4.1. Game Model of the Distributed Honeypots
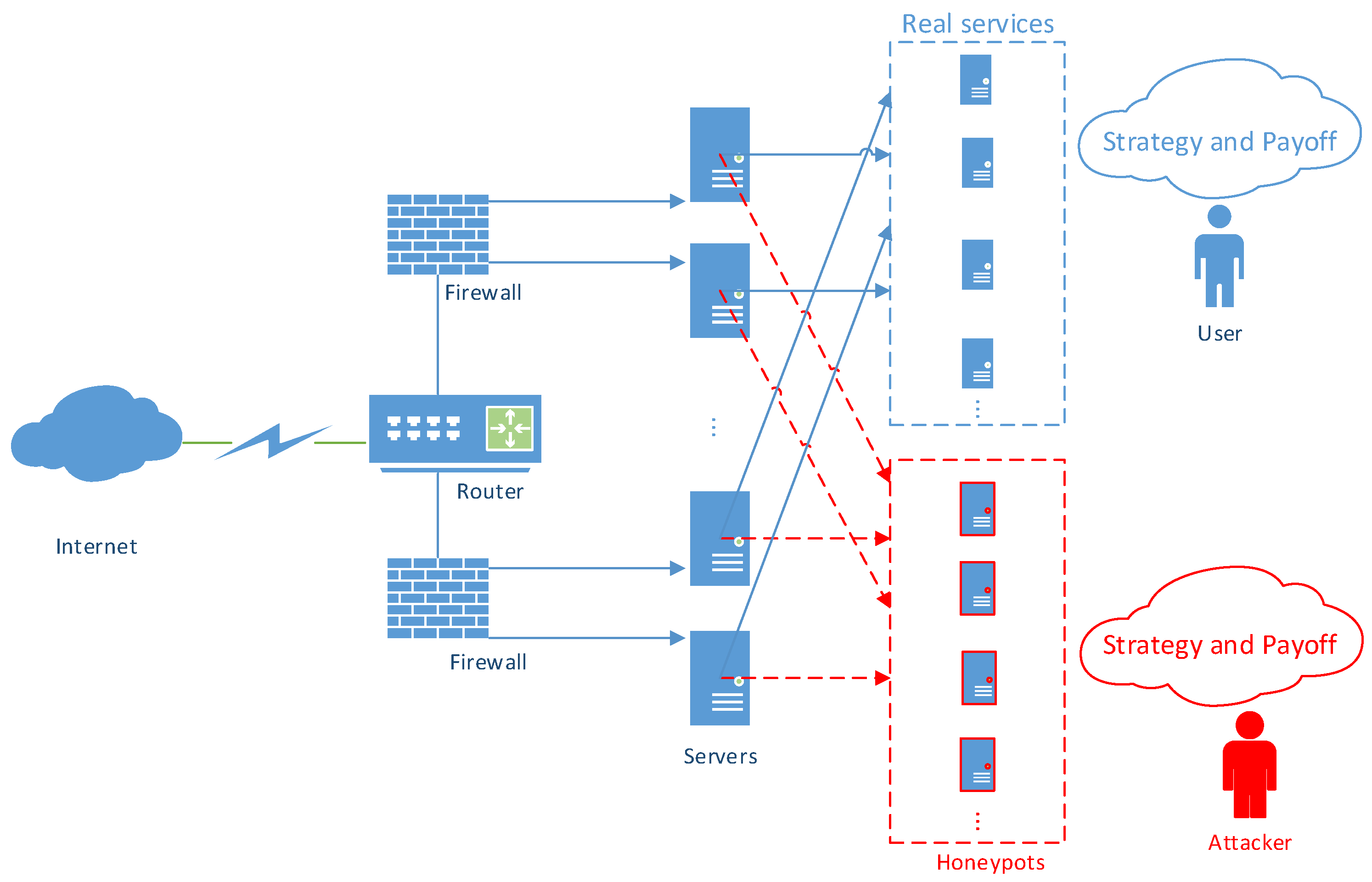
Taking attack-defense countermeasure into consideration, there are two kinds of players (i.e., attacker and defender) participating in a game. Since both the real service and honeypot exist in the same server and the real one aims at providing real resources for legal users to access, there are three kinds of players = {}. We model our proposed scheme as follows.
There are n kinds of services = {, , …, }. Because of the existence of honeypots, these services are changed to = {, , , , …, , }, and these parameters can be generalized into = {, }, i∈ [1,n]. Visitors = {, } = {, } is a common name for the last two players mentioned in . Therefore, players participating in the game are included in = {, }. They may take different activities in a game. However, they will only choose a relatively good strategy when they interact with each other under different circumstances.
As mentioned above, there are several services provided in our system. Due to a variation characteristic, every server provides different kinds of services during different periods. Therefore, a server can turn on a service or turn off it. As for visitors, they can decide whether to access it or not. The strategy sets are composed of = {,} and = {, , …, , , } for a server and a visitor respectively.
It is necessary to specify the basic parameters that reflect all players’ payoffs, as shown in
Table 5.
Based on our system model, the payoffs are described for two cases as follows.
