
Analysing Key Steps of the Photogrammetric Pipeline for Museum Artefacts 3D Digitisation

 ,
,  ,
,  and
and 
Abstract
:1. Introduction
- The availability of sensors and equipment;
- The number of objects to be digitised;
- The artefact dimension, shape and material [5];
- The museum spaces dedicated to object digitization;
- The time available for tackling the acquisition and processing phases.
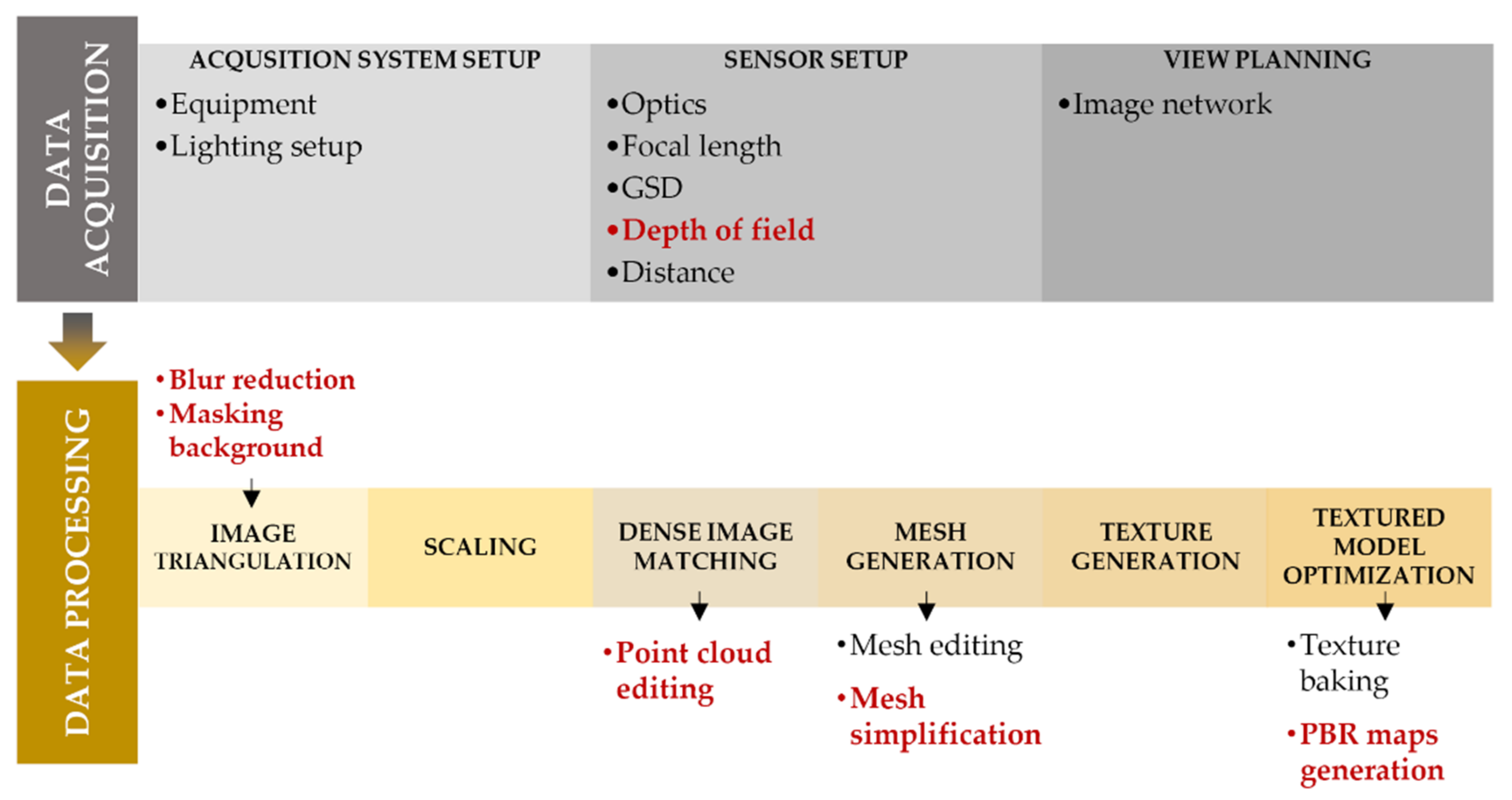
Aim and Paper Contribution
- -
- Acquisition phase: depth of field (DoF) effects when digitisation medium and small-sized artefacts are investigated. Experiments capturing images with different aperture settings and several focal lengths are proposed.
- -
- Data pre-processing phase: automatic image deblurring algorithms and object background masking are considered.
- -
- Data post-processing phase: tests are performed with point cloud cleaning solutions, while mesh optimization procedures are deepened by comparing software performance for polygons decimation. Some insights on the texture mapping are also provided.
