Abstract
Effective situation awareness relies on the robust processing of high-dimensional data streams generated by onboard sensors. However, the application of deep generative models to extract features from complex UAV sensor data (e.g., GPS, IMU, and radar feeds) faces two fundamental challenges: critical training instability and the difficulty of representing multi-modal distributions inherent in dynamic flight maneuvers. To address this, this paper proposes a novel unsupervised sensor data processing framework to overcome these issues. Our core innovation is a deep generative model, VAE-WRBM-MDN, specifically engineered for stable feature extraction from non-linear time-series sensor data. We demonstrate that while standard Variational Autoencoders (VAEs) often struggle to converge on this task, our introduction of Weighted-uncertainty Restricted Boltzmann Machines (WRBM) for layer-wise pre-training ensures stable learning. Furthermore, the integration of a Mixture Density Network (MDN) enables the decoder to accurately reconstruct the complex, multi-modal conditional distributions of sensor readings. Comparative experiments validate our approach, achieving 95.69% classification accuracy in identifying situational patterns. The results confirm that our framework provides robust enabling technology for real-time intelligent sensing and raw data interpretation in autonomous systems.
1. Introduction
In recent years, Unmanned Aerial Vehicles (UAVs) have been increasingly deployed in complex and dynamic environments [1]. The success of these missions hinges on the UAV’s ability to autonomously perceive and comprehend its operational environment—a capability known as situation awareness (SA) [2]. In a typical engagement, such as the 1V1 scenario depicted in Figure 1, a modern UAV is equipped with a plethora of sophisticated sensors, including Inertial Navigation Systems (INS), radar, and electro-optical pods. These sensors generate exponential volumes of high-dimensional, non-linear time-series data [3]. Consequently, the challenge has shifted from data acquisition to intelligent sensor data interpretation and fusion. The development of robust systems capable of fusing and understanding these multi-variate sensor streams in real-time has become a paramount challenge [4,5].
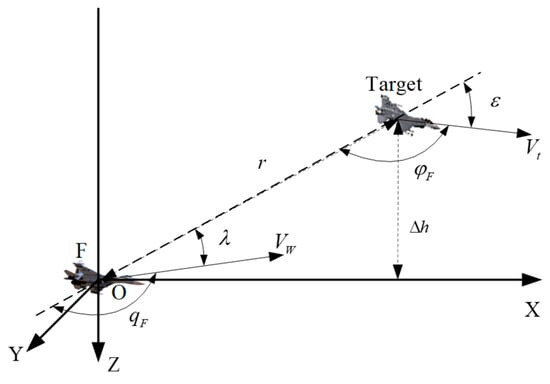
Figure 1.
Position relationship between both agents in Relative state estimation.
Traditionally, SA relied on methods like fuzzy Bayesian networks [6,7], which struggle with the high-dimensional, non-linear, and temporal nature of modern UAV data. To address this, the field has shifted towards deep learning. Recent advancements include the use of Transformer-based architectures to model long-range temporal dependencies in flight trajectories [8,9]. Other promising directions involve Generative Adversarial Networks (GANs) for detecting anomalous flight patterns [10] and contrastive learning frameworks to learn discriminative representations from unlabeled data in a self-supervised manner [11,12,13]. These approaches have demonstrated significant progress in automatically extracting meaningful features from complex sensor streams.
However, despite their success, these state-of-the-art methods often overlook critical practical challenges when applying deep generative models, a cornerstone of unsupervised representation learning. For instance, the popular Variational Autoencoder (VAE) [14,15,16,17], while powerful in theory, is notoriously difficult to train on complex, real-world time-series data. They suffer from critical training instability and are prone to converging to poor local minima, a limitation we quantitatively analyze in Section 6.3, where standard VAEs exhibited non-convergence during our experiments. Furthermore, both discriminative and generative models often make a simplifying unimodal assumption, which is inadequate for UAV engagement scenarios where a single tactical state can manifest through multiple, distinct sensor patterns (i.e., a multi-modal distribution)
To address these specific gaps, this paper proposes an improved deep generative framework, termed VAE-WRBM-MDN, built upon a Bidirectional Long Short-Term Memory (BLSTM) backbone to effectively model temporal dynamics. Our architecture is engineered to be a robust, specialized solution through three key contributions. First, to solve the critical problem of training instability, we introduce Weighted-uncertainty Restricted Boltzmann Machines (WRBM) [18,19,20,21,22] for layer-wise pre-training. This ensures stable convergence by guiding the model to a superior region of the parameter space, a step we found essential for our task. Second, to capture the complex, multi-modal nature of UAV data, we integrate a Mixture Density Network (MDN) [23,24] into the VAE decoder, allowing it to model complex conditional output distributions far more accurately than standard approaches. Third, our entire framework operates in a fully unsupervised manner, which is crucial given the infeasibility of acquiring large, comprehensively labeled datasets for all possible aerial situations [25,26,27]. This synergistic design transforms the VAE from a general tool into a robust solution specifically tailored for the challenges of UAV situation awareness.
Building on this integrated design, the main contributions of this paper are summarized as follows:
- We propose a novel, fully unsupervised situation awareness framework built on a BLSTM backbone to effectively capture temporal dynamics from high-dimensional UAV sensor data.
- We introduce a WRBM-based pre-training strategy that fundamentally solves the training instability of deep VAEs on this complex task, transforming it from an unusable baseline into a robust feature extractor.
- We enhance the model’s representational power by integrating an MDN into the decoder, enabling it to accurately model the multi-modal distributions inherent in real-world engagement data.
- We develop a hybrid classification process that synergizes data-driven clustering with a knowledge-based refinement step, ensuring the final situational assessment is both mathematically robust and operationally sound.
The remainder of this paper is organized as follows: In Section 1, factors of situation awareness are analyzed according to the characteristics of relative motion dynamics, and the model of situation awareness is built. In Section 2, a new model, deep VAE-WRBM-MDN, is proposed to improve the performance of feature extraction. In Section 3, two clustering algorithms: k-means++ and density peak are applied to cluster extracted features into four classes: our superiority , the Target’s superiority , neutrality and balance of forces . In Section 4, combining Heuristic Evaluation Function with experts’ interpretation, the classification results are amended. In the experiments, feature extraction algorithms, principal components analysis (PCA), VAE, VAE-WRBM and VAE-WRBM-MDN are matched with classification algorithms, k-means++ and density peak respectively, forming 10 horizontal and vertical contrast experiments. Indicators like classification accuracy, the run time of single-group data and the occupancy peak of CPU are selected to evaluate the effectiveness of the algorithm.
2. Model Construction of Relative State Estimation Situation
2.1. Modeling of Multi-Variate Sensor Data for Relative States
In a 1V1 engagement scenario, the state of our UAV can be represented by a vector , where are its position coordinates, is its velocity, and are its Euler angles. The state vector is derived from the fusion of onboard GPS, IMU, and radar tracking data. The raw sensor measurements are processed to yield relative parameters, as summarized in Table 1.

Table 1.
Nomenclature for Situational Parameters.
The primary task of the UAV’s situation awareness system is to determine its tactical advantage relative to a Target (which could be another UAV or a ground object) based on parameters like position, attitude, and motion state. The geometric relationship between the UAV and the Target is shown in Figure 1. In the UAV axis OXYZ, the center of gravity of the UAV is taken as the origin , X-axis is in accordance with the longitudinal axis of the UAV, pointing to the head direction, Y-axis perpendiculars to the symmetry of the UAV, pointing to the right side; Z-axis lies in the symmetry of the UAV and perpendicular to the longitudinal axis, pointing downwards. Azimuth angle refers to the angle between Target’s line of sight and speed direction of our UAV, Target entry angle refers to the angle between extension line of Target’s line of sight and speed direction of Target UAV, refers to the angle between velocity vectors of two UAVs.
