
A Joint Global and Local Temporal Modeling for Human Pose Estimation with Event Cameras

Abstract
1. Introduction
- This paper proposes a novel framework, JGLTM, for event-based human pose estimation. It explicitly captures both long-range contextual motion cues through the GMN module and short-range spatial–temporal consistency via the LST module, enhancing robustness to event sparsity. Furthermore, the MPR module is introduced, where global context from the GMN is injected into the middle frame’s features in LST using a cross-attention mechanism to improve prediction quality.
- This paper extends previous a dataset, CDEHP, to a larger benchmark CDEHP-E (CDEHP-E dataset is available at: https://cdehp-dataset.github.io/ accessed on 1 March 2025), including both indoor and outdoor scenarios, providing a more comprehensive evaluation platform.
- Extensive experiments on CDEHP, CDEHP-E, MMHPSD, and DHP19 demonstrate that the method proposed in this paper outperforms existing CNN-based and attention-based baselines, showing strong generalization across diverse conditions.
2. Related Work
2.1. Video-Based Human Pose Estimation
2.2. Event-Based Human Pose Estimation
2.3. Vision Transformer for HPE
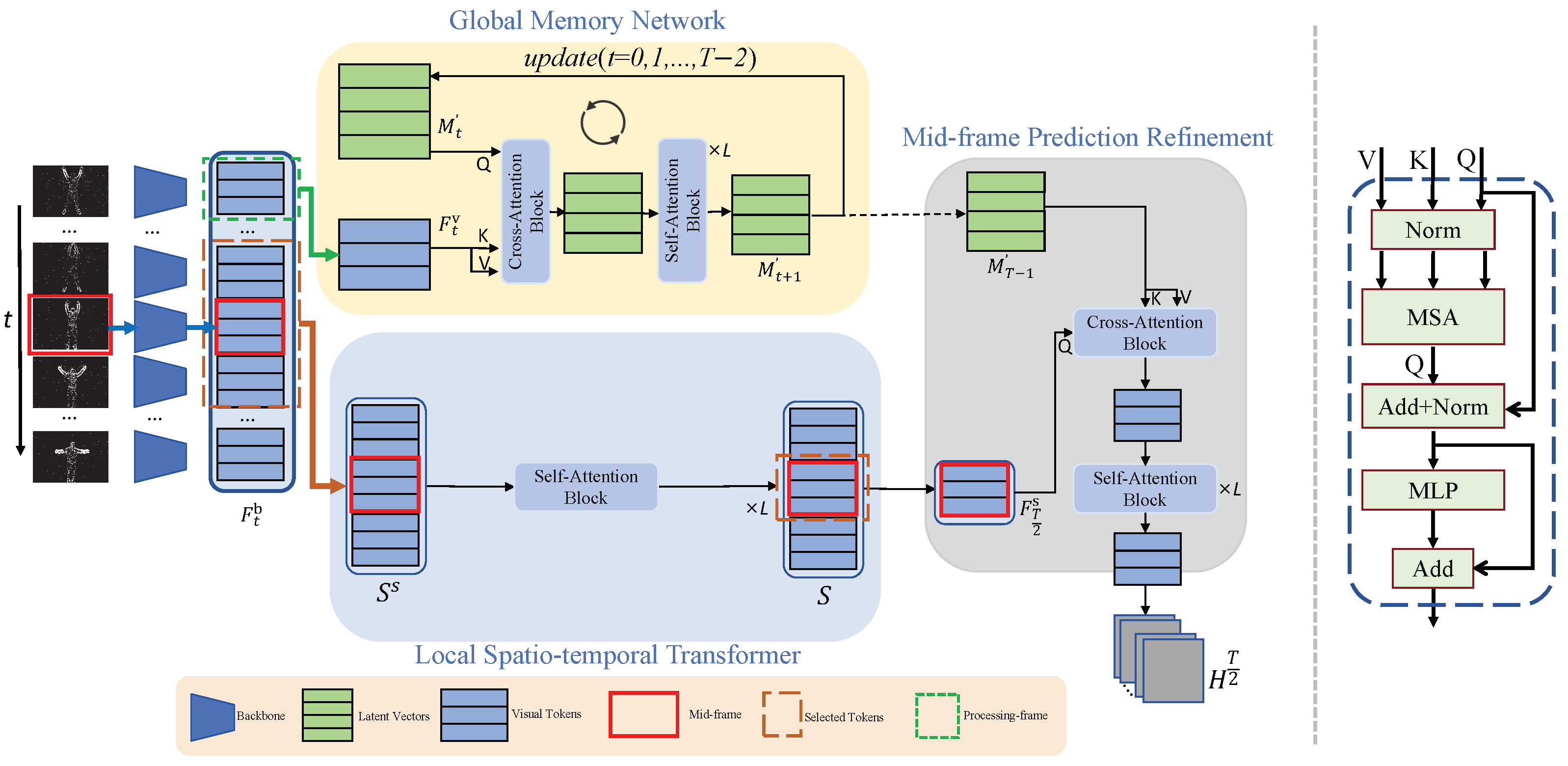
3. Method
3.1. Preliminary Details
3.1.1. -
3.1.2.
