
Correntropy-Based Constructive One Hidden Layer Neural Network

 ,
,
Abstract
1. Introduction
- The proposed method is robust to non-Gaussian noises, especially impulse noise, since it takes advantage of the correntropy objective function. In particular, the Gaussian kernel provides better results than the sigmoid kernel. The reason for the robustness of the proposed method is discussed in Section 4 analytically, and in Section 5 experimentally.
- Most of the methods that employ correntropy as the objective function to adjust their parameters suffer from local solutions. In the proposed method, the amount of correntropy of the network is increased by adding new nodes and converging to its maximum; thus, the global solution is provided.
- The network size is determined automatically; consequently, the network does not suffer from over/underfitting, which results in satisfactory performance.
2. Mathematical Notations, Definitions and Preliminaries
2.1. Measure Space, Probability Space and Function Space
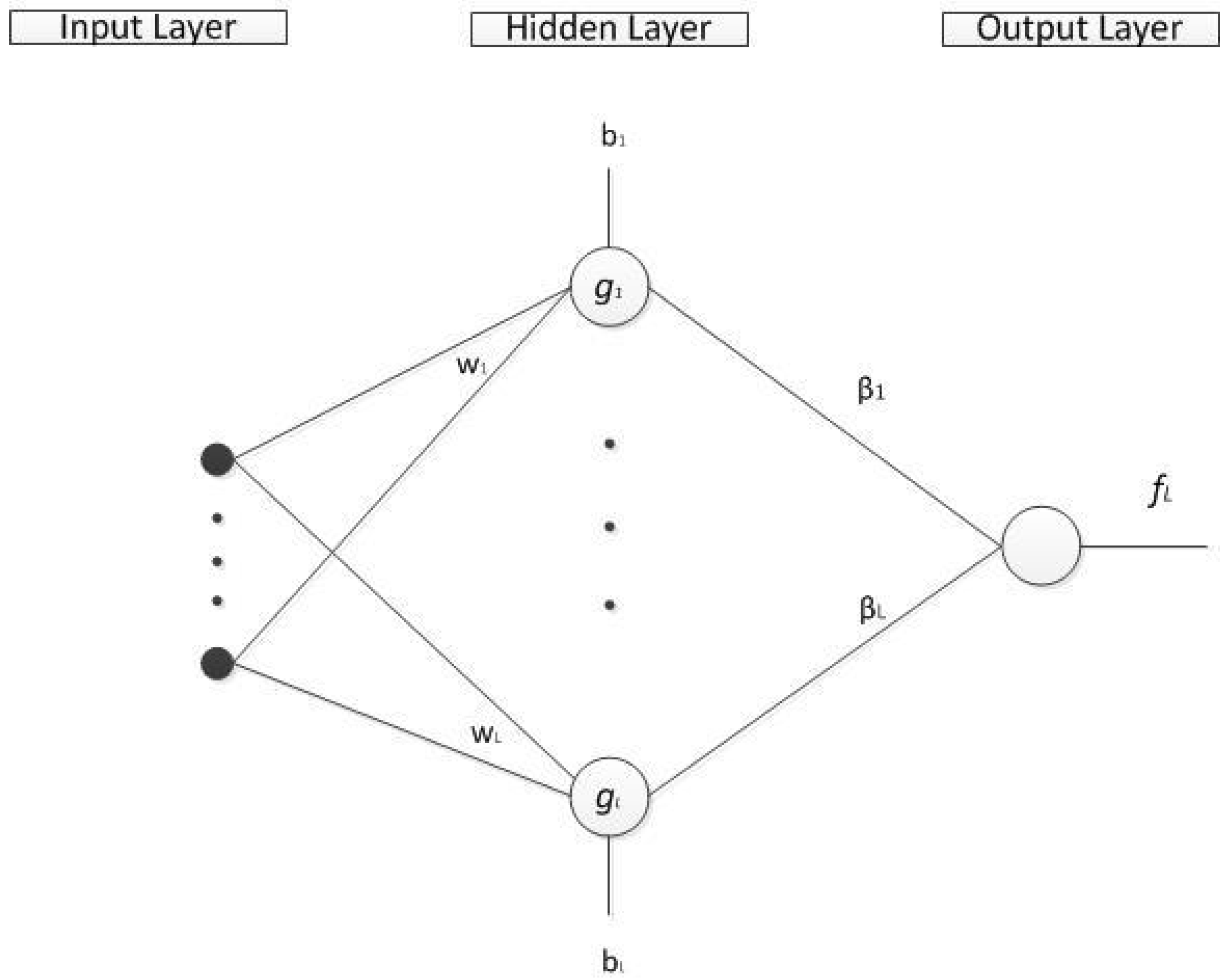
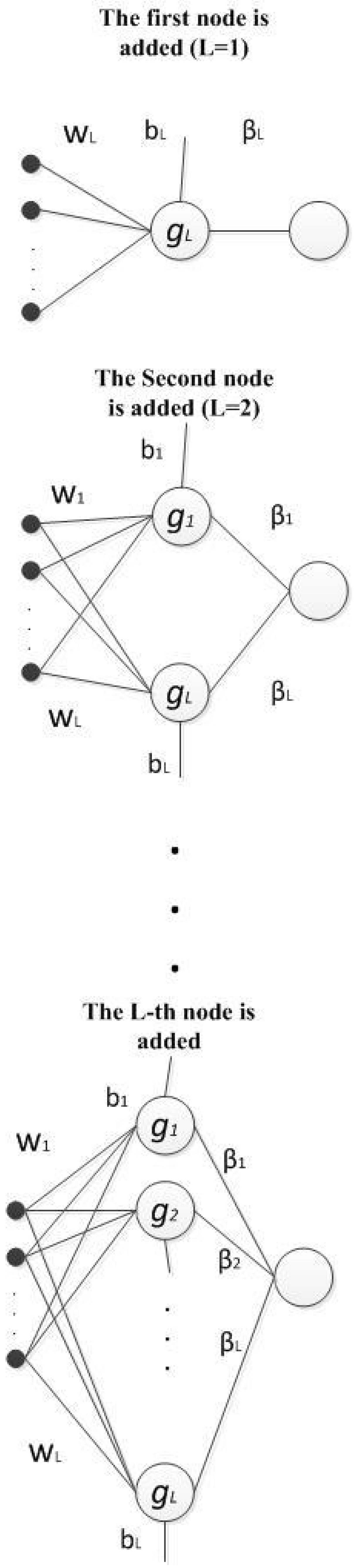
2.2. Network Structure
- For additive nodes
- 2.
- For RBF nodes
3. Previous Work
3.1. The Networks Introduced in [3]
3.2. Cascade Correntropy Network (CCOEN) [28]
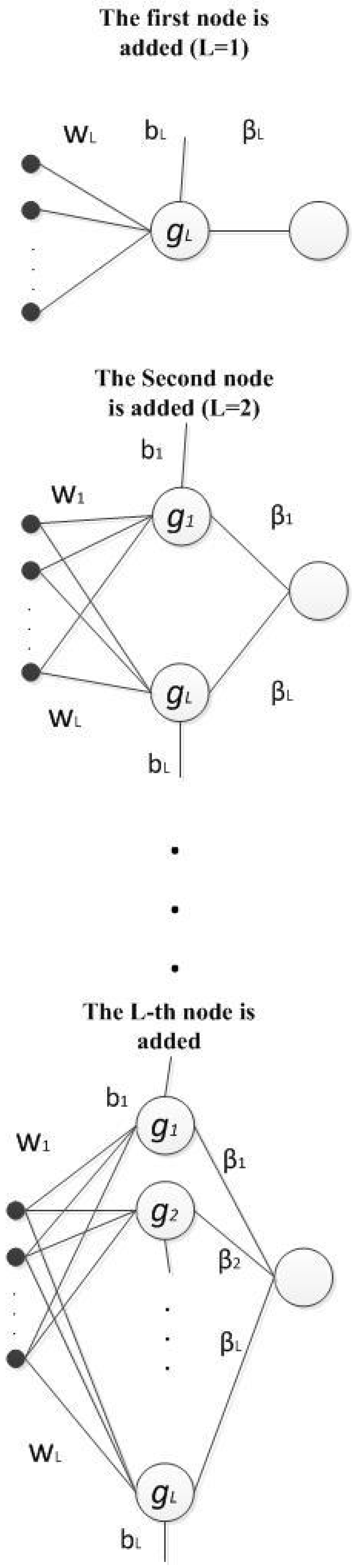
4. Proposed Method
4.1. Preliminaries for Presenting the Proposed Method
4.2. C2N2: Objective Function for Training the New Node
- In contrast to CCOEN, which uses correntropy with a sigmoid kernel to adjust the input parameters of a cascade network, the proposed method uses correntropy with a Gaussian kernel to adjust the whole parameters of an SLFN.
- CCOEN uses correntropy to adjust the input parameters of the new node in a cascade network to provide a more robust method. However, the output parameter of the new node in a cascade network is still adjusted based on the least mean square error. In contrast, the proposed method uses correntropy with Gaussian kernel to obtain both the input and output parameters of the new node in a constructive SLFN. Therefore, the proposed method is more robust than CCOEN and other networks introduced in [3] when the dataset is contaminated by impulsive noise.
- Employing Gaussian kernel for correntropy as the objective function to adjust the network’s parameters provides a closed-form formula introduced in the next section. In other words, both the input and output parameters are adjusted by two closed-form formulas.
