
Real-Time Vehicle Detection Based on Improved YOLO v5

 , ,
, ,
Abstract
1. Introduction
2. Related Work
3. Data Collection and Data Processing
- (1)
- Due to the different installation scenarios of traffic monitoring, there are differences in the viewing angle and height of monitoring, which will produce scene changes. For example, the monitoring perspective and scene characteristics in the tunnel are different from the highway. This discrepancy leads to a significant reduction in the detection accuracy and also leads to a large number of vehicle targets missing inspection.
- (2)
- The same scene in different weather conditions also varies greatly. Affected by the brightness of the scene picture under bad weather conditions and the noise of the camera acquisition equipment, the body contour feature extraction of the target vehicle is susceptible to interference. If the dataset does not contain such scene data, the detection effect is not ideal.
- (3)
- The vehicle target has noticeable deformation in different positions in the picture. The same vehicle target undergoes significant size deformation at the distal and proximal positions of the picture. It affects the detection accuracy of small targets.
- (4)
- Vehicle occlusion is common to vehicle targets on actual roads, which can lead to the detection of multiple targets as a single target, and there are missed and false detections.
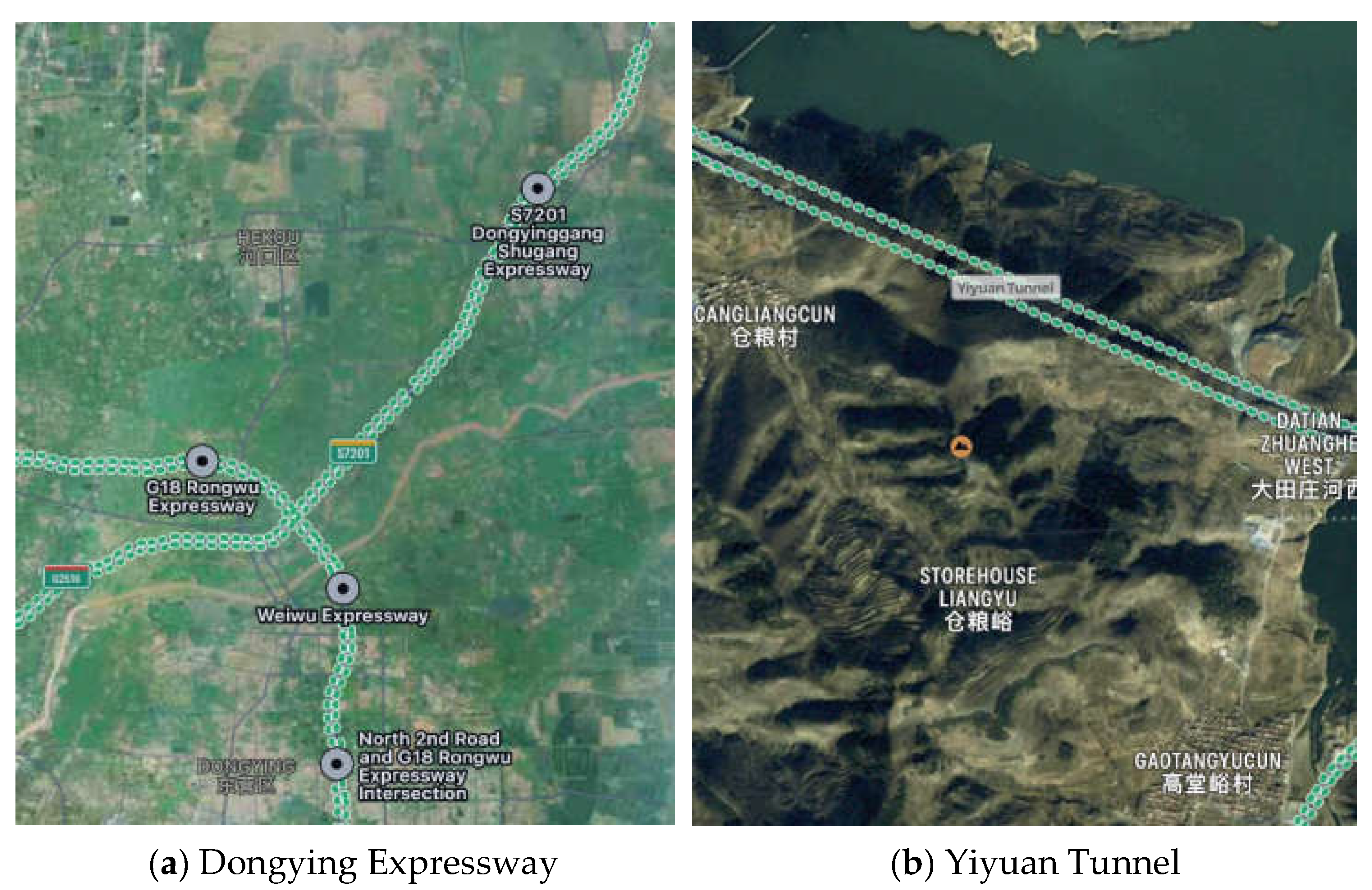
3.1. Data Collection
3.2. Image Labeling Method for Vehicle Detection
3.3. Image Annotation
- (1)
- Because the object detection task recognizes the part outside the callout box as a negative sample of the background class, the vehicles that appear in the image should be labeled as much as possible, including a small part of the vehicle body that is covered by text information.
