
Mutual Guidance Meets Supervised Contrastive Learning: Vehicle Detection in Remote Sensing Images



Abstract
:1. Introduction
- applying the mutual guidance idea to a remote sensing context;
- formulating supervised contrastive learning as an auxiliary loss in a detection problem, which, to the best of our knowledge, is the first approach using supervised contrastive learning for object detection, especially in the context of Earth observation;
- improving existing detection networks for vehicle detection by combining mutual guidance and contrastive learning, termed contrastive mutual guidance or CMG;
2. Related Work
2.1. Vehicle Detection in Remote Sensing
2.2. Misalignment in Object Detection
2.3. Contrastive Learning
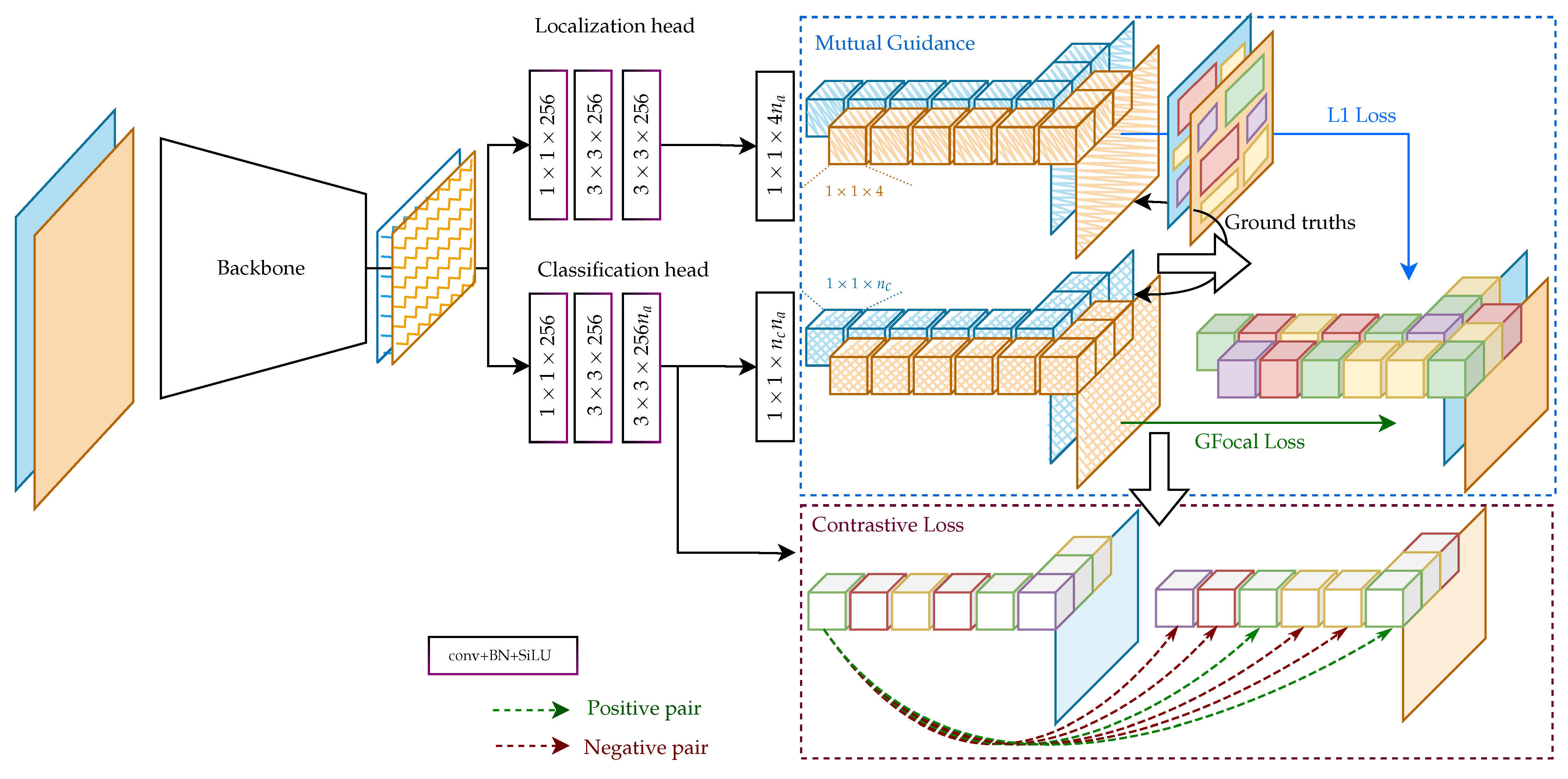
3. Method
3.1. Generation of Detection Targets
| Algorithm 1 Generating targets with common matching |
| Input: list of ground truth boxes , and corresponding labels , list of anchors , negative and positive threshold , , where Output: list of target boxes , and corresponding target labels for each anchor
|
| Algorithm 2 Generating classification targets from predicted localization |
| Input: list of ground truth boxes , and corresponding labels , list of anchors , list of predicted boxes Output: list of target labels for all anchors
|
| Algorithm 3 Generating localization targets from predicted class labels |
| Input: list of ground truth boxes , and corresponding labels , list of anchors , list of confidence scores for all classes , Output: list of target box specifications for all anchors
|
3.2. Losses
4. Experiments
4.1. Setup
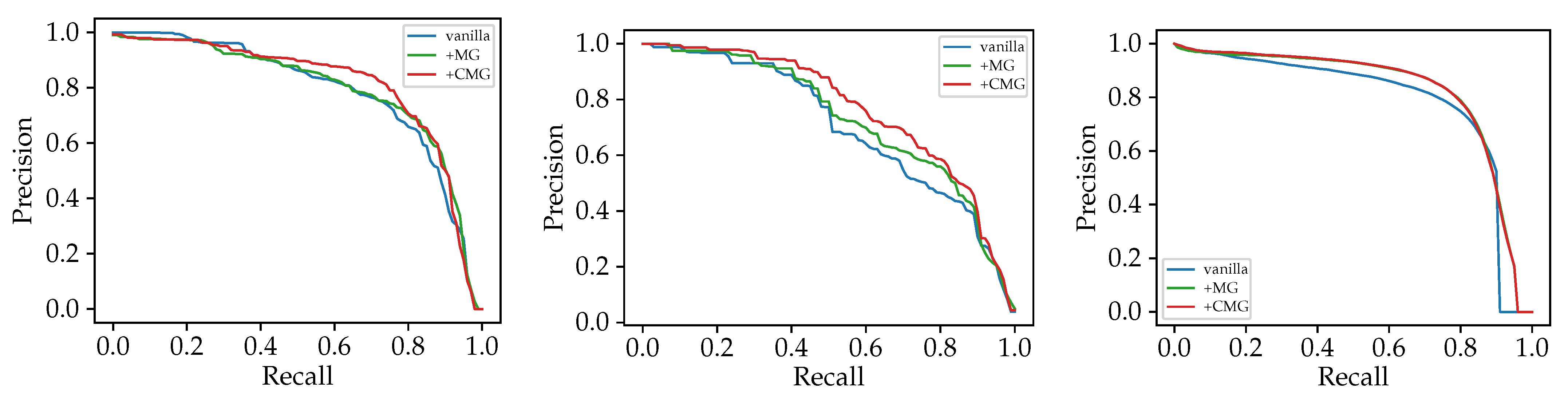
4.2. Mutual Guidance
4.3. Contrastive Loss
4.4. Mutual Guidance Meets Contrastive Learning
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wu, Y.; Chen, Y.; Yuan, L.; Liu, Z.; Wang, L.; Li, H.; Fu, Y. Rethinking Classification and Localization for Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Jiang, B.; Luo, R.; Mao, J.; Xiao, T.; Jiang, Y. Acquisition of Localization Confidence for Accurate Object Detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Song, G.; Liu, Y.; Wang, X. Revisiting the Sibling Head in Object Detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Zhang, H.; Fromont, E.; Lefevre, S.; Avignon, B. Localize to Classify and Classify to Localize: Mutual Guidance in Object Detection. In Proceedings of the Asian Conference on Computer Vision (ACCV), Online, 30 November–4 December 2020. [Google Scholar]
