Topology-Aware Road Network Extraction via Multi-Supervised Generative Adversarial Networks



Abstract
:1. Introduction
2. Related Work
3. Method
3.1. Automatic Sample Production
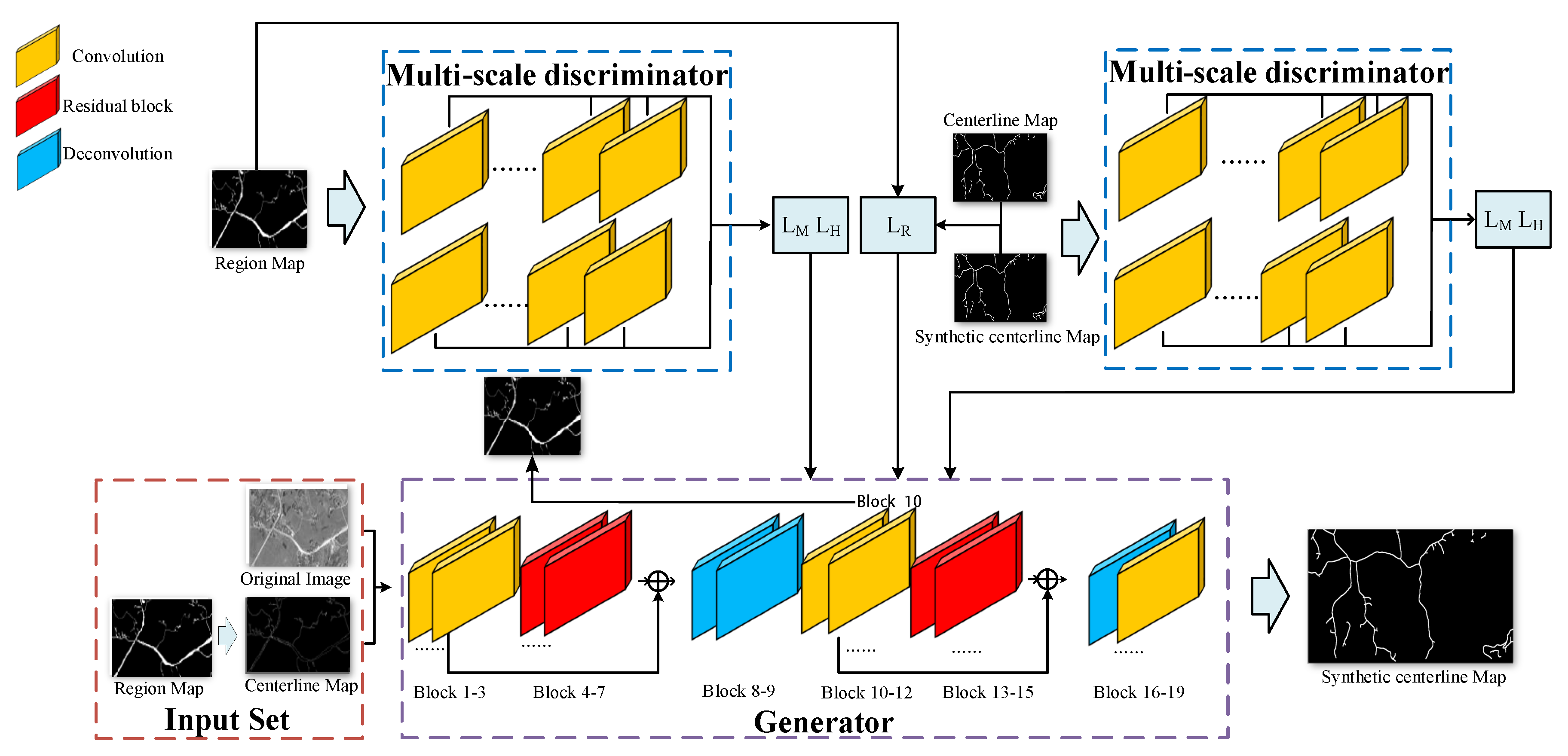
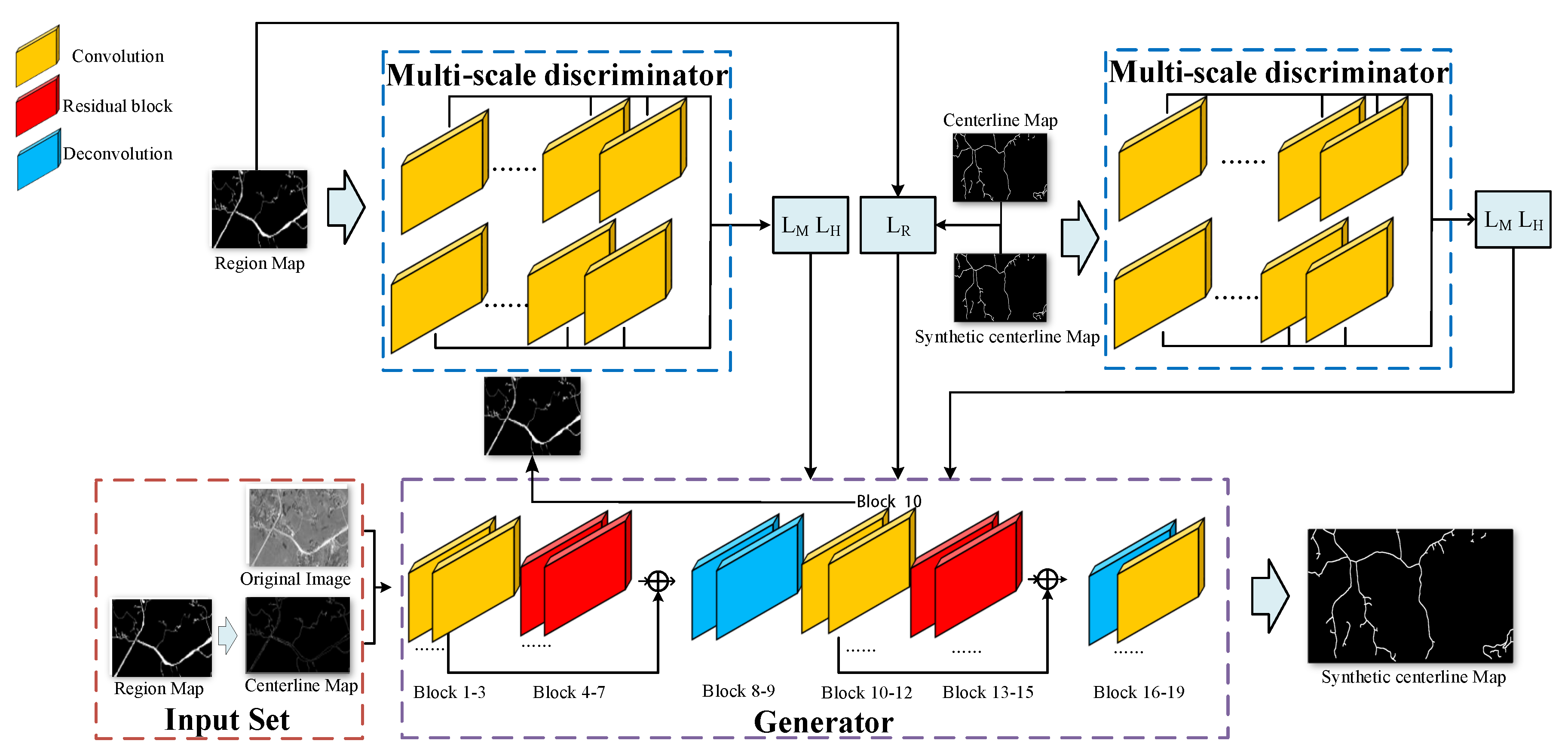
3.2. Network Architecture
3.3. Loss Function
4. Results and Analysis
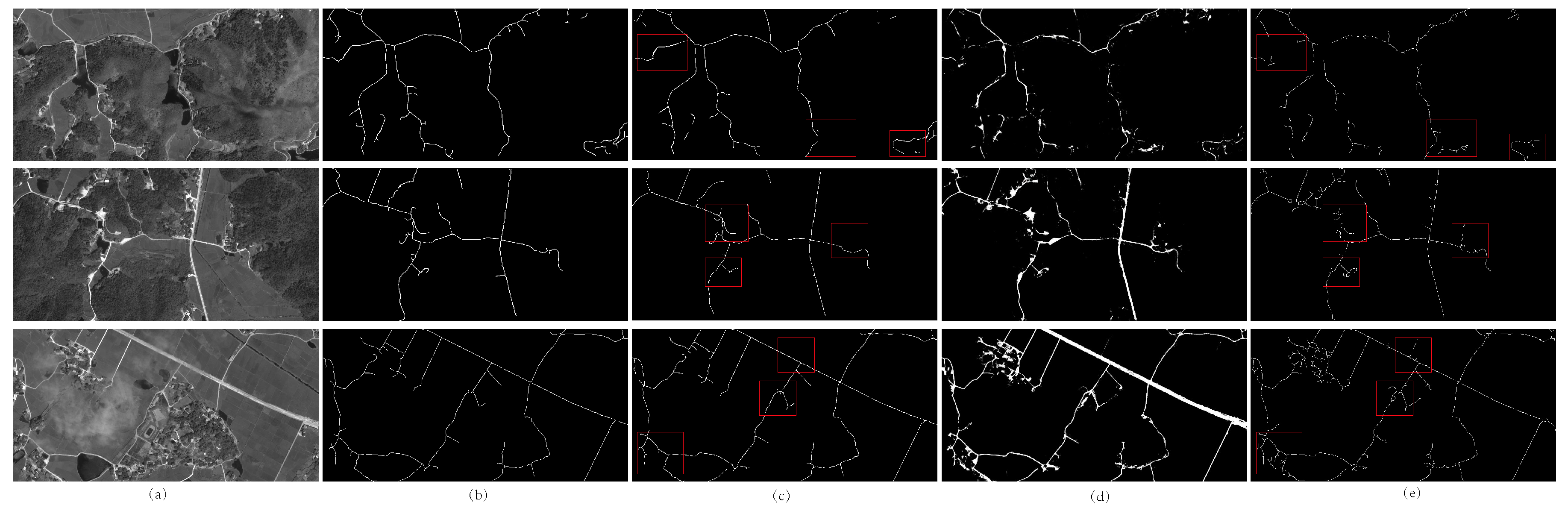
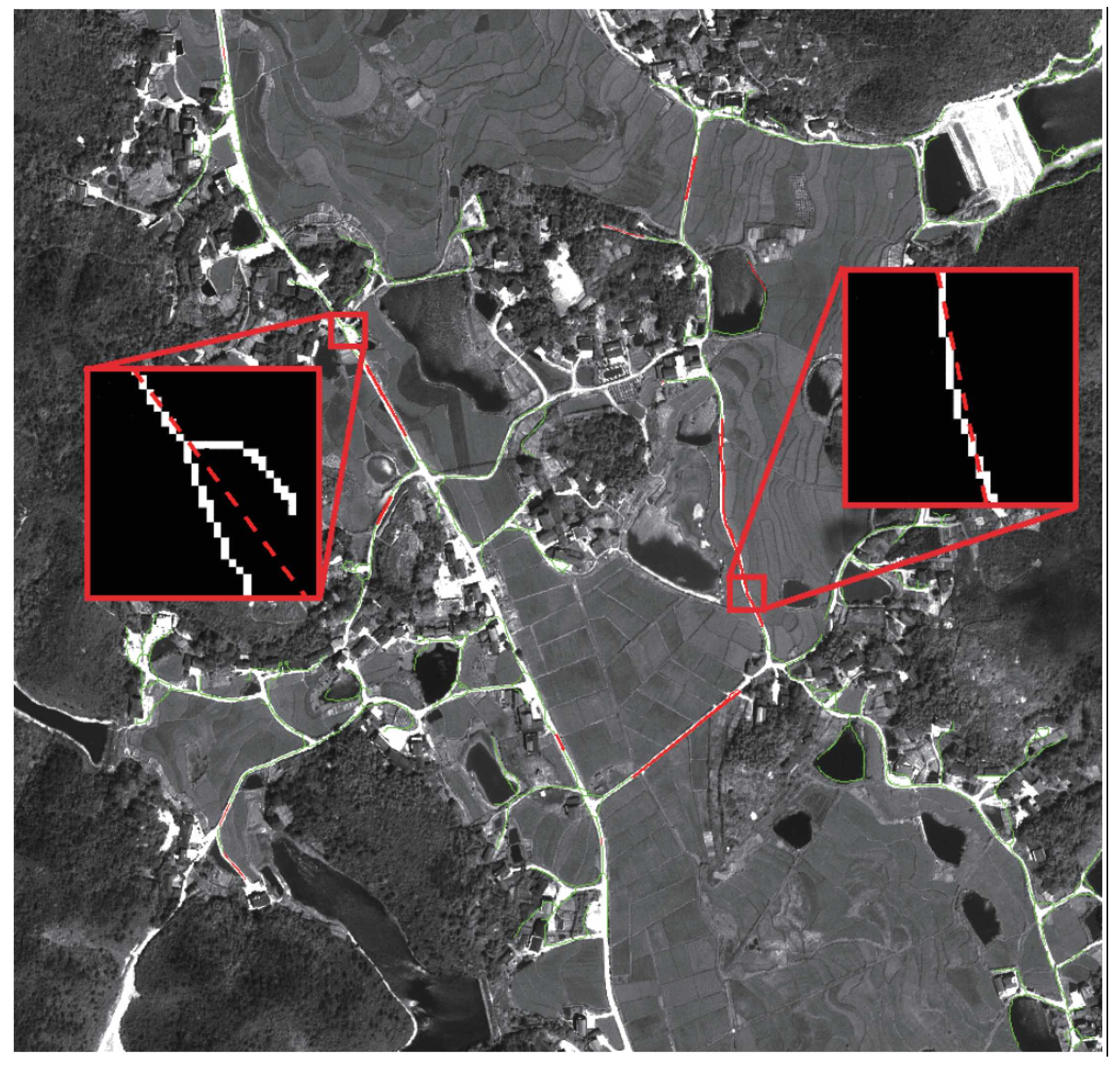
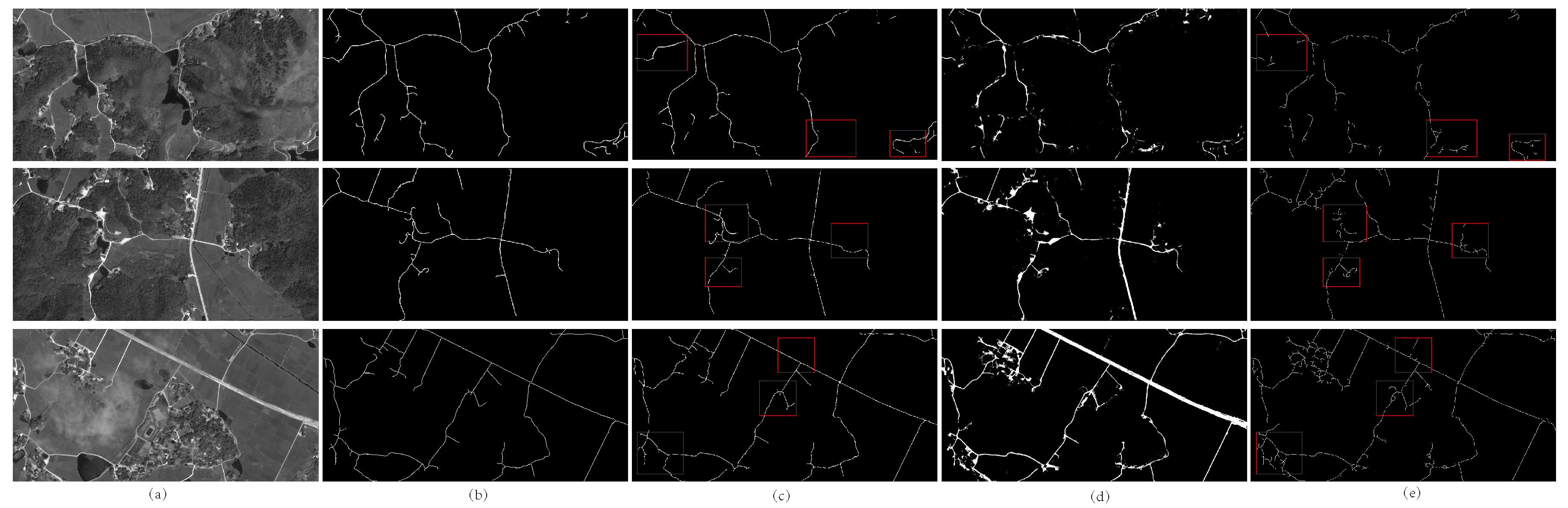
4.1. Evaluation of the Network Performance
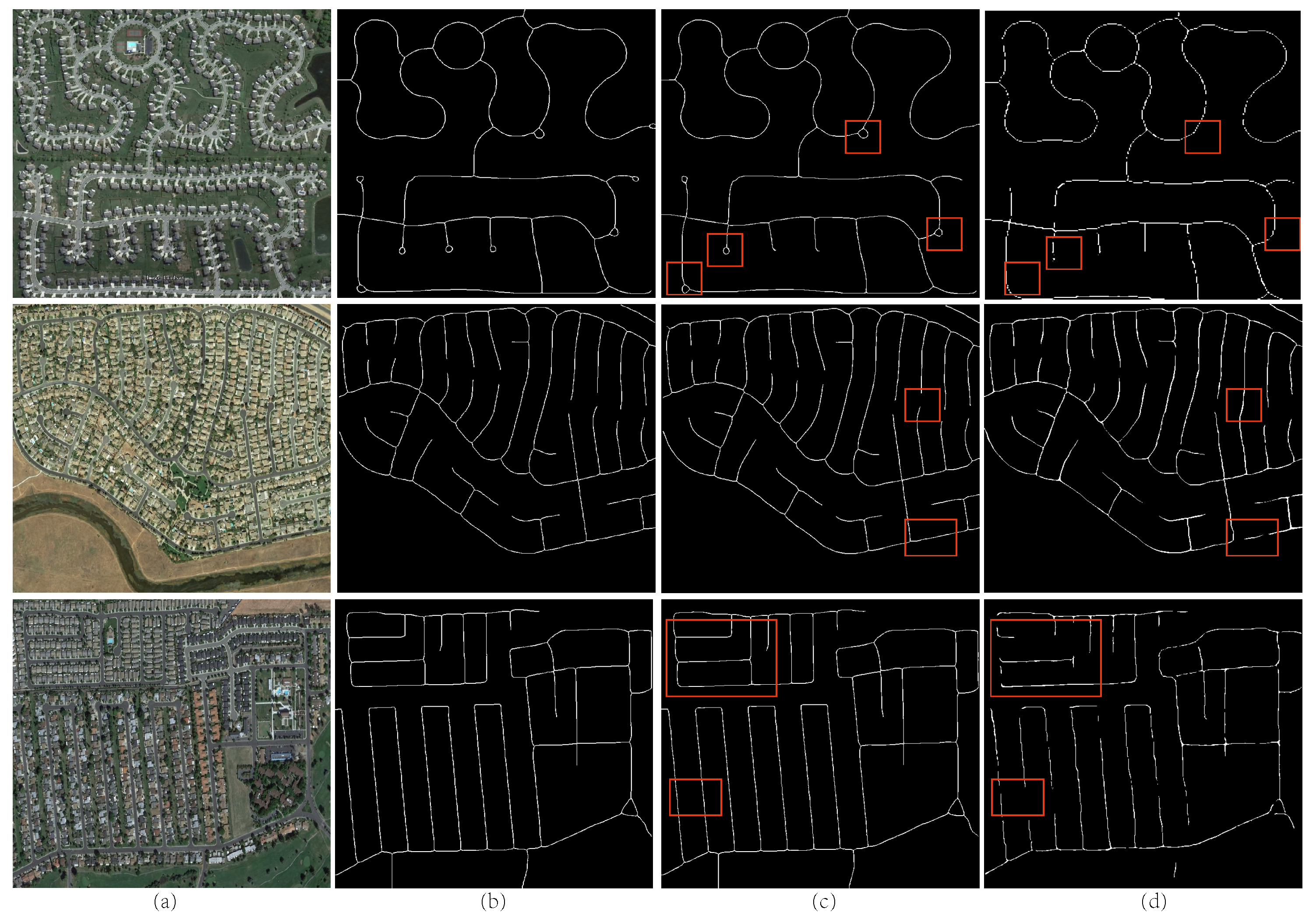
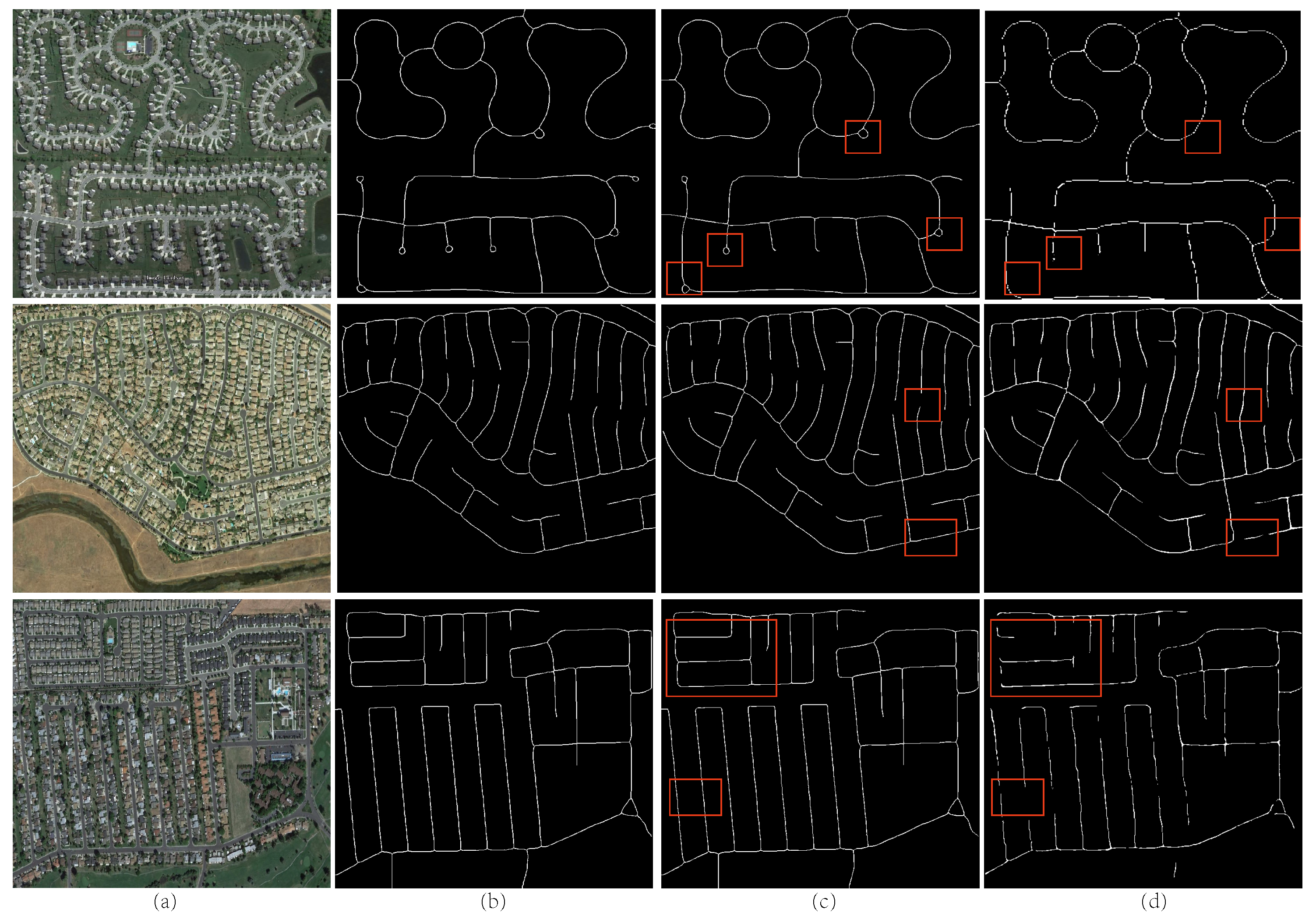
4.2. Evaluation on Various Datasets
4.3. Comparisons
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Mnih, V.; Hinton, G.E. Learning to Detect Roads in High-Resolution Aerial Images. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2010; pp. 210–223. [Google Scholar]
- Martin, D.R.; Fowlkes, C.C.; Malik, J. Learning to detect natural image boundaries using local brightness, color, and texture cues. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 530–549. [Google Scholar] [CrossRef]
- Zang, Y.; Wang, C.; Cao, L.; Yu, Y.; Li, J. Road Network Extraction via Aperiodic Directional Structure Measurement. IEEE Trans. Geosci. Remote Sens. 2016, 54, 1–14. [Google Scholar] [CrossRef]
- Baumgartner, A.; Steger, C.; Mayer, H.; Eckstein, W. Multi-Resolution, Semantic Objects, and Context for Road Extraction. In Semantic Modeling for the Acquisition of Topographic Information from Images and Maps; Birkhäuser: Basel, Switzerland, 1997; pp. 140–156. [Google Scholar]
- Ünsalan, C.; Sirmacek, B. Road network detection using probabilistic and graph theoretical methods. IEEE Trans. Geosci. Remote Sens. 2012, 50, 4441–4453. [Google Scholar] [CrossRef]
