
Wi-Filter: WiFi-Assisted Frame Filtering on the Edge for Scalable and Resource-Efficient Video Analytics




Abstract
1. Introduction
- Introduction of Wi-Filter: We propose Wi-Filter, a novel filtering framework that leverages Wi-Fi signals from wireless edge devices, such as Wi-Fi-enabled cameras, to dynamically adjust the filtering threshold. To the best of our knowledge, this is the first approach that utilizes Wi-Fi-based activity recognition to enhance frame filtering mechanisms.
- On-device CSI Data Processing with Lightweight 1D CNN: Our proposed framework employs a one-dimensional convolutional neural network (1D CNN) instead of the commonly used 2D CNN models in Wi-Fi sensing for processing run-time collected CSI data. This choice allows the filtering module to operate on-device with minimal computational overhead, making it a more practical solution for resource-constrained environments.
- Prototype Implementation and Evaluation: We implemented a prototype of Wi-Filter using low-capacity edge devices and a GPU-enabled edge server. Testbed deployments demonstrated that our system achieved the same frame analysis accuracy while significantly reducing the GPU and CPU load of the cloud server, as well as network traffic.
- Comprehensive Summary of Recent Work: We also provide a comprehensive summary of intelligent video analytics systems, highlighting relevant research and existing methods to contextualize the importance and contribution of our proposed solution.
2. Related Work
2.1. Efficient Video Analytics at the Edge
2.2. Filtration for Analytics at the Edge
2.3. WiFi-Based Sensing Technologies
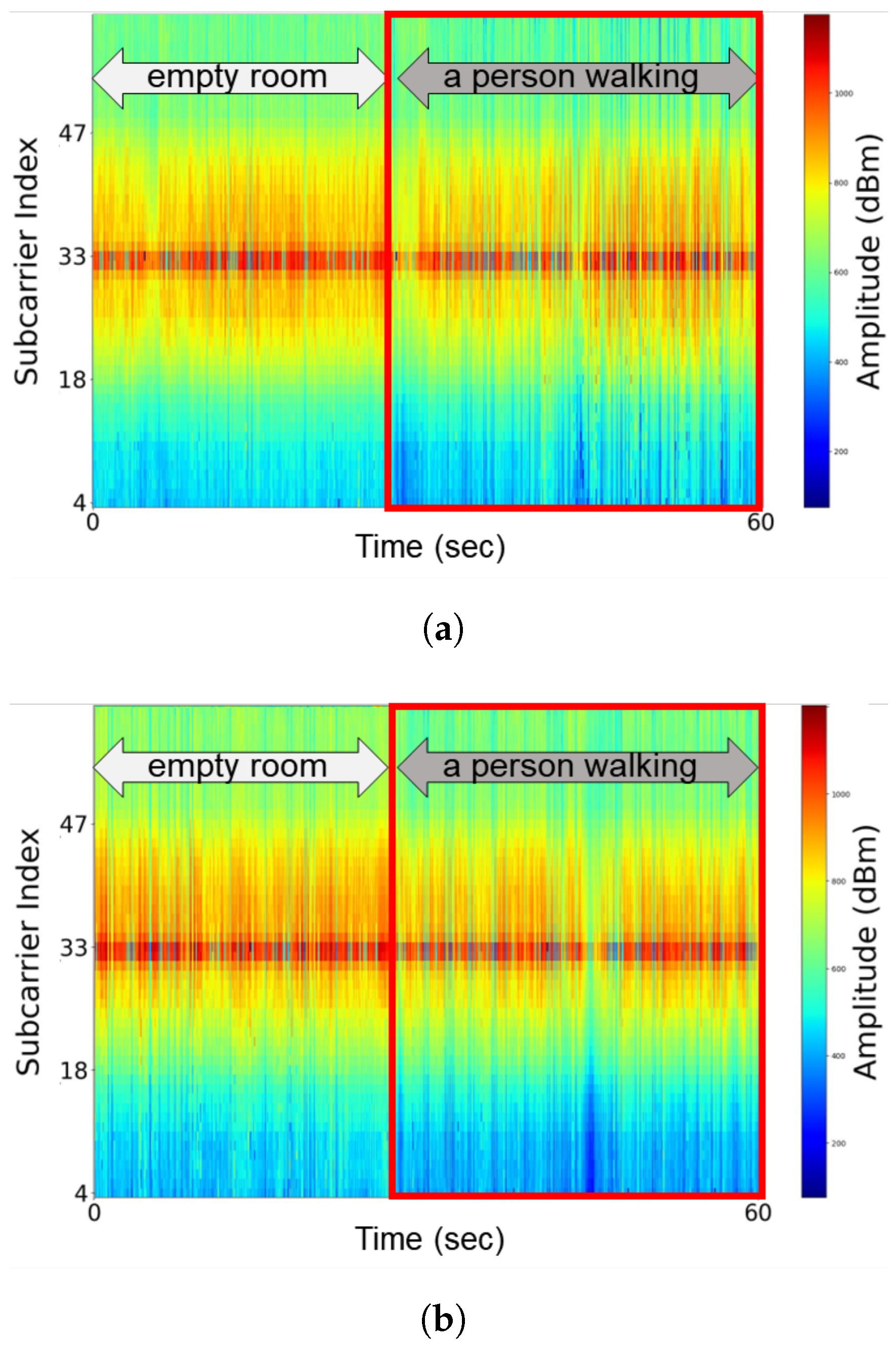
3. Motivation
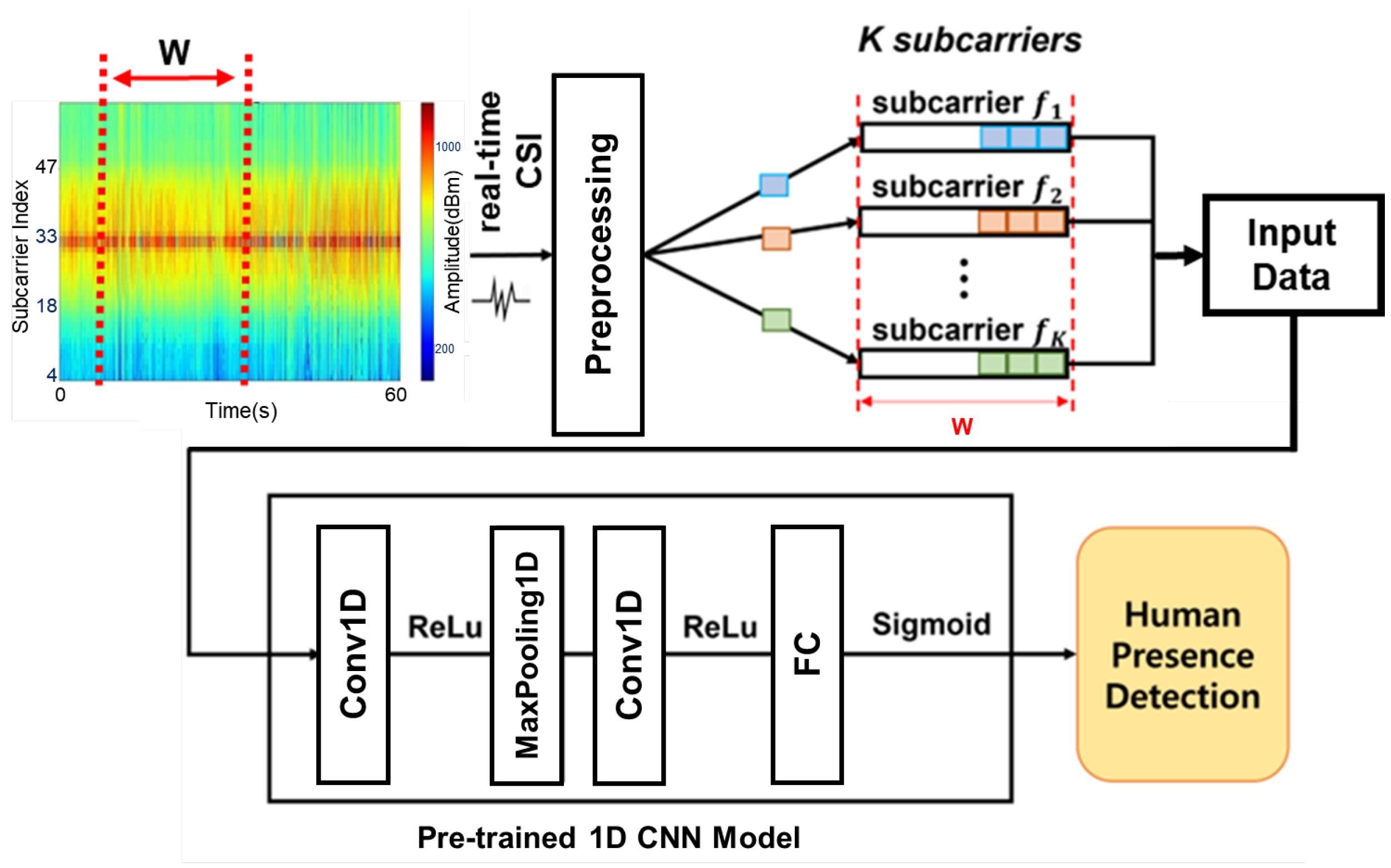
