Abstract
This paper considers problems associated with the large size of the hyperspectral pansharpening network and difficulties associated with learning its spatial-spectral features. We propose a deep mutual-learning-based framework (SSML) for spectral-spatial information mining and hyperspectral pansharpening. In this framework, a deep mutual-learning mechanism is introduced to learn spatial and spectral features from each other through information transmission, which achieves better fusion results without entering too many parameters. The proposed SSML framework consists of two separate networks for learning spectral and spatial features of HSIs and panchromatic images (PANs). A hybrid loss function containing constrained spectral and spatial information is designed to enforce mutual learning between the two networks. In addition, a mutual-learning strategy is used to balance the spectral and spatial feature learning to improve the performance of the SSML path compared to the original. Extensive experimental results demonstrated the effectiveness of the mutual-learning mechanism and the proposed hybrid loss function for hyperspectral pan-sharpening. Furthermore, a typical deep-learning method was used to confirm the proposed framework’s capacity for generalization. Ideal performance was observed in all cases. Moreover, multiple experiments analysing the parameters used showed that the proposed method achieved better fusion results without adding too many parameters. Thus, the proposed SSML represents a promising framework for hyperspectral pansharpening.
1. Introduction
HSIs usually contain information on tens to hundreds of continuous spectral bands in the target area. Therefore, HSIs have a high spectral resolution but lower spatial resolution due to hardware limitations. In contrast, PANs are usually single-band images in the visible range, having high spatial resolution but low spectral resolution. Pansharpening involves the reconstruction of low-resolution (LR) HSIs and high-resolution (HR) PANs to generate HR-HSIs, and has been widely used in image classification [1], target detection [2], and road recognition [3].
Traditional HSI pansharpening technologies can be broadly divided into four categories: component substitution-based methods [4,5], model-based methods [6,7], multi-resolution analysis [8], and hybrid methods [9]. Each of these categories has certain limitations. Component substitution-based methods can cause certain types of spectral distortion; multi-resolution analysis-based methods require complex calculations; hybrid methods combine component substitution and multi-resolution analysis, thus providing good spectral retention but fewer spatial details; and, finally, model-based methods are limited by network parameter number and computational complexity.
In recent years, deep learning has been widely used in the field of image processing [10,11,12,13,14,15,16], while pansharpening has been at the primary stage of exploration [17]. Yang et al. [18] proposed a convolutional neural network (CNN) for pansharpening (PanNet), which was performed via ResNet [19] in the high-pass filter domain. Zhu et al. [20] designed a spectral attention module (SeAM) to extract the spectral features of HSIs. Zhang et al. [21] designed a residual channel attention module (RCAM) to solve the spectral reconstruction problem. However, as is well-known, CNNs can learn one feature more easily than multiple features, and have fewer parameters. Moreover, in the feature extraction process, simultaneous learning of multiple features is affected by the features’ effects on each other. To reduce the influence of these effects, Zhang et al. [22] improved classification results by measuring the difference in the probabilistic behavior between the spectral features of two pixels. Xie et al. [23] used the mean square error (MSE) loss and spectral angle mapper (SAM) loss to constrain spatial and spectral feature losses, respectively. Qu et al. [15] proposed a residual hyper-dense network and a CNN with cascade residual hyper-dense blocks. The former network extends Denset to solve the problem of spatial spectrum fusion. The latter network allows direct connections between pairs of layers within the same stream and those across different streams, which means that it learns more complex combinations between the HS and PAN images.
The above studies show that the better the spatial and spectral feature learning, the better the fusion result for deep-learning-based hyperspectral pansharpening methods. However, it is well known that hyperspectral images contain a large amount of data because of many bands. Thus, it is a challenge for the hyperspectral pansharpening method to fully learn and utilize the spatial and spectral features without increasing computation excessively. Commonly, single feature learning is easier than multiple feature learning, while multiple collaborative learning is more effective than single feature learning. Inspired by mutual learning, in this paper, we explore a novel pansharpening method that learns the spatial and spectral characteristics separately and establishes the relationship between them to learn from each other to achieve desirable results.
In recent years, a deep mutual-learning strategy (DML) [24] has been proposed for image classification, and includes multiple original networks that mutually learn from each other. This unique training strategy has great potential for multi-feature learning of a single task using few parameters. It therefore has research value in the field of HSI pansharpening. To the authors’ knowledge, there has been no application of DML to HSI pansharpening.
This paper proposes a deep mutual-learning framework integrating spectral-spatial information-mining (SSML) for HSI pansharpening. In the SSML framework, two simple networks, a spectral and a spatial network, are designed for mutual learning. The two networks learn different features independently; for instance, the spectral network captures only spectral features, while the spatial network focuses only on spatial details. Then, the DML strategy enables them to learn each other’s features. In addition, a hybrid loss function is derived by constraining spectral and spatial information between the two networks. The main contributions of this paper are summarized below:
- This paper proposes an SSML framework which introduces a DML strategy into HSI pansharpening for the first time; four cross experiments are performed to verify the proposed SSML framework’s effectiveness, and the network’s generalization ability is confirmed by the latest research results in the field of HSI generalization sharpening.
