

Enhancing Security Operations Center: Wazuh Security Event Response with Retrieval-Augmented-Generation-Driven Copilot

 ,
, 
Abstract
1. Introduction
2. Background and Related Works
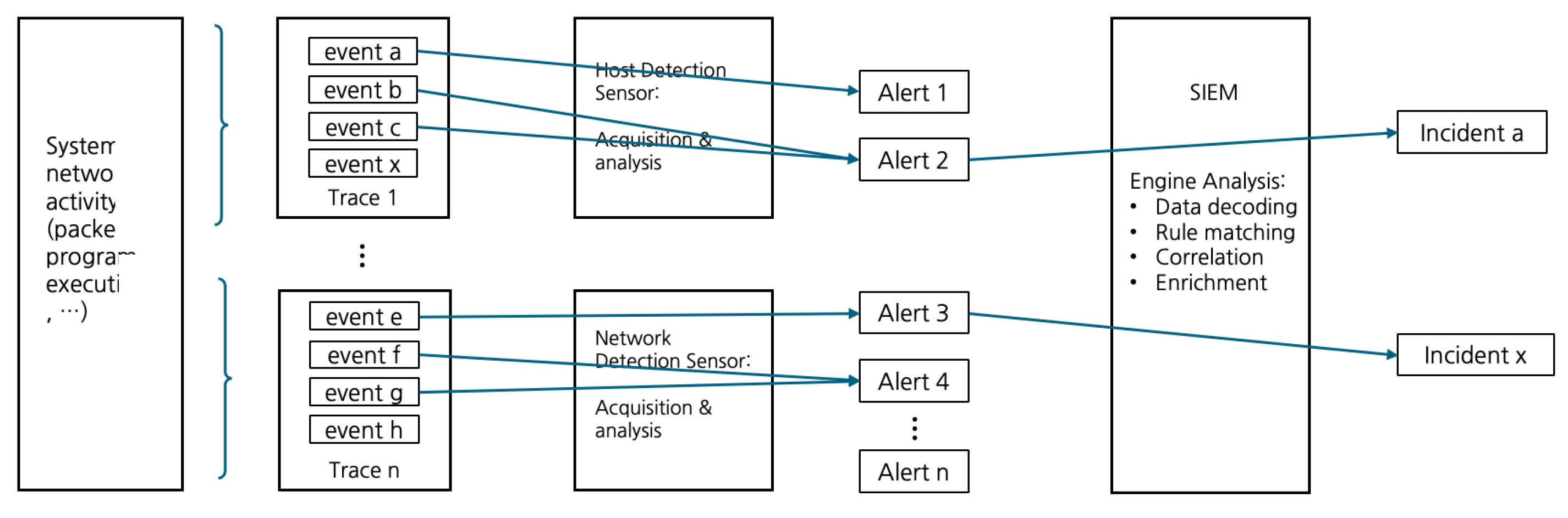
2.1. Security Event Definition and Flow
2.2. Wazuh as a Versatile SIEM Solution
2.3. MITRE ATT&CK Framework
- 1.
- Enterprise: addresses behaviors against enterprise IT networks and cloud environments.
- 2.
- Mobile: focuses on adversary behaviors targeting mobile devices.
- 3.
- Industrial Control Systems (ICSs): covers behaviors against industrial control systems.
2.3.1. Core Components
- 1.
- Tactics: represent the overarching why behind an adversary’s actions during an attack. They define the adversary’s strategic goals, such as Initial Access, Privilege Escalation, or Defense Evasion. Each tactic serves as a high-level category under which specific techniques are grouped, providing context for an adversary’s behavior across various stages of an attack lifecycle. This categorization allows defenders to align their detection and mitigation efforts with adversarial objectives [42,43].
- 2.
- 3.
- Sub-techniques: offer a deeper layer of specificity, breaking down broader techniques into distinct variations. These enable defenders to focus on nuanced adversarial behaviors and tailor their detection strategies accordingly. Sub-techniques illustrate the evolving nature of adversarial actions and enhance the utility of the framework in addressing targeted threats [42].
- 4.
- Procedures: describe how techniques or sub-techniques are implemented in real-world scenarios. These include specific tools, commands, or methods adversaries employ during an attack. For instance, a procedure for Command and Control might document the use of HTTPS traffic to obfuscate malicious communication. Understanding procedures aid defenders in recognizing and mitigating adversarial actions as they unfold [43].
- 5.
- Mitigation: the strategies address the ’what-to-do’ aspect by proposing defensive measures to counter specific techniques or sub-techniques. For instance, multi-factor authentication is recommended to mitigate the Valid Accounts technique, while network segmentation is effective in addressing Lateral Movement. These recommendations enable organizations to enhance their defensive posture against specific adversarial behaviors, thereby improving their overall security framework. [42,44].
2.3.2. Applications of ATT&CK in Categorizing TTPs
- 1.
- Adversary emulation and threat hunting: the ATT&CK framework serves as a foundational tool for adversary emulation, enabling red teams to simulate real-world attack scenarios based on documented TTPs. Similarly, it supports proactive threat hunting by aligning detection strategies with known adversarial behaviors, enhancing the efficiency of SOCs [43].
- 2.
- Mapping and gap analysis: ATT&CK aids in mapping organizational defenses against adversarial TTPs, helping identify coverage gaps, and emphasizes the importance of accurate mapping practices to maximize the framework’s utility [42]. This process involves aligning observed attack data with ATT&CK’s techniques and sub-techniques, ensuring comprehensive coverage of defensive measures.
- 3.
- Behavioral analytics development: by integrating ATT&CK into behavioral analytics, organizations can create robust detection mechanisms that identify anomalies aligned with known adversarial actions. This integration improves the speed and accuracy of incident response efforts, reducing potential damage from attacks [44].
2.4. NIST Cybersecurity Framework (CSF)
2.5. Large Language Models for Cybersecurity
- 1.
- GPT-4: Large language models (LLMs) like GPT-4 have shown immense potential in advancing cybersecurity workflows, particularly in tasks such as summarizing threat intelligence reports and analyzing phishing emails. These models leverage their extensive knowledge base and human-like text generation to effectively process and interpret complex textual data. However, when applied to more technical challenges, such as binary reverse engineering or the analysis of highly detailed logs, GPT-4 often encounters limitations. Studies by Wu, Fangzhou et al. [48], and Pordanesh, Saman, et al. [49] reveal that while GPT-4 performs well in general software security tasks, its ability to handle nuanced and domain-specific problems diminishes without fine-tuning. These findings underscore the need for targeted training and domain adaptation to fully harness GPT-4’s capabilities for specialized cybersecurity applications, bridging the gap between general language understanding and technical precision.
- 2.
- T5 (Text-to-Text Transfer Transformer): The T5 model’s text-to-text architecture has demonstrated effectiveness in translating log data into actionable insights, with successful applications in parsing security documentation, generating attack scenario summaries, and conducting vulnerability assessments. However, deploying T5 in real-time cybersecurity scenarios necessitates optimization for speed [50]. Additionally, research on full-stack optimization of transformer inference provides insights into improving efficiency for real-time deployment [51]. These advancements are crucial for implementing T5 in real-time cybersecurity contexts, where rapid response is essential.
- 3.
- LLaMA: Meta’s LLaMA models have demonstrated strong performance in reasoning and analytical tasks. For instance, the LLaMA 3.3-70B model exhibits significant improvements in handling complex analytical tasks, enhancing its reliability for problem-solving across various domains [52].However, applying LLaMA in specialized domains like cybersecurity presents challenges. A comprehensive review of generative AI and large language models for cybersecurity highlights that while LLaMA models offer potential benefits, their deployment requires significant customization to effectively address domain-specific tasks [53].
- 4.
- CyberBERT: CyberBERT, a model fine-tuned from BERT for cybersecurity applications, has demonstrated proficiency in tasks such as malware classification, log analysis, and phishing pattern identification. For instance, the SecureBERT model, a domain-specific adaptation of BERT, has shown significant improvements in predicting masked words within cybersecurity texts, outperforming models like RoBERTa and SciBERT [54].However, these models primarily excel in discriminative tasks, such as classification and sequence labeling, due to their training objectives. Their generative capabilities are limited, which poses challenges in applications requiring text generation, such as automated report writing or threat scenario simulation. This limitation is inherent in BERT-based architectures, which are designed for understanding and classification rather than generation [55].
- 5.
- Pixtral 12B: Mistral AI’s Pixtral 12B is an open-source multimodal model with 12 billion parameters, excelling in both image and text data processing. Its architecture combines the Mistral Nemo text model with a custom vision encoder, enabling it to handle a wide array of tasks, including instruction following and text-only benchmarks [56].While Pixtral 12B’s versatility positions it as a valuable tool across various domains, specific applications in cybersecurity, such as intrusion detection and phishing email classification, would require fine-tuning the model with domain-specific data to enhance its performance in these specialized tasks. Techniques like Low-Rank Adaptation (LoRA) [57] can be employed for efficient fine-tuning, allowing the model to adapt to custom datasets without extensive computational resources [58].Additionally, Pixtral 12B’s compatibility with cloud services and NVIDIA GPUs facilitates faster deployments, making it suitable for resource-constrained environments. Its open-source nature and support for variable image sizes further contribute to its adaptability in diverse operational settings [56].
