Abstract
Convolutional neural networks (CNNs) have achieved great progress in the classification of surface objects with hyperspectral data, but due to the limitations of convolutional operations, CNNs cannot effectively interact with contextual information. Transformer succeeds in solving this problem, and thus has been widely used to classify hyperspectral surface objects in recent years. However, the huge computational load of Transformer poses a challenge in hyperspectral semantic segmentation tasks. In addition, the use of single Transformer discards the local correlation, making it ineffective for remote sensing tasks with small datasets. Therefore, we propose a new Transformer layered architecture that combines Transformer with CNN, adopts a feature dimensionality reduction module and a Transformer-style CNN module to extract shallow features and construct texture constraints, and employs the original Transformer Encoder to extract deep features. Furthermore, we also designed a simple Decoder to process shallow spatial detail information and deep semantic features separately. Experimental results based on three publicly available hyperspectral datasets show that our proposed method has significant advantages compared with other traditional CNN, Transformer-type models.
1. Introduction
In recent years, due to the vigorous development of earth observation projects, the application of hyperspectral sensors has received extensive attention. A large number of hyperspectral images (HSIs) can be captured using spaceborne or airborne sensors. These images have rich spectral and spatial information, which brings opportunities for various applications such as image reconstruction [1], change monitoring [2], and crop classification [3].
With the continuous progress in the field of computer vision, computer vision models have attracted the attention of a large number of scholars and have been used in the field of remote sensing. Convolutional neural networks have been widely used in hyperspectral remote sensing. However, using a fixed-size convolution kernel will provide a small receptive field, which makes CNN unable to effectively model long-range dependencies and global context [4]. For patch-based hyperspectral image classification, contextual hints can be used to disambiguate between objects that may have similar visual features, and ultimately guide the model to better solve the classification task. For semantic segmentation, local pixel classification is more accurate if supported by global context information [5]. In order to solve the above problems, some studies modify the convolution operation of the model [6] or use the attention mechanism [7]. The former aims to expand the receptive field by using larger convolution kernels, dilated convolutions or feature pyramids, while the latter introduces spatial or point attention modules in CNNs to better capture contextual information. However, these methods fail to free the network from the dependence on convolutional encoders, and they are more biased towards local interactions.
Fortunately, the emergence of Vision Transformer [8] has meant that Transformer is widely used in computer vision tasks. Transformer formulates the semantic segmentation task as a sequence-to-sequence problem and effectively extract semantic features with long-range dependencies. Vision Transformer has also been widely used in hyperspectral image classification tasks, after Zhong et al. [9] proposed a novel spectral spatial transformation network (SSTN), which combines spatial attention and spectral correlation modules to overcome the constraints of convolution kernels. Hong et al. [10] re-explored hyperspectral image classification from a sequential perspective and proposed SpectralFormer, which uses skip connections and adaptively learned residual connections for cross-layer fusion to transfer information from shallow to deep layers. Yu et al. [11] developed a multi-stage spectral spatial transformation network (MSTNet) for hyperspectral image classification. They designed a self-attention encoder and combined CNN with a four-layer Transformer encoder to learn deep features. Su et al. [12] proposed a spectral–spatial feature tokenization transformer (SSFTT) method to capture spectral–spatial features and high-level semantic features. The above methods all demonstrate the great potential of Transformer in hyperspectral classification tasks.
However, the above models do not consider the superiority of the hierarchical model, nor do they fully combine the advantages of CNN and Transformer. Swin Transformer [13] employs a hierarchical architecture and integrates both CNN and Transformer components to achieve a state-of-the-art performance in various computer vision tasks. By combining Transformers and CNN, the advantages of the two architectures can be integrated to capture the long-term dependencies and spatial features in remote sensing data. This further enhances Transformer’s potential in different tasks, and is widely used in various remote sensing tasks, especially in the hyperspectral field. For example, Chen et al. [7] proposed a multi-scale mixed-spectral-attention model based on Swin Transformer, using the spectral attention module and multi-scale feature extraction module to enrich spectral features and classify ground objects. Peng et al. [14] proposed a spectral shifted window self-attention-based transformer. They enriched spatial features by adding a spatial-feature-extraction module, and also used Swin Transformer to classify ground objects. The above works have improved the model’s feature-extraction ability at the spectral and spatial levels, respectively, but unfortunately, have not fully considered the shortcomings caused by single-feature enhancement.
Most of the traditional hyperspectral object classification methods are based on patch [12,15,16,17,18], which requires cumbersome preprocessing and takes up a lot of storage space. The diagram of patch-based method is shown in Figure 1. Using the patch-based method, one can only classify a single feature point at a time, and the data set needs to be cut into pieces before testing, which leads to low efficiency and complicates data-processing. Recently, a large number of hyperspectral object classification methods based on semantic segmentation have been introduced [11,19,20,21]. We attempted to perform a direct segmentation of hyperspectral images and achieved satisfactory results. The semantic segmentation method is presented in Figure 2. The use of the semantic segmentation method does not require too much preprocessing of the data, and directly predicts the ground features end-to-end, treats the hyperspectral image as an ordinary image containing multiple bands, and labels the real ground features externally. These processes can be viewed as manually marking and selecting regions of interest (ROIs) in the software. In the loss calculation process, only mask is used to calculate the gradient of known types of ground objects. After experimental verification, this method was shown to be simple but very effective.
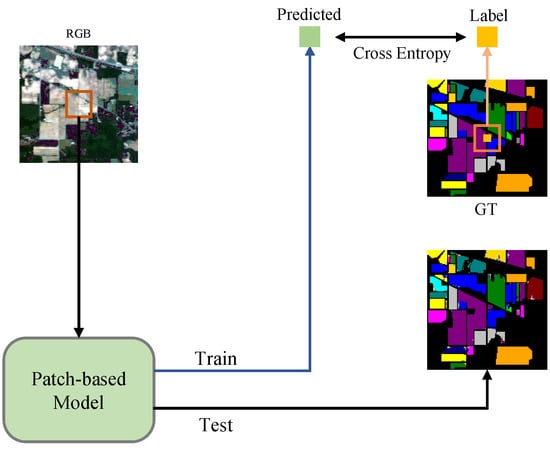
Figure 1.
