Integration of National Forest Inventory and Nationwide Airborne Laser Scanning Data to Improve Forest Yield Predictions in North-Western Spain

 ,
,  ,
,  and
and 
Abstract
1. Introduction
2. Materials and Methods
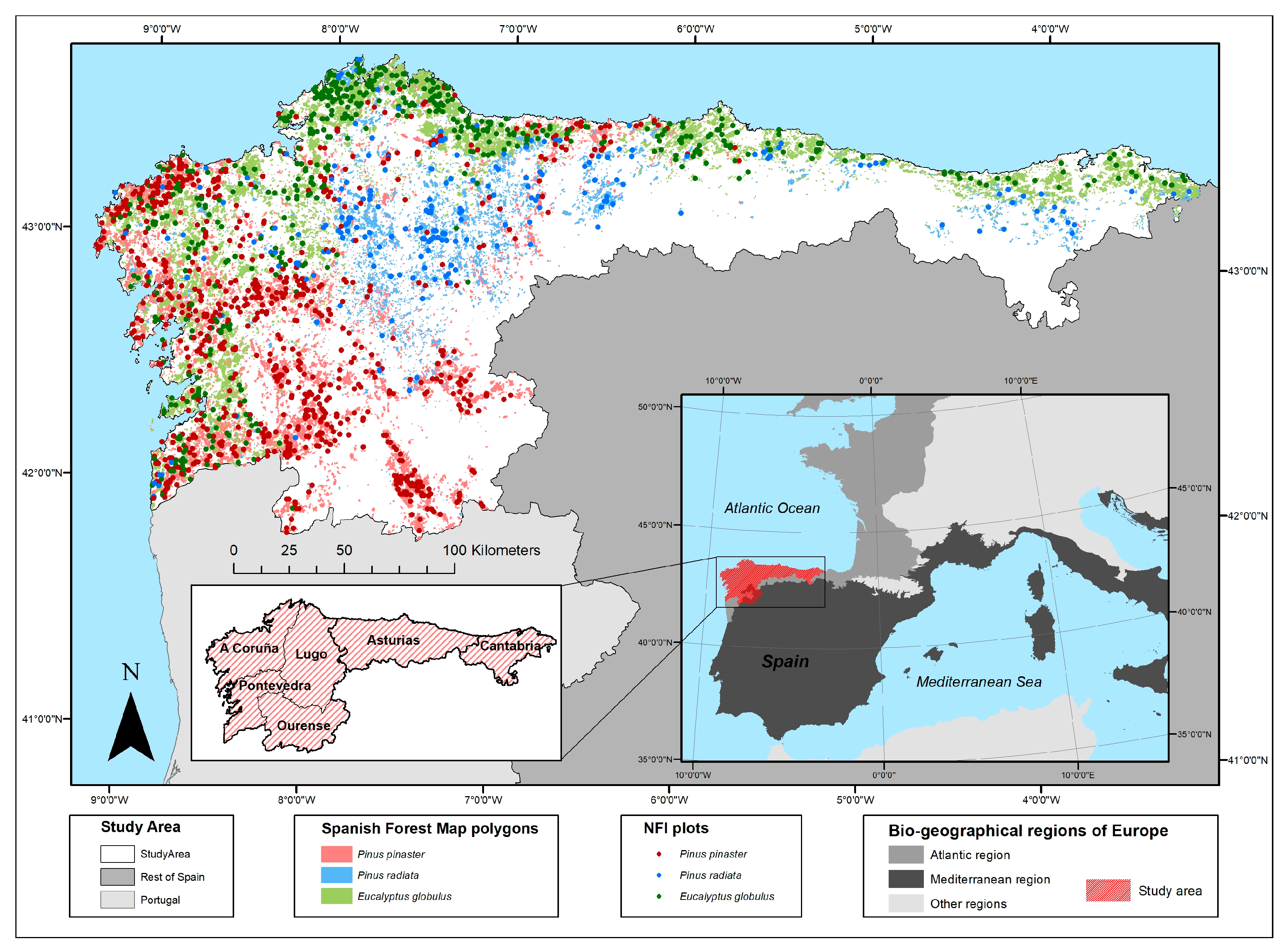
2.1. Study Area
2.2. Data Collection
2.2.1. SNFI Data
2.2.2. ALS Data
2.2.3. Harmonization of SNFI and ALS Data
2.3. Data Analysis
2.3.1. Regression Techniques
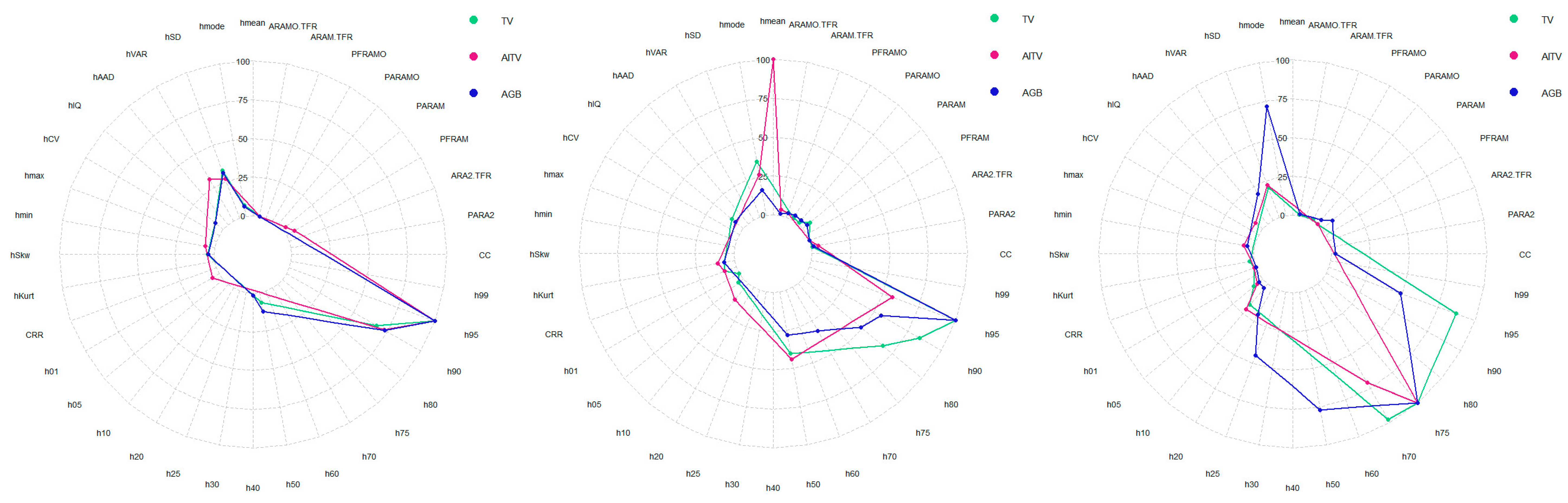
2.3.2. Feature Selection and Parametrization
2.3.3. Performance Evaluation
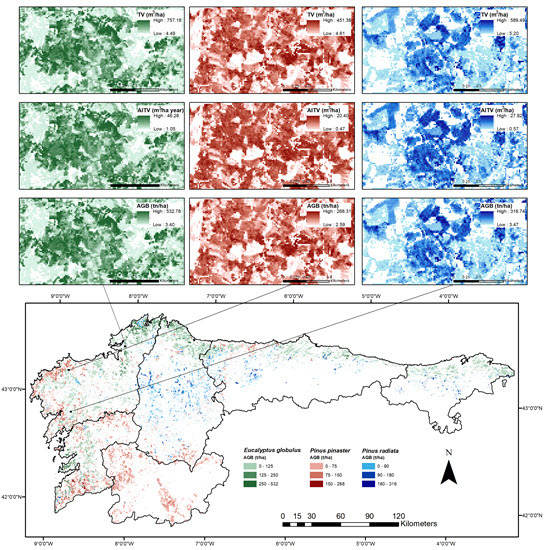
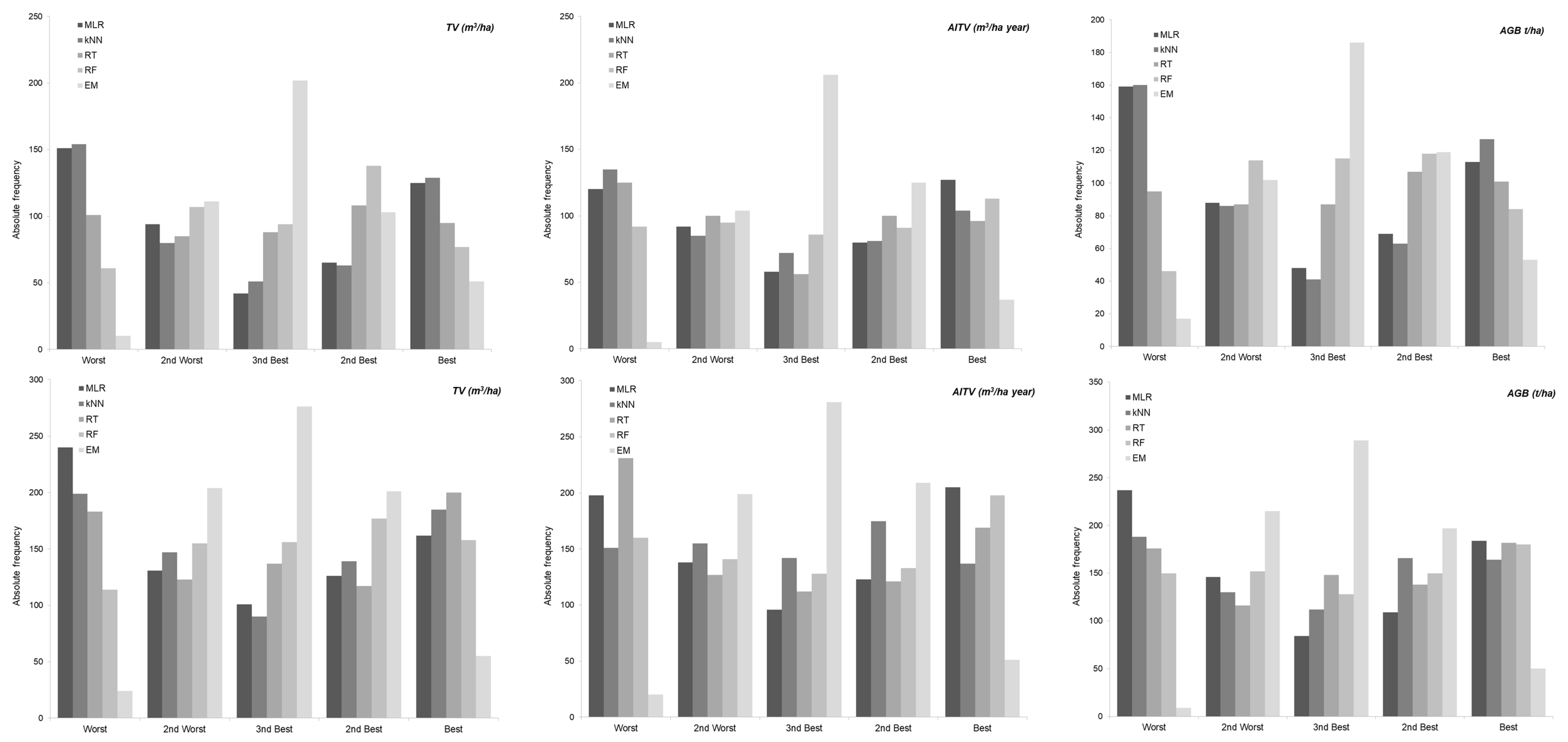
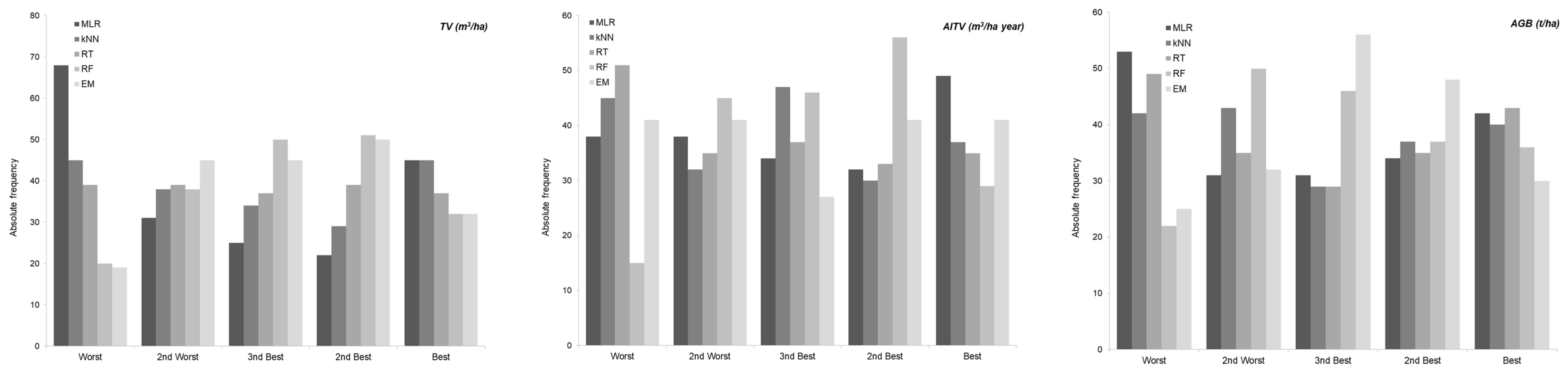
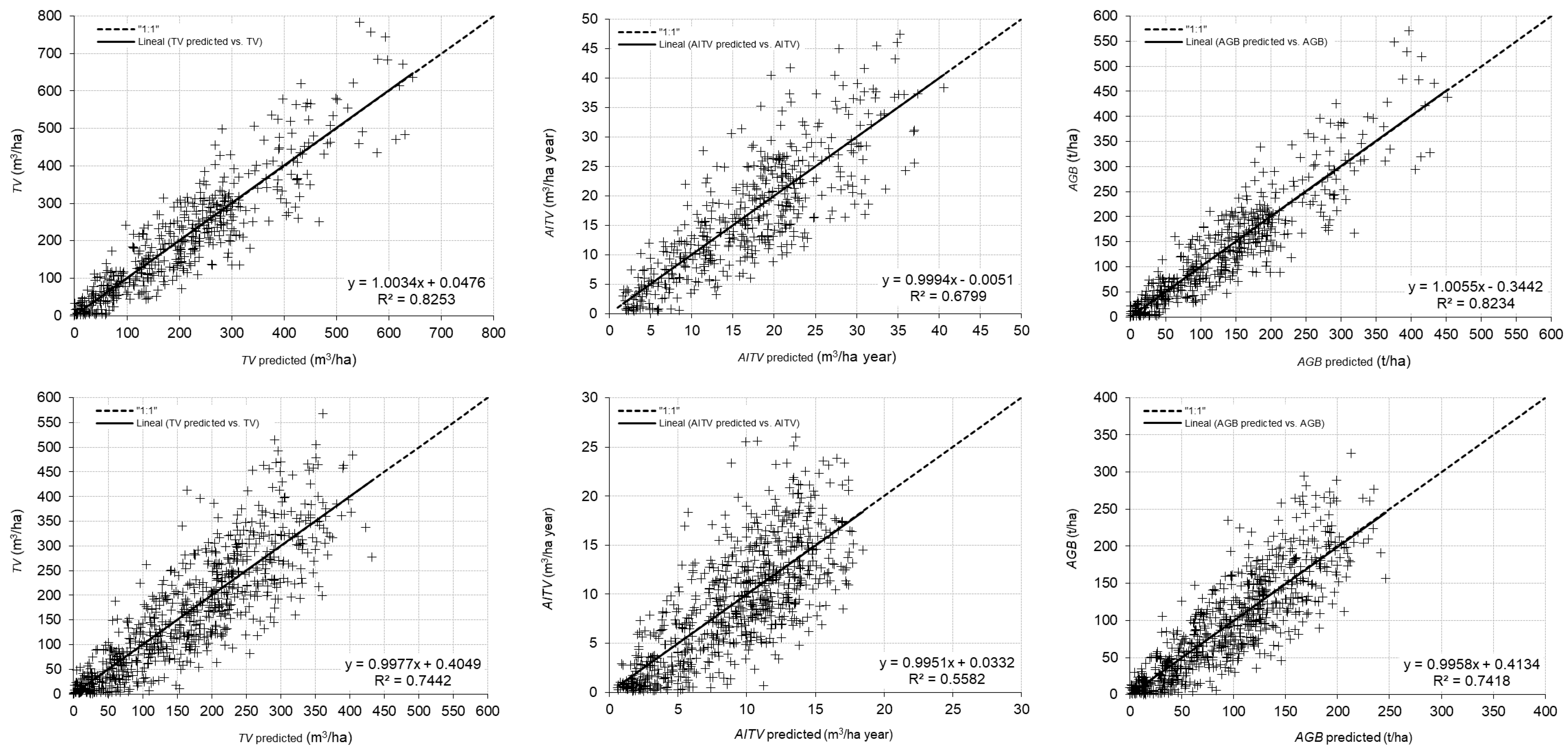
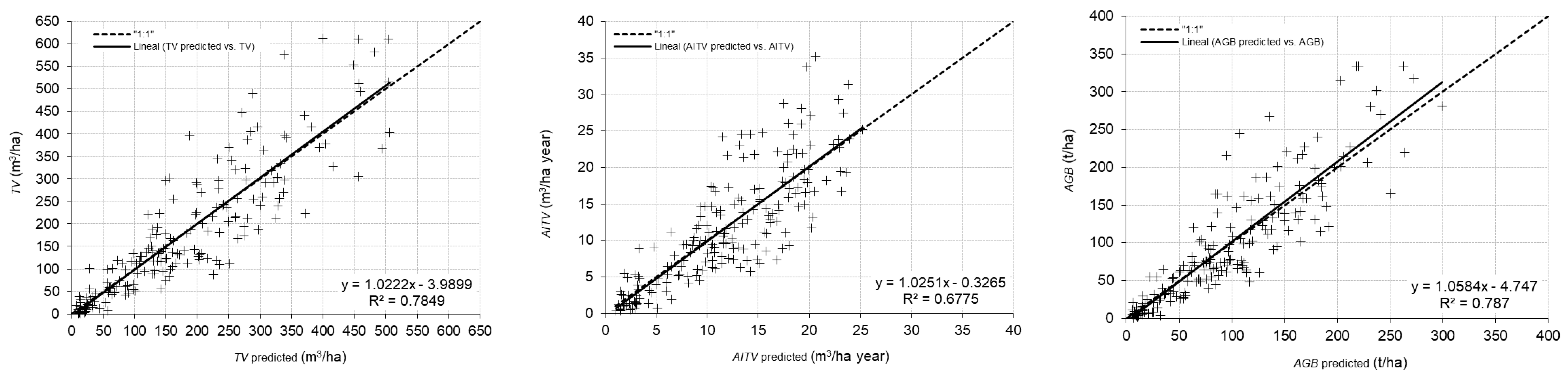
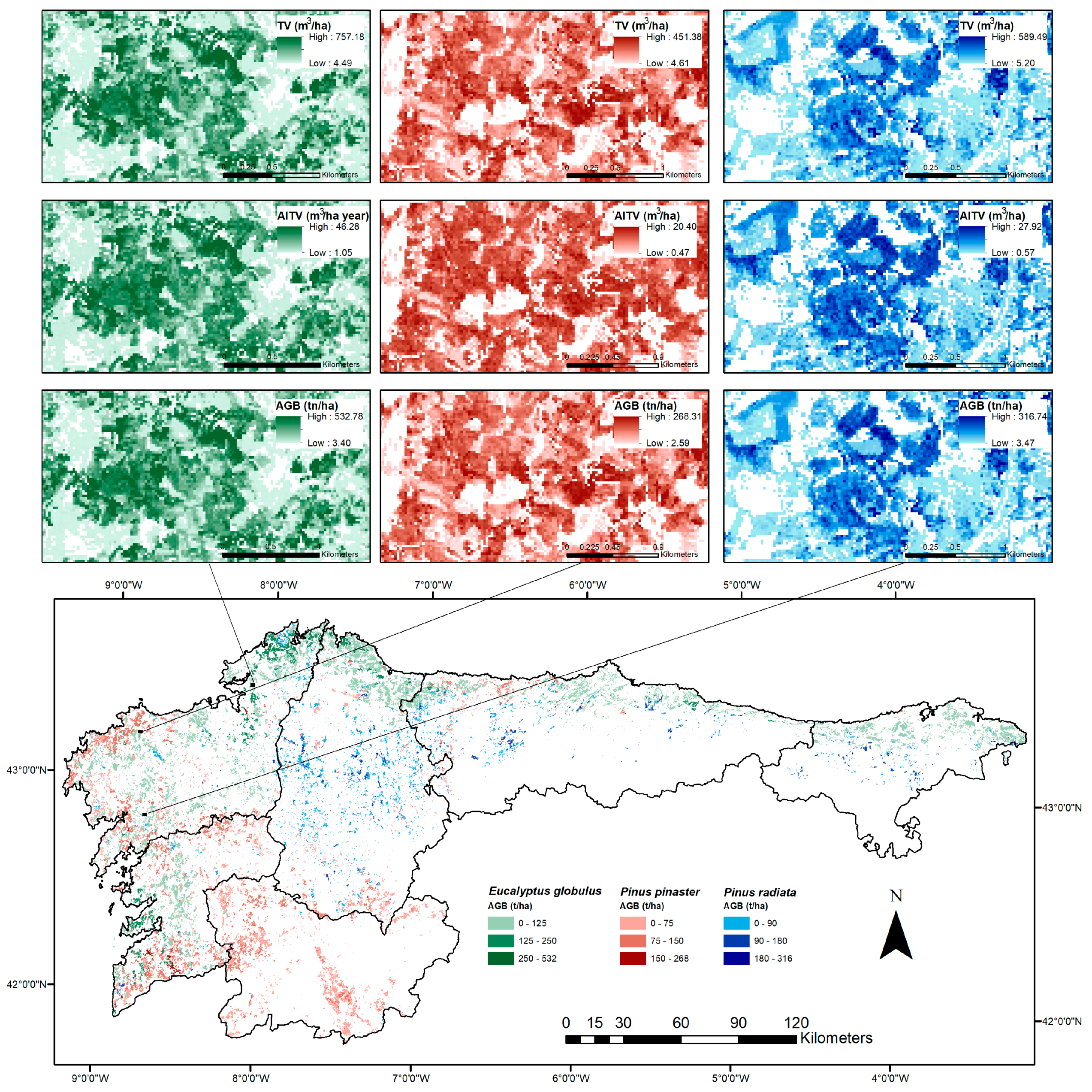
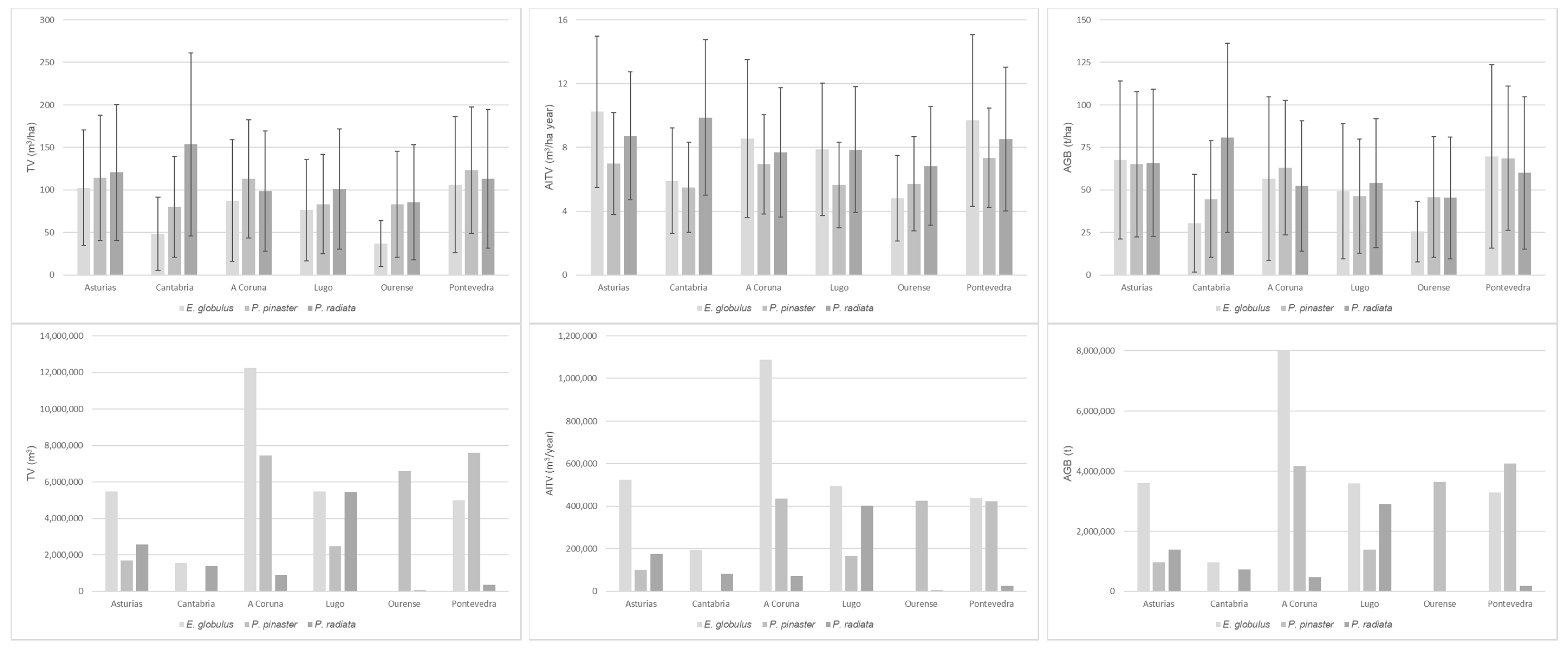
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Moser, P.; Vibrans, A.C.; McRoberts, R.E.; Næsset, E.; Gobakken, T.; Chirici, G.; Mura, M.; Marchetti, M. Methods for variable selection in Lidar-assisted forest inventories. Forestry 2017, 90, 112–124. [Google Scholar] [CrossRef]
- Nilsson, M.; Nordkvist, K.; Jonzén, J.; Lindgren, N.; Axensten, P.; Wallerman, J.; Egberth, M.; Larsson, S.; Nilsson, L.; Eriksson, J.; et al. A nationwide forest attribute map of Sweden predicted using airborne laser scanning data and field data from the National Forest Inventory. Remote Sens. Environ. 2017, 194, 447–454. [Google Scholar] [CrossRef]
- McRoberts, R.E.; Westfall, J.A. Effects of uncertainty in model predictions of individual tree volume on large area volume estimates. For. Sci. 2014, 60, 34–42. [Google Scholar] [CrossRef]
- Jiménez, E.; Vega, J.A.; Fernández-Alonso, J.M.; Vega-Nieva, D.; Ortiz, L.; López-Serrano, P.M.; López-Sánchez, C.A. Estimation of aboveground forest biomass in Galicia (NW Spain) by the combined use of LiDAR, LANDSAT ETM+ and National Forest Inventory data. IFOREST 2017, 10, 590–596. [Google Scholar] [CrossRef]