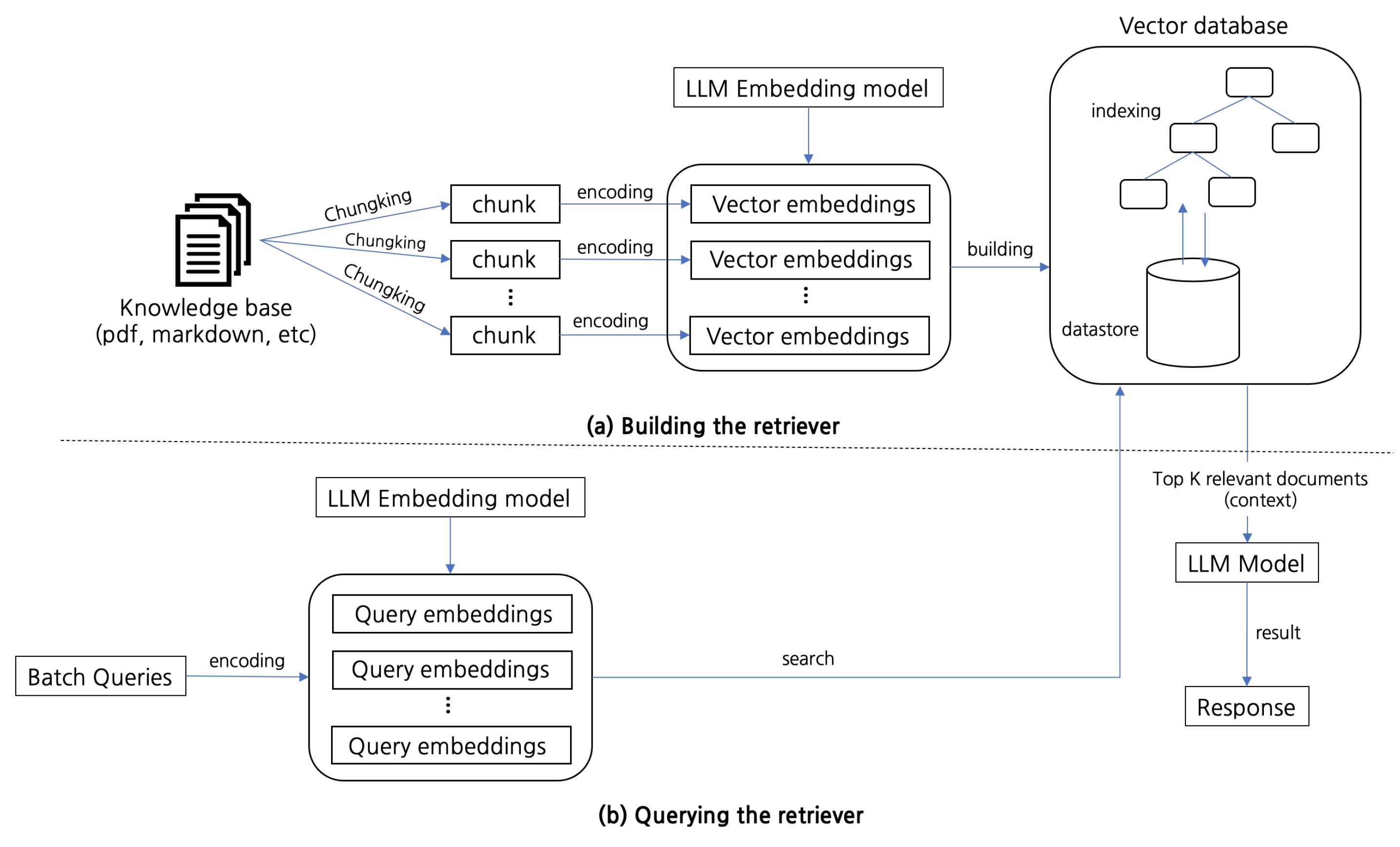
2.6. Architecture of RAG Frameworks
2.7. Role of Large Language Model Copilots in Enhancing Efficiency, Personalization, and Cybersecurity
2.8. Challenges When Using LLM in SOC Space
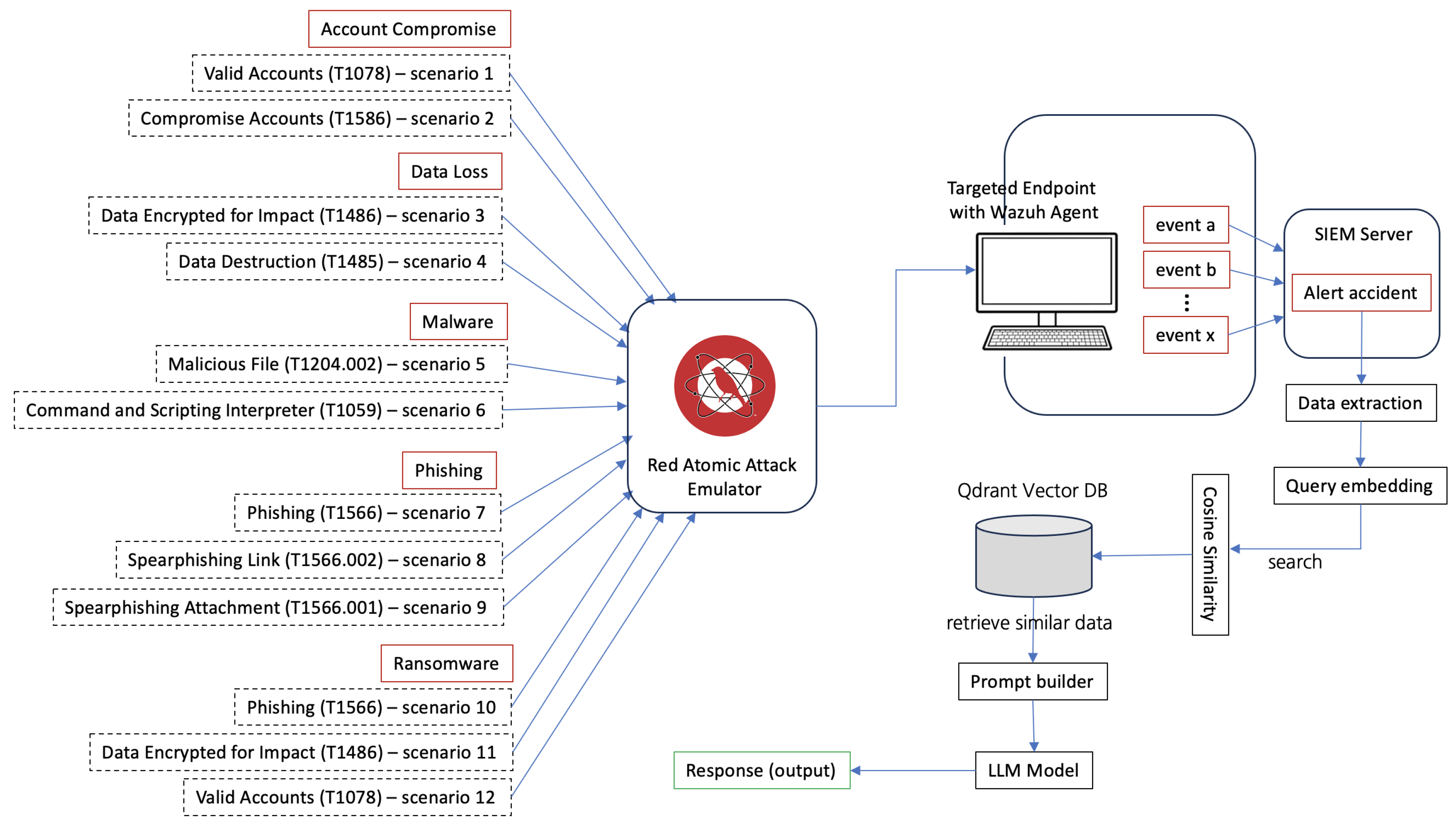
2.9. Atomic Red Team: A Modular Framework for Adversary Simulation and Detection Validation
3. Methodology
3.1. Proposed RAG Components
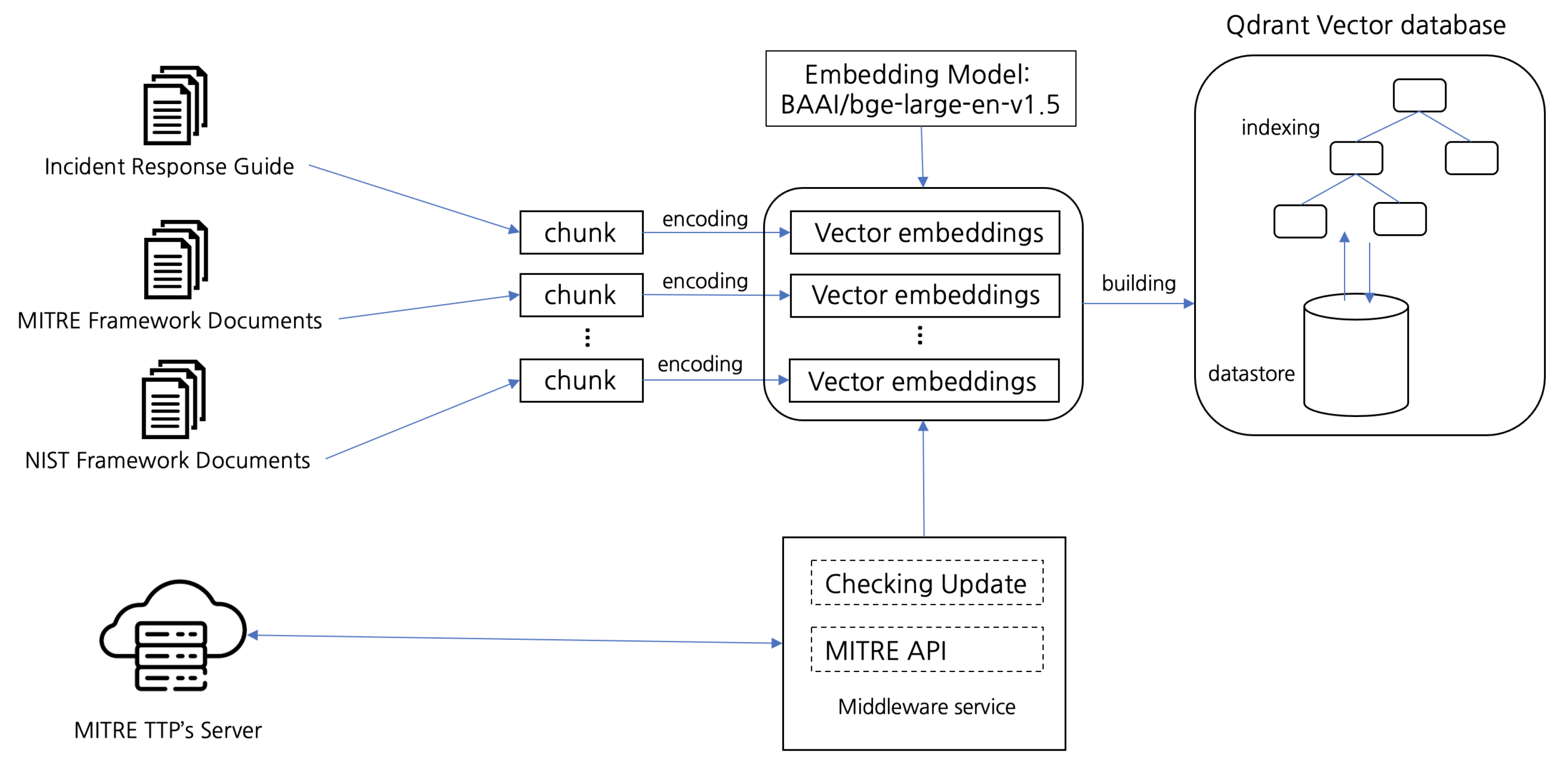
3.1.1. Qdrant Vector Database
3.1.2. Embedding Model: BAAI/bge-large-en-v1.5
- 1.
- Efficiency and scale: the model demonstrates high efficiency in processing large volumes of text data while maintaining high accuracy in similarity detection. It uses a technique known as Matryoshka Representation Learning [81], which enables the model to generate embeddings in multiple dimensions (e.g., 1024, 768, 512, down to 64 dimensions) without significant loss of accuracy.
- 2.
- Performance comparison: compared to similar models such as OpenAI’s Ada [82] and traditional BERT-based models [83], BAAI/bge-large-en-v1.5 is optimized for faster responses and adaptability with large datasets. Its open-source nature also makes it more cost-effective than proprietary models, which is an important consideration for scalable cybersecurity applications.
3.1.3. Similarity Metric: Cosine Distance
- and are the vectors being compared;
- is their dot product;
- and are the magnitudes of the vectors.
3.2. RAG Workflow
3.2.1. Augmentation Process
- 1.
