
Solar Irradiance Prediction with Machine Learning Algorithms: A Brazilian Case Study on Photovoltaic Electricity Generation


Abstract
:1. Introduction
2. Machine Learning Algorithms
2.1. Support Vector Machines (SVM)
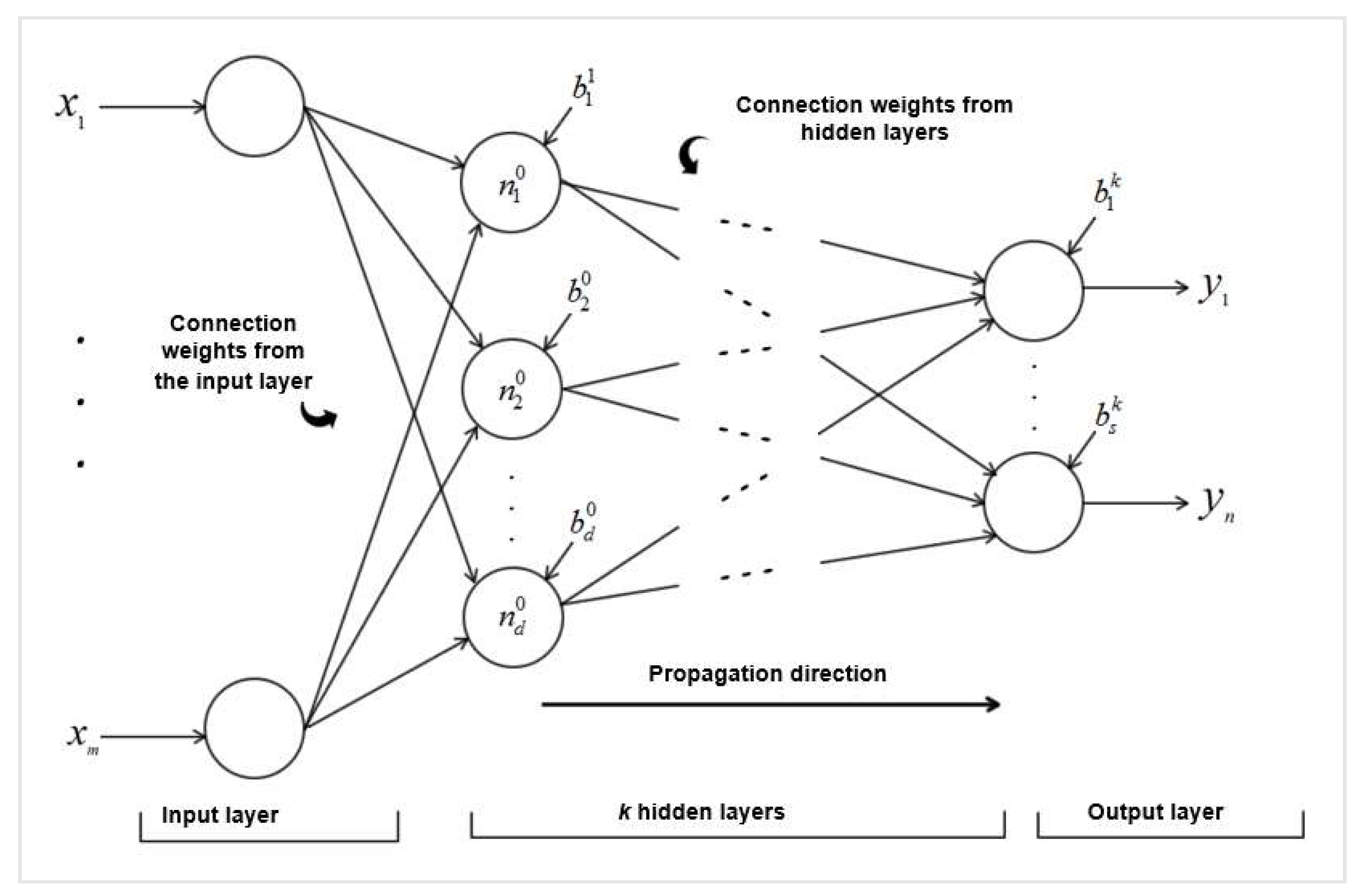
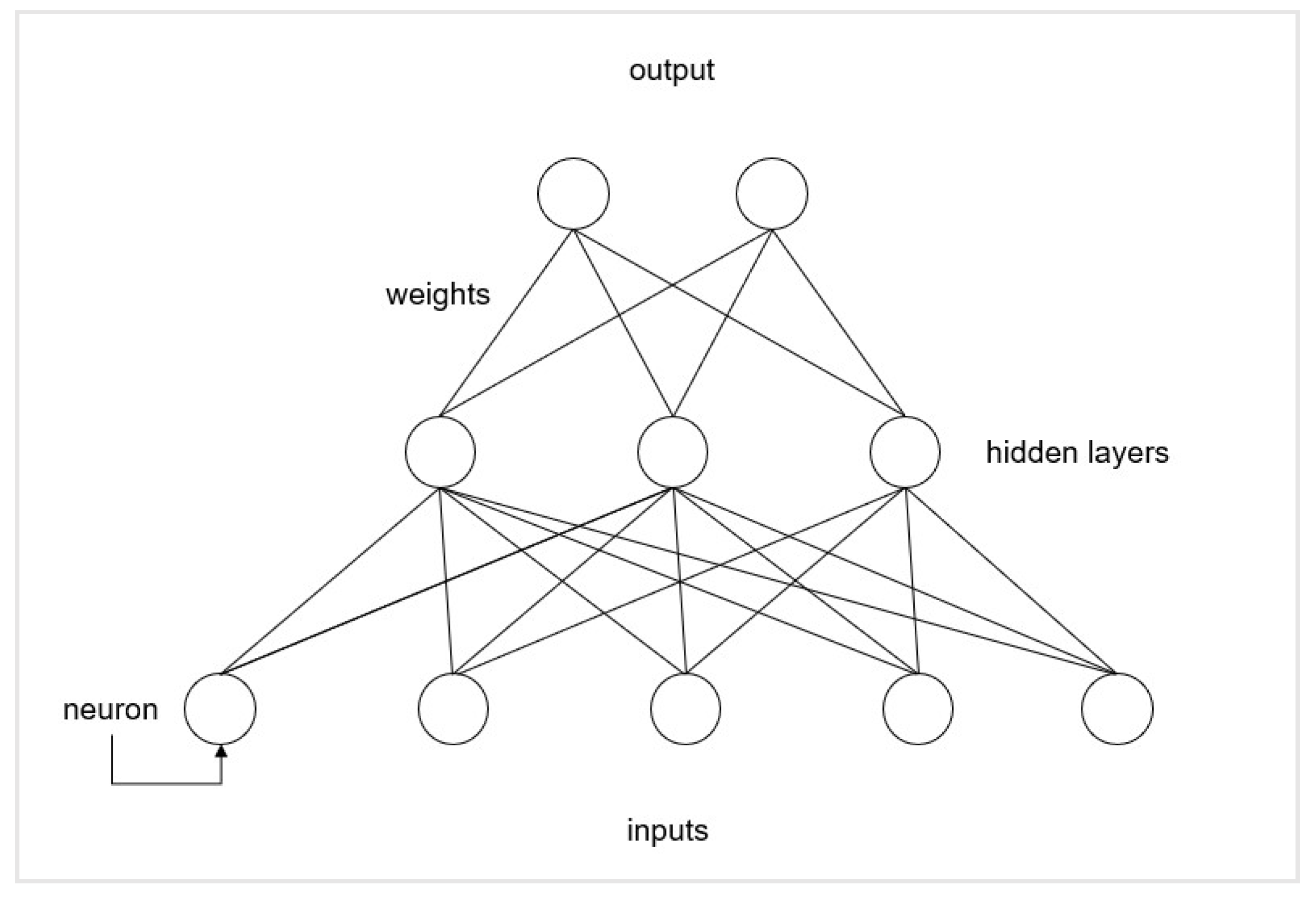
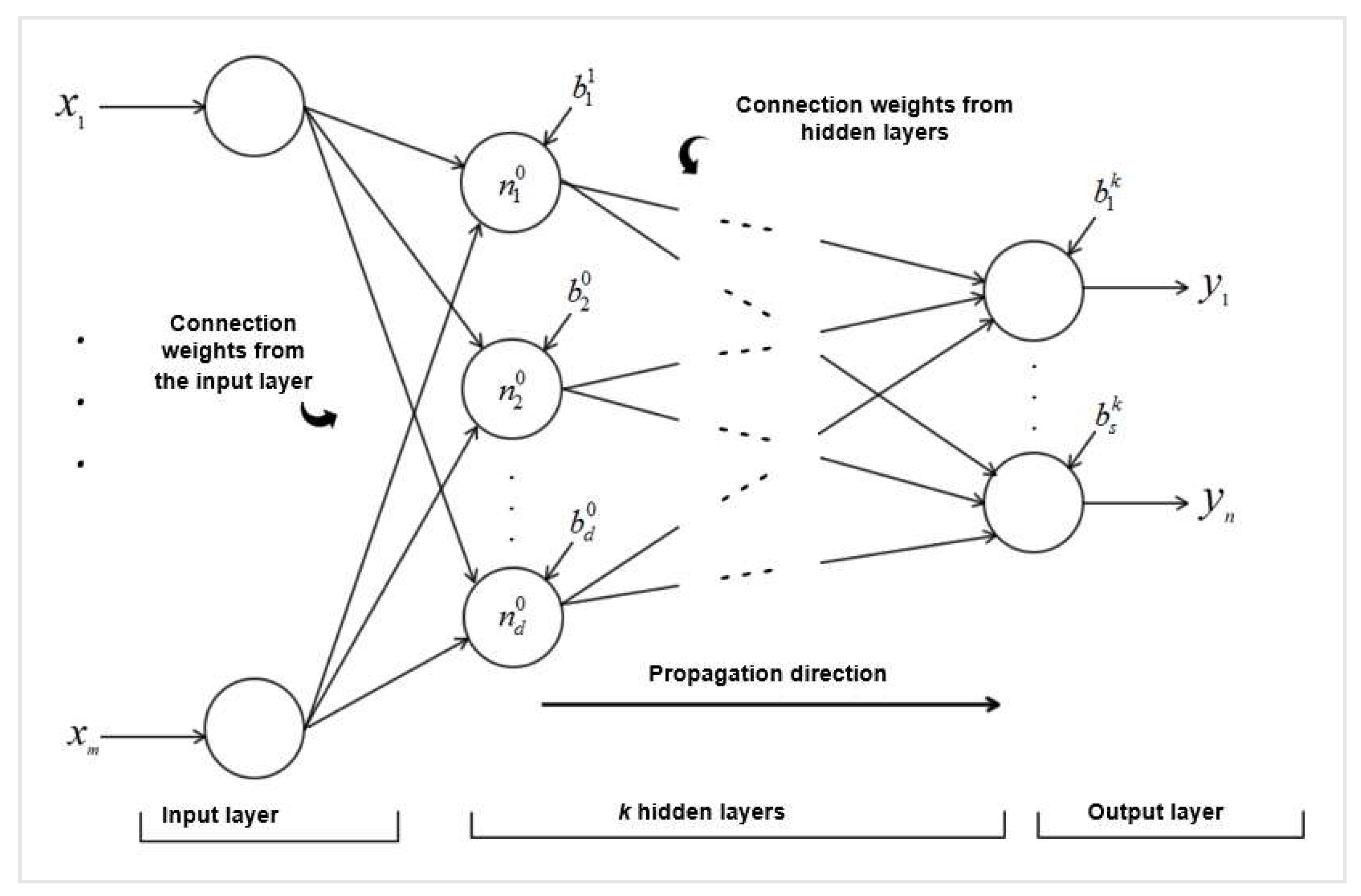
2.2. Artificial Neural Networks (ANN)
- σ is the activation function which, besides adding nonlinearity components to the neural network, follows the value assumed by the neuron so that the neural network is not paralyzed by divergent neurons;
- N is the number of input neurons;
- Vij corresponds to the model weights;
- xj are the inputs of the input neurons;
- is the definition of cut lines for hidden neurons.