2. Related Works
2.1. Data Acquisition
Depth of Field (DoF)
2.2. Data Pre-Processing
2.2.1. Unsharp Images
2.2.2. Masking Object Background
2.3. Data Post-Processing
2.3.1. Dense Point Cloud Cleaning
2.3.2. Mesh Simplification and Texture Mapping
2.3.3. PBR Rendering Pipeline
3. Image Acquisition
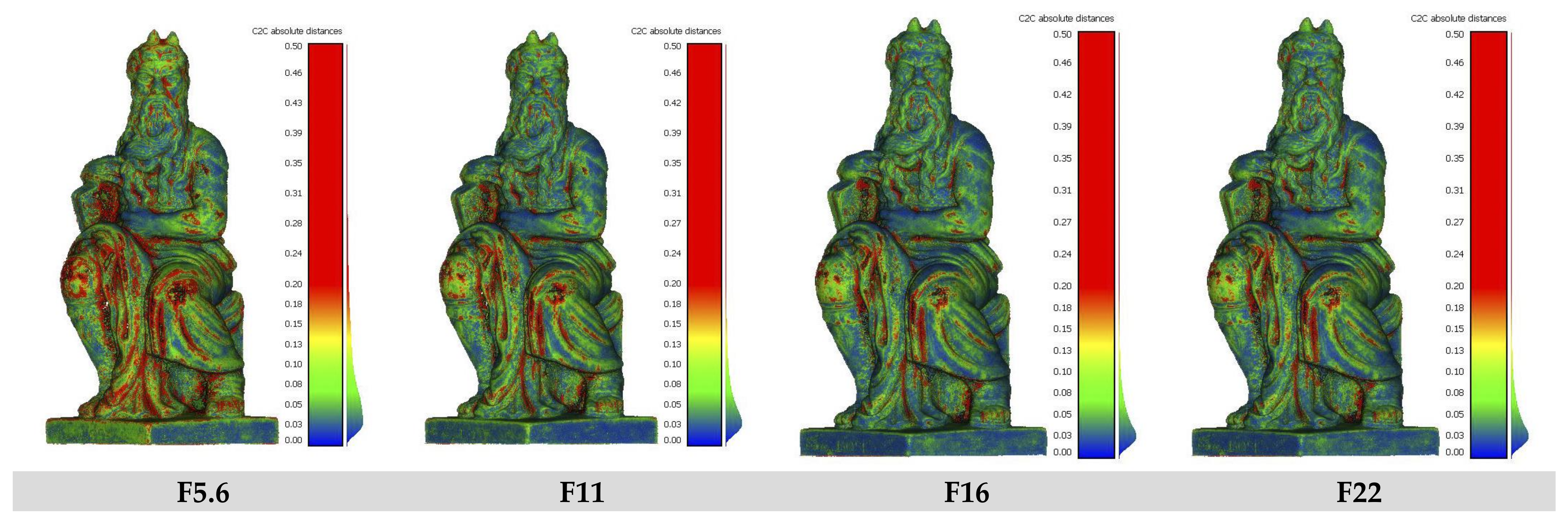
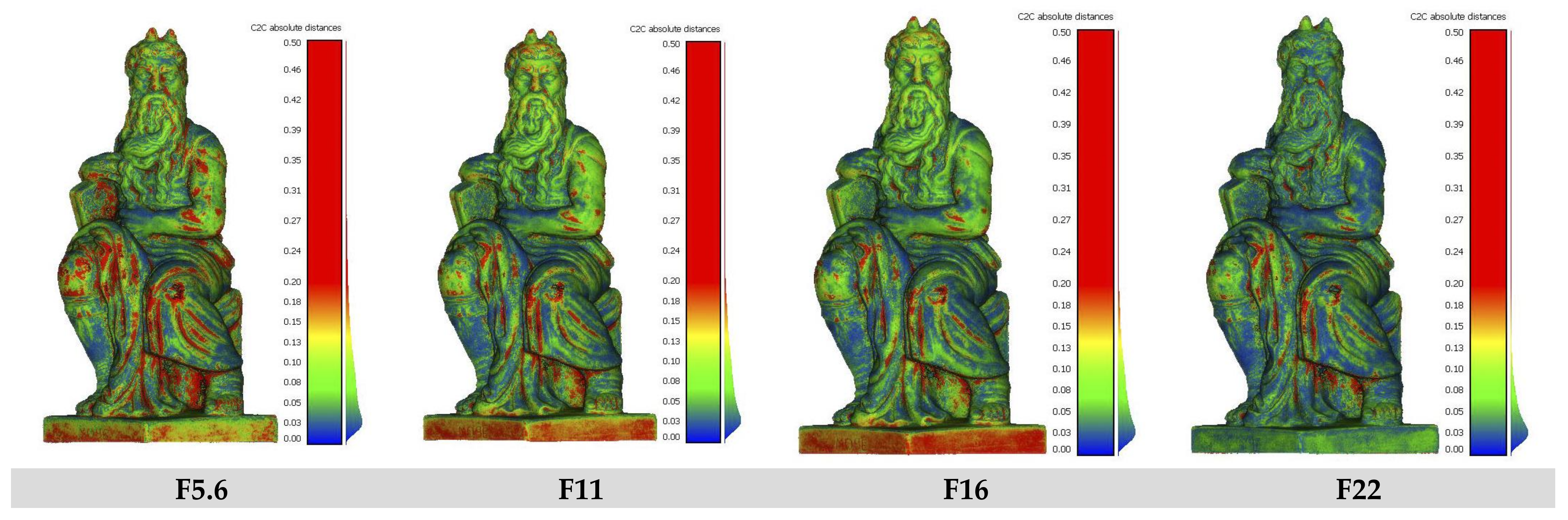
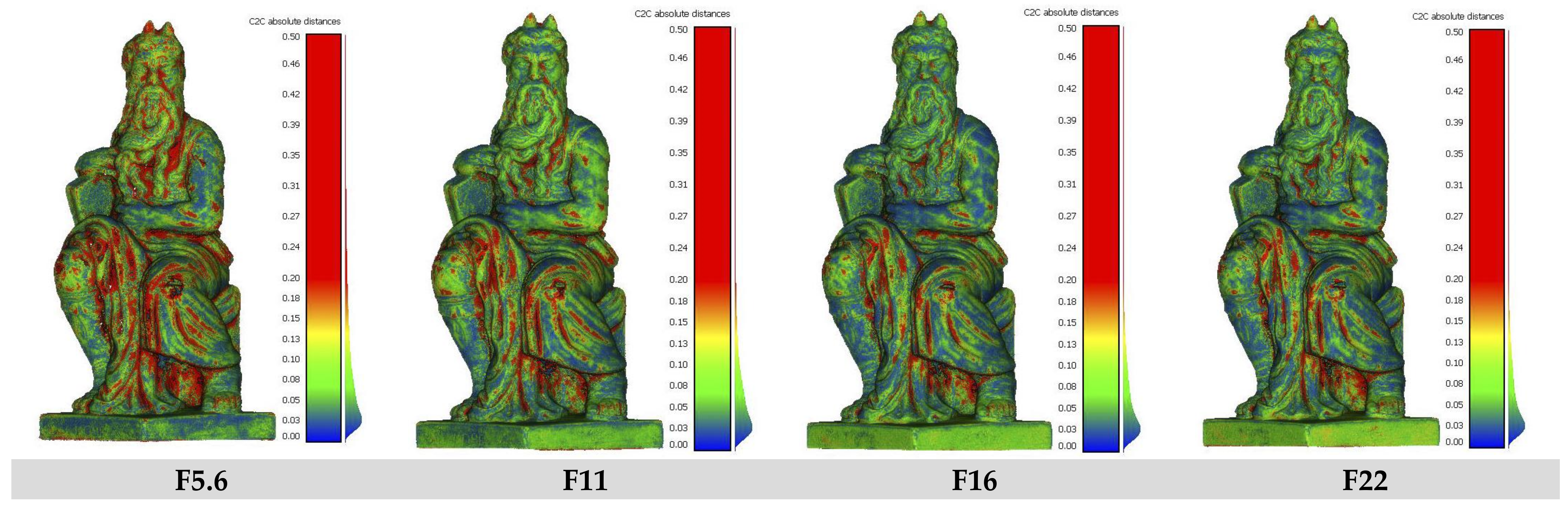
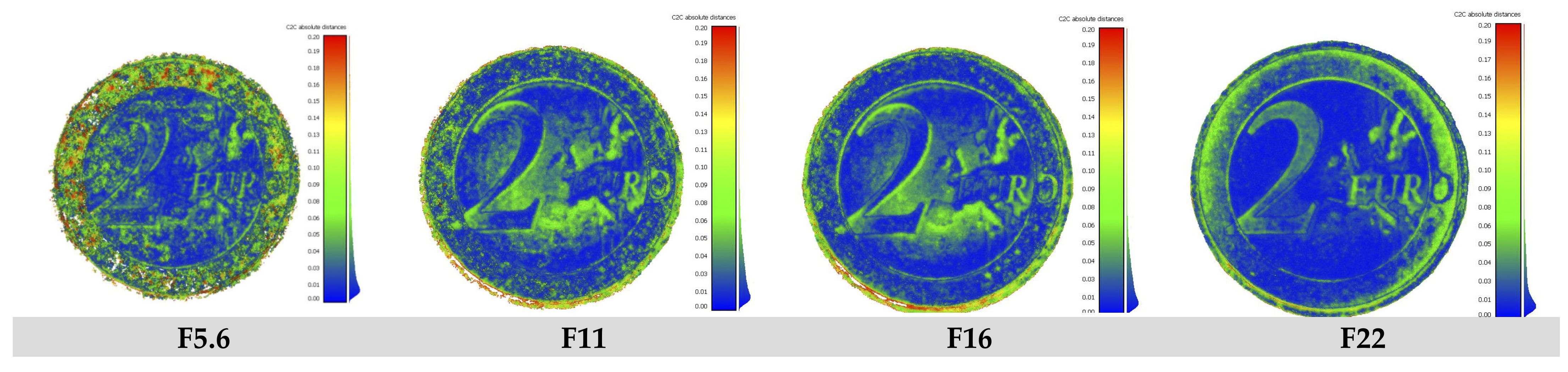
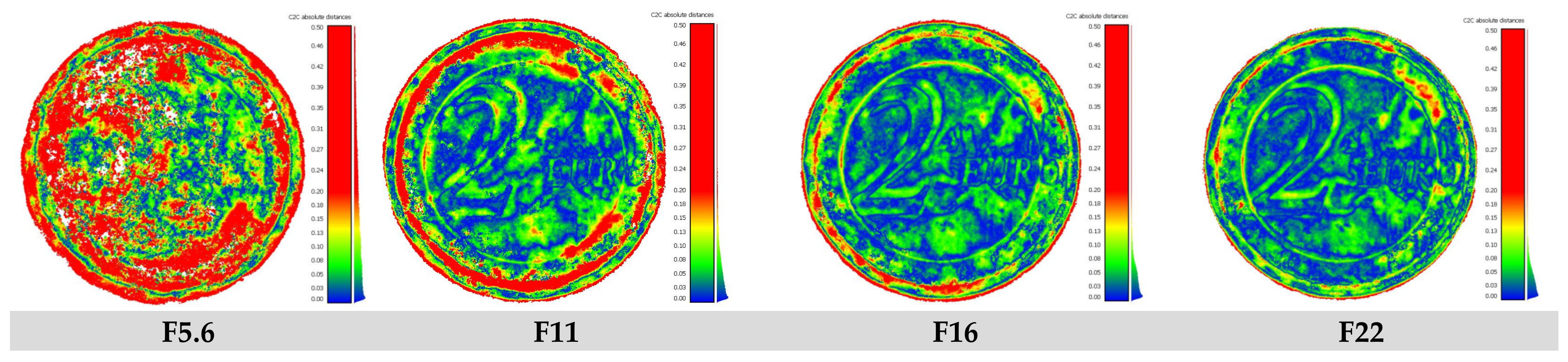
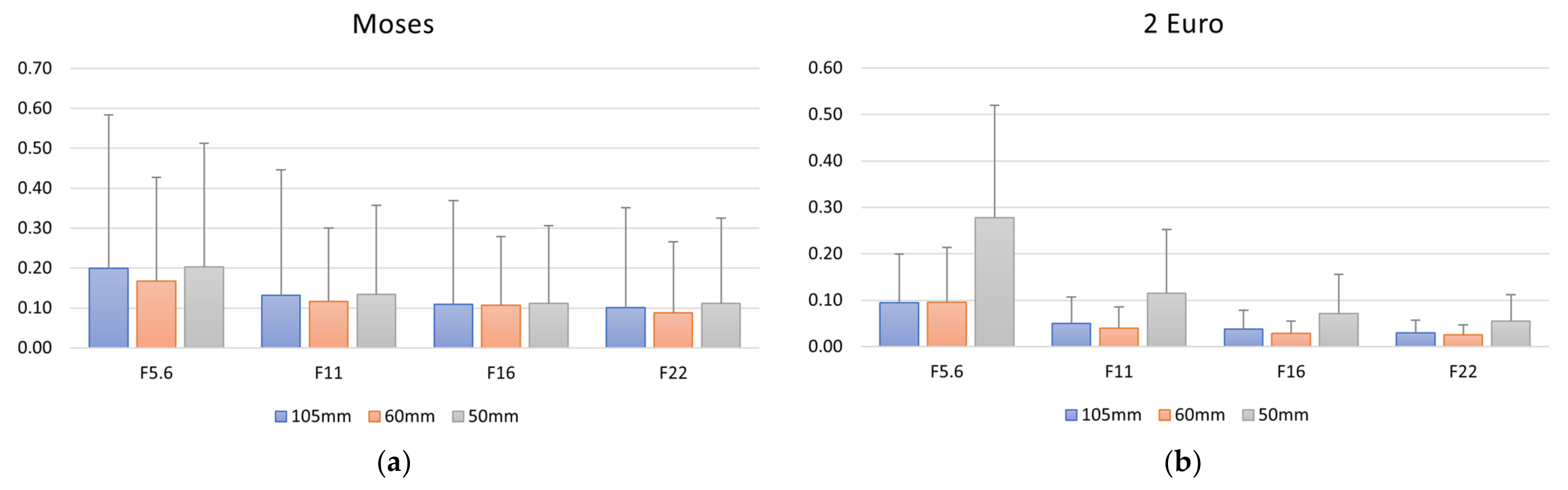
3.1. DoF Investigations
The Influence of DoF on 3D Reconstruction
4. Image Pre-Processing
4.1. Deblur Images
4.1.1. Investigated Approaches
4.1.2. Experiments
4.2. Automatic Masking Backgrounds
4.2.1. Masking Methods
- Unsupervised learning approach: the K-means clustering approach breaks an unlabelled dataset into K groups of data points (referred to as clusters) based on their similarities. Considering that colour similarity is a fundamental feature in image segmentation, some pre-processing is applied to improve the results. In particular, RGB images are converted into the CIELAB colour space, where L* indicates the luminance and a* and b* axes respectively extend from green to blue and blue to yellow. Based on the prevailing chromatic object range, different channels can be chosen. Once the K-means algorithm is run, outputs are used to create binary masks, automatically refined through morphological processes (e.g., erosion and dilation) to remove minor undesirable components or fill small holes.
