
Improving Academic Advising in Engineering Education with Machine Learning Using a Real-World Dataset



Abstract
1. Introduction
- Which features from the dataset are the most significant when predicting student performance and qualification choice?
- What is the performance of classification models when predicting student performance, qualification enrollment, and determining whether a student is better suited to enrol for mainstream or extended qualification?
2. Literature Review
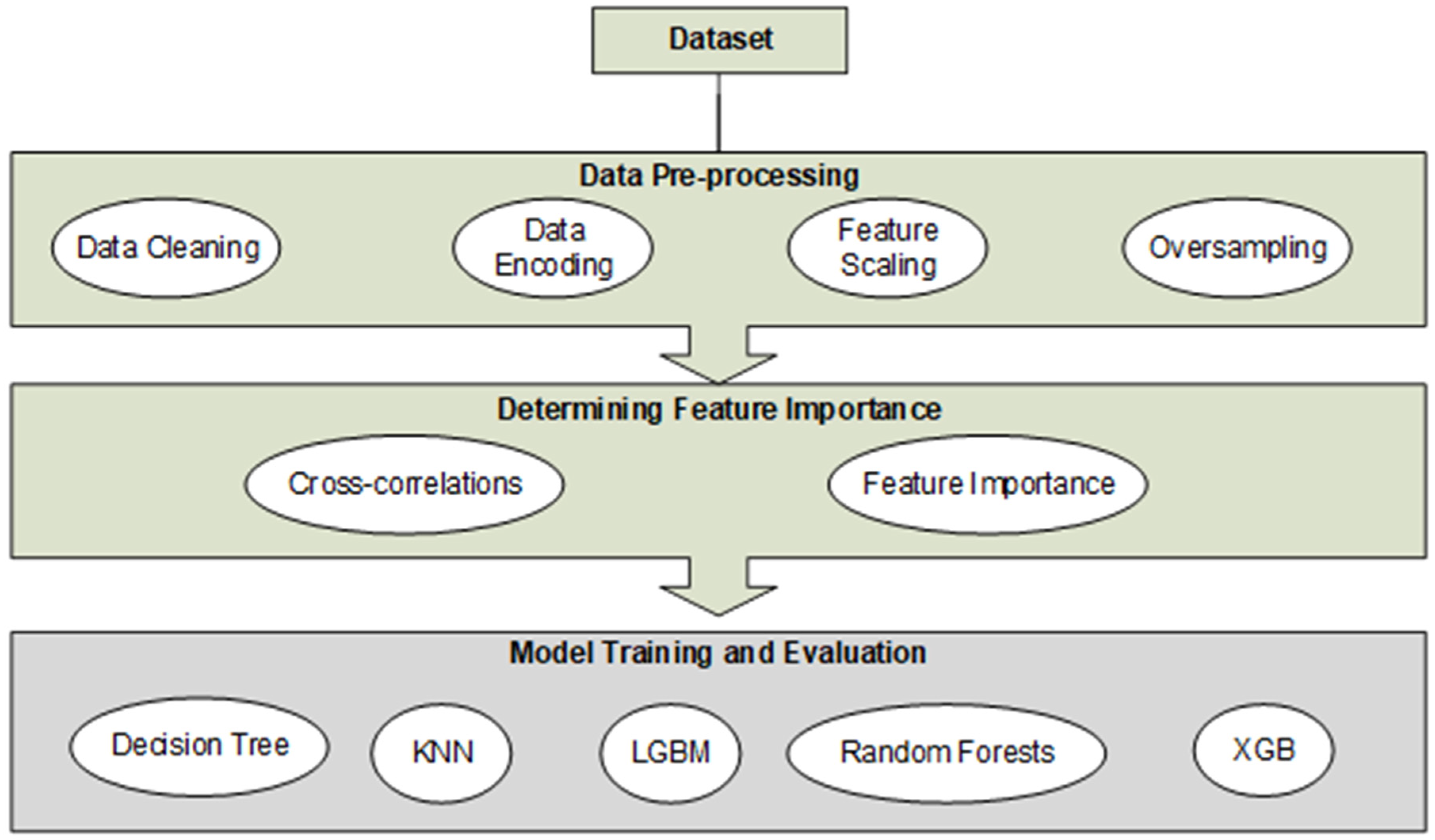
3. Methodology
3.1. Experimental Setup
3.2. Dataset Description
3.3. Data Pre-Processing
3.3.1. Data Cleaning
3.3.2. Data Encoding
3.3.3. Feature Scaling
3.3.4. Oversampling
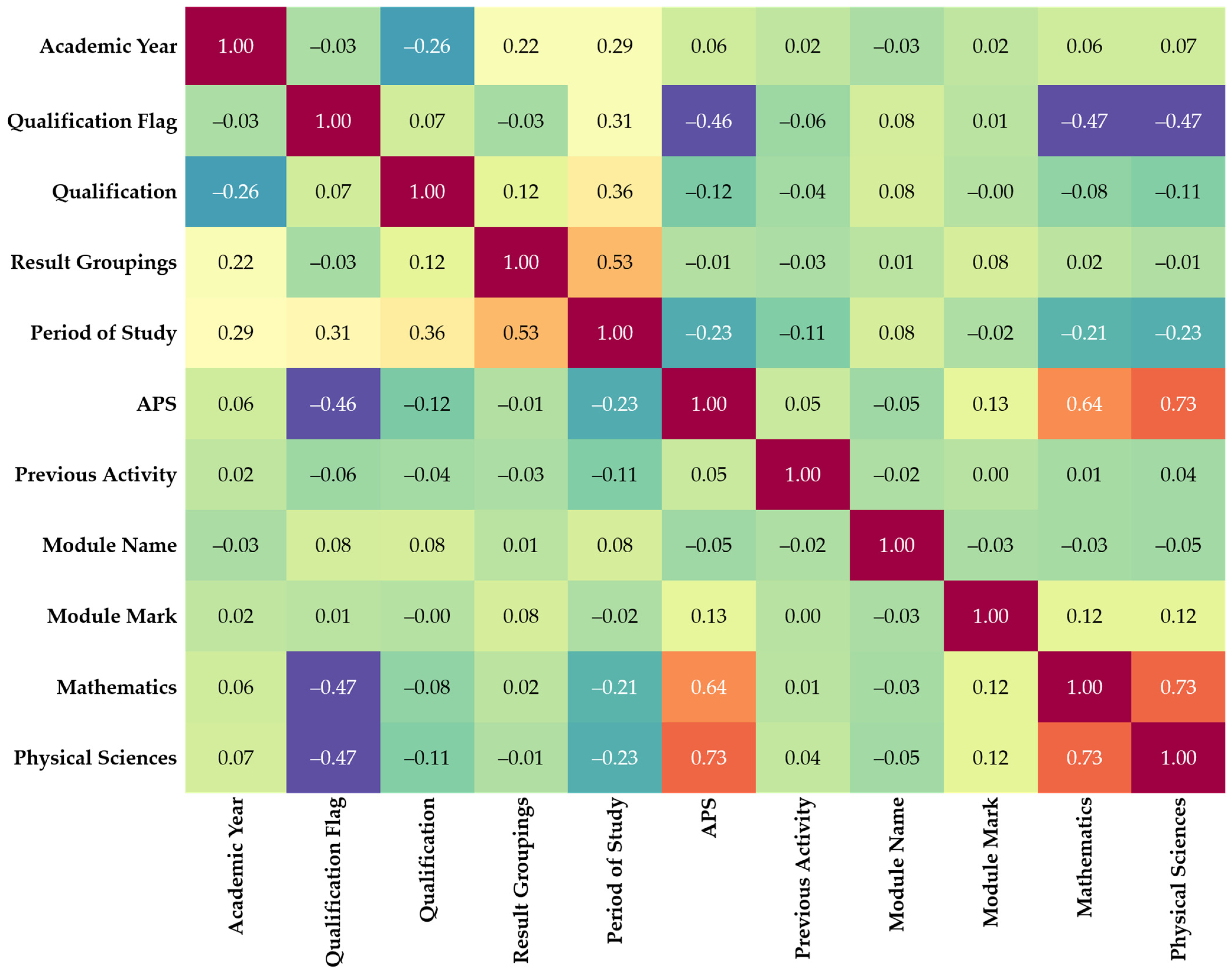
3.4. Determining Feature Importance
Cross-Correlations
3.5. Model Training and Evaluation
4. Results
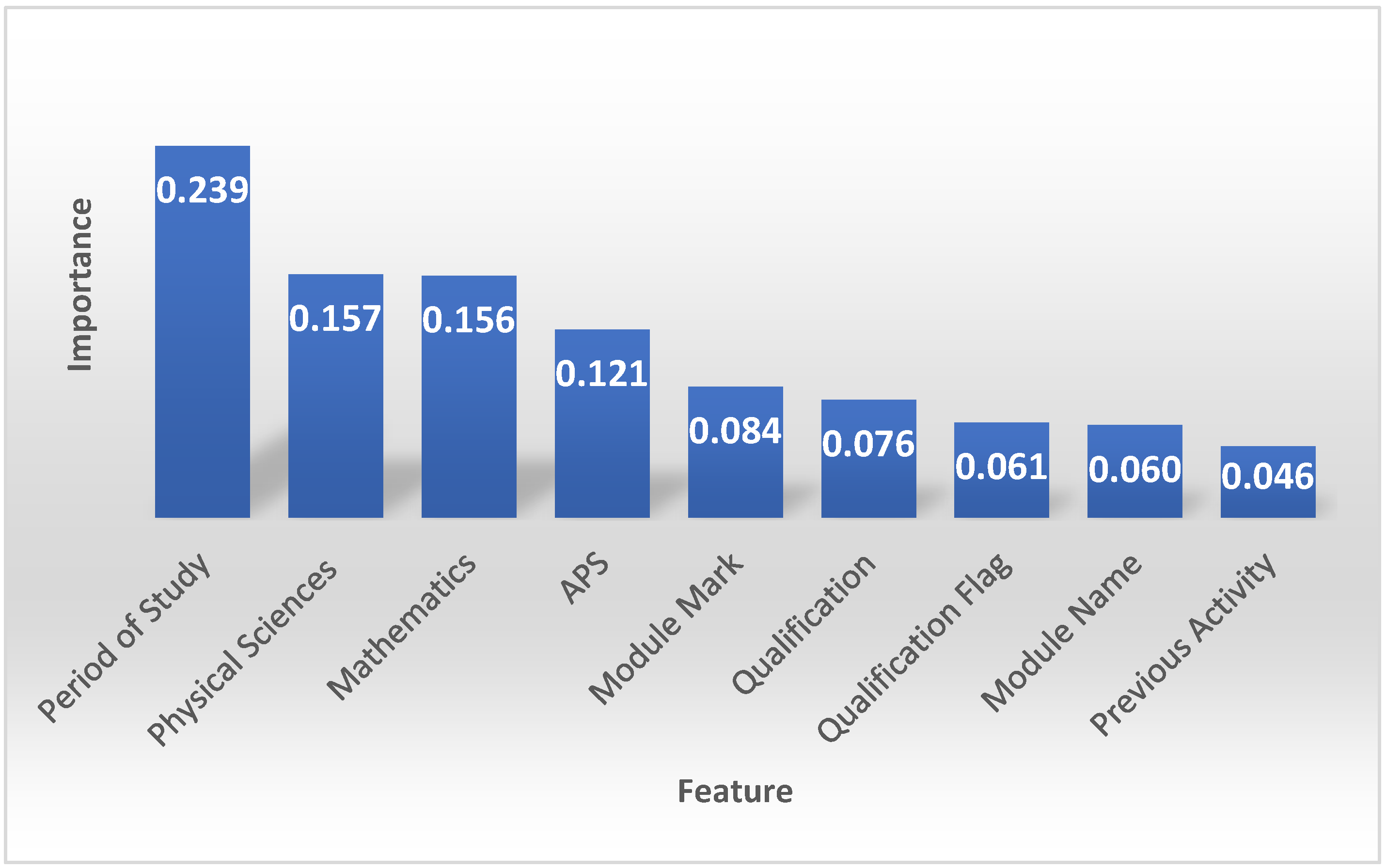