Patch -based training method.
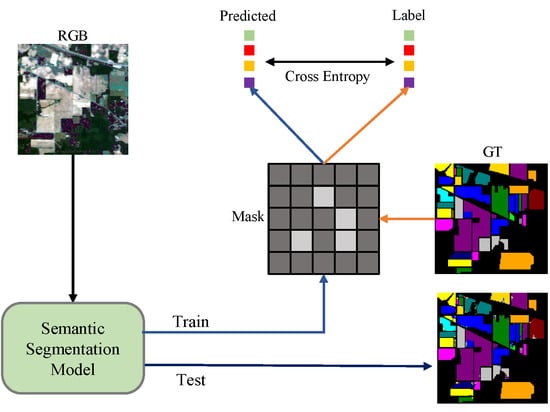
Figure 2.
Semantic Segmentation Training Method.
In addition, the guidance of shallow information is crucial to the model, especially for remote sensing tasks [22,23]. For example, Meng et al. [22] proposed a category information-guided Swin Transformer, and believed that category information and shallow spatial details are crucial to accurate semantic segmentation. They applied convolution to automatically extract category-based semantic features with rich spatial details from the input remote sensing images, jointly processed them with the features extracted by Swin Transformer, and achieved excellent results on multiple datasets.
Based on the above method, we propose a shallow-guided hierarchical Transformer (SGHViT). We deploy simple convolution and max-pooling modules as shallow spatial-detail feature-extraction modules, and combine CNN with Transformer. We also redesign the Decoder module, introduce a feature-aggregation module to process deep information, and exploit shallow spatial-detail features at appropriate positions. Satisfactory results were achieved on three datasets.
The main contributions of this paper can be summarized as follows:
- (1)
- This paper proposes a concise and efficient hierarchical model combining CNN and Transformer. While using CNNs to reduce the spatial dimension and spectral dimension of input HSIs, we introduce the concept of shallow guidance, and use shallow spatial-detail information to make up for the lack of spatial modeling abilities in hierarchical models.
- (2)
- We design a simple decoder module for processing deep semantic information and shallow spatial details separately. At the same time, detailed ablation experiments are carried out to prove the effectiveness and high efficiency of our designed Decoder in hyperspectral semantic segmentation tasks.
- (3)
- We qualitatively and quantitatively evaluate our proposed method (SGHViT) on five public datasets, and conduct comprehensive comparisons with patch-based and semantic segmentation-based methods, including advanced CNN-based methods and Transformer-based methods.
2. Method
To facilitate image semantic segmentation tasks for remote sensing images, our proposed model, SGHViT, takes advantage of the adoption of convolution modules in the model’s shallow layer. SGHViT follows the classic hierarchical designs of Transformers [13,24,25,26]. SGHViT is a pyramid-structure model consisting of four hierarchical stages. Multi-level features are obtained at {1/2, 1/4, 1/8, 1/16} of the original image resolution through the modules of Stages 1–4. Differing from classical works, to make the model more suitable for the classification of hyperspectral objects and to fully obtain the shallow spatial details of different objects, our architecture includes an additional shallow information-extraction module. An overview of SGHVIT is shown in Figure 3.
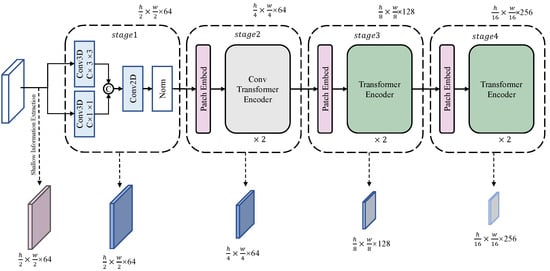
Figure 3.
The architecture of SGHViT.
The shallow information extraction module, as its name implies, extracts the detailed features of shallow space. Specifically, the module consists of 2D convolution and maximum value pooling, and the size of the output feature map is . Directly converting images to tokens often ignores the structural information of images, which is intolerable for remote sensing images [27,28]. Therefore, in Stage 1, we compress the spectral dimension information. Two parallel three-dimensional convolutions are used to extract spectral information, and the use of convolution kernels of different sizes allows for the spectral and spatial dimension information to be the focus. Afterwards, we splice the feature maps of two convolution kernels into different sizes, then perform normalization processing through a two-dimensional convolution module, and convert the hyperspectral data into .
In Stage 2, our module consists of convolutions. Our module is similar to the Transformer encoder, but replaces attention with group convolution, and replaces the feedforward network () with a conv feedforward network (). Compared with standard convolution, group convolution reduces the number of parameters and computational complexity, which can speed up training and improve model efficiency. Group convolution can also be used to encourage feature diversity by enforcing that the kernel weights are shared only within each group, but not across groups. This can help prevent overfitting and improve the generalization ability of the model [29]. pays more attention to spatial information than . In Stages 3 and 4, the original Transformer Encoder is utilized. In Stages 2–4, Patch Embed [13] is used to perform feature map downsampling, and the sampling factor is 2. Specifically, patch embed consists of a convolutional layer with a convolution kernel size of 2 and a layer normalization operation [30]. After the above process, we obtain 4 sets of feature maps with different sizes. It is worth noting that the dimensionality reduction feature map of Stage 1 is not used, and we use the result of the shallow information extraction module.