- Supervised Machine Learning approach [45]: to train the random forest algorithm and assign a class label (object or background) to each image pixel, image features and user annotations are necessary components. Colours, edge filters and texture features are used to characterise the pixel information in a multi-scale approach. Then, the model is built from a few annotated images, and the semantic segmentation is extended to the entire and/or similar datasets. Finally, the segmentation output is transformed into binary masks and further refined with morphological processes.
- Depth map-based approach: given a set of images of an artefact, depth maps are extracted by applying photogrammetric processing at a low image resolution. Possible points belonging to the artefact background are removed from the dense reconstruction before exporting the depth maps, correcting correspondent brightness and contrast values. Then, some image processing filters are applied to the exported depth maps, such as (i) a Gaussian blur filter, or Gaussian smoothing, to minimise image noise, and (ii) a Posterisation filter to reduce the amount of image colours while restoring sharper edges. In the developed procedure, the post-processing phase is run in a single round until mask generation. It is also worth noting that depth maps could be quickly predicted using monocular techniques and deep learning networks [97]. However, while promising for dealing with the typical ill-posed problem, these approaches are not well suited for masking artefact datasets, and further research in this field is required.
4.2.2. Masking Experiments
5. Data Post-Processing
5.1. Automatic Point Clouds Cleaning
5.1.1. Investigated Denoising Methods
- The Statistical Outlier Removal (S.O.R.): it is a popular and efficient method implemented in Cloud Compare [98] as part of the Point Cloud Library (PCL, [99]). Once the number of points to be considered as neighbours is set, using a K-means nearest neighbours approach [100], the average distance of each sampling point to its neighbours is calculated. Points outside the range defined by the global average distances and standard deviation are recognized as outliers and removed from data.
- PointCleanNet (PCNet—[64]): as one of the pioneering learning-based denoising approaches, this method exploits an architecture adapted from PCPNet [101] for locally estimating 3D shape point cloud characteristics. In its implementation, a first module allows removing detected outliers, while some correction vectors are later calculated for projecting noisy points on the estimated clean surface.
- Score-based denoising [66]: it relies on a neural network architecture that employs the estimated score of some point distributions to perform gradient ascent and denoise the point cloud. A noisy point cloud distribution is treated as a set of noise-free points p(x) convolved with a noise model n. The (p*n)(x) mode is, in this case, the underlying clean surface. The log-likelihood of each point is increased via gradient ascent and each point position is iteratively updated, while outliers are neither detected nor removed.
5.1.2. Denoising Experiments
5.2. Mesh Simplification
5.2.1. Investigated Tools for Mesh Decimation
5.2.2. Decimation Tests
5.3. Texture Mapping
5.3.1. PBR Texture Maps
- Albedo map: this texture contains the base colour information of the surface or the base reflectivity when texels are metallic. Compared to the diffuse map, the Albedo map does not contain any lighting information. Shadows and reflections are added subsequently and coherently with the visualisation scene.
- Normal map: this is a texture map containing a unique normal for each fragment to describe irregular surfaces. Normal mapping is a common technique in 3D computer graphics for adding details on simplified models.
- Metallic map: this map represents whether each texel is metallic or not. It is a black and white texture acting as a mask for defining whether the texture behaves as metal or not.
- Roughness map: this texture map defines how rough each texel is, influencing the light diffusion and direction, while the light intensity remains constant.
- Ambient Occlusion map (AO): this map is used to provide indirect lighting information, introducing an extra shadowing factor for enhancing the geometry surface. The map is a grayscale image, where white regions indicate areas receiving all indirect illumination.
- The next section presents some texture outputs and their capability of enhancing the object visualisation.
5.3.2. Generating Texture Maps
6. Discussions
6.1. Image Acquisition
6.2. Image Pre-Processing
6.3. Data Post-Processing
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tausch, R.; Domajnko, M.; Ritz, M.; Knuth, M.; Santos, P.; Fellner, D. Towards 3D Digitization in the GLAM (Galleries, Libraries, Archives, and Museums) Sector—Lessons Learned and Future Outlook. IPSI Trans. Internet Res. 2020, 16, 45–53. [Google Scholar]
- European Commission Commission Recommendation of 27 October 2011 on the Digitisation and Online Accessibility of Cultural Material and Digital Preservation (2011/711/EU); 2011. Available online: https://eur-lex.europa.eu/LexUriServ/LexUriServ.do?uri=OJ:L:2011:283:0039:0045:EN:PDF (accessed on 17 February 2022).
- Network of European Museum Organisations Working Group on Digitilisation and Intellectual Property Rights, Digitisation and IPR in European Museums; 2020. Available online: https://www.ne-mo.org/fileadmin/Dateien/public/Publications/NEMO_Final_Report_Digitisation_and_IPR_in_European_Museums_WG_07.2020.pdf (accessed on 17 February 2022).
- Remondino, F.; Menna, F.; Koutsoudis, A.; Chamzas, C.; El-Hakim, S. Design and Implement a Reality-Based 3D Dig-itisation and Modelling Project. In Proceedings of the 2013 Digital Heritage International Congress (Digital Heritage), Marseille, France, 28 October–1 November 2013; Volume 1. [Google Scholar]
- Mathys, A.; Brecko, J.; van den Spiegel, D.; Semal, P. 3D and Challenging Materials. In Proceedings of the IEEE 2015 Digital Heritage, Granada, Spain, 28 September–2 October 2015; Volume 1, pp. 19–26. [Google Scholar]
- Cultlab3d. Available online: https://www.cultlab3d.de/ (accessed on 17 February 2022).
- Witikon. Available online: http://witikon.eu/ (accessed on 17 February 2022).
- The British Museum. Available online: https://sketchfab.com/britishmuseum (accessed on 7 February 2022).