2.2. Classification of Situation Space
Based on established tactical doctrine, the engagement situation can be qualitatively categorized into four classic archetypes, as shown in Figure 2. It is crucial to note that these are not predefined classes with rigid, quantitative boundaries. Instead, they represent tactically meaningful concepts that we expect our unsupervised framework to discover as distinct clusters from high-dimensional data.
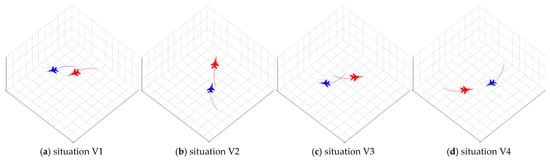
Figure 2.
Four kinds of classic aerial encounter situations.
- ➢
- (Advantageous): Our UAV is in an offensive position (e.g., at the Target’s rear), with superior speed or altitude, meeting the conditions for a successful engagement.
- ➢
- (Disadvantageous): The Target is in an offensive position relative to our UAV, posing a significant threat.
- ➢
- (Neutral-Passive): The distance between the UAV and the Target is large, and neither side is in a position to engage effectively. This is often the initial approach phase.
- ➢
- (Mutual Engagement/Balance of Power): Both the UAV and the Target are in a position to engage each other, representing a high-stakes, balanced confrontation.
This section has defined the high-dimensional feature space that describes physical engagement. The primary challenge, which the following sections address, is to develop a deep learning methodology capable of automatically extracting a low-dimensional, meaningful representation from this complex data stream without relying on manual labels.
3. Feature Extraction
The Time-series sensor data sequence is represented by a time series of length , where . In order to avoid dimensionality curse and improve the accuracy of classification, a new unsupervised deep learning model—VAE-WRBM-MDN is proposed to extract key features from situation data.
3.1. Data Processing
Raw Time-series sensor data is often corrupted by anomalies (outliers) and noise, which can be attributed to volatile operational environments and sensor instability. Therefore, data cleaning is a necessary preprocessing step before classification. Our data cleaning process consists of the following steps:
- (1)
- Anomaly Elimination
We employ the Isolation Forest algorithm, a non-parametric and unsupervised method, for anomaly detection. This algorithm is particularly well-suited for rapidly processing large datasets and has been shown to outperform ORCA, LOF, and Random Forest in similar tasks. In this study, we use it to identify and remove outliers from the Time-series sensor data.
- (2)
- Coordinate conversion
In order to achieve quantitative analysis of the relative situation among UAVs, the WGS-84 geodetic coordinate system obtained by GPS is transformed into China’s national coordinate system.
- (3)
- Normalization
As for data of large range, there will be problems of slow convergence speed and long training time emerging in deep learning algorithms. So, the data is normalized to maintain the uniformity of the data range:
3.2. VAE Model with Bidirectional Long Short-Term Memory (BLSTM)
With a typical variational inference framework, VAE can be used to learn low dimension latent variables , given the visible variables . In contrast to standard autoencoder, and in VAE are stochastic variables, the output of VAE are parameter distribution values, and the weights of VAE represent the variational parameters and .
It is possible for VAE to get the encoding distribution given the visible variables, a prior over the latent variables, and the decoding distribution given the latent variables. Where estimates the true and unknown posterior , and implements the generative model.
BLSTM is suitable to work with time series for its superiority in obtaining information forward and backward simultaneously. Compared with LSTM, BLSTM reveals higher precision and convergence speed in time-series prediction. Thus, it is applied to be the basic model of encoder and decoder. Meanwhile, in order to improve learning ability, multiple BLSTMs are stacked to construct deep BLSTM network. As for BLSTM with single layer, forward sequence, backward sequence and the output are:
where represents the activation function, represents the weight, and represents bias.
For visual variables and its corresponding latent variables, we assume the joint probability distribution factorizes over time as follows, where the generative and inference models are parameterized by deep BLSTM networks:
This equation is crucial as it mathematically formalizes the temporal generative process our model assumes for the time-series sensor data. It explicitly defines how the joint probability distribution factorizes over time, showing how the current observation is generated from the current latent variable and historical context (via the BLSTM’s hidden states). The decoding model, , the generative model , and the priors are all implemented by multiple BLSTMs with weights and , and hidden states , , and . The output and input data of these BLSTMs are corresponding to all the parameters of the distribution, such as input data , then these BLSTMs output and .
The objective of VAE with BLSTMs is to maximize the following lower variational bound of the log likelihood with respect to the parameters and :
This objective function, known as the Evidence Lower Bound (ELBO), is central to the training of any VAE. It consists of two key terms. The first, , is the reconstruction loss, measuring how accurately the decoder can regenerate the input data x from its latent representation z. The second, , is the Kullback-Leibler (KL) divergence, which acts as a regularization term. It penalizes the model if the learned posterior distribution deviates too far from a predefined prior p(z) (typically a standard normal distribution), thus encouraging a smooth and well-organized latent space. In the context of our work, this equation represents the standard VAE objective that serves as a baseline, which we aim to stabilize and enhance. To optimize this objective function via gradient descent, we employ the reparameterization trick, which allows the gradient to be backpropagated through the stochastic sampling process by re-expressing the latent variable as a deterministic function of the encoder’s output and a random noise variable. In the context of our work, this equation represents the standard VAE objective that serves as a baseline, which we aim to stabilize and enhance.
3.3. Optimizing VAE Initialization with WRBM Pre-Training
As identified in the Introduction and confirmed by our preliminary experiments where a standard VAE failed to converge, the training instability of deep VAEs is a primary obstacle to their application on complex time-series data. This instability often stems from poor weight initialization, which can lead to vanishing/exploding gradients or convergence to suboptimal local minima. To address this fundamental problem, we introduce a greedy, layer-wise pre-training strategy using Weighted-uncertainty Restricted Boltzmann Machines (WRBM) to find a highly effective set of initial weights for the entire VAE network.
The pre-training process unfolds in a sequential manner, treating the deep VAE as a stack of individual layers to be initialized one by one. The procedure is as follows:
- Encoder Pre-training (Bottom-up):
Layer 1: A WRBM is constructed where its visible layer matches the dimension of the input data and its hidden layer matches the dimension of the VAE encoder’s first hidden layer. This WRBM is trained on the raw input data until it learns to effectively reconstruct the input. The learned weight matrix from this WRBM is then used to initialize the weights of the first layer of the VAE encoder.
Layer 2 to N: Once the first WRBM is trained, the training data is passed through it to obtain the activations of its hidden units. These activations then serve as the input data for training a second WRBM, which corresponds to the second layer of the VAE encoder. This process is repeated greedily for all subsequent layers of the encoder, with the output of one trained layer becoming the input for the next.
- 2.
- Decoder Pre-training (Top-down): The same layer-wise strategy is applied to the decoder, but in reverse. The final hidden representation from the encoder pre-training is used as the initial input to train the WRBM corresponding to the top-most layer of the decoder, and the process continues downwards until the output layer is reached.
Clarification on Stochasticity: It is crucial to distinguish between the roles of stochasticity in WRBM and VAE. The WRBM, as a probabilistic energy-based model, is used here for a deterministic purpose: to find a single, high-quality set of initial weights. Once the pre-training is complete, these learned weights are fixed as the starting point for the VAE. The stochasticity inherent to the VAE’s operation—namely, the sampling of the latent variable z from the posterior distribution q(z|x) via the reparameterization trick—proceeds from this well-initialized state. Therefore, the WRBM does not introduce additional randomness into the VAE’s final inference process; rather, it ensures that the VAE’s gradient-based optimization begins in a favorable region of the parameter space, dramatically improving the likelihood of stable and meaningful convergence.
By following this procedure, the entire deep VAE is initialized with weights that have already been learned to extract hierarchical features from the data. This provides the subsequent end-to-end fine-tuning process with a powerful head start, effectively circumventing the convergence issues that plague randomly initialized deep VAEs.
