Abstract
The Chinese South–North Water Transfer Project is an important project to improve the freshwater supply environment in the Chinese interior and greatly alleviates the water shortage in the Chinese North China Plain; its sustainable, healthy, and safe operation guarantees ecological protection and economic development. However, due to the special expansive soil and deep excavation structure, the first section of the South–North Water Transfer Project canal faces serious disease risk directly manifested by cracks in the slope of the canal. Currently, relying on manual inspection not only consumes a lot of human resources but also unnecessarily repeats and misses many inspection areas. In this paper, a monitoring method combining depth learning and Uncrewed Aerial Vehicle (UAV) high-definition remote sensing is proposed, which can detect the cracks of the channel slope in time and accurately and can be used for long-term health inspection of the South–North Water Transfer Project. The main contributions are as follows: (1) aiming at the need to identify small cracks in reinforced channels, a ground-imitating UAV that can obtain super-clear resolution remote-sensing images is introduced to identify small cracks on a complex slope background; (2) to identify fine cracks in massive images, a channel crack image dataset is constructed, and deep-learning methods are introduced for the intelligent batch identification of massive image data; (3) to provide the geolocation of crack-extraction results, a fast field positioning method for non-modeled data combined with navigation information is investigated. The experimental results show that the method can achieve a 92.68% recall rate and a 97.58% accuracy rate for detecting cracks in the Chinese South–North Water Transfer Project channel slopes. The maximum positioning accuracy of the method is 0.6 m, and the root mean square error is 0.21 m. It provides a new technical means for geological risk identification and health assessment of the South–North Water Transfer Central Project.
1. Introduction
The Central Line Project of the South-to-North Water Diversion is a mega infrastructure project implemented to optimize the spatial and temporal allocation of water resources in China and is a key project for the future sustainable development of China [1]. Due to the wide area covered by the South–North Water Diversion Project and the changing geographical conditions, the slope of the channel is affected by many factors, such as precipitation, temperature, soil quality, and settlement, where the channel section with a complex geological foundation often faces the risk of structural instability. Surface cracks on channel slopes are a visual reflection of changes in the internal geological structure of the channel and have serious consequences if they are not detected and repaired in time [2,3]. On the one hand, the channel cracks lead to a large amount of water seepage and water loss in the process of conveying; on the other hand, the cracks gradually develop and become larger over time with the rinsing of channel water, which may also induce channel slope instability and affect the normal operation of the channel. Since the completion of the South–North Water Diversion Project, crack detection mainly relies on regular manual inspection, which also produces consequences. One is the high labor cost, and the others include unavoidable leakage, mis-inspection, and re-inspection. With the development of remote-sensing technology, we can collect high-resolution images of the whole channel of the South–North Water Transfer Project by remote sensing means, which provides a good data source for us to carry out comprehensive channel crack detection. Given this, this paper intends to take the deep excavation channel section of the South–North Water Diversion Central Project as the engineering background and proposes to carry out research on intelligent crack monitoring technology based on remote sensing and artificial intelligence, and the research results can provide new technical means for the intelligent detection of cracks in the South–North Water Diversion Channel.
However, the automatic identification of fine cracks using remote sensing is a challenging scientific task. First, the height difference of the deep excavation channel section of the South–North Water Transfer is large, and it is very difficult to obtain ultra-high-definition channel images using traditional fixed aerial high- and low-altitude photogrammetry. Second, the exploration of fine cracks has high requirements for remote-sensing image resolution, and if the relative flight height is high, it is difficult to obtain ultra-high-resolution UAV remote-sensing images, which, in turn, cannot meet the identification needs of fine cracks. Combined with the engineering characteristics of this study area, in this paper, we chose UAV ground-like flight photogrammetry technology to obtain ultra-high-resolution remote-sensing data, which can change the relative flight height according to the terrain so that the relative flight height is always the set height in the data-acquisition process, which ensures a consistent image resolution, where the resolution of the acquired image is 6000 × 4000 and the ground resolution can reach 0.47 cm/pixel. Third, the acquisition of ultra-high-resolution images often introduces a significant increase in the total amount of data, and the processing of massive data also brings great arithmetic challenges.
To solve the core problem of efficient and accurate detection of cracks in deep excavated canal sections of the South–North Water Transfer and automatic processing of massive data, in this paper, we adopt the ground-imitating flying technique of a UAV and deep-learning method to research the intelligent extraction of cracks in the deep excavation channels of the South–North Water Diversion. The main contributions are as follows:
- (1)
- Introducing the ground-imitating flying technique of a UAV to obtain ultra-high-resolution remote-sensing image data of channel slopes; the image resolution can reach millimeter level, which can meet the identification needs of fine cracks;
- (2)
- Using deep-learning image-processing methods and constructing a channel crack image dataset for intelligent, fast, and accurate acquisition of fracture information from massive, ultra-high-resolution remote-sensing images;
- (3)
- Using unmodeled data for combined UAV navigation information and pixel information of cracks on the image, a pioneering method for rapidly locating crack fields is proposed.
2. Review
2.1. Analysis of the Current Status of the South–North Water Transfer Channel Safety Monitoring Study
The long routes and complex geological conditions of the South–North Water Transfer Central Project are subject to geological hazards from various uncertainties during operation. At this stage, the main methods for monitoring the safety of the South–North Water Transfer Channel are InSAR technology monitoring [4,5,6], instrumentation monitoring [7,8], and manual inspection. Remote-sensing technology has become the main method for infrastructure deformation monitoring at this stage because of its wide monitoring range, fast imaging speed, and low influence of ground factors. Dong et al. used multi-track Sentinel-1 data for multi-scale InSAR analysis to detect deformation along the South–North Water Transfer Central Canal [9]. J.R. et al. used GAMIT/GLOBK scientific software and GNSS-r technology to process GPS data to obtain the 3D deformation trend of the dam [10]. Xie et al. proposed an end-to-end framework to monitor the deformation of the dam after completion based on open-source remote-sensing data [11]. Chen et al. proposed a method to monitor the internal deformation of the dam by continuously measuring the flexible pipes buried in the dam body deformation, which can simultaneously measure vertical settlement and horizontal displacement along the pipe direction, achieving more accurate dam-deformation monitoring [7]. All of the above methods monitor channel deformation and cannot obtain channel crack information, while most of the pre-existing manifestations of geological hazards are cracks, so obtaining ultra-high-resolution images to find cracks is a crucial task.