- Menna, F.; Nocerino, E.; Morabito, D.; Farella, E.M.; Perini, M.; Remondino, F. An Open Source Low-Cost Automatic System for Image-Based 3D Digitization. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 42, 155. [Google Scholar] [CrossRef] [Green Version]
- Gattet, E.; Devogelaere, J.; Raffin, R.; Bergerot, L.; Daniel, M.; Jockey, P.H.; de Luca, L. A Versatile and Low-Cost 3D Acquisition and Processing Pipeline for Collecting Mass of Archaeological Findings on the Field. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, 40, 299. [Google Scholar] [CrossRef] [Green Version]
- Farella, E.M.; Morelli, L.; Grilli, E.; Rigon, S.; Remondino, F. Handling Critical Aspects in Massive Photogrammetric Digitization of Museum Assets. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2022, 46, 215–222. [Google Scholar] [CrossRef]
- Fraser, C.S. Network Design Considerations for Non-Topographic Photogrammetry. Photogramm. Eng. Remote Sens. 1984, 50, 1115–1126. [Google Scholar]
- Hosseininaveh, A.; Serpico, M.; Robson, S.; Hess, M.; Boehm, J.; Pridden, I.; Amati, G. Automatic Image Selection in Photogrammetric Multi-View Stereo Methods. In Proceedings of the 13th International Symposium on Virtual Reality, Archaeology, and Cultural Heritage, incorporating the 10th Eurographics Workshop on Graphics and Cultural Heritage, VAST—Short and Project Papers, Brighton, UK, 19–21 November 2012. [Google Scholar]
- Alsadik, B.; Gerke, M.; Vosselman, G. Automated Camera Network Design for 3D Modeling of Cultural Heritage Objects. J. Cult. Herit. 2013, 14, 515–526. [Google Scholar] [CrossRef]
- Ahmadabadian, A.H.; Robson, S.; Boehm, J.; Shortis, M. Stereo-Imaging Network Design for Precise and Dense 3d Reconstruction. Photogramm. Rec. 2014, 29, 317–336. [Google Scholar] [CrossRef]
- Voltolini, F.; Remondino, F.; Pontin, M.G.L. Experiences and Considerations in Image-Based-Modeling of Complex Architectures. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2006, 36, 309–314. [Google Scholar]
- El-Hakim, S.; Beraldin, J.A.; Blais, F. Critical Factors and Configurations for Practical Image-Based 3D Modeling. In Proceedings of the 6th Conference Optical 3D Measurements Techniques, Zurich, Switzerland, 23–25 September 2003; pp. 159–167. [Google Scholar]
- Fraser, C.S.; Woods, A.; Brizzi, D. Hyper Redundancy for Accuracy Enhancement in Automated Close Range Photogrammetry. Photogramm. Rec. 2005, 20, 205–217. [Google Scholar] [CrossRef]
- Menna, F.; Rizzi, A.; Nocerino, E.; Remondino, F.; Gruen, A. High resolution 3d modeling of the behaim globe. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2012, 39, 115–120. [Google Scholar] [CrossRef] [Green Version]
- Sapirstein, P. A High-Precision Photogrammetric Recording System for Small Artifacts. J. Cult. Herit. 2018, 31, 33–45. [Google Scholar] [CrossRef]
- Lastilla, L.; Ravanelli, R.; Ferrara, S. 3D High-Quality Modeling of Small and Complex Archaeological Inscribed Objects: Relevant Issues and Proposed Methodology. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, 4211, 699–706. [Google Scholar] [CrossRef] [Green Version]
- Webb, E.K.; Robson, S.; Evans, R. Quantifying depth of field and sharpness for image-based 3d reconstruction of heritage objects. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 43, 911–918. [Google Scholar] [CrossRef]
- Brecko, J.; Mathys, A.; Dekoninck, W.; Leponce, M.; VandenSpiegel, D.; Semal, P. Focus Stacking: Comparing Commercial Top-End Set-Ups with a Semi-Automatic Low Budget Approach. A Possible Solution for Mass Digitization of Type Specimens. ZooKeys 2014, 464, 1. [Google Scholar] [CrossRef] [Green Version]
- Gallo, A.; Muzzupappa, M.; Bruno, F. 3D Reconstruction of Small Sized Objects from a Sequence of Multi-Focused Images. J. Cult. Herit. 2014, 15, 173–182. [Google Scholar] [CrossRef]
- Clini, P.; Frapiccini, N.; Mengoni, M.; Nespeca, R.; Ruggeri, L. Sfm technique and focus stacking for digital documentation of archaeological artifacts. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 41, 229–236. [Google Scholar] [CrossRef] [Green Version]
- Kontogianni, G.; Chliverou, R.; Koutsoudis, A.; Pavlidis, G.; Georgopoulos, A. Enhancing Close-up Image Based 3D Digitisation with Focus Stacking. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 42, 421–425. [Google Scholar] [CrossRef] [Green Version]
- Niederost, M.; Niederost, J.; Scucka, J. Automatic 3D Reconstruction and Visualization of Microscopic Objects from a Monoscopic Multifocus Image Sequence. Int. Arch. Photogramm. 2003, 34. [Google Scholar] [CrossRef]
- Guidi, G.; Gonizzi, S.; Micoli, L.L. Image Pre-Processing for Optimizing Automated Photogrammetry Performances. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2014, 2, 145–152. [Google Scholar] [CrossRef] [Green Version]
- Gaiani, M.; Remondino, F.; Apollonio, F.I.; Ballabeni, A. An Advanced Pre-Processing Pipeline to Improve Automated Photogrammetric Reconstructions of Architectural Scenes. Remote Sens. 2016, 8, 178. [Google Scholar] [CrossRef] [Green Version]
- Calantropio, A.; Chiabrando, F.; Seymour, B.; Kovacs, E.; Lo, E.; Rissolo, D. Image pre-processing strategies for enhancing photogrammetric 3d reconstruction of underwater shipwreck datasets. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 43, 941–948. [Google Scholar] [CrossRef]
- Verhoeven, G.J. Focusing on Out-of-Focus: Assessing Defocus Estimation Algorithms for the Benefit of Automated Image Masking. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 42, 1149–1156. [Google Scholar] [CrossRef] [Green Version]
- Kupyn, O.; Martyniuk, T.; Wu, J.; Wang, Z. DeblurGAN-v2: Deblurring (Orders-of-Magnitude) Faster and Better. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Tao, X.; Gao, H.; Shen, X.; Wang, J.; Jia, J. Scale-Recurrent Network for Deep Image Deblurring. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Xu, R.; Xiao, Z.; Huang, J.; Zhang, Y.; Xiong, Z. EDPN: Enhanced Deep Pyramid Network for Blurry Image Restoration. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Nashville, TN, USA, 19–25 June 2021. [Google Scholar]
