1. Introduction
Synthetic aperture radar (SAR) is an active microwave remote sensor, which has the advantage of providing high-resolution and super-wide coverage remote sensing images in all-day and all-weather conditions. In recent years, with the vigorous development of SAR-related technologies, the rapid and accurate target detection of SAR images has become a very challenging task, and research into this topic is very valuable.
In the traditional SAR target detection methods, the constant false alarm rate (CFAR) detection method [
1] is widely studied because of its simple model and fast detection speed. The CFAR detection method first calculates the detection threshold based on the statistical characteristics of the clutter and the given false alarm rate and then compares the current pixel with the threshold to determine whether it is a target. The two-parameter CFAR [
1], also known as Gaussian CFAR, is a widely used CFAR detection method, which assumes that the background clutter of the SAR image obeys Gaussian distribution. The two-parameter CFAR can achieve excellent detection performance in some simple scenes, but detection performance will be reduced in complex scenes.
In recent years, with the development of deep learning technology, convolutional neural networks (CNNs) have achieved remarkable success in the fields of computer vision, speech processing, and so on [
2]. CNN can extract the most suitable features for the current task using a data-driven method. Because of the powerful feature extraction capability, CNN-based target detection methods can achieve superior performance compared to many traditional methods. There are two types of target detection methods based on CNN. One is the two-stage target detector, including region-based CNN (R-CNN) [
3], Faster R-CNN [
4], and FPN [
5], etc. The two-stage detector first extracts candidate regions from the input image and then performs further classification and bounding box regression on the candidate regions. The detection performance of this method is excellent, but the detection speed is slow. The other is the single-stage target detector, including you only look once (YOLO) [
6] and single shot multibox detector (SSD) [
7], etc. Without the candidate region extraction step, the detection speed of the single-stage detector is faster than the two-stage detector. Compared with YOLO, SSD can achieve higher detection performance by applying default boxes and multi-scale prediction [
8]. Besides optical images, CNN-based target detection methods also achieve good detection performance in SAR images [
9,
10,
11,
12,
13]. Wang et al. [
11] proposed a SAR target detection method based on SSD and achieved good detection performance. Du et al. [
12] proposed S-SSD target detection method, which integrates the saliency information into SSD and improves the detection performance.
Although the existing CNN-based SAR target detection methods can achieve good performance, most of them are fully supervised learning algorithms. The training of these networks requires a large number of target-level labeled training samples, which must include the targets of interest, and the positions of the targets in the images must be marked. However, in actual situations, it takes a lot of labor and material resources to label the SAR images at target-level. Semi-supervised learning target detection methods are effective to solve this problem. They require only a small number of target-level labeled training samples and an additional set of unlabeled or weakly labeled training samples. The image-level labeled training samples are the weakly-level labeled training samples. Compared with target-level labeling, image-level labeling is easier and requires less labor and material resources, which simply marks whether the image contains the target of interest or not and does not need to mark the specific location of the target. Therefore, the target detection network can be trained by a semi-supervised learning method using a small number of target-level labeled training samples and a large number of image-level labeled training samples. Rosenberg et al. [
14] proposed a target detection method based on semi-supervised self-training. In this method, the self-training method is simply applied to an existing target detector, which improves the performance of target detection. Zhang et al. [
15] proposed a target detection network based on a self-training method. In this method, negative slices are obtained from image-level labeled training samples and given pseudo-labels by the prediction results of the classifier, and then those negative slices are used to update the dataset and train the network. This method can achieve good detection performance for optical remote sensing images. The above methods can reduce the demand for the number of target-level labeled training samples in the network training process. However, those methods only use a simple target detection method as the basic framework for semi-supervised learning, and thus the detection performance will be degraded when the SAR image scene is complex in practice. Further, since some clutter and the targets are relatively similar in SAR images with complex scenes, there is a risk that the clutter could be wrongly selected as the target during the sample selection process of the self-training method.