- (2)
- In the case of vehicles and the environment, and vehicles obscuring each other, any vehicle of which no more than half is obstructed still needs to be marked. As shown in Figure 6, when that much information is lost, it does not need to be labeled, because such vehicles have basically no target characteristics.
3.4. Dataset Characteristics
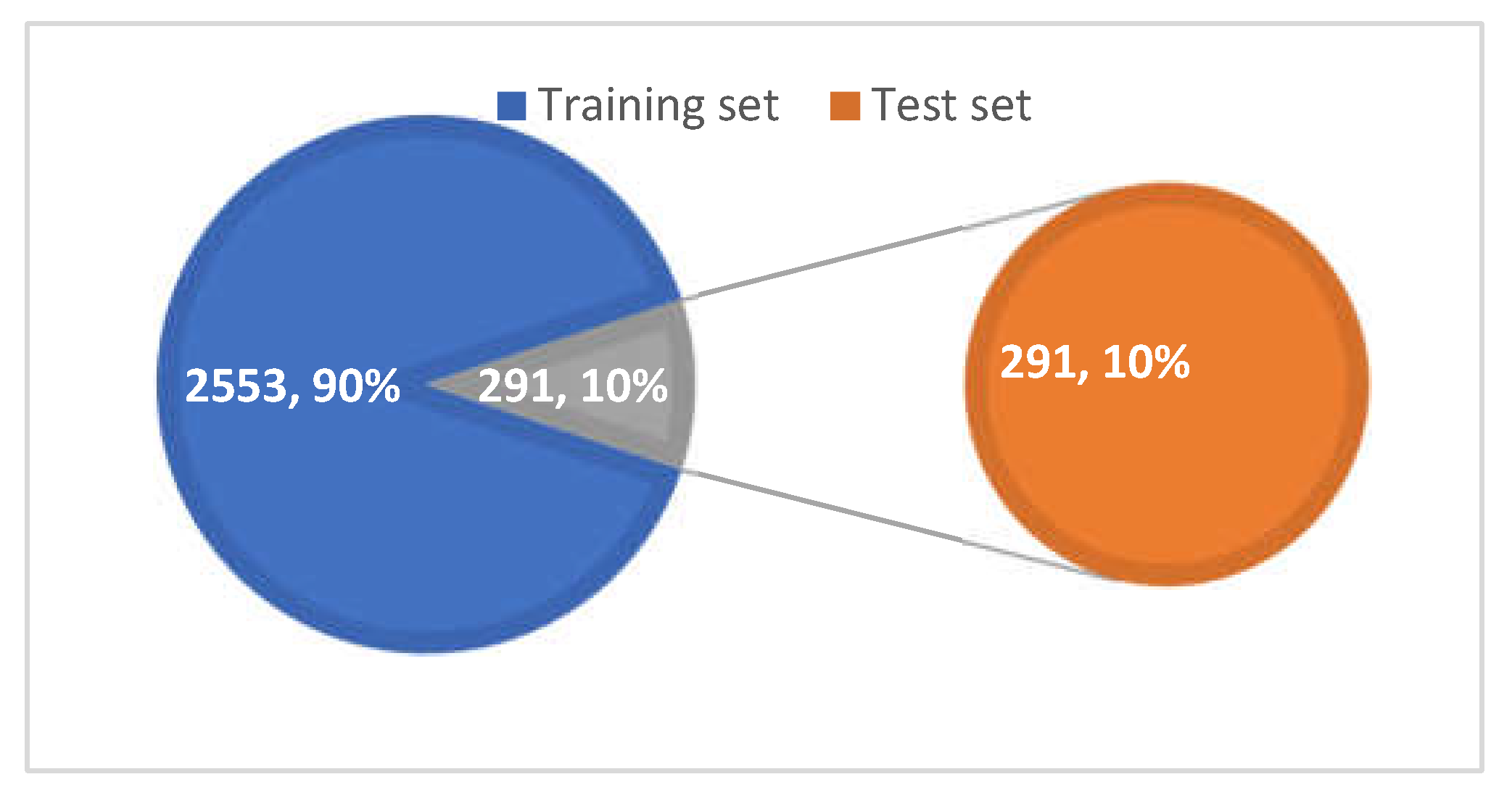
3.5. Dataset Division
4. Research on Highway Vehicle Detection Based on Improved YOLO v5 Algorithm
4.1. YOLO v5 Algorithm
- (1)
- The input is a vehicle image input link, which consists of three parts: Data enhancement [37], picture size processing [38], and automatic adaptation anchor frame [39]. The traditional YOLO v5 uses mosaic data enhancement to randomly scale, crop, arrange, and then stitch the input to improve the detection effect of small targets. When training the dataset, the input image size is changed to a uniform size and then the image is fed into the model for inspection. The initial set sizes are set to 460 × 460 × 30. The initial anchor frame for YOLO v5 is (116,90,156,198,373,326).