- A hybrid loss function, which considers the HSI characteristics, is designed to enable each network in the SSML framework to learn a certain feature independently, thus improving its overall performance so that the SSML framework can successfully generate a high-quality HR-HSI.
2. Related Work
The DML strategy [24] was initially proposed for image classification, but, after several years of development, it has been applied in many fields [25,26,27]. The DML strategy uses a mutual-loss learning function, which allows multiple small networks to learn the same task together under different initial conditions, thereby improving the performance of each of the networks [24]. For classification problems, Kullback–Leibler (KL) divergence [28] has often been used as a mutual learning loss function in the DML because it can calculate the asymmetric measure of the probability distribution between two networks; it is defined by:
where calculates the distance from to
However, in the field of HSI pansharpening, it is usually necessary to evaluate the image quality rather than the probability distribution of pixels. HSIs have a high correlation between pixels in each band. Therefore, it is necessary to consider other loss functions as the mutual learning loss function instead of the KL divergence. Traditionally, MSE and SAM [29] have been used to evaluate the spatial quality and spectral distortion of HSIs. Therefore, the effects of the MSE and SAM on the proposed SSML framework’s performance are examined in this paper.
3. Method
This section describes the proposed SSML framework and introduces the hybrid loss function.
In general, the HSI pansharpening problem can be considered a process in which a network generates an HR-HSI by inputting an LR-HSI and an HR-PAN , and using the loss function constraint to network learning, which can be expressed as:
where represents the mapping function between a CNN’s input and output data, denotes the parameters to be optimized, and is the loss function.
3.1. Image Preprocessing
As shown in Figure 1, the proposed framework first performs bicubic interpolation on an LR-HSI H to obtain the , which has the same size as HR-PAN P [30]. Then a contrast-limited adaptive histogram equalization is applied to the image P to obtain with richer edge details [31,32]. Finally, is obtained by injecting into through guided filtering, that is , for enhancing the spatial details of HSIs.
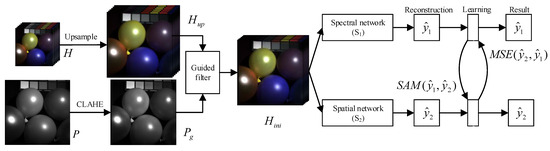
Figure 1.
The structure of the proposed SSML framework.
3.2. SSML Framework
As previously mentioned, the proposed SSML framework includes two networks, a spectral network, and a spatial network. They use specific structures to extract specific features—for instance, residual blocks for extracting spatial features and channel attention blocks for extracting spectral features. In addition, they constrain each other to learn other features by minimizing the hybrid loss function. Without loss of generality, their structures are designed to be universal and simple, as shown in Figure 2. The spectral network uses a spectral attention structure to extract spectral information, while the spatial network adopts residual learning and a spatial attention structure to capture spatial information.
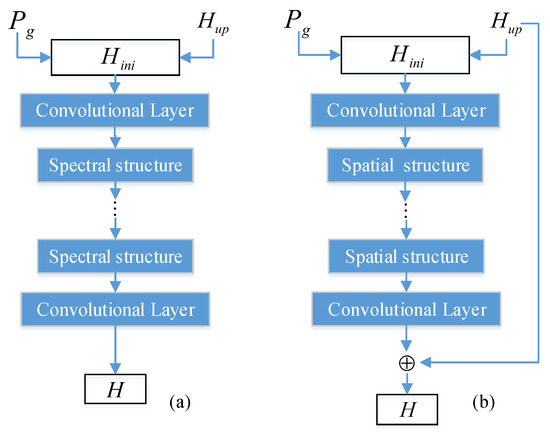
Figure 2.
(a) The structure of the spectral network (), (b) the structure of the spatial network ().
Two popular structures of the spectral network are illustrated in Figure 3a,b. The specific settings of the network are shown in Table 1. RCAM uses four convolutional layers, the size of the convolution kernel of the first two layers is 3 × 3, and the size of the last two layers is 1 × 1. The sigmoid function is used to process the feature map of the four convolutional layers, which is multiplied by the convolution result of the second layer. Then the results and input are processed in element-wise addition. The SeAM is divided into two branches after the convolution of the first two layers, which are the same as RCAM. The structure of the first branch is the same as that of the third and fourth layers of RCAM. The second branch replaces AvgPooling in the first branch with MaxPooling. The results of the two branches are processed in element-wise addition, and the subsequent steps are similar to RCAM.
