Abstract
The convolutional neural network (CNN) method has been widely used in the classification of hyperspectral images (HSIs). However, the efficiency and accuracy of the HSI classification are inevitably degraded when small samples are available. This study proposes a multidimensional CNN model named MDAN, which is constructed with an attention mechanism, to achieve an ideal classification performance of CNN within the framework of few-shot learning. In this model, a three-dimensional (3D) convolutional layer is carried out for obtaining spatial–spectral features from the 3D volumetric data of HSI. Subsequently, the two-dimensional (2D) and one-dimensional (1D) convolutional layers further learn spatial and spectral features efficiently at an abstract level. Based on the most widely used convolutional block attention module (CBAM), this study investigates a convolutional block self-attention module (CBSM) to improve accuracy by changing the connection ways of attention blocks. The CBSM model is used with the 2D convolutional layer for better performance of HSI classification purposes. The MDAN model is applied for classification applications using HSI, and its performance is evaluated by comparing the results with the support vector machine (SVM), 2D CNN, 3D CNN, 3D–2D–1D CNN, and CBAM. The findings of this study indicate that classification results from the MADN model show overall classification accuracies of 97.34%, 96.43%, and 92.23% for Salinas, WHU-Hi-HanChuan, and Pavia University datasets, respectively, when only 1% HSI data were used for training. The training and testing times of the MDAN model are close to those of the 3D–2D–1D CNN, which has the highest efficiency among all comparative CNN models. The attention model CBSM is introduced into MDAN, which achieves an overall accuracy of about 1% higher than that of the CBAM model. The performance of the two proposed methods is superior to the other models in terms of both efficiency and accuracy. The results show that the combination of multidimensional CNNs and attention mechanisms has the best ability for small-sample problems in HSI classification.
1. Introduction
Hyperspectral images (HSIs) are three-dimensional (3D) volumetric data with a spectrum of continuous and narrow bands, which can reflect the characteristics of ground objects in detail [1]. In recent years, many mini-sized and low-cost HSI sensors have appeared, which makes it easy to obtain HSI data with rich spatial–spectral information, such as AisaKESTREL10, AisaKESTREL16, and FireflEYE [2,3]. In this context, HSI is widely used in the fields of resource detection, environmental analysis, disaster monitoring, etc. [4,5,6]. The classification of HSI is a basic analysis task that has become very popular [7]. However, due to the influence of the small number of samples (small samples), the high-dimensional characteristics, the similarity between the spectra, and the mixed pixels, efficient and accurate classification of HSI data has been a challenging task for many years [8,9,10]. To solve these problems, some deep learning network models have been applied in HSI processing [11], especially the convolutional neural network (CNN).
Recently, CNN has attracted extensive attention due to its efficacy in many visual applications, for instance, classification, object detection, and semantic segmentation [12,13,14]. Three types of CNNs—namely, one-dimensional (1D), two-dimensional (2D), and three-dimensional CNNs—are successfully applied in HSI classification tasks. The 1D and 2D CNNs can obtain more abstract level spectral or spatial features of HSI [15]. The 3D CNN can learn the structural spatial–spectral feature representation using a 3D core, which can comprehensively characterize ground objects [16]. Recently, 3D CNNs have attracted extensive attention in HSI classification. Li et al. presented a novel approach that uses a 3D CNN to view HSI cube data altogether [17]. Mayra et al. used a 3D CNN to show the great potential of using HSI to map tree species [18]. Although these two 3D CNN models offer a simple and effective method for HSI classification, their accuracy and efficiency can be still further improved.
As can be seen from the literature, the results of using a single CNN of the three CNNs have a few shortcomings in achieving high accuracy [19]. The main reason is that HSI data are volumetric data and have information representation in both spatial and spectral dimensions. The 1D CNN and 2D CNN alone are not able to extract discriminating feature maps from both spatial and spectral dimensions. Similarly, a deep 3D CNN is more computationally complex, and it is difficult to classify a large volume of HSI data with its use. In addition, the performance of using a 3D CNN alone cannot satisfy the analysis of classes with similar textures over many spectral bands [19]. To address these issues, hybrid CNNs for HSI classification are developed. Swalpa et al. proposed a hybrid spectral CNN model (HybridSN), which assembles the 3D and 2D convolutional layers for reducing the complexity of the 3D CNN model [19]. Zhang et al. used a 3D–1D CNN model and showed improved accuracy in the classification of vegetation species [16]. Since the performance of these two models is still limited for classification applications in the condition of ground scenes with many different land cover types, a hybrid 3D–2D–1D CNN has been proposed by Liu et al. [20]. Notably, it does not perform well in terms of accuracy when the sample data are small. In this study, a new model that makes full use of multidimensional CNNs is proposed and uses some refinement mechanisms to overcome these shortcomings of the previous methods.
