1. Introduction
The last decade has seen various systems deploy Learning Management Systems (LMSs) in educational institutions [
1,
2]. Such systems are used to support online learning by including educational resource presentation and communication tools such as forums, tests, exercise tools, and administrative functions. An LMS provides the same service to all learners in an institution, rather than personalized learning. Personalized learning environments can be perceived by users as more relevant and motivational [
3]. Typically, they have a content recommendation feature, which supports learners in various ways. For example, learners can choose their individual learning path that helps them continuously gain knowledge. Similarly, by recommended learning resources from a large number of resources, learners can avoid an information overload problem. Furthermore, recommendation systems can integrate context information such as prior knowledge, learning goals, progress, etc., to help recommend precise resources and improve the learners’ performance [
4].
To facilitate personalized learning, various Artificial Intelligence (AI)-based Learning eXperience Platforms (LXPs) have been developed. These platforms are designed to provide personalized learning resources by curating content from various sources and recommending them to learners individually based on their level of learning and personal preferences [
5]. Curated learning resources such as quizzes, digital books, online resources, and Open Educational Resources (OERs) are highly beneficial to learners. However, finding these resources can be quite challenging, especially when there is an overwhelming number of resources [
6].
The LXP market is predominantly occupied by proprietary vendors such as Degreed, Valamis, and Learning Pool, which mainly focus on workspace learning [
7]. In higher education, LMSs have been in use for several years. However, transitioning to a different platform involves significant costs and effort. Especially in Germany, Moodle and other open source LMSs have more than 50% of the market share [
8], prompting questions about whether or not their capabilities can be expanded to include LXP features. Enhancing Moodle with such functions offers advantages such as smooth transitions to new features and provides teachers with flexibility to utilize both the classical LMS tools and the new comprehensive learning support for their students.
The literature covers extensively the proposal, documentation, and evaluation of recommendation systems for e-learning content [
9,
10,
11,
12]. However, their integration into typical e-learning environments or LMSs is rare. An exception is MoodleRec, a recommendation system integrated as a Moodle plug-in [
13]. The plug-in recommends external content, the so-called learning objects, to lecturers. In contrast, the approach described in this paper recommends both internal and external resources for learners.
However, AI-driven recommendations in LXPs offer a solution by identifying relevant resources based on the learner’s competencies and preferences. These recommendations can be classified into the following types: Content-based recommendations that utilize textual information such as tags, keywords, or short descriptions to suggest learning materials. Collaborative recommendations, on the other hand, are based on the assessment of the past behavior of learners, which can be ratings, reviews, and interactions with learning resources [
14]. Hybrid recommendations combine both approaches, incorporating additional knowledge about individual preferences and interests for personalized experience [
15].
In our project, the recommended learning resources have a special didactic purpose: As the central goal of the project is to improve the knowledge related to AI, the recommended resources are used as a vehicle to learn about AI. It is called ‘learning with AI’ [
16]. While students learn in their Moodle learning environment, they receive individual recommendations on what they could learn next. These recommendations are of the following types:
Rating-based: What resources in the course were best rated?
Content-based: Which resources have content similar to the resource currently being worked on?
Trends: Which resources in the course have been clicked very often recently?
Session-based: What resources have the user clicked on in a similar session?
All these types of recommendations will be explained in technical detail in
Section 2,
Section 4 and
Section 5. It is important to note that we avoid hybrid recommendations because they are difficult to understand as they are a mix of different approaches: the AI-concepts and AI-algorithms should be clear and understandable, so that students learn about AI while working with Moodle. Typically, students who use recommendations will think about questions such as:
Where do these recommendations come from?
Which of my personal data are used for them?
Is my professor tracking me?
How are the recommendations created?
To help learners find answers to these questions, a short explanation is appended to each type of recommendation plug-in in Moodle, so that interested students can learn about AI concepts and AI algorithms for recommendations. An example of similar item recommendation (content-based) can be seen in
Figure 1.
If a student wants to know more details, a more comprehensive explanation of every type of recommendation is available in a special Moodle course called ‘Ethics and Privacy’. It is important to mention that the courses at our university are small: 15 to 70 students. That means that the database for the recommendations in one course does not encompass hundreds of thousands of datasets, as typical recommendations do [
17]. The databases are rather small, which is a special requirement for the implementation: recommendation algorithms should give good results on the basis of a few datasets. Furthermore, in our university, teaching is performed personally in the classroom. This means that students usually use recommendations when they repeat the lecture content or if they learn on their own, often after the lecture, or in preparation for presentations and examinations.
Given our access to high-quality educational resources, we can utilize these resources by providing them as recommendations when they interact with AI-Chatbot to enhance their learning experience. AI-Chatbot is an interactive tool for learners to ask questions and satisfy their curiosity. Therefore, this platform offers an ideal setting for delivering recommendations related to queries or inquiries students may have while interacting with the chatbot.
The primary contribution of this work is the design and implementation of AI-driven recommendation systems integrated into the existing Moodle platform in a higher education context. It supports a pedagogical approach we call ‘Learning with AI’ by effectively guiding students to internal learning materials, enriching their educational experience within the Moodle framework. In addition, the integration of a chatbot with the Retrieval-Augmented Generation (RAG) capability in the Moodle platform is also developed as a way to offer recommendations when students ask questions.
In this paper, we present an architecture that extends Moodle into an LXP through the integration of AI-based recommendations for learning. We identified various components and designed an architecture that works in the Moodle platform.
2. LXP Architecture: Design and Implementation
Moodle [
18] is a widely used learning management system that provides various features and benefits in the educational sector. With its open-source model, it has benefits such as data control and integration to various teaching methodologies, and it allows flexibility in customization and modifications. Moodle provides web services support using the Extensible Markup Language Remote Procedure Call (XML-RPC) protocol. It is useful for data exchange between Moodle and other systems, making it easier to extend Moodle.
Our university has used Moodle LMS for many years to provide students with learning resources for their courses. During the use, a significant amount of content has been created, and many features are implemented in the courses, such as tests or gamification elements. Hence, replacing Moodle with a new LXP was not an option. Instead, we decided to gradually expand Moodle into an LXP with AI-based learning recommendations, so that the existing features of the original Moodle will remain available.
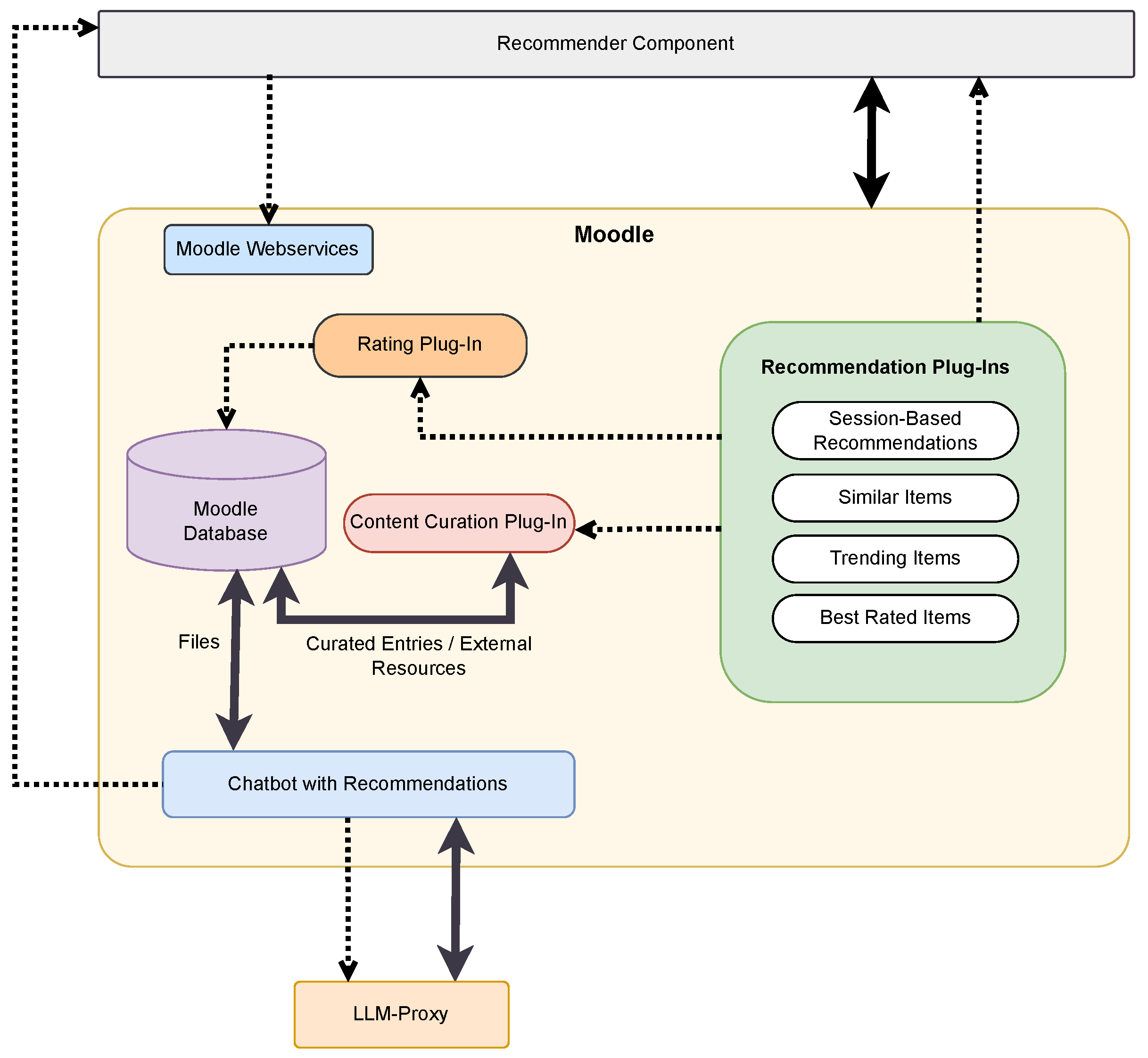
There were a few architectural constraints for the project, such as the user interface and user interactions must take place within the Moodle platform, where learners interact often. Apart from user interaction, operations such as calculations and data processing can occur in a separate system. With these constraints, we have devised the following components for the project, as shown in
Figure 2.