2.1. Conv Transformer Encoder
Figure 4 shows the architecture of the conv Transformer Encoder. Transformer’s high emphasis on global information will lead to excessive parameters and calculations, so using Transformer on the upper layer of the model is very unfriendly to the device. Moreover, the most important task of hyperspectral surface object classification should be the correlation of local object features, not the global correlation. Using convolution in the upper layer of the model not only retains more locally relevant features, but also maked the model more compact. PoolFormer [25] proves the superiority of the Transformer architecture, which can only achieve reasonable results in semantic segmentation tasks by replacing the attention in the Transformer structure with average pooling. Average pooling is a type of pooling operation that reduces the dimensionality of an input image by computing the average value of non-overlapping rectangular regions. We also follow the structure of PoolFormer, replacing the attention module in Transformer with a convolution module, and replacing with BatchNorm. In addition, we introduce relative positional encoding at the beginning of the module. There are two main motivations for using relative positional encoding. First, it enhances the model’s inductive bias, which is crucial for learning and generalization [31,32]. Secondly, it can enhance the local modeling ability of the model, and enable the model to implicitly encode the position information, which plays a key role in the classification of hyperspectral objects. In addition, [6,33] found that adding lightweight 3 × 3 depthwise convolutions to can improve performance. We inherit and extend this convolutional embedding mechanism. The feedforward network () is completely replaced by a convolutional module, which we call the conv feedforward network ().
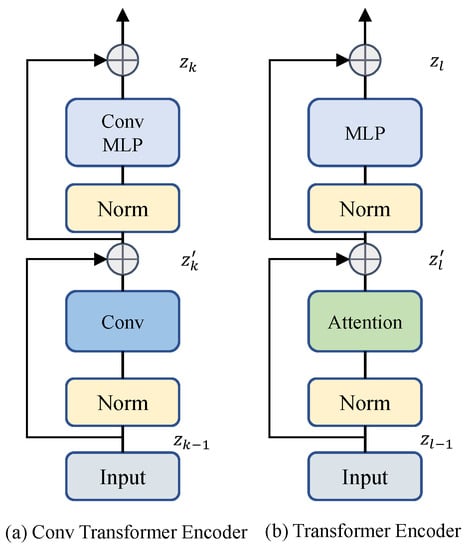
Figure 4.
The architecture of Transformer Block.
Specifically, our Attention module consists of three layers of 2D convolutional layers to replace MSA and carry out local feature extraction instead of global feature extraction. The relative position encoding consists of grouped convolutions with a kernel size of 3. consists of two layers of 2D convolutions that pay more attention to spatial information, and the convolution kernel size is set to 1. Also, the GELU activation function [34] is used for the first convolutional layer. The forward pass can be formulated as follows:
where represents the input feature map of the module, represents the intermediate variable, represents the relative position encoding, represents the Attention module, which is composed of convolutions, represents the formed by convolutions, and represents batch normalization.
2.2. Transformer Encoder
Figure 4 shows the architecture of the Transformer Encoder [35]. We use the Transformer module designed in the ViT [8]. Transformer uses multi-head self-attention (MSA) to capture global information, extracting richer spatial features and high-level semantic features than convolution.
For classification tasks [12,36], transformers have shown to be effective at extracting deep semantic features that are more linearly separable than pure convolutional models. This is because transformers can capture long-range dependencies and global context information, which can be useful for understanding the relationships between different parts of the input image.
For semantic segmentation tasks [37,38], transformers can be used to model long-range dependencies and global context information, which can help to improve the accuracy of the segmentation results. By incorporating transformer layers into the encoder–decoder architecture, the model can capture global context information from the input image, which can help to improve the segmentation performance by allowing the model to better understand the relationship between different parts of the image. The decoder part of the architecture can then use the features extracted by the encoder to determine the segmentation position.
Specifically, our Transformer Encoder steps are as follows: first, obtain the relative position code of the feature map entering the current stage, then pass and , and finally enter the feedforward network () module. comprises two fully connected layers of neural networks, referred to as multilayer perceptrons (MLPs), followed by a non-linear activation function GELU [39]. The MLPs compute discrete transformations of the input at each position in the sequence independently and identically, making them non-continuous. The captures non-linear dependencies between different parts of the sequence, enhancing the model’s ability to represent complex patterns and features in the input. The forward pass can be formulated as follows:
In the above formula, represents the relative position code, represents a layer normalization operator, and represents the intermediate variable.
Multi-head Self-attention is the core of the Transformer Encoder. This component allows the model to attend to different parts of the input sequence and capture dependencies between them. It computes multiple attention heads in parallel, with each head attending to a different part of the sequence. The attention heads are then combined to produce a single output sequence that incorporates information from all the heads, through the following equation
where represent query, key, and value, respectively, and C represents input features. The number of channels of the graph is denoted by , which represents the linear layer, and linearly projects the input feature to obtain vectors.
In the above formula, represents the , and matrices of the i-th head. It is obtained by dividing ,, according to n in the channel dimension. represents the learned parameter. d represents the dimension of and . means to concat the matrix.
2.3. Decoder
The decoder of the model is illustrated in Figure 5. In this part of the model, we leverage the feature maps obtained from the Encoder (Stages 3 and 4) through the use of UperNet [40]. Notably, we process the features generated by the Transformer Encoder and the convolutional Transformer Encoder separately to improve the model’s capacity to capture non-linear dependencies between different parts of the input.
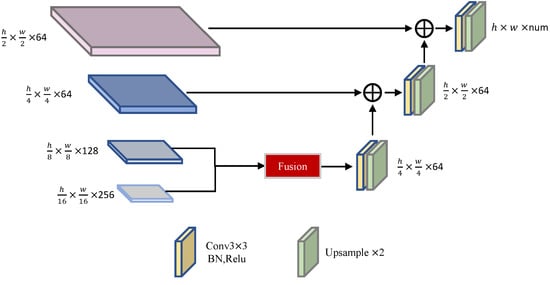
Figure 5.
The Decoder of SGHViT. Fusion refers to the UperNet module, which comes from [40].
To produce the final output, we combine the feature maps from Stages 2–4 and shallowly extracted feature maps. Our decision to exclude the feature map from Stage 1 is based on the observation that it does not preserve shallow spatial details well. Instead, we use the feature map that passes through the shallow information-extraction module. Specifically, we performed the add operation on the feature map that is mixed and upsampled by Stages 2, 3, and 4 before upsampling, and then used the superposition of shallow information. This approach allows us to incorporate information from both the shallow and deep layers effectively, enabling the model to capture fine-grained details.
