Ultra-Short-Term Wind Power Prediction Based on Multivariate Phase Space Reconstruction and Multivariate Linear Regression


Abstract
1. Introduction
2. Related Works
3. Prepare Knowledge and System Modeling
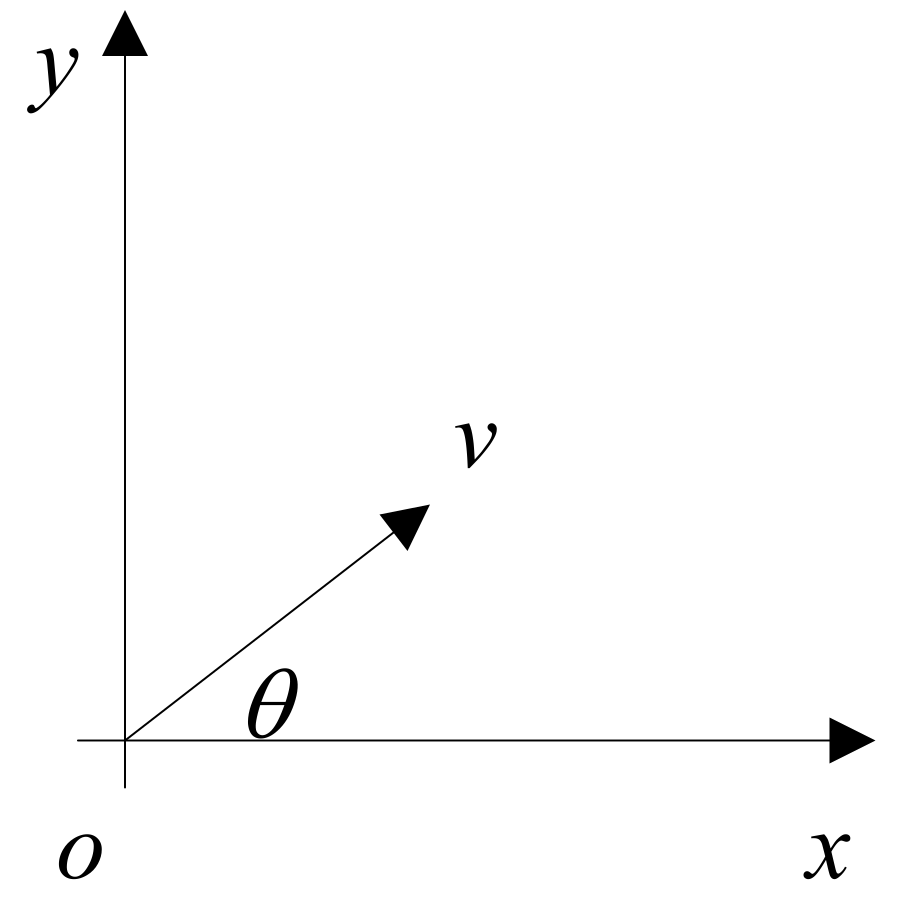
3.1. Time-Series Similarity
3.2. Multi-Variable Phase Space Reconstruction
3.3. Ultra-Short-Term WPP Modeling
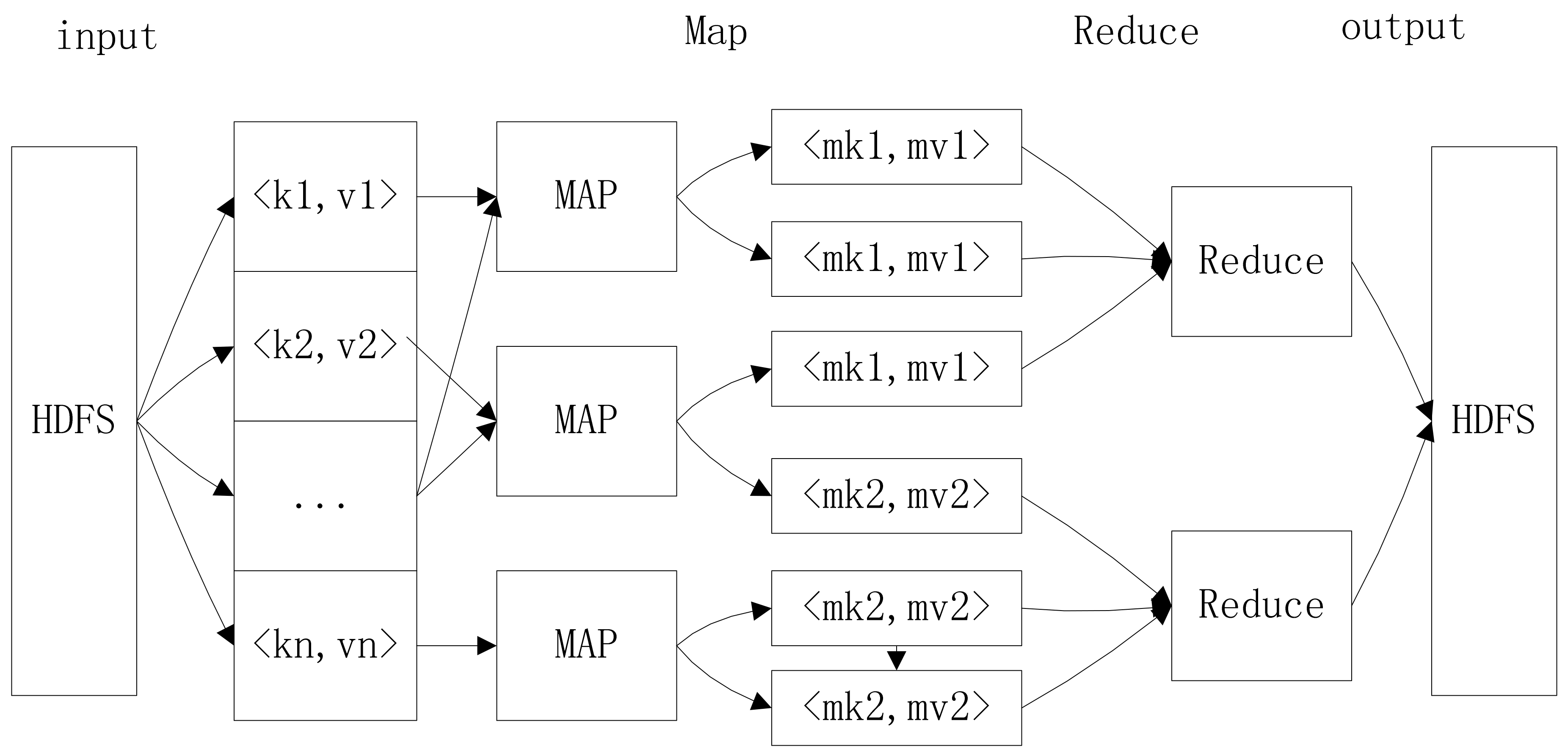
4. Parallel Algorithm Based on Map/Reduce
4.1. Map/Reduce Programming Model
- The raw data are input into the key/value pairs (key, value), and the data are processed as much as possible without communication. The intermediate data created in map phase are also saved as key/value pairs (intermediate-key, intermediate-value).
- The intermediate pairs with the same intermediate-key are transferred to the same reducing process with the completion of the mapping process. The reducing process starts when all intermediate data are transferred. When both mapping and reducing processes are completed, the final results are achieved.
4.2. The Algorithm of Ultra-Short-Term WPP
| Algorithm 1. Parallel Ultra-short-term wind power prediction based on Map/reduce. |
| Job 1: Reducing dimension of NWP matrix. |
| Map: The NWP matrix is separated into N sub-matrixes , where i = 1, 2, …, N. Each sub-matrix is a reduced dimension based on the method in Section 3.2. |
| (1) Each map process reads sub-matrix of . |
| (2) The intermediate data pairs is achieved by reducing the data dimension of each sub-matrix , according to Equation (8). |
| Reduce: The reducing dimension series is created by connecting in order all , which are from map process. |
| (1) ; |
| (2) For i = 1:N is added to the end of ; end for |
| (3) Output ; |
| For the sake of convenience, is the reduced NWP data series during 2L hours, which consists of two equal parts, namely, the former L hours and the latter L hours. is removed from , and the remainder of is divided into N sub-series, , where , the head of is the first node in X, and the head of is the (8L − 1)-th node of from the bottom, . |