2.2. Image Fine Line Target Detection Methods
Line target detection of images [12] has been a popular research topic in the scientific community, and Line Segment Detector (LSD) [13,14], Line Band Descriptor (LBD) [15], and Hough [16,17] transform representative methods have been developed, all of which can extract line cracks on the graph. LSD targets the detection of local linear contours in images, which can be obtained with sub-pixel accuracy in linear time [14]. LBD makes it more robust to small changes in the line direction by extracting line segments in the scale space [15]. Hough transform first transforms the binary map into the Hough parameter space, and then the detection of polar points is used to complete the detection and segmentation of line targets [16]. However, the irregularity of the crack shape and the linear background of the large number of non-cracks contained on the channel slope limit the traditional methods in their ability to detect cracks on the slope accurately, comprehensively, and automatically, especially without a large amount of a priori knowledge and manual intervention.
With the development of deep learning, especially the introduction of Convolutional Neural Networks (CNNs) [18], the application of deep learning in target detection has become more refined [19,20,21]. For target-detection tasks, one-stage and two-stage algorithms face different application domains. Two-stage algorithms first generate all possible candidate regions on the image for detection targets by convolutional neural networks and then classify and perform boundary regression on each candidate region based on its features [22,23]. This algorithm has high accuracy, but its efficiency is limited in processing tasks facing huge amounts of data. In contrast, the one-stage algorithm eliminates the step of generating candidate regions and directly uses convolutional neural networks to classify and localize all targets of the whole image, which is faster and more suitable for real-time and near-real-time work [24,25]. Yang et al. applied SSD deep-learning networks embedded with receptive field modules for the automatic detection and classification of pavement cracks [26]. However, the base size and shape of the prior box in the network need to be set and adjusted repeatedly during the training process in conjunction with prior knowledge, resulting in weak generalization ability, which limits the detection requirements of different regions of the SSD. The Faster RCNN algorithm achieves higher accuracy in target-detection performance through two-stage networks. Compared with one-stage networks, the Faster RCNN algorithm has more obvious advantages for high accuracy, multi-scale and small-object problems. Chen et al. used grid-surveillance video to detect and analyze the motion of maintenance personnel based on the MASK-RCNN network, and the experimental results showed that the algorithm could accurately detect multiple people and obtain key features of the video content [27]. Sharma et al. proposed a model based on Faster RCNN, which eventually showed a great improvement in detecting the average accuracy by using significance detection, proposal generation, and bounding box regression [28]. The YOLO algorithm has better applicability, a low false-recognition rate of the background, and a strong generalization ability [29]. Zhang et al. proposed an automatic bridge surface crack detection and segmentation method, improving it based on the YOLO algorithm, which finally made the method better than other benchmark methods in terms of model size and detection speed [24]. Liu et al. proposed an image-enhancement algorithm, based on which a variety of networks were tested for road crack detection, and the final one concluded that the YOLO v5 model has the best evaluation index and can perform the crack-detection task well [30]. In general, the deep-learning method has potential application in detecting fine cracks in the slopes of the South–North Water Transfer Project.
2.3. Rapid Geolocation Method for Images
At the present stage, field positioning of optical images generally requires null-three calculations and leveling calculations for the whole, and finally, a high-precision three-dimensional model can be obtained [31,32]. In the monitoring and management of channel slope cracks, it is unnecessary to spend a lot of time and material resources to obtain a high-precision 3D model, and it is more difficult to establish a 3D model for the whole South–North Water Transfer Central Line project. Based on the engineering background of the deep excavation channel section of the South–North Water Transfer Central Line, quickly locating the channel slope cracks for later maintenance is an urgent need.
In this study, we propose a method to identify and obtain universal transverse Mercator grid system (UTM) coordinates of channel slope cracks by combining deep learning and a UAV positioning navigation system without processing the original data. The problem of the low resolution of channel slope crack images is solved by introducing UAV ground-like flight photogrammetry technology to collect ultra-high definition remote-sensing images; the deep-learning target-detection algorithm is used to significantly reduce the time and workload of crack detection and realize the intelligent identification of crack information from remote-sensing images; the non-modeled data of UAV combining navigation information and the pixel information of cracks on the images are used to realize the accurate location of channel cracks. The accurate location of channel cracks was achieved by using the non-modeled data combining the UAV navigation information and pixel information of cracks on images.
3. Materials and Methods
3.1. The Crack Plane’s Overall Right-Angle Coordinate-Acquisition Process
The intelligent detection and location method of channel slope cracks proposed in this research can be divided into three main parts. First, the UAV ground-imitating flying photogrammetry technology is used to obtain large data of ultra-high-resolution UAV remote-sensing images that can reflect the channel slope cracks. Second, according to the acquired image characteristics of the slope of the South–North Water Transfer Channel, a suitable channel slope crack detection model was selected by comparing the experimental method while considering the detection speed, detection accuracy, and size of the model. Finally, for the remote-sensing image crack detection results, the field location of the cracks was quickly obtained by combining the UAV navigation information and pixel information of the cracks. The overall process is shown in Figure 1.
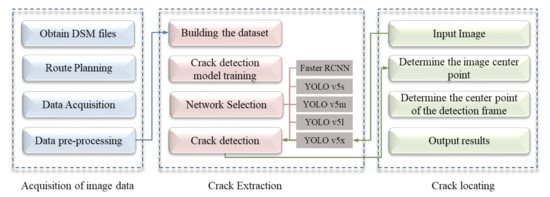
Figure 1.
Flow chart of the method of crack detection and location.
3.2. UAV Ground-Imitating Flying Measurement Remote-Sensing Image Acquisition
The study area is a drain head deep-cut canal slope at the middle route of the South–North Water Transfer Central Canal, mainly located in Jiu Chong Town, Nanyang City, Henan Province. For the acquisition of ultra-high-definition image data in the study area, the first method obtained image data by flying a UAV at a fixed altitude and low altitude, with the altitude set at 30 m, but it was found that no effective fracture information could be extracted using this method. The reason for this is that due to the large topographic drop in the deep-cut canal slope, the maximum drop is as high as 47 m, and the opening width is 373.2 m. Even with a 30 m fixed flight height, the relative flight height at the bottom of the channel exceeds 70 m, and the image data obtained are unclear, causing great difficulties in fracture extraction and fracture pixel information acquisition, as shown in Figure 2a. Moreover, a fixed relative aerial height is a key prerequisite in the subsequent crack field localization process. UAV ground-mimicking technology ensures that relative altitude remains constant; thus, we introduced UAV ground-imitating flying photogrammetry technology to obtain ultra-high-resolution remote-sensing image data. The image data of the channel slope collected by the ground-imitating flying are shown in Figure 2b, and the crack information is clearly visible on the image of the channel slope.
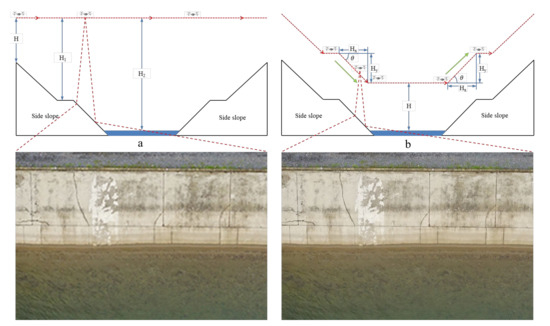
Figure 2.
