
Strategies and Challenges in Detecting XSS Vulnerabilities Using an Innovative Cookie Collector

 , , , , and
, , , , and
Abstract
1. Introduction
1.1. Cross-Site Scripting (XSS) Attacks: Characteristics and Analysis
1.1.1. Key Characteristics
- Injection of malicious code: attackers insert JavaScript or other client-side scripting into web pages viewed by other users [3].
- Browser execution: the injected code is executed in victims’ browsers with the privileges of the legitimate website [4].
- Trust exploitation: XSS leverages the trust relationship between a user and a website [5].
1.1.2. Main Types of XSS Attacks
- Reflected (non-persistent) XSS: malicious script is reflected off a web server, typically through URL parameters, and executes immediately when the page loads [6].
- Stored (Persistent) XSS: the malicious script is permanently stored on target servers (in databases, message forums, visitor logs, etc.) and executes when victims access the stored content [4].
- DOM-based XSS: vulnerability exists in client-side code rather than the server-side code, with the attack payload never reaching the server.
- Universal XSS (UXSS): exploits vulnerabilities in browsers or browser extensions rather than websites [7].
1.1.3. Attack Vectors and Exploitation Techniques
- URL parameters and query strings;
- Form inputs and submissions;
- HTTP headers;
- JSON data structures;
- Cookie values;
- DOM manipulation.
1.1.4. Impact and Consequences
- Cookie theft and session hijacking;
- Credential harvesting through fake login forms;
- Sensitive data exfiltration;
- Website defacement;
- Browser history and clipboard stealing;
- Installation of keyloggers and trojans.
1.2. Limitations of Traditional Detection Methods
1.2.1. Primary Prevention Strategies
- Input validation and sanitization;
- Content Security Policy (CSP) implementation;
- Output encoding;
- HttpOnly and Secure cookie flags;
- X-XSS-Protection header;
- Framework security features [9].
1.2.2. Pattern Matching and Signature-Based Limitations
- Evasion through obfuscation: traditional signature-based detection methods struggle against sophisticated obfuscation techniques that disguise malicious payloads while preserving their functionality [10].
- Limited coverage of attack vectors: recent research by Melicher et al. demonstrates that pattern-based approaches cannot keep pace with the rapidly evolving XSS attack patterns, particularly DOM-based vectors [11].
- Polymorphic XSS dhallenges: as shown by Parameshwaran et al., attackers can use polymorphic techniques to generate functionally equivalent but syntactically different attack payloads that evade signature detection [12].
1.2.3. Static Analysis Shortcomings
- Framework complexity: modern JavaScript frameworks like React, Angular, and Vue introduce complexities that traditional static analyzers fail to properly model, creating blind spots in detection.
- Event-driven architecture challenges: traditional tools struggle with the event-driven nature of modern web applications, missing XSS vectors triggered through complex event chains.
- Template engine vulnerabilities: as highlighted by Lekies et al., traditional static analysis often fails to detect XSS vulnerabilities arising from template engines that dynamically generate code [13].
1.2.4. Dynamic Analysis Challenges
- Single-path execution: dynamic analysis methods typically explore only a single execution path during testing, missing vulnerabilities in alternate code paths [14].
- Performance overhead: runtime protection mechanisms introduce significant performance penalties that limit their practicality in production environments [15].
- Browser engine differences: Pan et al. demonstrate that dynamic analysis tools may miss XSS vulnerabilities that only manifest in specific browser engines or versions [16].
1.2.5. Machine Learning Limitations
- Adversarial evasion: recent ML-based XSS detection systems are vulnerable to adversarial examples specifically crafted to bypass their detection mechanisms.
- Feature engineering inadequacies: current ML approaches often struggle with selecting robust features that remain effective against evolving attack techniques.
- Transfer learning challenges: Song and Lee demonstrate that ML models trained on one set of applications often perform poorly when applied to different codebases with unique characteristics [17].
1.3. Real-World Implications
- Session cookie theft: access to bank accounts, educational platforms, and social networks without the need for credentials [18].
- Capture of input data: keystrokes, browsing history, and clipboard contents, facilitating identity fraud.
- Authentication token extraction: allows attackers to operate as legitimate users in federated systems (Google Classroom, Moodle).
- Privacy violation.
- Online victimization.
- Financial losses.
- Account hijacking (account hijacking)
- Obtaining the user’s complete search history on Google, Bing, and Baidu.
- Extracting the contact list and sending emails from the user’s Yahoo account.
- Exposure of the user’s purchase history (partial on Amazon, complete on eBay).
- Revealing the user’s name and email address on almost all websites.
- Access to the pages visited by the user through advertising networks such as DoubleClick.
- Ability to obtain home and work addresses and websites visited from providers such as Google and Bing.
1.4. Research Gap
- Development of sanitization mechanisms that allow for safe experimentation without eliminating the educational value of malicious code [24].
- Integration with existing university learning platforms (Moodle, Canvas).
- Adaptation to different pedagogical models in cybersecurity [25].
- Balance between technical functionality and usability for inexperienced students [26].
1.5. Goal and Research Question
2. Cookies and the Rising Threat of XSS Vulnerabilities: A Literature Review
3. Cookie Collector Methodology
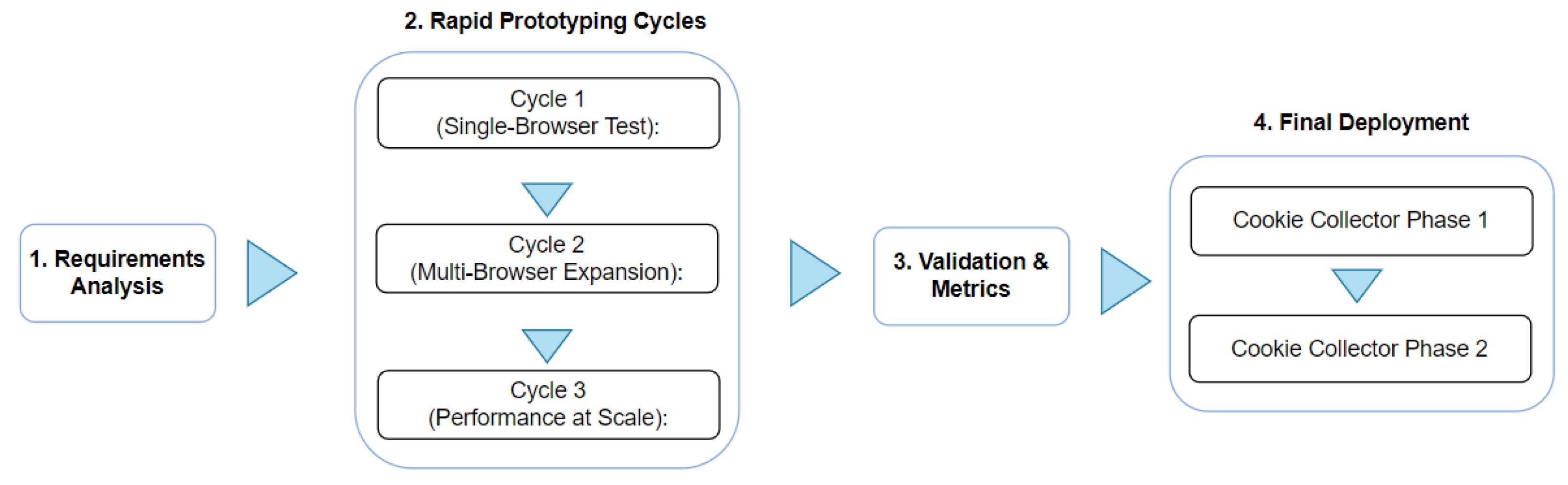
3.1. Phase 1: Requirements Analysis
- Objective: define the main functionalities for the collection of cookies in the five most-used browsers by university students (Chrome, Firefox, Edge, Opera, and Brave).
- Identified key challenges: automatic collection of first-party and third-party cookies.
3.2. Phase 2: Rapid Prototyping Cycles
3.2.1. Cycle 1 (Single-Browser Test)
- Prototype: Implementation of a bot for an initial browser (Chrome) with basic navigation. Connection of the bot with the cookie database to extract information. Make a copy of the cookie database to avoid blocking while the browser is open.
- Testing: cookie extraction success rate of 99%, simulating opening the browser, entering a URL, searching, waiting until the page is completely loaded, extracting cookies, and closing the browser.
- Findings: URLs with usernames that allowed student identification.
- Improvements: a URL anonymization system is required in the deployment phase to remove any personally identifiable information.
3.2.2. Cycle 2 (Multi-Browser Expansion)
- Prototype: Implementation of a bot for additional browsers (Firefox, Brave, Opera, Edge). Connection of each bot with the cookie database of each browser to extract information. Identify the location of the cookie database of each browser. Automate and generalize the search so it works on anyone’s computer.
- Testing: Running each bot to look up a URL and collect the cookies. Individual and joint tests (five bots at a time).
- Findings: Edge, Chrome, Opera, and Brave are based on Chromium for their operation. Cookie databases have the same storage path; only the folder name changes for each browser. The cookies of the four browsers have the same number of attributes.
- Improvements: analyze and select the common attributes of the cookies of each of the browsers.
3.2.3. Cycle 3 (Performance at Scale)
- Prototype: feed all the bots with the web search database of a computer laboratory at the University of the Armed Forces-ESPE.
- Testing: test continuously searching for each URL and extracting all cookies generated by that URL.
- Findings: problems with repeated URLs.
- Improvements: implement a script that allows us to eliminate repeated URLs.
3.3. Phase 3: Validation & Metrics
- Success criteria: Accuracy: It will be considered successful if each bot manages to collect cookies from the entire URL base (without repetition). For each URL, you must register all first- and third-party cookies.
- Performance: Number of URLs per hour. Number of cookies generated per domain. Number of days to complete the search for all URLs.
- Ethical safeguards: analyze and apply data protection laws related to the use of students’ web search histories.