- Álvarez-González, J.G.; Cañellas, I.; Alberdi, I.; Gadow, K.V.; Ruiz-González, A.D. National Forest Inventory and forest observational studies in Spain: Applications to forest modelling. For. Ecol. Manag. 2014, 316, 54–64. [Google Scholar] [CrossRef]
- López-Serrano, P.M.; López-Sánchez, C.A.; Álvarez-González, J.G.; García-Gutiérrez, J. A Comparison of Machine Learning Techniques Applied to Landsat-5 TM Spectral Data for Biomass Estimation. Can. J. Remote Sens. 2016, 42, 690–705. [Google Scholar] [CrossRef]
- Corona, P.; Cartisano, R.; Salvati, R.; Chirici, G.; Floris, A.; Di Martino, P.; Marchetti, M.; Scrinzi, G.; Clementel, F.; Travaglini, D.; et al. Airborne laser scanning to support forest resource management under alpine, temperate and Mediterranean environments in Italy. Eur. J. Remote Sens. 2012, 45, 27–37. [Google Scholar] [CrossRef]
- Teobaldelli, M.; Cona, F.; Saulino, L.; Migliozzi, A.; Dùrso, G.; Langella, G.; Manna, P.; Saracino, A. Detection of diversity and stand parameters in Mediterranean forests using leaf-off discrete return LiDAR data. Remote Sens. Environ. 2017, 192, 126–138. [Google Scholar] [CrossRef]
- Mauro, F.; Valbuena, R.; Manzanera, J.A.; García-Abril, A. Influence of Global Navigation Satellite System errors in positioning inventory plots for tree-height distribution studies. Can. J. For. Res. 2011, 41, 11–23. [Google Scholar] [CrossRef]
- Gobakken, T.; Næsset, E. Assessing effects of positioning errors and sample plot size on biophysical stand properties derived from airborne laser scanning data. Can. J. For. Res. 2009, 39, 1036–1052. [Google Scholar] [CrossRef]
- Maclean, G.A.; Krabill, W.B. Gross-merchantable timber volume estimating using an airborne lidar systems. Can. J. Remote Sens. 1986, 12, 7–18. [Google Scholar] [CrossRef]