- (2)
- The backbone network consists of the Focus structure [40] and CSP structure [41]. The Focus structure is responsible for slicing the image before it enters the backbone network. As shown in Figure 10, the original 608 × 608 × 3 image is sliced. The feature map of 304 × 304 × 12 is reached, and then the feature map of the 32 convolutional kernels is formed through the convolutional operation. The Focus operation can downsample the input dimensions without parameters and preserve the original image information as much as possible. The CSP structure is a transition of the input feature using two 1*1 convolutions. It is beneficial for improving the learning ability of CNNs [42], breaking through computing bottlenecks, and reducing memory costs.
- (3)
- The Neck part is a network layer that combines image features and passes them to the prediction layer. The Neck section of YOLO v5 uses the structure of FPN+PAN. The FPN upsamples the high-level feature information and communicates and fuses it in a top-to-bottom manner to obtain a feature map for prediction. PAN is the underlying pyramid, which conveys strong positioning characteristics in a bottom-to-top manner [43].
- (4)
- The prediction layer predicts the image features and generates the bounding box to predict the category. YOLO v5 uses GIOU_Loss as a loss function for Boundingbox. In overlapping object detection, GIOU_NMS is more effective than traditional non-maximum suppression (NMS).
4.2. Improved YOLO v5 Algorithm
- (1)
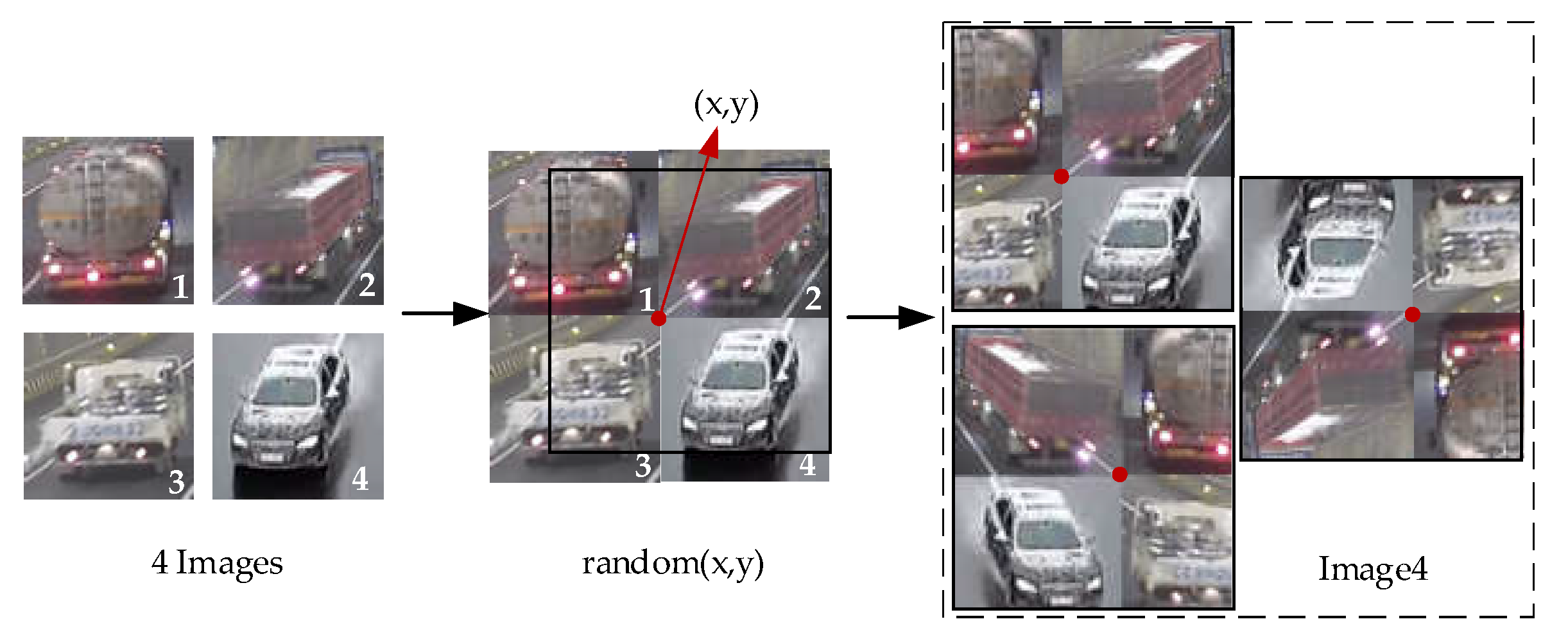
- For each image in the dataset, three images were randomly selected again in the dataset.
- (2)
- Flattening points (x, y) in a blank image were randomly selected. The blank pictures were divided into four parts. The four pictures were divided into four parts divided by the center point, and the excess parts were discarded directly. The flattening process is shown in Figure 12.