3.2. Feature Extraction
3.3. Local Spatio-Temporal Transformer
3.4. Global Memory Network
3.4.1. Memory Refinement
3.4.2. Memory Update
3.5. Mid-Frame Prediction Refinement
3.6. Training of the Network
3.7. CDEHP-E Dataset
4. Experiment
4.1. Experiment Setup
4.1.1. Dataset
4.1.2. Implementation
4.1.3. Evaluation Metric
4.2. Experimental Analysis
4.2.1. The Influence of Input Resolution
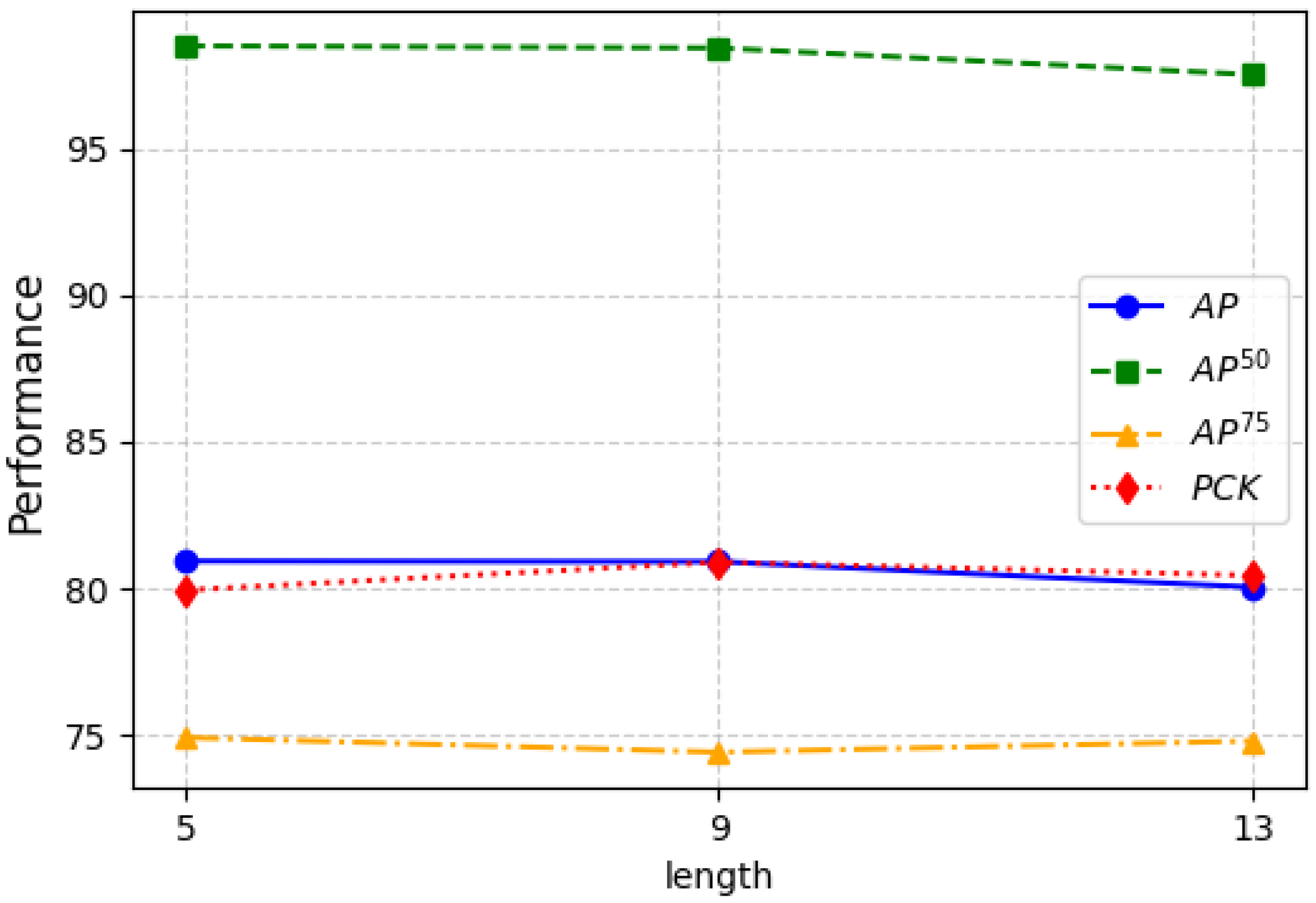
4.2.2. Effect of the Global Temporal Length
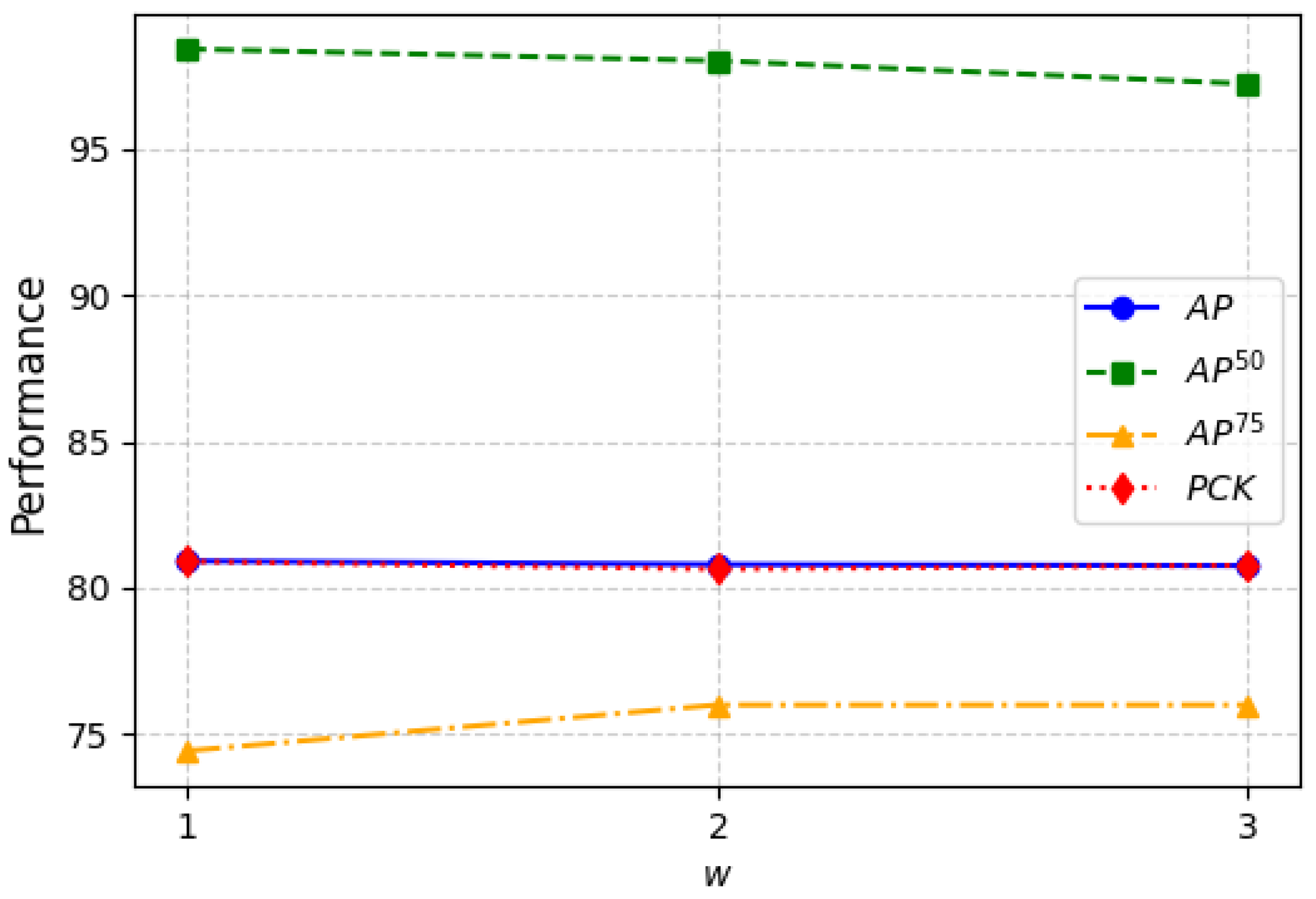
4.2.3. Effect of the Local Temporal Length
4.2.4. Contribution of Each Component
4.3. Comparisons with State of the Art
4.3.1. Results on DHP19
4.3.2. Results on CDEHP
4.3.3. Result on CDEHP-E
4.3.4. Results on MMHPSD
4.3.5. Action-Wise Result Comparison on CDEHP Dataset
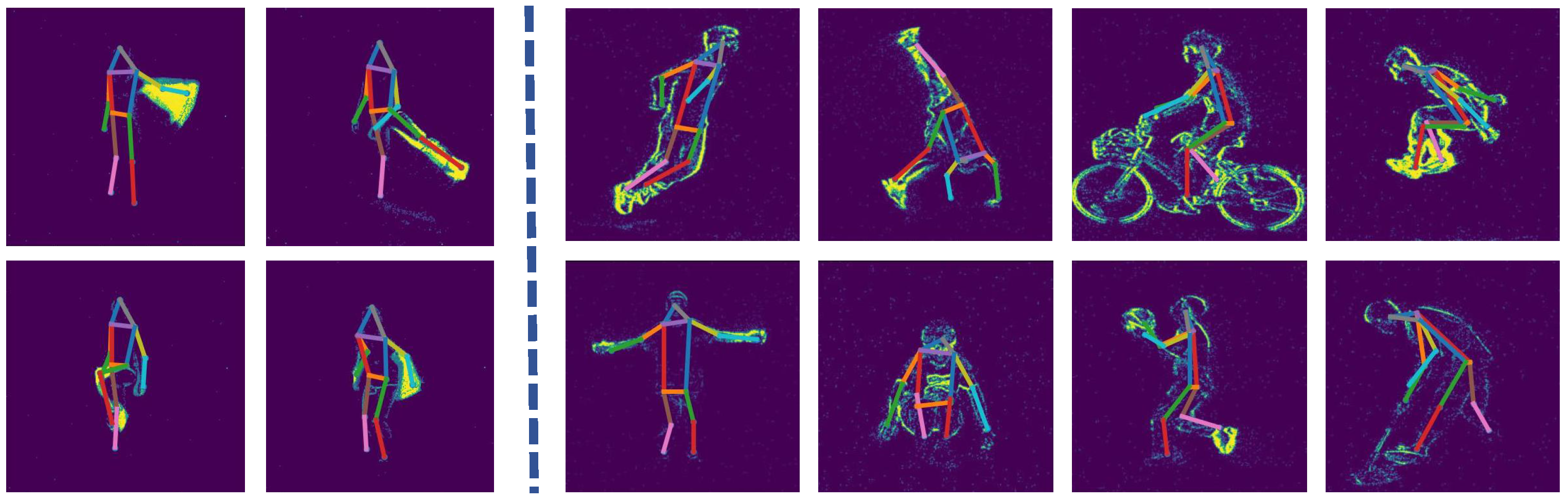
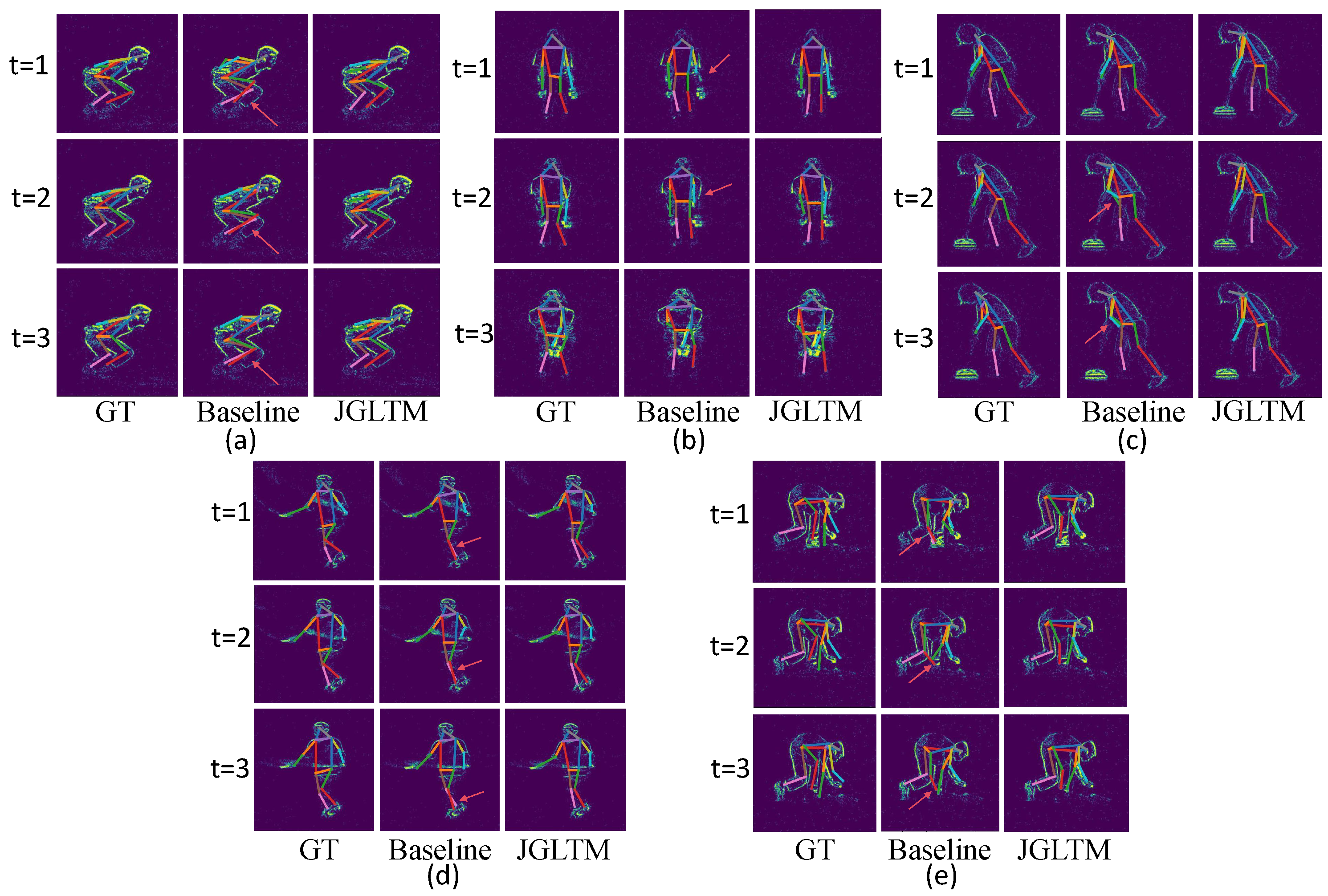
4.4. Result Visualization
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Xiao, B.; Wu, H.; Wei, Y. Simple baselines for human pose estimation and tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 466–481. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5693–5703. [Google Scholar]
- Li, Y.; Zhang, S.; Wang, Z.; Yang, S.; Yang, W.; Xia, S.T.; Zhou, E. Tokenpose: Learning keypoint tokens for human pose estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 11313–11322. [Google Scholar]
- Ma, H.; Wang, Z.; Chen, Y.; Kong, D.; Chen, L.; Liu, X.; Yan, X.; Tang, H.; Xie, X. Ppt: Token-pruned pose transformer for monocular and multi-view human pose estimation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 424–442. [Google Scholar]
- Luo, Y.; Ren, J.; Wang, Z.; Sun, W.; Pan, J.; Liu, J.; Pang, J.; Lin, L. Lstm pose machines. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5207–5215. [Google Scholar]
- Liu, Z.; Chen, H.; Feng, R.; Wu, S.; Ji, S.; Yang, B.; Wang, X. Deep dual consecutive network for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 525–534. [Google Scholar]