- General knowledge: this collection provides foundational knowledge for computer security incident handling, derived from sources such as security operations and automation response (SOAR) playbooks and general cybersecurity incident handling guides. It serves as a primary resource for addressing general security incident management needs.
- 2.
- NIST knowledge: specifically structured to align with the NIST Cybersecurity Framework, it includes guidelines, policies, and standards that ensure relevance to regulatory frameworks and assist in the compliance verification process.
- 3.
- MITRE knowledge: designed around the MITRE ATT&CK framework, this collection supports the retrieval of documents directly relevant to threat mitigation and response strategies. By mapping queries to specific MITRE tactics and techniques, this collection enhances the precision of actionable insights for mitigating cyberthreats. To ensure that the collection remains aligned with the state-of-the-art MITRE tactics and techniques, a dedicated service periodically checks the MITRE servers for updates and synchronizes the local collection in the vector database, enabling real-time adaptability to emerging threats and maintaining the relevance of the system.
3.2.2. Chunking Techniques
3.2.3. Large Language Model Configuration
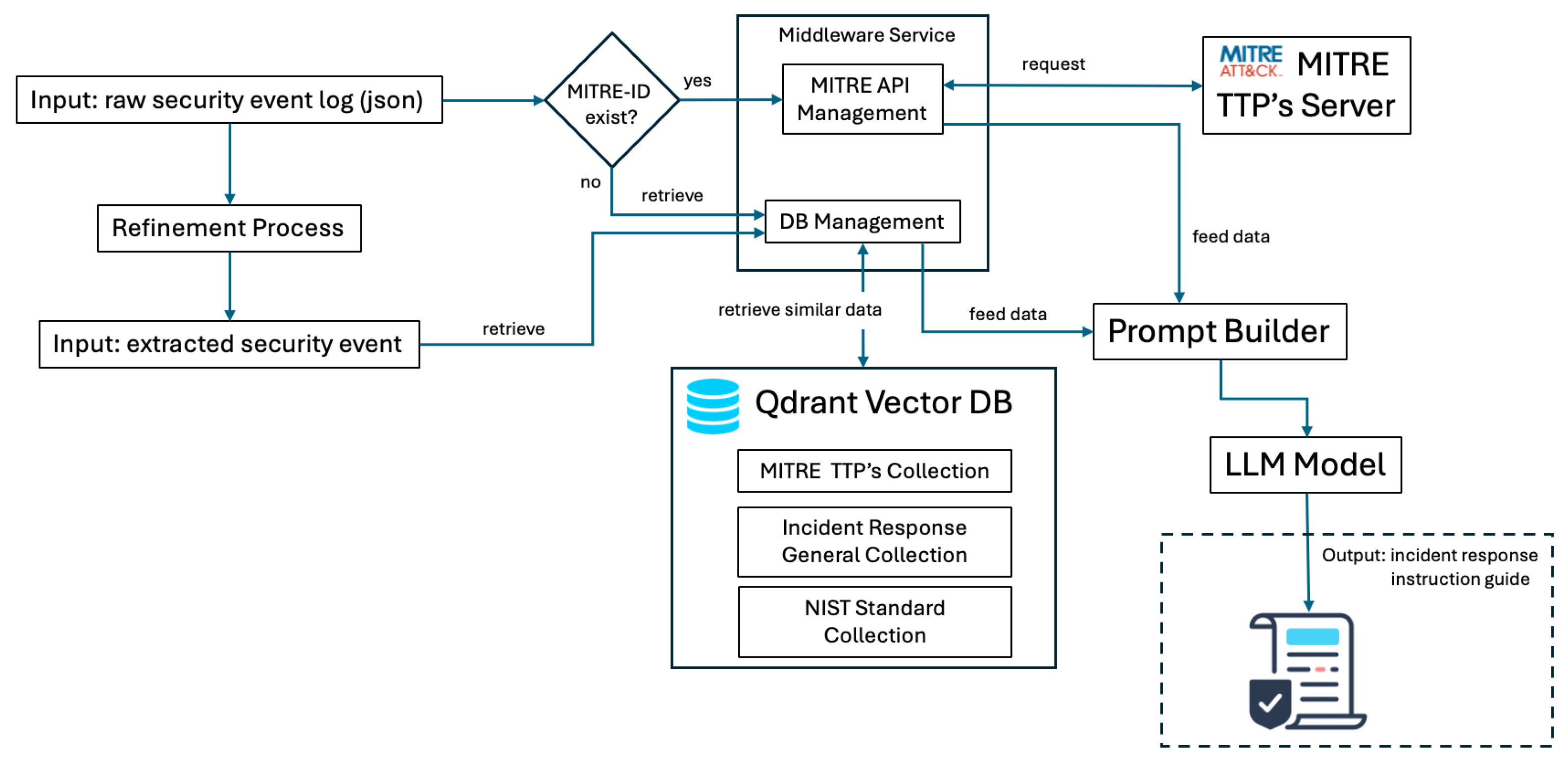
3.3. Wazuh Event Security Data Extraction and Refinement
3.4. Retrieval Methodology for Security Event Log Analysis and Response
4. Experiment Results
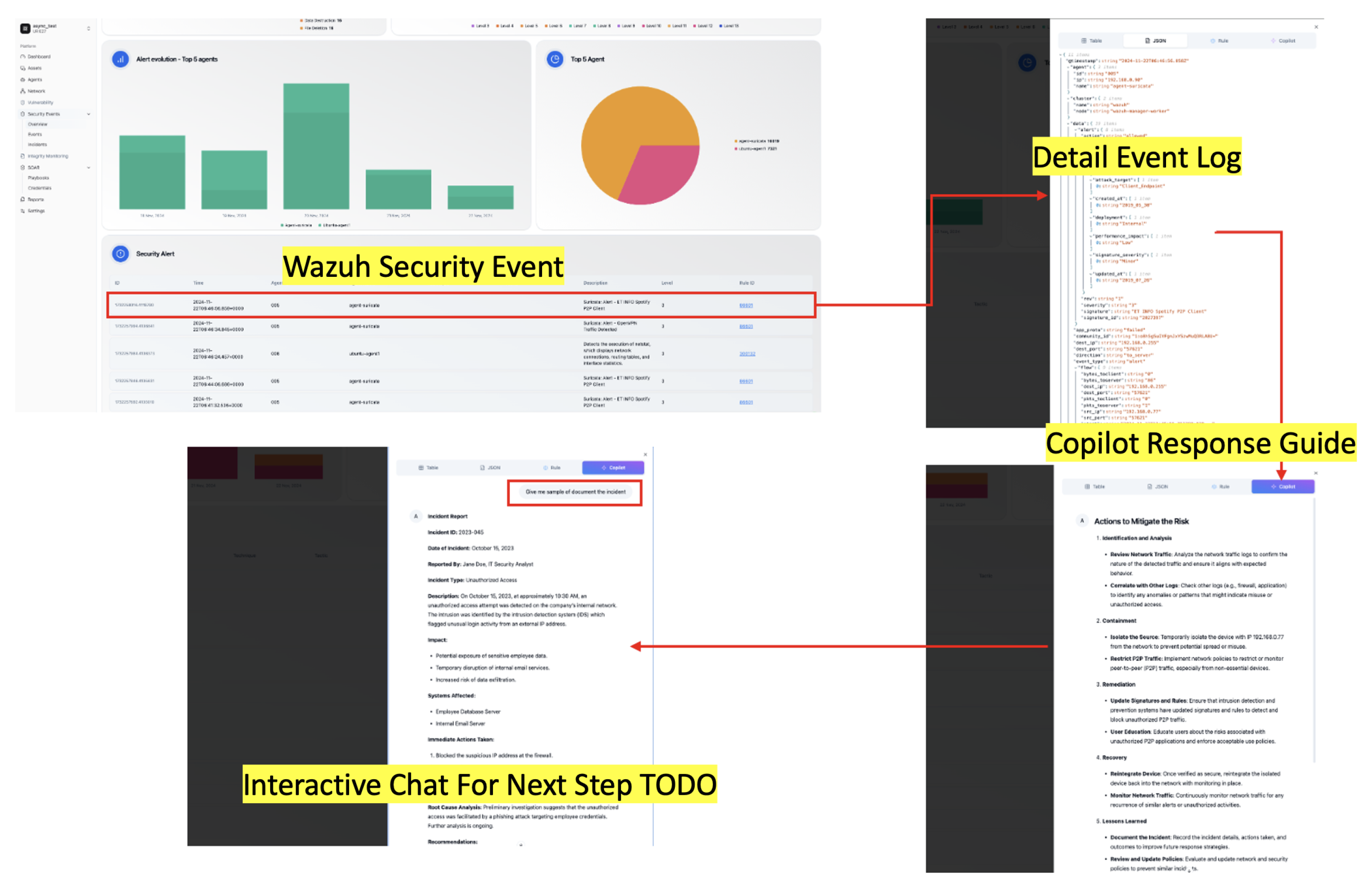