Moreover, for the problem of small samples, an attention mechanism was applied to an HSI analysis task [21,22]. The attention mechanism is a resource allocation scheme that can improve the performance of a model with a little computational complexity [23], such as the squeeze-and-excitation networks (SENets) [24], the selective kernel networks (SKNets) [25], the convolutional block attention module (CBAM) [26], and the bottleneck attention module (BAM) [27]. Compared with SENet, SKNet, and BAM, CBAM is a lightweight model, and it can extract attention features in spatial–spectral dimensions for adaptive feature refinement. Considering HSI is a 3D feature map, CBAM is selected to enhance the expression ability of the HSI classification model. Additionally, to make it applicable to the characteristics of HSI and obtain a higher accuracy of the classification using HSI, a convolutional block self-attention module named CBSM is also proposed based on the CBAM.
For the application of the CBSM model, this study proposes a multidimensional CNN with an attention mechanism model named MDAN. The MDAN model contains three types of CNNs components and the CBSM model for higher efficiency and accuracy of classification purposes.
The main contributions of this study are as follows:
- An improved graph convolutional network MDAN is proposed for HSI classification with small samples;
- A multidimensional CNN and a classical attention mechanism CBAM are used to create deeper feature maps from small samples;
- Based on CBAM, an attention module CBSM is designed to improve HSI classification accuracy. The CBSM has increased connections, which is more suitable for the classification of HSI data. Comparative experiments are carried out on three open datasets, and the experimental results indicate that the MDAN model and the CBSM model are superior to other state-of-the-art HSI classification models.
The rest of the paper is organized as follows: Section 2 introduces the proposed MDAN and CBSM. Section 3 presents the parameter settings and the results of the proposed approaches on the three different HSI datasets. The discussion of the results is described in Section 4. Finally, the conclusions are shown in Section 5.
2. MDAN and CBSM Models
2.1. MDAN Model
The structure of the MDAN model is demonstrated in Figure 1. It can be seen that MDAN uses the characteristics of all three types of CNNs and an attention mechanism CBSM to extract different features from small samples. The spatial spectrum’s representation features are extracted by two 3D convolutional layers from the input data. The spatial features are obtained at the 2D convolutional layer from the spatial-spectrum features. The spatial features are modified by the attention module CBSM, which is set between the 2D convolutional and 1D convolutional layers, to improve the classification accuracy. The 1D convolutional layer is performed to further extract spectral features; then, the classification is carried out based on spectral enhancement information.
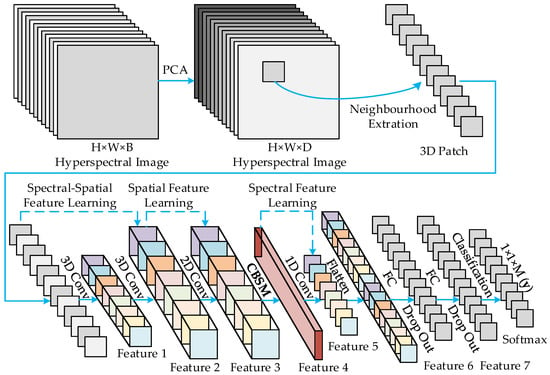
Figure 1.
Architecture of the MDAN model; notably, the attention module CBSM is used to obtain the modified Feature 4.
In the MDAN model, the original input HSI data cube is denoted by , where , and are the height, width, and the number of spectral bands, respectively. The band number of one pixel in I is equal to , and the pixel contains rich feature information for a label vector , where denotes the classes of ground objects. However, HSI data contain narrow and continuous bands, high intraclass variability, and interclass similarity; thus, it is a considerable challenge for the classification of HSI tasks [28]. In this case, the principal component analysis (PCA) is commonly used to decrease the spectral feature dimensions of the original input data cube , and the output data are denoted by , where D is the number of the spectral bands after the PCA is used [29,30,31].
2.2. CBSM Model
CBSM is an attention model for improving the accuracy of the HSI classification for the problems of small samples, as portrayed in Figure 2. Let the intermediate HSI feature map be denoted by , where, C is the number of the spectral bands of the input map. CBSM can be regarded as a dynamic-weight adjustment process to identify salient regions in complex scenes through the 1D channel attention map denoted by , and the 2D spatial attention map denoted by . During the processes of CBSM, the input data are refined sequentially by and . As a result, the overall process of CBSM can be written as
where represents the multiplication by the element, and denotes the elementwise addition. In the computational process of the multiplication, the refined map and are broadcasted accordingly to form a 3D attention map—the channel attention map is broadcasted following the spatial dimension, and the spatial attention map is broadcasted following the spectral dimension. Then, all the 3D attention maps are multiplied with the input map or in an elementwise manner. In the computational process of the addition, the process between two maps denotes that two elements in the same 3D spatial position are added together, and the process between the and a map represents each element of the map plus 1. indicate the intermediate feature map refined by . is the final refined feature map through the CBSM model, which is illustrated in Figure 2.
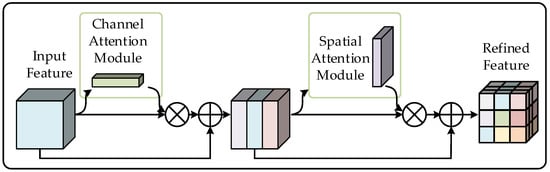
Figure 2.