- (3)
- The composited pictures were processed by three random operations for the homogeneous distribution. The data were enhanced by flipping the image left and right and up and down, and the data were maintained originally. The process is shown in Figure 13. At the same time, some random noise was reasonably introduced to enhance the discriminating force of the network model on the small target sample in the image and improve the generalization force of the model.
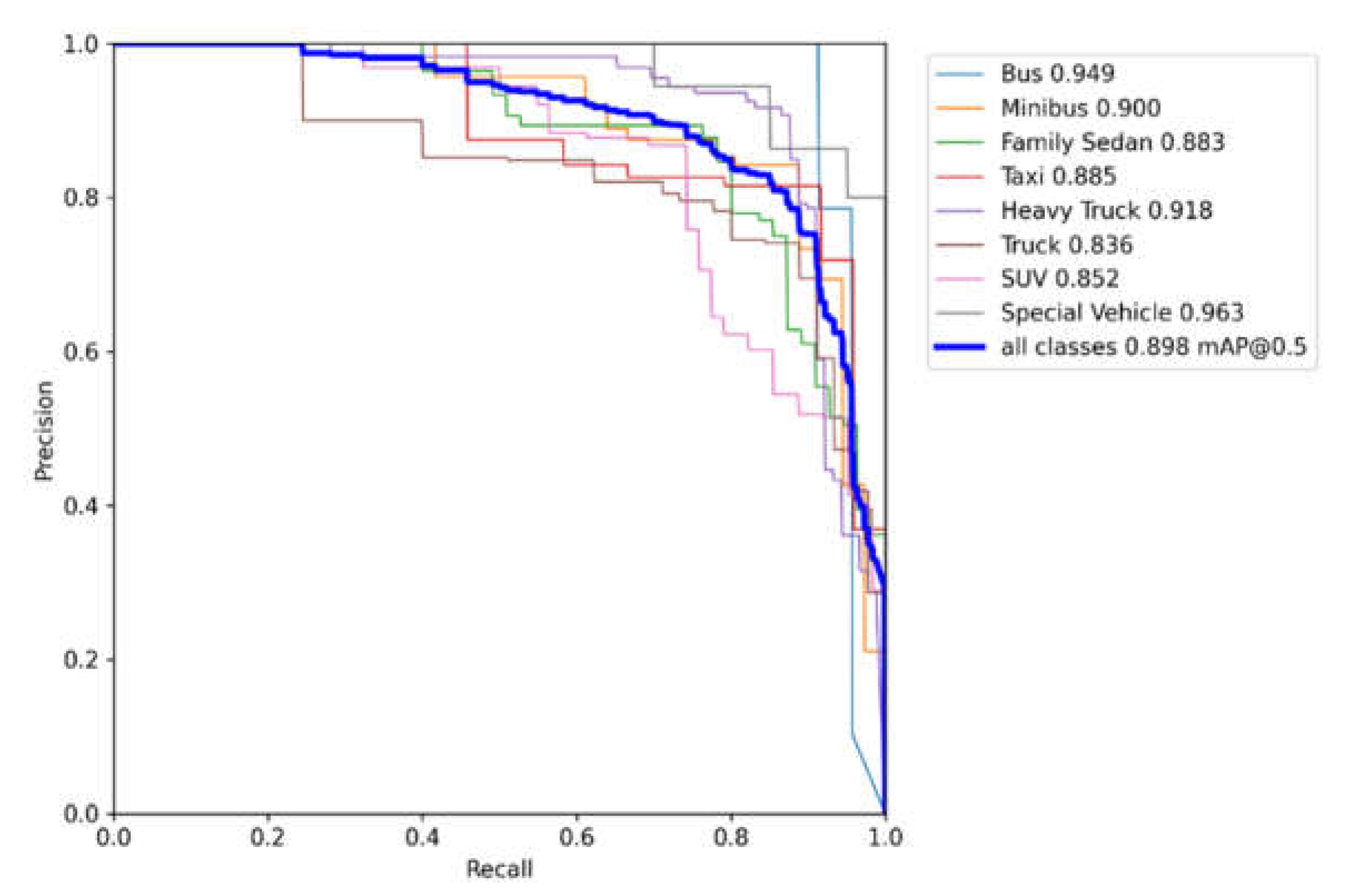
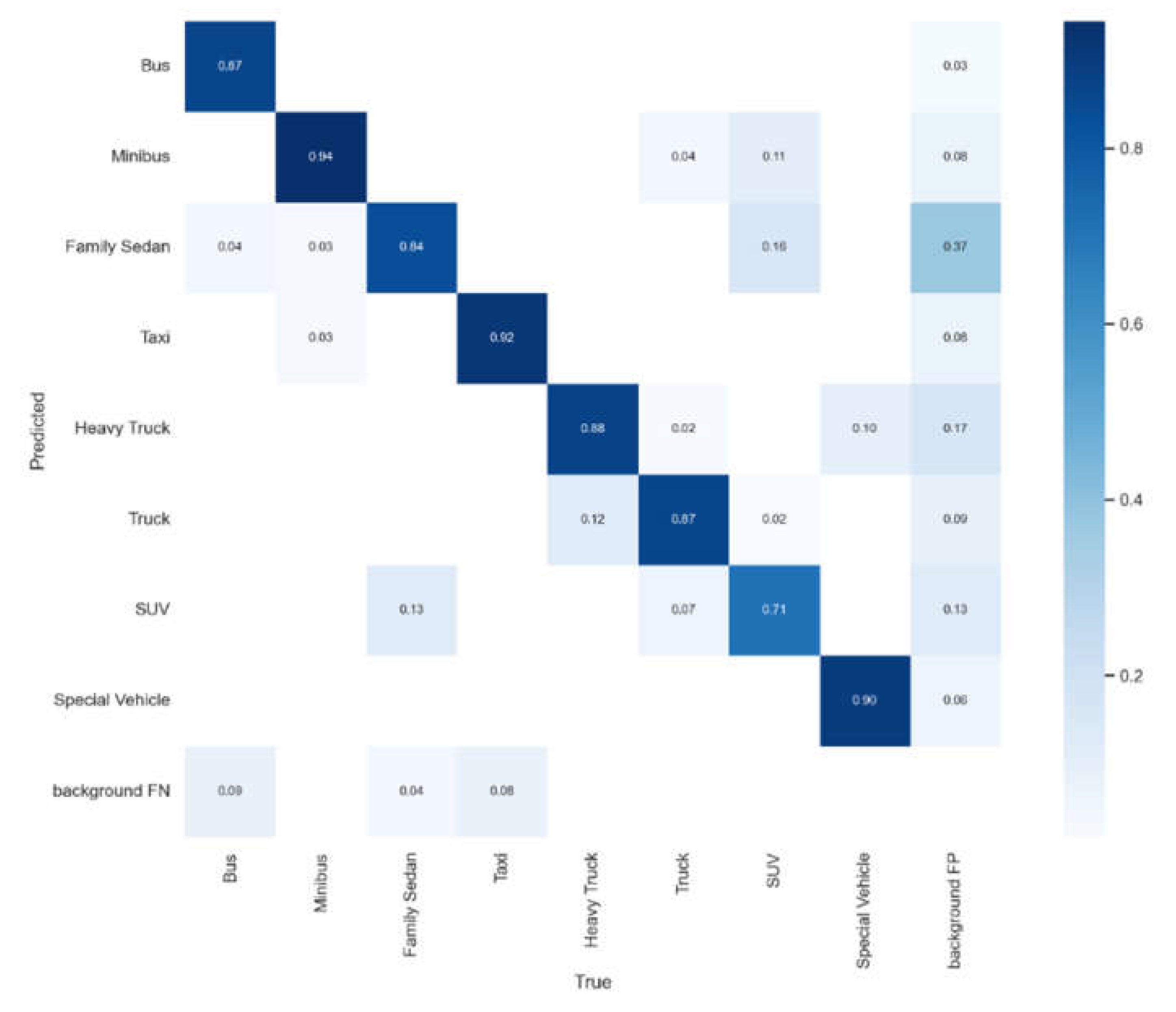
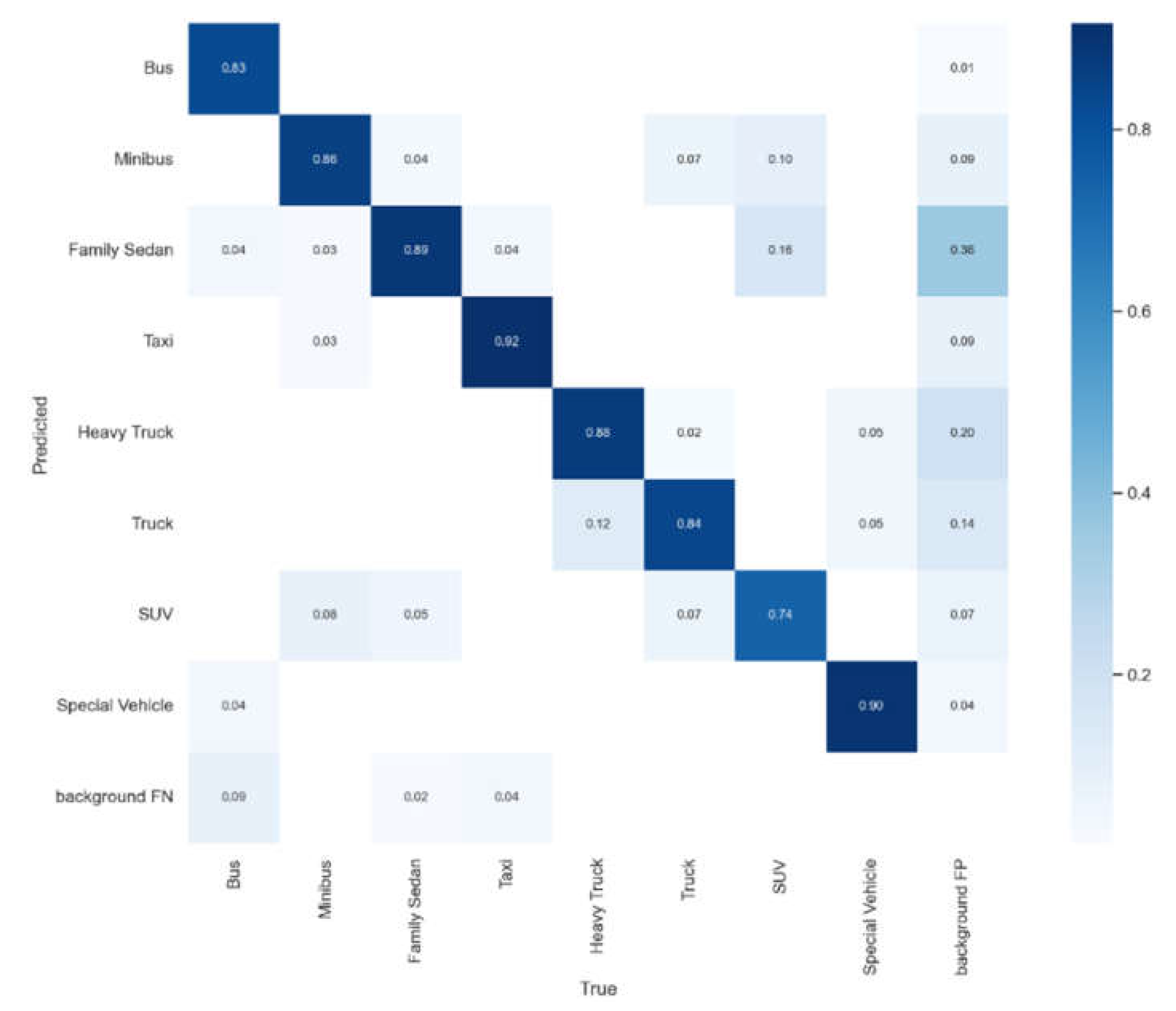
5. Experimental Results
6. Conclusions
- (1)
- Due to the difficulty of obtaining highway surveillance video data, the highway scene surveillance videos that could be collected in this paper were limited. More scenes, angles, and better lighting conditions of the surveillance video should be collected to further improve the generalization ability of the vehicle detection model.
- (2)
- Regarding the influence of bad weather, we need to reduce the influence of the weather environment on detection. These problems indicate that the target detection algorithm still needs to be optimized and researched.