Ground-imitating and fixed high-flight acquisition images.
Ground-imitating flying, also known as terrain following, means that the UAV maintains a fixed relative height difference between the route and the 3D terrain in real time during the aerial-survey operation. This type of aerial flight makes it possible to keep the image ground resolution unaffected by terrain changes by adjusting the route with the terrain changes. The use of ground-imitating flying photogrammetry technology requires a DSM database with a certain level of accuracy before accurate ground-mimicking can be carried out. Therefore, this study uses the DJI Phantom 4RTK UAV to collect DSM terrain data in the survey area using a fixed altitude flight method, with the flight altitude set to 80 m and the heading overlap and the side overlap both set to 75%. The DSM file of the test area was obtained after data processing, as shown in Figure 3.
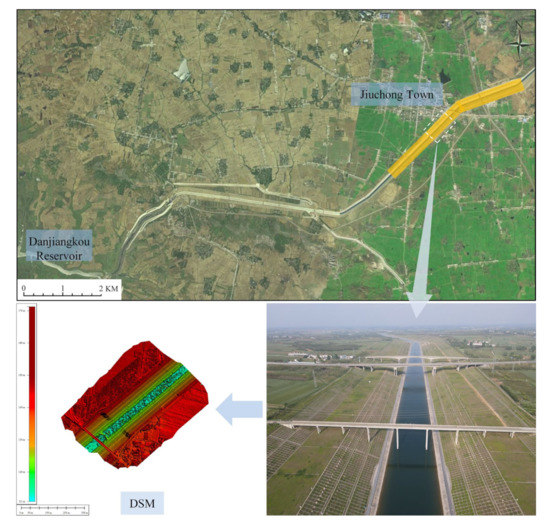
Figure 3.
Digital surface model of the study area.
Ground-imitating flying is mainly conducted through the UAV’s flight control module to control the altitude change of the UAV; when the terrain changes, the UAV generates a pitch angle θ (when θ > 0°, UAV elevation; when θ < 0°, UAV decline), causing the UAV flight altitude to change, thus, ensuring that the UAV always performs the route mission according to the fixed altitude, as shown in Figure 2b.
To ensure the accuracy of the completed 3D model, the image’s control points should be evenly distributed in the survey area, and the image’s control points should be distributed in a flat area without obstruction to ensure the stability and visibility of the image-control markers. There are 6 control points laid in the experimental area, and the accuracy of the control points is shown in Table 1. After the field survey, we found that the highest surface feature height in the survey area was 21 m, and there were high-voltage transmission lines on both sides of the channel slope; to ensure flight safety and the clarity of the channel slope cracks on the image, the final setting of the relative flight height of the imitation ground flight was 30 m, the heading overlap rate was 80%, and the side overlap rate was 70%. Route planning is shown in Figure 4.

Table 1.
Control points’ error table.
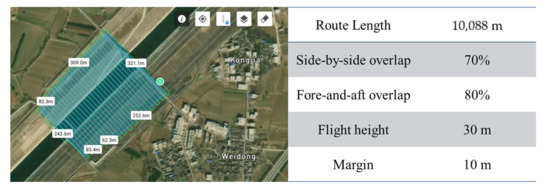
Figure 4.
UAV route planning and basic parameter-setting chart.
3.3. Channel Slope Crack-Detection Methods
YOLO v5 is one of the most stable and widely recognized target-detection methods in the current one-stage algorithm. YOLO v5 is characterized by small average-weight files, short training time, and fast inference speed. However, the YOLO v5 network is not ideal for small target detection, so we added an image-cropping module to the YOLO v5 network to crop the input images for preprocessing. Since the original image resolutions are all 6000 × 4000, the pixel coordinate values of the upper left corner point and lower right corner point of the cropped area are (2100, 1400) and (3900, 2600), respectively. Only 9% of the center area of the original image is retained, making the relative size of the cracks on the image larger and effectively solving the problem of YOLO v5’s difficulty in recognizing small targets. Thus, we chose the corrected YOLO v5 network framework to conduct the remote-sensing image crack-target-detection study. Its network structure is shown in Figure 5, which consists of four main parts: input, trunk network, neck, and prediction. Mosaic data enhancement on the input side improves the detection of small targets, the addition of adaptive anchor frames improves the recall of detection, and the unification of the input image size is achieved by adaptive image scaling; the trunk network uses the CSPDarknet53 network structure to enhance the learning capability of the network and reduce the volume of the model while maintaining accuracy; the neck uses the FPN+PAN structure to achieve the goal of predicting three different scales by combining the two and aggregating parameters from different backbone layers to different detection layers; the output side uses GIOU Loss as the loss function of the Bounding box to improve the speed and accuracy of detection.
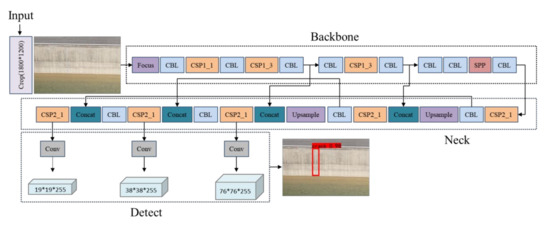
Figure 5.
YOLO v5s network structure diagram.
Among them, the Crop module is a cropping operation for the input image, cropping out 1800 × 1200 pixels from the center area of the original image and using the cropped image as the input data. The Focus module is a slicing operation on the input image, extracting a value from every pixel on an image so that we obtain four images, and each channel can generate four channels, and the stitched-together image becomes 12 channels from the RGB three-channel mode of the original image. Finally, we obtain a two-fold downsampling feature map with no information loss. The CBL module consists of Conv (Convolution) + BN (Fully Connected) + Leaky_relu activation function, where the Conv module extracts the labeled features by convolutional kernel operations in the convolutional layer. The BN module readjusts the data distribution to solve the gradient problem in the propagation process. The Cross Stage Partial (CSP) module allows the model to learn more features by splitting the input into two branches and performing separate convolution operations to halve the number of channels. The SPP (Spatial Pyramid Pooling) module can convert feature maps of arbitrary size into feature vectors of fixed size, which is used to solve the problem of non-uniform size of input images.
YOLO v5 can be divided into four different network structures of different sizes according to different network depths and widths, YOLO v5s, YOLO v5m, YOLO v5l, and YOLO v5x; the structural parameters of the four networks are shown in Table 2. In the table, Depth_multiple and Width_multiple are the two scaling factors of the network. Depth_multiple is used to control the depth of the network, i.e., to control the number of layers of the network. Width_multiple is used to control the width of the network, i.e., to control the size of the network output channels.