Structure of CBSM.
is generated by pooling the weight of each channel feature. First, for determining the relationship representation between channels efficiently, feature F is squeezed along the spatial dimension. In this step, two parallel branches, i.e., global-average-pooling (GAP) and global-max-pooling (GMP) operations are used for the feature extraction of each image. The two parallel branches output two parallel spatial context features, i.e., and . Then, the two features are delivered to a shared network, which consists of a multilayer perceptron (MLP) and one hidden layer, generating two intermediate features denoted as . In the shared network, the value of hidden activation is set to for computational efficiency, where is the reduction ratio. Finally, the output feature vectors are merged by element to produce the channel attention map , which is computed as
where represents the sigmoid function, which maps variables into the range of . In the process of the MLP, the rectified linear unit (ReLU) activation function is followed by . It is noted that and , are shared for both inputs.
is generated by pooling the weight of each spatial feature. First, the input map is computed in the two processes of GAP and GMP along the channel dimension to generate two 2D maps, i.e., and . These maps are then concatenated and convolved through a standard convolution layer, producing the 2D map, i.e., , which encodes locations to emphasize or suppress. Consequently, the spatial attention of CBSM is computed as
where denotes a 2D CNN filtering with the size of .
The above two attention maps are complementary in CBSM, and they can capture rich contextual dependencies to enhance representation power in both the spectral and spatial dimensions of the input map.
3. Experiments and Results
3.1. Datasets
Three test datasets of Salinas (SA), WHU-Hi-HanChuan (WHU), and Pavia University (PU) datasets were selected for validating the MDAN and CBSM models. The WHU dataset contains high-quality data collected from a city in central China, which belongs to an agricultural area in a combined urban and rural region, and it was used as a benchmark dataset for the test results. Different from this dataset, SA and PU datasets were broadly used in the verification of HSI classification algorithms [32,33].
3.1.1. The SA Dataset
The SA dataset was collected by an AVIRIS sensor in 1992 in the Salinas Valley area of the United States. This dataset has a spatial resolution of 3.7 m, a spectral resolution of , and a spectral range of . In this dataset, the image size is 512 × 217 pixels, and the number of labeled classes is 16. It composes 224 bands, including 20 bands with atmospheric moisture absorption and a low signal-to-noise ratio should be deleted. In this study, 204 bands were retained for the experiments. Figure 3a shows the ground truth of the land cover of the SA dataset. Table 1 shows the real mark classes of the dataset, the s of samples in the training, and the testing set.
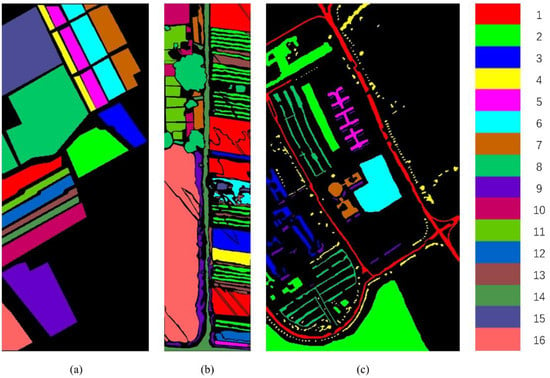

Table 1.
The SA dataset.
3.1.2. The WHU Dataset
The WHU dataset was acquired by an 8 mm focal length Headwall Nano-Hyperspec imaging sensor in 2016 in HanChuan, Hubei Province, China. The image of the WHU dataset contains pixels with a spatial resolution of 0.109 m and 274 bands, with a wavelength range of . Since the dataset was acquired during the afternoon, when the solar elevation angle was low, many shadow-covered areas are shown in the image. Figure 3b shows the ground truth of the land cover of the WHU dataset. Table 2 shows the real mark classes of the dataset, the number of samples in the training, and the testing set.
Table 2.
The WHU dataset.
3.1.3. The PU Dataset
The PU dataset was obtained by the ROSIS-03 sensor, which captures the urban area of Pavia. The size of the dataset is 610 × 340 pixels, and the spatial resolution is about 1.3 m. The dataset consists of 115 bands and 9 main ground objects, with a wavelength range of 0.43–0.86 μm. After removing 12 bands with high noise, the remaining 103 bands were selected for the experiments. Figure 3c shows the ground truth of the land cover of the PU dataset. Table 3 shows the real mark classes of the dataset, the number of samples in the training, and the testing set.
Table 3.
The PU dataset.
3.2. Experimental Parameter Settings
The MDAN model contains two 3D convolutional layers, one 2D convolutional layer, one CBSM module, one 1D convolutional layer, one flatten layer, and two fully connected layers. In the experiments, the patch sizes of the three datasets were set to , where 15 denotes the value of D, i.e., the number of the remaining spectral parameters in the remote sensing image reduced by the PCA. The patch size was determined according to studies by [19,34]; thus, one patch could roughly cover one single class. Empirically, the epochs of the training data were set to 20 for all three datasets, as the convergence of the MDAN model was achieved within the 20 epochs. The optimal learning rate was set to 0.001, also based on the above literature. For each class, only 1% of the pixels were randomly selected for model training, and the remaining 99% of the pixels were used for performance evaluation. Thus, the minimum number of training samples was close to 10 in all three datasets. Finally, two fully connected layers were used to connect all neurons with the Adam optimizer. Across the board, the MDAN model was randomly initialized and trained by the back-propagation algorithm with no batch normalization and data augmentation. The class probability vector of each pixel was generated through the MDAN model and then was compared with the real label on the ground for the performance evaluation of MDAN. The experiment was carried out under the environment of the Windows 10 operating system and NVIDIA Geforce RTX 2080ti graphics card. More details on class information are provided in Table 4, where Run CBSM Here denotes that the CBSM process was carried out at this position in the MDAN Process.