2.3. Extreme Learning Machines (ELM)
3. Site, Dataset, and Algorithm Preparation
3.1. Site
3.2. Dataset
3.3. Algorithm Implementation
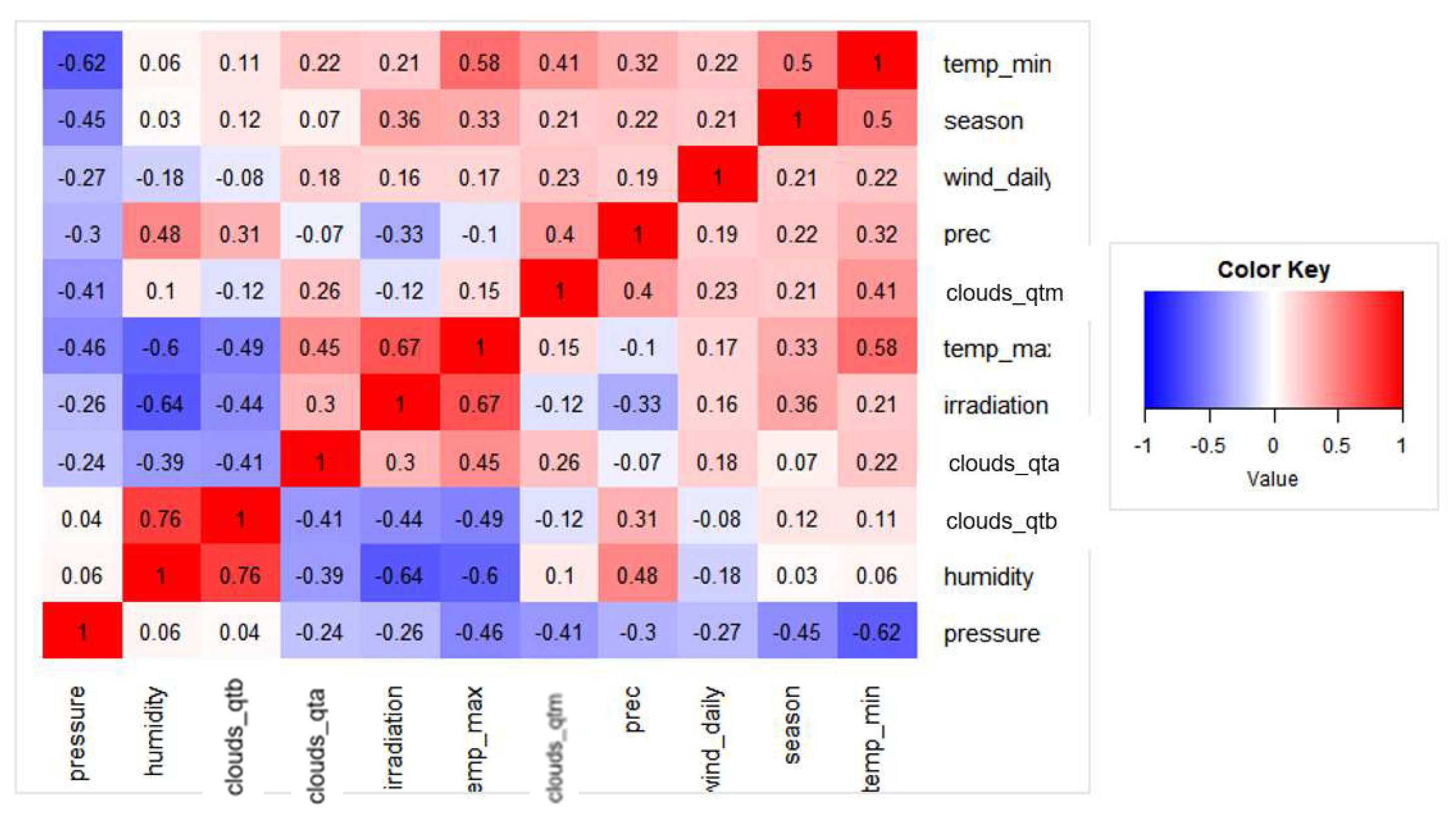
