1. Introduction
Student dropout remains a critical challenge in higher education, with significant implications for institutional effectiveness and student success. Early identification of at-risk students enables timely interventions that can improve retention rates and academic outcomes. Traditional approaches to dropout prediction have primarily relied on static features and conventional machine learning methods, which fail to capture the dynamic nature of student behavior throughout a course.
Recent advances in educational data mining and learning analytics have demonstrated the value of temporal modeling for understanding student learning patterns [
1,
2]. Learning Management Systems (LMSs) such as Canvas generate rich longitudinal data capturing student interactions, assignment submissions, and engagement over time. Macfadyen and Dawson [
3] pioneered the use of LMS data for early warning systems, demonstrating that student activity patterns contain predictive signals for academic risk. However, most existing prediction models treat these temporal sequences as aggregated statistics, losing critical information about behavioral trajectories and engagement patterns that distinguish successful students from those at risk of failure [
4,
5].
The application of machine learning to student performance prediction has evolved considerably. Traditional approaches using Random Forest, Logistic Regression, and Support Vector Machines have shown promising results when applied to static feature representations [
6,
7]. More recently, ensemble methods such as Extreme Gradient Boosting (XGBoost) have achieved strong performance [
8]. Aouarib et al. [
9] demonstrated the effectiveness of genetic algorithms combined with XGBoost for dropout prediction in Massive Open Online Courses (MOOCs), achieving high accuracy. However, these methods fundamentally treat student data as static snapshots rather than continuous temporal processes.
Temporal modeling approaches have emerged to address this limitation. Long Short-Term Memory (LSTM) networks [
10] have been successfully applied to student dropout prediction by capturing sequential dependencies in learning behaviors [
11,
12]. Fei and Yeung [
13] introduced temporal models for predicting student dropout in MOOCs, demonstrating that recurrent architectures can learn meaningful representations from time series data. Despite these advances, LSTM networks suffer from discrete time assumptions and difficulty handling irregularly sampled observations common in real-world educational data.
Neural Ordinary Differential Equations (Neural ODEs), introduced by Chen et al. [
14], offer a powerful framework for modeling continuous-time dynamics. Unlike discrete recurrent architectures, Neural ODEs parameterize the continuous dynamics of hidden states using ordinary differential equations, enabling natural handling of irregular time intervals. Rubanova et al. [
15] extended this framework to handle irregularly sampled time series through Latent ODEs. While Neural ODEs have been successfully applied in various domains, their application to educational data mining remains limited.
A critical gap in existing approaches is the failure to explicitly model assignment completion patterns, despite extensive evidence that missing work is a primary cause of student failure. Márquez-Vera et al. [
16] identified that early dropout detection requires careful feature selection focused on engagement and completion indicators. This observation motivates our completion-focused approach, which extends temporal modeling with three novel engineered features: completion rate, early warning score, and engagement variability.
The challenge of model interpretability in student risk prediction has gained increasing attention [
17,
18]. Adadi and Berrada [
19] surveyed explainable artificial intelligence (XAI) techniques, emphasizing the importance of transparency in educational applications. SHapley Additive exPlanations (SHAP), introduced by Lundberg and Lee [
20], provides a unified approach to interpreting model predictions. Recent work has demonstrated the effectiveness of SHAP for understanding student dropout models [
21], though prior studies have focused primarily on static feature importance rather than temporal behavioral patterns.
In this paper, we introduce Completion-aware Risk Neural ODE (CR-NODE), a temporal deep learning algorithm that integrates completion-focused features with Neural ODE dynamics for early student risk detection. Our contributions are (1) a CR-NODE architecture combining temporal behavioral sequences with completion-focused static features, (2) three engineered features capturing assignment completion patterns critical for identifying at-risk students, (3) comprehensive evaluation against six baselines including LSTM, XGBoost, and basic Neural ODE with statistical significance testing, and (4) explainable AI analysis using SHAP revealing interpretable failure patterns and root causes.
Our experiments on Canvas LMS data from 100,878 students across 89,734 temporal sequences demonstrate that CR-NODE achieves a 0.8747 Macro F1 score, significantly outperforming LSTM (0.8123), XGBoost (0.8300), and basic Neural ODE without completion features (0.8682). McNemar’s test [
22] confirms statistical significance with
p-values less than 0.0001 for all baseline comparisons.
The remainder of this paper is organized as follows:
Section 2 reviews related work in educational data mining and temporal modeling.