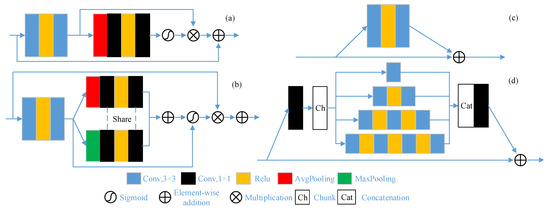
Figure 3.
The structures of the candidate networks. (a) RCAM; (b) SeAM; (c) traditional ResNet; (d) MSRNet.

Table 1.
The specific parameter settings of the spatial network.
As for the spectral structure, most of them have been designed using the pooling operation and then stimulated. The equation is:
where f represents the stimulated process, indicates the pooling operation. Then, by multiplying by F, a new feature map can be obtained as follows:
where and represent the weight and feature map of the ith feature.
Two popular spatial network structures are presented in Figure 3c,d. The specific settings of the network are shown in Table 2. ResNet uses two convolutional layers of equal size. The convolution kernel size is 3 × 3, and the convolution result and input are processed by element-wise addition. The first layer of MSRNet uses a size of 1 × 1 convolution kernels. The convolution results are chunked into four feature maps of equal size, which are sent to four corresponding branches for convolution operations. The first branch uses a convolution layer size of 1 × 1. Branches 2, 3, and 4 added a Relu layer and convolution compared with the previous branch. Finally, the results of the four branches are concatenated and a 1 × 1 convolution is used in the last layer.
Table 2.
The specific parameter settings of the spectral network.
Assume H denotes an HR-HSI and denotes an LR-HSI and suppose there is a residual in H and , which is expressed as:
A CNN can be used to learn between H and , and H can be obtained from and as follows:
3.3. Hybrid Loss Function
Inspired by KL divergence, this paper defines a hybrid loss function for the SSML framework according to the characteristics of the two networks in the proposed framework, forcing them to learn from each other. The hybrid loss function is defined by:
where is the prediction of , is the prediction of , y is the ground truth, and are the weights of the hybrid loss function, and are additional loss functions that constrain spatial information and spectral information, respectively, and is the main loss function to constrain the whole network.
In the two networks in the SSML framework, the -norm is used as the main loss function () due to its good convergence [33], and is defined by:
For spectral feature learning in the network, chooses the MSE to constrain the spatial information loss between y and as follows:
Similarly, for spatial feature learning in the network, chooses the SAM to constrain the spectral information loss between y and .
Finally, the SSML framework alternately updates the weights of and using the SGD as follows:
4. Results
4.1. Datasets and Metrics
The proposed method was evaluated on two public datasets, CAVE [34] and Pavia Center [35]. In CAVE, the wavelength range was 400 nm–700 nm, the resolution was , and there were 31 bands for a total of 32 HSIs. In Pavia Center, the range was 430 nm–860 nm, the resolution was , and 102 bands were used for one HSI. In training, of the overall data was selected as a training set, and the remaining data were used as a test set. Before training, the Wald protocol [30] was adopted to obtain LR-HSIs through down-sampling. In the training set, the data size was bands, and the batch size was 32. In testing, the original image size was the same as the input size. All networks were developed using the PyTorch framework, and the experiments were performed on NVIDIA GeForce GTX 2080ti GPU. In training, SGD’s weight decay was , the momentum was , the learning rate was , the number of iterations was , and the learning rate was reduced by half every 1000 iterations. The proposed method was implemented in Python 3.7.3.
The performance of the proposed method was analyzed both quantitatively and visually. The evaluation indicators used in the performance analysis included the SAM [29], peak signal-to-noise ratio (PSNR) [36], correlation coefficient (CC) [37], erreur relative globale adimensionnelle de synthèse (ERGAS) [38] and root mean squared error (RMSE) [39]. These metrics reflect the image similarity, image distortion, spectral similarity, spectral distortion, and the difference between the fused image and the reference image, respectively, which are described below.
Peak signal-to-noise ratio (PSNR): The peak SNR (PSNR) is used to evaluate the spatial quality of the fused image in the unit of the band. The PSNR of the kth band is defined as
where H and W represent the height and width dimensions with the reference image, respectively. and represent the reference image and the fused image of the kth band. refers to the two-norm. The final PSNR is the average of the PSNRs of all bands. The higher the PSNR, the better the performance.
Correlation coefficient (CC): This is mainly used to score the similarity of the content between two images, which is defined as
where and denote the spectral vector of the reference image and the fused image, respectively, at the pixel position of . The CC in HSI fusion is calculated as the average over all bands. The larger the CC is, the better the fusion image can be. Spectral angle mapper (SAM): The SAM is generally utilized to evaluate the degree of spectral information preservation at each pixel, which is defined as
where refers to the inner product of and ; the overall SAM is the average of the SAMs of all pixels. The lower the SAM, the better the performance.
