1. Introduction
Ore size detection plays a critical role in mineral processing and mining operations. Accurate measurement of ore particle size directly impacts the efficiency of crushing, grinding, and beneficiation processes, ensuring optimal resource utilization and cost-effectiveness. Proper size detection aids in assessing ore density, improving separation precision, and maintaining consistent product quality. Moreover, it facilitates better control of equipment performance, reducing energy consumption and operational downtime. Many scholars have pointed out that reliable ore size detection is becoming increasingly important for achieving sustainable and economically viable mining methods [
1]. However, due to the harsh working environment of ore size detection and the complex characteristics of the ore itself, detection methods have consistently been a technical bottleneck.
Since the introduction of ore particle size detection in the 1950s and 1970s, significant academic achievements have been made. Over the past few decades, more than a dozen detection methods have been proposed, including sieve analysis [
2], laser diffraction [
3], sedimentation analysis [
4], and X-ray tomography [
5], among others. These methods have greatly contributed to the theoretical and experimental development of particle size detection. However, they have also faced common challenges in practical applications. In [
2], the labor intensity involved in handling large numbers of ore samples is very high, leading to inefficiencies and worker fatigue, which ultimately disrupts the continuity of the detection process. In [
3,
5], many of the instruments used are expensive and require stable environmental conditions to function properly. In certain mining sites, the presence of harsh environmental conditions—such as large temperature fluctuations, high humidity, and dust—can adversely affect the accuracy and reliability of the detection results. In [
4], sedimentation analysis is time-consuming, and material characteristics such as the density and shape of the ore can influence the settling rate. In contrast, machine vision methods enable real-time acquisition of ore particle size information, providing immediate feedback and adjustments to the parameters of beneficiation equipment such as crushers. This not only improves beneficiation efficiency but also reduces energy consumption, making it widely adopted by researchers for particle size detection [
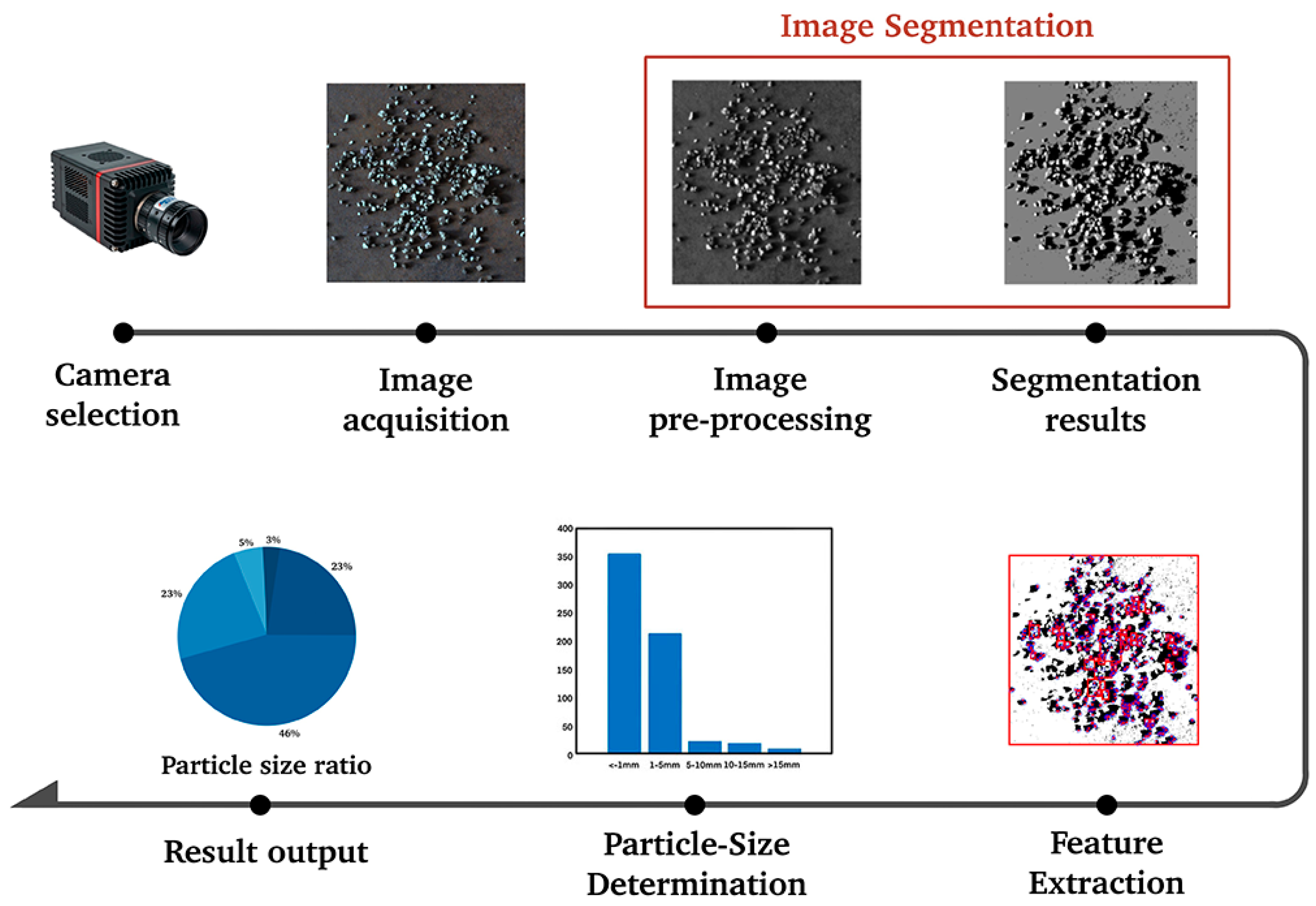
6]. For machine vision-based ore particle size detection, first of all, a suitable camera should be selected according to the characteristics of the ore and the detection environment. Then, the lighting settings and image acquisition parameter settings are carried out. After that, image segmentation is performed through image preprocessing. Once the ore particles are segmented, their size features are extracted for particle size detection, The specific process of particle size detection is shown in
Figure 1. Among the various techniques used in machine vision-based detection, image segmentation is one of the most essential and critical steps in image processing. Incomplete segmentation of ore particle images can severely interfere with the accuracy of the particle size distribution of ore particles. When an ore particle is segmented into multiple regions, these segmented parts may be misjudged as multiple independent ore particles. If only a part of an ore particle is segmented, it will lead to an underestimation of the actual particle size of the ore particle. Therefore, the quality and accuracy of ore particle image segmentation have a significant impact on particle size detection.
