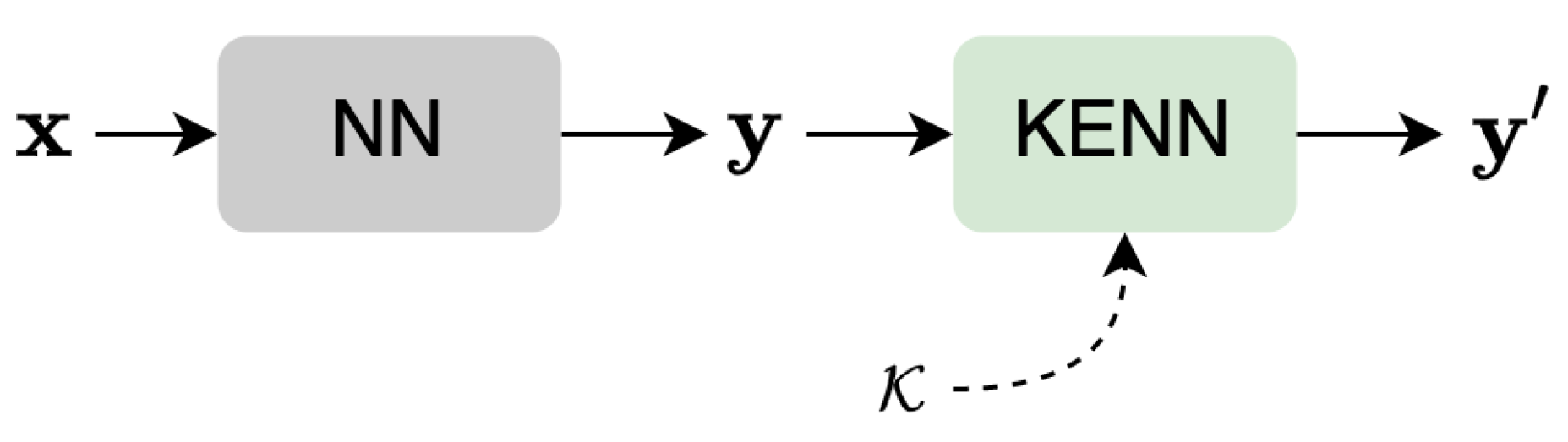
To evaluate the effectiveness of the proposed approach, three benchmark datasets are considered: the ISPRS Vaihingen 3D [
20] (
Section 4.1), Hessigheim 3D [
3] (
Section 4.2), and the Stanford 2D-3D-Semantics Dataset (S3DIS) [
26] (
Section 4.3). The first two datasets depict urban scenarios and are derived from ALS LiDAR surveys. S3DIS depicts an indoor environment. Each dataset presents very different geometric resolutions, a different number of classes, and diverse features (
Table 2). Three different learning configurations are tested for each benchmark:
For a fair comparison, each configuration is run for the same number of epochs (300), with an early-stop criterion that relies on the mean F1 score calculated over the validation set. The network, in particular, stops when the mF1 does not increase in 20 successive strips. To be in line with the results already published for the benchmarks [
3,
20,
26], the individual F1 or IuO score per class, the mean F1 score (mF1) or mIuO, and the Overall Accuracy (OA) are used as evaluation criteria.
4.1. ISPRS Vaihingen
The ISPRS 3D Semantic Labeling Contest Dataset of Vaihingen [
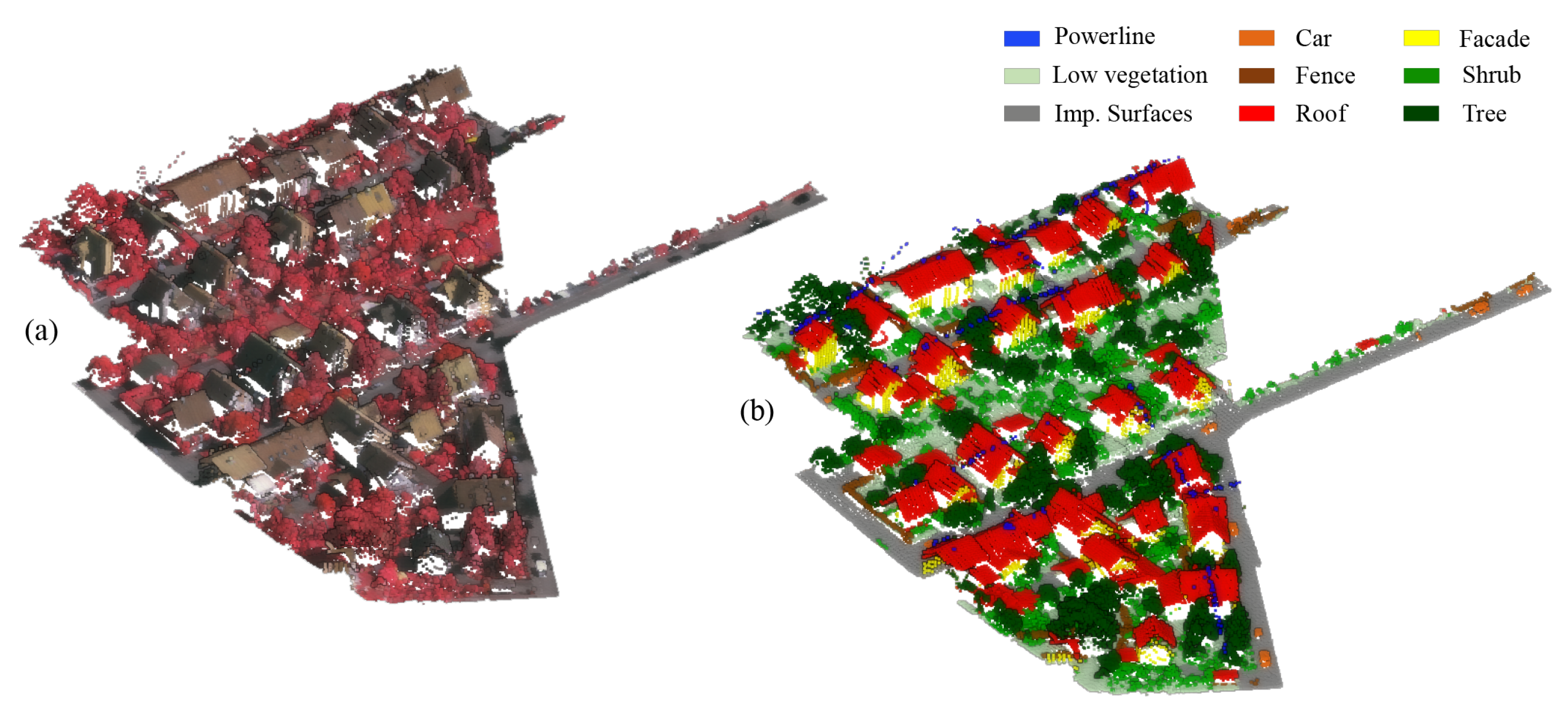
20] is one of the most often used datasets for benchmarking urban-scale geospatial point cloud classification methods. The available point cloud, collected using a Leica ALS50 LiDAR scanner, contains intensities, the number of returns, and return numbers. Additionally, IR-R-G orthophotos (infrared, red, and green channels) are offered and can be used to colourize the point cloud. The dataset consists of nine classes: “powerline”, “low vegetation” (grass), “impervious surface” (ground), “automobile”, “fence”, “roof”, “facade”, and “shrub”. As shown in
Figure 7, the dataset presents some unbalanced classes, such as “Powerline”, “Car”, and “Fence”.
The following covariance features were employed for the processing of vaihingen: R, G, B, Intensity Roughness (r = 1.5 m), Number of neighbors (r = 1.5 m), Omnivariance (r = 1.5 m), Surface variation (r = 1.5 m), Verticality (r = 1.5 m), Surface variation (r = 2 m), Number of neighbors (r = 2 m), Verticality (r = 2 m), Verticality (r = 2.5 m), and the height below 1m with respect to the lowest point within a cylinder of 10 m.