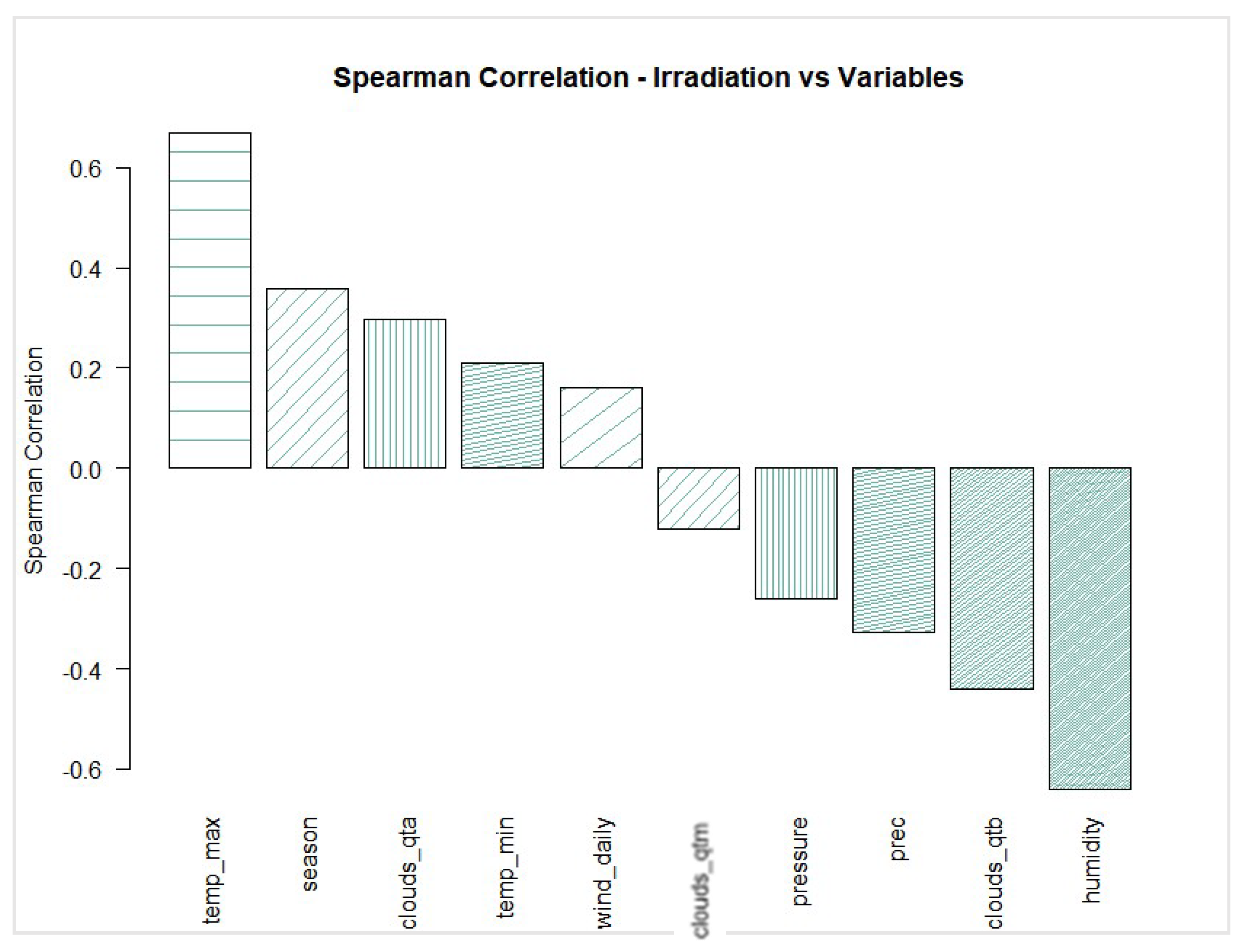
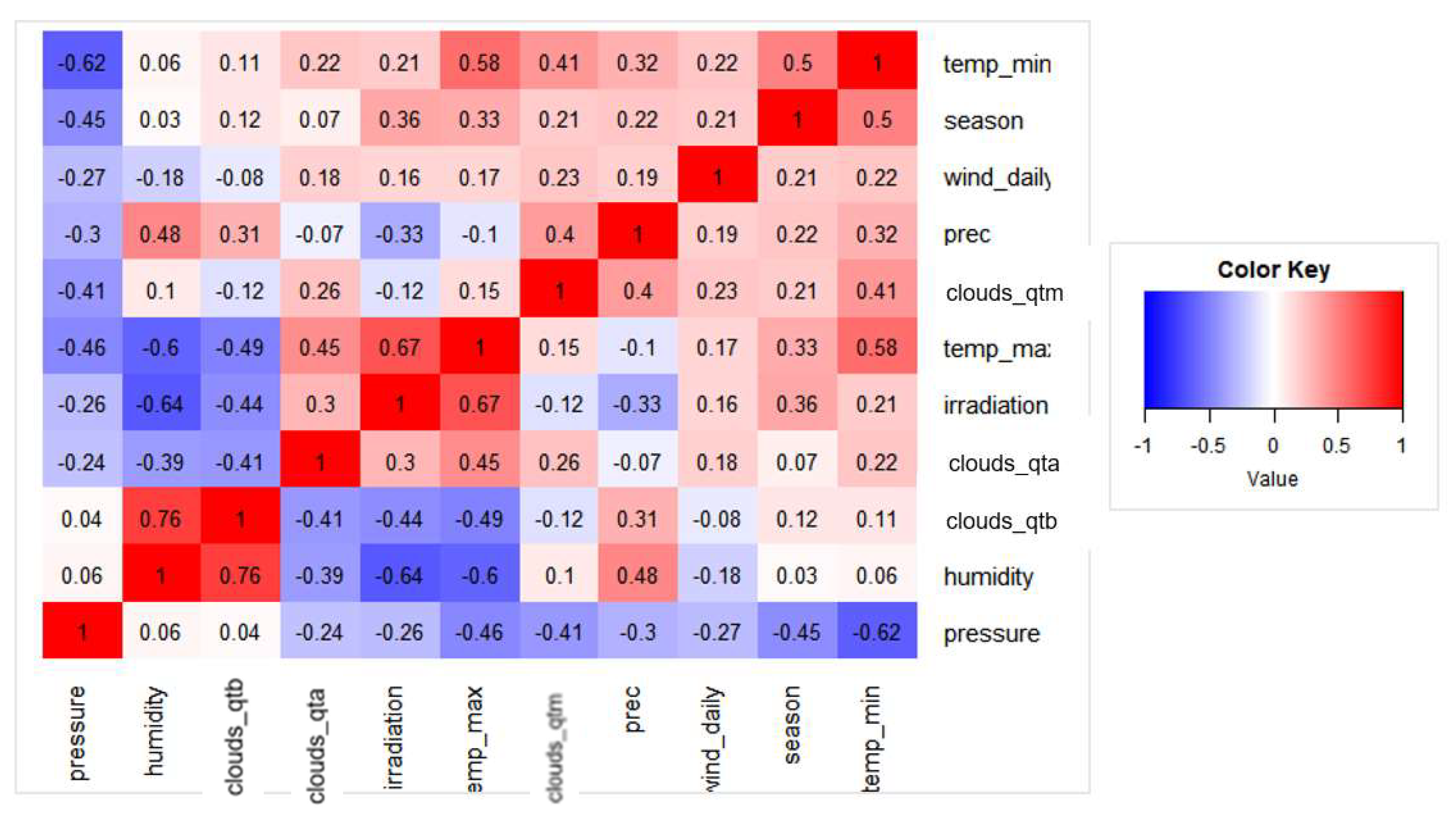
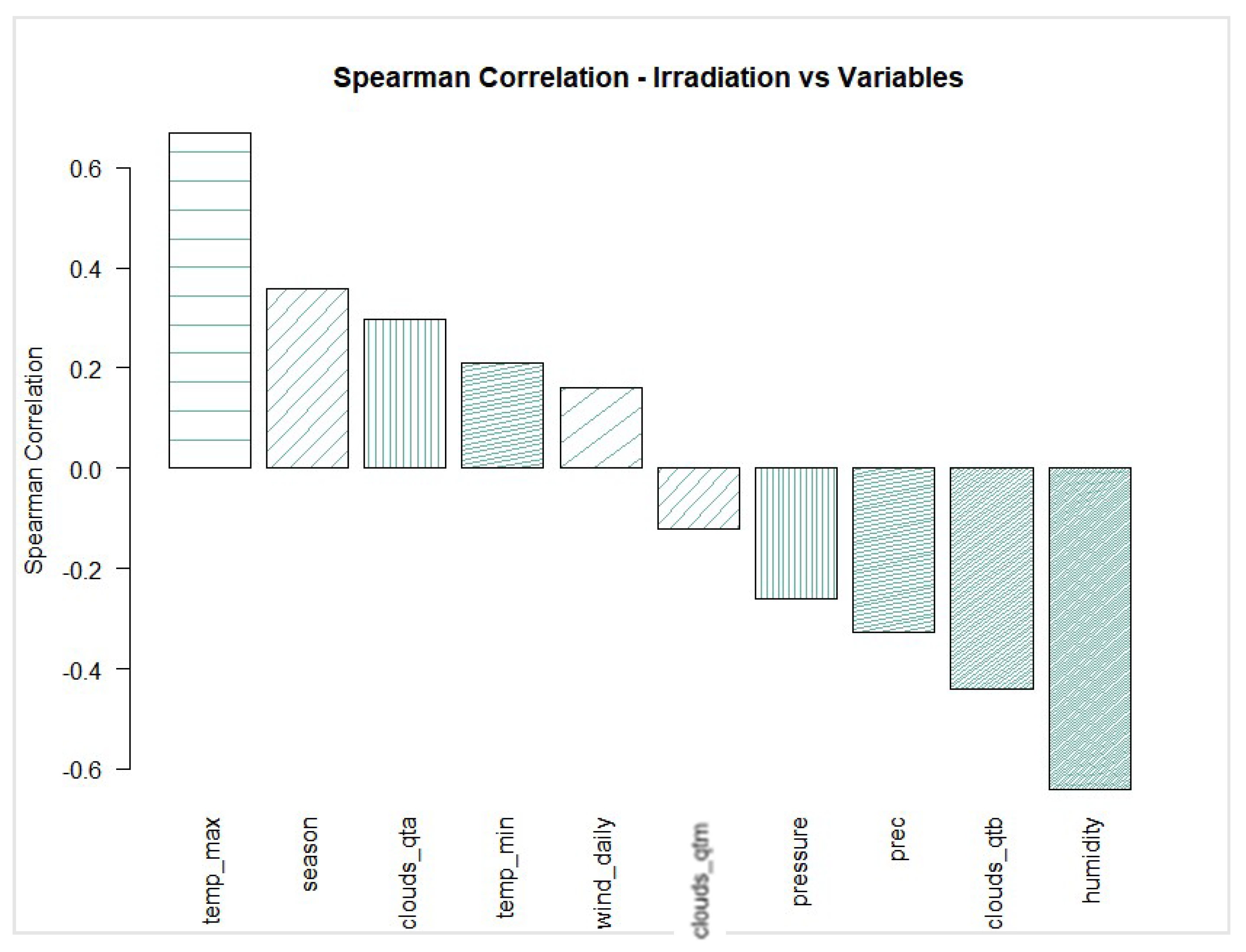
3.3.1. Correlation Analysis
3.3.2. Algorithm Implementation and Training
- n is the number of predicted and observed values;
- yi = observed value;
- = predicted value.
- n is the number of predicted and observed values;
- yi = observed value;
- = predicted value.
