
Accuracy–Efficiency Trade-Off: Optimizing YOLOv8 for Structural Crack Detection


Abstract
1. Introduction
- Crack patterns are irregular, and complex backgrounds hinder effective feature extraction;
- Fine crack features are easily lost in deeper network layers;
- High-precision models often have significant computational demands, making them unsuitable for embedded deployment.
- Integration of the parameter-free SimAM attention mechanism to enhance key feature responses;
- Adoption of the C3Ghost module to replace standard convolution layers, reducing model complexity and parameter count;
- Design of a Concat_BiFPN multi-scale feature fusion structure to improve the detection of fine cracks;
- Development of a self-constructed dataset with 1959 images, covering scenes such as concrete, roads, and tunnels;
- Validation of the proposed method’s generalization and superiority on public benchmark datasets.
2. Related Work
2.1. Development of Crack Detection Methods
2.2. Improvements of the YOLO Series Models
2.3. Model Selection
- Excellent Balance Between Detection Performance and Efficiency
- 2.
- Innovative Architectural Design
- 3.
- Flexible Model Scaling and Lightweight Support
2.4. Image Input
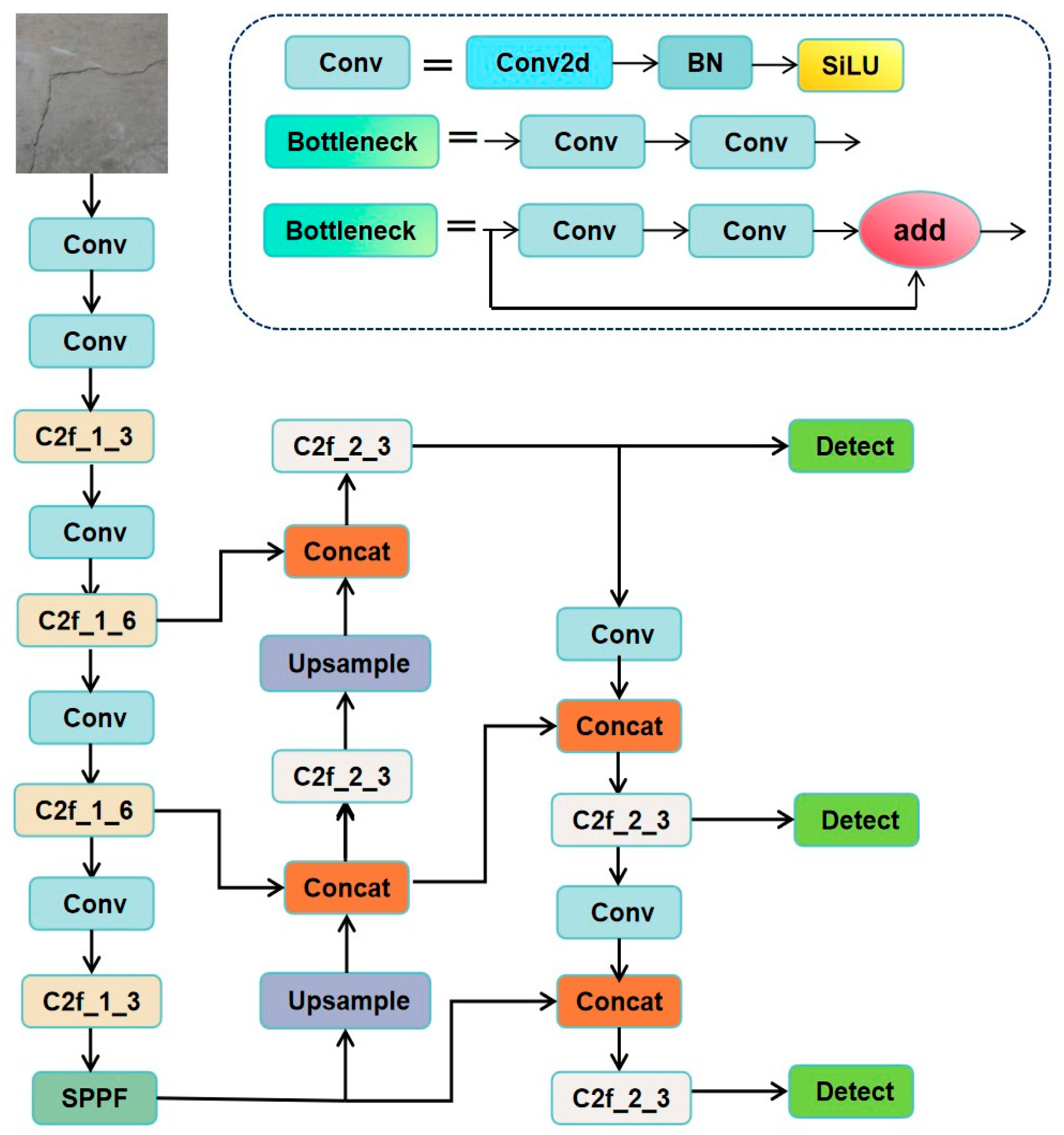
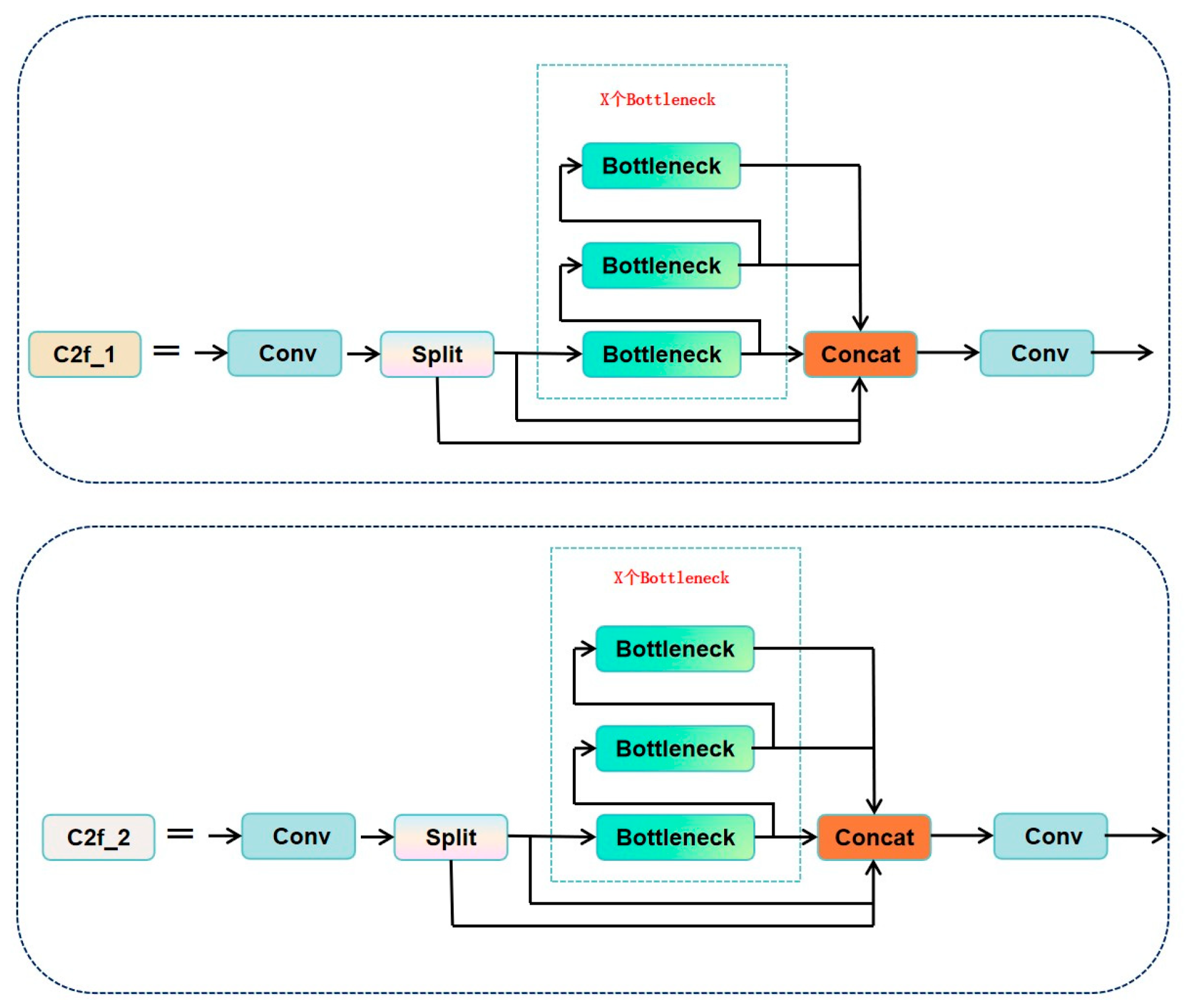
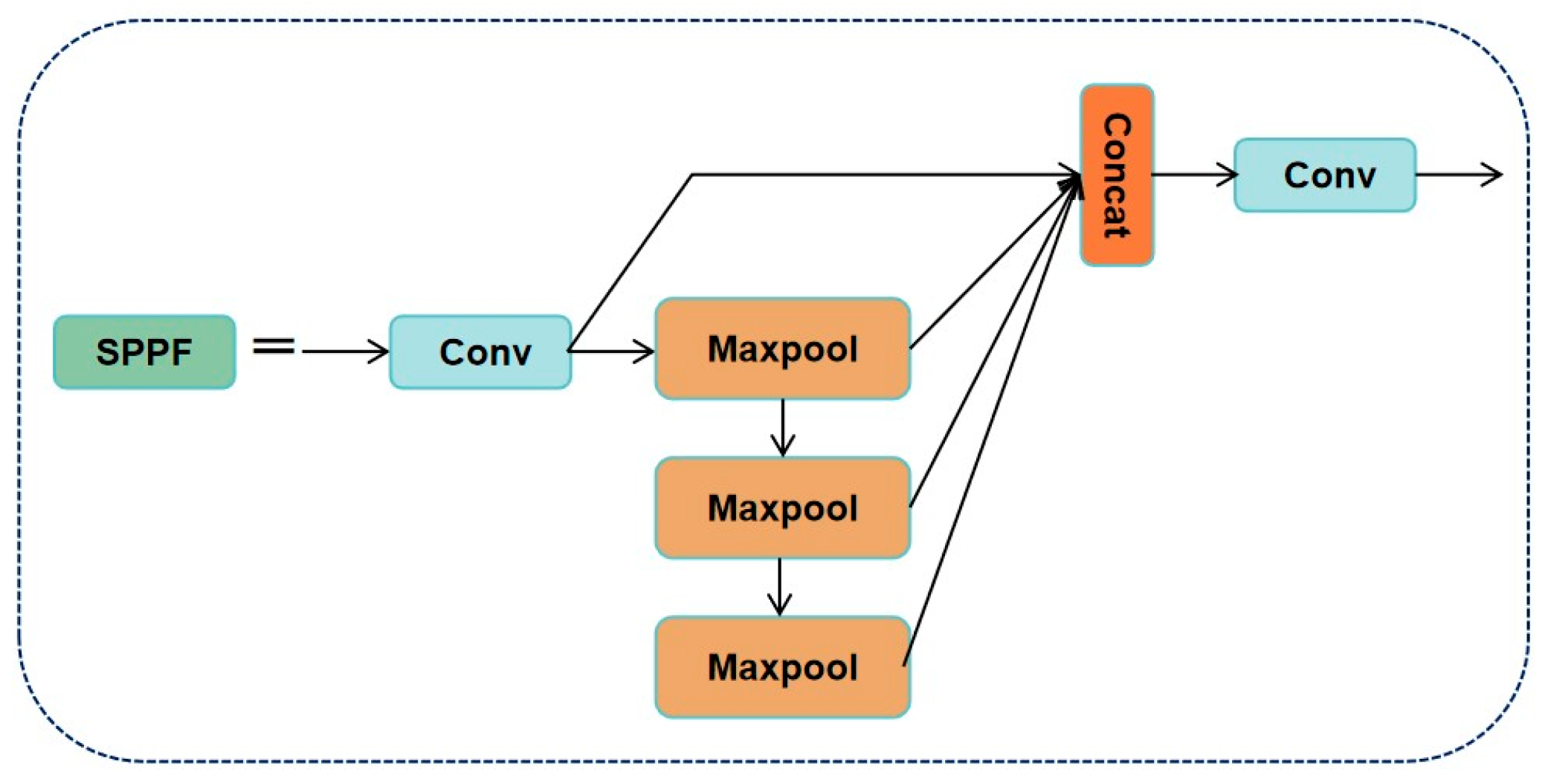
2.5. Backbone Network
2.6. Neck
2.7. Head
3. Improved YOLOv8 Model Design
3.1. Overall Architecture
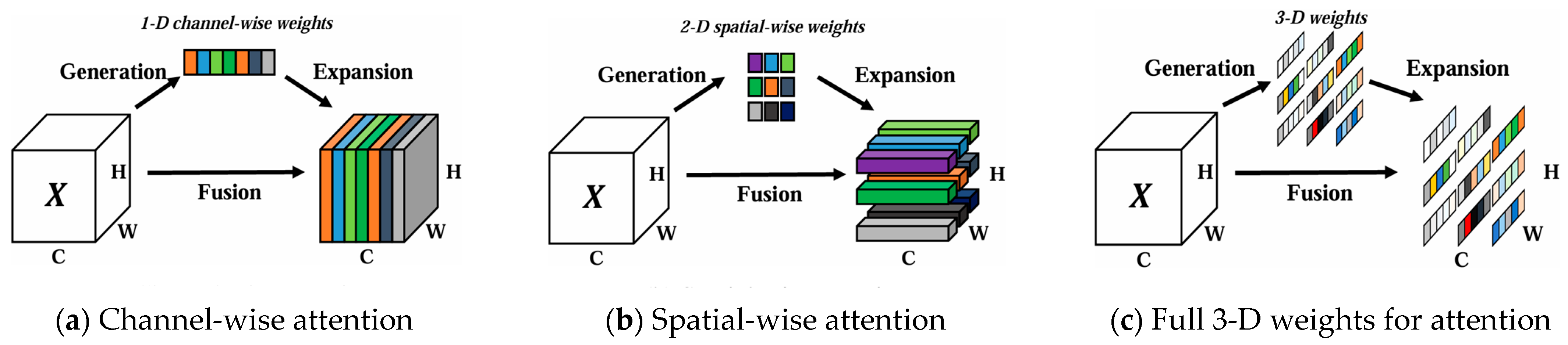
3.2. SimAM Attention Mechanism (Parameter-Free Attention)
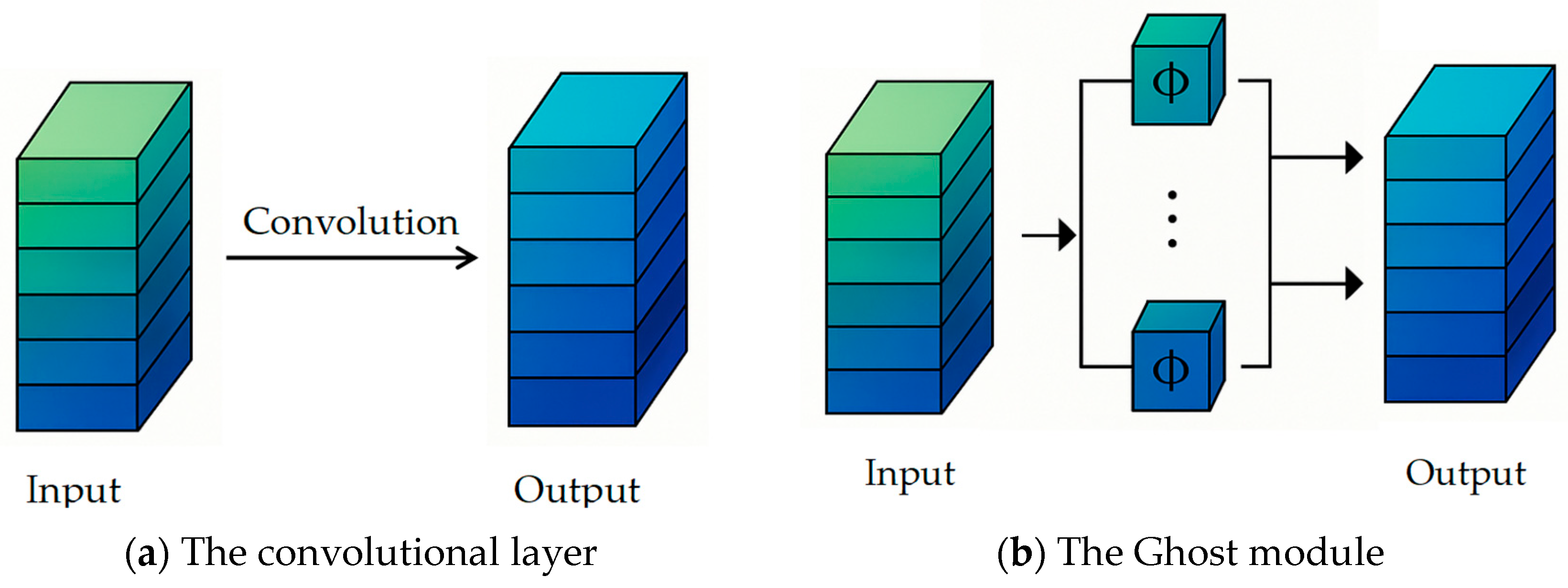
3.3. C3Ghost Module Optimization
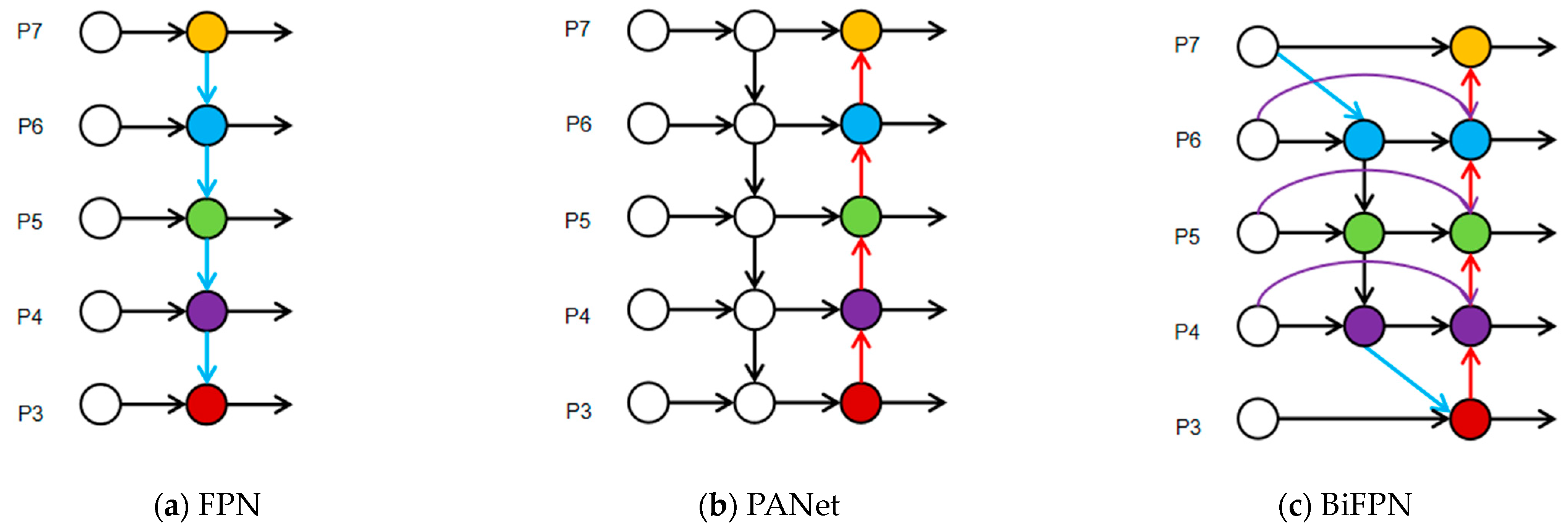
3.4. Concat_BiFPN Feature Fusion
- Scale Adaptability of Bidirectional Paths
- 2.
