation. J. Vis. Commun. Image Represent. 2021, 78, 103170. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Chintala, S. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8024–8035. [Google Scholar]
- Huan, H.; Sheng, Y.; Zhang, Y.; Liu, Y. Strip Attention Networks for Road Extraction. Remote Sens. 2022, 14, 4516. [Google Scholar] [CrossRef]
- Wiedemann, C.; Heipke, C.; Mayer, H.; Jamet, O. Empirical evaluation of automatically extracted road axes. In Empirical Evaluation T echniques in Computer Vision; IEEE Computer Society Press: Los Alamitos, CA, USA, 1998; pp. 172–187. ISBN 978-0-818-68401-2. [Google Scholar]
- Sharma, C.; Bagga, A.; Sobti, R.; Shabaz, M.; Amin, R. A robust image encrypted watermarking technique for neurodegenerative disorder diagnosis and its applications. Comput. Math. Methods Med. 2021, 2021, 8081276. [Google Scholar] [CrossRef]
- Arunkumar, S.; Subramaniyaswamy, V.; Vijayakumar, V.; Chilamkurti, N.; Logesh, R. SVD-based robust image steganographic scheme using RIWT and DCT for secure transmission of medical images. Measurement 2019, 139, 426–437. [Google Scholar] [CrossRef]
- Mousavi, S.M.; Naghsh, A.; Manaf, A.A.; Abu-Bakar, S.A.R. A robust medical image watermarking against salt and pepper noise for brain MRI images. Multimed. Tools Appl. 2017, 76, 10313–10342. [Google Scholar] [CrossRef]
- Lin, S.; Zhang, C.; Ding, L.; Zhang, J.; Liu, X.; Chen, G.; Wang, S.; Chai, J. Accurate Recognition of Building Rooftops and Assessment of Long-Term Carbon Emission Reduction from Rooftop Solar Photovoltaic Systems Fusing GF-2 and Multi-Source Data. Remote Sens. 2022, 14, 3144. [Google Scholar] [CrossRef]
- Yang, Z.; Zhou, D.; Yang, Y.; Zhang, J.; Chen, Z. Road Extraction From Satellite Imagery by Road Context and Full-Stage Feature. In IEEE Geoscience and Remote Sensing Letters; IEEE: New York, NY, USA, 2022. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Image Size | Learning Rate | Epoch | Batch Size |
|---|---|---|---|---|
| RCFSNet | 512 × 512 | 0.01 | 150 | 2 |
| CoANet | 512 × 512 | 0.01 | 150 | 2 |
| UNet | 512 × 512 | 0.1 | 150 | 8 |
| DeepLabV3+ | 512 × 512 | 0.1 | 150 | 8 |
| DiResNet | 512 × 512 | 0.1 | 150 | 8 |
| MS-AGAN | 512 × 512 | 0.001 | 150 | 2 |
| Model | Precision | Recall | F1 | IoU |
|---|---|---|---|---|
| RCFSNet | 61.54 | 62.87 | 58.72 | 43.09 |
| CoANet | 63.97 | 60.26 | 58.89 | 42.93 |
| UNet | 62.73 | 59.67 | 57.70 | 41.30 |
| DeepLabV3+ | 62.92 | 62.15 | 59.47 | 43.33 |
| DiResNet | 65.34 | 59.88 | 59.08 | 42.76 |
| MS-AGAN | 61.05 | 65.04 | 59.51 | 45.96 |
| Model | Precision | Recall | F1 | IoU |
|---|---|---|---|---|
| RCFSNet | 75.90 | 77.34 | 74.83 | 62.09 |
| CoANet | 74.05 | 77.18 | 74.58 | 60.75 |
| UNet | 72.82 | 76.07 | 74.40 | 59.24 |