4.3. Convergence Analysis
4.4. Learning from Data Samples
4.4.1. Input Side Optimization
4.4.2. Output Side Optimization
| Algorithm 1 C2N2 |
|
5. Experimental Results
5.1. Framework for Experiments
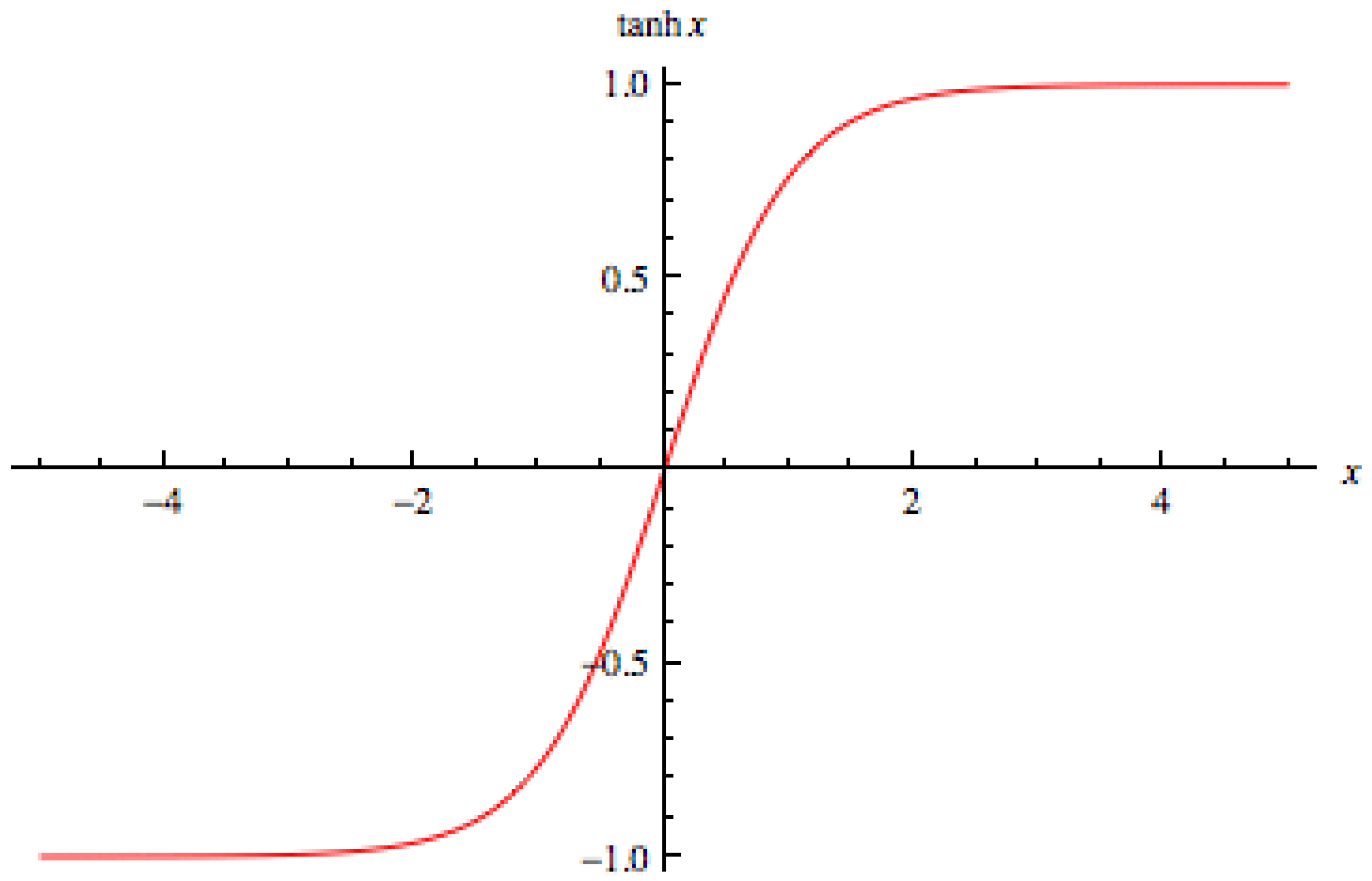
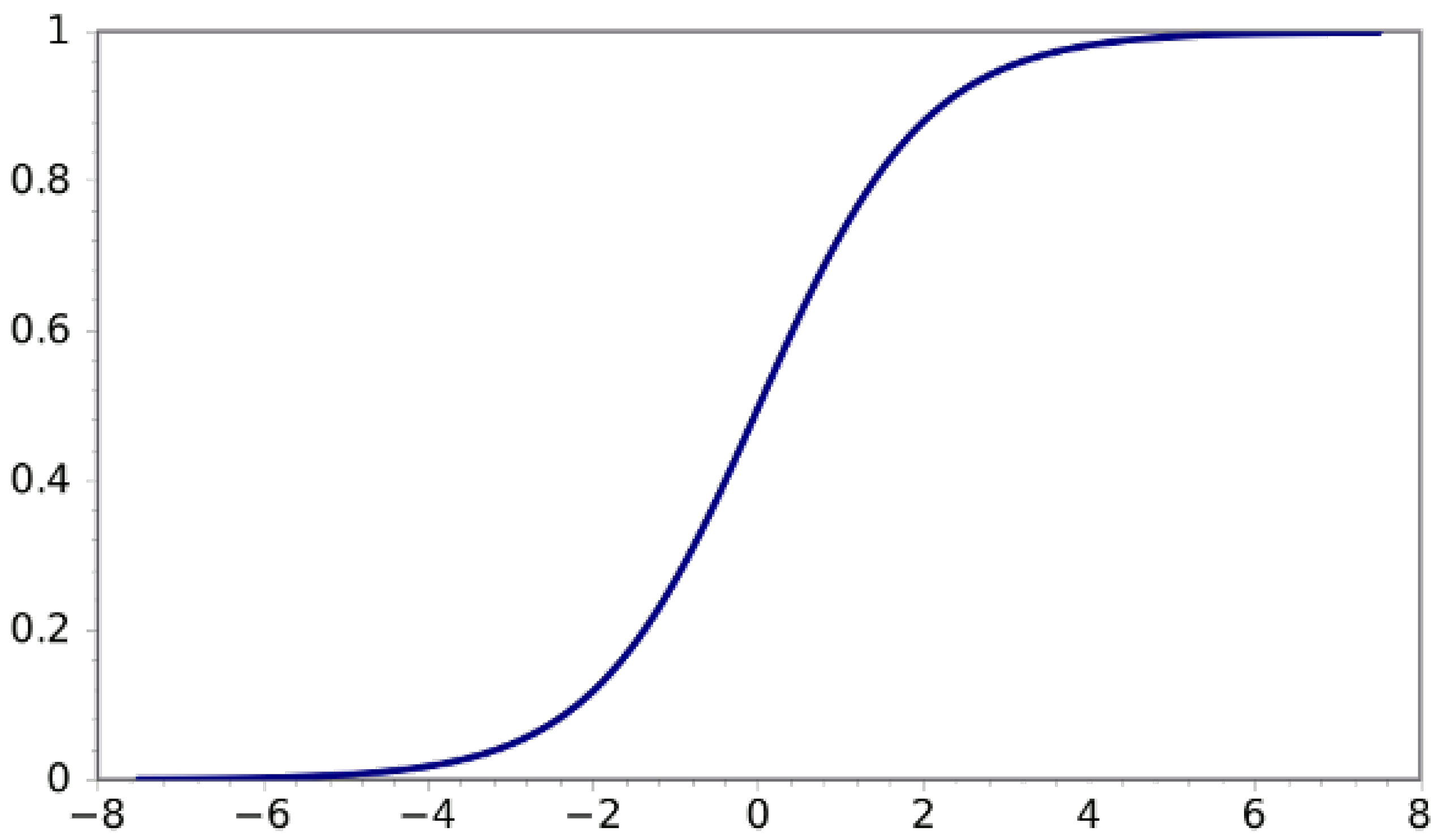
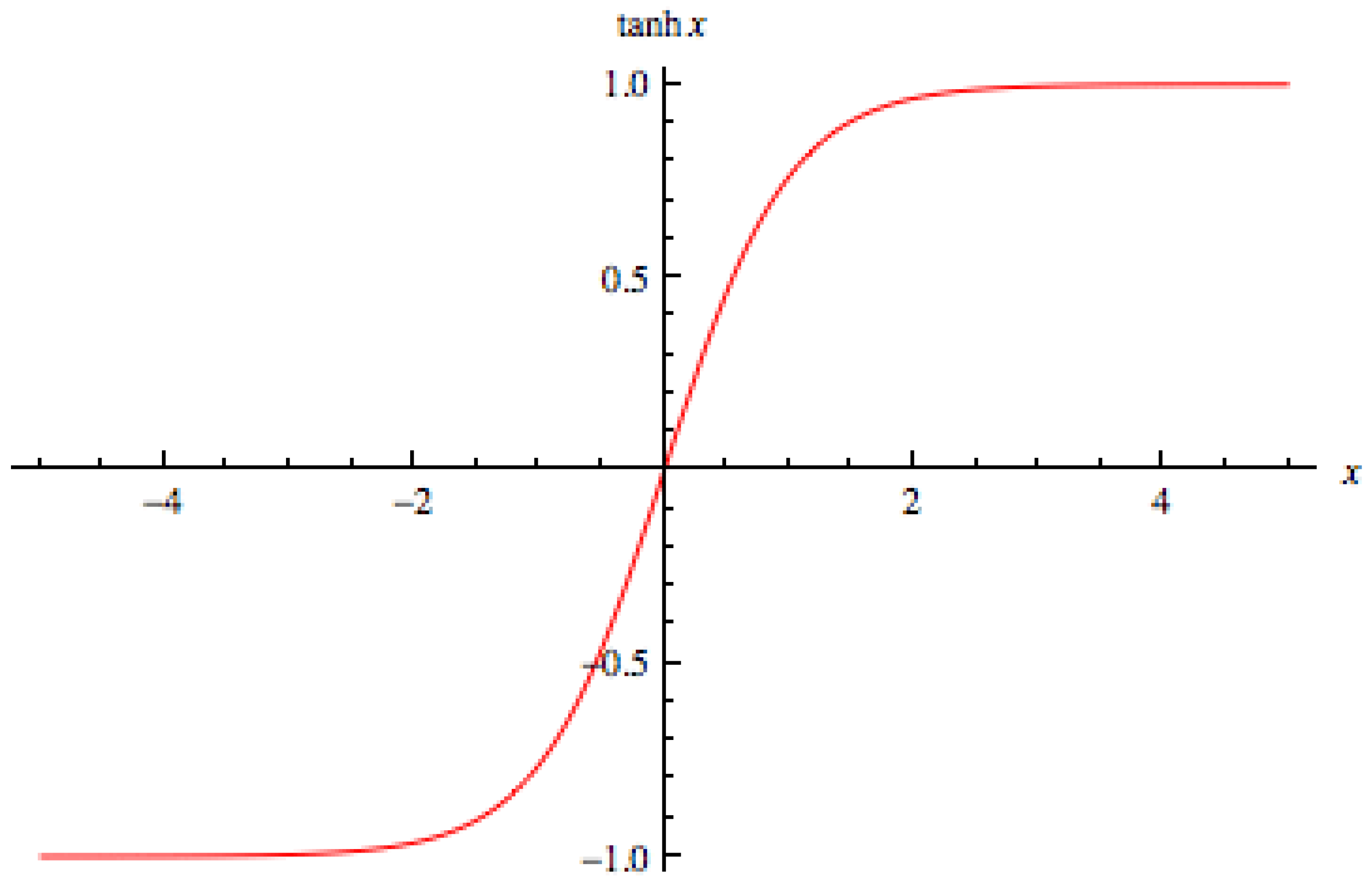
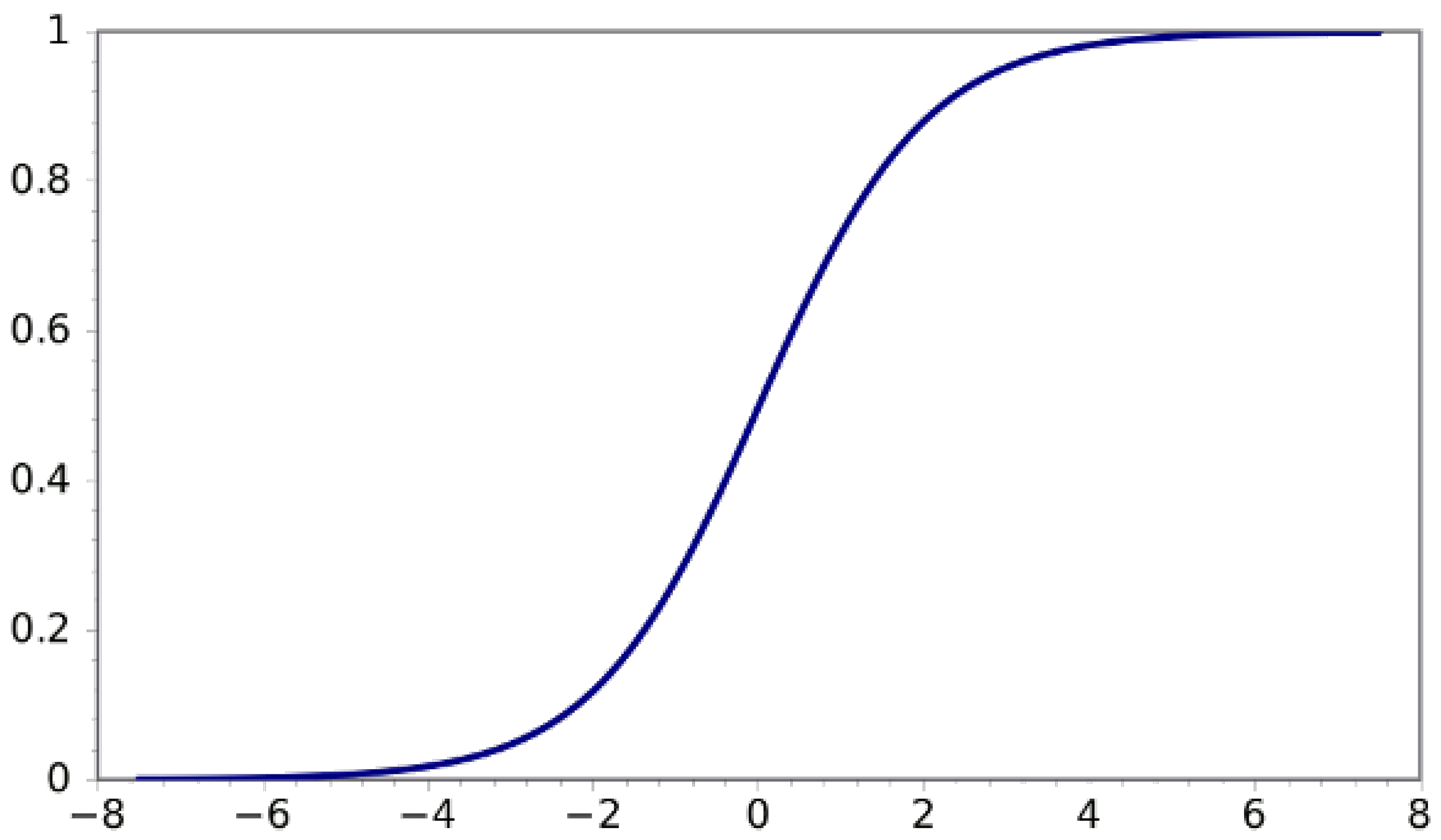
5.1.1. Activation Function and Kernel