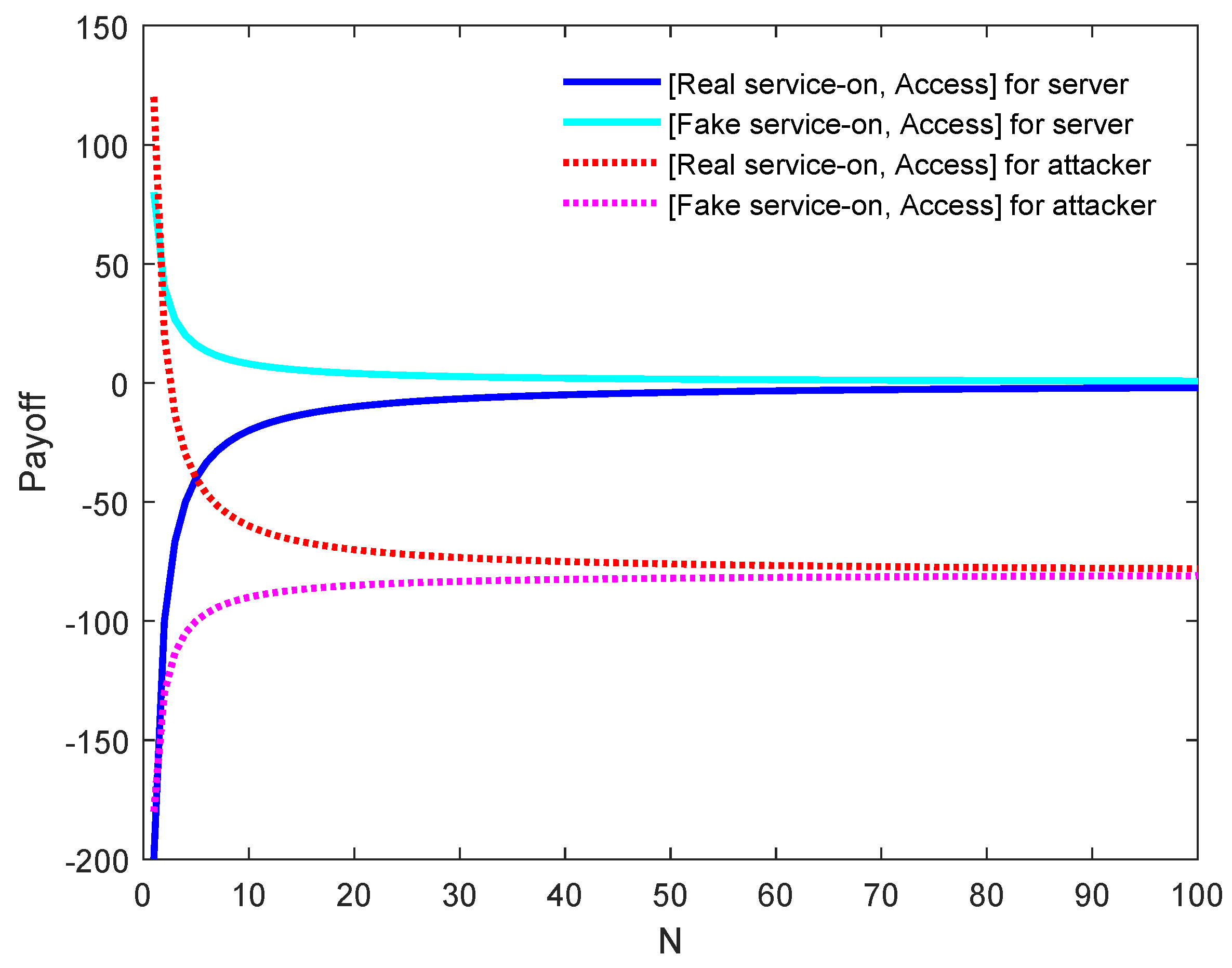
A real service is provided by a server. If an attacker gains access to a real service (i.e., ), the payoffs are for . The server suffers from providing a real service to the attacker. If a user accesses a real service (i.e., ), the payoffs are for . Both have normal payoffs, which indicates that the server provides the legal user with a normal service. If visitors access other services, the payoffs are for and for , which means that they are suffering a loss when they do not have access to real resources.
A fake service is provided by a server. If an attacker visits a fake service (i.e., ), the payoffs are for . The attacker suffers a loss in attacking the honeypot and the server’s payoff is an optimistic value. If a user accesses a fake service (i.e., ), the payoffs are for . In this case, the fake resources are provided to the user who ought to access a real service, making it suffer losses. Besides, if visitors do not access any service (i.e., ), the payoff is 0 for all players.
