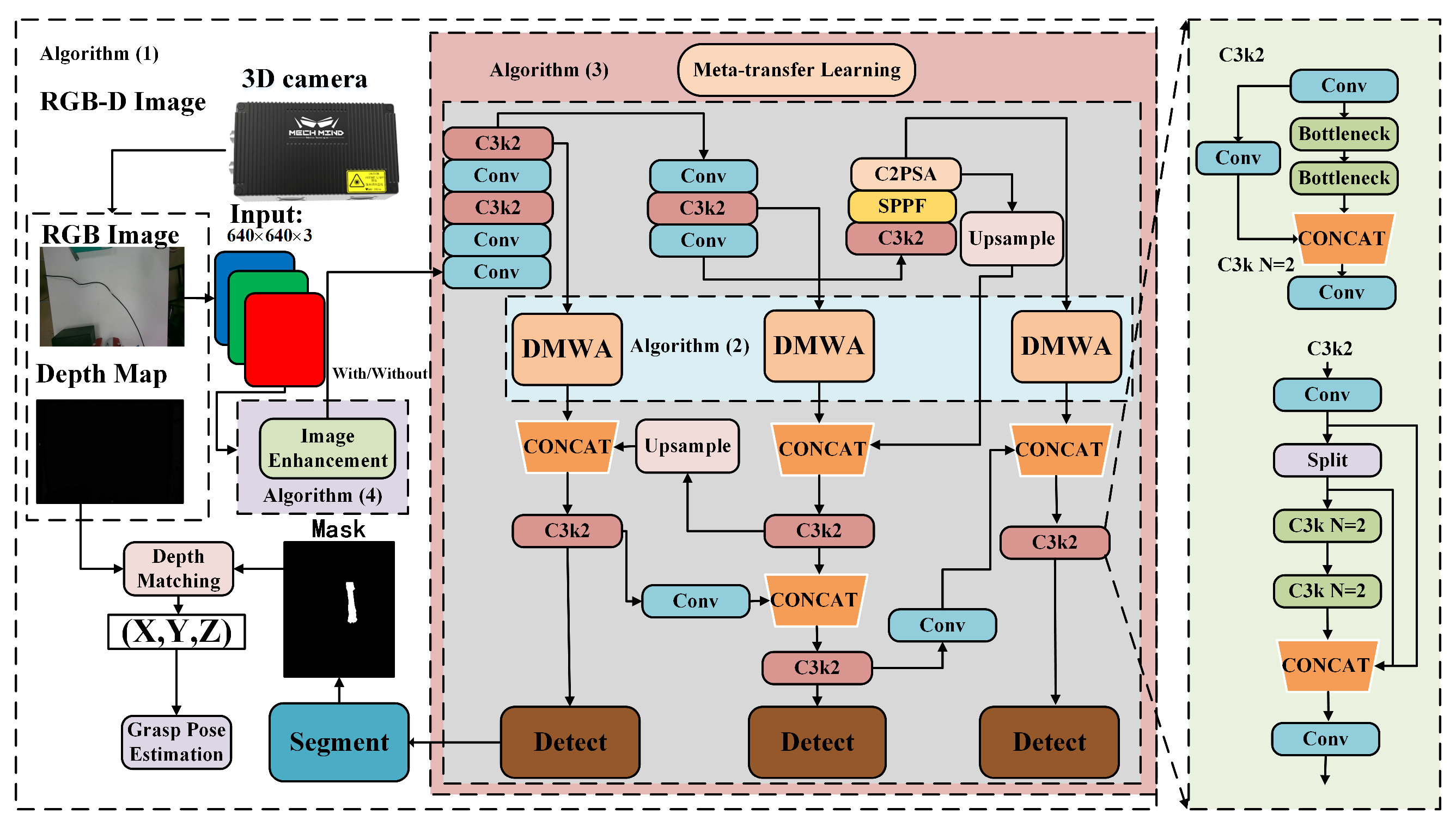
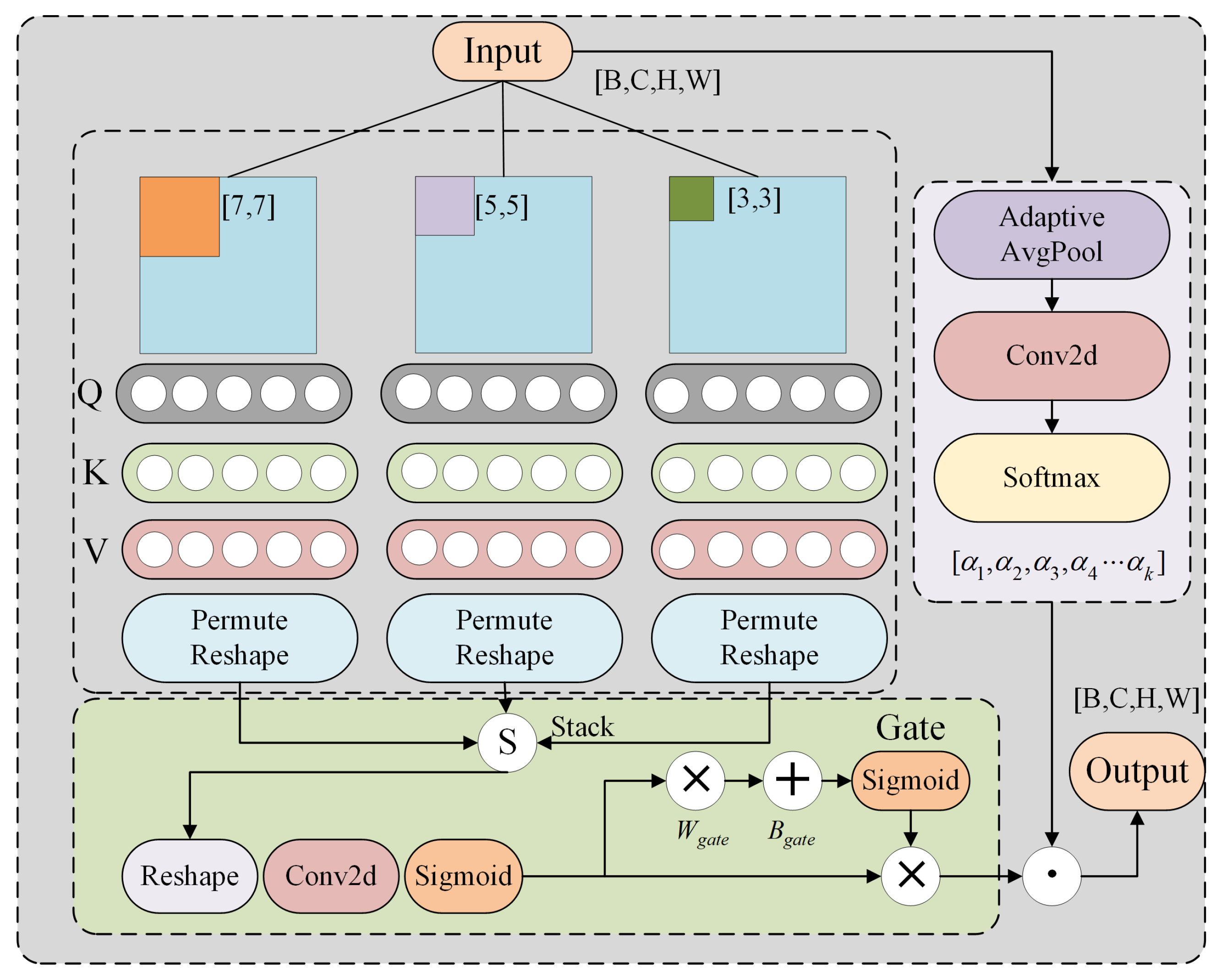
4.3.1. DMWA Module Effectiveness Verification
To evaluate the effectiveness of the proposed attention mechanism, we replaced the original attention module in our framework with several commonly used alternatives. Experiments were conducted on our normal-light dataset (400–600 lux) and on the complex background dataset, where we compared W-MSA [
42], SW-MSA [
42], SE [
43], CBAM [
44], ECA [
45], and SRM [
46]. The results are summarized in
Table 3 and
Table 4.
As shown in
Table 3 and
Table 4, on the normal-light dataset (400–600 lux), our proposed DMWA achieves the largest gains across four key metrics: detection accuracy (+14.99%), detection F1-Score (+13.54%), segmentation accuracy (+13.02%), and segmentation F1-Score (+11.06%). These improvements significantly outperform all competing methods. Notably, on the complex background dataset, SRM’s performance increases slightly compared with the normal-light dataset (detection