- Kaack, L.H.; Chen, G.H.; Morgan, M.G. Truck Traffic Monitoring with Satellite Images. In Proceedings of the ACM SIGCAS Conference on Computing and Sustainable Societies, Accra, Ghana, 3–5 July 2019. [Google Scholar]
- Arora, N.; Kumar, Y.; Karkra, R.; Kumar, M. Automatic vehicle detection system in different environment conditions using fast R-CNN. Multimed. Tools Appl. 2022, 81, 18715–18735. [Google Scholar] [CrossRef]
- Zhou, H.; Creighton, D.; Wei, L.; Gao, D.Y.; Nahavandi, S. Video Driven Traffic Modelling. In Proceedings of the IEEE/ASME International Conference on Advanced Intelligent Mechatronics, Wollongong, NSW, Australia, 9–12 July 2013. [Google Scholar]
- Kamenetsky, D.; Sherrah, J. Aerial Car Detection and Urban Understanding. In Proceedings of the International Conference on Digital Image Computing: Techniques and Applications (DICTA), Adelaide, SA, Australia, 23–25 November 2015. [Google Scholar]
- Shi, F.; Zhang, T.; Zhang, T. Orientation-Aware Vehicle Detection in Aerial Images via an Anchor-Free Object Detection Approach. IEEE Trans. Geosci. Remote. Sens. 2021, 59, 5221–5233. [Google Scholar] [CrossRef]
- Zheng, K.; Wei, M.; Sun, G.; Anas, B.; Li, Y. Using Vehicle Synthesis Generative Adversarial Networks to Improve Vehicle Detection in Remote Sensing Images. ISPRS Int. J. -Geo-Inf. 2019, 8, 390. [Google Scholar] [CrossRef] [Green Version]
- Bouguettaya, A.; Zarzour, H.; Kechida, A.; Taberkit, A.M. Vehicle Detection From UAV Imagery With Deep Learning: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2021. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Bachman, P.; Hjelm, R.D.; Buchwalter, W. Learning Representations by Maximizing Mutual Information across Views. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Dosovitskiy, A.; Springenberg, J.T.; Riedmiller, M.; Brox, T. Discriminative Unsupervised Feature Learning with Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A Simple Framework for Contrastive Learning of Visual Representations. In Proceedings of the ICML, 2020, Machine Learning Research, Vienna, Austria, 13–18 July 2020. [Google Scholar]
- Khosla, P.; Teterwak, P.; Wang, C.; Sarna, A.; Tian, Y.; Isola, P.; Maschinot, A.; Liu, C.; Krishnan, D. Supervised Contrastive Learning. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–12 December 2020. [Google Scholar]
- Wei, F.; Gao, Y.; Wu, Z.; Hu, H.; Lin, S. Aligning Pretraining for Detection via Object-Level Contrastive Learning. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–14 December 2021. [Google Scholar]