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ministry of Transport of the People’s Republic of China, Statistical Bulletin of Transport Industry Development 2020. Available online: https://www.mot.gov.cn/jiaotongyaowen/202105/t20210519_3594381.html (accessed on 9 May 2022).
- Jiangsu Provincial Department of Transport, Framework Agreement on Regional Cooperation of Expressway. Available online: http://jtyst.jiangsu.gov.cn/art/2020/8/24/art_41904_9471746.html (accessed on 9 May 2022).
- Park, S.-H.; Kim, S.-M.; Ha, Y.-G. Highway traffic accident prediction using VDS big data analysis. J. Supercomput. 2016, 72, 2832. [Google Scholar] [CrossRef]
- Paragios, N.; Chen, Y.; Faugeras, O.D. Handbook of Mathematical Models in Computer Vision; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Liu, P.; Fu, H.; Ma, H. An end-to-end convolutional network for joint detecting and denoising adversarial perturbations in vehicle classification. Comput. Vis. Media 2021, 7, 217–227. [Google Scholar] [CrossRef]
- Lee, D.S. Effective Gaussian mixture learning for video background subtraction. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 827–832. [Google Scholar] [PubMed]
- Deng, G.; Guo, K. Self-Adaptive Background Modeling Research Based on Change Detection and Area Training. In Proceedings of the IEEE Workshop on Electronics, Computer and Applications (IWECA), Ottawa, ON, Canada, 8–9 May 2014; Volume 2, pp. 59–62. [Google Scholar]