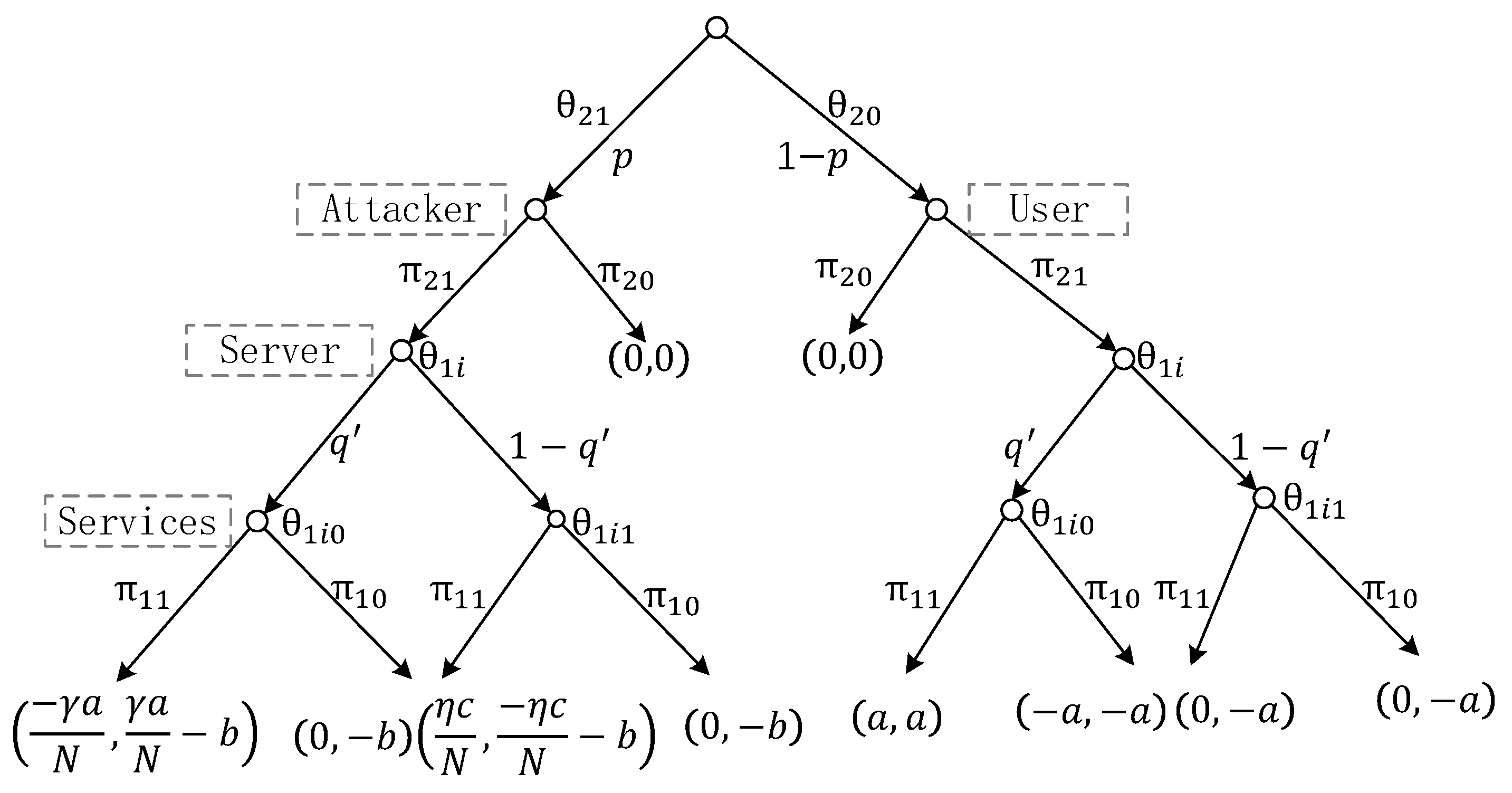
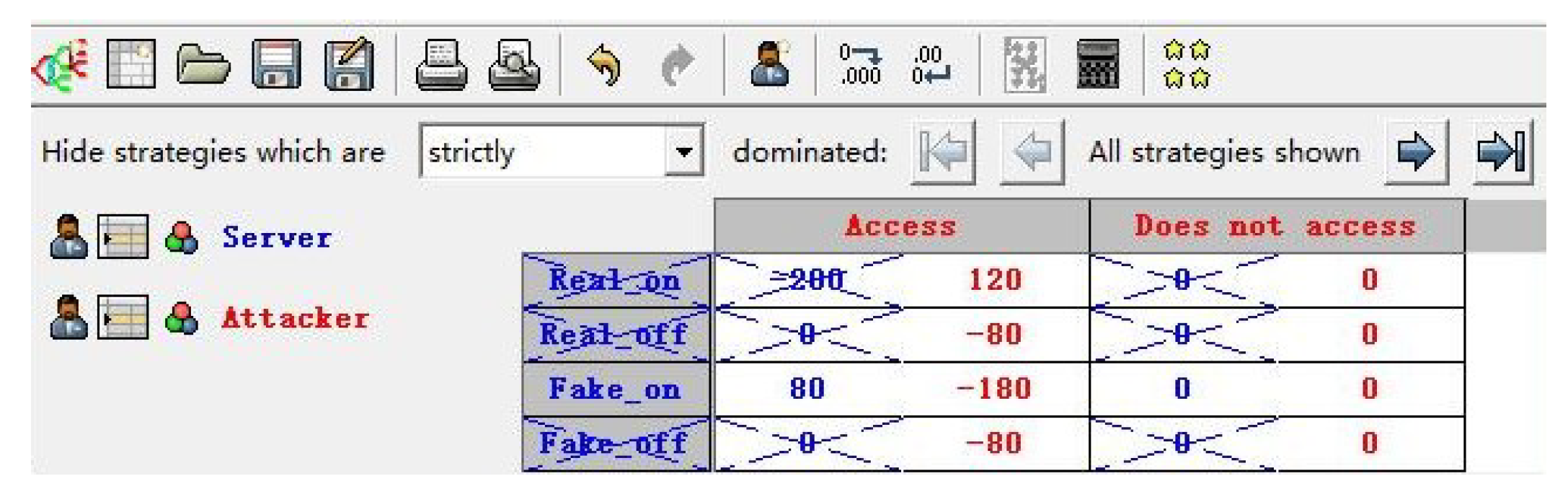
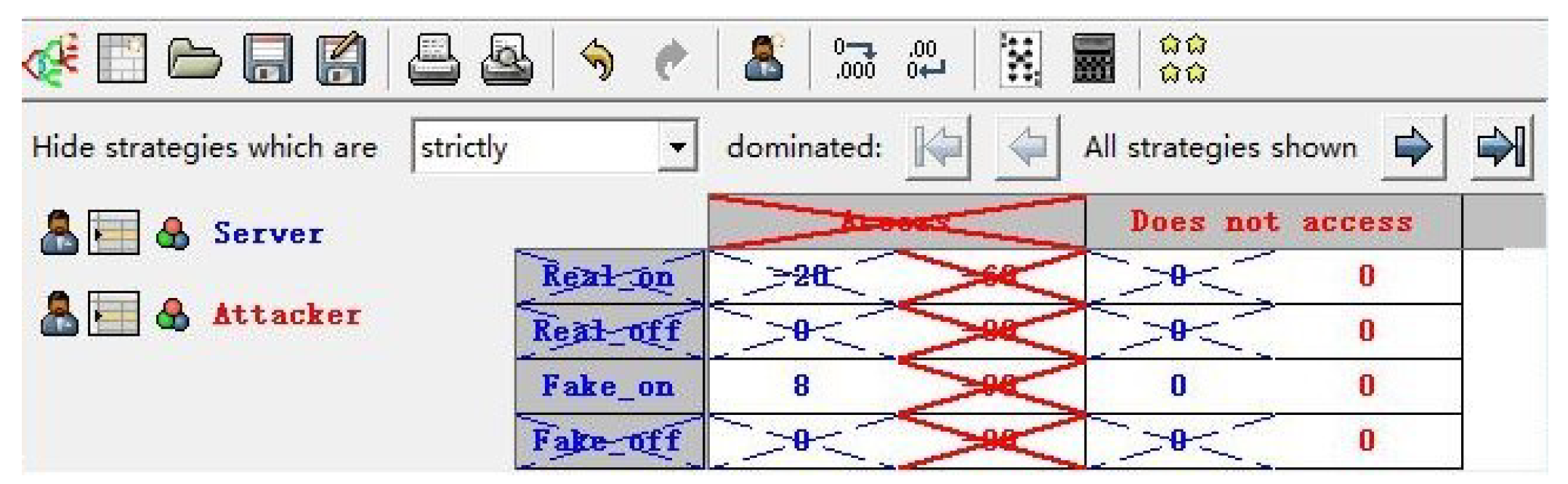
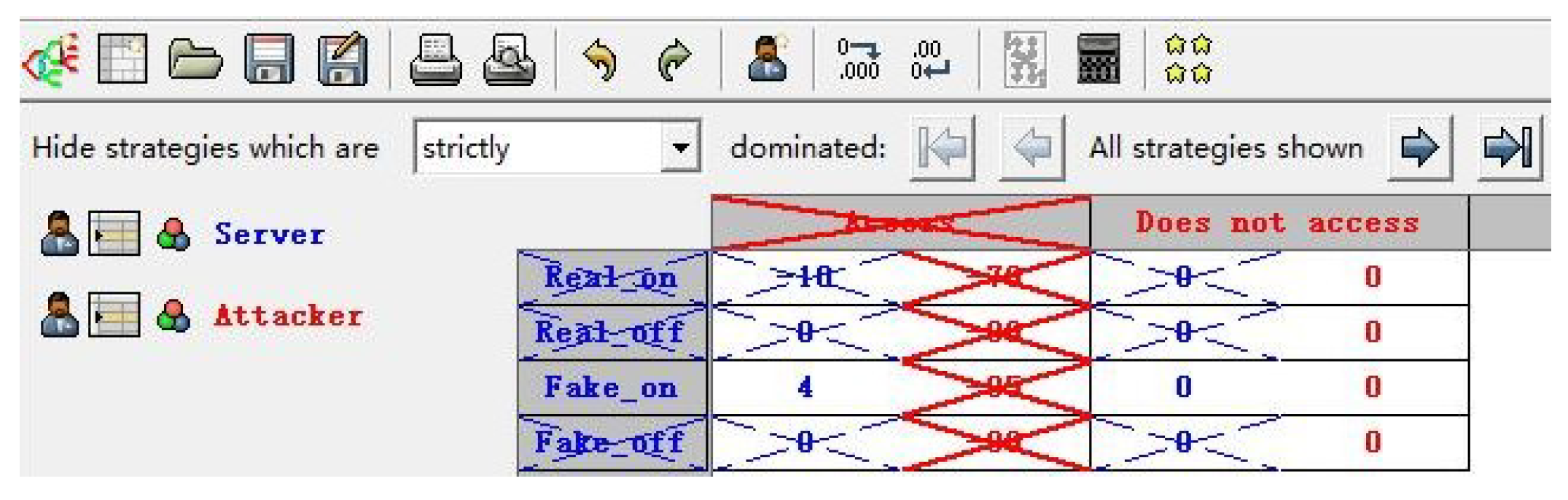