- Dynamic Weighting and Scale Balancing
4. Experiments and Analysis
4.1. Dataset Preparation
4.1.1. Core Features of the Dataset
4.1.2. Dataset Bias Analysis
4.1.3. Mitigation Strategies
4.2. Experimental Environment Setup
4.3. Model Training
4.4. Evaluation Metrics
- Bounding Box Coordinates: Four-dimensional coordinates (x1, y1, x2, y2) in pixels, representing the upper-left and lower-right corner coordinates of the rectangular box. Example: (120, 345, 280, 410) indicates a horizontal crack region with a width of 160 pixels and a height of 65 pixels.
- Confidence Score: A floating-point value ranging from 0 to 1, reflecting the model’s confidence in the detection result.
- Class Label: Uniformly labeled as crack.
4.5. Ablation Study
4.6. Training Results Analysis
4.6.1. Loss Value Comparison
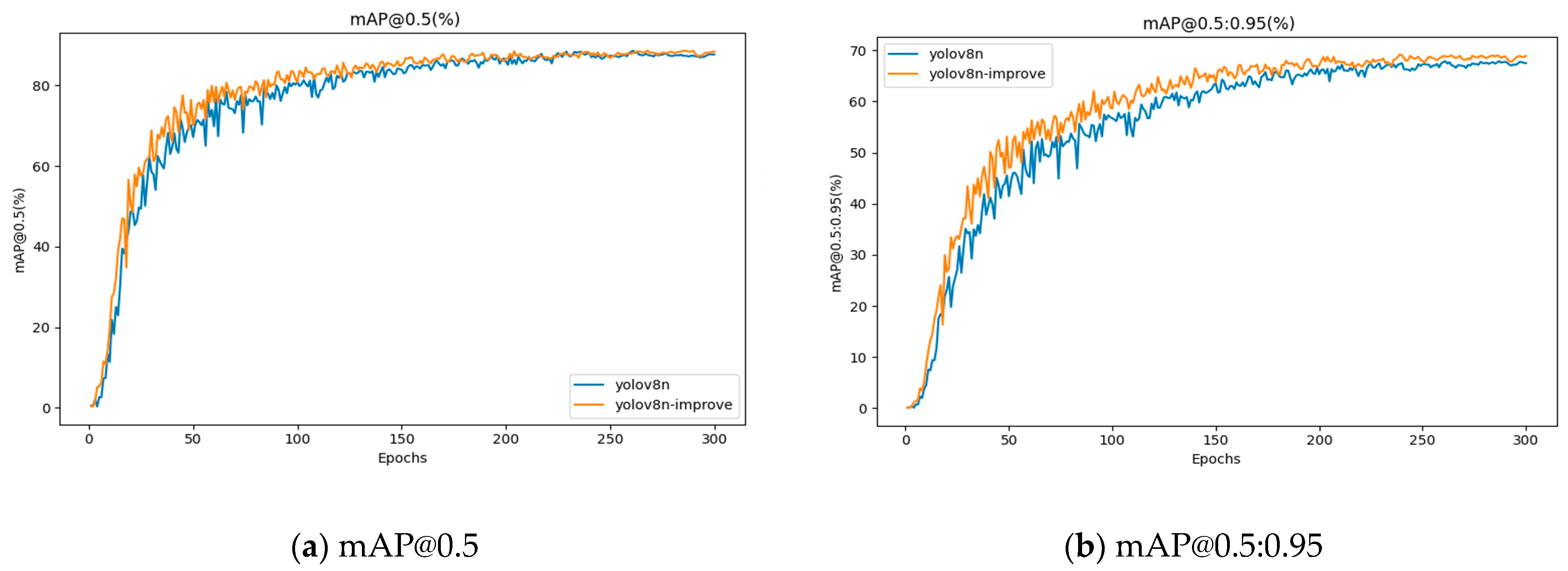
4.6.2. Comparison of mAP Values
4.6.3. Comparison of Lightweight Metrics
4.6.4. Detection Results Visualization
4.7. Validation on Public Dataset
4.8. Performance-Enhanced Bootstrap Statistical Verification
4.8.1. Method Adaptability and Analysis Process
4.8.2. Statistical Characteristics of the Public Dataset
4.8.3. Statistical Characteristics of the Self-Constructed Dataset
4.8.4. Statistical Conclusions and Engineering Implications
5. Conclusions
- Accuracy improvement: The improved model achieves 88.7% mAP@0.5 (0.9% improvement over the original YOLOv8) and 69.4% mAP@0.5:0.95 (1.4% improvement over the original YOLOv8) in the crack detection task. The detection of tiny cracks is significantly enhanced thanks to the SimAM attention mechanism focusing on low-contrast cracks (0.64% improvement in F1-score).
- Efficient and lightweight: A 16.33% reduction in the number of parameters by the C3Ghost module, accelerated inference by Concat_BiFPN (11.63% improvement in FPS), and a 12.3% reduction in GFlops, which opens up the possibility of embedded deployment.
- Strong generalization: Validated on the PDD2022 public dataset, mAP@0.5 improves by 0.7%, indicating that the model adapts to complex engineering scenarios.
- False negatives in low-light conditions: In areas with insufficient lighting, such as tunnels or at night, the contrast between cracks and the background is low, making it difficult for the model to effectively identify them.
- False positives due to background interference: For example, water stains, shadows, and stains on concrete surfaces, which resemble crack patterns, can easily lead to misclassification.
- Difficulty in identifying capillary cracks: For extremely fine, blurry, or partially obscured cracks, due to their discontinuous edges and weak pixel representation, the model still exhibits false negatives.
- Fusion of multi-modal data such as infrared thermography to improve the robustness under occluded environments;
- Explore operator fusion (e.g., Conv-BN-ReLU) to further compress the model;
- Deploy to embedded platforms such as Jetson to verify real-time power performance.
- Develop small sample learning modules to adapt to data scarcity scenarios.