- Nelson, R.; Krabill, W.; Tonelli, J. Estimating forest and volume using airborne laser data. Remote Sens. Environ. 1988, 24, 247–267. [Google Scholar] [CrossRef]
- Nelson, R. How did we get here? An early history of forestry lidar. Can. J. Remote Sens. 2013, 39, S6–S17. [Google Scholar] [CrossRef]
- Means, J.E.; Acker, S.A.; Fitt, B.J.; Renslow, M.; Emerson, L.; Hendrix, C.J. Predicting forest stand characteristics with airborne scanning Lidar. Photogramm. Eng. Remote Sens. 2000, 66, 1367–1371. [Google Scholar]
- Næsset, E. Predicting forest stand characteristics with airborne scanning laser using a practical two-stage procedure and field data. Remote Sens. Environ. 2002, 80, 88–99. [Google Scholar] [CrossRef]
- Popescu, S.C.; Wynne, R.H.; Scrivani, J.A. Fusion of small-footprint lidar and multispectral data to estimate plot-level volume and biomass in deciduous and pine forests in Virginia. USA For. Sci. 2004, 50, 551–565. [Google Scholar]
- Tesfamichael, S.; Ahmed, F.; van Aardt, J. Investigating the impact of discrete return lidar point density on estimations of mean and dominant plot-level tree height in Eucalyptus grandis plantations. Int. J. Remote Sens. 2010, 31, 2925–2940. [Google Scholar] [CrossRef]
- Dalponte, M.; Martinez, C.; Rodeghiero, M.; Gianelle, D. The role of ground reference data collection in the prediction of stem volume with lidar data in mountain areas. ISPRS J. Photogramm. Remote Sens. 2011, 66, 787–797. [Google Scholar] [CrossRef]
- García-Gutiérrez, J.; Martínez-Álvarez, F.; Troncoso, A.; Riquelme, J.C. A comparison of machine learning regression techniques for LiDAR-derived estimation of forest variables. Neurocomputing 2015, 167, 24–31. [Google Scholar] [CrossRef]
- Chen, G.; Hay, G.J.; St-Onge, B. A GEOBIA framework to estimate forest parameters from lidar transects, Quickbird imagery and machine learning: A case study in Quebec, Canada. Int. J. Appl. Earth Obs. Geoinf. 2012, 15, 28–37. [Google Scholar] [CrossRef]