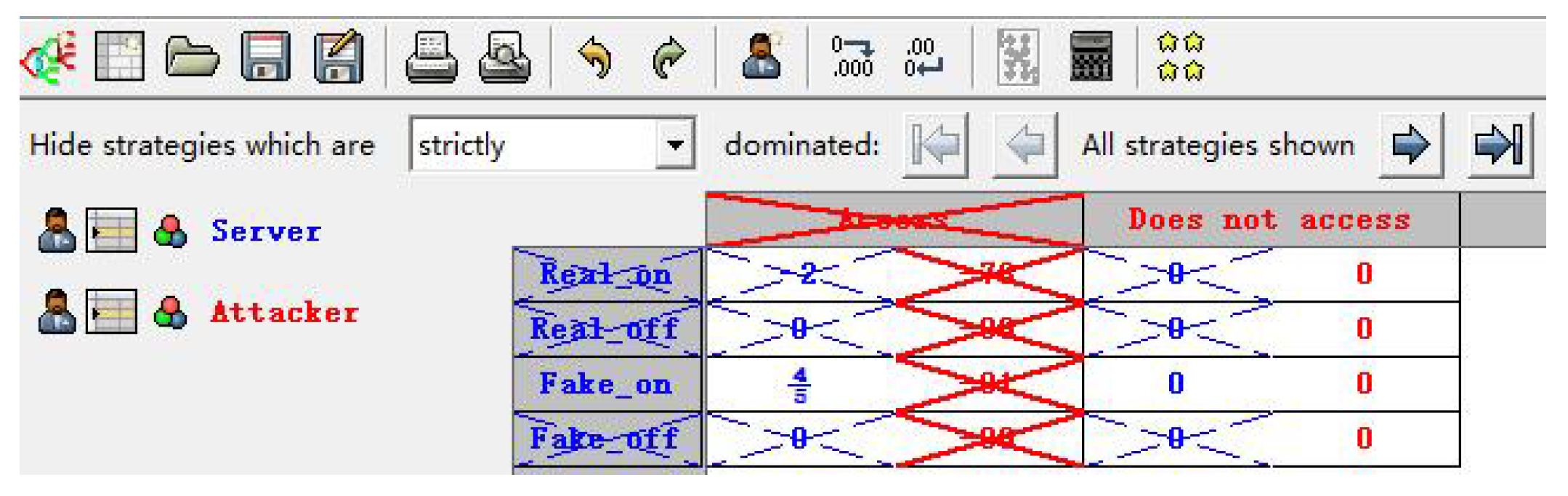
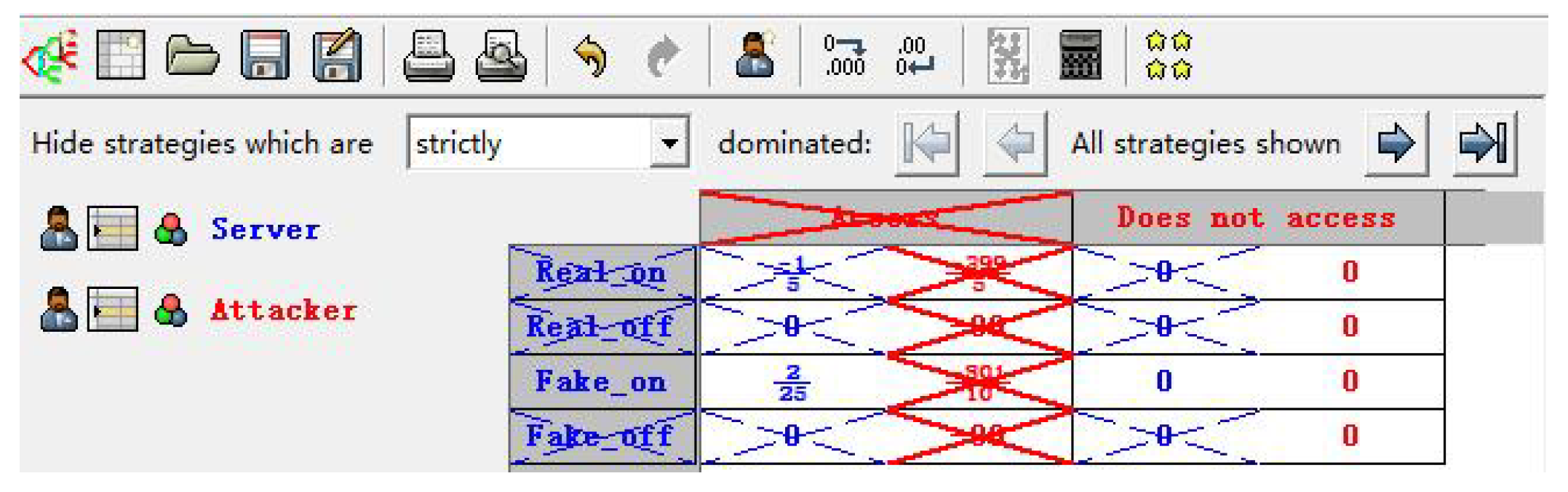
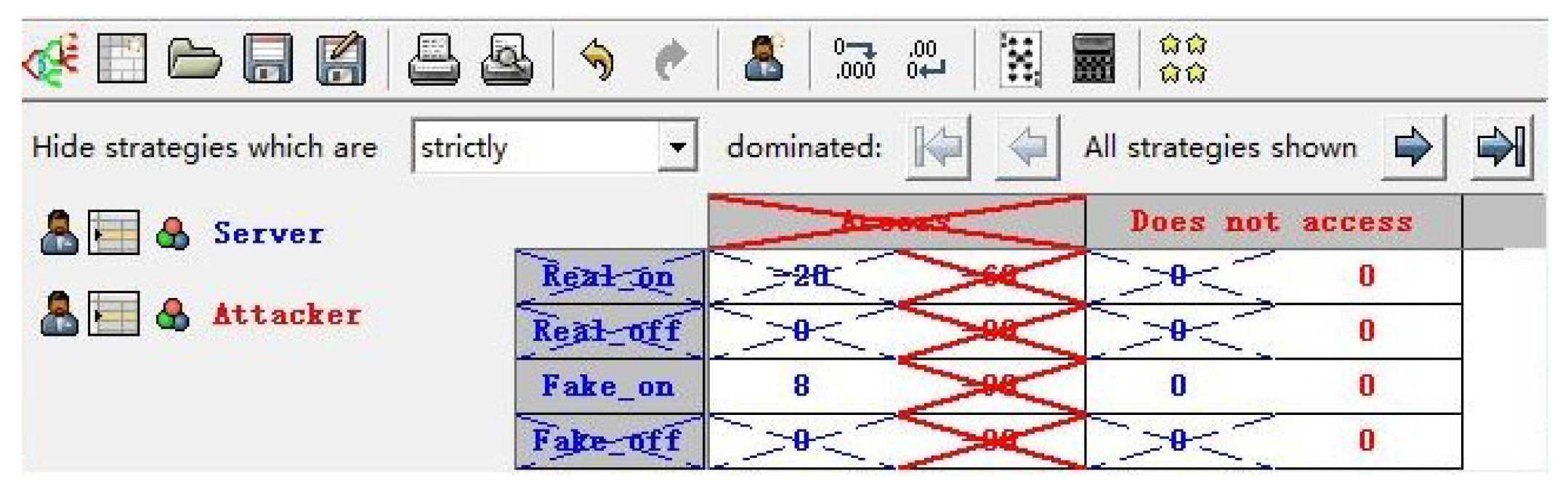
The corresponding payoff matrix is shown in
Table 6. The simplified payoff matrix is shown in
Table 7 and its game tree is illustrated in
Figure 4.