3.4. Phase 4: Final Deployment
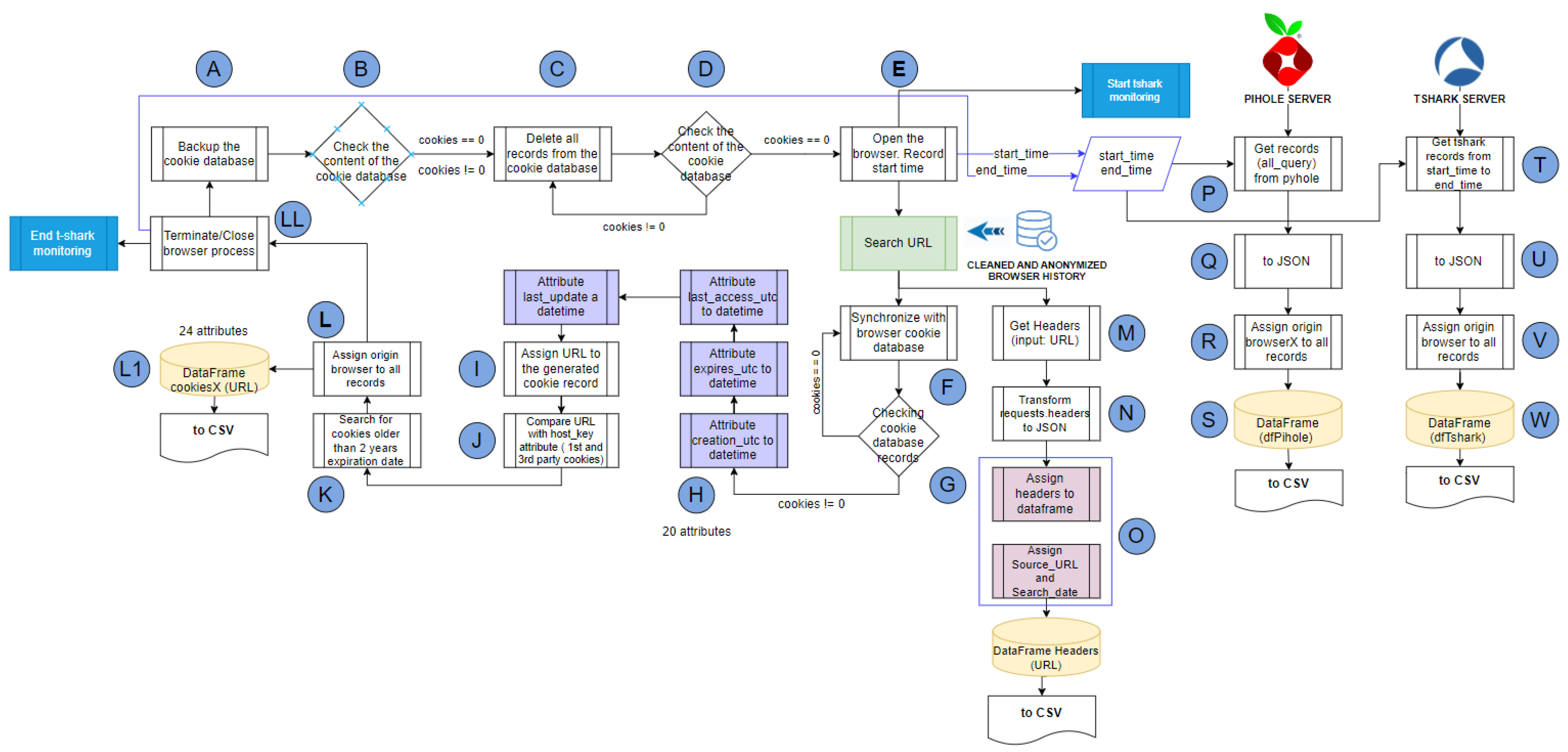
3.4.1. Cookie Collector Phase 1
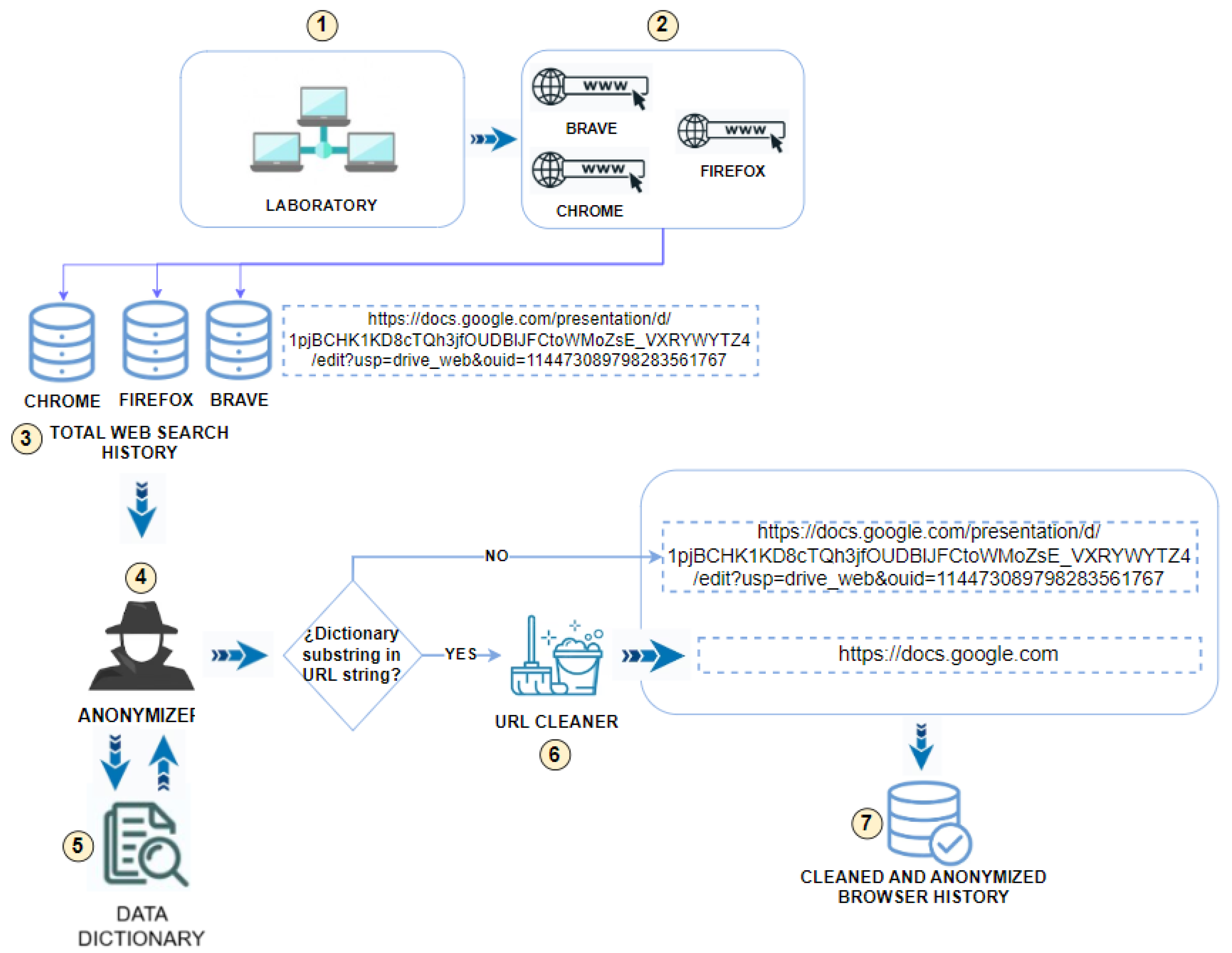
 of the research process.
of the research process. , we meticulously analyzed all the attributes of the search databases obtained from each computer. Table 2 provides comprehensive details of the database location, tables, and attributes that contain web search history information for each browser.
, we meticulously analyzed all the attributes of the search databases obtained from each computer. Table 2 provides comprehensive details of the database location, tables, and attributes that contain web search history information for each browser. titled Total Web Search History. SQLite Studio was used as the Database Management System (DBMS) with which the information in this total database was created, managed, and accessed.
titled Total Web Search History. SQLite Studio was used as the Database Management System (DBMS) with which the information in this total database was created, managed, and accessed. , and after a search treatment of matching first names, last names, usernames, and their combinations within the visited URLs.
, and after a search treatment of matching first names, last names, usernames, and their combinations within the visited URLs. were used with all the records of names, surnames, usernames, and their combinations of all students who have used laboratory computers (in the set time range), using the Computer Equipment Use Records provided by the Director of Information Technology Degree and the Head of Laboratories.
were used with all the records of names, surnames, usernames, and their combinations of all students who have used laboratory computers (in the set time range), using the Computer Equipment Use Records provided by the Director of Information Technology Degree and the Head of Laboratories. , which was another Python script that cleaned up all the characters in the URL and only left the domain name in the format http://domain.com, https://domain.com, https://www.domain.com or http://www.domain.com. The repeated domains were also removed within this process, and CLEANED AND ANONYMIZED BROWSER HISTORY