- Ziems, M.; Breitkopf, U.; Heipke, C.; Rottensteiner, F. Multiple-model based verification of road data. In Proceedings of the XXII ISPRS Congress, Melbourne, Australia, 25 August–1 September 2012; Volume I-3. [Google Scholar]
- Shi, W.Z.; Miao, Z.L.; Debayle, J. An Integrated Method for Urban Main-Road Centerline Extraction From Optical Remotely Sensed Imagery. IEEE Trans. Geosci. Remote Sens. 2014, 52, 3359–3372. [Google Scholar] [CrossRef]
- Zang, Y.; Wang, C.; Yu, Y.; Luo, L.; Yang, K.; Li, J. Joint Enhancing Filtering for Road Network Extraction. IEEE Trans. Geosci. Remote Sens. 2016, 99, 1–15. [Google Scholar] [CrossRef]
- Mokhtarzade, M.; Zoej, M.J.V. Road detection from high-resolution satellite images using artificial neural networks. Int. J. Appl. Earth Obs. Geoinf. 2007, 9, 32–40. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, L. Road centreline extraction from high resolution imagery based on multiscale structural features and support vector machines. Int. J. Remote Sens. 2009, 30, 1977–1987. [Google Scholar] [CrossRef]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the Dimensionality of Data with Neural Networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Wegner, J.D.; Montoya-Zegarra, J.A.; Schindler, K. A Higher-Order CRF Model for Road Network Extraction. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1698–1705. [Google Scholar]
- Cheng, G.; Wang, Y.; Xu, S.; Wang, H.; Xiang, S.; Pan, C. Automatic Road Detection and Centerline Extraction via Cascaded End-to-End Convolutional Neural Network. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3322–3337. [Google Scholar] [CrossRef]
- Amo, M.; Martinez, F.; Torre, M. Road extraction from aerial images using a region competition algorithm. IEEE Trans. Image Process. 2006, 15, 1192–1201. [Google Scholar] [CrossRef]
- Kong, H.; Audibert, J.Y.; Ponce, J. General road detection from a single image. IEEE Trans. Image Process. 2010, 19, 2211–2220. [Google Scholar] [CrossRef]
