1. Introduction
Hydroelectric power is a kind of environmentally friendly renewable energy, so hydropower stations are of great significance for solving the energy shortage problem in economic development, improving the ecological environment and promoting the coordination and sustainable development of regional economies [
1]. Globally, hydropower accounts for approximately
of total electricity generation, and the installed capacity of hydropower accounts for more than
of the global installed capacity of renewable energy. As of 2024, the cumulative installed capacity of hydropower worldwide reached 427 million kilowatts, and the annual electricity generation reached
trillion kilowatt-hours. The normal operation of hydropower stations’ equipment is of great significance for ensuring power supply and preventing safety accidents [
2,
3]. Fault detection is an indispensable step in ensuring the safe and reliable operation of industrial systems [
4], such as power transmission, manufacturing industry, and transportation and telecommunication systems. Specially, due to the complexity of hydropower station systems, such as in the large number of equipment and variable operating environment, equipment failures are difficult to completely avoid. This not only leads to significant economic losses but may also cause serious production safety accidents, posing adverse effects on society and the environment.
With the development of intelligence and information technologies, the monitoring systems of hydropower stations are now capable of collecting a large amount of real-time operation data from equipment. These data contain rich information [
5,
6], providing the possibility for fault prediction. By analyzing these data, potential anomalies and fault signs of equipment can be detected in a timely manner [
7], so as to take corresponding preventive measures and avoid the occurrence of accidents.
Traditional fault detection technologies mainly rely on signal processing and statistical methods. The former extracts the characteristics of fault data through time–frequency conversion methods such as wavelet transform [
8], the empirical mode decomposition method [
9], short-time Fourier transform (STFT) [
10], and spectral analysis. The latter mainly uses some multivariate statistical analysis methods, such as partial least squares [
11], to calculate the fault thresholds for identifying abnormal data. Although these methods can identify, to a certain extent, the potential faults of equipment, their applicability is mainly limited to scenarios with a limited data scale and a relatively simple system structure. Facing the complex data bias problems commonly existing in the operation environment of hydropower stations, such as large data scale and severely imbalanced sample class distribution, traditional methods face significant technical bottlenecks in terms of the robustness of feature extraction, the stability of model training, and the accuracy of fault diagnosis. Firstly, the extracted data features may not fully reflect the real state of the equipment. Secondly, the calculated fault thresholds may no longer be applicable under new operating conditions, and continuous updates are required to maintain the effectiveness of detection. In addition, the above methods only analyze the fault data, and it is impossible to conduct the same analysis and prediction for the huge amount of normal detection data. That is to say, it is difficult to deal with the nonlinear relationships in the data and the dynamic non-stationary changes in time series, and there are also high requirements for the professional knowledge and experience of operators.
At present, some studies have researched intelligent detection technologies for the increasingly complex faults of hydropower stations. This is mainly based on the breakthroughs and developments of artificial intelligence technologies, among which machine learning is the most representative. A fault detection method is proposed based on support vector machine (SVM) in [
12], which is optimized based on the particle swarm algorithm [
13], thereby improving the judgment accuracy of the model. An improved random forest algorithm [
14] is proposed to achieve accurate fault detection and enhance the processing ability of the detection model through optimized parallel processing methods.
The above-mentioned machine learning models usually have a relatively simple structure, and may not fully capture the complex data features. In contrast, deep learning, which uses neural network models for analysis and prediction, can extract more in-depth feature information from the data, and has significant advantages in handling complex data structures and performing accurate modeling and prediction [
15]. Through its multi-layer structure, the neural network automatically learns nonlinear relationships. This enables it to more effectively identify potential fault patterns when facing systems with high complexity and dynamic change characteristics such as hydropower stations. In addition, deep learning models can also adapt to changes in the data and enhance the accuracy and robustness of prediction through learning. For example, a fault diagnosis network based on the convolutional neural network (CNN) architecture was designed [
16], and its performance has been greatly improved compared with traditional machine learning methods. A residual CNN algorithm based on Bayesian optimization was studied [
17]. This algorithm achieved a significant improvement in model performance by embedding residual connections and automatically optimizing hyperparameters. Stacked attention autoencoder fault monitoring methods [
18,
19] have been put forward to pretrain the model and derive deep fault features for improving the classification accuracy.
Compared with the CNN and SAE models, the recurrent neural network (RNN) model that can acquire the correlation of time series is more applicable to time series prediction tasks. For example, a power grid fault diagnosis scheme based on feature clustering and RNN [
20] has significantly improved the utilization rate of unlabeled samples and the diagnostic accuracy. However, RNN often encounters the issues of gradient vanishing or explosion in deep network training, which limits its ability to learn long-distance temporal dependencies. To overcome this obstacle, the long short-term memory (LSTM) network solves the problem of gradient vanishing by introducing a gating mechanism, learning long-distance temporal dependencies. Then, fault detection models for industrial machines and large-scale multi-machine power systems were developed based on the LSTM architectures [
21,
22,
23]. The advantages of LSTM are mainly the following: Firstly, it has excellent memory ability and can store long-term dependency information in the data. Secondly, the gating design of LSTM ensures the training stability and significantly reduces the risk of gradient vanishing and explosion. Finally, LSTM shows good adaptability to processing sequence data of different lengths. In addition, hybrid ensemble learning methods can improve prediction accuracy generally by combining multiple weak learners [
24]; however, their structural homogeneity limits comprehensive feature extraction and introduces computational inefficiencies. Meanwhile, due to the high sensitivity of ensemble learning to the selection of base learners and the quality of data, it is difficult to always ensure a robust and reliable performance in the scenario of hydropower stations. The Transformer model, a deep learning framework built on the self-attention mechanism, excels at capturing long-distance relationships within sequences by leveraging global attention [
25,
26]. This unique capability enables it to deliver outstanding results in natural language processing (NLP) tasks, with sentiment analysis serving as a notable example. However, its direct application to time series forecasting faces limitations, as the strong local correlations inherent in temporal data fundamentally differ from the global semantic requirements of NLP, causing standard attention mechanisms to potentially overlook local temporal patterns.
On the other hand, the equipment of hydropower stations is usually designed with a large safety margin, which leads to a severely imbalanced distribution of actual fault data compared with normal data. In this situation, it is particularly difficult to extract fault features and conduct effective detection. Although meta-learning [
27] and contrastive learning [
28] are capable of improving the model’s generalization performance for new tasks, their high complexity may lead to overfitting in new tasks, thus affecting the expected performance of the model. In addition, this type of method has limitations in generalization ability. Even after training, the model may demand a large volume of new task data to attain the desired performance. In this situation, the generative adversarial network (GAN) [
29], which was originally used for image processing, has gradually been discovered to have the potential to expand samples. It does not have to consider the adaptability of the model to small sample data. Instead, by simulating the data generation process, it directly creates new samples that are extremely similar to the real fault data in statistical features, thus enriching the fault sample library and providing more data support for the training of the fault detection model.
In response to the challenges faced by the fault detection technology of hydropower stations, this paper proposes a fault detection method for data prediction and enhancement based on CNN-LSTM-GAN to enhance the accuracy of fault detection in hydropower stations. In this case, the specific criticalities are dealing with data credibility, imbalance distribution, prediction accuracy and fault missed detection. The main contributions of the paper are as follows.