Section 3 describes the CR-NODE algorithm and methodology.
Section 4 presents the experimental setup and results.
Section 5 provides the explainable AI analysis.
Section 6 discusses implications and limitations.
Section 6 concludes with future directions.
3. Materials and Methods
3.1. Dataset and Preprocessing
We conducted experiments using Canvas Learning Management System data collected from a large public university over multiple academic terms. The dataset comprises comprehensive longitudinal records of student interactions, assignment submissions, communication patterns, and final outcomes across diverse course offerings.
Table 1 summarizes the complete dataset characteristics.
The data includes 100,878 student enrollments with final grade information, from which we extracted 89,734 valid temporal sequences satisfying minimum observation requirements. Student success was defined as achieving a final score of 70% or higher, resulting in a binary classification task. The test set exhibits class distribution of 71.9% passing students and 28.1% failing students, reflecting realistic educational settings where class imbalance necessitates careful evaluation using metrics appropriate for imbalanced data [
37].
Data preprocessing involved several steps to ensure temporal consistency and data quality. All timestamps were converted to hours elapsed since course start using UTC timezone normalization. We filtered observations to the first 10 weeks (1680 h) of each course, corresponding to the period when early intervention is most effective [
16]. Temporal sequences were aggregated into 4 h time buckets to reduce noise while preserving fine-grained behavioral patterns; however, students exhibit activity only in a subset of buckets, resulting in non-uniform intervals between consecutive observations. For students with sequences exceeding 60 observations, we applied uniform downsampling using linear interpolation to maintain temporal coverage while limiting computational requirements. Sequences with fewer than 3 observations were excluded as insufficient for temporal modeling. The dataset was partitioned into training and test sets using stratified random sampling with 80-20 split ratio and random seed 42 for reproducibility.
3.2. Feature Engineering
Our feature set comprises temporal features capturing time-varying student behavior and static features representing cumulative course performance.
Table 2 provides complete definitions for all features used in this study.
The four temporal features capture student behavior across complementary dimensions: page_views measures engagement intensity through LMS access frequency, submission_score quantifies academic performance on submitted work, late_count tracks time management patterns, and messages reflects communication activity with instructors. These features are observed at each 4 h time bucket throughout the course duration, enabling continuous-time modeling of behavioral dynamics.
The static features consist of two categories. The eight baseline static features represent standard predictors commonly used in educational data mining [
1], including cumulative activity time, current grade standing, submission counts and scores, and communication volume. These features aggregate student behavior over the entire observation period.
The three completion-focused features were engineered specifically to capture assignment completion patterns identified through root cause analysis of failing students. The completion rate measures the proportion of expected coursework completed, defined mathematically as
where expected_submissions represents the unique assignment count per course, and the denominator offset prevents division by zero. The early warning score aggregates incompletion signals with differential weighting:
where missing assignments receive double weight relative to late submissions, reflecting their stronger association with course failure. The engagement variability quantifies consistency in daily activity patterns:
where
and
denote standard deviation and mean, respectively, computed across all days with recorded activity. Higher values indicate erratic engagement patterns potentially signaling disengagement or external barriers to consistent participation.
All features were standardized using z-score normalization with statistics computed on the training set and applied consistently to both the training and test sets:
This normalization ensures that features with different scales contribute proportionally to model learning while preventing data leakage from test set statistics.
3.3. CR-NODE Architecture
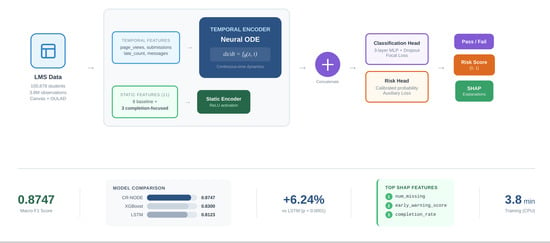
Completion-aware Risk Neural ODE (CR-NODE) integrates continuous-time temporal modeling via Neural Ordinary Differential Equations with completion-focused static features for student dropout prediction. The architecture comprises four interconnected components: a temporal observation encoder, an ODE-based latent dynamics module, a static feature encoder, and dual prediction heads for classification and risk estimation.
Figure 1 provides a schematic overview of the complete architecture and
Table 3 defines all mathematical notation used throughout the model description.
