1. Introduction
In urban conditions of frequent starting and stopping, about 30–50% of the kinetic energy is consumed by the frictional braking process. Due to the large mass and more frequent start–stop events of city buses, a large amount of braking energy is wasted. Therefore, recovering this energy is a way to increase the travel mileage of the vehicle [
1,
2]. At present, it is more common to charge the braking current to the battery or supercapacitor. However, this approach to energy recovery efficiency is not ideal, due to battery life, safety, and other issues [
3]. Hydraulic accumulators have higher power densities and better charging–discharging energy ratios than batteries, supercapacitors, and other energy storage components [
4].
The regenerative braking control strategy determines the distribution coefficient of the braking force and the intervention time during regenerative braking, which has an important impact on the safety of the vehicle braking, fuel economy, and power of the vehicle [
5,
6]. Taghavipour et al. found that the use of radial-basis-based neural networks improved the fuel economy of the vehicle while obtaining better maneuvering and stability [
7]. Rule-based control strategies are widely accepted because they are simple to implement, but they take a long time to optimize because they usually require a large amount of experimental data and expert experience [
8,
9]. At the same time, it is difficult to explore the full potential of the regenerative braking system and to adapt flexibly to different driving conditions.
Based on the complex nonlinear time-varying characteristics of the regenerative braking of hybrid vehicles, many scholars have transformed the regenerative braking control problem of hybrid vehicles into an optimal solution problem [
10,
11,
12]. Shangguan globally optimized the main parameters of a parallel hydraulic hybrid vehicle based on the dynamic programming algorithm, and the simulation results showed that the energy recovery efficiency was improved [
13]. Larsson et al. simplified the dynamic planning algorithm by reducing the number of grid points generated by discretization, thereby reducing the computational effort [
14]. Tate et al. proposed a control strategy based on stochastic dynamic planning, which is similar to the Markov decision process involved in artificial intelligence theory [
15]. Global optimization algorithms such as dynamic programming techniques can calculate the optimal solution of each parameter of the system under known cycle conditions. However, due to the complexity of the hybrid vehicle system and the many constraints, the calculations are large and difficult to apply.
Along with the rapid development of learning-based artificial intelligence technology, many researchers have started to apply machine learning, deep learning, and other algorithms to automotive control [
16,
17]. Tian et al. separately collected data recorded during past vehicle driving experiences and used machine learning methods to learn automotive control strategies from them [
18]. Reinforcement learning algorithms can learn through continuous repetitive experiments using the model, do not require the accumulation of preliminary data, and have a strong self-adjustment capability [
19,
20,
21]. Qi et al. developed a control strategy for a vehicle by continuously rewarding and penalizing their model through the Q algorithm [
22]. The learning algorithm based on neuron dynamic programming does not depend on the known information of cyclic working conditions and can adjust the energy management strategy parameters by itself, having good adaptability to different working conditions [
23].
However, most of the research on hydraulic regenerative braking systems involves theoretical analyses and simulation experiments, and there is a lack of experiments further verifying the influence of each component on the braking effect in the process of hydraulic regenerative braking. Meanwhile, most of the existing regenerative braking force distribution schemes are rule based. If the setting cannot be changed, it cannot be applied to different driving conditions, and the braking energy of the vehicle cannot be fully recovered. This paper proposes a hydraulic regenerative braking energy recovery efficiency optimization algorithm based on fuzzy Q-learning (FQL) and a reward function based on the hydraulic regenerative braking energy recovery system, which can solve the problems of Q-learning and speed up the computation by introducing the method of fuzzy logic. Xian et al. and Zhou et al. made improvements on the basis of fuzzy logic and obtained a predictive model that is superior to other methods [
24,
25]. Furthermore, reinforcement learning is a knowledge-free online learning process that can adapt the regenerative braking control strategy to different driving conditions over time, which is more advantageous than fuzzy control, which requires expert experience [
26,
27].
In
Section 2, this paper establishes the vehicle dynamics model and the mathematical model based on parallel hydraulic hybrid power systems (PHHPS). In
Section 3, an optimized algorithm based on FQL for braking energy recovery efficiency is proposed. In
Section 4, we describe our experimental bench. By comparing the experimental and simulated data, we obtain an accurate simulation model and combine it with the ADVISOR. Finally, the simulation simulates the braking energy recovery of the fuzzy control, DP algorithm and the fuzzy reinforcement learning control strategy under the 1015 cycle and UDDS cycle. The conclusions are presented in
Section 5.
2. Model of Hydraulic Regenerative Braking System (HRBS)
Electric vehicle batteries are energy storage devices that have high energy density and low power density. However, such batteries cannot withstand high-power inrush currents, resulting in electric regenerative braking being less effective than expected, impacting the battery life.