We propose a fault prediction framework for the hydropower station with unbalanced and unreliable data. First, we propose a controllable credibility detection mechanism based on principal components analysis (PCA). This mechanism calculates the credibility of the data by analyzing the main change directions of the monitoring data to reduce the impact of the unreliable data. Then, we utilize the GAN to expand the training fault data of the hydropower station, thereby addressing the issue of insufficient fault data volume and imbalanced data distribution. In addition, the CNN-LSTM network is designed to extract detail data features and the long-term dependencies in the time series data for fault prediction.
We propose a multi-scale feature extraction network architecture based on joint time–frequency information for fault detection. First, the model extracts the local and global time-domain features of the data by distributing the sample to multiple independent network branches with different depths. Then, we analyze the frequency-domain parameters of the sample sequence using discrete STFT, and the frequency-domain information is used to assist in the time-domain feature for improving fault detection accuracy.
We propose a dynamic multi-task training algorithm for our deep network framework to ensure the convergence and training efficiency. In this paper, both time series prediction tasks and fault detection tasks are considered, but it is difficult to jointly train the entire network model. Therefore, we dynamically adjust the proportion between the prediction sub-network loss and the global detection network loss during each training iteration. This allows the model to focus more on fine-grained subtask errors in the early stages, and gradually shift attention to the global fault detection objective as training progresses.
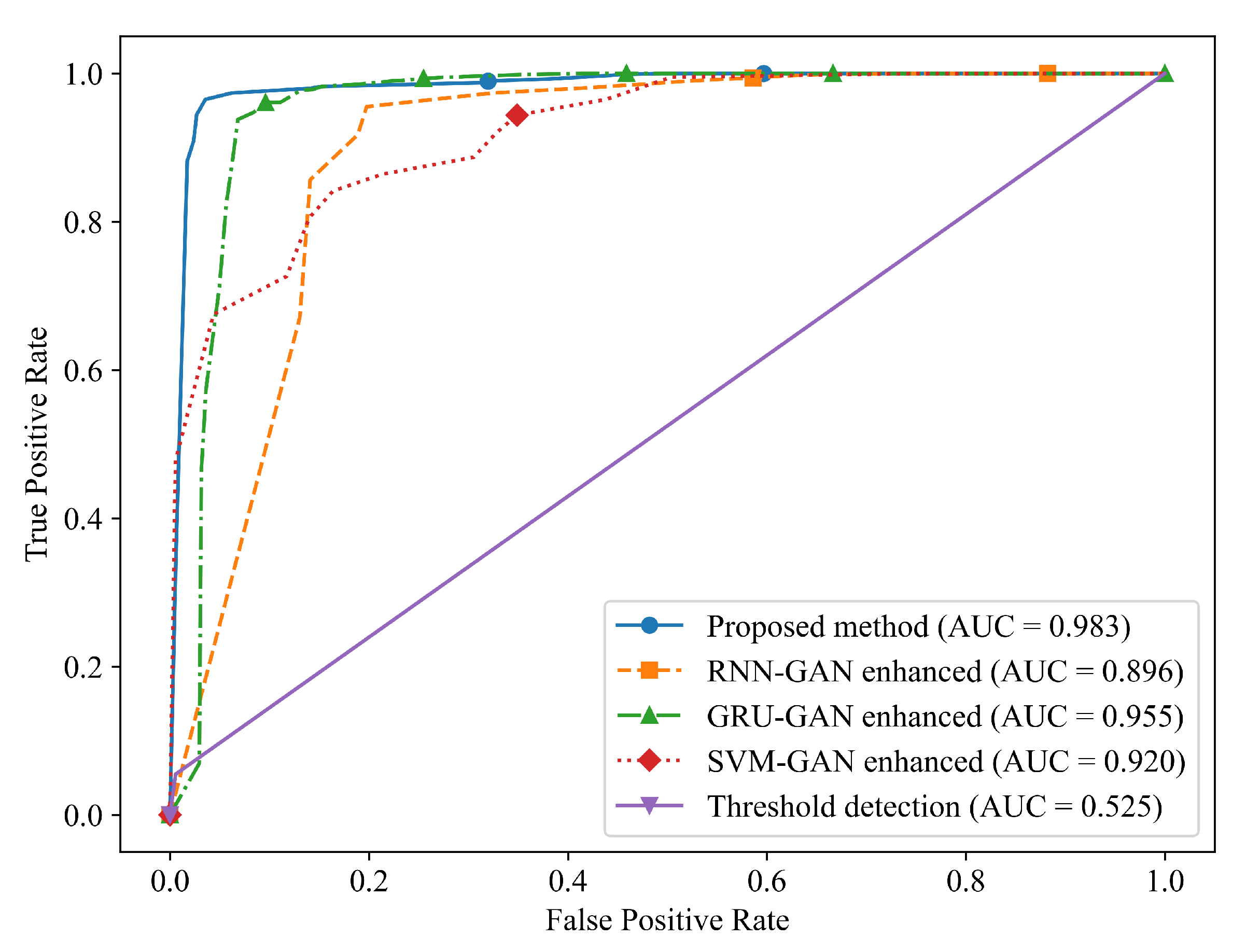
The proposed method improves the detection accuracy compared to the existing schemes within a manageable time cost. In particular, our method has a significant improvement in recall performance, which is of great significance in scenarios with low fault tolerance and imbalanced data such as hydropower stations.
2. Fault Detection Method Based on CNN-LSTM-GAN
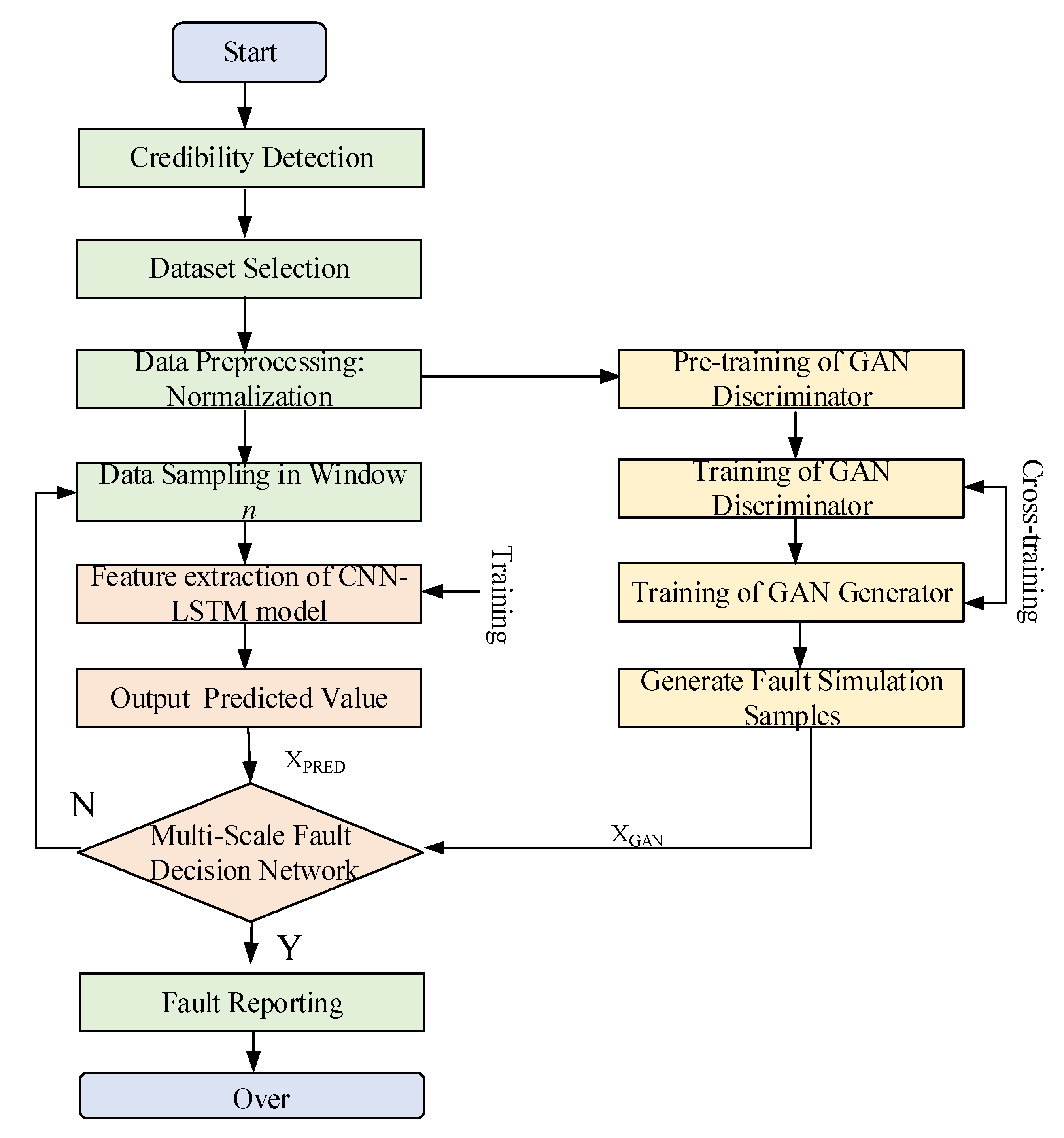
The process of the proposed fault detection method for hydropower stations is illustrated in
Figure 1. Firstly, a controllable credibility detection mechanism is designed to analyze the mainstream data trends of the same monitoring data, calculate the credibility of different monitoring data, and screen out the dataset with the highest credibility to ensure the accuracy of the simple data and the efficiency of network training. Then, the dataset is normalized, and the normal monitoring data are sampled according to a time window with a length of
n to capture the time series characteristics of the data.
