
Remaining Useful Life Prediction for Rolling Bearings Based on TCN–Transformer Networks Using Vibration Signals

 , ,
, ,
Abstract
1. Introduction
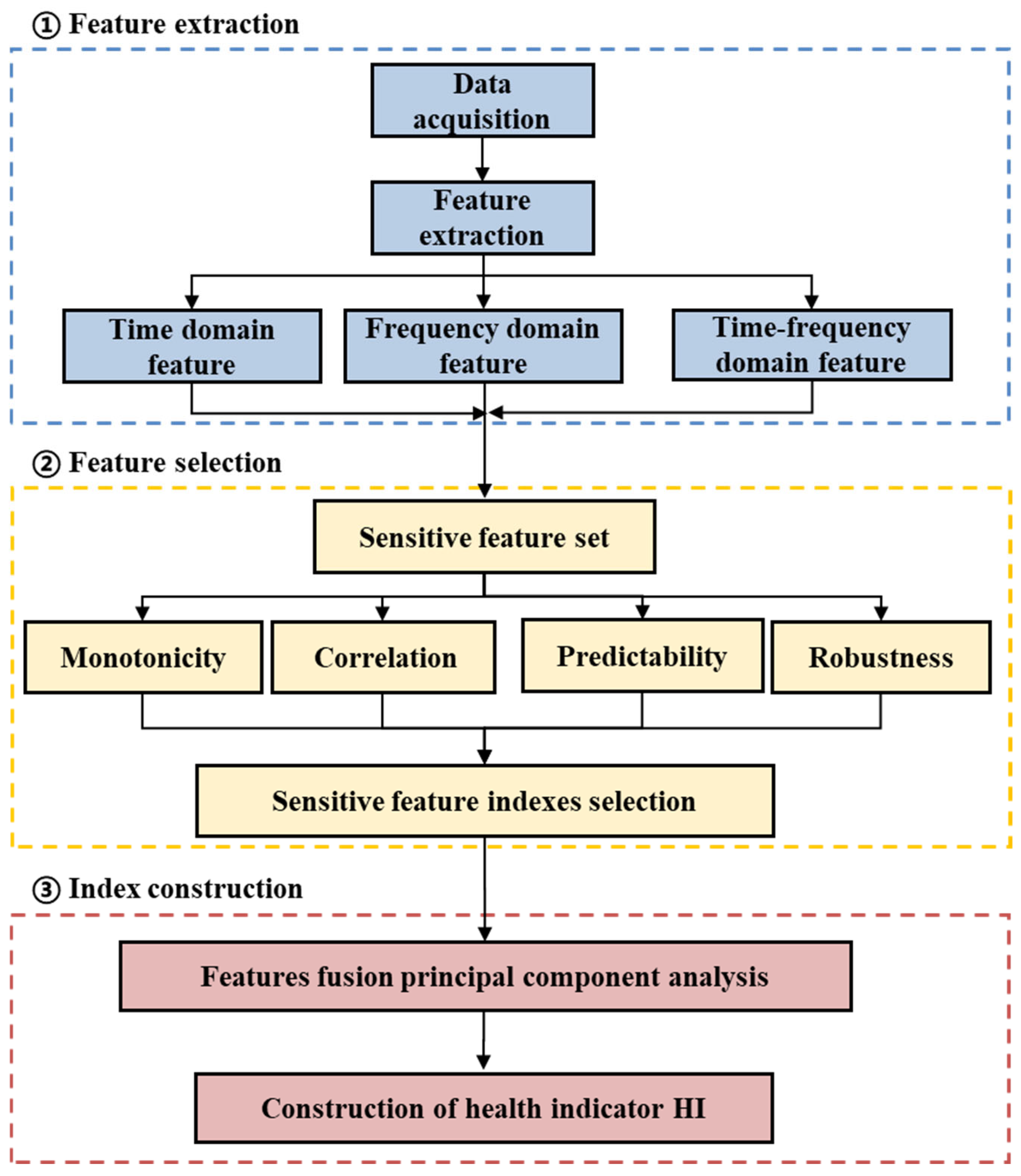
2. Feature Extraction and Health Index Construction Method
2.1. Feature Extraction Method
- Time domain feature extraction
- 2.
