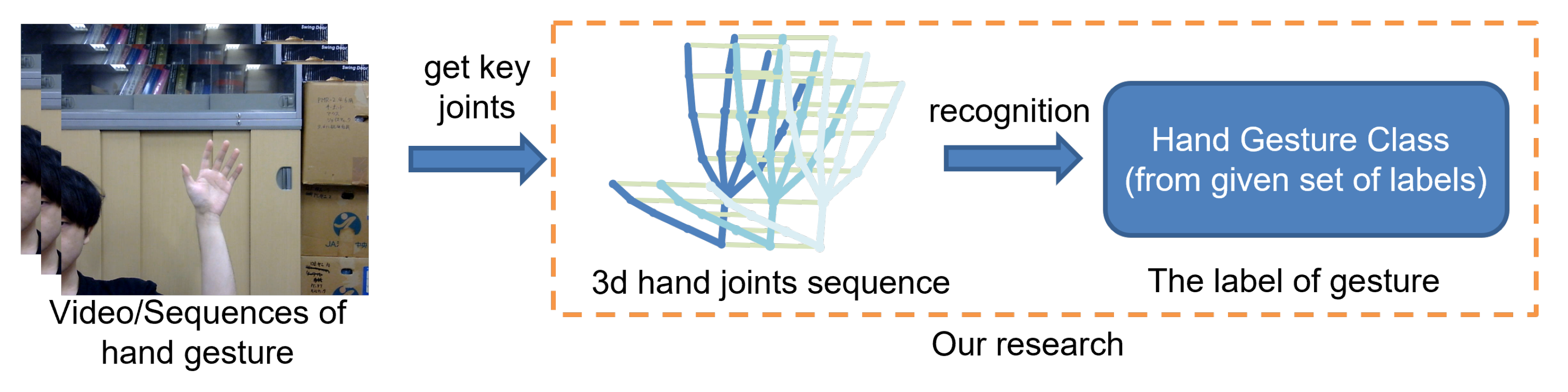
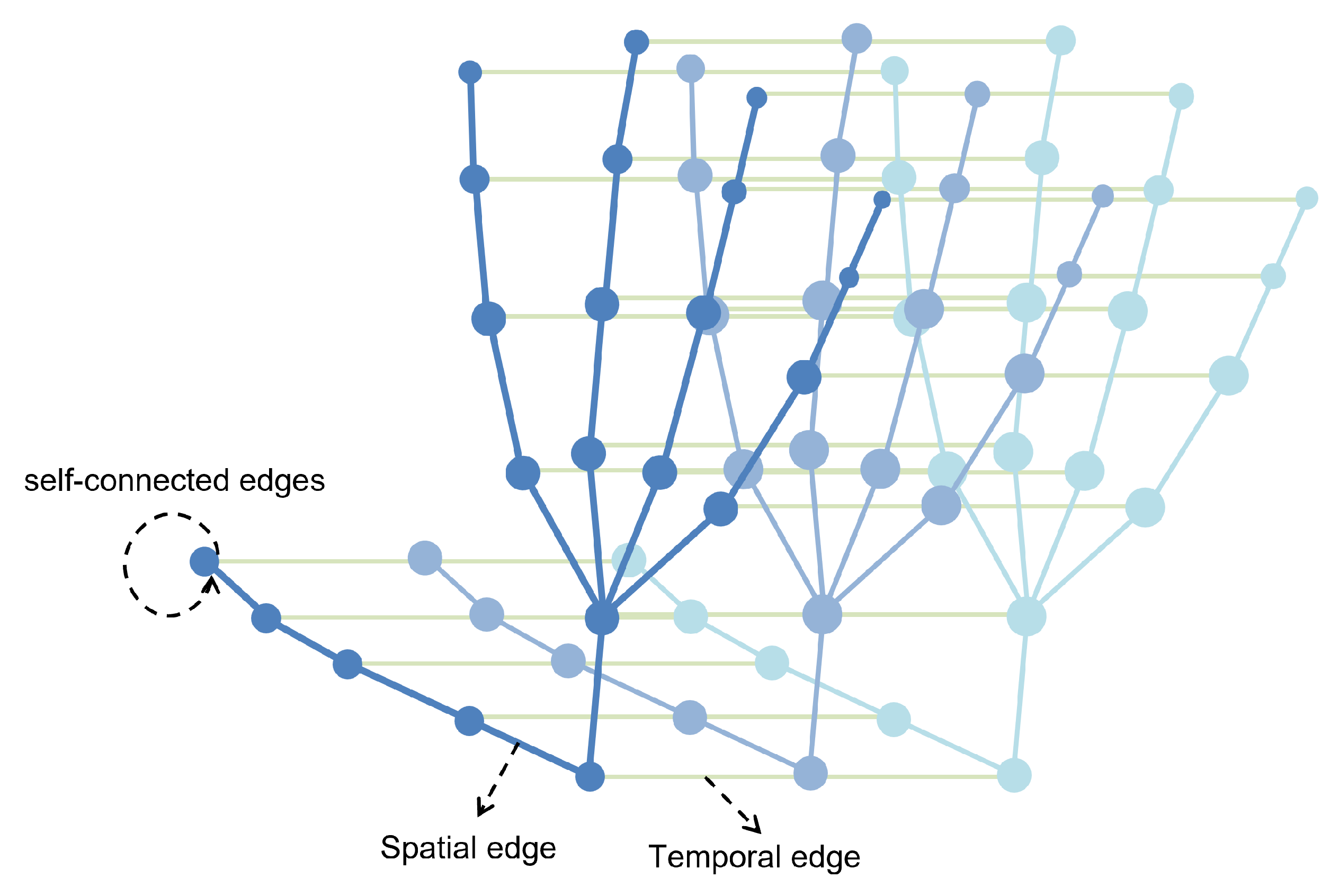
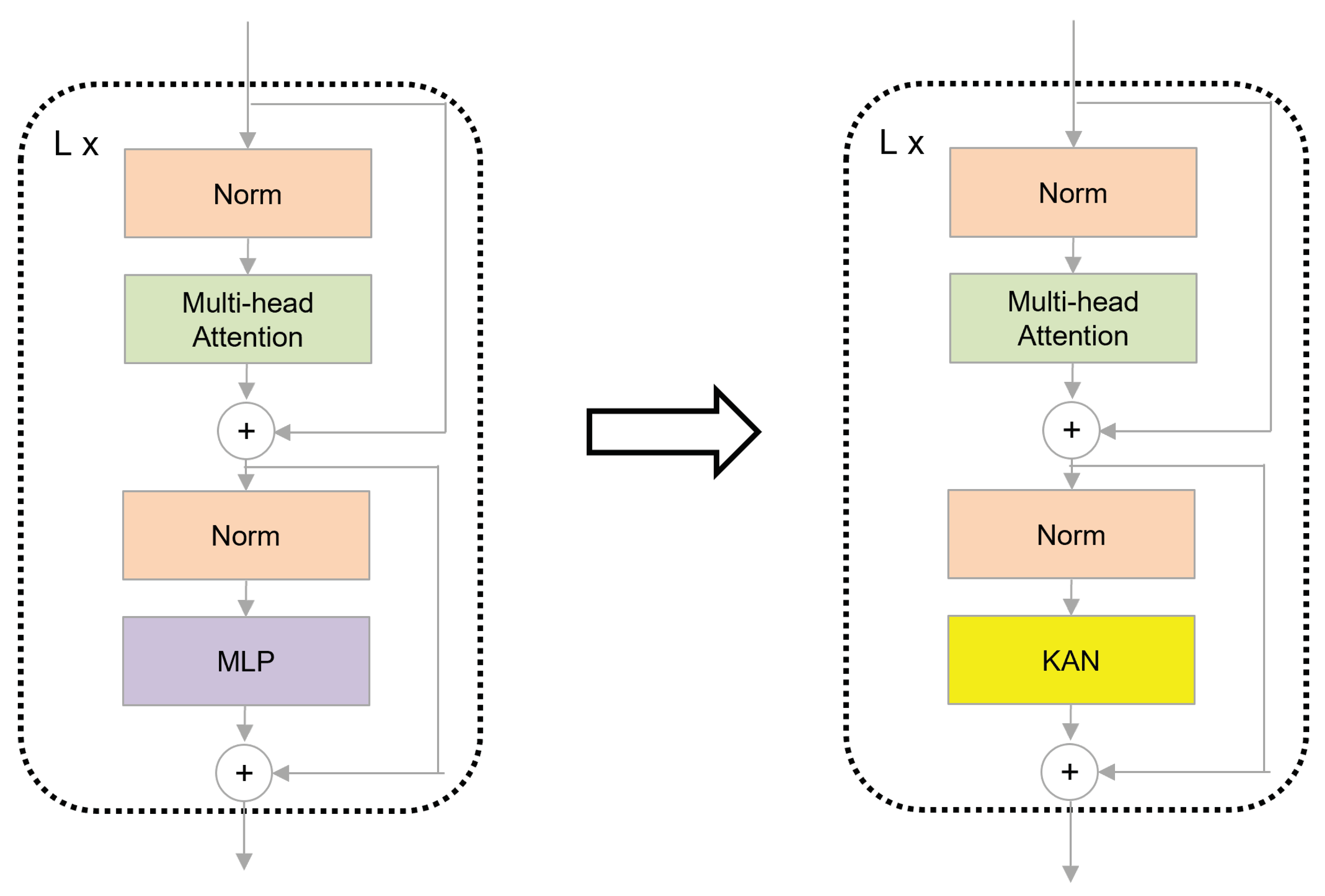
4.2. Training Details
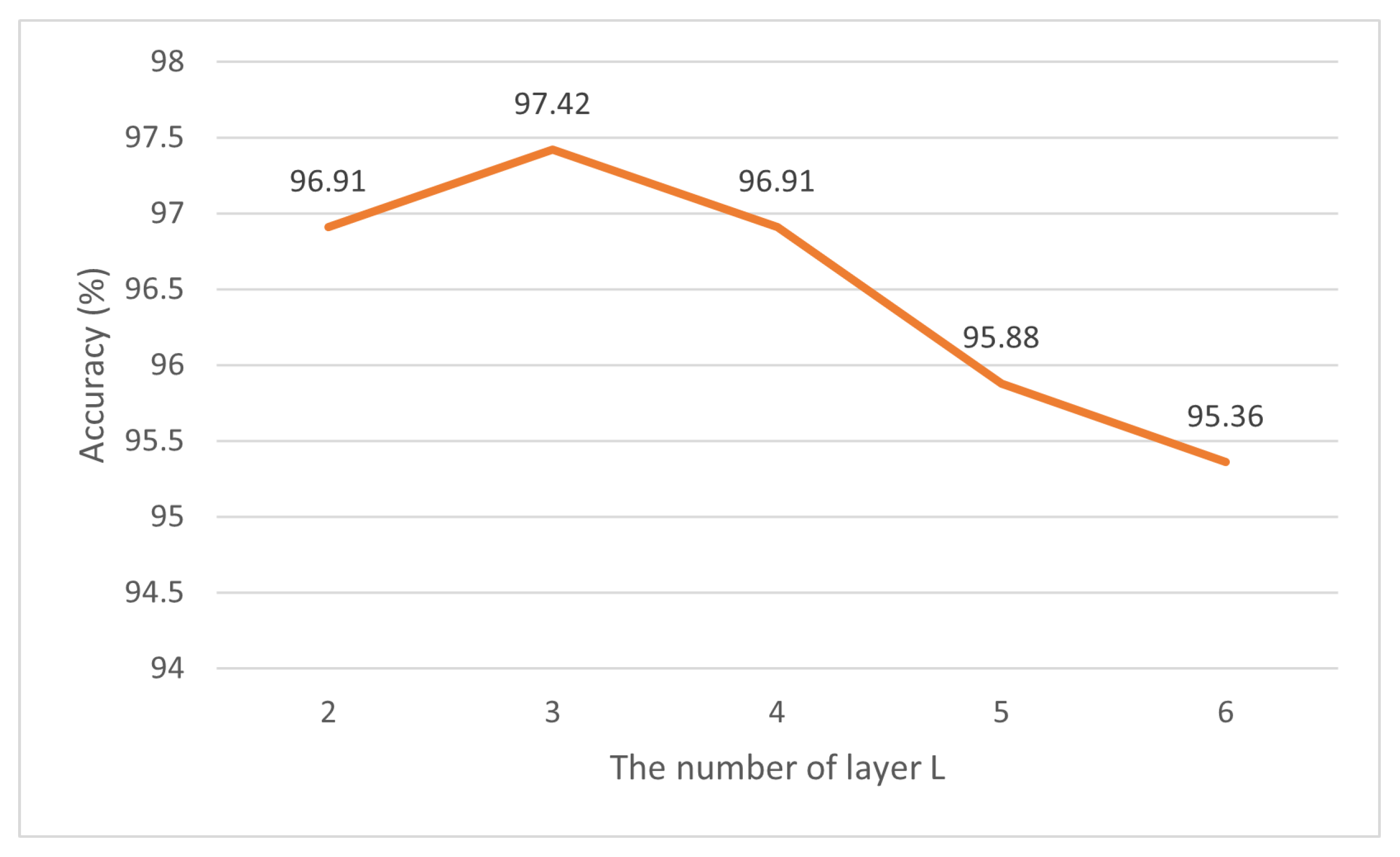
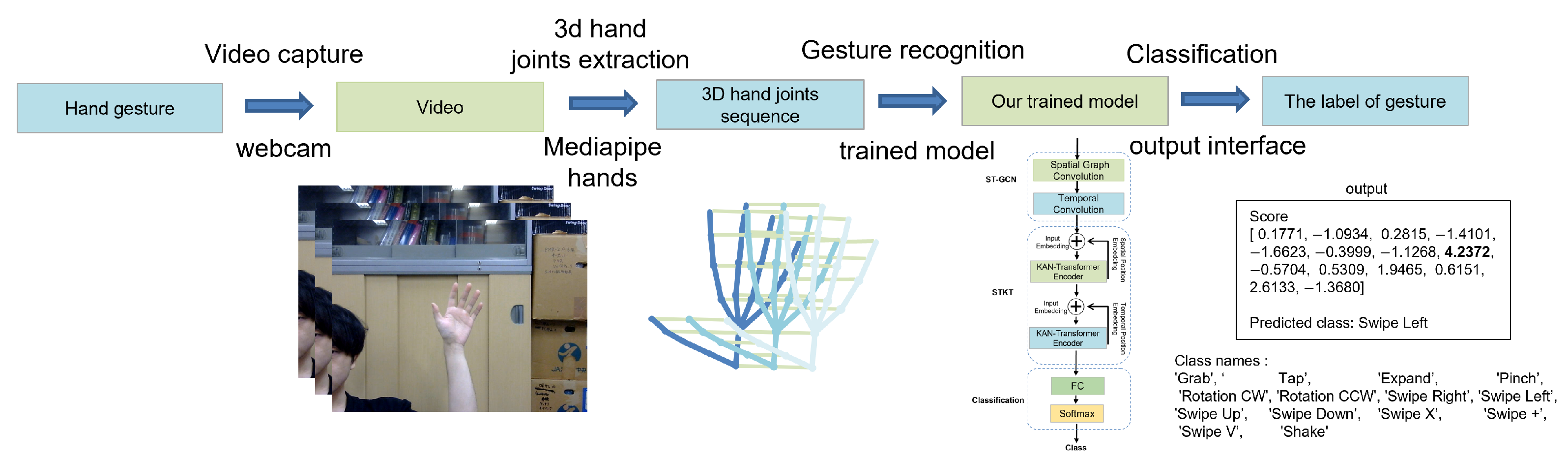
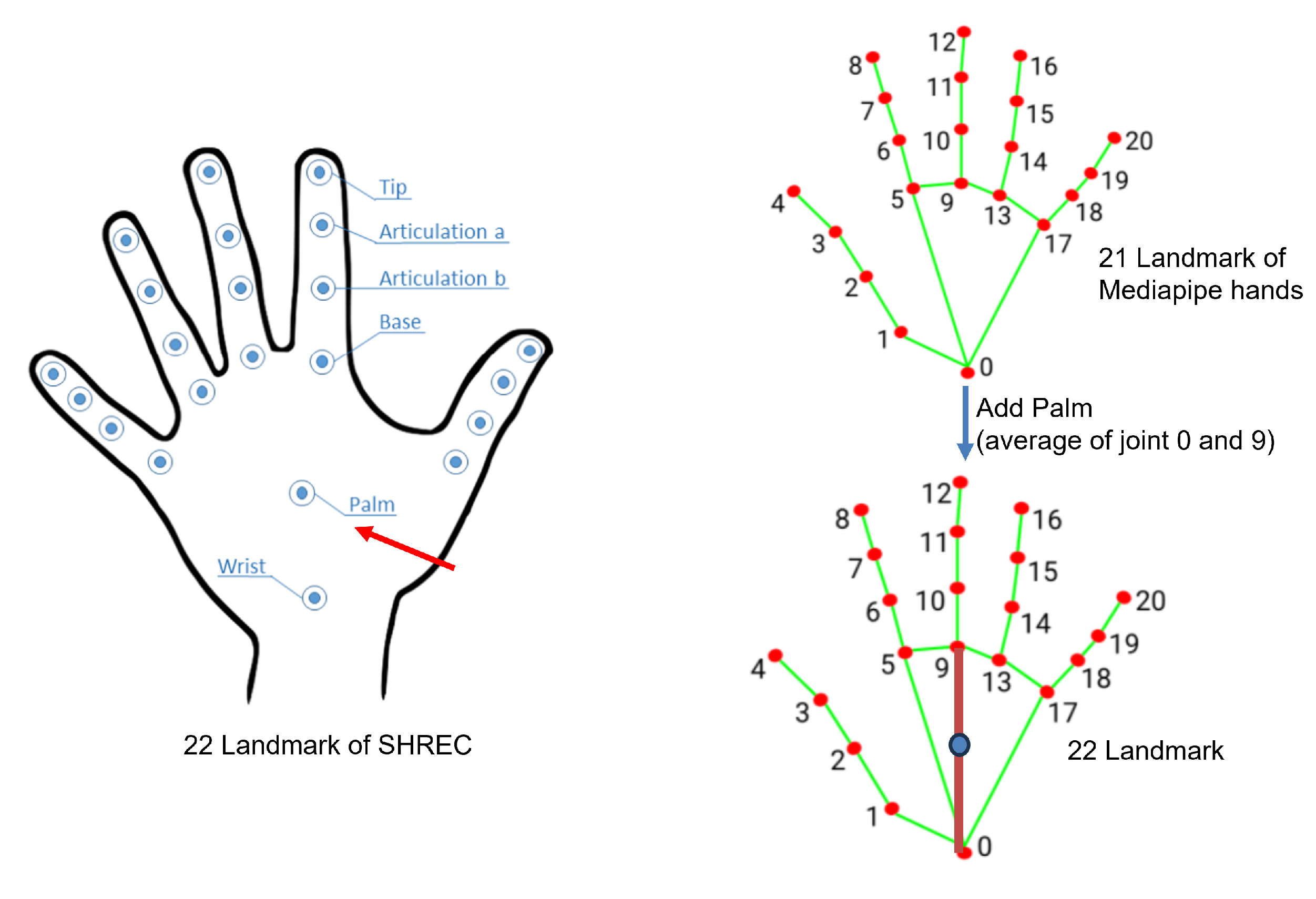
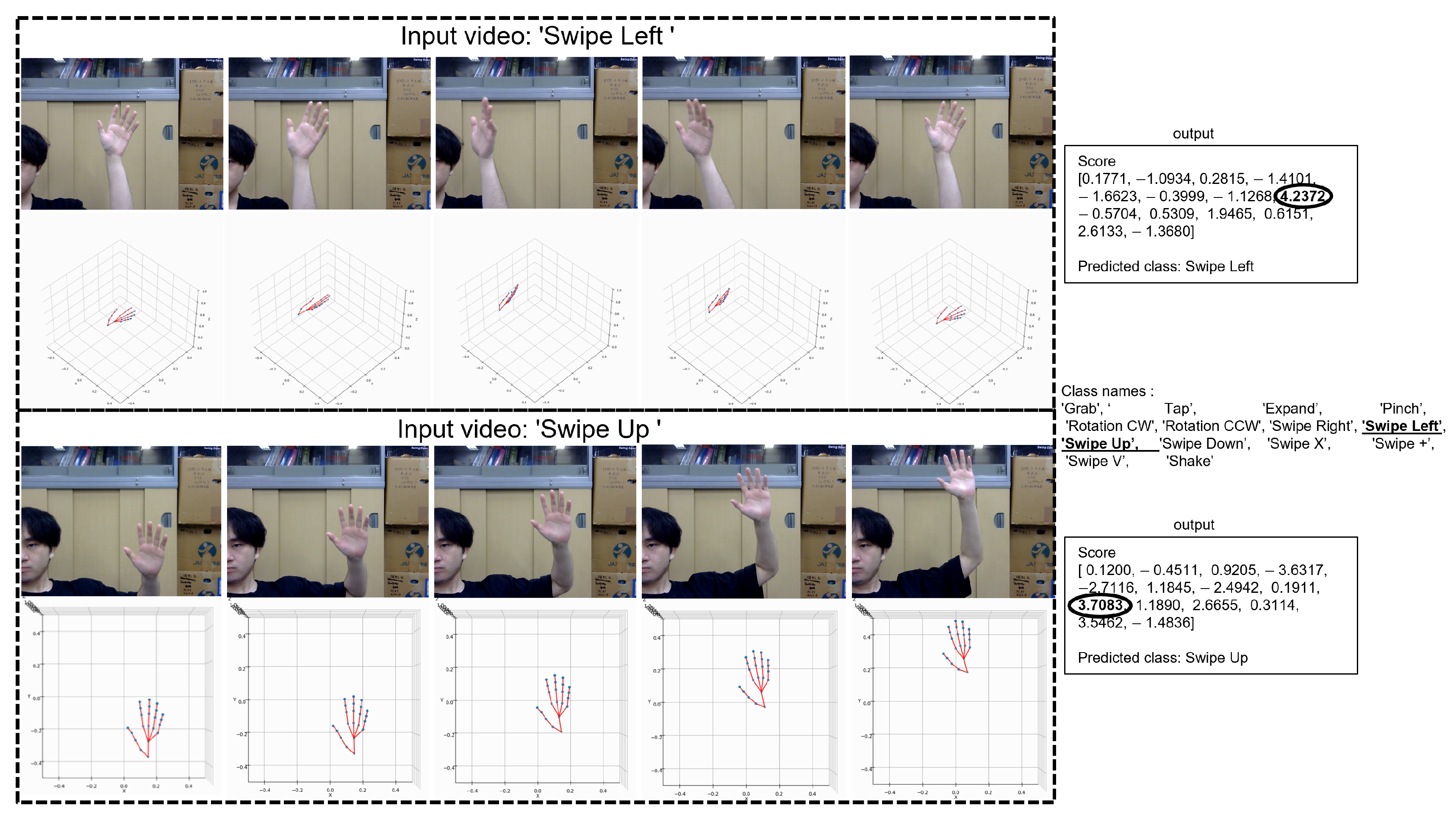
Our proposed network was implemented based on the PyTorch platform. We utilized the SDG optimizer with a Nesterov momentum of 0.9. The initial learning rate used to train our model was . During model training, we employed the Cosine-Annealing-Warm-Restarts learning rate schedule. The learning rate gradually decreased from a higher value to a lower value in a cosine curve and then returned to the initial learning rate in a new cycle. The initial restart occurred at 10 epochs, with