Abstract
Phishing attacks pose significant risks to security, drawing considerable attention from both security professionals and customers. Despite extensive research, the current phishing website detection mechanisms often fail to efficiently diagnose unknown attacks due to their poor performances in the feature selection stage. Many techniques suffer from overfitting when working with huge datasets. To address this issue, we propose a feature selection strategy based on a convolutional graph network, which utilizes a dataset containing both labels and features, along with hyperparameters for a Support Vector Machine (SVM) and a graph neural network (GNN). Our technique consists of three main stages: (1) preprocessing the data by dividing them into testing and training sets, (2) constructing a graph from pairwise feature distances using the Manhattan distance and adding self-loops to nodes, and (3) implementing a GraphSAGE model with node embeddings and training the GNN by updating the node embeddings through message passing from neighbors, calculating the hinge loss, applying the softmax function, and updating weights via backpropagation. Additionally, we compute the neighborhood random walk (NRW) distance using a random walk with restart to create an adjacency matrix that captures the node relationships. The node features are ranked based on gradient significance to select the top k features, and the SVM is trained using the selected features, with the hyperparameters tuned through cross-validation. We evaluated our model on a test set, calculating the performance metrics and validating the effectiveness of the PhishGNN dataset. Our model achieved a precision of 90.78%, an F1-score of 93.79%, a recall of 97%, and an accuracy of 93.53%, outperforming the existing techniques.
1. Introduction
Phishing, as defined by the Anti-Phishing Working Group (APWG), is the use of social engineering and technical deception to steal users’ banking and personal identifying information [1,2,3,4]. Browsers serve as the first line of defense against phishing scams, often employing blacklist-based defense mechanisms. However, blacklists have limitations. Security software such as Intrusion Prevention Systems (IPSs) and Intrusion Detection Systems (IDSs) can be used for phishing detection, but they struggle with zero-day phishing attacks, which involve newly created phishing domains. These attacks remain undetectable for a significant period since they are not immediately blacklisted. Given that phishing websites are generated rapidly and have short lifespans, maintaining blacklists is an arduous task. To overcome the limitations of blacklist-based detection, discovery-based techniques have emerged. These approaches use prediction algorithms to determine websites as legitimate or malicious based on their URL characteristics and webpage contents [5,6,7,8,9,10]. In recent years, researchers have explored various machine learning (ML) methods for phishing detection.
Phishing detection techniques are generally classified into four main categories: scenario-based techniques (ST) and the ML, deep learning (DL), and hybrid approaches [11,12,13,14].
Scenario-based techniques analyze different situational conditions to improve attack detection. They rely on predefined scenarios that describe various attack vectors and behaviors. By assessing input data against these scenarios, ST-based systems can efficiently identify and respond to specific context-based attacks [15,16,17].
ML-based approaches extract phishing detection features and classify them using unsupervised and supervised learning algorithms. The choice of ML algorithm significantly impacts the classification accuracy. Some commonly used ML algorithms include Naïve Bayes (NB) [18], Support Vector Machine (SVM) [19], decision tree (DT) [20], Random Forest (RF) [21], k-Nearest Neighbor (kNN) [22], J48, and C4.5 algorithms [23,24]. ML techniques offer several advantages over blacklists, including the ability to detect phishing attacks in real time (zero-hour detection). Unlike heuristic-based methods, ML algorithms can automatically build classification models from large datasets, reducing the need for manual analysis while also achieving lower false-positive rates. Furthermore, as phishing strategies evolve, ML classifiers adapt to new attack trends.
DL, a subfield of ML, enhances predictive models by automatically discovering hierarchical feature representations. Recent advancements in DL have enabled its successful application to various cybersecurity challenges, including website defacement, IDSs, phishing detection, spam filtering, and malware identification [15,16]. DL architectures analyze complex data structures by learning in a hierarchical manner. While DL-based phishing detection methods are still evolving, they offer the advantage of automatic feature extraction from raw data without requiring prior knowledge. However, DL models require larger datasets and longer training times compared to traditional ML techniques. Some DL approaches used in phishing detection include Convolutional Neural Networks (CNNs), recurrent neural networks (RNNs), Multilayer Perceptron (MLP), gated recurrent units (GRUs), Deep Neural Networks (DNNs), and long short-term memory (LSTM). Due to their strong performances, DL-based techniques are likely to play an important role in phishing detection.
Given that cybercriminals continuously evolve their tactics to exploit weaknesses in anti-phishing mechanisms, relying on a single detection method is often insufficient. Consequently, hybrid models have been proposed to enhance the detection performance by integrating multiple classification techniques. These models combine different algorithms to leverage their respective strengths while mitigating their weaknesses. Studies suggest that hybrid models achieve higher accuracies than those of standalone algorithms, making them a promising method for improving phishing detection effectiveness.
In summary, this study makes the following contributions:
- Improvement in the accuracy and adaptability to evolving phishing behaviors by utilizing graph convolutional networks (GCNs) for feature extraction and combining them with SVMs.
- The introduction of an innovative feature selection process using Manhattan similarity and the neighborhood random walk method, ensuring that the model can dynamically capture the relationships between features.
- The use of the hinge loss function alongside similarity metrics to enhance the model’s classification performance, improving its ability to discriminate between real and phishing sites.
The rest of this paper is organized as follows. Section 2 examines recent phishing detection strategies, concentrating on a hybrid deep learning-based model. Section 3 describes the suggested model’s functioning premise. Section 4 provides the evaluation dataset, experimental setup, model performance metrics, experiment outcomes, and discussions. Section 5 summarizes the findings and discusses future work.
2. Literature Review
In this section, we review related works in the field of phishing detection. The deployment of phishing websites is rapidly expanding, prompting the blacklisting of websites to thwart phishing. Because of their capability for coping with phishing websites and attackers’ dynamics, ML strategies have attracted attention rapidly in the phishing website diagnosis domain. Induced bias, the weak accuracy of diagnosis, and a high false-alarm rate (FAR) are some of the ML methods’ cons. Because of active phishing attempts, a significant requirement exists for new solutions based on ML for diagnosing phishing websites.