| Job 2: Searching top k sub-series, which are the most similar to X0. |
| Map: |
| (1) Each map process reads the pairs ; |
| (2) For j = 1:||Xi|| − L % where ||Xi|| is the length of Xi [31]. |
| (1) We compute the DTW between and , which is ’s sub-series including L elements and starting with the j-th element of Xi; |
| (2) The intermediate data are key/value pairs (i, ‘j, DTW’) |
| End for |
| Reduce: |
| (1) ; |
| (2) ; |
| (3) Output . |
| The sub-series are sorted by according to the method in reference [35], and the top k sub-series of NWP and wind power are selected. The top k most similar sub-series of NWP and wind power are denoted as and , where k = 1, 2, …, k. |
| The sub-series are sorted by according to the method in reference [35], and the top k sub-series of NWP and wind power are selected. The top k most similar sub-series of NWP and wind power are denoted as and where k = 1, 2, …, k. |
| Job 3: The embedding dimension and delaying time of P and X are computed in this job. |
| For the sake of convenience, the time series P and X in our algorithm are denoted as P1 and P2, respectively. |
| Map: |
| (1) ; % and are obtained by C-C algorithm |
| (2) ; % calculating the starting index of Pi |
| (3) The intermediate data of this map are data pairs , where , and are the embedding dimension, delaying time, and starting point of Pi, respectively. |
| Reduce: |
| (1) J = |
| (2) ; |
| (3) Output . |
| Job 4: Multivariate phase space reconstruction |
| Map: |
| (1) , where Xk and Pk are the most similar sub-series of top K achieved from Job 2, and . |
| Reduce: |
| (1) Output reconstructed phase space . |
| Job 5: Multi-variables linear regression |
| Map: |
| (1) Input , where is the reconstructed phase space during 2L hours. |
| (2) The linear model is trained by , where is the j-th phase point of reconstructed phase space , j = 1, 2, …, ; |