- Liu, Z.; Feng, R.; Chen, H.; Wu, S.; Gao, Y.; Gao, Y.; Wang, X. Temporal feature alignment and mutual information maximization for video-based human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11006–11016. [Google Scholar]
- Gai, D.; Feng, R.; Min, W.; Yang, X.; Su, P.; Wang, Q.; Han, Q. Spatiotemporal learning transformer for video-based human pose estimation. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 4564–4576. [Google Scholar] [CrossRef]
- Pfister, T.; Charles, J.; Zisserman, A. Flowing convnets for human pose estimation in videos. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1913–1921. [Google Scholar]
- Song, J.; Wang, L.; Van Gool, L.; Hilliges, O. Thin-slicing network: A deep structured model for pose estimation in videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4220–4229. [Google Scholar]
- Wei, S.E.; Ramakrishna, V.; Kanade, T.; Sheikh, Y. Convolutional pose machines. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4724–4732. [Google Scholar]
- Girdhar, R.; Gkioxari, G.; Torresani, L.; Paluri, M.; Tran, D. Detect-and-track: Efficient pose estimation in videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 350–359. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Wang, M.; Tighe, J.; Modolo, D. Combining detection and tracking for human pose estimation in videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11088–11096. [Google Scholar]
- Feng, R.; Gao, Y.; Tse, T.H.E.; Ma, X.; Chang, H.J. Diffpose: Spatiotemporal diffusion model for video-based human pose estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 14861–14872. [Google Scholar]
- Calabrese, E.; Taverni, G.; Awai Easthope, C.; Skriabine, S.; Corradi, F.; Longinotti, L.; Eng, K.; Delbruck, T. DHP19: Dynamic vision sensor 3D human pose dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Xu, L.; Xu, W.; Golyanik, V.; Habermann, M.; Fang, L.; Theobalt, C. Eventcap: Monocular 3d capture of high-speed human motions using an event camera. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4968–4978. [Google Scholar]