- Gleason, C.J.; Im, J. Forest biomass estimation from airborne LiDAR data using machine learning approaches. Remote Sens. Environ. 2012, 125, 80–91. [Google Scholar] [CrossRef]
- Lary, D.J.; Alavi, A.H.; Gandomi, A.H.; Walker, A.L. Machine learning in geosciences and remote sensing. Geosci. Front. 2016, 7, 3–10. [Google Scholar] [CrossRef]
- Hollaus, M.; Dorigo, W.; Wagner, W.; Schadauer, K.; Höfle, B.; Maier, B. Operational wide-area stem volume estimation based on airborne laser scanning and national forest inventory data. Int. J. Remote Sens 2009, 30, 5159–5175. [Google Scholar] [CrossRef]
- Nord-Larsen, T.; Schumacher, J. Estimation of forest resources from a country wide laser scanning survey and national forest inventory data. Remote Sens. Environ. 2012, 119, 148–157. [Google Scholar] [CrossRef]
- González-Ferreiro, E.; Arellano-Pérez, S.; Castedo-Dorado, F.; Hevia, A.; Vega, J.A.; Vega-Nieva, D.; Álvarez-González, J.G.; Ruiz-González, A.D. Modelling the vertical distribution of canopy fuel load using national forest inventory and low-density airborne laser scanning data. PLoS ONE 2017, 12, e0176114. [Google Scholar] [CrossRef]
- Fernández-Landa, A.; Fernández-Moya, J.; Tomé, J.L.; Algeet-Abarquero, N.; Guillén-Climent, M.L.; Vallejo, R.; Sandoval, V.; Marchamalo, M. High resolution forest inventory of pure and mixed stands at regional level combining National Forest Inventory field plots, Landsat, and low density lidar. Int. J. Remote Sens. 2018, 39, 14. [Google Scholar] [CrossRef]
- Merino, A.; Balboa, M.A.; Rodríguez-Soalleiro, R.; Alvarez-González, J.G. Nutrient exports under different harvesting regimes in fast growing forest plantations in southern Europe. For. Ecol. Manag. 2005, 207, 325–339. [Google Scholar] [CrossRef]