- Explore lightweight GAN networks to generate extreme scenario data to improve robustness.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, X.; Xu, L.; Wei, M.; Zhang, L.; Zhang, C. An Underwater Crack Detection Method Based on Improved YOLOv8. Ocean Eng. 2024, 313, 119508. [Google Scholar] [CrossRef]
- Silva, W.R.L.D.; Lucena, D.S.D. Concrete Cracks Detection Based on Deep Learning Image Classification. Proceedings 2018, 2, 489. [Google Scholar] [CrossRef]
- Golding, V.P.; Gharineiat, Z.; Munawar, H.S.; Ullah, F. Crack Detection in Concrete Structures Using Deep Learning. Sustainability 2022, 14, 8117. [Google Scholar] [CrossRef]
- Gupta, P.; Dixit, M. Image-Based Crack Detection Approaches: A Comprehensive Survey. Multimed. Tools Appl. 2022, 81, 40181–40229. [Google Scholar] [CrossRef]
- Zhang, L.; Yang, F.; Zhang, Y.D.; Zhu, Y.J. Road Crack Detection Using Deep Convolutional Neural Network. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3708–3712. [Google Scholar]
- Yamane, T.; Chun, P. Crack Detection from a Concrete Surface Image Based on Semantic Segmentation Using Deep Learning. J. Adv. Concr. Technol. 2020, 18, 493–504. [Google Scholar] [CrossRef]
- Laxman, K.C.; Tabassum, N.; Ai, L.; Cole, C.; Ziehl, P. Automated Crack Detection and Crack Depth Prediction for Reinforced Concrete Structures Using Deep Learning. Constr. Build. Mater. 2023, 370, 130709. [Google Scholar] [CrossRef]
- Dong, X.; Liu, Y.; Dai, J. Concrete Surface Crack Detection Algorithm Based on Improved YOLOv8. Sensors 2024, 24, 5252. [Google Scholar] [CrossRef]
- Ren, W.; Zhong, Z. LBA-YOLO: A Novel Lightweight Approach for Detecting Micro-Cracks in Building Structures. PLoS ONE 2025, 20, 1–31. [Google Scholar] [CrossRef]
- Li, X.; Zhang, Y. A Lightweight Method for Road Damage Detection Based on Improved YOLOv8n. Eng. Lett. 2025, 33, 114–123. [Google Scholar]
- Yang, F.; Huo, J.; Cheng, Z.; Chen, H.; Shi, Y. An Improved Mask R-CNN Micro-Crack Detection Model for the Surface of Metal Structural Parts. Sensors 2023, 24, 62. [Google Scholar] [CrossRef]
- Alshawabkeh, S.; Dong, D.; Cheng, Y.; Li, L.; Wu, L. A Hybrid Approach for Pavement Crack Detection Using Mask R-CNN and Vision Transformer Model. CMC 2025, 82, 561–577. [Google Scholar] [CrossRef]
- Yang, X.; Li, H.; Yu, Y.; Luo, X.; Huang, T.; Yang, X. Automatic Pixel-level Crack Detection and Measurement Using Fully Convolutional Network. Comput.-Aided Civ. Eng. 2018, 33, 1090–1109. [Google Scholar] [CrossRef]
- Chen, W.; Chen, C.; Liu, M.; Zhou, X.; Tan, H.; Zhang, M. Wall Cracks Detection in Aerial Images Using Improved Mask R-CNN. Comput. Mater. Contin. 2022, 73, 767. [Google Scholar] [CrossRef]
- Wang, G.; Wang, K.C.P.; Zhang, A.A.; Yang, G. A Deep and Multiscale Network for Pavement Crack Detection Based on Function-Specific Modules. Smart Structures and Systems 2023, 32, 135–151. [Google Scholar] [CrossRef]
- Kurien, M.; Kim, M.-K.; Kopsida, M.; Brilakis, I. Real-Time Simulation of Construction Workers Using Combined Human Body and Hand Tracking for Robotic Construction Worker System. Autom. Constr. 2018, 86, 125–137. [Google Scholar] [CrossRef]
- Gavilán, M.; Balcones, D.; Marcos, O.; Llorca, D.F.; Sotelo, M.A.; Parra, I.; Ocaña, M.; Aliseda, P.; Yarza, P.; Amírola, A. Adaptive Road Crack Detection System by Pavement Classification. Sensors 2011, 11, 9628–9657. [Google Scholar] [CrossRef]
- Zou, Q.; Zhang, Z.; Li, Q.; Qi, X.; Wang, Q.; Wang, S. DeepCrack: Learning Hierarchical Convolutional Features for Crack Detection. IEEE Trans. Image Process. 2019, 28, 1498–1512. [Google Scholar] [CrossRef] [PubMed]
- Rengasamy, D.; Jafari, M.; Rothwell, B.; Chen, X.; Figueredo, G.P. Deep Learning with Dynamically Weighted Loss Function for Sensor-Based Prognostics and Health Management. Sensors 2020, 20, 723. [Google Scholar] [CrossRef]
- Wang, C.; Gu, Y. Research on Infrared Nondestructive Testing and Thermal Effect Analysis of Small Wind Turbine Blades under Natural Excitation. Infrared Phys. Technol. 2023, 130, 104621. [Google Scholar] [CrossRef]
- Zou, Q.; Cao, Y.; Li, Q.; Mao, Q.; Wang, S. CrackTree: Automatic Crack Detection from Pavement Images. Pattern Recognit. Lett. 2012, 33, 227–238. [Google Scholar] [CrossRef]
- Prasanna, P.; Dana, K.J.; Gucunski, N.; Basily, B.B.; La, H.M.; Lim, R.S.; Parvardeh, H. Automated Crack Detection on Concrete Bridges. IEEE Trans. Automat. Sci. Eng. 2016, 13, 591–599. [Google Scholar] [CrossRef]
- Reis, D.; Kupec, J.; Hong, J.; Daoudi, A. Real-Time Flying Object Detection with YOLOv8. arXiv 2024, arXiv:2305.09972. [Google Scholar]
- Xing, J.; Liu, Y.; Zhang, G. Concrete Highway Crack Detection Based on Visible Light and Infrared Silicate Spectrum Image Fusion. Sensors 2024, 24, 2759. [Google Scholar] [CrossRef]
- Ma, S.; Zhao, X.; Wan, L.; Zhang, Y.; Gao, H. A Lightweight Algorithm for Steel Surface Defect Detection Using Improved YOLOv8. Sci. Rep. 2025, 15, 8966. [Google Scholar] [CrossRef]
- Wu, D.; Yang, W.; Li, J.; Du, K.; Li, L.; Yang, Z. CRL-YOLO: A Comprehensive Recalibration and Lightweight Detection Model for AAV Power Line Inspections. IEEE Trans. Instrum. Meas. 2025, 74, 3533721. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, S.; Cen, J.; Cao, X. CMLNet: An Improved Lightweight High-Precision Network for Solar Cell Surface Defect Detection. Nondestruct. Test. Eval. 2025, 11, 1–23. [Google Scholar] [CrossRef]
- Yang, L.; Zhang, R.-Y.; Li, L.; Xie, X. SimAM: A Simple, Parameter-Free Attention Module for Convolutional Neural Networks. Available online: https://proceedings.mlr.press/v139/yang21o/yang21o.pdf (accessed on 17 May 2025).
