
Towards Predictive Communication: The Fusion of Large Language Models and Brain–Computer Interface


Abstract
1. Introduction
2. Predictive Writing: Intelligent Text Entry Systems
2.1. Early Language Models in Predictive Writing
2.2. Large Language Models in Predictive Writing
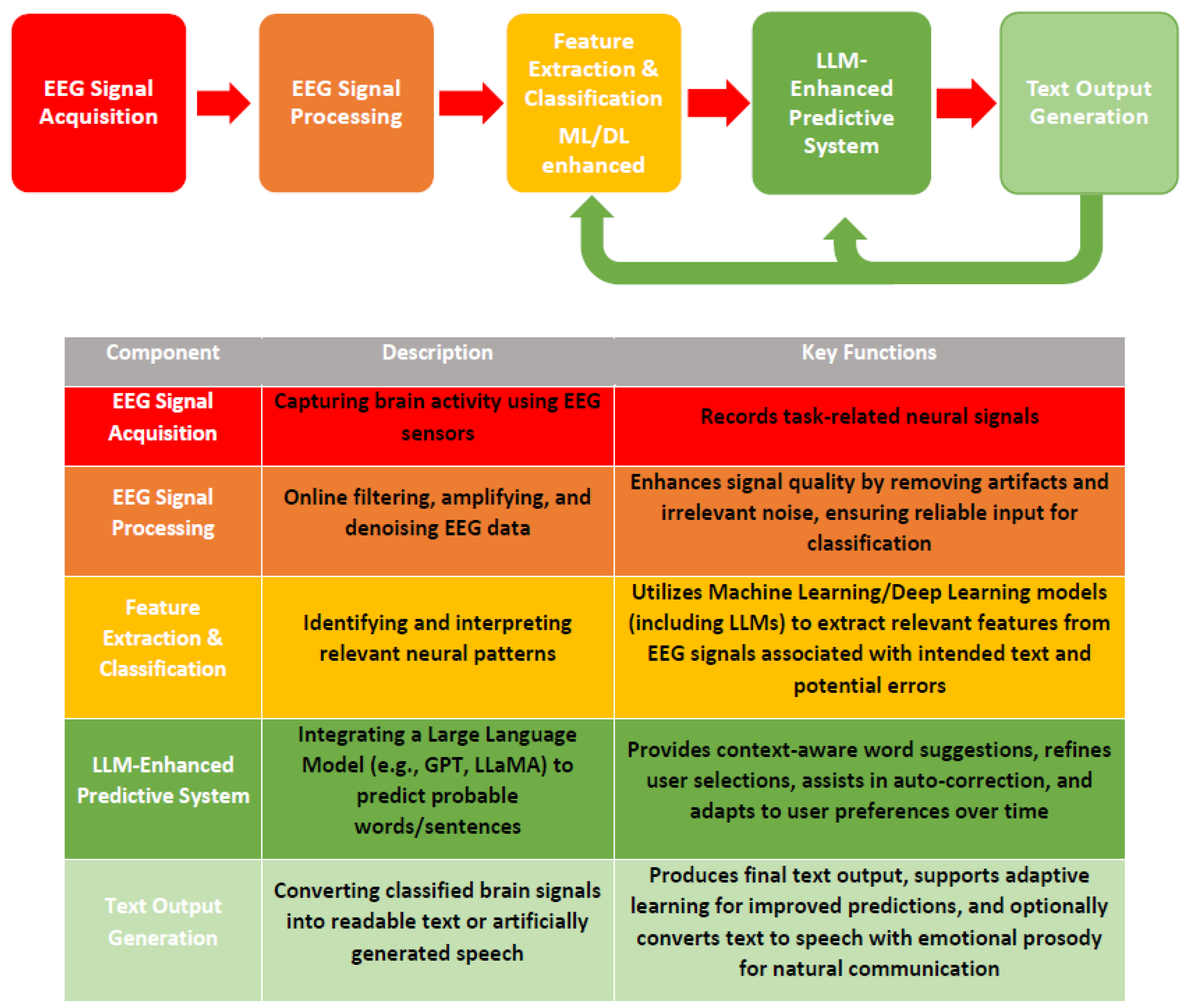
3. Language Models and Brain–Computer Interfaces
3.1. Integration of Early Language Models with BCI Spellers
3.2. Integration of Large Language Models with BCI Spellers
4. Discussion
4.1. Key Challenges for the Integration of LLMs with BCI Spellers

{kind=link}
| Model | Training Data Size 1 | Feature Engineering 2 | Model Complexity 3 | Interpretability 4 | Performance 5 | Hardware Requirements 6 |
|---|---|---|---|---|---|---|
| GPT-3 | ~570 GB of text data | Minimal manual feature engineering; relies on extensive unsupervised learning | 175 billion parameters | Low; operates as a black-box model | High performance across diverse NLP tasks | Requires substantial computational resources for training and inference |
| GPT-2 | ~40 GB of text data | Minimal manual feature engineering; utilizes unsupervised learning | 1.5 billion parameters | Low; similar black-box characteristics as GPT-3 | Competent performance on various NLP tasks, though less capable than GPT-3 | Moderate hardware requirements; more accessible than GPT-3 |
| BERT | Trained on 16 GB of text data | Incorporates tokenization and context handling; designed for bidirectional context understanding | 340 million parameters | Moderate; allows for some interpretability through attention mechanisms | Excels in tasks requiring an understanding of context within sentences | Lower hardware requirements; feasible for deployment on consumer-grade GPUs |
| RoBERTa | Trained on 160 GB of text data | Builds upon BERT with optimized training approaches and larger data volume | 355 million parameters | Moderate; retains interpretability features similar to BERT | Outperforms BERT on several NLP benchmarks due to enhanced training | Requires more computational power than BERT but remains manageable |
| T5 | Trained on 120 TB of text data | Treats all NLP tasks as text-to-text transformations; requires task-specific input formatting | 11 billion parameters | Low; complexity increases with model size, reducing transparency | High versatility across a wide range of NLP tasks | Demands significant computational resources, though less than GPT-3 |
| XLNet | Trained on billions of words | Integrates permutation-based training to capture bidirectional contexts | 340 million parameters | Moderate; attention mechanisms provide some level of interpretability | Achieves strong performance on tasks involving contextual understanding | Comparable hardware requirements to BERT and RoBERTa |
| Llama 2 | Trained on 2 trillion tokens | Utilizes advanced training techniques with a focus on efficiency | Model sizes up to 65 billion parameters | Low; large-scale models with limited transparency | Demonstrates robust performance across various applications | High hardware demands, though optimized for better efficiency than some counterparts |
| Llama 3 | Trained on up to 15 trillion tokens | Incorporates extensive pre-training and human fine-tuning | Model sizes up to 405 billion parameters | Low; complexity and scale limit interpretability | Superior performance, handling complex tasks, and supporting multiple languages | Exponentially higher hardware and training intensity compared to Llama 2 |