Table 2.
YOLO v5 network specifications by size.
Another important reason for choosing the YOLO v5 network structure in this study is that YOLO v5 uses Complete Intersection over Union (CIoU) Loss to calculate the rectangular frame loss, which calculates the overlap area, centroid distance, and aspect ratio simultaneously, further improving the training efficiency, overcoming the defect that the traditional Intersection over Union (IoU) Loss can only represent the ratio of the intersection and merge of the prediction box and the real box, and cannot reflect the relative position of the prediction frame and the real frame. The equation for calculating CIoU Loss is shown in Equation (1). denotes the distance between the prediction frame and the center point of the target frame, denotes the diagonal length of the smallest enclosing rectangle, and and denote the aspect ratio of the prediction frame and the target frame, respectively.
Faster RCNN is one of the most representative algorithms in the two-stage algorithm, and the whole network can be divided into four main modules. The first is the conv layers module, which extracts the feature maps of the input image by a set of conv + relu + pooling layers. The second is the Region Proposal Network (RPN) module, which generates candidate frames. The first stage is to dichotomize the anchors, determine whether all the pre-defined anchors are positive or negative, generate the coordinate values of the four corner points of the pre-selected frames, and correct the anchors to obtain more accurate proposals. The third is the RoI Pooling module, which takes the outputs of the first two modules as input and combines the two modules to obtain a fixed-size region-feature map and output to the fully connected network for classification later. The fourth is classification and egression; this layer classifies the image by softmax and corrects the exact position of the object using edge regression. The output is the class to which the object belongs in the region of interest and the exact position of the object in the image.
To evaluate the performance of the channel slope crack-detection models selected in this study, the performance of each network model was compared and analyzed using precision (P), recall (R), the weighted average of precision and recall (F1-score, F1), and frames per second (FPS) of detected images. In general, the higher the F1 score, the more stable the model is, the higher the detection accuracy, and the higher the robustness. The algorithm for the F1 fraction is shown in Equation (2). The positive label and positive classification is denoted as true positive (TP); negative labeling and negative classification is denoted as false positive (FP); positive label but negative classification is denoted as false negative (FN); negative labels and positive classifications is denoted as true negative (TN).
3.4. Channel Slope Crack Plane Right-Angle Coordinate-Acquisition Method
When UAV ground-imitating flight-image-data acquisition is performed, a set of POS data will be generated simultaneously for each photo, and the POS data of some images are shown in Table 3. POS data can accurately record the 3D coordinates of the UAV and the flight altitude of the UAV when collecting aerial images. The standard POS data include the photo number; the latitude (B0) and longitude (L0) of the aerial point; the UAV altitude (i); the roll angle (β), pitch angle (α), and heading angle (K) during flight.
Table 3.
Example of M300 ground-like flight POS data.
The aerial images captured by the UAV contain information on the dimensions of the image, including the image width (W0), the image height (H0), and the focal length (f) of the aerial camera. Because of the influence of the pitch and roll angle, the image is also not absolutely horizontal, and the same is true for the mapped area of the image changes. Figure 6a represents the change of its mapping area when the image undergoes side deviation; is the flight altitude and is the ground elevation. Since there are geometric distortions in the image and the deviation is greater in the area farther away from the image center, replacing the prediction frame with its shape center point can improve the positioning accuracy. The geometric relationship between the remote-sensing image and its mapping area is used to determine the rectangular plane coordinates of the crack point on the image. First, the latitude and longitude (B0, L0) of the aerial point collected in POS data are converted into UTM coordinates (X0, Y0), and the orthographic projection of the aerial point on the image deviates from the center point of the image because the orthophoto is not horizontal. Thus, the image center point coordinates need to be corrected. As shown in Figure 6b, where point A is the vertical projection point of the aerial point on the image, point B (X, Y) is the actual center point of the image.
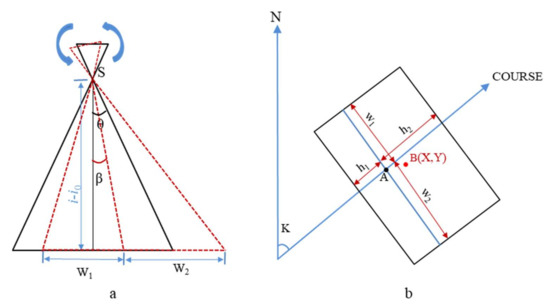
Figure 6.
Image mapping area and image centroid correction map.
The pitch and side offset correction of the X coordinate of the image aerial point is shown in Equation (3):
The pitch and side deflection correction for the Y-coordinate of the image aerial point is shown in Equation (4):
Then, the actual center point coordinates of the image can be derived as shown in Equation (5):
From this, the center point (X, Y) of the actual image can be determined, and then the distance and relative position of the center point of the crack on the image can be determined from the pixel value of the center point of the crack-detection frame and the pixel value of the center point of the image, and the azimuth angle from the center point to the crack point can be determined from the heading angle. According to the geometric relationship of the central projection, the field coordinates of the crack point on the ground can be determined, as shown in Figure 7.
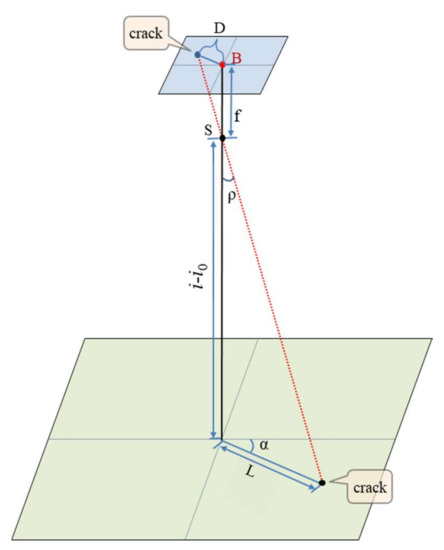
Figure 7.
Positioning geometry schematic.
If we set the pixel value of the center point of the detection frame as (a, b), then we have:
The azimuth angle from the image center to the center of the detection frame, the distance D from the image center to the center of the detection frame shape, and the distance from the image center to the center of the crack shape on the field are obtained from Equation (6).