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Sohaib, M.; Arif, M.; Kim, J.-M. Evaluating YOLO Models for Efficient Crack Detection in Concrete Structures Using Transfer Learning. Buildings 2024, 14, 3928. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, H.; Huang, Q.; Han, Y.; Zhao, M. DsP-YOLO: An Anchor-Free Network with DsPAN for Small Object Detection of Multiscale Defects. Expert Syst. Appl. 2024, 241, 122669. [Google Scholar] [CrossRef]
- Shen, L.; Lang, B.; Song, Z. Object Detection for Remote Sensing Based on the Enhanced YOLOv8 with WBiFPN. IEEE Access 2024, 12, 158239–158257. [Google Scholar] [CrossRef]
- Khalili, B.; Smyth, A.W. SOD-YOLOv8—Enhancing YOLOv8 for Small Object Detection in Traffic Scenes. arXiv 2024, arXiv:2408.04786. [Google Scholar]
- Nguyen, L.A.; Tran, M.D.; Son, Y. Empirical Evaluation and Analysis of YOLO Models in Smart Transportation. AI 2024, 5, 2518–2537. [Google Scholar] [CrossRef]
- Ultralytics YOLOv8. Available online: https://docs.ultralytics.com/zh/models/yolov8 (accessed on 5 June 2025).
- Xu, W.; Li, H.; Li, G.; Ji, Y.; Xu, J.; Zang, Z. Improved YOLOv8n-Based Bridge Crack Detection Algorithm under Complex Background Conditions. Sci. Rep. 2025, 15, 13074. [Google Scholar] [CrossRef]
- Choi, S.-M.; Cha, H.-S.; Jiang, S. Hybrid Data Augmentation for Enhanced Crack Detection in Building Construction. Buildings 2024, 14, 1929. [Google Scholar] [CrossRef]
- Elsharkawy, Z.F.; Kasban, H.; Abbass, M.Y. Efficient Surface Crack Segmentation for Industrial and Civil Applications Based on an Enhanced YOLOv8 Model. J. Big Data 2025, 12, 16. [Google Scholar] [CrossRef]
- Xu, X.; Li, Q.; Li, S.; Kang, F.; Wan, G.; Wu, T.; Wang, S. Crack Width Recognition of Tunnel Tube Sheet Based on YOLOv8 Algorithm and 3D Imaging. Buildings 2024, 14, 531. [Google Scholar] [CrossRef]
- Ding, Z.; Yao, X.; Li, Y. Earthquake Damaged Buildings Identification Based on Improved YOLOv8. In Proceedings of the Fourth International Conference on Advanced Algorithms and Neural Networks (AANN 2024), Qingdao, China, 8 November 2024; Volume 13416, p. 134163P. [Google Scholar]
- Zhu, X.; Wan, X.; Zhang, M. EMC-YOLO: A Feature Enhancement and Fusion Based Surface Defect Detection for Hot Rolled Strip Steel. Eng. Res. Express 2025, 7, 015227. [Google Scholar] [CrossRef]
- Li, Q.; Zhang, G.; Yang, P. CL-YOLOv8: Crack Detection Algorithm for Fair-Faced Walls Based on Deep Learning. Appl. Sci. 2024, 14, 9421. [Google Scholar] [CrossRef]
- Wang, X.; Gao, H.; Jia, Z.; Li, Z. BL-YOLOv8: An Improved Road Defect Detection Model Based on YOLOv8. Sensors 2023, 23, 8361. [Google Scholar] [CrossRef]
- Ma, Y.; Yin, J.; Huang, F.; Li, Q. Surface Defect Inspection of Industrial Products with Object Detection Deep Networks: A Systematic Review. Artif. Intell. Rev. 2024, 57, 333. [Google Scholar] [CrossRef]
- Cao, T.; Li, W.; Sun, H.; Wang, P.; Gong, Z. YOLOv8-PCD: A Pavement Crack Detection Method Based on Enhanced Feature Fusion. In Proceedings of the Eighth International Conference on Traffic Engineering and Transportation System (ICTETS 2024), Dalian, China, 20 December 2024; Volume 13421, p. 134210F. [Google Scholar]
- Su, Q.; Mu, J. Complex Scene Occluded Object Detection with Fusion of Mixed Local Channel Attention and Multi-Detection Layer Anchor-Free Optimization. Automation 2024, 5, 176–189. [Google Scholar] [CrossRef]
- Zhou, S.; Peng, Z.; Zhang, H.; Hu, Q.; Lu, H.; Zhang, Z. Helmet-YOLO: A New Method for Real-Time, High-Precision Helmet Wearing Detection. IEEE Access 2024. [Google Scholar] [CrossRef]
- Liu, J.; Zhang, C.; Li, J. Use Anchor-Free Based Object Detectors to Detect Surface Defects. In Proceedings of the TEPEN International Workshop on Fault Diagnostic and Prognostic, Qingdao, China, 8–11 May 2024; Chen, B., Liang, X., Lin, T.R., Chu, F., Ball, A.D., Eds.; Springer: Cham, Switzerland, 2024; pp. 348–357. [Google Scholar]
- Wu, Q.; Zhang, L. A Real-Time Multi-Task Learning System for Joint Detection of Face, Facial Landmark and Head Pose. arXiv 2023, arXiv:2309.11773. [Google Scholar]
- Wang, J.; Wu, J.; Wu, J.; Wang, J.; Wang, J. YOLOv7 Optimization Model Based on Attention Mechanism Applied in Dense Scenes. Appl. Sci. 2023, 13, 9173. [Google Scholar] [CrossRef]
- Cai, Z.; Qiao, X.; Zhang, J.; Feng, Y.; Hu, X.; Jiang, N. RepVGG-SimAM: An Efficient Bad Image Classification Method Based on RepVGG with Simple Parameter-Free Attention Module. Appl. Sci. 2023, 13, 11925. [Google Scholar] [CrossRef]
- Guan, X.; Dong, Y.; Tan, W.; Su, Y.; Huang, P. A Parameter-Free Pixel Correlation-Based Attention Module for Remote Sensing Object Detection. Remote Sens. 2024, 16, 312. [Google Scholar] [CrossRef]
- Xu, M.; Li, B.; Su, J.; Qin, Y.; Li, Q.; Lu, J.; Shi, Z.; Gao, X. PAS-YOLO: Improved YOLOv8 Integrating Parameter-Free Attention and Channel Shuffle for Object Detection of Power Grid Equipment. J. Phys. Conf. Ser. 2024, 2835, 012034. [Google Scholar] [CrossRef]