Erreur relative globale adimensionnelle de synthèse (ERGAS): The ERGAS is specially designed to assess the quality of high-resolution synthesized images, and measures the global statistical quality of the fused image. It is defined as
where r refers to the ratio of the spatial downsampling ratio from HR-HSI to LR-HSI. u denotes the mean value of the reference image of the kth band. The smaller the ERGAS, the better the performance.
Root mean squared error (RMSE): RMSE can be used to measure the difference between R and Z, which is defined as
where L represents the number of spectral bands. (i, j) and (i, j) denote the element value at spatial location in band k of the reference image and the fused image.The smaller the root mean squared error (RMSE), the better the performance.
4.2. DML Strategy Validation for Different Cases
The comparison results of the SSML framework for different deep networks are presented in Table 3 and Table 4. Four cases were analyzed: The network uses RCAM or SeAM, and the network uses MSRNet or ResNet. Depending on the experience, it was set that and .
Table 3.
Comparison results of the SSML for different deep networks on the CAVE dataset.
Table 4.
Comparison results of the SSML for different deep networks on the Pavia Center dataset.
As shown in Table 3 and Table 4, the performance of and networks in the SSML exceeded that of the original network in most cases. Without loss of generality, the loss value curve of the SSML, having with the SeAM and with the ResNet, was analyzed at the Pavia Center to determine the reasons for the advantage of the DML strategy. A comparison of the loss value curves of in the SSML and original during 5000 training iterations on the Pavia Center is presented in Figure 4a, and their difference curve is presented in Figure 4b. As shown in Figure 4b, the loss values of in the SSML were slightly higher than those of the original before 1000 iterations; however, after 1000 iterations, the loss values of in the SSML were lower than those of the original . Thus, it can be concluded that the SSML had a slow convergence speed in the early training stage because of the alternate optimization. Nonetheless, it exhibited advantages of minimum loss value and convergence speed with increase in the training iteration number. This indicates that introducing the DML strategy in the SSML can help to achieve better results in HSI pansharpening.
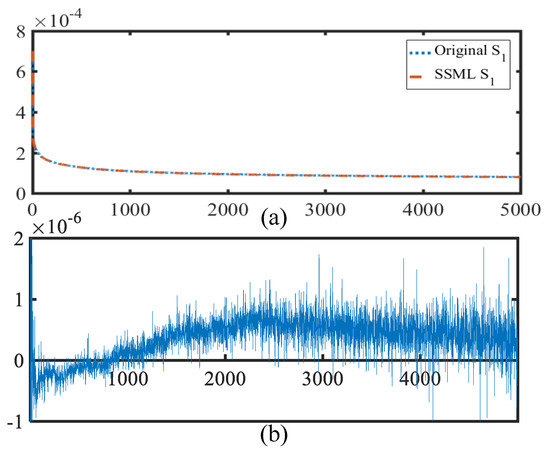
Figure 4.
(a) Loss function curves of the SeAM () of the SSML framework and the original SeAM during 5000 iterations of training; (b) the difference curve between the loss values of the original SeAM and the SeAM () in the SSML framework during 5000 training iterations.
4.3. Effect of the Number of Training Samples
This experiment investigated the effect of the proportion of the training set on the fusion effect. Usually, deep-learning-based hyperspectral image sharpening training sets and test sets select and content, respectively. In the experiment, and , and , and and were selected for the training and testing sets, respectively. The number of iterations, learning rate, and other parameters was the same. Each group of experiments was repeated 10 times; the experimental results are shown in Table 5. It can be seen that when of the training samples were selected, the training samples were moderated, and the fusion results were improved. Therefore, and of the training and testing sets were selected for subsequent experiments.
Table 5.
Experimental results of different proportions of training samples.
4.4. Comparisons with Advanced Methods
The proposed SSML was compared with five state-of-the-art methods, including three traditional methods, namely, CNMF [6], Bayesian naive [7], GFPCA [9], and two deep-learning-based methods, namely, PanNet [18] and DDLPS [40]. The two deep-learning methods and our method were repeated 10 times for each group of experiments. The experiments were performed on the CAVE and Pavia Center datasets.
4.4.1. Results on CAVE Data Set
The results of different methods on the CAVE dataset are presented in Figure 5, Figure 6 and Figure 7. The result in Figure 5b denotes a fuzzy visualization result; Figure 5d is too sharp, and Figure 5e has a color difference. In colormap, Figure 5a includes a large area of spectral distortion on the surface of the balloon; Figure 5b,c,e have significant spectral distortions at the edges.

Figure 5.
The visual results of different methods on the CAVE dataset. (a) CNMF; (b) Bayesian naive; (c) GFPCA; (d) PanNet; (e) DDLPS; (f) Original RCAM; (g) Original MSRNet; (h) (RCAM) in the SSML framework; (i) (MSRNet) in the SSML framework; (j) Ground truth. Note that the false color image is selected for clear visualization (red: 30, green: 20, and blue: 10). The even rows show the difference maps of the corresponding methods.