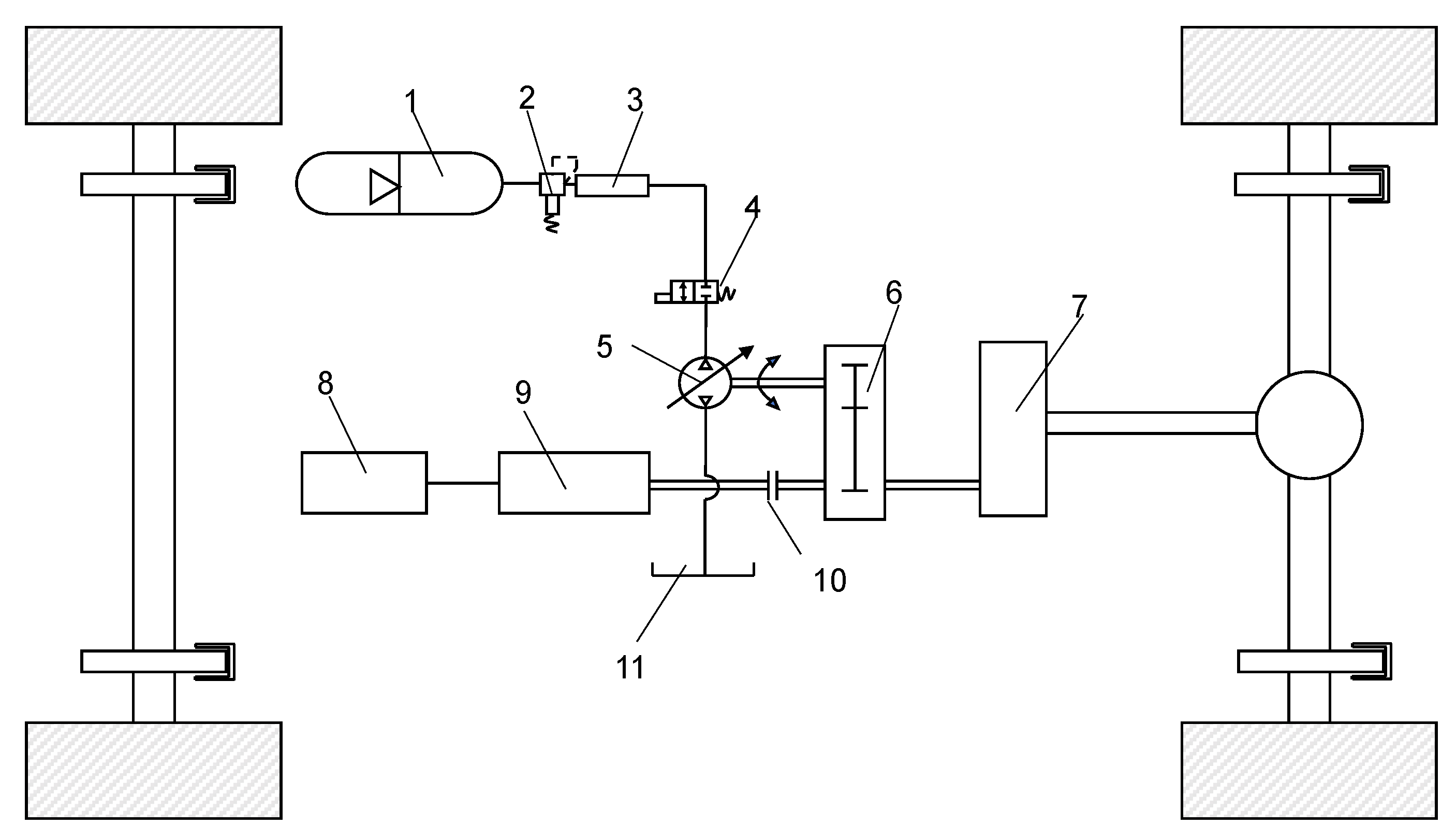
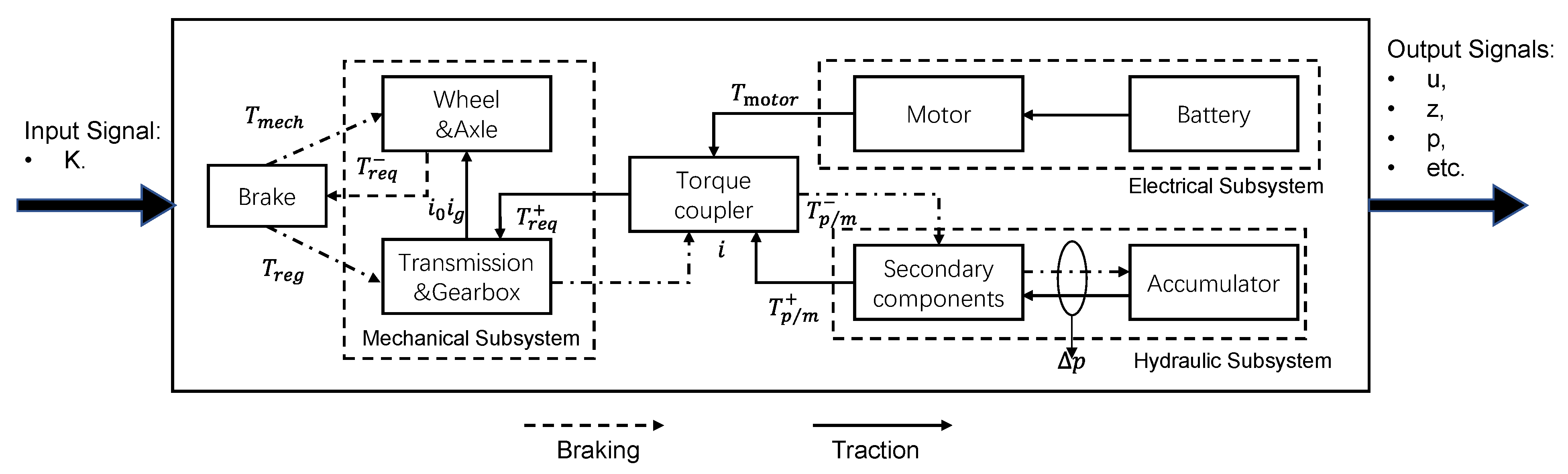
The considered hydraulic braking energy recovery system is a parallel hydraulic hybrid system (PHHS) consisting of a battery, an electric motor, a secondary component, a hydraulic accumulator, a clutch, and a torque coupling. By using the torque coupler to match the torque and speed, the torque is transmitted to the gearbox, the final reducer, and finally the wheels (
Figure 1). Secondary components and hydraulic accumulators are used to recover the braking energy. Since the two power systems, namely the electric drive and hydraulic drive, are connected in parallel, the parallel hybrid vehicle has multiple operating modes, including a pure electric drive mode, pure hydraulic drive mode, and hybrid drive mode.