4. Wi-Filter System Design
4.1. Overview
4.2. Data Collection and Auto-Labeling Stage
4.3. Run-Time Stage
- MAC Filtering and Feature Removal: During the preprocessing stage, packets are filtered based on their MAC addresses to ensure only data relevant to the target devices are processed. Then, irrelevant features such as MAC addresses and timestamps are removed from the collected packets to focus on the CSI values and minimize the data size.
- Subcarrier Selection: Among the subcarriers, 12 subcarriers—including null subcarriers (used to protect the band and enable coexistence with other wireless technologies) and pilot subcarriers (used for Wi-Fi link control)—are excluded. This leaves only 52 meaningful subcarriers for further analysis.
- Outlier Handling: Outliers in the remaining CSI amplitude samples, which are common in real-world environments, are not removed. Instead, they are retained and incorporated into the learning process to ensure the model’s robustness.
- Dimensionality Reduction: For the selected 52 subcarriers, data collected over a window size W result in an original data dimension of . To enable faster inference, principal component analysis (PCA) is applied to reduce the input size to . These reduced-dimensional data serve as the final input to the proposed model.
5. System Implementation and Evaluation
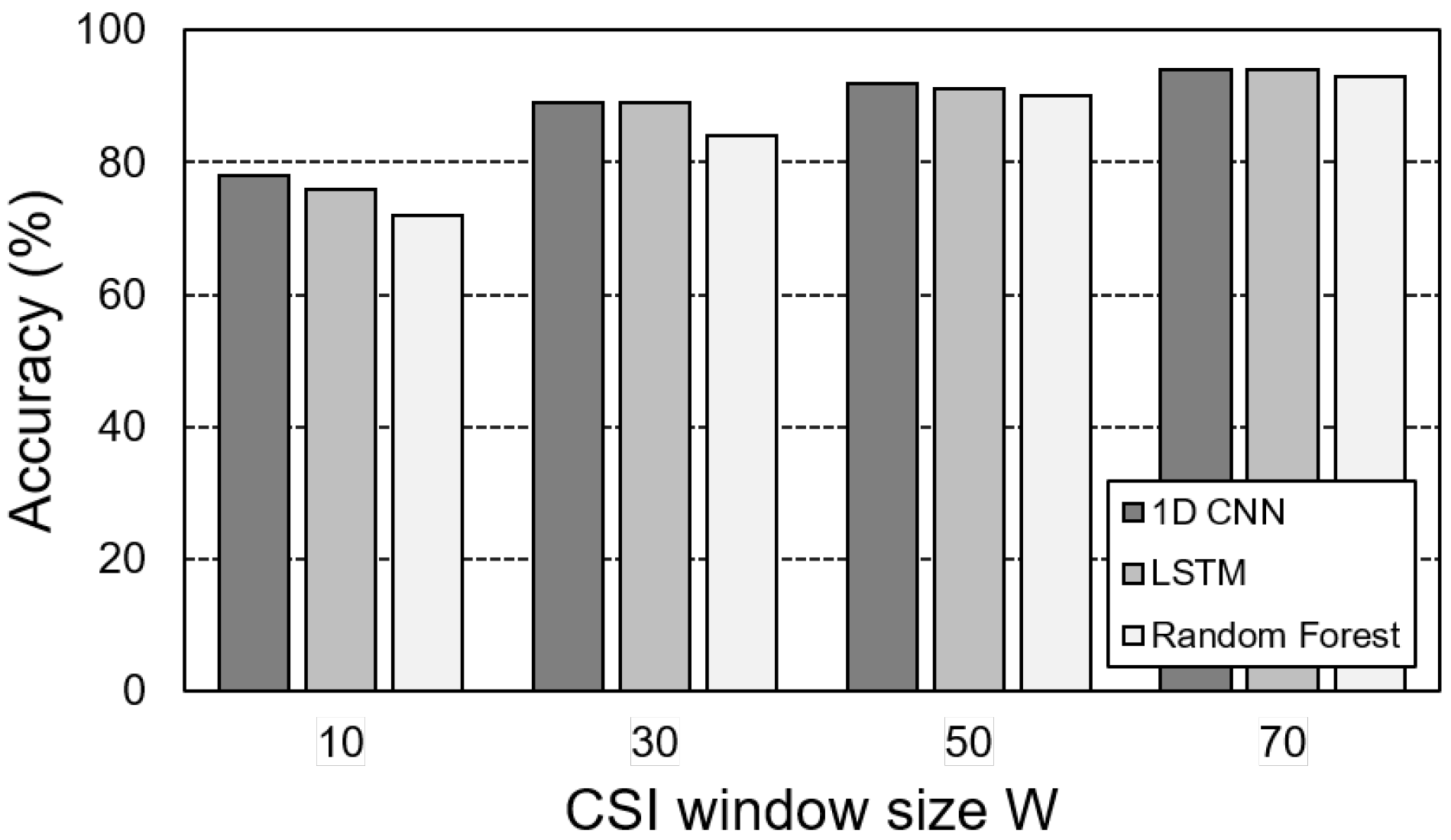
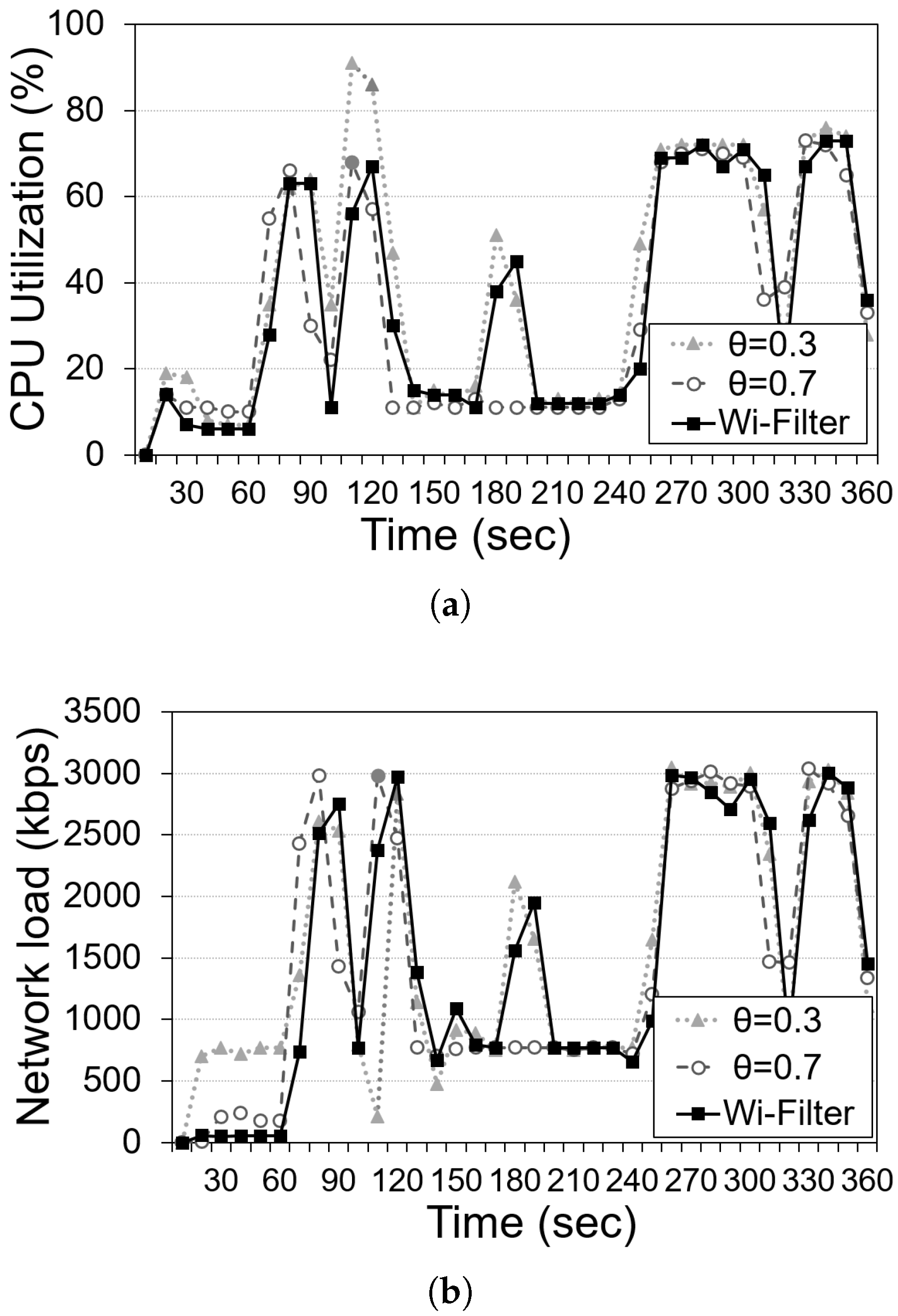
5.1. Implementation and Experiments
5.2. Experiment Results
6. Conclusions and Discussion
- (i)
- optimizing threshold selection through the development of dynamic mechanisms that adjust filtering thresholds based on real-time environmental and contextual factors;
- (ii)