4.1. Important Features When Predicting Student Performance
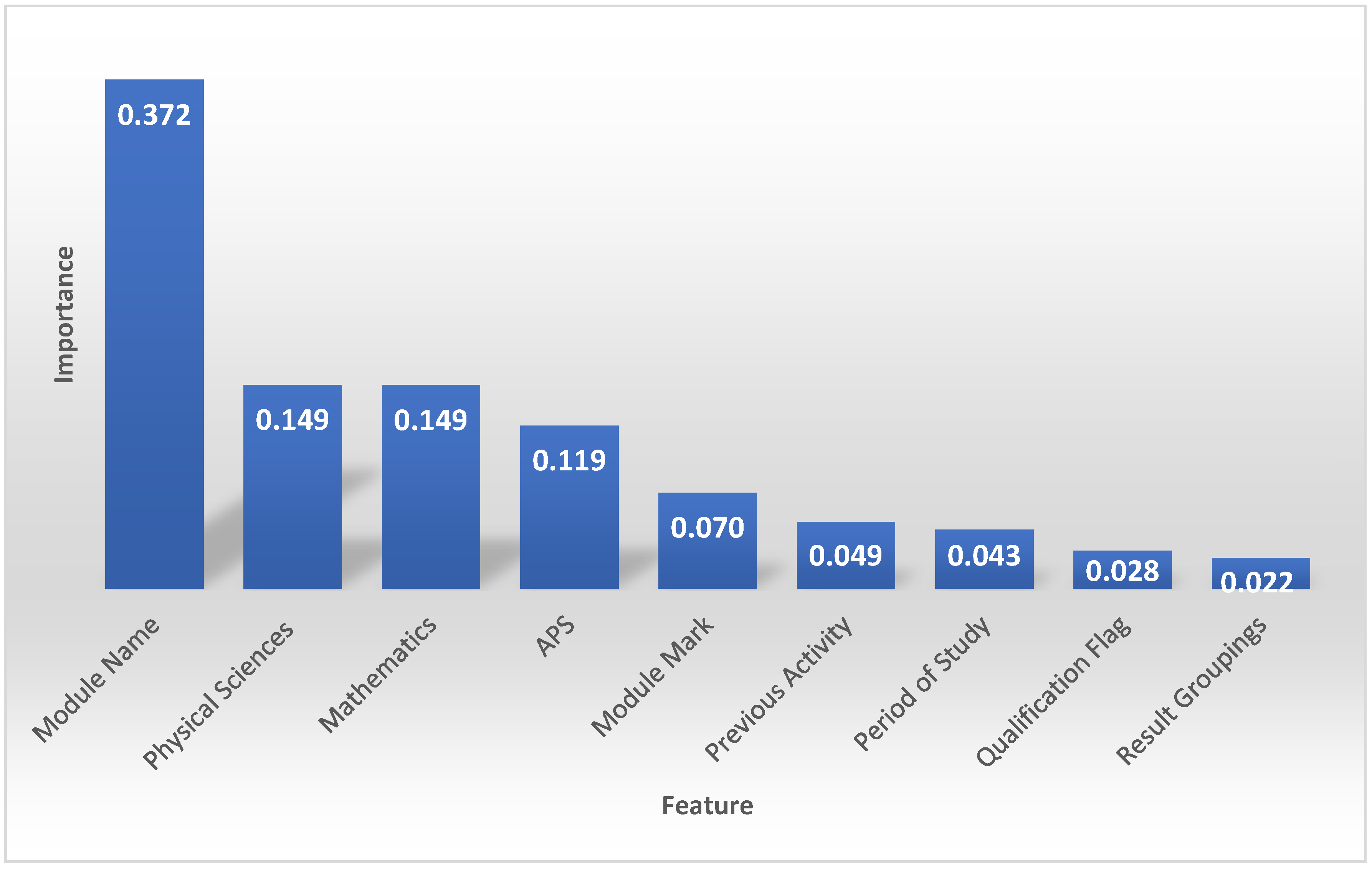
4.2. Important Features When Predicting Qualifications
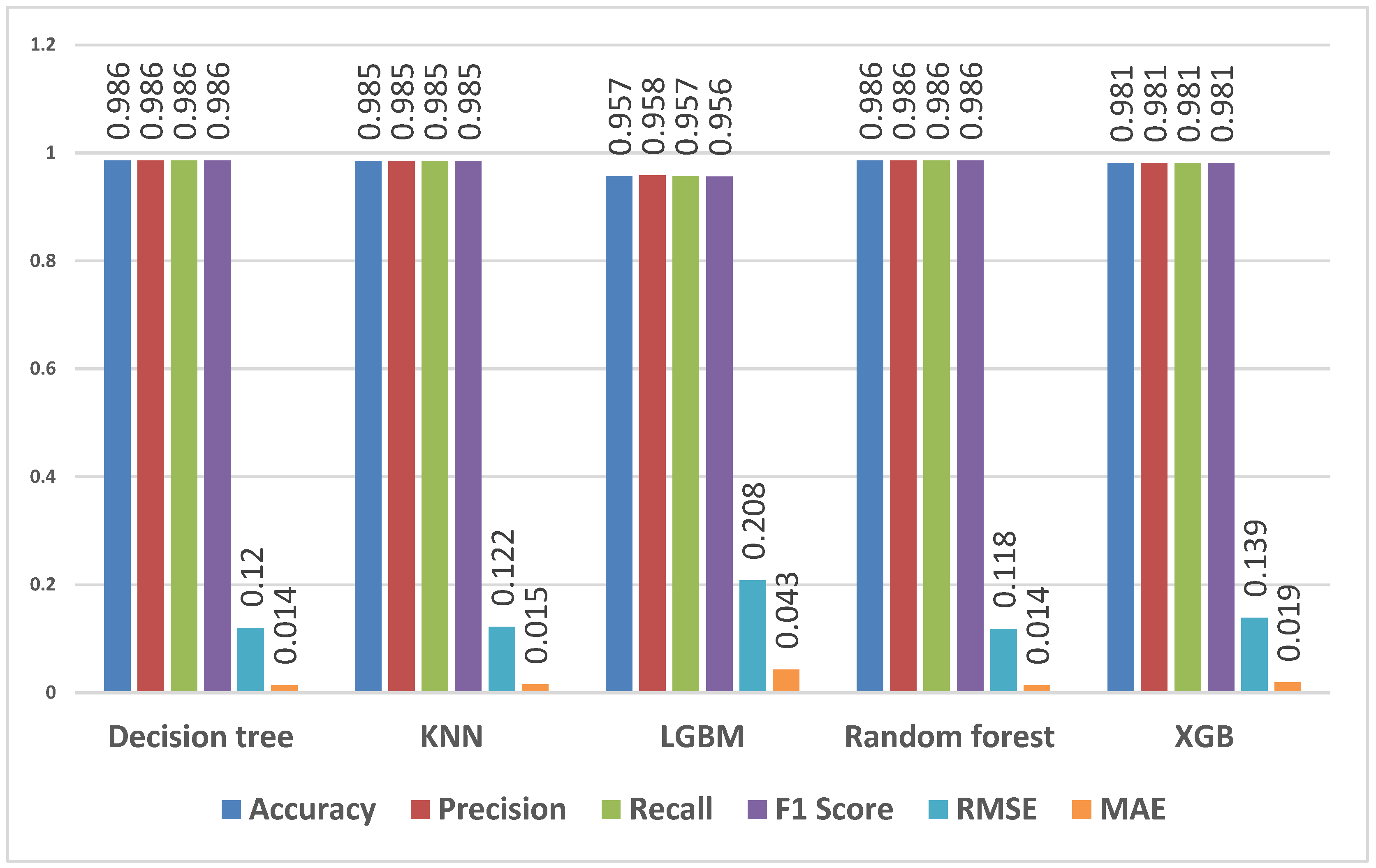
4.3. Training and Evaluating the Performance of the Models
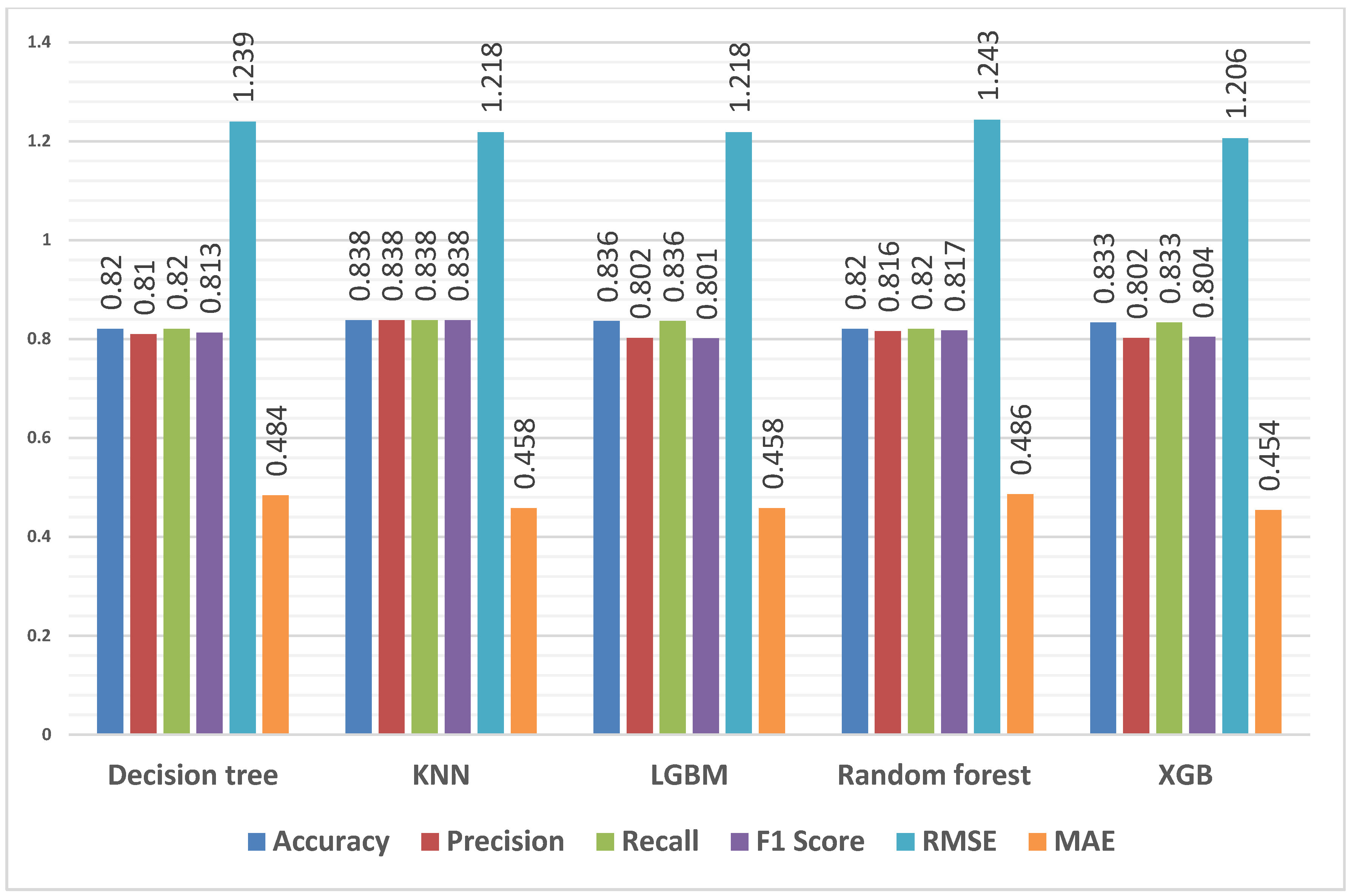
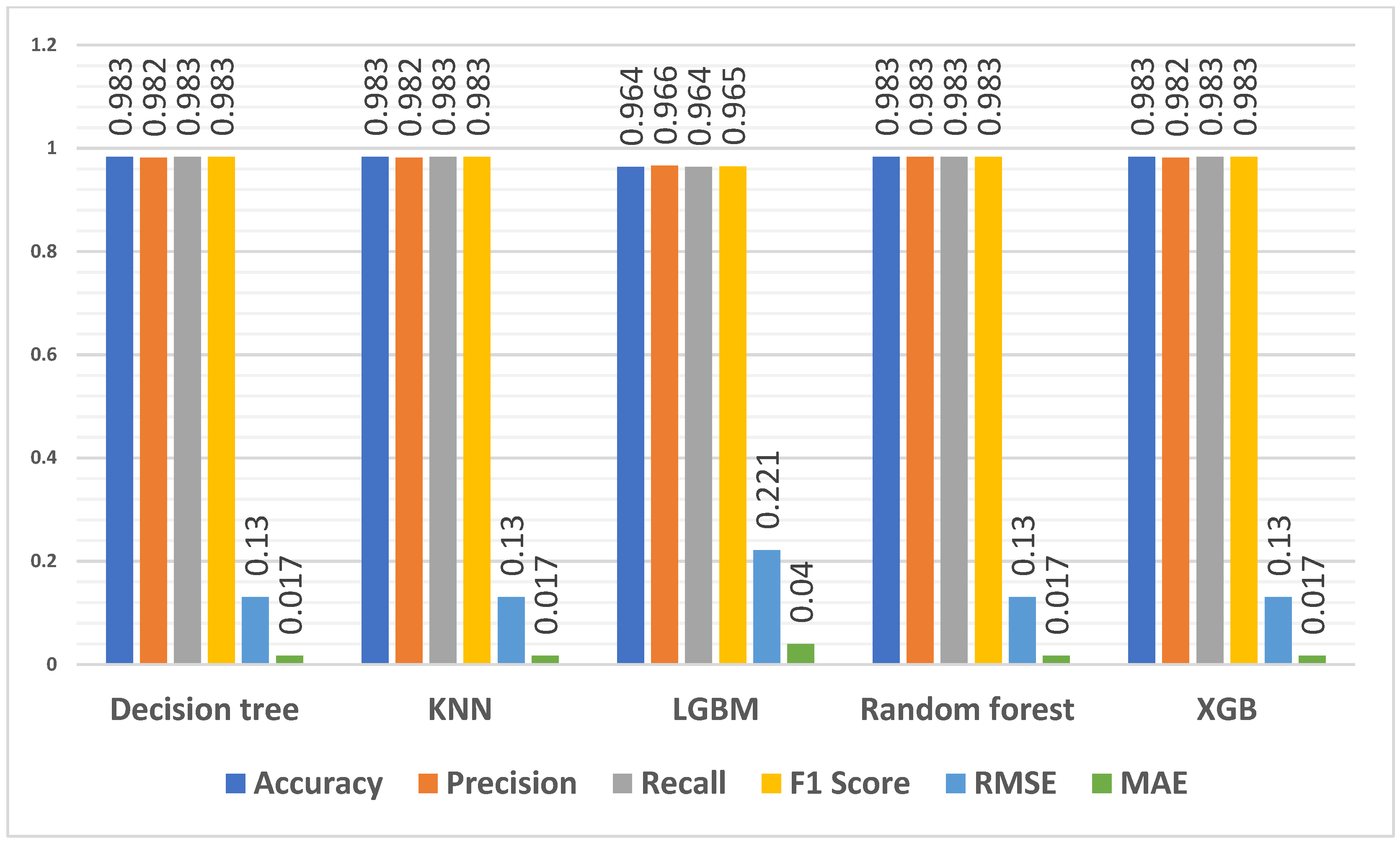
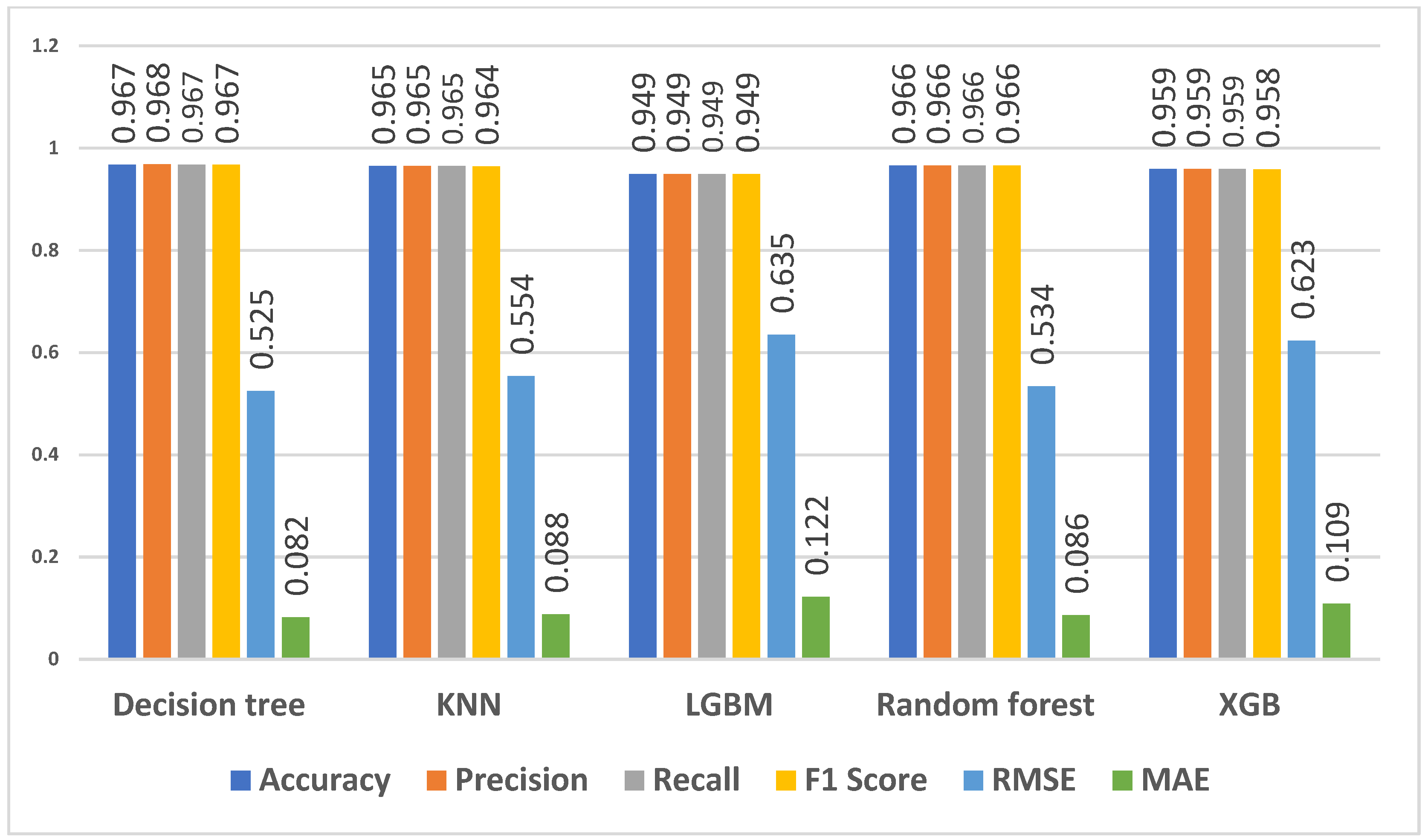
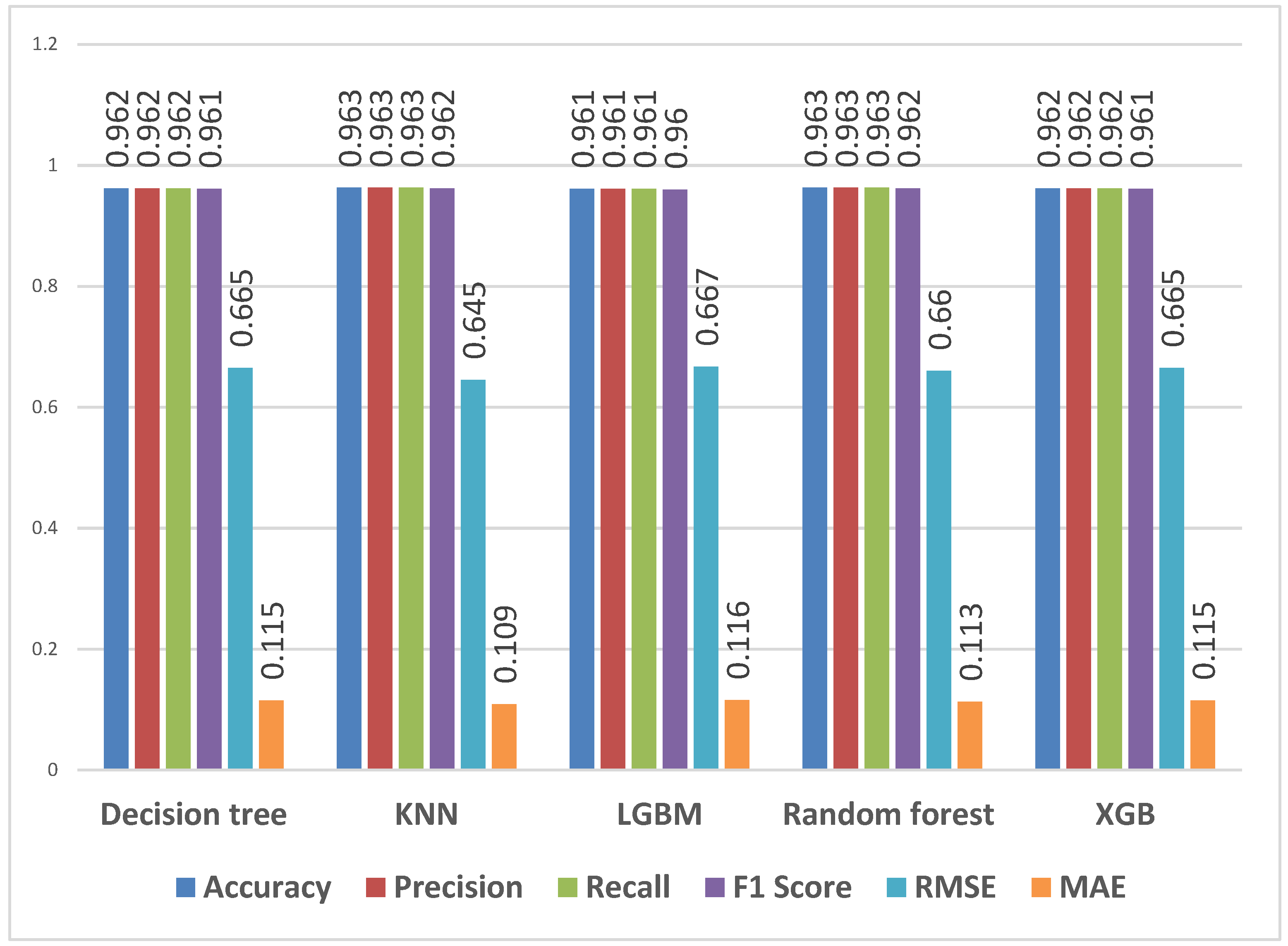
4.3.1. Predicting Overall Students’ Performance
4.3.2. Predicting First-Year Students’ Performance
4.3.3. Predicting Qualifications for All Students
4.3.4. Predicting Qualifications for First-Year Students
4.3.5. Predicting Qualification Flag for First-Year Students
5. Discussion
5.1. Important Features When Predicting Student Performance and Predicting Qualifications
5.2. Performance of Models
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ahmed, N.; Kloot, B.; Collier-Reed, B.I. Why Students Leave Engineering and Built Environment Programmes When They Are Academically Eligible to Continue. Eur. J. Eng. Educ. 2015, 40, 128–144. [Google Scholar] [CrossRef]
- Cole, M. Literature Review Update: Student Identity about Science, Technology, Engineering and Mathematics Subject Choices and Career Aspirations; Australian Council of Learned Academies: Melbourne, Australia, 2013; Available online: https://www.voced.edu.au/content/ngv:56906 (accessed on 7 July 2023).