The motor output torque and the hydraulic system output torque of the two-axis parallel structure are connected through a torque coupler. Since the motor and the secondary components are on two separate drive shafts, the electric system and the hydraulic system can output torque independently, ignore the influence of speed and operate independently in their respective high-efficiency zones, and make it easy to match the two power sources. At this time, since the double-shaft parallel structure is relatively simple, there are fewer energy transmission levels, which reduces the energy loss in the mechanical transmission process.
During the vehicle braking process, the secondary component works as a hydraulic pump that converts the kinetic energy into hydraulic energy, and then this energy is stored in the accumulator. During the vehicle starting and hill climbing processes, the secondary component acts as a motor, releasing the energy stored in the accumulator to drive the vehicle. When the hydraulic accumulator is unable to provide the torque in the drive phase, the electric motor will participate instead. During daily driving, the hydraulic system also participates in providing torque when the motor output torque is insufficient.
In the HRBS, the secondary component has both energy storage and driving functions. The torque provided by the secondary component is calculated as follows
[
28]:
where
is the amount of accumulator pressure change
,
is the displacement of the hydraulic pump motor
,
is the mechanical efficiency of the secondary component,
is the torque coupling ratio,
is the speed ratio of the gearbox, and
is the speed ratio of the final drive.
The braking force required to brake the vehicle is expressed as:
where
is the driving force provided for the motor,
is the driving force provided by the secondary component,
is the mechanical friction braking force, and
is the braking force provided by the secondary component.
The main parameters of the hydraulic accumulator include the initial pressure, volume, displacement, and maximum working pressure. In the hydraulic system, when the initial pressure of the accumulator is high, the braking torque and energy recovery efficiency provided by the HRBS will also be high, but the maximum energy absorbed will be reduced. The smaller the volume of the accumulator, the faster the accumulator pressure rises during braking, the greater the regenerative braking torque, and the higher the regenerative braking efficiency, but this will also cause the same energy storage capacity problem. In consideration of the airtightness and safety of the accumulator, the maximum pressure of the accumulator is usually 31.5 Mpa. According to Boyle’s law:
During braking, the energy recovered by the hydraulic accumulator is calculated as:
where
is the initial inflation pressure,
is the initial volume of the accumulator,
is the minimum working pressure,
is the minimum working volume,
is the maximum working pressure of the accumulator, and
denotes the maximum energy that can be stored in the accumulator (when
).
The kinetic energy of the vehicle is selected as the main objective in braking energy recovery, which is simplified as follows:
where
is the mass of vehicle,
is the speed of the vehicle before braking, and
is the speed of the vehicle at the end of the braking phase.
The braking energy recovery efficiency can be expressed as follows:
Combined with the operating characteristics of the PHHS, the secondary component needs to meet the following requirements: (1) in the starting phase of the vehicle, the hydraulic system can drive the vehicle independently, i.e., the hydraulic system’s output torque is greater than the vehicle’s demand torque; (2) in the braking phase, the hydraulic pump needs to provide as much regenerative braking force as possible to improve the efficiency of the braking energy recovery.
To meet the requirements of the starting phase, the torque provided by the hydraulic motor needs to be greater than the combined force of the rolling resistance, aerodynamics resistance, and slope resistance. Therefore, the motor displacement needs to satisfy the following equation:
where
is the total mechanical efficiency,
is the wheel radius,
is the gravitational constant,
is the sum of the vehicle driving resistance,
is the rolling resistance coefficient,
is the ground inclination angle,
is the density of air,
is the aerodynamics resistance coefficient, and
is the front area of the vehicle.
In pursuit of maximum energy recovery efficiency, the HRBS needs to meet the light braking conditions for all braking forces provided by the hydraulic pump; when the braking strength is 0.1 (braking strength is defined as the ratio of deceleration to gravitational acceleration), the hydraulic pump displacement needs to meet:
where
is the braking strength.