| (3) After the linear model has been trained, the next phase point is obtained according to Equation (12) and the last point of . |
| (4) The step 3 is executed iteratively, and then the forecasting reconstructed phase space is achieved. |
| (5) The forecasting power sequence is obtained based on an inverse process of the phase space reconstruction and reconstructed phase space . |
| (6) The intermediate data are . |
| Reduce: |
| The comprehensive wind power is given as follows. |
| where j = 1, 2, …, B, and B is the forecasting time-scale |
5. Application and Case Study
5.1. The Experimental Data and Environments
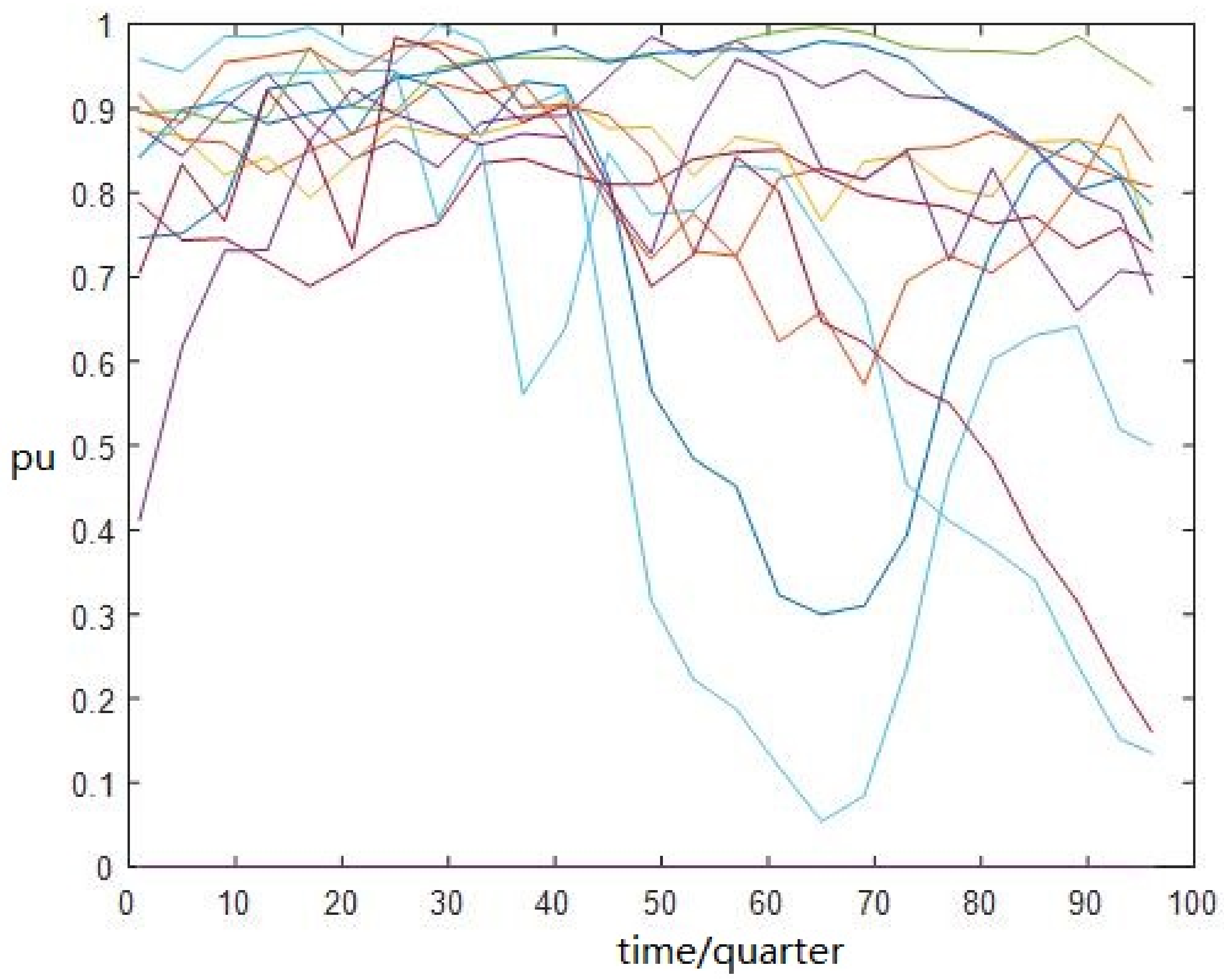
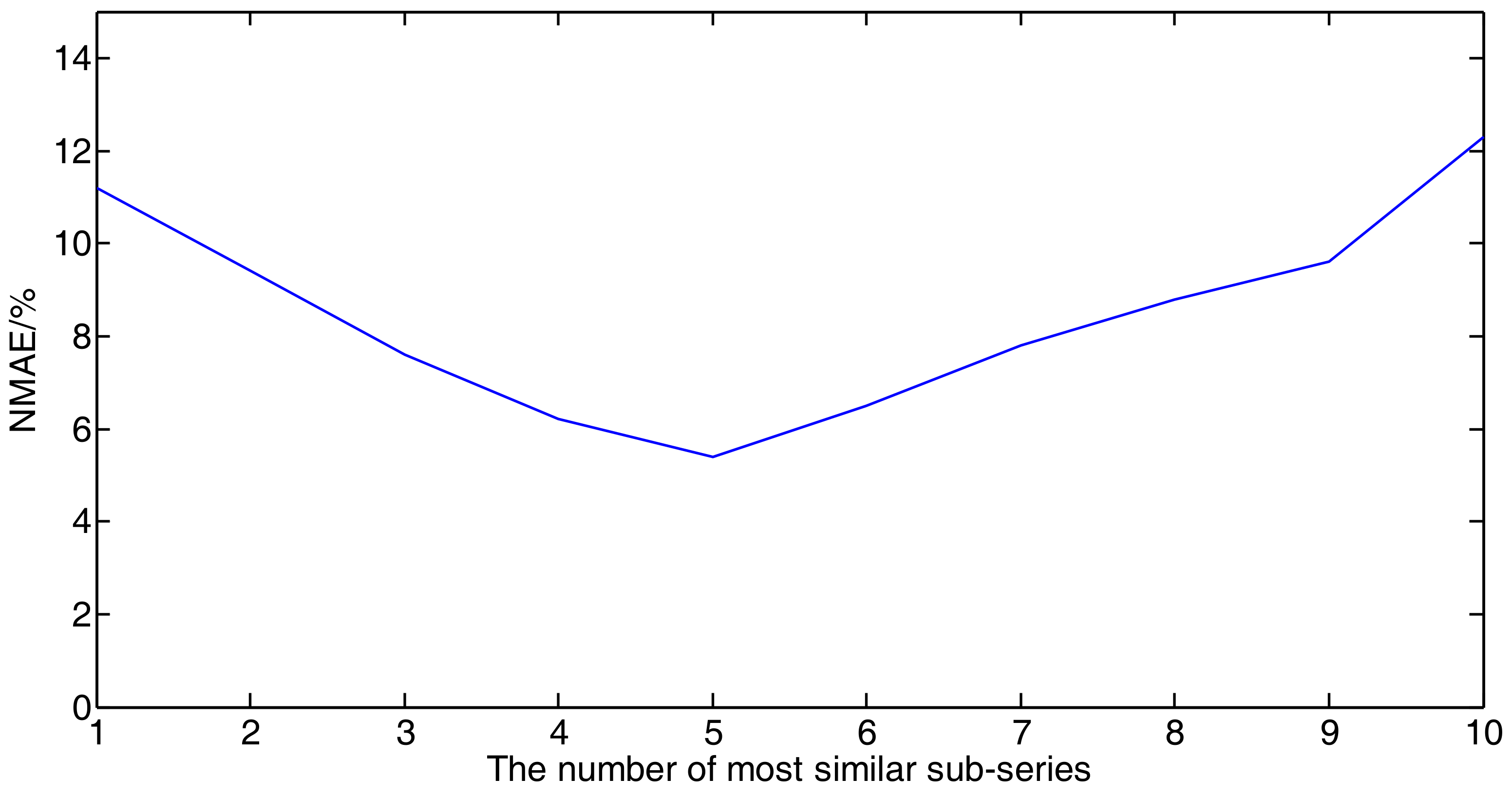
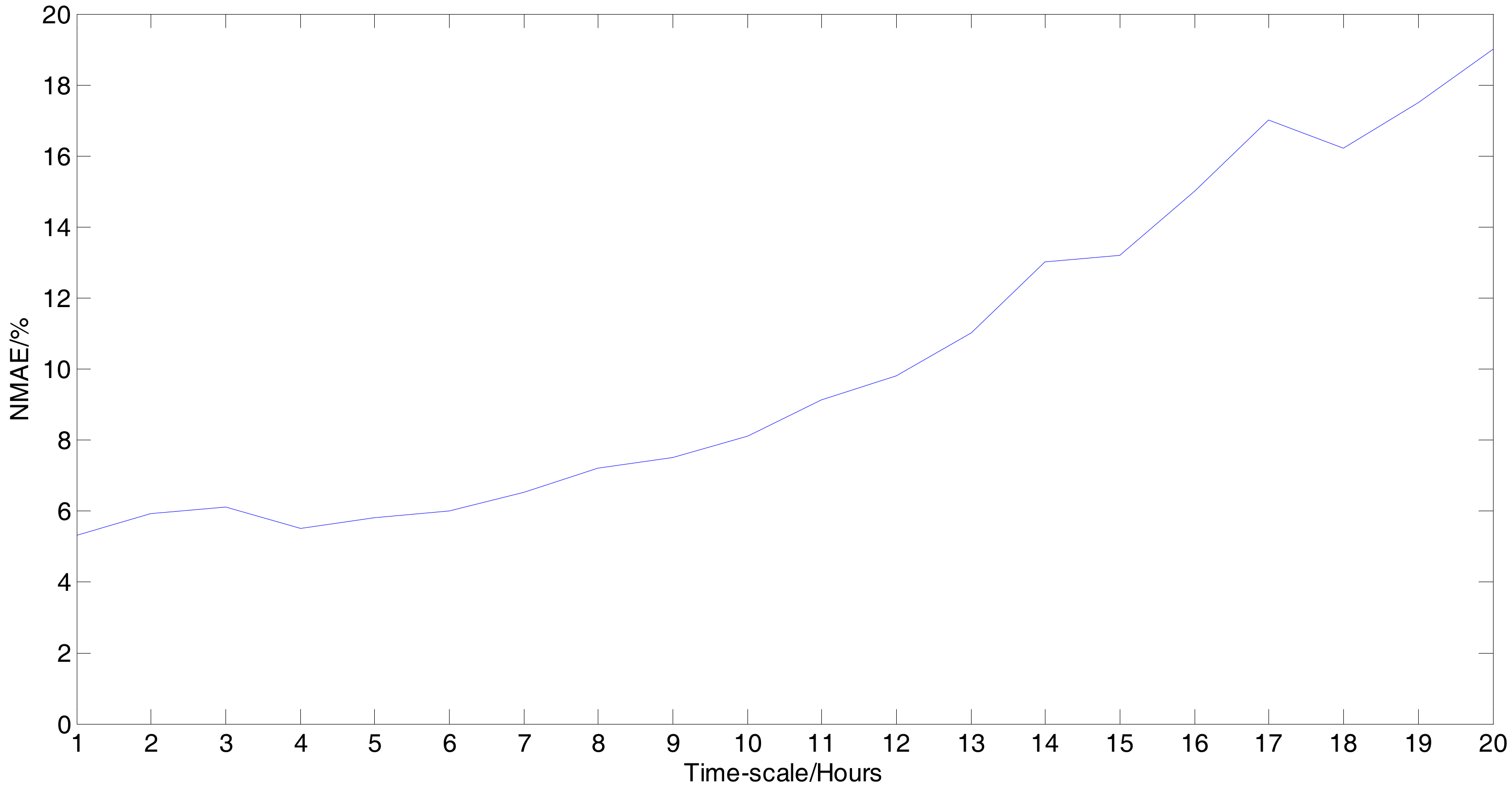
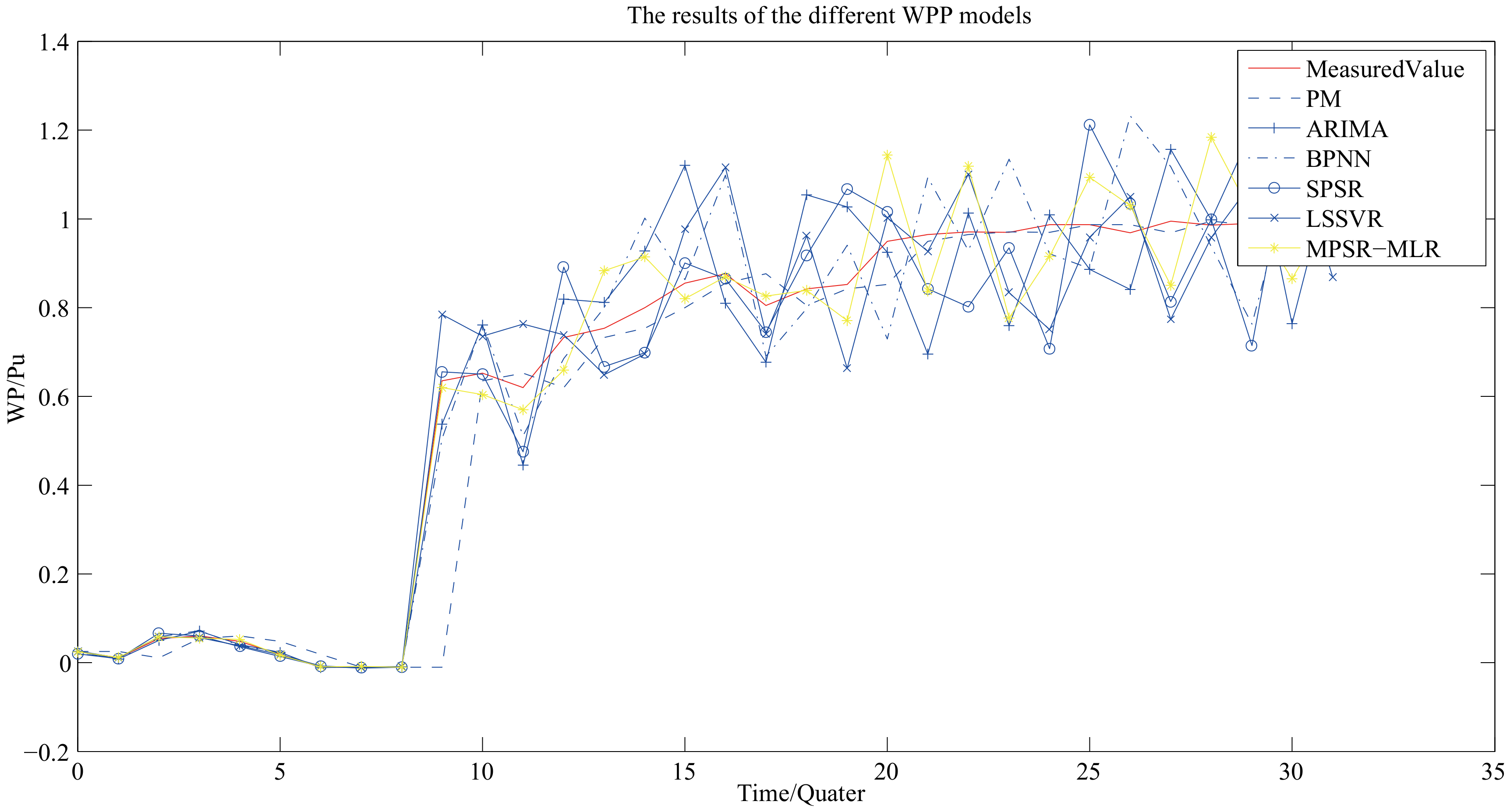
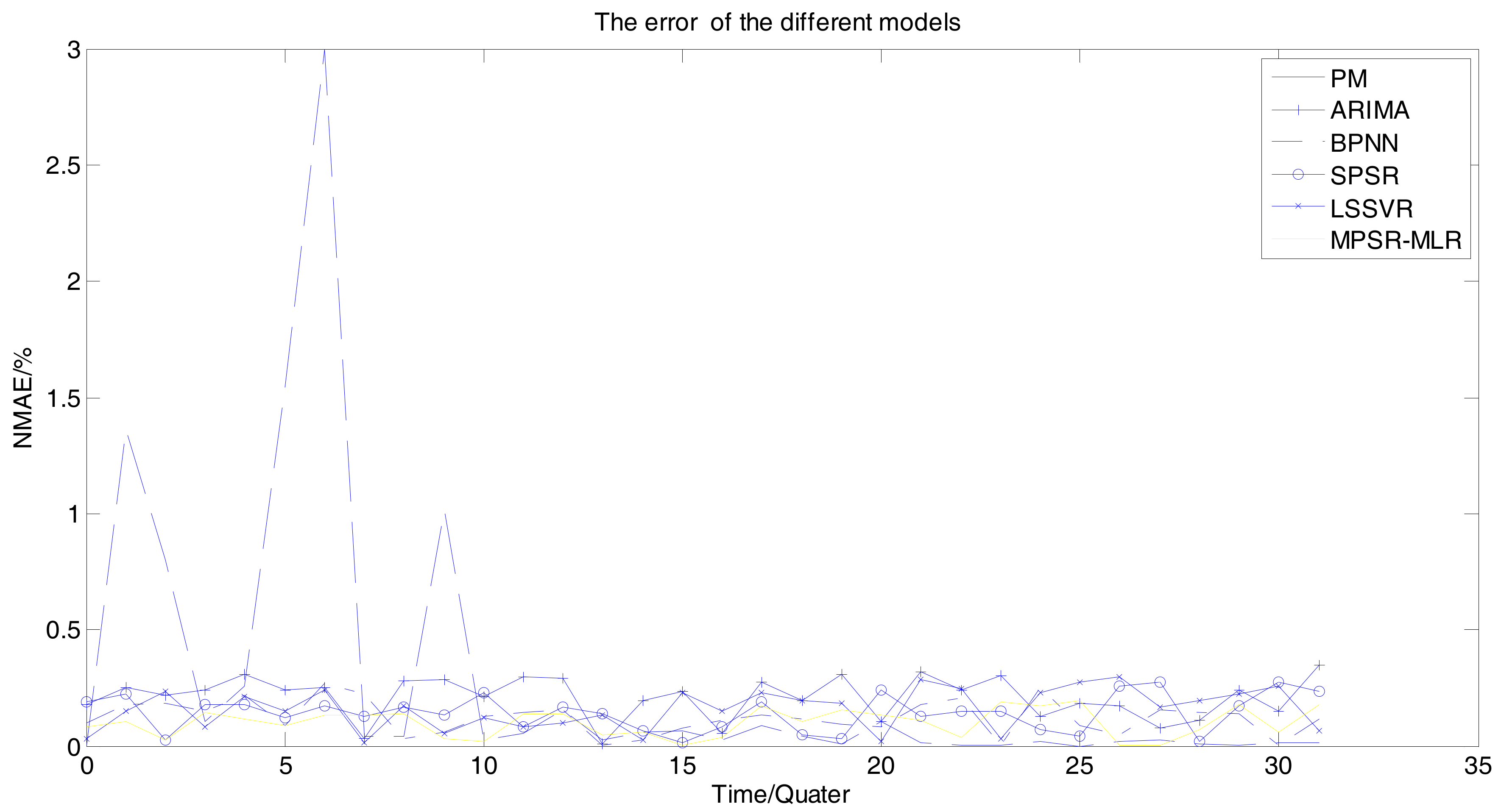
5.2. Results and Analysis of the Experiment
6. Conclusions
- Wind power is a chaotic time series, and multi-variate phase space reconstruction can improve the ultra-short-term WPP by mining the correlation of these wind power series.
- It is very difficult to forecast wind power, especially when the wind power series fluctuates seriously. The proposed model improves the performance during the wind ramp drastically.
- The forecasting speed is accelerated by adopting both the map/reduce-based parallel algorithm and the cloudy computing platform.
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Xue, Y.; Yu, C.; Zhao, J.; Li, K.; Liu, X.; Wu, Q.; Yang, G. A Review on Short-term and Ultra-short-term Wind Power Prediction. Autom. Electric Power Syst. 2015, 39, 141–151. [Google Scholar]
- Rafique, M.M.; Rehman, S.; Alam, M.M.; Alhems, L.M. Feasibility of a 100MW Installed CapacityWind Farm for Different Climatic Conditions. Energies 2018, 11, 2147. [Google Scholar] [CrossRef]
- Xie, W.; Zhang, P.; Chen, R.; Zhou, Z. A Nonparametric Bayesian Framework for Short-Term Wind Power Probabilistic Forecast. IEEE Trans. Power Syst. 2018. [Google Scholar] [CrossRef]