Nowadays, the main methods for ore particle image segmentation include thresholding [
7,
8], edge detection [
9,
10], region growing [
11,
12], the watershed algorithm [
13,
14], and deep learning techniques [
15,
16]. Thresholding is known for its good effectiveness, but its adaptability in varying lighting conditions and complex operational environments is relatively weak. Edge detection, on the other hand, is prone to generating false edges. The region growing algorithm, while simple in its segmentation principle, requires a significant amount of time to segment the entire image. The watershed algorithm is sensitive to weak edges, which helps preserve edge information, but it may lead to over-segmentation or under-segmentation in complex environments, thus reducing segmentation accuracy. Deep learning techniques have demonstrated remarkable advantages in the field of image segmentation. Among them, architectures such as U-Net have achieved high-precision segmentation across various domains, primarily due to their unique encoder–decoder structure and skip connection design. In [
17], an improved model integrating the Swin Transformer into the U-Net architecture was proposed. By leveraging the global modeling capabilities of the Transformer, the model significantly improved the accuracy of semantic segmentation for remote sensing images. In [
18], residual connections and attention mechanisms were introduced to form the RAR-U-Net model, which effectively addressed the challenge of spinal segmentation under noisy labels. This highlights the robustness of U-Net in scenarios with limited data quality. In [
19], a U-Net-based deep learning model was successfully applied to the classification and segmentation of urban villages in high-resolution satellite images, further demonstrating the practical utility of this architecture in image segmentation tasks. In [
20], an intelligent sorting scheme for coal and gangue that is adaptable to complex industrial scenarios was proposed by fusing multi-dimensional image features and combining machine learning or deep learning methods. This study is similar to the application concept of the aforementioned U-Net variants, both of which are committed to improving the segmentation accuracy through multi-modal feature fusion and model optimization. However, deep learning-based methods still face numerous challenges in practical applications. In the scenario of ore particle detection, a large amount of representative ore image data needs to be collected. Nevertheless, the complex and changeable environment of industrial sites makes it difficult to obtain high-quality and diverse data. Deep learning models have high requirements for hardware and need the support of high-performance GPUs, making it difficult to deploy them on industrial devices with limited resources. Existing models often have latency issues when processing high-resolution images or video streams in real time, failing to meet the stringent real-time requirements of scenarios such as industrial granularity detection.
