
SG-Det: Shuffle-GhostNet-Based Detector for Real-Time Maritime Object Detection in UAV Images


Abstract
1. Introduction
- (1)
- We propose a lightweight object detector named SG-Det, which meets the requirements of high precision and high-speed detection of UAV images in SAR.
- (2)
- We design a lightweight classification network named Shuffle-GhostNet, refactor the original GhostNet, and introduce the channel shuffle operation to enhance the flow between information groups and the robustness of the network model.
- (3)
- We design a lightweight feature fusion architecture named BiFPN-tiny, which enhances the corresponding features to capture the characteristics of small, dense objects in UAV images.
- (4)
- We validate the effectiveness of the proposed network on the aerial-drone floating objects (AFO) dataset, demonstrating its ability to achieve real-time detection with high accuracy.
2. Related Work
2.1. Lightweight Neural Network
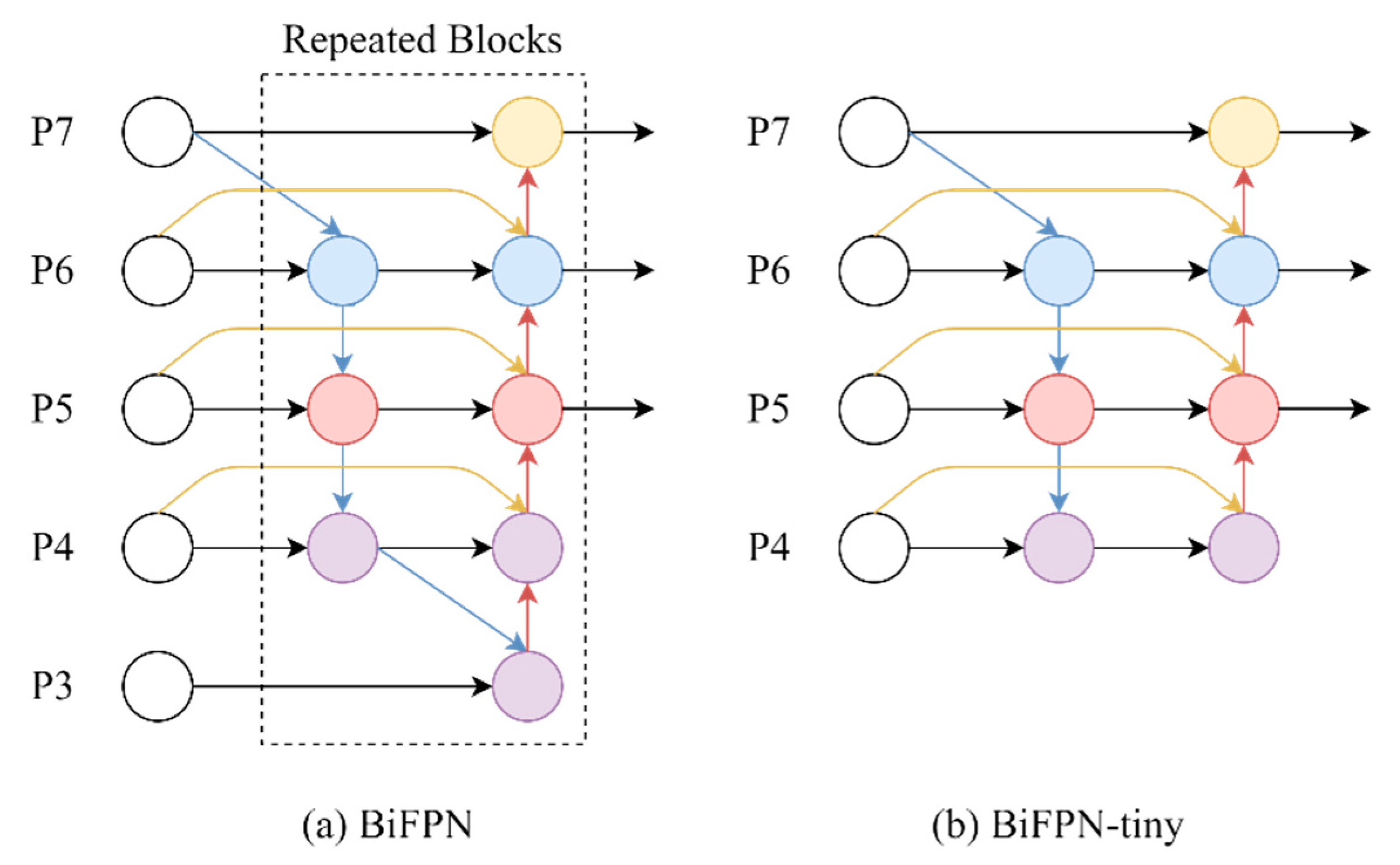
2.2. Feature Pyramid Network
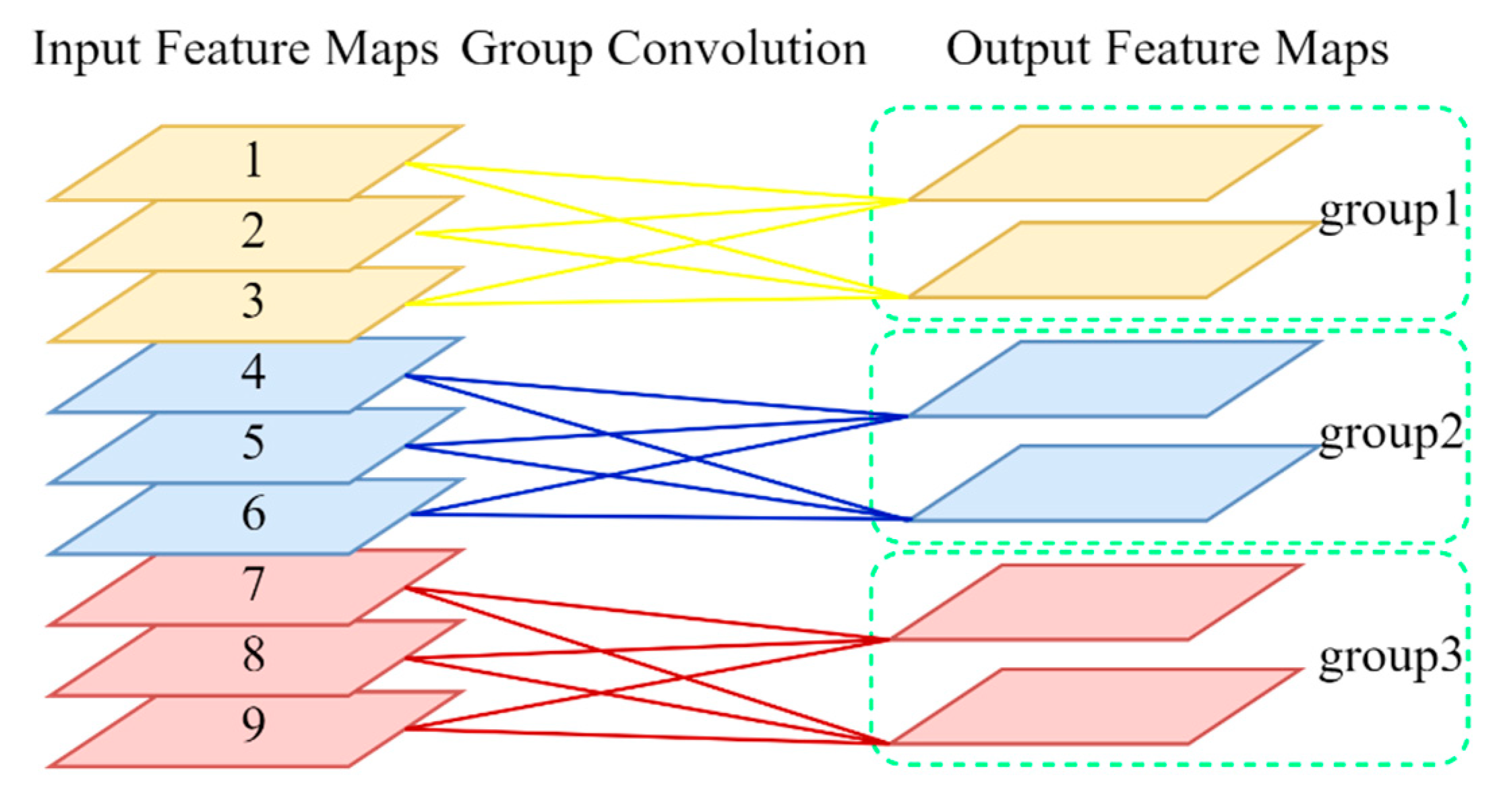
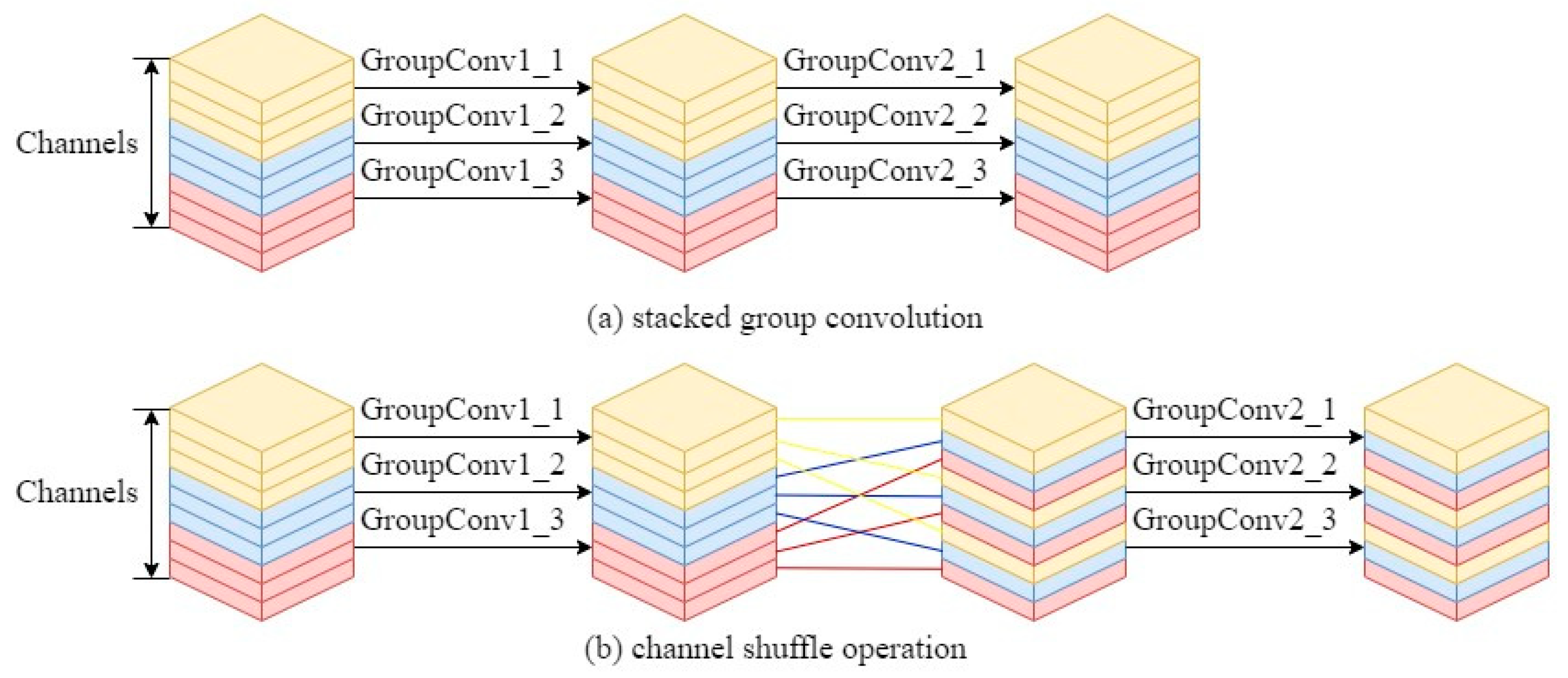
2.3. Group Convolution
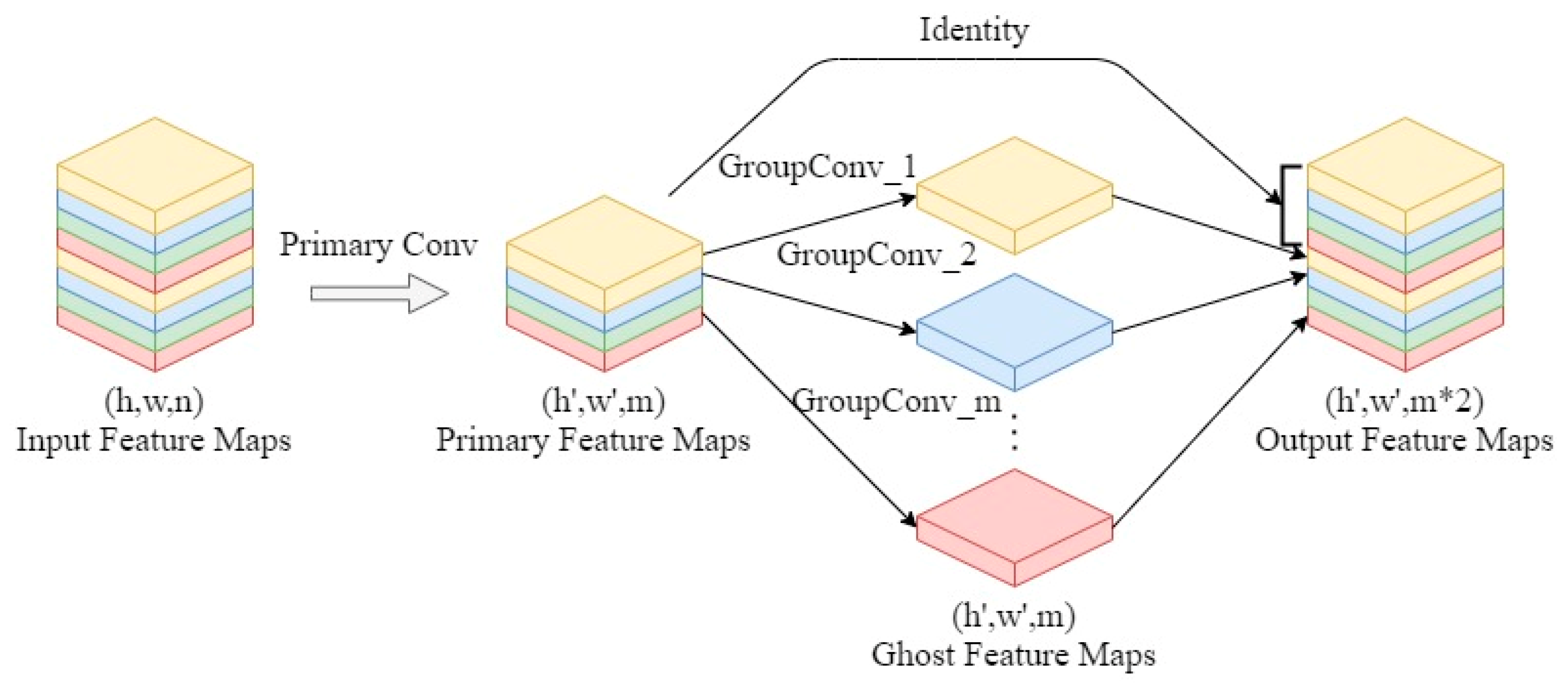
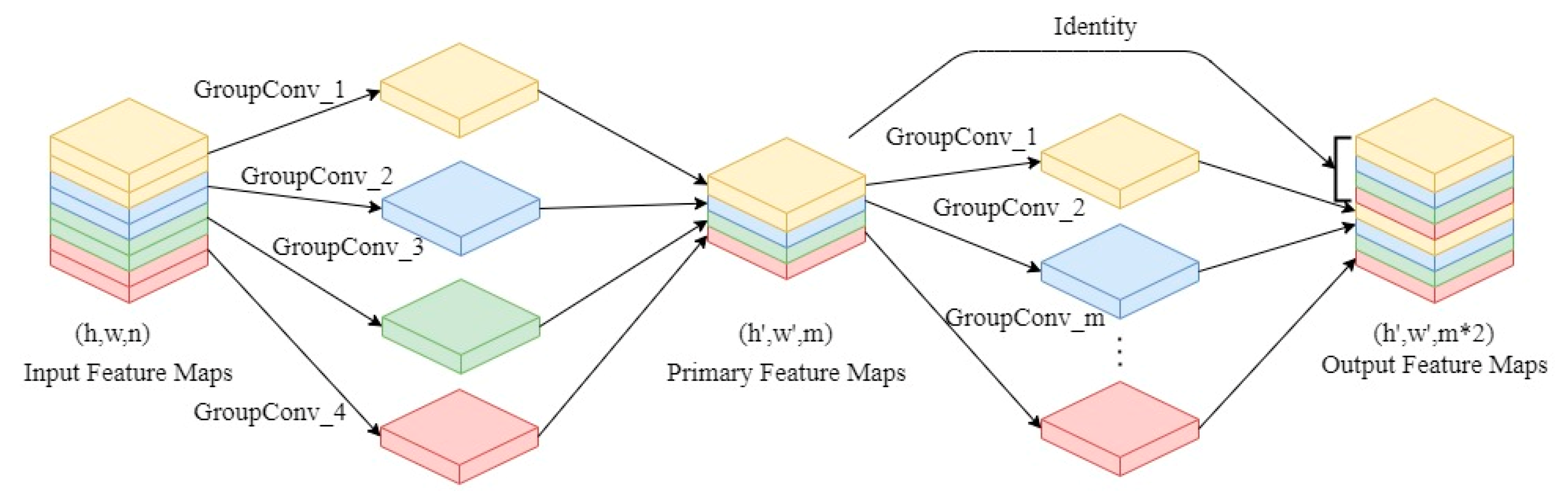
2.4. Ghost Convolution
3. Methods
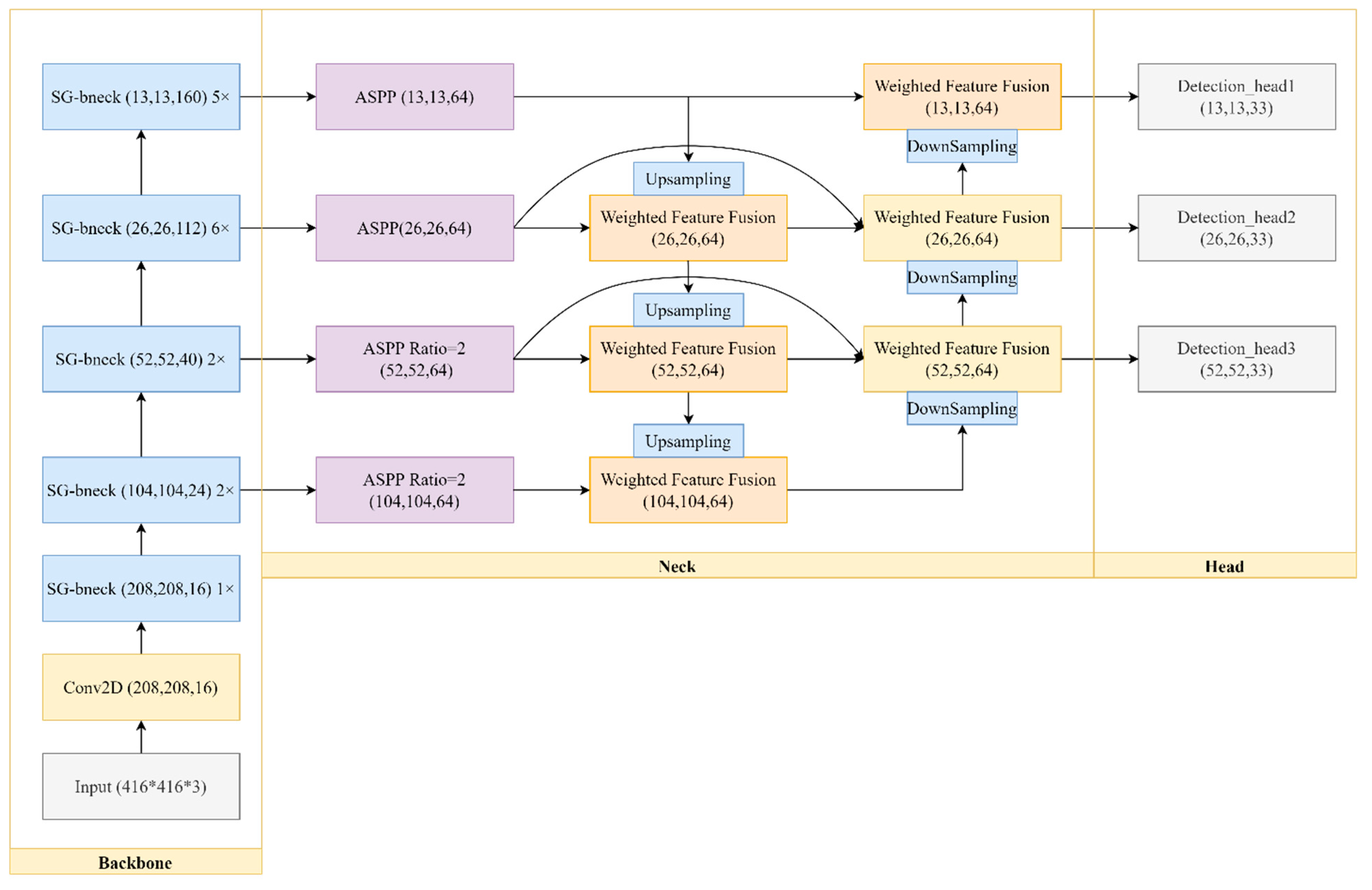
3.1. Overall Framework
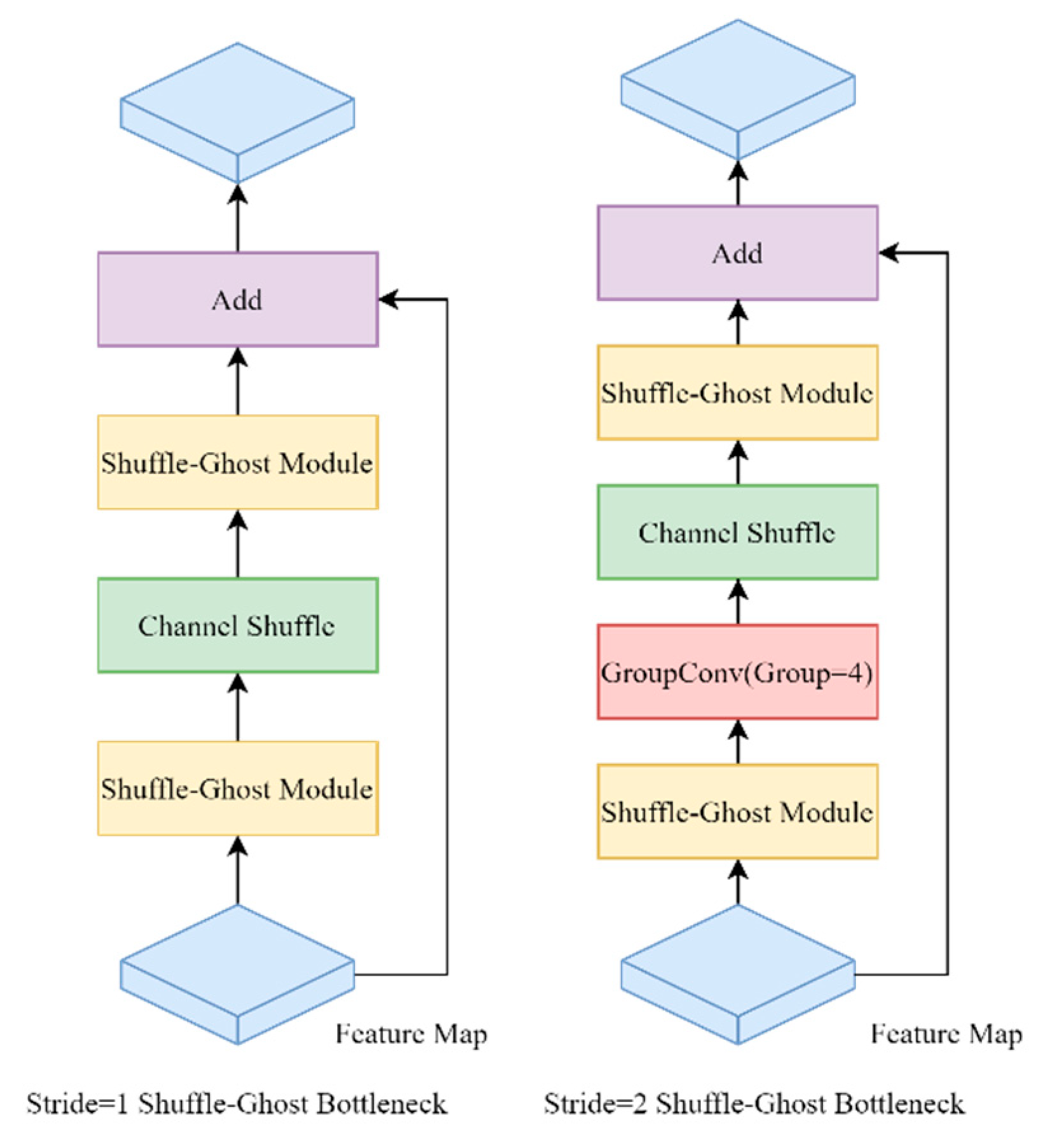
3.2. Backbone
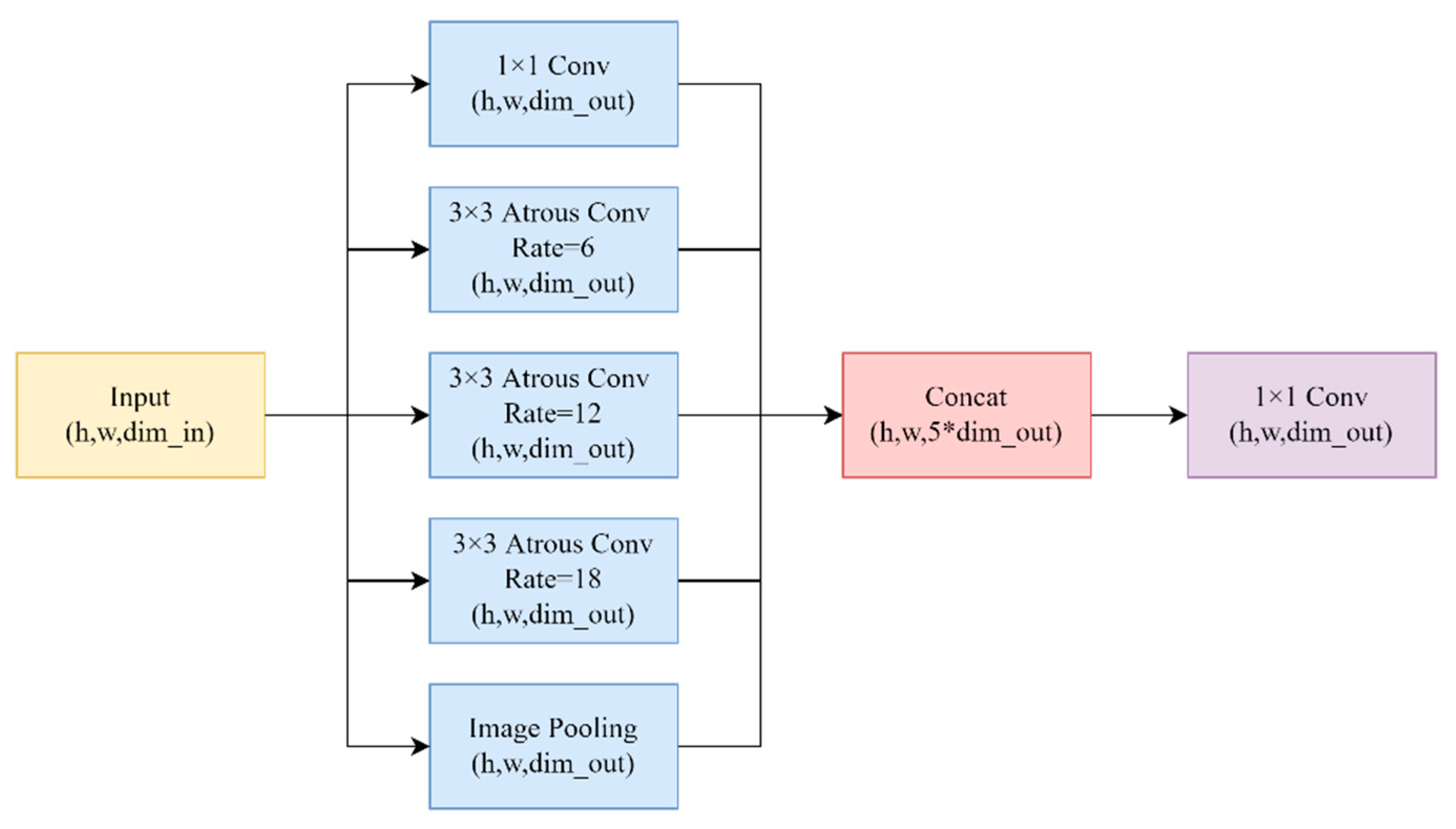
3.3. Neck
3.4. Head
4. Experiment and Discussion
4.1. Model Training
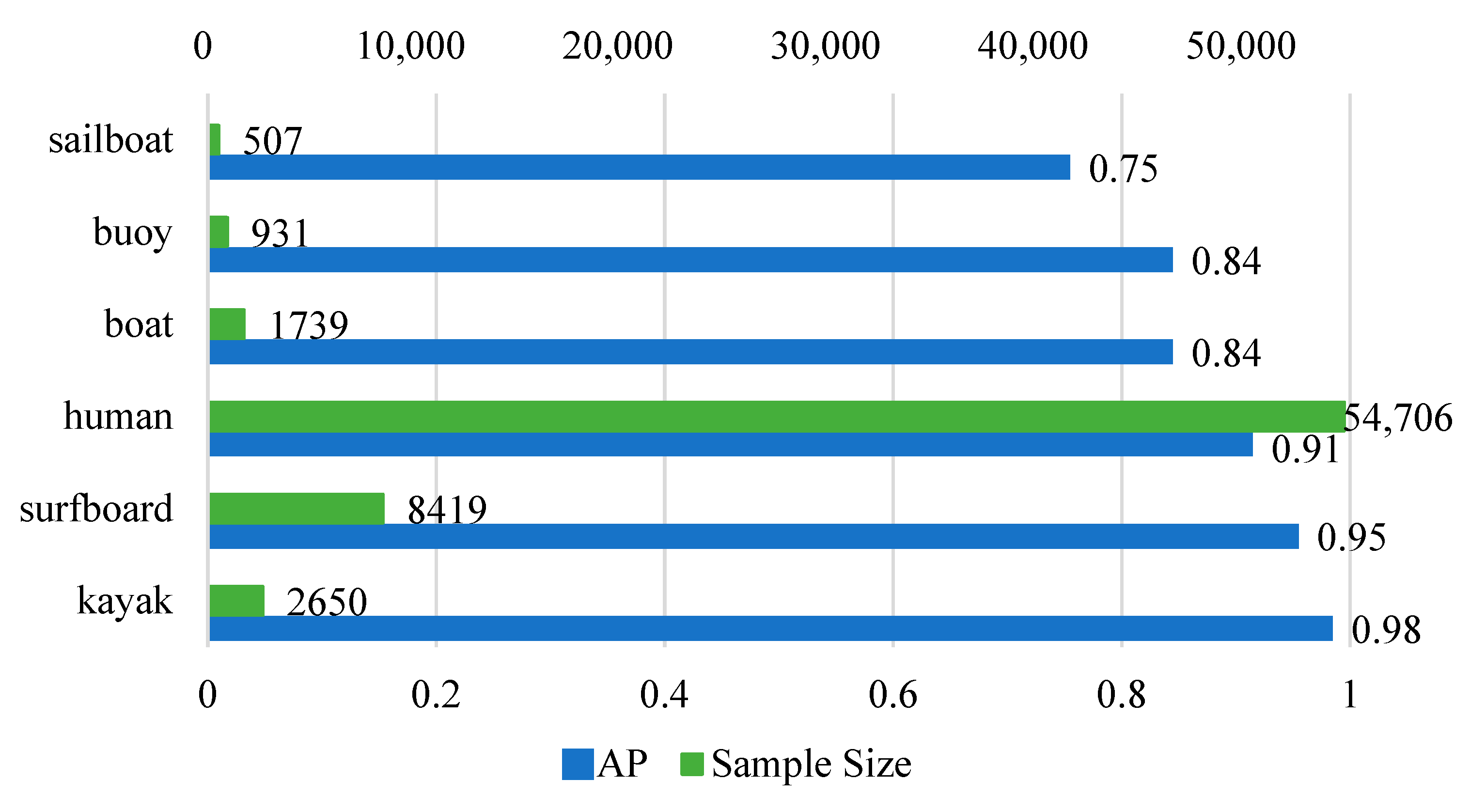
4.2. Dataset
4.3. Comparison Experiment
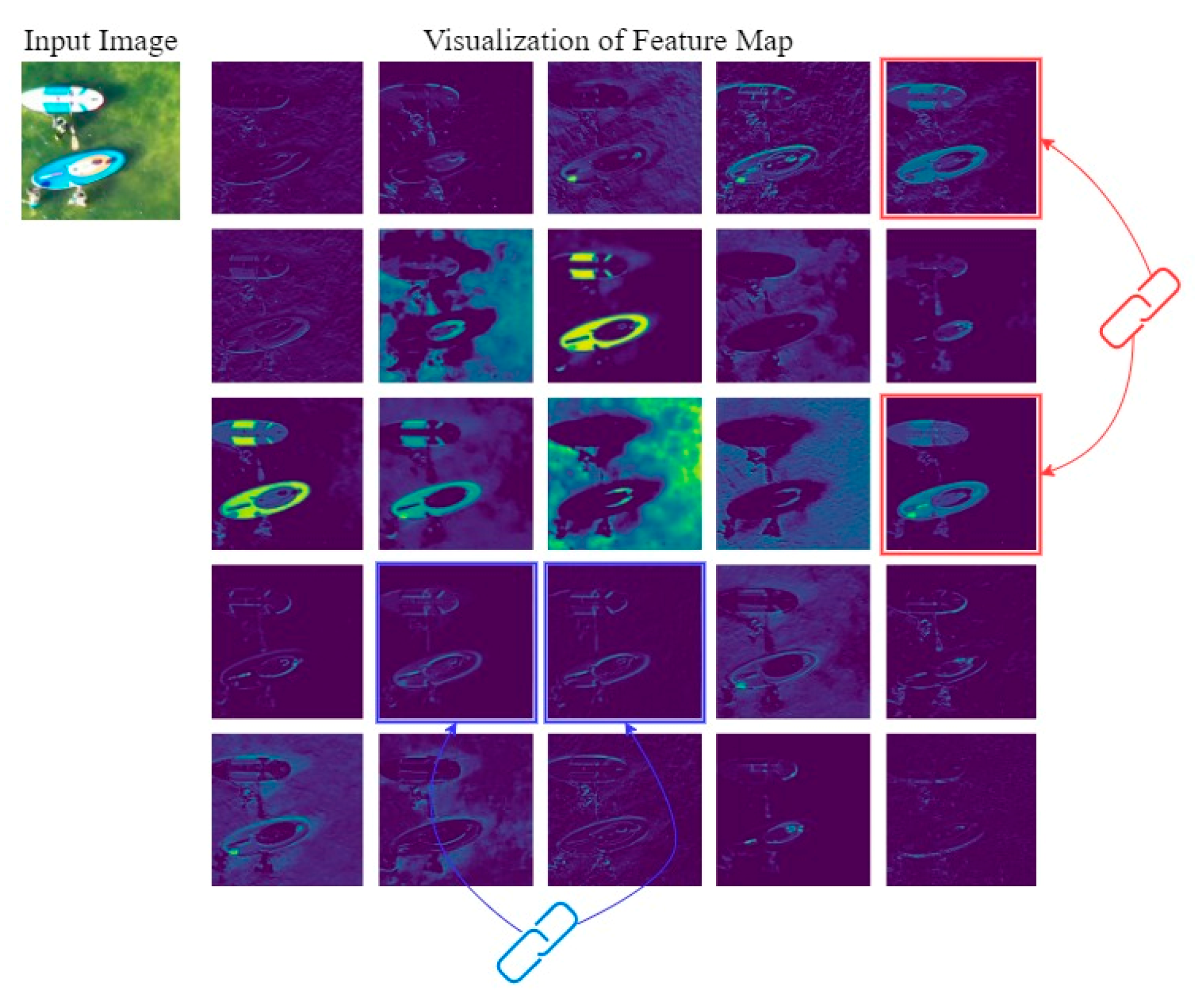
4.4. Ablation Experiment