, which was another Python script that cleaned up all the characters in the URL and only left the domain name in the format http://domain.com, https://domain.com, https://www.domain.com or http://www.domain.com. The repeated domains were also removed within this process, and CLEANED AND ANONYMIZED BROWSER HISTORY  was obtained.
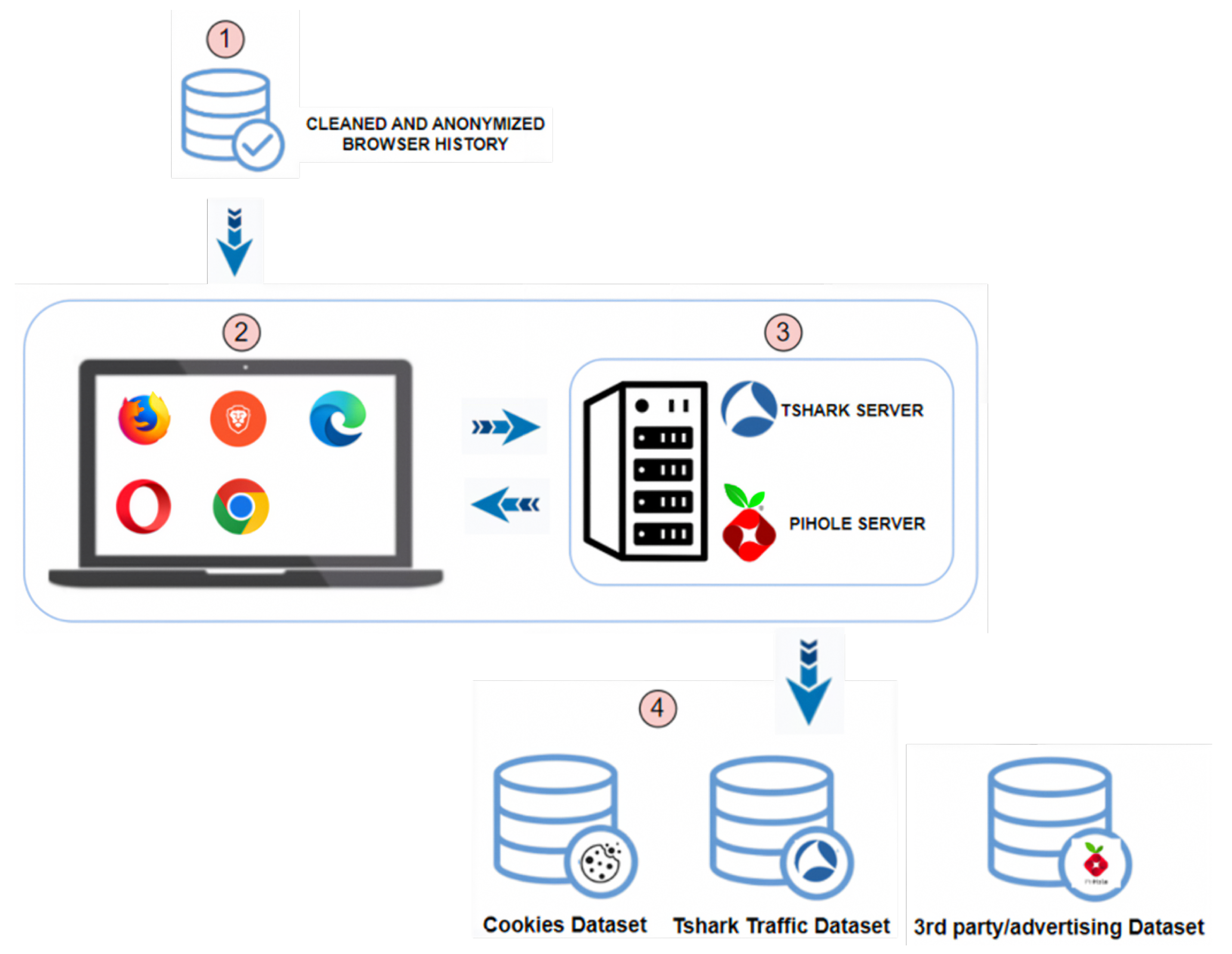
was obtained.3.4.2. Cookie Collector Phase 2
 , we fed the Phase 2 of our cookie collector, as shown in Figure 4. This infrastructure was configured with a Windows operating system computer with an Internet connection, on which the following web browsers were installed: Google Chrome, Mozilla Firefox, Microsoft Edge, Brave, and Opera
, we fed the Phase 2 of our cookie collector, as shown in Figure 4. This infrastructure was configured with a Windows operating system computer with an Internet connection, on which the following web browsers were installed: Google Chrome, Mozilla Firefox, Microsoft Edge, Brave, and Opera  . On the other hand, a server with Ubuntu OS was configured
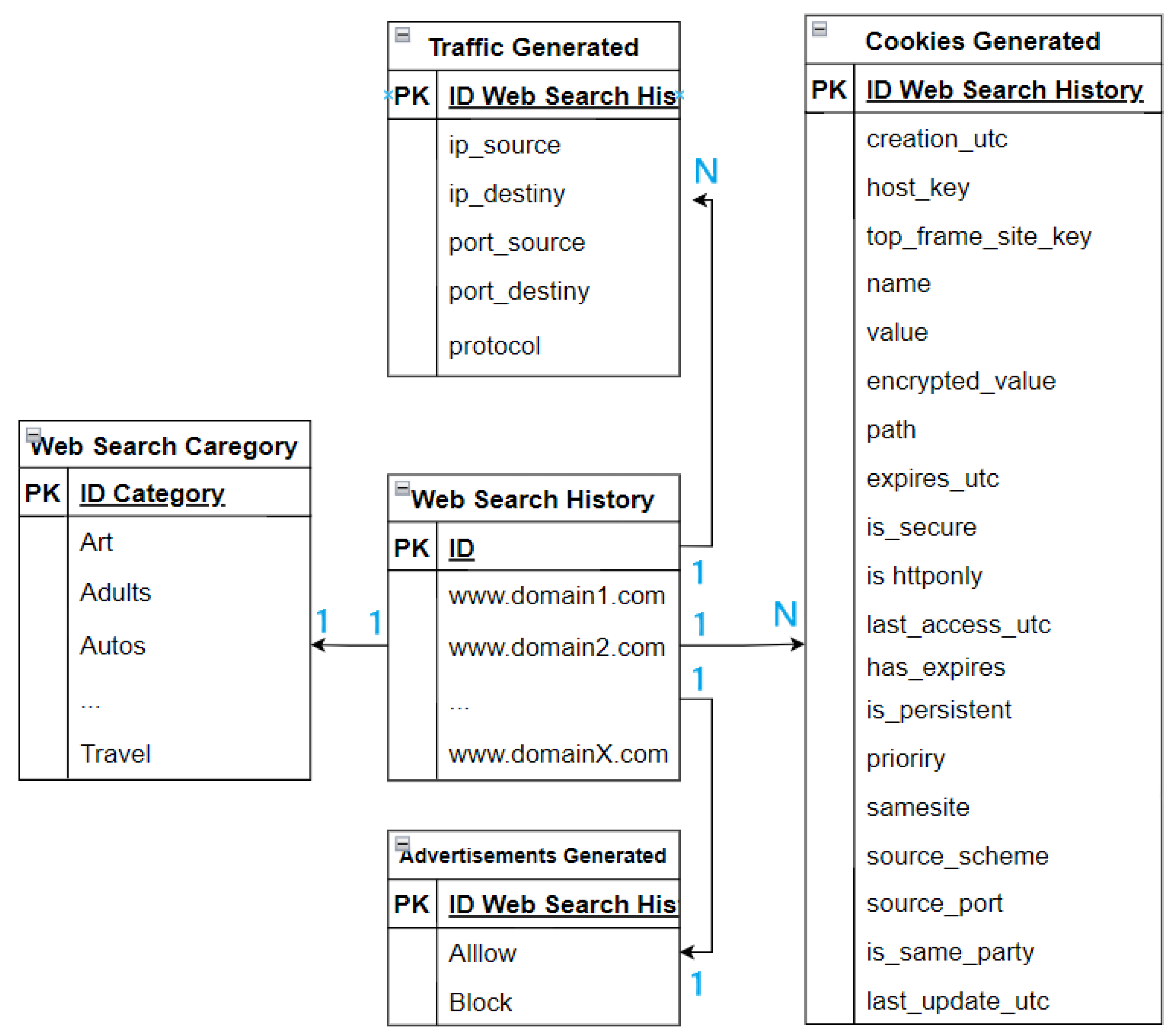
. On the other hand, a server with Ubuntu OS was configured  with the following active services: PiHole [47] and Tshark [48]. The basis of our proposal was to collect and associate all the types of cookies generated by each URL (Cookies Dataset), capture the traffic generated while the bot executed the search (Tshark Traffic Dataset), and finally, associate this information with communications that were established with third-party or advertising domains (3rd party/advertising Dataset) and that were recorded by PyHole
with the following active services: PiHole [47] and Tshark [48]. The basis of our proposal was to collect and associate all the types of cookies generated by each URL (Cookies Dataset), capture the traffic generated while the bot executed the search (Tshark Traffic Dataset), and finally, associate this information with communications that were established with third-party or advertising domains (3rd party/advertising Dataset) and that were recorded by PyHole  .
.3.4.3. BotSoul Algorithm Operation
.| Algorithm 1 Pseudocode-operation of the BotSoul Algorithm for collecting cookies |
|
|
|

























4. Results Analysis
4.1. Training
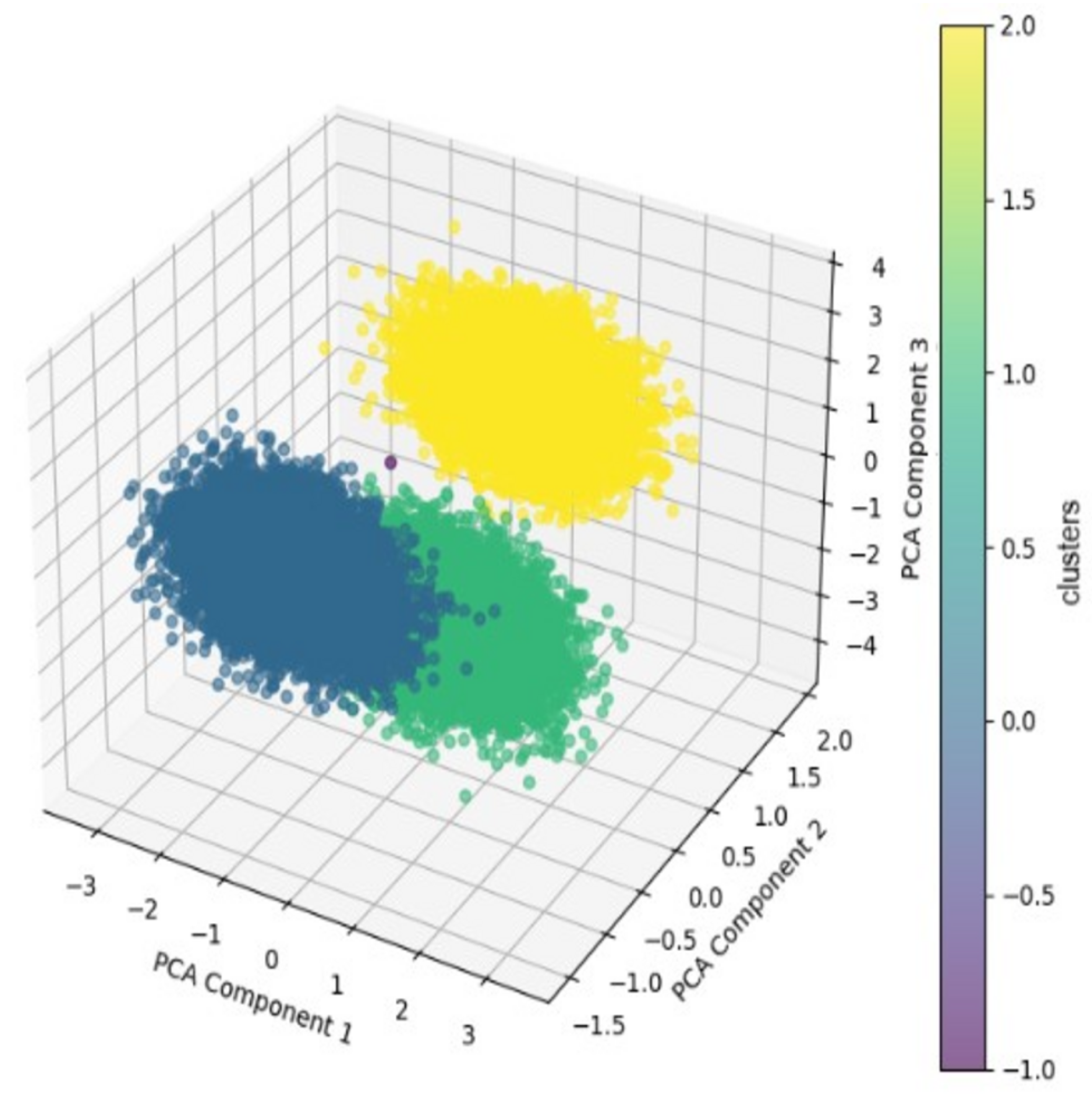
4.2. Prediction
- K-Means;
- DBSCAN;
- Hierarchical clustering.