- Scarpellini, G.; Morerio, P.; Del Bue, A. Lifting monocular events to 3d human poses. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1358–1368. [Google Scholar]
- Zou, S.; Guo, C.; Zuo, X.; Wang, S.; Wang, P.; Hu, X.; Chen, S.; Gong, M.; Cheng, L. Eventhpe: Event-based 3d human pose and shape estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10996–11005. [Google Scholar]
- Goyal, G.; Di Pietro, F.; Carissimi, N.; Glover, A.; Bartolozzi, C. Moveenet: Online high-frequency human pose estimation with an event camera. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 4024–4033. [Google Scholar]
- Shao, Z.; Wang, X.; Zhou, W.; Wang, W.; Yang, J.; Li, Y. A temporal densely connected recurrent network for event-based human pose estimation. Pattern Recognit. 2024, 147, 110048. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Yang, S.; Quan, Z.; Nie, M.; Yang, W. Transpose: Keypoint localization via transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 11802–11812. [Google Scholar]
- Yuan, Y.; Fu, R.; Huang, L.; Lin, W.; Zhang, C.; Chen, X.; Wang, J. Hrformer: High-resolution vision transformer for dense predict. Adv. Neural Inf. Process. Syst. 2021, 34, 7281–7293. [Google Scholar]
- Mao, W.; Ge, Y.; Shen, C.; Tian, Z.; Wang, X.; Wang, Z. Tfpose: Direct human pose estimation with transformers. arXiv 2021, arXiv:2103.15320. [Google Scholar]
- Li, H.; Shi, B.; Dai, W.; Zheng, H.; Wang, B.; Sun, Y.; Guo, M.; Li, C.; Zou, J.; Xiong, H. Pose-oriented transformer with uncertainty-guided refinement for 2d-to-3d human pose estimation. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 1296–1304. [Google Scholar]
- Sabater, A.; Montesano, L.; Murillo, A.C. Event transformer. a sparse-aware solution for efficient event data processing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 2677–2686. [Google Scholar]