5.1.2. Hyperparameters
5.1.3. Data Normalization
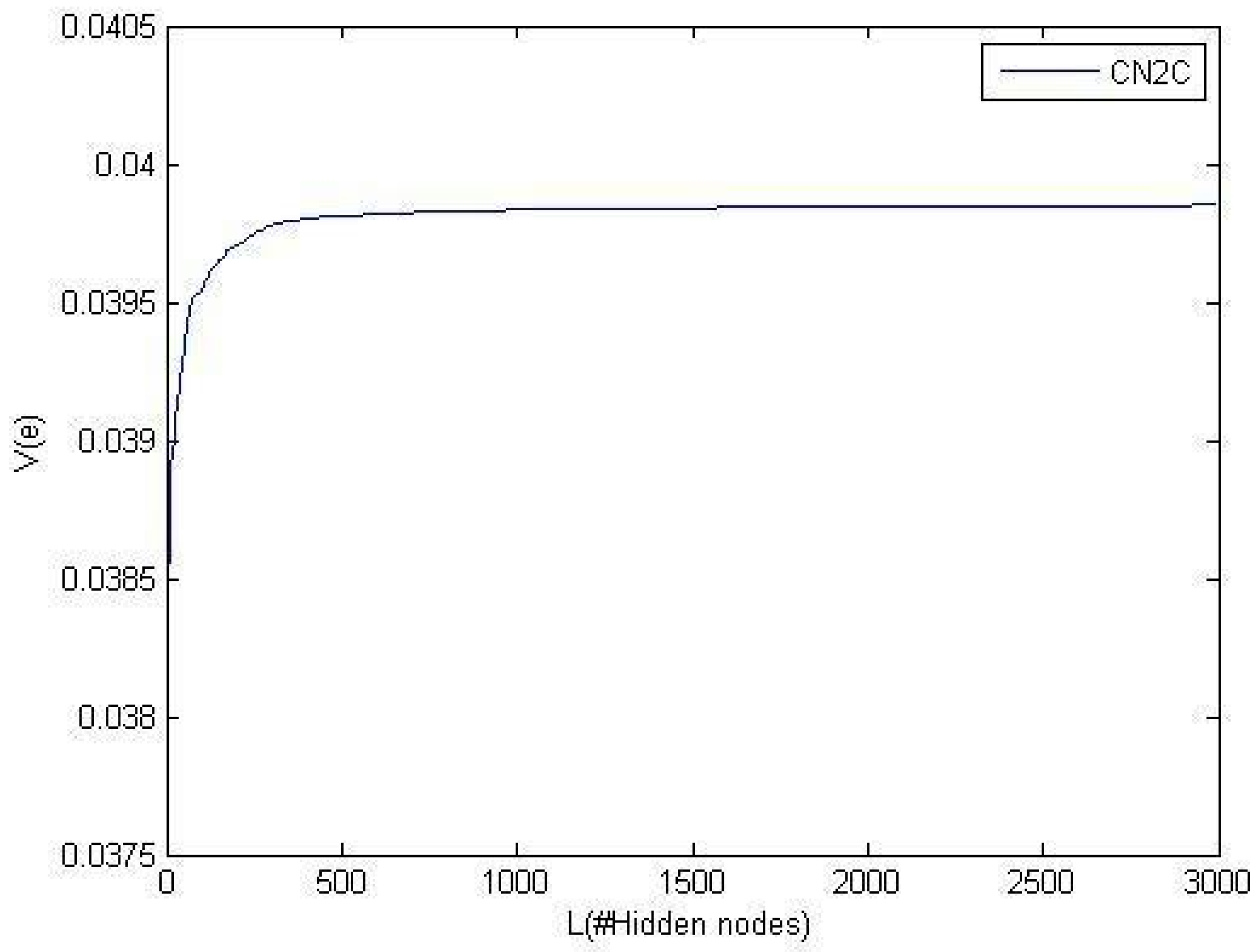
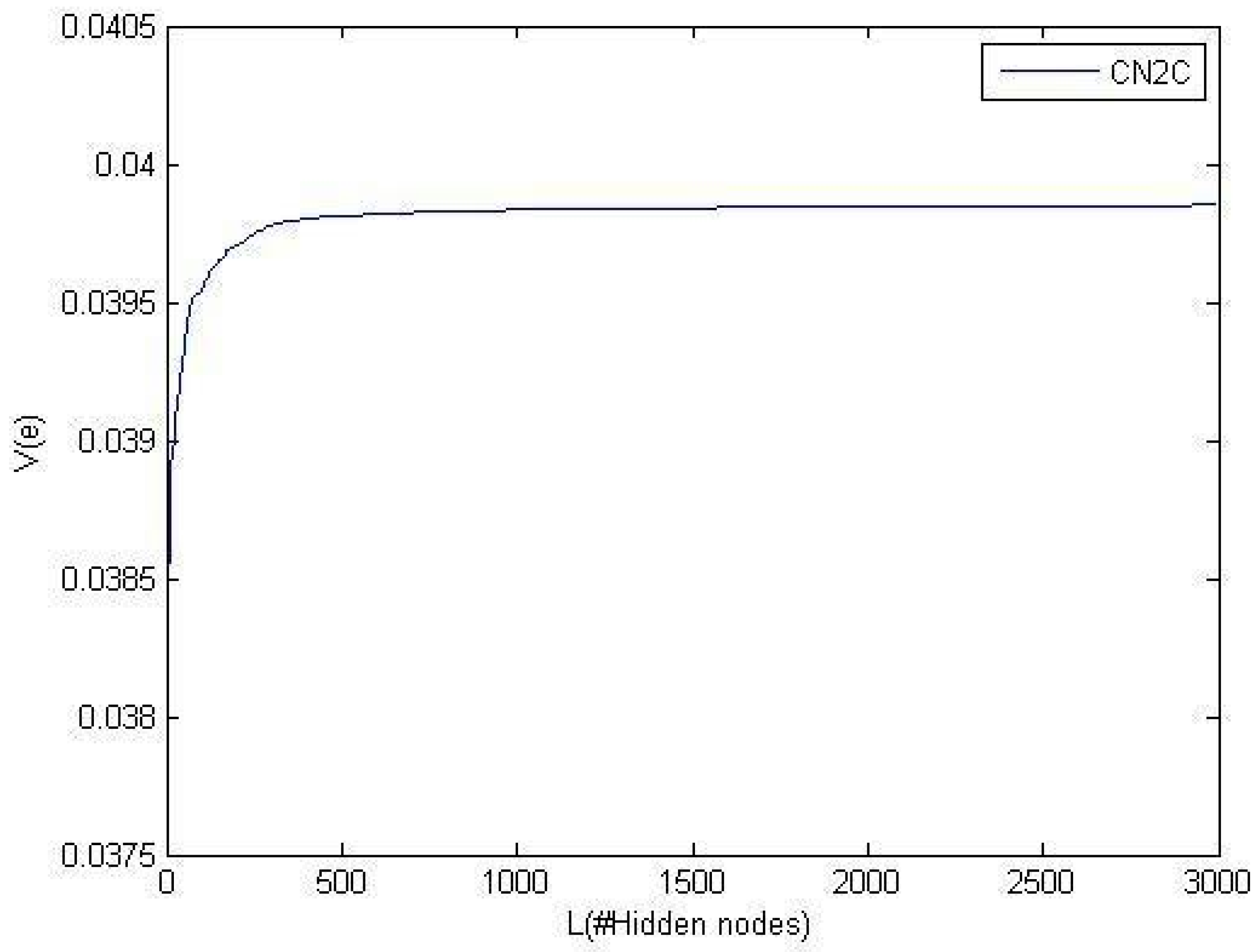
5.2. Convergence
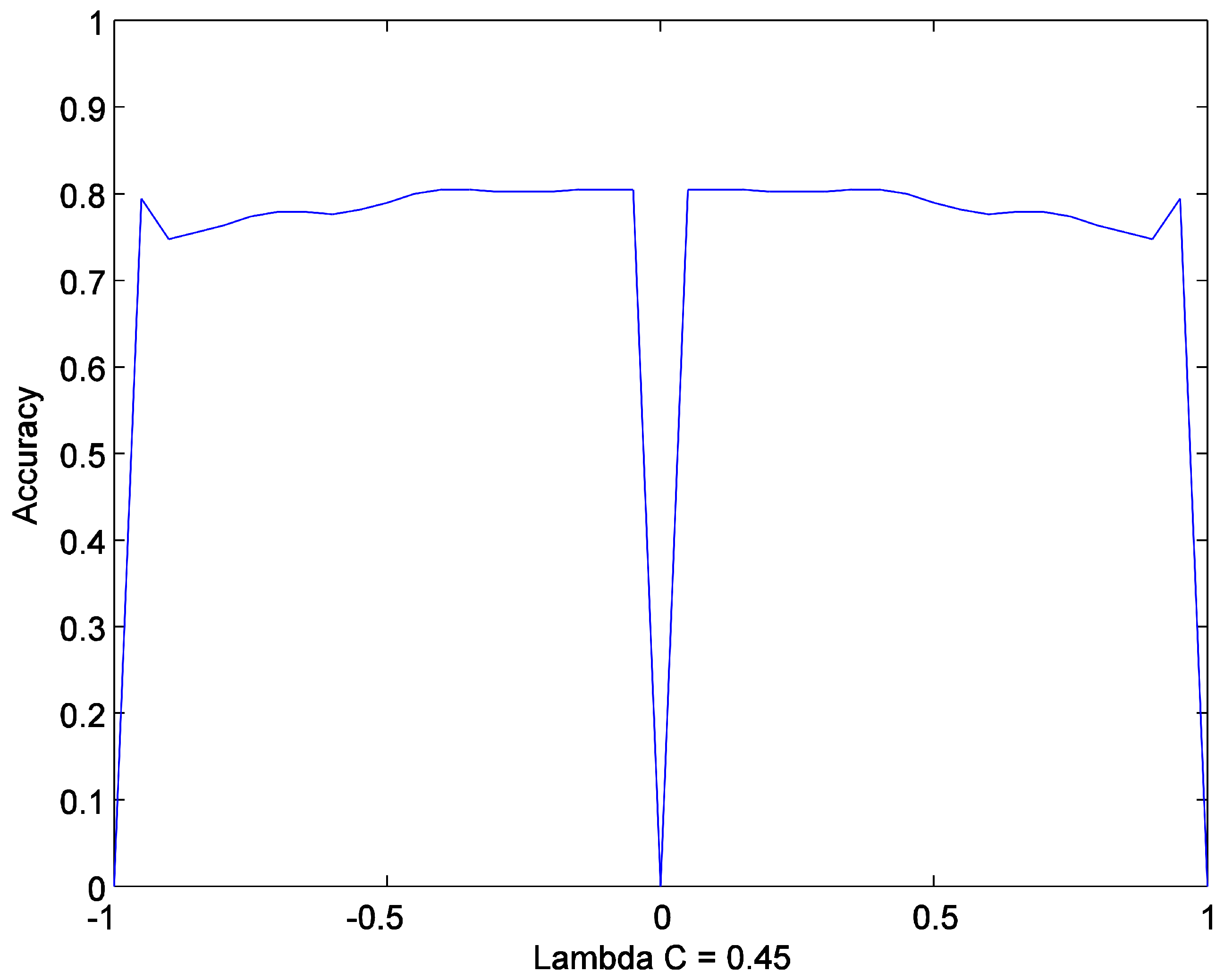
5.2.1. Investigation of Theorem 6
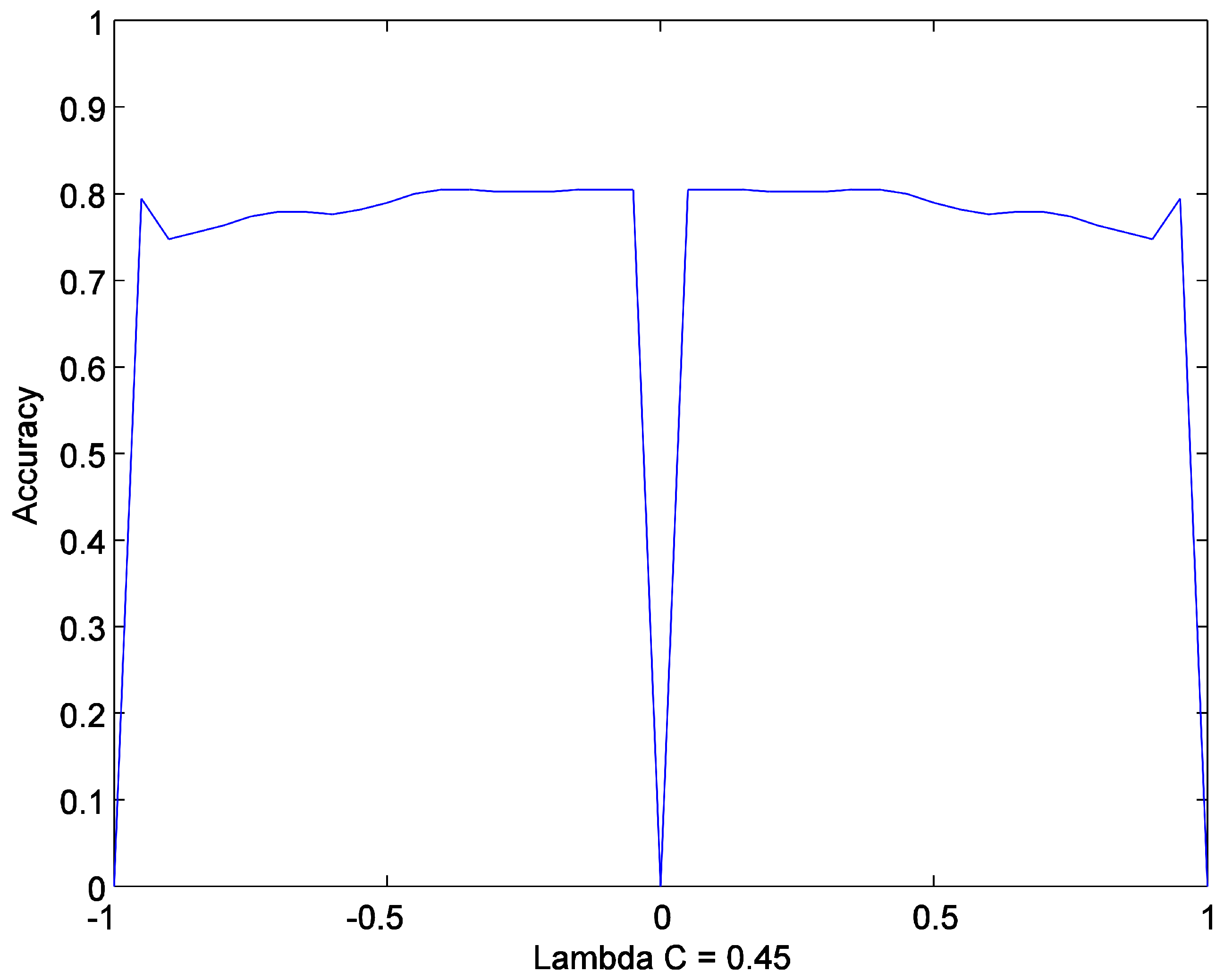
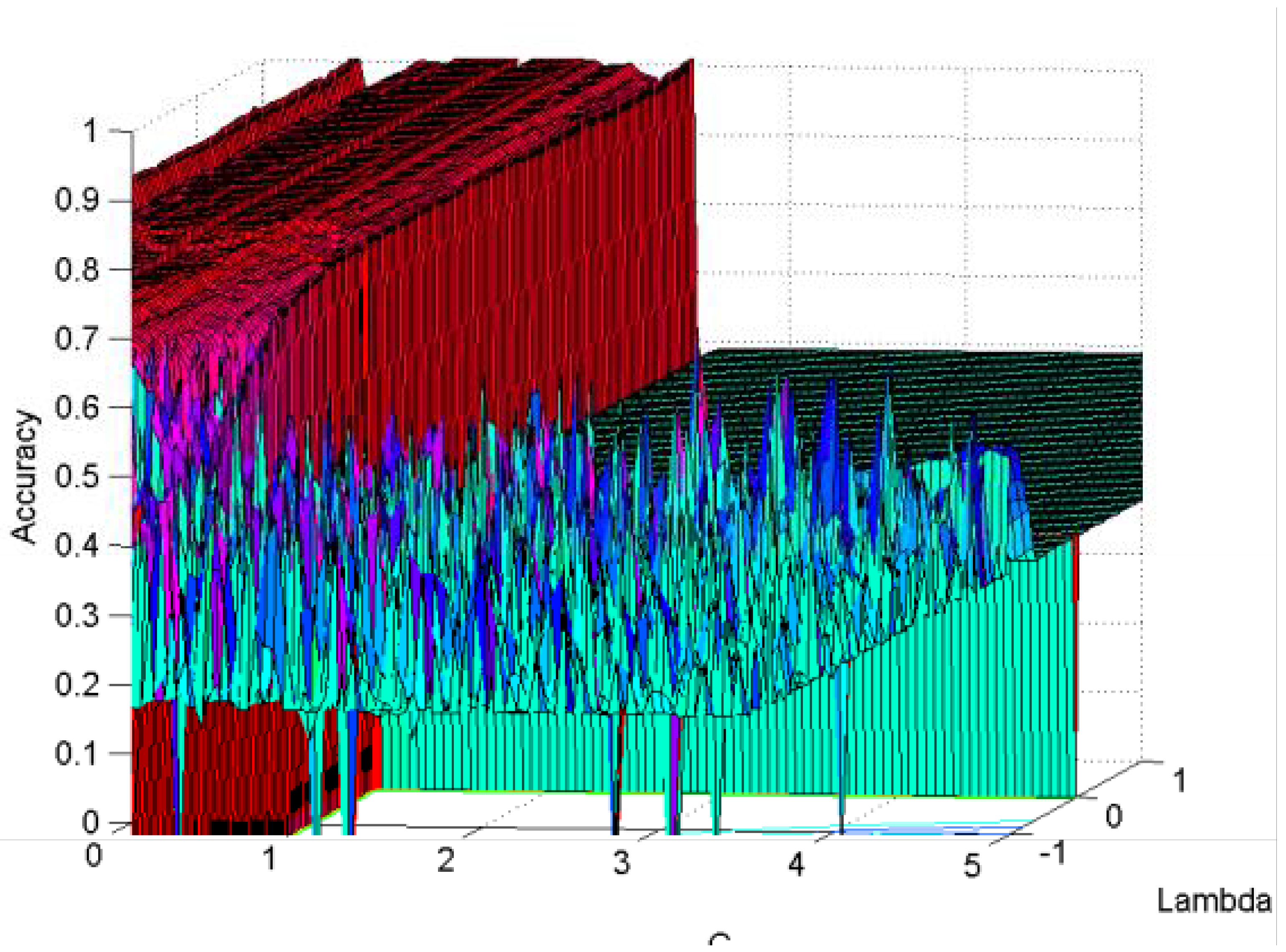
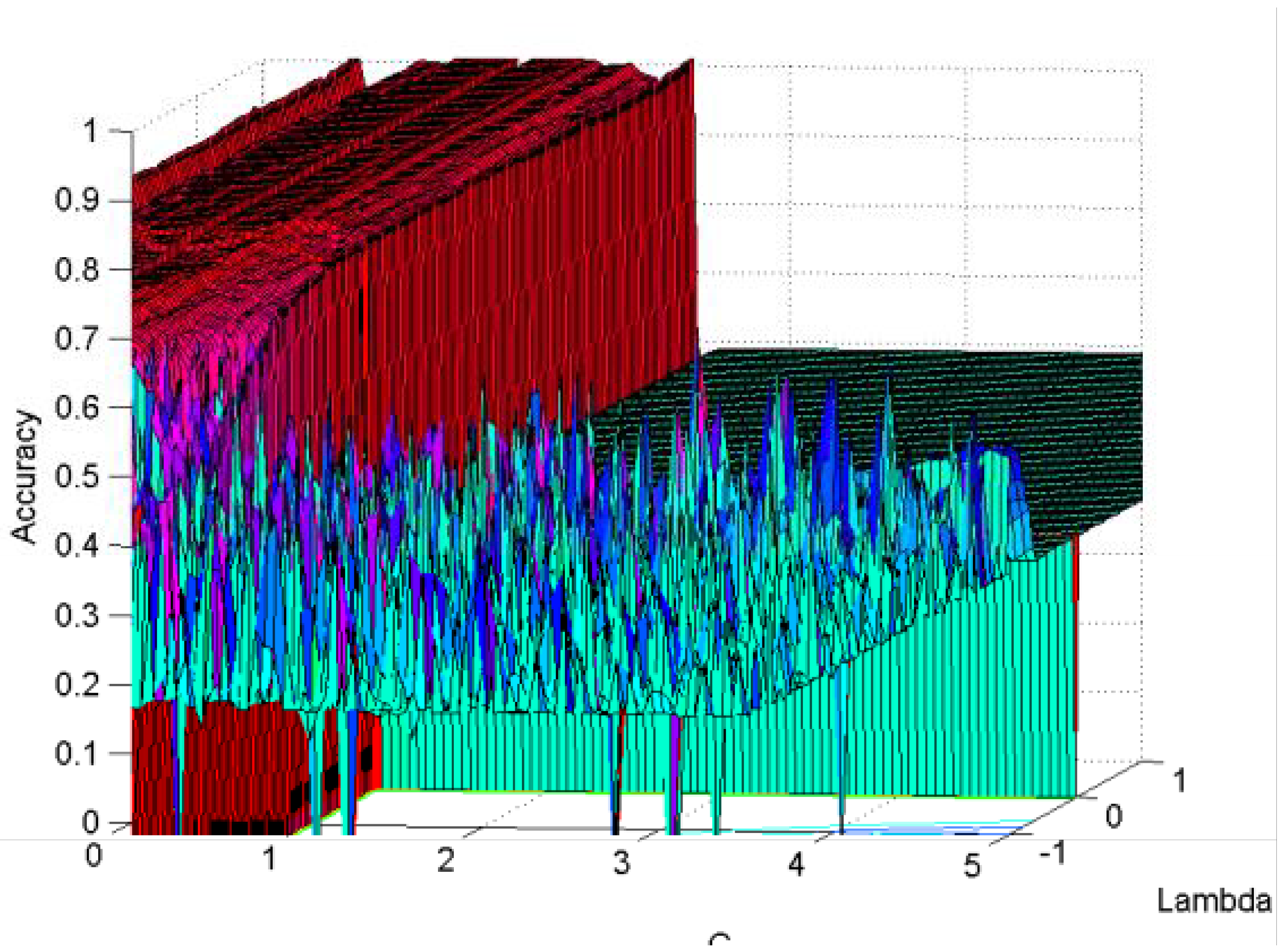
5.2.2. Hyperparameter Evaluation