When the stored energy of the energy storage system reaches its limit, it is unable to receive the recovered energy from the outside world and cannot effectively deliver the required braking torque of the vehicle. In some braking situations, the increased braking force of the HRBS cannot fully provide the required braking torque for the vehicle, so friction braking is required in the achieving braking process. The total braking force of the vehicle consists of the front and rear braking forces:
where
consists of mechanical braking and regenerative braking, and
consists of mechanical braking only. During vehicle braking, the braking effect is related to the utilization rate of the road attachment conditions.
When the adhesion conditions are not fully utilized, the vehicle is likely to slide sideways or show braking instability. When the front and rear axles of the car are clutched, the utilization rate of the road adhesion conditions is the highest, and the stability of the vehicle when braking is also the best. Therefore, when both the front and rear axles are locked:
where
is the horizontal distance from the center of mass of the vehicle to the front axle,
is the horizontal distance from the center of mass of the vehicle to the rear axle,
is the wheelbase of the vehicle, and
is the height of the center of mass of the vehicle.
For each possible coefficient of adhesion, the following method can be used to obtain the front wheel braking force with the front and rear wheels locked simultaneously:
The regenerative braking factor
proposed in the HRBS is defined as the braking force provided by the hydraulic pump divided by the demanded braking torque of the front wheel:
The regenerative braking distribution strategy is based on safety, first through the distribution of the front and rear axle braking torque so that the vehicle brake safely, and then in the form of a combined regenerative and mechanical braking distribution in the front axle.
3. FQL Algorithm and Models
A large number of researchers have introduced fuzzy control theory to the vehicle control process and achieved some results, but fuzzy control still relies on expert experience, and for some nonlinear systems, fuzzy control cannot achieve optimal control results [
29]. In addition, once a fuzzy controller has been designed and produced, the vehicle equipped with the controller will follow this control rule in all operating conditions, leading to neglect of some of the recoverable energy.
Therefore, to solve the problem whereby fuzzy control cannot handle complex nonlinear systems, we introduce reinforcement learning algorithms and adjust the fuzzy rules of the fuzzy controller using the Q-Learning algorithm. In our proposed controller, the FQL algorithm acts as a decision engine that learns approaches to map the input states to the desired output decisions. The controller can maintain the original expert experience, while the FQL has an exploration function that improves the braking energy recovery performance.
The Q-learning algorithm is a table-driven learning algorithm. On the one hand, the use of fuzzy logic can solve the computational capacity limit and storage problems of Q-learning in the face of large-scale continuous state action problems, and fuzzy logic can improve the generalization ability of the reinforcement learning state action space. On the other hand, the FQL can optimize the control effect of the controller. Therefore, the FQL algorithm makes up for the shortcomings of fuzzy control and Q-learning algorithms.
3.1. FQL Model
The Markov decision process is the basic model of reinforcement learning. To solve a specific learning task, an agent is placed in an unknown environment, the agent takes an action based on the state in the environment, and the action can change its state in the environment and return a delayed numerical reward to the agent. The goal of the agent is to learn a strategy with which to take an action that allows the agent to maximize the accumulated reward in the task. Q- learning is a popular reinforcement learning algorithm that learns knowledge by updating a Q-table through a reward mechanism. The Q value is the expected cumulative reward that can be obtained by following the optimal policy after taking a certain action in each state. After learning, the agent is able to construct an optimal policy by simply selecting the action with the highest Q value in each state. The RL problem is modeled as follows:
is the set of all environment states, indicates the state of the agent at the moment ;
is the set of all actions that the controlled object can perform, and indicates the actions performed by the agent at the moment ;
is a scalar quantity indicating that the object of the controlled pair is under the state , where at this time action is taken and the environmental state shifts to , at which time the controlled object gets an immediate reward;
The Q value corresponding to each state action is updated by the temporal difference (TD) method with the following rules:
Here, is the observed reward, is the learning rate, and 0 ≤ ≤ 1. High values of result in rapid learning and adaptation, while low values of slow down the learning and prevent the impact on the q-table from possible outliers. The denotes the state of the estimated optimal value of Q under the discount factor , 0 ≤ ≤ 1. The value of determines whether the optimization process should consider the long-term reward or not.
Q-learning is not good at dealing with situations where the state space is relatively large, since a large amount of memory is needed to store the q-table. Even if a large amount of memory can be provided, agent learning requires a lot of trials and time to learn the required behavior, and vehicles driving urban routes require different environments to satisfy q-table updates in all cases, thereby causing a lot of learning costs.
FQL is a fuzzy extension of Q-learning that can overcome this problem [
30]. We can encapsulate expert knowledge into a learning table to speed up the learning process. In FQL, the decision part is represented by a fuzzy inference system (FIS), which takes continuous and large discrete states as the inputs. The idea of the FQL algorithm is to use the FIS to integrate continuous and large discrete state inputs into a so-called q-table, which is different from the original q-table; the new q-table is based on evaluating the fuzzy rules in the FIS as the basis for updating the q-table. Compared to the infinite action- state space, fuzzy rules are finite and are used as inputs to the q-table so that the q-table can learn knowledge without relying on large amounts of memory.
In FQL, the FIS is represented by a set of fuzzy rules
. Rule
∈
is defined as:
where
is the label of the input variable
base on rule
,
is the action of the rule
,
is the modal vector under rule
, and
is the modal vector
and the action
of rule
in the Q value.