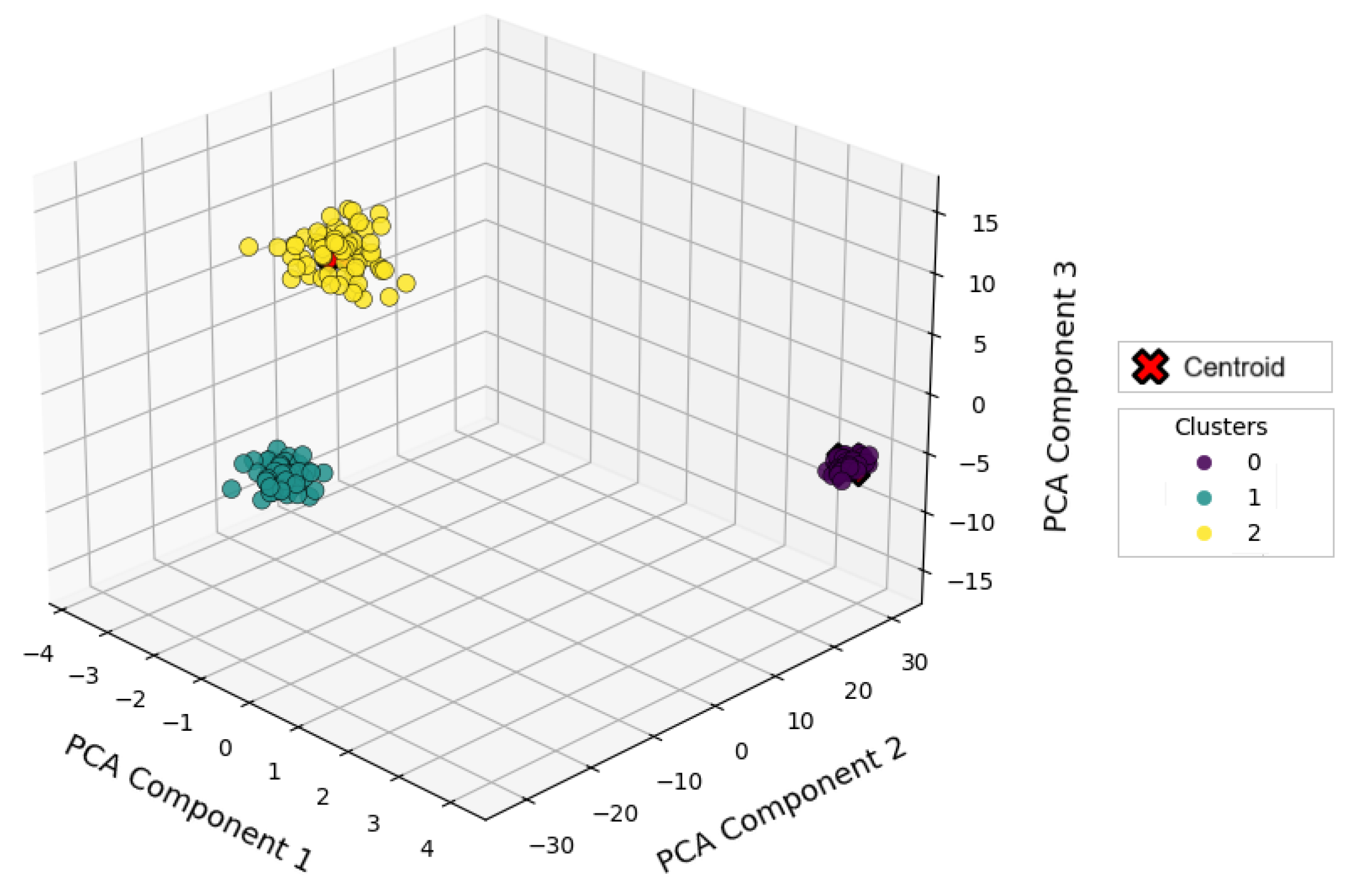
4.2.1. K-Means
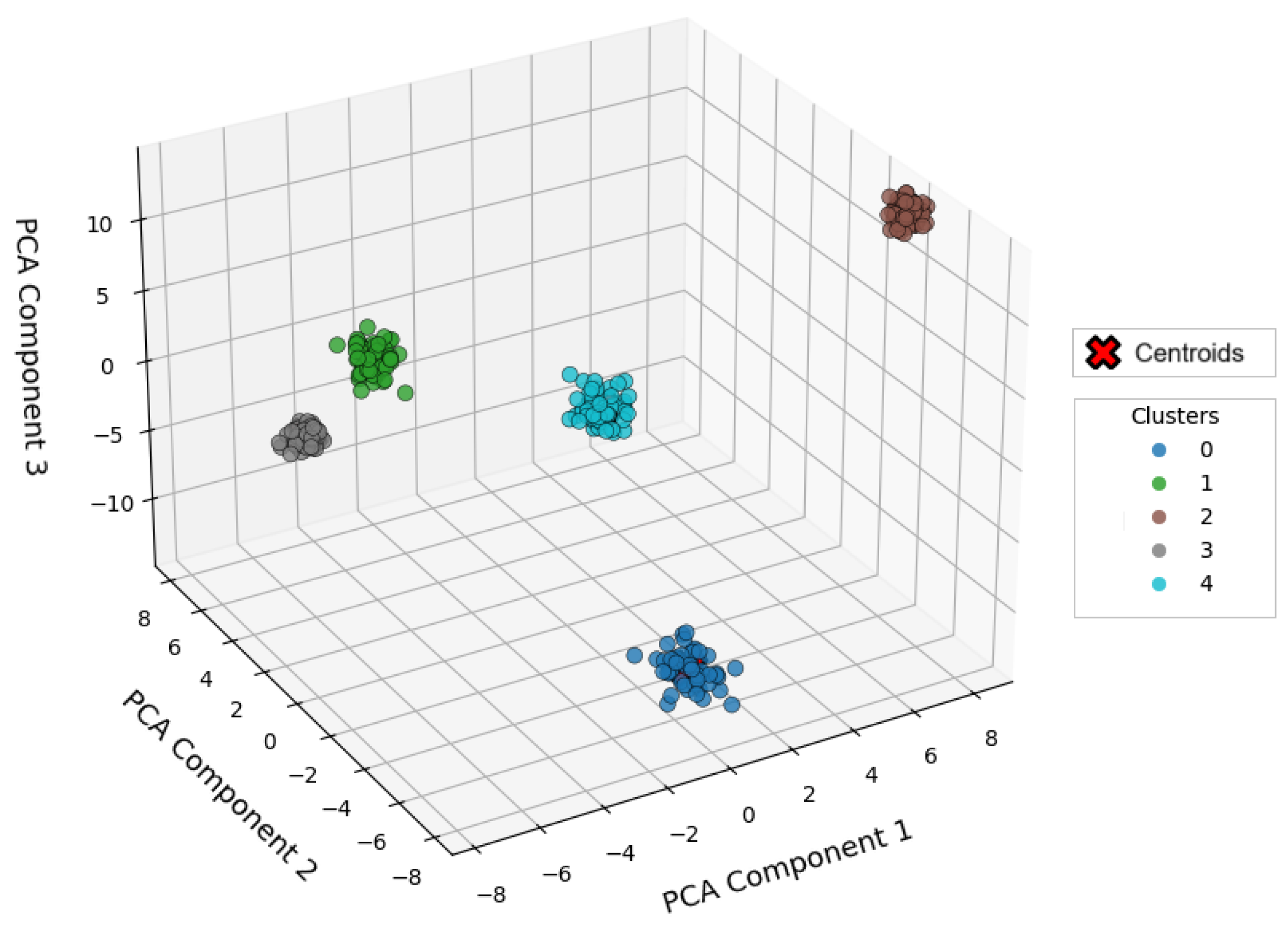
4.2.2. DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
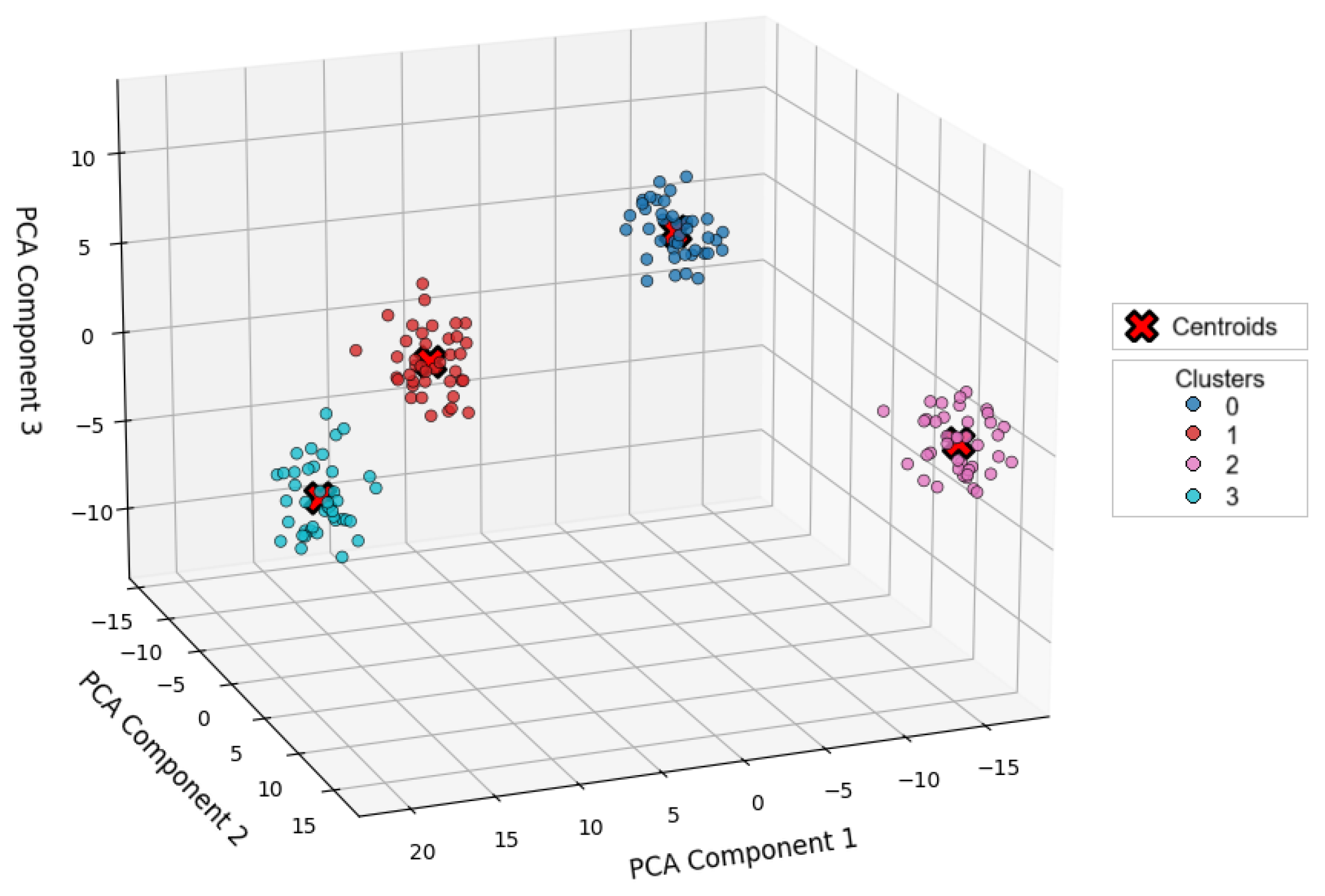
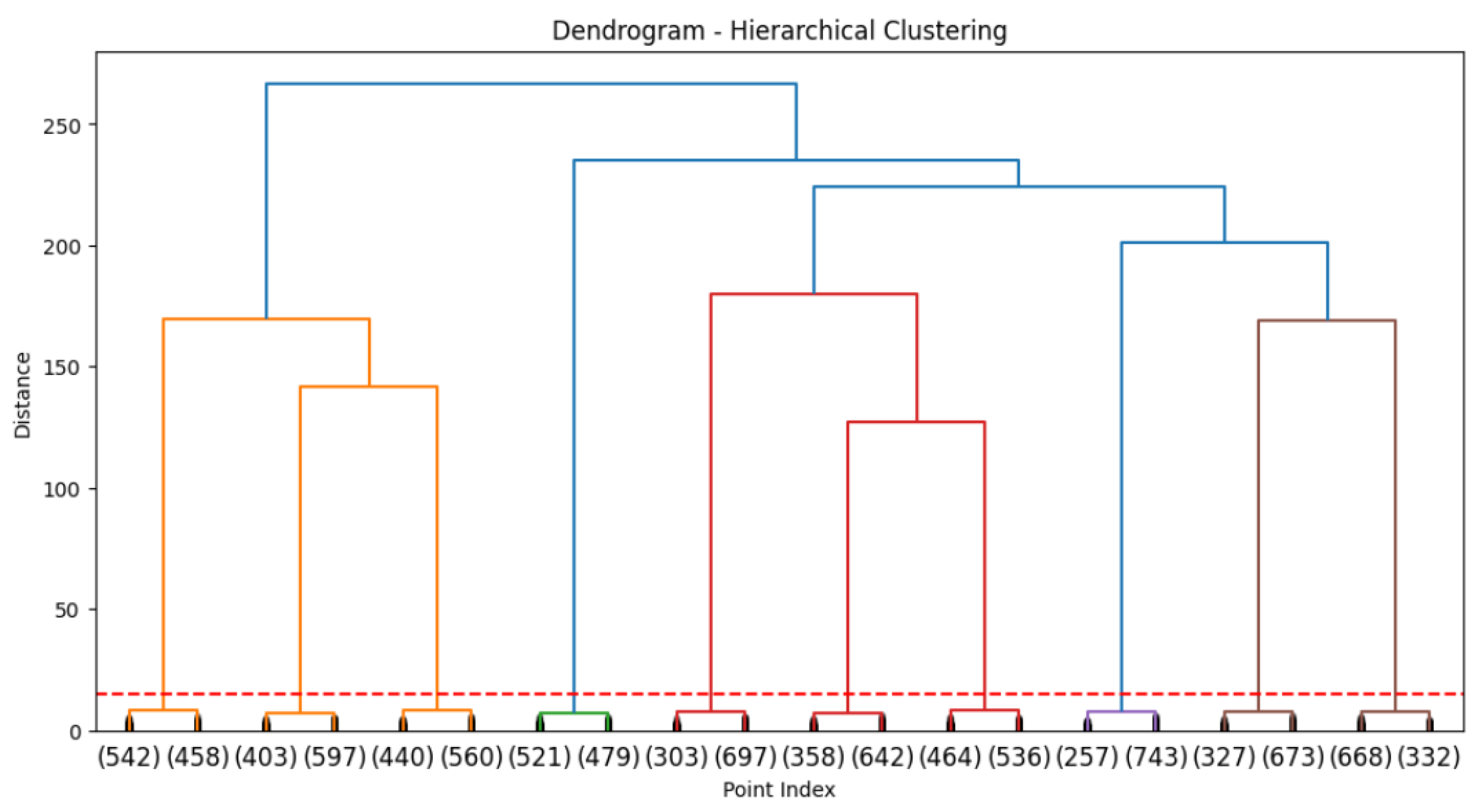
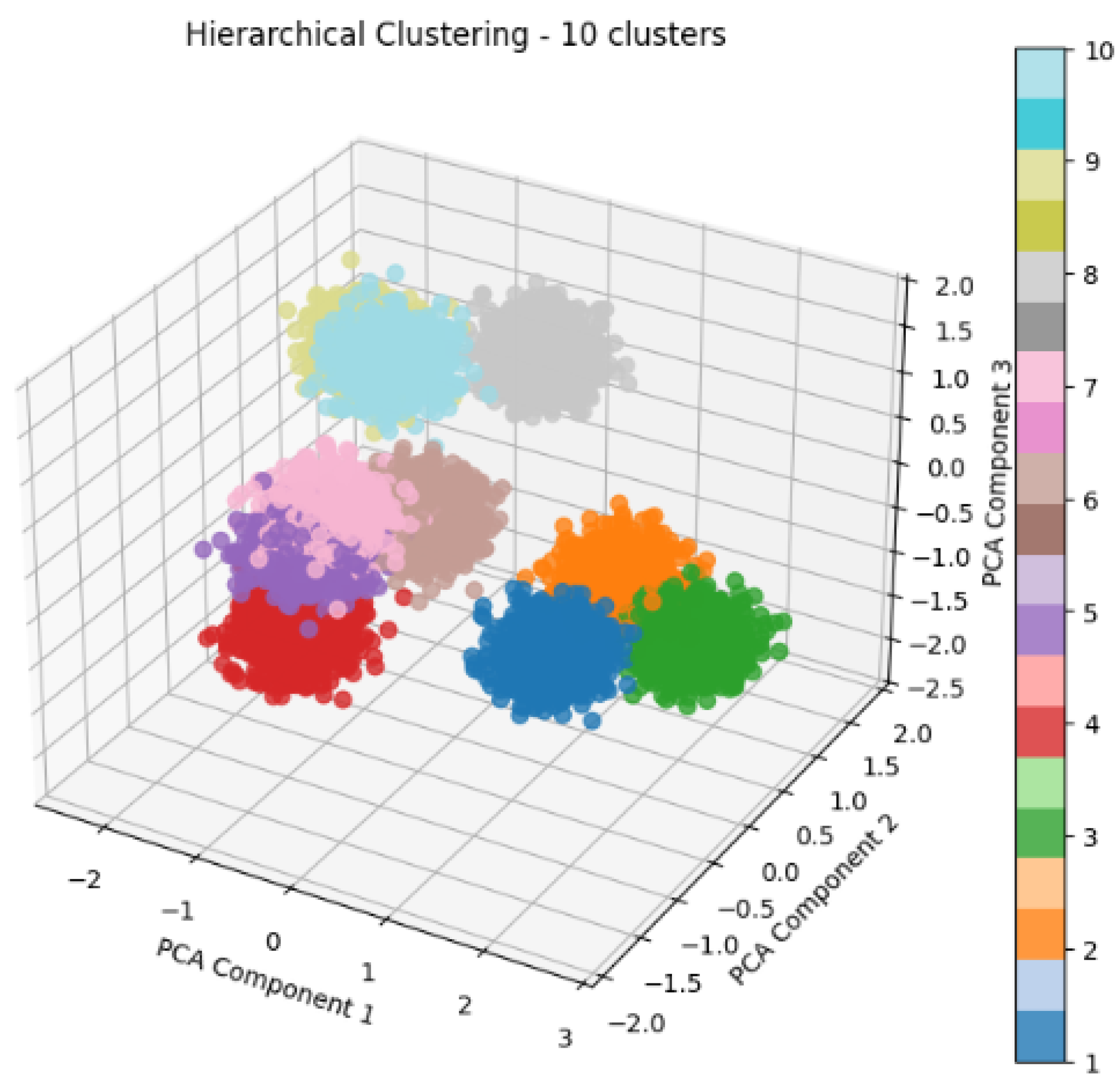
4.2.3. Hierarchical Clustering
- User segmentation: grouping users into clusters based on the cookies generated allows segments with similar interests and browsing behaviors to be identified.
- Personalized recommendations: based on the identified clusters, the browser can recommend web pages relevant to each cluster’s browsing patterns.
- Anomaly detection and security: identification of cookies that do not fit normal patterns (anomalies), helping to detect possible security threats.
- User experience optimization: improving the relevance of recommendations, providing a more personalized and efficient browsing experience for students.
5. Discussion
5.1. Automation of Cookie Collection in Educational Contexts
- Multidimensional integration of systems, through the combination of Pi-hole and Tshark, which allowed the correlation of cookies with advertising and tracking domains.
- Specific adaptation to university environments, focusing the analysis on platforms commonly used by students.
- Dynamic analysis of entire browsing, overcoming the limitations of traditional GDPR [53] compliance scanners by including traffic capture over entire browsing cycles.
5.2. Predictive Modeling of XSS Vulnerabilities Based on Cookie Attributes
5.3. Behavioral Segmentation Using Clustering Algorithms
