Abstract
Artistic style transfer aims to transfer the style of an artwork to a photograph while maintaining its original overall content. Although current style-transfer methods have achieved promising results when processing photorealistic images, they often struggle with brushstroke preservation in artworks, especially in styles such as oil painting and pointillism. In such cases, the extracted style and content features tend to include redundant information, leading to issues such as blurred edges and a loss of fine details in the transferred images. To address this problem, this paper proposes a multi-scale general style-transfer network based on diffusion models. The proposed network consists of a coarse style-transfer module and a refined style-transfer module. First, the coarse style-transfer module is designed to perform mainstream style-transfer tasks more efficiently by operating on downsampled images, enabling faster processing with satisfactory results. Next, to further enhance edge fidelity, a refined style-transfer module is introduced. This module utilizes a segmentation component to generate a mask of the main subject in the image and performs edge-aware refinement. This enhances the fusion between the subject’s edges and the target style while preserving more detailed features. To improve overall image quality and better integrate the style along the content boundaries, the output from the coarse module is upsampled by a factor of two and combined with the subject mask. With the assistance of ControlNet and Stable Diffusion, the model performs content-aware edge redrawing to enhance the overall visual quality of the stylized image. Compared with state-of-the-art style-transfer methods, the proposed model preserves more edge details and achieves more natural fusion between style and content.
1. Introduction
The goal of image style transfer is to transfer the style of a reference image onto a given content image, where the output image should retain the style of the reference (e.g., color, texture, brushstrokes, and tone) while preserving the structural content of the original image. Due to its importance in practical applications, image style transfer has attracted widespread attention from the academic, industrial, and artistic communities. Existing methods can be broadly categorized into two groups: optimization-based methods and feed-forward network-based methods. Optimization-based methods [,,] perform style transfer through iterative optimization for each image, which makes them computationally expensive and complex. In contrast, feed-forward methods [,,,,,,] are much more time-efficient. These feed-forward approaches generally consist of three stages. First, a fixed encoder (such as a pre-trained VGG-19 []) is used to extract content and style features. Second, a well-designed transfer module is employed to shift the style statistics from the style features to the content features. Finally, a learnable decoder transforms the modified features into a realistic stylized image. However, during the transfer process, these methods often sacrifice fine structural details—particularly at object edges—in order to incorporate style features more thoroughly, leading to a loss of edge detail in the content image.
To address the aforementioned issues, An et al. [] introduced the content leak problem, pointing out that after multiple rounds of stylization, convolutional neural network-based methods tend to cause significant structural changes in the image. Deng et al. [] and Zhang et al. [] demonstrated that Transformer-based methods can alleviate this issue to some extent. Unlike previous approaches, IEST [] and CAST [] adopt contrastive learning strategies to enhance visual quality. However, in certain cases, the results generated by existing methods still suffer from edge blurring, making it difficult to distinguish objects within the image. In this work, we propose a multi-scale general style-transfer network based on diffusion models, which operates in two stages: a coarse style-transfer stage and a refined style-transfer stage. In the coarse style-transfer stage, stylization is performed on low-resolution images to achieve efficient initial transformation. In the refined style-transfer stage, the stylized image is upsampled, and a combination of the Segment Anything Model (SAM) and a diffusion model is introduced to enhance edge details. This two-stage process enables the generation of more stable and realistic stylized images while preserving the fine details of the main subject in the original content image to the greatest extent.
Overall, the main contributions of this paper can be summarized as follows:
- This paper proposes a novel multi-scale general style-transfer network based on diffusion models, which is structured into two stages: a coarse style-transfer stage and a refined style-transfer stage. This design effectively achieves a better balance between content features and style features;
- The coarse style-transfer stage is performed on low-resolution images, enabling efficient initial style transfer and generating a preliminary stylized image;
- The refined style-transfer stage introduces SAM and diffusion models to enhance the edge details of the image produced in the previous stage, enabling the model to generate more stable and realistic stylized images.