In the fuzzification layer of the FIS (
Figure 2), the input states are fuzzified into the affiliation degree of the corresponding label by the affiliation function, and each input state is fuzzified to obtain a fuzzy set
. Let
denote the set of all rules in the rule evaluation layer, and each rule is a scalar obtained by multiplying the fuzzy sets corresponding to the input states, then the set of rules is the Cartesian product of the fuzzy sets corresponding to the input states. For the rules
(
),
denotes the activation degree of this rule, which can be expressed as follows:
In the FQL algorithm, we take a two-stage action selection approach. In the first stage, we select the local action according to the
strategy to select local actions
. The agent makes it possible to explore untried actions instead of the action with the largest Q value, in order to ensure a higher long-term payoff. At each time step, the agent selects random actions with a fixed probability of
. At the beginning of the exploration, we let the agent take more random actions instead of greedily choosing the optimal action in the q-table.
where
is the local action of the rule
. In the second stage of the action selection, the activation degree of the rule is obtained according to the input state, and the activation degree multiplied by the local action can be used to obtain the final action; here, the agent chooses the final action with the highest activation degree of the rule; then the final action output can be expressed as:
By adding the time index to the equation, the Q value can be approximated as:
After taking action, the agent obtains the status
and reward
. Then, the state
of the Q value is calculated as follows:
Based on the above equation, the error is calculated by the TD algorithm as follows [
31]:
Ultimately, we can update the Q value of each activation rule by using the above equation as follows:
where
and
are the same as in Equation (15).
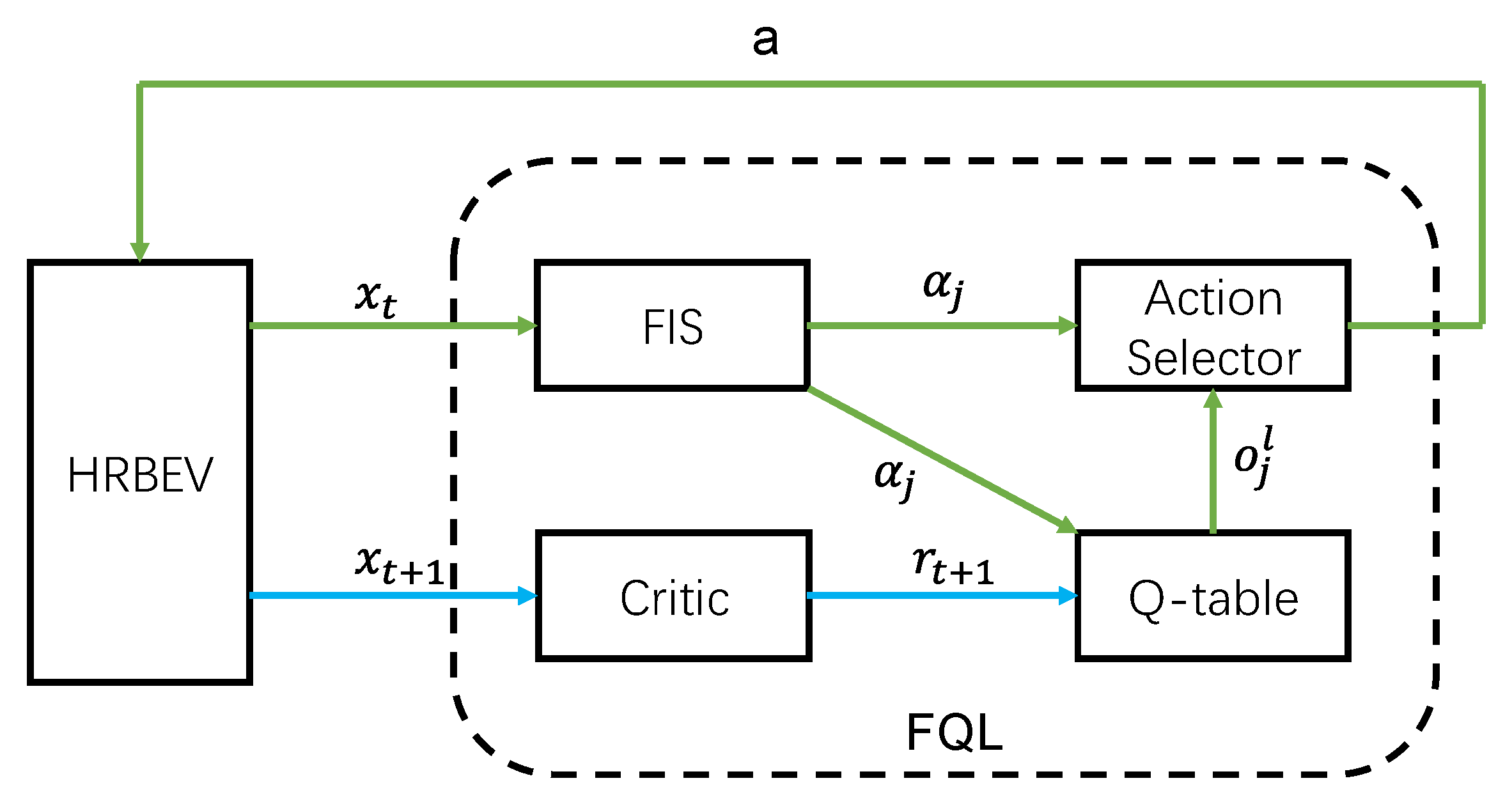
3.2. Regenerative Braking Based on FQL
In this section, the above fuzzy reinforcement learning model will be simulated jointly with the regenerative braking system for electric vehicles. Here, the HRBS for the electric vehicles (HRBEV) is built in MATLAB and Simulink, which will be introduced later. The FQL model is built in Python and simulated jointly with Python and MATLAB. At each time step, the HBREV outputs state
as the input of the FQL, which is fuzzed in the FIS. Then, the optimal action is selected according to the fuzzy rules and q-table, and the agent outputs action
to the HRBEV. In the next time step, the state
is output to the FQL model from the HRBEV. The critic gives
from
. Finally, the q-table is updated using the TD method (
Figure 3).