The temporal encoder transforms observed behavioral features into latent representations suitable for continuous-time dynamic modeling. At each observation time
, we construct an augmented feature vector by concatenating temporal features with absolute time and inter-observation gaps:
where
for
and
. Including temporal gaps explicitly enables the model to distinguish between regular consistent engagement patterns and sporadic irregular access patterns. The encoder maps these augmented observations to a latent space via
where
and
are learnable parameters. The hyperbolic tangent activation function bounds latent states within
, improving numerical stability during subsequent ODE integration.
Given a variable-length sequence with binary mask
indicating valid observations, we compute an aggregated initial state through masked averaging:
where
prevents division by zero for edge cases. This pooling operation provides a summary representation that remains robust to variable sequence lengths while incorporating information from all valid observations.
The core of CR-NODE models continuous temporal evolution of student states through a Neural Ordinary Differential Equation:
where
represents a neural network parameterized by learnable weights
. This continuous-time formulation naturally accommodates irregular observation intervals without requiring imputation or resampling of missing time points [
15]. The ODE function is instantiated as a two-layer feedforward network:
where
,
, and corresponding biases constitute learnable parameters. The expanded hidden dimension (
) provides sufficient representational capacity for modeling complex temporal dynamics. While the function signature includes time
t following standard Neural ODE notation [
14], our implementation treats dynamics as time-invariant by depending solely on the latent state
.
To ensure numerical stability during integration, we apply state clamping before each ODE function evaluation:
This prevents extreme values that could cause overflow or underflow in subsequent computations. The ODE is solved numerically using the Euler method with fixed step size
h:
We evaluate the ODE trajectory at three normalized time points
and extract the final state:
During backpropagation, gradients are computed efficiently using the adjoint sensitivity method [
14], which provides memory complexity independent of the number of ODE solver steps, enabling scalable training on long sequences.
Static features are processed through a separate encoding pathway:
where
projects static features to match the dimensionality of temporal representations. The ReLU activation introduces nonlinearity while maintaining computational efficiency. The encoded temporal and static representations are then concatenated to form a unified feature vector:
This combined representation feeds into two parallel prediction heads. The primary classifier employs a three-layer fully connected architecture with dropout regularization:
with layer dimensions
. The output logits
represent un-normalized log-probabilities for failure and success, respectively. Dropout rates decrease in deeper layers following common practice to balance regularization with representational capacity.
The auxiliary risk predictor provides complementary fine-grained probability estimates through a similar three-layer architecture:
with layer dimensions
. The sigmoid activation
in the output layer constrains risk scores to the unit interval
, providing interpretable probability estimates for student failure risk. The complete CR-NODE forward pass is formalized in Algorithm 1.
| Algorithm 1 CR-NODE forward pass algorithm showing temporal encoding, ODE evolution, static feature integration, and dual-head prediction. |
| Input: Temporal sequence , static features , mask |
| Output: Class logits , risk score r |
| // Encode temporal observations |
| for to T do |
| |
| |
| end for |
| // Aggregate initial state |
|
| // Solve ODE |
|
| // Encode static features |
|
| // Combine representations |
|
| // Classification |
|
|
|
| // Risk prediction |
|
|
|
| return
|
3.4. Training Procedure
CR-NODE is optimized using a composite loss function that combines primary classification objectives with auxiliary risk prediction. To address the inherent class imbalance in dropout prediction, we employ Focal Loss [
38], which down-weights well-classified examples and concentrates learning effort on hard misclassified cases:
where
represents the predicted probability for the true class,
denotes a class-specific weighting factor, and
controls the focusing strength. Based on validation experiments, we set
for the failure class,
for the success class, and
. This configuration increases emphasis on the minority failure class while the focusing parameter reduces the relative loss contribution from easy examples.
The auxiliary risk predictor is trained using binary cross-entropy loss with inverted labels to map high risk of failure:
where
represents the true label (0 for failure, 1 for success),
denotes the predicted risk probability, and
balances the auxiliary objective against the primary classification loss. The risk target
ensures that failing students receive high risk scores while successful students receive low scores, providing interpretable probability estimates suitable for prioritizing interventions.
The complete training objective combines both loss components:
We optimize this objective using AdamW [
39], an adaptive learning rate method with decoupled weight decay regularization:
with momentum parameters
and
, learning rate
, and weight decay
. Gradient clipping with maximum L2 norm of 1.0 prevents exploding gradients that could destabilize training. The learning rate is reduced by a factor of 0.5 when the validation Macro F1 score fails to improve for 8 consecutive epochs, enabling fine-tuning in later training stages. Training proceeds for a maximum of 60 epochs with early stopping triggered if no improvement occurs within 20 epochs, preventing overfitting while ensuring convergence. Mini-batches of 64 sequences are processed with shuffling enabled during training.