5.3. Comparison
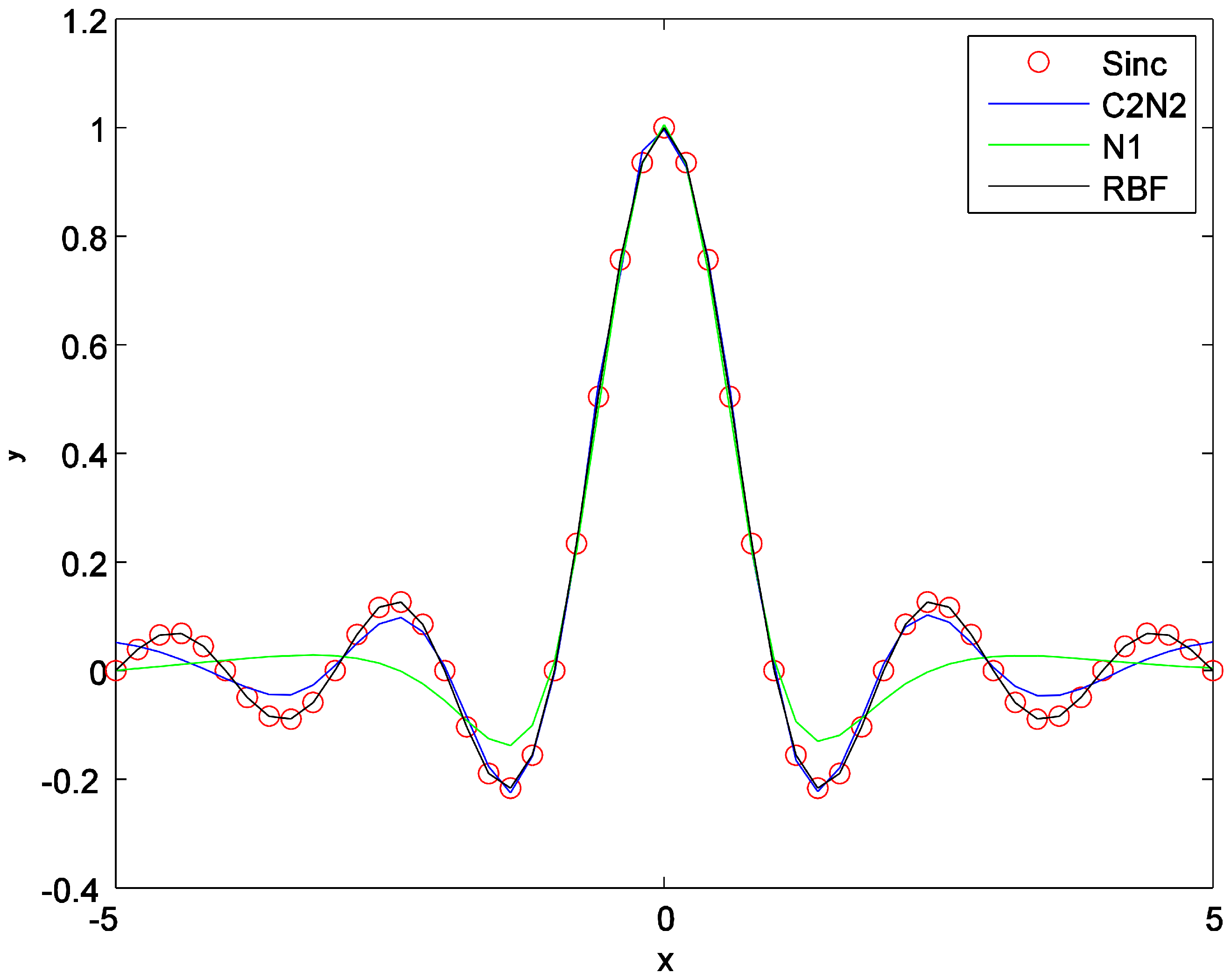
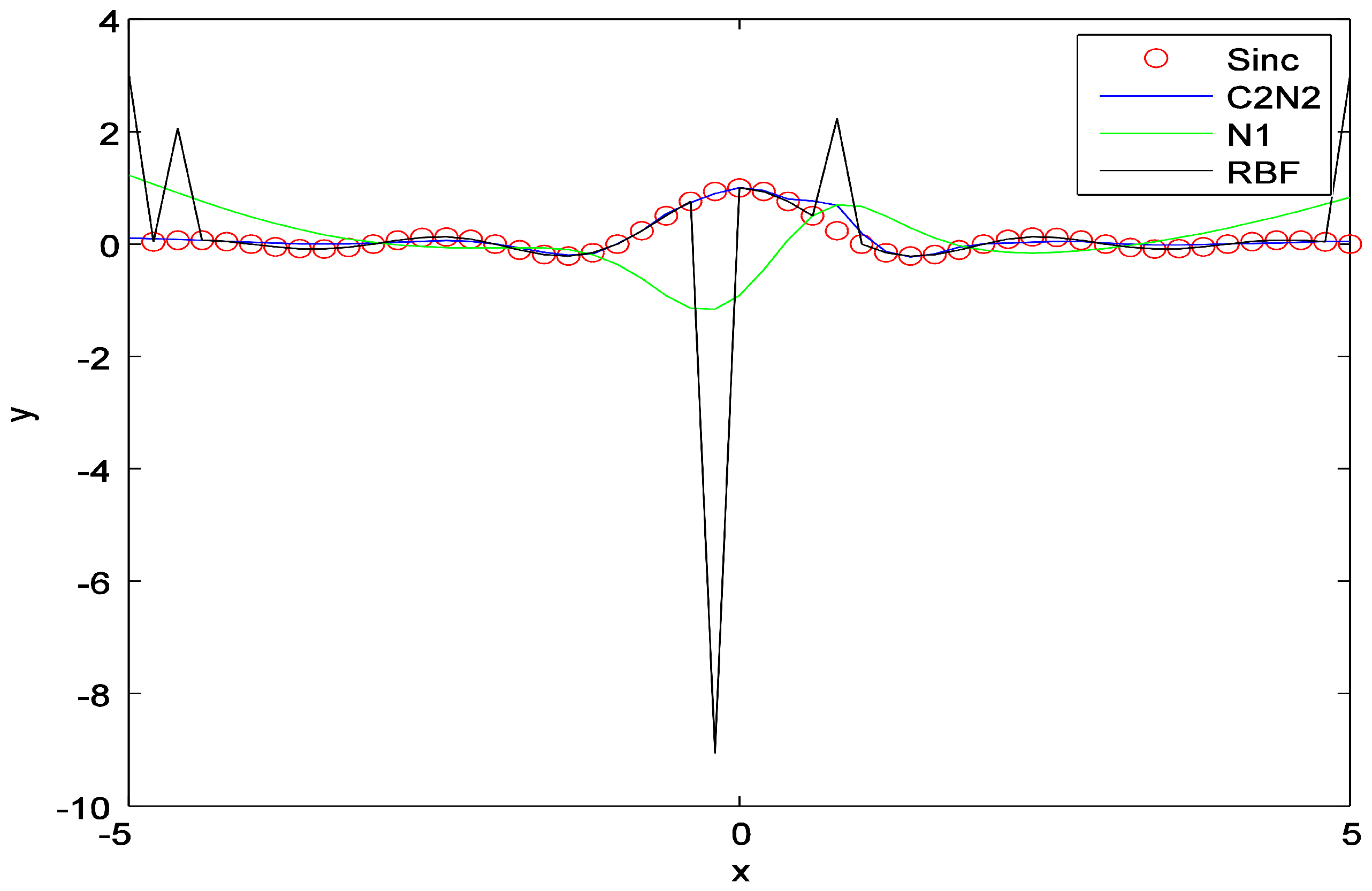
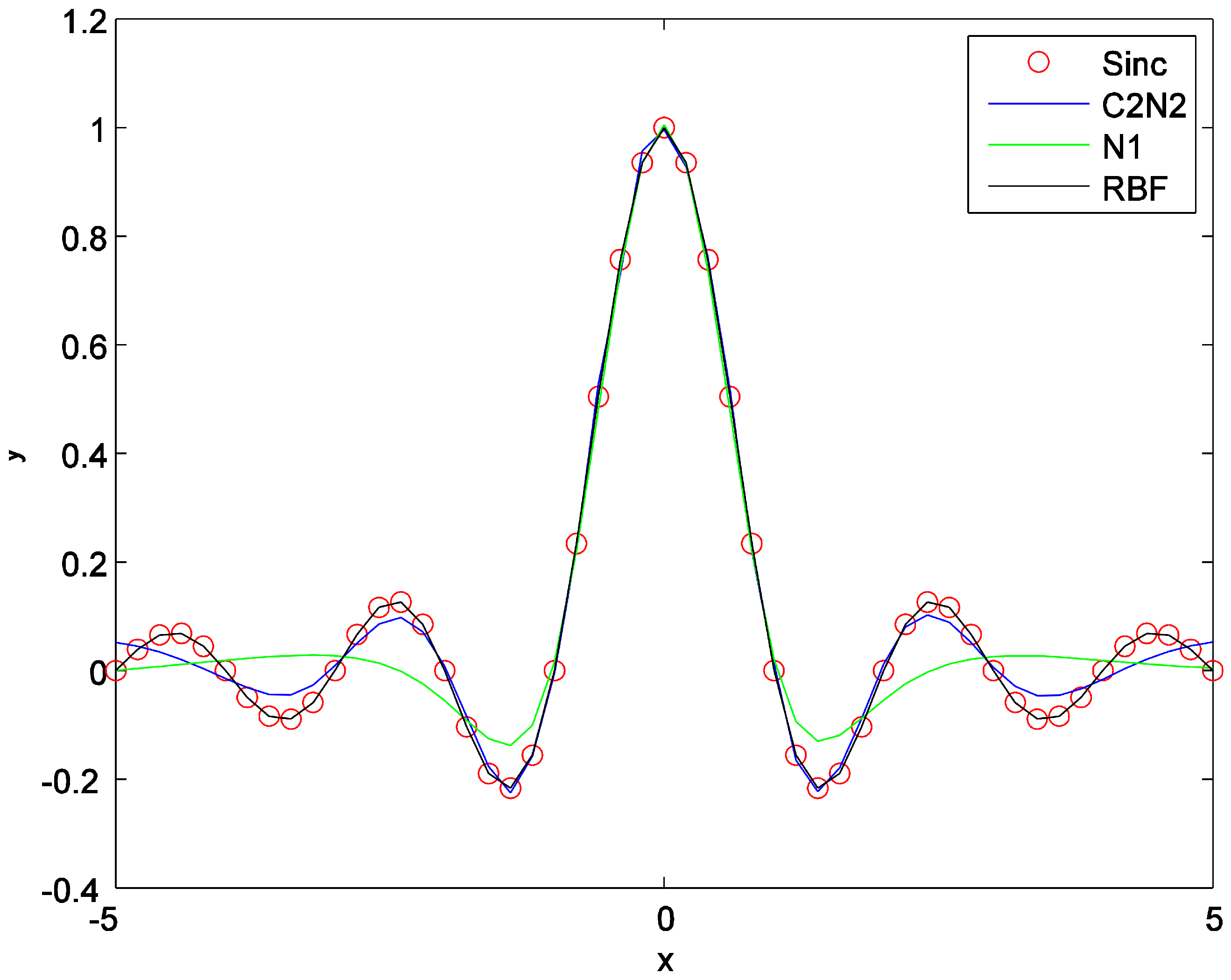
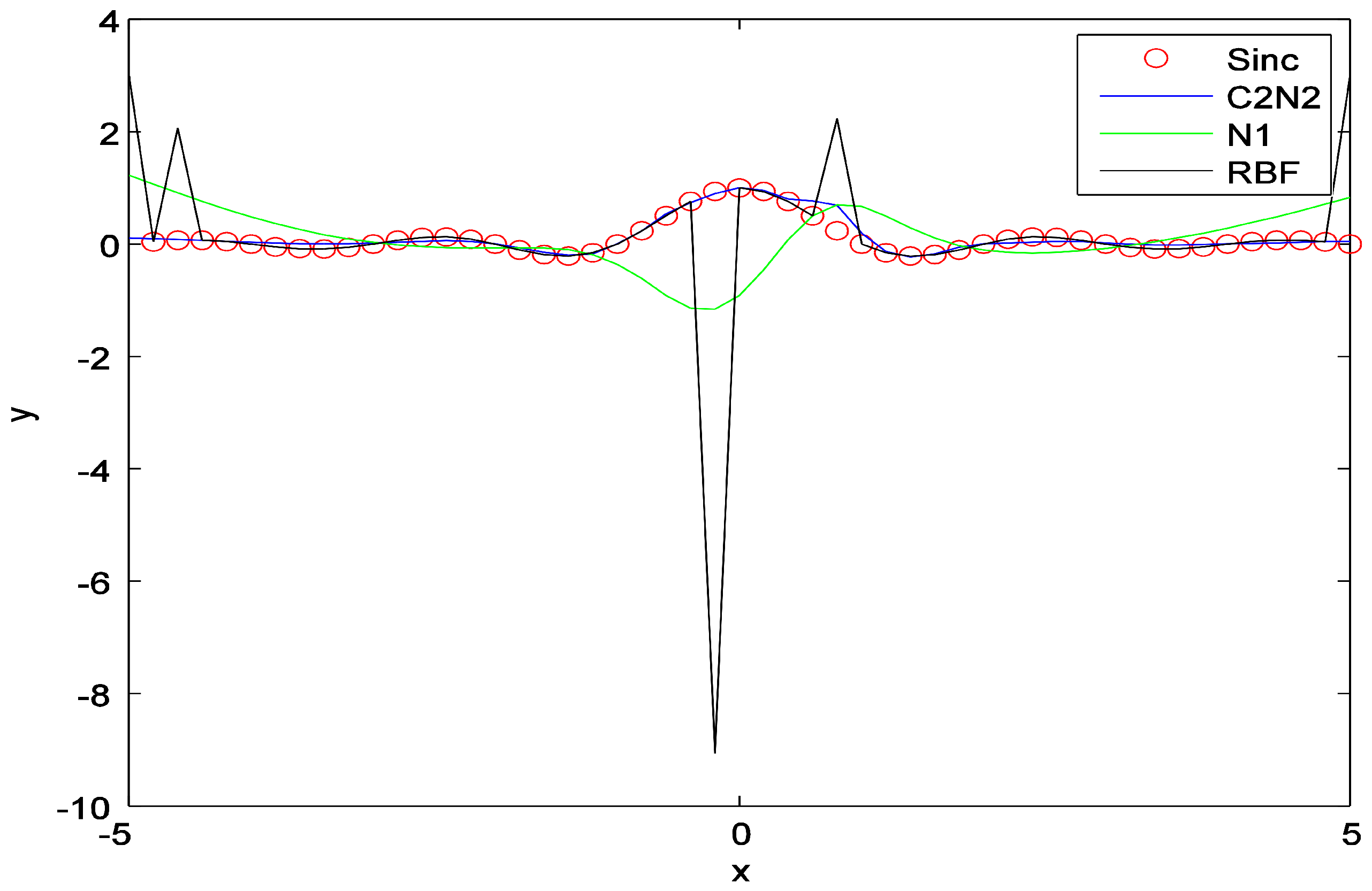
5.3.1. Synthetic Dataset (Sinc Function)
5.3.2. Other Synthetic Dataset
5.4. Discussion
5.4.1. Discussion on Table 7

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | C2N2 | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