2. Related Work
This section provides an overview of recent research developments in the field of style transfer.
2.1. Image Style Transfer
Before the advent of deep learning, style transfer was typically achieved by analyzing a specific style and texture and then building corresponding models. Meier et al. [] proposed a brush-based rendering model to achieve oil painting-style transfer. Hertzmann et al. [] introduced image analogies for style transfer, while Efros et al. [] utilized Markov models to perform style transfer through pixel-based texture synthesis. Wei et al. [] employed a texture synthesis approach and introduced vectorization, which significantly accelerated the synthesis process. Han et al. [] developed a multi-scale texture synthesis algorithm to handle texture generation at different image scales. Ashikhmin et al. [] proposed an algorithm capable of effectively transferring styles in natural landscape images. Although these traditional methods can accomplish style transfer to some extent, they have inherent limitations. Each program is typically confined to a single style, and these approaches lack the ability to extract high-level texture features, making it difficult to achieve fine-grained texture details.
With the advent of deep learning, style transfer is typically achieved by learning the characteristics of a particular style through algorithms and then applying the learned style to other images. Luan et al. [] improved style transfer for photographic applications through a technique called “Deep Photo Style Transfer,” which better preserved the structural content while transferring the style. Li et al. [] proposed an unsupervised universal style-transfer method that separates style and content via feature transformation, providing greater flexibility for handling diverse styles. In terms of supporting multiple styles, Chen et al. [] introduced StyleBank, which enables a single model to transfer multiple styles, significantly improving model efficiency and adaptability. Gatys et al. [] refined the control mechanisms in style transfer, enhancing the controllability of various perceptual factors during the transfer process. Park et al. [] proposed Adaptive Instance Normalization (AdaIN) based on instance normalization, enabling real-time arbitrary style transfer and greatly expanding the potential for real-time applications. An et al. [] explored the automatic synthesis of artistic works using a conditional class-aware generative adversarial network (ArtGAN), offering new perspectives and techniques for high-quality artistic style synthesis. Gatys et al. [] also proposed a deep learning-based style-transfer method that extracts specific features of images using a pre-trained network and builds corresponding models for subsequent transfer. However, this method is computationally intensive and involves a complex process.
2.2. Universal Style Transfer
Recently, universal style transfer has attracted significant attention. Many approaches focus on developing a general framework capable of performing artistic, photorealistic, and video style transfer. Bai et al. [] propose a data-efficient text-based style-transfer method that maps text inputs to the style space of a pretrained VGG network and leverages CLIP embeddings, enabling real-time arbitrary style transfer without inference-time optimization or paired data. Kim et al. [] propose an implicit neural representation-based controllable style transfer framework that enables pixel-wise control through test-time training, offering stable convergence and improved generalization compared to traditional optimization and learning-based methods. NeAT [] reformulates feed-forward style transfer as image editing to achieve improved content preservation and style matching, while introducing a large-scale dataset (BBST-4M) to enhance generalization across diverse styles. TSSAT [] imitates the human drawing process via a two-stage statistics-aware transformation, aligning global statistics and enhancing local style details through local statistics swapping, combined with novel content and style losses for improved stylization quality. Chuang et al. [] propose a diffusion model-based style-transfer method that directly manipulates self-attention features without optimization, enabling efficient content preservation and local texture-based style transfer, while introducing query preservation, attention temperature scaling, and latent AdaIN for improved stylization performance. Zhu et al. [] propose StyA2K, an all-to-key attention mechanism that matches content features to key style positions via distributed and progressive attention, achieving superior semantic preservation and consistent style patterns with improved efficiency over conventional all-to-all attention methods.
3. Proposed Method
This paper proposes a multi-scale universal style-transfer network based on a diffusion model, with the overall architecture illustrated in Figure 1. This section first introduces the motivation behind the model design, then describes the overall network architecture, and finally details the loss functions employed.