Table 4.
Layer summary of the MDAN model based on the PU dataset.
In the two 3D convolutional layers, the dimensions of the 3D convolution kernels are and ; the latter means 3D kernels have the number of 16, and the dimension of for all 8 3D input feature maps, , and 5 means the spatial and the spectral dimension of the 3D kernels, respectively. In the 2D convolutional layers, the size of the kernel is , where 32 is the number of the 2D kernels with the size of , and 80 represents the size of the 2D input data. The CBSM model was used to improve classification accuracy with the two attention maps, in which the channel attention was implemented by GAP and GMP operation across the spatial dimension; the spatial attention module has the characteristics of GAP and GMP in the channel dimension with a convolution kernel size of . Finally, in the 1D convolution layer, the kernel size is , where 64 is the spectral dimension of the 1D kernels, and 608 indicates the size of the 1D input data. For the practical efficiency of the model, the 3D, 2D, and 1D convolution layers were used before the flatten layer. The 3D layer can extract the spatial–spectral information in one convolution process. The 2D layer can strongly discriminate the spatial information within different bands. The 1D layer can strengthen and compress the spectral information for efficient classification. It can be observed from Table 4 that in the PU dataset, the parameters take up to 278784 at the dense_1 layer of the MDAN Process. The number of the nodes in the Dense_3 layer at the end of the MDAN Process is nine, which depends on the number of the real label classes. In this case, the total number of the trainable weight parameters in the MDAN model is 459,391.
3.3. Classification Results
In this section, the overall accuracy (OA), average accuracy (AA), Kappa coefficient (KAPPA), training time, and testing time evaluation measures are used to assess the performance of the two proposed approaches. The OA is obtained by dividing correctly classified samples by all the test samples in a dataset; the AA denotes the average accuracies of all classes, which is as important as OA. When the sample is unbalanced, the accuracy will be biased towards multiple classes. In this case, the KAPPA needs to be obtained for a consistency test. The closer the KAPPA is to 1, the higher the consistency is. Finally, the efficiency of the MDAN model is reflected by the training and testing time.
The results of the two models are compared with the most broadly used methods, including the support vector machine (SVM) [35], 2D CNN [36], 3D CNN [37], and CBAM [26]. For a further evaluation of the classification performance of the two models, the 3D–2D–1D CNN [20] and the intermediate model of 3D–2D–CBAM–1D CNN are also compared with the MDAN model. Table 5 shows the results of the three datasets.
Table 5.
Classification accuracies and efficiencies of the proposed two models and selected methods using the WHU, SA, and PU datasets, respectively, and the best performances are highlighted in bold.
The test results of the three datasets classification are shown in Table 6, Table 7 and Table 8, respectively, and the best performances are highlighted in bold. Obviously, the MDAN model achieves a good classification accuracy in almost all classes. The accuracy of the model of SVM and 3D CNN is slightly lower.
Table 6.
Classification accuracies of the SA dataset. This table shows the best performances in bold.
Table 7.
Classification accuracies of the WHU dataset. This table shows the best performances in bold.
Table 8.
Classification accuracies of the PU dataset. This table shows the best performances in bold.
The test results are illustrated in Figure 4, Figure 5 and Figure 6, and the category number is the same as that in Table 1, Table 2 and Table 3. It is found that, in the selected models, there are some ground objects with low accuracy in the marked area of the yellow circle. The MDAN model can solve this problem and provides the highest accuracy for most ground objects. However, the results of MDAN have some misclassified in the marked area of the red circle. The points in the red circles in each figure are too small to avoid the reduction in the overall accuracy of the MDAN model.

Figure 4.
Ground truth and classification results of the SA dataset: (a) ground truth; (b) SVM; (c) 2D CNN; (d) 3D CNN; (e) 3D–2D–1D CNN; (f) 3D–2D–CBAM–1D CNN; (g) MDAN (3D–2D–CBSM–1D CNN). This figure shows the classes with lower classification accuracy in the yellow circle and the red circle.
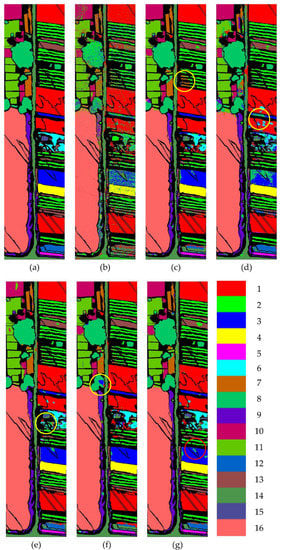
Figure 5.