Testing
RMSE | #N | Time (s) |
Testing
RMSE | #N | Time (s) |
Testing
RMSE | #N | Time (s) |
Testing
RMSE | #N | Time (s) | |
| 0.1358 | 0.69 | 0.1555 | 4.85 | 1.48 | 6.30 | 1.78 | 0.1536 | 7.05 | 0.81 | |||
| 6.25 | 0.91 | 0.3244 | 0.44 | 0.2460 | 0.72 | 0.2750 | 4.40 | 2.40 | ||||
| 1.09 | 5.90 | 1.91 | 4.55 | 1.57 | 5.45 | 2.18 | ||||||
| 3.98 | 0.3676 | 5.25 | 1.08 | 0.2790 | 0.89 | 0.3226 | 5.65 | 1.16 | ||||
| 1.05 | 0.0940 | 6.80 | 0.12 | 0.0943 | 1.34 | 0.0935 | 6.40 | 0.34 | ||||
| 4.15 | 1.12 | 0.2949 | 4.15 | 0.64 | 0.2309 | 0.51 | 0.2555 | 4.35 | 0.57 | |||
| 1.81 | 4.55 | 1.34 | 8.10 | 2.02 | 0.1963 | 4.70 | 0.87 | |||||
| 7.70 | 3.01 | 0.2928 | 1.54 | 0.2569 | 4.20 | 0.98 | 0.2961 | 4.85 | 0.45 | |||