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- EMSA. Annual Overview of Marine Casualties and Incidents; EMSA: Lisboa, Portugal, 2018. [Google Scholar]
- Lin, L.; Goodrich, M.A. UAV intelligent path planning for wilderness search and rescue. In Proceedings of the 2009 IEEE/RSJ International Conference on Intelligent Robots and Systems, St. Louis, MO, USA, 10–15 October 2009; pp. 709–714. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Li, K.; Deng, Q.; Li, K.; Yu, P.S. Distributed Deep Learning Model for Intelligent Video Surveillance Systems with Edge Computing; IEEE Transactions on Industrial Informatics: Piscataway, NJ, USA, 2019. [Google Scholar]
- Xu, Y.; Wang, H.; Liu, X.; He, H.R.; Gu, Q.; Sun, W. Learning to See the Hidden Part of the Vehicle in the Autopilot Scene. Electronics 2019, 8, 331. [Google Scholar] [CrossRef]
- Goswami, G.; Ratha, N.; Agarwal, A.; Singh, R.; Vatsa, M. Unravelling robustness of deep learning based face recognition against adversarial attacks. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 1–3 February 2018; Volume 32. [Google Scholar]
- Guo, S.; Liu, L.; Zhang, C.; Xu, X. Unmanned aerial vehicle-based fire detection system: A review. Fire Saf. J. 2020, 113, 103117. [Google Scholar]
- Zhang, J.; Liu, S.; Chen, Y.; Huang, W. Application of UAV and computer vision in precision agriculture. Comput. Electron. Agric. 2020, 178, 105782. [Google Scholar]
- Ke, Y.; Im, J.; Son, Y.; Chun, J. Applications of unmanned aerial vehicle-based remote sensing for environmental monitoring. J. Environ. Manag. 2020, 255, 109878. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23 June 2014; pp. 580–587. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Wang, Y.; Liu, W.; Liu, J.; Sun, C. Cooperative USV–UAV marine search and rescue with visual navigation and reinforcement learning-based control. ISA Trans. 