- Atalla, S.; Daradkeh, M.; Gawanmeh, A.; Khalil, H.; Mansoor, W.; Miniaoui, S.; Himeur, Y. An Intelligent Recommendation System for Automating Academic Advising Based on Curriculum Analysis and Performance Modeling. Mathematics 2023, 11, 1098. [Google Scholar] [CrossRef]
- Kuhail, M.A.; Al Katheeri, H.; Negreiros, J.; Seffah, A.; Alfandi, O. Engaging Students With a Chatbot-Based Academic Advising System. Int. J. Human–Comput. Interact. 2023, 39, 2115–2141. [Google Scholar] [CrossRef]
- Ball, R.; Duhadway, L.; Feuz, K.; Jensen, J.; Rague, B.; Weidman, D. Applying Machine Learning to Improve Curriculum Design. In Proceedings of the 50th ACM Technical Symposium on Computer Science Education, Minneapolis, MN, USA, 27 February–2 March 2019; SIGCSE ’19. Association for Computing Machinery: New York, NY, USA, 2019; pp. 787–793. [Google Scholar] [CrossRef]
- Gordon, V.N.; Habley, W.R.; Grites, T.J. Academic Advising: A Comprehensive Handbook; John Wiley & Son: Hoboken, NJ, USA, 2011. [Google Scholar]
- Daramola, O.; Emebo, O.; Afolabi, I.; Ayo, C. Implementation of an Intelligent Course Advisory Expert System. Int. J. Adv. Res. Artif. Intell. 2014, 3, 6–12. [Google Scholar] [CrossRef]
- Soares, A.P.; Guisande, A.M.; Almeida, L.S.; Páramo, F.M. Academic achievement in first-year Portuguese college students: The role of academic preparation and learning strategies. Int. J. Psychol. 2009, 44, 204–212. [Google Scholar] [CrossRef] [PubMed]
- Vulperhorst, J.; Lutz, C.; De Kleijn, R.; Van Tartwijk, J. Disentangling the Predictive Validity of High School Grades for Academic Success in University. Assess. Eval. High. Educ. 2018, 43, 399–414. [Google Scholar] [CrossRef]
- Mengash, H.A. Using Data Mining Techniques to Predict Student Performance to Support Decision Making in University Admission Systems. IEEE Access 2020, 8, 55462–55470. [Google Scholar] [CrossRef]
- Maphosa, M.; Doorsamy, W.; Paul, B. A Review of Recommender Systems for Choosing Elective Courses. Int. J. Adv. Comput. Sci. Appl. IJACSA 2020, 11, 287–295. [Google Scholar] [CrossRef]
- Maphosa, M.; Doorsamy, W.; Paul, B.S. Factors Influencing Students’ Choice of and Success in STEM: A Bibliometric Analysis and Topic Modeling Approach. IEEE Trans. Educ. 2022, 65, 657–669. [Google Scholar] [CrossRef]
- Maphosa, M.; Doorsamy, W.; Paul, B.S. Student Performance Patterns in Engineering at the University of Johannesburg: An Exploratory Data Analysis. IEEE Access 2023, 11, 48977–48987. [Google Scholar] [CrossRef]
- Nachouki, M.; Naaj, M.A. Predicting Student Performance to Improve Academic Advising Using the Random Forest Algorithm. Int. J. Distance Educ. Technol. 2022, 20, 1–17. [Google Scholar] [CrossRef]
- Albreiki, B.; Zaki, N.; Alashwal, H. A Systematic Literature Review of Student’ Performance Prediction Using Machine Learning Techniques. Educ. Sci. 2021, 11, 552. [Google Scholar] [CrossRef]
- Haixiang, G.; Yijing, L.; Shang, J.; Mingyun, G.; Yuanyue, H.; Bing, G. Learning from Class-Imbalanced Data: Review of Methods and Applications. Expert Syst. Appl. 2017, 73, 220–239. [Google Scholar] [CrossRef]
- Rahman, S.R.; Islam, M.A.; Akash, P.P.; Parvin, M.; Moon, N.N.; Nur, F.N. Effects of Co-Curricular Activities on Student’s Academic Performance by Machine Learning. Curr. Res. Behav. Sci. 2021, 2, 100057. [Google Scholar] [CrossRef]
- Assiri, A.; AL-Ghamdi, A.A.-M.; Brdesee, H. From Traditional to Intelligent Academic Advising: A Systematic Literature Review of e-Academic Advising. Int. J. Adv. Comput. Sci. Appl. IJACSA 2020, 11, 507–517. [Google Scholar] [CrossRef]
- Noaman, A.Y.; Ahmed, F.F. A New Framework for E Academic Advising. Procedia Comput. Sci. 2015, 65, 358–367. [Google Scholar] [CrossRef]
- Coleman, M.; Charmatz, K.; Cook, A.; Brokloff, S.E.; Matthews, K. From the Classroom to the Advising Office: Exploring Narratives of Advising as Teaching. NACADA Rev. 2021, 2, 36–46. [Google Scholar] [CrossRef]
- Mottarella, K.E.; Fritzsche, B.A.; Cerabino, K.C. What Do Students Want in Advising? A Policy Capturing Study. NACADA J. 2004, 24, 48–61. [Google Scholar] [CrossRef][Green Version]
- Zulkifli, F.; Mohamed, Z.; Azmee, N. Systematic Research on Predictive Models on Students’ Academic Performance in Higher Education. Int. J. Recent Technol. Eng. 2019, 8, 357–363. [Google Scholar] [CrossRef]
- Shahiri, A.M.; Husain, W.; Rashid, N.A. A Review on Predicting Student’s Performance Using Data Mining Techniques. Procedia Comput. Sci. 2015, 72, 414–422. [Google Scholar] [CrossRef]
- Putpuek, N.; Rojanaprasert, N.; Atchariyachanvanich, K.; Thamrongthanyawong, T. Comparative Study of Prediction Models for Final GPA Score: A Case Study of Rajabhat Rajanagarindra University. In Proceedings of the 2018 IEEE/ACIS 17th International Conference on Computer and Information Science (ICIS), Singapore, 6–8 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 92–97. [Google Scholar]
- Aluko, R.O.; Daniel, E.I.; Oshodi, O.S.; Aigbavboa, C.O.; Abisuga, A.O. Towards Reliable Prediction of Academic Performance of Architecture Students Using Data Mining Techniques. J. Eng. Des. Technol. 2018, 16, 385–397. [Google Scholar] [CrossRef]
- Singh, W.; Kaur, P. Comparative Analysis of Classification Techniques for Predicting Computer Engineering Students’ Academic Performance. Int. J. Adv. Res. Comput. Sci. 2016, 7, 31–36. [Google Scholar]
- Anuradha, C.; Velmurugan, T. A Comparative Analysis on the Evaluation of Classification Algorithms in the Prediction of Students Performance. Indian J. Sci. Technol. 2015, 8, 1–12. [Google Scholar] [CrossRef]
- Guo, B.; Zhang, R.; Xu, G.; Shi, C.; Yang, L. Predicting Students Performance in Educational Data Mining. In 2015 International Symposium on Educational Technology (ISET); IEEE: Wuhan, China, 2015; pp. 125–128. [Google Scholar] [CrossRef]
- Iatrellis, O.; Kameas, A.; Fitsilis, P. Academic Advising Systems: A Systematic Literature Review of Empirical Evidence. Educ. Sci. 2017, 7, 90. [Google Scholar] [CrossRef]
- Manouselis, N.; Drachsler, H.; Verbert, K.; Duval, E. Recommender Systems for Learning; SpringerBriefs in Electrical and Computer Engineering; Springer: New York, NY, USA, 2013. [Google Scholar] [CrossRef]
- Wu, Z.; Lin, W.; Ji, Y. An Integrated Ensemble Learning Model for Imbalanced Fault Diagnostics and Prognostics. IEEE Access 2018, 6, 8394–8402. [Google Scholar] [CrossRef]
- Elreedy, D.; Atiya, A.F. A Comprehensive Analysis of Synthetic Minority Oversampling Technique (SMOTE) for Handling Class Imbalance. Inf. Sci. 2019, 505, 32–64. [Google Scholar] [CrossRef]
- Barua, S.; Islam, M.M.; Murase, K. A Novel Synthetic Minority Oversampling Technique for Imbalanced Data Set Learning. In Neural Information Processing; Lu, B.-L., Zhang, L., Kwok, J., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2011; pp. 735–744. [Google Scholar] [CrossRef]