- Frequency domain feature extraction
- 3.
- Time–frequency domain feature extraction
2.2. Constructing the Sensitive Feature Set for Rolling Bearings
2.3. Dimensionality Reduction Method for Sensitive Feature Index
- Feature extraction of vibration signals. There are 32 feature indexes used here, namely 10 dimensionless time domain indexes (S1–S10), 9 dimensionless time domain indexes (S11–S19), 5 frequency domain characteristics (S20–S24), and 8 time–frequency domain indexes (S25–S32), regarding the energy ratio of sub-bands. Using the original vibration signal, a total of 32 feature indexes above are extracted to form the original feature set.
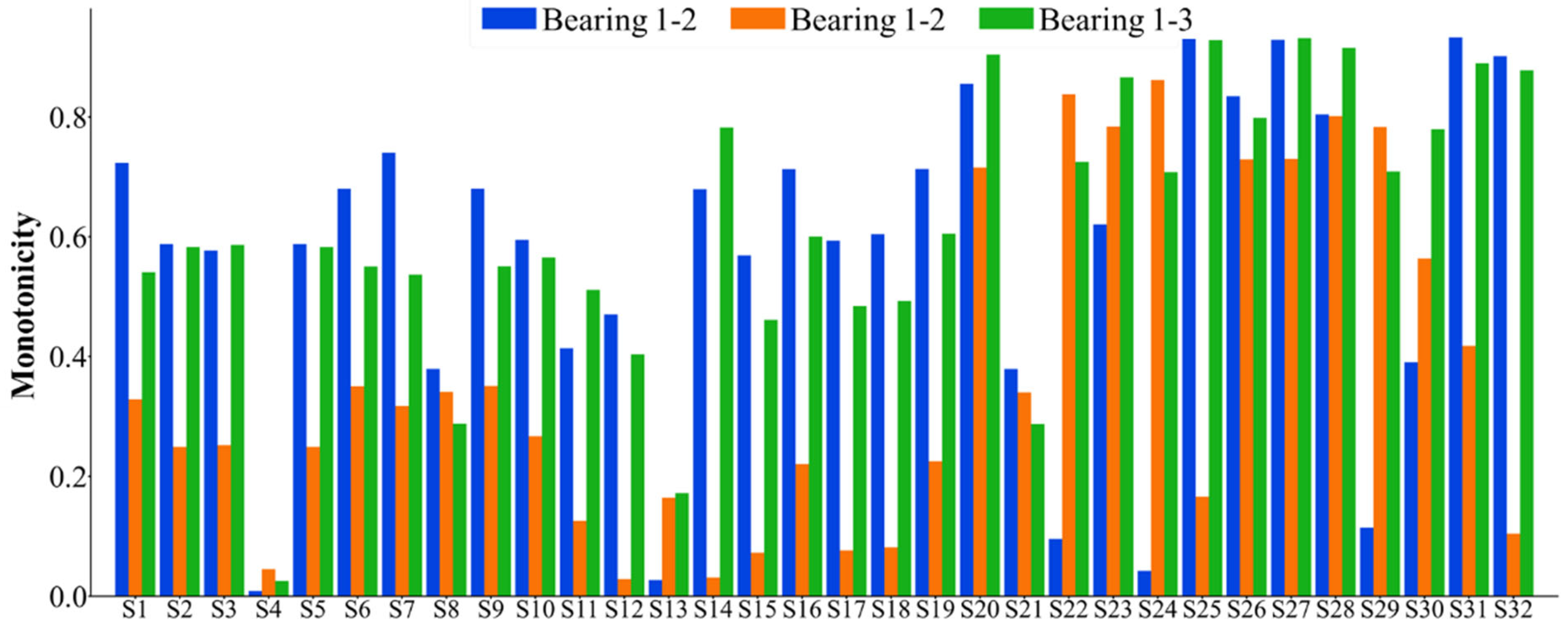
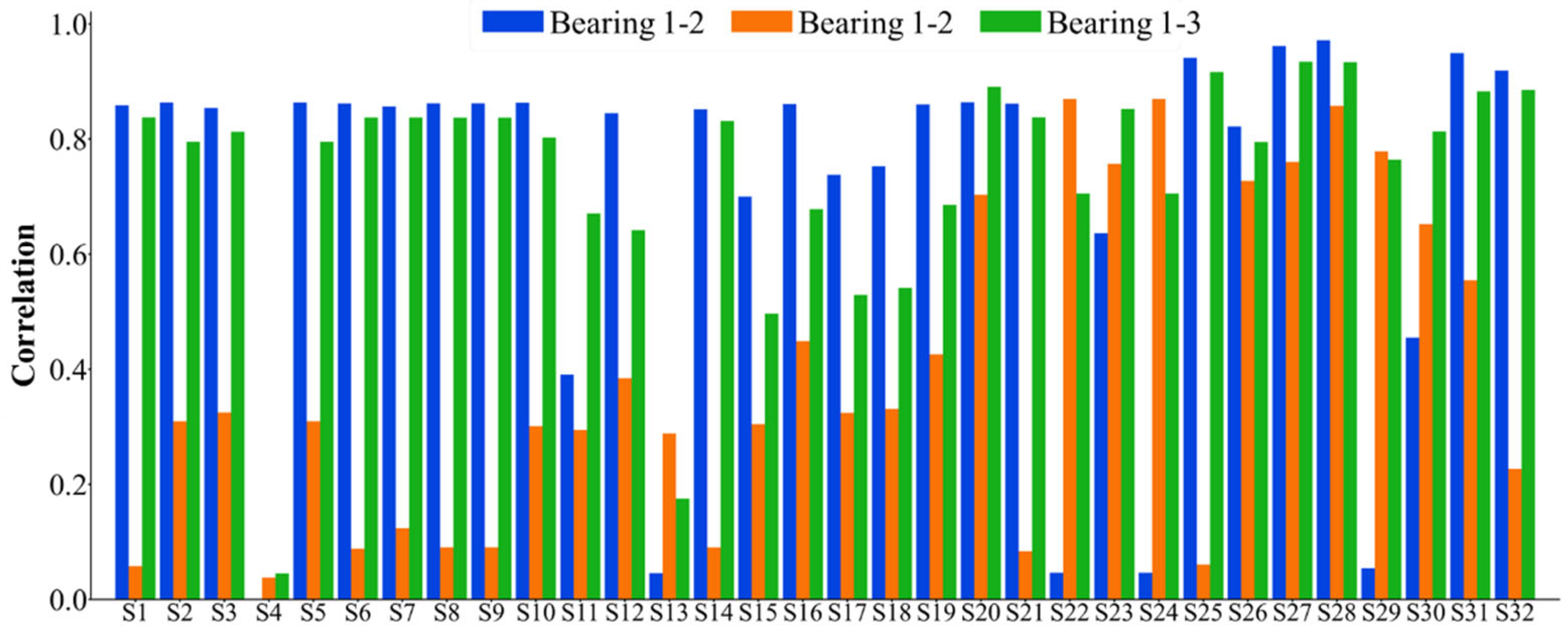
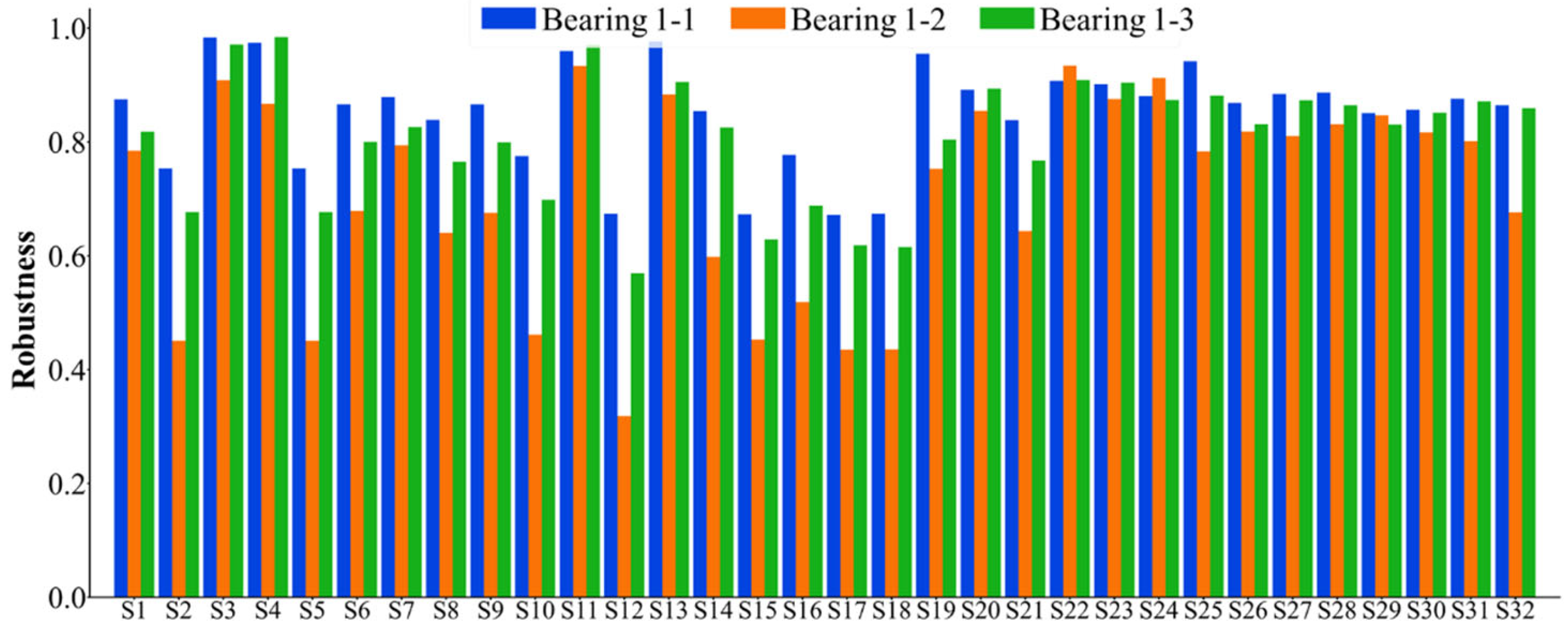
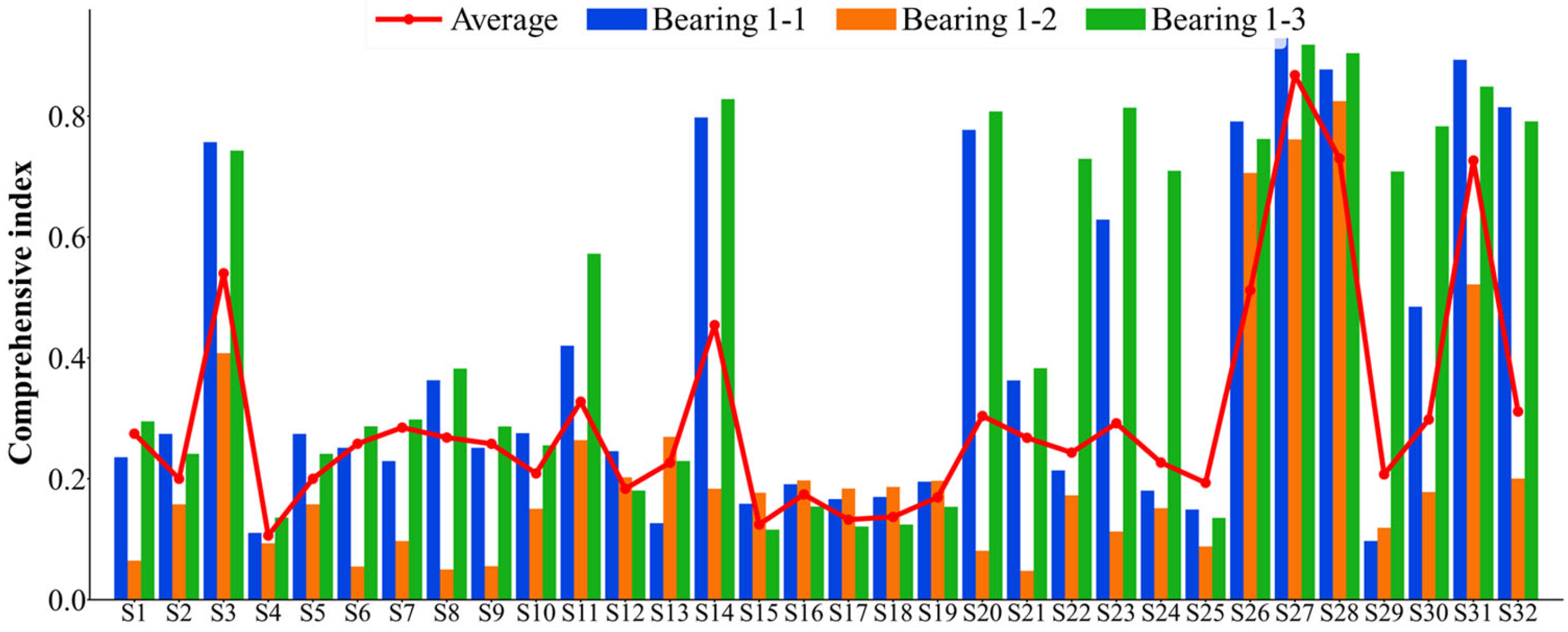