From the distance and azimuth of the center point of the image on the field to the center of the crack shape, the plane’s right-angle coordinates (x, y) of the center of the crack shape on the field can be obtained from Equation (7):
The main factors affecting positioning accuracy are, first, the existence of lateral deviation and pitch of the orthophoto causes the mapping range of the orthophoto to change. Second, the deep excavation canal section has large variations in ground undulation, resulting in inconsistent photographic scales in different areas of the image. Third, the center projection image features are geometrically distorted, and the further away from the projection center, the greater the distortion. To improve the positioning accuracy, we mainly proceed by reducing the flight height of the UAV and controlling the size of the angle between the projected ray and the plumb line; as shown in Figure 8, the lower the altitude, the smaller the angle, and the smaller the point error. Influenced by the terrain and features of the measurement area, it was finally decided that the UAV would fly at an altitude of 30 m and only retain the effective detection area in the middle of the image, accounting for 9% of the overall image. This means that the area of repeated detection is reduced, and the work process is accelerated. It can also largely attenuate the influence of geometric image distortion and effectively improve the accuracy of fracture georeferencing.
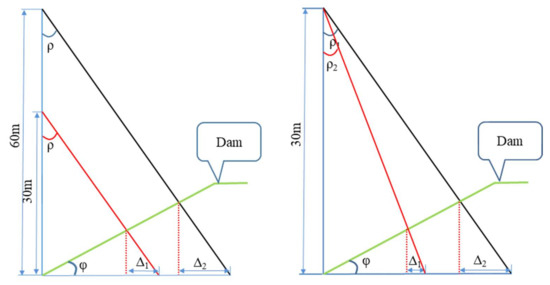
Figure 8.
Variation of point error for different flight altitudes (left) and camera angles (right).
By comparing with the corresponding crack location information on the 3D modeling, the point accuracy of the crack information detected by using the combined navigation and positioning information of deep learning and UAV is evaluated. The 3D model of the test area is highly accurate, with an average ground resolution of 0.81cm/pixel. The position information on the model can be used as an evaluation criterion, and the detection position accuracy can be evaluated by calculating the point error of both. The point error is calculated as shown in Equation (8). ∆x is the difference between the x-coordinate of the crack obtained from the detection and the x-coordinate of the crack form center point acquired on the 3D model; ∆y is the difference between the y-coordinate of the crack obtained from the detection and the y-coordinate of the crack form center point acquired on the 3D model.
4. Experiment and Discussion
4.1. Experimental Data and Environment Configuration
The study was conducted in a deep-cut canal slope section of the South–North Water Diversion Project, and the RTK signal was normal during the data acquisition. The terrain of the deep-cut canal slope channel section is highly undulating, and the height difference can reach tens of meters. The width of the channel slope cracks is only a few millimeters, so traditional image acquisition means cannot clearly obtain the crack images. For this reason, this experiment introduced the ground-imitating flying technique of UAV for channel slope image acquisition for the first time. The parameters of the UAV and lens used for the measurement are shown in Figure 9.

Figure 9.
UAV survey site and main equipment specifications.
The format of the dataset in this study is VOC2007. To improve the recognition rate of intelligent channel crack extraction using the deep-learning method, this study first preprocessed the collected image data, i.e., the original image was cropped and preprocessed, only 9% of the center area of the original image was retained, and the image size was changed to 1800 × 1200. The labeling software was then used to label the data, and a total of 15,478 cracks were labeled as the dataset, of which the training set accounted for 80%, the validation set accounted for 10%, and the test set accounted for 10%. During the labeling process, the labeling frame was ensured to fit the crack pattern as much as possible, and the labeling details are shown in Figure 10. Each annotated image generates information on the pixel coordinates of the cracks on the image for one object.

Figure 10.
Marking details display.
In this experiment, the whole training process of the algorithm used was set to 100 epochs, and 1 epoch is the process of importing the whole dataset for complete training, with the weight decay coefficient of 0.0005 and the momentum parameter set to 0.9. Since the first fifty epoch parameters were adjusted with a large difference from the true value, the training learning rate of the first 50 epochs was set to 0.001. Each epoch was iterated 50 times, and the batch size was set to 16 to make the parameters converge faster. The learning rate of the last 50 epochs was set to 0.0001, with each epoch iterated 100 times, and the batch size was set to 8. The configuration of the experimental environment is shown in Figure 11.
Figure 11.
Deep-learning model training and experimental environment configuration diagram.
4.2. Detection Results of Slope Cracks in Different Models of Channels
To compare the crack-detection effect of each model, four models of YOLO v5 and Faster RCNN were tested under the same dataset in this study. A total of 700 preprocessed images were selected for the dataset. After the images were cropped and preprocessed, the relative size of the side slope cracks became larger, which effectively improved the small-sized crack detection accuracy of the crack-detection model. The dataset contained a total of 1945 cracks, and the performance indexes of the model were obtained, as shown in Table 4.
Table 4.
Performance indicators for crack detection of various models.
In Table 4, we can see that the Faster RCNN detection model has the best detection effect, with an F1 value of 0.96. Of the 1945 cracks included in the test, the Faster RCNN model correctly detected 1812, with a recall rate of 93.15%, which is 9.05% higher than YOLO v5s, 6.12% higher than YOLO v5m, 2.57% higher than YOLO v5l, and 0.5% higher than YOLO v5x. It is 2.57% higher than YOLO v5x and 0.5% higher than YOLO v5x; in terms of detection accuracy, Faster RCNN is somewhat higher than YOLO v5s, YOLO v5m, YOLO v5l, and YOLO v5x. Regarding detection speed, YOLO v5s, which has the smallest volume, is the fastest, with FPS up to 34.5. Regarding model volume, YOLO v5s is the smallest and has the fastest training and inference speed.
The detection results of each algorithm are shown in Figure 12. YOLO v5x and Faster RCNN have better detection results, and YOLO v5s, YOLO v5m, and YOLO v5l detection effects improved sequentially. Due to the complexity of the background of the channel slope, the detection results can be missed or wrongly detected, and the detection frame can be too small and too large, as shown in Figure 13. When cracks and expansion joints are connected, it is easy to identify them all as cracks. The water pattern paths and cracks on the channel side slopes have strong similarities in shape and tone, and the YOLO v5s and YOLO v5m algorithms do not have a strong ability to distinguish water pattern paths and cracks. The Faster RCNN and YOLO v5x algorithms perform better in detecting channel slope cracks during the experiments, with a higher recall rate; less missed detection, wrong detection, too-small and too-large detection frames; and robustness in recognizing cracks of different shapes and sizes. The overall performance of YOLO v5x is optimal considering the accuracy of detection, speed, and model volume factors. YOLO v5x has some advantages as a channel slope crack-detection algorithm.
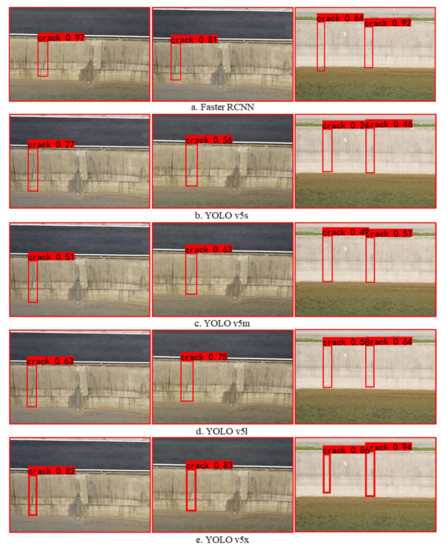
Figure 12.