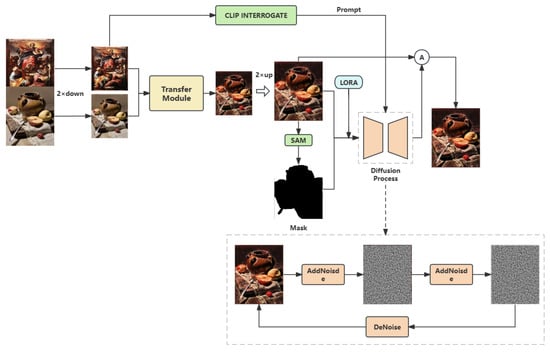
Figure 1.
Overall model architecture.
3.1. Motivation
Although existing universal style-transfer methods perform well in overall style transfer, they often introduce redundant information during the extraction of style and content features. This affects the final transfer quality, resulting in unnatural fusion between the style and original content, and relatively coarse handling of edge details, as shown in Figure 2. While some current style-transfer networks have partially addressed redundant information and edge processing, pixel-level analysis of images before and after transfer still reveals fusion inconsistencies. Moreover, the refinement of content subject edges is not specifically optimized in the current style transfer stage. Therefore, this paper aims to design a model that can both refine edge details and eliminate fusion inconsistencies.

Figure 2.
Fusion inconsistencies in the transferred images.
3.2. Overall Architecture
The model is divided into two stages: a coarse style-transfer module and a refined style-transfer module. Specifically, given a content image and a style image, the first stage performs an initial style transfer to generate a transferred image. Next, a segmentation module is used to extract the content subject from the image, producing an edge mask. The image and the mask are then fed into ControlNet [] and Stable Diffusion (SD) [] for a second style refinement. During this refinement, CLIP [] is used to process the style image. To achieve better style fusion, LoRA [] is employed for model fine-tuning, helping the model to learn and apply specific styles more stably. Finally, the output from the second step is fused to produce the final stylized image. The following sections will focus on introducing the coarse style-transfer module and the refined style-transfer module.
3.2.1. Coarse Style-Transfer Module
The purpose of the first round of style transfer is to quickly complete the initial image transformation while ensuring the quality of the transfer. By comparing the runtime and performance of several style-transfer modules, the main style-transfer module selected here is the currently effective CAP-VSTNet []. The overall module consists of three parts: an invertible residual module, a channel pruning module, and a linear transformation module. First, the content and style images are downsampled separately to obtain new content and style images. Given a content image and a style image, the invertible residual module is first used to map the input content and style images into a latent space. Next, the channel pruning module removes redundant channel information from the content- and style-image features to enable more efficient style transfer. Finally, the linear transformation module transfers the content representation to match the statistical characteristics of the style representation. The invertible residual module is illustrated in Figure 3.
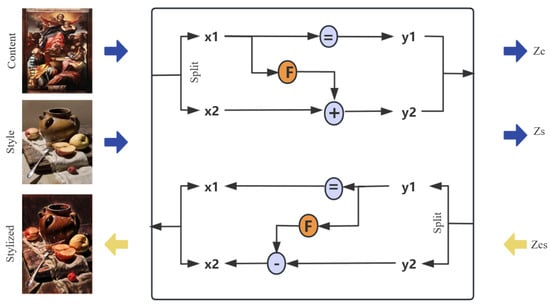
Figure 3.
Invertible residual block structure.
In the network architecture, each invertible residual block takes a pair of inputs and outputs . The module applies a channel-wise splitting strategy that divides the input features equally along the channel dimension. Because the invertible residual block processes only half of the channels at each step, it is necessary to perturb the feature maps along the channel axis. Each block within the invertible residual network can be reversed by subtracting the residual, as detailed in the following equations:
The residual functions F are implemented by consecutive convolutions with a kernel size of 3. Each transformation layer is followed by a ReLU activation, except for the last one. To capture large-scale style information, a squeezing module is used to reduce the spatial dimensions by a factor of 2 while increasing the channel dimensions by a factor of 4. By combining reversible residual blocks and the squeezing module, a multi-scale architecture is realized.