3.4. MDN-VAE Model
To overcome the limited representational power of a standard VAE decoder, which assumes a simple unimodal output distribution, we introduce a Mixture Density Network (MDN). The specific advantage of MDN is its ability to model complex, multi-modal data distributions, which is essential for accurately reconstructing UAV sensor data. MDN can obtain the probability distribution of each output value through weighted sum of multiple probability distribution functions at the output layer. However, compared with MDN, VAE ignores the weights of different outputs and directly outputs distribution parameters. Therefore, MDN is introduced into VAE model.
For the output layer, the Gaussian function is chosen as probability density function (PDF), which can be defined as:
where represents the ground truth, represents the number of PDF, represents the weight of the PDF, represents the Gaussian function.
The parameters in are normalized as follows:
where , , and are mean value of output, variance of output, weight of PDF and the correlation of the Gaussian component respectively.
The objective of MDN-VAE is to maximize the following lower variational bound of the log likelihood :
The key difference from the standard VAE objective in Equation (4) is that the reconstruction term is now computed using the probability density of the Gaussian mixture output by the MDN. This modification is the mathematical embodiment of our model’s enhanced capability. It allows the objective function to reward the model for accurately capturing multi-modal data distributions, directly addressing a core limitation of conventional VAEs that assume a simple, unimodal output.
The structure and flow chart of the improved VAE are shown in Figure 3 and Figure 4, respectively. As illustrated in Figure 4, the training process begins with layer-wise pre-training of the encoder and decoder weights using WRBMs (as detailed in Section 3.3). These pre-trained weights are then used to initialize the VAE-MDN model. The entire network is subsequently fine-tuned end-to-end using the Adam optimizer to maximize the objective function (Equation (7)). During inference, new flight data is passed through the trained encoder to obtain the latent representation z, which represents the extracted situational features.
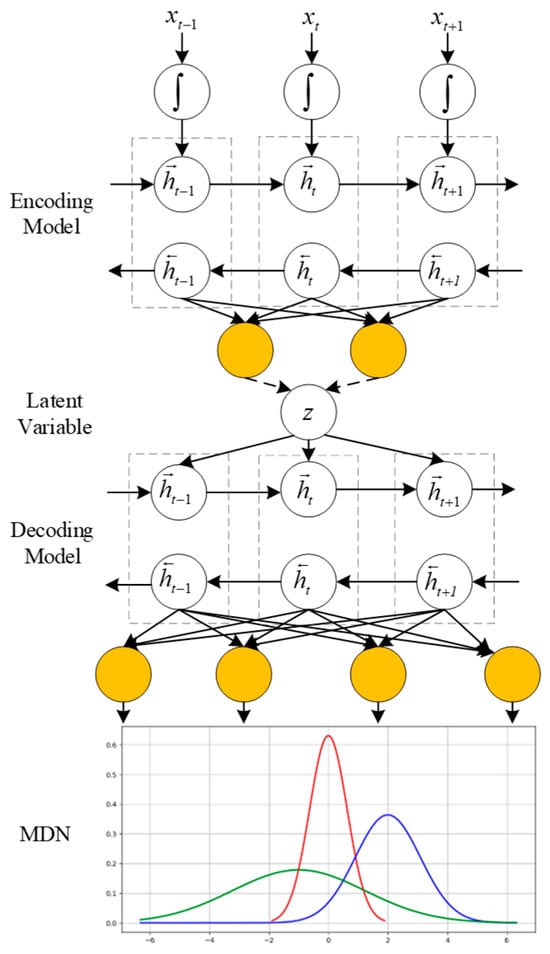
Figure 3.
The architecture of the VAE-WRBM-MDN model. In the figure, the red curve represents our UAV’s dominance function value (corresponding to the advantageous situation V1), the blue curve denotes the target’s dominance function value (corresponding to the disadvantageous situation V2), and the green curve indicates the balanced confrontation state (corresponding to the mutual engagement situation V3).
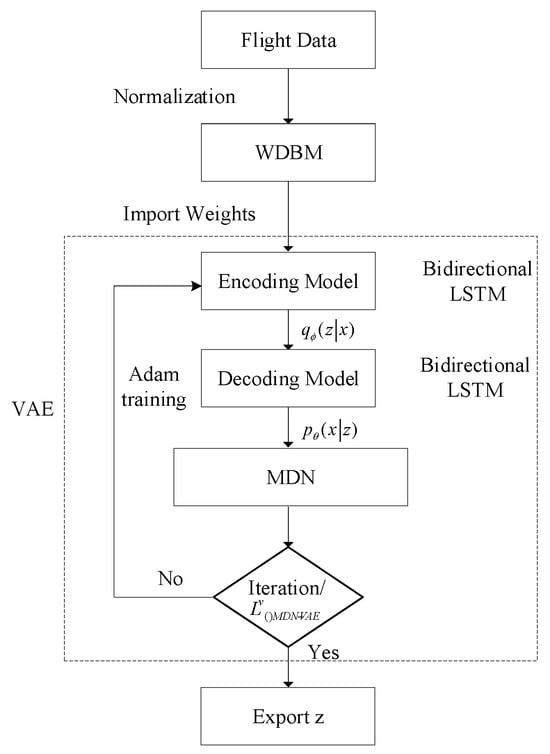
Figure 4.
The training and inference workflow of the VAE-WRBM-MDN model.
4. Clustering with k-Means++ and Density Peak
After extracting low-dimensional latent features, we apply clustering algorithms to group them into distinct situational classes. We selected two representative algorithms: k-means++, as a robust and widely used baseline, and the density peak algorithm, which is adept at identifying clusters of arbitrary shapes and is less sensitive to initialization. The number of clusters was set to four, a choice directly motivated by the established air combat doctrine described in Section 2.2, which provides a tactically meaningful and interpretable partitioning of the situation space.
From Section 1, there are obvious differences in the feature values of four typical Relative state estimation situations, and extracted features corresponding to the same type of situation congregate together. Therefore, two typical clustering algorithms, including k-means++ and density peak are introduced to classify extracted situation features.
4.1. k-Means++
K-means++, proposed by Arthur and Vassilvitskii in 2007 [28], is an improved k-means algorithm in clustering centers. A new algorithm (Algorithm 1) is adopted in k-means++ to replace stochastic clustering centers. Compared with k-means, k-means++ achieves higher accuracy and speed.
| Algorithm 1 k-means++(k) initialization |
| do |
| 5: end while |
4.2. Density Peak
As for density peak [29], two vital features of data point need to be achieved: local density and its minimum distance from points of higher density:
where represents cutoff distance, represents the number of points whose distance from point is shorter than , reflects the distance between points with higher density, which is defined as:
Center points of clustering should be surrounded by points with low density and keep a relatively longer distance from the other center points. Therefore, a data point can be considered as center point of clustering only if both and are over a certain threshold.
5. Construction of Knowledge-Based Heuristic Evaluation Functions for Data Refinement
Solely relying on data-driven clustering may lead to misinterpretations due to sensor noise or ambiguous states. To strictly align the classification with operational physics, we introduce a hybrid sensor fusion strategy. We refine the data-driven results using a knowledge-based Heuristic Evaluation Function derived from expert rules. This acts as a physics-guided constraint on the deep learning outputs. While calculating the Heuristic Evaluation Function values at some point, sample a total of 25 points forward and backward, whose weights are determined according to the interval from the moment. The closer the sample point is, the higher its weight is.
To ensure the reliability and objectivity of the expert knowledge used in this refinement step, a structured validation protocol was implemented. The “expert knowledge” was sourced from a panel of five subject matter experts (SMEs), each with over 10 years of experience in UAV operations and tactical analysis. The refinement process involved two key stages: First, the initial clustering results were independently reviewed by each SME against the calculated dominance function values and established tactical doctrines. Second, any discrepancies or ambiguous classifications were discussed by the panel in a consensus-building session to arrive at a final, validated classification. This structured, multi-expert approach, anchored by the quantitative dominance function, minimizes individual subjectivity and ensures the refined results are consistent with operational realities.