Figure 6.
The visual results of different methods on the CAVE dataset. (a) CNMF; (b) Bayesian naive; (c) GFPCA; (d) PanNet; (e) DDLPS; (f) Original RCAM; (g) Original ResNet; (h) (SeAM) in the SSML framework; (i) (ResNet) in the SSML framework; (j) Ground truth. Note that the false color image is selected for clear visualization (red: 30, green: 20, and blue: 10). The even rows show the difference maps of the corresponding methods.

Figure 7.
The visual results of different methods on the CAVE dataset. (a) CNMF; (b) Bayesian naive; (c) GFPCA; (d) PanNet; (e) DDLPS; (f) Original SeAM; (g) Original ResNet; (h) (RCAM) in the SSML framework; (i) (ResNet) in the SSML framework; (j) Ground truth. Note that the false color image is selected for clear visualization (red: 30, green: 20, and blue: 10). The even rows show the difference maps of the corresponding methods.
The results of the SSML framework with the (SeAM and ResNet) hybrid function and the other methods are presented in Figure 6. There is a certain spectral distortion in Figure 6h,i, which was generated by (SeAM) and (ResNet) in the SSML framework, but was lower than that of the other methods. The results of the SSML framework with the (RCAM and ResNet) hybrid function and the other methods are presented in Figure 6. The results in Figure 6h,i had higher visual image quality than the other results.
Table 6 and Table 7 show the evaluation indicators for the proposed method and several state-of-the-art methods. As shown in Table 6, CNMF, Bayesian naive, and GFPCA are not deep-learning methods. The results were stable, and the time was short, but the methods were found to be not as effective as the deep-learning methods. The SSML framework with S1 (RCAM) had slightly lower values of the ERGAS and RMSE than the original RCAM; in most cases, the SSML framework with S1 (RCAM) and SSML S2 (MSRNet) achieved better results than the other methods for all evaluation indicators. Regarding time consumption, the proposed method framework was much shorter in duration than DDLP and slightly higher than PanNet, but fusion performance was improved.
Table 6.
The quality indicator results of different methods on the CAVE data set.
Table 7.
The quality indicator results of different methods on the Pavia Center data set.
4.4.2. Results on Pavia Center Dataset
The results of different methods on the Pavia Center dataset are presented in Figure 8. The SSML framework used the (RCAM and MSRNet) hybrid function. The colormaps in Figure 8a,c,d indicate that the corresponding methods performed relatively poorly in dealing with the shadow part; in Figure 8e, certain details, such as the river surface, are missing. In Figure 8h,i, it can be seen that the proposed framework improved image details on the image compared to the original network. This also demonstrates the effectiveness of the proposed hybrid loss function in the mutual learning strategy.

Figure 8.
The visual results of different methods on the Pavia Center dataset. (a) CNMF; (b) Bayesian naive; (c) GFPCA; (d) PanNet; (e) DDLPS; (f) Original RCAM; (g) Original MSRNet; (h) (RCAM) in the SSML framework; (i) (MSRNet) in the SSML framework; (j) Ground truth. Note that the false color image is selected for clear visualization (red: 70, green: 53, and blue: 19). The even rows show the difference maps of the corresponding methods.
As presented in Table 7, the indicator results of the proposed SSML framework were better than those of the comparison methods. Compared with the original networks, the SSML achieved obvious improvements for all indicators, which demonstrated the effectiveness of the proposed hybrid loss function in the mutual learning strategy.
4.5. Hybrid Loss Function Analysis
In this section, the reason for using a hybrid loss function consisting of two different loss functions (e.g., Equations (12) and (13)) instead of a single mutual learning loss function is explained. We compare the proposed SSML framework with the typical DML model [24].
Table 8 shows the effect of different mutual learning loss functions on the model performance. The SSML framework used the combination of the SeAM () and MSRNet () functions on the CAVE dataset. When and used the () loss function, there was a positive effect on but a negative effect on . The reason was that paid more attention to spectral features and no more spatial features could be learned from , while did the opposite. When and used the () loss function, used its own spectral feature learning advantage and obtained spatial information form , which yielded good results in the PSNR and SAM. Thus, the experimental results demonstrated the feasibility of the proposed hybrid loss function.
Table 8.
Effects of different loss functions.
4.6. Generalization Ability of SSML
To verify the generalization ability of the proposed SSML framework, we applied the SSML framework to the state-of-the-art residual hyper-dense network (RHDN) method [15]. The original fusion results of the RHDN method were used as in the SSML framework, as shown in Figure 1. Then the spectral , spatial networks, and their hybrid loss functions based on mutual learning strategies, were used to transfer information of different features to improve the results.