Recommender Component: A combination of different modules hosted on a separate server that performs tasks such as syncing data from Moodle, calculating recommendations, and providing interfaces to connect to Moodle plug-ins.
Moodle: System that hosts various plug-ins through which learners can interact.
LLM-Proxy: An external server that hosts a vector database and provides interfaces to connect to the database as well as API to connect to OpenAI’s large language models.
2.1. Recommender Component
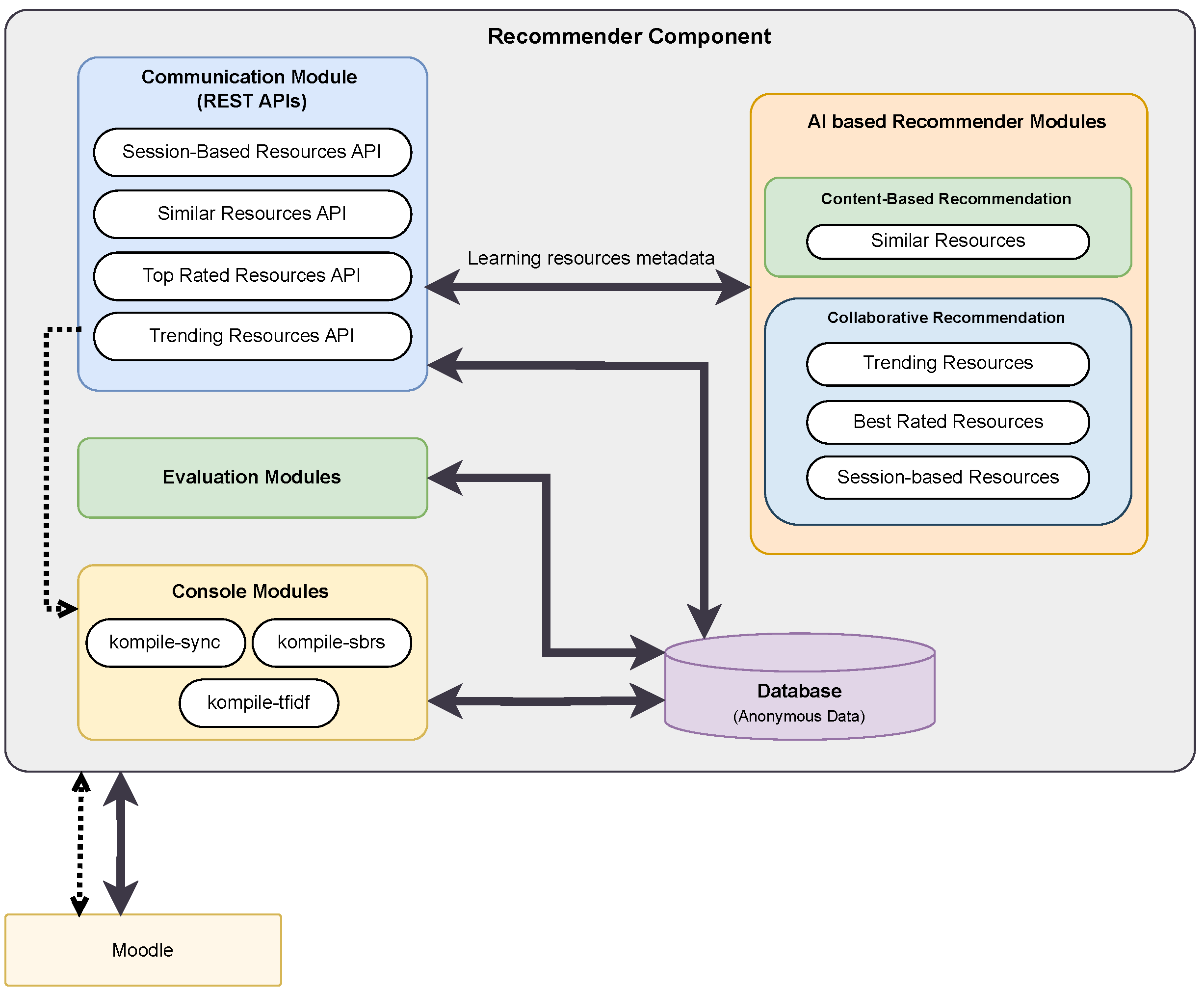
As the Moodle system does not have any computational role in our architecture, all calculations are performed on another server where a “Recommender Component” is installed. The Recommender Component, in simple terms, is a companion that has additional features that Moodle should not implement or are not feasible to implement due to various other reasons.
The Recommender Component is divided into different modules, namely, Communication Module, Evaluation Module, Console Modules, and AI-based Recommender Modules, as shown in
Figure 3. The Communication Module provides bi-directional communication between Moodle and various modules of the Recommender Component using Representational State Transfer (REST) Application Programming Interfaces (APIs). It also facilitates communication between AI-based Recommender Modules and Moodle. More information on AI-based Recommender Modules is explained in
Section 2.4. The Communication Module has interfaces for recommendation techniques such as content-based and collaborative recommendation. These interfaces are used by Moodle plug-ins and AI-based Recommender Modules. The MySQL database serves as a storage backend for the Recommender Component. Console Modules, as the name implies, are various command-line programs that are invoked by the Recommender Component. These modules are implemented in different programming languages. These modules have three tasks.
Synchronize the information of the courses and learning resources to the MySQL database, performed by kompile-sync.
Calculate TF-IDF and similarity between learning resources using metrics such as cosine similarity, executed by kompile-tfidf.
Predict the next learning resources for a particular user based on their action during a session. kompile-sbrs.
The last module is the Evaluation Module. It displays a list of learning resources that are similar to a learning resource. It offers an opportunity for lecturers and teachers to individually evaluate the results.
Our implementation leverages Symfony’s API Platform [
19], which includes a caching component and other well-tested components, alongside a server with sufficient specifications, despite operating as a virtual machine.
2.2. Moodle Plug-Ins
We have created various plug-ins to enhance Moodle and provide various recommendations to learners, which are explained in the following sections.
Figure 4 shows the different plug-ins of the project integrated with Moodle. These plug-ins are as follows:
Session-Based Recommendation Plug-in: One of the extensions that we have developed is the session-based recommendation plug-in. It displays the list of learning resources (v) based on clicks (a) of a learner for a particular session. It utilizes the interfaces exposed by the Communication Module to retrieve recommendations.