- Mena, J.B. State of the art on automatic road extraction for GIS update: a novel classification. Pattern Recognit. Lett. 2003, 24, 3037–3058. [Google Scholar] [CrossRef]
- Unsalan, C.; Boyer, K.L. A system to detect houses and residential street networks in multispectral satellite images. Comput. Vision Image Underst. 2005, 98, 423–461. [Google Scholar] [CrossRef]
- Das, S.; Mirnalinee, T.T.; Varghese, K. Use of Salient Features for the Design of a Multistage Framework to Extract Roads From High-Resolution Multispectral Satellite Images. IEEE Trans. Geosci. Remote Sens. 2011, 49, 3906–3931. [Google Scholar] [CrossRef]
- Katartzis, A.; Sahli, H.; Pizurica, V.; Cornelis, J. A model-based approach to the automatic extraction of linear features from airborne images. IEEE Trans. Geosci. Remote Sens. 2001, 39, 2073–2079. [Google Scholar] [CrossRef]
- Stoica, R.; Descombes, X.; Zerubia, J. A Gibbs Point Process for Road Extraction from Remotely Sensed Images. Int. J. Comput. Vis. 2004, 57, 121–136. [Google Scholar] [CrossRef]
- Gamba, P.; Dell’Acqua, F.; Lisini, G. Improving urban road extraction in high-resolution images exploiting directional filtering, perceptual grouping, and simple topological concepts. IEEE Geosci. Remote Sens. Lett. 2006, 3, 387–391. [Google Scholar] [CrossRef]
- Movaghati, S.; Moghaddamjoo, A.; Tavakoli, A. Road Extraction From Satellite Images Using Particle Filtering and Extended Kalman Filtering. IEEE Trans. Geosci. Remote Sens. 2010, 48, 2807–2817. [Google Scholar] [CrossRef]
- Shi, W.; Zhu, C. The line segment match method for extracting road network from high-resolution satellite images. IEEE Trans. Geosci. Remote Sens. 2002, 40, 511–514. [Google Scholar]
- Yang, J.; Wang, R.S. Classified road detection from satellite images based on perceptual organization. Int. J. Remote Sens. 2007, 28, 4653–4669. [Google Scholar] [CrossRef]