subsequent restart intervals doubled. The minimum learning rate was set to , ensuring smooth convergence and effective learning rate adjustments throughout training. And we set the batch size to 32 with a dropout rate of 0.2. The number of encoders in our model was set to 6, with 8 heads for multi-head attention. To enhance training stability and generalization performance, we set the minimum sequence length to 180 for the SHREC’17 track and DHG datasets, and to 250 for the LMDHG dataset. We set the number of hand joints to 22 for the SHREC’17 track and DHG datasets and 46 for the LMDHG dataset.
Additionally, to enhance the robustness and generalization of our skeleton-based hand gesture recognition model, we implemented a comprehensive data augmentation strategy. This strategy is designed to simulate a wide range of realistic scenarios that the model might encounter in practical applications. The augmentation techniques employed are as follows:
Scaling: Scale the skeleton data to represent different body types. This variation addresses the diversity of human body types and ensures the model is valid across a wide range of people. We uniformly scale the coordinates of the skeleton joints by a factor randomly selected from a predefined range, simulating changes in the user’s physical size.
Shift: Shift the skeleton data horizontally and vertically to represent different initial positions relative to the sensor. This shift is performed by adding a constant offset (randomly selected from a set range) to the joint coordinates to ensure that the model remains valid regardless of the user’s position within the sensor’s field of view.