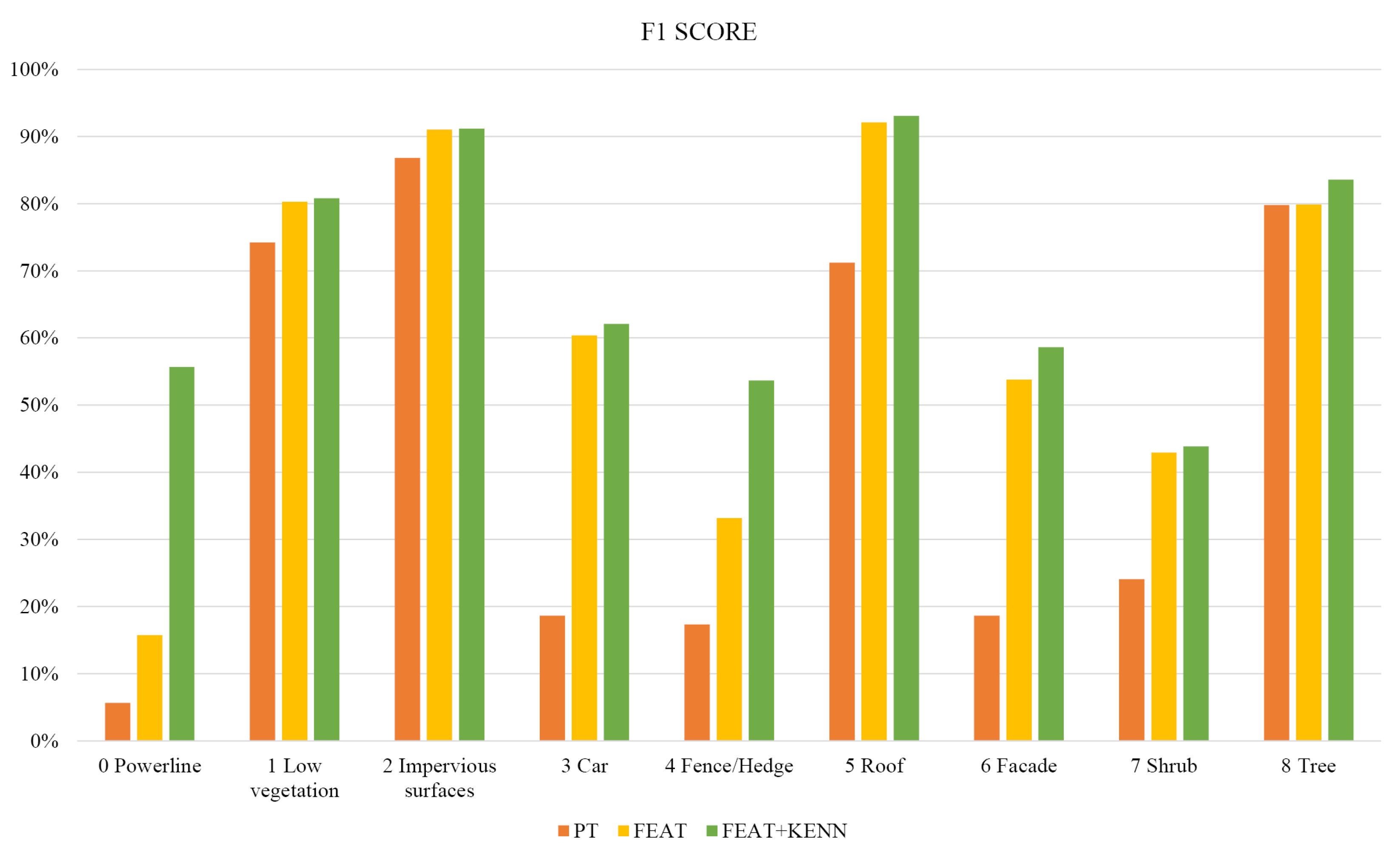
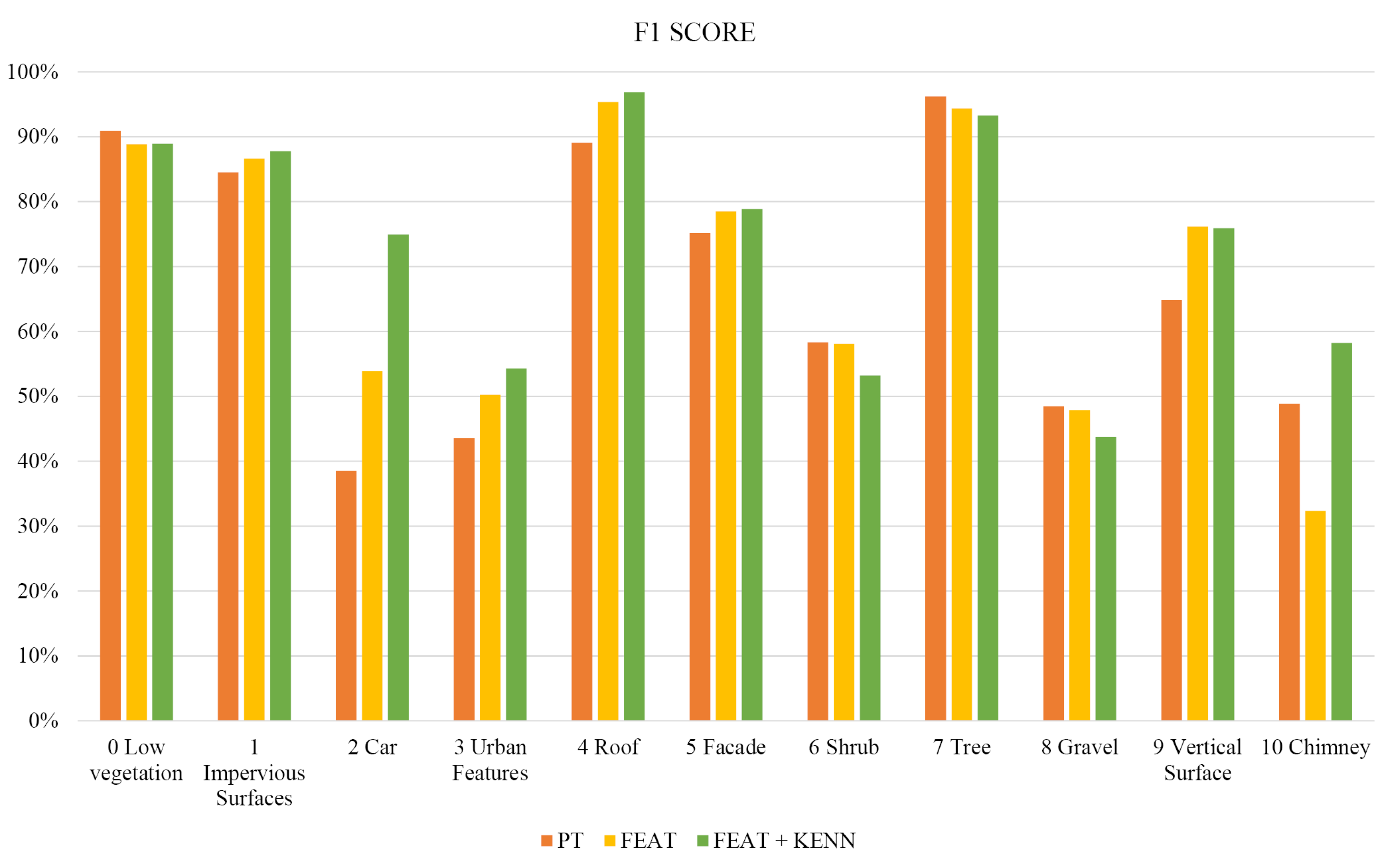
In
Table 3, the F1 scores per class reached with the three previously introduced approaches are reported (also graphically summarized in
Figure 8), as are the Overall Accuracy (OA) and mean F1 Score (mF1). As shown, the baseline configuration (PT) achieves quite low levels of accuracy, in particular for the unbalanced classes. The introduction of features (FEAT configuration) allows to raise the “car” F1 score from 18% to 60% for the “cable” class, it goes from a 5% to a still poor 15% F1 score. Overall, the mF1 score increased from the 44.0% baseline to 61.6% with the feature inclusion.