Three models of learning given the Forest Penalizing Attribute (ForestPA) mechanism were provided by the authors of [25]. Using the power of all features on a given dataset, the ForestPA generates highly effective decision trees using weight assignment and weight augmentation techniques.
Website classification in phishing/legal groups basically relies on significant status on the website. Different solutions have been presented for decreasing phishing attacks, although no solution exists for fully solving the issue, which is one of the motivating strategies in the data mining domain. Data mining specifically refers to “inducing classification laws”. In [26], a novel mechanism of classification is offered and applied to popular phishing website datasets in the UCI repository.
In [27], a novel mechanism of association classification (AC) is provided as automatic and synthetic means for developing classification process accuracy levels in the search for malicious websites. In order to ensure the discovery of hidden patterns not produced by AC methods, an intelligent associative classification (IAC) algorithm is proposed.
An improved ensemble-based approach is presented in [28] to identify phishing websites. Some ensemble ML methods, such as GradientBoost, LightGBM, RFs, AdaBoost, XGBoost, and bagging, have their parameters optimized by applying genetic algorithms (GAs). After ranking the developed classifiers, the first three models were chosen as basic stacked set classifiers.
The UCI phishing dataset was reviewed in [29]. The dimensions of the dataset were reduced, and the effectiveness of the classification systems was compared using a smaller dataset of phishing websites.
Since phishing attacks have a few basic characteristics, machine learning is the best option for detecting them. A number of machine learning approaches were used in [30] to detect phishing attacks. There were two priority-based algorithms proposed here. The final fusion classifier was selected based on the output of these algorithms.
To achieve high accuracy and reproducible outcomes for phishing website detection, Ref. [31] investigates the problems of developing cost-effective deep learning models and parameter settings.
The researchers of [32] proposed a technique for phishing website detection combining feature selection with a nonlinear regression algorithm based on a meta-heuristic algorithm. This paper used a dataset consisting of 11,055 valid and phishing URLs to validate the proposed approach. Then, 20 features were selected for retrieval from the websites. In this work, two feature selection strategies were used to determine the best feature subset: decision trees and packing. The presented regression model parameters were determined by applying the method of HS, and the nonlinear regression strategy was applied for grouping websites. The dynamic pitch adjustment rate employed by the proposed HS algorithm produces new harmonics.
The researchers in [33] have proposed a multilayer ensemble learning strategy using estimators at various levels. The present-layer estimators’ predictions are presented as input to the next layer.
The gradient-boosting paradigm is presented in [34] for issues of classification and regression in ML for small data sources with various sharing. Using Bayesian optimization, the model parameters are gradually adjusted from an initial hypothesis for specific usage scenarios. This study focuses on using the framework to identify fake websites.
ML classifiers can be applied for properly recognizing phishing websites. So, various ML classifiers, like HNB, Naive Bayes, and J48, have been applied here [35].
Despite the various phishing detection methods in the research literature, relatively few studies consider the feature selection strategy. This strategy removes unnecessary or irrelevant features for the problem of detecting phishing websites. Based on the importance of each feature for the detection accuracy, the authors of [36] investigated the key features for detecting phishing websites. A benchmark phishing dataset was used as a feature selection tool, and a gravitational search algorithm (GSA) was used.
In [37], a public dataset was used, and a diagnostic mechanism was proposed to identify bad URLs applying recurrent neural network models like bidirectional long short-term memory (Bi-LSTM), gated recurrent units (GRUs), and LSTM.
In [38], a developed binary bat mechanism version was applied for designing neural networks, which groups websites into phishing and non-phishing groups. Here, the DL-based swarm intelligence binary bat algorithm (SI-BBA) model is provided for diagnosing phishing websites. The binary bat mechanism was applied to setting the presented CNN network’s hyperparameters. Various mechanisms of optimization were applied in the CNN network.
In [39], a novel ML strategy for grouping phishing websites applying CNNs on URL-based features is provided. CNNs include a fully connected layer, a convolution stack, and pooling layers. For preventing the gradient-vanishing issue, recent CNNs apply entropy loss tasks with rectified linear units (ReLUs). For applying CNNs, the vectors of features are converted into images.
In [40], the authors present a model for detecting phishing scams that is enriched by the community. They propose a methodology for detecting network phishing using graph neural networks. First, they created an Ethereum transaction network and extracted transaction subgraphs as well as related content components. They provide a diagnosis strategy given the community-developed GCN. The algorithm improves the node representation in GCN neighborhoods and investigates graph semantics through community structure and node similarity measurements.
In [41], the authors employ a GCN. The authors discovered that the network is highly heterophilic and models Ethereum transaction records as a large-scale transaction network, with accounts with varying features and labels connected. To address this issue, we propose a GCN-based model termed the EH-GCN.
In [42], a multiscale feature fusion technique is used with a graph convolutional network model to detect phishing frauds. As a result, in the edge-embedding representation module, all the transaction times and values between two nodes are classified, and a gate recurrent unit (GRU) neural network is developed to obtain temporal features in the order of transactions, resulting in a representation of the fixed-length edge embedding from variable-length input. Weights of attention are defined for complete embedding representations surrounding a node, collecting edge-embedding representations and structural relations into a node in the time-trading feature module. At last, primary and time-trading node features, graph attention networks (GATs), GCNs, and SAGEConv are integrated and used for grouping nodes of phishing. The related works in phishing detection are summarized in Table 1.

Table 1.
Summary of previous works in the field of phishing detection.
3. Materials and Methods
The considerable concern in phishing website diagnosis is choosing a suitable DL algorithm tailored to particular diagnosis function aims. A poor selection of the algorithm may lead to unpredictable results, a waste of time and resources, and low recognition accuracy. To effectively manage these types of attacks, the detection model must study new phishing website behaviors and be able to dynamically reflect changes in newly established phishing patterns. Most classification methods are not able to investigate new behaviors and subsequently are not able to modify themselves in order to reflect environmental changes. We present a hybrid deep learning-based model to address these issues. We also offer a hybrid strategy for detecting phishing attempts, as well as a feature extraction approach based on a graph convolution network. The detailed flowchart of our proposed phishing detection with the GNN and SVM pipelines is illustrated in Figure 1 for clarity and reproducibility.