The sampled data is subsequently input into the CNN-LSTM network for accurate prediction, and the GAN is utilized to generate new samples with statistical characteristics similar to real fault data for data augmentation. Finally, in order to grasp the global features of the detection data and make fault evaluation more accurate, a multi-scale deep neural network (DNN) model is designed to extract and classify the features of the data predicted by the CNN-LSTM network, so as to determine whether there is fault data in the predicted data and output the fault identification results accordingly. If there is no fault, the sampling window is returned to continue predicting and inspecting the next batch of data.
2.1. Data Prediction Model Based on PCA and CNN-LSTM
2.1.1. Data Credibility Detection Based on PCA
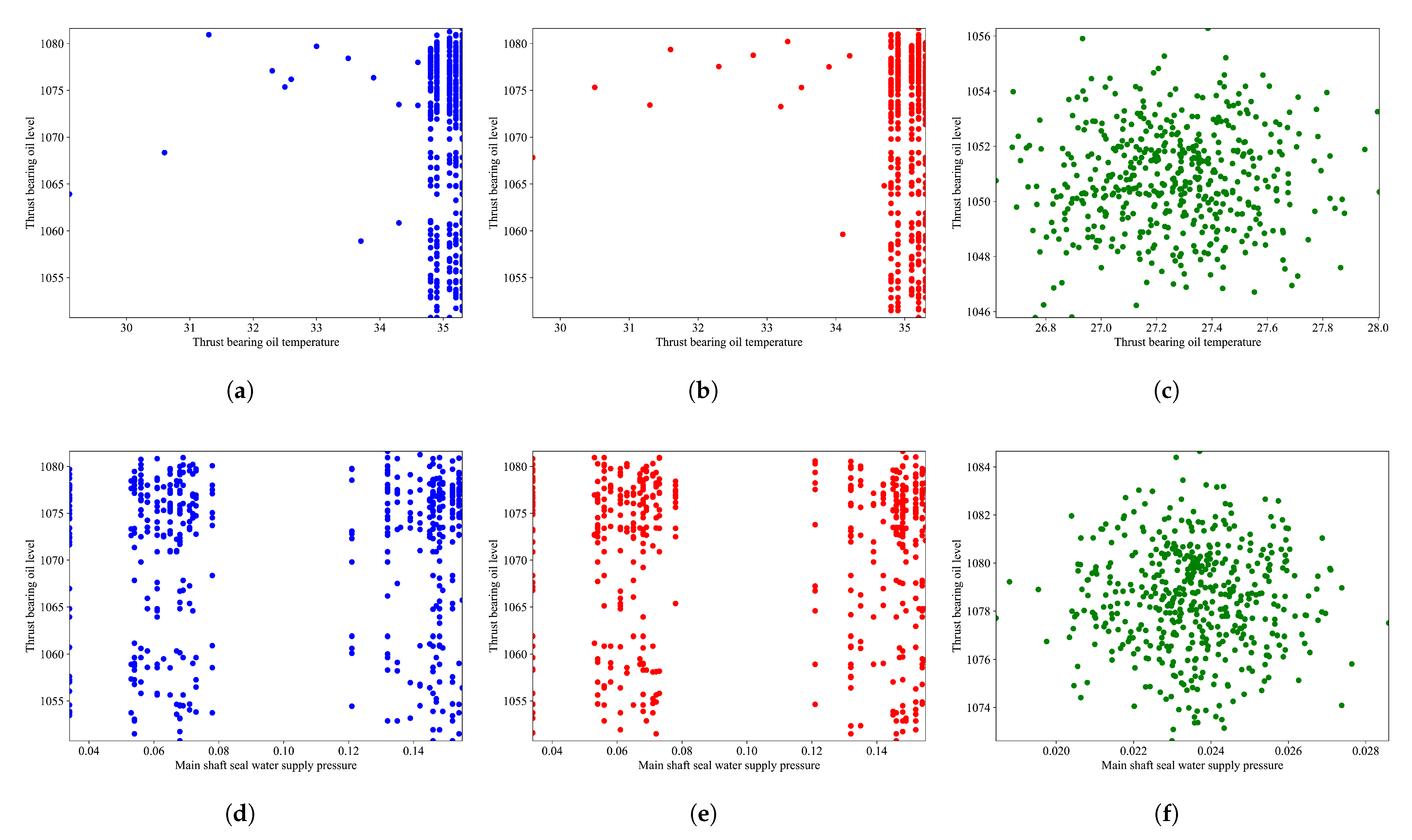
Before formal data prediction, data screening and preprocessing are required. In this study, a controllable credibility mechanism is adopted for data screening, which mainly includes two key steps: data analysis and feature selection. Firstly, principal component analysis is utilized to identify the main change directions of the monitoring data, due to its key feature extraction capability [
30] and the statistical distribution of data samples. By calculating the component matrix
P and the proportion of explained variance
, the data are projected into a new coordinate system, so as to find the direction with the largest variance, that is, the principal component. These principal components represent the main change patterns of the data and help to identify the structure of the data. Then, we calculate the contribution degree of each group of monitoring data to the PCA results to evaluate the credibility of the data as
where
is the contribution degree of the
i-th group of monitoring data to the PCA result.
J is the number of principal components,
is the load of the
j-th component for the corresponding variable of the
i-th group of data, and
is the variance of the
j-th component. Then, sort each group of monitoring data according to these contribution degrees and assign selection probabilities. The higher the contribution degree of the data, the greater the probability of being selected. In the PCA, normal data, that is, data with the main change pattern, have a greater weight when calculating the contribution degree. By screening out the dataset with the highest contribution degree, those data that best conform to the main change pattern of the data are actually selected, thus ensuring the accuracy and reliability of the subsequent network training.