We argue that preserving shallow spatial detail information is crucial for the success of hyperspectral semantic segmentation tasks, as demonstrated by the ablation studies presented in Section 3. These studies provide detailed analyses of the role of shallow spatial-detail information in the model’s performance. Specifically, we examine the impact of excluding Stage 1’s feature map and the effectiveness of using the feature map that has undergone shallow information extraction. Our findings demonstrate that the inclusion of shallow spatial-detail information significantly improves the model’s performance, indicating the importance of this information for hyperspectral semantic segmentation tasks.
To summarize, the decoder of the model combines feature maps obtained from the Encoder through UperNet and processes features generated by the Transformer Encoder and the convolutional Transformer Encoder separately. We excluded the feature map from Stage 1 and used the feature map that has undergone shallow information extraction to preserve shallow spatial detail information effectively. Our ablation studies reveal the critical role of shallow spatial detail information in hyperspectral semantic segmentation tasks, emphasizing the importance of preserving this information in the model’s success. The process of feature map aggregation in the decoder is similar to that of LinkNet [41,42], while UperNet is used to combine feature maps from the Encoder. Overall, our approach enables the model to capture both shallow and deep spatial details effectively, leading to an improved performance in hyperspectral semantic segmentation tasks.
3. Experiments
3.1. Experimental Platform Parameter Settings
All experiments were run on Windows 11 and Nvidia GeForce RTX 3060 graphics card, and the models were run on pytorch 1.9. In order to reduce the experimental error, the model selects limited samples from the training set for training, and all experimental results take the average of 5 experiments. For the semantic segmentation method, the optimizer to be selected had the default parameters AdamW optimizer [43]. The learning rate is in [42], in [11], in [25], and in [13,38]. In order to compare various models more fairly, we set the learning rate to , and set the epoch to 200 to ensure that the model can fully converge. AdamW is a variant of the Adam optimizer that decouples weight decay from the learning rate and applies it directly to the weight updates to improve stability and prevent overfitting in deep learning models. For patch-based methods, the optimizer to be chosen had a default parameter AdamW optimizer with a learning rate set to and epoch set to 400.
To evaluate the performance of different models in terms of hyperspectral image classification, overall accuracy (OA), average accuracy (AA), and Kappa coefficient (K) were used as evaluation criteria. OA reflected the total correct classifications, AA considered the correctness within each category, and K accounted for chance agreement to determine the true accuracy and reliability of the predictions. Higher values of OA, AA, and K indicated a better performance in hyperspectral image classification.
In this study, we evaluated the performance of different models for hyperspectral image classification. We used a variety of traditional semantic segmentation methods, including Unet [44], FPN [45], Deeplabv3 [46], and Deeplabv3+ [47]. For these methods, we used ResNet50 as the backbone to extract features from the input data. We also used several hierarchical backbones, including ConvNeXt [26], Swin [13], ResT [48], PVT [24], and PoolFormer [25], and paired them with the UperNet decoder. For SegFormer [38], we used the proposed decoder, which consisted of fully connected layers. For SGHViT, we also paired this with UperNet as the decoder, as discussed in the ablation experiments section. For the semantic segmentation method, the number of input channels of all models was the same as the bands in Table 1, and the output was classes + 1, where 1 represented the background.

Table 1.
Three public dataset parameters.
Regarding the patch-based methods, we used the principal component analysis (PCA) method to reduce the dimensionality of the dataset to a specific size. Specifically, for 1DCNN [16], we set the patch size to 1 and the number of principal components to 18. For 3DCNN [17] and Hybrid [15], we set the patch size to 15 and the number of principal components to 18. For SSFTT [12], we set the patch size to 11 and the number of principal components to 30.
3.2. Datasets
Indian Pines. The Indian Pines dataset was captured at a farm test site in northwest Indiana and collected using AVIRIS, an onboard sensor. The band range of the data set was 400–2500 nm, the spatial resolution was 20 m, and the original size of the image was 145 × 145. In this paper, the data of 200 bands were classified after water absorption and low signal-to-noise ratio bands were eliminated. During the experiment, 10% of each type of ground objects was randomly selected for training, and the remaining samples were used for testing. When the number of selected samples of each type of ground object was less than 5, we set it to 5. The specific training samples and test samples are shown in Table 2.
Table 2.
The number of training and testing pixels per category in the IA dataset.
Pavia University. The dataset of Pavia University (PU) was shot in the University of Pavia, northern Italy, and was collected by airborne sensor ROSIS. The spatial resolution was 1.3 m, and the original image size was 610 × 340. In this paper, the data of 103 bands were classified by eliminating the bands affected by noise. Compared with the Indian Pines dataset, this dataset has a larger sample size and fewer categories. During the experiment, 3% of each type of ground objects were randomly selected for training, and the remaining samples were used for testing. The specific training samples and test samples are shown in Table 3.
Table 3.
The number of training and testing pixels per category in the PU dataset.
Salinas. The Salinas (SA) dataset was taken in the Salinas Valley, California, USA, and, like the India dataset, was collected using the airborne sensor AVIRIS. However, unlike Indian Pines, it has a spatial resolution of 3.7 m. During the experiment, 1% of each type of ground objects were randomly selected for training, and the remaining samples were used for testing. The specific training samples and test samples are shown in Table 4.
Table 4.
The number of training and testing pixels per category in the SA dataset.
3.3. Comparative Experiment
We conducted a comparative evaluation of various methods for hyperspectral image classification using a publicly available dataset. The results are presented in Table 5, Table 6 and Table 7. Our analysis showed that the patch-based approach is not very effective for hyperspectral image classification. Ordinary 1DCNN and 3DCNN models have difficulties classifying ground objects with similar spectral characteristics. However, Hybrid, which combines 2DCNN and 3DCNN, can mitigate this limitation to some extent.
Table 5.
Classification accuracy (%) of the IA image with different methods.
Table 6.
Classification accuracy (%) of the PU image with different methods.
Table 7.
Classification accuracy (%) of the SA image with different methods.
