
An Efficient Internet-Wide Scan Approach Based on Location Awareness



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- Through experiments, we introduced the concept of being location-aware. Specifically, scanning nodes in a particular country are more efficient when scanning their own country’s IP addresses compared to scanning IP addresses from other countries. This phenomenon indicates that geographical proximity has a significant positive impact on network scanning efficiency.
- We propose a novel location-aware method that overcomes the limitations of geographical factors to achieve efficient network scanning. Using this method, we can more accurately identify live IP addresses across the entire network, significantly improving the detection scanning and accuracy of network resources.
- We conducted experimental analysis in real-world network environments. Compared to existing methods, our scanning efficiency is more effective, thus demonstrating the validity of the proposed method.
2. Related Works
3. Considered Scenario and Motivation
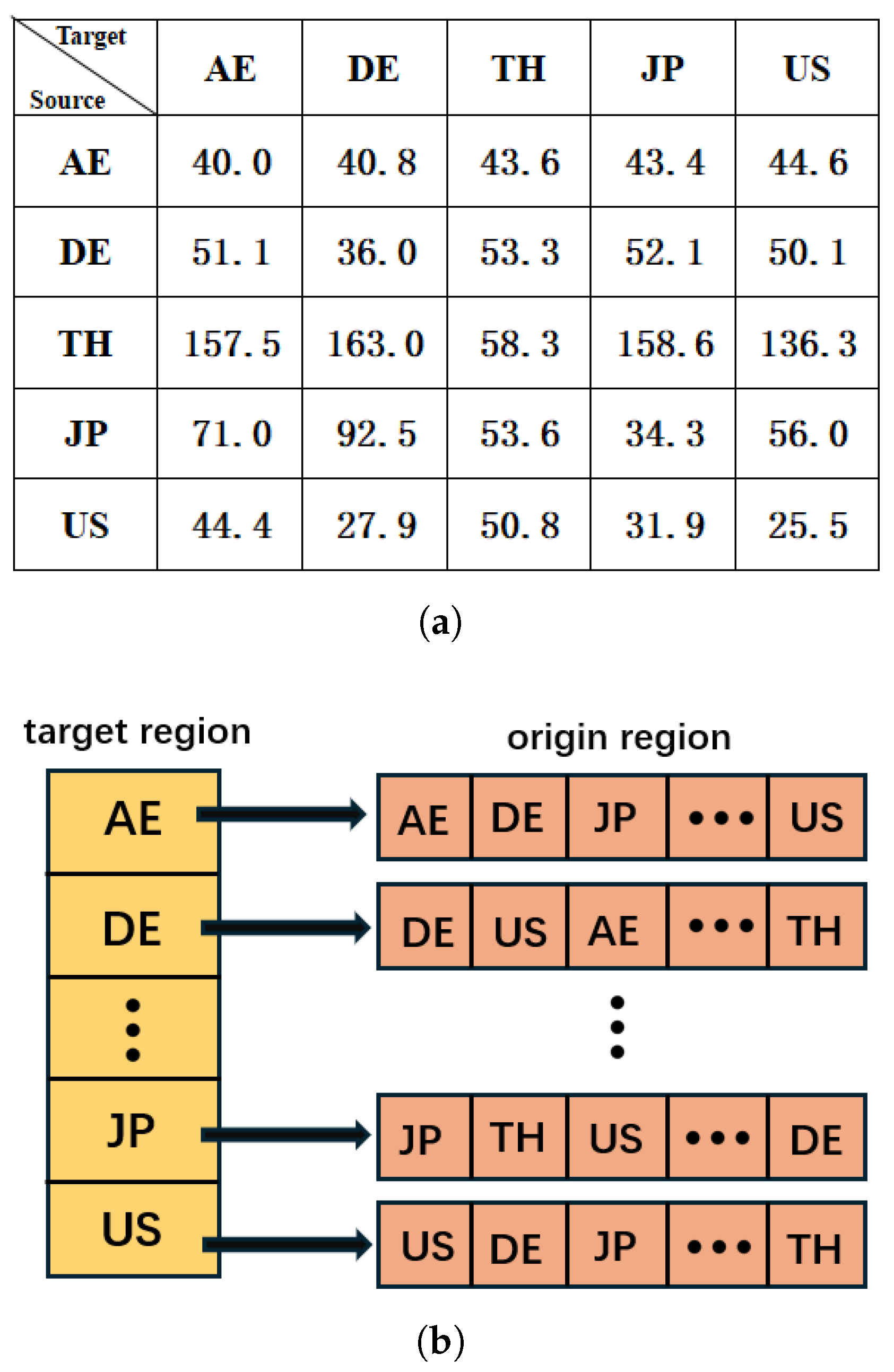
3.1. Considered Scenario
3.2. Motivation
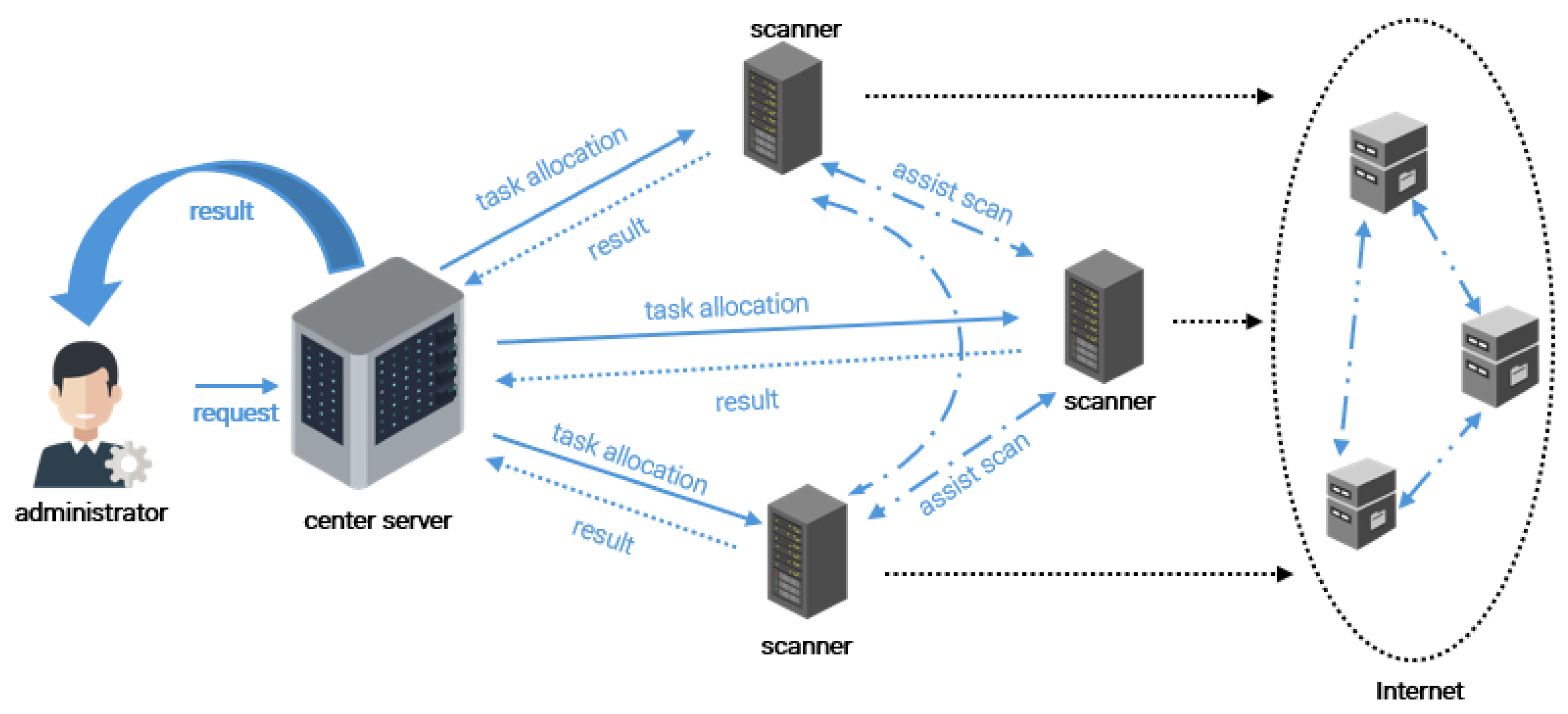
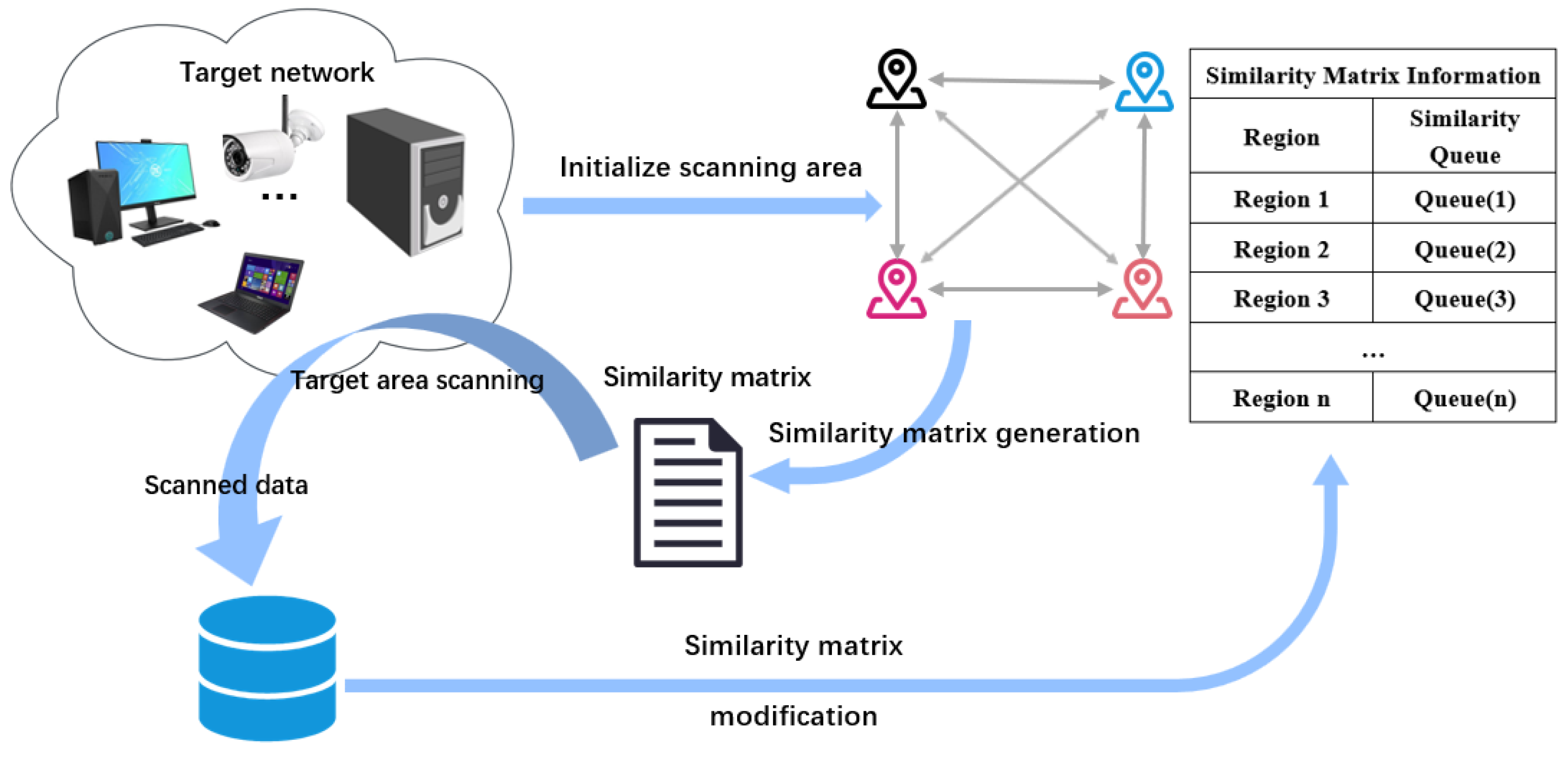
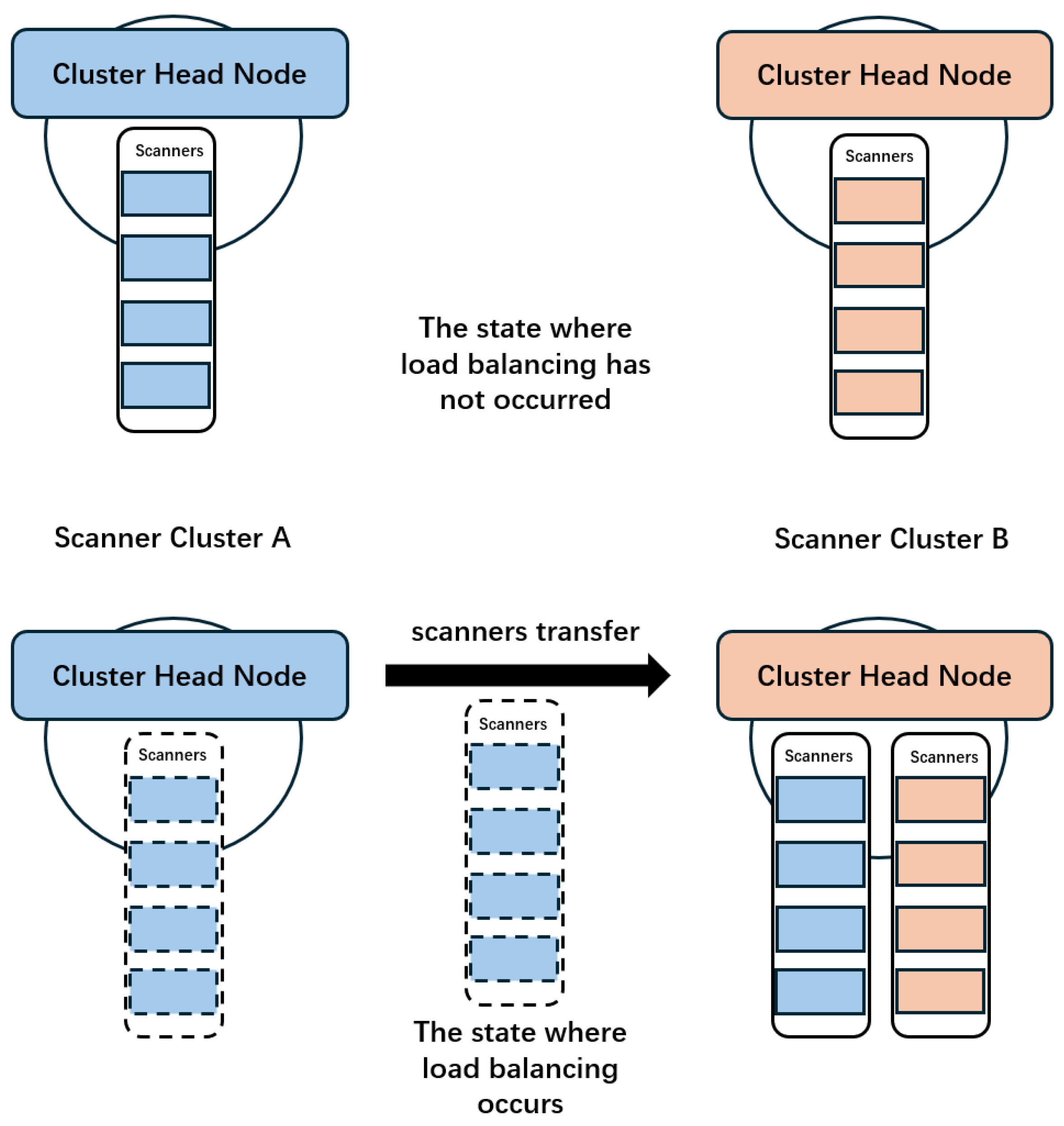
4. Proposed Approach
4.1. Delay Model
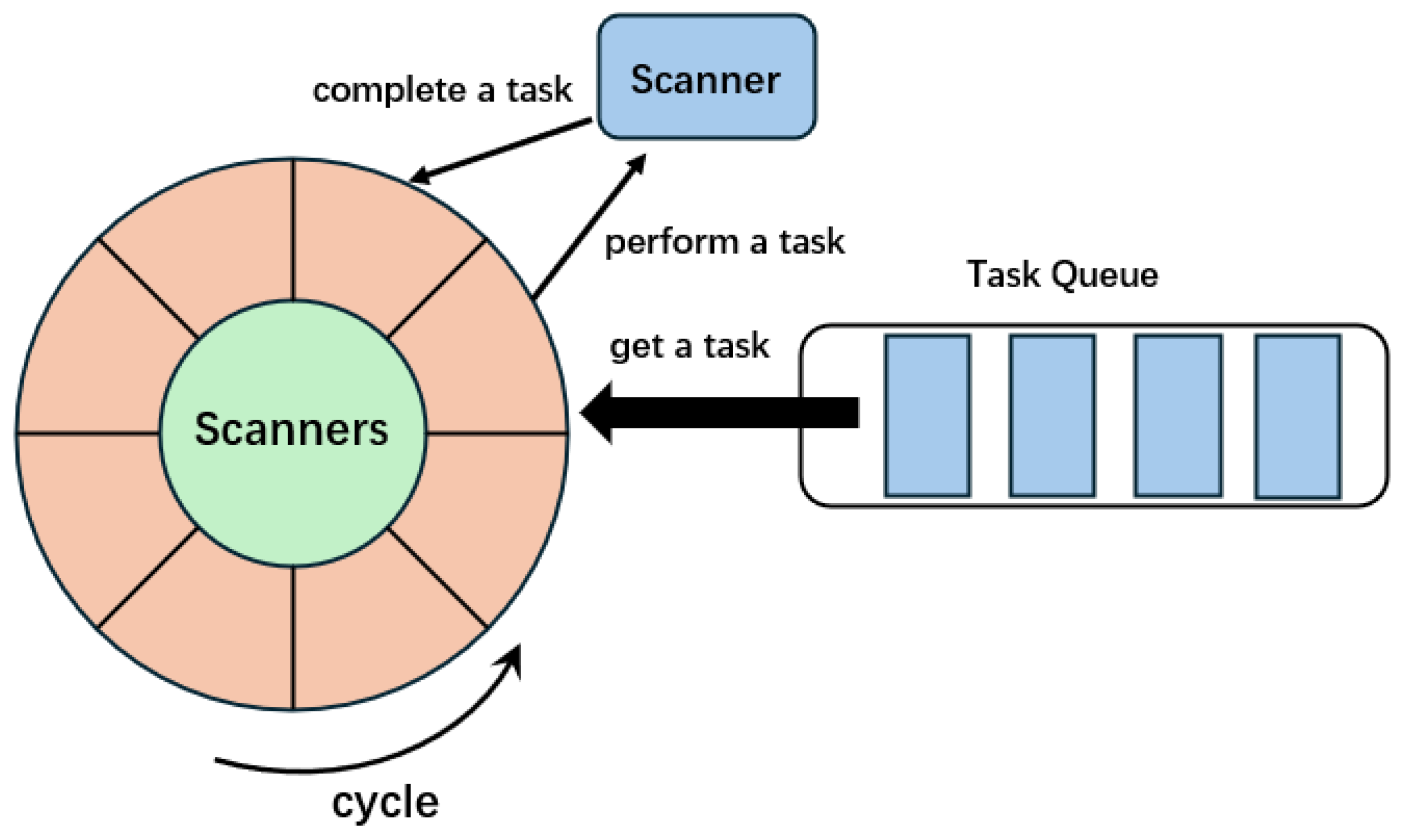
4.2. Overview of Proposed Approach