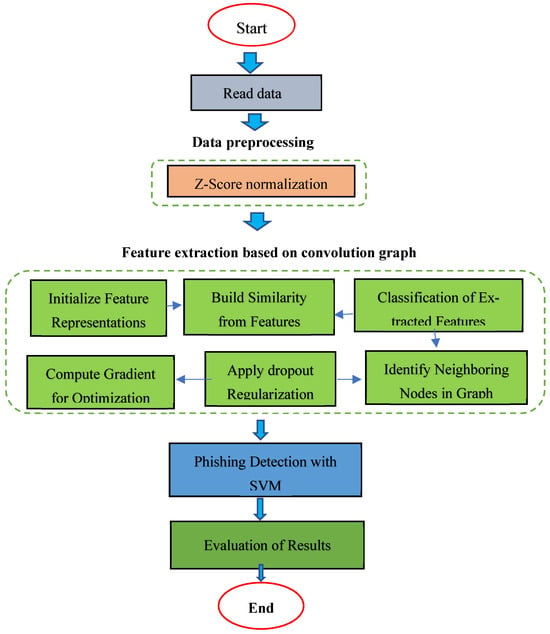
Figure 1.
Flowchart of phishing detection with GNN and SVM algorithm.
3.1. Preprocessing
Normalization refers to a method of preprocessing applied in ML and data analysis which transforms the numbers of features in the usual range/scale, normally between 0 and 1 or between −1 and 1. This is to ensure that all features are considered equally important and that no feature dominates the others [43]. There are different methods for normalizing feature weights. The Z-Score normalization [44] method was used in this study.
In this method, the feature values are included in a standard interval applying Equation (1):
where
x_norm = (x − μ)/σ
- x_norm is the normalized feature value;
- μ is the mean of the feature;
- x is the value of the main feature;
- σ is the standard deviation of the feature.
3.2. Extracting Features Based on Graph Convolution Network
Feature extraction based on a graph convolutional network is performed with an algorithm with five main components, including the elimination of multiples, feature initialization, gradient computation, graph construction, and a neural network. The basic aim is to iteratively explore a collection of optimum features causing the highest decrease in the loss of optimization.
Step 1: Feature initialization
Feature initialization is based on a matrix of features with n << p or . First, we define the bias feature (for instance, a column with amounts equal to 1) in X and index it with zero. The sum of the features’ numbers is p + 1, and basic features have similar index numbers.
The chosen feature set (S = {0}) is initialized as the bias feature. The bias feature functions as the basic feature selected for beginning the process of feature selection.
Step 2: Construction of similarity graph
To construct the similarity graph, the Manhattan similarity criterion is used based on the selected features in the set (S). The Manhattan similarity is measured between two data samples (i and j) in the form of vectors. and are redefined and calculated. All the dataset features are of the non-binary categorical type, and as a result, it is possible to use the Manhattan distance criterion. It is calculated by comparing the structural similarity between two vectors. To calculate the Manhattan similarity between two vectors with equal lengths, first, the number of corresponding locations with similar values is calculated. Then, this value is divided by the length of the vector. Each row of the correlation matrix represents a vector of zeros and ones. This vector actually reflects the degree of communication between the nodes. As a result, it is possible to calculate the degree of Manhattan similarity between both nodes.
The Manhattan distance is referred to as the L1 distance. When u = (x1, y1) and v = (x2, y2) are two points, the Manhattan distance between u and v is represented by Equation (2):
MH (a, b) = |x1 − x2| + |y1 − y2|
Instead of 2 dimensions, when points have n dimensions, like a = (x1, x2, …, xn) and b = (y1, y2, …, yn) after that, Equation (2) can be generalized by describing the Manhattan distance among a and b as follows [45]:
Step 3: Finding neighboring nodes
1. Graph dimensions and structural features
The first step in the graph construction phase is the creation of a structural feature graph. We have a collection of nodes that represent data samples. In addition, there is another set of nodes that represent feature values. A node is added for each value of each feature. Based on the feature value (V) and data sample (R), the set of nodes in the graph is formed.
2. Calculation of transition probability matrix
In the next stage, a feasibility matrix of transitions is computed. The matrix row and column numbers rely on data instances and feature numbers:
- Pv means the probability of the nodes corresponding to the data sample;
- A means the relation of the data sample with the Vs (feature node);
- B means the connection of the v with the sample data;
- O means that the relation between the V and V in the matrix is null because each V is not related to itself.
In the next step, an matrix is calculated in the form of a distance matrix based on the neighborhood random walk (NRW) method:
The higher the entry number of the matrix, the closer the two nodes are to each other.
Step 4:
The neural network is made with three layers, such as an input layer equal to the sum of the features’ numbers, a GCN, as well as an output layer:
For the feature selection, only selected features in the input-layer weight matrix are used iteratively:
In the first iteration, S = {0}, so only the first column of the weight matrix is used.
The GCN layer is used to build representations (embedding) based on graph similarity:
The output layer has the same number of neurons as there are classes. Following this, the probability for each class is calculated:
Step 5: Loss calculation
The hinge loss is a cost function used to train statistical classification. The hinge loss function is mostly used to determine the maximum classification margin in support vector machines. For the output t = ±1 and the hinge loss classification order, the prediction y is defined as follows:
where y is the actual value of the class (0 or 1); y’ is the output of the classification model.
ℓ = max(0, 1 − y ∗ y’)
The hinge loss function is a nonlinear cost function used for classification models with any type of architecture. This cost function has many desirable properties, such as stability and accuracy sensitivity. To use this hinge loss function in phishing, we set the values of the classes of phishing and valid pages to −1 and 1, respectively.