Of the different methods, one of the most effective is the clustering method. The most widely applied clustering methods include fuzzy C-means [
21], mountain clustering [
22], K-means [
23], and subtractive clustering [
24]. The K-means algorithm is a kind of representative hard partitioning approach, which assigns data points to the nearest centroid. Then, positions of the centroids are iteratively updated based on their corresponding members to minimize the sum of squared errors. Many scholars have pointed out that K-means performs better than other clustering algorithms in practical applications [
25]. In addition, K-means is widely applied medicine [
26,
27], agriculture [
28,
29], oceanography [
30,
31], and remote sensing [
32,
33]. However, the K-means algorithm has notable drawbacks, including high randomness and a tendency to get stuck in local optima, as well as the inability to effectively control the placement of cluster centers. In [
34], in order to improve the calculation efficiency of K-means, a novel weighted bilateral k-means (WBKM) algorithm was proposed to cluster big data. On the basis of WBKM, a fast multi-view clustering algorithm with spectral embedding (FMCSE) was designed in [
35]. To avoid falling into locally optimal clustering centers, many intelligent iterative optimization algorithms were applied. In [
36], an improved PSO-K algorithm was applied for image segmentation, and the results of the experiments showed that it is possible to accurately segment the target from various kinds of agricultural images after the gray processing, which involves RGB with super green features. In [
37], a hybrid algorithm combining the firefly algorithm and K-means (KM-FA) is proposed, with the Otsu criterion employed as the fitness function, demonstrating excellent performance in medical image applications. In [