3.5. Baseline Models
We compare CR-NODE against six baseline approaches (Logistic Regression, Random Forest, XGBoost, Gradient Boosting, LSTM, and Basic Neural ODE) representing diverse modeling paradigms to establish comprehensive performance benchmarks. The comparison includes both traditional machine learning methods operating on static aggregated features and modern temporal deep learning architectures.
For fair comparison, all static machine learning baselines utilize the complete feature set including both the eight baseline static features and the three completion-focused features defined in
Table 2, ensuring that performance differences reflect algorithmic capabilities rather than feature availability. Logistic Regression serves as a linear baseline with L2 regularization, balanced class weights to address class imbalance, and LBFGS optimization for up to 1000 iterations. Random Forest implements an ensemble of 100 decision trees with maximum depth constrained to 10 and balanced class weights applied during tree construction. XGBoost employs gradient boosting with 100 estimators, maximum tree depth of 6, learning rate of 0.1, and automatically computed scale_pos_weight parameter equal to the ratio of negative to positive training examples. Gradient Boosting uses scikit-learn’s implementation with 100 estimators and maximum depth of 5, providing an alternative boosting baseline.
The temporal deep learning baseline models sequential behavioral patterns directly. LSTM employs a two-layer recurrent architecture with hidden dimension 64 and inter-layer dropout of 0.2. The complete set of 11 static features, including the 3 completion-focused features, is encoded through a separate fully connected layer and concatenated with the final LSTM hidden state before classification, ensuring identical feature access to CR-NODE. The LSTM model uses the same three-layer classifier architecture as CR-NODE (dimensions ) with dropout rates of 0.3 and 0.2, and is trained using identical loss functions (Focal Loss without auxiliary risk loss) and optimizer settings to isolate the impact of the temporal modeling approach.
The Basic Neural ODE baseline provides an ablation study isolating the contribution of completion-focused feature engineering. This model employs an architecture identical to CR-NODE in all respects except that it processes only the eight baseline static features, excluding the three completion-focused features (completion_rate, early_warning_score, engagement_variability). All hyperparameters, training procedures, and evaluation protocols remain consistent with CR-NODE. Performance differences between CR-NODE and Basic Neural ODE therefore directly quantify the value added by explicit completion-focused feature engineering.
Table 4 provides a comprehensive summary of hyperparameter configurations for all models evaluated in this study.
3.6. Evaluation Methodology
We evaluate all models using metrics specifically appropriate for imbalanced binary classification in educational contexts where both false negatives (missing at-risk students) and false positives (unnecessarily flagging successful students) carry significant consequences.
For each class
corresponding to failure and success, respectively, we compute precision, recall, and F1 score:
where
,
, and
denote true positives, false positives, and false negatives for class
c. Precision quantifies the fraction of predicted positives that are correct, recall measures the fraction of actual positives successfully identified, and F1 score provides their harmonic mean.
Our primary evaluation metric is Macro F1 score, which averages F1 across both classes:
Macro averaging treats both classes with equal importance regardless of their frequency in the dataset. This is particularly appropriate for educational risk prediction where correctly identifying the minority failure class is as critical as correctly identifying the majority success class [
37]. Unlike accuracy, which can be misleadingly high when dominated by majority class performance, Macro F1 requires strong performance on both classes simultaneously.
To assess the statistical significance of performance differences between CR-NODE and baseline models, we apply McNemar’s test [
22]. This non-parametric test evaluates whether two models make errors on different subsets of examples by analyzing their disagreement patterns. Given predictions from CR-NODE (model A) and a baseline (model B) on the same test set, we construct a
contingency table:
where
represents examples correctly classified by A but incorrectly by B, while
represents the reverse. The test focuses on disagreement cases where models differ in their predictions.
The McNemar test statistic with continuity correction is computed as
Under the null hypothesis that both models have equal error rates, this statistic follows a chi-squared distribution with 1 degree of freedom. We reject the null hypothesis at significance level
when the computed
p-value satisfies
, concluding that one model significantly outperforms the other. This paired test is more powerful than comparing accuracy scores independently because it accounts for the fact that models are evaluated on identical test examples, reducing variance from test set sampling.