An essential assumption of our game model is that players are insensible of each other’s strategies. For judgment of a server and visitors, the priori probabilities are assumed to be:
As aforementioned in
Table 7,
and
are two basic strategies for visitors. They can decide whether to access a server or not.
and
are two basic strategies for servers. They can choose to open or close a service. There are two strategy sets, each one consists of four strategy subsets:
The former denotes visitors’ tactics to access a service or not. Meanwhile, the latter is a set of strategies of servers, in which real services and honeypots will be turned on or turned off.
4.2. Bayesian Equilibriums of the Server
From the perspective of a server, there are four kinds of access strategies of visitors. Among these strategies, is in line with reality. Therefore, taking as an example, we analyze whether a game equilibrium exists or not. Based on the strategy , the server knows that opposite players will visit the system. Posteriori probabilities are assumed to be:
Based on the posteriori probabilities, payoffs of a honeypot for the strategies
and
are denoted as
and
where
From Equations (
1) and (
2), it can be inferred that
, which indicates
is an absolutely dominant strategy for
. No matter which kind of visitors enters, the honeypot tends to be on.
As for real services, we get the following payoff equations.
Solving Equations (
3) and (
4) simultaneously, we obtain
. Consider the case when
. In this case, the dominant strategy is
for a real server. When
,
is the optimal choice. Considering the absolutely dominant strategy
of a honeypot, we can infer that
and
respectively acts as the optimal selection for a server under circumstances of
and
, as illustrated in
Table 8.
4.3. Bayesian Equilibriums When
Then, we illustrate if there exist a dominant strategy for visitors in the case of and . The posteriori probabilities are set to