4.1. Copilot Integration for Security Event Analysis in Wazuh
4.2. Simulation Scenario
Setting the Stage: Building the Simulation
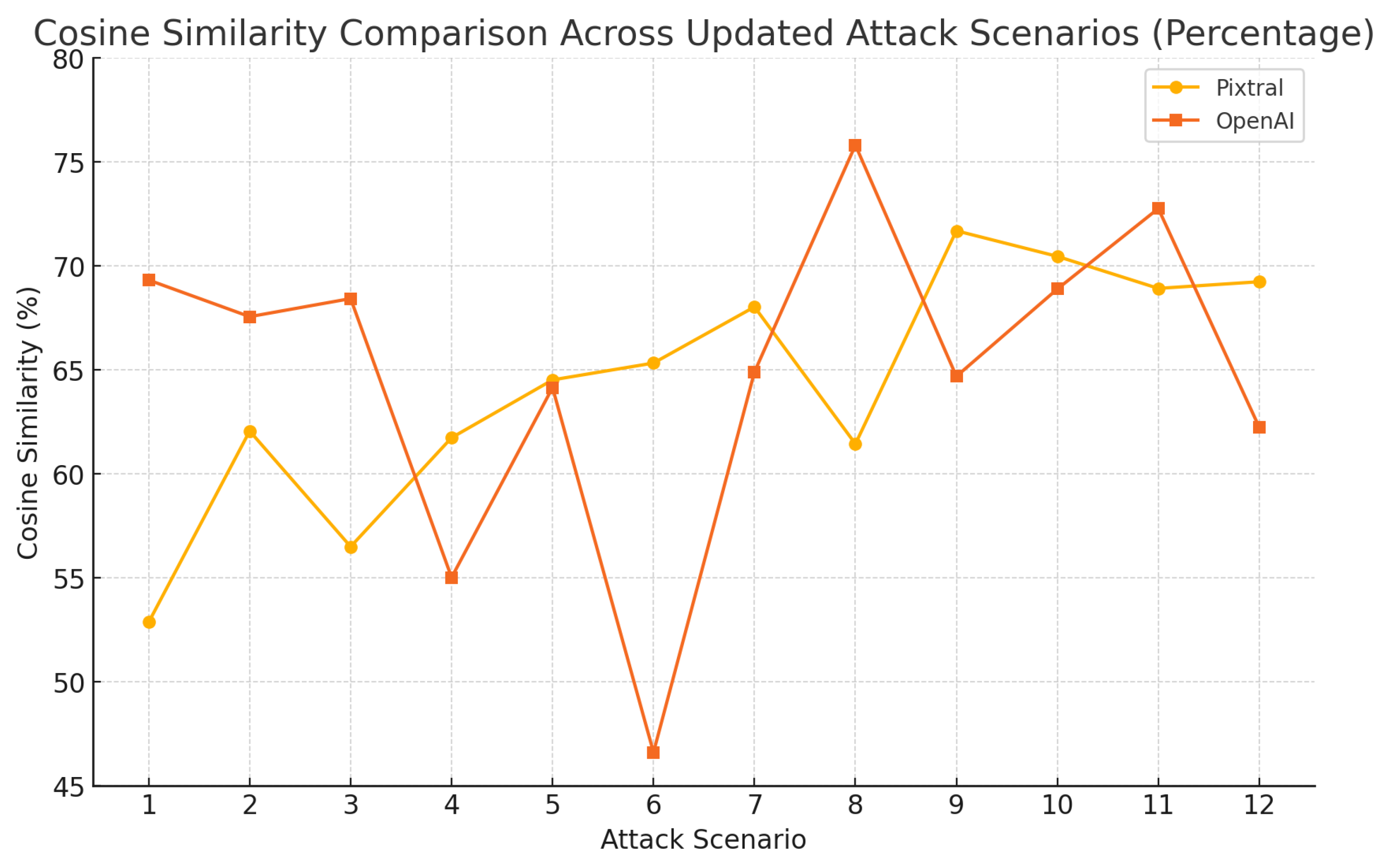
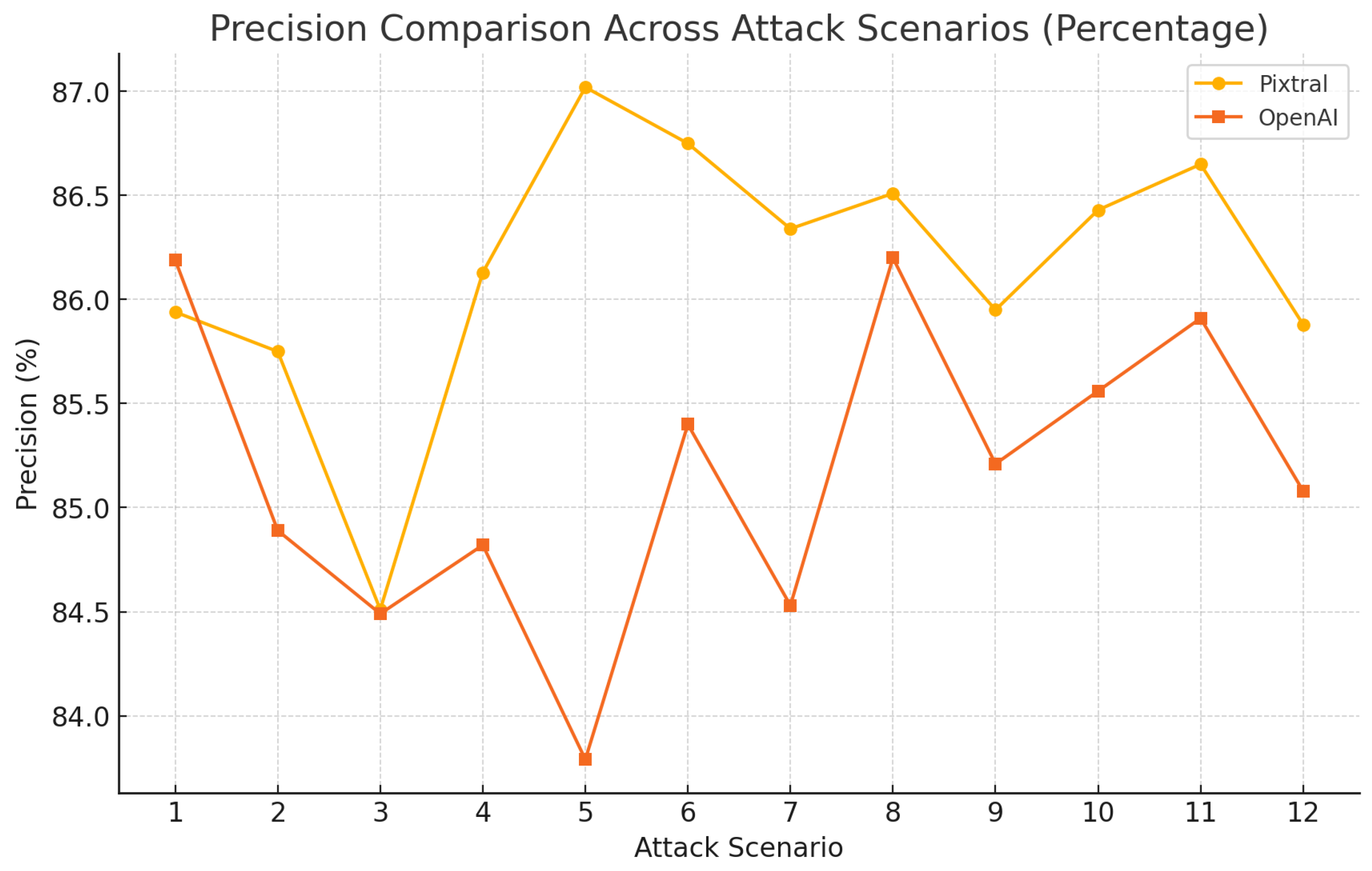
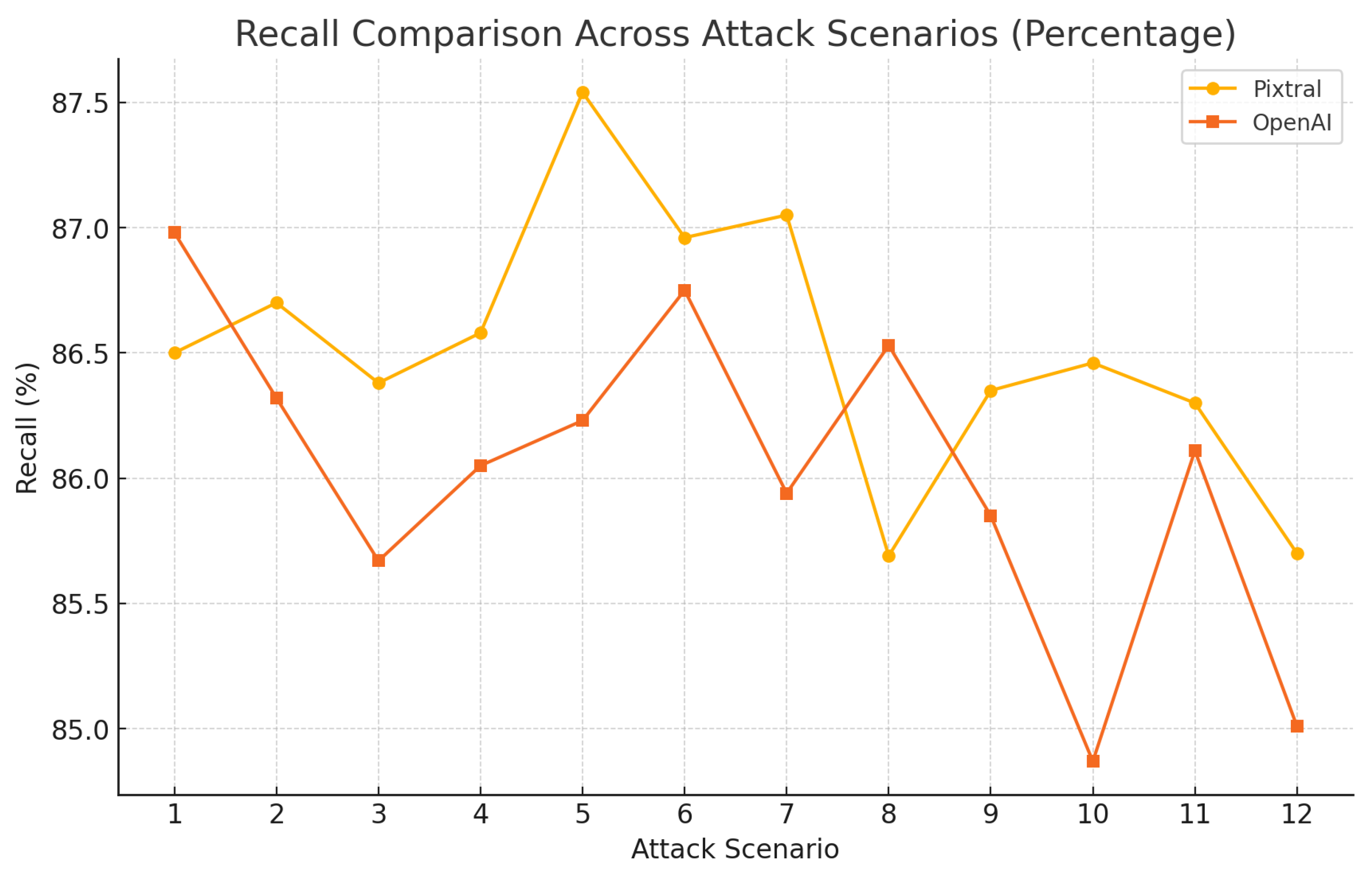
4.3. Performance Evaluation
5. Discussion and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Closing the Talent Gap: Technological Considerations for SOC Analyst Retention. Available online: https://solutionsreview.com/security-information-event-management/closing-the-talent-gap-technological-considerations-for-soc-analyst-retention (accessed on 16 December 2024).
- Homegrown SOC Automation: Pros and Cons|Enterprise Tech News EM360Tech. Available online: https://em360tech.com/tech-article/homegrown-soc-automation-pros-and-cons (accessed on 16 December 2024).
- Common SOC Challenges and How to Overcome Them—Sennovate. Available online: https://sennovate.com/common-soc-challenges-and-how-to-overcome-them/ (accessed on 16 December 2024).
- How to Train Your SOC Staff: What Works and What Doesn’t-SecurityWeek. Available online: https://www.securityweek.com/how-train-your-soc-staff-what-works-and-what-doesnt/ (accessed on 16 December 2024).
- Vielberth, M.; Bohm, F.; Fichtinger, I.; Pernul, G. Security Operations Center: A Systematic Study and Open Challenges. IEEE Access 2020, 8, 227756–227779. [Google Scholar] [CrossRef]