Similar Items Plug-in: The next extension to Moodle is a block plug-in named ’Similar Items’ to display resources that are similar to particular learning resources. The similarity is calculated using AI-based Recommender Modules. The plug-in also utilizes the interfaces exposed by the Communication Module.
Trending Items Plug-in: The trending items plug-in lists current popular learning resources using an algorithm that analyzes trends. It identifies and lists the most frequently accessed learning resources by tracking the learner’s interaction with various courses. Only the user interaction (o) is stored, not the user information.
Rating Plug-in: Moodle provides a rating system for forums, databases, and glossaries; however, it does not have this feature for other learning resources. To address this gap, a new Moodle plug-in was developed. This plug-in allows learners to rate various learning resources using a one-to-five star scale. Additionally, learners can provide reviews such as “This Portable Document Format (PDF) covers the current topic extensively and is easy to understand”. The plug-in also computes and displays the average ratings anonymously, helping the learners to benefit from each other’s experiences, thus fostering a collaborative learning environment.
Best Rated Items Plug-in: This plug-in displays a list of learning resources that are highly rated by the cohorts. It depends on the Rating plug-in, as it reuses the stars from the Rating plug-in.
Content Curation Plug-in: When you have a platform that offers various learning resources, using forums and databases, it is only logical to have a centralized place where learners and lecturers can add relevant and high-quality external learning resources. For this purpose and for the purpose of collaborating between lecturers and learners, it was crucial to have an additional plug-in to curate external learning resources. In addition, encouraging collaboration among learners by curating shared resources can grow a sense of community and collective learning. Furthermore, having a content curation database ensures that only relevant, accurate, and high-quality resources are available and fosters collaborative learning that results in increased productivity and improved performance [
20].
Chatbot with Recommendations: The main reason for implementing a basic chat system is to offer recommendations to students when they ask questions and get answers from the chat system. The chatbot uses Large Language Models (LLMs) and Retrieval-Augmented Generation (RAG) to offer responses primarily through the resources that are available in the course, thus reducing hallucinations. Through RAG, we extract information about the learning resources and provide links to similar curated learning resources.
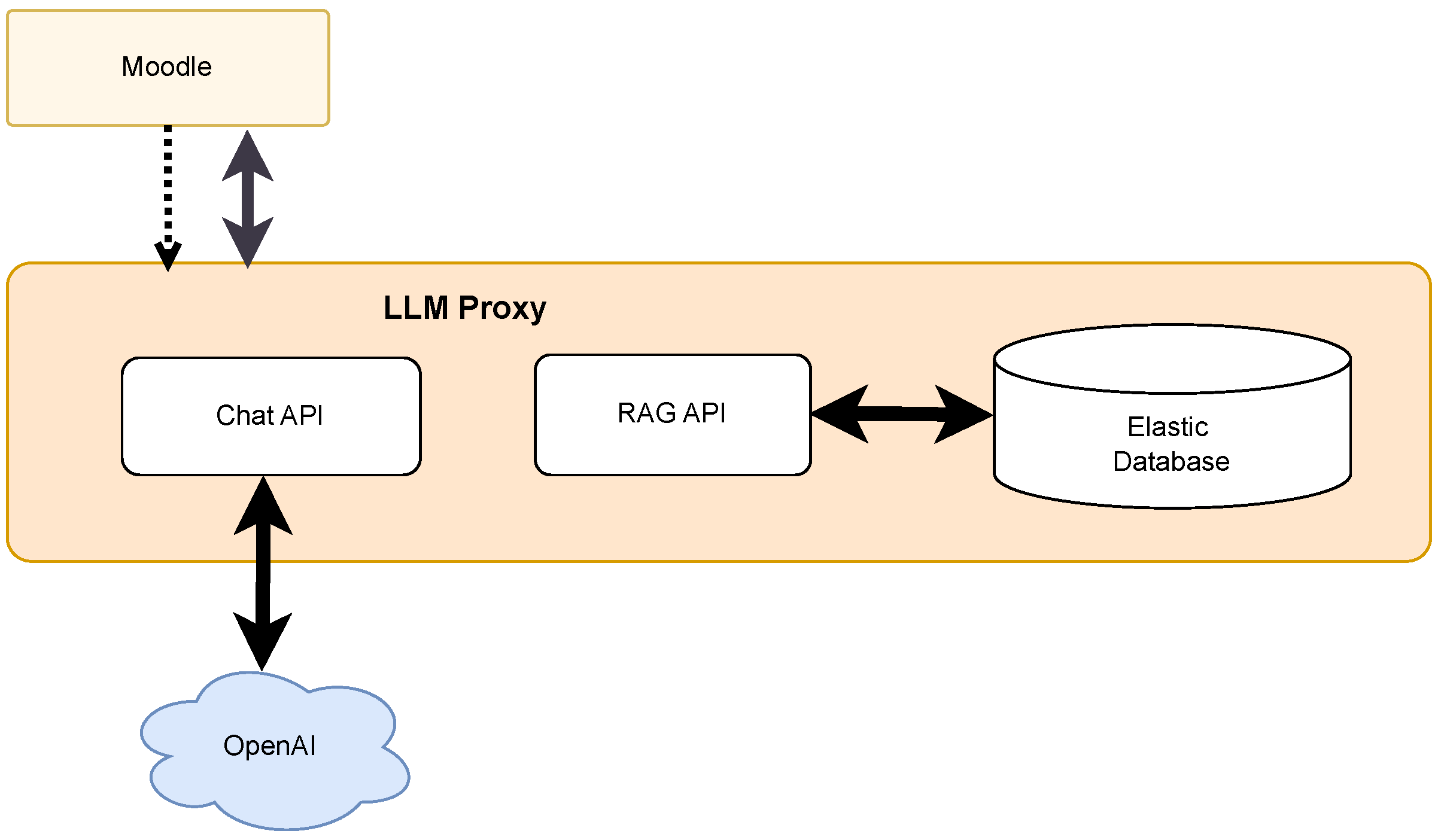
2.3. LLM-Proxy
The AI-Chatbot communicates with OpenAI’s ChatGPT-4o (Chat Generative Pre-trained Transformer) using a mediator named LLM-Proxy, as shown in
Figure 5. LLM-Proxy is an external service provided by the Institute of Machine Learning and Analytics (IMLA) of our university [
21]. Its main function is to provide API access for a wide range of commercial and open-source LLMs for research and teaching. The key features of LLM-Proxy are a single API for multiple models, access control and accounting for individual users and teams, and easy model integration with LangChain, OpenAI API, and REST. Additionally, the LLM-Proxy implements a vector database that is accessible via APIs.
2.4. AI-Based Recommender Modules
AI-based Recommender Modules are basically collection algorithms that provide recommendations for learning resources. For content-based recommendations, we use the metadata of learning resources, such as the title and description provided to the resources, to calculate similar resources. The algorithm we use is based on Natural Language Processing (NLP) and Term Frequency–Inverse Document Frequency (TF-IDF). Content-based recommendation processes the metadata of the learning resources when a user hovers over certain resources in the Moodle course. A background process requests the Communication Module to acquire resources that are similar to the resource in question.
AI-based Recommender Modules also implement various collaborative features, such as calculating trends, finding best rated learning resources, and providing recommendations based on the current user’s session. When a learning resource is clicked by learners in Moodle, the interaction is stored as number of clicks. These clicks are stored for several other learning resources and trends (or trending items) are calculated based on these clicks over a certain interval. The interval is configurable. Session-based recommendation systems are particularly beneficial, as they do not require user information and can provide accurate and timely recommendations [
22].
2.4.1. Trending Learning Resources
Interactions with resources are often used to calculate trends. These resources, which are popular among learners, already tell us that they have been vetted by other learners, and that learners have already found value in it. The use of trends and systems that predict recommendations based on these trends has been extensively studied over a long period of time, providing insight into their strengths, limitations, and advantages.
Various algorithms and technologies have already been proposed and developed for use in this field, such as slope analysis (Mann–Kendall and Sen’s slope analysis), z-score calculations, and chi-squared tests [
23,
24]. However, we have selected the z-score to calculate the trends. Various sample sizes are used in different courses, ranging from 7 days to 14 days, to evaluate the results of the trends. The Z score (or standard score) is especially helpful because it calculates the probability of a score falling within a normal distribution and allows two scores to be compared from different distributions [
25].