- Wiedemann, C.; Hinz, S. Automatic extraction and evaluation of road networks from satellite imagery. Int. Arch. Photogramm. Remote Sens. 1999, 32, 95–100. [Google Scholar]
- Wiedeman, C.; Ebner, H. Automatic completion and evaluation of road networks. Int. Arch. Photogramm. Remote Sens. 2000, 33, 976–986. [Google Scholar]
- Hinz, S.; Wiedemann, C. Increasing efficiency of road extraction by self-diagnosis. Photogramm. Eng. Remote Sens. 2004, 70, 1457–1466. [Google Scholar] [CrossRef]
- Poullis, C.; You, S. Delineation and geometric modeling of road networks. ISPRS J. Photogramm. Remote Sens. 2010, 65, 165–181. [Google Scholar] [CrossRef]
- Grote, A.; Heipke, C.; Rottensteiner, F. Road network extraction in suburban areas. Photogramm. Rec. 2012, 27, 8–28. [Google Scholar] [CrossRef]
- Hu, J.; Razdan, A.; Femiani, J.C.; Cui, M.; Wonka, P. Road Network Extraction and Intersection Detection From Aerial Images by Tracking Road Footprints. Int. J. Remote Sens. 2007, 45, 4144–4157. [Google Scholar] [CrossRef]
- Zhang, J.; Lin, X.; Liu, Z.; Shen, J. Semi-automatic road tracking by template matching and distance transformation in urban areas. IEEE Trans. Geosci. Remote Sens. 2011, 32, 8331–8347. [Google Scholar] [CrossRef]
- Steger, C. An Unbiased Detector of Curvilinear Structures. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 113–125. [Google Scholar] [CrossRef]
- Steger, C.; Mayer, H.; Radig, B. The role of grouping for road extraction. In Automatic Extraction of Man-Made Objects from Aerial and Space Images (II); Springer: Basel, Switzerland, 1997; pp. 245–256. [Google Scholar]
- Peteri, R.; Ranchin, T. Automated road network extraction using collaborative linear and surface models. In Proceedings of the MAPPS/ASPRS 2006 Fall Conference “Measuring the Earth II: Latest Develoopments with Digital Surface Modelling and Automated Feature Extration”, San Antonio, TX, USA, 6–10 November 2006. [Google Scholar]