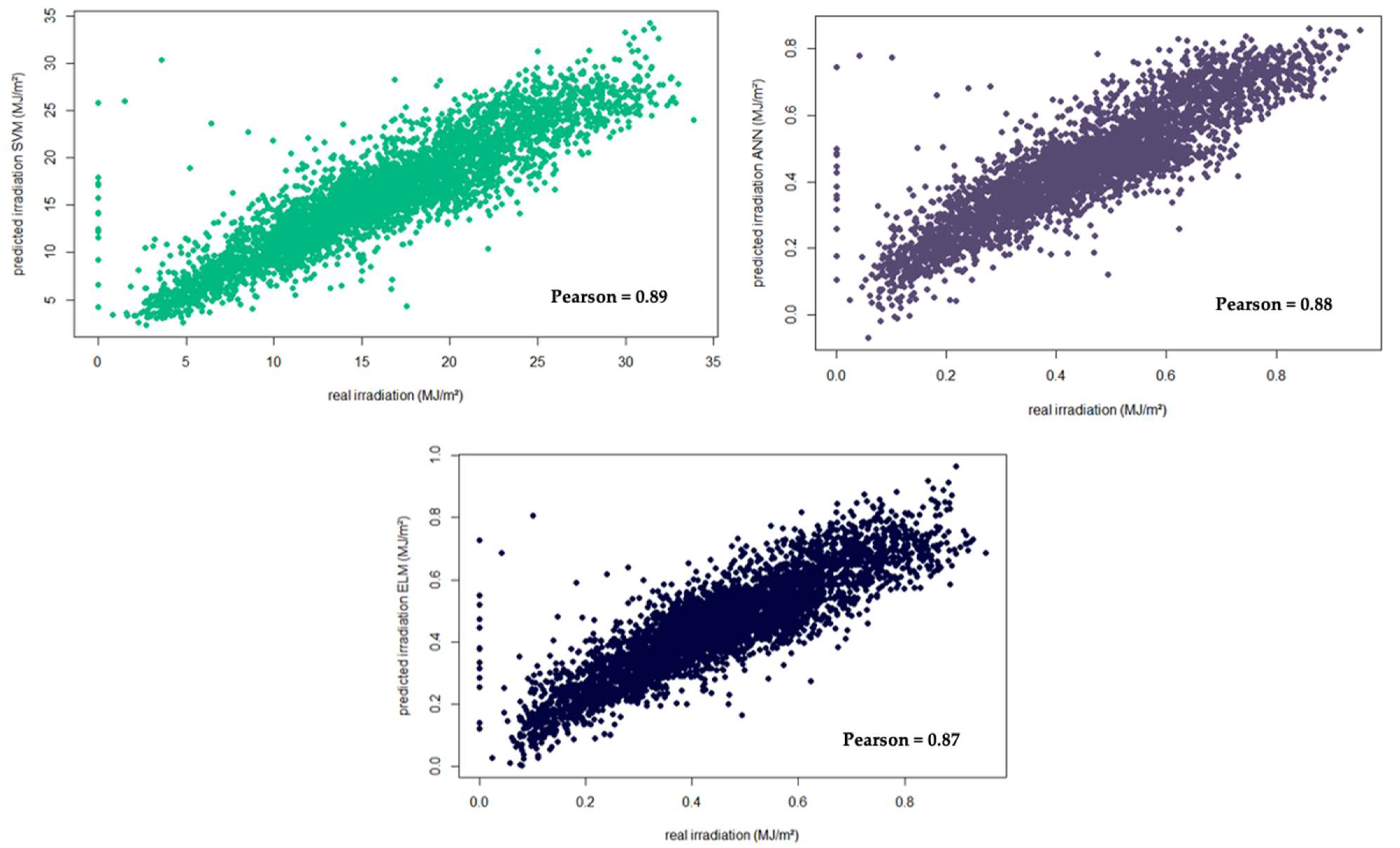
4. Results and Discussion
4.1. Modeling Approach
4.2. Modeling Results
5. Conclusions and Future Work
Future Research Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- IRENA; ADFD. Advancing Renewables in Developing Countries: Progress of Projects Supported through the IRENA/ADFD Project Facility; International Renewable Energy Agency (IRENA); Abu Dhabi Fund for Development (ADFD): Abu Dhabi, United Arab Emirates, 2020.
- IRENA. Renewable Capacity Statistics 2019; International Renewable Energy Agency (IRENA): Abu Dhabi, United Arab Emirates, 2019. [Google Scholar]
- EPE. O Compromisso Do Brasil No Combate às Mudanças Climáticas: Produção e Uso de Energia; Empresa de Pesquisa Energética: Rio de Janeiro, Brazil, 2016. [Google Scholar]
- MME/EPE. Plano Decenal de Expansão de Energia 2027/Ministério de Minas e Energia; Empresa de Pesquisa Energética: Rio de Janeiro, Brazil, 2018. [Google Scholar]
- Shuo, L.; Jun, M.; Xiong, M.; Hui, H.G.; Wei, H.R. The platform of monitoring and analysis for solar power data. In Proceedings of the 2016 China International Conference on Electricity Distribution (CICED), Xi’an, China, 10–13 August 2016. [Google Scholar] [CrossRef]
- Haupt, S.; Kosovic, B. Variable Generation Power Forecasting as a Big Data Problem. IEEE Trans. Sustain. Energy 2017, 8, 725–732. [Google Scholar] [CrossRef]
- Singh, B.; Dwivedi, S.; Hussain, I.; Verma, A.K. Grid integration of solar PV power generating system using QPLL based control algorithm. In Proceedings of the 2014 6th IEEE Power India International Conference (PIICON), Delhi, India, 5–7 December 2014; pp. 1–6. [Google Scholar] [CrossRef]
- Francisco, A.C.C.; de Miranda Vieira, H.E.; Romano, R.R.; Roveda, S.R.M.M. Influência de Parâmetros Meteorológicos na Geração de Energia em Painéis Fotovoltaicos: Um Caso de Estudo do Smart Campus Facens, SP. 2019. Available online: https://www.scielo.br/j/urbe/a/f5NZ33Mv5FNCFVpjjv6DsSn/?lang=pt (accessed on 5 July 2021).
- Revankar, P.S.; Thosar, A.G.; Gandhare, W.Z. Maximum Power Point Tracking for PV Systems Using MATALAB/SIMULINK. In Proceedings of the 2010 Second International Conference on Machine Learning and Computing, Bangalore, India, 9–11 February 2010; pp. 8–11. [Google Scholar] [CrossRef]
- Chia, Y.; Lee, L.; Shafiabady, N.; Isa, D. A load predictive energy management system for supercapacitor-battery hybrid energy storage system in solar application using the Support Vector Machine. Appl. Energy 2015, 137, 588–602. [Google Scholar] [CrossRef]
- Simmhan, Y.; Aman, S.; Kumbhare, A.; Liu, R.; Stevens, S.; Zhou, Q.; Prasanna, V. Cloud-Based Software Platform for Big Data Analytics in Smart Grids. Comput. Sci. Eng. 2013, 15, 38–47. [Google Scholar] [CrossRef]
- Aybar-Ruiz, A.; Jiménez-Fernández, S.; Cornejo-Bueno, L.; Casanova-Mateo, C.; Sanz-Justo, J.; Salvador-González, P.; Salcedo-Sanz, S. A novel Grouping Genetic Algorithm–Extreme Learning Machine approach for global solar radiation prediction from numerical weather models inputs. Sol. Energy 2016, 132, 129–142. [Google Scholar] [CrossRef]
- Burianek, T.; Stanislav, M. Solar Irradiance Forecasting Model Based on Extreme Learning Machine. In Proceedings of the 2016 IEEE 16th International Conference on Environment and Electrical Engineering (EEEIC), Florence, Italy, 7–10 June 2016. [Google Scholar] [CrossRef]
- Shamshirband, S.; Mohammadi, K.; Yee, P.; Petković, D.; Mostafaeipour, A. A comparative evaluation for identifying the suitability of extreme learning machine to predict horizontal global solar radiation. Renew. Sustain. Energy Rev. 2015, 52, 1031–1042. [Google Scholar] [CrossRef]
- Kitchenham, B.; Charters, S. Guidelines for Performing Systematic Literature Reviews in Software Engineering. 2007. Available online: https://userpages.uni-koblenz.de/~laemmel/esecourse/slides/slr.pdf (accessed on 7 June 2020).