UAV’s System performance state and operational environment situation are two main aspects deliberated in situation awareness. Heuristic Evaluation Function of Relative state estimation capability is
where represents System performance state, represents maneuvering parameters, represents onboard systems parameter, represents detection parameter, represents steering coefficient, represents Safety margin coefficient, represents voyage coefficient and represents Signal interference coefficient.
Angle Heuristic Evaluation Function , distance Heuristic Evaluation Function , speed Heuristic Evaluation Function , and height Heuristic Evaluation Function are considered in Relative state estimation situation awareness. Weight coefficient is calculated by fuzzy analytic hierarchy process, synthesized situation Heuristic Evaluation Function is obtained by weighted combination of five Heuristic Evaluation Functions:
where , , , , refer to weights of Relative state estimation capability advantage, angle advantage, distance advantage, speed advantage and height advantage, respectively.
Storage form of specific situation awareness data is shown in Figure 5:
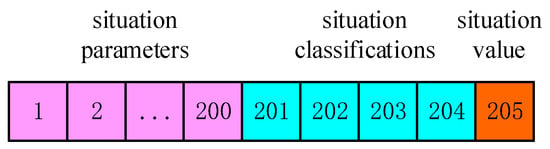
Figure 5.
Format of data.
The specific process of situation classification is shown in Figure 6.
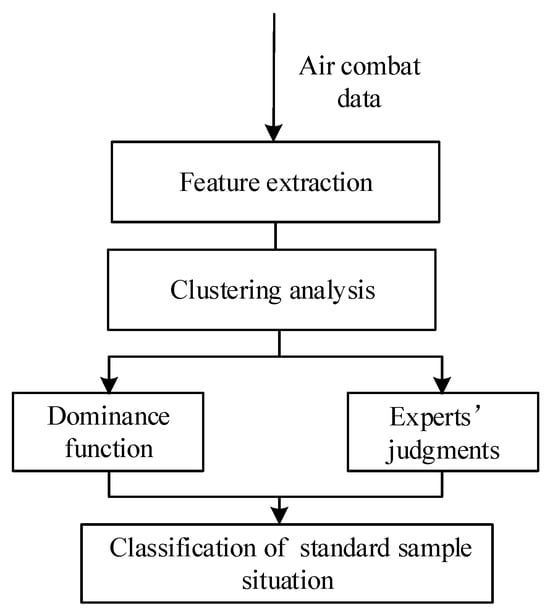
Figure 6.
Flow chart of situation classification.
Figure 6 illustrates the complete workflow of our proposed situation classification framework. This hybrid approach is designed to ensure that the final results are both mathematically robust and operationally relevant. The process consists of two parallel streams that are ultimately synthesized:
- Data-Driven Unsupervised Classification: The primary path begins with raw air combat data, which is fed into our deep feature extraction model (VAE-WRBM-MDN). The resulting low-dimensional features are then processed by a clustering algorithm (e.g., density peak) to generate an initial, purely data-driven classification of the situation.
- Knowledge-Based Refinement: In parallel, the same data is used to calculate dominance function values, which provide a quantitative assessment based on established tactical principles. These values, combined with expert knowledge, serve as a reference for validating and correcting the initial clustering results.
The final and critical step involves fusing these two streams. The initial classifications from the clustering analysis are amended using the insights from the dominance function and expert judgments, particularly in ambiguous or rapidly changing situations where purely data-driven methods may falter. This synthesis ensures the final classification of the standard sample situation is accurate and aligned with real-world tactical realities.
6. Experiments
To validate the effectiveness and generalization capability of the proposed framework, all experiments were conducted on 10 distinct datasets. These datasets were generated from a high-fidelity aerial maneuvering simulator built upon the nonlinear six-degrees-of-freedom (6-DOF) equations of motion using Python 3.10. The simulation incorporates standard atmospheric models and aerodynamic coefficients to ensure the data reflects realistic physical flight dynamics Each dataset consists of 50,000 data points for training and 5000 for testing. This multi-dataset approach allows for a rigorous evaluation of the model’s performance across varied Sensor data patterns. The experimental hardware environment was a high-performance processor with 12 Intel Xeon(R) E5 CPU and 4GB RAM, and the software platform was Tensorflow 2.15.0.
6.1. Feature Extraction Experiments
We set a 4-layer VAE network by stacking BLSTMs to minimize information loss through hierarchical feature extraction. To determine the optimal network configuration and training parameters, we performed a systematic hyperparameter tuning process. We conducted a series of experiments by varying key parameters, including the network architecture (number of neurons in each layer), the optimizer’s learning rate, and the batch size, to identify the combination that yielded the best performance in terms of convergence speed and final loss value.
We specifically chose the Adam optimizer because it is an adaptive learning rate optimization algorithm that is well-suited for training deep neural networks with complex, non-stationary objectives like that of a VAE. Specifically, its adaptive nature is particularly effective for balancing the reconstruction loss and the KL divergence regularization term, which often have different gradient magnitudes.
It combines the advantages of both AdaGrad and RMSProp, providing efficient computation and requiring little memory, which leads to faster convergence in practice.
The process involved a grid search over a predefined range of values. For instance, we evaluated several network structures (e.g., [1024, 256, 64, 2], [512, 128, 32, 2]), learning rates (e.g., 0.01, 0.005, 0.001), and batch sizes (e.g., 32, 64, 128). The training processes for these different parameter settings are illustrated in Figure 7. From these experiments, we concluded that a network structure of [1024, 256, 64, 2], combined with an Adam optimizer using a learning rate of 0.005 and a batch size of 64, achieved the most robust convergence and the lowest fitness value. This configuration was therefore selected for all subsequent experiments.
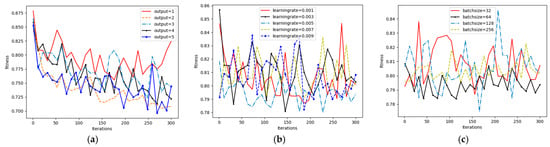
Figure 7.
Hyperparameter tuning process for the VAE network. (a) Training loss with different network structures; (b) Training loss with different learning rates; (c) Training loss with different batch sizes.
From Figure 7, it can be found that VAE-WRBM-MDN with the structure of [1024, 256, 64, 2] and an Adam optimizer with a learning rate of 0.005 and a batch size of 64 achieve robust and lower fitness.
According to the method above, optimal parameters of different networks can be reached: (1) WRBM: a learning rate of 0.001, a batchsize of 64, a dropout of 0.6 and iterations of 500. (2) VAE: a learning rate of 0.005, a batchsize of 64, a dropout of 0.6 and iterations of 300. (3) VAE-MDN: a learning rate of 0.005, a batchsize of 64, a dropout of 0.6 and iterations of 300.
The red, green, blue, and yellow elements in Figure 8 correspond to the 1st to 4th layers of the WRBM: the curves in the upper subplots (marked with these colors) denote the training loss variation with iterations for the encoder layers (encode1 to encode4), while the columnar plots in the lower subplots (of the same colors) represent the loss fluctuations of the decoder layers (decode1 to decode4); this color-coding enables intuitive differentiation of convergence states across hierarchical WRBM layers, visually validating the effectiveness of layer-wise pre-training for providing stable initial weights to the subsequent VAE model. It can be seen in Figure 8 that WRBM is well-trained in respects of convergence speed and accuracy and effectively pretrains the initial weights of the VAE model.
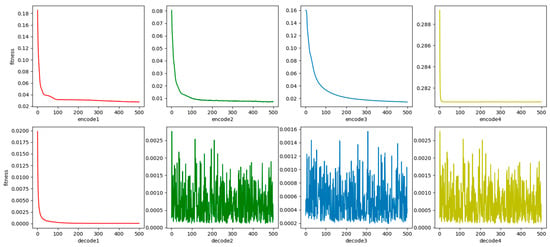
Figure 8.
The training process of WRBM.