3.2.1. FQL Components
The RBFQL consists of the HRBEV and FQL, and the FQL consists of the following components.
State: The input state consists of the vehicle speed, braking intensity, accumulator pressure, demand braking torque, hydraulic pump providing torque, and other components. Here, the vehicle speed, braking intensity, and pressure of the accumulator are used as inputs of the FIS, while other components are used as inputs to the FQL observation reward value:
where
denotes the vehicle speed,
denotes the braking intensity, and
is the accumulator pressure.
Reward function: The design of the reward function is the key to building a reinforcement learning system. The agent gets a reward based on the observed state and uses the reward to update the q-table. The goal of reinforcement learning is to maximize the cumulative reward over time, and the agent seeks to produce the action with the maximum Q value. In our system, the reinforcement learning goal is to seek to maximize the regenerative braking energy. Therefore, our reward function can be expressed as:
where
is the required speed at time
and
is the real vehicle speed at time
,
is the accumulator pressure change under braking conditions,
is the maximum pressure of the accumulator (31.5 Mpa here), and
is the minimum working pressure of the accumulator. Obviously, to obtain a larger reward, it is necessary to make the real vehicle speed
as small as possible and the accumulator pressure variation as large as possible. If the reward is close to 0, this means that the action is invalid, and a negative reward means a penalty for the action. For example, if the agent takes an aggressive action in a certain state, i.e., takes a larger regenerative braking factor, the accumulator pressure change becomes large, and a large reward is obtained. However, due to the torque limitation of the pump, the pump does not provide enough braking torque, which will result in the
being large, and the penalty will increase at this time. Therefore, the method for dealing with the relationship between the reward and punishment is the key to reinforcement learning.
3.2.2. Fuzzy Inference System
In this paper, we simulate the vehicle dynamics model in urban cyclic conditions (1015 cycle and UDDS cycle). Due to the limitation of the vehicle′s operating environment, it is not possible for all action states to be traversed, but we need the agent to output a more appropriate action even when facing an inexperienced environment. Therefore, we choose the fuzzy control approach to add knowledge to the action selection process in the form of rules, which can improve the speed of the agent in dealing with complex continuous state spaces or multidimensional discrete spaces [
32].
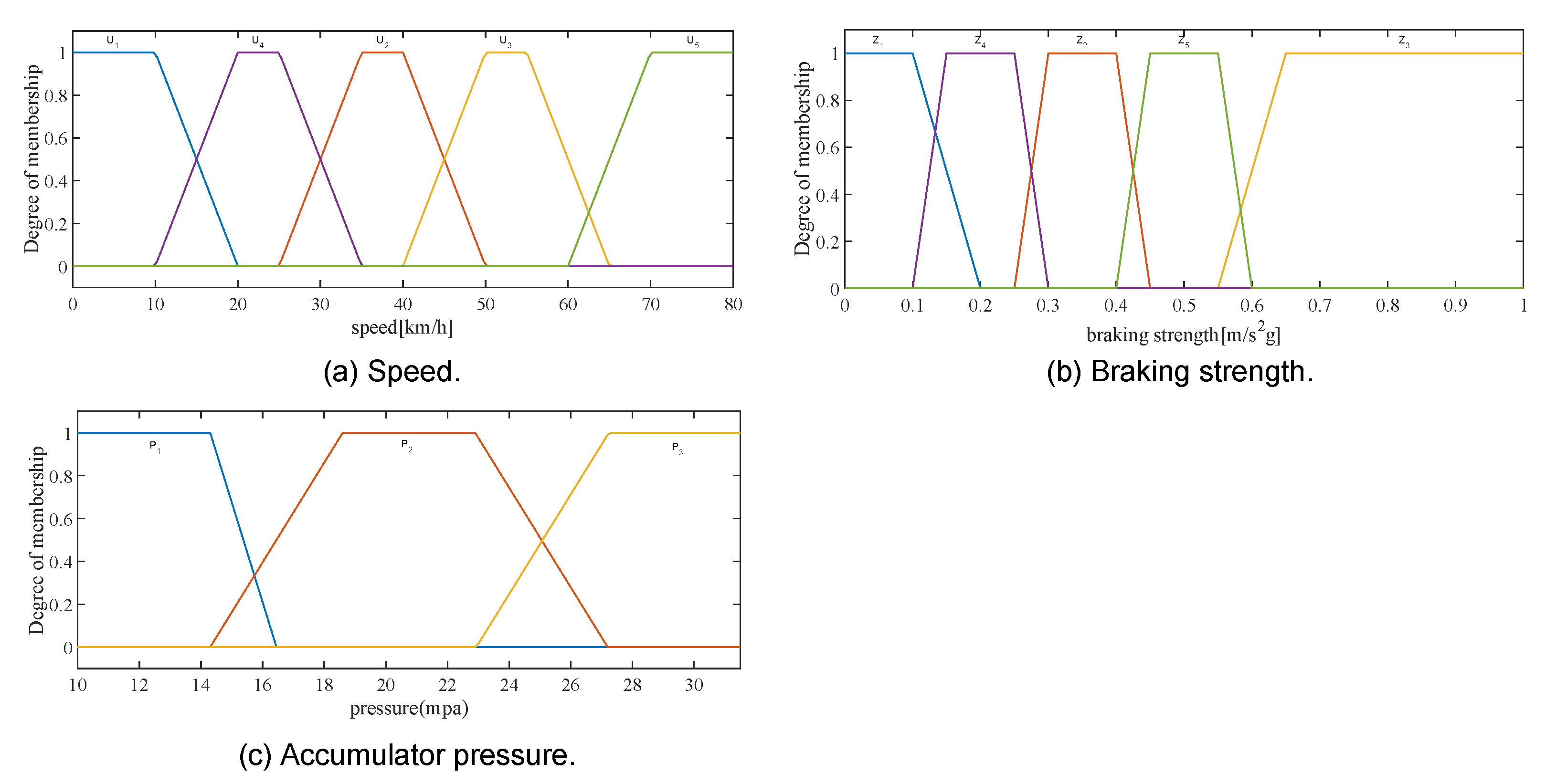
The FQL system inputs three input variables: (1) vehicle speed , (2) braking intensity , and (3) accumulator pressure ; and one output—(4) regenerative braking distribution coefficient . The fuzzy division of these four variables is as follows:
The vehicle speed .
, and the range of the theoretical domain is (0–80) (
);
The braking strength .
, and the theoretical domain range is (0–1) (
);
The hydraulic accumulator pressure . , and the theoretical domain range is (10–31.5) (
);
The regenerative braking coefficient . , and the theoretical domain range is (0–1).
The Sugeno method has the advantage of allowing simple calculations and facilitating data analyses, so we chose to set up the fuzzy control system using the first-order Sugeno method. The fuzzy control system performs the fuzzy inference process using fuzzy rules to obtain the output under different operating conditions. The knowledge base of the fuzzy system is described by a series of fuzzy logic rules in the form of IF–THEN, and the fuzzy rules are used as follows:
where
,
, and
. The regenerative braking coefficient
(
Figure 4). For example, when the vehicle speed is very low, the braking intensity is medium, and the accumulator pressure is very low, the regenerative braking distribution coefficient will be very high. When the vehicle speed is high, the braking intensity will be high, and the accumulator pressure is medium, the regenerative braking distribution coefficient will be very low. The idea of the rule set is to try to recover more energy at low speeds and ensure safety at high speeds, and regenerative braking is not involved in the work. The total number of rules in the rule set is
.
The FIS will be improved using the QL method to obtain better performance.
3.2.3. FQL Setup
In the FQL setup, we will set the discount factor through the phasing , learning rate , and random action selection probability . In the early stage of learning and the exploration stage, we set the discount factor to 0.2, because in the early stage of training, and do not converge, meaning the agent cannot correctly measure the expected future benefits. A higher discount factor will cause the agent to incorrectly estimate the current action value, leading to instability when the algorithm is updated, even making it difficult to converge. The discount factor will gradually increase as the training process proceeds. Meanwhile, we set the learning rate value to 0.9, as a larger learning rate at the early stage of learning can reduce the training time, and the subsequent reduction in the learning rate is beneficial to maintaining the system stability. The probability of random action selection in the exploration phase is set to 0.5; the agent needs to balance the maximum value action and develop potential higher value actions, while the random action selection probability will decrease with the learning process. Here, we compare the regenerative braking system with the fuzzy controller without adding the QL algorithm, so that we can judge the learning process and modify the above parameters. In addition, we initialize the q-table to zero to start the knowledge learning process from zero.