accuracy: +3.11% to +4.14%, detection F1: +4.22% to +5.13%; segmentation accuracy: +4.78% to +5.07%). In contrast, other attention modules see drops in their metrics under complex backgrounds, yet DMWA still delivers superior improvements over all other attention mechanisms.
Moreover, DMWA also demonstrates strong practical performance in terms of inference speed, achieving 47.9 FPS and an inference latency of only 1.5 ms. Compared with sliding-window-based mechanisms, DMWA achieves a better trade-off between accuracy and efficiency. While both W-MSA and SW-MSA yield competitive accuracy, they fall short in inference speed, highlighting the superior balance offered by DMWA.
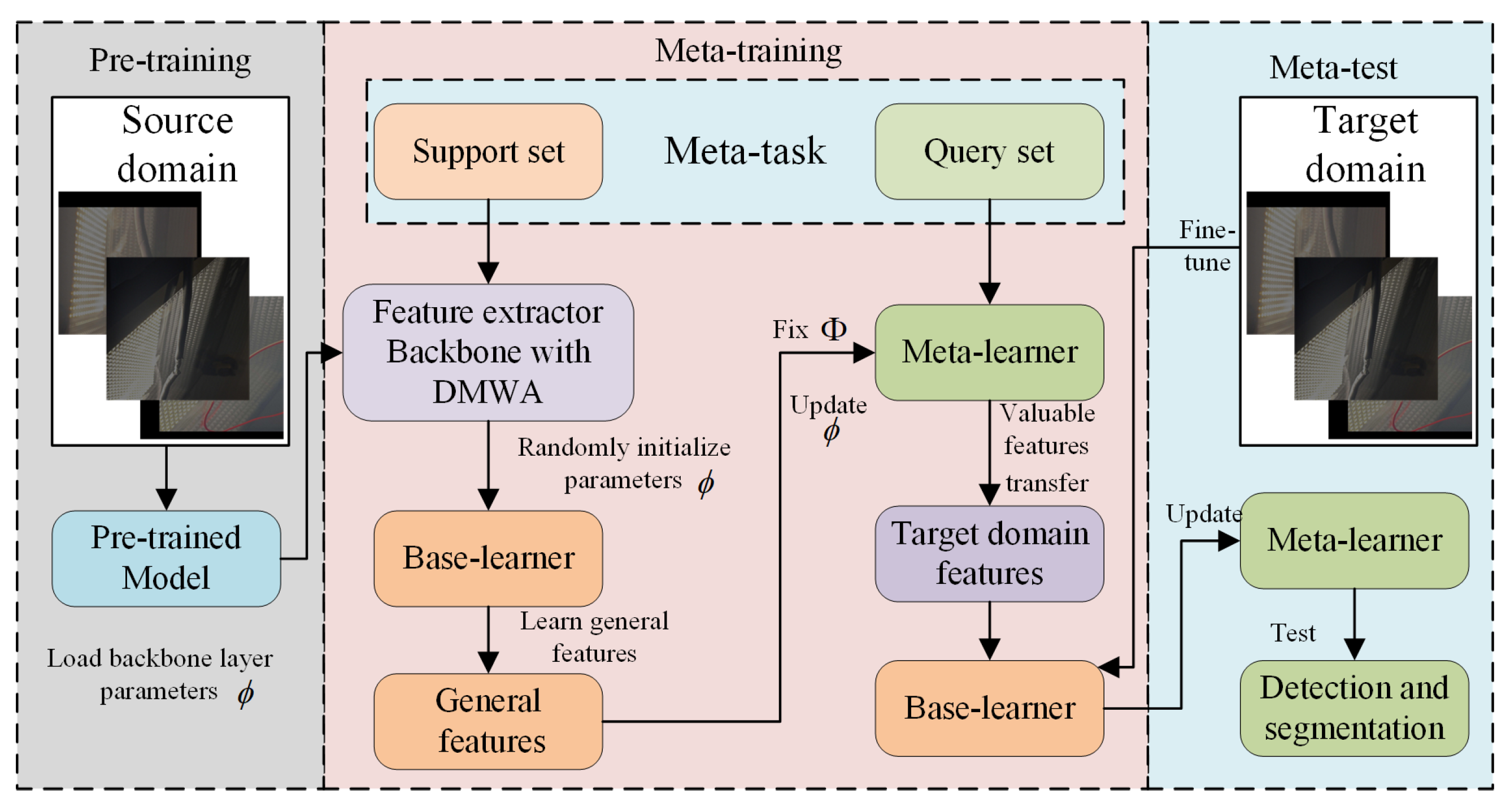
4.3.2. Multi-Stage Meta-Transfer Learning Effectiveness Verification
We adopt different transfer learning strategies to train the visual module, including Transfer Learning (TL) [
24] and Meta-Transfer Learning (MTL) [
47], with the following configurations:
TL: The model is first pretrained on the source domain for 50 epochs, during which the Backbone layers are frozen to preserve feature extraction capabilities and prevent overfitting on limited data. The remaining layers are then fine-tuned for another 100 epochs.
MTL: Each meta-batch contains 10 meta-tasks. Both the support and query sets follow a five-way five-shot setting and cover six illumination conditions. The learning rate for both the base learner and the meta learner is set to 0.001. The base learner is trained for 10 inner-loop steps, while the meta learner updates once per meta-iteration. The total training comprises 150 epochs.
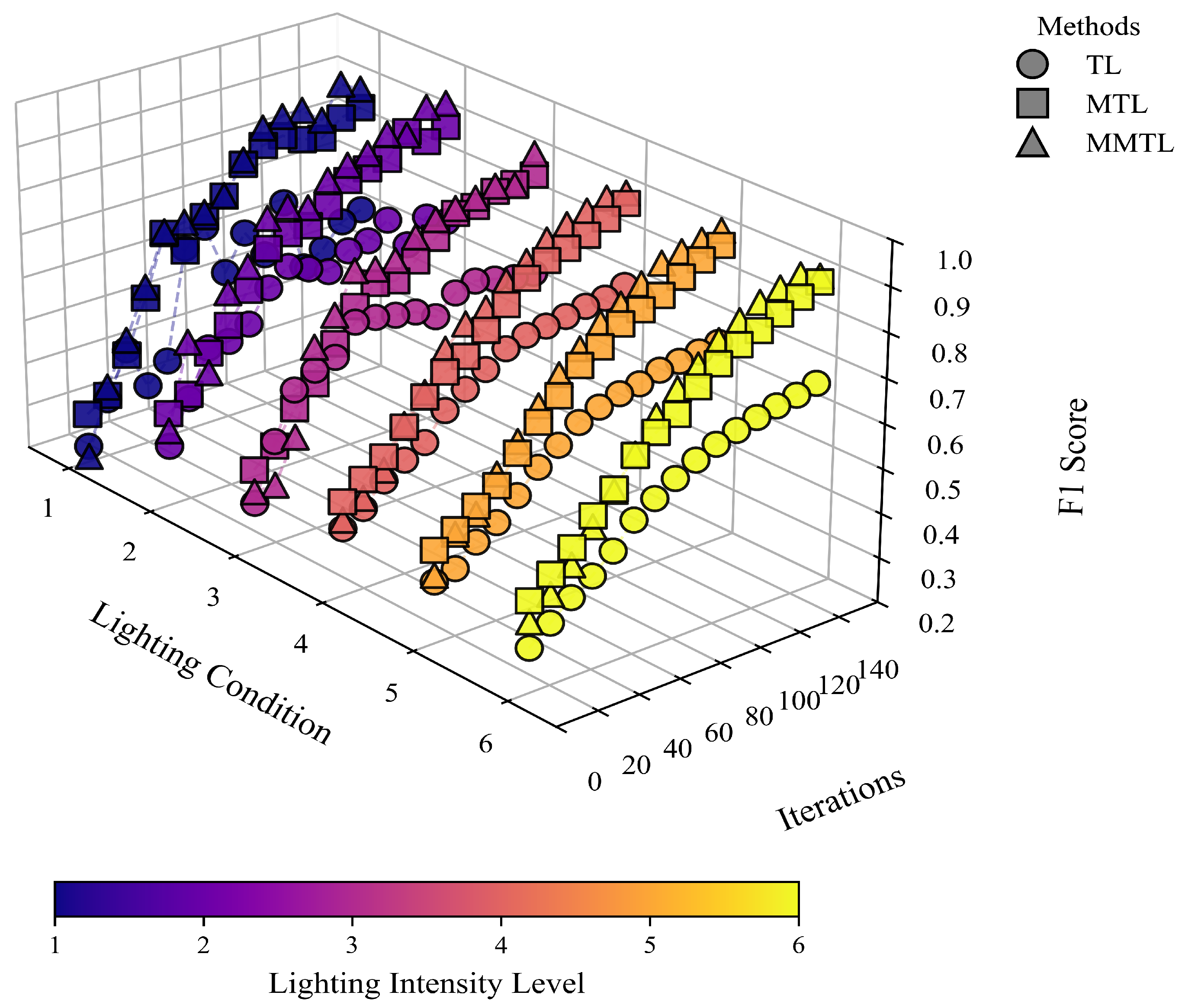
To enhance learning efficiency under few-shot, multi-illumination, and multi-scene conditions, and to mitigate the issue of negative transfer in conventional methods, we propose a multi-stage meta-transfer learning approach (MMTL). MMTL achieves faster convergence with limited data and significantly improves the F1-Score, thereby enhancing generalization performance.