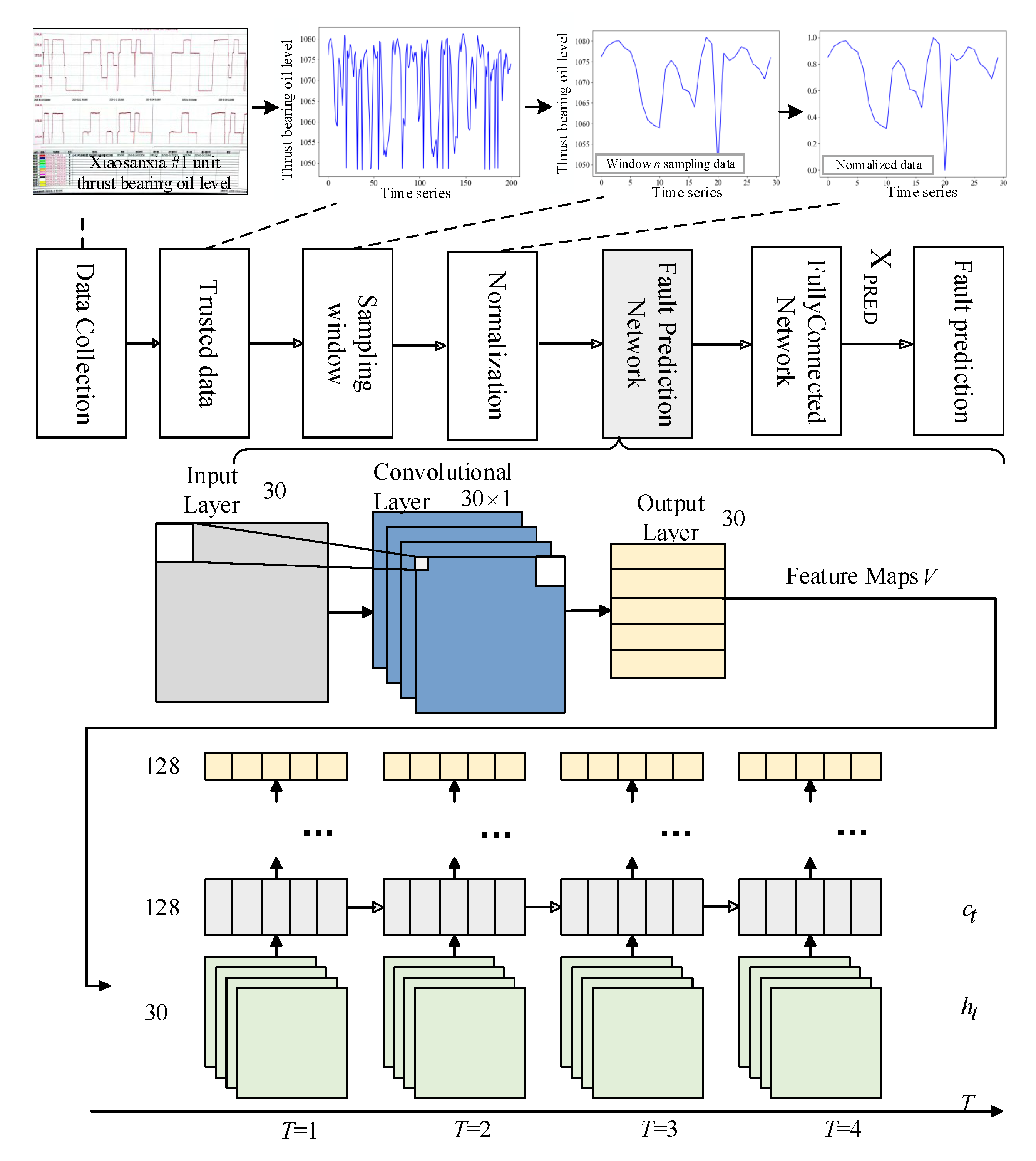
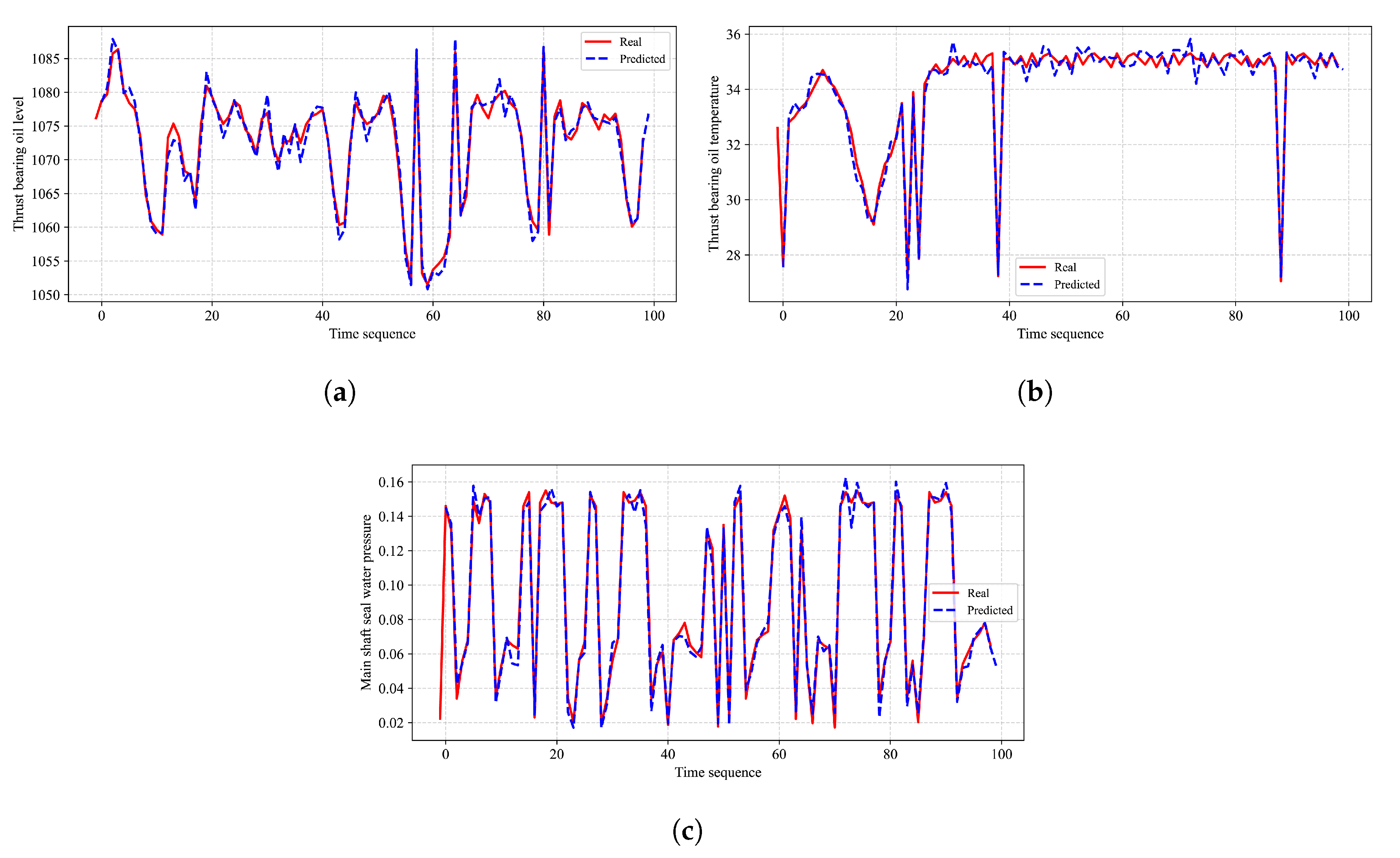
2.1.2. CNN-LSTM Data Prediction
The data are normalized as a preprocessing step. The structure of this prediction model is provided in
Figure 2. This model possesses the advantages of both a CNN and LSTM, extracting features from the monitoring data and using a gating mechanism to control the transmission state, thereby maintaining long-term memory of certain features. The network structure mainly consists of CNN layers, LSTM layers, and fully connected layers. The network’s input dimension, represented by the window size n, is configured as 30. This indicates that the model utilizes historical data from the past 30 time steps to predict the value at the subsequent (
) time step. Given the 2 min sampling interval, this window size corresponds to 1 hour of temporal coverage. This parameter selection achieves an optimal balance between capturing meaningful temporal patterns and maintaining computational efficiency by preventing oversampling-induced redundancy [
31].