- MAPAMA. Anuario de Estadística. Avance 2017. Ministerio de Agricultura, Pesca y Alimentación: Madrid, 2018. Available online: https://www.mapa.gob.es/es/desarrollo-rural/estadisticas/avance_2017_web_tcm30-510675.pdf (accessed on 15 July 2019).
- EEA. Biogeographical Regions. European Environment Agency: Copenhagen, Denmark, 2016. Available online: https://www.eea.europa.eu/data-and-maps/data/biogeographical-regions-europe-3 (accessed on 2 October 2018).
- MAPAMA. Mapa Forestal de España 1:25.000 (MFE25). 2012. Available online: https://www.miteco.gob.es/es/cartografia-y-sig/ide/descargas/biodiversidad/mfe.aspx (accessed on 2 October 2018).
- MARM. Cuarto Inventario Forestal Nacional; Comunidad Autónoma de Galicia, Dirección General del Medio Natural y Política Forestal: Madrid, Spain, 2011.
- MARM. Cuarto Inventario Forestal Nacional. Principado de Asturias; Ministerio de Medio Ambiente, y Medio Rural y Marino, Dirección General de Desarrollo Rural y Política Forestal: Madrid, Spain, 2012.
- MARM. Cuarto Inventario Forestal Nacional. Cantabria; Ministerio de Medio Ambiente, y Medio Rural y Marino, Dirección General de Desarrollo Rural y Política Forestal: Madrid, Spain, 2012.
- Alberdi, I.; Cañellas, I.; Vallejo, R. The Spanish National Forest Inventory: History, development, challenges and perspectives. Pesqui. Florest. Bras. 2017, 37, 361. [Google Scholar] [CrossRef]
- Castaño-Santamaría, J.; Barrio-Anta, M.; Álvarez-Álvarez, P. Potential above ground biomass production and total tree carbon sequestration in the major forest species in NW Spain. Int. For. Rev. 2013, 15, 273–289. [Google Scholar] [CrossRef]
- McGaughey, R.J. FUSION/LDV: Software for LIDAR Data Analysis and Visualization. In US Department of Agriculture, F.S.; Pacific Northwest Research Station: Seattle, WA, USA, 2014; p. 123. Available online: http://forsys.cfr.washington.edu/fusion/fusionlatest.html (accessed on 15 July 2019).