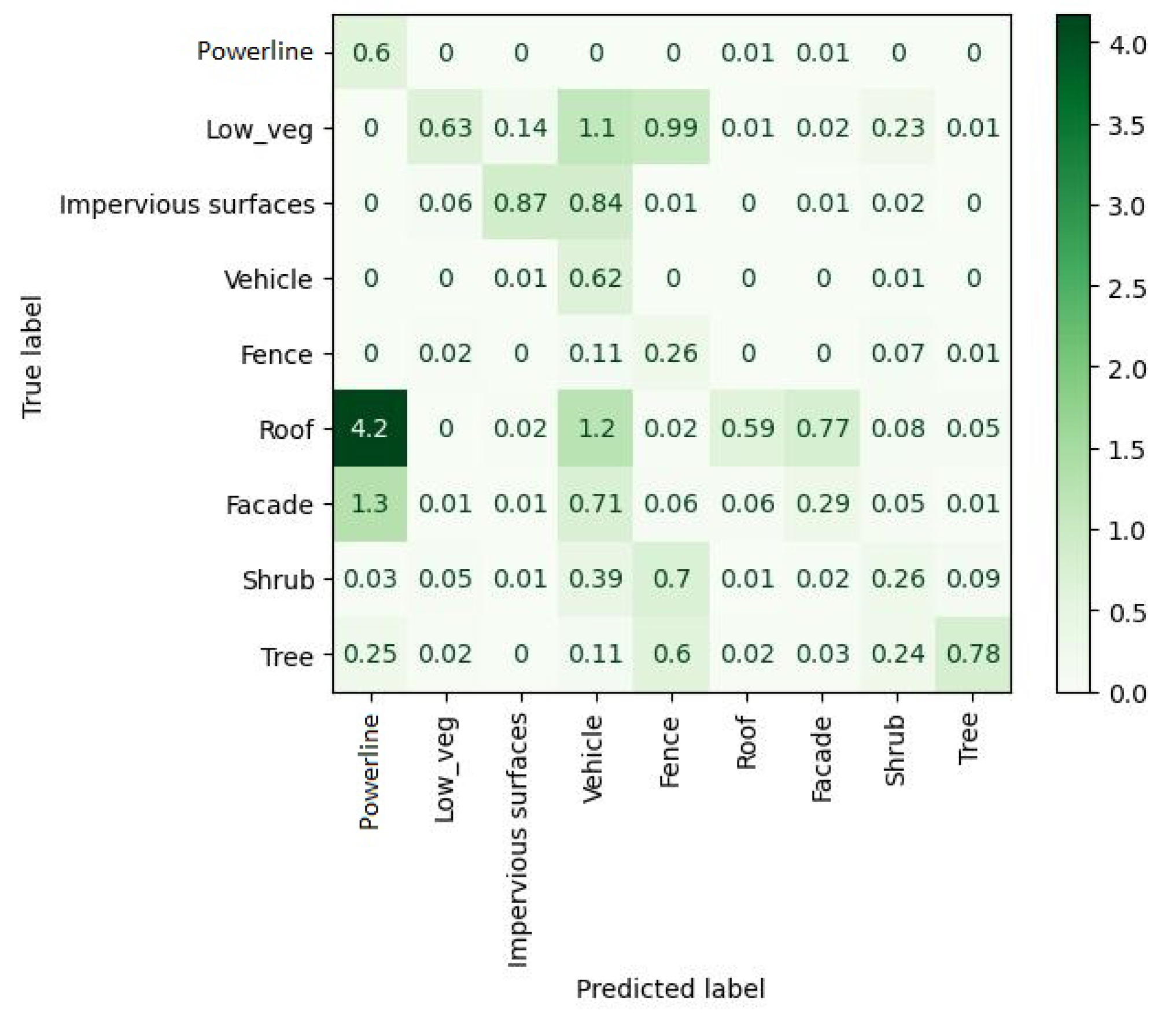
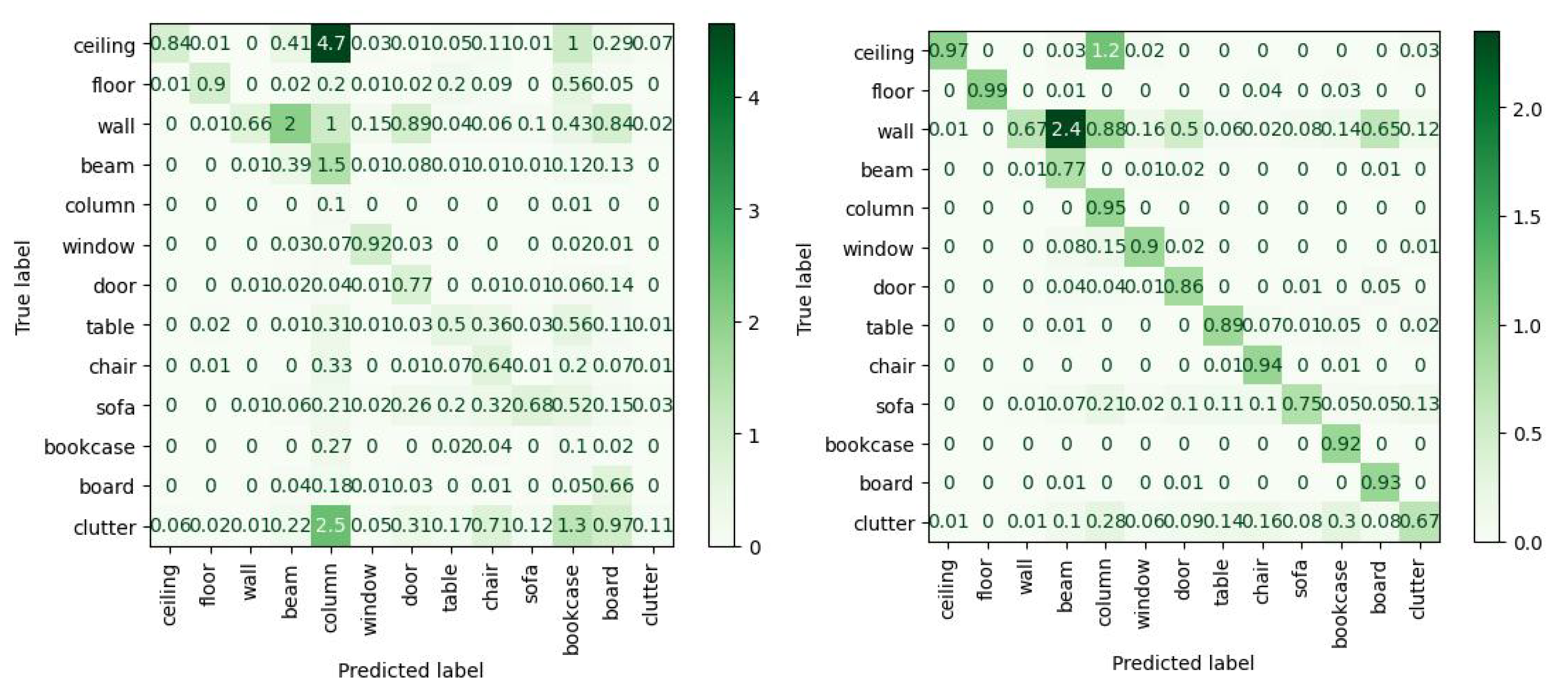
Through an accurate analysis of the confusion matrix extracted for the FEAT configuration (
Figure 9), it is possible to understand that most of the points belonging to the class “powerline” are actually predicted as “roof”.
Therefore, in order to intervene and correct such a problem, three types of rules, related to the classes “powerline” and “roof”, have been introduced:
In the first two rules, we state that points belonging to the class “powerline” are among the highest points of the dataset and, contrary to the “roof” points, have a reduced number of neighbors. This type of rule works, in particular, in relation to two of the hand-crafted features that have been defined for the dataset: height_below and number_of_neighbours. Height_below considers the difference in the height of each point in a certain neighborhood, while number_of_neighbours the number of points in a fixed radius. Finally, the third rule specifies that points belonging to the classes “roof” and “cable” should be far from each other. The threshold near for this case study has been set to 0.8 m, equal to the double of the point cloud resolution.