The hinge loss is especially useful in the GNN context because it fosters a distinct separation in the learnt node embeddings, making the model more resilient against noisy or overlapping graph characteristics. Unlike the cross-entropy loss, which focuses on probabilistic outputs, the hinge loss directly optimizes the margin, which is useful for distinguishing phishing URLs from authentic ones based on tiny feature changes in the network structure. This results in better generalization and robustness in spotting phishing patterns.
Algorithm 1 describes the technique for detecting phishing nodes. This technique uses a GNN, an SVM, and the NRW distance to increase the feature selection and classification accuracy in the detection of phishing attacks. The dataset is separated into training and testing sets, and a graph (G) is created from feature vectors using pairwise distances. To capture the graph’s local structure, the technique computes the neighborhood random walk (NRW) distance between nodes, which aids in the construction of an adjacency matrix that better portrays the node interactions based on neighborhood connectedness. This adjacency matrix is then used to train a graph model, which includes self-loops for better message delivery and uses the hinge loss to optimize the node categorization.
| Algorithm 1: Phishing Detection with GNN and SVM |
Input:
|
After training the GNN model, the approach uses feature gradients to choose the most informative features, thereby lowering the dataset’s dimension. These selected features are then fed into an SVM classifier, which refines the phishing detection model using the hinge loss. Finally, predictions are generated on the test set, and performance metrics like the precision, accuracy, and AUC are calculated to determine the model’s effectiveness. The technique intends to improve high-precision phishing attack detection by incorporating the NRW to improve graph representation and merge the GNN with the SVM.
3.3. Phishing Detection with SVM
The SVM classifier is an important and adaptable ML method which performs the two functions of classification and regression. It acts by assigning an optimum hyperplane which optimally shares points of data at various levels in a high-dimensional space. This hyperplane was selected for optimizing the distance/margin among the nearest points of data at every level, called support vectors. SVMs strive for developing the abilities and accuracy of the model’s generalization. SVMs can be changed for controlling nonlinear data by developing kernel tasks that change the space of input in higher-dimensional space where linear separation is feasible. The adaptability makes SVMs appropriate for a broad, challenging classification problem range.
3.4. Computational Complexity
Our method involves three stages: feature extraction, graph construction, and classification. The most computationally demanding part is the construction of the hyperlink graph and the subsequent GNN-based feature selection and learning. Let n be the number of nodes (HTML elements/URLs) and d the feature dimension. The feature extraction process is O(n·d), and the graph construction using pairwise distance-based edge creation has a complexity of O(n2). The node random walk (NRW) procedure, which involves transition matrix calculations and repeated matrix multiplications, has an approximate computational complexity of O(n3). The GCN training is linear in the number of edges and epochs; i.e., O(e·h·T), where e is the number of edges, h is the number of hidden units per layer, and T is the number of epochs. In our case, n is moderate (~100–300), so the method is computationally feasible even without GPU support. Finally, the SVM classifier is trained on the reduced feature set, with a complexity of roughly O(m2·k), where m is the number of training samples, and k is the number of selected features. Due to dimensionality reduction, this step is efficient and fast.
4. Experiments
In this section, we provide the experimental outcomes achieved applying the presented phishing diagnosis model and describe the parameters applied. Tests were performed applying Google Colab for performing and testing the model. By comparing the outcomes with those achieved applying other techniques and parameter variations, we assessed the model’s precision in phishing diagnosis and analyzed the effects of the different parameters on the performance.
4.1. Dataset
In this study, we applied phishing and legitimate URLs collected from public blacklists, including OpenPhish and PhishTank, comprising over 30,000 phishing URLs and approximately 10,000 legitimate URLs. Each URL was analyzed to extract handcrafted features grouped into three categories:
- Lexical features: These features included the dash count, symbol, domain length, IP address, and domain depth (the dot number in the domain name).
- Content features: These features included the proper HTML, an iframe, and a form with a URL. References are inserted for the Top of Form and elements, with the proper src, features href, and action.
- Domain features: These features included the field age (seconds between the last update and the expiry date), certificate validity (like confirmed and dynamic via Rustls), and certificate reliability (computed applying the certificate’s duration and when the issuer was trusted).
Based on these features, a hyperlink graph was constructed for each URL. In this graph, the nodes represent the HTML elements or linked resources, and the edges represent hyperlinks or DOM connections. The graph structure was designed to preserve the semantic layout of a webpage, following the design of the PhishGNN framework [46], which we adopted as our modeling backbone.
4.2. Experimental Setup
Tests were executed on the Google Colaboratory area. This is a free Jupyter Notebook area developed in the cloud. This presented development area based on the collaborative cloud is able to present the abilities of high processing for developers.
In our experiments, the key hyperparameters were tuned through a combination of manual and grid search methods, aiming to optimize the validation accuracy on a held-out subset of the training data. The hyperparameters tuned included the following:
- The hidden-layer sizes (final selected: [64, 32]);
- The learning rate (final: 0.001);
- The dropout probability (final: 0.1);
- The alpha threshold for graph edge construction (final: 0.95);
- The batch size (final: 16);
- The number of epochs (final: 50).
These values were chosen based on the best trade-off between the model accuracy, convergence speed, and training stability.
4.3. Evaluation Criteria
The model performance was assessed according to the following measures, as shown in Table 2.
Table 2.
Confusion table.
The accuracy [47], which is the percentage of accurately grouped emails:
The recall [47], which is the phishing email fraction accurately grouped as phishing out of the sum of the phishing emails’ numbers:
The precision [47], which is the phishing email fraction accurately grouped as phishing out of the entire instances predicted as phishing emails:
The F-Measure [47], which is the harmonic precision and recall mean:
where TP refers to the sum of the emails’ numbers which are appropriately grouped as phishing emails, FP shows the sum of the emails’ numbers that are inappropriately grouped as phishing emails, FN shows the sum of the emails’ numbers that are inappropriately grouped as non-phishing; and last, TN shows the sum of the emails’ numbers that are appropriately grouped as non-phishing. For creating our model, 30% of the data was used for testing and 70% for training.