The input data shape of the network is [
BatchSize,
Channels,
SequenceLength], where
BatchSize refers to the batch size, which is 32.
Channels refers to the number of input data channels, i.e., the feature dimension.
SequenceLength is the sequence length, which is 30. Since the input sequence contains data from 30 time steps, with each time step corresponding to one channel, the total number of input channels is also 30. The kernel size is set to 1, indicating that this CNN layer performs cross-channel weighted fusion of data at each time step (with weights shared across all time steps). This design integrates multi-channel information through linear transformation to provide fused features for the subsequent LSTM layer, rather than extracting local temporal patterns. By performing convolution operations using the predefined kernels over the input sequence, the network generates output features that maintain the same dimensionality as the input data. These feature maps can be represented as
where
and
represent the convolution kernel weights and the input matrix, respectively.
z is the activation function,
b is the bias parameter, and
i is the element index. After several layers of convolution and pooling operations, the resulting feature maps are sequentially flattened into a vector, which is then fed into the fully connected layer as the final output.
Next, the LSTM layer receives the output from the convolutional layer as its input. The hidden state and cell state are then initialized with the shape [NumLayers, BatchSize, HiddenSize]. In this model, there are three hidden layers, each containing 128 neurons. This design ensures the model has sufficient learning capacity while also being able to capture complex patterns within the sequence. Compared to a standard RNN, which only has a single hidden state , the LSTM introduces a distinctive cell state . This cell state evolves slowly throughout the sequence, allowing important temporal features to be retained over long periods or forgotten when necessary. To manage this cell state effectively, the LSTM includes three key gating units. They work together to determine how the cell state is updated and how the final hidden state is produced. During computation in this prediction network, each gate multiplies the input vector by a weight matrix, and the result is processed by an activation function. The outcome is a value between 0 and 1, which serves as the gate activation controlling the information flow. This architecture allows the LSTM to flexibly and effectively capture key features in time series data, especially when dealing with long sequences.
The forget gate selectively removes information from the prior cell state that is no longer relevant, based on the current input. So, the model can focus on retaining critical information while freeing up memory capacity to incorporate new data. The gating mechanism of the forget gate is expressed as
where
is the current value of the forget gate.
is the activation function,
is the weight matrix of the forget gate, and
is the input vector at
t.
is the hidden state vector from
, and
is the bias vector of the forget gate.
The input gate plays a filtering role. It selects useful information from the current input that is relevant to the prediction and incorporates it into the new candidate cell state. This process ensures that the cell states are continuously updated with the most recent sequence information. The first step involves using the sigmoid function
to determine the weight of information
being accepted as
Next, the candidate cell state
that contains the new information is
The output gate is responsible for determining which information needs to be transmitted to the hidden state, or to serve as the current model output. These updated pieces of information are passed to the next layer or directly used as the output of the model as
The updates of the hidden state and the cell state shown above are