We also evaluated SSFTT, which uses a combination of Transformer and CNN to fully extract spatial and spectral features. However, this method is limited by patch-based data-processing methods, which restrict its ability to model the global scene effectively. In contrast, semantic segmentation-based methods can make good use of spatial features for global scene modeling. Nevertheless, most of these methods were designed for three-channel images and did not fully consider the spectral dimension. Additionally, traditional semantic segmentation methods tended to focus on regional features, which could make it challenging to extract deep semantic features. Although models like Unet, FPN, and Deeplabv3 were widely used for various computer vision tasks, they did not perform optimally for hyperspectral semantic segmentation. Moreover, these models tend to have a large number of parameters, which can lead to higher computational costs and memory requirements. In contrast, SGHViT had promising results on hyperspectral semantic segmentation tasks while utilizing significantly fewer parameters and moderate floating-point operations per second (FLOPS). Thus, SGHViT was a more effective choice for hyperspectral semantic segmentation tasks.
Transformer-based models showed promising results for hyperspectral semantic segmentation tasks. This is attributed to Transformer’s ability to extract features effectively and model spectral dimension information accurately. Swin, SegFormer, ResT, and other Transformer-based models demonstrated impressive potential in hyperspectral semantic segmentation tasks. In particular, SegFormer achieved comparable results to our proposed model on the three datasets, indicating that a simple decoder could often achieve a better performance for hyperspectral semantic segmentation tasks.
To further improve the performance of our proposed model, we designed a novel decoder architecture that efficiently the transmitted texture information extracted by the upper layers of the model to the decoder. This reduced the misclassification of the model and enhanced its segmentation accuracy. In the ablation experiment section, we compared our decoder architecture with UperNet, and the results demonstrated the effectiveness of our proposed approach.
It is worth noting that PoolFormer is a hierarchical model that uses simple pooling modules. It achieved good results on the three datasets, which further confirms the importance of the hierarchical structure in hyperspectral image classification. In our study, we also adopted the traditional hierarchical structure and used stages 1–4 to represent the model structure.
The ConvNeXt experiment provided additional evidence supporting the importance of the hierarchical structure for hyperspectral semantic segmentation tasks. We found that pure convolution-based Transformer-like models cannot fully extract deep semantic information, and therefore cannot achieve a good segmentation performance. To address this limitation, our model combines CNN and Transformer layers to extract shallow and deep information, respectively. Specifically, we used CNN to extract shallow information in the early layers of the model, and Transformer to extract deep information in the later layers.
Our analysis of the AA showed that our proposed method could effectively leverage the shallow spatial detail information of hyperspectral images. Specifically, the shallow layer information extraction module significantly enhanced the model’s ability to extract texture information. At the same time, the segmentation accuracy of the model was also enhanced, and the location of the ground objects generated by the model was limited to the effective area. The incorporation of the Decoder part, which operated on the output of the Transformer layer, further improved the segmentation accuracy of our model. The Decoder part effectively refined the output of the model and ensured that the predicted ground objects were within the valid area of the image. As a result, the AA of our model was significantly higher than other, similar models.
Based on the results presented in Table 5 and Figure 6, SGHViT achieved the highest classification accuracy for most ground objects in the IA dataset, with some objects reaching 100%. However, for certain objects, such as alfalfa, corn-notill, corn-mintill, soybean-clean, and stone-Steel-Towers, SGHViT did not achieve optimal results, with a gap of approximately ∼2% compared to the best-performing model. This is because SGHViT needs to fully consider the distribution of various ground objects for classification. The location of these features is concentrated and often difficult to distinguish at the edge. Figure 6 indicates that 1DCNN and Unet had a high number of misclassifications, while 3DCNN exhibited many misclassifications in certain areas. Hybrid models improved a substantial number of misclassifications, and SSFTT only had misclassifications in the edge areas of ground objects. Models such as FPN, Deeplabv3, and Swin only showed misclassifications for some challenging features. Although SGHViT also exhibits misclassifications for some difficult-to-classify objects, it outperforms the semantic segmentation-based methods, improving classification accuracy for most areas.

Figure 6.
Comparative experiments on IA dataset.
According to the results presented in Table 6 and Figure 7, SGHViT achieved the best classification accuracy for almost all ground objects in the PU dataset. Specifically, SGHViT achieved 100% accuracy for Gravel, Metal sheets, Bare Soil, and Bitumen, and was only slightly worse than the best-performing model for Meadows, by approximately ∼0.1%. Figure 7 indicates that patch-based methods did not perform well on the challenging PU dataset, with all methods exhibiting misclassifications in the central area of ground objects. However, semantic segmentation-based methods had no misclassifications in the central region of Bare Soil and other objects. Unet, Deeplabv3, and SegFormer exhibit numerous misclassifications for Asphalt, Shadows, and Trees, whereas SGHViT significantly improves the misclassification of these features, especially Trees and Shadows. Overall, SGHViT demonstrates reasonable classification accuracy for different ground objects and outperforms other methods in terms of comprehensive indicators such as OA, AA, and K.
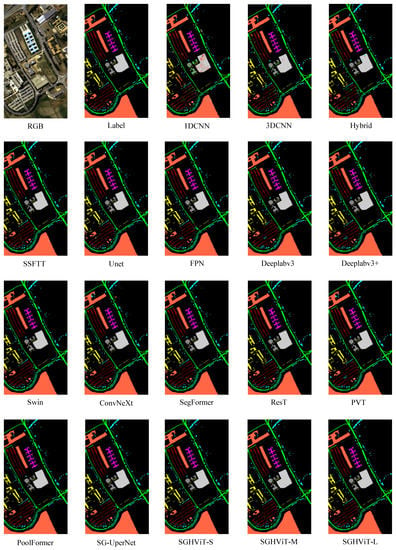
Figure 7.
Comparative experiments on PU dataset.