Supposing that the number of clicks
x to a learning resource follows a normal distribution, where the mean is specified by
and the standard deviation by
, the time series can then be standardized by [
26,
27]:
The standardized
z, shown in Equation (
1), follows a standard normal distribution. This value can be used to identify trends. A higher and positive value signifies that the learning resource is popular. In contrast, a negative value of
z indicates that the resource is falling out of trends.
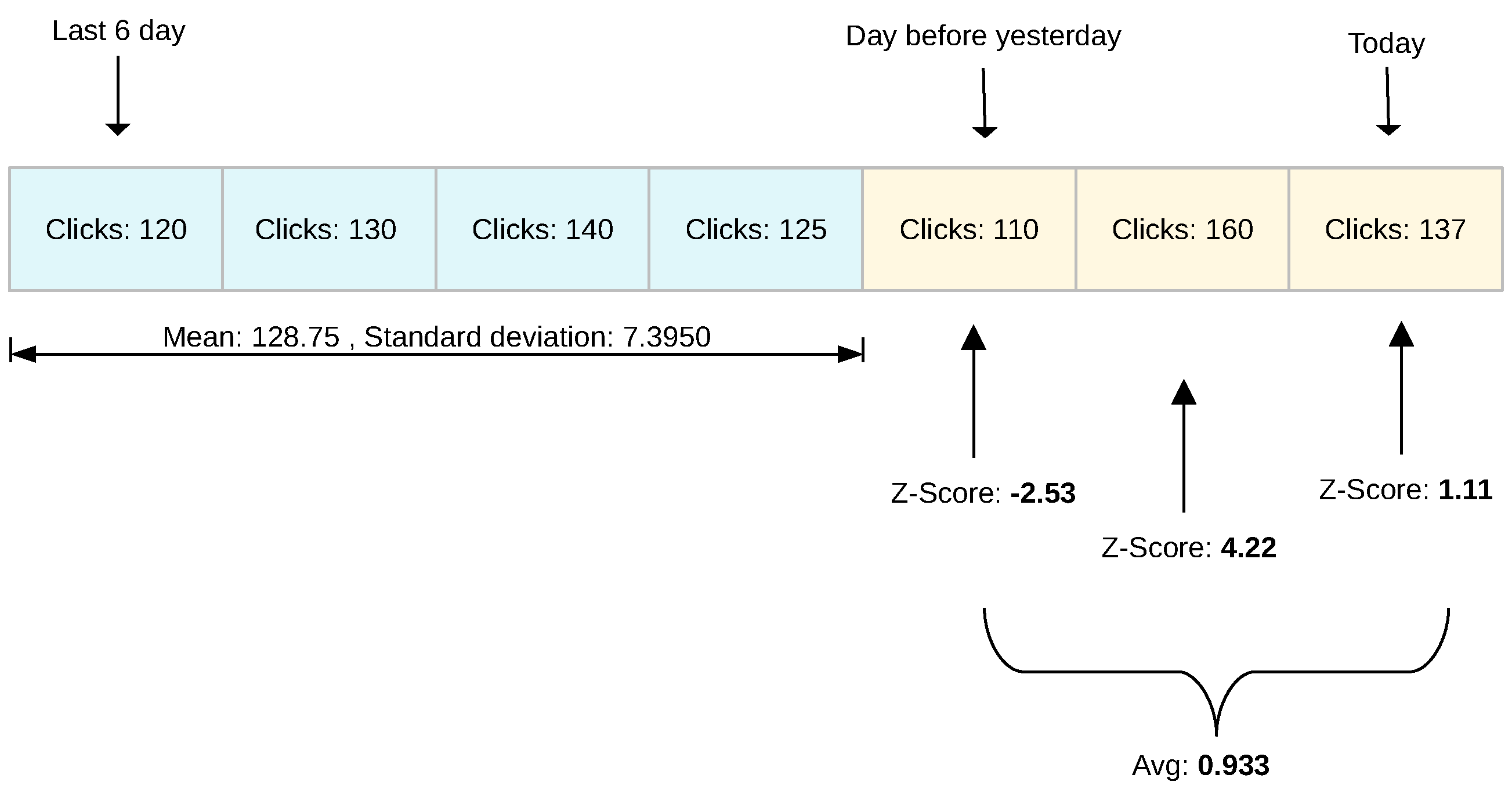
To effectively use this score, we have taken several factors into account. First, the period of specific days was considered. This period is considered a window. We divided the window into panes. The length of a pane is one day. The trending-items plug-in tracks the action (clicks) of a particular resource for the whole duration of a window. The window then slides daily, removing the last pane and adding a new pane for the current day, thereby making it a continuous sliding window.
Furthermore, the window is divided into two sections: history panes and current panes. The history panes are used to calculate the mean and standard deviation of the time-series data. Alternatively, current panes are used to calculate the z-scores. The average of the z-scores in the current panes, as shown in Equation (
2), represents the final score of the learning resource. This score is then compared with other resources, and those resources with the highest scores are displayed in the trending items plug-in.
Figure 6 shows this design.
The average z-score for current panes is given by the formula:
= Number of current panes.
= Number of clicks stored in the pane.
= Mean number of clicks calculated from the history panes.
= Standard deviation calculated from the history panes.
During initial testing of the trending items plug-in, we observed minimal latency due to our external server being located within the same local network.
2.4.2. Similar Learning Resources
Recommendation systems based on content analyze metadata associated with learning resources and provide recommendations. These systems are particularly helpful for discovering learning resources that otherwise are not easily discoverable. Given that learners and lecturers collaborate to curate external learning resources, it becomes practical to have the resources readily accessible. To make the resources discoverable, we have the Moodle plug-in that displays the list of recommended learning resources based on the metadata of the learning resources.
AI-based Recommender Modules implement content-based recommendation systems that use the metadata of the learning resources. This information is transferred to the Recommender Component using the Moodle webservice APIs. The following steps are processed. Initially, the text describing the learning resources (i.e., descriptions) is split into tokens using a process termed tokenization. Then, the resulting text is analyzed by the Lemmatizer, an NLP tool. This tool identifies the lemma or base form of each word. Words that have less meaning and that do not contribute in the analysis are excluded from further analysis. The resulting text is then used to compute the TF-IDF scores, which results in a multidimensional vector. These vectors are the input for the cosine similarity algorithm, which is used to calculate the similarity of the learning resources. The results of these calculations are sent as JavaScript Object Notation (JSON) strings to the Recommender Component, which stores the results in the database. The basic steps are shown in
Figure 7.
Similar learning resources are designed to recommend text-based resources
that are similar to resource
s [
15]. The content is usually described with words or a set of words. Let
N denote the total number of documents
d and
be the document frequency, the number of documents
d that include the term
t [
28,
29]. The term frequency,
, denotes the number of occurrences of the term
t in the document
d [
28,
29]. The inverse document frequency (
) is defined as follows [
28,
30]:
Then, we can define
as follows [
28]:
The lecturers provide a description for each learning resource to learners with concise information about the learning resource. The content-based recommendation algorithm uses descriptions to identify similarities between learning resources. The Jaccard index, also known as the Jaccard similarity coefficient [
31] and shown in Equation (
5), is used to evaluate the outcome of the content-based recommendation [
32]. The intersection of
(the set of similarity evaluation results conducted by lecturers) and
(the set of scores computed using TF-IDF and cosine similarity) will be divided by the size of the union of these sets to obtain the overall accuracy of the recommendations.