- Debayle, J.; Pinoli, J.C. General Adaptive Neighborhood Image Processing: Part I: Introduction and Theoretical Aspects. J. Math. Imaging Vis. 2006, 25, 245–266. [Google Scholar] [CrossRef]
- Qin, Y.; Chi, M.; Liu, X.; Zhang, Y.; Zeng, Y.; Zhao, Z. Classification of High Resolution Urban Remote Sensing Images Using Deep Networks by Integration of Social Media Photos. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 7243–7246. [Google Scholar]
- Chi, M.; Sun, Z.; Qin, Y.; Shen, J.; Benediktsson, J.A. A novel methodology to label urban remote sensing images based on location-based social media photos. Proc. IEEE 2017, 105, 1926–1936. [Google Scholar] [CrossRef]
- Zhou, J.; Yu, B.; Qin, J. Multi-level spatial analysis for change detection of urban vegetation at individual tree scale. Remote Sens. 2014, 6, 9086–9103. [Google Scholar] [CrossRef]
- He, F.; Zhou, T.; Xiong, W.; Hasheminnasab, S.; Habib, A. Automated aerial triangulation for UAV-based mapping. Remote Sens. 2018, 10, 1952. [Google Scholar] [CrossRef]
- Zhao, X.; Yu, B.; Liu, Y.; Chen, Z.; Li, Q.; Wang, C.; Wu, J. Estimation of Poverty Using Random Forest Regression with Multi-Source Data: A Case Study in Bangladesh. Remote Sens. 2019, 11, 375. [Google Scholar] [CrossRef]
- Cheng, M.M.; Mitra, N.J.; Huang, X.; Torr, P.H.S.; Hu, S.M. Global Contrast based Salient Region Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 569–582. [Google Scholar] [CrossRef] [PubMed]
- Cheng, M.M.; Warrell, J.; Lin, W.Y.; Zheng, S.; Vineet, V.; Crook, N. Efficient salient region detection with soft image abstraction. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 1529–1536. [Google Scholar]