- Zhang, J.; Dong, B.; Zhang, H.; Ding, J.; Heide, F.; Yin, B.; Yang, X. Spiking transformers for event-based single object tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 8801–8810. [Google Scholar]
- Cheng, B.; Xiao, B.; Wang, J.; Shi, H.; Huang, T.S.; Zhang, L. Higherhrnet: Scale-aware representation learning for bottom-up human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13– 19 June 2020; pp. 5386–5395. [Google Scholar]
- Hua, G.; Li, L.; Liu, S. Multipath affinage stacked—Hourglass networks for human pose estimation. Front. Comput. Sci. 2020, 14, 1–12. [Google Scholar] [CrossRef]
- Nie, X.; Li, Y.; Luo, L.; Zhang, N.; Feng, J. Dynamic kernel distillation for efficient pose estimation in videos. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6942–6950. [Google Scholar]
- Xu, Y.; Zhang, J.; Zhang, Q.; Tao, D. Vitpose++: Vision transformer for generic body pose estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 46, 1212–1230. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Speed | Action |
|---|---|
| slow | walking, picking up, sweeping |
| medium | squat jumping, boxing, suping jumping, |
| kicking, spinning, throwing | |
| fast | open and close jumping, crotch high five, |
| alternating squat jump, spreading arm big jump |
| Dataset | Sub# | Act# | MM | Frame# | Total Duration (min) | Resolution | Event Camera Number | Scenes |
|---|---|---|---|---|---|---|---|---|
| DHP19 | 17 | 33 | No | 87 K | 196.35 | 346 × 260 | 4 | indoor |
| MMHPSD | 15 | 12 | Yes | 240 K | 270 | 1280 × 800 | 1 | indoor |
| CDEHP | 20 | 25 | Yes | 101 K | 14.09 | 1280 × 800 | 1 | outdoor |
| CDEHP-E | 30 | 25 | Yes | 146 K | 20.32 | 1280 × 800 | 1 | outdoor & indoor |
| Resolution | Patch Size | N | B | |
|---|---|---|---|---|
| 224 × 224 | 7 × 7 | 64 | 64 | 79.29 |
| 256 × 256 | 8 × 8 | 64 | 64 | 80.91 |
| 384 × 384 | 12 × 12 | 64 | 64 | 78.54 |
| Method | ↑ | ↑ | ↑ | ↑ |
|---|---|---|---|---|
| JGLTM-w/o-local | 79.80 | 97.64 | 70.47 | 79.39 |
| JGLTM-w/o-global | 80.26 | 97.38 | 72.66 | 79.18 |