- integrating advanced Wi-Fi-based positioning models to make the system more versatile and applicable across diverse environments;
- (iii)
- leveraging meta-learning techniques to enable quick adaptation to new domains with minimal additional data, thereby improving the system’s robustness and performance in dynamic scenarios.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shi, W.; Li, Q.; Yu, Q.; Wang, F.; Shen, G.; Jiang, Y.; Xu, Y.; Ma, L.; Muntean, G.M. A Survey on Intelligent Solutions for Increased Video Delivery Quality in Cloud-Edge-End Networks. IEEE Commun. Surv. Tutor. 2024. [Google Scholar] [CrossRef]
- Badidi, E.; Moumane, K.; El Ghazi, F. Opportunities, applications, and challenges of edge-AI enabled video analytics in smart cities: A systematic review. IEEE Access 2023, 11, 80543–80572. [Google Scholar] [CrossRef]
- Ferrer, A.J.; Marquès, J.M.; Jorba, J. Towards the decentralised cloud: Survey on approaches and challenges for mobile, ad hoc, and edge computing. Acm Comput. Surv. CSUR 2019, 51, 1–36. [Google Scholar] [CrossRef]
- Dong, S.; Tang, J.; Abbas, K.; Hou, R.; Kamruzzaman, J.; Rutkowski, L.; Buyya, R. Task offloading strategies for mobile edge computing: A survey. Comput. Netw. 2024, 254, 110791. [Google Scholar] [CrossRef]
- Nguyen, D.V.; Choi, J. Toward Scalable Video Analytics Using Compressed-Domain Features at the Edge. Appl. Sci. 2020, 10, 6391. [Google Scholar] [CrossRef]
- Hsieh, K.; Ananthanarayanan, G.; Bodik, P.; Venkataraman, S.; Bahl, P.; Philipose, M.; Gibbons, P.B.; Mutlu, O. Focus: Querying large video datasets with low latency and low cost. In Proceedings of the 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18), Carlsbad, CA, USA, 8–10 October 2018; pp. 269–286. [Google Scholar]