38], an improved colony optimization K-means (IABCKMC) was applied for selecting typical wind power output scenarios. It can be summarized from the literature that improvements in K-means mainly focus on reducing the calculation time and avoiding falling into local optimal clustering centers.
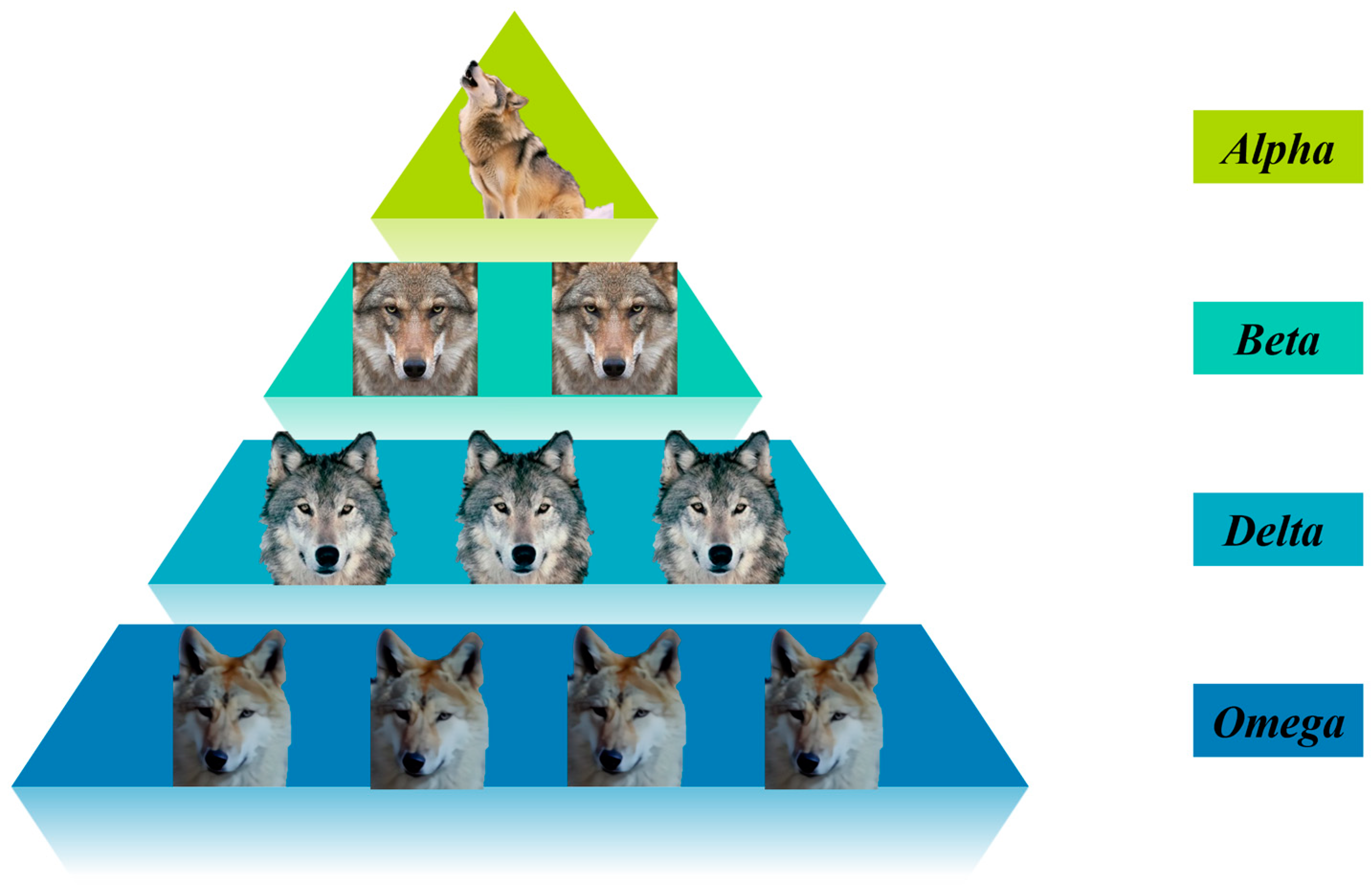
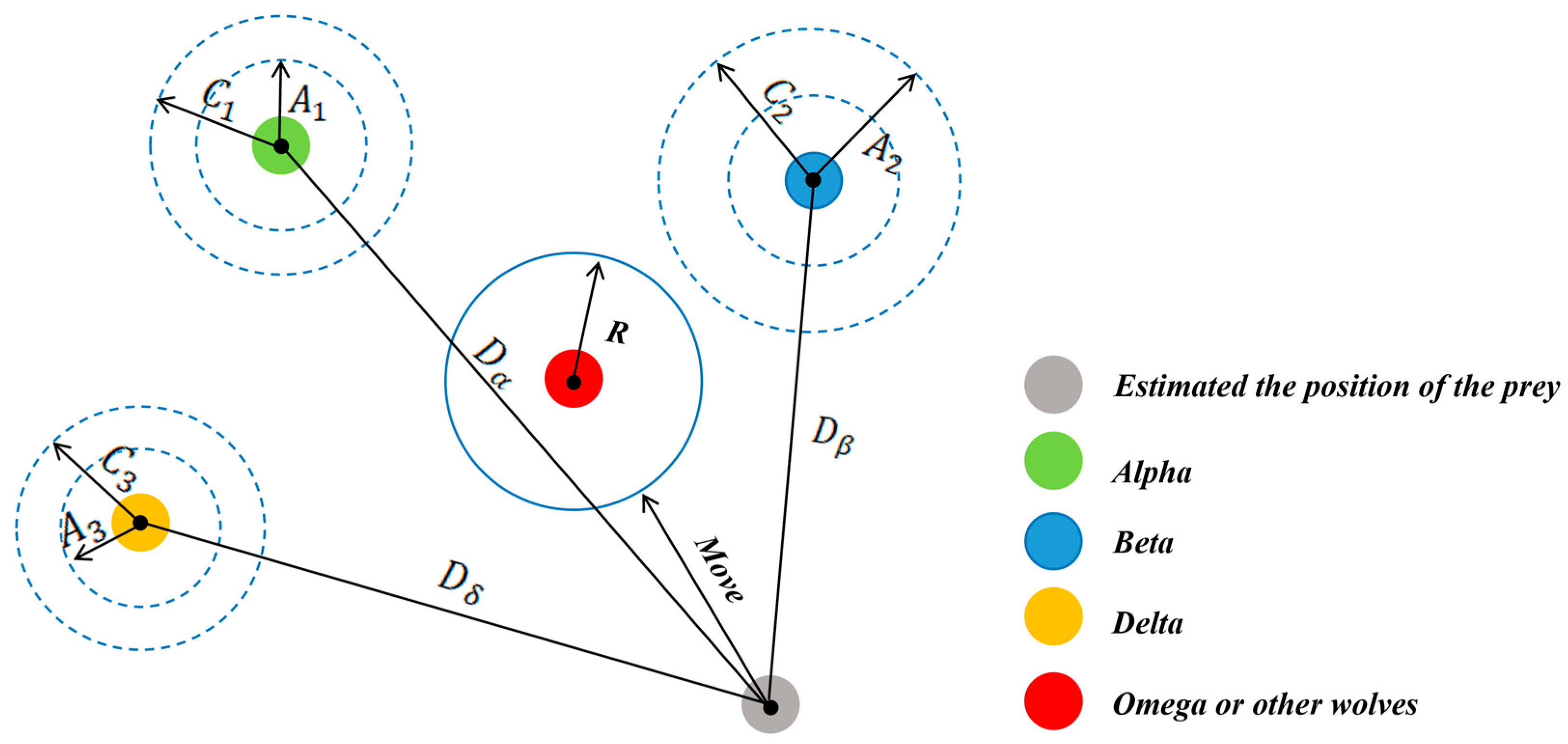
The grey wolf optimization (GWO) algorithm is a heuristic optimization method inspired by the social behavior model of grey wolves [
39]. It incorporates adaptively adjustable convergence factors and an information feedback mechanism, enabling a balance between local exploitation and global exploration. Consequently, the GWO algorithm demonstrates strong performance in terms of solution accuracy and convergence speed. However, like other optimization algorithms, its convergence speed tends to decrease during the later stages of optimization. As iterations progress, other wolves (β, δ, and ω) continue to converge towards the leading wolves (α, β, and δ), which increases the likelihood of the algorithm becoming trapped in local optima [
40]. In [
41], in order to avoid the local optimal solution, a method that introduces a differential perturbation operator and improves the value assignment of control parameters is proposed to solve the problem of data clustering. In [
42], An adaptive position update and circular population initialization (SGWO) method is applied to the parameter optimization of the Elman neural network, endowing the prediction method based on SGWO–Elman with accurate prediction performance and enabling it to excel in relevant data prediction tasks. In [
43], an improved GWO algorithm with variable weights (VW–GWO) was proposed, and a new control parameter dominance equation was developed to reduce the likelihood of entrapment in local optima effectively.