Evidenced by the results presented in Table 7 and Figure 8, SGHViT achieves the best classification accuracy for most ground objects in the SA dataset, with the exception of fallow-rough-plow, grapes-untrained, corn-senesced-green-weeds, lettuce-romaine-7wk, and vinyard-vertical-trellis.SGHViT achieves 100% accuracy for multiple ground objects. Figure 8 clearly shows a significant number of misclassifications in the patch-based and Unet methods. However, other models based on semantic segmentation exhibit partial misclassifications for Vinyard_u, Grapes, Lettuce_4wk, Lettuce_5wk, Lettuce_6wk, Lettuce_7wk, and Corn, which are particularly noticeable at the edge between Vinyard_u and Grapes. SGHViT effectively overcomes the aforementioned misclassification issues, exhibiting very few misclassifications for difficult-to-classify objects such as Vinyard_u and Grapes.

Figure 8.
Comparative experiments on SA dataset.
3.4. Ablation Experiment
We present the results of the ablation experiments in Table 8 and Table 9, where we comprehensively evaluated the impact of different modules on the performance of the model. Specifically, we investigated the effect of stacking Transformer blocks on the model’s performance, as well as the performance impact of our designed Decoder compared to the widely used UperNet [13,49].
Table 8.
Backbone experiments on different Decoders and different numbers of Transformer blocks.
Table 9.
Ablation experiments on three datasets.
- (1)
- The impact of using different Decoders on the SGHViT backbone.
We evaluated the use of UperNet as the Decoder of our model, and present the results in Table 8. Specifically, we designed an SG-UperNet model that used SGHViT-S as the backbone and UperNet as the Decoder. Our results showed that using SGHViT-S as the backbone, combined with UperNet, could achieve good results for hyperspectral semantic segmentation tasks. This reflected the ability of SGHViT-S to effectively extract both shallow and deep semantic information from hyperspectral images and model both local and global context.
However, using UperNet as the Decoder could result in a high parameter quantity and computational complexity. To address this, we proposed a simplified LinkNet-like Decoder that could achieve comparable results with a lower computational cost. Our proposed method used the feature maps of stage3 and stage4 from the Transformer module for feature aggregation, and then applied our simplified Decoder to generate the final segmentation map.
- (2)
- The effect of using different numbers of Transformer blocks on the SGHViT backbone.
We evaluated the effect of stacking Transformer blocks on the performance of our model, and the specific results are presented in Table 8. Specifically, we investigated the impact of varying the number of components of SGHViT-S, SGHViT-M, and SGHViT-L, with the number of components set to [1, 1, 1], [2, 2, 2], and [2, 6, 2], respectively.
Our experimental results showed that, as the number of stacked Transformer blocks increased, the performance of our model improved on all three datasets. This demonstrated the effectiveness of our method in leveraging the multi-scale context information of hyperspectral images.
- (3)
- The effect of different components.
We conducted ablation experiments to evaluate the impact of different modules on the performance of our model for hyperspectral semantic segmentation tasks. Specifically, we evaluated the relative position encoding module (Pos), shallow feature extraction module (Shallow), and feature aggregation module (Fusion).
Our results showed that the relative position encoding module improved the performance of the model in the classification of lower hyperspectral ground objects and had a positive impact on all three datasets. The shallow feature extraction module also had a crucial impact on the correct classification of ground objects, particularly for dense prediction tasks. The OA, AA, and K indicators of the model without the shallow feature extraction module showed a significant decline, especially on the AA indicator. This highlighted the importance of incorporating shallow spatial detail features in the model to reduce misclassifications.
We also found that the feature aggregation module had a significant impact on hyperspectral images with high spatial resolution. For lower-resolution images, the effect of the module was not as significant. However, the module significantly improved various performance indicators for high-resolution images, which was consistent with the module’s design goal. This demonstrated the necessity of feature aggregation processing on the feature maps extracted by Transformer, as discussed in the previous literature [38].
3.5. Comparative Experiments on Other Datasets
To further evaluate the effectiveness of our method, we compared it with several representative models on two challenging datasets, namely the Pavia Center and Botswana datasets. The experimental results of these comparisons were presented in Table 10. For the Pavia Center dataset, we used 0.2% of the total samples for training and the remaining 99.8% for testing. Similarly, for the Botswana dataset, we randomly selected 5% of the data for training and the remaining 95% for testing. To ensure the effective execution of our method on the device, we replaced the multi-head self-attention in the Transformer Encoder at Stages 3 and 4 with window-based self-attention. Window-based self-attention restricted the attention mechanism to a fixed-size window around each token, reducing the computational complexity of the self-attention operation and improving the efficiency of the model. However, this also limited the ability of tokens to attend to distant information in the sequence. Despite this limitation, our method demonstrated a superior performance on these challenging datasets, which demonstrated the reliability and superiority of the SGHViT architecture, especially in scenarios with limited training data.
Table 10.
Comparative experiments on other datasets.
3.6. Robustness Evaluation
We evaluated the robustness of SGHViT by conducting experiments on our proposed model and several representative models under different numbers of training samples. Figure 9 showed the experimental results on the three datasets. We varied the number of training samples by selecting 2%, 4%, 6%, 8% and 10% of the samples for the IA dataset, 0.5%, 1%, 1.5%, 2% and 3% of the samples for the PU dataset, and 0.2%, 0.4%, 0.6%, 0.8% and 1% of the samples for the SA dataset.
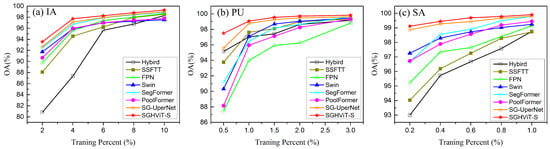
Figure 9.
Classification results in different training percent of samples on the three datasets. (a) IA dataset. (b) PU dataset. (c) SA dataset.
Our results showed that SGHViT outperformed other models in all cases. As the number of training samples decreased, SGHViT achieved higher accuracy compared to other models. This reflected the robustness of SGHViT in small-sample scenarios, where it could achieve a superior performance, even with extremely limited training data.