SAR images with complex scenes contain significant amounts of clutter, and some man-made clutter is very similar to the target of interest in shape contour and the distribution of scattering intensity, making them difficult to discriminate. As a result, there may be many false alarms in the detection results. The attention mechanism is one of the most effective methods to solve this problem. The idea of the attention mechanism is to automatically focus on important regions and suppressing unnecessary ones by learning from the data [
16], therefore, the performance of the CNN can be improved by using attention mechanisms. Woo et al. [
16] proposed a convolutional block attention module (CBAM), a channel and spatial attention module that can be easily integrated into CNN architectures, which improved the performance of target detection and classification. Jetley et al. [
17] proposed an end-to-end attention module for CNN architectures built for image classification. This method generates attention maps using global features and local features to enhance the targets and suppress the background, and its classification performance is better than other traditional CNN-based methods. Li et al. [
18] proposed a deep learning-based model named the point-wise discriminative auto-encoder for target recognition. With the attention mechanism of this method, the features of the target area are automatically selected for target recognition, and the performance of target recognition has been improved.
In this paper, a SAR target detection network based on semi-supervised learning and attention mechanism is proposed with regard to the analysis above. The proposed semi-supervised learning method takes SSD as the detection branch and constructs an auxiliary scene recognition branch, where these two branches share a feature extraction module and an attention module. In the feature extraction module, the deep features of the input SAR image will be extracted. In the attention module, the network can generate the attention map automatically, and then the feature maps and attention map are multiplied to focus on the target area and suppress the background clutter area. The detection branch can output the bounding boxes of the targets in the SAR image, and the scene recognition branch outputs the binary classification result indicating whether the input SAR image contains targets. During the training stage, the target-level labeled training samples will pass through the detection branch, and the image-level labeled training samples will pass through the scene recognition branch. During the test stage, a novel coarse-to-fine detection procedure is used to reduce the false alarms. Considering the help of global scene information in SAR images, we first apply the coarse scene recognition branch to the input SAR image, and the scene recognition results of the coarse scene recognition branch are binary classification results indicating if the input SAR images contain the targets or not. According to the scene recognition results, the fine target detection branch is performed on the input SAR images which may contain the targets, and the final detection results of the fine target detection branch are the predicted specific locations of the targets. In this way, the proposed method can reduce the number of false alarms.
The experimental results based on the measured SAR dataset demonstrate that the proposed method outperforms the existing SAR target detection method in terms of detection performance. More specifically, the main contributions of the proposed target detection method are as follows:
- (1)
We propose a semi-supervised SAR target detection framework with a detection branch and a scene recognition branch. The proposed method can use a small number of target-level labeled training samples and a large number of image-level labeled training samples simultaneously to learn the network, and the entire network is end-to-end jointly optimized. The feature extraction module is shared across the two branches, and the learning of image-level labeled training samples by the newly added scene recognition branch will enhance the feature extraction capability of the shared feature extraction module, which is helpful for the detection task. Thus, the proposed method can reduce the dependence of network training on target-level labeled training samples which are difficult to obtain.
- (2)
We introduce an attention mechanism into the SAR image target detection network. In contrast to the attention mechanisms commonly used in the existing detection networks, we introduce global descriptor into the attention mechanism to guide local features to calculate the attention map. With the fusion of global descriptors and local features, the attention mechanism can not only consider local information but also consider global information, thus the attention mechanism can learn a more accurate attention map.
The remainder of this paper is organized as follows.
Section 2 and
Section 3 introduce the network structure and the algorithm flow of the proposed SAR target detection method in detail, respectively.
Section 4 shows the experimental results and analysis based on the miniSAR real data. Finally, the discussion and conclusion are presented in
Section 5 and
Section 6, respectively.