- Nah, S.; Son, S.; Timofte, R.; Lee, K.M.; Tseng, Y.; Xu, Y.S.; Chiang, C.M.; Tsai, Y.M.; Brehm, S.; Scherer, S.; et al. NTIRE 2020 Challenge on Image and Video Deblurring. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Burdziakowski, P. A Novel Method for the Deblurring of Photogrammetric Images Using Conditional Generative Adversarial Networks. Remote Sens. 2020, 12, 2586. [Google Scholar] [CrossRef]
- Repoux, M. Comparison of Background Removal Methods for XPS. Surf. Interface Anal. 1992, 18, 567–570. [Google Scholar] [CrossRef]
- Gordon, G.; Darrell, T.; Harville, M.; Woodfill, J. Background Estimation and Removal Based on Range and Color. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Fort Collins, CO, USA, 23–25 June 1999; Volume 2. [Google Scholar] [CrossRef]
- Mazet, V.; Carteret, C.; Brie, D.; Idier, J.; Humbert, B. Background Removal from Spectra by Designing and Minimising a Non-Quadratic Cost Function. Chemom. Intell. Lab. Syst. 2005, 76, 121–133. [Google Scholar] [CrossRef]
- Grilli, E.; Battisti, R.; Remondino, F. An Advanced Photogrammetric Solution to Measure Apples. Remote Sens. 2021, 13, 3960. [Google Scholar] [CrossRef]
- Likas, A.; Vlassis, N.; Verbeek, J. The Global K-Means Clustering Algorithm. Pattern Recognit. 2003, 36, 451–461. [Google Scholar] [CrossRef] [Green Version]
- Surabhi, A.R.; Parekh, S.T.; Manikantan, K.; Ramachandran, S. Background Removal Using K-Means Clustering as a Preprocessing Technique for DWT Based Face Recognition. In Proceedings of the 2012 International Conference on Communication, Information and Computing Technology, ICCICT 2012, Mumbai, India, 19–20 October 2012. [Google Scholar]
- Pugazhenthi, A.; Sreenivasulu, G.; Indhirani, A. Background Removal by Modified Fuzzy C-Means Clustering Algorithm. In Proceedings of the ICETECH 2015—2015 IEEE International Conference on Engineering and Technology, Coimbatore, India, 20 March 2015. [Google Scholar]
- Bezdek, J.C.; Keller, J.; Krisnapuram, R.; Pal, N.R. Fuzzy Models and Algorithms for Pattern Recognition and Image Processing; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Haubold, C.; Schiegg, M.; Kreshuk, A.; Berg, S.; Koethe, U.; Hamprecht, F.A. Segmenting and Tracking Multiple Dividing Targets Using Ilastik. Adv. Anat. Embryol. Cell Biol. 2016, 219, 199–229. [Google Scholar] [CrossRef]
- Frank, E.; Hall, M.A.; Witten, I.H. The WEKA Workbench Data Mining: Practical Machine Learning Tools and Techniques. In Data Mining, 4th ed.; Morgan Kaufmann: Burlington, MA, USA, 2016. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Lecture Notes in Computer Science in Artificial Intelligence and Lecture Notes in Bioinformatics, Munich, Germany, 5–9 October 2015; Volume 9351. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [Green Version]
- Jegou, S.; Drozdzal, M.; Vazquez, D.; Romero, A.; Bengio, Y. The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 1215. [Google Scholar] [CrossRef]
- Fang, W.; Ding, Y.; Zhang, F.; Sheng, V.S. DOG: A New Background Removal for Object Recognition from Images. Neurocomputing 2019, 361, 85–91. [Google Scholar] [CrossRef]
- Kang, M.S.; An, Y.K. Deep Learning-Based Automated Background Removal for Structural Exterior Image Stitching. Appl. Sci. 2021, 11, 3339. [Google Scholar] [CrossRef]
- Eitel, A.; Springenberg, J.T.; Spinello, L.; Riedmiller, M.; Burgard, W. Multimodal Deep Learning for Robust RGB-D Object Recognition. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Hamburg, Germany, 28 September–2 October 2015. [Google Scholar]
- Beloborodov, D.; Mestetskiy, L. Foreground detection on depth maps using skeletal representation of object silhouettes. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 42, 7. [Google Scholar] [CrossRef] [Green Version]
- Han, X.-F.; Jin, J.S.; Wang, M.-J.; Jiang, W.; Gao, L.; Xiao, L. A Review of Algorithms for Filtering the 3D Point Cloud. Signal Processing: Image Commun. 2017, 57, 103–112. [Google Scholar] [CrossRef]
- Jia, C.; Yang, T.; Wang, C.; Fan, B.; He, F. A New Fast Filtering Algorithm for a 3D Point Cloud Based on RGB-D Information. PLoS ONE 2019, 14. [Google Scholar] [CrossRef] [Green Version]
- Li, W.L.; Xie, H.; Zhang, G.; Li, Q.D.; Yin, Z.P. Adaptive Bilateral Smoothing for a Point-Sampled Blade Surface. IEEE/ASME Trans. Mechatron. 2016, 21, 2805–2816. [Google Scholar] [CrossRef]
- Farella, E.M.; Torresani, A.; Remondino, F. Sparse Point Cloud Filtering Based on Covariance Features. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, 42, 465–472. [Google Scholar] [CrossRef] [Green Version]
- Nurunnabi, A.; West, G.; Belton, D. Outlier Detection and Robust Normal-Curvature Estimation in Mobile Laser Scanning 3D Point Cloud Data. Pattern Recognit. 2015, 48, 1404–1419. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.; Zhang, K.; Huang, G.; Wu, P. Outliers Detection Method Based on Dynamic Standard Deviation Threshold Using Neighborhood Density Constraints for Three Dimensional Point Cloud. Jisuanji Fuzhu Sheji Yu Tuxingxue Xuebao/J. Comput. Aided Des. Comput. Graph. 2018, 30, 1034–1045. [Google Scholar] [CrossRef]
- Duan, C.; Chen, S.; Kovacevic, J. 3D Point Cloud Denoising via Deep Neural Network Based Local Surface Estimation. In Proceedings of the ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing, Brighton, UK, 12–17 May 2019. [Google Scholar]
- Casajus, P.H.; Ritschel, T.; Ropinski, T. Total Denoising: Unsupervised Learning of 3D Point Cloud Cleaning. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27–18 October 2019. [Google Scholar]
- Erler, P.; Guerrero, P.; Ohrhallinger, S.; Mitra, N.J.; Wimmer, M. Points2Surf Learning Implicit Surfaces from Point Clouds. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 108–124. [Google Scholar]