| DeepSeek R1 | Not specified | Employs reinforcement learning and a “mixture of experts” approach | 671 billion parameters, with selective activation reducing active parameter count to 37 billion for each token | Moderate; the “mixture of experts” method may offer enhanced interpretability | Recognized for superior performance in tasks like math and coding | Reduced power and processing needs; operates effectively on less advanced hardware |
| Model * | Accuracy 1 | Calibration 2 | Robustness 3 | Efficiency 4 |
|---|---|---|---|---|
| GPT-4 | 10 | 8 | 10 | 3 |
| GPT-3 | 8 | 6 | 8 | 3 |
| BERT | 6 | 8 | 8 | 7 |
| RoBERTa | 7 | 8 | 9 | 6 |
| T5 | 8 | 8 | 6 | 6 |
| Llama 2 | 8 | 6 | 8 | 8 |
| Llama 3 | 10 | 8 | 10 | 8 |
| DeepSeek R1 | 8 | 6 | 6 | 10 |
4.1.1. Communication Error Correction
4.1.2. Patient-Centered Communication Perspective
4.1.3. LLMs for Brain Decoding in BCI Spellers
4.2. Other LLM-BCI Applications
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Edelman, B.J.; Zhang, S.; Schalk, G.; Brunner, P.; Muller-Putz, G.; Guan, C.; He, B. Non-invasive Brain-Computer Interfaces: State of the Art and Trends. IEEE Rev. Biomed. Eng. 2024, 18, 26–49. [Google Scholar] [CrossRef] [PubMed]
- Wolpaw, J.R.; Birbaumer, N.; McFarland, D.J.; Pfurtscheller, G.; Vaughan, T.M. Brain-computer interfaces for communication and control. Clin. Neurophysiol. 2002, 113, 767–791. [Google Scholar] [CrossRef] [PubMed]
- Birbaumer, N. Breaking the silence: Brain-computer interfaces (BCI) for communication and motor control. Psychophysiology 2006, 43, 517–532. [Google Scholar] [CrossRef] [PubMed]
- Chaudhary, U.; Birbaumer, N.; Ramos-Murguialday, A. Brain-computer interfaces in the completely locked-in state and chronic stroke. Prog. Brain Res. 2016, 228, 131–161. [Google Scholar] [CrossRef]
- Chaudhary, U.; Birbaumer, N.; Ramos-Murguialday, A. Brain-computer interfaces for communication and rehabilitation. Nat. Rev. Neurol. 2016, 12, 513–525. [Google Scholar] [CrossRef]
- Chaudhary, U.; Vlachos, I.; Zimmermann, J.B.; Espinosa, A.; Tonin, A.; Jaramillo-Gonzalez, A.; Khalili-Ardali, M.; Topka, H.; Lehmberg, J.; Friehs, G.M.; et al. Spelling interface using intracortical signals in a completely locked-in patient enabled via auditory neurofeedback training. Nat. Commun. 2022, 13, 1236. [Google Scholar] [CrossRef]
- Moses, D.A.; Metzger, S.L.; Liu, J.R.; Anumanchipalli, G.K.; Makin, J.G.; Sun, P.F.; Chartier, J.; Dougherty, M.E.; Liu, P.M.; Abrams, G.M.; et al. Neuroprosthesis for Decoding Speech in a Paralyzed Person with Anarthria. N. Engl. J. Med. 2021, 385, 217–227. [Google Scholar] [CrossRef]
- Metzger, S.L.; Liu, J.R.; Moses, D.A.; Dougherty, M.E.; Seaton, M.P.; Littlejohn, K.T.; Chartier, J.; Anumanchipalli, G.K.; Tu-Chan, A.; Ganguly, K.; et al. Generalizable spelling using a speech neuroprosthesis in an individual with severe limb and vocal paralysis. Nat. Commun. 2022, 13, 6510. [Google Scholar] [CrossRef] [PubMed]
- Wairagkar, M.; Card, N.S.; Singer-Clark, T.; Hou, X.; Iacobacci, C.; Miller, L.M.; Hochberg, L.R.; Brandman, D.M.; Stavisky, S.D. An instantaneous voice-synthesis neuroprosthesis. Nature 2025. [Google Scholar] [CrossRef]
- Willett, F.R.; Avansino, D.T.; Hochberg, L.R.; Henderson, J.M.; Shenoy, K.V. High-performance brain-to-text communication via handwriting. Nature 2021, 593, 249–254. [Google Scholar] [CrossRef]
- Metzger, S.L.; Littlejohn, K.T.; Silva, A.B.; Moses, D.A.; Seaton, M.P.; Wang, R.; Dougherty, M.E.; Liu, J.R.; Wu, P.; Berger, M.A.; et al. A high-performance neuroprosthesis for speech decoding and avatar control. Nature 2023, 620, 1037–1046. [Google Scholar] [CrossRef] [PubMed]
- Littlejohn, K.T.; Cho, C.J.; Liu, J.R.; Silva, A.B.; Yu, B.; Anderson, V.R.; Kurtz-Miott, C.M.; Brosler, S.; Kashyap, A.P.; Hallinan, I.P.; et al. A streaming brain-to-voice neuroprosthesis to restore naturalistic communication. Nat. Neurosci. 2025, 28, 902–912. [Google Scholar] [CrossRef] [PubMed]