Ground truth and classification results of the WHU dataset: (a) ground truth; (b) SVM; (c) 2D CNN; (d) 3D CNN; (e) 3D–2D–1D CNN; (f) 3D–2D–CBAM–1D CNN; (g) MDAN (3D–2D–CBSM–1D CNN). This figure shows the classes with lower classification accuracy in the yellow circle and the red circle.

Figure 6.
Ground truth and classification results of the PU dataset: (a) ground truth; (b) SVM; (c) 2D CNN; (d) 3D CNN; (e) 3D–2D–1D CNN; (f) 3D–2D–CBAM–1D CNN; (g) MDAN (3D–2D–CBSM–1D CNN). This figure shows the classes with lower classification accuracy in the yellow circle and the red circle.
Figure 7 portrays the confusion matrices of the proposed MDAN model using all the three selected datasets. It can be seen that the MDAN model achieves correct classification in almost all classes. The training curves for 100 epochs of the three datasets are shown in Figure 8 for the MDAN model. It indicates that in roughly 20 epochs, the MDAN model roughly reaches perfect convergence.
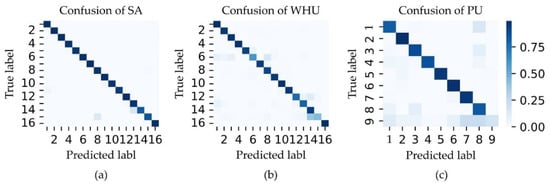
Figure 7.
The confusion matrices of MDAN in the three selected datasets: (a) the confusion of the SA dataset; (b) the confusion of the WHU dataset; (c) the confusion of the PU dataset.
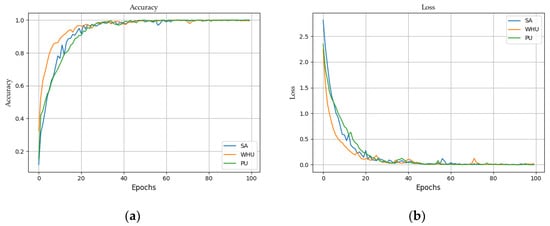
Figure 8.
Accuracies and loss convergence versus epochs of the proposed MDAN model using on the WHU, SA, and PU datasets: (a) accuracies; (b) loss.
According to studies in the literature, the algorithms for HSI classification are sensitive to unbalanced datasets in the predictor classes [23,38]. A model developed based on unbalanced datasets tends to result in false predictions in small samples, but the overall accuracy of the predictions is not necessarily low. Therefore, supplementary experiments are further carried out using balanced training samples, i.e., all ground objects have the same number of samples. Among all three datasets, the PU dataset is a more representative dataset, with medium spatial resolutions, lower accuracy, and a diverse set of ground scenes; thus, the PU dataset was only used for the following experiments. In this study, the training epoch was set to 100, and the range of the training samples was set to . Table 9 shows the supplementary experiment results.
Table 9.
Classification results of MDAN using a balanced training sample of the PU dataset.
As shown in Table 9, 20 samples can roughly meet the required accuracy in the low training time of the HSI classification; hence, it is promising for the application and popularization of the MDAN model. Then, with the expansion of the number of training samples, the accuracy increases slowly. The highest classification accuracy is achieved in the case of 50 samples; thus, more training samples (i.e., 60 or 70) are not necessarily needed for the use of the MDAN model in the task of HSI classification.
4. Discussion
The results of the proposed models and the selected models are shown in Figure 4, Figure 5, Figure 6, Figure 7, Figure 8, Table 5, Table 6, Table 7, Table 8 and Table 9. It can be seen that the MDAN model achieves the best performance among all of the selected models in terms of both accuracy and efficiency and achieves the overall accuracies of 97.34%, 92.23%, and 96.42%, respectively, in the test results of the SA, PU, and WHU datasets. In addition, compared with the two basic algorithms of 2D CNN and 3D CNN, the efficiency of MDAN is significantly improved. Additionally, compared with the 3D–2D–1D CNN, which is the most efficient model among all of the selected CNN models, MDAN takes slightly longer in terms of training and testing times. Different from the selected CNN models, the SVM model achieves the lowest accuracy but the highest efficiency among all of the selected models; thus, it is suitable for the situation of HSI classification that does not require high accuracy but needs high efficiency.
The classification results of the 2D CNN indicate lower efficiency but higher accuracy than those of the 3D CNN in the case of small samples. However, if the samples are sufficiently large, the 3D CNN is better capable of extracting discriminating features than the 2D CNN; then, the accuracy of the 3D CNN can meet the most requirements [37]. This is because the 3D CNN can obtain higher-level features than the 2D CNN and can further reduce the number of training samples. In general, a CNN model needs massive volumes of data for a good performance; thus, the classification accuracy of the 3D CNN is lower than that of the 2D CNN with small samples when the valid information of the HSI features is removed. Moreover, the 2D CNN retains more parameters, which tend to consume a large amount of time in the stage of using a classifier. As a result, the efficiency of the 2D CNN is the lowest efficiency among all selected models.
In the case of small samples, the hybrid 3D–2D–1D CNN is more efficient and accurate than the 3D CNN. However, the accuracy of this hybrid model is not as good as that of the 2D CNN, and it is reduced in the results of the SA and PU datasets, while it remains the same in the results of the WHU dataset. Therefore, this method still can be improved regarding the accuracy of the classification using HSI.