- Rakotosaona, M.-J.; la Barbera, V.; Guerrero, P.; Mitra, N.J.; Ovsjanikov, M. PointCleanNet: Learning to Denoise and Remove Outliers from Dense Point Clouds. Comput. Graph. Forum 2019, 39, 185–203. [Google Scholar] [CrossRef] [Green Version]
- Luo, S.; Hu, W. Differentiable Manifold Reconstruction for Point Cloud Denoising. In Proceedings of the 28th ACM International Conference on Multimedia, Virtual Event, Seattle, WA, USA, 9–12 May 2020. [Google Scholar]
- Luo, S.; Hu, W. Score-Based Point Cloud Denoising. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 4583–4592. [Google Scholar]
- Zhou, Y.; Shen, S.; Hu, Z. Detail Preserved Surface Reconstruction from Point Cloud. Sensors 2019, 19, 1278. [Google Scholar] [CrossRef] [Green Version]
- Jancosek, M.; Pajdla, T. Multi-View Reconstruction Preserving Weakly-Supported Surfaces. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Colorado Spring, CO, USA, 20–25 June 2011. [Google Scholar]
- Caraffa, L.; Marchand, Y.; Brédif, M.; Vallet, B. Efficiently Distributed Watertight Surface Reconstruction. In Proceedings of the IEEE 2021 International Conference on 3D Vision (3DV), London, UK, 1–3 December 2021; pp. 1432–1441. [Google Scholar]
- Sulzer, R.; Landrieu, L.; Boulch, A.; Marlet, R.; Vallet, B. Deep Surface Reconstruction from Point Clouds with Visibility Information. arXiv 2022, arXiv:2202.01810. [Google Scholar]
- Chabra, R.; Lenssen, J.E.; Ilg, E.; Schmidt, T.; Straub, J.; Lovegrove, S.; Newcombe, R. Deep Local Shapes: Learning Local SDF Priors for Detailed 3D Reconstruction; Lecture Notes in Computer Science in Bioinformatics; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12374. [Google Scholar]
- Gropp, A.; Yariv, L.; Haim, N.; Atzmon, M.; Lipman, Y. Implicit Geometric Regularization for Learning Shapes. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, Virtual Event, 13–18 July 2020. [Google Scholar]
- Zhao, W.; Lei, J.; Wen, Y.; Zhang, J.; Jia, K. Sign-Agnostic Implicit Learning of Surface Self-Similarities for Shape Modeling and Reconstruction from Raw Point Clouds. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–21 June 2021. [Google Scholar]
- Bahirat, K.; Lai, C.; Mcmahan, R.P.; Prabhakaran, B. Designing and Evaluating a Mesh Simplification Algorithm for Virtual Reality. ACM Trans. Multimed. Comput. Commun. Appl. 2018, 14, 1–26. [Google Scholar] [CrossRef]
- Schroeder, W.J.; Zarge, J.A.; Lorensen, W.E. Decimation of Triangle Meshes. In Proceedings of the 19th Annual Conference on Computer Graphics and Interactive Techniques, Chicago, IL, USA, 1 July 1992; Volume 26. [Google Scholar] [CrossRef]
- Klein, R.; Liebich, G.; Strasser, W. Mesh Reduction with Error Control. In Proceedings of the IEEE Visualization Conference, San Francisco, CA, USA, 17 October–1 November 1996. [Google Scholar]
- Luebke, D.; Hallen, B. Perceptually Driven Simplification for Interactive Rendering. In Rendering Techniques 2001; Springer: Vienna, Austria, 2001; pp. 223–234. [Google Scholar]
- Boubekeur, T.; Alexa, M. Mesh Simplification by Stochastic Sampling and Topological Clustering. Comput. Graph. 2009, 33, 241–249. [Google Scholar] [CrossRef]
- Hoppe, H. New Quadric Metric for Simplifying Meshes with Appearance Attributes. In Proceedings of the IEEE Visualization Conference, San Francisco, CA, USA, 24–29 October 1999. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Zheng, J.; Wang, H. Fast Mesh Simplification Method for Three-Dimensional Geometric Models with Feature-Preserving Efficiency. Sci. Program. 2019, 2019, 4926190. [Google Scholar] [CrossRef]
- Low, K.L.; Tan, T.S. Model Simplification Using Vertex-Clustering. In Proceedings of the Symposium on Interactive 3D Graphics, Providence, RI, USA, 27–10 April 1997. [Google Scholar]
- Chao, Y.; Jiateng, W.; Guoqing, Q.; Kun, D. A Mesh Simplification Algorithm Based on Vertex Importance and Hierarchical Clustering Tree. In Proceedings of the Eighth International Conference on Digital Image Processing (ICDIP 2016), Chengdu, China, 20–22 May 2016; Volume 10033. [Google Scholar]
- Yao, L.; Huang, S.; Xu, H.; Li, P. Quadratic Error Metric Mesh Simplification Algorithm Based on Discrete Curvature. Mathematical Probl. Eng. 2015, 2015, 428917. [Google Scholar] [CrossRef]
- Liang, Y.; He, F.; Zeng, X. 3D Mesh Simplification with Feature Preservation Based on Whale Optimization Algorithm and Differential Evolution. Integr. Comput. Aided Eng. 2020, 27, 417–435. [Google Scholar] [CrossRef]
- Pellizzoni, P.; Savio, G. Mesh Simplification by Curvature-Enhanced Quadratic Error Metrics. J. Comput. Sci. 2020, 16, 1195–1202. [Google Scholar] [CrossRef]
- Benoit, M.; Guerchouche, R.; Petit, P.D.; Chapoulie, E.; Manera, V.; Chaurasia, G.; Drettakis, G.; Robert, P. Is It Possible to Use Highly Realistic Virtual Reality in the Elderly? A Feasibility Study with Image-Based Rendering. Neuropsychiatr. Dis. Treat. 2015, 11, 557. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pharr, M.; Jakob, W.; Humphreys, G. Physically Based Rendering: From Theory to Implementation, 3rd ed.; Morgan Kaufmann: Burlington, MA, USA, 2016. [Google Scholar]
- Kumar, A. Beginning PBR Texturing: Learn Physically Based Rendering with Allegorithmic’s Substance Painter; Apress: New York, NY, USA, 2020. [Google Scholar]
- Learn OpenGL. Available online: https://learnopengl.com/PBR/Theory (accessed on 15 February 2022).
- Guillaume, H.L.; Schenkel, A. Photogrammetry of Cast Collection, Technical and Analytical Methodology of a Digital Rebirth. In Proceedings of the 23th International Conference on Cultural Heritage and New Technologies CHNT 23, Vienna, Austria, 12–15 November 2018. [Google Scholar]
- Adobe Photoshop. Available online: https://www.adobe.com/it/products/photoshop.html (accessed on 17 February 2022).