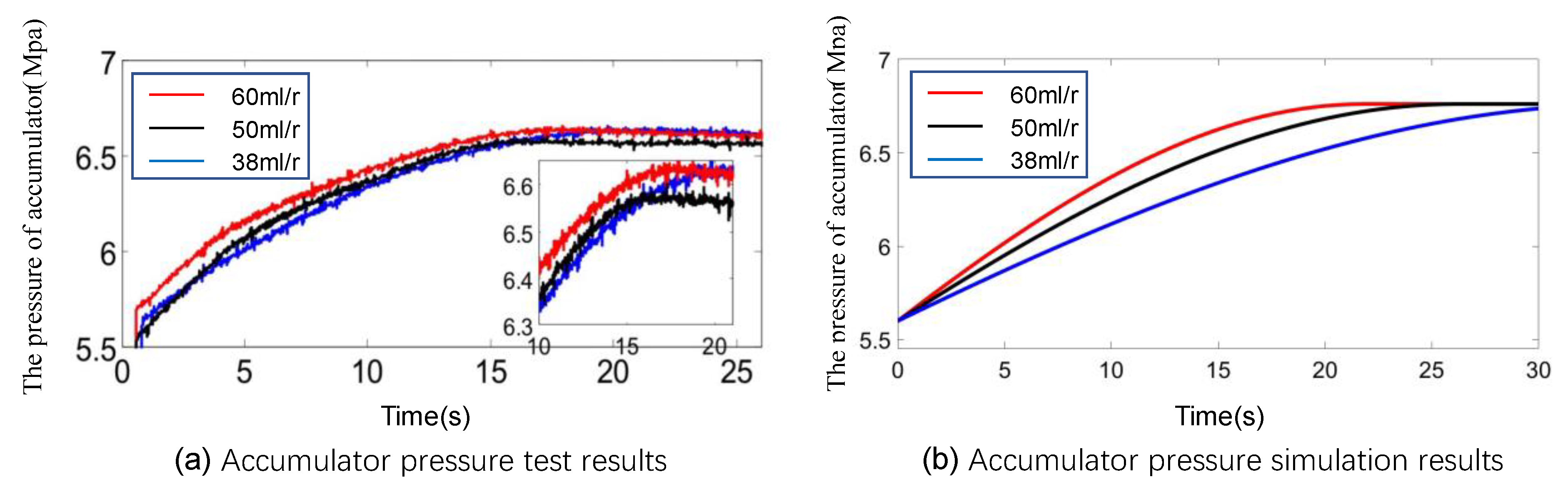
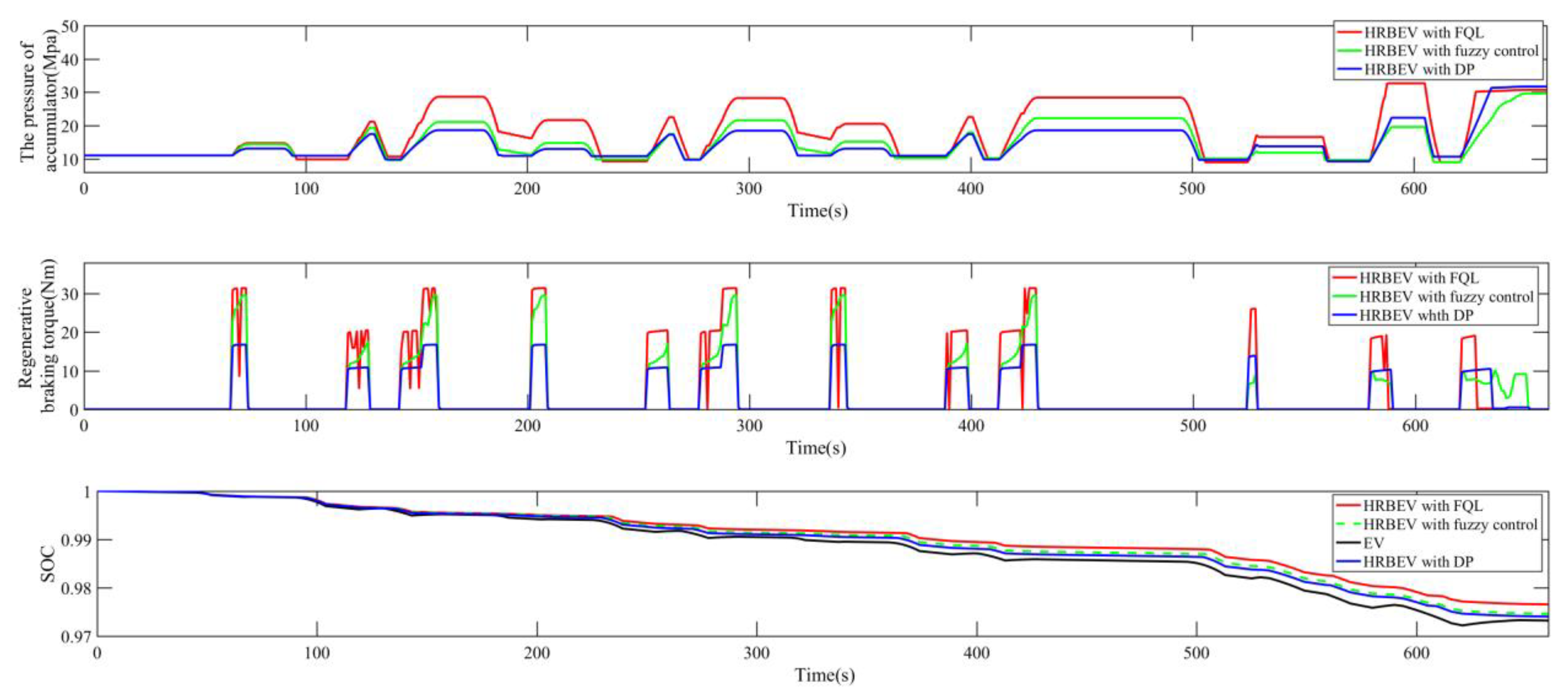
So far, this paper has completed the modeling of the hydraulic parallel hybrid braking system and vehicle dynamics, combined with the FQL to model the vehicle regenerative braking problem. The next section will verify the above system and the simulation of vehicle braking efficiency through experimental and simulation comparison methods.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}