3.7. Implementation Details
All models were implemented in Python 3.9 using PyTorch 1.13 for neural network architectures and scikit-learn 1.2 for traditional machine learning methods. Neural ODE integration was performed using the torchdiffeq library [
14] with automatic differentiation for gradient computation. XGBoost version 1.7 was used for gradient boosting baselines. All experiments were conducted on CPU hardware to ensure broad reproducibility without specialized GPU requirements. Random seed 42 was set globally across all random number generators to ensure deterministic reproducibility of results.
Training CR-NODE on the complete training set of 68,444 sequences required approximately 3.8 min on a standard multi-core CPU, demonstrating computational efficiency suitable for practical deployment. The final CR-NODE model contains 39,395 trainable parameters distributed across the temporal encoder, ODE function, static encoder, classifier, and risk predictor components.
4. Results
4.1. Overall Performance Comparison
We evaluated CR-NODE against six baseline approaches (Logistic Regression, Random Forest, XGBoost, Gradient Boosting, LSTM, and Basic Neural ODE) on the held-out test set comprising 17,111 student sequences.
Table 5 presents comprehensive performance metrics for all models. CR-NODE achieved the highest Macro F1 score of 0.8747, demonstrating substantial improvements over all baselines.
CR-NODE outperformed all baselines with statistically significant margins. Compared to LSTM [
10], CR-NODE achieved Macro F1 improvement of 6.24 percentage points (0.8747 vs. 0.8123), with particularly strong gains in failure class prediction where F1 increased by 9.70 percentage points (0.8186 vs. 0.7216), demonstrating the advantage of continuous-time modeling via Neural ODEs [
14,
15] over discrete recurrent architectures. Among static machine learning methods, XGBoost achieved the strongest performance with Macro F1 of 0.8300. CR-NODE exceeded XGBoost by 4.47 percentage points, with improvement concentrated in failure class detection (0.8186 vs. 0.7482). Logistic Regression achieved Macro F1 of 0.7262, confirming that nonlinear modeling is essential. The Basic Neural ODE baseline achieved Macro F1 of 0.8682. The 0.65 percentage point gap directly quantifies the contribution of completion-focused feature engineering.
Figure 2 presents confusion matrices for all seven models. CR-NODE correctly identified 3865 of 4805 failing students and 11,533 of 12,306 passing students, yielding 940 false positives and 773 false negatives. Compared to LSTM, CR-NODE reduced false negatives by 10.3% (850 to 773) while maintaining competitive false-positive rates, critical for practical deployment [
3,
23].
Figure 3 presents Receiver Operating Characteristic (ROC) curves with corresponding AUC values. CR-NODE achieved an Area Under the Curve (AUC) of 0.927, closely followed by Basic Neural ODE at 0.923. Both substantially exceeded LSTM (0.884), XGBoost (0.895), and traditional baselines. For imbalanced educational datasets, precision–recall-based metrics provide more informative evaluation than ROC-based metrics [
37].
4.2. Statistical Significance Analysis
To rigorously assess whether CR-NODE’s performance improvements represent statistically significant differences, we applied McNemar’s test [
22] comparing CR-NODE predictions against each baseline model. McNemar’s test evaluates disagreement patterns between paired classifiers, providing more statistical power by accounting for evaluation on the same examples [
40].
Figure 3.
ROC curves comparing all models. Neural ODE variants (CR-NODE and Basic Neural ODE) achieve superior discrimination ability with AUC exceeding 0.92, substantially outperforming both temporal (LSTM) and static machine learning baselines.
Figure 3.
ROC curves comparing all models. Neural ODE variants (CR-NODE and Basic Neural ODE) achieve superior discrimination ability with AUC exceeding 0.92, substantially outperforming both temporal (LSTM) and static machine learning baselines.
Table 6 presents McNemar’s test results. CR-NODE demonstrated statistically significant superiority over all six baselines with
p-values below 0.0001. Against LSTM, CR-NODE correctly classified 1514 students that LSTM misclassified, while making errors on only 764 students that LSTM classified correctly, yielding a net improvement of 750 students and a chi-squared of 246.27 (
p < 0.0001), confirming that continuous-time Neural ODE modeling provides genuine advantages over discrete-time recurrent architectures.
Against static baselines, CR-NODE correctly classified 2983 students that Logistic Regression misclassified while erring on only 802, yielding chi-squared of 1255.59. Against XGBoost, CR-NODE achieved net improvement of 521 students with chi-squared of 138.31, demonstrating that temporal modeling captures predictive information absent from aggregated static features. Against Basic Neural ODE, CR-NODE achieved a net improvement of 95 students and chi-squared of 22.48 (p < 0.0001), confirming that explicit completion metrics provide measurable performance gains.