- Khorramdel, B.; Chung, C.Y.; Safari, N.; Price, G.C.D. A Fuzzy Adaptive Probabilistic Wind Power Prediction Framework Using Diffusion Kernel Density Estimators. IEEE Trans. Power Syst. 2018, 958–965. [Google Scholar] [CrossRef]
- Wang, Y.; Liao, W.; Chang, Y. Gated Recurrent Unit Network-Based Short-Term Photovoltaic Forecasting. Energies 2018, 11, 2163. [Google Scholar] [CrossRef]
- Foley, A.; Leahy, P.G.; Marvuglia, A.; McKeogh, E.J. Current methods and advances in forecasting of wind power generation. Renew. Energy 2012, 31, 1–8. [Google Scholar] [CrossRef]
- Khodayar, M.; Wang, J.; Manthouri, m. Interval Deep Generative Neural Network for Wind Speed Forecasting. IEEE Trans. Smart Grid 2018, 1–16. [Google Scholar] [CrossRef]
- Pimkumwong, N.; Wang, M.-S. Online Speed Estimation Using Artificial Neural Network for Speed Sensorless Direct Torque Control of Induction Motor based on Constant V/F Control Technique. Energies 2018, 11, 2176. [Google Scholar] [CrossRef]
- Lu, P.; Ye, L.; Sun, B.; Zhang, C.; Zhao, Y.; Teng, J. A New Hybrid Prediction Method of Ultra-Short-Term Wind Power Forecasting Based on EEMD-PE and LSSVM Optimized by the GSA. Energies 2018, 11, 697. [Google Scholar] [CrossRef]
- Ozkan, M.B.; Karagoz, P. A Novel Wind Power Forecast Model: Statistical Hybrid Wind Power Forecast Technique (SHWIP). IEEE Trans. Ind. Inform. 2015, 11, 375–387. [Google Scholar] [CrossRef]
- Shi, J.; Ding, Z.; Lee, W.-J.; Yang, Y.; Liu, Y.; Zhang, M. Hybrid Forecasting Model for Very-Short-Term Wind Power Forecasting Based on Grey Relational Analysis and Wind Speed Distribution Features. IEEE Trans. Smart Grid 2014, 5, 521–526. [Google Scholar] [CrossRef]
- Xu, Q.; He, D.; Zhang, N.; Kang, C.; Xia, Q.; Bai, J.; Huang, J. A Short-Term Wind Power Forecasting Approach with Adjustment of Numerical Weather Prediction Input by Data Mining. IEEE Trans. Sustain. Energy 2015, 6, 1283–1291. [Google Scholar] [CrossRef]