- White, J.; Tompalski, P.; Vastaranta, M.; Wulder, M.; Saarinen, N.; Stepper, C.; Coops, N. A Model Development and Application Guide for Generating an Enhanced Forest Inventory Using Airborne Laser Scanning Data and an Area-Based Approach; CWFC Information Report FI-X-018. Canadian Forest Service, Pacific Forestry Centre: Victoria, BC, Canada, 2017. [CrossRef]
- Guerra-Hernández, J.; Bastos Görgens, E.; García-Gutiérrez, J.; Estraviz Rodriguez, L.C.; Tomé, M.; González-Ferreiro, E. Comparison of ALS based models for estimating aboveground biomass in three types of Mediterranean forest. Eur. J. Remote Sens. 2016, 49, 185–204. [Google Scholar] [CrossRef]
- Görgens, E.B.; Montaghi, A.; Estraviz Rodriguez, L.C. A performance comparison of machine learning methods to estimate the fast-growing forest plantation yield based on laser scanning metrics. Comput. Electron. Agric. 2015, 116, 221–227. [Google Scholar] [CrossRef]
- Næsset, E.; Gobakken, T. Estimation of above-and below-ground biomass across regions of the boreal forest zone using airborne laser. Remote Sens. Environ. 2008, 112, 3079–3090. [Google Scholar] [CrossRef]
- Murgaš, V.; Sačkov, I.; Sedliak, M.; Tunák, D.; Chudý, F. Assessing horizontal accuracy of inventory plots in forests with different mix of tree species composition and development stage. J. For. Sci. 2018, 64, 478–485. [Google Scholar] [CrossRef]
- Alberdi, I.; Sandoval, V.; Condés, S.; Cañellas, I.; Vallejo, R. El Inventario Forestal Nacional Español, una herramienta para el conocimiento, la gestión y la conservación de los ecosistemas forestales arbolados. Ecosistemas 2016, 25, 88–97. [Google Scholar] [CrossRef]
- Smith, J.E.; Heath, L.S.; Jenkins, J.C. Forest Volume-to-Biomass Models and Estimates of Mass for Live and Standing Dead Trees of U.S. Forests; Gen. Tech. Rep. NE-298. U.S. Department of Agriculture, Forest Service, Northeastern Research Station: Newtown Square, PA, USA, 2003.
- Boudewyn, P.A.; Song, X.; Magnussen, S.; Gillis, M.D. Model-Based, Volume-to-Biomass Conversion for Forested and Vegetated Land in Canada; Information Report BC-X-411. Natural Resources Canada, Canadian Forest Service, Pacific Forestry Centre: Victoria, BC, Canada, 2007.
- Arias-Rodil, M.; Barrio-Anta, M.; Diéguez-Aranda, U. Developing a dynamic growth model for maritime pine in Asturias (NW Spain): Comparison with nearby regions. Ann. For. Sci. 2016, 73, 297–320. [Google Scholar] [CrossRef]
- Diéguez-Aranda, U.; Burkhart, H.E.; Rodríguez-Soalleiro, R. Modelling dominant height growth of radiata pine (Pinus radiata D. Don) plantations in north-western Spain. For. Ecol. Manag. 2005, 215, 271–284. [Google Scholar] [CrossRef]
- García-Villabrille, D. Modelización del Crecimiento y la Producción de Plantaciones de Eucalyptus globulus Labill. en el noroeste de España. Ph.D. Thesie, Universidad de Santiago de Compostela, Higher Polytechnic Engineering School, Lugo, Spain, 2015; 181p. Available online: https://core.ac.uk/download/pdf/75994613.pdf (accessed on 2 October 2018).
- Barrio-Anta, M.; Cámara-Obregón, A.; Castedo-Dorado, F.; López-Sanchez, C.A. Modelling and mapping the current and future optimal habitat and productivity for maritime pine stands under climate change in Northwestern Spain. 2019; in preparation. [Google Scholar]
- López-Sánchez, C.A.; Cámara-Obregón, A.; Castedo-Dorado, F.; Barrio-Anta, M. Modelling and mapping current and future optimal distribution and site productivity for radiata pine stands in Northwestern Spain. 2019; in preparation. [Google Scholar]
- López-Sánchez, C.A.; Cámara Obregón, A.; Oliveros, A.; Barrio-Anta, M. Predicting and mapping Eucalyptus globulus productivity from biophysical variables in Northwestern Spain. 2019; in preparation. [Google Scholar]
- Fassnacht, F.E.; Hartig, F.; Latifi, H.; Berger, C.; Hernández, J.; Corvalán, V.; Koch, B. Importance of sample size, data type and prediction method for remote sensing-based estimations of aboveground forest biomass. Remote Sens. Environ. 2014, 154, 102–114. [Google Scholar] [CrossRef]
- Shataee, S. Forest attributes estimation using aerial laser scanner and TM Data. For. Syst. 2013, 22, 484–496. [Google Scholar]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Quinlan, R.J. Learning with Continuous Classes. In Proceedings of the 5th Australian Joint Conference on Artificial Intelligence, Hobart, Tasmania, 16–18 November 1992; World Scientific: Singapore, 1992; pp. 343–348. [Google Scholar]
- Wang, Y.; Witten, I.H. Induction of model trees for predicting continuous classes. In Proceedings of the 9th European Conference on Machine Learning, Prague, Czech Republic, 23–25 April 1997. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Immitzer, M.; Vuolo, F.; Atzberger, C. First Experience with Sentinel-2 Data for Crop and Tree Species Classifications in Central Europe. Remote Sens. 2016, 8, 166. [Google Scholar] [CrossRef]
- Gislason, P.O.; Benediktsson, J.A.; Sveinsson, J.R. Random Forests for land cover classification. Pattern Recognit. Lett. 2006, 27, 294–300. [Google Scholar] [CrossRef]
- Wolpert, D. Stacked generalization. Neural Netw. 1992, 5, 241–259. [Google Scholar] [CrossRef]
- Naimi, A.I.; Balzer, L.B. Stacked generalization: An introduction to super learning. Eur. J. Epidemiol. 2018, 33, 459–464. [Google Scholar] [CrossRef]
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The WEKA data mining software: An update. Sigkdd Explor. 2009, 11, 10–18. [Google Scholar] [CrossRef]
- Valbuena, R.; Hernando, A.; Manzanera, J.A.; Görgens, E.B.; Almeida, D.R.A.; Mauro, F.; García-Abril, A.; Coomes, D.A. Enhancing of Accuracy Assessment for Forest Above-Ground Biomass Estimates Obtained from Remote Sensing via Hypothesis Testing and Overfitting Evaluation. Ecol. Model. 2017, 366, 15–26. [Google Scholar] [CrossRef]
- Zhiwei, X.; Xinghua, W. Research for information extraction based on wrapper model algorithm. In Proceedings of the Second International Conference on Computer Research and Development, Haiphong City, Vietnam, 7–10 May 2010; pp. 652–655. [Google Scholar]