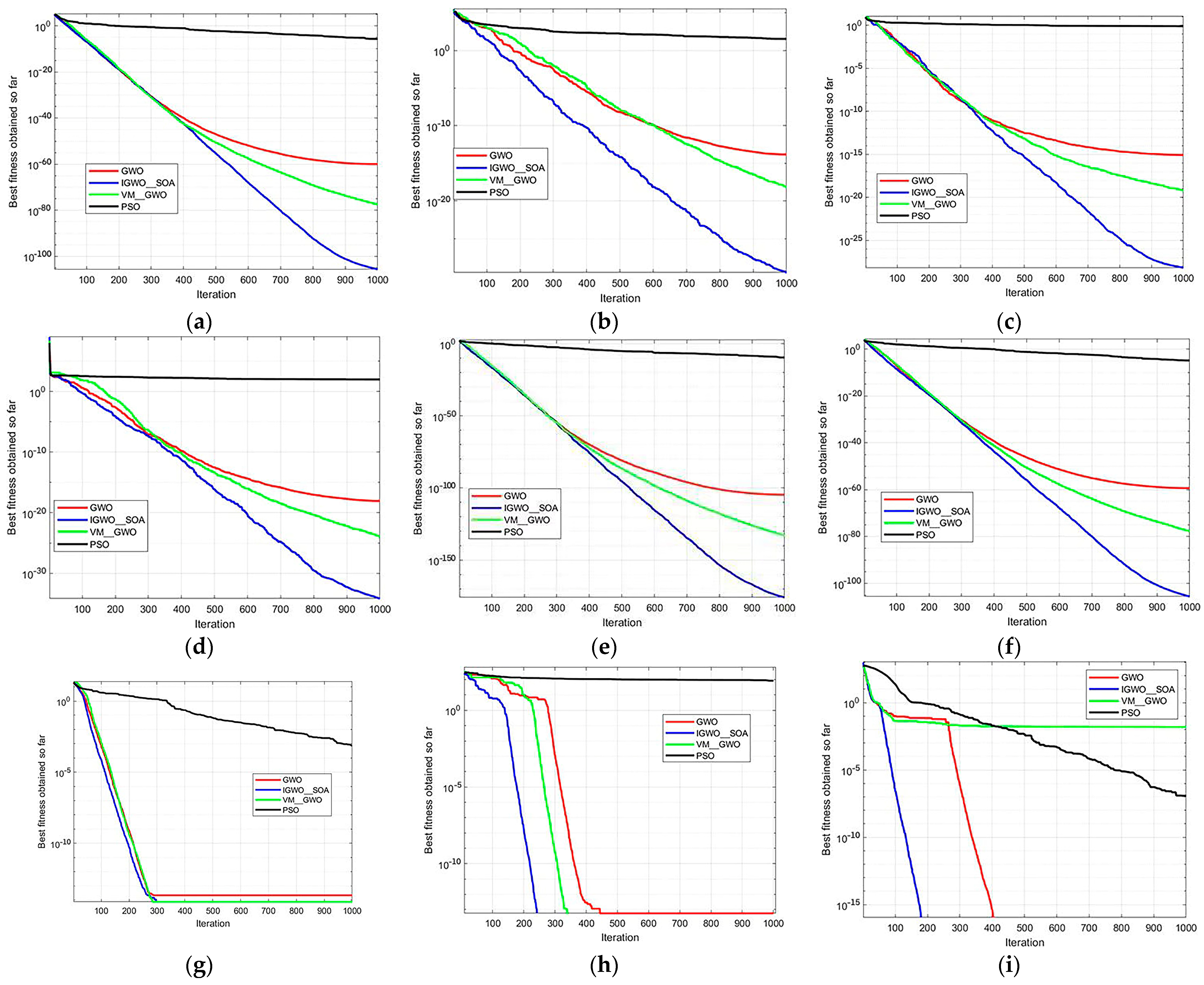
Based on the above research, this paper aims to overcome the disadvantages of poor quality, low efficiency, and low reliability of previous methods by proposing a convenient and reliable segmentation method for ore particle images. Since the basic K-means clustering algorithm is prone to falling into local optima and is sensitive to the initial cluster centers, a hybrid method is adopted to optimize it. Moreover, this comprehensive optimization method combines the improvement of the convergence factor in the improved grey wolf optimizer with the seagull optimization algorithm (IGWO_SOA) to balance the search speed and population density. Specifically, in the process of updating the positions of the original grey wolf algorithm, some wolves are updated by introducing the migration mechanism and the spiral attack mechanism.