In experiments performed, we used the Pavia Center dataset-added, which was divided into 160 × 160 image blocks for training the RHDN method. As shown in Figure 9, four cases were also analyzed: the network used RCAM or SeAM, and the network used MSRNet or ResNet. The fusion results of the RHDN network were guided by mutual learning. From five performance indexes, especially SAM, RMSE, and ERGAS, we can see that the SSML framework was able to effectively improve the fusion effect when selecting the appropriate spectral and spatial network structure. Furthermore, the SSML framework only took a short time to upgrade the fusion results. Thus, the proposed SSML framework demonstrated generalization ability for HSI pansharpening.
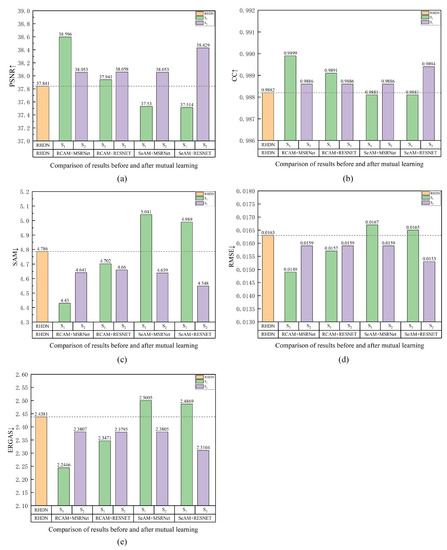
Figure 9.
Quality evaluation for the comparison of results before and after mutual learning. (a) PSNR; (b) CC; (c) SAM; (d) RMSE; (e) ERGAS.
4.7. Effect of Deep Network Parameter Number on SSML Performance
SSML aims to learn the same tasks from each other to achieve optimal results. In Table 9, the parameter number comparison of and in the SSML framework and the PanNet and DDLPS is given. Compared with the PanNet, the number of parameters of the SSML networks was greatly reduced; in particular, the parameter number of the SeAM was only one fifth that of the PanNet. Compared with the DDPLS, the parameter number of the SeAM was reduced by 24.8%, MSRNet by 28%, ResNet by 31%, and RCAM by 62.2%. These results indicate that SSML has better feature extraction capability and has fewer parameters under the same task.
Table 9.
The number of parameters of different deep-learning networks.
5. Conclusions
This paper proposes an SSML framework integrating spectral-spatial information-mining for HSI pansharpening. In contrast to the existing CNN-based hyperspectral pansharpening framework, based on the DML strategy, we designed spectral and spatial networks for learning the spectral and spatial features. Furthermore, a set of mixed loss functions, based on a mutual learning strategy, is proposed for transfer of information for different features, which can extract features without introducing excessive computation through mutual learning. In experiments undertaken, several cases were examined to evaluate the effect of DML on the pansharpening result. The results demonstrated that introducing the DML strategy into the SSML framework was able to help achieve improved results in HSI pansharpening. The performance of the SSML framework was compared with several state-of-the-art methods; the results of the comparisons demonstrated the effectiveness and advantages of the proposed SSML framework. The latest fusion results were used to verify the generalization ability of the SSML framework, with improved results observed. Discussion of the feasibility of the hybrid loss function and the number of deep network parameters suggested that the proposed SSML framework represents a promising framework for HSI pansharpening.
In future, HSI pansharpening under the SSML framework will be explored further to identify improved spectral-spatial features for HSIs. A further research direction will involve the application of the DML strategy to other image-processing fields.
Author Contributions
X.P.: conceptualization, methodology, validation, writing—original draft; Y.F.: conceptualization, methodology, visualization, writing—original draft; S.P.: methodology, supervision, formal analysis; K.M.: conceptualization, writing—review and editing, supervision; L.L.: supervision, investigation; J.W.: supervision, writing—review. All authors have read and agreed to the published version of the manuscript.
Funding
This research is supported by the National Natural Science Foundation of China (62101446, 62006191), the Xi’an Key Laboratory of Intelligent Perception and Cultural Inheritance (No. 2019219614SYS011CG033), the Key Research and Development Program of Shaanxi (2021ZDLSF06-05, 2021ZDLGY15-04), and the Program for Changjiang Scholars and Innovative Research Team in University (No. IRT_17R87). Supported by the International Science and Technology Cooper-ation Research Plan in Shaanxi Province of China (No. 2022KW-08).