- Safari, N.; Chung, C.Y.; Price, G.C.D. Novel Multi-Step Short-Term Wind Power Prediction Framework Based on Chaotic Time Series Analysis and Singular Spectrum Analysis. IEEE Trans. Power Syst. 2018, 33, 590–601. [Google Scholar] [CrossRef]
- Lee, D.; Baldick, R. Short-Term Wind Power Ensemble Prediction Based on Gaussian Processes and Neural networks. IEEE Trans. Smart Grid 2014, 5, 501–510. [Google Scholar] [CrossRef]
- Chen, L.; Lai, X. Comparision between ARIMA and ANN models used in short-term wind speed forecasting. In Proceedings of the 2011 Asia-Pacific Power and Energy Engineering Conference, Wuhan, China, 25–28 March 2011; pp. 1–4. [Google Scholar]
- Zeng, J.; Qiao, W. Short-Term Wind Power Prediction Using a Wavelet Support Vector Machine. IEEE Trans. Sustain. Energy 2012, 3, 255–264. [Google Scholar] [CrossRef]
- Giorgi, M.G.D.; Campilongo, S.; Ficarella, A.; Congedo, P.M. Comparison between wind power prediction models based on wavelet decomposition with least-squares support vector machine (LSSVM) and artificial neural network (ANN). Energies 2014, 7, 5251–5272. [Google Scholar] [CrossRef]
- Wu, Q.; Peng, C. Wind power generation forecasting using least square support machine combined with ensemble empirical model decomposition, principal component analysis and a bat algorithm. Energies 2016, 9, 261. [Google Scholar] [CrossRef]
- An, X.L.; Jiang, D.X.; Zhao, M.H.; Liu, C. Short-term preciton of wind power using EMD and chaotic theory. Commun. Nonlinear Sci. Numer. Simul. 2012, 17, 1036–1042. [Google Scholar] [CrossRef]
- Zhang, Y.; Lu, J.; Meng, Y.; Yan, H.; Li, H. Wind power short-term forecasting Based on Empirical Mode Decomposition and Chaotic Phase Space Recontruction. Autom. Electric Power Syst. 2012, 36, 24–28. [Google Scholar]
- Yang, L.; He, M.; Zhang, J.; Vittal, V. Support-Vector-Machine-Enhanced Markov Model for Short-Term Wind Power Forecast. IEEE Trans. Sustain. Energy 2015, 6, 791–799. [Google Scholar] [CrossRef]