We compare the F1-Scores of TL, MTL, and MMTL after 150 training epochs under various illumination settings (as shown in
Figure 6). Experimental results show that TL struggles to exceed an F1-Score of 0.7 in few-shot scenarios and is prone to negative transfer. Although MTL performs better, global fine-tuning can lead to the loss of some generalizable features. In contrast, MMTL integrates meta-learning mechanisms with a staged freezing strategy, effectively avoiding negative transfer and achieving high F1-Scores (up to 0.93) within a shorter training period. These results demonstrate its strong generalization ability and stability in low-data regimes.
4.3.3. Generalization and Robustness Verification of Vision Modules
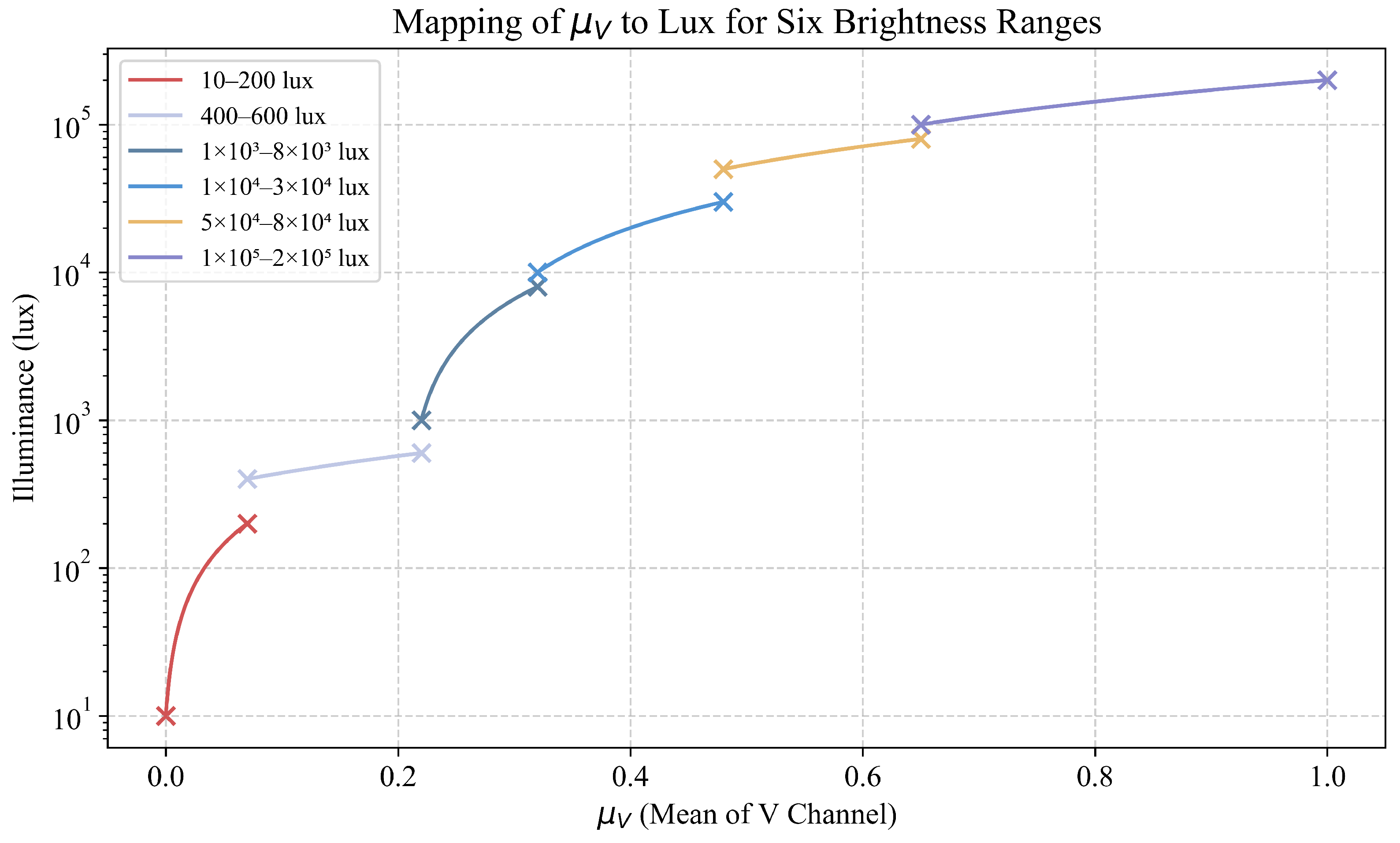
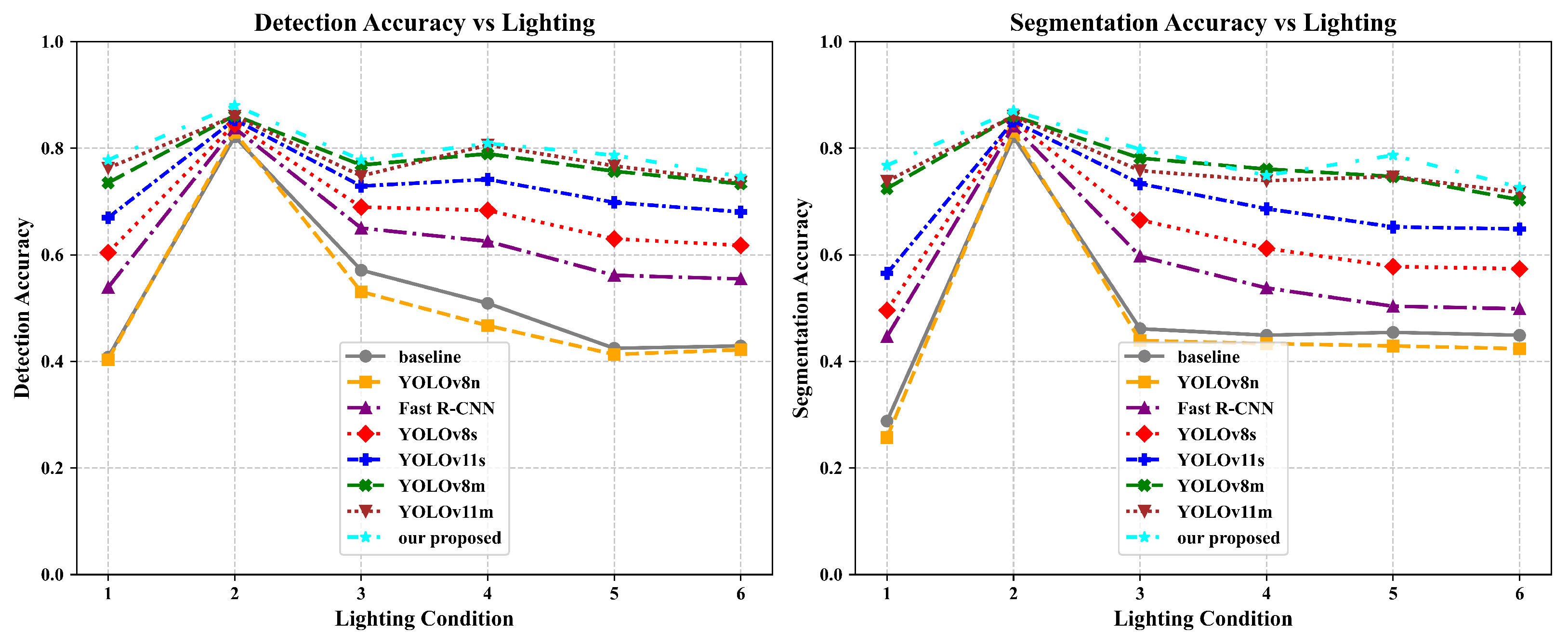
To evaluate the performance and robustness of the proposed visual model Yolov11n: DMWA-MMTL under complex backgrounds and varying lighting conditions, we conducted tests on an illumination-variant dataset, with a focus on detection and segmentation accuracy. The overall performance results are illustrated in
Figure 7.
In terms of detection and segmentation accuracy, our method consistently outperforms the YOLO series (e.g., YOLOv8n, YOLOv11s, YOLOv11m) and Fast R-CNN across all lighting scenarios. Under low-light conditions (10–200 lux), our model achieves a detection accuracy of 0.7778, significantly higher than that of Fast R-CNN (0.4032) and the baseline (0.4078). In normal lighting (400–600 lux), it reaches the highest accuracy of 0.8804, surpassing YOLOv11m (0.7628) by approximately 12%. Even under high illumination (1 × 105–2 × 105 lux), the model maintains a strong accuracy of 0.7467, clearly outperforming the baseline (0.4289) and other methods.
A similar trend is observed in segmentation tasks. Our model achieves 0.7678 segmentation accuracy in low-light conditions, far exceeding Fast R-CNN (0.4467), and reaches 0.8704 under standard lighting, outperforming all comparison models. Overall, the proposed method not only achieves higher average accuracy, but also demonstrates greater robustness and stability under extreme illumination conditions.
4.3.4. Validation of the Proposed Image Enhancement Method and Overall Framework