The “fence” class also had particularly low accuracy outcomes. The confusion matrix showed that points belonging to this class were, in general, misclassified as “shrub”, “tree”, and “vegetation”. For this reason, the following two rules have been introduced:
They state that elements that are short and have a high degree of roughness (local noise) have a high probability of belonging to the class “shrub” (first rule) and not “fence” (second rule). Looking again at
Table 3 and
Figure 8, we can see that the introduction of logic rules was particularly effective for the classes “powerline” and “fence”.
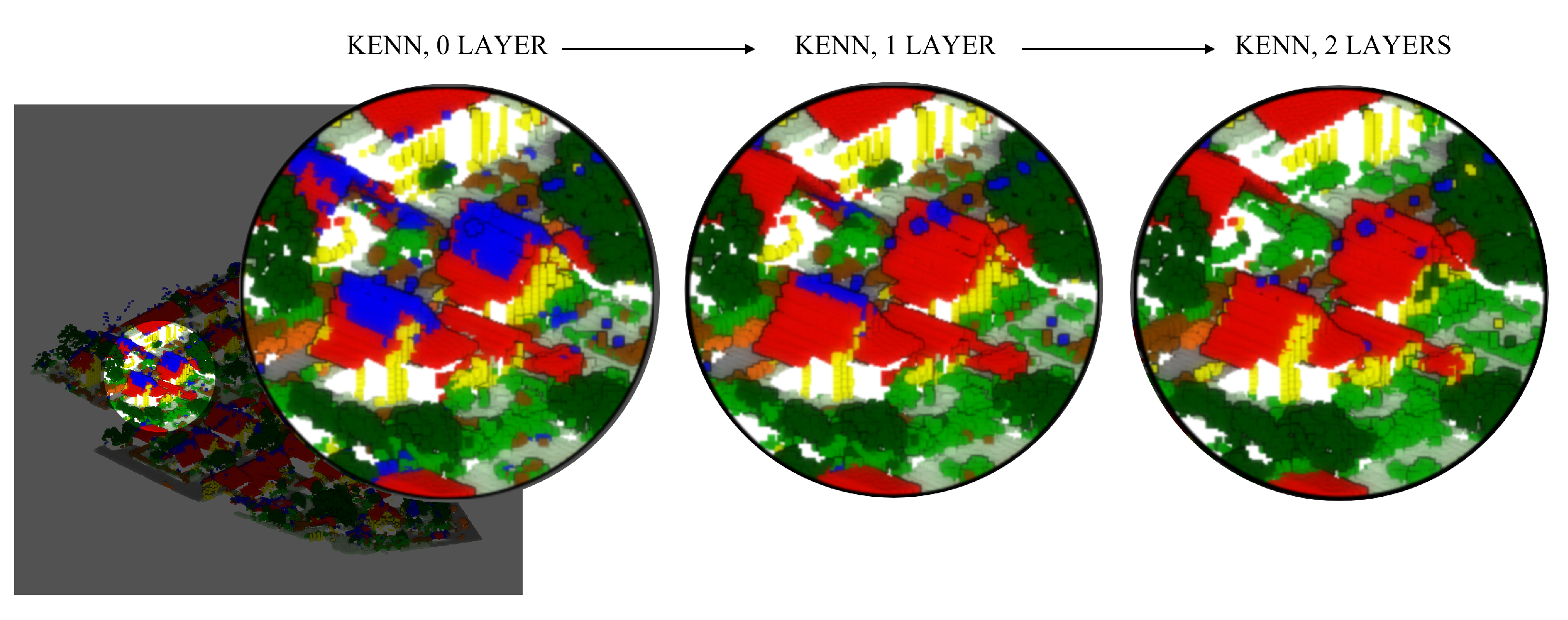
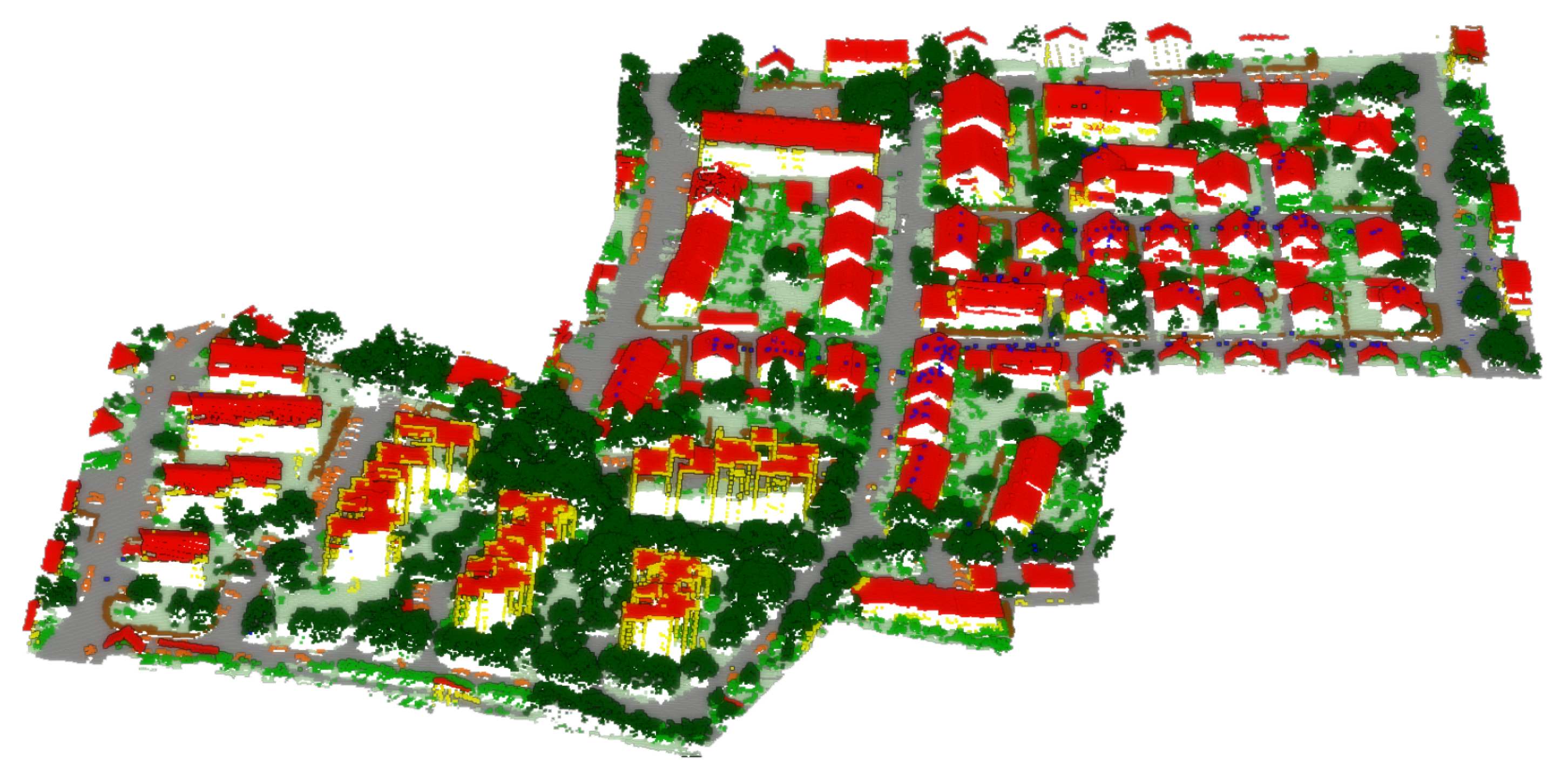
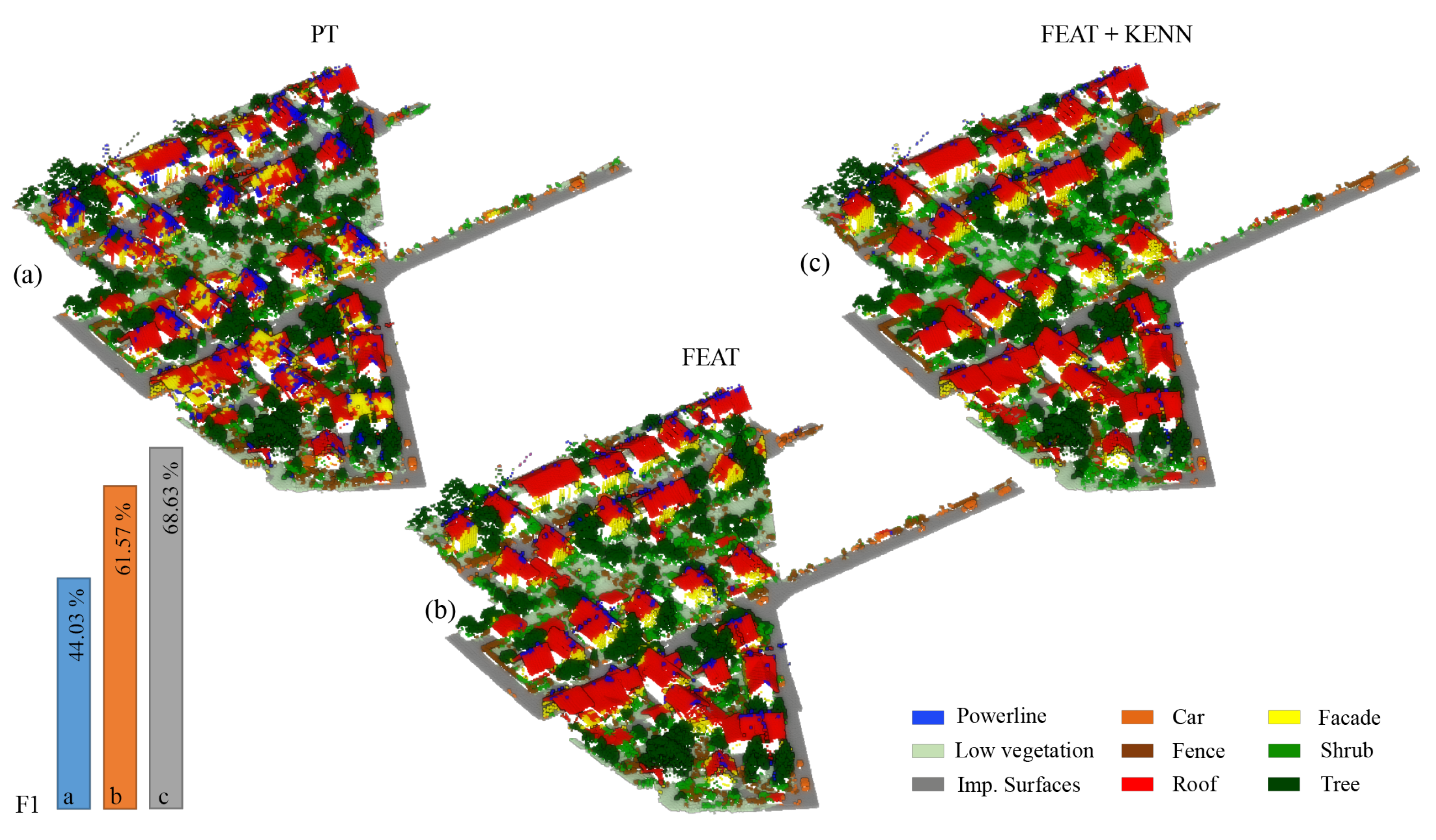
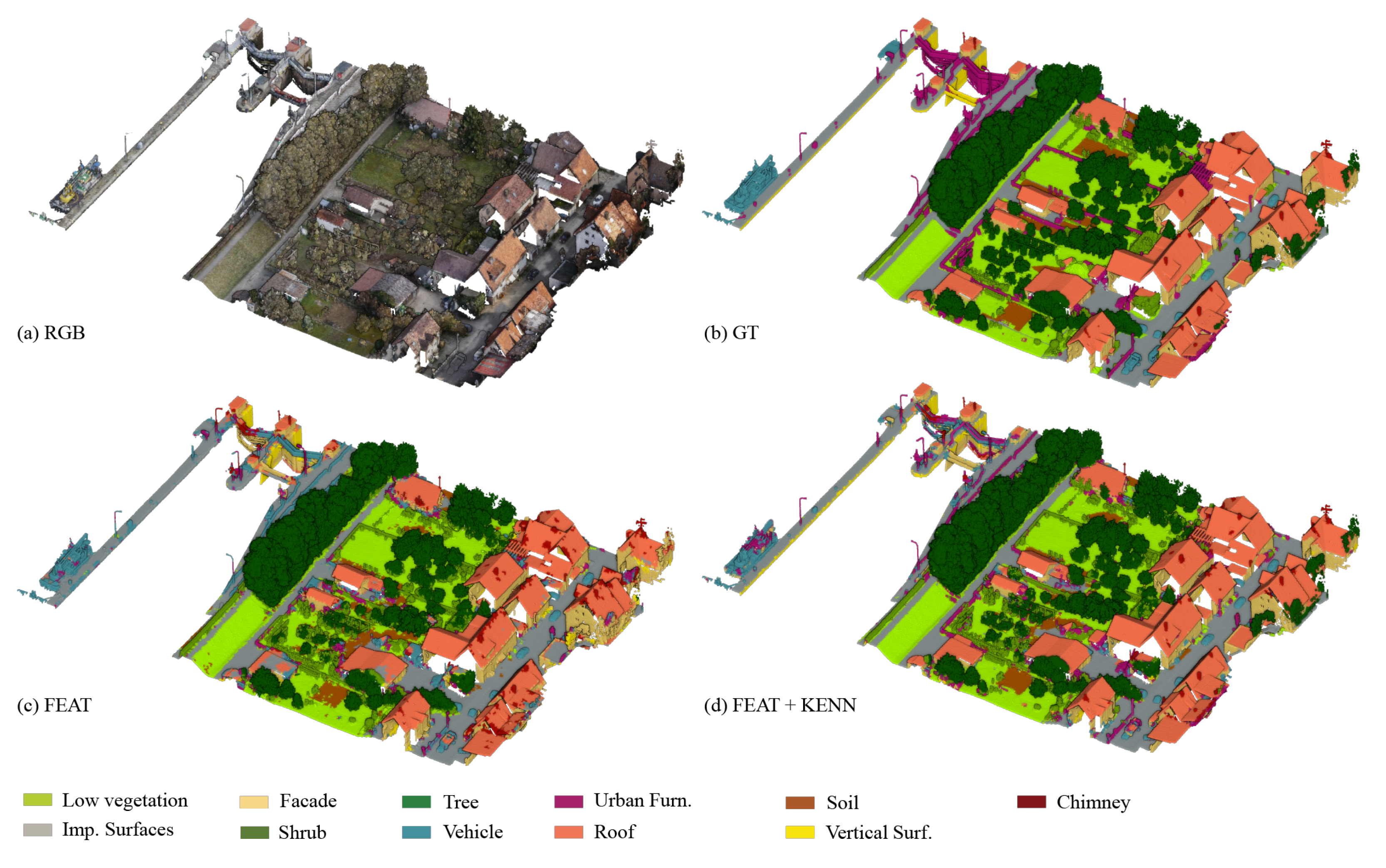
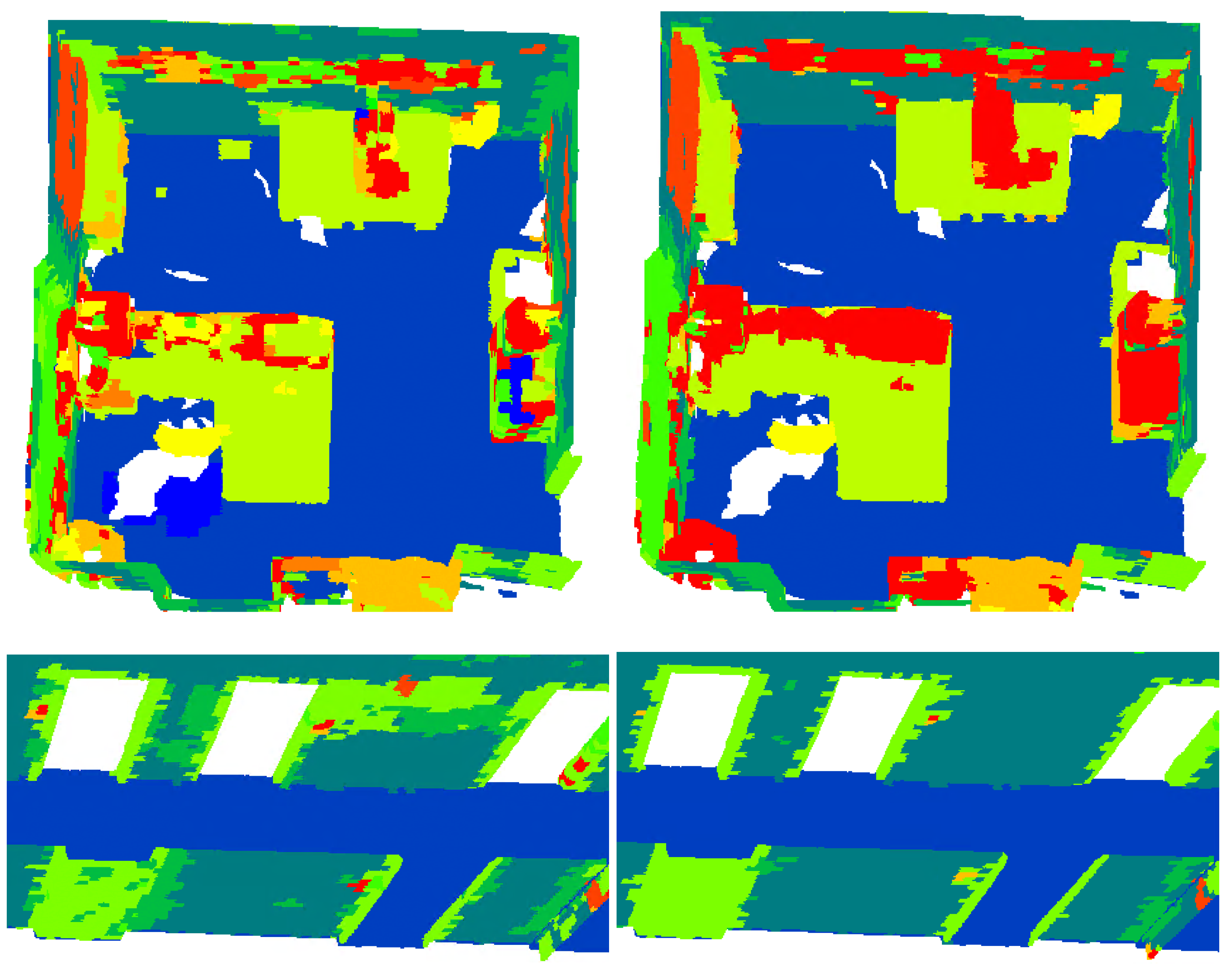
For an overall qualitative evaluation, the manually annotated test dataset (
Figure 10) can be compared with the ones semantically segmented using PT, PT plus hand-crafted features (FEAT), and PT plus features and logic rules (FEAT + KENN) (