Noise injection: Real-world measurements often contain noise due to sensor inaccuracies or slight involuntary movements. We simulated these conditions by adding Gaussian noise to the skeleton joint coordinates. The noise parameters (mean and standard deviation) were chosen based on empirical observations of sensor noise characteristics in preliminary testing.
Temporal interpolation: Temporal interpolation was applied to the skeleton sequence to simulate different speeds of gesture execution. This method involves subsampling or oversampling the time frames in the sequence, speeding up or slowing down the motion. In addition, we set all input time lengths T to 180.
Rotation: Given that users may interact with the sensor from various directions, our model must be able to accurately interpret gestures from multiple angles. We achieved this by rotating the skeleton data around the vertical axis. The rotation angle is randomly selected from a specified range, allowing the model to learn and predict gestures that are not affected by changes in orientation.
During the training phase, each augmentation technique is applied individually or in combination to create a robust dataset that simulates a variety of real-world conditions. The augmented dataset significantly improves the performance of the model, especially in its ability to generalize across different users and environment settings.
4.4. Comparison with Relevant Approaches
We compared our method with relevant approaches on the SHREC’17 track dataset, DHG dataset, and LMDHG dataset. The SOTA methods include methods utilizing GCN and methods employing self-attention and a transformer. The GCN-based methods include spatio-temporal graph convolutional network methods ST-GCN (2018) [
10] and spatio-temporal dynamic attention graph convolutional network STDA-GCN (2024) [
33]. The transformer-based methods include spatio-temporal attention network methods based on dynamic graphs DG-STA (2019) [
22], decoupled spatio-temporal attention network DSTA-Net (2020) [
34], the method with multi-scale multi-head attention module proposed by Li et al. (2024) [
35], and spatial graph convolutional and temporal attention-based methods STr-GCN (2023) [
36]. The results are shown in
Table 5,
Table 6 and
Table 7.