- de Freitas Viscondi, G.; Alves-Souza, S.N. A Systematic Literature Review on big data for solar photovoltaic electricity generation forecasting. Sustain. Energy Technol. Assess. 2019, 31, 54–63. [Google Scholar] [CrossRef]
- Belaid, S.; Mellit, A. Prediction of daily and mean monthly global solar radiation using support vector machine in an arid climate. Energy Convers. Manag. 2016, 118, 105–118. [Google Scholar] [CrossRef]
- Chow, S.K.H.; Lee, E.W.M.; Li, D.H.W. Short-Term Prediction of Photovoltaic Energy Generation by Intelligent Approach. Energy Build. 2012, 55, 660–667. [Google Scholar] [CrossRef]
- Yadav, A.K.; Chandel, S.S. Solar radiation prediction using Artificial Neural Network techniques: A review. Renew. Sustain. Energy Rev. 2014, 33, 772–781. [Google Scholar] [CrossRef]
- Khatib, T.; Mohamed, A.; Sopian, K.; Mahmoud, M. Assessment of Artificial Neural Networks for Hourly Solar Radiation Prediction. Int. J. Photoenergy 2012, 2012, 946890. [Google Scholar] [CrossRef]
- Melzi, F.N.; Touati, T.; Same, A.; Oukhellou, L. Hourly Solar Irradiance Forecasting Based on Machine Learning Models. In Proceedings of the 2016 15th IEEE International Conference on Machine Learning and Applications (ICMLA), Anaheim, CA, USA, 18–20 December 2016. [Google Scholar] [CrossRef]
- Al-Dahidi, S.; Ayadi, O.; Adeeb, J.; Alrbai, M.; Qawasmeh, B.R. Extreme Learning Machines for Solar Photovoltaic Power Predictions. Energies 2018, 10, 2725. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.-B.; Zhu, Q.; Siew, C. Extreme Learning Machine: Theory and Applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Pasion, C.; Wagner, T.; Koschnick, C.; Schuldt, S.; Williams, J.; Hallinan, K. Machine Learning Modeling of Horizontal Photovoltaics Using Weather and Location Data. Energies 2020, 13, 2570. [Google Scholar] [CrossRef]
- Mahesh, B. Machine Learning Algorithms—A Review. Int. J. Sci. Res. 2019, 9, 381–386. [Google Scholar]
- IDC. Worldwide Global DataSphere Forecast, 2021–2025: The World Keeps Creating More Data—Now, What Do We Do with It All? International Data Corporation (IDC): Needham, MA, USA, 2021. [Google Scholar]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A training algorithm for optimal margin classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory-COLT’92, Pittsburgh, PA, USA, 27 July 1992. [Google Scholar] [CrossRef]
- Lorena, A.C.; de Carvalho, A.C.P.L.F. Uma introdução às Support Vector Machines. In Revista de Informática Aplicada e Teórica; Universidade Federal do Rio Grande do Sul: Porto Alegre, Brazil, 2007. [Google Scholar]
- Steinwart, I.; Christmann, A. Support Vector Machines. Information Science and Statistics; Springer Science & Business Media: Berlin, Germany, 2008. [Google Scholar] [CrossRef]
- Noble, W.S. What is a support vector machine? Nat. Biotechnol. 2006, 24, 1565–1567. [Google Scholar] [CrossRef] [PubMed]
- Namba, M.; Zhang, Z. Cellular Neural Network for Associative Memory and Its Application to Braille Image Recognition. In Proceedings of the 2006 IEEE International Joint Conference on Neural Network Proceedings, Vancouver, BC, Canada, 16–21 July 2006. [Google Scholar] [CrossRef]
- Odom, M.D.; Sharda, R. A neural network model for bankruptcy prediction. In Proceedings of the 1990 IJCNN International Joint Conference on Neural Networks, San Diego, CA, USA, 17–21 June 1990. [Google Scholar] [CrossRef]
- Cherry, K.M.; Qian, L. Scaling up molecular pattern recognition with DNA-based winner-take-all neural networks. Nature 2018, 559, 370–376. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.-C. Artificial Neural Network. In Interdisciplinary Computing in Java Programming; Springer: Boston, MA, USA, 2003; pp. 81–100. [Google Scholar] [CrossRef]
- Ripley, B.D. Pattern Recognition and Neural Networks; Cambridge University Press: Cambridge, UK, 1996. [Google Scholar]
- Tang, J.; Deng, C.; Huang, G.-B. Extreme Learning Machine for Multilayer Perceptron. In IEEE Transactions on Neural Networks and Learning Systems; IEEE: Piscataway, NJ, USA, 2016; Volume 27, pp. 809–821. [Google Scholar] [CrossRef]
- Huang, G.-B.; Zhou, H.; Ding, X.; Zhang, R. Extreme learning machine for regression and multiclass classification. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2012, 42, 513–529. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, G.-B. An Insight into Extreme Learning Machines: Random Neurons, Random Features and Kernels. Cogn. Comput. 2014, 6, 376–390. [Google Scholar] [CrossRef]
- Huang, G.-B.; Chen, L.; Siew, C.-K. Universal approximation using incremental constructive feedforward networks with random hidden nodes. IEEE Trans. Neural Netw. 2006, 17, 879–892. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- São Paulo será 6ª Cidade Mais Rica do Mundo até 2025. Price Waterhouse & Coopers e BBC Brasil. November 2009. Available online: https://www.bbc.com/portuguese/noticias/2009/11/091109_ranking_cidades_price_rw (accessed on 4 July 2021).