Figure 11). Overall, the mF1 score increased from the 61.57% baseline to 68.63% with the inclusion of a-posteriori knowledge.
Finally, in
Table 4, the results achieved with our KENN approach are reported in comparison with other state-of-the-art approaches. It can be seen that there is currently no network predominant over the others and that the proposed KENN method achieves results that are generally in line with the state of the art.
4.2. Hessigheim 3D
The Hessigheim 3D dataset proposed by the University of Stuttgart as an evolution of the Vaihingen dataset serves as a standard in the task of urban-level 3D semantic segmentation. The Hessigheim dataset [
3] is high-density LiDAR data of ca 800 points/m
2, enhanced with RGB colors from onboard cameras (GSD of ca 2–3 cm). The dataset is divided into 11 categories: “Low Vegetation,” “Impervious Surface,” “Vehicle,” “Urban Furniture,” “Roof,” “Facade,” “Shrub,” “Tree,” “Soil/Gravel,” “Vertical Surface,” and “Chimney”. Hessingheim, similar to the Vaihingen dataset, contains several unbalanced classes that are challenging to spot, i.e., “car” and “chimney” (
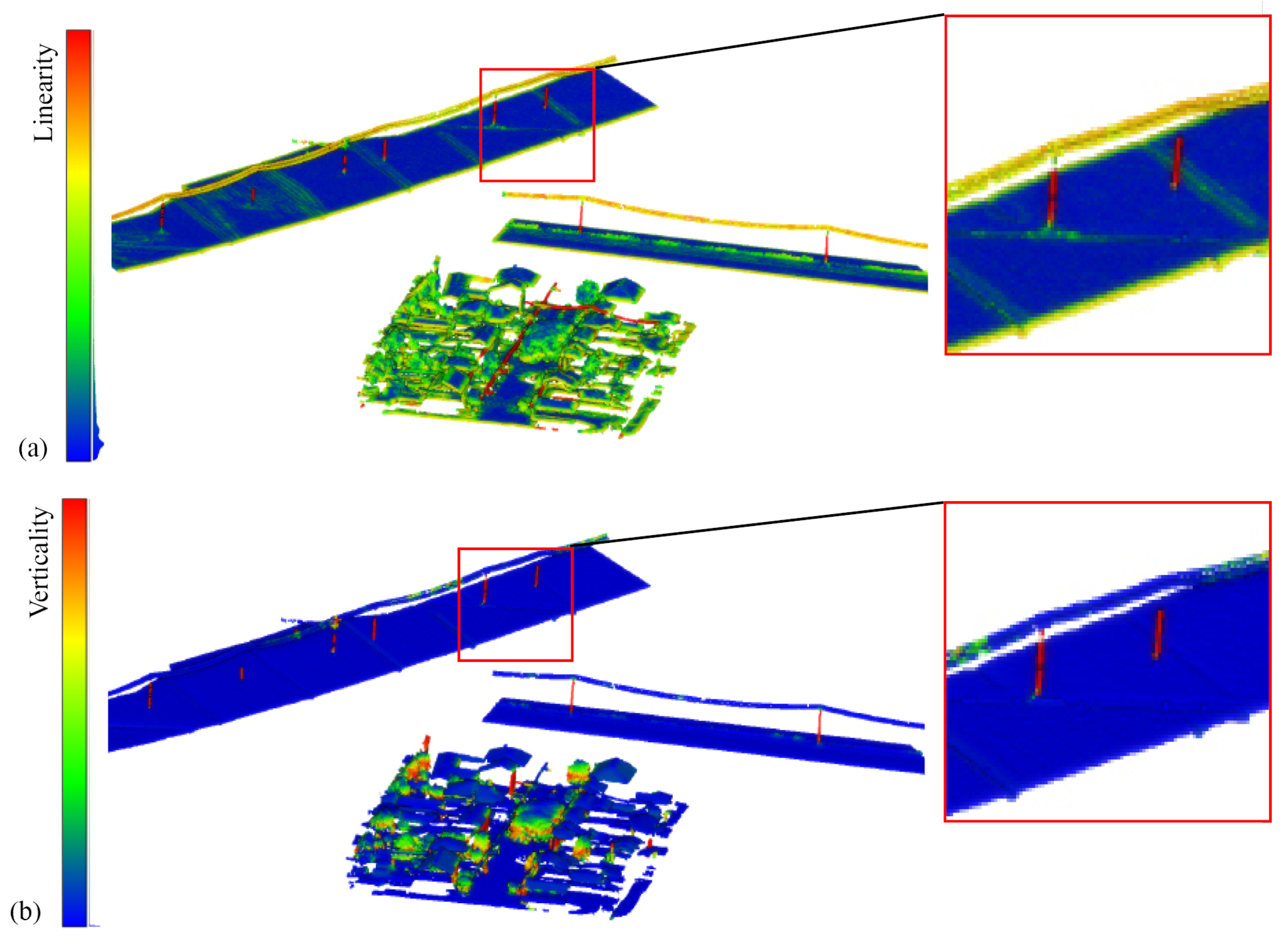
Figure 12 and
Figure 13).