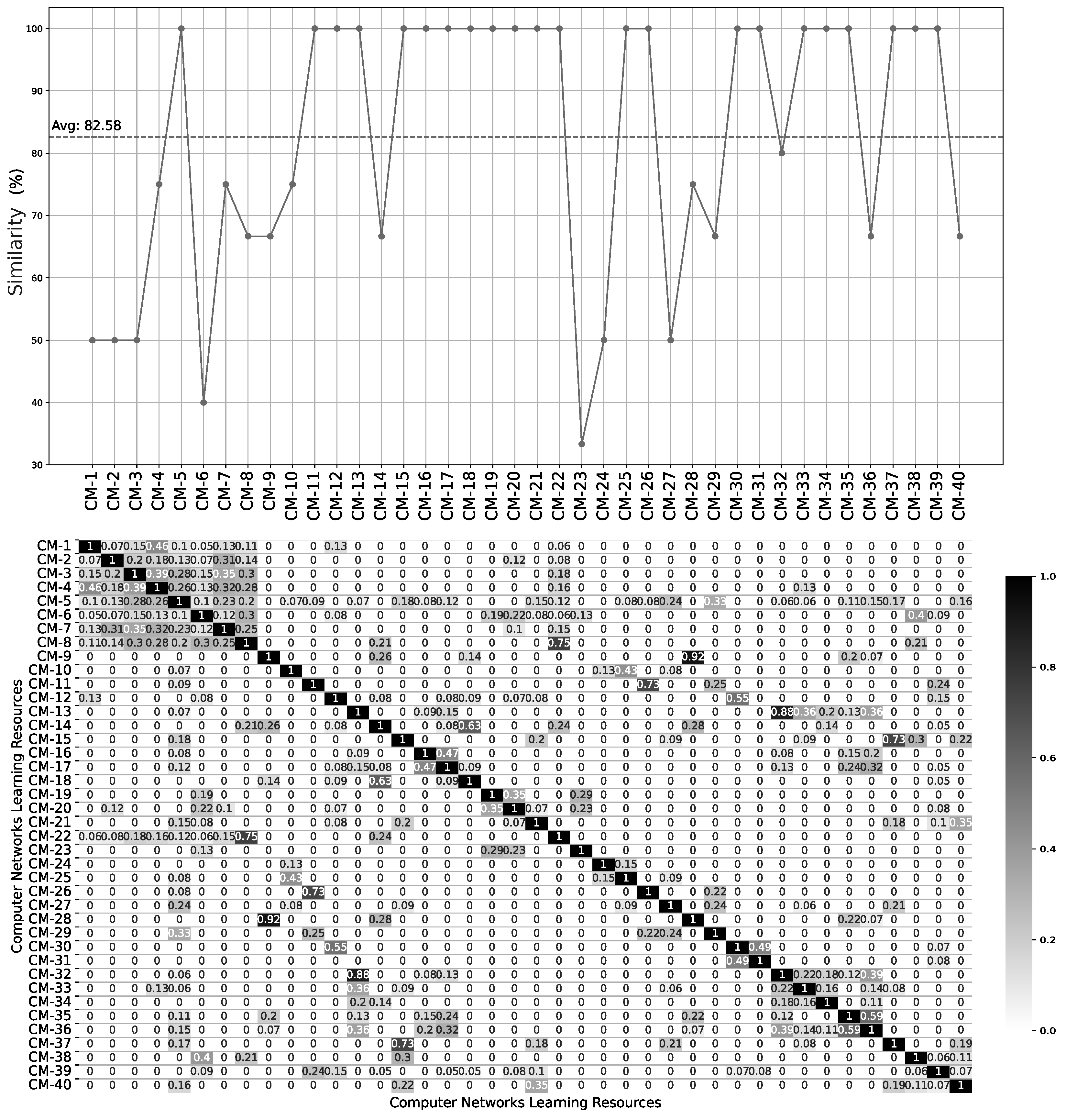
Figure 8 shows the accuracy (Jaccard index) in percentage and the heat map representation of a similarity matrix (cosine similarity) for the learning resources of the Computer Networks course. The CM-
i |
in the figure refer to the learning resources available in the course. The heat map displays darker shades to represent stronger similarity among learning resources, whereas lighter shades denote weaker similarity between them. The heat map is calculated when the information about the learning resources changes and is stored in the database of the Recommender Component as JSON. The time it takes to calculate the heat map is around five seconds, as the Recommender Component has to recalculate TF-IDF and the cosine similarity each time the learning resource is added or updated. Whenever recommending learning resources based on similarity metrics, we can refer to the heat map stored in the database. This does not cause any latency issues because we do not have to recalculate the similarity scores every time. We only store the result of the calculations, so we do not need much storage space. Calculations are done by console commands in such a way that once the command execution is finished, the memory is reclaimed by the operating system. For parallel execution of the APIs, we depend on the functionality of the Apache2 web server [
33]. Apache2 is one of the most used web servers. It can handle multiple users and simultaneous requests.
During initial testing of the Similar Items Plug-Ins, we observed minimal latency because our external server is located within the same local network. This reduced concerns about latency issues in this context.
We evaluated the courses Software Engineering and Computer Networks, which have 79 and 40 learning resources, respectively. A high similarity value indicates good quality of the recommendation system provided for students. The Software Engineering course has an average similarity value of 72.50%. In addition, the average of similarity values in the Computer Networks course was 82.58%.
2.4.3. Best Rated Learning Resources
Learning resources that have received the highest level of emotional impact and are likely to be recommended to cohorts are generally referred to as best rated learning resources [
34,
35]. These resources are deemed high quality and learners can benefit from such resources, which in turn contribute to successful learning experiences. The Recommender Component calculates the resources that are rated highly by the cohorts and recommends these resources through Moodle’s best rated plug-in.
2.5. Content Curation and Open Educational Resources
OERs are very important for knowledge, as they support the exchange of knowledge and learning [
36]. There are a large number of OER repositories that can be used by both teachers and learners. Teachers, also in the university context, benefit from OERs because they do not have to design all learning materials themselves [
37] but can share and reuse high-quality materials. Learners can be individually supported according to their preferences and current level of learning. In general, the large number of existing OERs is associated with the challenge of obtaining the relevant learning resources to suit the respective learning content. Content curation, search, selection, grouping, enrichment, and sharing of learning resources on specific topics [
37] help integrate OER into the current learning context. This perfectly complements content-based and collaborative learning recommendations by providing the relevant data for the recommendation systems. The summaries and tags added to the learning resources form the basis of content-based recommendation algorithms. Comments and ratings are the basis for collaborative recommendations, such as ‘best rated activities’.
For Moodle LXP, all external learning resources of a course are represented in an adapted Moodle database and provided with metadata so that they can be searched for. These external learning resources are typically integrated into the database by weblinks from platforms such as YouTube or LinkedLearning. They can be suggested by teachers and learners. However, teachers are currently checking for their relevance in the learning context and possibly supplementing or adapting suggestions before they are published.
3. Evaluation
In a first formative evaluation, the acceptance of the LXP, in particular, the learning recommendations, by students in three different computer science bachelor’s courses (Software Engineering, Computer Networks, and Databases) was examined.
One result of the evaluation shows that around 74% of 38 students use external learning resources regularly or frequently for learning and assume that they provide positive support for their learning process (see
Figure 9). This result confirms the efforts to integrate OER by content curation into existing learning platforms. However, learning recommendations are therefore likely to become more important, as they are the only way to find individually suitable learning content in the large number of available OERs.
The learning recommendations, and in particular the recommendation ‘best rated learning resources’, are based on the active participation of the students. They must reflect on how the learning materials support them in the learning process and make this available to their fellow students through the star rating and eventually an explanatory comment. The current ratings from the students show that only a small proportion of students (approximately 16%) are willing to give regular evaluations (see
Figure 10a). The majority of students rarely (approximately 18%) or never (50%) evaluate the learning resources. So far, the feedback from students in all courses has often been very positive (five stars), or they point out technical or content-related problems with the learning resources.
Although most of the students do not regularly rate and comment on learning resources, the majority who gave ratings evaluated the ratings of fellow students as helpful (see
Figure 10b). More than 55% use ratings and comments regularly or frequently to find appropriate learning resources. As things stand at present, this discrepancy between the willingness to rate and the desire to use ratings from others seems very difficult or even impossible to change. Hence, there will be a lack of ratings. A possible approach to replace missing ratings, at least partially, could be collaborative recommendations based on sessions. We replace explicit ratings with session-based recommendations because they are interpreted as a kind of implicit rating: recommendations based on earlier sessions suggest learning resources that fit into the actual session. If many users found a certain learning resource helpful in a given session context, the same is true for other learners in a similar session context.
In addition, session-based recommendations are interesting from an ethical point of view because they do not need personal data. That is in contrast to collaborative recommendations that rely on user profiles. Hence, session-based recommendations are interesting for the approach ‘learning with AI’ because learners learn more about AI, data, and privacy, as it should be the learners’ own concern if their own data are used or not for recommendations.
4. Enhancement: Session-Based Recommendations
With the increasing amount and diversity of learning resources, recommendations become even more important as it becomes more difficult to find the best learning resource in a certain learning situation. Recommendations help learners select suitable learning resources to study [
38,
39,
40,
41]. A session-based recommendation system learns learners’ preferences [
42] from associated sessions created during their study of learning resources in the Moodle system.