The training process of VAE-WRBM and VAE-WRBM-MDN is shown in Figure 9.
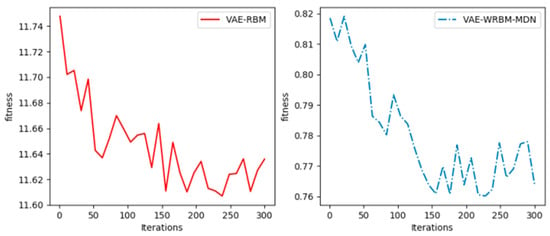
Figure 9.
The training process of VAE-WRBM.
The training process of WRBM with the structure of [200, 1024], [1024, 256], [256, 64], [64, 2] and [2, 64], [64, 256], [256, 1024], [1024, 200] is shown in Figure 8:
From Figure 9, the loss of VAE-WRBM and VAE-WRBM-MDN converges rapidly to a relatively stable value, which demonstrates the efficiency of WRBM. However, in the experiment of VAE, we find its loss is always infinite. Through analysis, it is caused by stochastic, small initial weights and complex training data. Therefore, the optimization of weights by WRBM is indispensable to VAE models.
6.2. Classification Experiments
K-means++ and density peak methods are applied to classify the extracted features. In order to visualize the classification results, we take one set of test data as an example. The distribution results of density peak algorithm are shown in Figure 10:
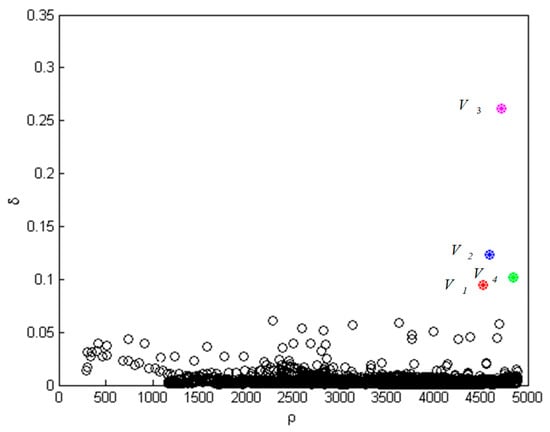
Figure 10.
Value of density peaks algorithm.
In Figure 10, points of magenta, blue, green and red represent four centers of situation classification. Starting from four centers, take a certain distance as the classification radius to classify the remaining data. If there is an overlap, reclassify points in the light of the distance from the center points. The result of the classification is shown in Figure 11.
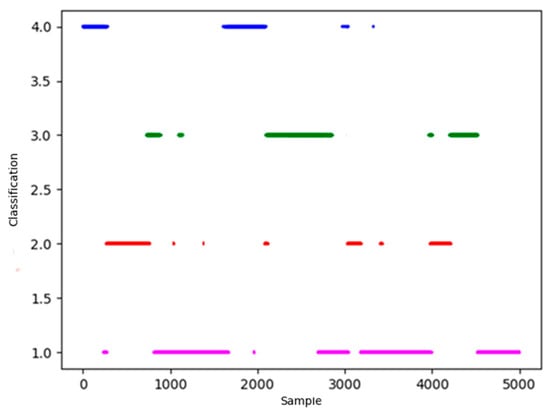
Figure 11.
Cluster results of density peaks algorithm.
In Figure 11, blue, green and red represent four centers of situation classification. The horizontal axis represents 5000 test data involved in clustering, the vertical axis represents four types of situation. It is obvious that there are many discrete points in the classified results, which do not conform to the characteristic of situation continuity that need to be revised.
According to Section 4, Heuristic Evaluation Function values of four types of data are calculated to determine the corresponding classification. Four colors are matched with four categories through Heuristic Evaluation Function and actual mission space situation: Magenta represents situation V3, red represents situation V1, green represents situation V4, and blue represents situation V2.
The distribution results of k-means++ algorithm are shown in Figure 12.
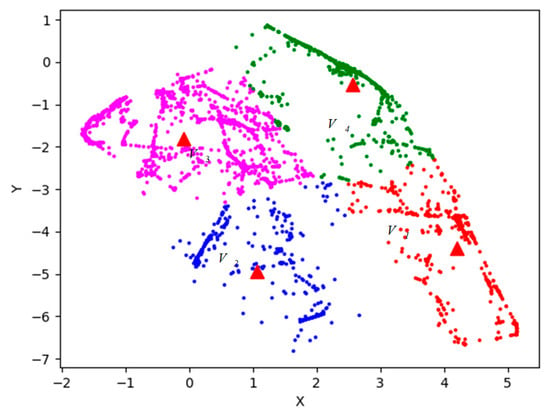
Figure 12.
Value of k-means++ algorithm.
In Figure 12, four red triangle points represent four clustering centers. Points of magenta, blue, green and red represent four types of situation. The specific classification result is shown in Figure 13.
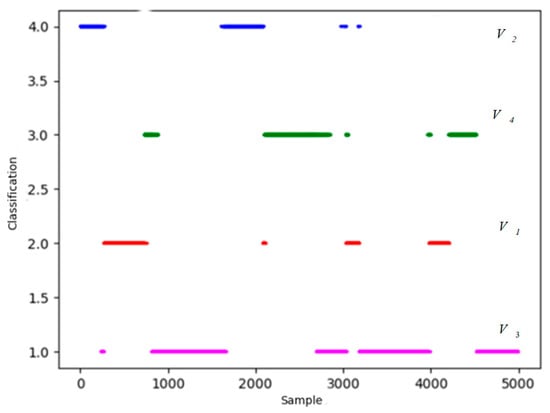
Figure 13.
Cluster results of k-means++ algorithm.
Similarly, in Figure 13 there are also some discrete points in the classified data, not in conformity with the physics of relative motion that need to be revised in light of the dominant values and experts’ perspectives. The Heuristic Evaluation Function values and clustering results of partial situation data are shown in Figure 14.
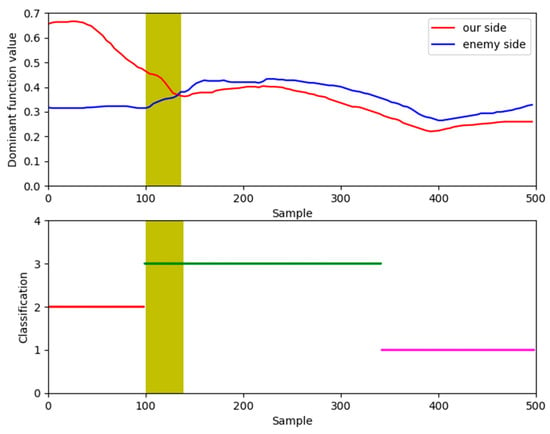
Figure 14.
Comparison of two algorithms.
Figure 14 provides a compelling visual justification for the necessity of our refinement step by comparing the initial clustering results against the calculated dominance functions for a segment of the engagement. In the plot, the continuous red and blue lines represent the dominance function values for our UAV and the Target, respectively; a higher red line signifies our tactical advantage. The colored points at the bottom of the plot represent the situational class assigned by the unsupervised clustering algorithm.
The yellow shaded area highlights a critical discrepancy. Within this period, the dominance function clearly indicates that our UAV holds a significant advantage (the red line is consistently above the blue line). However, the clustering algorithm misclassifies this entire segment as a neutral situation (V3), failing to capture the shift in tactical advantage. Such errors are common in purely data-driven approaches, especially during transitional moments of an engagement. This discrepancy underscores the importance of the final refinement step, where the dominance function and expert knowledge are used to correct these misclassifications, as shown in the final results in Figure 15 and Figure 16, leading to a more accurate and operationally consistent situation assessment.