- Sensitive feature index selection based on evaluation indices. Based on the comprehensive index that takes into account the monotonicity, correlation, predictability, and robustness of the features, eight sensitive feature indexes of rolling bearings are selected.
- Dimensionality reduction in sensitive feature indexes. The selected sensitive degradation features are input into the PCA algorithm as input data, and the first principal component is extracted as the rolling bearing performance degradation feature index after dimensionality reduction.
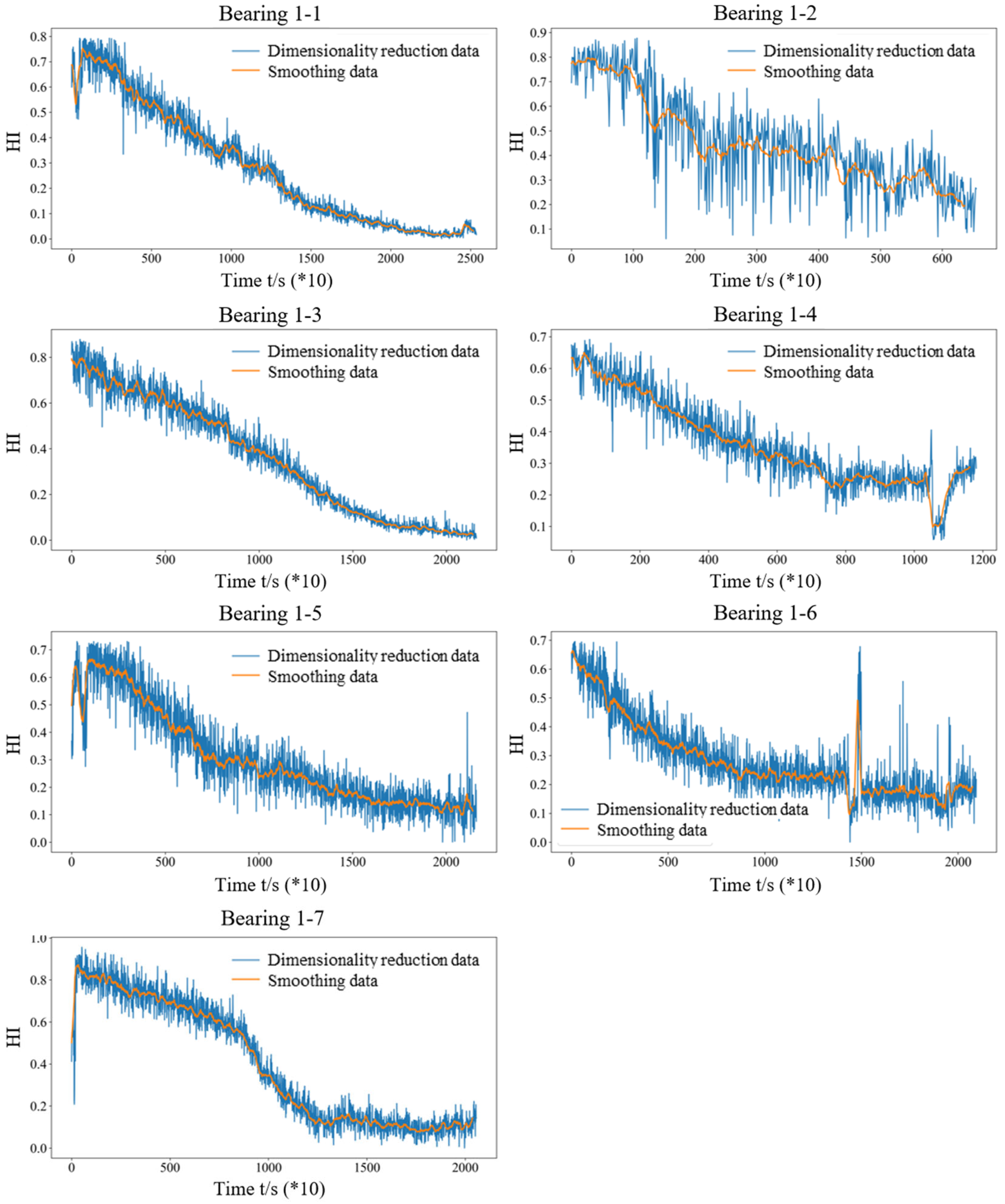
2.4. Constructing the Health Index for Rolling Bearing
3. TCN–Transformer Networks and RUL Prediction
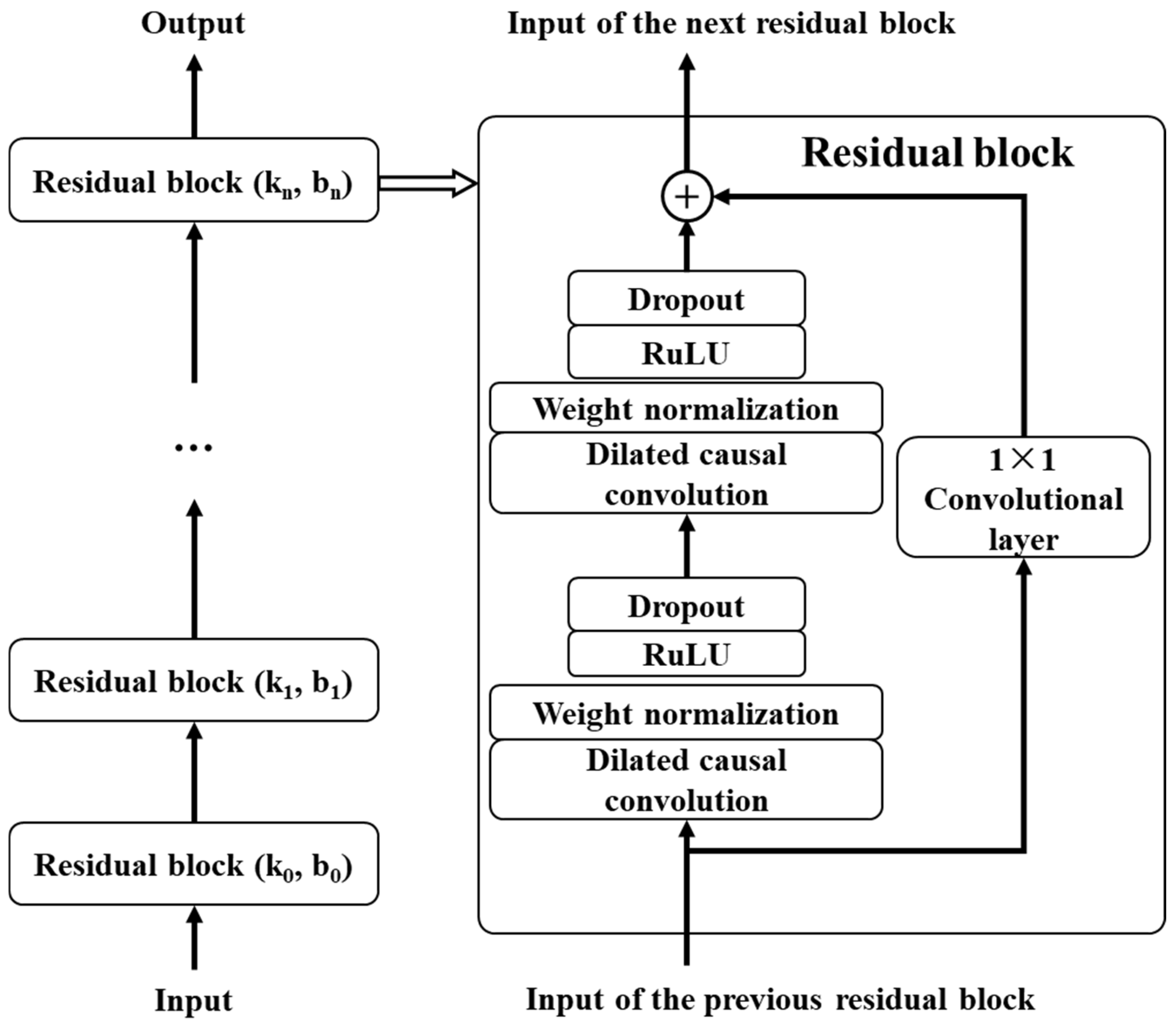
- Causal convolution
- 2.
- Dilated convolution
- 3.