Based on user information, sessions can be divided into non-anonymous sessions and anonymous sessions [
42]. Non-anonymous sessions will include information about learners who interact with learning resources during the session. In Moodle, in our case, the non-anonymous data related to the user may consist of the userid, username, user’s browser session, user’s interaction history, user’s grade and competencies, etc. In anonymous sessions, only contextual information about learning resources from the current session can be used for recommendations, while learners’ information is not used to link sessions.
Thai-Nghe et al. [
41] proposed a session-based recommendation system for learning resources using the Neural Attentive Session-Based Recommendation (NARM) and Recurrent Neural Network (GRU4REC) models. Sessionid, datetime, timestamp, itemid, and category are the attributes used in a session-based recommendation system for learning resources [
41]. Based on the experimental results, the session-based recommender system using the NARM model is more effective than the GRU4REC model [
41].
The session-based recommendation system suggests potential next learning resources for the learner that are suitable for the current session. If numerous learners found a specific learning resource beneficial in a certain session context, the same is expected to apply to other learners in a comparable session context. To learn more about the classification of session-based recommendation system approaches, see [
42]. The session-based recommendation with the graph neural network, which is one of the subcategories of deep neural networks [
42], predicts user actions based on anonymous sessions [
22,
42]. We utilized session-based recommendation with the graph neural network [
22] because it does not require personal data.
The Graph Neural Network (GNN) is a deep learning architecture that describes a distributed algorithm that performs local computations on the vertices of the graph [
43]. In GNN, the input graph
consists of a set of vertices
V and a set of edges
E [
44]. Let node
and node
represent the learning resources and activities (collectively called learning resources) chosen by the learners. Each node
is randomly and independently connected to other nodes
based on the order in which the learning resources are chosen by the students during the session
s and ordered by timestamps. The edge
is a directed path from node
u to node
v that represents the sequence of learning resources selected by the learner in a session
s [
22]. The learner selects the learning resource
v after the learning resource
u has been previously selected. Each node has vector
with a dimensionality of
d [
22]. Each session
s is constructed from the node vectors of the graph
G [
22]. We use SR-GNN (Session-Based Recommendation with Graph Neural Network) [
22] to predict the next learning resources recommended to learners.
We store information such as the session (
sessionid), the course (
courseid), the learning resource (
cmid), the external curated resource ID (
instanceid), and the timestamp obtained from user clicks on learning resources in Moodle. The structure of an entry into the session table is shown in
Figure 11. When a user clicks on a learning resource in Moodle, the anonymous interaction of
in a session
s at a time
t is stored in the database. A learning resource of
v is the combination of
courseid,
cmid, and
instanceid.
A session contains the list of anonymous interactions
o ordered by timestamp
t, that is,
[
42]. A set of sessions
will be filtered in the pre-processing data. Sessions in which the number of interactions is greater than 1, that is,
, will be used as training data. The frequency of learning resources appearing in various sessions also needs to be determined. A series of sequences of learning resources and the next learning resource chosen by the user are generated from the input session
s [
22]. The data are organized into training data and evaluation data in the pre-processing data. We have followed the techniques described in [
22] for the learning process of node vectors in session graphs using update functions, generating session embeddings, and making recommendation and model training.
Figure 12 shows the sequence diagram for predicting the next learning resources using session-based recommendation with a GNN. When learners click to select learning resources in a session, the Moodle session-based plug-in issues a network request to the Communication Module to give a list of predictions of the next learning resources. The session-based recommendation with the GNN module [
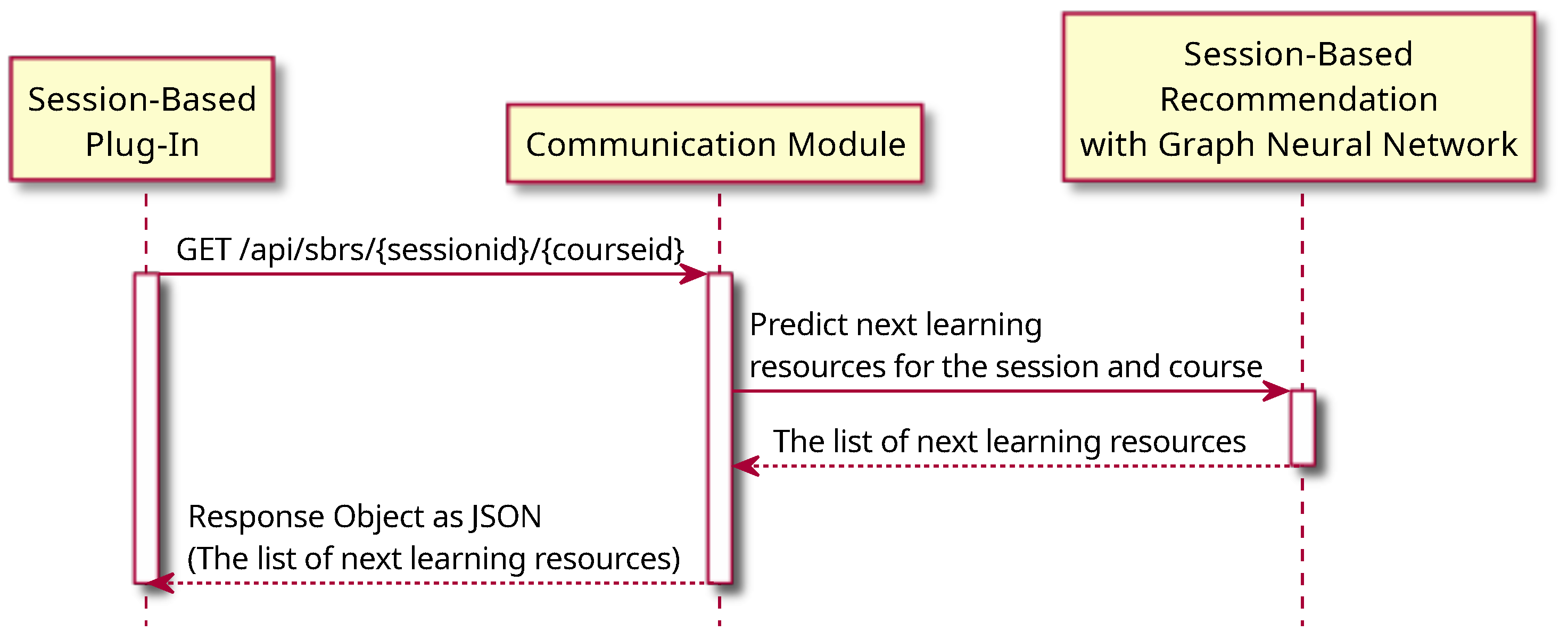
22] will return the next learning resources. The Communication Module creates a JSON response object from the list of the prediction of the next learning resources to the session-based plug-in. The session-based plug-in refreshes the list of the next learning resources.
The dataset for session-based recommendation comes directly from the user’s interaction with the learning resources in Moodle. For a period of two months, we collected the interactions in a course. The dataset has, in total, 4427 interactions , 1236 sessions , and 235 learning resources . Let a session s consist of the sequence of learning resources . We separated the series into two parts, where is the sequence and is the next predicted learning resource. We performed some pre-processing of the dataset, such as removing the sessions that have fewer than a certain number of interactions as we presume that they do not contribute much.
We use the Session-Based Recommendation with GNN (SR-GNN) because SR-GNN outperforms all the methods experimented in [
22]. For evaluation, we used Precision (P) and Mean Reciprocal Rank (MRR) [
22].
is widely used to predict the precision of the results. Among the top-20 items, this metric represents the proportion of correctly recommended items. Similarly,
measures the average reciprocal ranks of the items that are correctly recommended. The large value of MRR indicates that the recommendations are correct and are in the top-20 list of recommendations [
22]. From the experiments, we get
and
.