- Rahmanian, A.; Amin, S.; Gustafsson, H.; Ali-Eldin, A. CVF: Cross-Video Filtration on the Edge. In Proceedings of the 15th ACM Multimedia Systems Conference, Bari, Italy, 15–18 April 2024; pp. 231–242. [Google Scholar]
- Canel, C.; Kim, T.; Zhou, G.; Li, C.; Lim, H.; Andersen, D.G.; Kaminsky, M.; Dulloor, S.R. Scaling video analytics on constrained edge nodes. arXiv 2019, arXiv:1905.13536. [Google Scholar]
- Chen, T.Y.H.; Ravindranath, L.; Deng, S.; Bahl, P.; Balakrishnan, H. Glimpse: Continuous, real-time object recognition on mobile devices. In Proceedings of the 13th ACM Conference on Embedded Networked Sensor Systems, Seoul, Republic of Korea, 1–4 November 2015; pp. 155–168. [Google Scholar]
- Li, Y.; Padmanabhan, A.; Zhao, P.; Wang, Y.; Xu, G.H.; Netravali, R. Reducto: On-Camera Filtering for Resource-Efficient Real-Time Video Analytics. In Proceedings of the Annual Conference of the ACM Special Interest Group on Data Communication on the Applications, Technologies, Architectures, and Protocols for Computer Communication, New York, NY, USA, 10–14 August 2020; SIGCOMM ’20. pp. 359–376. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, W.; Zhang, J.; Jiang, J.; Chen, K. Bridging the edge-cloud barrier for real-time advanced vision analytics. In Proceedings of the 11th USENIX Workshop on Hot Topics in Cloud Computing (HotCloud 19), Renton, WA, USA, 8 July 2019. [Google Scholar]
- Wu, Y.; Liu, L.; Kompella, R. Parallel detection for efficient video analytics at the edge. In Proceedings of the 2021 IEEE Third International Conference on Cognitive Machine Intelligence (CogMI), Atlanta, GA, USA, 13–15 December 2021; pp. 01–10. [Google Scholar]