- Xie, E.; Ding, J.; Wang, W.; Zhan, X.; Xu, H.; Sun, P.; Li, Z.; Luo, P. DetCo: Unsupervised Contrastive Learning for Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Xie, Z.; Lin, Y.; Zhang, Z.; Cao, Y.; Lin, S.; Hu, H. Propagate Yourself: Exploring Pixel-Level Consistency for Unsupervised Visual Representation Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Razakarivony, S.; Jurie, F. Vehicle detection in aerial imagery: A small target detection benchmark. J. Vis. Commun. Image Represent. 2016, 34, 187–203. [Google Scholar] [CrossRef] [Green Version]
- Lam, D.; Kuzma, R.; McGee, K.; Dooley, S.; Laielli, M.; Klaric, M.; Bulatov, Y.; McCord, B. xView: Objects in Context in Overhead Imagery. arXiv 2018, arXiv:1802.07856. [Google Scholar]
- Froidevaux, A.; Julier, A.; Lifschitz, A.; Pham, M.T.; Dambreville, R.; Lefèvre, S.; Lassalle, P. Vehicle detection and counting from VHR satellite images: Efforts and open issues. In Proceedings of the IGARSS 2020-2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020. [Google Scholar]
- Srivastava, S.; Narayan, S.; Mittal, S. A survey of deep learning techniques for vehicle detection from UAV images. J. Syst. Archit. 2021, 117, 102152. [Google Scholar] [CrossRef]
- Zou, Z.; Shi, Z.; Guo, Y.; Ye, J. Object detection in 20 years: A survey. arXiv 2019, arXiv:1905.05055. [Google Scholar]
- Ji, H.; Gao, Z.; Mei, T.; Li, Y. Improved faster R-CNN with multiscale feature fusion and homography augmentation for vehicle detection in remote sensing images. IEEE Geosci. Remote. Sens. Lett. 2019, 16, 1761–1765. [Google Scholar] [CrossRef]
- Mo, N.; Yan, L. Improved faster RCNN based on feature amplification and oversampling data augmentation for oriented vehicle detection in aerial images. Remote. Sens. 2020, 12, 2558. [Google Scholar] [CrossRef]
- Pham, M.T.; Courtrai, L.; Friguet, C.; Lefèvre, S.; Baussard, A. YOLO-Fine: One-Stage Detector of Small Objects Under Various Backgrounds in Remote Sensing Images. Remote. Sens. 2020, 12, 2501. [Google Scholar] [CrossRef]
- Koay, H.V.; Chuah, J.H.; Chow, C.O.; Chang, Y.L.; Yong, K.K. YOLO-RTUAV: Towards Real-Time Vehicle Detection through Aerial Images with Low-Cost Edge Devices. Remote Sens. 2021, 13, 4196. [Google Scholar] [CrossRef]
- Guo, Y.; Xu, Y.; Li, S. Dense construction vehicle detection based on orientation-aware feature fusion convolutional neural network. Autom. Constr. 2020, 112, 103124. [Google Scholar] [CrossRef]