- To Rule or Not to Rule: SIEMs and Their False Positives|CSO Online. Available online: https://www.csoonline.com/article/563285/to-rule-or-not-to-rule-siems-and-their-false-positives.html (accessed on 16 December 2024).
- Kaliyaperumal, L.N. The Evolution of Security Operations and Strategies for Building an Effective SOC. ISACA J. 2021, 5, 1–7. [Google Scholar]
- Perera, A.; Rathnayaka, S.; Perera, N.D.; Madushanka, W.W.; Senarathne, A.N. The Next Gen Security Operation Center. In Proceedings of the 2021 6th International Conference for Convergence in Technology, I2CT 2021, Maharashtra, India, 2–4 April 2021; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2021. [Google Scholar] [CrossRef]
- Arora, A. MITRE ATT&CK vs. NIST CSF: A Comprehensive Guide to Cybersecurity Frameworks; CloudDefense. Available online: https://www.clouddefense.ai/mitre-attck-vs-nist-csf/ (accessed on 15 December 2024).
- Abo El Rob, M.F.; Islam, M.A.; Gondi, S.; Mansour, O. The Application of MITRE ATT&CK Framework in Mitigating Cybersecurity Threats in the Public Sector. Issues Inf. Syst. 2024, 25, 62–80. [Google Scholar] [CrossRef]
- Stine, K.; Quinn, S.; Witte, G.; Gardner, R.K. Integrating Cybersecurity and Enterprise Risk Management (ERM); U.S. Department of Commerce, National Institute of Standards and Technology: Gaithersburg, MD, USA, 2020. [CrossRef]
- Wainwright, T. Aligning MITRE ATT&CK for Security Resilience-Security Risk Advisors; Security Risk Advisors. Available online: https://sra.io/blog/the-road-to-benchmarked-mitre-attck-alignment-defense-success-metrics/ (accessed on 15 December 2024).