2. Network Structure of the Proposed Method
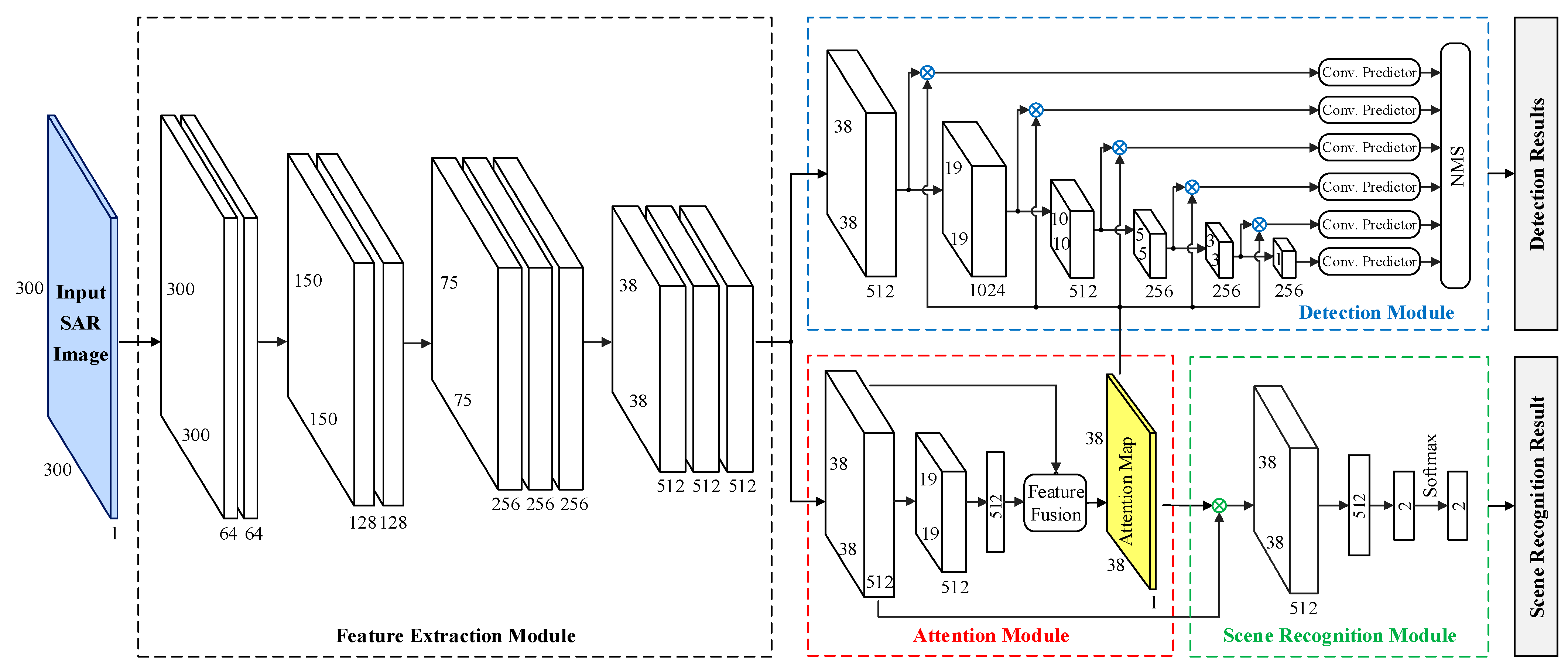
Figure 1 shows the whole flowchart of the proposed SAR target detection network based on semi-supervised learning and attention mechanism.
As shown in
Figure 1, the proposed SAR target detection network consists of four modules, including the feature extraction module, attention module, scene recognition module, and detection module. The input of the feature extraction module is the input SAR image
, where
,
,
denotes the height of the input SAR images, the width of the input SAR images, the number of channels of the input SAR images, respectively. We take
,
,
as 300, 300, 1, respectively, to describe the flow of the proposed method. Given an input SAR image
, the feature extraction module is first employed to extract the deep features
of
by the deep convolutional network. Then the attention module takes
as input. By fusing the deep features and the global descriptor and applying the softmax activation function, the attention module can obtain the attention map
. In the scene recognition module, the inputs are the deep features
and the attention map
. They are multiplied to obtain the global feature
, then a fully connected layer and softmax function are used to get the output of the scene recognition module
, it denotes whether the input SAR image
contains targets or not. In the detection module, the inputs are also the deep features
and the attention map
. By performing a series of convolution operations and pooling operations on
, the multi-scale feature maps
,
,
,
,
, are obtained, then these multi-scale feature maps are multiplied by attention map
. Finally, the convolution predictors composed of some convolution layers are used to predict the targets, and the details about the convolution predictors can be traced in [
7]. After the non-maximum suppression (NMS) [
19], the outputs of the detection module can be obtained, which are the predicted specific locations of the targets.