The cascaded reversible residual blocks and squeezing module design in CAP-VSTNet lead to the accumulation of redundant information during the forward inference process as the number of squeezing modules increases exponentially. This redundant information negatively impacts the stylization quality. In [,], channel compression is employed to address the redundancy issue and promote better stylization. In the design of this main network module, a Channel Refinement (CR) module is used, which is better suited for connecting cascaded reversible residual blocks. As shown in Figure 4, the CR [,] module first applies a zero-padding module that increases the latent dimension to ensure that the input content- and style-image feature channels are divisible by the target channel size. Then, patch reversible residual blocks are utilized to integrate large-scale contextual information.

Figure 4.
Channel refinement module. IP and RRB denote injective padding module and reversible residual block, respectively.
Where and denote the input content and style features, respectively, and and denote the output content and style features, respectively. The spread operation refers to expanding the channel information into a spatial dimension patch.
3.2.2. Refined Style-Transfer Module
Most existing style-transfer networks can effectively accomplish style-transfer tasks, but the fusion of style and content often suffers from uneven stylization. To ensure better integration of style into the target image, the second-stage refined style-transfer module incorporates the segmentation module Segment Anything Model (SAM) [] and ControlNet. First, the refinement focuses on the edges of the content subject. SAM can intelligently segment any part of the image and generate a mask for the selected region, which is used here to roughly separate the content subject from the background. Next, ControlNet is employed to preserve the main content area. ControlNet’s primary function is to retain the original model’s main parameters while maintaining and refining them through additional branches added on both sides of the original model. Thus, the use of ControlNet ensures fast processing and low cost while achieving effective optimization. The processing workflow of the second-stage refined style-transfer module is illustrated in Figure 5.
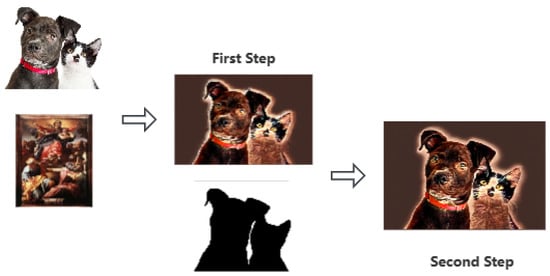
Figure 5.
Refined style-transfer module.
During the style-refinement process, to ensure maximum style consistency, the large model is fine-tuned using LoRA with a Baroque style image dataset and integrated into the style-refinement module. This helps the model to stably generate images in the Baroque style. Additionally, to obtain the final stylized image, the result from the first round of style transfer is upsampled by a factor of two and then fused again with the output of the second round, maximizing the preservation of the main content details of the original content image.
3.3. Loss Function
This paper trains the network in two stages. In the first stage, the coarse style-transfer network is trained using Laplacian loss , style loss , and cycle consistency loss . The Laplacian loss function is defined as follows:
where N is the number of image pixels; denotes the vectorized stylized image in channel c; and M denotes the matched Laplacian matrix of the content image .
The style loss function is defined as:
where denotes the style image; denotes the stylized image; represents the first several layers (from to ) of the VGG-19 network; and and denote the mean and standard deviation of the feature maps, respectively. However, invertible networks may suffer from numerical errors, which can lead to noticeable artifacts. Therefore, this paper introduces a cycle consistency loss to enhance the robustness of the network, which is defined as follows:
where denotes the process of converting the style-transferred image back to the original content image.
In the second part, the Stable Diffusion (SD) model is pre-trained and fine-tuned. We use sd-1.5 as the base model, retaining the original hyperparameter settings of SD. Due to the latent space of CLIP’s text embeddings, our optimization process benefits from strong guidance. We adopt a multi-layer cross-attention learning approach. The input artistic image is first fed into the CLIP image encoder, which produces corresponding text embeddings. The segmentation model also automatically provides the corresponding mask information. By applying multi-layer attention to both the text embeddings and masks, the model can quickly capture the key information of the image. During training, the model is guided solely by the corresponding text embeddings and mask constraints. To prevent overfitting, a dropout strategy is applied at each cross-attention layer, with a rate of 0.05. In addition, the generative model is fine-tuned to ensure it can reliably generate images in the desired style during the refinement and repainting process.