4. Conclusions
In this paper, we explore the possibility of using hierarchical Transformers in hyperspectral semantic segmentation tasks. We designed a backbone for the hyperspectral semantic segmentation task. The hyperspectral space and spectral features are fully extracted through the shallow-information feature-extraction module and the spectral feature-extraction module. The conv Transformer Encoder and Transformer Encoder were used in appropriate locations to effectively combine CNN and Transformer. At the same time, we designed a simple Decoder, which allows the model to achieve remarkable results in the hyperspectral semantic segmentation task. We conducted detailed comparison experiments with mainstream hierarchical Transformer models, traditional semantic segmentation models, and Patch-based methods. The experimental results show that the hierarchical Transformer has great potential in the field of hyperspectral remote sensing due to its advantages of high precision and low computational cost.
Although the SGHViT model presented in this paper demonstrates excellent hyperspectral object classification performance, the introduction of Transformers for feature extraction enhances the model’s capacity to model long-range dependencies and capture global context information, thus improving segmentation performance. However, this improvement comes at the cost of an increase in the number of model parameters and computational complexity. Therefore, future research efforts will focus on designing lightweight models that balance performance and efficiency.
In addition, we did not consider introducing Transformers into the Decoder component of the model. Future research will continue to explore the application of lightweight models in hyperspectral object classification tasks and investigated how to effectively integrate Transformers into the Decoder to improve the model’s ability to capture spatial information. Specifically, we will investigate techniques for reducing the computational cost of incorporating Transformers into the Decoder, such as knowledge distillation and model compression.
Overall, the successful application of Transformers in hyperspectral object classification tasks highlights their potential for improving the performance of deep learning models in the hyperspectral domain. However, the increased computational cost of using Transformers underscores the need for more efficient model designs. Future research efforts will focus on developing lightweight models that balance performance and efficiency while exploring the potential benefits of integrating Transformers into the Decoder component of the model.
Author Contributions
Conceptualization, methodology, software, Y.C., P.L. and Q.Y.; validation, Y.C., Q.Y., P.L., J.Z. and K.H.; writing—original draft preparation, Y.C.; writing—review and editing, P.L., Q.Y., J.Z. and K.H.; visualization, Y.C. and Q.Y.; supervision, Q.Y.; project administration, Q.Y.; funding acquisition, Q.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by (1) Key Laboratory of Land Satellite Remote Sensing Application, Ministry of Natural Resources of the People’s Republic of China, under Grant (KLSMNR-G202206), (2) the National Natural Science Foundation of China (42001362) to Q.Y., and (3) The Startup Foundation for Introducing Talent of NUIST (1523142301011) to P.L.
Data Availability Statement
The datasets presented in this paper is available through https://www.ehu.eus/ccwintco/index.php/Hyperspectral_Remote_Sensing_Scenes, accessed on 11 February 2023.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| CNN | Convolutional Neural Network |
| HSI | Hyperspectral Image |
| ViT | Vision Transformer |
| RNN | Recurrent Neural Network |
| GNN | Graph Convolutional Neural Network |
| ROI | Regions Of Interest |
| Feed-Forward Network | |
| MLP | Multi-Layer Perceptron |
| OA | Overall Accuracy |
| AA | Average Accuracy |
| K | Kappa coefficient |
| IA | Indian |
| PU | Pavia University |
| SA | Salinas |
References
- Cai, Y.; Lin, J.; Hu, X.; Wang, H.; Yuan, X.; Zhang, Y.; Timofte, R.; Van Gool, L. Mask-guided spectral-wise transformer for efficient hyperspectral image reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17502–17511. [Google Scholar]
- Hu, M.; Wu, C.; Zhang, L. HyperNet: Self-supervised hyperspectral spatial–spectral feature understanding network for hyperspectral change detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5543017. [Google Scholar] [CrossRef]
- Tian, S.; Lu, Q.; Wei, L. Multiscale Superpixel-Based Fine Classification of Crops in the UAV-Based Hyperspectral Imagery. Remote Sens. 2022, 14, 3292. [Google Scholar] [CrossRef]
- Zhou, L.; Zhang, C.; Wu, M. D-LinkNet: LinkNet with pretrained encoder and dilated convolution for high resolution satellite imagery road extraction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 182–186. [Google Scholar]
- Li, R.; Zheng, S.; Zhang, C.; Duan, C.; Wang, L.; Atkinson, P.M. ABCNet: Attentive bilateral contextual network for efficient semantic segmentation of Fine-Resolution remotely sensed imagery. ISPRS J. Photogramm. Remote Sens. 2021, 181, 84–98. [Google Scholar] [CrossRef]
- Ding, X.; Zhang, X.; Han, J.; Ding, G. Scaling up your kernels to 31 × 31: Revisiting large kernel design in cnns. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11963–11975. [Google Scholar]
- Chen, Y.; Wang, B.; Yan, Q. Hyperspectral Remote-Sensing Classification Combining Transformer and Multiscale Residual Mechanisms. Laser Optoelectron. Prog. 2023, 60, 1228002. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Zhong, Z.; Li, Y.; Ma, L.; Li, J.; Zheng, W.S. Spectral–spatial transformer network for hyperspectral image classification: A factorized architecture search framework. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5514715. [Google Scholar] [CrossRef]
- Hong, D.; Han, Z.; Yao, J.; Gao, L.; Zhang, B.; Plaza, A.; Chanussot, J. SpectralFormer: Rethinking hyperspectral image classification with transformers. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5518615. [Google Scholar] [CrossRef]
- Yu, H.; Xu, Z.; Zheng, K.; Hong, D.; Yang, H.; Song, M. MSTNet: A Multilevel Spectral–Spatial Transformer Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5532513. [Google Scholar] [CrossRef]