4.3. Model Training and Convergence
Figure 4 illustrates CR-NODE’s training dynamics across 60 epochs. Training loss decreased smoothly from 0.42 to 0.07, while validation loss declined from 0.48 to 0.12, exhibiting no overfitting despite 39,395 trainable parameters. Training Macro F1 improved from 0.73 to 0.87, tracking validation F1 which increased from 0.72 to 0.8747. The best model was selected at epoch 59.
Training required approximately 3.8 min on standard CPU hardware to process 68,444 sequences, demonstrating computational efficiency suitable for practical deployment without specialized hardware. The adjoint sensitivity method [
14] enables memory-efficient gradient computation despite continuous-time formulation. CR-NODE achieved strong performance without extensive hyperparameter tuning, contrasting with some deep learning approaches requiring extensive computational resources [
11,
27].
4.4. Ablation Study: Feature Contribution Analysis
To systematically evaluate completion-focused feature contributions, we conducted an ablation study training CR-NODE variants with different configurations.
Table 7 presents results across six configurations.
Removing individual features revealed that early_warning_score provides the largest contribution, reducing Macro F1 by 0.96 percentage points (0.8747 to 0.8651) and Fail F1 by 1.52 percentage points. Completion_rate contributed 1.24 percentage points to Macro F1 and 1.99 percentage points to Fail F1. Engagement_variability provided 0.58 percentage points to Macro F1 and 0.88 percentage points to Fail F1. These demonstrate that all three features encode complementary predictive signals. The configuration using only completion-focused features achieved Macro F1 of 0.7234, substantially below all other configurations, confirming that completion metrics alone cannot replace comprehensive behavioral features but provide complementary information. The gap between this configuration and Basic Neural ODE (0.7234 vs. 0.8682) demonstrates that baseline features capture fundamental patterns, while completion-focused features provide incremental but significant improvements. These results validate our feature engineering approach grounded in root cause analysis, aligning with prior research emphasizing assignment completion and submission timeliness as leading indicators of academic risk [
5,
16,
24].
4.5. Temporal Pattern Analysis
Figure 5 illustrates temporal behavioral patterns distinguishing passing and failing students across 10 weeks, revealing systematic differences enabling Neural ODE temporal modeling to achieve superior performance.
LMS engagement patterns exhibit persistent divergence. Passing students maintain average page views between 180 and 330 per week with peak activity during weeks 2–3, while failing students exhibit consistently lower engagement averaging 100–200 page views with declining trajectory after week 4, supporting that continuous monitoring provides early signals of academic risk [
4,
41]. Assignment submission patterns reveal the most striking differences. Passing students maintain steady submission rates of 8–12 assignments per week, with a characteristic peak around week 4. Failing students show dramatically lower volumes averaging 3–7 per week with erratic patterns. The submission gap widens progressively, validating our completion-focused feature engineering and explaining why Neural ODE temporal modeling outperforms static aggregation methods.
Late submission behavior provides complementary signals. Passing students maintain stable low rates around 2–3 per week. Failing students exhibit escalating patterns starting around week 5–6, reaching 6–7 per week by week 10, enabling Neural ODE dynamics to model progressive deterioration in time management. Communication patterns reveal differential help-seeking behaviors. Passing students maintain moderate volumes of 4–8 per week, with a notable spike around week 2. Failing students show consistently lower communication, averaging 1–3 messages per week, potentially indicating disengagement or social isolation.
These patterns collectively demonstrate why continuous-time Neural ODE modeling achieves superior performance. The Neural ODE formulation [
14,
15] naturally accommodates irregular observation intervals while capturing smooth temporal trajectories characterizing behavioral evolution. In contrast, LSTM models require fixed time-step discretization that may miss important dynamics [
32], while static methods aggregate away temporal patterns entirely.
4.6. Feature Importance and Interpretability
To enhance model transparency, we analyzed feature importance using SHAP 0.42.1 (SHapley Additive exPlanations) [
20].
Figure 6 presents a SHAP summary plot showing each feature’s impact on CR-NODE’s dropout predictions.
Completion-focused features appear prominently among the most influential predictors. Early_warning_score ranks as the second-most important feature, with high values strongly increasing dropout prediction scores, validating that missing and late assignment counts serve as powerful early indicators. Num_missing emerges as the single most influential feature, aligning with research identifying assignment completion as a fundamental predictor of academic success [
16,
24]. Num_late shows complex patterns where both very low and very high values increase risk, potentially reflecting complete disengagement versus chronic time management problems.