- Xiao, Z.; Xia, Z.; Zheng, H.; Zhao, B.Y.; Jiang, J. Towards performance clarity of edge video analytics. In Proceedings of the 2021 IEEE/ACM Symposium on Edge Computing (SEC), San Jose, CA, USA, 14–17 December 2021; pp. 148–164. [Google Scholar]
- Li, X.; Cho, B.; Xiao, Y. Balancing latency and accuracy on deep video analytics at the edge. In Proceedings of the 2022 IEEE 19th Annual Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 8–11 January 2022; pp. 299–306. [Google Scholar]
- Ong, K.S.H.; Niyato, D.; So-In, C.; Friedrichs, T. Accelerating low-cost edge-based real-time video analytics using task scheduling. In Proceedings of the 2021 IEEE 7th World Forum on Internet of Things (WF-IoT), New Orleans, LA, USA, 14 June–31 July 2021; pp. 598–603. [Google Scholar]
- Guo, J.; Xia, S.; Peng, C. Vpplus: Exploring the potentials of video processing for live video analytics at the edge. In Proceedings of the 2022 IEEE/ACM 30th International Symposium on Quality of Service (IWQoS), Oslo, Norway, 10–12 June 2022; pp. 1–11. [Google Scholar]
- Lin, J.; Yang, P.; Wu, W.; Zhang, N.; Han, T.; Yu, L. Edge learning for low-latency video analytics: Query scheduling and resource allocation. In Proceedings of the 2021 IEEE 18th International Conference on Mobile Ad Hoc and Smart Systems (MASS), Denver, CO, USA, 4–7 October 2021; pp. 252–259. [Google Scholar]
- Hwang, J.; Kim, M.; Kim, D.; Nam, S.; Kim, Y.; Kim, D.; Sharma, H.; Park, J. CoVA: Exploiting Compressed-Domain analysis to accelerate video analytics. In Proceedings of the 2022 USENIX Annual Technical Conference (USENIX ATC 22), Carlsbad, CA, USA, 11–13 July 2022; pp. 707–722. [Google Scholar]
- Zhang, Y.; Wang, X.; Wen, J.; Zhu, X. WiFi-based non-contact human presence detection technology. Sci. Rep. 2024, 14, 3605. [Google Scholar] [CrossRef]