- Freitas, S.; Kalajdjieski, J.; Gharib, A.; McCann, R. AI-Driven Guided Response for Security Operation Centers with Microsoft Copilot for Security. arXiv 2024, arXiv:2407.09017. [Google Scholar]
- Fysarakis, K.; Lekidis, A.; Mavroeidis, V.; Lampropoulos, K.; Lyberopoulos, G.; Vidal, I.G.M.; i Casals, J.C.T.; Luna, E.R.; Sancho, A.A.M.; Mavrelos, A.; et al. PHOENI2X–A European Cyber Resilience Framework With Artificial-Intelligence-Assisted Orchestration, Automation and Response Capabilities for Business Continuity and Recovery, Incident Response, and Information Exchange. In Proceedings of the 2023 IEEE International Conference on Cyber Security and Resilience (CSR), Venice, Italy, 31 July–2 August 2023. [Google Scholar]
- Cado Security. Best Open Source SOC Tools You Should Use. Available online: https://www.cadosecurity.com/wiki/best-open-source-soc-tools-you-should-use (accessed on 18 December 2024).
- Absoluit. Building a Powerful Open-Source Security Operations Center (SOC)-Absoluit. Available online: https://absoluit.com/building-a-powerful-open-source-security-operations-center-soc/ (accessed on 18 December 2024).
- Wazuh Inc. Wazuh—Open Source XDR. Open Source SIEM. Available online: https://wazuh.com/ (accessed on 18 November 2024).
- HG Insights. Companies Using Wazuh, Market Share, Customers and Competitors. Available online: https://discovery.hgdata.com/product/wazuh (accessed on 18 November 2024).
- Younus, Z.S.; Alanezi, M. Detect and Mitigate Cyberattacks Using SIEM. In Proceedings of the Proceedings-International Conference on Developments in eSystems Engineering, Istanbul, Turkiye, 18–20 December 2023; DeSE. Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2023; pp. 510–515. [Google Scholar] [CrossRef]
- OpenAI. Hello GPT-4o|OpenAI. Available online: https://openai.com/index/hello-gpt-4o/ (accessed on 22 November 2024).
- Mistral AI. Pixtral Large|Mistral AI|Frontier AI in Your Hands. Available online: https://mistral.ai/news/pixtral-large/ (accessed on 21 November 2024).
- Wiemer, R.D.; Eurecom, M.D. Security Operations & Incident Management Knowledge Area Version. Available online: http://www.nationalarchives.gov.uk/doc/open- (accessed on 18 December 2024).
- Abuneama, J.M.; Matar, M.A.I.; Abusamra, A.A. Enhancing Cybersecurity with IDS and SIEM Integration Detection. In AI in Business: Opportunities and Limitations: Volume 2; Khamis, R., Buallay, A., Eds.; Springer Nature: Cham, Switzerland, 2024; pp. 57–63. [Google Scholar] [CrossRef]
- Zeinali, S.M. Analysis of Security Information and Event Management (Siem) Evasion and Detection Method; Tallinn University of Technology: Tallinn, Estonia, 2016. [Google Scholar]
- Cinque, M.; Cotroneo, D.; Pecchia, A. Challenges and Directions in Security Information and Event Management (SIEM). In Proceedings of the 2018 IEEE International Symposium on Software Reliability Engineering Workshops (ISSREW), Memphis, TN, USA, 15–18 October 2018; pp. 95–99. [Google Scholar] [CrossRef]
- Gartner Peer Insights. IBM Security QRadar SIEM vs. Wazuh—The Open Source Security Platform 2024|Gartner Peer Insights. Available online: https://www.gartner.com/reviews/market/security-information-event-management/compare/product/ibm-security-qradar-siem-vs-wazuh-the-open-source-security-platform (accessed on 18 December 2024).
- SourceForge. IBM QRadar SIEM vs. Splunk Enterprise vs. Wazuh Comparison. Available online: https://sourceforge.net/software/compare/IBM-QRadar-SIEM-vs-Splunk-vs-Wazuh/ (accessed on 18 December 2024).
- PeerSpot. IBM Security QRadar vs. Wazuh Comparison 2024|PeerSpot. Available online: https://www.peerspot.com/products/comparisons/ibm-security-qradar_vs_wazuh (accessed on 18 December 2024).
- Kinney Group. Splunk vs. QRadar: A SIEM Solution Comparison—Kinney Group. Available online: https://kinneygroup.com/blog/splunk-vs-qradar/ (accessed on 18 December 2024).
- InfosecTrain. IBM QRadar vs. Splunk SIEM—InfosecTrain. Available online: https://www.infosectrain.com/blog/ibm-qradar-vs-splunk-siem/ (accessed on 18 December 2024).
- TechRepublic. QRadar vs. Splunk (2023): SIEM Tool Comparison. Available online: https://www.techrepublic.com/article/qradar-vs-splunk/ (accessed on 18 December 2024).
- eWeek. QRadar vs. Splunk: SIEM Tools Review|eWeek. Available online: https://www.eweek.com/security/splunk-vs-ibm-qradar-siem-head-to-head/ (accessed on 18 December 2024).
- Wazuh, Inc. Wazuh Documentation. Available online: https://documentation.wazuh.com/current/index.html (accessed on 18 December 2024).
- Elastic, N.V. Elastic Stack: (ELK) Elasticsearch, Kibana & Logstash|Elastic. Available online: https://www.elastic.co/elastic-stack (accessed on 18 December 2024).
- teTrain. Wazuh vs. Other SIEM Tools. Available online: https://www.tetrain.com/tetra-blogs/post/107/wazuh-vs-other-siem-tools.html (accessed on 18 December 2024).
- Šuškalo, D.; Morić, Z.; Redžepagić, J.; Regvart, D. Comparative Analysis of IBM QRadar and Wazuh for Security Information and Event Management. In Proceedings of the 34th DAAAM International Symposium on Intelligent Manufacturing and Automation, Vienna, Austria, 26–27 October 2023. [Google Scholar] [CrossRef]
- Dunsin, D.; Ghanem, M.C.; Ouazzane, K.; Vassilev, V. A Comprehensive Analysis of the Role of Artificial Intelligence and Machine Learning in Modern Digital Forensics and Incident Response Article info. Forensic Sci. Int. Digit. Investig. 2023, 48, 301675. [Google Scholar]
- Hays, S.; White, J. Employing LLMs for Incident Response Planning and Review. arXiv 2024, arXiv:2403.01271. [Google Scholar]
- Georgiadou, A.; Mouzakitis, S.; Askounis, D. Assessing Mitre ATT&CK Risk Using a Cyber-Security Culture Framework. Sensors 2021, 21, 3267. [Google Scholar] [CrossRef]
- ExtraHop. RevealX™ and the MITRE ATT&CK® Framework: How RevealX Differentiators Fuel Breadth and Depth of MITRE ATT&CK Coverage. Available online: https://www.extrahop.com/resources/revealx-mitre-attack-framework/ (accessed on 13 December 2024).
- Cybereason. MITRE ATT&CK and Building Better Defenses. Available online: https://www.cybereason.com/hubfs/White%20Papers/MITRE_ATT&CK_and_Building_Better_Defenses.pdf (accessed on 13 December 2024).
- Att, M. Best Practices for MITRE ATT&CK® Mapping; MITRE Corporation: Bedford, MA, USA, 2021. Available online: http://www.cisa.gov/tlp/.TLP:WHITE (accessed on 13 December 2024).
- Daszczyszak, R.; Ellis, D.; Luke, S.; Whitley, S. Sponsor: USCYBERCOM TTP-Based Hunting. 2019. Dept. No.: P522; Contract No.: W56KGU-16-C-0010; Project No.: 0718N00A-WF. This Technical Data Deliverable Was Developed Using Contract Funds Under Basic Contract No. W56KGU-18-D-0004. Approved for Public Release; Distribution Unlimited. Public Release Case Number 19-3892. ©2020 The MITRE Corporation. All rights reserved. The MITRE Corporation: Annapolis Junction, MD, USA, 2020. Available online: https://www.mitre.org/sites/default/files/2021-11/prs-19-3892-ttp-based-hunting.pdf (accessed on 16 December 2024).
- Al-Sada, B.; Sadighian, A.; Oligeri, G. MITRE ATT&CK: State of the Art and Way Forward. ACM Comput. Surv. 2023, 57, 1–37. [Google Scholar]
- National Institute of Standards and Technology. Framework for Improving Critical Infrastructure Cybersecurity, Version 1.1; NIST: Gaithersburg, MD, USA, 2018. Available online: http://nvlpubs.nist.gov/nistpubs/CSWP/NIST.CSWP.04162018.pdf (accessed on 20 December 2024). [CrossRef]
- The White House. Foreign Policy Cyber Security Executive Order 13636|The White House; The White House: Washington, DC, USA, 2013. Available online: https://obamawhitehouse.archives.gov/issues/foreign-policy/cybersecurity/eo-13636 (accessed on 20 December 2024).