- Yang, J.; Xie, X.; Shi, G.; Yang, W. A feature-enhanced anchor-free network for UAV vehicle detection. Remote. Sens. 2020, 12, 2729. [Google Scholar] [CrossRef]
- Li, Y.; Pei, X.; Huang, Q.; Jiao, L.; Shang, R.; Marturi, N. Anchor-free single stage detector in remote sensing images based on multiscale dense path aggregation feature pyramid network. IEEE Access 2020, 8, 63121–63133. [Google Scholar] [CrossRef]
- Tseng, W.H.; Lê, H.Â.; Boulch, A.; Lefèvre, S.; Tiede, D. CroCo: Cross-Modal Contrastive Learning for Localization of Earth Observation Data. In Proceedings of the ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, Nice, France, 6–11 June 2022. [Google Scholar]
- Sohn, K. Improved Deep Metric Learning with Multi-class N-pair Loss Objective. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Weinberger, K.Q.; Blitzer, J.; Saul, L. Distance Metric Learning for Large Margin Nearest Neighbor Classification. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 5–8 December 2005. [Google Scholar]
- Wang, X.; Zhang, R.; Shen, C.; Kong, T.; Li, L. Dense Contrastive Learning for Self-Supervised Visual Pre-Training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Jaccard, P. The distribution of the Flora in the Alpine Zone. 1. New Phytol. 1912, 11, 37–50. [Google Scholar] [CrossRef]
- Li, X.; Wang, W.; Wu, L.; Chen, S.; Hu, X.; Li, J.; Tang, J.; Yang, J. Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–12 December 2020. [Google Scholar]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra R-CNN: Towards Balanced Learning for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. Scaled-yolov4: Scaling cross stage partial network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Matching Strategy | Loss | YOLOX-s | YOLOX-m | YOLOv3 |
|---|---|---|---|---|
| IOU-Based | Focal | 70.20 | 74.30 | 70.78 |
| Mutual Guidance | Focal | 71.48 | 74.47 | 74.13 |
| Mutual Guidance | GFocal | 73.04 | 79.82 | 74.88 |
| Matching Strategy | Loss | YOLOX-s | YOLOX-m | YOLOv3 |
|---|---|---|---|---|
| IOU-Based | Focal | 70.20 | 74.30 | 70.78 |
| GFocal | 71.53 | 79.89 | 75.53 | |
| GFocal | 74.20 | 77.81 | 74.41 |
| Matching Strategy | Loss | YOLOX-s | YOLOX-m | YOLOv3 |
|---|---|---|---|---|
| Mutual Guidance | GFocal | 73.04 | 79.82 | 74.88 |
| GFocal | 75.57 | 80.95 | 76.26 | |
| GFocal | 76.67 | 81.57 | 77.41 |
| Configuration | VEDAI12 | VEDAI25 | xView30 |