- Muyun, W.; Guoce, H.; Xinyu, D. A New Interframe Difference Algorithm for Moving Target Detection. In Proceedings of the 2010 3rd International Congress on Image and Signal Processing, Yantai, China, 16–18 October 2010; pp. 285–289. [Google Scholar]
- Zhang, H.; Zhang, H. A Moving Target Detection Algorithm Based on Dynamic Scenes. In Proceedings of the 8th International Conference on Computer Science and Education (ICCSE), Colombo, Sri Lanka, 26–28 April 2013; pp. 995–998. [Google Scholar]
- Barnich, O.; Van Droogenbroeck, M. ViBe: A Universal Background Subtraction Algorithm for Video Sequences. IEEE Trans. Image Process. 2011, 20, 1709–1724. [Google Scholar] [CrossRef] [PubMed]
- Fang, Y.; Dai, B. An Improved Moving Target Detecting and Tracking Based On Optical Flow Technique and Kalman Filter. In Proceedings of the 4th International Conference on Computer Science and Education, Nanning, China, 25–28 July 2008; pp. 1197–1202. [Google Scholar]
- Computer Vision-ECCV 2002. In Proceedings of the 7th European Conference on Computer Vision. Proceedings, Part I (Lecture Notes in Computer Science), Copenhagen, Denmark, 28–31 May 2002; Volume 2350, pp. xxviii+817.