Testing results of each model.

Figure 13.
Crack-detection problem diagram. (a) Crack-detection frame is too large. (b) Crack-detection box is too small. (c) There is no crack in the field, and the test result shows a crack. (d) Cracks in the field and no cracks in the test results.
4.3. Application Analysis
Based on the above method, we conducted a related application study with an aerial camera sortie. To verify the feasibility of the fracture field localization method, we performed a 3D reconstruction of the whole scene and manually extracted the fractures on the model. The length of the experimental area is 730 m, the width is 270 m, and its completed 3D model is shown in Figure 14. By finding cracks on the slope of the channel of the 3D model, we determined that the area contains 74 pieces of crack information in total. By recording the crack latitude and longitude (B, L) on the 3D model and converting the latitude and longitude to UTM coordinates (X, Y), checkpoint plane accuracy was better than 0.5 pixels, the average ground resolution of the 3D model was 8.10762 mm/pixel, and the crack location information obtained through the 3D model was used for analyzing and evaluating the crack-location information obtained from the crack-detection model.
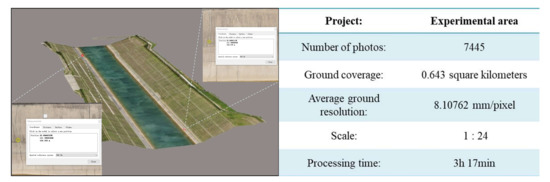
Figure 14.
Three-dimensional model of the experimental area and its accuracy index.
The aerial image data were input into the deep-learning model for crack identification and localization, and the detection results contained information about 76 cracks, including 2 cases of detection errors, as shown in Figure 15. The field-location information of cracks on 74 3D models was recorded, the field information of crack output by deep learning was integrated, and some data are shown in Table 5. In the table, (B, L) represent the latitude and longitude of the crack center point collected from the 3D model; (X, Y) are the UTM coordinate values transformed by the latitude and longitude of the crack points on the 3D model, respectively; (x, y) represent the rectangular plane coordinates of the corresponding cracks obtained from the model detection. The point error of each crack-detection location relative to its corresponding 3D model location can be calculated, and the value of each point error and the interval distribution of its point error are shown in Figure 16. Because the orthophoto is not horizontal and the channel slope is an inclined surface, the image has geometric distortion, which leads to errors in the field positioning of cracks. By controlling the flight height of the UAV, retaining the central area with less geometric distortion on the image as the effective detection area, and correcting the location of the image center point, we finally controlled the positioning error of the cracks to within 0.6 m, of which the point error of less than 0.3 m accounted for 73%, and the interval of the point error approximately obeyed normal distribution. Thus, it can be seen that the accuracy of the crack plane’s right-angle coordinate points obtained by the model can fully meet the needs of channel slope crack maintenance, which verifies the effectiveness of this research method in the detection and positioning of cracks on the slope of the South–North Water Transfer Channel.

Figure 15.
Detection of incorrect images.
Table 5.
Three-dimensional model and model’s detected crack location information.
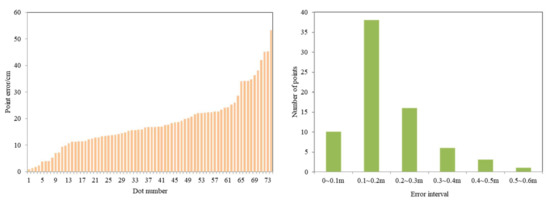
Figure 16.
Point error interval distribution.
5. Discussion
5.1. Data Acquisition and Pre-Processing Methods
In this study, visible light images of channel slopes were collected by UAV. Compared with the InSAR method used in the literature ((7) and (9)) to acquire images, visible-light images can retain the hue and texture characteristics of cracks, which provides a basis for the identification and detection of cracks. In this paper, the data acquisition of the study area is carried out using the ground-imitating flying technique of a UAV. Compared with the traditional fixed-flight-height method, the ground-mimicking flight technique can ensure the consistent resolution of the images acquired in areas with different terrain, which enhances the recognition and clarity of the cracks on the complex slope background.
According to the overlap setting of the ground-imitating flying technique of a UAV, this study crops the original data for preprocessing with the same aspect ratio as the original image and retains 9% of the effective detection area in the middle part of the image. The cropped image data can cover the entire survey area to ensure that no missed detections are produced and improve the overall experiment as follows:
- Making a dataset with cropped and preprocessed image data can improve the overall performance of the crack-detection model. The UAV flight height is set to 30 m due to the terrain characteristics of the survey area. The crack is small compared to the whole image, and the YOLO v5x network is less effective in recognizing small targets, so the features of small-sized cracks will be lost during the training process. After the data are preprocessed by cropping, the cracks are relatively larger than the cropped image, so the YOLO v5x network will be more comprehensive in learning the crack features, making the trained model more robust.
- The accuracy of crack positioning can be improved in the crack-positioning stage. Since geometric distortion exists in all orthophotos, the geometric distortion is larger the farther away it is from the central region. In this study, the fast-localization principle based on a single image is based on the geometric relationship between the image and its mapping area, so the cropped preprocessed image retains the area with less geometric distortion, reducing the impact of geometric image distortion on the localization accuracy.
5.2. Processing Massive Data Using Deep Learning
Super-clear resolution images are acquired using the ground-imitating flying technique of a UAV, and the amount of data collected is huge for the South–North Water Transfer Central Line Project. For crack detection on massive image data, compared with the LSD method in the literature (13), the LBD method in the literature (15), and the Hough transform method in the literature (16), deep learning is far superior to the other methods in terms of detection speed and detection accuracy. In this paper, 15,478 cracks are labeled as the training data set, and the latest and fastest YOLO v5 algorithm and Faster RCNN algorithm are explored. YOLO v5s, YOLO v5m, YOLO v5l, YOLO v5x, and Faster RCNN are compared and analyzed in terms of their accuracy rate, recall rate, F1 score, number of frames per second of the detected images, and model volume to compare the performance of each network model. Finally, YOLO v5x, with better overall performance, was selected as the channel slope crack-detection algorithm.