To validate the effectiveness of our proposed image enhancement approach in improving segmentation performance under low-light conditions, we conducted a series of ablation studies by replacing both the visual detection and segmentation modules as well as the image enhancement module. These experiments were performed on a low-light dataset (10–200 lux) to evaluate detection and segmentation capabilities.
To ensure real-time inference on resource-constrained edge devices, this work follows a real-time-first principle and therefore compares only lightweight architectures that have been proven feasible for mobile and embedded scenarios. Deep, high-capacity models such as the UNet family were excluded from our comparative experiments because their higher FLOPs and memory footprint prevent them from achieving over 20 FPS on platforms like Raspberry Pi 4B and Jetson Nano under the low-power and low-latency requirements of our target applications.
As shown in
Table 5, using our proposed visual module alone without any enhancement module (Model B) already yields a significant improvement in detection and segmentation performance under low-light conditions compared with the baseline (Model A). However, this comes at a slight cost to real-time performance, with FPS dropping from 128.8 to 47.9. When the proposed image enhancement (IE) module is further incorporated (Model H), both detection and segmentation accuracy are further improved (e.g., detection precision increases from 0.763 to 0.862, and recall improves from 0.791 to 0.881). Meanwhile, the inference speed only slightly decreases to 46.4 FPS, which still meets real-time processing requirements.
Detection and segmentation models with strong generalization capabilities can partially mitigate the accuracy loss caused by noise and reduced clarity. Our image enhancement method places a higher emphasis on improving global contrast, whereas large-scale image enhancement modules invest substantial computational resources into denoising and sharpening. As shown in
Figure 8, our shallow LP-MSR outperforms MSRCR, which has similar computational overhead, and achieves performance on par with four deeper image enhancement methods. Moreover, when our enhanced images are used for segmentation, the edges at both ends of damaged conductors are detected more accurately. However, such large network-based enhancement modules are not well suited for industrial applications that demand real-time performance.