The payoff equations for an attacker can be calculated as:
Similarly to Equations (
3) and (
4), we assume
. Then, we have
. When
, it is obviously that the strategy
gains more profits than
. We can infer that if
, the strategy
will dominate in the view of an attacker. When
, we obtain
where the attacker would like to choose the strategy
to abandon visiting the server.
The payoff equations for a user can be calculated as:
Assuming that , we have . When , the strategy will be better for the user. Otherwise, the strategy is a better choice. Since our system should provide the user with normal services, the strategy (i.e., the user does not visit the server) is inconsistent with the reality, which should be aborted.
Equilibriums of visitors are illustrated in
Table 9. Based on the dominant strategy
and
, the best access condition for an attacker and a user are individually
and
, where
In general, there are two Bayesian equilibriums for all players, shown in
Table 10. In the condition of
,
and
, a Bayesian equilibrium is formed under the strategy set
. The other is obtained when
in the strategy set
. Such a strategy set illustrates an ideal circumstance in our life, indicating that the attacker will not launch an attack and the legal user will access the server.
4.5. Effectiveness Analysis of Our System
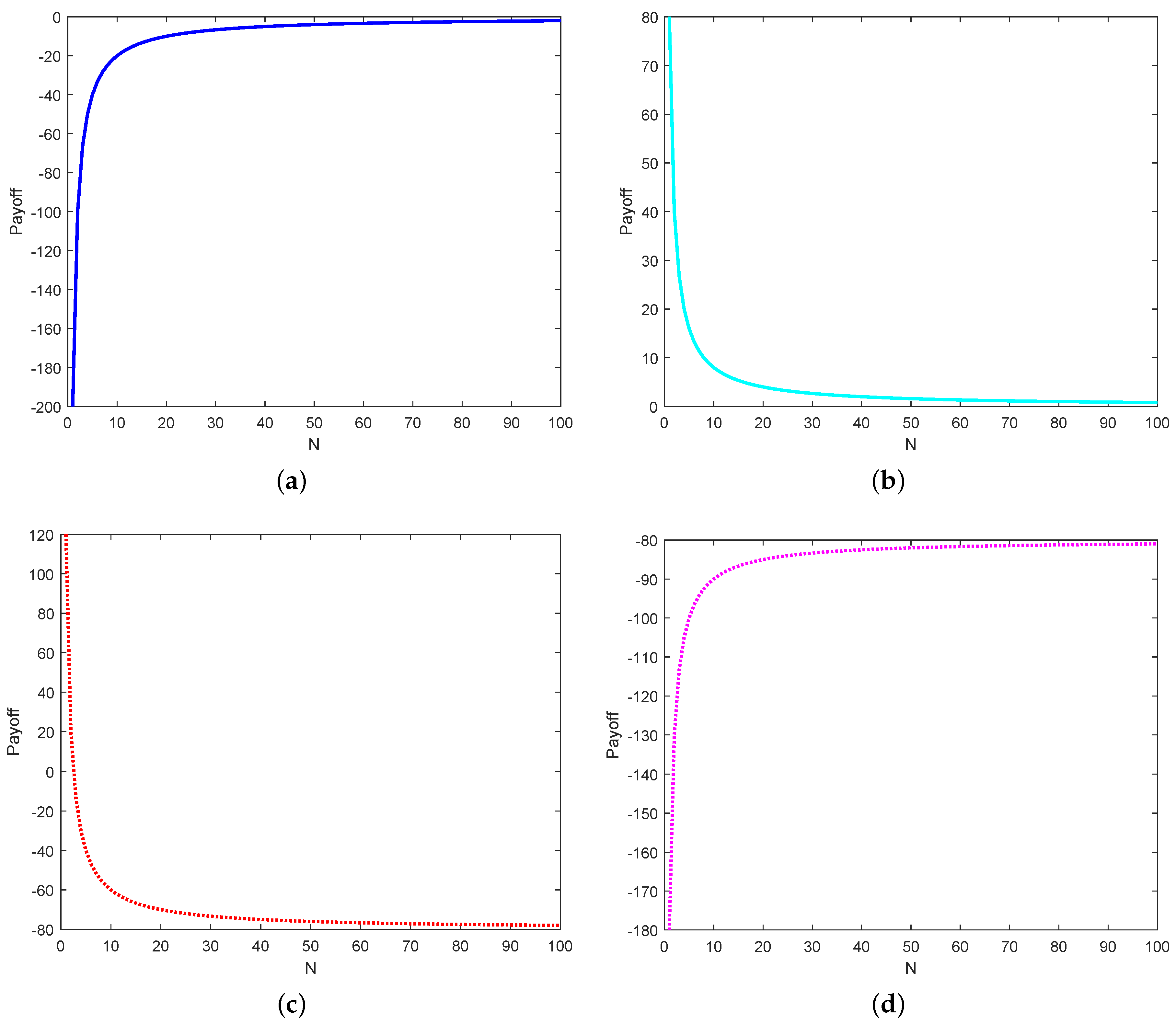
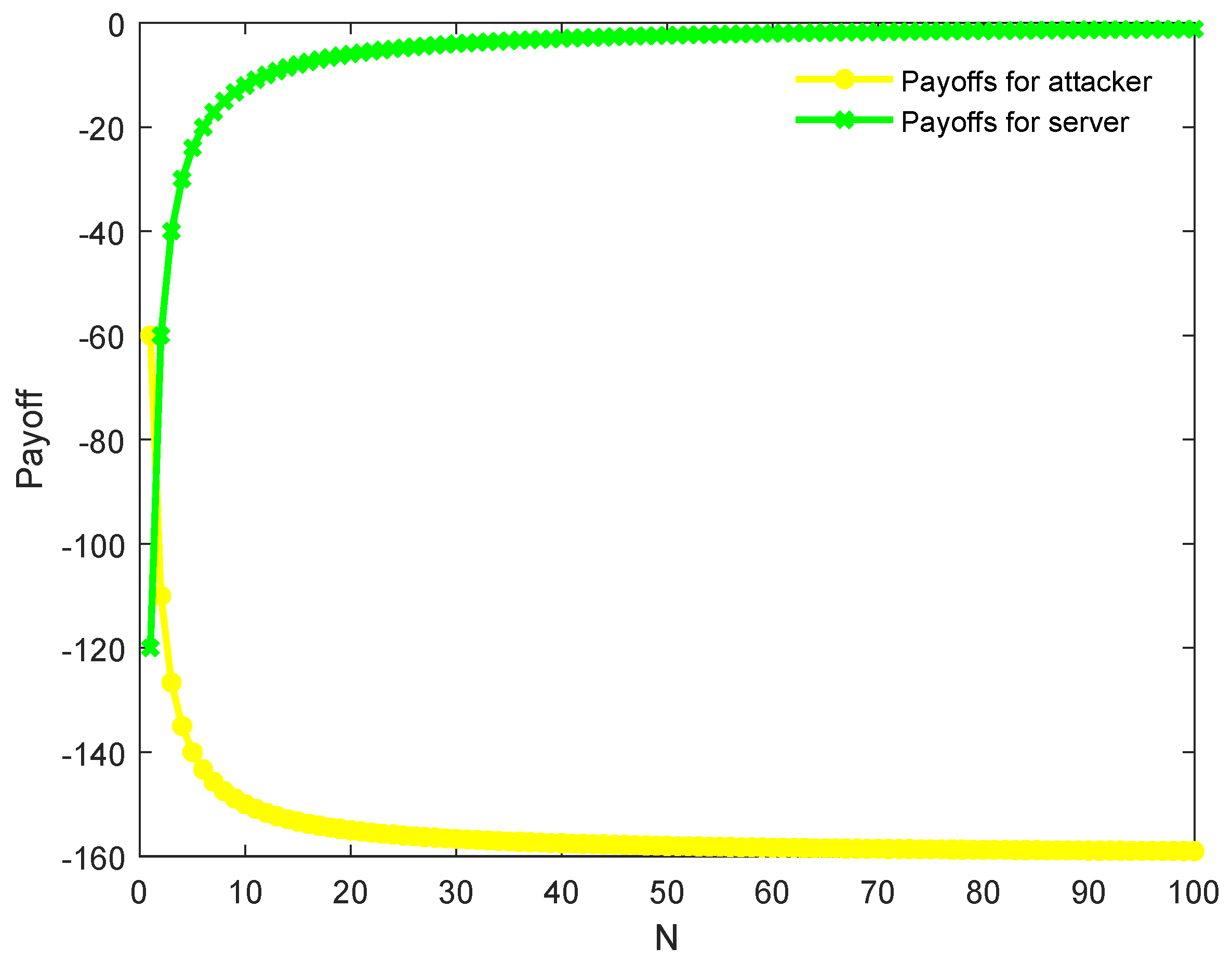
From the above, we arrive at a conclusion that the relationship between q and determines different Bayesian equilibriums when . This indicates that the aforementioned relationship plays an important role in payoffs of diverse strategies. It is conspicuous that (i.e., an attacker does not access to a server and a user visits it) is the optimal choice for the system defender. Its precondition contains , a decisive factor related to q rather than p, which means our system comprises an innovative system defense by adjusting the probability value q in network defense.