- Clusters of users differentiated according to the prevalence and type of third-party cookies present in their browsing.
- Significant correlation between these clusters and exposure to XSS vulnerabilities.
- A trade-off between model accuracy and performance in high data volume environments.
- Detection of anomalies in browsing patterns, which could alert to risky behavior of students.
- Optimization of web recommendations, adapting them to the risk profiles of users.
- Identification of groups with a greater propensity to visit vulnerable domains, allowing proactive interventions.
5.4. Technical Challenges and Scalability Considerations
- Normalization of domains with spelling variants, such as login.institution.edu and www.institution.edu/login.
- Real-time processing of Tshark data streams, which presented latency-related difficulties.
- A balance between accuracy and performance in machine learning models is critical in educational environments with limited computational resources.
6. Conclusions
6.1. Theoretical Contributions
- This work proposes a novel methodological approach for the characterization of cookies by combining web traffic analysis techniques, cookie analysis, and unsupervised clustering, which represents a significant contribution to the study of privacy and security in student web browsing.
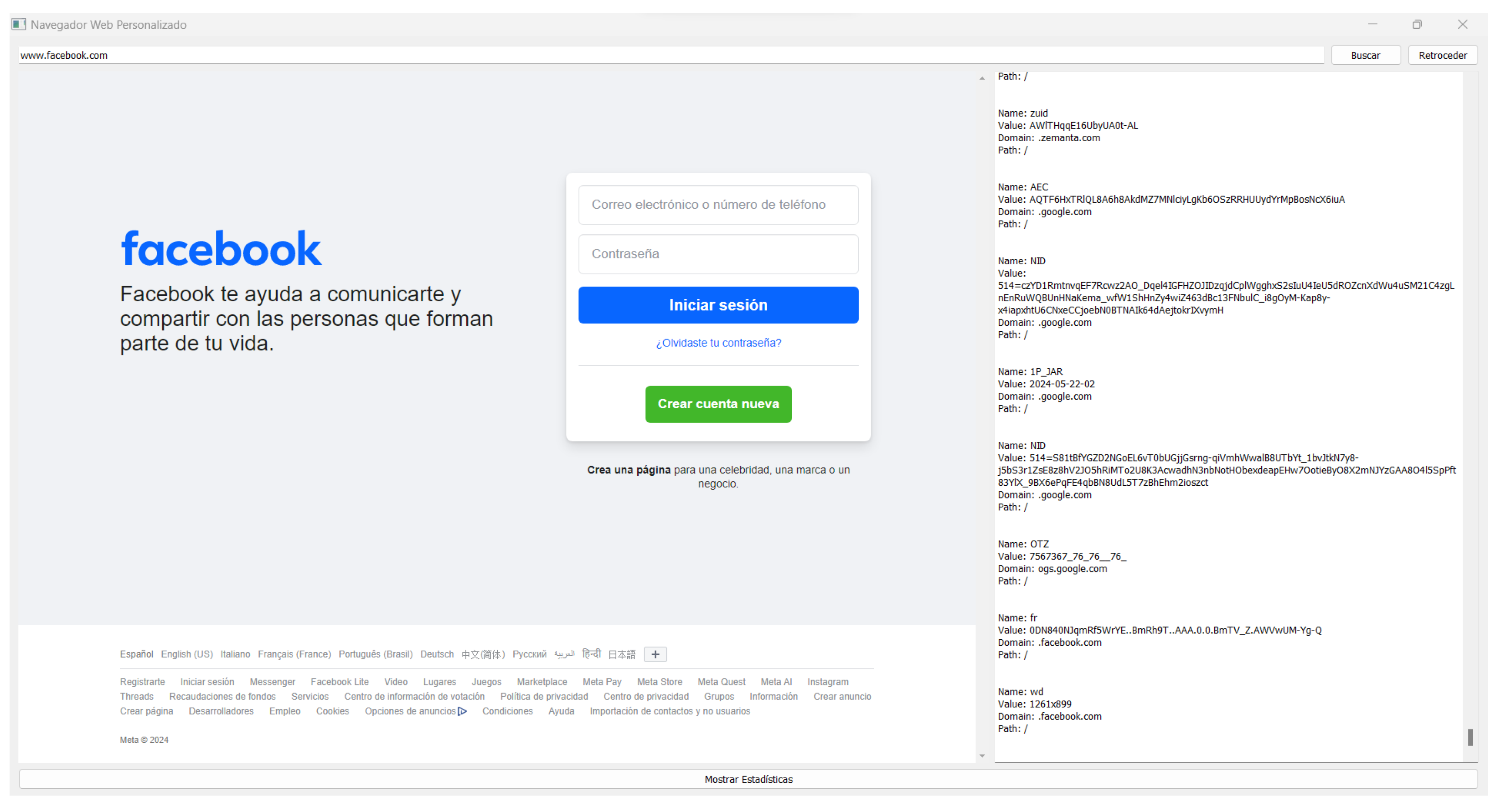
- The experimental browser BOOKIE was introduced, which integrates cookie-based visualization, classification, and vulnerability prediction, showing how data analysis can be applied directly in a browsing environment.