- Sun, L.; Zhao, G.; Zheng, Y.; Wu, Z. Spectral–spatial feature tokenization transformer for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5522214. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Peng, Y.; Ren, J.; Wang, J.; Shi, M. Spectral-Swin Transformer with Spatial Feature Extraction Enhancement for Hyperspectral Image Classification. Remote Sens. 2023, 15, 2696. [Google Scholar] [CrossRef]
- Ghaderizadeh, S.; Abbasi-Moghadam, D.; Sharifi, A.; Zhao, N.; Tariq, A. Hyperspectral image classification using a hybrid 3D-2D convolutional neural networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 7570–7588. [Google Scholar] [CrossRef]
- Hu, W.; Huang, Y.; Wei, L.; Zhang, F.; Li, H. Deep convolutional neural networks for hyperspectral image classification. J. Sensors 2015, 2015, 258619. [Google Scholar] [CrossRef]
- Hamida, A.B.; Benoit, A.; Lambert, P.; Amar, C.B. 3-D deep learning approach for remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4420–4434. [Google Scholar] [CrossRef]
- Gong, H.; Li, Q.; Li, C.; Dai, H.; He, Z.; Wang, W.; Li, H.; Han, F.; Tuniyazi, A.; Mu, T. Multiscale information fusion for hyperspectral image classification based on hybrid 2D-3D CNN. Remote Sens. 2021, 13, 2268. [Google Scholar] [CrossRef]
- García, J.L.; Paoletti, M.E.; Jiménez, L.I.; Haut, J.M.; Plaza, A. Efficient Semantic Segmentation of Hyperspectral Images Using Adaptable Rectangular Convolution. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6005905. [Google Scholar] [CrossRef]
- Pan, B.; Xu, X.; Shi, Z.; Zhang, N.; Luo, H.; Lan, X. DSSNet: A Simple Dilated Semantic Segmentation Network for Hyperspectral Imagery Classification. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1968–1972. [Google Scholar] [CrossRef]
- Zhu, Q.; Deng, W.; Zheng, Z.; Zhong, Y.; Guan, Q.; Lin, W.; Zhang, L.; Li, D. A spectral-spatial-dependent global learning framework for insufficient and imbalanced hyperspectral image classification. IEEE Trans. Cybern. 2021, 52, 11709–11723. [Google Scholar] [CrossRef] [PubMed]
- Meng, X.; Yang, Y.; Wang, L.; Wang, T.; Li, R.; Zhang, C. Class-Guided Swin Transformer for Semantic Segmentation of Remote Sensing Imagery. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6517505. [Google Scholar] [CrossRef]
- Zhu, Q.; Zhang, Y.; Wang, L.; Zhong, Y.; Guan, Q.; Lu, X.; Zhang, L.; Li, D. A global context-aware and batch-independent network for road extraction from VHR satellite imagery. ISPRS J. Photogramm. Remote Sens. 2021, 175, 353–365. [Google Scholar] [CrossRef]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pvt v2: Improved baselines with pyramid vision transformer. Comput. Vis. Media 2022, 8, 415–424. [Google Scholar] [CrossRef]
- Yu, W.; Luo, M.; Zhou, P.; Si, C.; Zhou, Y.; Wang, X.; Feng, J.; Yan, S. Metaformer is actually what you need for vision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10819–10829. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11976–11986. [Google Scholar]
- Chang, S.; Wang, P.; Lin, M.; Wang, F.; Zhang, D.J.; Jin, R.; Shou, M.Z. Making Vision Transformers Efficient from a Token Sparsification View. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 6195–6205. [Google Scholar]
- Ding, M.; Xiao, B.; Codella, N.; Luo, P.; Wang, J.; Yuan, L. Davit: Dual attention vision transformers. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part XXIV. Springer: Berlin, Germany, 2022; pp. 74–92. [Google Scholar]
- Pan, X.; Ge, C.; Lu, R.; Song, S.; Chen, G.; Huang, Z.; Huang, G. On the integration of self-attention and convolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 815–825. [Google Scholar]
- Xu, J.; Sun, X.; Zhang, Z.; Zhao, G.; Lin, J. Understanding and improving layer normalization. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2019; Volume 32. [Google Scholar]
- Sun, J.; Shen, Z.; Wang, Y.; Bao, H.; Zhou, X. LoFTR: Detector-free local feature matching with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8922–8931. [Google Scholar]
- d’Ascoli, S.; Touvron, H.; Leavitt, M.L.; Morcos, A.S.; Biroli, G.; Sagun, L. Convit: Improving vision transformers with soft convolutional inductive biases. In Proceedings of the International Conference on Machine Learning (PMLR), Virtual, 18–24 June 2021; pp. 2286–2296. [Google Scholar]
- Pan, Z.; Cai, J.; Zhuang, B. Fast vision transformers with hilo attention. arXiv 2022, arXiv:2205.13213. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2017; Volume 30. [Google Scholar]
- He, X.; Chen, Y.; Lin, Z. Spatial-spectral transformer for hyperspectral image classification. Remote Sens. 2021, 13, 498. [Google Scholar] [CrossRef]
- Strudel, R.; Garcia, R.; Laptev, I.; Schmid, C. Segmenter: Transformer for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 7262–7272. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2021; Volume 34, pp. 12077–12090. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Gaussian error linear units (gelus). arXiv 2016, arXiv:1606.08415. [Google Scholar]
- Xiao, T.; Liu, Y.; Zhou, B.; Jiang, Y.; Sun, J. Unified perceptual parsing for scene understanding. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 418–434. [Google Scholar]
- Chaurasia, A.; Culurciello, E. Linknet: Exploiting encoder representations for efficient semantic segmentation. In Proceedings of the 2017 IEEE Visual Communications and Image Processing (VCIP), St. Petersburg, FL, USA, 10–13 December 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–4. [Google Scholar]
- Yan, Q.; Chen, Y.; Jin, S.; Liu, S.; Jia, Y.; Zhen, Y.; Chen, T.; Huang, W. Inland Water Mapping Based on GA-LinkNet from CyGNSS Data. IEEE Geosci. Remote Sens. Lett. 2022, 20, 1500305. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Martinsson, J.; Mogren, O. Semantic segmentation of fashion images using feature pyramid networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October –2 November 2019. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Zhang, Q.; Yang, Y.B. Rest: An efficient transformer for visual recognition. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2021; Volume 34, pp. 15475–15485. [Google Scholar]
- Chu, X.; Tian, Z.; Wang, Y.; Zhang, B.; Ren, H.; Wei, X.; Xia, H.; Shen, C. Twins: Revisiting the design of spatial attention in vision transformers. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2021; Volume 34, pp. 9355–9366. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).