- Silva, A.B.; Liu, J.R.; Metzger, S.L.; Bhaya-Grossman, I.; Dougherty, M.E.; Seaton, M.P.; Littlejohn, K.T.; Tu-Chan, A.; Ganguly, K.; Moses, D.A.; et al. A bilingual speech neuroprosthesis driven by cortical articulatory representations shared between languages. Nat. Biomed. Eng. 2024, 8, 977–991. [Google Scholar] [CrossRef]
- Défossez, A.; Caucheteux, C.; Rapin, J.; Kabeli, O.; King, J.R. Decoding speech perception from non-invasive brain recordings. Nat. Mach. Intell. 2023, 5, 1097–1107. [Google Scholar] [CrossRef]
- Nieto, N.; Peterson, V.; Rufiner, H.L.; Kamienkowski, J.E.; Spies, R. Thinking out loud, an open-access EEG-based BCI dataset for inner speech recognition. Sci. Data 2022, 9, 52. [Google Scholar] [CrossRef]
- Zhang, Z.; Ding, X.; Bao, Y.; Zhao, Y.; Liang, X.; Qin, B.; Liu, T. Chisco: An EEG-based BCI dataset for decoding of imagined speech. Sci. Data 2024, 11, 1265. [Google Scholar] [CrossRef]
- Anumanchipalli, G.K.; Chartier, J.; Chang, E.F. Speech synthesis from neural decoding of spoken sentences. Nature 2019, 568, 493–498. [Google Scholar] [CrossRef]
- Chen, X.; Wang, Y.; Nakanishi, M.; Gao, X.; Jung, T.P.; Gao, S. High-speed spelling with a noninvasive brain-computer interface. Proc. Natl. Acad. Sci. USA 2015, 112, E6058–E6067. [Google Scholar] [CrossRef]
- Nagel, S.; Spuler, M. World’s fastest brain-computer interface: Combining EEG2Code with deep learning. PLoS ONE 2019, 14, e0221909. [Google Scholar] [CrossRef]
- Nagel, S.; Spuler, M. Asynchronous non-invasive high-speed BCI speller with robust non-control state detection. Sci. Rep. 2019, 9, 8269. [Google Scholar] [CrossRef]
- Speier, W.; Arnold, C.; Pouratian, N. Integrating language models into classifiers for BCI communication: A review. J. Neural Eng. 2016, 13, 031002. [Google Scholar] [CrossRef] [PubMed]
- Mora-Cortes, A.; Manyakov, N.V.; Chumerin, N.; Van Hulle, M.M. Language model applications to spelling with Brain-Computer Interfaces. Sensors 2014, 14, 5967–5993. [Google Scholar] [CrossRef] [PubMed]
- Speier, W.; Arnold, C.W.; Deshpande, A.; Knall, J.; Pouratian, N. Incorporating advanced language models into the P300 speller using particle filtering. J. Neural Eng. 2015, 12, 046018. [Google Scholar] [CrossRef] [PubMed]
- Blank, I.A. What are large language models supposed to model? Trends Cogn. Sci. 2023, 27, 987–989. [Google Scholar] [CrossRef]
- Mahowald, K.; Ivanova, A.A.; Blank, I.A.; Kanwisher, N.; Tenenbaum, J.B.; Fedorenko, E. Dissociating language and thought in large language models. Trends Cogn. Sci. 2024, 28, 517–540. [Google Scholar] [CrossRef]
- Raiaan, M.A.K.; Mukta, M.S.H.; Fatema, K.; Fahad, N.M.; Sakib, S.; Mim, M.M.J.; Ahmad, J.; Ali, M.E.; Azam, S. A Review on Large Language Models: Architectures, Applications, Taxonomies, Open Issues and Challenges. IEEE Access 2024, 12, 26839–26874. [Google Scholar] [CrossRef]
- Liu, S.; Smith, D.A. Adapting Transformer Language Models for Predictive Typing in Brain-Computer Interfaces. arXiv 2023, arXiv:2305.03819. [Google Scholar]
- Cai, S.; Venugopalan, S.; Seaver, K.; Xiao, X.; Tomanek, K.; Jalasutram, S.; Morris, M.R.; Kane, S.; Narayanan, A.; MacDonald, R.L.; et al. Using large language models to accelerate communication for eye gaze typing users with ALS. Nat. Commun. 2024, 15, 9449. [Google Scholar] [CrossRef]
- Caria, A. Integrating Large Language Models and Brain Decoding for Augmented Human-Computer Interaction: A Prototype LLM-P3-BCI Speller. Lecture Notes in Networks and Systems. In Proceedings of the Future of Information and Communication Conference, Berlin, Germany, 27–28 April 2025; p. 1283. [Google Scholar]