| Algorithm 1: Efficient Scanning Algorithms for Location Awareness |
 |
4.3. Approach
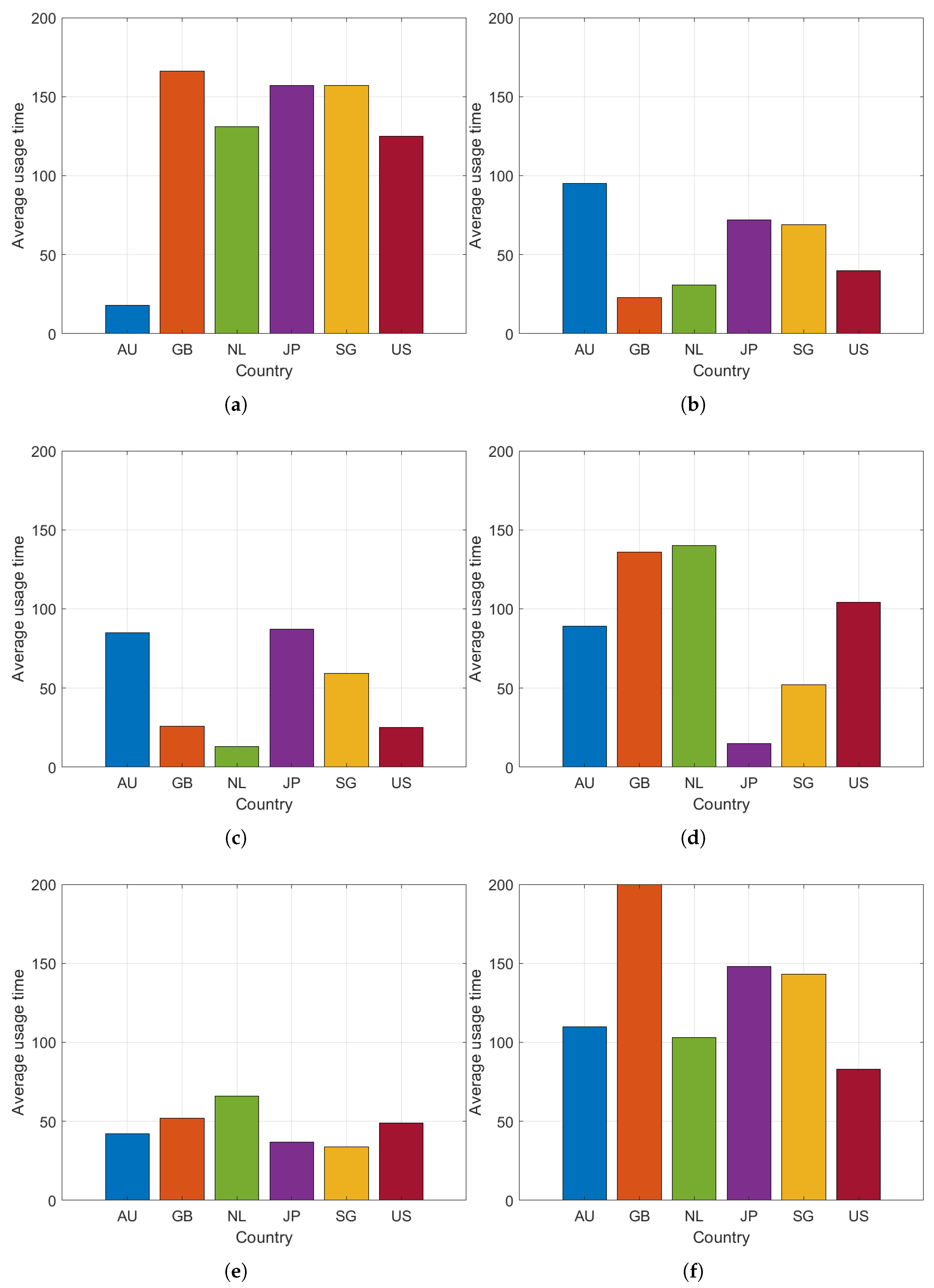
5. Experiments
5.1. Experimental Setup
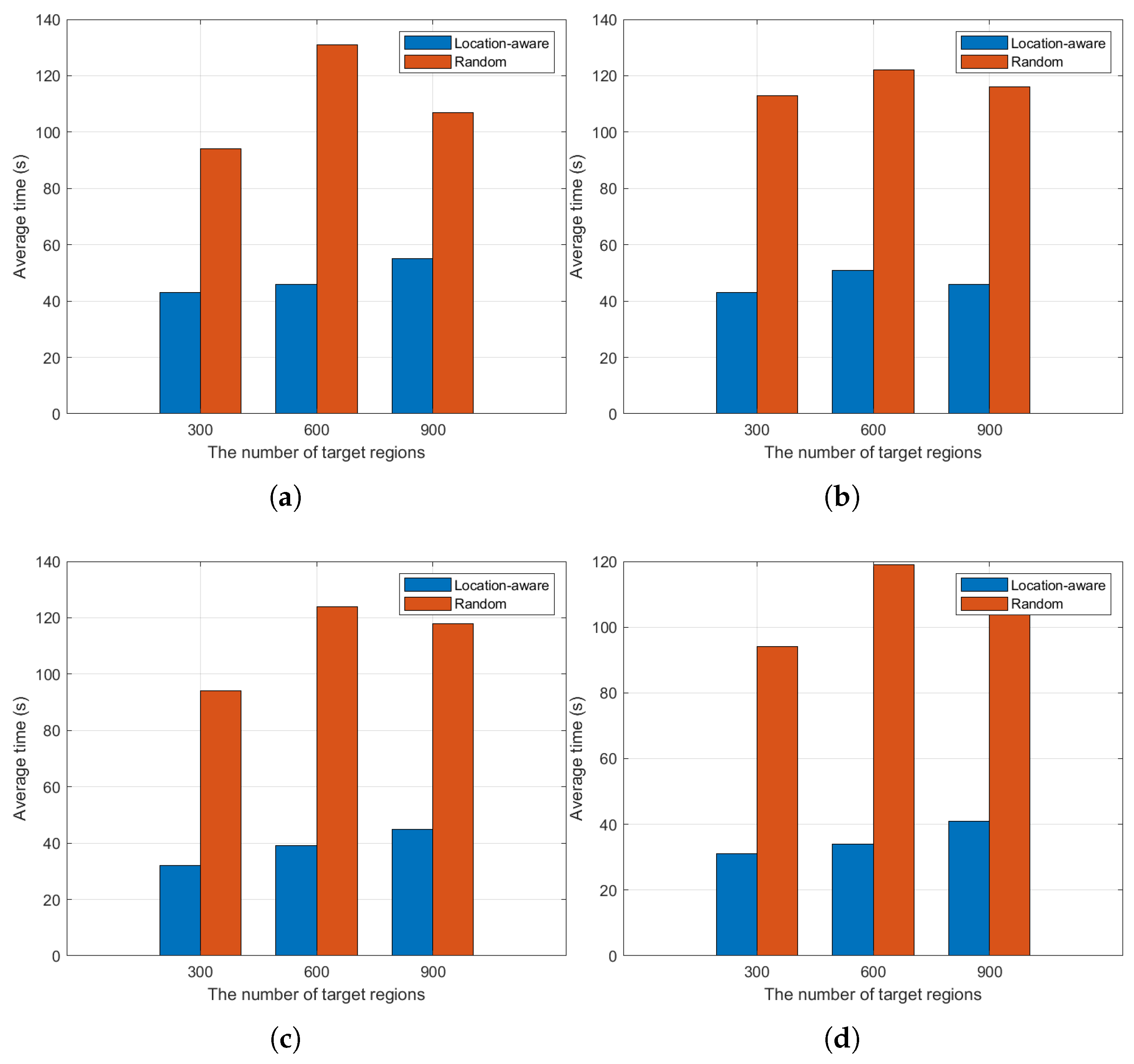
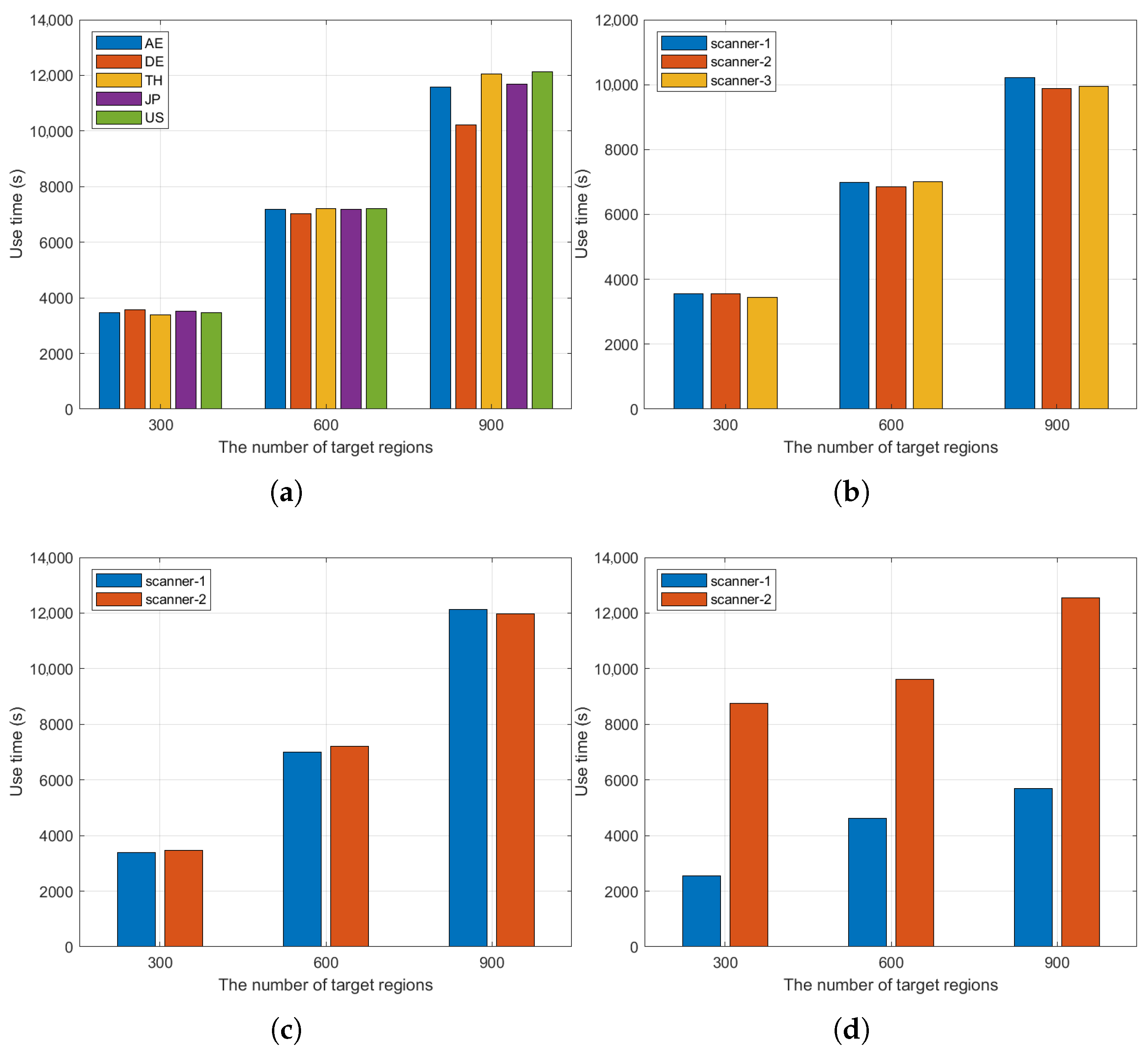
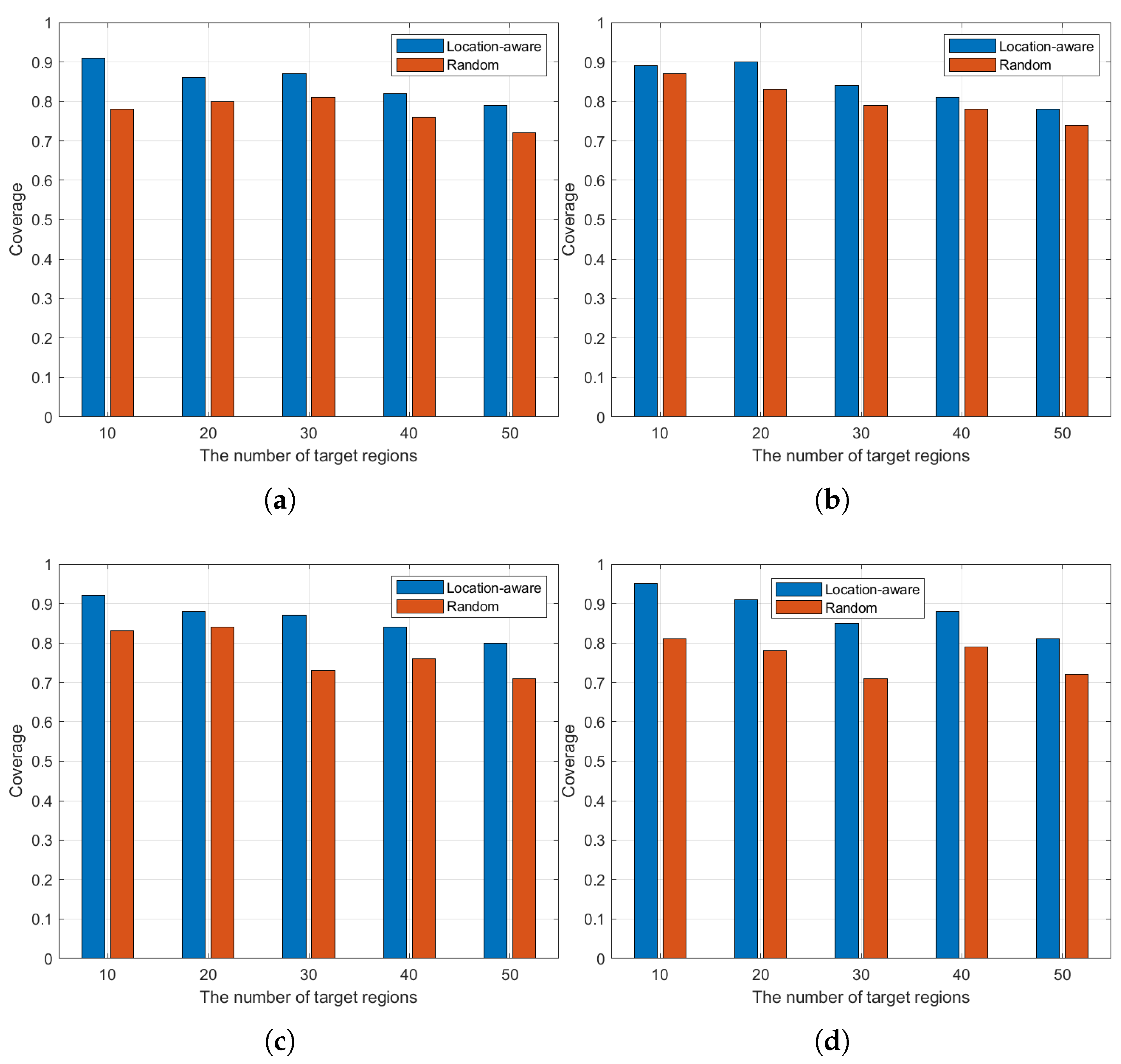
5.2. Experiments Analysis
6. Conclusions
7. Limitations and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mazurczyk, W.; Caviglione, L. Cyber reconnaissance techniques. Commun. ACM 2021, 64, 86–95. [Google Scholar] [CrossRef]