4.4. Results and Discussion
We assessed our presented model’s performance applying a PhishGNN set of data. The achieved outcomes were compared to the same models in this study. Our model obtained 93.52%, 90.78%, 97.00%, and 93.78% in terms of the accuracy, precision, recall, and F-score, respectively. In Table 3, we illustrate the outcomes reported in this study for some phishing diagnosis models applied in the assessment.
Table 3.
Classification performances of different methods.
For assessing the presented strategy’s performance, we compared it with seven baseline and state-of-the-art techniques, such as GATConv [42], LightGBM [40], and EH-GCN [41]. In comparison to the last study, which achieved their ham and phishing emails from the PhishGNN dataset, our enhanced model performed better than the last outcomes of the study for accuracy.
By evaluating the confusion matrix in Figure 2, we discovered that 97% of positive cases were correctly sorted as positive cases, while 75.40% of negative cases were correctly grouped. Our model was able to correctly distinguish between actual and suspected phishing nodes. However, there is a 24.60% chance of misclassifying normal nodes as phishing nodes since their network structure is similar to that of phishing nodes. The receiver operating characteristic curves (ROCs) are shown in Figure 3. These demonstrate the classification performance of the proposed model. The area under the ROC curve (AUC) value is 0.94, indicating a great classification model.
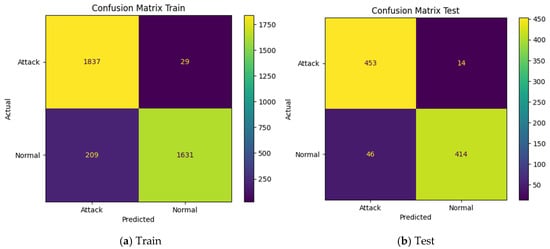
Figure 2.
Confusion matrix for classification results: (a) training; (b) testing.
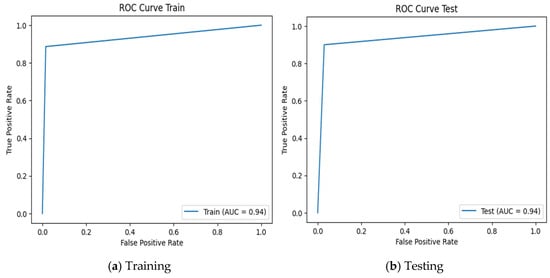
Figure 3.
ROC curves of the proposed model: (a) training; (b) testing.
As illustrated in Figure 4, in the chosen feature relation matrix, some of the features illustrate higher relation degrees that put their significance in the diagnosis process of phishing into perspective. For instance, features like Feature_1, Feature_7, and Feature_5 show average to high relations with other features, showing that they obtained basic dataset relations. The higher-relation features, especially those that are related positively, might show crucial phishing attack natures like specific technical markers/user communications that are important for recognizing potential phishing attempts. In other words, less related features, like Feature_22 or Feature_18, might obtain independent/single information which could develop the model performance by decreasing the feature set redundancy.
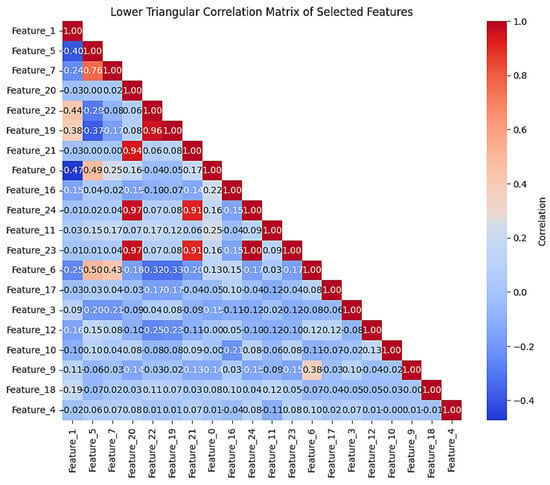
Figure 4.
Correlation matrix of features selected by the proposed method.
Features like Feature_1, Feature_7, and Feature_5 have moderate to high levels of association with other features. These features characterize the dataset’s underlying linkages and are important for identifying phishing-related actions. Features with high positive correlations may indicate certain technical signs or user activities that are frequently seen in phishing attacks. In convolutional graph network models, these features serve as pivot nodes, collecting information from nearby nodes to increase the data-embedding quality. In contrast, characteristics like Feature_18 and Feature_22, which have fewer links with other features, provide independent and non-repetitive data. These features can reduce the dataset redundancy while also improving the model performance. The independent information provided by these qualities is particularly useful for detecting unknown or complex attacks with more diversified data. These qualities retain the diversity of the data and improve the model’s generalizability. Features with stronger correlations (such as Feature_1) play an important role in distinguishing between phishing attacks and non-phishing actions. The proper selection of these features not only minimizes overfitting but also ensures the model’s accuracy in the test dataset. By selecting and ranking effective features, the model can attain a peak performance while balancing feature relationships and independent information.
In conclusion, the feature correlation matrix demonstrates that combining strong and independent features can reduce redundancy, enhance the model efficiency, and increase the accuracy in detecting phishing assaults. This approach enables the detection of unknown phishing attempts while maintaining the model’s generalizability and quality.
Figure 5 depicts the decision bounds of a machine learning model used to detect phishing. The figure depicts a two-dimensional representation of the feature space obtained by principal component analysis (PCA) for reducing the dimensionality of raw data. The graph’s dots reflect phishing websites (brown) and legal websites (blue). The colorful background represents the classification model’s decision boundaries and the class to which the samples were assigned in each region of the feature space.