Among baseline features, current_score shows strong intuitive patterns where low values increase dropout risk and high values decrease risk. However, current_score exhibits more dispersed impact compared to completion-focused features, suggesting it alone provides incomplete risk assessment, supporting our approach of combining performance metrics with behavioral completion patterns. Engagement_variability demonstrates that both very low and very high variability increase dropout risk, with consistent moderate engagement associated with success. This U-shaped relationship validates that erratic engagement patterns signal either disengagement or ineffective study strategies. Communication features show weaker scattered importance, suggesting messaging behavior provides less reliable risk signals.
SHAP analysis reveals CR-NODE’s superior performance stems from leveraging complementary information from multiple feature types: temporal behavioral patterns captured by Neural ODE dynamics, cumulative performance metrics from baseline features, and explicit completion signals from engineered features, aligning with recommendations for actionable learning analytics [
2,
42]. The interpretability addresses critical requirements for ethical deployment in educational settings [
17,
18]. By exposing which features drive individual predictions, SHAP enables educators to understand not just which students are at risk, but why, facilitating targeted interventions addressing specific underlying issues.
4.7. Error Analysis and Misclassification Patterns
To provide deeper insight into model behavior beyond aggregate performance metrics, we conducted systematic analysis of CR-NODE’s prediction errors, examining the characteristics of misclassified students and identifying patterns that explain model limitations.
4.7.1. Characterization of Misclassified Students
CR-NODE produced 940 false positives (successful students incorrectly predicted to fail) and 773 false negatives (failing students incorrectly predicted to pass) from the 17,111 test set students.
Table 8 compares the behavioral characteristics of correctly classified versus misclassified students across key features.
False negatives (missed at-risk students) exhibit behavioral profiles remarkably similar to passing students: high current scores (86.81 vs. 90.28 for true negatives), moderate engagement levels (839 vs. 1035 page views), and comparable completion rates (0.06 vs. 0.06). These students maintain performance indicators suggesting success throughout most of the course but ultimately fail, likely due to poor performance on final assessments or late-semester disengagement not fully captured within the 10-week observation window. The SHAP analysis (
Figure 6) provides insight into this pattern: current score exhibits relatively concentrated SHAP values near zero compared to completion-focused features, indicating the model appropriately prioritizes behavioral completion patterns over instantaneous grade standing—yet this design choice means students with strong current scores but latent risk factors may be missed.
False positives (incorrectly flagged successful students) display high current scores (88.69) and lower engagement variability (0.95 vs. 1.02 for true negatives), suggesting these students exhibited early warning indicators but subsequently recovered. The model correctly identifies initial risk signals but cannot fully predict successful self-correction or the effects of intervention.
4.7.2. Confidence–Accuracy Relationship
We examined the relationship between prediction confidence (maximum softmax probability) and classification accuracy to assess model calibration.
Table 9 presents accuracy stratified by confidence level.
CR-NODE exhibits well-calibrated confidence estimates: predictions with confidence ≥0.85 achieve 99.8% accuracy, while intermediate confidence predictions (0.50–0.60) yield only 70.4% accuracy. This calibration has practical implications for deployment—students receiving intermediate-confidence predictions warrant closer human review and additional monitoring, while high-confidence predictions can reliably inform automated engagement or support workflows.
4.7.3. Performance Across Engagement Subgroups
To assess whether model performance varies systematically across student populations, we stratified the test set into engagement terciles based on total page views.
Table 10 presents performance metrics for each subgroup.
Performance remains robust across engagement levels, with Macro F1 ranging from 0.861 to 0.878. However, fail recall decreases in the high-engagement subgroup (0.76 vs. 0.81–0.83 for lower engagement groups), reflecting increased difficulty in identifying at-risk students whose high engagement levels mask underlying academic struggles. High-engagement students who ultimately fail represent only 20.9% of their subgroup but are disproportionately likely to be missed by the model. This finding has practical implications: high-engagement students flagged with intermediate confidence may benefit from assessment-focused review rather than engagement-based interventions.