- Prati, R.C.; Batista, G.E.; Monard, M.C. Data Mining with Imbalanced Class Distributions: Concepts and Methods. In Proceedings of the 4th Indian International Conference on Artificial Intelligence, Tumkur, India, 16–18 December 2009; pp. 359–376. [Google Scholar]
- Fernández-García, A.J.; Rodríguez-Echeverría, R.; Preciado, J.C.; Manzano, J.M.C.; Sánchez-Figueroa, F. Creating a Recommender System to Support Higher Education Students in the Subject Enrollment Decision. IEEE Access 2020, 8, 189069–189088. [Google Scholar] [CrossRef]
- Sothan, S. The Determinants of Academic Performance: Evidence from a Cambodian University. Stud. High. Educ. 2019, 44, 2096–2111. [Google Scholar] [CrossRef]
- Kamiran, F.; Calders, T. Classifying without Discriminating. In Proceedings of the 2009 2nd International Conference on Computer, Control and Communication, Karachi, Pakistan, 17–18 February 2009; IEEE: Karachi, Pakistan, 2009; pp. 1–6. [Google Scholar] [CrossRef]
- Gębka, B. Psychological Determinants of University Students’ Academic Performance: An Empirical Study. J. Furth. High. Educ. 2014, 38, 813–837. [Google Scholar] [CrossRef]
- Maphosa, M.; Maphosa, V. Educational Data Mining in Higher Education in Sub-Saharan Africa: A Systematic Literature Review and Research Agenda. In Proceedings of the 2nd International Conference on Intelligent and Innovative Computing Applications; ICONIC ’20, Plaine Magnien, Mauritius, 24–25 September 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 1–7. [Google Scholar] [CrossRef]
- Petwal, S.; John, K.S.; Vikas, G.; Rawat, S.S. Recommender System for Analyzing Students’ Performance Using Data Mining Technique. In Data Science and Security; Jat, D.S., Shukla, S., Unal, A., Mishra, D.K., Eds.; Lecture Notes in Networks and Systems; Springer: Singapore, 2021; pp. 185–191. [Google Scholar] [CrossRef]
- Arunkumar, N.M.; Miriam A, A. Automated Student Performance Analyser and Recommender. Int. J. Adv. Res. Comput. Sci. 2018, 9, 688–698. [Google Scholar] [CrossRef]
- Cassel, M.; Lima, F. Evaluating One-Hot Encoding Finite State Machines for SEU Reliability in SRAM-Based FPGAs. In Proceedings of the 12th IEEE International On-Line Testing Symposium (IOLTS’06), Lake Como, Italy, 10–12 July 2006; pp. 1–6. [Google Scholar] [CrossRef]
- Yao, S.; Huang, B. New Fairness Metrics for Recommendation That Embrace Differences. arXiv 2017. Available online: http://arxiv.org/abs/1706.09838 (accessed on 30 October 2023).
- Obeid, C.; Lahoud, I.; El Khoury, H.; Champin, P.-A. Ontology-Based Recommender System in Higher Education. In Companion Proceedings of the The Web Conference 2018, Lyon France, 23–27 April 2018; WWW ’18; International World Wide Web Conferences Steering Committee: Geneva, Switzerland, 2018; pp. 1031–1034. [Google Scholar] [CrossRef]
- Cerda, P.; Varoquaux, G.; Kégl, B. Similarity Encoding for Learning with Dirty Categorical Variables. Mach. Learn. 2018, 107, 1477–1494. [Google Scholar] [CrossRef]
- Ozsahin, D.U.; Mustapha, M.T.; Mubarak, A.S.; Ameen, Z.S.; Uzun, B. Impact of Feature Scaling on Machine Learning Models for the Diagnosis of Diabetes. In Proceedings of the 2022 International Conference on Artificial Intelligence in Everything (AIE), Lefkosa, Cyprus, 2–4 August 2022; pp. 87–94. [Google Scholar] [CrossRef]
- Seiffert, C.; Khoshgoftaar, T.M.; Van Hulse, J. Improving Software-Quality Predictions with Data Sampling and Boosting. IEEE Trans. Syst. Man Cybern. Part Syst. Hum. 2009, 39, 1283–1294. [Google Scholar] [CrossRef]
- Huynh-Cam, T.-T.; Chen, L.-S.; Le, H. Using Decision Trees and Random Forest Algorithms to Predict and Determine Factors Contributing to First-Year University Students’ Learning Performance. Algorithms 2021, 14, 318. [Google Scholar] [CrossRef]
- Alsubihat, D.; Al-shanableh, D.N. Predicting Student’s Performance Using Combined Heterogeneous Classification Models. Int. J. Eng. Res. Appl. 2023, 13, 206–218. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Charbuty, B.; Abdulazeez, A. Classification Based on Decision Tree Algorithm for Machine Learning. J. Appl. Sci. Technol. Trends 2021, 2, 20–28. [Google Scholar] [CrossRef]
- Hosmer, D.W.; Lemeshow, S.; Sturdivant, R.X. Applied Logistic Regression, 1st ed.; Wiley Series in Probability and Statistics; Wiley: Hoboken, NJ, USA, 2013. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NW, USA, 2017; Volume 30. [Google Scholar]
- Lorena, A.C.; Jacintho, L.F.O.; Siqueira, M.F.; Giovanni, R.D.; Lohmann, L.G.; de Carvalho, A.C.P.L.F.; Yamamoto, M. Comparing Machine Learning Classifiers in Potential Distribution Modelling. Expert Syst. Appl. 2011, 38, 5268–5275. [Google Scholar] [CrossRef]
- Athey, S.; Tibshirani, J.; Wager, S. Generalized Random Forests. Ann. Stat. 2019, 47, 1148–1178. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; KDD ’16. Association for Computing Machinery: New York, NY, USA, 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Ferri, C.; Hernández-Orallo, J.; Modroiu, R. An Experimental Comparison of Performance Measures for Classification. Pattern Recognit. Lett. 2009, 30, 27–38. [Google Scholar] [CrossRef]
- Sokolova, M.; Lapalme, G. A Systematic Analysis of Performance Measures for Classification Tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Isinkaye, F.O.; Folajimi, Y.O.; Ojokoh, B.A. Recommendation Systems: Principles, Methods and Evaluation. Egypt. Inform. J. 2015, 16, 261–273. [Google Scholar] [CrossRef]
- Goldberg, K.; Roeder, T.; Gupta, D.; Perkins, C. Eigentaste: A Constant Time Collaborative Filtering Algorithm. Inf. Retr. 2001, 4, 133–151. [Google Scholar] [CrossRef]
- Kumar, S.; Gupta, P. Comparative Analysis of Intersection Algorithms on Queries Using Precision, Recall and F-Score. Int. J. Comput. Appl. 2015, 130, 28–36. [Google Scholar] [CrossRef]
- Ben-David, A. About the Relationship between ROC Curves and Cohen’s Kappa. Eng. Appl. Artif. Intell. 2008, 21, 874–882. [Google Scholar] [CrossRef]
- Kleiman, R.; Page, D. AUCμ: A Performance Metric for Multi-Class Machine Learning Models. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; PMLR. pp. 3439–3447. [Google Scholar]
- Aldino, A.A.; Saputra, A.; Nurkholis, A.; Setiawansyah, S. Application of Support Vector Machine (SVM) Algorithm in Classification of Low-Cape Communities in Lampung Timur. Build. Inform. Technol. Sci. BITS 2021, 3, 325–330. [Google Scholar] [CrossRef]
- Saarela, M.; Jauhiainen, S. Comparison of Feature Importance Measures as Explanations for Classification Models. SN Appl. Sci. 2021, 3, 272. [Google Scholar] [CrossRef]
- Dibbs, R. Forged in Failure: Engagement Patterns for Successful Students Repeating Calculus. Educ. Stud. Math. 2019, 101, 35–50. [Google Scholar] [CrossRef]