In the following sections, the structure of each module is introduced in detail.
2.1. Feature Extraction Module
The feature extraction module is the basic part of the entire network, which is employed to extract the deep features of the input SAR image. Similar to SSD, the feature extraction module is a modified VGGNet. VGGNet has been widely used in the field of SAR target detection [
11,
12,
13] and has excellent performance. It has a deep architecture to achieve good feature representation. According to the 6 ConvNet configurations of VGGNet in [
20], and under the premise of comprehensive consideration of accuracy and speed, our feature extraction module is designed to contain four convolution stages. There are two convolutional layers in the first two convolutional stages, and three convolutional layers in the last two convolutional stages.
The size of the convolutional kernels of the convolutional layers in the feature extraction module is all 3 × 3, and each convolutional stage is composed of multiple cascaded convolutional layers. Compared with using one convolutional layer with a larger convolution kernel directly, the advantage of the cascade of multiple convolutional layers with a smaller convolution kernel size is that a large receptive field can be achieved with a small number of parameters. For example, a stack of two convolutional layers with 3 × 3 convolutional kernels has the same effective receptive field with one convolutional layer with 5 × 5 convolutional kernels. However, the stack of two convolutional layers with 3 × 3 convolutional kernels increases the non-linearity and decreases the number of parameters compared with the single convolutional layers with 5 × 5 convolutional kernels. The ReLU [
21] activation function has the advantages of overcoming the problems of gradient disappearance and gradient explosion, and it can speed up the training process. Therefore, in the proposed method, each convolutional layer is followed by a ReLU activation function layer to improve the non-linear representation capability of the network. At the end of each convolutional stage is the pooling layer, which is used to decrease computational cost, reduce the risk of overfitting and increase the speed of network operations.
2.2. Attention Module
The attention module is one of the core parts of the proposed SAR target detection method. The attention module can automatically generate the attention map, and then the attention map and the feature map are multiplied by the spatial position, so that the network automatically enhances the target area and suppresses the clutter area.
Figure 2 shows the flowchart of the attention module.
As shown in
Figure 2, the input of the attention module is the deep features
obtained by the feature extraction module, where
and
are the spatial size and the channel dimension of
. The local feature of
at the spatial position
can be represented by a vector
. First, the deep features
are fed into a convolutional layer, and then we use a max pooling layer with a pixel window of
and a stride of 2 to down-sample the feature maps. Finally, a fully connected layer is adopted after the max pooling layer to obtain the global descriptor
, which can be regarded as a global representation of the input SAR image. In the fusion module, the local feature
and the global descriptor
are fused by a compatibility measure. Specifically, each local feature
is added to the global descriptor
, and then multiplied by the learnable weight
to obtain the compatibility score
:
Finally, the compatibility scores
are normalized by softmax operation to acquire the attention map
:
The attention map and the feature map are dot-multiplied according to the spatial position, which can enhance the target area and suppress the clutter area.
The global information represents the overall feature information of the input SAR image, and the local information represents the information of a certain area of the input SAR image, which contains more detailed information. It is beneficial to fuse these two kinds of information when calculating the spatial attention map. However, the attention mechanisms [
16,
22,
23] commonly used in existing detection networks don’t do this. In contrast, we fuse the global descriptor and local features in our attention module. In this way, the fusion features used to calculate the attention map will be richer, which will make the attention module not only consider the local information but also consider the global information, thus our attention module can learn a more accurate attention map. Since our attention module can automatically enhance the target area and suppress the clutter area, the false alarm and missed alarm of the detection results can be reduced, and the performance of target detection can be improved.
2.3. Scene Recognition Module
The scene recognition module is also one of the core parts of the proposed SAR target detection method, which is used to classify the input SAR image. The input of the scene recognition module is the deep features and attention map of the SAR image, and the output is the scene classification result of the SAR image.