- Shen, L.H.; Hsiao, A.H.; Chu, F.Y.; Feng, K.T. Time-Selective RNN for Device-Free Multi-Room Human Presence Detection Using WiFi CSI. IEEE Trans. Instrum. Meas. 2024, 73, 2505817. [Google Scholar] [CrossRef]
- Shen, L.H.; Hsiao, A.H.; Lu, K.I.; Feng, K.T. Attention-Enhanced Deep Learning for Device-Free Through-the-Wall Presence Detection Using Indoor WiFi Systems. IEEE Sens. J. 2024, 24, 5288–5302. [Google Scholar] [CrossRef]
- Abuhoureyah, F.S.; Wong, Y.C.; Isira, A.S.B.M. WiFi-based human activity recognition through wall using deep learning. Eng. Appl. Artif. Intell. 2024, 127, 107171. [Google Scholar] [CrossRef]
- Shi, Z.; Cheng, Q.; Zhang, J.A.; Da Xu, R.Y. Environment-robust WiFi-based human activity recognition using enhanced CSI and deep learning. IEEE Internet Things J. 2022, 9, 24643–24654. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Gringoli, F.; Cominelli, M.; Blanco, A.; Widmer, J. AX-CSI: Enabling CSI extraction on commercial 802.11 ax Wi-Fi platforms. In Proceedings of the 15th ACM Workshop on Wireless Network Testbeds, Experimental evaluation & CHaracterization, New Orleans, LA, USA, 31 January–4 February 2022; pp. 46–53. [Google Scholar]
- Gringoli, F.; Schulz, M.; Link, J.; Hollick, M. Free your CSI: A channel state information extraction platform for modern Wi-Fi chipsets. In Proceedings of the 13th International Workshop on Wireless Network Testbeds, Experimental Evaluation & Characterization, Los Cabos, Mexico, 25 October 2019; pp. 21–28. [Google Scholar]
- Ma, Y.; Zhou, G.; Wang, S. WiFi sensing with channel state information: A survey. ACM Comput. Surv. CSUR 2019, 52, 1–36. [Google Scholar] [CrossRef]