where ⊙ represents element-wise multiplication,
is the cell state at time
, and
is the candidate state at the previous moment
. Through this ingenious gating mechanism, the LSTM can not only effectively capture the long-term dependencies but also avoid gradient vanishing or explosion. Consequently, it can model the long-distance dependencies in the data more accurately.
Finally, the network includes a fully connected layer with a shape of [BatchSize, HiddenSize]. The hidden layer has 128 neurons, and its function is to map the output of the LSTM layer to a single neuron for predicting future data values.
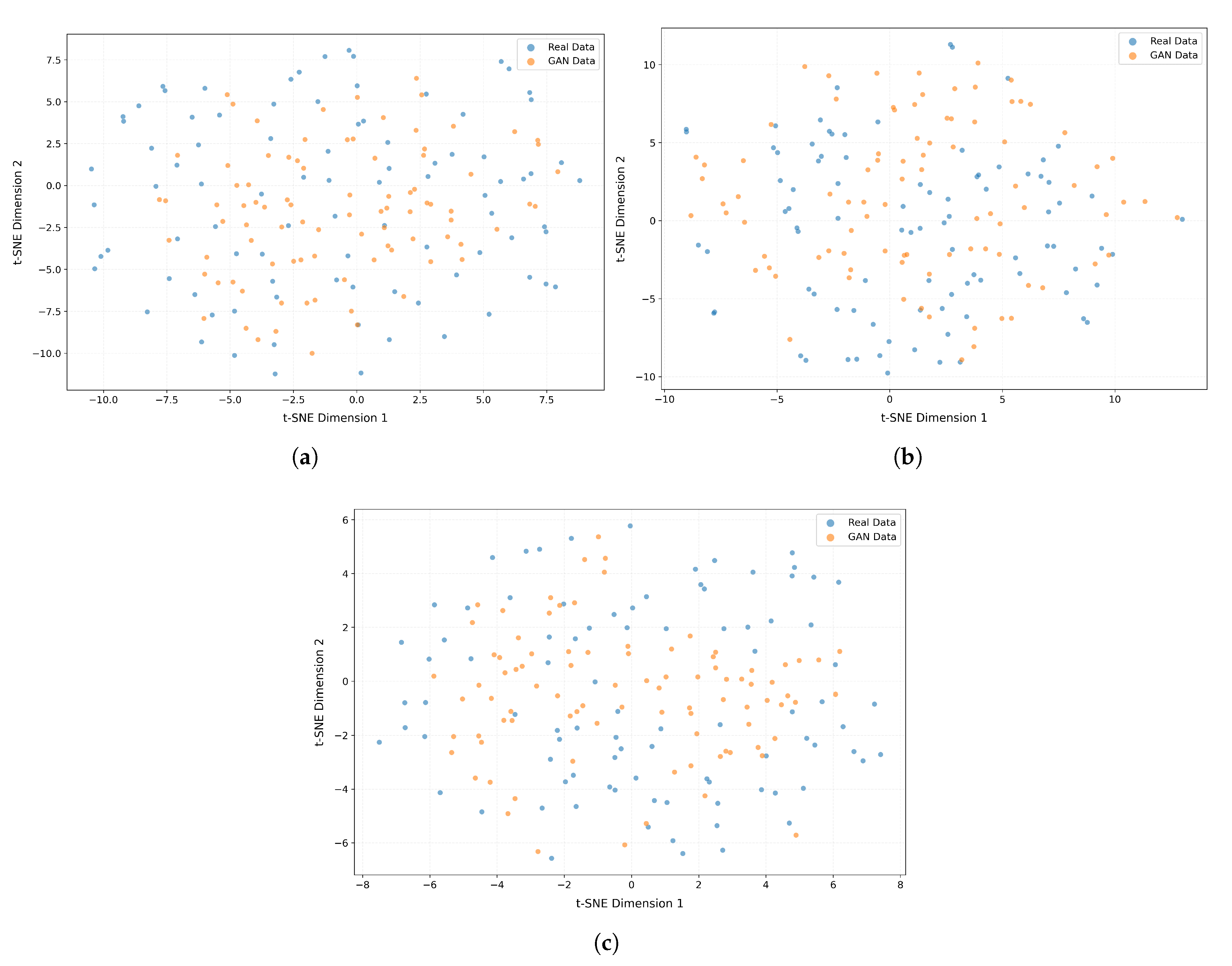
2.2. Fault Data Augmentation Model Based on GAN
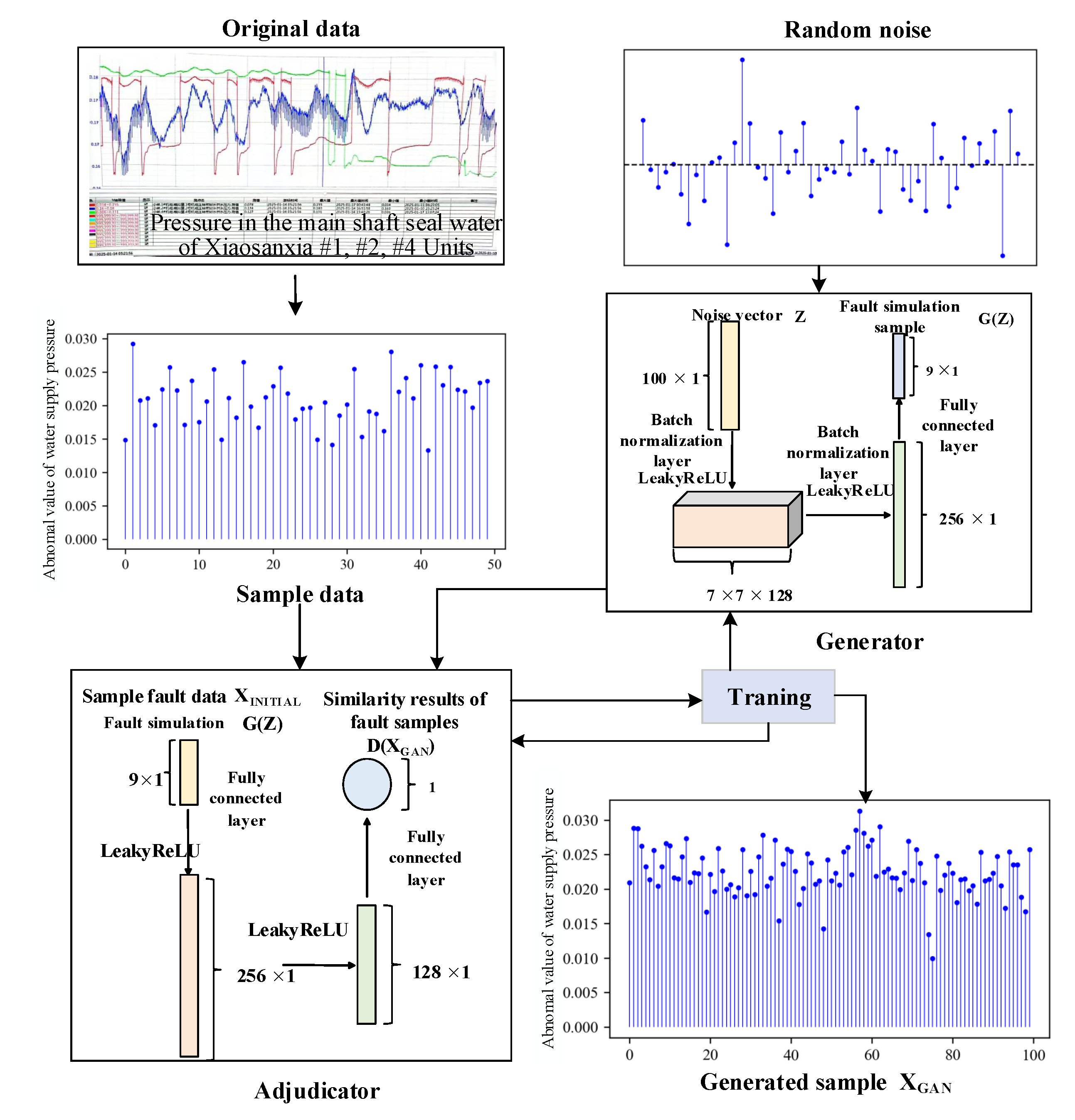
The hydropower fault data enhancement model based on GAN is shown in
Figure 3. It mainly consists of two modules: the generator
and the discriminator
[
32]. During the training process of the model, a unique and dynamic adversarial relationship is formed between
and
. The responsibility of
is to create new data through algorithms. Its goal is to mimic the real-world data to deceive the discriminator
.
represents the data generated by
, where
z is a random noise vector. This noise vector is mapped to a vector of shape
through a fully connected layer. Subsequently, the batch normalization (BN) layer normalizes the output of the previous layer.
Immediately afterwards, the leaky rectified linear unit (Leaky-ReLU) activation function provides a non-zero gradient for negative input values. This characteristic helps mitigate the gradient vanishing and maintains the nonlinearity during training. To further improve the performance of the generator, a second fully connected layer with 256 units is incorporated into the model. Finally, the output layer uses the
activation function to activate the generated data, restricting the output values to the range of
. Such a restriction helps match or limit the range of the generated data, making it closer to the distribution of the real fault data. The input layer receives data samples from the generator or the dataset and utilizes a fully connected layer to derive features from the input data. The Leaky-ReLU layer and the Dropout layer are used to introduce nonlinearity and regularization techniques, respectively, reducing the risk of model overfitting. In the output layer generating a scalar value, the
function is used to compress the output within the range of
. Among them, a value close to 1 indicates that the model considers the input to be real, while a value close to 0 indicates that the input is generated. The objective function is
where
x represents the actual data,
describes the distribution of this data, and
denotes the expectation. Variable
z refers to Gaussian random noise, with
as its distribution.
evaluates the generated data, yielding
, and similarly assesses real data, producing
. The discriminator’s outputs are fed back to the generator, guiding it to create more precise and lifelike data. Through this adversarial training mechanism, the generator and discriminator iteratively improve in a competitive process. Eventually, when the GAN objective function stabilizes, the generator can generate increasingly realistic data that cannot be accurately distinguished, thus achieving the global optimum.
As the training progresses continuously, becomes closer and closer to the real data, and the discriminative ability of is also constantly improving. In this mutually adversarial process, the capabilities of both and are enhanced. Under the ideal training state, can eventually create fake data that is almost indistinguishable from the real data. For the discriminator , since the data given by are already very realistic, will be hesitant when judging these data; that is, is close to , indicating that the discriminator cannot determine whether these data are real or fake. Finally, a batch of generated fault values that are close to the real fault values are obtained.