- Morshedizadeh, M.; Kordestani, M.; Carriveau, R.; Ting, D.S.-K.; Saif, M. Power production prediction of wind turbines using a fusion of MLP and ANFIS networks. IET Renew. Power Gener. 2018, 12, 1025–1033. [Google Scholar] [CrossRef]
- Rarki, R.; Thapa, S.; Billinto, R. A Simplified risk-based method for short-term wind power commitment. IEEE Trans. Sustain. Energy 2012, 3, 498–505. [Google Scholar]
- Wen, Y.; Li, W.; Hunag, G.; Liu, X. Frequency dynamaics constrained unit commitment with battery energy storage. IEEE Trans. Power Syst. 2016, 31, 5115–5125. [Google Scholar] [CrossRef]
- Bitaraf, H.; Rahman, S.; Pipattanasomporn, M. Sizing energy storage to mitigate wind power forecast error impacts by signal processing techniques. IEEE Trans. Sustain. Energy 2015, 6, 1457–1465. [Google Scholar] [CrossRef]
- Zhao, Y.; Ye, L.; Pinson, P.; Tang, Y.; Lu, P. Correlation-Constrained and Sparsity-Controlled Vector Autoregressive Model for Spatio-Temporal Wind Power Forecasting. IEEE Trans. Power Syst. 2018, 33, 5029–5040. [Google Scholar] [CrossRef]
- Cui, B.; Zhao, Z.; Tok, W.H. A Framework for similarity search of Time Series Cliques with Natural Relations. IEEE Trans. Knowl. Data Eng. 2012, 24, 385–398. [Google Scholar] [CrossRef]
- Schramm, R.; Jung, C.R.; Miranda, E.R. Dynamic Time Warping for Music Conducting Gestures Evaluation. IEEE Trans. Multimed. 2015, 17, 243–255. [Google Scholar] [CrossRef]
- Yin, H.; Yang, S.; Ma, S.; Liu, F.; Chen, Z. A novel parallel scheme for fast similarity search in large time series. China Commun. 2015, 12, 129–140. [Google Scholar] [CrossRef]
- Han, M.; Zhang, R.; Qiu, T. Multivariate Chaotic Time Series Prediction Based on Improved Grey Relational Analysis. IEEE Trans. Syst. Man Cybern. Syst. 2018, 1–11. [Google Scholar] [CrossRef]
- Mercorelli, P. Denoising and Harmonic Detection Using Nonorthogonal Wavelet Packets in Industrial Applications. J. Syst. Sci. Complex. 2007, 20, 325–343. [Google Scholar] [CrossRef]