- Hall, M.A.; Holmes, G. Benchmarking Attribute Selection Techniques for Discrete Class Data Mining. IEEE Trans. Knowl. Data Eng. 2003, 15, 3. [Google Scholar] [CrossRef]
- Packalén, P.; Maltamo, M. The k-MSN method for the prediction of species-specific stand attributes using airborne laser scanning and aerial photographs. Remote Sens. Environ. 2007, 109, 328–341. [Google Scholar] [CrossRef]
- Latifi, H.; Nothdurft, A.; Koch, B. Non-parametric prediction and mapping of standing timber volume and biomass in a temperate forest: Application of multiple optical/LiDAR-derived predictors. Forestry 2010, 83, 395–407. [Google Scholar] [CrossRef]
- Lee, J.; Im, J.; Kim, K.; Quackenbush, L.J. Machine Learning Approaches for Estimating Forest Stand Height Using Plot-Based Observations and Airborne LiDAR Data. Forests 2018, 9, 268. [Google Scholar] [CrossRef]
- Lefsky, M.A.; Harding, D.J.; Keller, M.; Cohen, W.B.; Carabajal, C.C.; Del Bom Espirito-Santo, F.; Hunter, M.O.; De Oliveira, R. Estimates of forest canopy height and aboveground biomass using ICESat. Geophys. Res. Lett. 2005, 32, L22S02. [Google Scholar] [CrossRef]
- Lefsky, M.A.; Cohen, W.B.; Harding, D.J.; Parker, G.G.; Acker, S.A.; Gower, S.T. LiDAR remote sensing of aboveground biomass in three biomes. Glob. Ecol. Biogeogr. 2002, 11, 393–400. [Google Scholar] [CrossRef]
- Li, M.; Im, J.; Quackenbush, L.; Liu, T. Forest biomass and carbon stock quantification using airborne lidar data: A case study over Huntington wildlife forest in the Adirondack Park. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 3143–3156. [Google Scholar] [CrossRef]
- Asner, G.P.; Mascaro, J.; Muller-Landau, H.C.; Vieilledent, G.; Vaudry, R.; Rasamoelina, M.; Hall, J.S.; Van Breugel, M. A universal airborne LiDAR approach for tropical forest carbon mapping. Oecologia 2012, 168, 1147–1160. [Google Scholar] [CrossRef] [PubMed]
- Bouvier, M.; Durrieu, S.; Fournier, R.A.; Renaud, J.P. Generalizing predictive models of forest inventory attributes using an area-based approach with airborne LiDAR data. Remote Sens. Environ. 2015, 156, 322–334. [Google Scholar] [CrossRef]
- Ni-Meister, W.; Lee, S.; Strahler, A.H.; Woodcock, C.E.; Schaaf, C.; Yao, T.; Ranson, K.J.; Sun, G.; Blair, J.B. Assessing general relationships between aboveground biomass and vegetation structure parameters for improved carbon estimate from lidar remote sensing. J. Geophys. Res. Biogeosci. 2010, 115. [Google Scholar] [CrossRef]
- Lekuona Zuazo, I.; Montealegre Gracia, A.L.; Lamelas Gracia, M.T. Cartografía de la biomasa aérea total en masas de Pinus radiata D. Don a partir de datos públicos LiDAR-PNOA e Inventario Forestal Nacional. GeoFocus 2017, 20, 87–107. [Google Scholar] [CrossRef]
- Tomé-Morán, J.L.; Esteban Cava, J.; Martín Alcón, S.; Escamochero, I.; Fernández-Landa, A. ForestMap, Online forest inventories using Murcia Regional Airborne LiDAR Data. In Proceedings of the XVII Congreso de la Asociación Española de Teledetección, Murcia, Spain, 3–7 Octubre 2017; pp. 147–150. [Google Scholar]
- González-Ferreiro, E.; Diéguez-Aranda, U.; Miranda, D. Estimation of stand variables in Pinus radiata D. Don plantations using different LiDAR pulse densities. Forestry 2012, 85, 281–292. [Google Scholar] [CrossRef]
- Gonzalez-Ferreiro, E.; Miranda, D.; Barreiro-Fernandez, L.; Bujan, S.; Garcia-Gutierrez, J.; Dieguez-Aranda, U. Modelling stand biomass fractions in Galician Eucalyptus globulus plantations by use of different LiDAR pulse densities. For. Syst. 2013, 22, 510–525. [Google Scholar] [CrossRef]
- Gonçalves-Seco, L.; González-Ferreiro, E.; Diéguez-Aranda, U.; Fraga-Bugallo, B.; Crecente, R.; Miranda, D. Assessing the attributes of high-density Eucalyptus globulus stands using airborne laser scanner data. Int. J. Remote Sens. 2011, 32. [Google Scholar] [CrossRef]
- García-Gutiérrez, J.; Gonzalez-Ferreiro, E.; Riquelme-Santos, J.C.; Miranda, D.; Dieguez-Aranda, U.; Navarro-Cerrillo, R.M. Evolutionary feature selection to estimate forest stand variables using LiDAR. Int. J. Appl. Earth Obs. Geoinf. 2014, 26, 119–131. [Google Scholar] [CrossRef]
- Navarro, J.A.; Fernández-Landa, A.; Tomé, J.L.; Guillén-Climent, M.L.; Ojeda, J.C. Testing the quality of forest variable estimation using dense image matching: A comparison with airborne laser scanning in a Mediterranean pine forest. Int. J. Remote Sens. 2018, 39. [Google Scholar] [CrossRef]
- Domingo, D.; Lamelas, M.T.; Montealegre, A.L.; García-Martín, A.; De la Riva, J. Estimation of Total Biomass in Aleppo Pine Forest Stands Applying Parametric and Nonparametric Methods to Low-Density Airborne Laser Scanning Data. Forests 2018, 9, 158. [Google Scholar] [CrossRef]
- Hernando, A.; Puerto, L.; Mola-Yudego, B.; Manzanera, J.A.; García-Abril, A.; Maltamo, M.; Valbuena, R. Estimation of forest biomass components using airborne LiDAR and multispectral sensors. iForest 2019, 12, 207–213. [Google Scholar] [CrossRef]
- Järnstedt, J.; Pekkarinen, A.; Tuominen, S.; Ginzler, C.; Holopainen, M.; Viitala, R. Forest variable estimation using a high-resolution digital surface model. ISPRS J. Photogramm. Remote Sens. 2012, 74, 78–84. [Google Scholar] [CrossRef]
- Kotivuori, E.; Korhonen, L.; Packalen, P. Nationwide airborne laser scanning based models for volume, biomass and dominant height in Finland. Silva Fenn. 2016, 50, 28. [Google Scholar] [CrossRef]
- Stephens, P.R.; Kimberley, M.O.; Beets, P.N.; Paul, T.S.H.; Searles, N.; Bell, A.; Brack, C.; Broadley, J. Airborne scanning LiDAR in a double sampling forest carbon inventory. Remote Sens. Environ. 2012, 117, 348–357. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Species | Nº Plots | TV (m3/ha) | AITV (m3/ha Year) | AGB (t/ha) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Mean | Min | Max | Std | Mean | Min | Max | Std | Mean | Min | Max | Std | ||