| JGLTM | 80.91 | 98.43 | 74.41 | 80.89 |
| Method | CDEHP [21] | MMHPSD [19] | DHP19 [16] | CDEHP-E | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ↑ | |||||||||||||
| Hourglass [31] | 75.87 | 91.78 | 59.47 | 71.32 | 76.47 | 94.88 | 65.55 | 91.74 | 7.18 | 79.12 | 96.15 | 68.83 | 74.87 |
| SimpleBaseline [1] | 77.51 | 93.10 | 63.20 | 73.60 | 77.16 | 95.12 | 67.73 | 91.84 | 7.15 | 80.03 | 96.76 | 71.05 | 75.98 |
| HigherHRNet [30] | 75.60 | 91.65 | 57.95 | 71.56 | 78.18 | 95.53 | 70.62 | 92.14 | 7.02 | 78.92 | 96.36 | 67.71 | 73.94 |
| LSTM-CPM [5] | 59.37 | 67.63 | 28.10 | 49.07 | 40.99 | 39.28 | 3.66 | 54.75 | 7.36 | 62.59 | 70.33 | 43.65 | 53.66 |
| DKD [32] | 78.97 | 95.37 | 67.36 | 76.79 | 81.07 | 97.44 | 77.90 | 94.41 | 5.40 | 81.45 | 97.52 | 75.63 | 78.95 |
| DCPose [6] | 77.56 | 93.65 | 63.18 | 74.80 | 81.97 | 97.45 | 80.62 | 95.02 | 6.62 | 80.42 | 96.96 | 73.48 | 76.84 |
| TokenPose [3] | 79.69 | 97.49 | 70.61 | 75.80 | 85.58 | 98.56 | 89.44 | 97.16 | 5.24 | 82.45 | 97.98 | 77.73 | 79.73 |
| FAMI-Pose [7] | 79.33 | 97.75 | 68.29 | 80.19 | 85.22 | 98.61 | 89.11 | 98.83 | 5.44 | 82.31 | 98.88 | 80.15 | 82.23 |
| VitPose [33] | 80.01 | 97.67 | 71.20 | 74.79 | 82.53 | 99.05 | 86.10 | 94.79 | 5.83 | 82.16 | 98.03 | 80.68 | 77.98 |
| tDenseRNN [21] | 80.18 | 95.51 | 71.50 | 79.70 | 86.96 | 99.09 | 91.77 | 97.14 | 5.08 | 82.76 | 96.35 | 78.05 | 82.31 |
| JGLTM-w/o-global | 80.26 | 97.38 | 72.66 | 79.18 | 88.97 | 99.21 | 92.33 | 98.62 | 4.91 | 82.91 | 98.68 | 79.96 | 83.09 |
| JGLTM | 80.91 | 98.43 | 74.41 | 80.89 | 90.04 | 99.45 | 92.85 | 99.08 | 4.65 | 83.72 | 98.69 | 82.35 | 84.04 |
| Train Set | Valid Set | ||
|---|---|---|---|
| CDEHP | CDEHP | 80.91 | 80.89 |
| CDEHP-E (CDEHP + indoor set) | CDEHP | 79.63 | 79.03 |
| Action | Hour- Glass | Simple Baseline | Higher HRNet | LSTM- CPM | DKD | DCPose | Token- Pose | FAMI- Pose | VitPose | tDense- RNN | JGLTM- w/o-Global | JGLTM |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| walking | 68.99 | 77.63 | 73.40 | 42.11 | 80.64 | 77.50 | 78.06 | 81.37 | 77.40 | 80.52 | 79.41 | 84.10 |