- Viola, P.; Jones, M. Rapid Object Detection Using a Boosted Cascade of Simple Features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. CVPR 2001, Kauai, HI, USA, 8–14 December 2001; Volume 1, p. I-511-18. [Google Scholar]
- Xu, Z.; Huang, W.; Wang, Y. Multi-class vehicle detection in surveillance video based on deep learning. J. Comput. Appl. 2019, 39, 700–705. [Google Scholar]
- Zhang, S.; Wang, X. Human Detection and Object Tracking Based on Histograms of Oriented Gradients. In Proceedings of the 9th International Conference on Natural Computation (ICNC), Shenyang, China, 23–25 July 2013; pp. 1349–1353. [Google Scholar]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef]
- Yu, K. A least squares support vector machine classifier for information retrieval. J. Converg. Inf. Technol. 2013, 8, 177–183. [Google Scholar]
- Felzenszwalb, P.; McAllester, D.; Ramanan, D. A discriminatively trained, multiscale, deformable part model. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, Alaska, 23–28 June 2008; p. 1984. [Google Scholar]
- He, N.; Zhang, P.-P. Moving Target Detection and Tracking in Video Monitoring System. Microcomput. Inf. 2010, 3, 229–230. [Google Scholar]
- Wu, X.; Song, X.; Gao, S.; Chen, C. Review of target detection algorithms based on deep learning. Transducer Microsyst. Technol. 2021, 40, 4–7+18. [Google Scholar]
- Xie, W.; Zhu, D.; Tong, X. Small target detection method based on visual attention. Comput. Eng. Appl. 2013, 49, 125–128. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 27th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. In Proceedings of the 13th European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 346–361. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the Tenth IEEE International Conference on Computer Vision, Beijing, China, 17–20 October 2005; pp. 1440–1448. [Google Scholar]
- Zheng, X.; Chen, F.; Lou, L.; Cheng, P.; Huang, Y. Real-Time Detection of Full-Scale Forest Fire Smoke Based on Deep Convolution Neural Network. Remote Sens. 2022, 14, 536. [Google Scholar] [CrossRef]
- Zhao, H.; Li, Z.; Zhang, T. Attention Based Single Shot Multibox Detector. J. Electron. Inf. Technol. 2021, 43, 2096–2104. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. arXiv 2016, arXiv:1612.08242. [Google Scholar]
- Li, J.; Huang, S. YOLOv3 Based Object Tracking Method. Electron. Opt. Control 2019, 26, 87–93. [Google Scholar]
- Bochkovskiy, A.; Chien-Yao, W.; Liao, H.Y.M. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Zhan, W.; Sun, C.; Wang, M.; She, J.; Zhang, Y.; Zhang, Z.; Sun, Y. An improved Yolov5 real-time detection method for small objects captured by UAV. Soft Comput. 2022, 26, 361–373. [Google Scholar] [CrossRef]
- St-Aubin, P.; Miranda-Moreno, L.; Saunier, N. An automated surrogate safety analysis at protected highway ramps using cross-sectional and before-after video data. Transp. Res. Part C Emerg. Technol. 2013, 36, 284–295. [Google Scholar] [CrossRef]
- Dong, Z.; Wu, Y.; Pei, M.; Jia, Y. Vehicle Type Classification Using a Semisupervised Convolutional Neural Network. Ieee Trans. Intell. Transp. Syst. 2015, 16, 2247–2256. [Google Scholar] [CrossRef]
- Manzano, C.; Meneses, C.; Leger, P. An Empirical Comparison of Supervised Algorithms for Ransomware Identification on Network Traffic. In Proceedings of the 2020 39th International Conference of the Chilean Computer Science Society (SCCC), Coquimbo, Chile, 16–20 November 2020; p. 7. [Google Scholar]
- Razakarivony, S.; Jurie, F. Vehicle detection in aerial imagery: A small target detection benchmark. J. Vis. Commun. Image Represent. 2016, 34, 187–203. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the 13th European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- de Haan, K.; Rivenson, Y.; Wu, Y.; Ozcan, A. Deep-Learning-Based Image Reconstruction and Enhancement in Optical Microscopy. Proc. IEEE 2020, 108, 30–50. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Casteleiro, M.A.; Demetriou, G.; Read, W.; Prieto, M.J.F.; Maroto, N.; Fernandez, D.M.; Nenadic, G.; Klein, J.; Keane, J.; Stevens, R. Deep learning meets ontologies: Experiments to anchor the cardiovascular disease ontology in the biomedical literature. J. Biomed. Semant. 2018, 9, 13. [Google Scholar] [CrossRef]