The following covariance features were employed for the processing of vaihingen: R, G, B, Reflectance, Verticality (r = 1 m), Linearity (r = 1 m), Number of neighbors (r = 1 m), Roughness (r = 1 m), and again the height below 1m with respect to the lowest point within a cylinder of 10 m.
The results achieved with the three different experiment configurations are reported in
Table 5. As shown, there has been a general improvement in the metrics thanks to the introduction of logic rules, in particular for those under-represented classes of the training data. Overall, the mF1 score slightly improved between the baseline (67.1%) and the feature inclusion (69.3%).
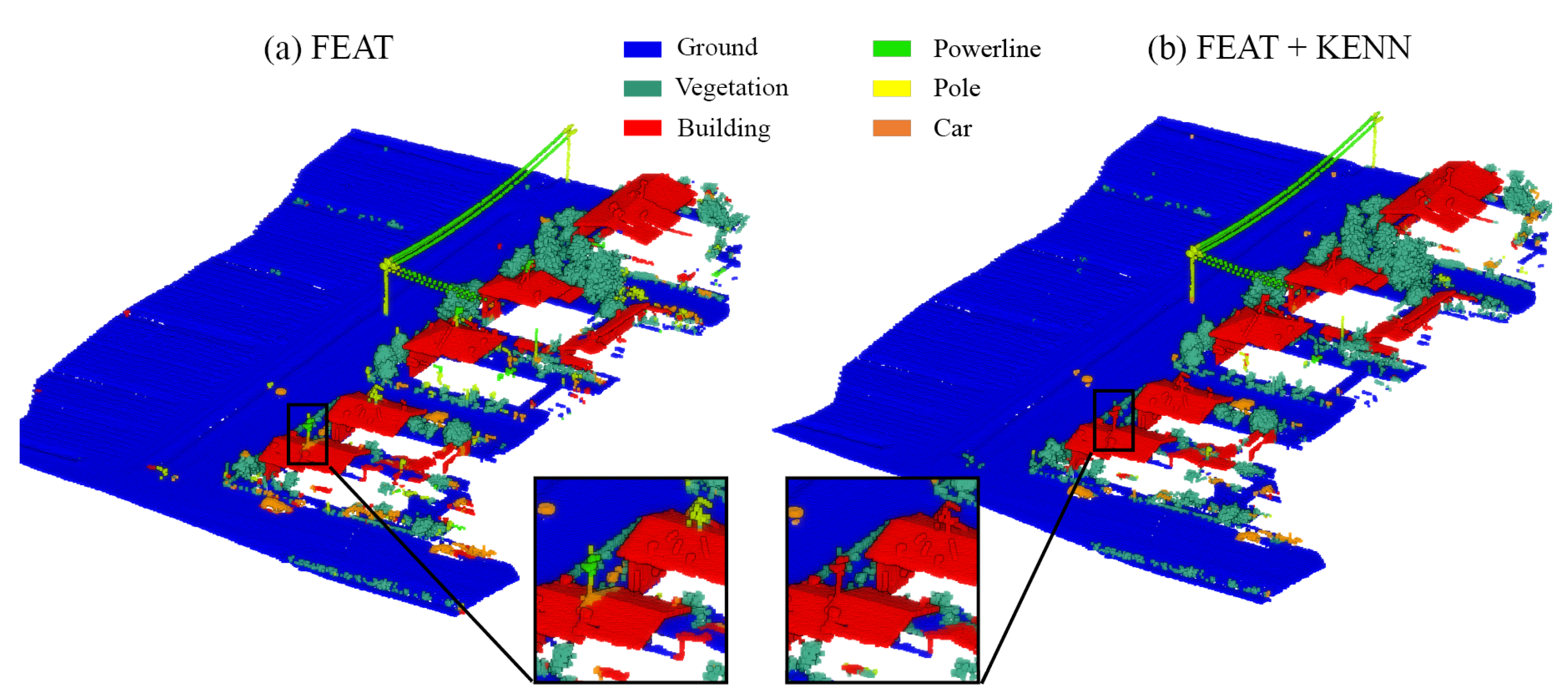
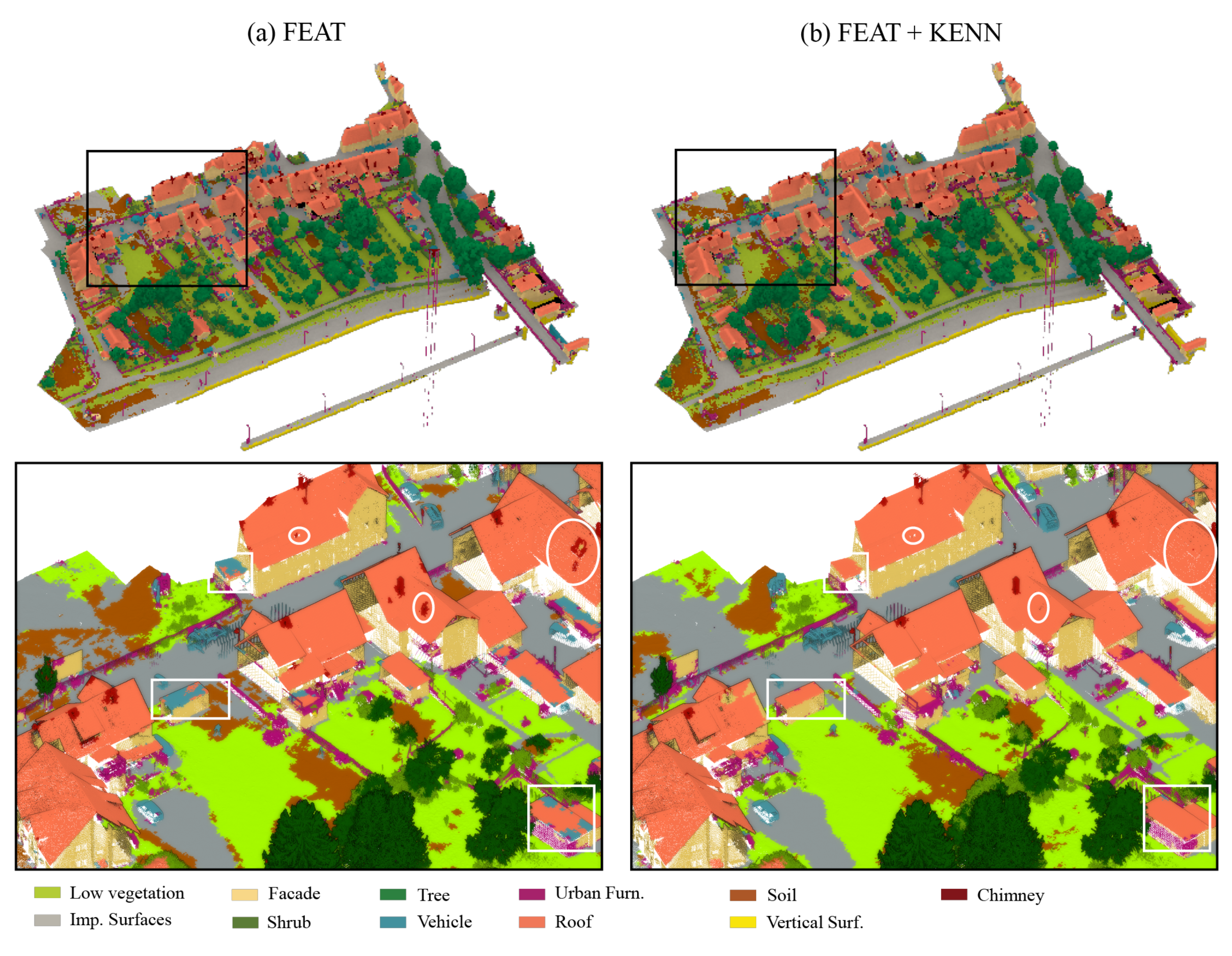
If we have a close look at
Figure 14, where the results achieved for the validation dataset are compared with the ground truth, we can see that the FEAT configuration output has two main categories of issues (
Figure 14c). First, different fences belonging to urban furniture (purple color) were erroneously predicted as vehicles (light blue color). Second, the majority of the roof’s ridges were identified as chimneys.