5.3. Single-Image Positioning Method
The detection of cracks on the slope of the channel of the South–North Water Transfer Project is different from the detection of cracks on bridges in the literature (22) and the detection of cracks on roads in the literature (26). Road crack detection and bridge crack detection can easily find the field location of the detected cracks based on the characteristic features and landforms on the images. In contrast, the long distance of the side slopes of the South–North Water Transfer Channel and the absence of obvious characteristic features make it impossible to determine the field location of cracks. At the present stage, the field location of remote-sensing images requires three empty calculations and overall leveling calculations, and finally, a high-precision, three-dimensional model is obtained. However, it is unnecessary and unrealistic to establish a 3D model for the South–North Water Transfer Central Project.
Thus, this study, based on the detection results of the YOLO v5x model, combined with the POS information corresponding to this image recorded by the UAV, first converts the latitude and longitude of aerial points in POS data to UTM coordinates, and determines the coordinates of the actual image center point (X, Y) after two corrections, replaces the location of the crack with the position of the shape center of the crack detection frame, and finds the rectangular plane coordinates corresponding to the crack by calculating the pixel value from the center point of the image to the center point of the detection frame. With this method, we can determine the plane’s right angle coordinates corresponding to the crack according to the geometric relationship between the UAV image and its corresponding mapping area and improve the positioning accuracy by controlling the effective detection area in the image. The experimental results show that the point accuracy of cracks in the field is within 0.6 m, and 73% are less than 0.3 m. Thus, it is clear that the point accuracy of the plane rectangular coordinates of cracks obtained by the single-image positioning method can fully meet the needs of channel slope crack maintenance.
6. Conclusions
This study proposes a method combining a Positioning Navigation System with deep learning to conduct batch crack detection and positioning in the field. We can preprocess the orthophotos collected by the UAV and mark the channel side slope cracks in the preprocessed images, then, make that a training dataset. The datasets contain a total of 15,478 cracks, and by training four different networks of the YOLO v5 series and Faster RCNN, evaluating the crack field localization accuracy, the following conclusions can be drawn:
- (1)
- This study marks the first collection of data from the deep-cut canal slope section of the Chinese South–North Water Transfer Project by using a ground-imitating flying UAV technique, which ensures that all the images collected from the deep-cut canal slope section are of super-clear resolution and provide excellent discrimination of the channel side slope cracks. At the head of the network, the image-cropping preprocessing module is added to ensure a good detection effect for small cracks, which speeds up the overall detection rate and improves the accuracy of crack localization.
- (2)
- The YOLO v5x deep-learning model is selected to detect the channel slope, and the experiments show that the model outperforms other models in both detection accuracy and recall rate index. The YOLO v5x model detects cracks with a recall rate of up to 92.65%, an accuracy rate of up to 97.58%, and an F1 value of 0.95. There are fewer misses and errors in the detection process, and crack detection can be completed well.
- (3)
- Based on the crack-detection results from the crack-detection model, the crack-field positioning of a single image is realized by combining the image with the UAV navigation information. It is verified that the error of crack field positioning is within 0.6 m, and 73% of the crack point position error can be controlled to within 0.3 m. The South–North Water Transfer Project is a linear feature, and the sub-meter level positioning accuracy is sufficient to provide the field position of cracks. The method of acquiring the geographical coordinates of channel side slope cracks proposed in this study can control the point position error to within 0.6 m, which is fully capable of detecting and locating the cracks of a wide range of channel slopes, reducing workloads and improving working efficiency.
This study provides new ideas and methods for the repair and inspection of cracks on the slopes of the channels of the South–North Water Transfer Project.
Author Contributions
Conceptualization, Q.H., P.W., S.L. and W.L. (Wenkai Liu); methodology, Q.H., P.H. and P.W.; software, P.W., Y.L., W.L. (Weiqiang Lu) and Y.K.; validation, Q.H., S.L. and F.W.; formal analysis, Q.H.; investigation, Q.H.; resources, Q.H. and A.Y.; data curation, P.W. and Y.L.; writing—original draft preparation, Q.H. and P.W.; writing—review and editing, W.L. (Wenkai Liu) and S.L.; supervision, Q.H. and W.L. (Wenkai Liu); project administration, Q.H. and W.L. (Wenkai Liu); funding acquisition, Q.H. and W.L. (Wenkai Liu). All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Joint Funds of the National Natural Science Foundation of China (No. U21A20109), the National Natural Science Foundation of China (Nos. 42277478 and 52274169) and Joint Fund of Collaborative Innovation Center of Geo-Information Technology for Smart Central Plains, Henan Province and Key Laboratory of Spatiotemporal Perception and Intelligent processing, Ministry of Natural Resources (No. 212110).
Acknowledgments
The authors would like to thank the editor and reviewers for their contributions on the paper.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Liu, W.; Gong, T.; Hu, Q.; Gong, E.; Wang, G.; Kou, Y. 3D reconstruction of deep excavation and high fill channel of South-to-North Water Diversion Project based on UAV oblique photography. J. North China Univ. Water Resour. Electr. Power (Nat. Sci. Ed.) 2022, 43, 51–58. [Google Scholar]
- Liu, Z.; Luo, H.; Zhang, M.; Shi, Y. Study on expansion-shrinkage characteristics and deformation model for expansive soils in canal slope of South-to-North Water Diversion Project. Rock Soil Mech. 2019, 40, 409–414. [Google Scholar]
- Dai, F.; Dong, W.; Huang, Z.; Zhang, X.; Wang, A.; Cao, S. Study on Shear Strength of Undisturbed Expansive Soil of Middle Route of South-to-North Water Diversion Project. Adv. Eng. Sci. 2018, 50, 123–131. [Google Scholar]