- Borji, A.; Cheng, M.M.; Hou, Q.; Jiang, H.; Li, J. Salient object detection: A survey. arXiv 2014, arXiv:1411.5878. [Google Scholar]
- Borji, A.; Cheng, M.M.; Jiang, H.; Li, J. Salient Object Detection: A Benchmark. IEEE Trans. Image Process. 2015, 24, 5706–5722. [Google Scholar] [CrossRef]
- Cheng, M.M.; Liu, Y.; Hou, Q.; Bian, J.; Torr, P.; Hu, S.M.; Tu, Z. HFS: Hierarchical feature selection for efficient image segmentation. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 867–882. [Google Scholar]
- Liu, Y.; Cheng, M.M.; Hu, X.; Wang, K.; Bai, X. Richer Convolutional Features for Edge Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3000–3009. [Google Scholar]
- Chen, M.; Habib, A.; He, H.; Zhu, Q.; Zhang, W. Robust feature matching method for SAR and optical images by using Gaussian-gamma-shaped bi-windows-based descriptor and geometric constraint. Remote Sens. 2017, 9, 882. [Google Scholar] [CrossRef]
- Yuan, J.; Wang, D.; Wu, B.; Yan, L.; Li, R. LEGION-Based Automatic Road Extraction From Satellite Imagery. IEEE Trans. Geosci. Remote Sens. 2011, 49, 4528–4538. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. Adv. Neural Inf. Process. Syst. 2014, 3, 2672–2680. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Instance Normalization: The Missing Ingredient for Fast Stylization. arXiv 2016, arXiv:1607.08022. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Johnson, J.; Alahi, A.; Li, F.F. Perceptual Losses for Real-Time Style Transfer and Super-Resolution. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 694–711. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Mnih, V. Machine Learning for Aerial Image Labeling. Ph.D. Thesis, University of Toronto, Toronto, ON, Canada, 2013. [Google Scholar]
- Wang, T.C.; Liu, M.Y.; Zhu, J.Y.; Tao, A.; Kautz, J.; Catanzaro, B. High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8798–8807. [Google Scholar]