First, the attention map and the deep features are dot-multiplied according to the spatial position, and then the vector corresponding to each spatial position of the feature maps are added to obtain the global feature:
where
is the value of the attention map at position
,
is the local feature of the deep features
at position
, and
is the output global feature vector. In other words, the global feature
is obtained by the weighted summation of all local features, where the weight is attention map. Then, the global feature
is used to obtain scene classification results by fully connected layers and softmax classifiers. The loss function of the scene recognition module is the cross-entropy loss function.
2.4. Detection Module
The detection module is an important part of the proposed SAR target detection method, whose task is to predict the bounding boxes of targets. As shown in
Figure 1, in the detection module, the deep features are passed through multiple convolution layers to extract multi-scale feature maps. In SSD, the multi-scale feature maps are directly fed into the convolution predictors for target detection. However, in our method, the multi-scale feature maps are first multiplied by the attention map and then fed into the convolution predictors. Since the sizes of multi-scale feature maps are different, they cannot be directly multiplied by a fixed-size attention map. Therefore, we down-sample the attention map many times to generate multiple attention maps with different sizes, which are matched with the sizes of multi-scale feature maps respectively. Compared with methods which require learning attention maps for each relevant feature map size, our method only needs to learn one attention map. The advantage of our method is that it increases less computational complexity while having a high detection performance. Then, the multi-scale feature maps after multiplication are fed into convolutional predictors to predict targets and their bounding boxes. Finally, the NMS algorithm is employed to remove redundant targets to obtain the final detection results.
In the detection module, the multi-scale feature maps and the attention map are multiplied to automatically enhance the features of the target area and suppress the clutter area, thus the performance of the detection results can be improved.
3. Algorithm Flow of the Proposed Method
In this section, the algorithm flow of the proposed method is introduced, including the training process, which is the semi-supervised learning process, and the test process, which is the coarse-to-fine SAR target detection procedure.