- Darragh, J.J.; Witten, I.H.; James, M.L. The Reactive Keyboard—A Predictive Typing Aid. Computer 1990, 23, 41–49. [Google Scholar] [CrossRef]
- Arnold, K.C.; Gajos, K.Z.; Kalai, A.T. On Suggesting Phrases vs. Predicting Words for Mobile Text Composition. In Proceedings of the Uist 2016: Proceedings of the 29th Annual Symposium on User Interface Software and Technology, Tokyo, Japan, 16–19 October 2016; pp. 603–608. [Google Scholar] [CrossRef]
- Quinn, P.; Zhai, S.M. A Cost-Benefit Study of Text Entry Suggestion Interaction. In Proceedings of the 34th Annual Chi Conference on Human Factors in Computing Systems, Chi 2016, San Jose, CA, USA, 7–12 May 2016; pp. 83–88. [Google Scholar] [CrossRef]
- Rosenfeld, R. Two decades of statistical language modeling: Where do we go from here? Proc. IEEE 2000, 88, 1270–1278. [Google Scholar] [CrossRef]
- Jurafsky, D.; Martin, J.H. N-Gram Language Models. Speech and Language Processing. Available online: https://web.stanford.edu/~jurafsky/slp3/ (accessed on 12 June 2025).
- Brown, P.F.; Della Pietra, V.J.; Desouza, P.V.; Lai, J.C.; Mercer, R.L. Class-based n-gram models of natural language. Comput. Linguist. 1992, 18, 467–480. [Google Scholar]
- Bengio, Y.; Senecal, J.S. Adaptive importance sampling to accelerate training of a neural probabilistic language model. IEEE Trans. Neural Netw. A Publ. IEEE Neural Netw. Counc. 2008, 19, 713–722. [Google Scholar] [CrossRef] [PubMed]
- Mesnil, G.; He, X.D.; Deng, L.; Bengio, Y. Investigation of Recurrent-Neural-Network Architectures and Learning Methods for Spoken Language Understanding. In Proceedings of the Interspeech 2013, Lyon, France, 25–29 August 2013; pp. 3738–3742. [Google Scholar] [CrossRef]
- Jozefowicz, R.; Vinyals, O.; Schuster, M.; Shazeer, N.; Wu, Y. Exploring the Limits of Language Modeling. arXiv 2016, arXiv:1602.02410. [Google Scholar]
- Vertanen, K.; Memmi, H.; Emge, J.; Reyal, S.; Kristensson, P.O. VelociTap: Investigating Fast Mobile Text Entry using Sentence-Based Decoding of Touchscreen Keyboard Input. In Proceedings of the Chi 2015: Proceedings of the 33rd Annual Chi Conference on Human Factors in Computing Systems, Seoul, Republic of Korea, 18–23 April 2015; pp. 659–668. [Google Scholar] [CrossRef]
- Vertanen, K.; Fletcher, C.; Gaines, D.; Gould, J.; Kristensson, P.O. The Impact of Word, Multiple Word, and Sentence Input on Virtual Keyboard Decoding Performance. In Proceedings of the 2018 Chi Conference on Human Factors in Computing Systems (Chi 2018), Montreal, QC, Canada, 21–26 April 2018. [Google Scholar] [CrossRef]
- Fiannaca, A.; Paradiso, A.; Shah, M.; Morris, M.R. AACrobat: Using Mobile Devices to Lower Communication Barriers and Provide Autonomy with Gaze-Based AAC. In Proceedings of the Cscw’17: Proceedings of the 2017 Acm Conference on Computer Supported Cooperative Work and Social Computing, Portland, OR, USA, 25 February–1 March 2017; pp. 683–695. [Google Scholar] [CrossRef]
- Kannan, A.; Kurach, K.; Ravi, S.; Kaufmann, T.; Tomkins, A.; Miklos, B.; Corrado, G.; Lukács, L.; Ganea, M.; Young, P.; et al. Smart Reply: Automated Response Suggestion for Email. In Proceedings of the Kdd’16: Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 955–964. [Google Scholar] [CrossRef]
- Chen, M.X.; Lee, B.N.; Bansal, G.; Cao, Y.; Zhang, S.Y.; Lu, J.; Tsay, J.; Wang, Y.A.; Dai, A.M.; Chen, Z.F.; et al. Gmail Smart Compose: Real-Time Assisted Writing. In Proceedings of the Kdd’19: Proceedings of the 25th Acm Sigkdd International Conferencce on Knowledge Discovery and Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2287–2295. [Google Scholar] [CrossRef]