- Miao, Z.; Shi, W.; Zhang, H.; Wang, X. Road centerline extraction from high-resolution imagery based on shape features and multivariate adaptive regression splines. IEEE IEEE Geosci. Remote Sens. Lett. 2013, 10, 583–587. [Google Scholar] [CrossRef]
- Cheng, G.; Zhu, F.; Xiang, S.; Wang, Y.; Pan, C. Accurate urban road centerline extraction from VHR imagery via multiscale segmentation and tensor voting. Neurocomputing 2016, 205, 407–420. [Google Scholar] [CrossRef]
- Wessel, B.; Wiedemann, C. Analysis of automatic road extraction results from airborne SAR imagery. Appl. Therm. Eng. 2003, 71, 276–290. [Google Scholar]
- Wei, Y.; Wang, Z.; Xu, M. Road Structure Refined CNN for Road Extraction in Aerial Image. IEEE Geosci. Remote Sens. Lett. 2017, 14, 709–713. [Google Scholar] [CrossRef]
- Wegner, J.D.; Montoya-Zegarra, J.A.; Schindler, K. Road networks as collections of minimum cost paths. ISPRS J. Photogramm. Remote Sens. 2015, 108, 128–137. [Google Scholar] [CrossRef]
- Zhong, Z.; Li, J.; Cui, W.; Jiang, H. Fully convolutional networks for building and road extraction: Preliminary results. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 1591–1594. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image 1 | Image 2 | Image 3 | Avg.(test set) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R | P | F | R | P | F | R | P | F | R | P | F | |
| SsGAN | 0.922 | 0.962 | 0.942 | 0.955 | 0.971 | 0.963 | 0.901 | 0.962 | 0.930 | 0.926 | 0.965 | 0.945 |
| MsGAN | 0.952 | 0.988 | 0.970 | 0.963 | 0.978 | 0.971 | 0.944 | 0.962 | 0.953 | 0.960 | 0.975 | 0.967 |
| Data | Recall | Precision | F1 Score |
|---|---|---|---|
| Geoeye | 0.888 | 0.841 | 0.864 |
| QuickBird | 0.861 | 0.855 | 0.858 |
| Pleiades-1A | 0.857 | 0.862 | 0.860 |
| GaoFen2 | 0.881 | 0.833 | 0.856 |