- Smartdeblur. Available online: http://smartdeblur.net/ (accessed on 17 February 2022).
- Sharpenai. Available online: https://www.topazlabs.com/sharpen-ai (accessed on 17 February 2022).
- Ai Background Removal. Available online: https://hotpot.ai/remove-background (accessed on 17 February 2022).
- Removal.Ai. Available online: https://removal.ai/ (accessed on 17 February 2022).
- RemoveBG. Available online: https://www.remove.bg/ (accessed on 17 February 2022).
- Ming, Y.; Meng, X.; Fan, C.; Yu, H. Deep learning for monocular depth estimation: A review. Neurocomputing 2021, 438, 14–33. [Google Scholar] [CrossRef]
- CloudCompare. 2021. Available online: http://www.cloudcompare.org/ (accessed on 17 February 2022).
- Rusu, R.B.; Cousins, S. 3D Is Here: Point Cloud Library (PCL). In Proceedings of the Proceedings—IEEE International Conference on Robotics and Automation, Shangai, China, 9–13 May 2011. [Google Scholar]
- Altman, N.S. An Introduction to Kernel and Nearest-Neighbor Nonparametric Regression. Am. Stat. 1992, 46, 175–185. [Google Scholar] [CrossRef] [Green Version]
- Guerrero, P.; Kleiman, Y.; Ovsjanikov, M.; Mitra, N.J. PCPNet Learning Local Shape Properties from Raw Point Clouds. Comput. Graph. Forum 2018, 37, 75–85. [Google Scholar] [CrossRef] [Green Version]
- Available online: https://github.com/3DOM-FBK/Mask_generation_scripts (accessed on 17 February 2022).

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| F-Number | F5.6 | F11 | F16 | F22 | ||||
|---|---|---|---|---|---|---|---|---|
| DoF [cm] | 0.61 | 1.22 | 1.72 | 2.43 | ||||
| Mean | St.dev. | Mean | St.dev. | Mean | St.dev. | Mean | St.dev. | |
| C2C | 0.1987 | 0.3851 | 0.1311 | 0.3147 | 0.1087 | 0.2607 | 0.1007 | 0.2501 |
| C2Mesh | −0.0498 | 0.4296 | −0.0325 | 0.3383 | −0.0245 | 0.2801 | −0.0260 | 0.2671 |
| F-Number | F5.6 | F11 | F16 | F22 | ||||
|---|---|---|---|---|---|---|---|---|
| DoF [cm] | 1.28 | 2.57 | 3.63 | 5.15 | ||||
| Mean | St.dev. | Mean | St.dev. | Mean | St.dev. | Mean | St.dev. | |
| C2C | 0.1669 | 0.2602 | 0.1166 | 0.1840 | 0.1063 | 0.1723 | 0.0877 | 0.1776 |
| C2Mesh | −0.0057 | 0.3078 | −0.0069 | 0.2162 | −0.0067 | 0.2007 | −0.0089 | 0.1962 |
| F-Number | F5.6 | F11 | F16 | F22 | ||||
|---|---|---|---|---|---|---|---|---|
| DoF [cm] | 1.43 | 2.86 | 4.05 | 5.74 | ||||
| Mean | St.dev. | Mean | St.dev. | Mean | St.dev. | Mean | St.dev. | |
| C2C | 0.2031 | 0.3092 | 0.1335 | 0.2236 | 0.1113 | 0.1943 | 0.1113 | 0.2141 |
| C2Mesh | 0.0096 | 0.3688 | 0.0006 | 0.2590 | -0.0003 | 0.2223 | −0.0023 | 0.2408 |
| F-Number | F5.6 | F11 | F16 | F22 | ||||
|---|---|---|---|---|---|---|---|---|
| DoF [cm] | 0.18 | 0.36 | 0.51 | 0.72 | ||||
| Mean | St.dev. | Mean | St.dev. | Mean | St.dev. | Mean | St.dev. | |
| C2C | 0.0944 | 0.1047 | 0.0497 | 0.0568 | 0.0377 | 0.0410 | 0.0289 | 0.0279 |
| C2Mesh | −0.0575 | 0.1282 | −0.0263 | 0.0702 | −0.0154 | 0.0529 | −0.0033 | 0.0393 |
| F-Number | F5.6 | F11 | F16 | F22 | ||||
|---|---|---|---|---|---|---|---|---|
| DoF [cm] | 0.26 | 0.53 | 0.75 | 1.06 | ||||
| Mean | St.dev. | Mean | St.dev. | Mean | St.dev. | Mean | St.dev. | |
| C2C | 0.0960 | 0.1174 | 0.0392 | 0.0461 | 0.0281 | 0.0266 | 0.0251 | 0.0213 |
| C2Mesh | −0.0513 | 0.1424 | −0.0149 | 0.0580 | −0.0043 | 0.0377 | −0.0007 | 0.0321 |
| F-Number | F5.6 | F11 | F16 | F22 | ||||
|---|---|---|---|---|---|---|---|---|
| DoF [cm] | 0.41 | 0.81 | 1.15 | 1.63 | ||||
| Mean | St.dev. | Mean | St.dev. | Mean | St.dev. | Mean | St.dev. | |
| C2C | 0.2772 | 0.2424 | 0.1147 | 0.1372 | 0.0712 | 0.0843 | 0.05436 | 0.0578 |
| C2Mesh | −0.0877 | 0.3412 | −0.0121 | 0.1777 | −0.0110 | 0.1085 | −0.0044 | 0.0784 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Farella, E.M.; Morelli, L.; Rigon, S.; Grilli, E.; Remondino, F. Analysing Key Steps of the Photogrammetric Pipeline for Museum Artefacts 3D Digitisation. Sustainability 2022, 14, 5740. https://doi.org/10.3390/su14095740
Farella EM, Morelli L, Rigon S, Grilli E, Remondino F. Analysing Key Steps of the Photogrammetric Pipeline for Museum Artefacts 3D Digitisation. Sustainability. 2022; 14(9):5740. https://doi.org/10.3390/su14095740
Chicago/Turabian StyleFarella, Elisa Mariarosaria, Luca Morelli, Simone Rigon, Eleonora Grilli, and Fabio Remondino. 2022. "Analysing Key Steps of the Photogrammetric Pipeline for Museum Artefacts 3D Digitisation" Sustainability 14, no. 9: 5740. https://doi.org/10.3390/su14095740
APA StyleFarella, E. M., Morelli, L., Rigon, S., Grilli, E., & Remondino, F. (2022). Analysing Key Steps of the Photogrammetric Pipeline for Museum Artefacts 3D Digitisation. Sustainability, 14(9), 5740. https://doi.org/10.3390/su14095740