- Chio, C.; Freeman, D. Machine Learning and Security: Protecting Systems with Data and Algorithms; O’Reilly Media: Sebastopol, CA, USA, 2018. [Google Scholar]
- Wu, F.; Zhang, Q.; Bajaj, A.P.; Bao, T.; Zhang, N.; Wang, R.F.; Xiao, C. Exploring the Limits of ChatGPT in Software Security Applications. arXiv 2023, arXiv:2312.05275. [Google Scholar]
- Pordanesh, S.; Tan, B. Exploring the Efficacy of Large Language Models (GPT-4) in Binary Reverse Engineering. arXiv 2024, arXiv:2406.06637. [Google Scholar]
- NVIDIA. Optimizing T5 and GPT-2 for Real-Time Inference with NVIDIA TensorRT|NVIDIA Technical Blog. Available online: https://developer.nvidia.com/blog/optimizing-t5-and-gpt-2-for-real-time-inference-with-tensorrt (accessed on 22 December 2024).
- Kim, S.; Hooper, C.; Wattanawong, T.; Kang, M.; Yan, R.; Genc, H.; Dinh, G.; Huang, Q.; Keutzer, K.; Mahoney, M.W.; et al. Full Stack Optimization of Transformer Inference: A Survey. arXiv 2023, arXiv:2302.14017. [Google Scholar]
- Geeky Gadgets. How Llama-3.3 70B Stacks Up Against GPT-4 and Other AI Models—Geeky Gadgets. Available online: https://www.geeky-gadgets.com/llama-3-3-70b-open-source-ai-model/ (accessed on 22 December 2024).
- Ferrag, M.A.; Alwahedi, F.; Battah, A.; Cherif, B.; Mechri, A.; Tihanyi, N. Generative AI and Large Language Models for Cyber Security: All Insights You Need. arXiv 2024, arXiv:2405.12750. [Google Scholar]
- Aghaei, E. ehsanaghaei/SecureBERT · Hugging Face. Available online: https://huggingface.co/ehsanaghaei/SecureBERT (accessed on 22 December 2024).
- Aghaei, E.; Niu, X.; Shadid, W.; Al-Shaer, E. SecureBERT: A Domain-Specific Language Model for Cybersecurity. In Lecture Notes of the Institute for Computer Sciences, Social-Informatics and Telecommunications Engineering, LNICST; Springer: Cham, Switzerland, 2023; Volume 462, pp. 39–56. [Google Scholar] [CrossRef]
- Geeky Gadgets. Mistral Pixtral 12B Open Source AI Vision Model Released—Geeky Gadgets. Available online: https://www.geeky-gadgets.com/mistral-pixtral-12b-ai-vision-model/ (accessed on 22 December 2024).
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. LoRA: Low-Rank Adaptation of Large Language Models. arXiv 2021, arXiv:2106.09685. [Google Scholar]
- Geeky Gadgets. Fine Tuning Mistral Pixtral 12B Multimodal AI-Geeky Gadgets. Available online: https://www.geeky-gadgets.com/fine-tuning-mistral-pixtral-12b-multimodal-ai/ (accessed on 22 December 2024).
- Gao, Y.; Xiong, Y.; Gao, X.; Jia, K.; Pan, J.; Bi, Y.; Dai, Y.; Sun, J.; Wang, M.; Wang, H. Retrieval-Augmented Generation for Large Language Models: A Survey. arXiv 2023, arXiv:2312.10997. [Google Scholar]
- NVIDIA. What is Retrieval-Augmented Generation (RAG)?|NVIDIA. Available online: https://www.nvidia.com/en-in/glossary/retrieval-augmented-generation/ (accessed on 16 December 2024).
- Lin, G.; Feng, T.; Han, P.; Liu, G.; You, J. Paper Copilot: A Self-Evolving and Efficient LLM System for Personalized Academic Assistance. arXiv 2024, arXiv:2409.04593. [Google Scholar]
- Li, R.; Patel, T.; Wang, Q.; Du, X. MLR-Copilot: Autonomous Machine Learning Research based on Large Language Models Agents. arXiv 2024, arXiv:2408.14033. [Google Scholar]
- Wen, H.; Wei, Z.; Lin, Y.; Wang, J.; Liang, Y.; Wan, H. OverleafCopilot: Empowering Academic Writing in Overleaf with Large Language Models. In Proceedings of the Applied Data Science Track Paper; Beijing Jiaotong University: Beijing, China; Hong Kong University of Science and Technology: Hong Kong, China, 2024. [Google Scholar]
- Fortinet. Meet Fortinet Advisor, a Generative AI Assistant that Accelerates Threat Investigation and Remediation; Fortinet: Sunnyvale, CA, USA, 2023; Available online: https://www.fortinet.com/corporate/about-us/newsroom/press-releases/2023/fortinet-advisor-a-generative-ai-assistant-accelerating-threat-investigation-and-remediation (accessed on 16 December 2024).
- Enhancing Cybersecurity: The Role and Benefits of Open Source SIEM|SubRosa. Available online: https://subrosacyber.com/en/blog/open-source-siem (accessed on 16 December 2024).
- Yao, S.; Zhao, J.; Yu, D.; Du, N.; Shafran, I.; Narasimhan, K.; Cao, Y. ReAct: Synergizing Reasoning and Acting in Language Models. arXiv 2022, arXiv:2210.03629. [Google Scholar]
- Han, Z.; Gao, C.; Liu, J.; Zhang, J.; Zhang, S.Q. Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey. arXiv 2024, arXiv:2403.14608. [Google Scholar]
- Outshift|Fine-Tuning Methods for LLMs: A Comparative Guide. Available online: https://outshift.cisco.com/blog/llm-fine-tuning-methods-comparative-guide (accessed on 18 December 2024).
- Challenges & Limitations of LLM Fine-Tuning|OpsMatters. Available online: https://opsmatters.com/posts/challenges-limitations-llm-fine-tuning (accessed on 18 December 2024).
- Wang, X.; Wang, Z.; Gao, X.; Zhang, F.; Wu, Y.; Xu, Z.; Shi, T.; Wang, Z.; Li, S.; Qian, Q.; et al. Searching for Best Practices in Retrieval-Augmented Generation. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Miami, FL, USA, 12–16 November 2024. [Google Scholar]
- NVIDIA. Explainer: What Is Retrieval-Augmented Generation?|NVIDIA Technical Blog. Available online: https://developer.nvidia.com/blog/explainer-what-is-retrieval-augmented-generation/ (accessed on 18 December 2024).
- Xu, H.; Wang, S.; Li, N.; Wang, K.; Zhao, Y.; Chen, K.; Yu, T.; Liu, Y.; Wang, H. Large Language Models for Cyber Security: A Systematic Literature Review. arXiv 2024, arXiv:2405.04760. [Google Scholar]
- Tseng, P.; Yeh, Z.; Dai, X.; Liu, P. Using LLMs to Automate Threat Intelligence Analysis Workflows in Security Operation Centers. arXiv 2024, arXiv:2407.13093. [Google Scholar]
- Eventus Security. Enhancing Cybersecurity: The Role of AI & ML in SOC and Deploying Advanced Strategies. Available online: https://eventussecurity.com/cybersecurity/soc/ai-ml/ (accessed on 18 December 2024).
- Red Canary. GitHub-Redcanaryco/Atomic-Red-Team: Small and Highly Portable Detection Tests Based on MITRE’s ATT&CK. Available online: https://github.com/redcanaryco/atomic-red-team (accessed on 18 December 2024).
- Test Your Defenses with Red Canary’s Atomic Red Team. Available online: https://redcanary.com/atomic-red-team/ (accessed on 18 December 2024).
- Landauer, M.; Mayer, K.; Skopik, F.; Wurzenberger, M.; Kern, M. Red Team Redemption: A Structured Comparison of Open-Source Tools for Adversary Emulation. arXiv 2024, arXiv:2408.15645. [Google Scholar]
- Qdrant. What is Qdrant?-Qdrant. Available online: https://qdrant.tech/documentation/overview/ (accessed on 18 December 2024).
- Qdrant. GitHub-Qdrant/Qdrant-Rag-Eval: This Repo Is the Central Repo for All the RAG Evaluation Reference Material and Partner Workshop. Available online: https://qdrant.tech/documentation/overview/ (accessed on 18 December 2024).
- Beijing Academy of Artificial Intelligence (BAAI). BAAI/bge-large-en · Hugging Face. Available online: https://huggingface.co/BAAI/bge-large-en (accessed on 18 December 2024).
- Kusupati, A.; Bhatt, G.; Rege, A.; Wallingford, M.; Sinha, A.; Ramanujan, V.; Howard-Snyder, W.; Chen, K.; Kakade, S.; Jain, P.; et al. Matryoshka Representation Learning. Adv. Neural Inf. Process. Syst. 2022, 35, 30233–30249. [Google Scholar]
- OpenAI. New and Improved Embedding Model|OpenAI. Available online: https://openai.com/index/new-and-improved-embedding-model/ (accessed on 18 December 2024).