4. Experiments
This section provides a comparative analysis of the proposed method and other state-of-the-art methods.
4.1. Implementation Details
The experiments were conducted on an RTX A5000 GPU. The content image dataset is based on COCO [], while the style image dataset is selected from the Baroque subset of WikiArt [], which is used for both training and testing the model. The WikiArt dataset covers 15 different artistic styles, featuring a wide range of subjects and diverse types of paintings.
4.2. Qualitative Comparison
This work compares the proposed method with several state-of-the-art image style-transfer methods, namely, ArtFlow [], AdaAIN [], AdaAttN [], StyTr2 [], and CAST []. All baseline methods were implemented using publicly available code and trained with their default settings. Prior to the evaluation, the participants were briefly instructed to understand the criteria for selection and assessment. Then, 30 pairs of content-style images were randomly selected, and the generated results of our method and one of the baseline methods were randomly shown to the participants. They were asked to evaluate the artistic consistency between the generated images and the reference-style images and to choose the better result for each content-style pair. Finally, a total of 2100 votes were collected from 70 participants. Table 1 reports the percentage of votes each method received, indicating that our method achieved the best results in terms of visual feature transfer. However, a more comprehensive analysis should be combined with quantitative results.

Table 1.
User research.
4.3. Quantitative Comparison
This paper proposes a multi-scale style-transfer network based on diffusion models, which includes a coarse transfer module and a style-refinement module. Style-transfer experiments were conducted on a Western dataset as an example, and the experimental results are shown in Figure 6.

Figure 6.
The experimental results of the style transfer using the proposed network.
This paper uses pixel-wise matching to calculate the similarity of the proposed algorithm. In the comparison between two images, identical regions are shown in light colors, while differing areas are highlighted in red. The key goal in style transfer is to change the style while preserving the original content as much as possible. Therefore, in a good style-transfer comparison image, the content regions (especially edges) should appear in light colors, whereas other areas affected by style changes should be shown in red (as illustrated in Figure 7). The four pairs of content- and style-transferred images in the figure were all generated using the proposed algorithm. The four selected images depict similar scenes, all close-ups of real objects containing many details. The bottom row shows the pixel-similarity comparison images. It is clear that areas without specific objects contain evenly distributed red dots, indicating substantial style changes, which aligns with the goal of style transfer. Conversely, areas with real objects show predominantly white regions, reflecting less style alteration in order to preserve the original content features. This demonstrates that the proposed algorithm subjectively achieves style-transfer effects consistent with its intended objectives.

Figure 7.
Pixel similarity comparison.
Similarly, pixel similarity can also be used to analyze the degree of fusion between style and content. Figure 8 presents a comparison from the perspective of pixel similarity between the proposed method and the CAP-VSTNet method. In the edge areas without large content blocks, where style changes are expected to be more significant, more red regions should appear. From the fusion perspective, a more uniform distribution of red dots indicates better style–content fusion. The area highlighted by the black box in Figure 8 corresponds to an edge region in the original content image, characterized by large blank spaces without specific objects. After style transfer, this region should exhibit evenly distributed style features, meaning red dots should be scattered uniformly within this area. The results from the two algorithms shown in the upper and lower parts of the figure indicate that the proposed style-transfer network achieves better fusion of style and content. As shown in Figure 9, after style refinement, the images display more detailed edge regions and a more natural fusion of style and content.

Figure 8.
The pixel-similarity comparison between the proposed method and CAP-VSTNet.

Figure 9.
Changes in the main subject’s edge areas before and after the style-refinement module.