In
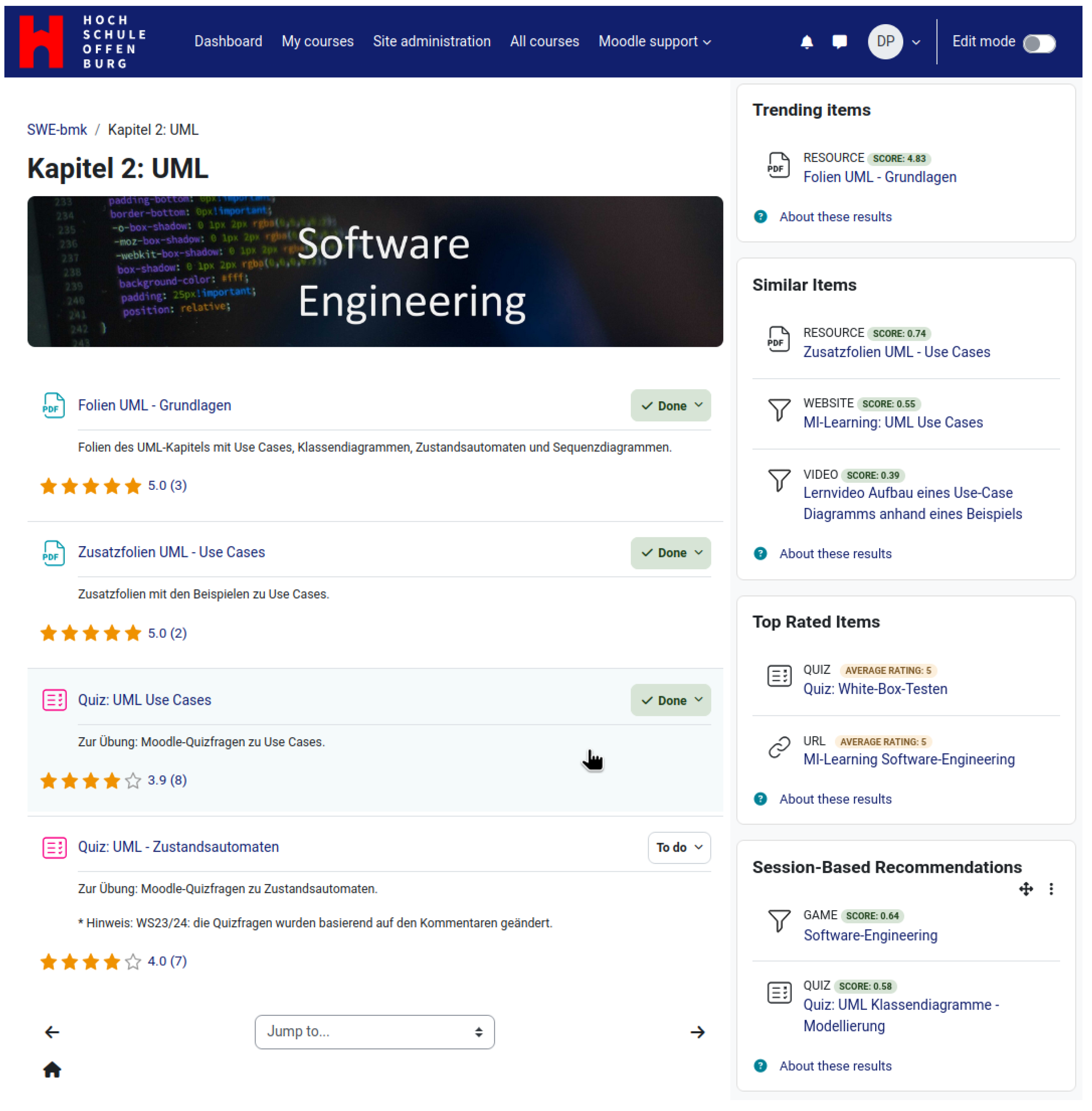
Figure 13, we see that ‘Folien UML—Grundlagen’ is on trend. Similarly, we see that a learner has hovered over ‘Quiz: UML Use Cases’, which can be seen by the light blue background with the hand cursor. The Recommender Component then recommends ‘Zusatzfolien UML-Use Cases’, ‘MI-Learning: UML Use Cases’, and ‘Lernvideo Aufbau eines Use-Case Diagramms anhand eines Beispiels’ as resources similar to the ‘Quiz: UML Use Cases’. Furthermore, ‘Quiz: White-Box-Testen’ and ‘MI-Learning Software-Engineering’ have been rated five stars by the learners. Furthermore, we can see that a learner has clicked on ‘Folien UML—Grundlangen’, ‘Zusatzfolien UML—Use cases’, and ‘Quiz: UML Use Cases’. These three interactions constitute a session and are sent to the Recommender Component. The Recommender Component then predicts ‘Software-Engineering’ and ‘Quiz: UML Klassendiagramme—Modellierung’ as the next resources that learners can learn.
Figure 14 shows an example of the next learning resources proposed using SR-GNN.
The primary latency issue arises from session-based recommendations for learning resources. Training the model occurs daily at 5 AM, taking approximately two minutes with current datasets. Predictions are generated in about eight seconds when learners interact with course materials during their sessions. These interactions are recorded and later processed asynchronously via AJAX to provide timely recommendations without disrupting the user experience.
5. LLM and RAG with Recommendation System for Moodle Chatbot
Previous research has demonstrated a growing interest in the use of conversational technology in education, predating the advent of large language models [
45]. The emergence of ChatGPT has further amplified this enthusiasm, as it has sparked attention and curiosity among educators and learners. Skjuve et al. have explored user motivations for using generative conversational AI, specifying that these tools are used for purposes such as creative work, learning and development, and entertainment [
46]. Although learners are curious about new technologies [
47], we have seen that they often hesitate to engage with existing learning resources. We can use the natural curiosity of learners and guide them toward appropriate learning materials by integrating a chatbot capable of providing recommended learning resources into Moodle, thus enhancing both user engagement and academic outcomes.
Generative Artificial Intelligence (GenAI) technologies, such as ChatGPT, utilize the knowledge derived from LLMs, demonstrating their ability to accommodate learners with varying expressions and cognitive abilities, effectively assisting them in identifying and addressing individual knowledge gaps through interactive conversations, providing tailored guidance that aligns with the foundational levels of Personalized Learning (PL) [
48]. ChatGPT, as GenAI, has a large positive impact on improving learning performance and a moderately positive impact on improving learning perception and fostering higher-order thinking [
49].
The advent of LLMs has improved information retrieval. However, challenges such as the limited capacity to update knowledge, lack of transparency, and hallucination continue to exist. In an attempt to mitigate these issues, the concept of RAG has been proposed [
50]. The integration of LLM and RAG into LMS such as KI-Campus can help learners in the learning process [
51].
The high-quality learning resources collected in the Moodle system by lecturers and learners are stored as embeddings in a vector database.
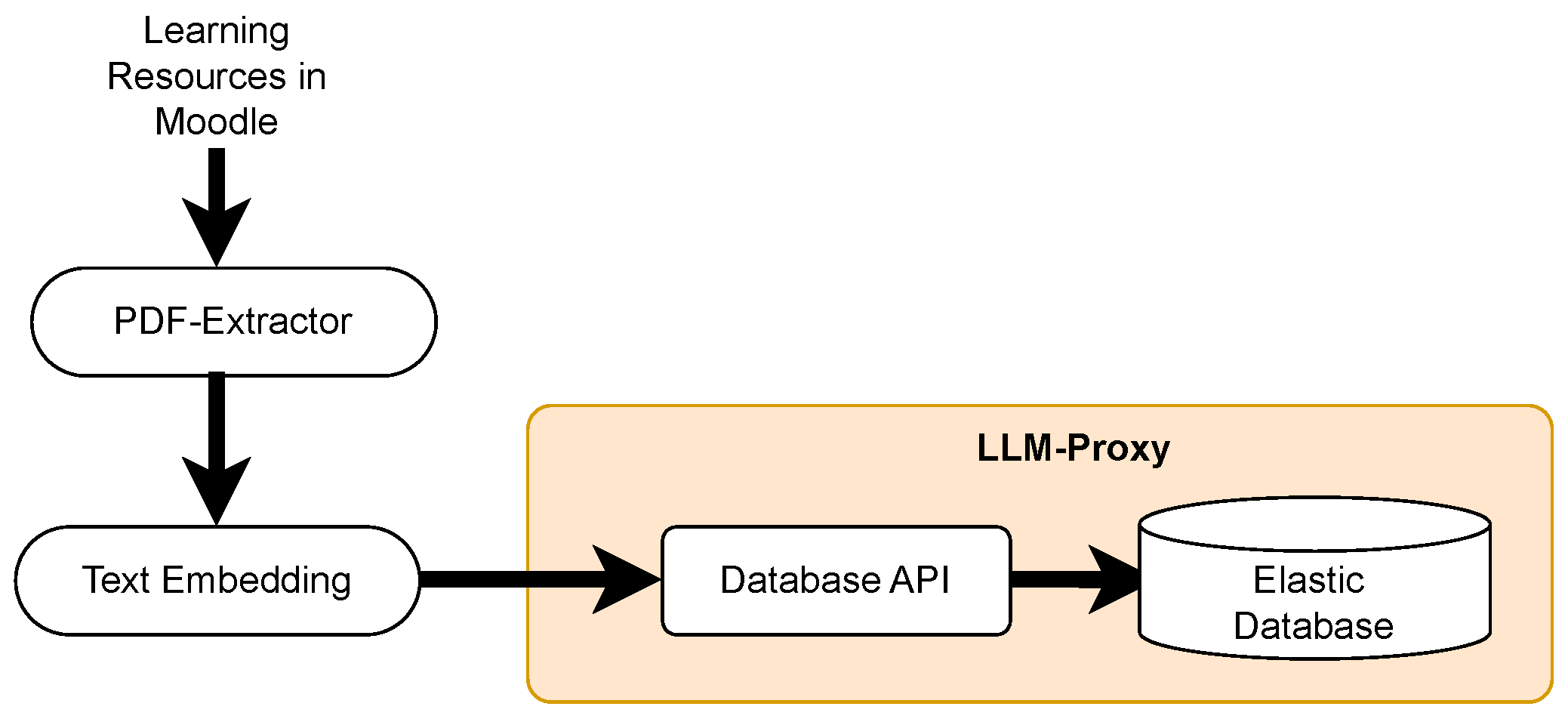
Figure 15 shows the synchronization of the learning resources for the RAG. In the learning resource synchronization process, the texts of learning resources stored in Moodle will be extracted using the PDF-Extractor. Text with embeddings or numerical vectors will be created to be stored in the Elastic Database [
52] using the RAG Application Programming Interface (API).