2023, 137, 222–235. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Zhang, H.; Zhao, Y. Yolov7-sea: Object detection of maritime uav images based on improved yolov7. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 233–238. [Google Scholar]
- Tran, T.L.C.; Huang, Z.-C.; Tseng, K.-H.; Chou, P.-H. Detection of Bottle Marine Debris Using Unmanned Aerial Vehicles and Machine Learning Techniques. Drones 2022, 6, 401. [Google Scholar] [CrossRef]
- Lu, Y.; Guo, J.; Guo, S.; Fu, Q.; Xu, J. Study on Marine Fishery Law Enforcement Inspection System based on Improved YOLO V5 with UAV. In Proceedings of the 2022 IEEE International Conference on Mechatronics and Automation (ICMA), Guilin, China, 7–10 August 2022; pp. 253–258. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Chen, Y.; Dai, X.; Chen, D.; Liu, M.; Dong, X.; Yuan, L.; Liu, Z. Mobile-former: Bridging mobilenet and transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5270–5279. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11976–11986. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Ghiasi, G.; Lin, T.Y.; Le, Q.V. Nas-fpn: Learning scalable feature pyramid architecture for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 7036–7045. [Google Scholar]
- Luo, Y.; Cao, X.; Zhang, J.; Guo, J.; Shen, H.; Wang, T.; Feng, Q. CE-FPN: Enhancing channel information for object detection. Multimed. Tools Appl. 2022, 81, 30685–30704. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 June 2017; pp. 1251–1258. [Google Scholar]
- Gąsienica-Józkowy, J.; Knapik, M.; Cyganek, B. An ensemble deep learning method with optimized weights for drone-based water rescue and surveillance. Integr. Comput.-Aided Eng. 2021, 28, 221–235. [Google Scholar] [CrossRef]
- Van Etten, A. You only look twice: Rapid multi-scale object detection in satellite imagery. arXiv 2018, arXiv:1805.09512. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 116–131. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. Scaled-yolov4: Scaling cross stage partial network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13029–13038. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Stoken, A.; Borovec, J.; Kwon, Y.; Fang, J.; Michael, K.; Montes, D.; Nadar, J.; Skalski, P.; et al. ultralytics/yolov5: V6.1—TensorRT, TensorFlow Edge TPU and OpenVINO Export and Inference. 2022. Available online: https://zenodo.org/record/6222936#.Y5GBLH1BxPZ (accessed on 20 December 2022).