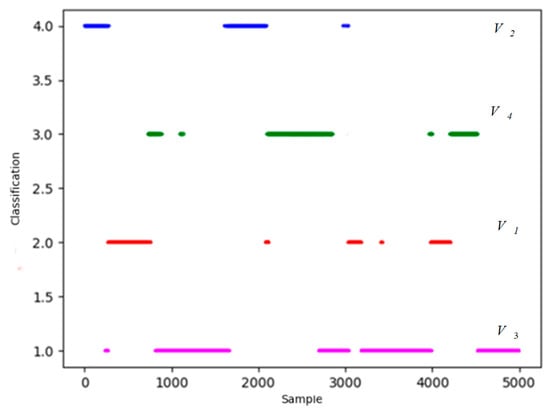
Figure 15.
Final classification results of density peak algorithm.
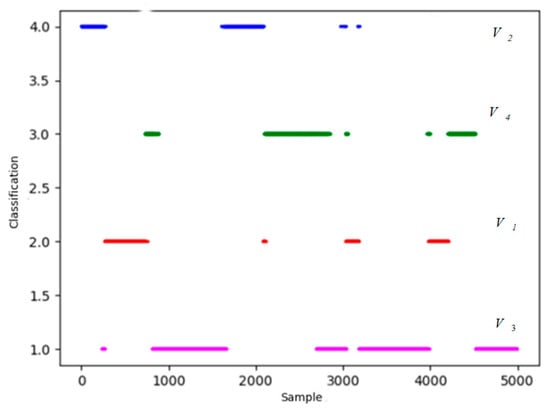
Figure 16.
Final classification results of k-means++ algorithm.
It is obvious that most discrete points are amended in Figure 15 and Figure 16. To verify the ability to extract features and classification accuracy, PCA is included to make the comparison. Follow the steps above, based on 10 sets of data, 10 comparative experiments are carried out. Training time and accuracy of the revised results are presented in Table 2.
Table 2.
Comparison of classification.
As can be known from Table 2:
- (1)
- The accuracy of the situation classification is low when k-means++ or density peak algorithm is directly used. It proves that the typical clustering algorithms are not suitable for high-dimensional data.
- (2)
- As for test sets and training sets, compared with PCA, VAE-WRBM and VAE-WRBM-MDN achieve more favorable results, and VAE-WRBM-MDN outperforms VAE-WRBM. Since PCA is mainly designed for linear data, it is not adequate for complex nonlinear multi-dimensional data.
- (3)
- Based on the extracted features, two typical clustering algorithms k-means++ and density peak both reach accurate classification results, and density peak performs better than k-means++. That implies that the extracted features can represent the whole dimension and the typical clustering methods are effective.
- (4)
- Six algorithms all meet the requirements of timeliness and low hardware condition.
While Table 2 demonstrates the superior final classification accuracy of our method after knowledge-based refinement, it is also crucial to objectively evaluate the quality of the initial, purely data-driven clustering results. To address this, we introduced three standard external validity metrics: the Adjusted Rand Index (ARI), Normalized Mutual Information (NMI), and V-measure. We used the classification derived from the dominance function as the ground truth to assess how well the raw clusters (e.g., as visualized in Figure 13 and Figure 15) align with the desired situational categories.
The quantitative results of this evaluation are presented in Table 3. The data clearly shows that the features extracted by our VAE-WRBM-MDN model lead to significantly better initial clusters compared to the PCA baseline. For instance, our full model paired with density peak clustering achieved an ARI of 0.931 and an NMI of 0.945, far surpassing the values obtained by PCA. This provides strong, quantitative evidence that our model learns a latent representation where the underlying situations are inherently more separable. A high-quality initial clustering is fundamental, as it provides a more accurate foundation for the subsequent knowledge-based refinement, which in turn explains the high final accuracy reported in Table 2. This two-step validation confirms the effectiveness of our framework from both a data-driven and a final application perspective.
Table 3.
Quantitative evaluation of initial clustering performance using external validity metrics.
Based on the combination of trained VAE-WRBM-MDN model and density peak algorithm, actual Relative state estimation data is processed and the Relative state estimation situation of each time period is classified. Furthermore, the classified results are compared with actual flight conditions to deeply analyze the Relative state estimation situation. Specific output results are shown in Figure 17 and Figure 18.
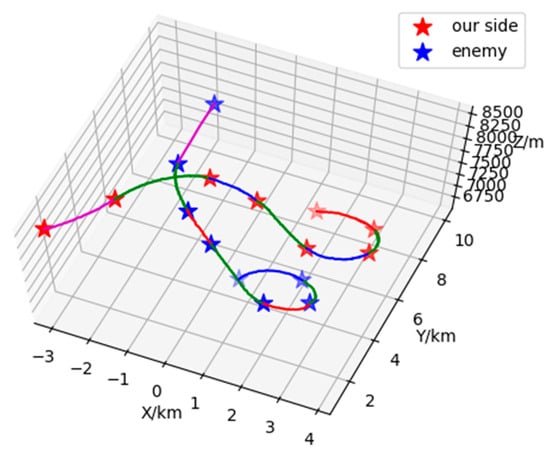
Figure 17.
Three-dimensional situation of 1V1 in Relative state estimation.
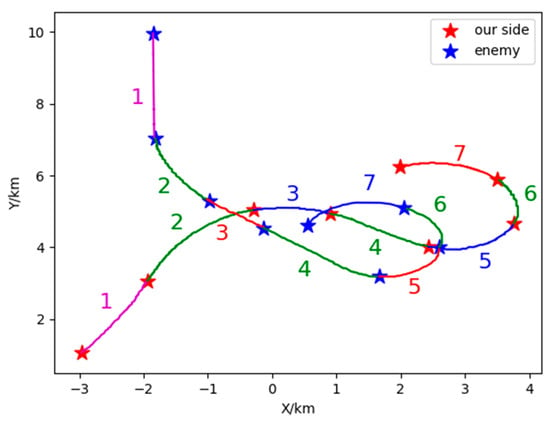
Figure 18.
Two-dimensional of 1V1 in Relative state estimation.
Figure 17 and Figure 18 show the classification results of two-dimensional and three-dimensional situation. Figure 19 displays the situation values and the corresponding classification results. In Figure 17 and Figure 18, red represents our UAV and blue represents the Target. The flight path is presented with red, blue, magenta and green in accordance with the situation V1~V4 respectively. The confrontation situation is divided into seven parts by the model. Part 1 corresponds to situation V3: at entry stage, the distance between both agents is large, far away from engage conditions; Part 2 corresponds to situation V4: both sides begin to maneuver and enter the confrontation area, threatening each other; Part 3 corresponds to situation V2: the Target emerges at the rear flank of our UAV, leaving us at a disadvantage. Part 4 corresponds to situation V4: our UAV has the advantage of altitude, while the Target occupy a slight advantage of angle, which contributes to the balance situation between both agents. Part 5 corresponds to situation V2: Target maneuvers heavily, expanding the advantage of the angle and narrowing the altitude gap. Therefore, our UAV is at a disadvantage. Part 6 corresponds to situation V4: both sides can maneuver to engage each other. Part 7 corresponds to situation V1: our UAV has the advantages of angle and altitude after Part 5 and Part 6, getting the opportunity to engage in the rear. Our UAV is at an advantage. The law of situation changes in Figure 19 is basically the same as the result of classification in Figure 17 and Figure 18. Therefore, the validity of the proposed model is verified in the actual confrontation process.
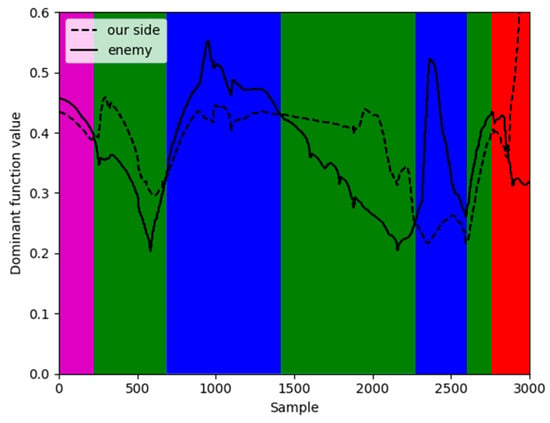
Figure 19.