Our model achieved an excellent accuracy of 97.5% on the 14-label dataset, outperforming the SOTA methods, and 94.1% on the 28-label dataset. This demonstrates the ability of our model to capture and analyze complex relationships and dynamic changes in skeleton sequences. In particular, the high accuracy on the 14-label dataset highlights the robustness of our model and its adaptability to various gesture complexities.
The 14-label classification task is a relatively coarse-grained classification task, and the differences between categories are more significant. The 28-label classification task is a fine-grained classification, involving subtle differences in the use of fingers in the same gesture action. This classification relies more on the identification of local details.
Our model achieved the best performance in the 14-label gesture recognition task, indicating strong overall feature extraction and modeling capabilities. Its global modeling capabilities enable it to capture the overall dynamic features of gestures well, so it performs well in this coarse-grained task. However, it may be because the feature extraction of our current model is mainly focused on the overall spatio-temporal pattern and lacks specific optimization for subtle finger movements, and it is less sensitive to local features. It performs worse than the GCN-based method on 28-label.
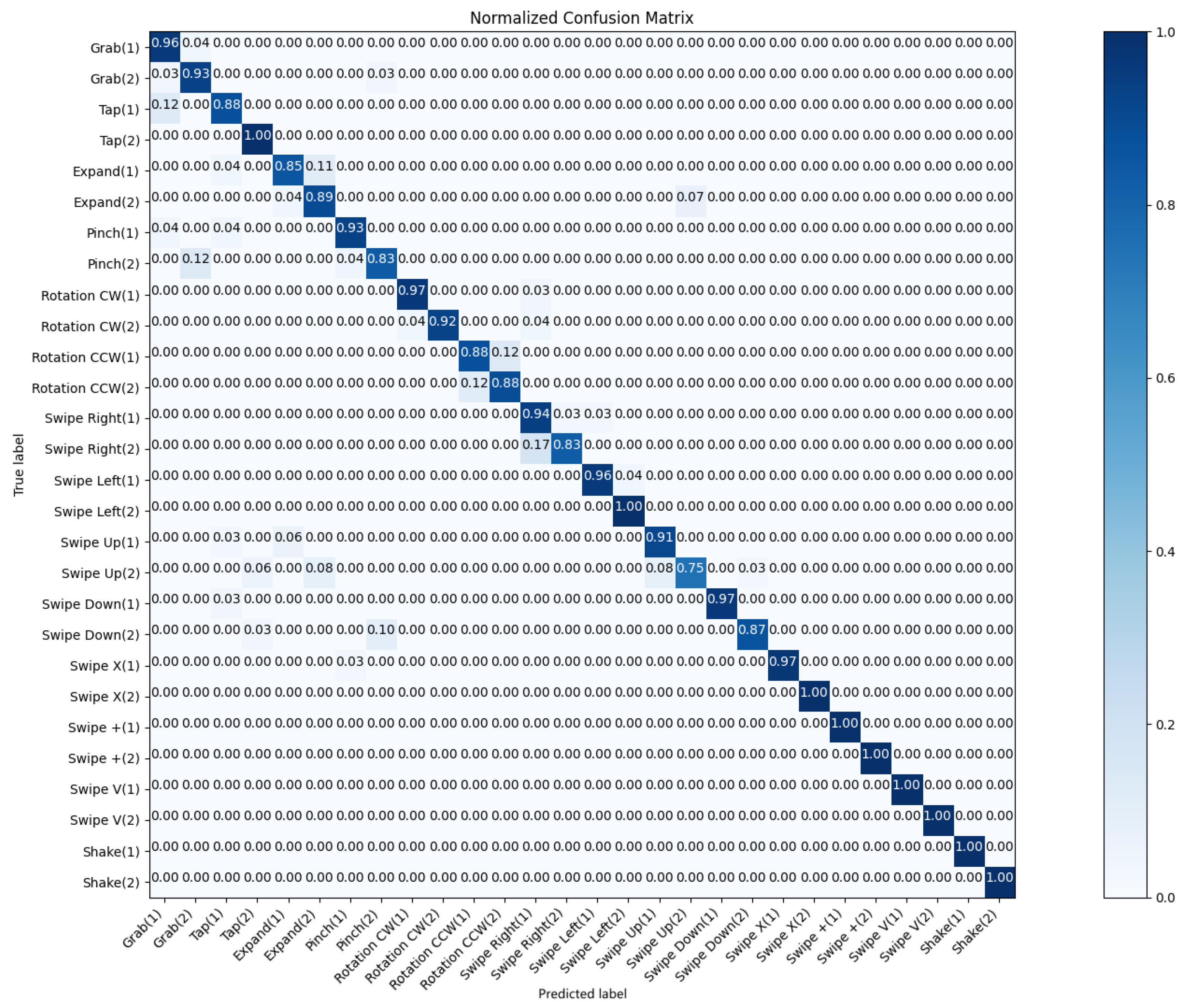
We also examined the performance of a multi-class hand gesture recognition model through the analysis of its confusion matrix. As shown in
Figure 6, the model demonstrates high overall accuracy on 14 labels, with particularly strong performance in certain classes while showing some limitations in others. The confusion matrix reveals a high level of accuracy across most classes, as evidenced by the predominantly dark blue diagonal elements. This indicates that the model is generally successful in correctly classifying the various hand gestures. The off-diagonal elements of the matrix show very low values, indicating minimal confusion between different classes. This suggests that the model successfully learned to differentiate between the various hand gestures with high precision.