- Thirunavukarasu, A.J.; Ting, D.S.J.; Elangovan, K.; Gutierrez, L.; Tan, T.F.; Ting, D.S.W. Large language models in medicine. Nat. Med. 2023, 29, 1930–1940. [Google Scholar] [CrossRef]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models are Unsupervised Multitask Learners. OpenAi 2019, 1, 9. [Google Scholar]
- Bowman, S.R. Eight Things to Know about Large Language Models. arXiv 2023, arXiv:2304.00612. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.0376. [Google Scholar]
- Chang, Y.; Wang, X.; Wang, J.; Wu, Y.; Yang, L.; Zhu, K.; Chen, H.; Yi, X.; Wang, C.; Wan, Y.; et al. A survey on evaluation of large language models. ACM Trans. Intell. Syst. Technol. 2024, 15, 1–45. [Google Scholar] [CrossRef]
- Ni, X.; Li, P. A Systematic Evaluation of Large Language Models for Natural Language Generation Tasks. In Proceedings of the 22nd Chinese National Conference on Computational Linguistics, Harbin, China, 3–5 August 2023. [Google Scholar]
- Krugmann, J.O.; Hartmann, J. Sentiment Analysis in the Age of Generative AI. Cust. Needs Solut. 2024, 11, 3. [Google Scholar] [CrossRef]
- Jelinek, F. Statistical Methods for Speech Recognition; MIT Press: Cambridge, MA, USA, 1997. [Google Scholar]
- Speier, W.; Chandravadia, N.; Roberts, D.; Pendekanti, S.; Pouratian, N. Online BCI Typing using Language Model Classifiers by ALS Patients in their Homes. Brain Comput. Interfaces 2017, 4, 114–121. [Google Scholar] [CrossRef]
- Speier, W.; Arnold, C.; Chandravadia, N.; Roberts, D.; Pendekanti, S.; Pouratian, N. Improving P300 Spelling Rate using Language Models and Predictive Spelling. Brain Comput. Interfaces 2018, 5, 13–22. [Google Scholar] [CrossRef] [PubMed]
- Ryan, D.B.; Frye, G.E.; Townsend, G.; Berry, D.R.; Mesa, G.S.; Gates, N.A.; Sellers, E.W. Predictive spelling with a P300-based brain-computer interface: Increasing the rate of communication. Int. J. Hum. Comput. Interact. 2011, 27, 69–84. [Google Scholar] [CrossRef] [PubMed]
- Kaufmann, T.; Volker, S.; Gunesch, L.; Kubler, A. Spelling is Just a Click Away—A User-Centered Brain-Computer Interface Including Auto-Calibration and Predictive Text Entry. Front. Neurosci. 2012, 6, 72. [Google Scholar] [CrossRef]
- Akram, F.; Han, H.S.; Kim, T.S. A P300-based brain computer interface system for words typing. Comput. Biol. Med. 2014, 45, 118–125. [Google Scholar] [CrossRef] [PubMed]
- Kindermans, P.J.; Verschore, H.; Schrauwen, B. A unified probabilistic approach to improve spelling in an event-related potential-based brain-computer interface. IEEE Trans. Biomed. Eng. 2013, 60, 2696–2705. [Google Scholar] [CrossRef]
- Speier, W.; Arnold, C.; Lu, J.; Taira, R.K.; Pouratian, N. Natural language processing with dynamic classification improves P300 speller accuracy and bit rate. J. Neural Eng. 2012, 9, 016004. [Google Scholar] [CrossRef]
- Park, J.; Kim, K.E. A POMDP approach to optimizing P300 speller BCI paradigm. IEEE Trans. Neural Syst. Rehabil. Eng. 2012, 20, 584–594. [Google Scholar] [CrossRef]
- Speier, W.; Arnold, C.; Lu, J.; Deshpande, A.; Pouratian, N. Integrating language information with a hidden Markov model to improve communication rate in the P300 speller. IEEE Trans. Neural Syst. Rehabil. Eng. 2014, 22, 678–684. [Google Scholar] [CrossRef]
- Ron-Angevin, R.; Varona-Moya, S.; da Silva-Sauer, L. Initial test of a T9-like P300-based speller by an ALS patient. J. Neural Eng. 2015, 12, 046023. [Google Scholar] [CrossRef]
- Akram, F.; Han, S.M.; Kim, T.S. An efficient word typing P300-BCI system using a modified T9 interface and random forest classifier. Comput. Biol. Med. 2015, 56, 30–36. [Google Scholar] [CrossRef]