The situation value of Relative state estimation.
6.3. Ablation Study
To systematically validate our central hypothesis—that standard deep VAEs are highly unstable for this task and that our proposed components are essential for success—we conducted a rigorous ablation study. This study serves not only as an internal validation but also as the most critical state-of-the-art comparison, benchmarking our model against the foundational deep generative approach that any researcher would first attempt.
As noted in Section 6.1, the loss for the standard VAE model remained infinite, indicating a failure to converge due to suboptimal weight initialization. This result is from a new experiment conducted to isolate the effect of the BLSTM backbone.
The results clearly demonstrate the necessity of each component:
- (1)
- Impact of WRBM: Overcoming a Fundamental Feasibility Barrier. The most dramatic and crucial finding of this study is the comparison between the standard VAE and our WRBM-enhanced version. The standard VAE, representing a direct and significant baseline, completely failed to converge, rendering it unusable for this task. The introduction of WRBM pre-training was not merely an incremental improvement; it was the enabling technology that made the entire deep generative modeling approach feasible, achieving a high accuracy of 94.86%. This confirms that our primary contribution is not just enhancing performance, but making it possible in the first place.
- (2)
- Impact of BLSTM: By replacing the BLSTM backbone with a standard Multi-Layer Perceptron (MLP), the accuracy dropped significantly from 94.86% to 89.34%. This substantial decrease highlights the importance of capturing temporal dependencies in the UAV Time-series sensor data, which the BLSTM architecture is specifically designed to do.
- (3)
- Impact of MDN: Adding the MDN to the VAE-WRBM model resulted in a further accuracy improvement from 94.86% to 95.69%. While the gain is more modest, it demonstrates that the MDN’s ability to model multi-modal output distributions provides a tangible benefit in representational power, leading to more precise feature extraction.
In summary, this ablation study validates our design choices, proving that the synergistic combination of WRBM for stability, BLSTM for temporal modeling, and MDN for expressive power is crucial for the high performance of our proposed framework.
7. Discussion
Our experimental results demonstrate that the proposed VAE-WRBM-MDN framework not only achieves high classification accuracy but also addresses fundamental challenges in applying deep generative models to real-world sensor data. This section provides a critical interpretation of these findings, discusses the study’s limitations, and outlines future research directions.
7.1. Interpretation and Implications of Key Findings
The most significant finding of this study is not merely the final accuracy figure, but the result from the ablation study (Table 4) showing that a standard VAE fails to converge. This is not a trivial point; it is a critical validation of our core hypothesis. It implies that for complex, non-linear time-series data typical of UAV engagements, applying deep generative models “out of the box” is not a viable strategy. The introduction of WRBM pre-training was not an incremental improvement but an enabling technology that transformed the VAE from an unusable theoretical construct into a practical and powerful feature extractor.
Table 4.
Ablation study results comparing different model configurations.
Furthermore, the performance gains from the BLSTM backbone and the MDN decoder highlight two other crucial aspects. The ~5% accuracy drop when replacing BLSTM with a simple MLP confirms that capturing temporal context is indispensable for situational understanding. The subsequent accuracy gain from adding the MDN, while more modest, demonstrates the benefit of modeling multi-modal distributions. This suggests that even within a single classified situation (e.g., “Mutual Engagement”), there exist multiple distinct sub-patterns in the sensor data, which our model can capture more effectively.
The broader implication of this work is a template for developing robust unsupervised learning systems for other complex autonomous platforms where labeled data is scarce or non-existent. The principle of stabilizing training (via WRBM), modeling temporal dynamics (via BLSTM), and capturing complex output distributions (via MDN) is a generalizable strategy.
7.2. Limitations and Future Work
Despite promising results, this study has several limitations that open avenues for future research.
Scenario and Environmental Complexity: The current framework was validated on a 1v1 engagement scenario under relatively clear conditions. Its performance in the presence of environmental factors like terrain masking, adverse weather, or electronic countermeasures remains untested. Future work must incorporate these real-world complexities into the simulation and validation datasets to enhance the framework’s operational robustness.
Scalability to Multi-Agent Systems: The model is designed for a single-target situation. Extending it to dynamic multi-UAV engagements, where the number of agents can vary, poses a significant challenge. The fixed-size input vector is insufficient for such scenarios. A promising direction is to integrate our VAE-WRBM-MDN backbone with Graph Neural Networks (GNNs). This would allow the model to represent the engagement as a dynamic graph, capturing the complex topological interactions between multiple agents and enabling scalable situation awareness in swarm scenarios.
Benchmarking Against Other Unsupervised Methods: While our framework significantly outperforms PCA and a baseline VAE, a broader comparison against other state-of-the-art unsupervised methods would further strengthen our findings. Future work should benchmark our model against advanced deep clustering algorithms (e.g., Deep Embedded Clustering, DEC) and contrastive learning approaches (e.g., SimCLR adapted for time-series data). This would provide deeper insights into the relative merits of generative versus discriminative paradigms for this specific task.
Transition to Real-World Deployment: Deploying this model onto a physical UAV requires addressing the significant constraints of onboard computation and real-time processing. The path to deployment involves model optimization through techniques like quantization and pruning, followed by implementation on specialized embedded hardware (e.g., NVIDIA Jetson, FPGA). Rigorous Hardware-in-the-Loop (HIL) simulation will be a critical intermediate step to validate the real-time performance and safety of the deployed system before any flight tests.
8. Conclusions
This paper introduced a novel, fully unsupervised situation awareness framework to overcome the critical challenges of applying deep generative models to high-dimensional UAV sensor data. By synergistically combining a Bidirectional Long Short-Term Memory (BLSTM) backbone, a Weighted-uncertainty Restricted Boltzmann Machine (WRBM) for pre-training, and a Mixture Density Network (MDN) in the decoder, our proposed VAE-WRBM-MDN model achieves both stable training and superior representational power.
Our key contributions are threefold: (1) We demonstrated that WRBM pre-training is an essential step to overcoming the training instability that renders standard VAEs unusable for this task. (2) We enhanced the model’s expressiveness by integrating an MDN, enabling it to capture the complex, multi-modal nature of engagement data. (3) We developed a hybrid classification process that refines the unsupervised clustering results with knowledge-based functions, ensuring the final assessment is both data-driven and operationally sound.
Extensive experiments confirmed the superiority of our approach, achieving a classification accuracy of 95.69%. The results validate that our framework provides a robust and generic solution for intelligent sensor data interpretation, paving the way for more autonomous and reliable UAV operations in complex environments.
Author Contributions
Conceptualization, A.G. and Z.Z.; methodology, Z.Z.; software, Z.Z.; validation, R.Y., Y.Z., L.H. and Z.Z.; formal analysis, L.H.; investigation, L.H.; resources, A.G.; data curation, A.G.; writing—original draft preparation, A.G. and Z.Z.; writing—review and editing, A.G. and Z.Z.; visualization, A.G. and Z.Z.; supervision, Y.Z., L.H. and L.L.; project administration, Y.Z., L.H. and L.L.; funding acquisition, Z.Z., All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Xi’an Young Talent Support Program (0959202513098).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are available on request from the corresponding author due to privacy concerns.