| Image 1 | Image 2 | Image 3 | Avg.(test set) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R | P | F | R | P | F | R | P | F | R | P | F | |
| Huang et al. [10] | 0.975 | 0.814 | 0.887 | 0.964 | 0.722 | 0.826 | 0.967 | 0.747 | 0.843 | 0.959 | 0.738 | 0.834 |
| Miao et al. [58] | 0.930 | 0.816 | 0.882 | 0.885 | 0.705 | 0.784 | 0.894 | 0.724 | 0.800 | 0.896 | 0.718 | 0.797 |
| Shi et al. [7] | 0.938 | 0.920 | 0.925 | 0.940 | 0.920 | 0.930 | 0.864 | 0.849 | 0.856 | 0.893 | 0.907 | 0.900 |
| Cheng et al. [59] | 0.960 | 0.910 | 0.935 | 0.990 | 0.907 | 0.946 | 0.949 | 0.824 | 0.881 | 0.931 | 0.896 | 0.913 |
| Casnet-baseline [13] | 0.942 | 0.908 | 0.921 | 0.927 | 0.911 | 0.919 | 0.933 | 0.791 | 0.856 | 0.924 | 0.874 | 0.898 |
| Casnet [13] | 0.979 | 0.946 | 0.962 | 0.997 | 0.965 | 0.981 | 0.957 | 0.943 | 0.950 | 0.963 | 0.954 | 0.959 |
| MsGAN | 0.983 | 0.968 | 0.975 | 0.995 | 0.981 | 0.988 | 0.953 | 0.973 | 0.963 | 0.960 | 0.974 | 0.967 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Xiong, Z.; Zang, Y.; Wang, C.; Li, J.; Li, X. Topology-Aware Road Network Extraction via Multi-Supervised Generative Adversarial Networks. Remote Sens. 2019, 11, 1017. https://doi.org/10.3390/rs11091017
Zhang Y, Xiong Z, Zang Y, Wang C, Li J, Li X. Topology-Aware Road Network Extraction via Multi-Supervised Generative Adversarial Networks. Remote Sensing. 2019; 11(9):1017. https://doi.org/10.3390/rs11091017
Chicago/Turabian StyleZhang, Yang, Zhangyue Xiong, Yu Zang, Cheng Wang, Jonathan Li, and Xiang Li. 2019. "Topology-Aware Road Network Extraction via Multi-Supervised Generative Adversarial Networks" Remote Sensing 11, no. 9: 1017. https://doi.org/10.3390/rs11091017
APA StyleZhang, Y., Xiong, Z., Zang, Y., Wang, C., Li, J., & Li, X. (2019). Topology-Aware Road Network Extraction via Multi-Supervised Generative Adversarial Networks. Remote Sensing, 11(9), 1017. https://doi.org/10.3390/rs11091017