The accuracy of the 3D–2D–CBAM–1D CNN is higher than that of the hybrid 3D–2D–1D CNN model. In addition, the 2D and the 1D convolutional layers are incorporated in the hybrid model for high efficiency; thus, the CBAM model is also used between the 2D and 1D convolutional layers to form the 3D–2D–CBAM–1D CNN for high accuracy. CBAM is a spatial-spectrum attention module, which significantly improves the performance of a vision task based on its rich representation power [26]. As shown in Table 3, this model achieves an accuracy improvement, as expected by using CBAM. However, due to the unique high-dimensional spectral characteristics of HSI, the best performance cannot be achieved by CBAM only, and the accuracy of the 3D–2D–CBAM–1D CNN is close to that of the 2D CNN.
According to the literature on attention models, different attention connections lead to different classification results [39,40,41]. Thus, the CBSM attention module with different attention structural connections from CBAM is proposed to suit the 3D characteristics of HSI data. CBSM can significantly improve CNN’s ability to classify HSI data, and the application of CBSM in MDAN, i.e., 3D–2D–CBSM–1D CNN further improves the accuracy from the CBAM used in 3D–2D–CBAM–1D CNN by 1%. Compared with the selected models of the SVM, 2D CNN,3D CNN, 3D–2D–1D CNN, and 3D–2D–CBAM–1D CNN, the MDAN model is the best performer on all three datasets. In addition, the MDAN model also performs well in balanced training samples and correctly classifies all classes, as shown in Table 4.
In summary, since the application of the attention mechanism, the MDAN model can make CNN more efficient and more accurate in HSI classification than other selected CNN models for small-sample problems. The attention module CBSM can further improve the accuracy of the HSI classification model and can be easily integrated into other CNN models to improve model performance.
5. Conclusions
In this study, to address the poor accuracy of HSI classification models on the small samples in the training data, an improved graph model MDAN was proposed from the perspective of multidimensional CNNs and attention mechanisms. The MDAN model can efficiently extract and refine features to obtain better performance in terms of both accuracy and efficiency. To make the model more suitable for HSI data structure, an attention module CBSM was also proposed in this study, which provided a better connection method than the most widely used CBAM model. The CBSM module was used in the MDAN model; thus, the spatial–spectral features were further refined, resulting in a model that significantly helps to improve the accuracy of the HSI classification under the condition of small samples. A series of comparative experiments were carried out using three open HSI datasets. The experiment results indicated that the combination of multidimensional CNN and attention mechanisms has a better performance on HSI data among all of the selected models using both balanced and unbalanced small samples. The connection method used in the CBSM model is more suitable for the extraction and classification of HSI data and further improved the accuracy.
However, the performance of CBSM is better than CBAM only in the connection method. Hence, future studies will be focused on finding a more targeted attention module for HSI data. Moreover, the accuracy improvement made by new models is still limited; thus, other strategies, such as supplementing the small samples using open high-dimensional spectral data, may be used in the future. In addition, future research will also focus on transfer learning and the samples randomly selected from anywhere when a large number of rich HSI data appear.
Author Contributions
Conceptualization, J.L. and K.Z.; methodology, J.L.; software, J.L.; validation, J.L.; formal analysis, J.L., H.S., Y.Z., Y.S. and H.Z.; investigation, J.L., Y.Z., Y.S., E.F. and H.Z.; resources, J.L.; data curation, J.L.; writing—original draft preparation, J.L.; writing—review and editing, J.L., K.Z., S.W., H.S., Y.Z., H.Z. and E.F.; visualization, J.L.; supervision, K.Z. and S.W.; project administration, K.Z.; funding acquisition, K.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Science Foundation of the Basic Research Project of Jiangsu Province, China (Grant No. BK20190645), the Key Laboratory of National Geographic Census and Monitoring, Ministry of Natural Resources (Grant No. 2022NGCM04), and the Xuzhou Key R&D Program (Grant No. KC20181 and Grant No. KC19111).
Data Availability Statement
The SA and PU datasets can be obtained from http://www.ehu.eus/ccwintco/index.php?title=Hyperspectral_Remote_Sensing_Scenes (accessed on 23 July 2021). The WHU dataset can be freely available at http://rsidea.whu.edu.cn/resource_WHUHi_sharing.htm (accessed on 2 February 2021).