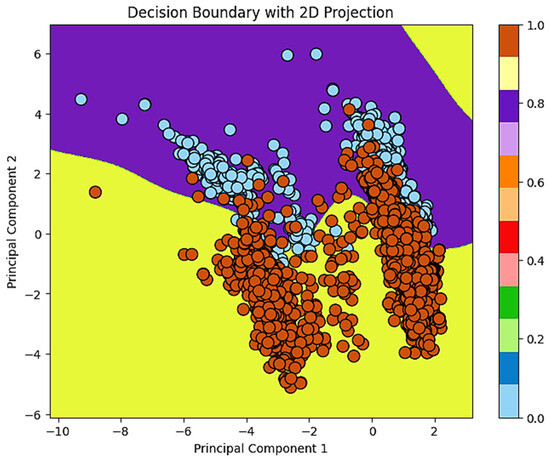
Figure 5.
The boundaries of the machine learning model decision making in detecting phishing and legitimate websites.
The analysis of this image demonstrates that the classification model can effectively discriminate between phishing and legal websites. However, data overlap is seen in some places, showing that it is difficult to identify some phishing samples from legal websites. This could be because some phishing websites are misleading, resembling authentic websites and making identification difficult. In addition, the color bar on the side of the image represents the model’s level of confidence in predicting classes; in places with intermediate probability, the model is uncertain about making decisions.
This investigation has a substantial impact on cybersecurity and phishing attack detection. Points in overlapping areas suggest that the model may have a type I error (false positive) or a type II error (false negative) in certain circumstances. A type I error refers to genuine websites, whereas a type II error can permit a phishing website to go undetected, endangering users’ security.
4.5. Limitations
The proposed phishing detection system using a GNN and an SVM yields promising results; however, some limitations must be addressed:
- The dataset primarily includes phishing and genuine URLs from publicly available sources, which may not fully capture new phishing patterns, zero-day assaults, or region-specific phishing campaigns.
- Our model relies on handmade lexical, content, and domain features, which may be disguised by phishing websites.
- While evaluated on a public dataset, the model’s applicability to other domains or multilingual phishing sites warrants additional examination.
- GNN-based models can be difficult to interpret in security-critical applications. More research is needed to improve the explainability for incident response.
5. Conclusions
Detecting phishing websites necessitates a strong and adaptable methodology that can handle the changing nature of phishing attacks. The traditional categorization methods are ineffective in modern circumstances because they cannot adapt to new patterns and behaviors. In this paper, we overcome these problems by presenting a hybrid deep learning-based model based on GCNs. The suggested methodology employs advanced techniques, such as feature extraction using GCNs, Manhattan similarity for graph creation, and the hinge loss for exact classification. This technique increases not only the feature selection but also the overall accuracy and adaptability of phishing detection systems. To gain deeper insights into the model’s performance, we analyzed the misclassified instances. Our observations indicate that most misclassifications occurred for borderline cases or obfuscated phishing sites, which share many characteristics with legitimate sites, making them inherently challenging to detect. This highlights potential areas for future improvement, such as incorporating more sophisticated feature representations or additional context to better distinguish these difficult cases. With future advances, these hybrid models have the potential to greatly improve online security and more successfully combat phishing attacks. In the future, incorporating real-time data streams and continuous learning methods into the model could allow it to respond more quickly to developing phishing patterns. Extending the feature extraction method to include advanced graph-based algorithms like hypergraph neural networks may increase the detection accuracy even more. Furthermore, investigating ensemble methods that mix different machine learning models may improve the reliability of phishing detection systems. The proposed method, which combines a GNN and an SVM, detects phishing with high accuracy and enhances the data resolution by selecting effective features and taking into account feature interactions. This strategy is scalable and effectively reduces the effects of uneven data. However, it faces several obstacles, including high computational complexity, the necessity for accurate hyperparameter tweaking, and the risk of overfitting. Furthermore, the model’s implementation necessitates significant computer resources, and the optimal number of features is directly proportional to its performance.
Author Contributions
Conceptualization, L.M.K. and H.E.; methodology, S.S.S. and H.E.; software, S.S.S.; validation, S.S.S.; formal analysis, S.S.S.; investigation, H.E.; resources, H.E.; data curation, S.S.S.; writing—original draft preparation, S.S.S.; writing—review and editing, L.M.K. and H.E.; visualization, S.S.S.; supervision, L.M.K.; project administration, L.M.K.; funding acquisition, L.M.K. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The data presented in this study are available on reasonable request from the corresponding author. The data are not publicly available due to institutional data use policies.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| SVM | Support Vector Machine |
| GNN | Graph Neural Network |
| APWG | Anti-Phishing Working Group |
| IPSs | Intrusion Prevention Systems |
| IDSs | Intrusion Detection Systems |
| ML | Machine Learning |
| ST | Scenario-Based Techniques |
| DL | Deep Learning |
| NB | Naïve Bayes |
| DT | Decision Tree |
| RF | Random Forest |
| kNN | k-Nearest Neighbor |
| CNN | Convolutional Neural Network |
| RNN | Recurrent Neural Network |
| MLP | Multilayer Perceptron |
| GRU | Gated Recurrent Unit |