The rest of this paper is organized as follows. In
Section 2, the basic theories of K-means, GWO, and SOA are presented. In
Section 3, the iteration process of the proposed IGWO_SOA is described, and the segmentation method based on K-means and IGWO_SOA (IGK-means) is elaborated on in detail. In order to verify the accuracy and superiority of the improved algorithm in segmenting ore particle images, experimental analysis is presented in
Section 4. Then, industrial experiments on ore particle size detection are also carried out in
Section 4. Some conclusions and prospects are summarized in
Section 5.
3. The Proposed Method
3.1. Improved Convergence Factor
When || > 1, the grey wolf group will expand the search range to look for prey, that is, it will conduct global search with a fast convergence speed. When || < 1, the grey wolf group will narrow the search range to attack the prey, that is, it will perform a local search with a slow convergence speed. Therefore, the magnitude of determines the global search and local search capabilities of the GWO. It can be seen from Formula (5) that changes with the change in the convergence factor . The convergence factor linearly decreases from 2 to 0 with the increase in the number of iterations. However, the process of the algorithm’s continuous convergence is not linear. From this, it can be understood that the linearly decreasing convergence factor cannot fully reflect the actual optimization search process.
To address the above issues, this paper proposes an improved nonlinear convergence factor
, whose expression is shown in Equation (19) as follows:
where
is experimentally determined,
is the current iteration, and
represents the maximum number of iterations.
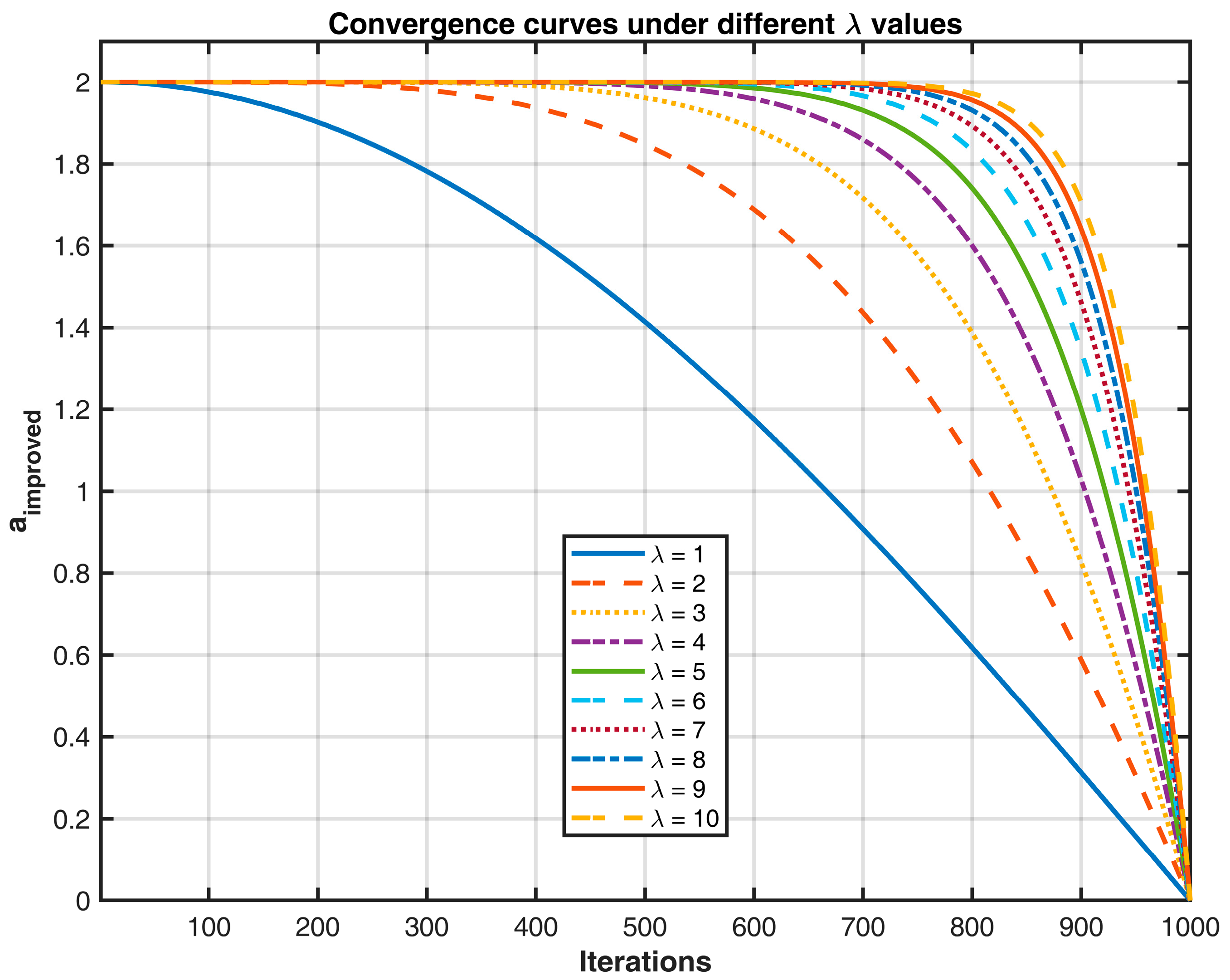
When
=1000, different values of the parameter aa in Equation (19) were tested. The results for
are shown in
Figure 5, where the curves from top to bottom correspond to
= 1, 2, …, 10.