Acknowledgments
The authors are very grateful to the providers of all the data used in this study for making their data available. Data used in this study were obtained from the GIC of the University of the Basque Country (http://www.ehu.eus/ccwintco/index.php?title=Hyperspectral_Remote_Sensing_Scenes, accessed on 23 July 2021), and the RSIDEA of Wuhan University (http://rsidea.whu.edu.cn/resource_WHUHi_sharing.htm, accessed on 2 February 2021).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Qing, Y.; Liu, W. Hyperspectral Image Classification Based on Multi-Scale Residual Network with Attention Mechanism. Remote Sens. 2021, 13, 335. [Google Scholar] [CrossRef]
- Lu, B.; Dao, P.D.; Liu, J.; He, Y.; Shang, J. Recent Advances of Hyperspectral Imaging Technology and Applications in Agriculture. Remote Sens. 2020, 12, 2659. [Google Scholar] [CrossRef]
- Zhong, Y.; Wang, X.; Xu, Y.; Wang, S.; Jia, T.; Hu, X.; Zhao, J.; Wei, L.; Zhang, L. Mini-UAV-Borne Hyperspectral Remote Sensing: From Observation and Processing to Applications. IEEE Geosci. Remote Sens. Mag. 2018, 6, 46–62. [Google Scholar] [CrossRef]
- Krupnik, D.; Khan, S. Close-Range, Ground-Based Hyperspectral Imaging for Mining Applications at Various Scales: Review and Case Studies. Earth-Sci. Rev. 2019, 198, 102952. [Google Scholar] [CrossRef]
- Jia, J.; Wang, Y.; Chen, J.; Guo, R.; Shu, R.; Wang, J. Status and Application of Advanced Airborne Hyperspectral Imaging Technology: A Review. Infrared Phys. Technol. 2020, 104, 103115. [Google Scholar] [CrossRef]
- Seydi, S.T.; Akhoondzadeh, M.; Amani, M.; Mahdavi, S. Wildfire Damage Assessment over Australia Using Sentinel-2 Imagery and MODIS Land Cover Product within the Google Earth Engine Cloud Platform. Remote Sens. 2021, 13, 220. [Google Scholar] [CrossRef]
- Cai, W.; Liu, B.; Wei, Z.; Li, M.; Kan, J. Triple-Attention Guided Residual Dense and BiLSTM Networks for Hyperspectral Image Classification. Multimed. Tools Appl. 2021, 80, 11291–11312. [Google Scholar] [CrossRef]
- Wang, W.; Liu, X.; Mou, X. Data Augmentation and Spectral Structure Features for Limited Samples Hyperspectral Classification. Remote Sens. 2021, 13, 547. [Google Scholar] [CrossRef]
- Paoletti, M.E.; Haut, J.M.; Plaza, J.; Plaza, A. A New Deep Convolutional Neural Network for Fast Hyperspectral Image Classification. ISPRS-J. Photogramm. Remote Sens. 2018, 145, 120–147. [Google Scholar] [CrossRef]
- Xu, X.; Li, J.; Wu, C.; Plaza, A. Regional Clustering-Based Spatial Preprocessing for Hyperspectral Unmixing. Remote Sens. Environ. 2018, 204, 333–346. [Google Scholar] [CrossRef]
- Jia, S.; Jiang, S.; Lin, Z.; Li, N.; Xu, M.; Yu, S. A Survey: Deep Learning for Hyperspectral Image Classification with Few Labeled Samples. Neurocomputing 2021, 448, 179–204. [Google Scholar] [CrossRef]
- Sultana, F.; Sufian, A.; Dutta, P. Evolution of Image Segmentation using Deep Convolutional Neural Network: A Survey. Knowl.-Based Syst. 2020, 201, 62. [Google Scholar] [CrossRef]
- Sun, Y.; Xue, B.; Zhang, M.; Yen, G.G. Evolving Deep Convolutional Neural Networks for Image Classification. IEEE Trans. Evol. Comput. 2020, 24, 394–407. [Google Scholar] [CrossRef] [Green Version]
- Wan, S.; Goudos, S. Faster R-CNN for Multi-Class Fruit Detection Using A Robotic Vision System. Comput. Netw. 2020, 168, 107036. [Google Scholar] [CrossRef]
- Lv, W.; Wang, X. Overview of Hyperspectral Image Classification. J. Sens. 2020, 2020, 4817234. [Google Scholar] [CrossRef]
- Zhang, B.; Zhao, L.; Zhang, X. Three-Dimensional Convolutional Neural Network Model for Tree Species Classification Using Airborne Hyperspectral Images. Remote Sens. Environ. 2020, 247, 111938. [Google Scholar] [CrossRef]
- Ying, L.; Haokui, Z.; Qiang, S. Spectral–Spatial Classification of Hyperspectral Imagery with 3D Convolutional Neural Network. Remote Sens. 2017, 9, 67. [Google Scholar] [CrossRef] [Green Version]
- Mayra, J.; Keski-Saari, S.; Kivinen, S.; Tanhuanpaa, T.; Hurskainen, P.; Kullberg, P.; Poikolainen, L.; Viinikka, A.; Tuominen, S.; Kumpula, T.; et al. Tree Species Classification From Airborne Hyperspectral and LiDAR Data Using 3D Convolutional Neural Networks. Remote Sens. Environ. 2021, 256, 112322. [Google Scholar] [CrossRef]
- Roy, S.K.; Krishna, G.; Dubey, S.R.; Chaudhuri, B.B. HybridSN: Exploring 3-D–2-D CNN Feature Hierarchy for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2020, 17, 277–281. [Google Scholar] [CrossRef] [Green Version]