- Hashida, H.; Kawamoto, Y.; Kato, N. Efficient delay-based internet-wide scanning method for IoT devices in wireless LAN. IEEE Internet Things J. 2020, 7, 1364–1374. [Google Scholar] [CrossRef]
- Song, G.; He, L.; Zhao, T.; Luo, Y.; Wu, Y.; Fan, L.; Li, C.; Wang, Z.; Yang, J. Which doors are open: Reinforcement learning-based internet-wide port scanning. In Proceedings of the 2023 IEEE/ACM 31st International Symposium on Quality of Service (IWQoS), Orlando, FL, USA, 19–21 June 2023; pp. 1–10. [Google Scholar] [CrossRef]
- Verma, S.; Kawamoto, Y.; Kato, N. A smart internet-wide port scan approach for improving IoT security under dynamic WLAN environments. IEEE Internet Things J. 2022, 9, 11951–11961. [Google Scholar] [CrossRef]
- Hou, B.; Cai, Z.; Wu, K.; Su, J.; Xiong, Y. 6Hit: A reinforcement learning-based approach to target generation for internet-wide IPv6 scanning. In Proceedings of the IEEE INFOCOM 2021—IEEE Conference on Computer Communications, Vancouver, BC, Canada, 10–13 May 2021; pp. 1–10. [Google Scholar] [CrossRef]
- Hou, B.; Cai, Z.; Wu, K.; Yang, T.; Zhou, T. 6Scan: A high-efficiency dynamic internet-wide IPv6 scanner with regional encoding. IEEE/ACM Trans. Netw. 2023, 31, 1870–1885. [Google Scholar] [CrossRef]
- Durumeric, Z. ZMap: The Internet Scanner. Available online: https://github.com/zmap/zmap (accessed on 26 July 2019).