|---|---|---|---|
| vanilla | 78.68 | 70.20 | 79.96 |
| +MG | 79.70 | 73.04 | 83.49 |
| +CMG | 81.25 | 76.67 | 83.67 |
| Architecture | VEDAI12 | VEDAI25 | xView30 |
|---|---|---|---|
| EfficientDet | 74.01 | 51.36 | 82.45 |
| YOLOv3 | 73.11 | 62.09 | 78.93 |
| YOLO-fine | 76.00 | 68.18 | 84.14 |
| YOLOv4 | 79.93 | 73.14 | 79.19 |
| Scaled-YOLOv4 | 78.57 | 72.78 | 81.39 |
| YOLOX-s+CMG (ours) | 81.25 | 76.67 | 83.67 |
| YOLOX-m+CMG (ours) | 83.07 | 81.57 | 84.79 |
| YOLOv3+CMG (ours) | 78.09 | 77.41 | 83.54 |
| Model | Car | Truck | Pickup | Tractor | Camping | Boat | Van | Other | mAP |
|---|---|---|---|---|---|---|---|---|---|
| EfficientDet | 69.08 | 61.20 | 65.74 | 47.18 | 69.08 | 33.65 | 16.55 | 36.67 | 51.36 |
| YOLOv3 | 75.22 | 73.53 | 65.69 | 57.02 | 59.27 | 47.20 | 71.55 | 47.20 | 62.09 |
| YOLOv3-tiny | 64.11 | 41.21 | 48.38 | 30.04 | 42.37 | 24.64 | 68.25 | 40.77 | 44.97 |
| YOLOv3-spp | 79.03 | 68.57 | 72.30 | 61.67 | 63.41 | 44.26 | 60.68 | 42.43 | 61.57 |
| YOLO-fine | 76.77 | 63.45 | 74.35 | 78.12 | 64.74 | 70.04 | 77.91 | 45.04 | 68.18 |
| YOLOv4 | 87.50 | 80.47 | 78.63 | 65.80 | 81.07 | 75.92 | 66.56 | 49.16 | 73.14 |
| Scaled-YOLOv4 | 86.78 | 79.37 | 81.54 | 73.83 | 71.58 | 76.53 | 63.90 | 48.70 | 72.78 |
| YOLOX-s+CMG (ours) | 88.92 | 85.92 | 79.66 | 77.16 | 81.21 | 65.22 | 64.90 | 70.33 | 76.67 |
| YOLOX-m+CMG (ours) | 91.26 | 85.34 | 84.91 | 76.22 | 85.03 | 78.68 | 82.02 | 69.08 | 81.57 |
| YOLOv3 +CMG (ours) | 92.20 | 85.98 | 87.34 | 77.27 | 85.56 | 53.74 | 73.94 | 64.13 | 77.41 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lê, H.-Â.; Zhang, H.; Pham, M.-T.; Lefèvre, S. Mutual Guidance Meets Supervised Contrastive Learning: Vehicle Detection in Remote Sensing Images. Remote Sens. 2022, 14, 3689. https://doi.org/10.3390/rs14153689
Lê H-Â, Zhang H, Pham M-T, Lefèvre S. Mutual Guidance Meets Supervised Contrastive Learning: Vehicle Detection in Remote Sensing Images. Remote Sensing. 2022; 14(15):3689. https://doi.org/10.3390/rs14153689
Chicago/Turabian StyleLê, Hoàng-Ân, Heng Zhang, Minh-Tan Pham, and Sébastien Lefèvre. 2022. "Mutual Guidance Meets Supervised Contrastive Learning: Vehicle Detection in Remote Sensing Images" Remote Sensing 14, no. 15: 3689. https://doi.org/10.3390/rs14153689
APA StyleLê, H.-Â., Zhang, H., Pham, M.-T., & Lefèvre, S. (2022). Mutual Guidance Meets Supervised Contrastive Learning: Vehicle Detection in Remote Sensing Images. Remote Sensing, 14(15), 3689. https://doi.org/10.3390/rs14153689