The adoption of specific rules for the vehicle and chimney classes led to the solution of these types of issues in the configuration FEAT + KENN (
Figure 14d). As regards the car class, the following binary predicates were added:
The above rules state that points of the vehicle class are likely to be close to either other points of the same class or points of impervious surfaces, but not points of the urban furniture class. Given the high density of the point cloud, the “Near” measure for this dataset was fixed to 0.15 m.
Additionally, we described the vehicle as “vertical” and “short” with the following unary statement, reading these values through the previously selected features
Verticality and
Distance from ground.
Two binary rules were established for the class “chimney”: points with a high level of
Verticality are assumed to belong to the “chimney” class, while points with a low level of
Verticality are expected to belong to the “roof” class.
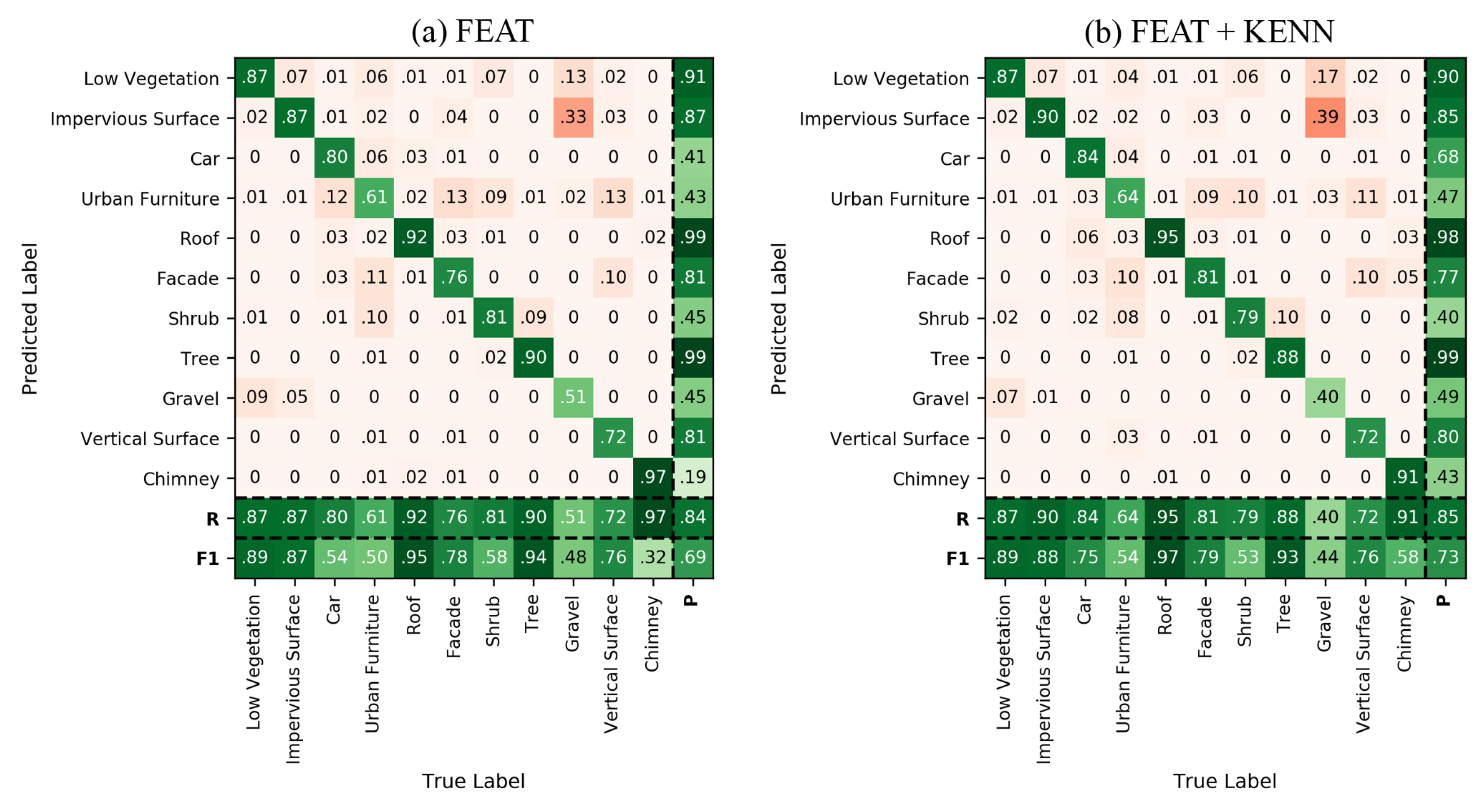
The graphical (
Figure 15) and numerical (
Figure 16) results achieved with and without the logic rules are compared below. Overall, the mF1 score increased from the 84.41% baseline to 85.33% with the inclusion of a-posteriori rules.
Finally,
Table 6 reports a comparison of our results with the state-of-the-art as presented in the Hessigheim portal.
4.3. S3DIS
The S3DIS [
26] dataset for semantic scene parsing consists of 271 rooms in six areas from three different buildings (
Figure 17). Each point in the scan is assigned a semantic label from 13 categories (ceiling, floor, table, etc.). The common protocol is to withhold Area 5 during training and use it during testing, or perform a cross-validation on Area 5. The evaluation metrics include mean classwise intersection over union (mIoU), mean of classwise accuracy (mAcc), and overall pointwise accuracy (OA). As of February 2023, the baseline Point Transformer is 9th in place of the S3DIS benchmark dataset and has been overtaken in recent months by significantly larger networks. However, this study on the relevance of knowledge infusion in Neural Networks is still highly relevant, as knowledge infusion can also be embedded in the newer networks. Moreover, class imbalance and the number of training samples remain a key issue in the S3DIS benchmark (
Table 7). The ceiling, floor, and wall classes are overly dominant with on average nearly 65% of the points and thus also achieve the highest detection rate (respectively 94.0%, 98.5%, 86.3% IoU on the baseline Point Transformer). S3DIS clearly shows that classes with percentual less training data, such as windows (3% of the data, 63.4% IoU) and doors (3% of the data, 74.3% IoU), have a significant drop in performance. Poor class delineations, as with the beams (38% IoU), remain unsolved.
Additionally, there is a significant catch to these fairly good detection rates. The base PointTansformer and even RandLA-Net [
33] network only achieve near 70% mIuO on the separated rooms of S3DIS, which is the original training data. When the rooms are combined into one region, which would be the case for a realistic project, the detection rates plummet. Point Tansformer barely achieves 46% mIuO, and so does RandLA-Net with 35% mIuO. Nearly all classes suffer from increased complexity from a room-based segmentation to an area-wide segmentation, except for some classes that already performed poorly with the conventional training data (
Table 7 first row).
Analogous to the above two datasets, the prior knowledge aims to improve performance on subideal training data, i.e., on the combined cross-validation of Area 5. The initial RandLA-Net and Point Transformer baselines indicated significant underperformance in all but the ceiling and floor classes. Therefore, we use the a-priori knowledge to generate distinct signatures for all the other classes. For S3DIS, the following features were introduced based on the inspection of the baseline classification: R, G, B, Planarity (r = 0.2 m), Verticallity (r = 0.5 m), Surface variation (r = 0.1 m), Sum of Eigenvalues (r = 0.1 m), Omnivariance (r = 0.05 m), Eigenentropy (r = 0.02 m), and the normalized Z value. The verticality and planarity help identify the more planar objects in the scene, such as tables, doors, and bookcases. In contrast, the Eigenentropy, Omnivariance, Surface variation, and Sum of Eigenvalues at different radii help describe the curvature of table, chair, and sofa elements.