| DeepLabV3+ | 76.97 | 76.18 | 74.61 | 62.03 |
| DiResNet | 79.92 | 73.99 | 74.75 | 62.39 |
| MS-AGAN | 75.66 | 78.46 | 75.25 | 62.64 |
| Model | Sub-Nets | Module | Precision | Recall | F1 | |||
|---|---|---|---|---|---|---|---|---|
| Segmentation | Discriminator | Supervision | ASPP | CRF | ||||
| ReNet | 54.60 | 55.07 | 54.83 | |||||
| MS-AGAN_ASPP | 56.41 | 55.13 | 55.76 | |||||
| GNet | 59.88 | 55.25 | 57.47 | |||||
| MS-AGAN_S | 60.95 | 59.47 | 60.20 | |||||
| MS-AGAN | 61.05 | 65.04 | 62.98 | |||||
| ID | Loss | Precision | Recall | F1 | IoU |
|---|---|---|---|---|---|
| 1 | 0.3 + 0.7 | 56.47 | 64.36 | 60.15 | 43.01 |
| 2 | 0.5 + 0.5 | 61.05 | 65.04 | 62.98 | 45.96 |
| 3 | 0.7 + 0.3 | 61.13 | 61.30 | 61.21 | 44.10 |
| ID | Loss | Precision | Recall | F1 | IoU |
|---|---|---|---|---|---|
| 1 | + 0.7 | 56.22 | 59.59 | 57.85 | 40.70 |
| 2 | + 0.5 | 61.05 | 65.04 | 62.98 | 45.96 |
| 3 | + 0.3 | 57.05 | 66.78 | 61.53 | 44.43 |
| Model | Training Time (s) | Inference Speed (s) | Parameters (M) | FLOPS (Gps) |
|---|---|---|---|---|
| RCFSNet | 589.00 | 73.79 | 59.278 | 207.816 |
| CoANet | 673.44 | 67.32 | 59.147 | 277.416 |
| UNet | 208.50 | 18.07 | 9.16 | 221.43 |
| DeepLabV3+ | 331.60 | 62.15 | 22.704 | 100.538 |
| DiResNet | 397.30 | 59.88 | 21.321 | 115.473 |
| MS-AGAN | 950.16 | 98.44 | 25.114 | 126.08 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, S.; Yao, X.; Liu, X.; Wang, S.; Chen, H.-M.; Ding, L.; Zhang, J.; Chen, G.; Mei, Q. MS-AGAN: Road Extraction via Multi-Scale Information Fusion and Asymmetric Generative Adversarial Networks from High-Resolution Remote Sensing Images under Complex Backgrounds. Remote Sens. 2023, 15, 3367. https://doi.org/10.3390/rs15133367
Lin S, Yao X, Liu X, Wang S, Chen H-M, Ding L, Zhang J, Chen G, Mei Q. MS-AGAN: Road Extraction via Multi-Scale Information Fusion and Asymmetric Generative Adversarial Networks from High-Resolution Remote Sensing Images under Complex Backgrounds. Remote Sensing. 2023; 15(13):3367. https://doi.org/10.3390/rs15133367
Chicago/Turabian StyleLin, Shaofu, Xin Yao, Xiliang Liu, Shaohua Wang, Hua-Min Chen, Lei Ding, Jing Zhang, Guihong Chen, and Qiang Mei. 2023. "MS-AGAN: Road Extraction via Multi-Scale Information Fusion and Asymmetric Generative Adversarial Networks from High-Resolution Remote Sensing Images under Complex Backgrounds" Remote Sensing 15, no. 13: 3367. https://doi.org/10.3390/rs15133367
APA StyleLin, S., Yao, X., Liu, X., Wang, S., Chen, H.-M., Ding, L., Zhang, J., Chen, G., & Mei, Q. (2023). MS-AGAN: Road Extraction via Multi-Scale Information Fusion and Asymmetric Generative Adversarial Networks from High-Resolution Remote Sensing Images under Complex Backgrounds. Remote Sensing, 15(13), 3367. https://doi.org/10.3390/rs15133367