| DNN | Deep Neural Network |
| LSTM | Long Short-Term Memory |
| GCN | Graph Convolutional Network |
| FAR | False-Alarm Rate |
| ForestPA | Forest Penalizing Attribute |
| AC | Association Classification |
| IAC | Intelligent Associative Classification |
| GA | Genetic Algorithm |
| Bi-LSTM | Bidirectional Long Short-Term Memory |
| SI-BBA | Swarm Intelligence Binary Bat Algorithm |
| ReLU | Rectified Linear Unit |
| GAT | Graph Attention Network |
| NRW | Neighborhood Random Walk |
| ROC | Receiver Operating Characteristic |
| AUC | Area Under the Curve |
| PCA | Principal Component Analysis |
References
- Chen, Y.; Zhang, X.; Deng, H. Trust calibration of automated security IT artifacts: A multi-domain study of phishing-website detection tools. Inf. Manag. 2021, 58, 103394. [Google Scholar] [CrossRef]
- Lokesh, G.H.; BoreGowda, G. Phishing website detection based on effective machine learning approach. J. Cyber Secur. Technol. 2021, 5, 1–14. [Google Scholar] [CrossRef]
- Sadiq, A.; Ahmad, R.W.; Salah, K.; Jayaraman, R.; Yaqoob, I. A review of phishing attacks and countermeasures for the Internet of things-based smart business applications in Industry 4.0. Hum. Behav. Emerg. Technol. 2021, 3, 854–864. [Google Scholar] [CrossRef]
- Alkawaz, M.H.; Alhassan, A.M.; Ismail, A.S. A comprehensive survey on identification and analysis of phishing website based on machine learning methods. In Proceedings of the 2021 IEEE 11th IEEE Symposium on Computer Applications & Industrial Electronics (ISCAIE), Penang, Malaysia, 3–4 April 2021. [Google Scholar]
- Deshpande, A.; Yadav, A.; Borkar, A.; Kale, S. Detection of phishing websites using machine learning. Int. J. Eng. Res. Technol. (IJERT) 2021, 10, 430–434. [Google Scholar]
- Zolfagharipour, L.; Kadhim, M.H.; Mandeel, T.H. Enhance the security of access to IoT-based equipment in fog. In Proceedings of the 2023 Al-Sadiq International Conference on Communication and Information Technology (AICCIT), Al-Muthana, Iraq, 4–6 July 2023. [Google Scholar]
- Das, S.; Nippert-Eng, C.; Camp, L.J. Evaluating user susceptibility to phishing attacks. Inf. Comput. Secur. 2022, 30, 1–18. [Google Scholar] [CrossRef]
- Alkhalil, Z.; Hewage, C.; Nawaf, L.; Khan, I. Phishing attacks: A recent comprehensive study and a new anatomy. Front. Comput. Sci. 2021, 3, 563060. [Google Scholar] [CrossRef]
- Chiew, K.L.; Yong, K.S.; Tan, C.L. A survey of phishing attacks: Their types, vectors, and technical approaches. Expert Syst. Appl. 2018, 106, 1–20. [Google Scholar] [CrossRef]
- Petrič, G.; Roer, K. The impact of formal and informal organizational norms on susceptibility to phishing. Telemat. Inform. 2022, 67, 101766. [Google Scholar] [CrossRef]
- Patil, R.R.; Kaur, G.; Jain, H.; Tiwari, A.; Joshi, S.; Rao, K.; Sharma, A. Machine learning approach for phishing website detection: A literature survey. J. Discrete Math. Sci. Cryptogr. 2022, 25, 817–827. [Google Scholar] [CrossRef]
- Al-Hagery, M.A.; Abdalla Musa, A.I. Automated Credit Card Risk Assessment using Fuzzy Parameterized Neutrosophic Hypersoft Expert Set. Int. J. Neutrosophic Sci. (IJNS) 2025, 25, 93–103. [Google Scholar]
- Patil, S.; Dhage, S. A methodical overview on phishing detection along with an organized way to construct an anti-phishing framework. In Proceedings of the 2019 5th International Conference on Advanced Computing & Communication Systems (ICACCS), Coimbatore, India, 15–16 March 2019. [Google Scholar]
- Ozcan, A.; Catal, C.; Donmez, E.; Senturk, B. A hybrid DNN–LSTM model for detecting phishing URLs. Neural Comput. Appl. 2021, 34, 10821–10837. [Google Scholar] [CrossRef] [PubMed]
- Zolfagharipour, L.; Kadhim, M.H. A Technique for Efficiently Controlling Centralized Data Congestion in Vehicular Ad Hoc Networks. Int. J. Comput. Networks Appl. 2025, 12, 267–277. [Google Scholar] [CrossRef]
- Kambar, M.E.Z.N.; Esmaeilzadeh, A.; Kim, Y.; Taghva, K. A survey on mobile malware detection methods using machine learning. In Proceedings of the 2022 IEEE 12th Annual Computing and Communication Workshop and Conference (CCWC), Virtual Conference, 26–29 January 2022. [Google Scholar]
- Do, N.Q.; Selamat, A.; Krejcar, O.; Herrera-Viedma, E.; Fujita, H. Deep learning for phishing detection: Taxonomy, current challenges, and future directions. IEEE Access 2022, 10, 80795–80815. [Google Scholar] [CrossRef]
- Anagora, R.A.R.; Rudini, R.; Taufiq, R.T.R.; Jubaedi, A.D.J.A.D.; Wirawan, R.W.R.; Putra, A.S. The Classification of Phishing Websites using Naive Bayes Classifier Algorithm. Int. J. Sci. Technol. Manag. 2022, 3, 553–562. [Google Scholar]
- Anupam, S.; Kar, A.K. Phishing website detection using support vector machines and nature-inspired optimization algorithms. Telecommun. Syst. 2021, 76, 17–32. [Google Scholar] [CrossRef]
- Zhu, E.; Ju, Y.; Chen, Z.; Liu, F.; Fang, X. DTOF-ANN: An artificial neural network phishing detection model based on decision tree and optimal features. Appl. Soft Comput. 2020, 95, 106505. [Google Scholar] [CrossRef]
- Zhu, E.; Chen, Z.; Cui, J.; Zhong, H. MOE/RF: A novel phishing detection model based on revised multi-objective evolution optimization algorithm and random forest. IEEE Trans. Netw. Serv. Manag. 2022, 19, 2400–2412. [Google Scholar] [CrossRef]
- Assegie, T.A. K-nearest neighbor based URL identification model for phishing attack detection. Indian J. Artif. Intell. Neural Netw. (IJAINN) 2021, 1, 45–53. [Google Scholar]
- Alhamad, H.; Alzyadh, T.; Badawi, M.A. Detecting e-banking phishing website using C4.5 algorithm. Int. J. Comput. Sci. Netw. Secur. 2020, 20, 46–52. [Google Scholar]