- Johnson, M.T.; Povinelli, R.J.; Lindgren, A.C.; Ye, J.; Liu, X.; Indrebo, K.M. Time-domain isolated phoneme classification using reconstructed phase spaces. IEEE Trans. Speech Audio Proc. 2005, 13, 458–466. [Google Scholar] [CrossRef]
- Zhao, F.; Sun, B.; Zhang, C. Cooling, Heating and Electrical Load Forecasting Method for CCHP System Based on Multivariate Phase Space Reconstruction and Kalman Filter. Proc. CSEE 2016, 36, 399–406. [Google Scholar]
- Jin, J. Research on Optimization of Sorting Algorithm under MapReduce. Comput. Sci. 2014, 41, 155–159. [Google Scholar]
- Chen, N.; Qian, Z.; Nabney, I.T.; Meng, X. Wind Power Forecasts Using Gaussian Processes and Numerical Weather Prediction. IEEE Trans Power Syst. 2014, 29, 656–665. [Google Scholar] [CrossRef]
- Han, Y. The Design and Implementation of a Wind Power Forecasting System for Wind Farm in Gansu Province; University of Electronic Science and Technology of China: Chengdu, China, 2017. [Google Scholar]
- Castellani, F.; Astolfi, D.; Mana, M.; Burlando, M.; Meißner, C.; Piccioni, E. Wind power forecasting techniques in complex terrain: ANN vs. ANN-CFD hybrid approach. J. Phys. Conf. Ser. 2016, 735, 082002. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Method | Time Horizon | Application |
|---|---|---|---|
| 1 | Long-term | Year | - planning wind farms - Planning of annual generation |
| 2 | Medium-term | Week or Month | - Scheduling maintenance |
| 3 | Short-term | 3 days | - Reducing the discarded wind power - Optimizing the maintenance scheduling - Optimizing the generation scheduling |
| 4 | Ultra-short-term | 4 h | - Optimizing the frequency - Optimizing the spinning reserve capacity - Optimizing the unit commitment online |
| No. | WPP Methods | Remarks |
|---|---|---|
| 1 | Persistence Method | - benchmark method - Very accurate for ultra-short and short term prediction - Low accuracy for drastically fluctuating wind power series |
| 2 | Physical Method | - Uses the meteorological and environmental data - Applied to WPP whose time horizon is more than 6 h |