- Yang, S.J.; Berndl, M.; Ando, D.M.; Barch, M.; Narayanaswamy, A.; Christiansen, E.; Hoyer, S.; Roat, C.; Hung, J.; Rueden, C.T.; et al. Assessing microscope image focus quality with deep learning. BMC Bioinform. 2018, 19, 77. [Google Scholar] [CrossRef]
- Guo, Y.; Zeng, Y.; Gao, F.; Qiu, Y.; Zhou, X.; Zhong, L.; Zhan, C. Improved YOLOV4-CSP Algorithm for Detection of Bamboo Surface Sliver Defects With Extreme Aspect Ratio. IEEE Access 2022, 10, 29810–29820. [Google Scholar] [CrossRef]
- Yinpeng, C.; Xiyang, D.; Mengchen, L.; Dongdong, C.; Lu, Y.; Zicheng, L. Dynamic Convolution: Attention over Convolution Kernels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 11027–11036. [Google Scholar]
- Kaixin, W.; Jun Hao, L.; Yingtian, Z.; Daquan, Z.; Jiashi, F. PANet: Few-shot image semantic segmentation with prototype alignment. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 9196–9205. [Google Scholar]
- Simon, M.; Milz, S.; Amende, K.; Gross, H.-M. Complex-YOLO: An Euler-Region-Proposal for Real-Time 3D Object Detection on Point Clouds. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 197–209. [Google Scholar]
- Wenqiang, X.; Haiyang, W.; Fubo, Q.; Cewu, L. Explicit Shape Encoding for Real-Time Instance Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 5167–5176. [Google Scholar]
- Huang, Z.; Wang, J. DC-SPP-YOLO: Dense connection and spatial pyramid pooling based YOLO for object detection. Inf. Sci. 2020, 522, 241–258. [Google Scholar] [CrossRef]
- Zhaohui, Z.; Ping, W.; Wei, L.; Jinze, L.; Rongguang, Y.; Dongwei, R. Distance-IoU loss: Faster and better learning for bounding box regression. Proc. AAAI Conf. Artif. Intell. 2019, 34, 12993–13000. [Google Scholar]
- Hendry; Chen, R.-C. Automatic License Plate Recognition via sliding-window darknet-YOLO deep learning. Image Vis. Comput. 2019, 87, 47–56. [Google Scholar] [CrossRef]
- Gao, J.; Chen, Y.; Wei, Y.; Li, J. Detection of Specific Building in Remote Sensing Images Using a Novel YOLO-S-CIOU Model. Case: Gas Station Identification. Sensors 2021, 21, 1375. [Google Scholar] [CrossRef]
- Yang, S.-D.; Zhao, Y.-Q.; Yang, Z.; Wang, Y.-J.; Zhang, F.; Yu, L.-L.; Wen, X.-B. Target organ non-rigid registration on abdominal CT images via deep-learning based detection. Biomed. Signal Process. Control 2021, 70, 102976. [Google Scholar] [CrossRef]
- Du, J. Understanding of Object Detection Based on CNN Family and YOLO. In Proceedings of the 2nd International Conference on Machine Vision and Information Technology (CMVIT), Hong Kong, China, 23–25 February 2018. [Google Scholar]
- Huang, R.; Pedoeem, J.; Chen, C. YOLO-LITE: A Real-Time Object Detection Algorithm Optimized for Non-GPU Computers. In Proceedings of the IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 2503–2510. [Google Scholar]
- Hou, Q.; Cheng, M.-M.; Hu, X.; Borji, A.; Tu, Z.; Torr, P.H.S. Deeply Supervised Salient Object Detection with Short Connections. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 815–828. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | x | y | w | h |
|---|---|---|---|---|
| 4 | 0.837022 | 0.602114 | 0.274942 | 0.499098 |
| 4 | 0.303379 | 0.385564 | 0.140371 | 0.243362 |
| 2 | 0.558019 | 0.140139 | 0.023202 | 0.037123 |
| Annotation Category Information of YOLO | |||
|---|---|---|---|
| Bus | 0 | Heavy Truck | 4 |
| Minibus | 1 | Truck | 5 |
| Family Sedan | 2 | SUV | 6 |
| Taxi | 3 | Special Vehicle | 7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Guo, Z.; Wu, J.; Tian, Y.; Tang, H.; Guo, X. Real-Time Vehicle Detection Based on Improved YOLO v5. Sustainability 2022, 14, 12274. https://doi.org/10.3390/su141912274
Zhang Y, Guo Z, Wu J, Tian Y, Tang H, Guo X. Real-Time Vehicle Detection Based on Improved YOLO v5. Sustainability. 2022; 14(19):12274. https://doi.org/10.3390/su141912274
Chicago/Turabian StyleZhang, Yu, Zhongyin Guo, Jianqing Wu, Yuan Tian, Haotian Tang, and Xinming Guo. 2022. "Real-Time Vehicle Detection Based on Improved YOLO v5" Sustainability 14, no. 19: 12274. https://doi.org/10.3390/su141912274
APA StyleZhang, Y., Guo, Z., Wu, J., Tian, Y., Tang, H., & Guo, X. (2022). Real-Time Vehicle Detection Based on Improved YOLO v5. Sustainability, 14(19), 12274. https://doi.org/10.3390/su141912274