| E. globulus | 477 | 209.52 | 1.50 | 812.69 | 155.15 | 16.84 | 0.45 | 50.48 | 10.19 | 140.17 | 1.37 | 570.33 | 106.24 |
| P. pinaster | 760 | 162.41 | 0.98 | 567.55 | 120.94 | 9.19 | 0.10 | 27.45 | 5.80 | 91.57 | 0.44 | 325.62 | 68.78 |
| P. radiata | 191 | 178.17 | 1.29 | 611.77 | 145.14 | 11.88 | 0.29 | 35.19 | 7.79 | 96.89 | 0.75 | 334.27 | 79.14 |
| ALS Metrics | Description | ||
|---|---|---|---|
| Height metrics | Metrics expressing the central trend in ALS height distribution | hmean | mean |
| hmode | mode | ||
| Metrics expressing the dispersion of ALS height distribution | hSD | standard deviation | |
| hVAR | variance | ||
| hAAD | absolute average deviation | ||
| hIQ | interquartile range | ||
| hCV | coefficient of variation | ||
| hmax, hmin | maximum and minimum | ||
| Metrics expressing the shape of ALS height distribution | hSkw | skewness | |
| hKurt | kurtosis | ||
| CRR | canopy relief ratio ((mean height−min height)/(max height−min height)) | ||
| Percentiles of the ALS height distribution | h01, h20,… h95, h99 | 1th,5th, 10th, 20th, 25th, 30th, 40th, 50th, 60th, 70th, 75th, 80th, 90th, 95th, 99th percentiles | |
| Canopy cover metrics | Fixed height break threshold (HBT) | CC | percentage of first returns above 2.00 m/total all returns |
| PARA2 | percentage of all returns above 2.00 m/total all returns | ||
| ARA2/TFR | ratio between all returns above 2.00 m and total of first returns | ||
| Variable HBT | PFRAM | percentage of first returns above mean/total all returns | |
| PARAM | percentage of all returns above mean/total all returns | ||
| PARAMO | percentage of all returns above mode/total all returns | ||
| PFRAMO | percentage of first returns above mode/total all returns | ||
| ARAM/TFR | ratio between all returns above mean and total of first returns | ||
| ARAMO/TFR | ratio between all returns above mode and total of first returns | ||
| Province | SNFI-4 (Year) | ALS (Year) |
|---|---|---|
| A Coruña | 2008–2009 | 2010 |
| Lugo | 2009 | 2009–2010 |
| Ourense | 2009 | 2009 |
| Pontevedra | 2009 | 2009–2010 |
| Asturias | 2009–2010 | 2012 |
| Cantabria | 2012 | 2010–2012 |
| Species | Statistics | Variable | MLR | kNN | RT | RF | EM | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Mean | Std | Mean | Std | Mean | Std | Mean | Std | Mean | Std | |||
| Eucalyptus globulus | R2 | TV | 0.80 | 0.02 | 0.78 | 0.03 | 0.81 | 0.03 | 0.83 | 0.03 | 0.82 | 0.03 |
| AITV | 0.67 | 0.05 | 0.65 | 0.05 | 0.66 | 0.05 | 0.67 | 0.05 | 0.68 | 0.05 | ||
| AGB | 0.79 | 0.03 | 0.77 | 0.04 | 0.81 | 0.03 | 0.82 | 0.03 | 0.82 | 0.03 | ||
| Bias | TV | −0.08 | 0.01 | −12.08 | 1.58 | −1.86 | 0.23 | −2.30 | 0.27 | −0.76 | 0.09 | |
| AITV | 0.01 | 0.00 | −0.38 | 0.05 | 0.00 | 0.00 | 0.00 | 0.00 | 0.01 | 0.00 | ||
| AGB | −0.18 | 0.02 | −7.00 | 0.92 | −1.17 | 0.15 | −1.36 | 0.16 | −0.43 | 0.05 | ||
| rRMSE (%) | TV | 33.16 | 3.99 | 35.23 | 4.78 | 31.78 | 3.77 | 30.71 | 3.55 | 30.81 | 3.46 | |
| AITV | 35.03 | 4.19 | 35.57 | 4.52 | 35.21 | 4.52 | 34.59 | 4.00 | 34.24 | 3.94 | ||
| AGB | 34.75 | 4.44 | 36.91 | 5.00 | 32.79 | 4.05 | 31.59 | 3.76 | 31.71 | 3.65 | ||
| Pinus pinaster | R2 | TV | 0.72 | 0.03 | 0.71 | 0.03 | 0.73 | 0.03 | 0.73 | 0.03 | 0.74 | 0.03 |
| AITV | 0.53 | 0.05 | 0.54 | 0.05 | 0.51 | 0.06 | 0.55 | 0.05 | 0.56 | 0.05 | ||
| AGB | 0.72 | 0.03 | 0.71 | 0.04 | 0.72 | 0.03 | 0.73 | 0.03 | 0.74 | 0.03 | ||
| Bias | TV | −0.01 | 0.00 | −4.01 | 0.42 | 0.49 | 0.05 | 0.36 | 0.03 | −0.02 | 0.00 | |
| AITV | 0.00 | 0.00 | −0.13 | 0.01 | −0.01 | 0.00 | 0.03 | 0.00 | 0.01 | 0.00 | ||
| AGB | −0.13 | 0.01 | −1.52 | 0.16 | 0.18 | 0.02 | 0.25 | 0.02 | −0.02 | 0.00 | ||
| rRMSE (%) | TV | 39.05 | 3.62 | 39.88 | 4.08 | 38.39 | 3.68 | 38.17 | 3.62 | 37.95 | 3.53 | |
| AITV | 43.03 | 4.17 | 42.88 | 4.25 | 44.09 | 4.09 | 42.33 | 3.79 | 41.95 | 3.91 | ||
| AGB | 39.58 | 3.56 | 40.21 | 4.05 | 39.44 | 3.67 | 39.00 | 3.65 | 38.51 | 3.57 | ||
| Pinus radiata | R2 | TV | 0.75 | 0.06 | 0.76 | 0.05 | 0.75 | 0.06 | 0.79 | 0.05 | 0.78 | 0.05 |
| AITV | 0.63 | 0.09 | 0.65 | 0.07 | 0.62 | 0.08 | 0.69 | 0.06 | 0.67 | 0.06 | ||
| AGB | 0.77 | 0.07 | 0.78 | 0.05 | 0.77 | 0.06 | 0.80 | 0.05 | 0.79 | 0.06 | ||
| Bias | TV | 1.16 | 0.25 | −5.45 | 1.20 | 0.52 | 0.12 | 0.03 | 0.00 | −1.01 | 0.19 | |
| AITV | 0.00 | 0.00 | −0.07 | 0.01 | 0.14 | 0.03 | 0.02 | 0.00 | −0.10 | 0.02 | ||
| AGB | −0.74 | 0.16 | −7.14 | 1.83 | −0.86 | 0.20 | −0.85 | 0.19 | −0.47 | 0.10 | ||
| rRMSE (%) | TV | 40.81 | 8.83 | 40.29 | 8.65 | 40.18 | 10.58 | 37.23 | 7.32 | 38.35 | 7.19 | |
| AITV | 39.60 | 8.63 | 39.11 | 7.70 | 40.43 | 8.14 | 36.67 | 6.32 | 37.50 | 6.52 | ||
| AGB | 40.61 | 9.54 | 42.28 | 11.02 | 40.86 | 9.67 | 38.27 | 8.77 | 39.02 | 8.71 | ||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Novo-Fernández, A.; Barrio-Anta, M.; Recondo, C.; Cámara-Obregón, A.; López-Sánchez, C.A. Integration of National Forest Inventory and Nationwide Airborne Laser Scanning Data to Improve Forest Yield Predictions in North-Western Spain. Remote Sens. 2019, 11, 1693. https://doi.org/10.3390/rs11141693
Novo-Fernández A, Barrio-Anta M, Recondo C, Cámara-Obregón A, López-Sánchez CA. Integration of National Forest Inventory and Nationwide Airborne Laser Scanning Data to Improve Forest Yield Predictions in North-Western Spain. Remote Sensing. 2019; 11(14):1693. https://doi.org/10.3390/rs11141693
Chicago/Turabian StyleNovo-Fernández, Alís, Marcos Barrio-Anta, Carmen Recondo, Asunción Cámara-Obregón, and Carlos A. López-Sánchez. 2019. "Integration of National Forest Inventory and Nationwide Airborne Laser Scanning Data to Improve Forest Yield Predictions in North-Western Spain" Remote Sensing 11, no. 14: 1693. https://doi.org/10.3390/rs11141693
APA StyleNovo-Fernández, A., Barrio-Anta, M., Recondo, C., Cámara-Obregón, A., & López-Sánchez, C. A. (2019). Integration of National Forest Inventory and Nationwide Airborne Laser Scanning Data to Improve Forest Yield Predictions in North-Western Spain. Remote Sensing, 11(14), 1693. https://doi.org/10.3390/rs11141693