Several classes showed near-perfect recognition rates, and the majority of classes demonstrated strong performance with accuracy rates above 0.90. While still showing good performance, the Pinch class had a slightly lower accuracy (0.90) compared to other hand gestures. This may indicate that Pinch gestures share some features similar to those of other classes, making them marginally more challenging to distinguish. In addition, by analyzing the gesture sequences of the dataset, we believe that there are two main reasons: (a) measurement errors caused by inaccurate skeletal joint collection and (b) limitation of sample number.
As shown in
Figure 7, the confusion matrix for the hand gesture recognition model with 28 labels reveals both its strengths and areas needing improvement. The matrix’s diagonal, representing correctly classified gestures, indicates a high overall accuracy, suggesting the model’s effectiveness in recognizing diverse gestures.
Our model faced challenges in differentiating between certain gesture pairs, such as “Grab” and “pinch”, and “swipe up” and “expand”. These confusions may arise from the visual or dynamic similarities between these gestures.
When dealing with inter-category confusion, our model exhibited confusion within specific categories, notably “Rotation CCW” and “swipe left”. This indicates the need for more refined feature extraction to capture subtle differences within gesture categories.
Our proposed model achieved an accuracy of 94.3% on the DHG-14 dataset, surpassing the best performance of the STDA-GCN model, and achieved 91.0% on DHG-28. This demonstrates that our model is able to capture complex spatio-temporal patterns and interactions in skeletal sequences more effectively. The superior performance, particularly on the DHG-14 dataset, underscores the robustness and adaptability of our model to variations in the dataset.
The results in the table highlight the effectiveness of our model in handling complex hand gesture recognition tasks. Despite the slower training speed, the model’s performance indicates strong generalization capabilities, especially when faced with diverse and new data. This trade-off between model size and accuracy suggests that our approach is well-suited for applications where a high recognition accuracy is paramount, even if computational resources are less constrained.
We compare our method with related methods on the LMDHG dataset. The state-of-the-art methods include the framework MMEGRN (2023) [
39], which combines multiple sub-networks (ConvLSTM, TCN, and 3DCNN); the spatio-temporal deep convolutional LSTM model DConvLSTM (2021) [
40]; and the method based on 3D pattern assembled trajectories proposed by Boulahia et al. (2017) [
14]. The results are shown in
Table 7.
Table 7.
Recognition accuracy comparison with state-of-the-art methods on LMDHG dataset. The best results are shown in bold.
Table 7.
Recognition accuracy comparison with state-of-the-art methods on LMDHG dataset. The best results are shown in bold.
| Model | Acc on LMDHG (%) |
|---|
| Boulahia et al. (2017) [14] | 84.78 |
| DConvLSTM (2021) [40] | 93.81 |
| MMEGRN (2023) [39] | 95.88 |
| Ours | 97.42 |
Our proposed model achieved the highest accuracy of 97.42% on the LMDHG dataset, which is 1.54% higher than the MMEGRN method. MMEGRN combines ConvLSTM, TCN, and 3DCNN with classifiers to improve the accuracy of skeleton hand gesture recognition. By combining various feature extraction and classification techniques, MMEGRN effectively captures and classifies dynamic changes in skeletal sequences, achieving superior performance compared to previous methods. However, for this dataset with significant differences between categories, our proposed method leverages its powerful overall feature extraction and modeling capabilities to achieve a more comprehensive feature representation.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}