3.2. Hybrid Optimization Algorithm
In the later stage of optimization using the GWO, the optimization range of individual grey wolves becomes smaller as the wolf pack gradually surrounds the prey, a process during which the positions of individuals may collide and overlap. This reduction in position diversity, a factor contributing to the algorithm getting trapped in local optimal values, can be addressed by integrating mechanisms from the SOA. The migration behavior, characterized by its ability to prevent seagulls from gathering in positions, is employed to increase diversity and improve the algorithm’s capability to escape local optima. Additionally, the spiral search, noted for its fast speed and high efficiency, is incorporated. As a result, the migration mechanism and spiral search are combined to refine the experienced delta wolves in the wolf pack, thereby enhancing the algorithm’s optimization ability.
After fusing with the SOA, the position update formula for the delta wolf is shown as follows:
where
is the helix radius, and
is a random normal distribution factor within the interval [0, 1]: when
, the migration mechanism is adopted to increase the randomness of the position update of the delta wolf, and when
, the spiral search mechanism is adopted. The position of the delta wolf is not only updated through the standard GWO but is also affected by the spiral radius, which can help the algorithm explore more effectively in the search space and thus find better solutions. The expression of
in the formula is:
The implementation process of the improved GWO (IGWO_SOA) is as follows:
Step 3.1: Initialization. Set the algorithm parameters, providing the population size N, the maximum number of iterations , and the radius of the spiral search , etc.
Step 3.2: Fitness evaluation. Calculate the fitness values of all grey wolf individuals in the population. Select the top three wolves with the highest fitness values as the alpha wolf, beta wolf, and delta wolf, and record their positions , , and , respectively.
Step 3.3: Update position. Update the positions of other grey wolf individuals in the population according to Formulas (12), (13), (15), and (20). Update and according to Formulas (6) and (7).
Step 3.4: Optimization iteration. If the wolves find the optimal value or the iteration number reaches the maximal N, the iteration process stops and the global optimal solution is output; otherwise, steps 3.2 to 3.4 are repeated.
The flowchart of the IGWO_SOA is presented in
Figure 6. For a comprehensive assessment of the performance of IGWO_SOA, kindly refer to
Appendix A. Meanwhile, the in-depth discussion on the adaptability of λ can be found in
Appendix B.
3.3. Image Segmentation Based on IGK-Means
When using the improved grey wolf algorithm to improve the K-means algorithm for image segmentation, the clustering centers are taken as the optimization variables of the grey wolf algorithm. Firstly, the target image is regarded as an n-dimensional spatial vector with the data sample point set
, and
m data points are randomly selected from it as the initial clustering centers. Then, the remaining data points in the set
are assigned to these m classes. Let
be the
j-th data point in the set
,
be the
i-th clustering center, and assume that
is the smallest at this time. Then, the data point
is assigned to the j-th class. The design of the fitness function is as follows:
After IGWO_SOA reaches the maximum number of iterations, the global optimal value obtained through optimization is used to initialize the clustering centers of the next process, the K-means clustering algorithm, thus overcoming the disadvantages of the K-means clustering algorithm, such as being sensitive to the initialization of clustering centers.