As indicated above,
is a requirement for
. Namely, if honeypots are deployed with a lower probability, an attacker tends to intrude into a system. At the meantime,
in Equation (
9) means that attack cost grows with the increase of
N.
N is determined by the number of services and hosts, which can be adjusted dynamically, further indicating proactive protection of our system.
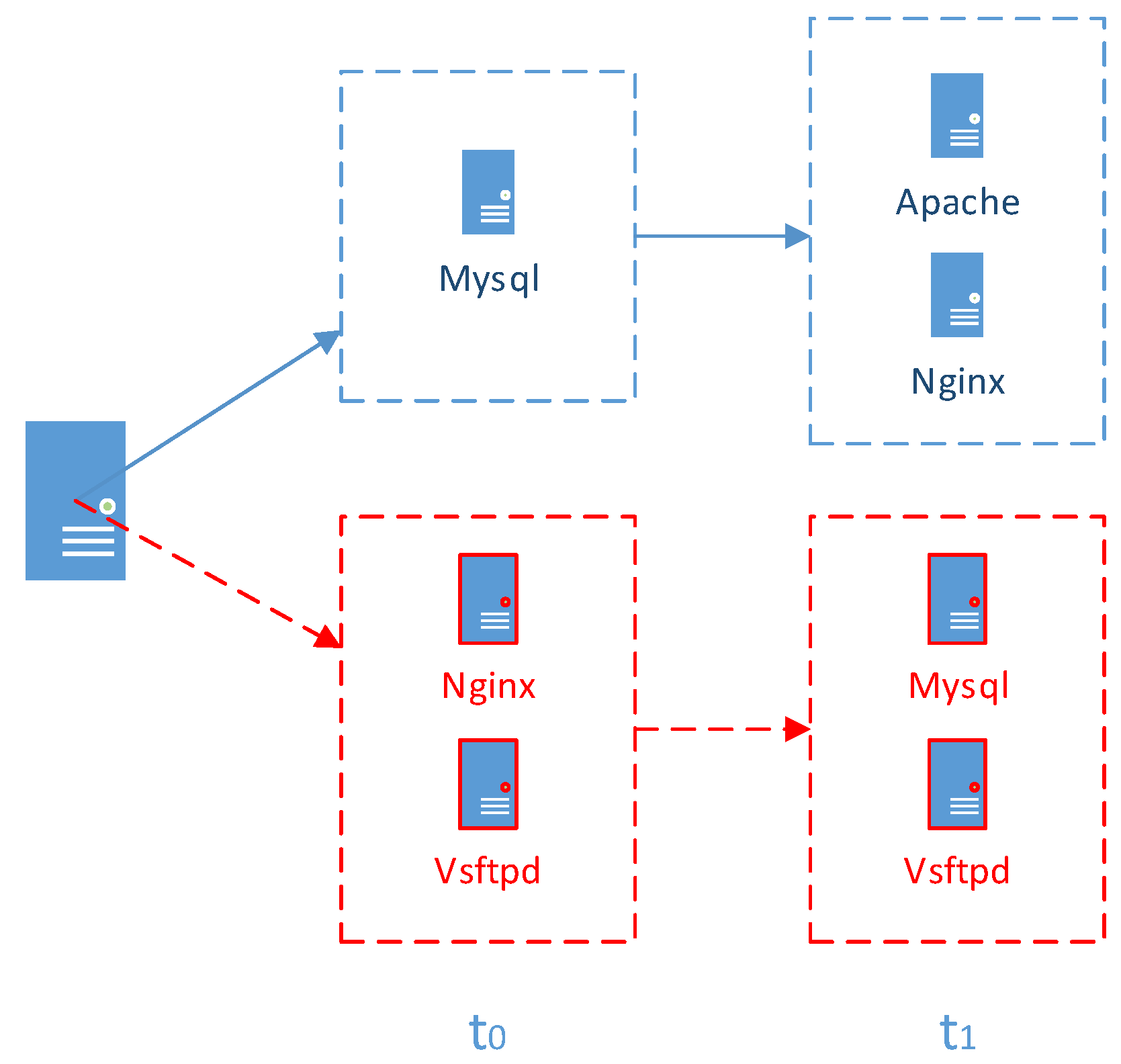
indicates the deployment of honeypots is a high-probability event. Since the honeypot trap will bring an attacker more losses than profits it makes by attacking a server, the attacker will not access the system in such a circumstance. The service allocation algorithm of our system keeps occurrence of honeypots in a high probability by periodically changing all services. The attacker may suffer a lot when it attacks our decoy system. Due to periodical transformation, services are unpredictable for an attacker and its traffic can be recognized quickly. Besides, a user can keep pace with real services via synchronization mechanism (i.e., the user can always access to real resources). Therefore, our scheme is effective.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}