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Liu, S.; Huang, D. Receptive field block net for accurate and fast object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 385–400. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 3–19. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Detection Framework | mAP | FPS | GFLOPs | Param |
|---|---|---|---|---|---|
| SqueezeNet | Faster R-CNN | 84.46% | 24.99 | 33.29 G | 29.91 M |
| MobileNetv2 | 85.86% | 26.31 | 61.23 G | 82.38 M | |
| MobileNetv3 | 82.93% | 27.03 | 21.34 G | 33.94 M | |
| ShuffleNetv2 | 74.77% | 25.64 | 52.14 G | 62.32 M | |
| GhostNet | 83.15% | 28.57 | 58.37 G | 60.49 M | |
| Shuffle-GhostNet | 84.81% | 30.30 | 21.16 G | 14.17 M |
| Model | mAP | FPS | GFLOPs | Param |
|---|---|---|---|---|
| Shuffle-GhostNet + Faster R-CNN | 84.81% | 30.30 | 21.16 G | 14.17 M |
| YOLOv3-tiny | 79.23% | 29.78 | 5.71 G | 9.09 M |
| YOLOv4-tiny | 81.80% | 34.75 | 6.83 G | 5.89 M |
| EfficientDet | 73.22% | 27.92 | 4.62 G | 3.83 M |
| YOLOv5-s | 84.47% | 33.21 | 6.76 G | 7.04 M |
| YOLOv7-tiny | 85.78% | 37.54 | 5.59 G | 6.03 M |
| Our method | 87.48% | 31.90 | 2.34 G | 3.32 M |
| Model | APS | APM | APL |
|---|---|---|---|
| SqueezeNet | 21.1% | 41.1% | 52.9% |
| MobileNetV2 | 19.8% | 47.1% | 58.6% |
| MobileNetV3 | 12.0% | 35.4% | 53.7% |
| ShuffleNetV2 | 13.6% | 31.2% | 45.4% |
| GhostNet | 17.8% | 38.0% | 53.0% |
| Shuffle-GhostNet | 18.3% | 40.5% | 54.9% |
| YOLOv3-tiny | 15.3% | 34.9% | 50.9% |
| YOLOv4-tiny | 19.1% | 32.2% | 41.3% |
| EfficientDet | 13.5% | 30.3% | 34.9% |
| YOLOv5-s | 27.0% | 37.0% | 51.1% |
| YOLOv7-tiny | 16.8% | 37.4% | 52.7% |
| Our method | 29.8% | 37.2% | 52.3% |
| BiFPN-Tiny | ASPP | RFB | CBAM | GroupConv (Group = 4) | GroupConv (Group = 2) | Channel Shuffle | mAP | FPS | GFLOPs | Param |
|---|---|---|---|---|---|---|---|---|---|---|
| ✓ | 78.96% | 27.48 | 1.65 G | 2.65 M | ||||||
| ✓ | ✓ | 84.20% | 25.94 | 3.20 G | 4.02 M | |||||
| ✓ | ✓ | 83.15% | 21.14 | 1.92 G | 2.89 M | |||||
| ✓ | ✓ | ✓ | 77.98% | 25.97 | 3.21 G | 4.03 M | ||||
| ✓ | ✓ | ✓ | 85.67% | 25.54 | 2.68 G | 3.35 M | ||||
| ✓ | ✓ | ✓ | 85.02% | 25.43 | 2.73 G | 3.42 M | ||||
| ✓ | ✓ | ✓ | ✓ | 87.48% | 31.90 | 2.34 G | 3.32 M |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, L.; Zhang, N.; Shi, R.; Wang, G.; Xu, Y.; Chen, Z. SG-Det: Shuffle-GhostNet-Based Detector for Real-Time Maritime Object Detection in UAV Images. Remote Sens. 2023, 15, 3365. https://doi.org/10.3390/rs15133365
Zhang L, Zhang N, Shi R, Wang G, Xu Y, Chen Z. SG-Det: Shuffle-GhostNet-Based Detector for Real-Time Maritime Object Detection in UAV Images. Remote Sensing. 2023; 15(13):3365. https://doi.org/10.3390/rs15133365
Chicago/Turabian StyleZhang, Lili, Ning Zhang, Rui Shi, Gaoxu Wang, Yi Xu, and Zhe Chen. 2023. "SG-Det: Shuffle-GhostNet-Based Detector for Real-Time Maritime Object Detection in UAV Images" Remote Sensing 15, no. 13: 3365. https://doi.org/10.3390/rs15133365
APA StyleZhang, L., Zhang, N., Shi, R., Wang, G., Xu, Y., & Chen, Z. (2023). SG-Det: Shuffle-GhostNet-Based Detector for Real-Time Maritime Object Detection in UAV Images. Remote Sensing, 15(13), 3365. https://doi.org/10.3390/rs15133365