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
| HSIs | Hyperspectral images |
| PAN | Panchromatic |
| HR | High resolution |
| LR | Low resolution |
| CNN | Convolutional neural network |
| PNN | Pansharpening neural network |
| KL | Kullback–Leibler |
| DML | deep mutual learning strategy |
| CC | Correlation coefficient |
| PSNR | Peak signal-to-noise ratio |
| SAM | Spectral angle mapper |
| RMSE | Root mean squared error |
| ERGAS | Erreur relative globale adimensionnelle de synthèse |
| SSIM | Structural similarity index measurement |
References
- Camps-Valls, G.; Tuia, D.; Bruzzone, L.; Benediktsson, J.A. Advances in hyperspectral image classification: Earth monitoring with statistical learning methods. IEEE Signal Process. Mag. 2013, 31, 45–54. [Google Scholar] [CrossRef]
- Wang, Z.; Zhu, R.; Fukui, K.; Xue, J.H. Matched shrunken cone detector (MSCD): Bayesian derivations and case studies for hyperspectral target detection. IEEE Trans. Image Process. 2017, 26, 5447–5461. [Google Scholar] [CrossRef] [PubMed]
- Abdollahi, A.; Pradhan, B.; Shukla, N.; Chakraborty, S.; Alamri, A. Deep learning approaches applied to remote sensing datasets for road extraction: A state-of-the-art review. Remote Sens. 2020, 12, 1444. [Google Scholar] [CrossRef]
- Aiazzi, B.; Baronti, S.; Selva, M. Improving component substitution pansharpening through multivariate regression of MS + Pan data. IEEE Trans. Geosci. Remote Sens. 2007, 45, 3230–3239. [Google Scholar] [CrossRef]
- Garzelli, A.; Nencini, F.; Capobianco, L. Optimal MMSE pansharpening of very high resolution multispectral images. IEEE Trans. Geosci. Remote Sens. 2007, 46, 228–236. [Google Scholar] [CrossRef]
- Yokoya, N.; Yairi, T.; Iwasaki, A. Coupled nonnegative matrix factorization unmixing for hyperspectral and multispectral data fusion. IEEE Trans. Geosci. Remote Sens. 2011, 50, 528–537. [Google Scholar] [CrossRef]
- Wei, Q.; Dobigeon, N.; Tourneret, J.Y. Fast fusion of multi-band images based on solving a Sylvester equation. IEEE Trans. Image Process. 2015, 24, 4109–4121. [Google Scholar] [CrossRef]
- Aiazzi, B.; Alparone, L.; Baronti, S.; Garzelli, A.; Selva, M. MTF-tailored multiscale fusion of high-resolution MS and Pan imagery. Photogramm. Eng. Remote. Sens. 2006, 72, 591–596. [Google Scholar] [CrossRef]
- Liao, W.; Huang, X.; Van Coillie, F.; Gautama, S.; Pižurica, A.; Philips, W.; Liu, H.; Zhu, T.; Shimoni, M.; Moser, G.; et al. Processing of multiresolution thermal hyperspectral and digital color data: Outcome of the 2014 IEEE GRSS data fusion contest. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2984–2996. [Google Scholar] [CrossRef]
- Cao, F.; Guo, W. Cascaded dual-scale crossover network for hyperspectral image classification. Knowl.-Based Syst. 2020, 189, 105122. [Google Scholar] [CrossRef]
- Liu, L.; Wang, J.; Zhang, E.; Li, B.; Zhu, X.; Zhang, Y.; Peng, J. Shallow—Deep convolutional network and spectral-discrimination-based detail injection for multispectral imagery pan-sharpening. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 1772–1783. [Google Scholar] [CrossRef]
- Peng, J.; Liu, L.; Wang, J.; Zhang, E.; Zhu, X.; Zhang, Y.; Feng, J.; Jiao, L. PSMD-Net: A Novel Pan-Sharpening Method Based on a Multiscale Dense Network. IEEE Trans. Geosci. Remote Sens. 2021, 59, 4957–4971. [Google Scholar] [CrossRef]
- Tan, Y.; Xiong, S.; Li, Y. Automatic Extraction of Built-Up Areas From Panchromatic and Multispectral Remote Sensing Images Using Double-Stream Deep Convolutional Neural Networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3988–4004. [Google Scholar] [CrossRef]
- Tang, X.; Li, M.; Ma, J.; Zhang, X.; Liu, F.; Jiao, L. EMTCAL: Efficient Multi-Scale Transformer and Cross-Level Attention Learning for Remote Sensing Scene Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1. [Google Scholar]
- Qu, J.; Xu, Z.; Dong, W.; Xiao, S.; Li, Y.; Du, Q. A Spatio-Spectral Fusion Method for Hyperspectral Images Using Residual Hyper-Dense Network. IEEE Trans. Neural Netw. Learn. Syst. 2022, PP, 1–15. [Google Scholar] [CrossRef]
- Tang, X.; Zhang, H.; Mou, L.; Liu, F.; Zhang, X.; Zhu, X.; Jiao, L. An Unsupervised Remote Sensing Change Detection Method Based on Multiscale Graph Convolutional Network and Metric Learning. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5626915. [Google Scholar] [CrossRef]