| 3 | Time-Series Models | - Accurate for short-term predictions - Cannot model the non-linearity |
| 4 | Artificial Intelligence | - Accurate for short-term predictions - Models the non-linearity - Cannot process the chaotic nature |
| 5 | Hybrid Method | - Accurate for medium and long term predictions |
| 6 | Spatial-Temporal Method | - Accurate for ultra-short-term predictions - Batch learning mode - Cannot update using the latest and real-time information |
| No. | Time 1 February 2013 | Wind Speed X-Direction (m/s) | Wind Speed Along Y Direction (m/s) | Atmosphere Pressure (atm) |
|---|---|---|---|---|
| 1 | 1:00 | 7.43 | 6.45 | 0.98 |
| 2 | 2:00 | 8.6 | 5.36 | 0.98 |
| 3 | 3:00 | 6.07 | 9.05 | 0.986 |
| … | … | … | … | … |
| No. | Methods | Max Error (%) | Min Error (%) | Avg Error (%) |
|---|---|---|---|---|
| 1 | PM | 389.64 | 0.75 | 24.25 |
| 2 | ARIMA | 26.00 | 0.0114 | 12.76 |
| 3 | BPNN | 25.16 | 0.0089 | 10.40 |
| 4 | LSSVR | 21.24 | 0.0071 | 9.34 |
| 5 | SPSR | 22.36 | 0.0016 | 11.86 |
| 6 | MPSR-MLR | 14.38 | 0.0042 | 6.46 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, R.; Peng, M.; Xiao, X. Ultra-Short-Term Wind Power Prediction Based on Multivariate Phase Space Reconstruction and Multivariate Linear Regression. Energies 2018, 11, 2763. https://doi.org/10.3390/en11102763
Liu R, Peng M, Xiao X. Ultra-Short-Term Wind Power Prediction Based on Multivariate Phase Space Reconstruction and Multivariate Linear Regression. Energies. 2018; 11(10):2763. https://doi.org/10.3390/en11102763
Chicago/Turabian StyleLiu, Rongsheng, Minfang Peng, and Xianghui Xiao. 2018. "Ultra-Short-Term Wind Power Prediction Based on Multivariate Phase Space Reconstruction and Multivariate Linear Regression" Energies 11, no. 10: 2763. https://doi.org/10.3390/en11102763
APA StyleLiu, R., Peng, M., & Xiao, X. (2018). Ultra-Short-Term Wind Power Prediction Based on Multivariate Phase Space Reconstruction and Multivariate Linear Regression. Energies, 11(10), 2763. https://doi.org/10.3390/en11102763