- NMAP.ORG. Available online: https://nmap.org/ (accessed on 26 July 2019).
- Wan, G.; Izhikevich, L.; Adrian, D.; Yoshioka, K.; Holz, R.; Rossow, C.; Durumeric, Z. On the origin of scanning: The impact of location on internet-wide scans. In Proceedings of the ACM Internet Measurement Conference (IMC ’20), New York, NY, USA, 27–29 October 2020; pp. 662–679. [Google Scholar] [CrossRef]
- Verma, S.; Kawamoto, Y.; Kato, N. A novel IoT-aware WLAN environment identification for efficient internet-wide port scan. In Proceedings of the 2020 IEEE Global Communications Conference (GLOBECOM), Taipei, Taiwan, 7–11 December 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Tang, F.; Kawamoto, Y.; Kato, N.; Yano, K.; Suzuki, Y. Probe delay-based adaptive port scanning for IoT devices with private IP address behind NAT. IEEE Netw. 2020, 34, 195–201. [Google Scholar] [CrossRef]
- Gong, Q.; Gu, C. A baseline modeling algorithm for internet port scanning radiation flows. In Proceedings of the 2021 IEEE 6th International Conference on Signal and Image Processing (ICSIP), Nanjing, China, 22–24 October 2021; pp. 1255–1259. [Google Scholar] [CrossRef]
- Yanyan, L.; Shanhou, H. Application of Bayesian optimization in router port testing: An improved port scanning technique. In Proceedings of the 2023 IEEE 5th International Conference on Power, Intelligent Computing and Systems (ICPICS), Shenyang, China, 14–16 July 2023; pp. 98–103. [Google Scholar] [CrossRef]
- Padmanabhan, R.; Schulman, A.; Levin, D.; Spring, N. Residential links under the weather. In ACM SIGCOMM, Proceedsings of the SIGCOMM ’19: ACM Special Interest Group on Data Communication, Beijing, China, 19–23 August 2019; Association for Computing Machinery: New York, NY, USA, 2019. [Google Scholar]
- Zhu, P.; Man, K.; Wang, Z.; Ensafi, R.; Halderman, J.A.; Duan, H. Characterizing transnational internet performance and the great bottleneck of China. In ACM Sigmetrics, Proceedsings of the SIGMETRICS ’20: Abstracts of the 2020 SIGMETRICS/Performance Joint International Conference on Measurement and Modeling of Computer Systems, Boston, MA, USA, 8–12 June 2020; Association for Computing Machinery: New York, NY, USA, 2020. [Google Scholar]
- Pearce, P.; Jones, B.; Li, F.; Ensafi, R.; Feamster, N.; Weaver, N.; Paxson, V. Global measurement of DNS manipulation. In USENIX Security Symposium, Proceedsings of the SEC’17: Proceedings of the 26th USENIX Conference on Security Symposium, Vancouver, BC, Canada, 16–18 August 2017; Association for Computing Machinery: New York, NY, USA, 2017. [Google Scholar]
- Hao, H.; Xu, C.; Zhang, W.; Yang, S.; Muntean, G.-M. Task-driven priority-aware computation offloading using deep reinforcement learning. IEEE Trans. Wirel. Commun. 2025. early access. [Google Scholar] [CrossRef]
- Hao, H.; Xu, C.; Zhang, W.; Yang, S.; Muntean, G.-M. Joint task offloading, resource allocation, and trajectory design for multi-UAV cooperative edge computing with task priority. IEEE Trans. Mob. Comput. 2024, 23, 8649–8663. [Google Scholar] [CrossRef]
- IP2Location. IP2Location API Open Platform. Available online: https://www.ip2location.com/ (accessed on 26 July 2019).
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, W.; Shi, H.; Hao, H.; Guan, Q. An Efficient Internet-Wide Scan Approach Based on Location Awareness. Future Internet 2025, 17, 330. https://doi.org/10.3390/fi17080330
Shi W, Shi H, Hao H, Guan Q. An Efficient Internet-Wide Scan Approach Based on Location Awareness. Future Internet. 2025; 17(8):330. https://doi.org/10.3390/fi17080330
Chicago/Turabian StyleShi, Wenqi, Huiling Shi, Hao Hao, and Qiuyu Guan. 2025. "An Efficient Internet-Wide Scan Approach Based on Location Awareness" Future Internet 17, no. 8: 330. https://doi.org/10.3390/fi17080330
APA StyleShi, W., Shi, H., Hao, H., & Guan, Q. (2025). An Efficient Internet-Wide Scan Approach Based on Location Awareness. Future Internet, 17(8), 330. https://doi.org/10.3390/fi17080330