| picking up | 73.39 | 73.94 | 72.14 | 56.86 | 76.66 | 73.58 | 75.20 | 75.42 | 79.02 | 75.01 | 75.22 | 75.87 |
| crawling | 62.79 | 64.39 | 62.65 | 31.27 | 66.79 | 65.04 | 68.38 | 68.37 | 71.52 | 70.02 | 68.96 | 71.48 |
| sweeping | 73.94 | 75.99 | 73.08 | 61.92 | 76.35 | 73.87 | 74.33 | 78.93 | 78.95 | 78.23 | 78.30 | 76.42 |
| shuttlecock kicking | 86.25 | 84.26 | 84.88 | 71.64 | 86.69 | 84.62 | 87.13 | 88.08 | 87.92 | 87.54 | 87.12 | 88.75 |
| Average | 73.07 | 75.24 | 73.23 | 52.76 | 77.43 | 74.92 | 76.62 | 78.43 | 78.94 | 78.27 | 77.80 | 79.32 |
| squat jump | 89.42 | 89.35 | 88.71 | 78.49 | 89.75 | 87.80 | 88.81 | 89.06 | 87.87 | 89.93 | 88.84 | 90.02 |
| frog jump | 79.99 | 79.11 | 79.45 | 57.50 | 82.63 | 80.89 | 82.51 | 84.66 | 81.85 | 83.09 | 83.60 | 83.74 |
| boxing | 81.50 | 80.64 | 75.25 | 71.45 | 80.66 | 81.31 | 81.82 | 82.09 | 81.49 | 83.58 | 82.90 | 81.90 |
| cartwheel | 57.49 | 58.06 | 56.80 | 36.67 | 60.20 | 59.48 | 60.59 | 68.91 | 60.70 | 63.37 | 59.66 | 64.48 |
| rope skipping | 75.30 | 75.18 | 73.10 | 65.75 | 76.76 | 77.62 | 77.98 | 78.95 | 77.33 | 78.18 | 78.25 | 79.08 |
| sit-up jump | 74.94 | 74.75 | 73.02 | 59.31 | 75.46 | 73.22 | 74.40 | 76.34 | 76.30 | 77.86 | 74.65 | 76.40 |
| kicking | 69.45 | 72.45 | 72.48 | 60.81 | 75.99 | 73.85 | 76.95 | 71.58 | 75.40 | 77.33 | 79.54 | 78.79 |
| jump shot | 74.30 | 75.68 | 72.59 | 58.02 | 77.90 | 76.41 | 77.10 | 79.68 | 81.34 | 79.52 | 79.32 | 80.08 |
| spinning | 69.11 | 75.39 | 72.27 | 56.00 | 74.37 | 73.54 | 71.85 | 74.91 | 73.38 | 74.26 | 73.10 | 74.61 |
| throwing | 74.20 | 75.08 | 70.94 | 57.46 | 74.49 | 75.29 | 73.93 | 77.56 | 76.95 | 78.04 | 77.46 | 76.66 |
| Average | 74.57 | 75.57 | 73.46 | 60.15 | 76.82 | 75.94 | 76.59 | 78.37 | 77.26 | 78.52 | 77.73 | 78.58 |
| jumping jack | 96.30 | 96.02 | 95.54 | 81.88 | 95.88 | 95.00 | 95.62 | 96.02 | 95.34 | 95.94 | 95.00 | 95.25 |