Cosine similarity is a commonly used method for measuring the similarity between vectors. It calculates the cosine of the angle between two vectors. In image similarity computation, images can be transformed into feature vectors (e.g., feature vectors extracted using convolutional neural networks), and the cosine similarity between these vectors can then be computed to assess the similarity between images. The calculation of cosine similarity is shown in Equation (7). The cosine similarity is defined as:
where and represent two vectors, · denotes the dot product of the vectors, and and represent the norm (i.e., the magnitude) of the vectors. The cosine similarity ranges from −1 to 1: values closer to 1 indicate higher similarity between the vectors, values closer to −1 indicate greater dissimilarity, and values near 0 suggest that there is no significant similarity or difference between the two vectors.
After style transfer, the proposed method was compared with ArtFlow, StyTr2, and CAP-VSTNet using quantitative metrics to evaluate style transfer performance. All test images had a resolution of 1024 × 512, and the evaluation metrics included SSIM, Gram Loss, cosine similarity, and inference time. The comparison results are presented in Table 2, which provides a quantitative analysis of general-purpose style transfer algorithms aimed at reducing edge blur and improving content-style fusion. The results show that although the proposed method has a slightly longer inference time due to the additional processing required by the diffusion model, it consistently outperforms the other methods in terms of transfer quality. Overall, the proposed algorithm demonstrates superior performance.
Table 2.
Quantitative analysis of style-transfer methods.
5. Conclusions
This paper addresses existing issues in current style-transfer networks for artistic image generation, such as poor fusion between style and content and insufficient smoothness at the edges of the main subject. To overcome these limitations, a multi-scale general style-transfer network based on diffusion models is proposed. The network consists of a coarse style-transfer module and a refined style-transfer module. In the first stage, the coarse style-transfer module quickly processes low-resolution images while ensuring the effectiveness of style transfer. To better handle the edge details of the content subject, the Segment Anything Model (SAM) is employed to segment the main content and generate a corresponding mask image to extract edge information. In the second stage, the preliminary style-transferred image and the mask image are used to refine the edge areas, enabling better fusion of content and style around the subject’s edges while preserving more details. To further enhance the overall image quality and improve style fusion along the subject’s edges, the initially generated image is upsampled by a factor of two and passed into the style-refinement module. With the aid of ControlNet, content-aware edge refinement is performed, resulting in improved image quality. Comprehensive experiments and analyses were conducted from both qualitative and quantitative perspectives. From a subjective visual standpoint, the proposed method achieves better fusion between the subject and the style compared to existing approaches. This is also supported by pixel-similarity comparison results, which show a higher degree of style–content fusion. In terms of quantitative metrics, the proposed method achieves superior performance in cosine similarity, Gram loss, and SSIM, demonstrating its overall advantage in style-transfer effectiveness. Future work will focus on constructing larger and more diverse datasets to support more comprehensive and in-depth experimental studies, thereby enhancing the effectiveness and generalization ability of style transfer. In addition, more targeted and extensive ablation studies will be designed and conducted to verify the contribution of each module and design choice from multiple perspectives. Furthermore, a wider range of visual evaluation metrics will be introduced to more thoroughly assess the quality of style–content fusion, providing a more detailed quantification of the model’s performance in terms of style consistency, structural preservation, and perceptual quality.
Author Contributions
Conceptualization, N.S. and Y.P.; methodology, N.S. and J.W.; data curation, N.S.; writing—original draft preparation, N.S. and J.W.; writing—review and editing, Y.P.; and supervision and project administration, Y.P. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Natural Science Foundation of China (62272040, 62201525 and 62172005) and research on the Fundamental Research Funds for the Central Universities CUC24QT08.
Data Availability Statement
The data presented in this study is available on request from the corresponding author.