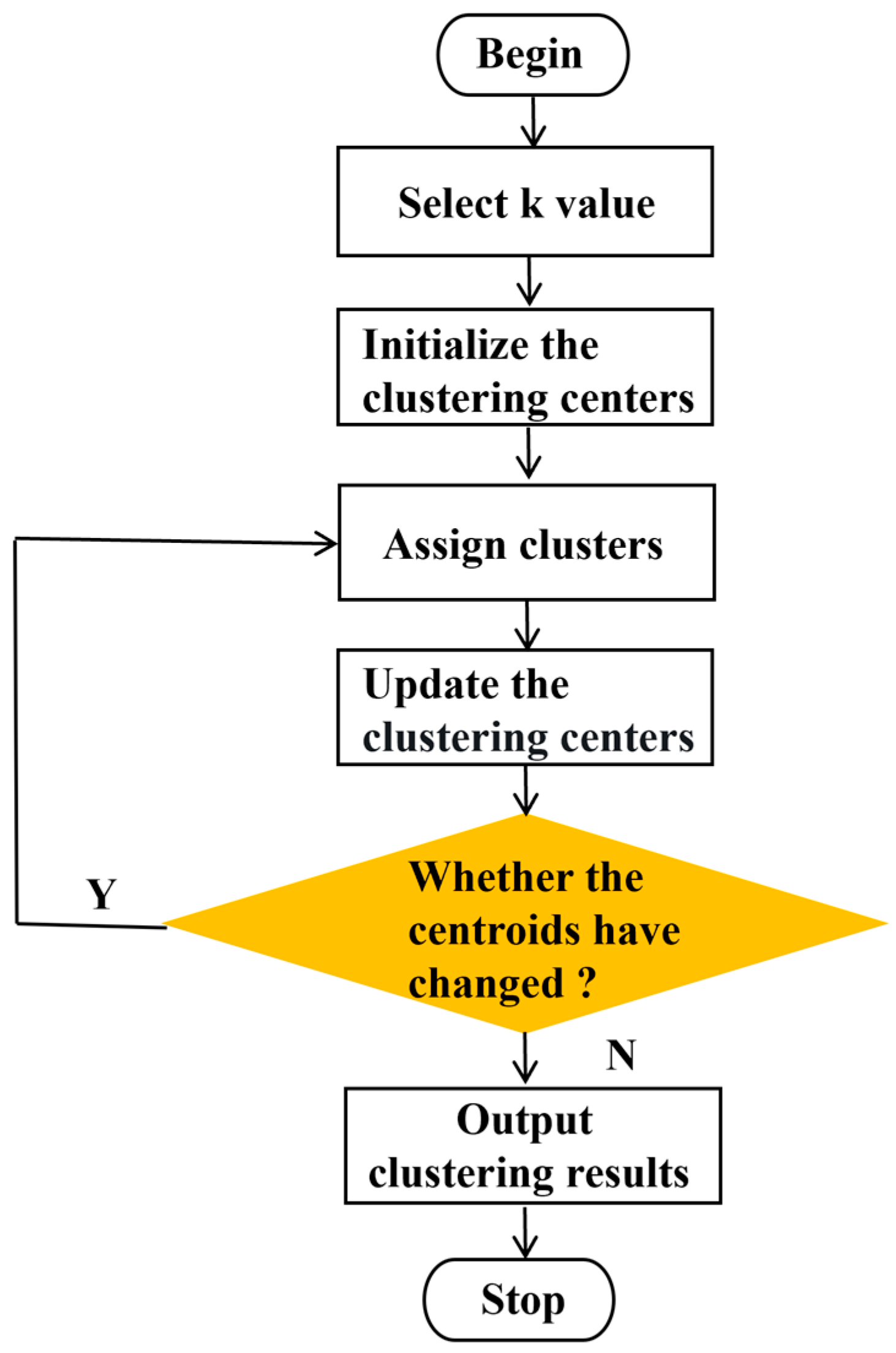
The image segmentation based on the combination of the IGWO_SOA-optimized K-means algorithm (IGK-means) mainly consists of two steps: Optimize the initial clustering centers through the global search ability of IGWO_SOA to find the reasonable and optimal initial clustering center positions in the image point set. Then, utilize the K-means clustering for local optimization until the end of the iteration. The implementation steps of the algorithm are as follows:
Step 4.1: Initialization. Set the number of populations N and clusters k, the size of the spiral search r, and the maximum number of iterations . Randomly initialize the positions of N grey wolves within the solution space.
Step 4.2: Fitness evaluation. According to the fitness function , wolves are ranked based on their fitness values. The top three wolves are designated as α, β, and δ, representing the best, second-best, and third-best solutions, respectively. The remaining wolves, known as ω, follow the guidance of α, β, and δ in the optimization process.
Step 4.3: Obtain group location. Wolves mathematically encircle their prey by adjusting their positions based on the prey’s location, using coefficient vectors and .
Step 4.4: Update position. During the hunting phase, wolves update their positions, and then the results are averaged.
Step 4.5: Iterative optimization. The iteration process terminates either when the wolves identify the optimal value or when the maximum number of iterations N is reached. If neither condition is met, steps 4.2 to 4.4 are repeated until convergence.
Step 4.5: Obtain the initial clustering center. Output the optimal value obtained from the IGWO_SOA algorithm iteration as the initial cluster centers for the K-means algorithm.
Step 4.6: Assignment. Compute the Euclidean distance between each point and the cluster centers, then assign each point to the nearest cluster center based on the minimum distance principle.
Step 4.7: Update. Calculate the mean of the points in each cluster to update and redefine the cluster centers.
Step 4.8: Convergence check. Compute the difference between the new and previous cluster centers. If the maximum difference is smaller than the stopping threshold or the maximum number of iterations is reached, the algorithm terminates, and the current cluster assignments and centers are taken as the final results. Otherwise, repeat steps 4.6 to 4.8.
The flowchart of the IGK-means is shown in
Figure 7.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}