- The results obtained with the clustering algorithms (K-Means, DBSCAN, and hierarchical clustering) confirm that it is possible to identify behavior patterns and user segmentation based on the cookies collected, which theoretically supports the hypothesis that cookies can be used as vectors for vulnerability analysis and digital behavior.
6.2. Practical Contributions
- An automated experimental environment was built and executed capable of collecting, processing, and analyzing more than 440,000 URLs from five university laboratories, generating three large data sets useful for threat characterization in real academic environments.
- BOOKIE allowed not only the display of cookies but also the prediction of the level of vulnerability to XSS attacks, offering personalized navigation recommendations based on the detected patterns.
- The application of K-Means and DBSCAN made it possible to effectively identify two main user segments based on their browsing behavior, improving the performance of the browser’s recommendation system.
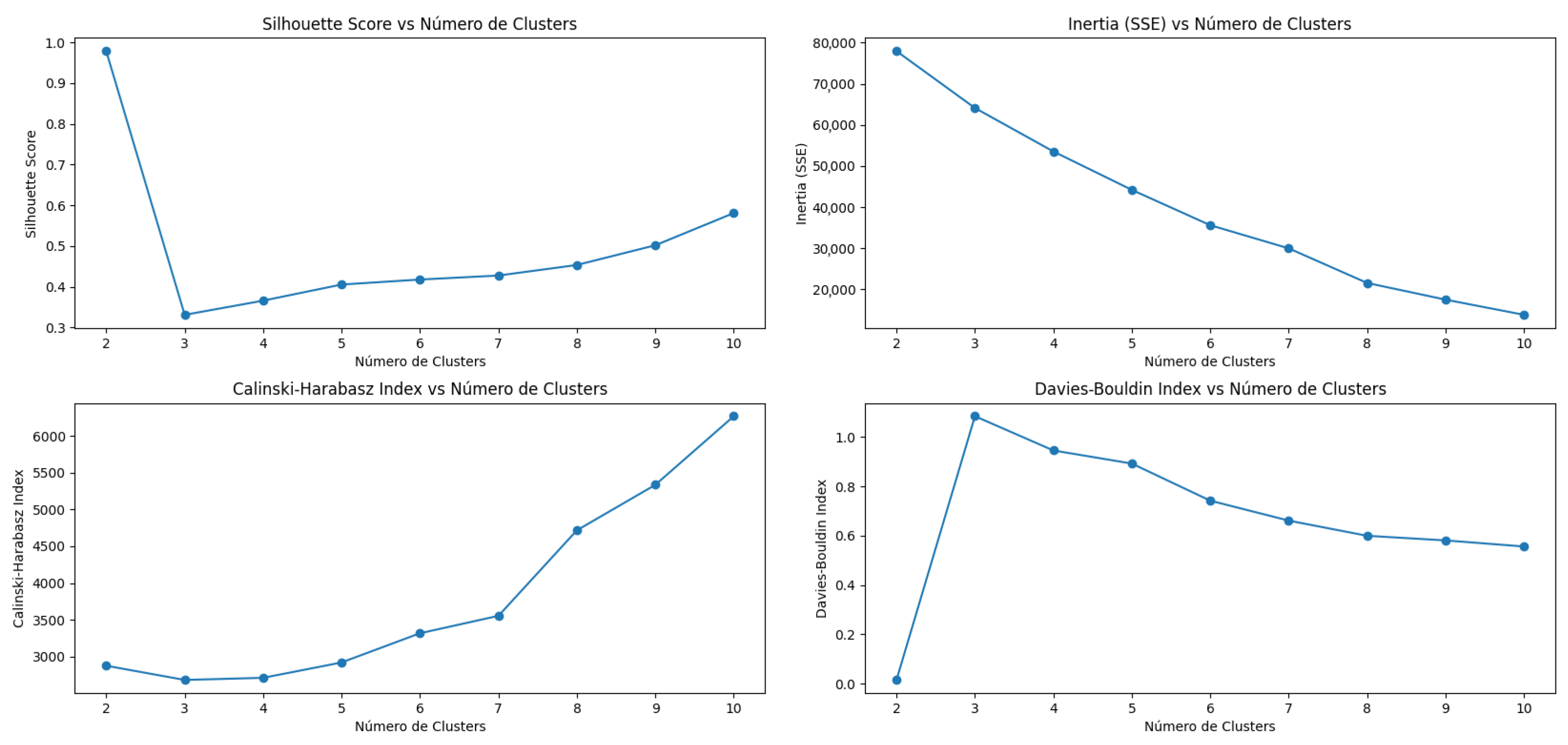
- The use of metrics such as Silhouette Score, Inertia, Calinski–Harabasz, and Davies–Bouldin empirically demonstrated the validity and precision of the applied models, with DBSCAN with eps = 10 offering the best cluster separation in the presence of noise.
7. Future Perspectives
- It is proposed to integrate incremental learning mechanisms so that the system continuously improves its predictions with each new navigation.
- The possibility of expanding the study to other types of web threats (such as CSRF or phishing) is considered, expanding the browser’s detection spectrum.
- It is planned to validate the system with real users in open educational scenarios in order to evaluate its impact on awareness of digital privacy and cybersecurity.
- Conduct a larger-scale evaluation between clustering algorithms applied to different types of web tracking data (cookies, DNS traffic, fingerprinting) to strengthen theoretical frameworks on browsing behavior analysis.
- Train supervised classifiers (such as SVM, Random Forest, or neural networks) to predict vulnerabilities or user profiles based on cookie sets already labeled as safe/suspicious.
- Design a theoretical individual “risk of exposure to XSS attacks” metric, based on user behavior and domains visited.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- QAwerk. CISA Urges Software Devs to Weed Out XSS Vulnerabilities. Available online: https://www.bleepingcomputer.com/news/security/cisa-urges-software-devs-to-weed-out-xss-vulnerabilities/ (accessed on 19 May 2025).
- Bates, D.; Barth, A.; Jackson, C. Regular expressions considered harmful in client-side XSS filters. In Proceedings of the 19th International Conference on World Wide Web (WWW’10), Raleigh, NC, USA, 26–30 April 2010; pp. 91–100. [Google Scholar] [CrossRef]
- Johns, M.; Engelmann, B.; Posegga, J. XSSDS: Server-Side Detection of Cross-Site Scripting Attacks. In Proceedings of the 2008 Annual Computer Security Applications Conference (ACSAC), Washington, DC, USA, 8–12 December 2008; pp. 335–344. [Google Scholar] [CrossRef]
- Melicher, W.; Das, A.; Sharif, M.; Bauer, L.; Jia, L. Riding out DOMsday: Towards Detecting and Preventing DOM Cross-Site Scripting. In Proceedings of the Network and Distributed System Security Symposium, San Diego, CA, USA, 18–21 February 2018. [Google Scholar]
- Lekies, S.; Stock, B.; Johns, M. 25 million flows later: Large-scale detection of DOM-based XSS. In Proceedings of the 2013 ACM SIGSAC Conference on Computer & Communications Security (CCS‘13), Berlin, Germany, 4–8 November 2013; pp. 1193–1204. [Google Scholar] [CrossRef]
- Wassermann, G.; Su, Z. Static detection of cross-site scripting vulnerabilities. In Proceedings of the 30th International Conference on Software Engineering (ICSE’08), Leipzig, Germany, 10–18 May 2008; pp. 171–180. [Google Scholar] [CrossRef]
- Kerschbaum, F. Simple cross-site attack prevention. In Proceedings of the 2007 Third International Conference on Security and Privacy in Communications Networks and the Workshops—SecureComm 2007, Nice, France, 17–21 September 2007; pp. 464–472. [Google Scholar] [CrossRef]
- Havryliuk, V. ¿Qué es Cross-Site Scripting (XSS) y Cómo Prevenirlo? Available online: https://qawerk.es/blog/que-es-cross-site-scripting/ (accessed on 19 May 2025).
- Weinberger, J.; Saxena, P.; Akhawe, D.; Finifter, M.; Shin, R.; Song, D. A Systematic Analysis of XSS Sanitization in Web Application Frameworks. In Proceedings of the Computer Security—ESORICS 2011; Atluri, V., Diaz, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 150–171. [Google Scholar]
- Balzarotti, D.; Cova, M.; Felmetsger, V.; Jovanovic, N.; Kirda, E.; Kruegel, C.; Vigna, G. Saner: Composing Static and Dynamic Analysis to Validate Sanitization in Web Applications. In Proceedings of the 2008 IEEE Symposium on Security and Privacy (sp 2008), Oakland, CA, USA, 18–22 May 2008; pp. 387–401. [Google Scholar] [CrossRef]
- Parameshwaran, I.; Budianto, E.; Shinde, S.; Dang, H.; Sadhu, A.; Saxena, P. DexterJS: Robust testing platform for DOM-based XSS vulnerabilities. In Proceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering (ESEC/FSE 2015), Bergamo, Italy, 30 August–4 September 2015; pp. 946–949. [Google Scholar] [CrossRef]
- Gupta, S.; Gupta, B.B. XSS-immune: A Google chrome extension-based XSS defensive framework for contemporary platforms of web applications. Secur. Commun. Netw. 2016, 9, 3966–3986. [Google Scholar] [CrossRef]
- Lekies, S.; Stock, B.; Wentzel, M.; Johns, M. The unexpected dangers of dynamic JavaScript. In Proceedings of the 24th USENIX Conference on Security Symposium (SEC’15), Washington, DC, USA, 12–14 August 2015; pp. 723–735. [Google Scholar]
- Stock, B.; Lekies, S.; Mueller, T.; Spiegel, P.; Johns, M. Precise client-side protection against DOM-based cross-site scripting. In Proceedings of the 23rd USENIX conference on Security Symposium (SEC’14), San Diego, CA, USA, 20–22 August 2014; pp. 655–670. [Google Scholar]
- Fang, Y.; Li, Y.; Liu, L.; Huang, C. DeepXSS: Cross Site Scripting Detection Based on Deep Learning. In Proceedings of the 2018 International Conference on Computing and Artificial Intelligence (ICCAI’18), Chengdu, China, 12–14 March 2018; pp. 47–51. [Google Scholar] [CrossRef]
- Pan, X.; Cao, Y.; Liu, S.; Zhou, Y.; Chen, Y.; Zhou, T. CSPAutoGen: Black-box Enforcement of Content Security Policy upon Real-world Websites. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security (CCS’16), Vienna, Austria, 24–28 October 2016; pp. 653–665. [Google Scholar] [CrossRef]
- V., S.C.; Selvakumar, S. BIXSAN: Browser independent XSS sanitizer for prevention of XSS attacks. SIGSOFT Softw. Eng. Notes 2011, 36, 1–7. [Google Scholar] [CrossRef]
- Report, M. XSS: La Vulnerabilidad Web que Puede Derribar su Negocio. Available online: https://mineryreport.com/blog/xss-vulnerabilidad-web-que-puede-derribar-su-negocio/ (accessed on 19 May 2025).
- Bugliesi, M.; Calzavara, S.; Focardi, R.; Khan, W. CookiExt: Patching the browser against session hijacking attacks. J. Comput. Secur. 2015, 23, 509–537. [Google Scholar] [CrossRef]
- Zheng, X.; Jiang, J.; Liang, J.; Duan, H.; Chen, S.; Wan, T.; Weaver, N.C. Cookies Lack Integrity: Real-World Implications. In Proceedings of the USENIX Security Symposium, Washington, DC, USA, 12–14 August 2015. [Google Scholar]
- Bortz, A. Origin Cookies : Session Integrity for Web Applications. 2011. Available online: https://sharif.edu/~kharrazi/courses/40441-011/read/session-integrity.pdf (accessed on 19 May 2025).