- Ahmad, I.; Ullah, A.; Choi, W. WiFi-Based Human Sensing With Deep Learning: Recent Advances, Challenges, and Opportunities. IEEE Open J. Commun. Soc. 2024, 5, 3595–3623. [Google Scholar] [CrossRef]
- Kiranyaz, S.; Avci, O.; Abdeljaber, O.; Ince, T.; Gabbouj, M.; Inman, D.J. 1D convolutional neural networks and applications: A survey. Mech. Syst. Signal Process. 2021, 151, 107398. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Type | Filter/Unit | Kernel Size | Output Shape |
|---|---|---|---|---|
| 1 | Input | - | - | |
| 2 | Conv1D | 128 | 3 | |
| 3 | MaxPooling1D | - | 2 | |
| 4 | Conv1D | 128 | 1 | |
| 5 | GlobalMaxPooling1D | - | - | |
| 6 | FC | 128 | - | |
| 7 | Dropout | 0.5 | - | |
| 8 | FC | 64 | - | |
| 9 | FC | 1 | - |
| Data Collection Site | 1 | 2 | 3 |
|---|---|---|---|
| Target site | 98.1 | 97.2 | 98.4 |
| Different site | 42.8 | 43.3 | 42.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lubwama, L.; Jang, J.; Pyo, J.; Yoo, J.; Choi, J. Wi-Filter: WiFi-Assisted Frame Filtering on the Edge for Scalable and Resource-Efficient Video Analytics. Sensors 2025, 25, 701. https://doi.org/10.3390/s25030701
Lubwama L, Jang J, Pyo J, Yoo J, Choi J. Wi-Filter: WiFi-Assisted Frame Filtering on the Edge for Scalable and Resource-Efficient Video Analytics. Sensors. 2025; 25(3):701. https://doi.org/10.3390/s25030701
Chicago/Turabian StyleLubwama, Lawrence, Jungik Jang, Jisung Pyo, Joon Yoo, and Jaehyuk Choi. 2025. "Wi-Filter: WiFi-Assisted Frame Filtering on the Edge for Scalable and Resource-Efficient Video Analytics" Sensors 25, no. 3: 701. https://doi.org/10.3390/s25030701
APA StyleLubwama, L., Jang, J., Pyo, J., Yoo, J., & Choi, J. (2025). Wi-Filter: WiFi-Assisted Frame Filtering on the Edge for Scalable and Resource-Efficient Video Analytics. Sensors, 25(3), 701. https://doi.org/10.3390/s25030701