2.3. Fault Detection Model Based on Multi-Scale Feature Network
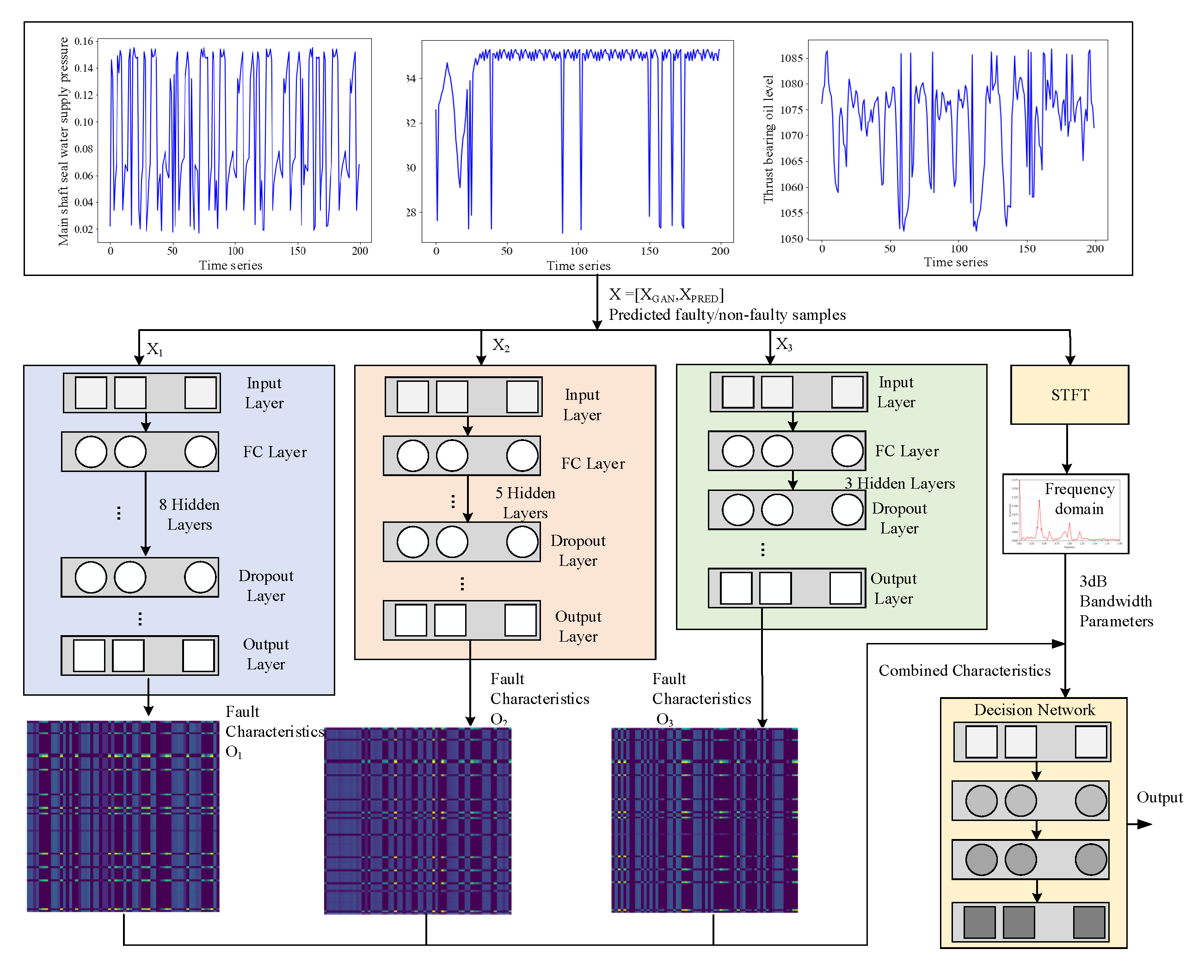
After the above process is completed, the batch of generated fault data is mixed with the predicted data of the CNN-LSTM, and then fed into the multi-scale feature extraction fault detection network for training, so as to enhance the recognition accuracy of the fault detection network. The trained multi-scale feature extraction network is used to conduct fault detection on the predicted values output by the CNN-LSTM network, and the detection results are output. The structure of this network is illustrated in
Figure 4. The same input data enters the network through three branches. Each sub-network independently processes the received data and extracts fault features. These features form a collection of all sub-network features through a merging layer. Subsequently, this collection is processed by the hidden layer again, and finally, the fault detection results are output.
The hidden layer of each sub-network is composed of several fully connected layers and Dropout layers. The former are responsible for learning the nonlinear relationships among the input data. As the learning progresses, the output dimensions of these layers will vary. In this network, from left to right, the sub-networks have three, five, and eight hidden layers, respectively, which reflects the extraction of features at different levels and depths, and increases the diversity of the model. When the features of these sub-networks are fused, since each sub-network focuses on different parts of the dataset, the fused features can provide a more comprehensive perspective. This fusion can also enhance the generalization ability, enabling the model to have better detection performance on unseen data, thereby enhancing the robustness.
In addition to the mixed time-domain features, we also use the frequency-domain parameters of the sample data, such as frequency peak position and 3 dB bandwidth, as auxiliary information to assist the model in making its diagnosis. Therefore, incorporating spectrograms as auxiliary inputs into the classification network can improve both the accuracy and robustness of fault detection. We employ the STFT,
to extract frequency-domain features from time series signals, where
denotes the time series signal,
is the sliding window function,
m represents the time shift, and
is the frequency variable. In practical applications, the discrete form is typically used as
where
is the number of samples. By applying the Fourier transform to each time window, a time–frequency representation is obtained, which is then used to enhance the discriminative performance of the multi-scale network.
2.4. Dynamic Multi-Task Training Algorithm
To ensure the convergence and training efficiency, we propose a dynamic multi-task training algorithm, as shown in Algorithm 1. We define the loss functions of the prediction network based on the CNN-LSTM for the regression task and the detection network based on multi-scale DNN for the classification task as
in SubNet and
in GlobalNet, respectively. We jointly optimize the parameters
of the SubNet and GlobalNet. The algorithm initializes the following inputs: training set
, validation set
, maximum training steps
N, early stopping patience
P, and minimum improvement threshold
. Finally, it outputs the optimal parameters
. After initializing network parameters, the dynamic weight coefficients are generated at each training iteration step
n as
where
decays with training steps to prioritize the subnet task, while
increases to amplify the global task influence, enabling a progressive shift in learning focus from local features to global semantics.
| Algorithm 1 Dynamic Multi-Task Training Algorithm |
- 1:
Input: Training data , Validation data , Max training steps N, Early stop patience P, Min improvement threshold . - 2:
Output: Optimized parameters . - 3:
Initialize , , , best , and ctr . - 4:
while and ctr do - 5:
- 6:
- 7:
- 8:
for each batch do - 9:
- 10:
- 11:
- 12:
- 13:
- 14:
- 15:
end for - 16:
- 17:
for each do - 18:
- 19:
end for - 20:
- 21:
if then - 22:
best - 23:
- 24:
ctr - 25:
else - 26:
ctr - 27:
end if - 28:
end while - 29:
return .
|
During training, each batch undergoes forward propagation to obtain the subnet regression predictions
and global network classification predictions
, with loss functions computed as
The weighted total loss can be set as
for parameter updating. After each iteration, the validation set is evaluated by
When is satisfied, is updated and the early stopping counter is reset. Otherwise, the counter increments. Training terminates when reaching N steps or when no significant improvement is observed for P consecutive iterations, returning the optimized parameters .