- Oken, B.S.; Orhan, U.; Roark, B.; Erdogmus, D.; Fowler, A.; Mooney, A.; Peters, B.; Miller, M.; Fried-Oken, M.B. Brain-computer interface with language model-electroencephalography fusion for locked-in syndrome. Neurorehabilit. Neural Repair 2014, 28, 387–394. [Google Scholar] [CrossRef] [PubMed]
- Dong, R.; Smith, D.A.; Dudy, S.; Bedrick, S. Noisy Neural Language Modeling for Typing Prediction in BCI Communication. In Proceedings of the Eighth Workshop on Speech and Language Processing for Assistive Technologies, Minneapolis, MN, USA, 7 June 2019; pp. 44–51. [Google Scholar]
- Dudy, S.; Xu, S.; Bedrick, S.; Smith, D. A multi-context character prediction model for a brain-computer interface. In Proceedings of the Second Workshop on Subword/Character LEvel Models, New Orleans, LA, USA, 1 January 2018; pp. 72–77. [Google Scholar]
- Belinkov, Y.; Bisk, Y. Synthetic and natural noise both break neural machine translation. arXiv 2017, arXiv:1711.02173. [Google Scholar]
- Xie, Z.; Wang, S.I.; Li, J.; Lévy, D.; Nie, A.; Jurafsky, D.; Ng, A.Y. Data noising as smoothing in neural network language models. arXiv 2017, arXiv:1703.02573. [Google Scholar]
- Kitaev, N.; Kaiser, L.; Levskaya, A. Reformer: The Efficient Transformer. arXiv 2020, arXiv:2001.04451. [Google Scholar]
- Dai, Z.; Yang, Z.; Yang, Y.; Carbonell, J.; Le, Q.V.; Salakhutdinov, R. Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context. arXiv 2019, arXiv:1901.02860. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Lee, D.H.; Chung, C.K. Enhancing Neural Decoding with Large Language Models: A GPT-Based Approach. In Proceedings of the 2024 12th International Winter Conference on Brain-Computer Interface, Gangwon, Republic of Korea, 26–28 February 2024. [Google Scholar] [CrossRef]
- Ahmad, H.; Goel, D. The Future of AI: Exploring the Potential of Large Concept Models. arXiv 2025, arXiv:2501.05487. [Google Scholar]
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. LoRA: Low-Rank Adaptation of Large Language Models. arXiv 2021, arXiv:2106.09685v2. [Google Scholar]
- Houlsby, N.; Giurgiu, A.; Jastrzebski, S.; Morrone, B.; de Laroussilhe, Q.; Gesmundo, A.; Attariyan, M.; Gelly, S. Parameter-Efficient Transfer Learning for NLP. arXiv 2019, arXiv:1902.00751v2. [Google Scholar]
- Sun, Y.; Li, X.; Dalal, K.; Hsu, C.; Koyejo, S.; Guestrin, C.; Wang, X.; Hashimoto, T.; Chen, C. Learning to (Learn at Test Time). arXiv 2023, arXiv:2310.13807. [Google Scholar]
- Shi, H.; Xu, Z.; Wang, H.; Qin, W.; Wang, W.; Wang, Y.; Wang, Z.; Ebrahimi, S.; Wang, H. Continual Learning of Large Language Models: A Comprehensive Survey. arXiv 2024, arXiv:2404.16789v3. [Google Scholar] [CrossRef]
- Wu, T.; Luo, L.; Li, Y.; Pan, S.; Vu, T.; Haffari, G. Continual Learning for Large Language Models: A Survey. arXiv 2024, arXiv:2402.01364v2. [Google Scholar]
- Dohare, S.; Hernandez-Garcia, J.F.; Lan, Q.; Rahman, P.; Mahmood, A.R.; Sutton, R.S. Loss of plasticity in deep continual learning. Nature 2024, 632, 768–774. [Google Scholar] [CrossRef]
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.T.; Rocktäschel, T.; et al. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. Adv. Neural Inf. Process. Syst. 2020, 33, 9459–9474. [Google Scholar]
- Van de Ven, G.M.; Siegelmann, H.T.; Tolias, A.S. Brain-inspired replay for continual learning with artificial neural networks. Nat. Commun. 2020, 11, 4069. [Google Scholar] [CrossRef]
- Furlanello, T.; Lipton, Z.C.; Tschannen, M.; Itti, L.; Anandkumar, A. Born-Again Neural Networks. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; Volume 80. [Google Scholar]
- Hendrycks, D.; Burns, C.; Basart, S.; Zou, A.; Mazeika, M.; Song, D.; Steinhardt, J. Measuring Massive Multitask Language Understanding. arXiv 2021, arXiv:2009.03300. [Google Scholar]