| running | 73.90 | 76.91 | 73.60 | 54.61 | 79.50 | 78.92 | 79.73 | 77.24 | 81.62 | 80.60 | 82.30 | 83.50 |
| burpee | 72.81 | 73.62 | 71.45 | 46.70 | 75.38 | 74.26 | 75.94 | 76.61 | 79.19 | 77.60 | 75.87 | 77.36 |
| mopping | 69.19 | 73.86 | 71.45 | 49.79 | 74.05 | 74.26 | 70.92 | 77.21 | 76.48 | 76.37 | 72.81 | 75.56 |
| cycling | 72.31 | 77.69 | 77.12 | 66.37 | 79.93 | 75.95 | 80.55 | 77.60 | 77.58 | 81.03 | 82.58 | 83.81 |
| big jump | 92.11 | 92.18 | 92.66 | 77.56 | 93.01 | 91.76 | 94.37 | 94.25 | 93.48 | 93.16 | 93.74 | 94.09 |
| long jump | 69.71 | 70.13 | 69.17 | 54.03 | 71.39 | 72.23 | 72.15 | 75.05 | 73.27 | 73.52 | 74.32 | 74.81 |
| crotch high five | 87.89 | 88.68 | 87.79 | 74.58 | 89.07 | 89.80 | 90.66 | 89.49 | 88.66 | 90.32 | 90.53 | 90.63 |
| alternate jumping lunge | 77.88 | 80.24 | 77.28 | 66.34 | 80.60 | 79.94 | 80.54 | 78.86 | 80.83 | 81.68 | 80.76 | 82.85 |
| jump fwd/ bwd/left/right | 87.56 | 87.87 | 86.33 | 80.19 | 87.84 | 87.58 | 86.81 | 86.89 | 86.32 | 87.37 | 86.16 | 86.94 |
| Average | 79.97 | 81.72 | 80.11 | 65.20 | 82.66 | 81.82 | 82.73 | 82.92 | 83.28 | 83.76 | 83.41 | 84.48 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Du, F.; Shao, Z.; Wang, X.; Yang, J.; Dai, J. A Joint Global and Local Temporal Modeling for Human Pose Estimation with Event Cameras. Sensors 2025, 25, 2868. https://doi.org/10.3390/s25092868
Du F, Shao Z, Wang X, Yang J, Dai J. A Joint Global and Local Temporal Modeling for Human Pose Estimation with Event Cameras. Sensors. 2025; 25(9):2868. https://doi.org/10.3390/s25092868
Chicago/Turabian StyleDu, Feifan, Zhanpeng Shao, Xueping Wang, Jianyu Yang, and Jianhua Dai. 2025. "A Joint Global and Local Temporal Modeling for Human Pose Estimation with Event Cameras" Sensors 25, no. 9: 2868. https://doi.org/10.3390/s25092868
APA StyleDu, F., Shao, Z., Wang, X., Yang, J., & Dai, J. (2025). A Joint Global and Local Temporal Modeling for Human Pose Estimation with Event Cameras. Sensors, 25(9), 2868. https://doi.org/10.3390/s25092868