DURC Statement
Current research is limited to the UAV Sensor Data Fusion, which is beneficial and does not pose a threat to public health or national security. Authors acknowledge the dual-use potential of the research involving UAV Sensor Data Fusion Collaboration and confirm that all necessary precautions have been taken to prevent potential misuse. As an ethical responsibility, authors strictly adhere to relevant national and international laws about DURC. Authors advocate for responsible deployment, ethical considerations, regulatory compliance, and transparent reporting to mitigate misuse risks and foster beneficial outcomes.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Xu, F.; Duo, B.; Xie, Y.; Pan, G.; Yang, Y.; Zhang, L.; Wang, Y. Multi-UAV Assisted Mixed FSO/RF Communication Network for Urgent Tasks: Fairness Oriented Design with DRL. IEEE Trans. Veh. Technol. 2025, 74, 1736–1741. [Google Scholar] [CrossRef]
- Endsley, M.R. Toward a Theory of Situation Awareness in Dynamic Systems. Hum. Factors 1995, 35, 32–45. [Google Scholar] [CrossRef]
- Wu, W.H.; Zhou, S.Y.; Gao, L.; Liu, J.-T. Improvements of Situation Awareness for Beyond-Visual-Range Relative state estimation Based on Onboard Systems Launching Envelope Analysis. Syst. Eng. Electron. 2011, 33, 2679–2685. [Google Scholar]
- Huang, Z.Z. V-Shaped Deformation Quadrotor Radar Cross-Section Analysis. Proc. Inst. Mech. Eng. G J. Aerosp. Eng. 2025, 239, 09544100251328443. [Google Scholar] [CrossRef]
- Boroujeni, S.P.H.; Razi, A.; Khoshdel, S.; Afghah, F.; Coen, J.L.; O’neill, L.; Fule, P.; Watts, A.; Kokolakis, N.-M.T.; Vamvoudakis, K.G. A Comprehensive Survey of Research Towards AI-Enabled Unmanned Aerial Systems in Pre-, Active-, and Post-Wildfire Management. Inf. Fusion 2024, 108, 102369. [Google Scholar] [CrossRef]
- Xiao, B.S.; Fang, Y.W.; Hu, S.G. New Threat Assessment Method in Beyond-the-Horizon Range Relative state estimation. Syst. Eng. Electron. 2009, 31, 2163–2166. [Google Scholar]
- Narayana, R.P.; Sudesh, K.; Kashyap, G. Situation Awareness in Air-Combat: A Fuzzy-Bayesian Hybrid Approach. In Proceedings of the International Conference on Aerospace Science and Technology, Bangalore, India, 26–28 June 2008. [Google Scholar]
- Hu, G.; Zhou, Z.; Li, Z.; Dong, Z.; Fang, J.; Zhao, Y.; Zhou, C. Multiscale Transformers With Contrastive Learning for UAV Anomaly Detection. IEEE Trans. Instrum. Meas. 2025, 74, 1–15. [Google Scholar] [CrossRef]
- Zhang, W.; Liu, Z.; Jia, Z.; Wang, X.; Yan, W.; Wang, K. Application of a Multimodal Deep Learning Model Based on Recursive Fusion Feature Map With Transformer–TCN for Complex Fault Diagnosis of Flying Wing UAV Actuators. IEEE Trans. Instrum. Meas. 2025, 74, 1–17. [Google Scholar] [CrossRef]
- Li, C.; Luo, K.; Yang, L.; Li, S.; Wang, H.; Zhang, X.; Liao, Z. A Zero-Shot Fault Detection Method for UAV Sensors Based on a Novel CVAE-GAN Model. IEEE Sens. J. 2024, 24, 22340–22355. [Google Scholar] [CrossRef]
- Xiao, B.W.; Xing, H.J.; Li, C.G. MulGad: Multi-Granularity Contrastive Learning for Multivariate Time Series Anomaly Detection. Inf. Fusion 2025, 119, 103008. [Google Scholar] [CrossRef]
- Darban, Z.Z.; Webb, G.I.; Pan, S.; Aggarwal, C.C.; Salehi, M. CARLA: Self-Supervised Contrastive Representation Learning for Time Series Anomaly Detection. Pattern Recognit. 2025, 157, 110874. [Google Scholar] [CrossRef]
- Kim, H.G.; Kim, S.; Min, S.; Lee, B. Contrastive Time-Series Anomaly Detection. IEEE Trans. Knowl. Data Eng. 2024, 36, 4407–4420. [Google Scholar] [CrossRef]
- Rezende, D.J.; Mohamed, S.; Wierstra, D. Stochastic Backpropagation and Approximate Inference in Deep Generative Models. In Proceedings of the 31st International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 1278–1286. [Google Scholar]
- Wu, Y.H.; Burda, Y.; Salakhutdinov, R.; Grosse, R. On the Quantitative Analysis of Decoder-Based Generative Models. In Proceedings of the Neural Information Processing Systems 29, Barcelona, Spain, 5–10 December 2016; pp. 2880–2888. [Google Scholar]
- Larsen, M.; Sønderby, S.K.; Larochelle, H.; Winther, O. Autoencoding beyond Pixels Using a Learned Similarity Metric. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1558–1566. [Google Scholar]
- Sutskever, I.; Martens, J.; Dahl, G.; Hinton, G. On the Importance of Initialization and Momentum in Deep Learning. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 1139–1147. [Google Scholar]
- Wang, X.Z.; Zhang, T.; Wang, R. Noniterative Deep Learning: Incorporating Restricted Boltzmann Machine Into Multilayer Random Weight Neural Networks. IEEE Trans. Syst. Man Cybern. Syst. 2019, 49, 1299–1308. [Google Scholar] [CrossRef]
- Zhang, C.; Li, S.; Ye, M.; Zhu, C.; Li, X. Learning Various Length Dependence by Dual Recurrent Neural Networks. Neurocomputing 2021, 465, 319–328. [Google Scholar] [CrossRef]
- Ceni, A. Random Orthogonal Additive Filters: A Solution to the Vanishing/Exploding Gradient of Deep Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2025, 36, 1121–1133. [Google Scholar] [CrossRef]
- Abuqaddom, I.; Mahafzah, B.A.; Faris, H. Oriented Stochastic Loss Descent Algorithm to Train Very Deep Multi-Layer Neural Networks Without Vanishing Gradients. Knowl. Based Syst. 2021, 230, 107391. [Google Scholar] [CrossRef]
- Xu, Y.; Zhang, T.; Tao, X.M. Cellular-Connected Multi-UAV MEC Networks: An Online Stochastic Optimization Approach. IEEE Trans. Commun. 2022, 70, 6630–6647. [Google Scholar] [CrossRef]
- Razavi, S.F.; Hosseini, R.; Behzad, T. FRMDN: Flow-Based Recurrent Mixture Density Network. Expert Syst. Appl. 2024, 237, 121360. [Google Scholar] [CrossRef]
- Jiang, W.; Zhang, C.; Cheng, Z.; Li, R. Uncertainty Evaluation for Dynamic Observations of Unknown Models Based on Mixture Density Network. Meas. Sci. Technol. 2025, 36, 025401. [Google Scholar] [CrossRef]
- Yang, P.; Esmaeili, K.; Goodfellow, S.; Calderón, J.C.O. Mine Pit Wall Geological Mapping Using UAV-Based RGB Imaging and Unsupervised Learning. Remote Sens. 2023, 15, 1641. [Google Scholar] [CrossRef]
- Yang, L.; Li, S.; Li, C.; Zhu, C.; Zhang, A.; Liang, G. Data-Driven Unsupervised Anomaly Detection and Recovery of Unmanned Aerial Vehicle Time-series sensor data Based on Spatiotemporal Correlation. Sci. China Technol. Sci. 2023, 66, 1304–1316. [Google Scholar] [CrossRef]
- Bu, J.; Sun, R.; Bai, H.; Xu, R.; Xie, F.; Zhang, Y.; Ochieng, W.Y. A Novel Integrated Method for the UAV Navigation Sensor Anomaly Detection. IET Radar Sonar Navig. 2017, 11, 847–853. [Google Scholar] [CrossRef]
- Arthur, D.; Vassilvitskii, S. K-Means++: The Advantages of Careful Seeding. In Proceedings of the 8th Annual ACM-SIAM Symposium Discrete Algorithms, New Orleans, LA, USA, 7–9 January 2007; pp. 1027–1035. [Google Scholar]
- Alex, R.; Alessandro, L. Clustering by fast search and find of density peaks. J. Sci. 2014, 344, 1492–1496. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.