- Kadavath, S.; Conerly, T.; Askell, A.; Henighan, T.; Drain, D.; Perez, E.; Schiefer, N.; Hatfield-Dodds, Z.; DasSarma, N.; Tran-Johnson, E.; et al. Language Models (Mostly) Know What They Know. arXiv 2023, arXiv:2207.05221. [Google Scholar]
- Desai, S.; Durrett, G. Calibration of Pre-trained Transformers. arXiv 2020, arXiv:2003.07892. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Meta AI. LLaMA 3 Technical Report. Available online: https://www.llama.com/models/llama-3/ (accessed on 12 June 2025).
- DeepSeek AI. DeepSeek R1: Scaling Multilingual Language Models Efficiently. Available online: https://deepseek.com (accessed on 12 June 2025).
- OpenAI. GPT-4 Technical Report. Available online: https://openai.com/research/gpt-4 (accessed on 12 June 2025).
- Rezeika, A.; Benda, M.; Stawicki, P.; Gembler, F.; Saboor, A.; Volosyak, I. Brain-Computer Interface Spellers: A Review. Brain Sci. 2018, 8, 57. [Google Scholar] [CrossRef]
- Dal Seno, B.; Matteucci, M.; Mainardi, L. Online detection of P300 and error potentials in a BCI speller. Comput. Intell. Neurosci. 2010, 2010, 307254. [Google Scholar] [CrossRef] [PubMed]
- Schmidt, N.M.; Blankertz, B.; Treder, M.S. Online detection of error-related potentials boosts the performance of mental typewriters. BMC Neurosci. 2012, 13, 19. [Google Scholar] [CrossRef]
- Spuler, M.; Bensch, M.; Kleih, S.; Rosenstiel, W.; Bogdan, M.; Kubler, A. Online use of error-related potentials in healthy users and people with severe motor impairment increases performance of a P300-BCI. Clin. Neurophysiol. 2012, 123, 1328–1337. [Google Scholar] [CrossRef] [PubMed]
- Gonzalez-Navarro, P.; Celik, B.; Moghadamfalahi, M.; Akcakaya, M.; Fried-Oken, M.; Erdogmus, D. Feedback Related Potentials for EEG-Based Typing Systems. Front. Hum. Neurosci. 2021, 15, 788258. [Google Scholar] [CrossRef] [PubMed]
- Dijkstra, K.V.; Farquhar, J.D.R.; Desain, P.W.M. The N400 for brain computer interfacing: Complexities and opportunities. J. Neural Eng. 2020, 17, 022001. [Google Scholar] [CrossRef]
- Kluender, R. Nothing Entirely New under the Sun: ERP Responses to Manipulations of Syntax. In The Cambridge Handbook of Experimental Syntax; University of California: San Diego, CA, USA, 2021; pp. 641–686. [Google Scholar] [CrossRef]
- Zander, T.O.; Krol, L.R.; Birbaumer, N.P.; Gramann, K. Neuroadaptive technology enables implicit cursor control based on medial prefrontal cortex activity. Proc. Natl. Acad. Sci. USA 2016, 113, 14898–14903. [Google Scholar] [CrossRef]
- Silva, A.B.; Littlejohn, K.T.; Liu, J.R.; Moses, D.A.; Chang, E.F. The speech neuroprosthesis. Nat. Rev. Neurosci. 2024, 25, 473–492. [Google Scholar] [CrossRef]
- Cui, W.H.; Jeong, W.; Thölke, P.; Medani, T.; Jerbi, K.; Joshi, A.A.; Leahy, R.M. Neuro-Gpt: Towards a Foundation Model for Eeg. In Proceedings of the 2024 IEEE International Symposium on Biomedical Imaging, Athens, Greece, 27–30 May 2024. [Google Scholar] [CrossRef]
- Mishra, A.; Shukla, S.; Torres, J.; Gwizdka, J.; Roychowdhury, S. Thought2Text: Text generation from EEG signal using large language models (llms). arXiv 2024, arXiv:2410.07507v1. [Google Scholar]
- Lin, C.-Y. ROUGE: A Package for Automatic Evaluation of Summaries. In Text Summarization Branches Out; Association for Computational Linguistics: Barcelona, Spain, 2004; Volume W04-1013, pp. 74–81. [Google Scholar]
- Zhang, T.; Kishore, V.; Wu, F.; Weinberger, K.Q.; Artzi, Y. BERTScore: Evaluating Text Generation with BERT. arXiv 2019, arXiv:1904.09675. [Google Scholar]