Conflicts of Interest
Author Na Sun was employed by the company Maschine Robot. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Gatys, L.A.; Ecker, A.S.; Bethge, M. Image style transfer using convolutional neural networks. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2414–2423. [Google Scholar]
- Kolkin, N.; Salavon, J.; Shakhnarovich, G. Style transfer by relaxed optimal transport and self-similarity. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10051–10060. [Google Scholar]
- Risser, E.; Wilmot, P.; Barnes, C. Stable and controllable neural texture synthesis and style transfer using histogram losses. arXiv 2017, arXiv:1701.08893. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part II 14. Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 694–711. [Google Scholar]
- Chen, T.Q.; Schmidt, M. Fast patch-based style transfer of arbitrary style. arXiv 2016, arXiv:1612.04337. [Google Scholar]
- Chen, D.; Yuan, L.; Liao, J.; Yu, N.; Hua, G. Stylebank: An explicit representation for neural image style transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1897–1906. [Google Scholar]
- Li, Y.; Fang, C.; Yang, J.; Wang, Z.; Lu, X.; Yang, M.-H. Universal style transfer via feature transforms. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Bai, Y.; Liu, J.; Dong, C.; Yuan, C. Itstyler: Image-optimized text-based style transfer. arXiv 2023, arXiv:2301.10916. [Google Scholar]
- Sheng, L.; Lin, Z.; Shao, J.; Wang, X. Avatar-net: Multi-scale zero-shot style transfer by feature decoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8242–8250. [Google Scholar]
- Park, D.Y.; Lee, K.H. Arbitrary style transfer with style-attentional networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5880–5888. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- An, J.; Huang, S.; Song, Y.; Dou, D.; Liu, W.; Luo, J. Artflow: Unbiased image style transfer via reversible neural flows. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 862–871. [Google Scholar]
- Deng, Y.; Tang, F.; Dong, W.; Ma, C.; Pan, X.; Wang, L.; Xu, C. Stytr2: Image style transfer with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11326–11336. [Google Scholar]
- Zhang, C.; Xu, X.; Wang, L.; Dai, Z.; Yang, J. S2wat: Image style transfer via hierarchical vision transformer using strips window attention. Proc. Aaai Conf. Artif. Intell. 2024, 38, 7024–7032. [Google Scholar] [CrossRef]
- Chen, H.; Zhao, L.; Wang, Z.; Zhang, H.; Zuo, Z.; Li, A.; Xing, W.; Lu, D. Artistic style transfer with internal-external learning and contrastive learning. Adv. Neural Inf. Process. Syst. 2021, 34, 26561–26573. [Google Scholar]
- Zhang, Y.; Tang, F.; Dong, W.; Huang, H.; Ma, C.; Lee, T.; Xu, C. Domain enhanced arbitrary image style transfer via contrastive learning. In ACM SIGGRAPH 2022 Conference Proceedings, Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference, Vancouver, BC, Canada, 7–11 August 2022; Association for Computing Machinery: New York, NY, USA, 2022; pp. 1–8. [Google Scholar]
- Meier, B.J. Painterly rendering for animation. In Proceedings of the 23rd Annual Conference on Computer Graphics and Interactive Techniques, New York, NY, USA, 4–9 August 1996; pp. 477–484. [Google Scholar]
- Ramesh, A.; Dhariwal, P.; Nichol, A.; Chu, C.; Chen, M. Hierarchical text-conditional image generation with clip latents. arXiv 2022, arXiv:2204.06125. [Google Scholar]
- Hertzmann, A.; Jacobs, C.E.; Oliver, N.; Curless, B.; Salesin, D.H. Image analogies. In Seminal Graphics Papers: Pushing the Boundaries; Association for Computing Machinery: New York, NY, USA, 2023; Volume 2, pp. 557–570. [Google Scholar]
- Wei, L.Y.; Levoy, M. Fast texture synthesis using tree-structured vector quantization. In Proceedings of the 27th Annual Conference on Computer Graphics and Interactive Techniques, New Orleans, LA, USA, 23–28 July 2000; pp. 479–488. [Google Scholar]
- Han, C.; Risser, E.; Ramamoorthi, R.; Grinspun, E. Multiscale texture synthesis. In ACM SIGGRAPH 2008 Papers; Association for Computing Machinery: New York, NY, USA, 2008; pp. 1–8. [Google Scholar]