- Wang, Z.; Li, T. A Lightweight CNN Model Based on GhostNet. Comput. Intell. Neurosci. 2022, 2022, 8396550. [Google Scholar] [CrossRef]
- Yang, L.; Cai, H.; Luo, X.; Wu, J.; Tang, R.; Chen, Y.; Li, W. A Lightweight Neural Network for Lung Nodule Detection Based on Improved Ghost Module. Quant. Imaging Med. Surg 2023, 13, 4205–4221. [Google Scholar] [CrossRef]
- Ma, D.; Li, S.; Dang, B.; Zang, H.; Dong, X. Fostc3net: A Lightweight YOLOv5 Based on the Network Structure Optimization. J. Phys. Conf. Ser. 2024, 2824, 012004. [Google Scholar] [CrossRef]
- Misbah, M.; Khan, M.U.; Kaleem, Z.; Muqaibel, A.; Alam, M.Z.; Liu, R.; Yuen, C. MSF-GhostNet: Computationally Efficient YOLO for Detecting Drones in Low-Light Conditions. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2025, 18, 3840–3851. [Google Scholar] [CrossRef]
- Xu, J.; Yang, H.; Wan, Z.; Mu, H.; Qi, D.; Han, S. Wood Surface Defects Detection Based on the Improved YOLOv5-C3Ghost with SimAm Module. IEEE Access 2023, 11, 105281–105287. [Google Scholar] [CrossRef]
- Chen, J.; Mai, H.; Luo, L.; Chen, X.; Wu, K. Effective Feature Fusion Network in BIFPN for Small Object Detection. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19 September 2021; pp. 699–703. [Google Scholar]
- Zhang, H.; Du, Q.; Qi, Q.; Zhang, J.; Wang, F.; Gao, M. A Recursive Attention-Enhanced Bidirectional Feature Pyramid Network for Small Object Detection. Multimed. Tools Appl. 2023, 82, 13999–14018. [Google Scholar] [CrossRef]
- Liu, B.; Jiang, W. LA-YOLO: Bidirectional Adaptive Feature Fusion Approach for Small Object Detection of Insulator Self-Explosion Defects. IEEE Trans. Power Deliv. 2024, 39, 3387–3397. [Google Scholar] [CrossRef]
- Wu, M.; Wang, G.; Zhang, W.; Wen, L.; Qu, H. Bi-YOLOv10: Sample Imbalance-Aware Feature Fusion-Based Object Detection for Power Inspection. In Proceedings of the 2024 IEEE First International Conference on Data Intelligence and Innovative Application (DIIA), Nanning, China, 23–25 November 2024; pp. 1–6. [Google Scholar]
- Arya, D.; Maeda, H.; Ghosh, S.K.; Toshniwal, D.; Sekimoto, Y. RDD2022: A Multi-National Image Dataset for Automatic Road Damage Detection. Geosci. Data J. 2024, 11, 846–862. [Google Scholar] [CrossRef]
- He, L.; Zhou, Y.; Liu, L.; Zhang, Y.; Ma, J. Research and Application of Deep Learning Object Detection Methods for Forest Fire Smoke Recognition. Sci. Rep. 2025, 15, 16328. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Stage | Core Methods | Technical Features | Typical Applications | |
|---|---|---|---|---|---|
| 1 | Traditional Image Processing Stage (1990s–2010s) | Edge detection: Sobel, Canny operators (1990s) | Simple computation, high real-time performance | Relies on manual feature design, sensitive to noise | Simple crack detection on concrete surfaces (static scenes) [16] |
| Threshold segmentation: Otsu method, adaptive threshold (2000s) | |||||
| Morphological operations: erosion, dilation, opening/closing | |||||
| 2 | Machine Learning Stage (2010–2016) | Feature engineering: HOG, LBP, gray-level co-occurrence matrix (2012) | Introduced statistical learning, improved generalization | Limited feature representation, poor performance in complex scenes | Automated road crack classification (requires manual feature labeling) [17] |
| Classifiers: SVM, Random Forest (2014) | |||||
| Ensemble learning: Adaboost (2015) | |||||
| 3 | Early Deep Learning Stage (2016–2020) | Fully Convolutional Network (FCN): ixel-level segmentation (2016) | End-to-end automatic feature learning | High computation cost, relies on GPU | High-precision bridge crack localization (server-side offline analysis) [18] |
| U-Net: medical image crack segmentation (2018) | |||||
| Faster R-CNN: two-stage object detection (2019) | |||||
| 4 | Lightweight Deep Learning Stage (2020–2022) | MobileNet-YOLO: MobileNetV2 + YOLOv4 (2020) | 50–70% fewer parameters, suitable for edge devices | Small object detection accuracy is still limited | Real-time crack detection for drone inspections (Jetson platform) [19] |
| GhostNet: feature reuse for lightweight design (2021) | |||||
| YOLOv5/8: anchor-free + automatic learning (2022) | |||||
| 5 | Multimodal and 3D Detection Stage (2023–Present) | SimAM + BiFPN: parameter-free attention + multi-scale fusion (2023) | Supports 3D quantification and multi-sensor fusion | High algorithm complexity, requires dedicated hardware acceleration | Non-destructive internal crack detection in building structures (LiDAR + thermal imaging) [20] |
| YOLO-3D: crack depth estimation from point cloud data (2024) | |||||
| Infrared-visible fusion: cross-modal feature alignment (2024) | |||||
| Technical Stages | Representative Models | mAP@0.5:0.95 (%) | FPS | Power Consumption (W) |
|---|---|---|---|---|