- Jinxiang, L.; Wei, B.; Yu, C.; Yaqin, S.; Huifu, Z.; Erjiang, F.; Kefei, Z. Multi-Dimensional CNN Fused Algorithm for Hyperspectral Remote Sensing Image Classification. ChJL 2021, 48, 1610003. [Google Scholar] [CrossRef]
- Xiong, Z.; Yuan, Y.; Wang, Q. AI-NET: Attention Inception Neural Networks for Hyperspectral Image Classification. In Proceedings of the 2018 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Valencia, Spain, 22–27 July 2018; pp. 2647–2650. [Google Scholar]
- Haut, J.M.; Paoletti, M.E.; Plaza, J.; Plaza, A.; Li, J. Visual Attention-Driven Hyperspectral Image Classification. ITGRS 2019, 57, 8065–8080. [Google Scholar] [CrossRef]
- Zhang, J.; Wei, F.; Feng, F.; Wang, C. Spatial–Spectral Feature Refinement for Hyperspectral Image Classification Based on Attention-Dense 3D-2D-CNN. Sensors 2020, 20, 5191. [Google Scholar] [CrossRef]
- Jie, H.; Li, S.; Albanie, S.; Gang, S.; Wu, E. Squeeze-and-Excitation Networks. ITPAM 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–9. [Google Scholar]
- Park, J.; Woo, S.; Lee, J.-Y.; Kweon, I.S. BAM: Bottleneck Attention Module. arXiv 2018, arXiv:1807.06514. [Google Scholar]
- Huang, H.; Shi, G.; He, H.; Duan, Y.; Luo, F. Dimensionality Reduction of Hyperspectral Imagery Based on Spatial–Spectral Manifold Learning. IEEE T. Cybern. 2019, 50, 2604–2616. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Haque, M.R.; Mishu, S.Z. Spectral-Spatial Feature Extraction Using PCA and Multi-Scale Deep Convolutional Neural Network for Hyperspectral Image Classification. In Proceedings of the 2019 22nd International Conference on Computer and Information Technology (ICCIT), Dhaka, Bangladesh, 18–20 December 2019; pp. 1–6. [Google Scholar]
- Yousefi, B.; Sojasi, S.; Castanedo, C.I.; Maldague, X.P.V.; Beaudoin, G.; Chamberland, M. Comparison Assessment of Low Rank Sparse-PCA Based-Clustering/Classification for Automatic Mineral Identification in Long Wave Infrared Hyperspectral Imagery. Infrared Phys. Technol. 2018, 93, 103–111. [Google Scholar] [CrossRef]
- Sellami, A.; Farah, M.; Riadh Farah, I.; Solaiman, B. Hyperspectral Imagery Classification Based on Semi-Supervised 3-D Deep Neural Network and Adaptive Band Selection. Expert Syst. Appl. 2019, 129, 246–259. [Google Scholar] [CrossRef]
- Imani, M.; Ghassemian, H. An Overview on Spectral and Spatial Information Fusion for Hyperspectral Image Classification: Current Trends and Challenges. Inf. Fusion 2020, 59, 59–83. [Google Scholar] [CrossRef]
- Zhong, Z.; Li, J.; Clausi, D.A.; Wong, A. Generative Adversarial Networks and Conditional Random Fields for Hyperspectral Image Classification. IEEE T. Cybern. 2020, 50, 3318–3329. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, X.; Zhang, X.; Ye, Y.; Lau, R.Y.; Lu, S.; Li, X.; Huang, X. Synergistic 2D/3D Convolutional Neural Network for Hyperspectral Image Classification. Remote Sens. 2020, 12, 2033. [Google Scholar] [CrossRef]
- Melgani, F.; Bruzzone, L. Classification of Hyperspectral Remote Sensing Images with Support Vector Machines. ITGRS 2004, 42, 1778–1790. [Google Scholar] [CrossRef] [Green Version]
- Makantasis, K.; Karantzalos, K.; Doulamis, A.; Doulamis, N. Deep Supervised Learning for Hyperspectral Data Classification Through Convolutional Neural Networks. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 4959–4962. [Google Scholar]
- Ben Hamida, A.; Benoît, A.; Lambert, P.; Ben Amar, C. 3-D Deep Learning Approach for Remote Sensing Image Classification. ITGRS 2018, 56, 4420–4434. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Li, Z.; Qiu, H.; Hou, G.; Fan, P. An Overview of Hyperspectral Image Feature Extraction, Classification Methods and The Methods Based on Small Samples. Appl. Spectrosc. Rev. 2021, 11, 1–34. [Google Scholar] [CrossRef]
- Guo, M.; Xu, T.; Liu, J.; Liu, Z.; Jiang, P.; Mu, T.; Zhang, S.; Martin, R.R.; Cheng, M.; Hu, S. Attention Mechanisms in Computer Vision: A Survey. arXiv 2021, arXiv:2111.07624. [Google Scholar]
- Yang, Z.; Zhu, L.; Wu, Y.; Yang, Y. Gated Channel Transformation for Visual Recognition. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11791–11800. [Google Scholar]
- Ma, X.; Guo, J.; Tang, S.; Qiao, Z.; Chen, Q.; Yang, Q.; Fu, S. DCANet: Learning connected attentions for convolutional neural networks. arXiv 2020, arXiv:2007.05099. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).