- Ashikhmin, M. Synthesizing natural textures. In Proceedings of the 2001 Symposium on Interactive 3D Graphics, Chapel Hill, NC, USA, 19–21 March 2001; pp. 217–226. [Google Scholar]
- Luan, F.; Paris, S.; Shechtman, E.; Bala, K. Deep photo style transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4990–4998. [Google Scholar]
- Gatys, L.A.; Ecker, A.S.; Bethge, M.; Hertzmann, A.; Shechtman, E. Controlling perceptual factors in neural style transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3985–3993. [Google Scholar]
- Huang, X.; Belongie, S. Arbitrary style transfer in real-time with adaptive instance normalization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1501–1510. [Google Scholar]
- Tan, W.R.; Chan, C.S.; Aguirre, H.E.; Tanaka, K. ArtGAN: Artwork synthesis with conditional categorical GANs. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3760–3764. [Google Scholar]
- Gatys, L.; Ecker, A.S.; Bethge, M. Texture synthesis using convolutional neural networks. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar]
- Kim, S.; Min, Y.; Jung, Y.; Kim, S. Controllable style transfer via test-time training of implicit neural representation. Pattern Recognit. 2024, 146, 109988. [Google Scholar] [CrossRef]
- Ruta, D.S.; Gilbert, A.; Collomosse, J.P.; Shechtman, E.; Kolkin, N. Neat: Neural artistic tracing for beautiful style transfer. In Proceedings of the European Conference of Computer Vision 2024 Vision for Art (VISART VII) Workshop, Milan, Italy, 30 September 2024. [Google Scholar]
- Chen, H.; Zhao, L.; Li, J.; Yang, J. TSSAT: Two-stage statistics-aware transformation for artistic style transfer. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–30 November 2023; pp. 6878–6887. [Google Scholar]
- Chung, J.; Hyun, S.; Heo, J.P. Style injection in diffusion: A training-free approach for adapting large-scale diffusion models for style transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 8795–8805. [Google Scholar]
- Zhu, M.; He, X.; Wang, N.; Wang, X.; Gao, X. All-to-key attention for arbitrary style transfer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 23109–23119. [Google Scholar]
- Zhang, L.; Rao, A.; Agrawala, M. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 3836–3847. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695. [Google Scholar]
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. Lora: Low-rank adaptation of large language models. arXiv 2021, arXiv:2106.09685. [Google Scholar]
- Wen, L.; Gao, C.; Zou, C. CAP-VSTNet: Content affinity preserved versatile style transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 18300–18309. [Google Scholar]
- Hu, D.; Zhang, Y.; Yu, C.; Wang, J.; Wang, Y. Image steganography based on style transfer. arXiv 2022, arXiv:2203.04500. [Google Scholar]
- Chiu, T.Y.; Gurari, D. Pca-based knowledge distillation towards lightweight and content-style balanced photorealistic style transfer models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 7844–7853. [Google Scholar]
- Wang, H.; Li, Y.; Wang, Y.; Hu, H.; Yang, M.-H. Collaborative distillation for ultra-resolution universal style transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1860–1869. [Google Scholar]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.-Y.; et al. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 4015–4026. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13. Springer International Publishing: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Sergey, K.; Matthew, T.; Helen, H.; Agarwala, A.; Darrell, T.; Hertzmann, A.; Winnemoeller, H. Recognizing image style. In Proceedings of the British Machine Vision Conference, Nottingham, UK, 1–5 September 2014; pp. 1–11. [Google Scholar]
- Liu, S.; Lin, T.; He, D.; Li, F.; Wang, M.; Li, X.; Sun, Z.; Li, Q.; Ding, E. Adaattn: Revisit attention mechanism in arbitrary neural style transfer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 6649–6658. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. A neural algorithm of artistic style. arXiv 2015, arXiv:1508.06576. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).