Compared with other classical or recent low-light enhancement methods (Models J–M), although they can also significantly boost detection and segmentation performance, most of them suffer from lower speeds (typically under 30 FPS), which limits their real-time applicability. Furthermore, when replacing different detection and segmentation networks (Models N–S), while keeping our IE module unchanged, a good balance between performance and speed can still be achieved. For instance, Model S reaches a detection precision and recall close to 0.86 while maintaining a high speed of 84.7 FPS.
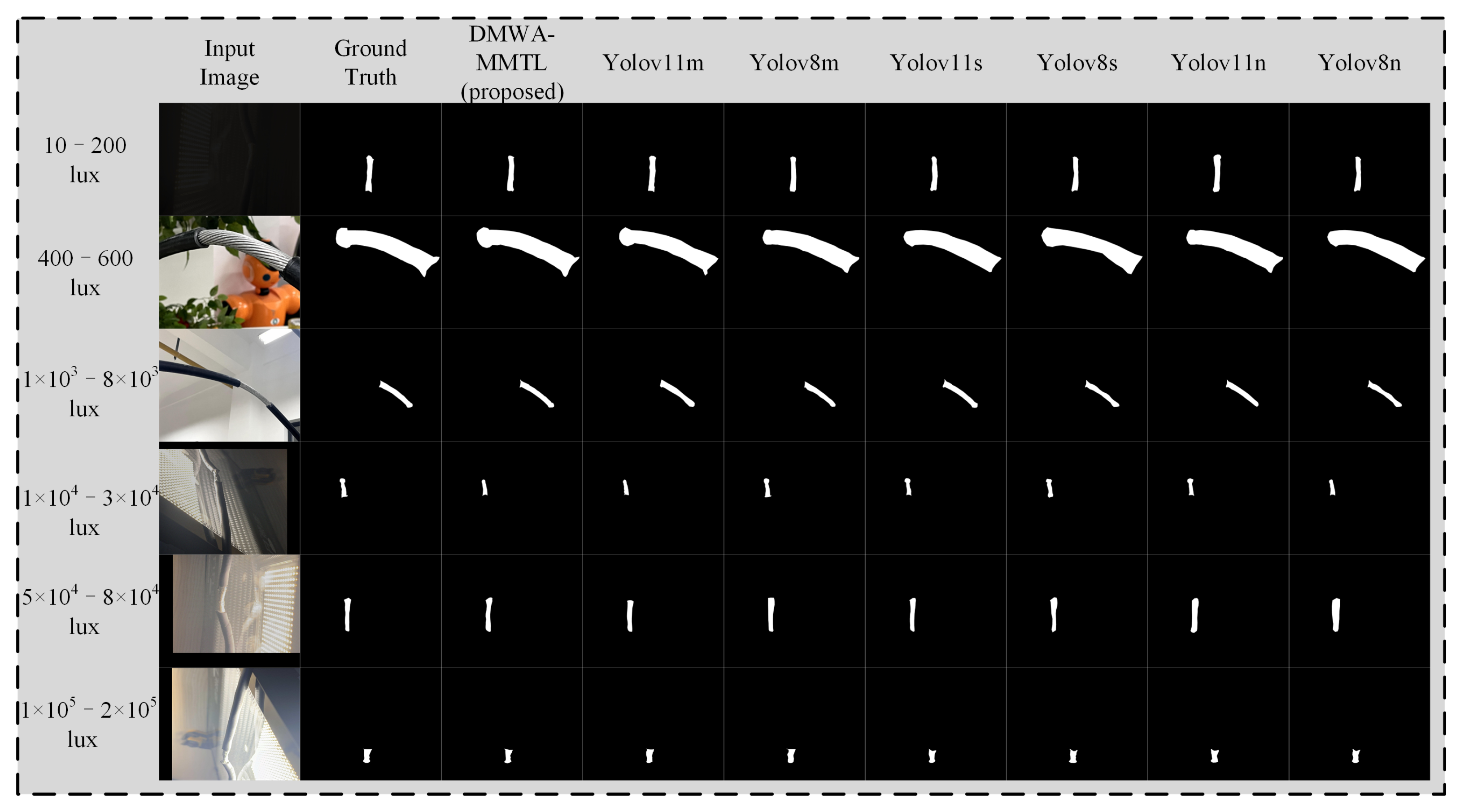
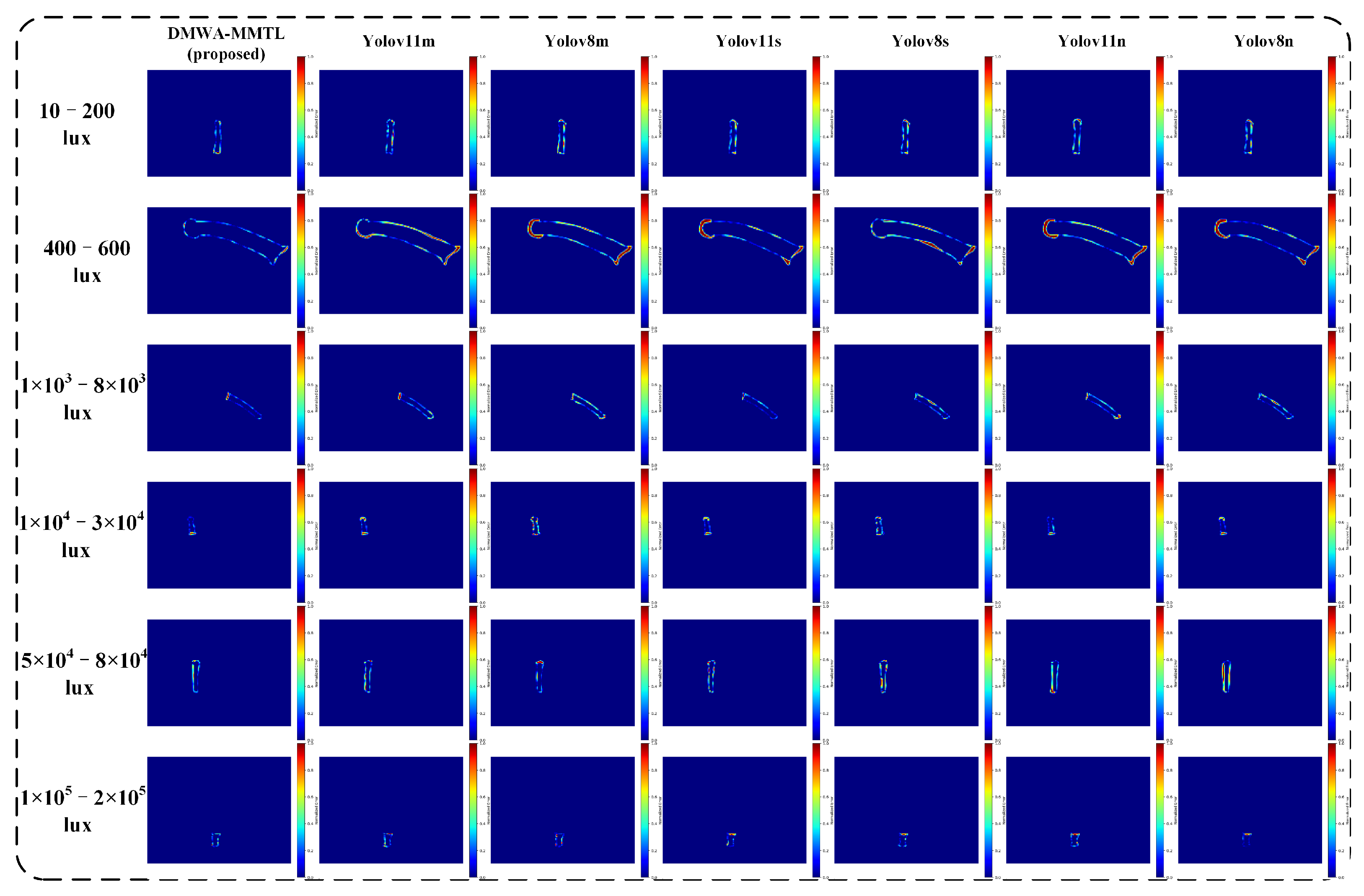
From
Figure 9 and
Figure 10, it is evident that our proposed DMWA-MMTL consistently produces accurate segmentation masks across a wide range of illumination conditions—from extremely low light (10–200 lux) to very high brightness (1 × 10
5–2 × 10
5 lux). Unlike the various YOLO-based models, which sometimes lose continuity or misinterpret edges under challenging lighting, our method retains the correct shape and boundary details, closely matching the ground truth. This robustness highlights the strong generalization capability and reliability of our approach, making it particularly suitable for industrial inspection tasks where lighting can vary dramatically.
In summary, the results demonstrate that our proposed image enhancement module can significantly improve detection and segmentation performance in low-light environments while maintaining high real-time performance. These findings further confirm the effectiveness and practicality of the overall framework for low-light vision tasks.
4.3.5. Edge Deployment Considerations