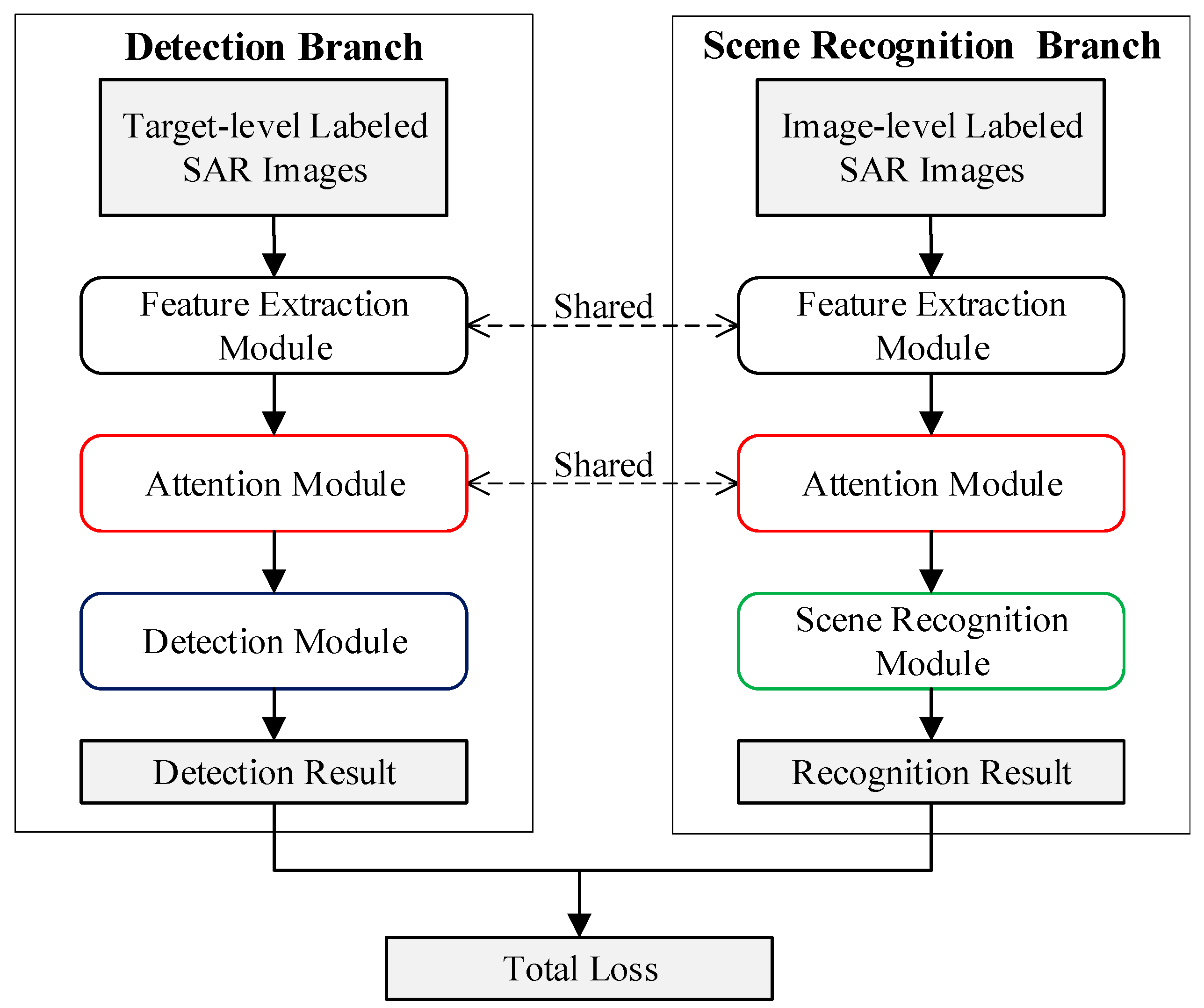
3.1. Semi-Supervised Learning
Figure 3 shows the flowchart of the proposed semi-supervised learning method. The entire network can be divided into detection branch and scene recognition branch. The detection branch includes feature extraction module, attention module, and detection module; the scene recognition branch includes feature extraction module, attention module, and scene recognition module. The feature extraction module and attention module are shared across the two branches. During training, the input of the detection branch is the target-level labeled SAR images, and the output is the detection results of these images. The detection loss function is calculated by the detection results and the ground truth bounding boxes. Specifically, the detection loss function is defined as follows:
where
is the index of an example in a minibatch,
and
are predicted probability and ground truth label, respectively. Similarly,
and
are the predicted bounding box and ground truth bounding box, respectively. The classification loss and regression loss are represented by
and
, and the two terms are normalized by
and
.
The classification loss
is the cross-entropy loss. The definition is as follows:
The regression loss is
is defined as:
where:
The scene recognition branch takes the image-level labeled SAR images as input and outputs the classification results of these images. The scene recognition loss function is a binary classification cross-entropy loss function, which is calculated by the classification results and the ground truth category. The overall loss function of the network is the sum of the loss function of the two branches.
The two branches are jointly trained with SAR images of different label types, and the entire network can achieve end-to-end semi-supervised learning. The proposed semi-supervised method can reduce the demand for the number of target-level labeled SAR images in the network training process.
3.2. Coarse-to-Fine SAR Target Detection
During the test, in order to take advantage of the global feature of the SAR image, a coarse-to-fine SAR target detection procedure is proposed. For the SAR image, it is difficult to predict the target very accurately only by the features of the target area itself. By using the global feature of SAR image, the global context information of SAR image can be fully considered during prediction, which can allow better detection resultsto be obtained. Since the scene recognition module uses global features to classify the input SAR image, this module can be used to classify the SAR image coarsely before fine target detection.