- Keromytis, A.D. Cookie Hijacking in the Wild: Security and Privacy Implications. 2016. Available online: https://api.semanticscholar.org/CorpusID:30033856 (accessed on 19 May 2025).
- Sivakorn, S.; Polakis, I.; Keromytis, A.D. The Cracked Cookie Jar: HTTP Cookie Hijacking and the Exposure of Private Information. In Proceedings of the 2016 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2016; pp. 724–742. [Google Scholar]
- ESET. Comprendiendo la Vulnerabilidad XSS (Cross-Site Scripting) en Sitios Web. Available online: https://www.welivesecurity.com/la-es/2015/04/29/vulnerabilidad-xss-cross-site-scripting-sitios-web/ (accessed on 19 May 2025).
- UNAM. Cross-Site Scripting (XSS). Available online: https://www.seguridad.unam.mx/cross-site-scripting-xss (accessed on 19 May 2025).
- Team, G. Pruebe la Seguridad de su Navegador en Busca de Vulnerabilidades. Available online: https://geekflare.com/es/browser-security-test/ (accessed on 19 May 2025).
- Mokbal, F.M.M.; Dan, W.; Imran, A.; Jiuchuan, L.; Akhtar, F.; Xiaoxi, W. MLPXSS: An Integrated XSS-Based Attack Detection Scheme in Web Applications Using Multilayer Perceptron Technique. IEEE Access 2019, 7, 100567–100580. [Google Scholar] [CrossRef]
- Cui, Y.; Cui, J.; Hu, J. A Survey on XSS Attack Detection and Prevention in Web Applications. In Proceedings of the 2020 12th International Conference on Machine Learning and Computing (ICMLC’20), Shenzhen, China, 15–17 February 2020; pp. 443–449. [Google Scholar] [CrossRef]
- Kumar, A.; Gupta, A.; Mittal, P.; Gupta, P.K.; Varghese, S. Prevention of XSS Attack Using Cryptography & API Integration with Web Security. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3833910 (accessed on 19 May 2025).
- Steffens, M.; Rossow, C.; Johns, M.; Stock, B. Don’t Trust The Locals: Investigating the Prevalence of Persistent Client-Side Cross-Site Scripting in the Wild. In Proceedings of the Network and Distributed Systems Security (NDSS) Symposium 2019, San Diego, CA, USA, 24–27 February 2019. [Google Scholar] [CrossRef]
- Klein, D.; Musch, M.; Barber, T.; Kopmann, M.; Johns, M. Accept All Exploits: Exploring the Security Impact of Cookie Banners. In Proceedings of the 38th Annual Computer Security Applications Conference (ACSAC’22), Austin, TX, USA, 5–9 December 2022. [Google Scholar] [CrossRef]
- Dembla, D.; Chaba, Y.; Yadav, K.; Chaba, M.; Kumar, A. A novel and efficient technique for prevention of xss attacks using knapsack based cryptography. Adv. Math. Sci. J. 2020, 9. [Google Scholar] [CrossRef]
- Mishra, P.; Gupta, C. Cookies in a Cross-site scripting: Type, Utilization, Detection, Protection and Remediation. In Proceedings of the 2020 8th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions) (ICRITO), Noida, India, 4–5 June 2020. [Google Scholar] [CrossRef]
- Nirmal, K.; Janet, B.; Kumar, R. It’s More Than Stealing Cookies—Exploitability of XSS. In Proceedings of the 2018 Second International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 14–15 June 2018. [Google Scholar] [CrossRef]
- Shrivastava, A.; Choudhary, S.; Kumar, A. XSS vulnerability assessment and prevention in web application. In Proceedings of the 2016 2nd International Conference on Next Generation Computing Technologies (NGCT), Dehradun, India, 14–16 October 2016. [Google Scholar] [CrossRef]
- Gupta, S.; Sharma, L. Exploitation of Cross-Site Scripting (XSS) Vulnerability on Real World Web Applications and its Defense. Int. J. Comput. Appl. 2012, 60, 28–33. [Google Scholar] [CrossRef]
- Takahashi, H.; Yasunaga, K.; Mambo, M.; Kim, K.; Youm, H.Y. Preventing Abuse of Cookies Stolen by XSS. In Proceedings of the 2013 Eighth Asia Joint Conference on Information Security, Seoul, Republic of Korea, 25–26 July 2013. [Google Scholar] [CrossRef]
- Putthacharoen, R.; Bunyatnoparat, P. Protecting cookies from Cross Site Script attacks using Dynamic Cookies Rewriting technique. In Proceedings of the 13th International Conference on Advanced Communication Technology (ICACT2011), Gangwon, Ruplic of Korea, 13–16 February 2011. [Google Scholar]
- Singh, T.; Mantoo, B.A. Loop Holes in Cookies and Their Technical Solutions for Web Developers; Springer: Singapore, 2020. [Google Scholar] [CrossRef]
- Kwon, H.; Nam, H.J.; Lee, S.; Hahn, C.; Hur, J. (In-)Security of Cookies in HTTPS: Cookie Theft by Removing Cookie Flags. IEEE Trans. Inf. Forensics Secur. 2019, 15, 1204–1215. [Google Scholar] [CrossRef]
- Kumar, U.; Kumar, S. Protection Against Client-Side Cross Side Scripting (XSS/CSS). 2014. Available online: https://www.semanticscholar.org/paper/Protection-against-Client-Side-Cross-Side-Scripting-Kumar-Kumar/a5b7284114f69c1e5c06b3360eb7f711018c443d (accessed on 19 May 2025).
- Hydara, I. The Limitations of Cross-Site Scripting Vulnerabilities Detection and Removal Techniques. Turk. J. Comput. Math. Educ. TURCOMAT 2021, 12, 1975–1980. [Google Scholar] [CrossRef]
- Yue, C.; Xie, M.; Wang, H. An automatic HTTP cookie management system. Comput. Netw. 2010, 54, 2182–2198. [Google Scholar] [CrossRef]
- Block, G.; Ogdin, P.L. Analysis of Tokenized HTTP Event Collector. 2016. Available online: https://patents.google.com/patent/US10169434B1/en?oq=10169434 (accessed on 19 May 2025).
- Bhagat, D.B.; Krishnan, M.R.; Sadhasivam, K.M.; Varanasi, R.K. HTTP Cookie Protection by a Network Security Device. U.S. Patent Application No. US11/406,107, 18 April 2006. [Google Scholar]
- Guia para Tratamiento de Datos Personales en Administracion Publica. Available online: https://www.gobiernoelectronico.gob.ec/wp-content/uploads/2019/11/Gu%C3%ADa-de-protecci%C3%B3n-de-datos-personales.pdf (accessed on 19 May 2025).
- Schaper, D. Pi-Hole Network-Wide Ad Blocking. Available online: https://pi-hole.net/ (accessed on 19 May 2025).
- Wireshark. Tshark(1) Manual Page. Available online: https://www.wireshark.org/docs/man-pages/tshark.html (accessed on 19 May 2025).
- Sphinx. PyAutoGUI’s Documentation. Available online: https://pyautogui.readthedocs.io/en/latest/ (accessed on 19 May 2025).
- Rodríguez, G.E.; Benavides, D.E.; Torres, J.; Flores, P.; Fuertes, W. Cookie Scout: An Analytic Model for Prevention of Cross-Site Scripting (XSS) Using a Cookie Classifier. In Proceedings of the International Conference on Information Technology & Systems (ICITS 2018), Península de Santa Elena, Ecuador, 10–12 January; Rocha, Á., Guarda, T., Eds.; Springer: Cham, Switzerland, 2018; pp. 497–507. [Google Scholar]
- Rodríguez, G.E.; Torres, J.G.; Benavides-Astudillo, E. DataCookie: Sorting Cookies Using Data Mining for Prevention of Cross-Site Scripting (XSS). In Emerging Trends in Cybersecurity Applications; Daimi, K., Alsadoon, A., Peoples, C., El Madhoun, N., Eds.; Springer International Publishing: Cham, Switzerland, 2023; pp. 171–188. [Google Scholar] [CrossRef]
- Telefonica. Triki: Herramienta de Recolección y anáLisis de Cookies. Available online: https://telefonicatech.com/blog/triki-herramienta-recoleccion-analisis-cookies (accessed on 19 May 2025).
- consentmanager. Auditoría de Cookies para Sitios Web: Cómo Hacerlo Manualmente o Con un escáNer de Cookies. Available online: https://www.consentmanager.net/es/conocimiento/cookie-audit/ (accessed on 19 May 2025).