5.4.2. Why C2N2 Denies Impulse Noises?
5.4.3. Benchmark Dataset
5.4.4. Discussion on Table 3
5.4.5. Discussion on Table 4
5.4.6. Discussion on Table 5 and Table 6
5.4.7. Computational Complexity
5.5. Comparison
5.5.1. Discussion on Table 9
5.5.2. Discussion on Table 10
| Dataset | C2N2 | CCOEN | ||
|---|---|---|---|---|
| Testing RMSE | #Nodes | Testing RMSE | #Nodes | |
| Abalone | 0.090 | 8.8 | ||
| Abalone (Noise) | 7.8 | |||
| Cleveland | 0.791 | 6.1 | ||
| Cleveland (Noise) | 0.821 | 8.5 | ||
| Cloud | 0.293 | 4.7 | ||
| Cloud (noise) | 0.302 | 5.6 | ||
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| C2N2 | Correntropy-based constructive neural network |
| MCC | Maximum correntropy criterion |
| MSE | Mean square error |
| MEE | Minimum Error Entropy |
| EMSE | Excess mean square error |
| OLS | Orthogonal least square |
| CCOEN | Cascade correntropy network |
| MLPMEE | Multi-Layer Perceptron based on Minimum Error Entropy |
| MLPMCC | Multi-Layer Perceptron based on correntropy |
| RLS-SVM | Robust Least Square Support Vector Machine |
| FFN | Feedforward network |
| RBF | Radial basis function |
| ITL | Information theoretic learning |
| CGN | Cascade correlation network |
| OHLCN | One hidden layer constructive adaptive neural network |
Appendix A
Appendix A.1. Proof of Lemma 1
- 2.
Appendix A.2. Proof of Theorem 6
References
- Erdogmus, D.; Principe, J.C. An error-entropy minimization algorithm for supervised training of nonlinear adaptive systems. Signal Process. IEEE Trans. 2002, 50, 1780–1786. [Google Scholar] [CrossRef]
- Fahlman, S.E.; Lebiere, C. The cascade-correlation learning architecture. In Proceedings of the Advances in Neural Information Processing Systems 2, NIPS Conference, Denver, CO, USA, 27–30 November 1989; pp. 524–532. [Google Scholar]
- Kwok, T.-Y.; Yeung, D.-Y. Objective functions for training new hidden units in constructive neural networks. Neural Netw. IEEE Trans. 1997, 8, 1131–1148. [Google Scholar] [CrossRef] [PubMed]
- Huang, G.; Song, S.; Wu, C. Orthogonal least squares algorithm for training cascade neural networks. Circuits Syst. Regul. Pap. IEEE Trans. 2012, 59, 2629–2637. [Google Scholar] [CrossRef]
- Ma, L.; Khorasani, K. New training strategies for constructive neural networks with application to regression problems. Neural Netw. 2004, 17, 589–609. [Google Scholar] [CrossRef] [PubMed]
- Ma, L.; Khorasani, K. Constructive feedforward neural networks using Hermite polynomial activation functions. Neural Netw. IEEE Trans. 2005, 16, 821–833. [Google Scholar] [CrossRef] [PubMed]
- Reed, R. Pruning algorithms-a survey. Neural Netw. IEEE Trans. 1993, 4, 740–747. [Google Scholar] [CrossRef] [PubMed]
- Castellano, G.; Fanelli, A.M.; Pelillo, M. An iterative pruning algorithm for feedforward neural networks. Neural Netw. IEEE Trans. 1997, 8, 519–531. [Google Scholar] [CrossRef] [PubMed]
- Engelbrecht, A.P. A new pruning heuristic based on variance analysis of sensitivity information. Neural Netw. IEEE Trans. 2001, 12, 1386–1399. [Google Scholar] [CrossRef]
- Zeng, X.; Yeung, D.S. Hidden neuron pruning of multilayer perceptrons using a quantified sensitivity measure. Neurocomputing 2006, 69, 825–837. [Google Scholar] [CrossRef]
- Sakar, A.; Mammone, R.J. Growing and pruning neural tree networks. Comput. IEEE Trans. 1993, 42, 291–299. [Google Scholar] [CrossRef]
- Huang, G.-B.; Saratchandran, P.; Sundararajan, N. A generalized growing and pruning RBF (GGAPRBF) neural network for function approximation. Neural Netw. IEEE Trans. 2005, 16, 57–67. [Google Scholar] [CrossRef]
- Huang, G.-B.; Saratchandran, P.; Sundararajan, N. An efficient sequential learning algorithm for growing and pruning RBF (GAP-RBF) networks. Syst. Man. Cybern. Part Cybern. IEEE Trans. 2004, 34, 2284–2292. [Google Scholar] [CrossRef] [PubMed]
- Wu, X.; Rozycki, P.; Wilamowski, B.M. A Hybrid Constructive Algorithm for Single-Layer Feedforward Networks Learning. IEEE Trans. Neural Netw. Learn. Syst. 2014, 26, 1659–1668. [Google Scholar] [CrossRef] [PubMed]
- Santamaría, I.; Pokharel, P.P.; Principe, J.C. Generalized correlation function: Definition, properties, and application to blind equalization. Signal Process. IEEE Trans. 2006, 54, 2187–2197. [Google Scholar] [CrossRef]
- Liu, W.; Pokharel, P.P.; Príncipe, J.C. Correntropy: Properties and applications in non-Gaussian signal processing. Signal Process. IEEE Trans. 2007, 55, 5286–5298. [Google Scholar] [CrossRef]
- Bessa, R.J.; Miranda, V.; Gama, J. Entropy and correntropy against minimum square error in offline and online three-day ahead wind power forecasting. Power Syst. IEEE Trans. 2009, 24, 1657–1666. [Google Scholar] [CrossRef]
- Singh, A.; Principe, J.C. Using correntropy as a cost function in linear adaptive filters. In Proceedings of the 2009 International Joint Conference on Neural Networks, Atlanta, GA, USA, 14–19 June 2009; pp. 2950–2955. [Google Scholar]
- Shi, L.; Lin, Y. Convex Combination of Adaptive Filters under the Maximum Correntropy Criterion in Impulsive Interference. Signal Process. Lett. IEEE 2014, 21, 1385–1388. [Google Scholar] [CrossRef]
- Zhao, S.; Chen, B.; Principe, J.C. Kernel adaptive filtering with maximum correntropy criterion. In Proceedings of the 2011 International Joint Conference on Neural Networks, San Jose, CA, USA, 31 July–5 August 2011; pp. 2012–2017. [Google Scholar]
- Wu, Z.; Peng, S.; Chen, B.; Zhao, H. Robust Hammerstein Adaptive Filtering under Maximum Correntropy Criterion. Entropy 2015, 17, 7149–7166. [Google Scholar] [CrossRef]
- Chen, B.; Wang, J.; Zhao, H.; Zheng, N.; Principe, J.C. Convergence of a fixed-point algorithm under Maximum Correntropy Criterion. Signal Process. Lett. IEEE 2015, 22, 1723–1727. [Google Scholar] [CrossRef]
- Chen, B.; Xing, L.; Liang, J.; Zheng, N.; Principe, J.C. Steady-state mean-square error analysis for adaptive filtering under the maximum correntropy criterion. Signal Process. Lett. IEEE 2014, 21, 880–884. [Google Scholar]
- Chen, L.; Qu, H.; Zhao, J.; Chen, B.; Principe, J.C. Efficient and robust deep learning with Correntropyinduced loss function. Neural Comput. Appl. 2015, 27, 1019–1031. [Google Scholar] [CrossRef]
- Singh, A.; Principe, J.C. A loss function for classification based on a robust similarity metric. In Proceedings of the 2010 International Joint Conference on Neural Networks (IJCNN), Barcelona, Spain, 18–23 July 2010; pp. 1–6. [Google Scholar]
- Feng, Y.; Huang, X.; Shi, L.; Yang, Y.; Suykens, J.A. Learning with the maximum correntropy criterion induced losses for regression. J. Mach. Learn. Res. 2015, 16, 993–1034. [Google Scholar]
- Chen, B.; Príncipe, J.C. Maximum correntropy estimation is a smoothed MAP estimation. Signal Process. Lett. IEEE 2012, 19, 491–494. [Google Scholar] [CrossRef]
- Nayyeri, M.; Yazdi, H.S.; Maskooki, A.; Rouhani, M. Universal Approximation by Using the Correntropy Objective Function. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 4515–4521. [Google Scholar] [CrossRef]
- Athreya, K.B.; Lahiri, S.N. Measure Theory and Probability Theory; Springer Science & Business Media: New York, NY, USA, 2006. [Google Scholar]
- Fournier, N.; Guillin, A. On the rate of convergence in Wasserstein distance of the empirical measure. Probab. Theory Relat. Fields 2015, 162, 707–738. [Google Scholar] [CrossRef]
- Leshno, M.; Lin, V.Y.; Pinkus, A.; Schocken, S. Multilayer feedforward networks with a nonpolynomial activation function can approximate any function. Neural Netw. 1993, 6, 861–867. [Google Scholar] [CrossRef]
- Yuan, X.-T.; Hu, B.-G. Robust feature extraction via information theoretic learning. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; pp. 1193–1200. [Google Scholar]
- Klenke, A. Probability Theory: A Comprehensive Course; Springer Science & Business Media: New York, NY, USA, 2013. [Google Scholar]
- Rudin, W. Principles of Mathematical Analysis; McGraw-Hill: New York, NY, USA, 1964; Volume 3. [Google Scholar]
- Yang, X.; Tan, L.; He, L. A robust least squares support vector machine for regression and classification with noise. Neurocomputing 2014, 140, 41–52. [Google Scholar] [CrossRef]
- Newman, D.; Hettich, S.; Blake, C.; Merz, C.; Aha, D. UCI Repository of Machine Learning Databases; Department of Information and Computer Science, University of California: Irvine, CA, USA, 1998; Available online: https://archive.ics.uci.edu/ (accessed on 29 November 2023).