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers); Burstein, J., Doran, C., Solorio, T., Eds.; Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 4171–4186. Available online: https://aclanthology.org/N19-1423/ (accessed on 23 December 2024). [CrossRef]
- Steck, H.; Ekanadham, C.; Kallus, N. Is Cosine-Similarity of Embeddings Really About Similarity? In Proceedings of the Companion Proceedings of the ACM on Web Conference 2024, Singapore, 13–17 May 2024. [Google Scholar] [CrossRef]
- Pinecone. Vector Similarity Explained|Pinecone. Available online: https://www.pinecone.io/learn/vector-similarity/ (accessed on 23 December 2024).
- Guo, K.H. Testing and Validating the Cosine Similarity Measure for Textual Analysis. SSRN 2022. Available online: https://ssrn.com/abstract=4258463 (accessed on 18 November 2024). [CrossRef]
- Cichonski, P.; Millar, T.; Grance, T.; Scarfone, K. Computer Security Incident Handling Guide: Recommendations of the National Institute of Standards and Technology; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2012. [CrossRef]
- IRM/EN at Main · Certsocietegenerale/IRM. Available online: https://github.com/certsocietegenerale/IRM/tree/main/EN (accessed on 19 November 2024).
- Diogenes, Y.; Ozkaya, E. Cybersecurity, Attack and Defense Strategies: Infrastructure Security with Red Team and Blue Team Tactics; Packt Publishing: Birmingham, UK, 2018. [Google Scholar]
- Nccic.; Ics-cert. Recommended Practice: Improving Industrial Control System Cybersecurity with Defense-in-Depth Strategies. U.S. Department of Homeland Security, National Cybersecurity and Communications Integration Center (NCCIC), Industrial Control Systems Cyber Emergency Response Team (ICS-CERT): Washington, DC, USA, 2016. Available online: https://www.cisa.gov/sites/default/files/publications/Defense_in_Depth_Strategies_2016.pdf (accessed on 19 November 2024).
- Cybersecurity and Infrastructure Security Agency (CISA). Cybersecurity Incident & Vulnerability Response Playbooks: Operational Procedures for Planning and Conducting Cybersecurity Incident and Vulnerability Response Activities in FCEB Information Systems. Available online: http://www.cisa.gov/tlp (accessed on 19 November 2024).
- Pascoe, C.; Quinn, S.; Scarfone, K. The NIST Cybersecurity Framework (CSF) 2.0; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2024. [CrossRef]
- MITRE Corporation. MITRE ATT&CK®. Available online: https://attack.mitre.org/ (accessed on 19 November 2024).
- LangChain. How to Split Text by Tokens|LangChain. Available online: https://python.langchain.com/docs/how_to/split_by_token/#nltk (accessed on 21 November 2024).
- Wazuh. Rules—Data Analysis · Wazuh Documentation. Available online: https://documentation.wazuh.com/current/user-manual/ruleset/rules/index.html (accessed on 19 November 2024).
- Wazuh. Event Logging—Wazuh Server · Wazuh Documentation. Available online: https://documentation.wazuh.com/current/user-manual/manager/event-logging.html (accessed on 21 November 2024).
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; tau Yih, W.; Rocktäschel, T.; et al. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. Adv. Neural Inf. Process. Syst. 2020, 33, 9459–9474. [Google Scholar]
- Wazuh. Vulnerability Detection—Use Cases · Wazuh Documentation. Available online: https://documentation.wazuh.com/current/getting-started/use-cases/vulnerability-detection.html (accessed on 21 November 2024).
- SOC Fortress. GitHub—Socfortress/Playbooks: Playbooks for SOC Analysts. Available online: https://github.com/socfortress/Playbooks (accessed on 22 November 2024).
- Red Canary. Atomic-Red-Team/Atomics/Indexes/Indexes-Markdown/index.md at Master · Redcanaryco/Atomic-Red-Team · GitHub. Available online: https://github.com/redcanaryco/atomic-red-team/blob/master/atomics/Indexes/Indexes-Markdown/index.md (accessed on 22 November 2024).
- Zhang, T.; Kishore, V.; Wu, F.; Weinberger, K.Q.; Artzi, Y. BERTScore: Evaluating Text Generation with BERT. arXiv 2019, arXiv:1904.09675. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Wazuh | IBM QRadar | Splunk-SIEM | Security Onion | GrayLog |
|---|---|---|---|---|---|
| Cost [26] | Free | High | High | Free | Free core |
| Log management [27] | Comprehensive | Strong | Very strong | Good | Good |
| FIM [28] | Yes | Limited | Limited | Limited | Limited |
| Integration [29] | High | High | Very High | Moderate | Moderate |
| Deployment [30] | Moderate | Complex | Moderate | Moderate | Easy |
| Scalability [31] | High | High | High | Moderate | Moderate |
| Community [32] | Strong | Moderate | Moderate | Strong | Moderate |
| Category | Content |
|---|---|
| General knowledge | Incident Response Guide [87,88,89,90] IRP [91] |
| NIST knowledge | CSF 2.0 [92] |
| MITRE knowledge | MITRE ATT&CK [93] |
| Parameter | Value |
|---|---|
| Temperature | Set to 0.1, ensuring high determinism by minimizing randomness in the model’s predictions, favoring the most probable outputs. |
| Top-k | Configured as 50, restricting token sampling to the top 50 most likely candidates, reducing the likelihood of low-probability tokens. |
| Top-p (Nucleus Sampling) | Set to 0.9, allowing dynamic token selection by considering tokens with a cumulative probability of 90%, ensuring a balance between determinism and contextual diversity. |
| Max Tokens | Defined as 4096, specifying the upper limit for the total number of tokens in the generated output, suitable for applications requiring concise yet comprehensive responses. |
| Prompt Format |
|---|
| Extract the primary issue or problem from the following Wazuh JSON log. |
| Focus on details like the alert description, severity level, associated tactics, compliance tags, and any specific event data that |
| clarifies the problem: |
| {input_event_json} |
| Present the extracted issue in a concise format, describing the main problem indicated in the log. |
| Expected Output Example: |
| ”’ |
| Given the JSON log provided, here’s how the response might look: |
| Extracted Problem: |
| Description: Wazuh agent ‘suricata-nids’ has stopped, indicating a potential disruption in NIDS monitoring. |
| Alert Level: 3 (Medium severity) |
| Associated Tactic: Defense Evasion (MITRE ID: T1562.001—Disable or Modify Tools) |
| Compliance Concerns: PCI DSS (10.6.1, 10.2.6), HIPAA (164.312.b), TSC (CC7.2, CC7.3, CC6.8), NIST 800-53 (AU.6, AU.14, AU.5), GDPR (IV_35.7.d) |
| Log Details: Full log message reads “Agent stopped: ’suricata-nids->any’,” suggesting possible interruption in security monitoring. |
| ”’ |
| Expected output above focuses on the core issue, making it easily readable and actionable for SOC and RAG systems. |
| Response Prompt Format |
|---|
| This is the context information for general knowledge purposes: |
| {context_general} |
| This is the context information knowledge of planning for generating the incident response playbook based on The NIST Cybersecurity Framework (CSF) 2.0: |
| {context_nist} |
| This is the context information knowledge from MITRE ATT&CK for security incident response mitigation purposes: |
| {context_mitre} |
| Based on the above context information, hope you can use and elaborate on the knowledge you have to analyze this incident and tell me what action to take: |
| json |
| Based on that incident, what should be done to mitigate the risk? Make sure to use knowledge of the NIST CSF 2.0 and the MITRE ATT&CK |
| framework to identify the tactics and techniques associated with the incident. |
| Do not mention the source of JSON or text input, just tell what action to take with Markdown format. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ismail; Kurnia, R.; Widyatama, F.; Wibawa, I.M.; Brata, Z.A.; Ukasyah; Nelistiani, G.A.; Kim, H. Enhancing Security Operations Center: Wazuh Security Event Response with Retrieval-Augmented-Generation-Driven Copilot. Sensors 2025, 25, 870. https://doi.org/10.3390/s25030870
Ismail, Kurnia R, Widyatama F, Wibawa IM, Brata ZA, Ukasyah, Nelistiani GA, Kim H. Enhancing Security Operations Center: Wazuh Security Event Response with Retrieval-Augmented-Generation-Driven Copilot. Sensors. 2025; 25(3):870. https://doi.org/10.3390/s25030870
Chicago/Turabian StyleIsmail, Rahmat Kurnia, Farid Widyatama, Ilham Mirwansyah Wibawa, Zilmas Arjuna Brata, Ukasyah, Ghitha Afina Nelistiani, and Howon Kim. 2025. "Enhancing Security Operations Center: Wazuh Security Event Response with Retrieval-Augmented-Generation-Driven Copilot" Sensors 25, no. 3: 870. https://doi.org/10.3390/s25030870
APA StyleIsmail, Kurnia, R., Widyatama, F., Wibawa, I. M., Brata, Z. A., Ukasyah, Nelistiani, G. A., & Kim, H. (2025). Enhancing Security Operations Center: Wazuh Security Event Response with Retrieval-Augmented-Generation-Driven Copilot. Sensors, 25(3), 870. https://doi.org/10.3390/s25030870