In this section, we choose to conduct our evaluations on the existing experimental equipment available to us and categorize the evaluated platforms into three groups. The first group consists of desktop/laptop-level discrete GPUs—namely, RTX 3090 (24 GB GDDR6X), RTX 1080 (8 GB GDDR5X), and RTX 3060 Laptop (6 GB GDDR6)—which offer very high deep neural network inference throughput, thanks to large numbers of CUDA cores and high-bandwidth VRAM (Video Random Access Memory). The second group comprises ultraportable hybrid-architecture CPUs: Intel Core Ultra 9 (36 MB L3 cache, 6 Performance+Efficient cores) and Core Ultra 7 (24 MB L3 cache, 6 P-Cores+8 E-Cores). Each integrates a Xe iGPU but relies heavily on its large L3 cache and heterogeneous core design to accelerate inference. Finally, the third group includes conventional CPUs—Intel Core i7 (16 MB L3, 6 cores/12 threads) and Core i5 (12 MB L3, 6 cores/12 threads)—which depend solely on FP32 multithreaded execution without heterogeneous cores or dedicated ML accelerators.
As illustrated in
Table 6, discrete GPU platforms (RTX 3090/1080/3060 Laptop) run our 17.7 GFLOPs model at 40.1–42.7 FPS versus YOLO11n (6.9 GFLOPs) at 101.9–128.8 FPS, maintaining over 30 FPS even with greater complexity. In the Core Ultra series, large 36 MB/24 MB L3 caches and heterogeneous P/E cores help reduce overhead: our model achieves 26.8 FPS (37.3 ms) on Ultra 9 and 21.3 FPS (46.9 ms) on Ultra 7, compared with YOLO11n’s 52.1 FPS and 39.9 FPS; nonetheless, throughput remains below GPU levels. Conventional CPUs face pronounced cache and memory-bandwidth bottlenecks: Core i7 (16 MB L3) yields only 10.9 FPS (91.7 ms) for our model versus 21.4 FPS for YOLO11n, and Core i5 (12 MB L3) achieves 8.9 FPS (112.4 ms) versus 19.6 FPS, both far below real-time requirements.