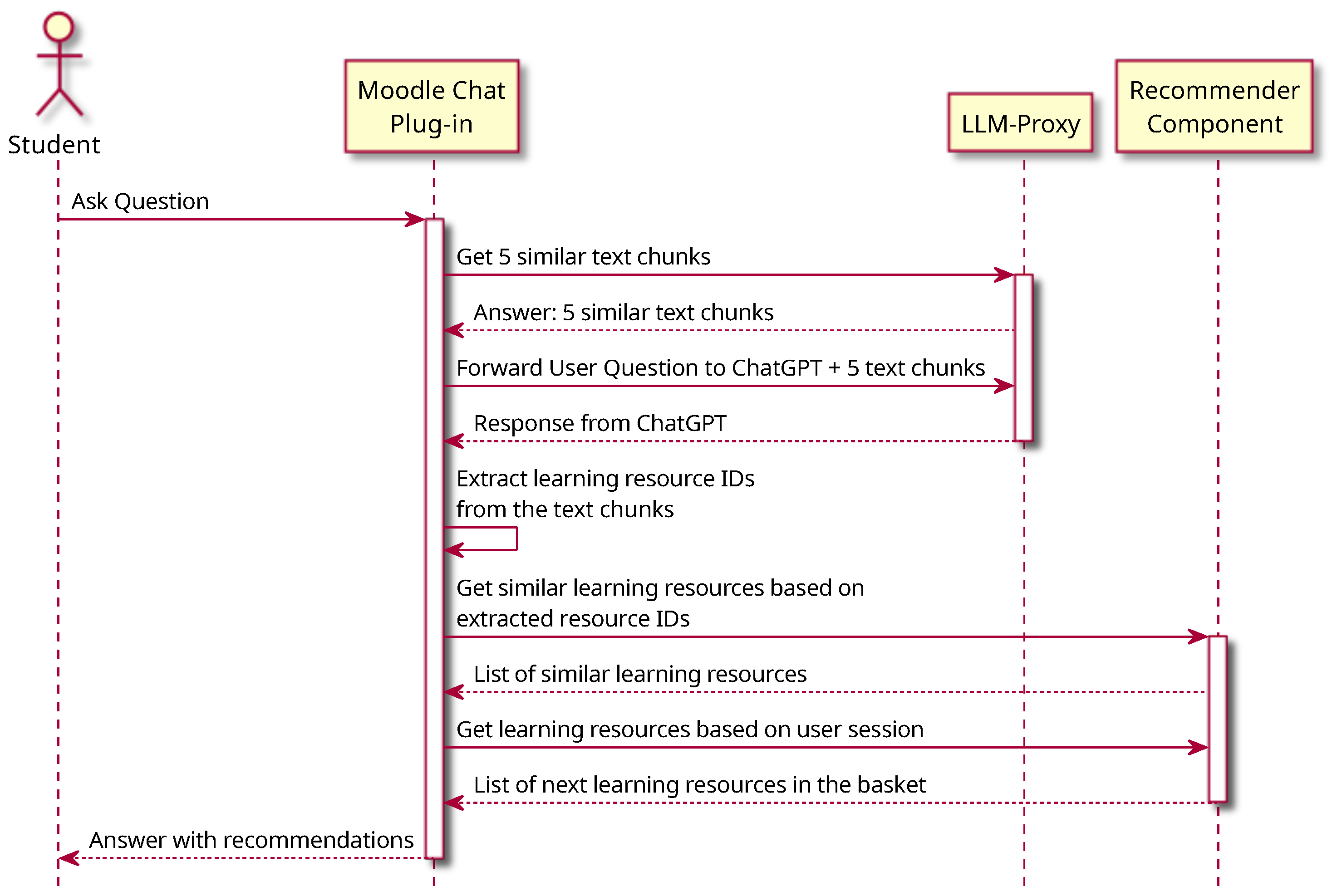
Figure 16 shows the interactions between the learners and various components of the chat system. The learner asks questions using the Moodle chat plug-in. The Moodle chat plug-in sends a request to the LLM proxy to obtain five similar text chunks using the RAG API. The LLM proxy will respond by sending relevant text chunks to the Moodle chat plug-in. After that, the Moodle chat plug-in forwards the user question and five text chunks to ChatGPT [
53] in the LLM proxy. The Moodle chat plug-in receives a response from the LLM-proxy and extracts learning resource IDs from the text chunks, which are saved as metadata related to the chunks in the vector database. The plug-in sends a request to the Recommender Component to obtain similar learning resources based on extracted resource IDs and another request to obtain learning resources based on the user session. The Recommender Component will respond to the Moodle chat plug-in with a list of similar learning resources and a list of predictions of the next learning resources. The plug-in then provides the answer with recommendations to the learner.
Figure 17 shows an example AI-Chatbot. The user asks questions such as “What is a UML class diagram?”. The AI-Chatbot responds with the response, as shown in
Figure 17. The response text contains the source through which the AI-Chatbot formulated its response. There are two sections after the response text. The first section displays learning resources similar to ‘SWE_2_UML_Grundlagen.pdf’, which we can see under the heading “You may find these similar resources helpful.”. The next section displays the recommendations based on the user’s session under the heading “These resources could be of interest to you.”.
6. Conclusions and Future Work
In this paper, we propose a way to address the challenges faced by our university in providing personalized learning experiences and effective discovery of learning resources within a traditional learning management system like Moodle. Transitioning to individual learning experience systems is often cost-intensive and requires significant effort, especially given the prevalence of Moodle in Germany. An initial evaluation of the rating systems revealed a low willingness among learners to actively rate learning resources.
To address these issues, we designed and implemented various features to transform Moodle into an LXP by integrating an AI-based recommendation system, ratings, content curation, and a chatbot. This approach aligns with the pedagogical goal of ‘Learning with AI’, which is to educate students about the underlying concepts of AI. Furthermore, the integration of a chatbot using large language models via LLM-Proxy and having RAG capability allows students to receive conversational support and contextually relevant recommendations directly based on their queries and course resources, mitigating issues like hallucination, which is an inherent problem of LLMs. The development of an AI-based system is particularly significant, offering an effective and privacy-preserving method for personalization, especially in contexts where explicit user feedback is limited.
Currently, there are a few courses that have used these plug-ins. It is hard to find out the exact memory usage and the real-world deployment usage. However, for our university, the external server is sufficient at present. The future plan includes analyzing the performance of the system once the user base and course numbers expand significantly. Similarly, the further steps of our project include sensitivity analysis and evaluation using the ResQue (Recommender systems’ Quality of User Experience) framework [
54] from the perspective of users who use this recommendation system.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}