- IEA. Next Generation Wind and Solar Power from Cost to Value; International Energy Agency: Paris, France, 2016. [Google Scholar]
- CPI. Developing Brazil’s Market for Distributed Solar Generation Climate Policy Initiative. 2017. Available online: https://www.oecd.org/publications/next-generation-wind-and-solar-power-9789264258969-en.htm (accessed on 4 July 2021).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Dataset Name | Unit |
|---|---|---|
| Solar irradiation | irradiation | MJ/m2 |
| Maximum daily temperature | temp_max | °C |
| Minimum daily temperature | temp_min | °C |
| Daily maximum wind speeds | wind_daily | m/s |
| Relative humidity | humidity | % |
| Daily precipitation | prec | mm |
| Atmospheric pressure | pressure | atm |
| Cloud quantity—low altitude | clouds_qtb | - |
| Cloud quantity—medium altitude | clouds_qtm | - |
| Cloud quantity—high altitude | clouds_qta | - |
| Measurement | Unit | Minimum Record | 1st Quantile | Median | Mean | 3rd Quantile | Maximum Record |
|---|---|---|---|---|---|---|---|
| irradiation | MJ/m2 | 0 | 11.93 | 15.99 | 16.19 | 20.49 | 35.56 |
| temp_max | °C | 8.60 | 22.00 | 25.50 | 25.08 | 28.40 | 37.20 |
| temp_min | °C | −1.10 | 12.60 | 15.20 | 14.95 | 17.80 | 23.20 |
| wind_daily | m/s | 0 | 5 | 6 | 6.41 | 8 | 28 |
| humidity | % | 33.87 | 76.41 | 82.15 | 81.06 | 87.12 | 99.25 |
| prec | mm | 0 | 0 | 0.1 | 4.1 | 2.4 | 146 |
| pressure | Atm | 893.6 | 923.4 | 925.7 | 925.8 | 928.2 | 939.6 |
| clouds_qtb | - | 0 | 2.22 | 4.61 | 4.82 | 7.39 | 10.00 |
| clouds_qtm | - | 0 | 0 | 0.44 | 1.32 | 1.94 | 9.89 |
| clouds_qta | - | 0 | 0 | 0.11 | 0.076 | 1.00 | 9.94 |
| Parameter Group Number | Criteria (Figure 4) | Parameters Selected for Model Training |
|---|---|---|
| 1 | Top 1—highest and lowest Spearman correlation | Temp_max + Humidity |
| 2 | Top 1 and 2—highest and lowest Spearman correlation | Temp_max + Humidity + Season + Clouds_qtb |
| 3 | Top 1, 2, and 3—highest and lowest Spearman correlation | Temp_max + Humidity + Season + Clouds_qtb + clouds_qta + prec |
| 4 | All parameters | Temp_max + Humidity + Season + Clouds_qtb + clouds_qta + prec + tem_min + pressure + wind_daily + clouds_qtm |
| Support Vector Machines (SVM) | |||||
|---|---|---|---|---|---|
| Model | Parameter Group | MAE [MJ/m2] | RMSE [MJ/m2] | Pearson Correlation | Training Time [s] |
| SVM_1 | 1 | 3.08 | 4.15 | 0.76 | 29.15 |
| SVM_2 | 2 | 2.54 | 3.43 | 0.84 | 28.99 |
| SVM_3 | 3 | 2.41 | 3.24 | 0.86 | 28.66 |
| SVM_4 | 4 | 2.05 | 2.78 | 0.89 | 35.10 |
| Artificial Neural Network (ANN) | |||||
|---|---|---|---|---|---|
| Model | Parameter Group | MAE [MJ/m2] | RMSE [MJ/m2] | Pearson Correlation | Training Time [s] |
| ANN_1 | 1 | 3.13 | 4.12 | 0.76 | 16.6 |
| ANN_2 | 2 | 2.70 | 0.36 | 0.83 | 25.9 |
| ANN_3 | 3 | 2.67 | 3.48 | 0.83 | 39.6 |
| ANN_4 | 4 | 2.24 | 2.99 | 0.88 | 29.4 |
| Extreme Learning Machine (ELM) | |||||
|---|---|---|---|---|---|
| Model | Parameter Group | MAE [MJ/m2] | RMSE [MJ/m2] | Pearson Correlation | Training Time [s] |
| ELM_1 | 1 | 3.31 | 4.30 | 0.73 | 3.27 |
| ELM_2 | 2 | 2.84 | 3.73 | 0.80 | 1.35 |
| ELM_3 | 3 | 2.77 | 3.63 | 0.82 | 1.19 |
| ELM_4 | 4 | 2.35 | 3.09 | 0.87 | 1.15 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
de Freitas Viscondi, G.; Alves-Souza, S.N. Solar Irradiance Prediction with Machine Learning Algorithms: A Brazilian Case Study on Photovoltaic Electricity Generation. Energies 2021, 14, 5657. https://doi.org/10.3390/en14185657
de Freitas Viscondi G, Alves-Souza SN. Solar Irradiance Prediction with Machine Learning Algorithms: A Brazilian Case Study on Photovoltaic Electricity Generation. Energies. 2021; 14(18):5657. https://doi.org/10.3390/en14185657
Chicago/Turabian Stylede Freitas Viscondi, Gabriel, and Solange N. Alves-Souza. 2021. "Solar Irradiance Prediction with Machine Learning Algorithms: A Brazilian Case Study on Photovoltaic Electricity Generation" Energies 14, no. 18: 5657. https://doi.org/10.3390/en14185657
APA Stylede Freitas Viscondi, G., & Alves-Souza, S. N. (2021). Solar Irradiance Prediction with Machine Learning Algorithms: A Brazilian Case Study on Photovoltaic Electricity Generation. Energies, 14(18), 5657. https://doi.org/10.3390/en14185657