- Pandey, P.; Prabhakar, R. An analysis of machine learning techniques (J48 & AdaBoost)-for classification. In Proceedings of the 2016 1st India International Conference on Information Processing (IICIP), Delhi, India, 12–14 August 2016. [Google Scholar]
- Alsariera, Y.A.; Elijah, A.V.; Balogun, A.O. Phishing website detection: Forest by penalizing attributes algorithm and its enhanced variations. Arab. J. Sci. Eng. 2020, 45, 10459–10470. [Google Scholar] [CrossRef]
- Alqahtani, M. Phishing websites classification using association classification (PWCAC). In Proceedings of the 2019 International Conference on Computer and Information Sciences (ICCIS), Sakaka, Saudi Arabia, 3–4 April 2019. [Google Scholar]
- Al-Fayoumi, M.; Alwidian, J.; Abusaif, M. Intelligent association classification technique for phishing website detection. Int. Arab J. Inf. Technol. 2020, 17, 488–496. [Google Scholar] [CrossRef]
- Al-Sarem, M.; Saeed, F.; Al-Mekhlafi, Z.G.; Mohammed, B.A.; Al-Hadhrami, T.; Alshammari, M.T.; Alreshidi, A.; Alshammari, T.S. An optimized stacking ensemble model for phishing websites detection. Electronics 2021, 10, 1285. [Google Scholar] [CrossRef]
- Karabatak, M.; Mustafa, T. Performance comparison of classifiers on reduced phishing website dataset. In Proceedings of the 2018 6th International Symposium on Digital Forensic and Security (ISDFS), Antalya, Turkey, 22–25 March 2018. [Google Scholar]
- Lakshmanarao, A.; Rao, P.S.P.; Krishna, M.M.B. Phishing website detection using novel machine learning fusion approach. In Proceedings of the 2021 International Conference on Artificial Intelligence and Smart Systems (ICAIS), Coimbatore, India, 25–27 March 2021. [Google Scholar]
- Almousa, M.; Zhang, T.; Sarrafzadeh, A.; Anwar, M. Phishing website detection: How effective are deep learning-based models and hyperparameter optimization? Secur. Privacy 2022, 5, e256. [Google Scholar] [CrossRef]
- Babagoli, M.; Aghababa, M.P.; Solouk, V. Heuristic nonlinear regression strategy for detecting phishing websites. Soft Comput. 2019, 23, 4315–4327. [Google Scholar] [CrossRef]
- Kalabarige, L.R.; Rao, R.S.; Abraham, A.; Gabralla, L.A. Multilayer stacked ensemble learning model to detect phishing websites. IEEE Access 2022, 10, 79543–79552. [Google Scholar] [CrossRef]
- Pavan, R.; Nara, M.; Gopinath, S.; Patil, N. Bayesian optimization and gradient boosting to detect phishing websites. In Proceedings of the 2021 55th Annual Conference on Information Sciences and Systems (CISS), Baltimore, MD, USA, 24–26 March 2021. [Google Scholar]
- Zaman, S.; Deep, S.M.U.; Kawsar, Z.; Ashaduzzaman; Pritom, A.I. Phishing Website Detection Using Effective Classifiers and Feature Selection Techniques. In Proceedings of the 2019 2nd International Conference on Innovation in Engineering and Technology (ICIET), Dhaka, Bangladesh, 23–24 December 2019. [Google Scholar]
- Priya, S.; Selvakumar, S.; Velusamy, R.L. Gravitational search-based feature selection for enhanced phishing websites detection. In Proceedings of the 2020 2nd International Conference on Innovative Mechanisms for Industry Applications (ICIMIA), Bangalore, India, 5–7 March 2020. [Google Scholar]
- Roy, S.S.; Awad, A.I.; Amare, L.A.; Erkihun, M.T.; Anas, M. Multimodel phishing URL detection using LSTM, bidirectional LSTM, and GRU models. Future Internet 2022, 14, 340. [Google Scholar] [CrossRef]
- Kumar, P.P.; Jaya, T.; Rajendran, V. SI-BBA–a novel phishing website detection based on swarm intelligence with deep learning. Mater. Today Proc. 2021, 45, 3741–3745. [Google Scholar]
- Kulkarni, A.D.; Convolution Neural Networks for Phishing Detection. Computer Science Faculty Publications and Presentations, 2023, Paper 23. Available online: http://hdl.handle.net/10950/4224 (accessed on 1 July 2025).
- Yin, K.; Ye, B. Phishing scam detection for Ethereum based on community enhanced graph convolutional networks. In Proceedings of the International Conference on Neural Information Processing, Changsha, China, 20–23 November 2023; pp. 191–206. [Google Scholar]
- Huang, T.; Lin, D.; Wu, J. Ethereum account classification based on graph convolutional network. IEEE Trans. Circuits Syst. II: Express Briefs 2022, 69, 2528–2532. [Google Scholar] [CrossRef]
- Chen, Z.; Huang, J.; Liu, S.; Long, H. Multiscale feature fusion and graph convolutional network for detecting Ethereum phishing scams. Electronics 2024, 13, 1012. [Google Scholar] [CrossRef]
- Zhou, Y.; Cheng, H.; Yu, J.X. Graph clustering based on structural/attribute similarities. Proc. VLDB Endow. 2009, 2, 718–729. [Google Scholar] [CrossRef]
- Nivaashini, M.; Soundariya, R.S. Deep stacked autoencoder based feature representation for phishing URLs detection. J. Adv. Res. Dyn. Control Syst. 2017, 9, 904–916. [Google Scholar]
- Gopi, R.; Sathiyamoorthi, V.; Selvakumar, S.; Manikandan, R.; Chatterjee, P.; Jhanjhi, N.Z.; Luhach, A.K. Enhanced method of ANN based model for detection of DDoS attacks on multimedia Internet of Things. Multimed. Tools Appl. 2022, 82, 15979–15993. [Google Scholar] [CrossRef]
- Bilot, T.; Geis, G.; Hammi, B. PhishGNN: A phishing website detection framework using graph neural networks. In Proceedings of the 19th International Conference on Security and Cryptography, Lisbon, Portugal, 11–13 July 2022; pp. 428–435. [Google Scholar]
- Han, J.; Kamber, M.; Pei, J. Data Mining: Concepts and Techniques, 4th ed.; Morgan Kaufmann: San Francisco, CA, USA, 2022. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).