- Meyer, M.; Vlachos, P. Statlib. 1989. Available online: https://lib.stat.cmu.edu/datasets/ (accessed on 29 November 2023).
- Pokharel, P.P.; Liu, W.; Principe, J.C. A low complexity robust detector in impulsive noise. Signal Process. 2009, 89, 1902–1909. [Google Scholar] [CrossRef]
- Feng, Y.; Fan, J.; Suykens, J.A. A Statistical Learning Approach to Modal Regression. J. Mach. Learn. Res. 2020, 21, 1–35. [Google Scholar]
- Feng, Y. New Insights into Learning with Correntropy-Based Regression. Neural Comput. 2021, 33, 157–173. [Google Scholar] [CrossRef]
- Ramirez-Parietti, I.; Contreras-Reyes, J.E.; Idrovo-Aguirre, B.J. Cross-sample entropy estimation for time series analysis: A nonparametric approach. Nonlinear Dyn. 2021, 105, 2485–2508. [Google Scholar] [CrossRef]
- Bagirov, A.; Karmitsa, N.; Mäkelä, M.M. Introduction to Nonsmooth Optimization: Theory, Practice and Software; Springer International Publishing: Cham, Switzerland; Heidelberg, Germany, 2014; Volume 12. [Google Scholar]

| Datasets | #Train | #Test | #Features |
|---|---|---|---|
| Baskball | 64 | 32 | 4 |
| Strike | 416 | 209 | 6 |
| Bodyfat | 168 | 84 | 14 |
| Quake | 1452 | 726 | 3 |
| Autoprice | 106 | 53 | 9 |
| Baloon | 1334 | 667 | 2 |
| Pyrim | 49 | 25 | 27 |
| Housing | 337 | 169 | 13 |
| Abalone | 836 | 3341 | 8 |
| Cleveland | 149 | 148 | 13 |
| Cloud | 54 | 54 | 7 |
| Dataset | #Train | #Test | #Features |
|---|---|---|---|
| Ionosphere | 175 | 176 | 34 |
| Australian Credit | 460 | 230 | 6 |
| Diabetes | 512 | 256 | 8 |
| Colon | 32 | 30 | 2000 |
| Liver | 230 | 115 | 6 |
| Leukemia | 36 | 36 | 7129 |
| Dimdata | 1000 | 3192 | 14 |
| Datasets | C2N2 | CCN | RBF | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
Testing
RMSE | #N |
Time
(s) |
Testing
RMSE |
Time
(s) |
Testing
RMSE |
Time
(s) |
Testing
RMSE |
Time
(s) |
Testing
RMSE |
Time
(s) |
Testing
RMSE |
Time
(s) | ||||||
| Autoprice | 4.8 | 0.54 | 0.2996 | 2 | 1.49 | 9.2 | 3.99 | 0.3681 | 5 | 6.99 | 0.2758 | 1.67 | 0.2725 | 79 | 0.008 | |||
| Autoprice (Noise) | 6.7 | 0.70 | 0.5521 | 1.07 | 0.3610 | 2.60 | 0.43 | 0.4295 | 3.77 | 1.41 | 0.4768 | 1.89 | 0.9082 | 79 | 0.009 | |||
| Baloon | 0.1065 | 5.9 | 10.73 | 0.1163 | 5.75 | 5.21 | 0.1066 | 10 | 4.96 | 0.1257 | 8.3 | 9.97 | 0.1317 | 2.09 | 150 | 0.086 | ||
| Baloon (Noise) | 5.1 | 3.25 | 0.1166 | 1.32 | 0.1252 | 8.9 | 4.66 | 0.1281 | 5 | 3.31 | 0.1358 | 2.9 | 2.12 | 1501 | 0.1351 | |||
| Pyrim | 6.7 | 0.23 | 0.0843 | 0.27 | 0.2062 | 0.07 | 0.1696 | 0.17 | 0.1694 | 0.17 | 0.0842 | 37 | 0.0090 | |||||
| Pyrim (noise) | 4.9 | 0.16 | 0.6666 | 0.32 | 0.4150 | 0.036 | 0.6203 | 0.62 | 0.5712 | 0.62 | 1.5034 | 37 | 0.0043 | |||||
| Datasets | RBF | CCN | C2N2 | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
Testing
Rate (%) |
Time
(s) |
Testing
Rate (%) |
Time
(s) |
Testing
Rate (%) |
Time
(s) |
Testing
Rate (%) |
Time
(s) |
Testing
Rate (%) |
Time
(s) |
Testing
Rate (%) |
Time
(s) | |||||||
| Ionospher | 70.97 | 0.12 | 65.45 | 0.11 | 78.98 | 2.40 | 0.25 | 82.61 | 175 | 0.14 | 78.04 | 0.21 | 1.30 | 0.22 | ||||
| Colon | 62.00 | 0.02 | 63.00 | 0.03 | 62.33 | 0.38 | 90.50 | 32 | 0.12 | 64.04 | 0.29 | 0.15 | ||||||
| Leukemia | 64.44 | 0.03 | 64.44 | 0.05 | 72.44 | 0.04 | 88.61 | 36 | 0.22 | 83.71 | 0.31 | 94.72 | 1 | 0.20 | ||||
| Dimdata | 89.74 | 7.05 | 15.31 | 88.44 | 6.60 | 9.39 | 88.77 | 4.30 | 7.34 | 1000 | 4.36 | 88.37 | 8.98 | 93.73 | 3.50 | 8.29 | ||
| Dataset | C2N2 | OLSCN | OHLCN | ||||||
|---|---|---|---|---|---|---|---|---|---|
|
Testing
RMSE | #Nodes |
Time
(s) |
Testing
RMSE | #Nodes |
Time
(s) |
Testing
RMSE | #Nodes |
Time
(s) | |
| Housing | 5.6 | 0.79 | 0.0988 | 1.44 | 0.0993 | 2.8 | 0.38 | ||
| Housing (Noise) | 5.87 | 1.07 | 0.2411 | 1.53 | 0.1824 | 4.3 | 0.09 | ||
| Strike | 2.8 | 1.11 | 2.77 | 0.2888 | 3.3 | 0.62 | |||
| Strike (Noise) | 4.4 | 0.87 | 0.3017 | 2.21 | 0.3912 | 6.0 | 0.07 | ||
| Quake | 6.6 | 2.05 | 0.1821 | 3.88 | 0.1815 | 6 | 0.023 | ||
| Quake (noise) | 0.42 | 0.1870 | 2.21 | 0.1849 | 4 | 0.021 | |||
| Dataset | C2N2 | OLSCN | OHLCN | ||||||
|---|---|---|---|---|---|---|---|---|---|
|
Testing
RMSE | #Nodes |
Time
(s) |
Testing
RMSE | #Nodes |
Time
(s) |
Testing
RMSE | #Nodes |
Time
(s) | |
| Australian (Noise) | 3 | 0.48 | 2 | 10.88 | 1.01 | ||||
| Liver (Noise) | 4 | 0.25 | 1.01 | 53.49 | 9 | 0.02 | |||
| Diabete (noise) | 1.11 | 78.65 | 2 | 3.36 | 40.56 | 6.23 | |||
| Noisy Data | |||||
| Noise-free data | |||||
| Dataset | C2N2 | MLPMEE | MLPMCC | RLS-LSVM | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
Testing
RMSE | #Nodes |
Time
(s) |
Testing
RMSE | #Nodes |
Time
(s) |
Testing
RMSE | #Nodes |
Time
(s) |
Testing
RMSE | #Nodes |
Time
(s) | |
| Bodyfat | 0.4623 | 0.0045 | 10 | - | 40 | - | 101 | |||||
| Bodyfat (Noise) | 10 | - | 10 | - | 0.00451 | 101 | 9.651 | |||||
| Pyrim | 0.2712 | 0.0798 | 20 | - | 0.0882 | 40 | - | 0.0817 | 37.3 | |||
| Pyrim (Noise) | 10 | - | 0.12034 | 30 | - | 0.12345 | 37 | 4.495 | ||||
| Baskball | 0.12293 | 0.1352 | 30 | - | 0.13114 | 20 | - | 48 | 0.3687 | |||
| Baskball (noise) | 0.14352 | 20 | - | 0.1328 | 20 | - | 0.12839 | 48 | 22.569 | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nayyeri, M.; Rouhani, M.; Yazdi, H.S.; Mäkelä, M.M.; Maskooki, A.; Nikulin, Y. Correntropy-Based Constructive One Hidden Layer Neural Network. Algorithms 2024, 17, 49. https://doi.org/10.3390/a17010049
Nayyeri M, Rouhani M, Yazdi HS, Mäkelä MM, Maskooki A, Nikulin Y. Correntropy-Based Constructive One Hidden Layer Neural Network. Algorithms. 2024; 17(1):49. https://doi.org/10.3390/a17010049
Chicago/Turabian StyleNayyeri, Mojtaba, Modjtaba Rouhani, Hadi Sadoghi Yazdi, Marko M. Mäkelä, Alaleh Maskooki, and Yury Nikulin. 2024. "Correntropy-Based Constructive One Hidden Layer Neural Network" Algorithms 17, no. 1: 49. https://doi.org/10.3390/a17010049
APA StyleNayyeri, M., Rouhani, M., Yazdi, H. S., Mäkelä, M. M., Maskooki, A., & Nikulin, Y. (2024). Correntropy-Based Constructive One Hidden Layer Neural Network. Algorithms, 17(1), 49. https://doi.org/10.3390/a17010049