- Qu, J.; Shi, Y.; Xie, W.; Li, Y.; Wu, X.; Du, Q. MSSL: Hyperspectral and Panchromatic Images Fusion via Multiresolution Spatial-Spectral Feature Learning Networks. IEEE Trans. Geosci. Remote. Sens. 2021, 60, 5504113. [Google Scholar] [CrossRef]
- Yang, J.; Fu, X.; Hu, Y.; Huang, Y.; Ding, X.; Paisley, J. PanNet: A deep network architecture for pan-sharpening. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5449–5457. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhu, M.; Jiao, L.; Liu, F.; Yang, S.; Wang, J. Residual Spectral–Spatial Attention Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote. Sens. 2020, 59, 449–462. [Google Scholar] [CrossRef]
- Zhang, T.; Fu, Y.; Wang, L.; Huang, H. Hyperspectral image reconstruction using deep external and internal learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 8559–8568. [Google Scholar]
- Zhang, E.; Zhang, X.; Yang, S.; Wang, S. Improving hyperspectral image classification using spectral information divergence. IEEE Geosci. Remote. Sens. Lett. 2013, 11, 249–253. [Google Scholar] [CrossRef]
- Xie, W.; Cui, Y.; Li, Y.; Lei, J.; Du, Q.; Li, J. HPGAN: Hyperspectral pansharpening using 3-D generative adversarial networks. IEEE Trans. Geosci. Remote. Sens. 2020, 59, 463–477. [Google Scholar] [CrossRef]
- Zhang, Y.; Xiang, T.; Hospedales, T.M.; Lu, H. Deep mutual learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4320–4328. [Google Scholar]
- Wu, R.; Feng, M.; Guan, W.; Wang, D.; Lu, H.; Ding, E. A mutual learning method for salient object detection with intertwined multi-supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8150–8159. [Google Scholar]
- Rajamanoharan, G.; Kanaci, A.; Li, M.; Gong, S. Multi-task mutual learning for vehicle re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Li, K.; Yu, L.; Wang, S.; Heng, P.A. Towards cross-modality medical image segmentation with online mutual knowledge distillation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 775–783. [Google Scholar]
- Kullback, S.; Leibler, R. On information and sufficiency. Ann. Math. Stat. 2006, 22, 79–86. [Google Scholar] [CrossRef]
- Yuhas, R.H.; Goetz, A.F.; Boardman, J.W. Discrimination among semi-arid landscape endmembers using the spectral angle mapper (SAM) algorithm. In Proceedings of the Summaries 3rd Annual JPL Airborne Geoscience Workshop, Pasadena, CA, USA, 1–5 June 1992; Volume 1, pp. 147–149. [Google Scholar]
- Wald, L.; Ranchin, T.; Mangolini, M. Fusion of satellite images of different spatial resolutions: Assessing the quality of resulting images. Photogramm. Eng. Remote. Sens. 1997, 63, 691–699. [Google Scholar]
- Ma, J.; Fan, X.; Yang, S.X.; Zhang, X.; Zhu, X. Contrast limited adaptive histogram equalization-based fusion in YIQ and HSI color spaces for underwater image enhancement. Int. J. Pattern Recognit. Artif. Intell. 2018, 32, 1854018. [Google Scholar] [CrossRef]
- Zheng, Y.; Li, J.; Li, Y.; Cao, K.; Wang, K. Deep residual learning for boosting the accuracy of hyperspectral pansharpening. IEEE Geosci. Remote. Sens. Lett. 2019, 17, 1435–1439. [Google Scholar] [CrossRef]
- Zhao, H.; Gallo, O.; Frosio, I.; Kautz, J. Loss functions for image restoration with neural networks. IEEE Trans. Comput. Imaging 2016, 3, 47–57. [Google Scholar] [CrossRef]
- Yasuma, F.; Mitsunaga, T.; Iso, D.; Nayar, S.K. Generalized assorted pixel camera: Postcapture control of resolution, dynamic range, and spectrum. IEEE Trans. Image Process. 2010, 19, 2241–2253. [Google Scholar] [CrossRef] [PubMed]
- Fauvel, M.; Tarabalka, Y.; Benediktsson, J.A.; Chanussot, J.; Tilton, J.C. Advances in spectral-spatial classification of hyperspectral images. Proc. IEEE 2012, 101, 652–675. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Alparone, L.; Wald, L.; Chanussot, J.; Thomas, C.; Gamba, P.; Bruce, L.M. Comparison of pansharpening algorithms: Outcome of the 2006 GRS-S data-fusion contest. IEEE Trans. Geosci. Remote. Sens. 2007, 45, 3012–3021. [Google Scholar] [CrossRef]
- Wald, L. Data Fusion: Definitions and Architectures: Fusion of Images of Different Spatial Resolutions; Presses des MINES: Paris, France, 2002. [Google Scholar]
- Yang, Y.; Wan, W.; Huang, S.; Lin, P.; Que, Y. A novel pan-sharpening framework based on matting model and multiscale transform. Remote Sens. 2017, 9, 391. [Google Scholar] [CrossRef]
- Li, K.; Xie, W.; Du, Q.; Li, Y. DDLPS: Detail-based deep Laplacian pansharpening for hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8011–8025. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).