| Traditional Image Processing [21] | Canny + Otsu | 42.1 | 60 | 5.0 |
| Machine Learning [22] | SVM + HOG | 53.6 | 25 | 8.2 |
| Early Stage Deep Learning [18] | U-Net | 68.3 | 12 | 75.0 |
| Lightweight Deep Learning [23] | YOLOv8n | 72.5 | 45 | 15.0 |
| Multimodal Fusion [24] | YOLO-3D + Infrared | 79.8 | 28 | 22.0 |
| Model | Input Size (Pixels) | mAP@0.5:0.95 (%) | Speed (CPU ONNX, ms) | Speed (A100 TensorRT, ms) | Params (M) | Giga Floating Point Operations (GFlops) |
|---|---|---|---|---|---|---|
| YOLOv8n | 640 | 37.3 | 80.4 | 0.99 | 3.2 | 8.7 |
| YOLOv8s | 640 | 44.9 | 128.4 | 1.2 | 11.2 | 28.6 |
| YOLOv8m | 640 | 50.2 | 234.7 | 1.83 | 25.9 | 78.9 |
| YOLOv8l | 640 | 52.9 | 375.2 | 2.39 | 43.7 | 165.2 |
| YOLOv8x | 640 | 53.9 | 479.1 | 3.53 | 68.2 | 257.8 |
| Computer | Windows11 |
|---|---|
| NVIDIA | GeForce RTX 4060 |
| Python | 3.8.0 |
| Pytorch | 1.10.1 |
| Numpy | 1.23.0 |
| Parameter | Configuration |
|---|---|
| Images-size | 640 × 640 |
| Epochs | 300 |
| Batch_size | 32 |
| optimizer | SGD |
| Initial LR | 0.01 |
| Final LR | 0.0001 |
| Momentum | 0.937 |
| Weight_decay | 0.0005 |
| Mosaic Probability | 1.0 |
| Flip LR Probability | 0.5 |
| Scale | 0.5 |
| Box Loss Gain | 7.5 |
| Cls Loss Gain | 0.5 |
| DFL Loss Gain | 1.5 |
| Algorithm Type | Simam | C3Ghost | Concat_BiFPN | F1-Score (%) | mAP@0.5 (%) | mAP@0.5:0.95 (%) | Giga Floating Point Operations (GFlops) | Detection Speed (FPS) | Parameters (M) |
|---|---|---|---|---|---|---|---|---|---|
| YOLOv8n | 84.14 | 87.8 | 68.0 | 8.1 | 208.33 | 3.0 | |||
| YOLOv8n-S | √ | 84.62 (+0.48) | 88.3 (+0.5) | 67.9 (−0.1) | 8.1 | 217.39 (+4.35%) | 3.0 | ||
| YOLOv8n-SC | √ | √ | 84.71 (+0.09) | 89.1 (+0.8) | 70 (+2.1) | 7.1 (−1) | 222.222 (+2.22%) | 2.51 (−16.33%) | |
| YOLOv8n-SCB | √ | √ | √ | 84.78 (+0.07) | 88.7 (−0.4) | 69.4 (−0.6) | 7.1 | 232.558 (+4.65%) | 2.51 |
| Algorithm Type | Box_loss | Cls_loss | Dfl_loss | |||
|---|---|---|---|---|---|---|
| Train | Val | Train | Val | Train | Val | |
| YOLOv8n | 0.71458 | 0.82127 | 0.70251 | 0.77063 | 1.1792 | 1.1373 |
| YOLOv8n-improve | 0.68871 | 0.80841 | 0.67436 | 0.73978 | 1.1691 | 1.1313 |
| Reduction amount | 0.02587 | 0.01286 | 0.02815 | 0.03085 | 0.0101 | 0.006 |
| Algorithm Type | F1-Score (%) | mAP@0.5 (%) | mAP@0.5:0.95 (%) | Giga Floating Point Operations (GFlops) | Detection Speed (FPS) | Parameters (M) |
|---|---|---|---|---|---|---|
| YOLOv3 | 67.9 | 70.2 | 37 | 18.9 | 208 | 12.13 |
| YOLOv5n | 79.2 | 83.1 | 53.1 | 4.1 | 45.24 | 3.2 |
| YOLOv7-tiny | 78.43 | 74.1 | 49.5 | 12.3 | 98 | 6.0 |
| YOLOv8n | 84.14 | 87.8 | 68 | 8.1 | 208.33 | 3.0 |
| YOLOv8n-improve | 84.78 | 88.7 | 69.4 | 7.1 | 232.558 | 2.51 |
| Algorithm Type | F1-Score (%) | mAP@0.5 (%) | Giga Floating Point Operations (GFlops) | Detection Speed (FPS) |
|---|---|---|---|---|
| Faster-R-CNN | 57.9 | 75.73 | 370.21 | 25.75 |
| SSD | 60 | 55.58 | 35 | 95.9 |
| YOLOv8n-improve | 84.78 | 88.7 | 7.1 | 232.558 |
| Algorithm Type | Crack Type | F1-Score (%) | mAP@0.5 (%) | mAP@0.5:0.95 (%) |
|---|---|---|---|---|
| YOLOv8n | D00 | 86.18 | 91.3 | 62.8 |
| D10 | 85.13 | 86.3 | 52.8 | |
| D20 | 90.74 | 95.1 | 65.5 | |
| All | 87.37 | 90.9 | 60.4 | |
| YOLOv8n-improve | D00 | 86.44 | 91.3 | 62.1 |
| D10 | 85.15 | 88.5 | 55.2 | |
| D20 | 92.78 | 95 | 67.5 | |
| All | 88.15 (+0.78) | 91.6 (+0.7) | 61.6 (+1.2) |
| Metric | Mean Increase (%) | 95% Confidence Interval (%) | Error Bar Calculation Logic (%) | |
|---|---|---|---|---|
| Self-constructed dataset | F1-score | 0.25 | [−1.22, 1.94] | Confidence interval half-width = (1.94 − (−1.22))/2 = 1.58 |
| mAP@0.5 | 0.29 | [−1.32, 2] | Confidence interval half-width = (2 − (−1.32))/2 = 1.66 | |
| mAP@0.5:0.95 | 0.21 | [−0.87, 1.51] | Confidence interval half-width = (1.51 − (−0.87))/2 = 1.19 | |
| Public dataset | F1-score | 0.21 | [−0.03, 0.65] | Confidence interval half-width = (0.65 − (−0.03))/2 = 0.34 |
| mAP@0.5 | 0.23 | [−0.01, 0.7] | Confidence interval half-width = (0.7 − (−0.23))/2 = 0.355 | |
| mAP@0.5:0.95 | 0.13 | [−0.06, 0.45] | Confidence interval half-width = (0.45 − (−0.06))/2 = 0.255 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Beliaeva, Z.V.; Huang, Y. Accuracy–Efficiency Trade-Off: Optimizing YOLOv8 for Structural Crack Detection. Sensors 2025, 25, 3873. https://doi.org/10.3390/s25133873
Zhang J, Beliaeva ZV, Huang Y. Accuracy–Efficiency Trade-Off: Optimizing YOLOv8 for Structural Crack Detection. Sensors. 2025; 25(13):3873. https://doi.org/10.3390/s25133873
Chicago/Turabian StyleZhang, Jiahui, Zoia Vladimirovna Beliaeva, and Yue Huang. 2025. "Accuracy–Efficiency Trade-Off: Optimizing YOLOv8 for Structural Crack Detection" Sensors 25, no. 13: 3873. https://doi.org/10.3390/s25133873
APA StyleZhang, J., Beliaeva, Z. V., & Huang, Y. (2025). Accuracy–Efficiency Trade-Off: Optimizing YOLOv8 for Structural Crack Detection. Sensors, 25(13), 3873. https://doi.org/10.3390/s25133873