Under a strict real-time requirement (≥30 FPS), only discrete GPUs (e.g., RTX 3060 Laptop or higher) can run the FP32 model over 30 FPS without further tuning. Core Ultra 9/Ultra 7 in FP32 yields FPS/FPS and require FP16 or INT8 quantization to exceed FPS. Core i7/i5 CPUs cannot reach FPS in FP32 (only 8–FPS), and quantization alone is insufficient.
Under a near-real-time requirement (20 FPS), Core Ultra 9/Ultra 7 in FP32 already meets the threshold (26 FPS/21 FPS). Since NVIDIA’s Jetson Xavier NX edge module offers roughly one quarter of the FP32 throughput of an RTX 3060 Laptop but compensates with Tensor Cores, we estimate that TensorRT FP16/INT8 on Xavier NX yields 20–25 FPS. Similarly, AGX Xavier (32 TOPS FP16) and Orin NX (60 TOPS FP16) can exceed 30 FPS with INT8 quantization. In contrast, Core i7/i5 remains below 20 FPS even after quantization, making it unsuitable without substantial model compression.
Additionally, when comparing various YOLOv8 and YOLOv11 variants, it is clear that model size and complexity have a direct impact on inference ability across platforms. On the discrete GPU, YOLOv8n (3.01 M params, 8.1 GFLOPs) achieves the highest FPS (129.6 FPS on RTX 3090, 109.6 FPS on RTX 1080, 100.1 FPS on RTX 3060 Laptop), closely matching YOLO11n’s performance and exceeding YOLOv8s (11.13 M params, 28.4 GFLOPs), which runs at 107.8 FPS/59.8 FPS/54.8 FPS, respectively. YOLOv8m (27.22 M params, 110.9 GFLOPs) and YOLO11m (21.58 M params, 64.9 GFLOPs) incur a larger latency penalty, dropping to 85.7 FPS/41.7 FPS/37.8 FPS (YOLOv8m) and 88.1 FPS/42.1 FPS/39.9 FPS (YOLO11m) on RTX 3090/1080/3060. This demonstrates that, on powerful GPUs, even the “m” variants can maintain well above 30 FPS, though at reduced margins.
On the Core Ultra series, the smallest variant (YOLOv8n) still runs acceptably: 47.1 FPS on Ultra 9 and 37.9 FPS on Ultra 7, indicating that the 8.1 GFLOPs cost can be handled by the integrated Xe iGPU and large L3 cache for sub-30 ms latency. By contrast, YOLOv8s’s 28.4 GFLOPs pushes both Ultra 9 and Ultra 7 to their limits—only 14.8 FPS and 11.8 FPS, respectively—falling well below near-real-time thresholds. YOLOv8m and YOLO11m similarly cannot run at all on these platforms due to memory bandwidth and cache constraints (denoted by “–”), as their 64.9 GFLOPs and 110.9 GFLOPs exceed what the heterogeneous core design can process without unacceptable stalling. YOLOv11s (21.3 GFLOPs) manages 15.9 FPS on Ultra 9 and 12.7 FPS on Ultra 7, again underperforming for most near-real-time use cases.
On conventional CPUs (Core i7/i5), only the “n” variants are feasible: YOLOv8n achieves 20.1 FPS on Core i7 and 17.8 FPS on Core i5, while YOLO11n hits 21.4 FPS and 19.6 FPS, respectively. The “s” and “m” variants of YOLOv8 and YOLOv11 all show “–” (cannot run) due to excessive computational and memory requirements. This reinforces that traditional CPUs without specialized accelerators simply cannot support these larger networks, making them unsuitable for anything beyond occasional offline inference.
The “n” variants of YOLOv8/YOLO11 can run on all tested platforms, but only on discrete GPUs and Core Ultra series do they exceed 30 FPS without quantization. The “s” variants require at least a Core Ultra 9 or higher and still fall short of real-time thresholds. The “m” variants are effectively restricted to high-end GPUs for both real-time and near-real-time applications.
Overall, our 17.7 GFLOPs model can meet or approach industrial near-real-time requirements under the hardware and optimization conditions described above. While maintaining high performance, it can also be deployed on a variety of computing devices.
4.3.6. Ablation Experiments
To evaluate the effectiveness of each component under low-light conditions, we designed four ablation models (A–H) by selectively integrating or removing the IE module (LP-MSR), the DMWA module, and the MMTL module. As shown in
Table 7, Model A, which incorporates all three modules, achieves the best overall performance in both detection and segmentation tasks, with detection mAP50 and mAP50-95 reaching 0.878 and 0.725 and segmentation mAP50 and mAP50-95 reaching 0.863 and 0.697, respectively—significantly outperforming other configurations.
A comparison between Models B and C reveals that removing either the IE (B) or DMWA (C) module leads to a considerable drop in detection and segmentation accuracy. This indicates that the IE module plays a crucial role in enhancing low-light imagery, while the DMWA module is essential for effective feature extraction and attention weighting under low-light conditions.
Although Model D excludes the MMTL module and thus achieves faster inference (1.5 ms), it suffers from reduced accuracy. The performance gap between Model D and the Model A confirms the importance of MMTL in boosting overall multi-task learning performance.
As shown in
Table 7, in the two-way and three-way ablations (E–H), performance drops far exceed the individual ablations (B–D), indicating no antagonistic effects among modules but rather tight synergy. Specifically, removing LP-MSR and DMWA (E) or LP-MSR and MMTL (F) yields mAP50 values significantly lower than what would be expected from summing the individual ablation effects; likewise, ablating DMWA and MMTL together (G) demonstrates the loss of their collaborative gain. The three-way ablation (H) further exacerbates performance degradation, reinforcing that LP-MSR, DMWA, and MMTL collectively provide complementary benefits to detection and segmentation performance.
In summary, the collaborative integration of the IE, DMWA, and MMTL modules significantly enhances both robustness and accuracy of the model in low-light environments, thereby expanding the applicability of substation monitoring systems under challenging lighting conditions.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}