- Vanneschi, C.; Eyre, M.; Francioni, M.; Coggan, J. The Use of Remote Sensing Techniques for Monitoring and Characterization of Slope Instability. Procedia Eng. 2017, 191, 150–157. [Google Scholar] [CrossRef]
- Casagli, N.; Cigna, F.; Bianchini, S.; Hölbling, D.; Füreder, P.; Righini, G.; Del Conte, S.; Friedl, B.; Schneiderbauer, S.; Iasio, C.; et al. Landslide mapping and monitoring by using radar and optical remote sensing: Examples from the EC-FP7 project SAFER. Remote Sens. Appl. Soc. Environ. 2016, 4, 92–108. [Google Scholar] [CrossRef]
- Jia, H.; Wang, Y.; Ge, D.; Deng, Y.; Wang, R. Improved offset tracking for predisaster deformation monitoring of the 2018 Jinsha River landslide (Tibet, China). Remote Sens. Environ. 2020, 247, 111899. [Google Scholar] [CrossRef]
- Chen, Z.; Yin, Y.; Yu, J.; Cheng, X.; Zhang, D.; Li, Q. Internal deformation monitoring for earth-rockfill dam via high-precision flexible pipeline measurements. Autom. Constr. 2022, 136, 104177. [Google Scholar] [CrossRef]
- Zhou, J.; Shi, B.; Liu, G.; Ju, S. Accuracy analysis of dam deformation monitoring and correction of refraction with robotic total station. PLoS ONE 2021, 16, e0251281. [Google Scholar] [CrossRef]
- Dong, J.; Lai, S.; Wang, N.; Wang, Y.; Zhang, L.; Liao, M. Multi-scale deformation monitoring with Sentinel-1 InSAR analyses along the Middle Route of the South-North Water Diversion Project in China. Int. J. Appl. Earth Obs. Geoinf. 2021, 100, 102324. [Google Scholar] [CrossRef]
- Vazquez-Ontiveros, J.R.; Martinez-Felix, C.A.; Vazquez-Becerra, G.E.; Gaxiola-Camacho, J.R.; Melgarejo-Morales, A.; Padilla-Velazco, J. Monitoring of local deformations and reservoir water level for a gravity type dam based on GPS observations. Adv. Space Res. 2022, 69, 319–330. [Google Scholar] [CrossRef]
- Xie, L.; Xu, W.; Ding, X.; Bürgmann, R.; Giri, S.; Liu, X. A multi-platform, open-source, and quantitative remote sensing framework for dam-related hazard investigation: Insights into the 2020 Sardoba dam collapse. Int. J. Appl. Earth Obs. Geoinf. 2022, 111, 102849. [Google Scholar] [CrossRef]
- Liu, Y.; Xie, Z.; Liu, H. LB-LSD: A length-based line segment detector for real-time applications. Pattern Recognit. Lett. 2019, 128, 247–254. [Google Scholar] [CrossRef]
- Von Gioi, R.G.; Jakubowicz, J.; Morel, J.-M.; Randall, G. LSD: A fast line segment detector with a false detection control. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 722–732. [Google Scholar] [CrossRef] [PubMed]
- Von Gioi, R.G.; Jakubowicz, J.; Morel, J.-M.; Randall, G. LSD: A Line Segment Detector. Image Process. Line 2012, 2, 35–55. [Google Scholar] [CrossRef]
- Zhang, L.; Koch, R. An efficient and robust line segment matching approach based on LBD descriptor and pairwise geometric consistency. J. Vis. Commun. Image Represent. 2013, 24, 794–805. [Google Scholar] [CrossRef]
- Yamaguchi, T.; Mizutani, T. Detection and localization of manhole and joint covers in radar images by support vector machine and Hough transform. Autom. Constr. 2021, 126, 103651. [Google Scholar] [CrossRef]
- Zhang, X.; Liao, G.; Yang, Z.; Li, S. Parameter estimation based on Hough transform for airborne radar with conformal array. Digit. Signal Process. 2020, 107, 102869. [Google Scholar] [CrossRef]
- Pang, S.; del Coz, J.J.; Yu, Z.; Luaces, O.; Díez, J. Deep learning to frame objects for visual target tracking. Eng. Appl. Artif. Intell. 2017, 65, 406–420. [Google Scholar] [CrossRef]
- Choi, K.; Lim, W.; Chang, B.; Jeong, J.; Kim, I.; Park, C.-R.; Ko, D.W. An automatic approach for tree species detection and profile estimation of urban street trees using deep learning and Google street view images. ISPRS J. Photogramm. Remote Sens. 2022, 190, 165–180. [Google Scholar] [CrossRef]
- Sayed, A.N.; Himeur, Y.; Bensaali, F. Deep and transfer learning for building occupancy detection: A review and comparative analysis. Eng. Appl. Artif. Intell. 2022, 115, 105254. [Google Scholar] [CrossRef]
- Zaidi, S.S.A.; Ansari, M.S.; Aslam, A.; Kanwal, N.; Asghar, M.; Lee, B. A survey of modern deep learning based object detection models. Digit. Signal Process. 2022, 126, 103514. [Google Scholar] [CrossRef]
- Joshi, D.; Singh, T.P.; Sharma, G. Automatic surface crack detection using segmentation-based deep-learning approach. Eng. Fract. Mech. 2022, 268, 108467. [Google Scholar] [CrossRef]
- Ali, R.; Chuah, J.H.; Talip, M.S.A.; Mokhtar, N.; Shoaib, M.A. Structural crack detection using deep convolutional neural networks. Autom. Constr. 2022, 133, 103989. [Google Scholar] [CrossRef]
- Zhang, J.; Qian, S.; Tan, C. Automated bridge surface crack detection and segmentation using computer vision-based deep learning model. Eng. Appl. Artif. Intell. 2022, 115, 105225. [Google Scholar] [CrossRef]
- Yu, Z.; Shen, Y.; Shen, C. A real-time detection approach for bridge cracks based on YOLOv4-FPM. Autom. Constr. 2021, 122, 103514. [Google Scholar] [CrossRef]
- Yang, J.; Fu, Q.; Nie, M. Road Crack Detection Using Deep Neural Network with Receptive Field Block. IOP Conf. Ser. Mater. Sci. Eng. 2020, 782, 042033. [Google Scholar] [CrossRef]
- Chen, T.; Jiang, Y.; Jian, W.; Qiu, L.; Liu, H.; Xiao, Z. Maintenance Personnel Detection and Analysis Using Mask-RCNN Optimization on Power Grid Monitoring Video. Neural Process. Lett. 2019, 51, 1599–1610. [Google Scholar] [CrossRef]
- Sharma, V.; Mir, R.N. Saliency guided faster-RCNN (SGFr-RCNN) model for object detection and recognition. J. King Saud Univ.—Comput. Inf. Sci. 2022, 34, 1687–1699. [Google Scholar] [CrossRef]
- Zhao, S.; Kang, F.; Li, J. Concrete dam damage detection and localisation based on YOLOv5s-HSC and photogrammetric 3D reconstruction. Autom. Constr. 2022, 143, 104555. [Google Scholar] [CrossRef]
- Liu, J.; Zhao, Z.; Lv, C.; Ding, Y.; Chang, H.; Xie, Q. An image enhancement algorithm to improve road tunnel crack transfer detection. Constr. Build. Mater. 2022, 348, 128583. [Google Scholar] [CrossRef]
- Herrero, M.J.; Pérez-Fortes, A.P.; Escavy, J.I.; Insua-Arévalo, J.M.; De la Horra, R.; López-Acevedo, F.; Trigos, L. 3D model generated from UAV photogrammetry and semi-automated rock mass characterization. Comput. Geosci. 2022, 163, 105121. [Google Scholar] [CrossRef]
- Elhashash, M.; Qin, R. Cross-view SLAM solver: Global pose estimation of monocular ground-level video frames for 3D reconstruction using a reference 3D model from satellite images. ISPRS J. Photogramm. Remote Sens. 2022, 188, 62–74. [Google Scholar] [CrossRef]
















Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).