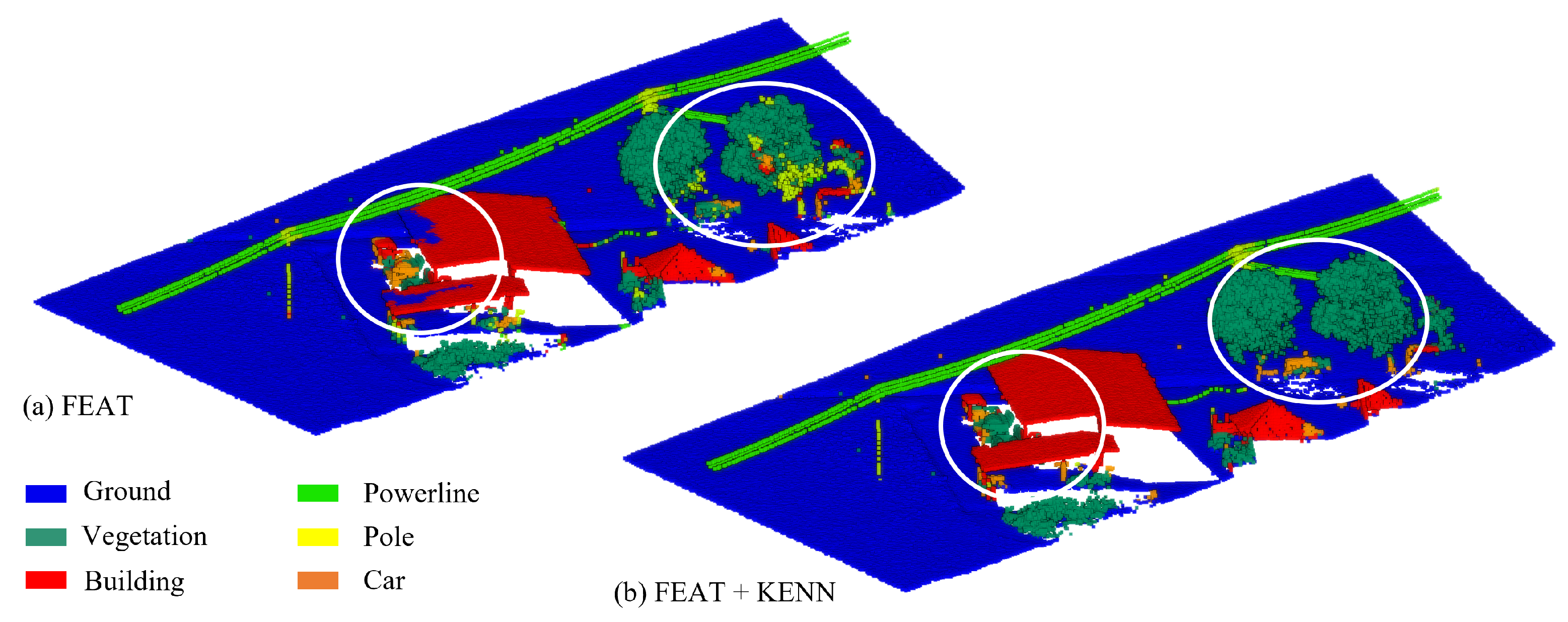
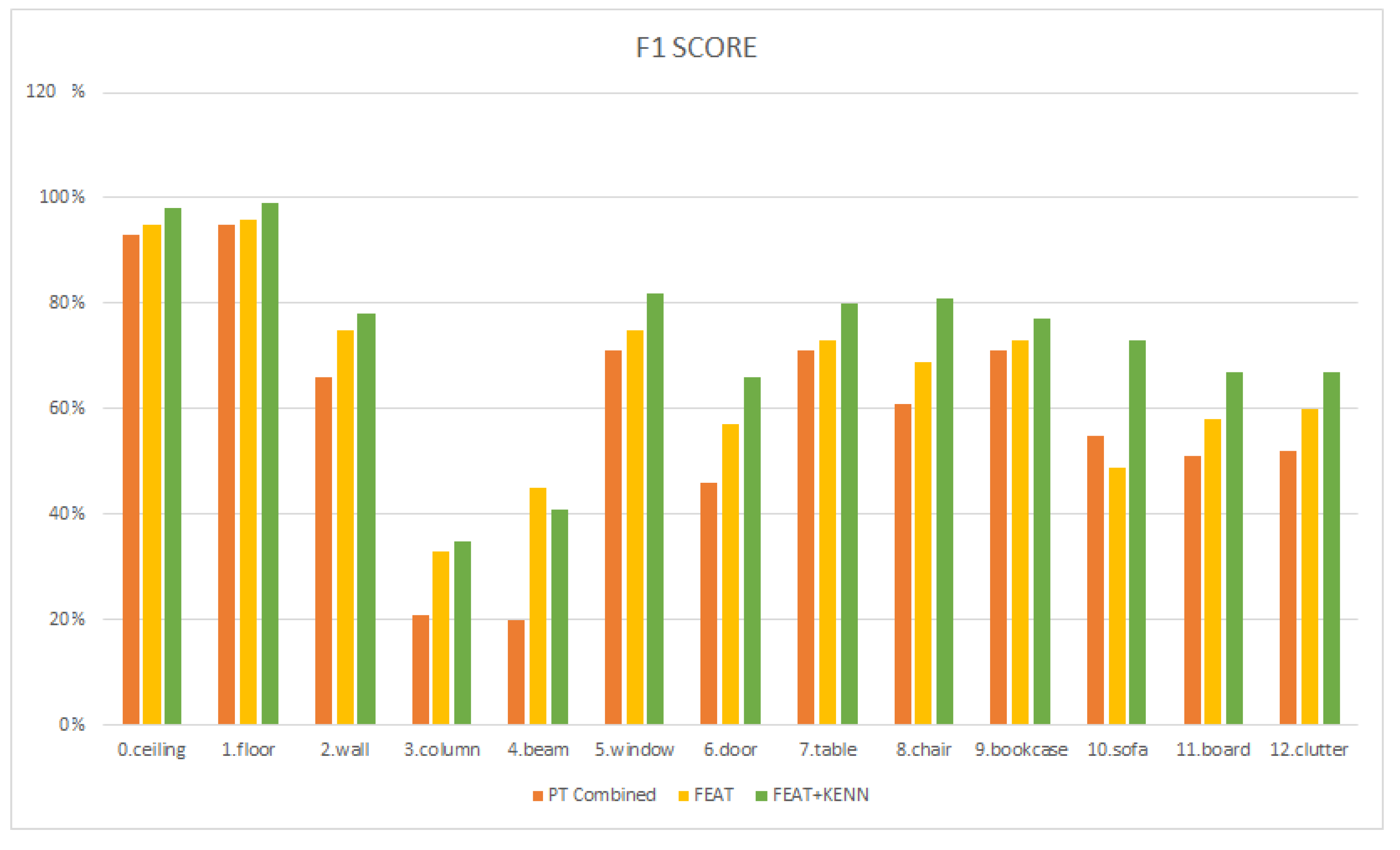
The results achieved with the a-priori knowledge are reported in
Table 7 line 3 and
Figure 18. There is a significant improvement in nearly all classes but sofa, with an overall increase in 6% mIuO. The best improvements are reported for the walls (10.5%), beams (17.0%), doors (10.0%), and chairs (9.1%), which now show significantly less confusion with clutter and with overlapping classes in the case of the walls (
Figure 19).
Despite the improvements, two key categories of confusion are identified (
Figure 20). First, there are a significant number of false negatives within the classes, despite the observations being surrounded by a large number of points attributed to a single class. Second, there is significant confusion between wall-based elements such as windows, doors, bookcases and the walls themselves. This is a known problem and remains a difficult obstacle for state-of-the-art networks.
The a-posteriori rules specifically target these two issues using binary rules. First, class consistency is forced between the classes using nearby class-associativity, e.g.,
where each class is incentivized to enforce class consistency at nearby points. Specifically for classes with a descent surface area, i.e., walls, windows, and doors, this is quite promising. Second, the expected topology can be formulated as ’Near’ rules to lower the confusion between neighboring classes, e.g.,
where the promixity of certain classes, i.e., furniture elements near the floor and windows, doors, boards, and columns near walls, is reinforced. Looking again at
Table 7 and
Figure 18, it is clear that the a-posteriori knowledge again significantly increased the performance from an average mIuO of 52.0% to 59.9% compared with the a-priori knowledge. The highest increase is noted in the sofa (23,8%), chair (14.5%), and table classes (9.5%), which are directly affected by the knowledge infusion. Similarly, the windows (8.9%), doors (9.3%), and walls (4.4%) also improved. Overall, separate training sessions indicated that the associativity knowledge offered a better statistical improvement as many stray points are now assigned to the correct class. In contrast, the topological knowledge remedied more isolated but important miss-classifications (
Figure 21).
4.4. Performance Evaluation
In this section, the performance of the three configurations for each test case is jointly discussed. For the experiments, a GPU Nvidia RTX 3080, 32 GB of RAM, and a 11th Gen Intel(R) Core(TM) CPU i7-11700KF @ 3.60 GHz were used. It is observed that the computational time increases with the infusion of knowledge (
Table 8). In the first dataset, the highest time increase is generated by adding the a-priori knowledge to the network, while this is less the case for the later two experiments. This can be partially explained by the number of features that are introduced to each network, i.e., 13 for Vaihingen, 9 for Hessigheim, and 10 for S3DIS. However, a prominent factor is the number of classes. These seem to inversely affect the proportional computational effort needed to train the expanded input layer in comparison to the training of the network itself, which is identical to the base network. A higher number of classes significantly complicates the training of the internal network, and thus networks with more classes (9 for Vaihingen, 11 for Hessigheim, and 13 for S3DIS) will be computationally less affected by an increased number of inputs.
The addition of the KENN layers significantly increases the computational effort of the training. The computational effort is a direct result of the number of rules, the number of KENN layers (3 for all networks), and the number of classes. The training times on average increased for Vaihingen by 30% (20 rules, 9 classes), Hessigheim by 36% (12 rules, 11 classes), and S3DIS by 39% (17 rules, 13 classes). This indicates that the number of classes is again the dominant factor in the increase in the computational effort of the proposed method.


 ,
, 
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}