- Nagel, S.; Spuler, M. Modelling the brain response to arbitrary visual stimulation patterns for a flexible high-speed Brain-Computer Interface. PLoS ONE 2018, 13, e0206107. [Google Scholar] [CrossRef]
- Fahimi, F.; Zhang, Z.; Goh, W.B.; Lee, T.S.; Ang, K.K.; Guan, C. Inter-subject transfer learning with an end-to-end deep convolutional neural network for EEG-based BCI. J. Neural Eng. 2019, 16, 026007. [Google Scholar] [CrossRef] [PubMed]
- Kim, M.S.; Park, H.; Kwon, I.; An, K.O.; Kim, H.; Park, G.; Hyung, W.; Im, C.H.; Shin, J.H. Efficacy of brain-computer interface training with motor imagery-contingent feedback in improving upper limb function and neuroplasticity among persons with chronic stroke: A double-blinded, parallel-group, randomized controlled trial. J. Neuroeng. Rehabil. 2025, 22, 1. [Google Scholar] [CrossRef] [PubMed]
- Nierhaus, T.; Vidaurre, C.; Sannelli, C.; Mueller, K.R.; Villringer, A. Immediate brain plasticity after one hour of brain-computer interface (BCI). J. Physiol. 2021, 599, 2435–2451. [Google Scholar] [CrossRef]
- Caria, A.; da Rocha, J.L.D.; Gallitto, G.; Birbaumer, N.; Sitaram, R.; Murguialday, A.R. Brain-Machine Interface Induced Morpho-Functional Remodeling of the Neural Motor System in Severe Chronic Stroke. Neurotherapeutics 2020, 17, 635–650. [Google Scholar] [CrossRef]
- Caria, A.; Weber, C.; Brotz, D.; Ramos, A.; Ticini, L.F.; Gharabaghi, A.; Braun, C.; Birbaumer, N. Chronic stroke recovery after combined BCI training and physiotherapy: A case report. Psychophysiology 2011, 48, 578–582. [Google Scholar] [CrossRef]
- Kleih, S.C.; Botrel, L. Post-stroke aphasia rehabilitation using an adapted visual P300 brain-computer interface training: Improvement over time, but specificity remains undetermined. Front. Hum. Neurosci. 2024, 18, 1400336. [Google Scholar] [CrossRef]
- Musso, M.; Hubner, D.; Schwarzkopf, S.; Bernodusson, M.; LeVan, P.; Weiller, C.; Tangermann, M. Aphasia recovery by language training using a brain-computer interface: A proof-of-concept study. Brain Commun. 2022, 4, fcac008. [Google Scholar] [CrossRef]
- Birbaumer, N.; Ghanayim, N.; Hinterberger, T.; Iversen, I.; Kotchoubey, B.; Kubler, A.; Perelmouter, J.; Taub, E.; Flor, H. A spelling device for the paralysed. Nature 1999, 398, 297–298. [Google Scholar] [CrossRef]
- Gordon, E.C.; Seth, A.K. Ethical considerations for the use of brain-computer interfaces for cognitive enhancement. PLoS Biol. 2024, 22, e3002899. [Google Scholar] [CrossRef]
| Feature | Autoregressive Models | Transformer-Based Models |
|---|---|---|
| Processing | Sequential (one token at a time) | Parallel (whole sequence at once) |
| Speed | Slow (token-by-token) | Fast (parallel computation) |
| Architecture | RNNs, LSTMs, AR processes | Self-attention, multi-head attention |
| Context | Limited to past tokens (causal) | Can use full context (self-attention) |
| Examples | GPT (autoregressive), ARIMA, LSTMs | GPT, BERT, T5, full transformer |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Carìa, A. Towards Predictive Communication: The Fusion of Large Language Models and Brain–Computer Interface. Sensors 2025, 25, 3987. https://doi.org/10.3390/s25133987
Carìa A. Towards Predictive Communication: The Fusion of Large Language Models and Brain–Computer Interface. Sensors. 2025; 25(13):3987. https://doi.org/10.3390/s25133987
Chicago/Turabian StyleCarìa, Andrea. 2025. "Towards Predictive Communication: The Fusion of Large Language Models and Brain–Computer Interface" Sensors 25, no. 13: 3987. https://doi.org/10.3390/s25133987
APA StyleCarìa, A. (2025). Towards Predictive Communication: The Fusion of Large Language Models and Brain–Computer Interface. Sensors, 25(13), 3987. https://doi.org/10.3390/s25133987