- Drakonakis, K.; Ioannidis, S.; Polakis, J. The Cookie Hunter: Automated Black-box Auditing for Web Authentication and Authorization Flaws. In Proceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security (CCS’20), Virtual Event, 9–13 November 2020; pp. 1953–1970. [Google Scholar] [CrossRef]
- Hamzah, K.; Osman, M.; Anthony, T.; Ismail, M.A.; Abdullah, Z.; Alanda, A. Comparative Analysis of Machine Learning Algorithms for Cross-Site Scripting (XSS) Attack Detection. JOIV Int. J. Inform. Vis. 2024, 8, 1678. [Google Scholar] [CrossRef]
- Njie, B.; Gabriouet, L. Machine Learning for Cross-Site Scripting (XSS) Detection. Bachelor’s Thesis, Dalarna University, Falun, Sweden, 2024. [Google Scholar]
- Keyrus. Qué es Clustering y para qué se Utiliza. Available online: https://keyrus.com/sp/es/insights/que-es-clustering-y-para-que-se-utiliza (accessed on 19 May 2025).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
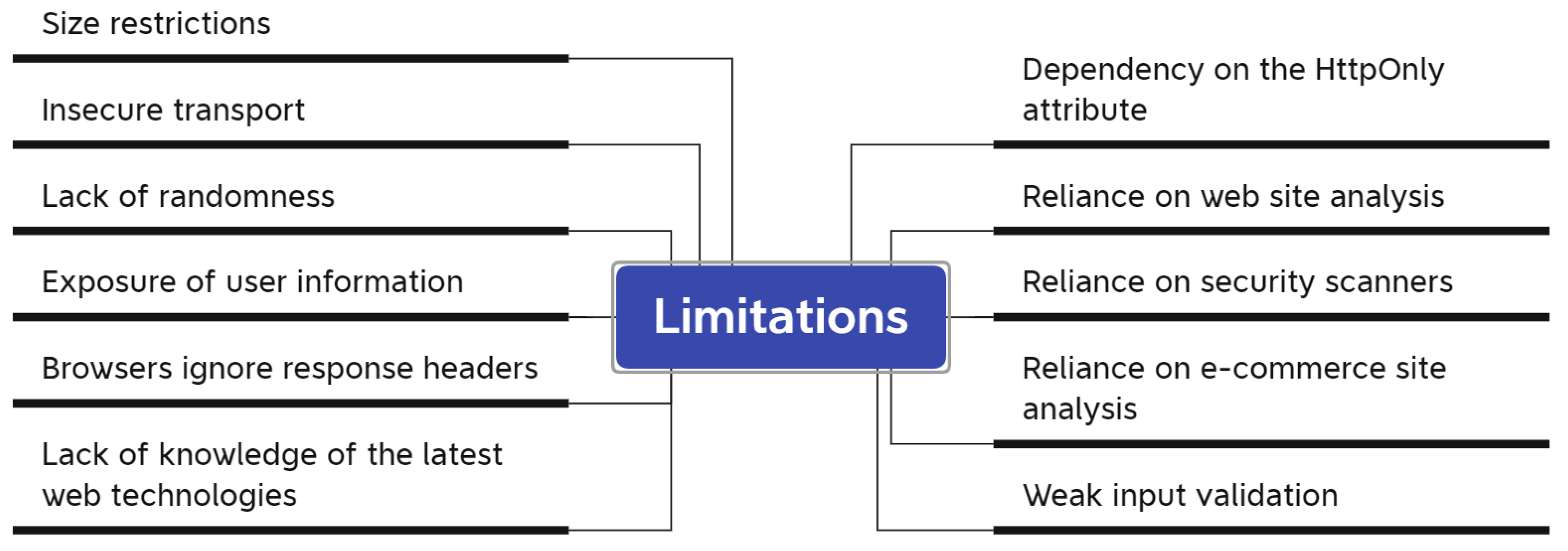
| Ref | Results | Methods Used | Limitations |
|---|---|---|---|
| [31] | Agreeing to cookie banners raises security-sensitive data flows by 63% and makes 55% more websites vulnerable to XSS exploits. | The paper proposes an automated way to increase cookie banner consent and examines its security impact through large crawls. | The study does not consider the prevalence of vulnerabilities on the Web. Few studies state the vantage point of their measurements. |
| [32] | Encrypting cookie values at a cryptographic local proxy can protect them from XSS attacks. | Encrypt the session-ID cookie attribute value at the cryptographic local proxy before sending it to the browser. | Cookies store user info but have size limits and need secure transport. XSS prevention techniques have limits. |
| [33] | Learning about identifying and protecting against cookie vulnerabilities in XSS attacks using effective methods and tools. | Secure cookies from XSS attacks with efficient methods. | Not defined. |
| [34] | Learning about XSS exploitation using CORS and discovering the shortcomings of automated security scanners. | Mitigation techniques for cross-site scripting (XSS). Automated security scans and manual security assessments for vulnerability detection. | Relying too much on automated security scans has serious disadvantages and limitations. |
| [35] | Web applications are still vulnerable to XSS attacks, and current approaches are inadequate in preventing more dangerous payloads. | Injection, detection, and prevention of stored-based XSS, reflected XSS, and DOM-based XSS. Use of security measures to block third-party intrusion. | Not defined. |
| [20] | Google and Bank of America have cookie vulnerabilities that can lead to privacy violations, online victimization, financial loss, and account hijacking. | In-depth empirical assessment of cookie injection attacks. Discussion of mitigation strategies and presentation of a proof-of-concept browser extension. | Web browsers are vulnerable to cookie-related issues, and e-commerce sites with mixed content can be attacked. |
| [36] | Use a sandbox environment to prevent XSS vulnerabilities on localhost servers and social networking sites. | This proposal addresses the exploitation of XSS vulnerabilities in XAMPP servers, social networking sites, and blogs. | Existing techniques cannot completely eliminate XSS vulnerabilities. Weak input validation and lack of awareness of latest web technologies. |
| [37] | The paper presents a method to stop cookie abuse by implementing one-time password and challenge–response authentication. | A one-time password has been used to identify the valid owner of the cookie. Challenge–response authentication has been used to verify the person’s identity. | Not defined. |
| [38] | The article introduces “Dynamic Cookie Rewriting” to prevent XSS attacks by rendering cookies useless. It has been implemented in a web proxy. | Dynamic Cookies Rewriting technique. Implementation in a web proxy. | Not defined. |
| [39] | The article discusses methods for improving cookie attacks in web applications, covering session hijacking and other cookie-related threats. | Techniques to optimize cookie attacks in web applications have been discussed. | Not defined. |
| [19] | The proposal has provided a mechanized non-interference test for the HttpOnly and Secure cookie flags. The article introduces CookieExt, a browser extension for client-side protection against session hijacking. | Mechanized proof of noninterference for HttpOnly and Secure cookie flags. Development of CookiExt browser extension for client-side protection against session hijacking. | Cookies not marked HttpOnly do not provide any protection against XSS attacks. |
| [40] | “Rotten cookie” is a novel cookie hijacking attack that can turn off cookie flags that are protected by TLS. Some web browsers can accept cookies without any cookie flag. | Exploiting a vulnerability in HTTP software. Removing cookie flags to obtain private cookies. | HTTP vulnerabilities can truncate messages, but major browsers ignore uninterpreted response headers. |
| [41] | The paper has analyzed the severe consequences of cross-site scripting attacks and focused on the theft of cookies, passwords, and personal credentials. | Client-side cross-site scripting (XSS/CSS) protection methods. Code vulnerabilities lead to the theft of personal credentials. | Not defined. |
| Browser | Location | Database Name | Table Name | Attribute |
|---|---|---|---|---|
| Mozilla Firefox | C:/…/AppData/Roaming/Mozilla/Firefox/ Profiles/(default) | places | moz_places | url |
| Google Chrome | C:…/AppData/Local/Google/Chrome/User Data/Default | History | urls | url |
| Brave | C:/…/AppData/Local/BraveSoftware/Brave-Browser/User Data/Default | History | urls | url |
| Name | Type | User Interface | Limitations |
|---|---|---|---|
| Wireshark | Network Packet Analyzer | Graphical user interface | Problems integrating with our bot using python commands |
| Scapy | Packet Handling Tool | Python compatible | Oriented to the manipulation of network packets |
| NtopNG | Next Generation Network Traffic Monitor | Graphical user interface | Oriented to the analysis of network flows |
| Requests | Python library that makes working with HTTP requests easier | Python compatible | Oriented to sending and receiving data from websites |
| Curl | Allows to make requests to a server and retrieve data from the command line | Python compatible | Used to create network requests to transfer data across a network |
| Wget | command line tool to download files from the internet | Python compatible | Functional only to recover or duplicate an entire website. |
| Network Miner | Forensic network analysis tool | Graphical user interface | Functional to analyze .pcap files (traffic already collected) |
| Arkime | Search and capture system for indexed packets | Graphical user interface | Difficult to handle, problems interfacing with our bot |
| Tshark | Network protocol analyzer | Python compatible | – |
| Name | Type | Interface Type | Orientation | Control of User’s Web Browsers? |
|---|---|---|---|---|
| UiPath | Open Source RPA tool | Visual Design | Technical and No Technical users | YES |
| Automation Anywhere | Comprehensive platform | User-friendly interface | – | – |
| Blue Prism | Enterprise-grade automation | Drag-and-drop interface | – | – |
| Open RPA | Lightweight open source RPA tool | Simplicity and ease of use | Suitable for smaller automation tasks | – |
| TagUI | Open source RPA | Command execution | For automating web interactions and data extraction | YES |
| Robot Framework | Generic open source automation framework | Command Line Interface | Making it versatile for various automation needs | JavaScript based technology called Playwright |
| Taskt | Free C# program, built using the .NET | Drag-and-drop interface | Automate processes without any coding | – |
| Name | Type | ¿Capture Cookies in Real Time? | ¿Get Stored Cookies? | Show All Cookie Attributes? |
|---|---|---|---|---|
| Wireshark | Network Packet Analyzer | YES | NOT ALL | NO |
| Scapy | Packet Handling Tool | YES | NO | NO |
| NtopNG | Next Generation Network Traffic Monitor | NO | NO | NO |
| Requests | Python library that makes working with HTTP requests easier | YES | NO | NO |
| Curl | Allows to make requests to a server and retrieve data from the command line | YES | NO | NO |
| Wget | command line tool to download files from the internet | NO | NO | NO |
| Network Miner | Forensic network analysis tool | NO | YES | NO |
| Arkime | search and capture system for indexed packets | NO | NO | NO |
| Browser | Location | Database Name | Table Name | No. Attributes |
|---|---|---|---|---|
| Mozilla Firefox | /AppData/Roaming/Mozilla/Firefox/Profiles/ user.default-release | cookies | moz _cookies | 15 |
| Google Chrome | /AppData/Local/Google/Chrome/User Data/Default/Network | Cookies | cookies | 19 |
| Brave | /AppData/Local/BraveSoftware/Brave-Browser/User Data/Default/Network | Cookies | cookies | 19 |
| Opera | /AppData/Roaming/Opera Software/Opera Stable/Default/Network | Cookies | cookies | 19 |
| Edge | /AppData/Local/Microsoft/Edge/User Data/Default/Network | Cookies | cookies | 21 |
| Clusters = 2 | Cluster = 5 | Clusters = 10 | ||||
|---|---|---|---|---|---|---|
| With PCA | Without PCA | With PCA | Without PCA | With PCA | Without PCA | |
| Silhouette Score | 0.9784 | 0.9784 | 0.2447 | 0.4056 | 0.1718 | 0.5810 |
| Inertia (SSE) | 16,689.46 | 77,963.1709 | 1401.95 | 44,201.2 | 259.1727 | 13,799.1350 |
| Calinski–Harabasz Index | 2874.24 | 2874.24 | 1805.9507 | 2918.76 | 890.5486 | 6269.1247 |
| Davies–Bouldin Index | 0.0152 | 0.0152 | 1.5933 | 0.8926 | 3.6921 | 0.5563 |
| eps = 2, min_samples = 25 | eps = 5, min_samples = 25 | eps = 10, min_samples = 25 | ||||
|---|---|---|---|---|---|---|
| With PCA | Without PCA | With PCA | Without PCA | With PCA | Without PCA | |
| Silhouette Score | few clusters | 0.5221 | few clusters | 0.5636 | few clusters | 0.8157 |
| Calinski–Harabasz Index | few clusters | 946.0439 | few clusters | 957.4706 | few clusters | 2167.0301 |
| Davies–Bouldin Index | few clusters | 1.5209 | few clusters | 1.3103 | few clusters | 0.1706 |
| With PCA | Without PCA | |
|---|---|---|
| Silhouette Score | 0.1649 | 0.5653 |
| Calinski–Harabasz Index | 886.0800 | 5430.3483 |
| Davies–Bouldin Index | 3.7704 | 0.6645 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rodríguez-Galán, G.; Benavides-Astudillo, E.; Nuñez-Agurto, D.; Puente-Ponce, P.; Cárdenas-Delgado, S.; Loachamín-Valencia, M. Strategies and Challenges in Detecting XSS Vulnerabilities Using an Innovative Cookie Collector. Future Internet 2025, 17, 284. https://doi.org/10.3390/fi17070284
Rodríguez-Galán G, Benavides-Astudillo E, Nuñez-Agurto D, Puente-Ponce P, Cárdenas-Delgado S, Loachamín-Valencia M. Strategies and Challenges in Detecting XSS Vulnerabilities Using an Innovative Cookie Collector. Future Internet. 2025; 17(7):284. https://doi.org/10.3390/fi17070284
Chicago/Turabian StyleRodríguez-Galán, Germán, Eduardo Benavides-Astudillo, Daniel Nuñez-Agurto, Pablo Puente-Ponce, Sonia Cárdenas-Delgado, and Mauricio Loachamín-Valencia. 2025. "Strategies and Challenges in Detecting XSS Vulnerabilities Using an Innovative Cookie Collector" Future Internet 17, no. 7: 284. https://doi.org/10.3390/fi17070284
APA StyleRodríguez-Galán, G., Benavides-Astudillo, E., Nuñez-Agurto, D., Puente-Ponce, P., Cárdenas-Delgado, S., & Loachamín-Valencia, M. (2025). Strategies and Challenges in Detecting XSS Vulnerabilities Using an Innovative Cookie Collector. Future Internet, 17(7), 284. https://doi.org/10.3390/fi17070284