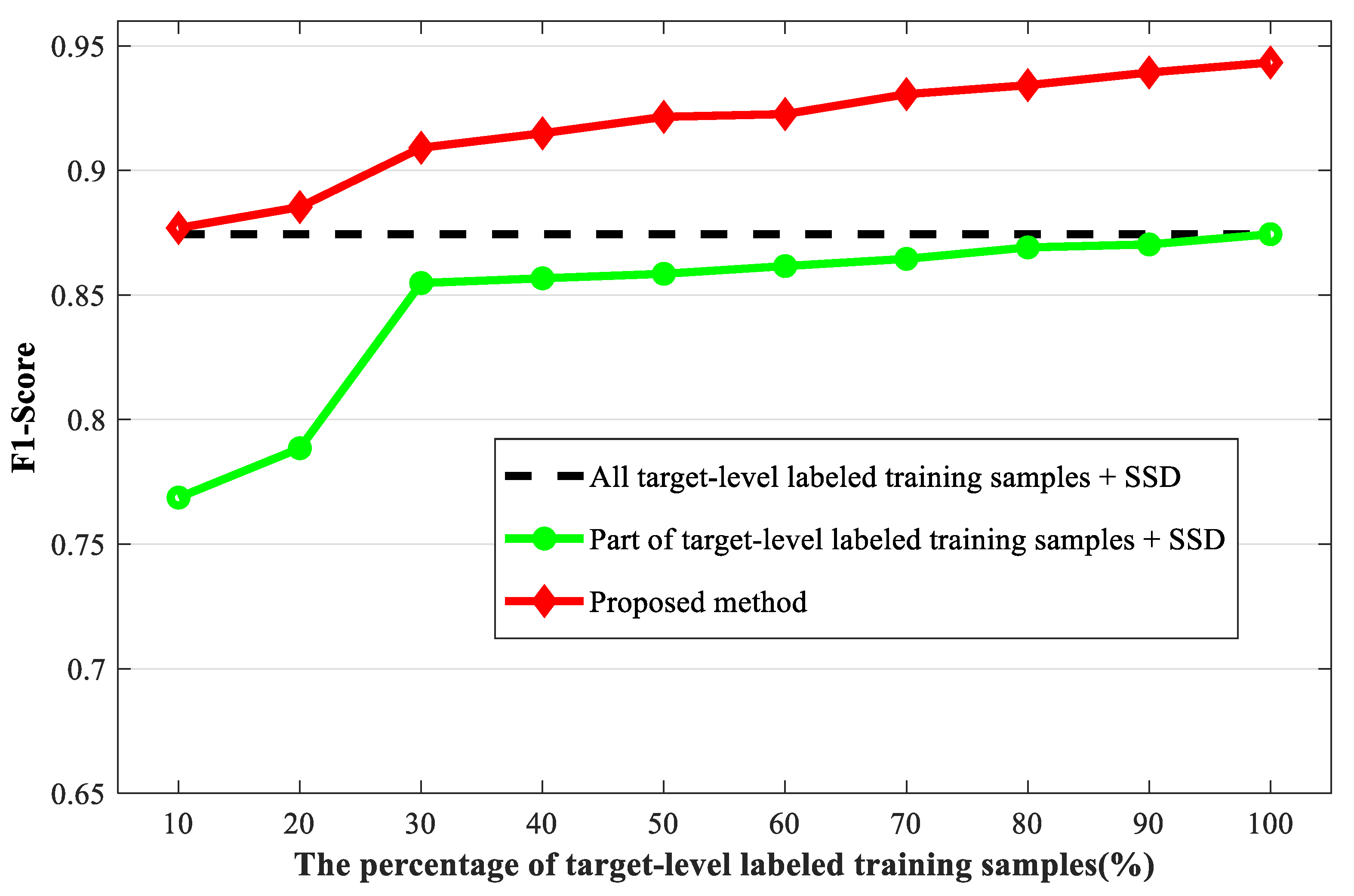
Figure 4 shows the proposed coarse-to-fine SAR target detection procedure. First, we apply the coarse scene recognition to the test SAR image. The test SAR image is fed into the feature extraction module and the attention module to extract deep features and attention map, and the scene recognition result of the test SAR image is obtained by the scene recognition module. Then, we apply the fine target detection to the image based on the scene recognition result. If the scene recognition result is the target class, indicating that the test SAR image may contain the target of interest, we use the detection module to further predict the specific location of the targets. If the scene recognition result is a clutter background class, it means that the SAR image does not contain targets.
Using coarse-to-fine SAR target detection, the scene recognition module may incorrectly recognize the test SAR images that have the targets as no targets, so then the few missing alarms may be added. However, due to the fact that the large number of test SAR images that do not have the targets can be removed, the false alarms of the detection results can be greatly reduced. Therefore, the comprehensive detection performance will be improved.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}