- Al-kmali, M.; Mugahed, H.; Boulila, W.; Al-Sarem, M.; Abuhamdah, A. A Machine-Learning Based Approach to Support Academic Decision-Making at Higher Educational Institutions. In Proceedings of the 2020 International Symposium on Networks, Computers and Communications (ISNCC), Montreal, QC, Canada, 20–22 October 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Johndrow, J.E.; Lum, K. An Algorithm for Removing Sensitive Information: Application to Race-Independent Recidivism Prediction. arXiv 2017. [Google Scholar] [CrossRef]
- Gutiérrez, F.; Seipp, K.; Ochoa, X.; Chiluiza, K.; De Laet, T.; Verbert, K. LADA: A Learning Analytics Dashboard for Academic Advising. Comput. Hum. Behav. 2020, 107, 105826. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Purpose | Advantages | Disadvantages |
|---|---|---|---|
| [1] | Addresses the concern of student retention in engineering and built environment programmes. | Provides insights into the factors influencing student persistence and attrition in higher education. | Does not investigate the relationship between emotional factors and academic performance in voluntary withdrawals. |
| [23] | To enhance students’ success and benefit educators and academic institutions. | We have identified the most suitable prediction methods for predicting students’ performance. | Lack of investigations on the factors affecting students’ achievements in particular courses within the Malaysian context |
| [31] | Proposes an imbalance learning algorithm that uses Synthetic Minority Over-sampling Technique (SMOTE) to augment minority faulty classes and to address the imbalanced class learning problem. | Addresses the issue of imbalanced distributions, leading to more precise fault diagnostics and prognostics in industrial systems. | Does not explicitly mention any disadvantages or limitations of the algorithm or the research approach used. |
| [32] | Investigates the accuracy of SMOTE in replicating the original data distribution and evaluates its impact on classification boundaries and overall performance. | Provides a comprehensive theoretical analysis of the popular over-sampling method, SMOTE, which needs to be improved in the literature. | There’s a point where bias becomes more critical than variance, indicating the need to stop generating more data. |
| [40] | Employs the K-means clustering algorithm to classify students into performance-based clusters. | Aids students and instructors in pinpointing areas for improvement. | Needs to provide specific information about the dataset size used to analyse students’ performance. |
| [41] | Introduces an automated student performance analyser and recommender system using prediction algorithms and content-based recommendations. | Employs an automated data visualiser to illustrate students’ performance, showcasing their strengths and weaknesses. | Does not fully implement automation, with room for improvements, such as automating processes like attendance checking. |
| Column | Description | Count | Data Type |
|---|---|---|---|
| Academic Year | Year of registration | 29,158 | Int8 |
| Student Number | Student’s unique identifier | 29,158 | Int16 |
| Qualification Flag | Type of qual (mainstream or extended) | 29,158 | Int8 |
| Qualification | The qualification enrolled for | 29,158 | Int8 |
| Result Groupings | Student’s results for the year | 29,158 | Int8 |
| Period of Study | Student’s year of study | 29,158 | Int8 |
| Gender | Student’s gender | 29,158 | Int8 |
| Birthdate | Student’s date of birth | 29,158 | Int16 |
| Marital Status | Student’s marital status | 29,158 | Int8 |
| Language | Student’s native language | 29,158 | Int8 |
| Nationality | Student’s country of birth | 29,158 | Int8 |
| Ethnic Group | Student’s ethnicity | 29,158 | Int8 |
| Race | Student’s race group | 29,158 | Int8 |
| APS | The student’s admission point score | 29,158 | Int8 |
| Urban-Rural | Student’s home location—urban or rural | 29,158 | Int8 |
| Study Address | Student’s residence | 29,158 | Int16 |
| Previous Activity | Student’s activity the previous year | 29,158 | Int8 |
| Matric Date Year | Year student completed matric | 29,158 | Int8 |
| Module Name | Name of module enrolled for | 29,158 | Int16 |
| Module Mark | Mark obtained from the module | 29,158 | Int8 |
| Mathematics | Mathematics mark in high school | 29,158 | Int8 |
| Physical Sciences | Science mark in high school | 29,158 | Int8 |
| Feature | Type | Classes/Value Range |
|---|---|---|
| Academic year | Categorical | 2 (2016, 2017) |
| Qualification flag | Categorical | 2 (mainstream, extended) |
| Qualification | Categorical | 8 (list of qualifications) |
| Result Grouping | Categorical | 5 (obtained qualification, continuing with studies, no/slow progress, no result, no readmission) |
| Period of study | Numerical | 4 (1, 2, 3, 4) |
| APS | Numerical | 18–46 |
| Previous activity | Categorical | 6 (employed, unemployed, grade 12, college, university, national service) |
| Module name | Categorical | 92 (list of modules) |
| Module mark | Numerical | 0–100 |
| Mathematics | Numerical | 0–100 |
| Physical Sciences | Numerical | 0–100 |
| Class | Before SMOTE | After SMOTE |
|---|---|---|
| May continue studies | 17,771 | 17,771 |
| No/slow progress | 2112 | 17,771 |
| Obtained qualification | 1320 | 17,771 |
| No re-admission | 655 | 17,771 |
| No result | 10 | 17,771 |
| Metric | Description |
|---|---|
| Accuracy | Measures the classification’s correctness. |
| Precision | Measures how accurately a classification is made. It represents a categorisation model’s capacity to return only pertinent instances. |
| Recall | Measures how accurately a classification was made. It represents a categorisation model’s capacity to find all pertinent examples. |
| F1 score | The standard harmonic mean of the precision and recall results in a single score representing the model’s quality. |
| MAE | Calculates the average square of the errors or the average square of the differences between the estimated and actual values. |
| RMSE | Indicates either the quadratic mean of these discrepancies or the square root of the second sample moment of the differences between expected and observed values. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Maphosa, M.; Doorsamy, W.; Paul, B. Improving Academic Advising in Engineering Education with Machine Learning Using a Real-World Dataset. Algorithms 2024, 17, 85. https://doi.org/10.3390/a17020085
Maphosa M, Doorsamy W, Paul B. Improving Academic Advising in Engineering Education with Machine Learning Using a Real-World Dataset. Algorithms. 2024; 17(2):85. https://doi.org/10.3390/a17020085
Chicago/Turabian StyleMaphosa, Mfowabo, Wesley Doorsamy, and Babu Paul. 2024. "Improving Academic Advising in Engineering Education with Machine Learning Using a Real-World Dataset" Algorithms 17, no. 2: 85. https://doi.org/10.3390/a17020085
APA StyleMaphosa, M., Doorsamy, W., & Paul, B. (2024). Improving Academic Advising in Engineering Education with Machine Learning Using a Real-World Dataset. Algorithms, 17(2), 85. https://doi.org/10.3390/a17020085