4.7.4. Sources of Prediction Error
Synthesizing across error characterization, confidence analysis, and SHAP-based feature importance (
Section 4.6), we identify three primary sources of CR-NODE prediction errors:
Engagement–performance dissociation: Students with high engagement but poor assessment outcomes present conflicting behavioral signals. As shown in
Table 8, false negatives maintain page views (839) approaching those of passing students (1035), yet their ultimate failure suggests engagement quantity does not guarantee learning quality. The SHAP analysis confirms the model prioritizes completion-focused features over raw engagement metrics, which successfully identifies most at-risk students but misses those whose activity levels mask academic difficulties.
Late behavioral transitions: False negatives exhibit current scores (86.81) nearly matching passing students (90.28), indicating that these students maintain successful performance trajectories through most of the observation period before experiencing late-semester decline. The 10-week feature extraction window, while aligned with early intervention goals [
16], may not capture critical end-of-term deterioration that determines final outcomes.
Recovery trajectories: False positives demonstrate early risk indicators that appropriately trigger high-risk predictions, but these students subsequently improve through self-correction or successful intervention. The model cannot distinguish between students who will persist in at-risk patterns versus those who will recover, representing an inherent limitation of early prediction systems that prioritize timely identification over waiting for behavioral stabilization.
These findings suggest several directions for model refinement: incorporating assessment-specific performance trajectories to complement behavioral features, developing adaptive prediction windows that extend monitoring for intermediate-confidence cases, and exploring separate modeling pathways for high-engagement students whose risk profiles differ from typical at-risk patterns.
4.8. Generalization to OULAD Dataset
To assess CR-NODE’s generalizability, we evaluated the model on the Open University Learning Analytics Dataset (OULAD) [
43], a widely used benchmark containing 32,593 student records. We extracted 17,928 valid temporal sequences (11,641 passing, 6287 failing) following identical preprocessing protocols. The model was trained with the same hyperparameters, using only the eight baseline static features available in OULAD, without completion-focused engineered features.
Table 11 presents CR-NODE’s performance compared to recent state-of-the-art results from Torkhani and Rezgui [
44].
CR-NODE achieved 84.44% accuracy on the OULAD test set (3,586 students), outperforming the best model from Torkhani and Rezgui [
44]—LSTM at 83.41%—by 1.03 percentage points. Our model demonstrated consistent superiority: 84.30% precision versus 82.20% for LSTM (2.10 point improvement), and 84.40% recall versus 81.88% for LSTM (2.52 point improvement). The confusion matrix revealed 920 correctly identified failing students, 2108 correctly identified passing students, with 338 false negatives and 220 false positives. Class-specific performance showed Fail F1 of 0.767 and Pass F1 of 0.883, yielding Macro F1 of 0.8252.
These results provide strong evidence for CR-NODE’s cross-dataset generalizability. Despite using a different institutional context (UK Open University versus US educational-based traditional university), different LMS platform (Open University VLE versus Canvas), and lacking engineered completion-focused features, CR-NODE maintained competitive performance and exceeded current state-of-the-art approaches. The model’s ability to achieve superior results using only baseline features demonstrates that the Neural ODE temporal modeling framework contributes substantially to predictive performance, independent of specialized feature engineering. Training required only 29.8 s on standard CPU hardware for 14,342 sequences, confirming computational efficiency for practical deployment across diverse educational settings.
6. Conclusions and Future Work
This study introduced CR-NODE, combining Neural Ordinary Differential Equations with completion-focused feature engineering for early student dropout prediction. Evaluated on over 100,000 Canvas LMS enrollments, CR-NODE achieved a Macro F1 of 0.8747, significantly outperforming LSTM, XGBoost, and traditional methods (McNemar’s test
p < 0.0001). Three primary contributions emerge: First, continuous-time Neural ODE modeling provides a 6.24 percentage point improvement over LSTM and 4.47 points over XGBoost, quantifying advantages for irregular observation patterns. Second, completion-focused features contribute 0.65 percentage points with high statistical significance, integrating data-driven learning with educational domain knowledge. Third, SHAP-based interpretability reveals completion patterns, engagement consistency, and performance trajectories as prediction drivers, supporting transparent early warning systems. Temporal analysis revealed behavioral divergence within 4-6 weeks, identifying the critical intervention window. Training in 3.8 min on a standard CPU with 39,395 parameters demonstrates practical deployment feasibility [
49,
53,
54].
The convergence of continuous-time modeling, completion-focused engineering, and interpretability establishes foundations for next-generation early warning systems. Maintaining focus on actionable, interpretable, equitable, and privacy-respecting predictions ensures learning analytics serve genuine educational objectives [
42]. Future research can advance methodological innovations and practical systems supporting student success at scale.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}