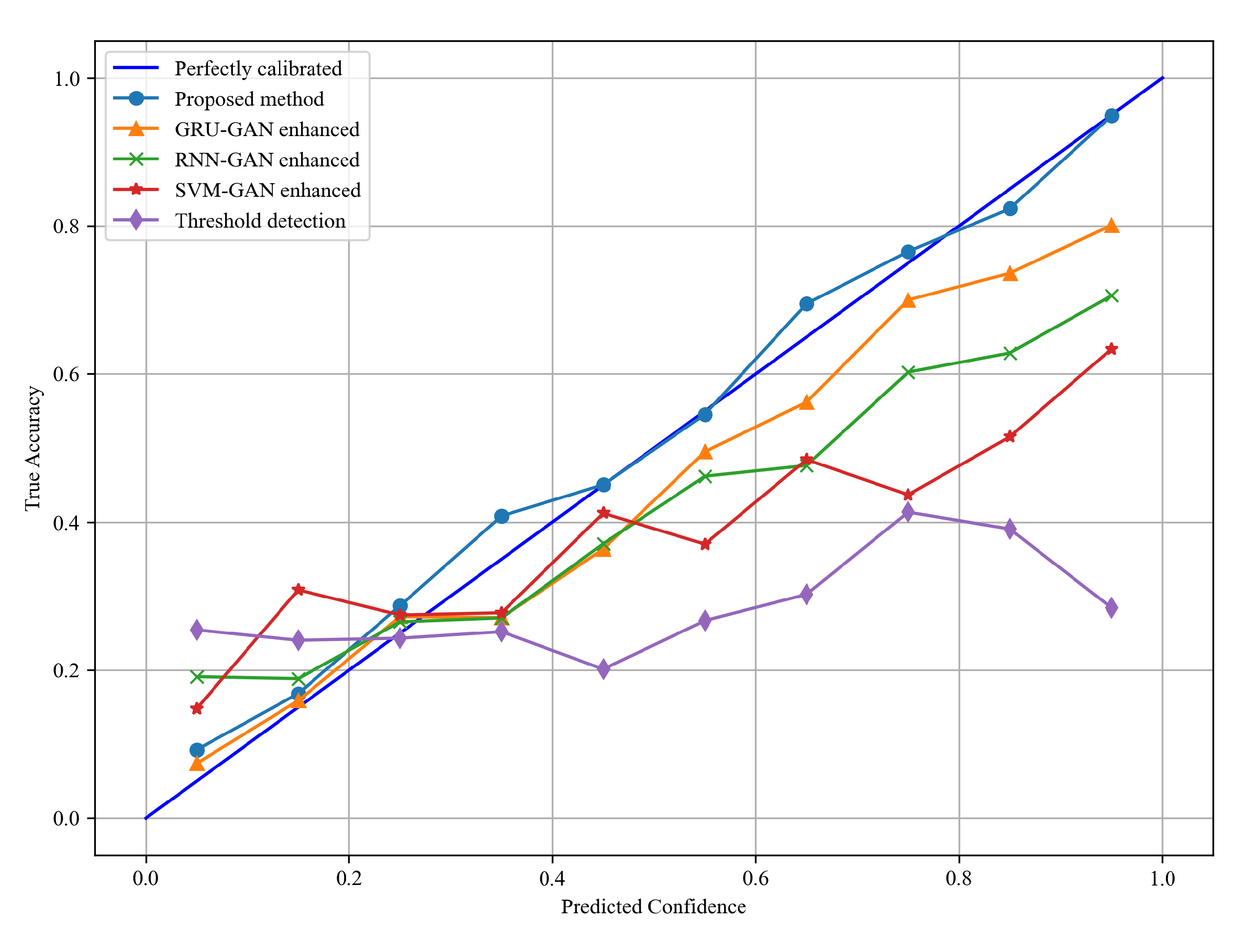
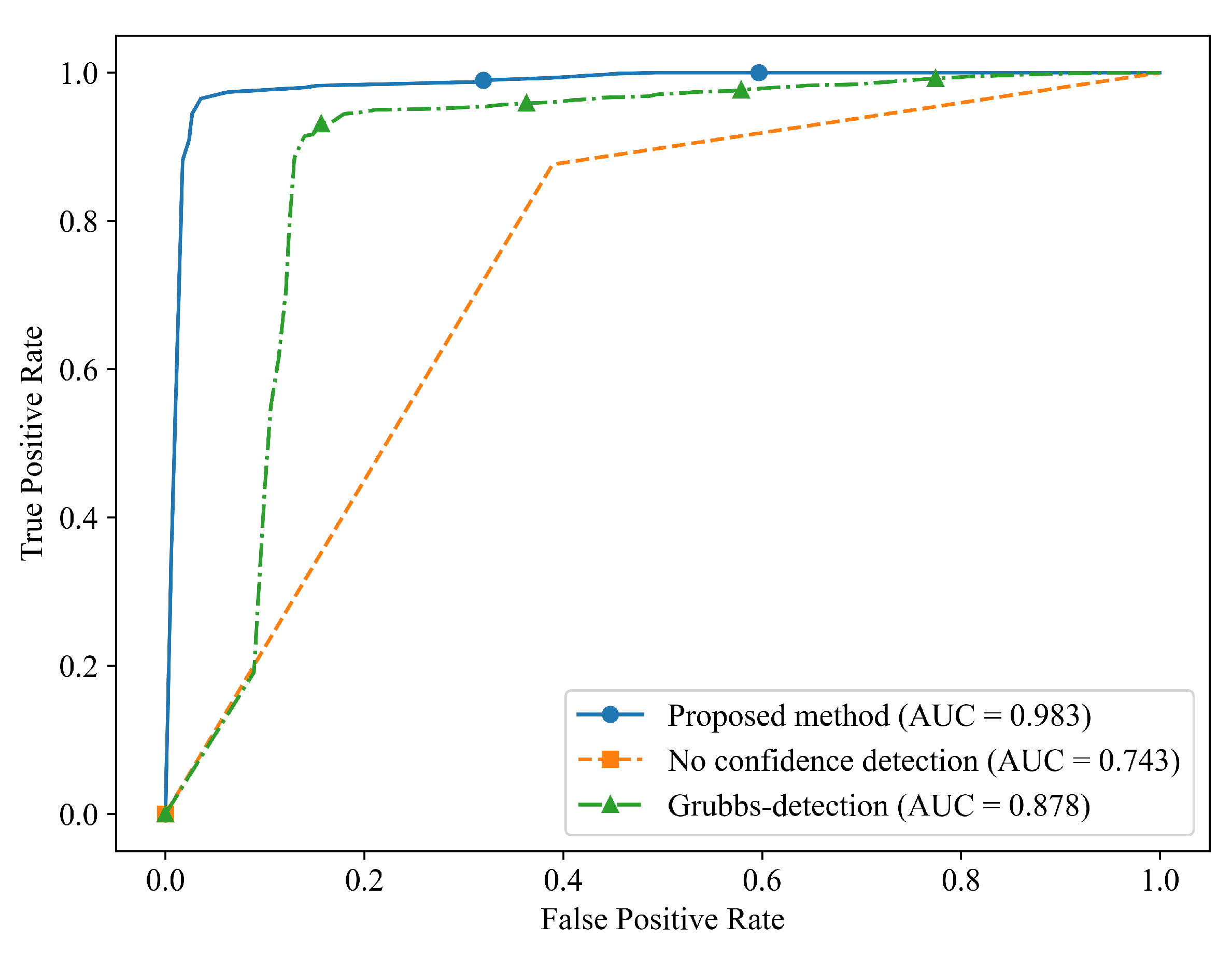

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}