- Residual module
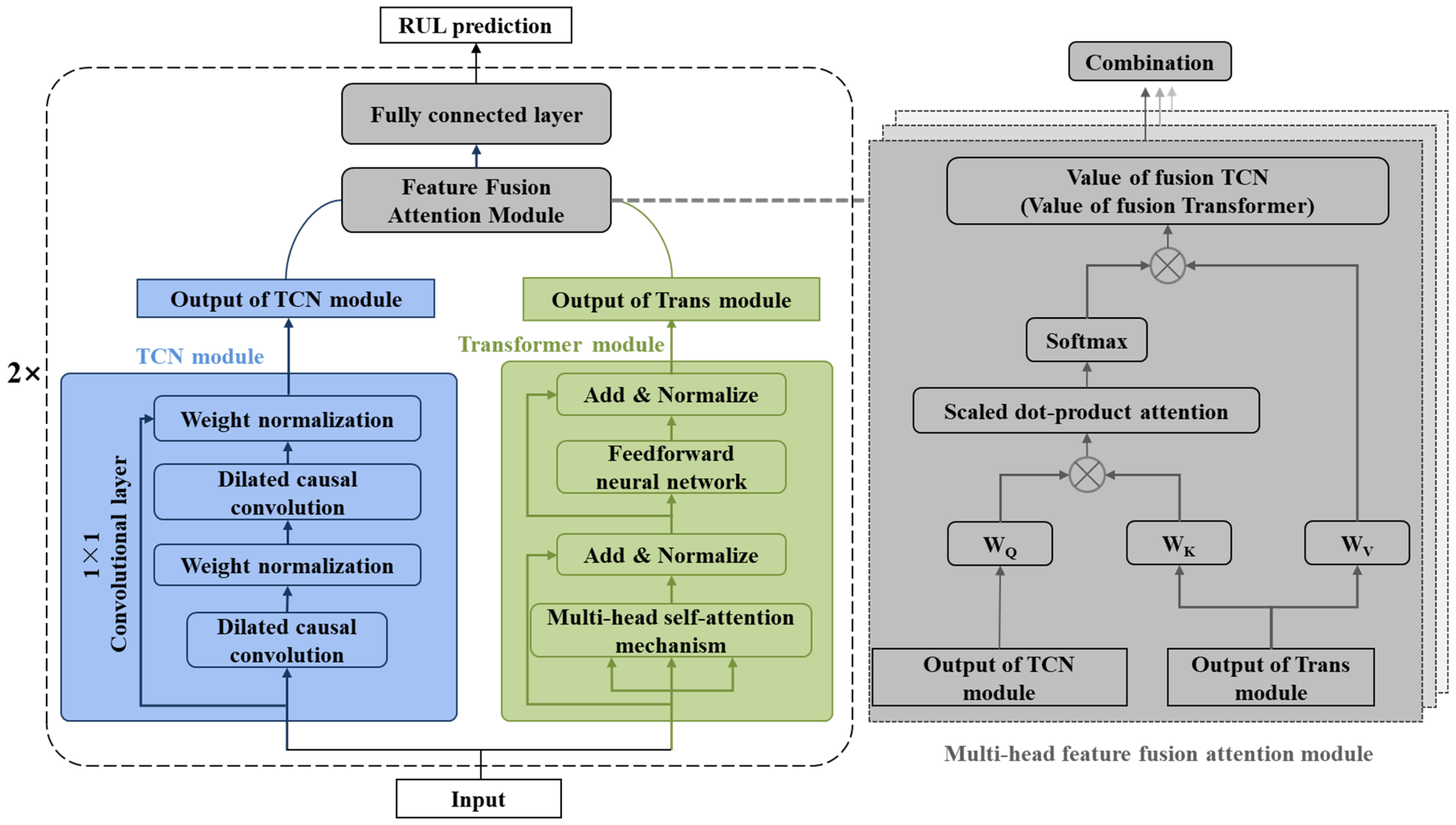
3.1. Construction of TCN–Transformer Networks
- (1)
- Hierarchical parallel design
- (2)
- Multi-head feature fusion attention module
3.2. RUL Prediction Based on TCN–Transformer
- (1)
- Data input. The original vibration signal data of the rolling bearing is processed. According to the method proposed, the original vibration signal is extracted in the time domain, frequency domain, and time–frequency domain. Subsequently, sensitive features are selected to construct a feature set. The selected sensitive degradation feature data is input into the model to train the model for remaining life prediction.
- (2)
- Dataset division. Referring to the most commonly used dataset division method, the dataset is divided into training set, validation set, and test set in a ratio of 7:1:2.
- (3)
- Model training. The training set data is input into the constructed TCN–Transformer networks. TCN–Transformer trains the model and completes the steps of forward propagation, backpropagation, and parameter optimization. The TCN–Transformer network with the optimal parameters is obtained.
- (4)
- Model prediction. Input the test set data into the optimal model trained in the third step and finally output the RUL prediction result of the rolling bearing.
4. Results and Discussion
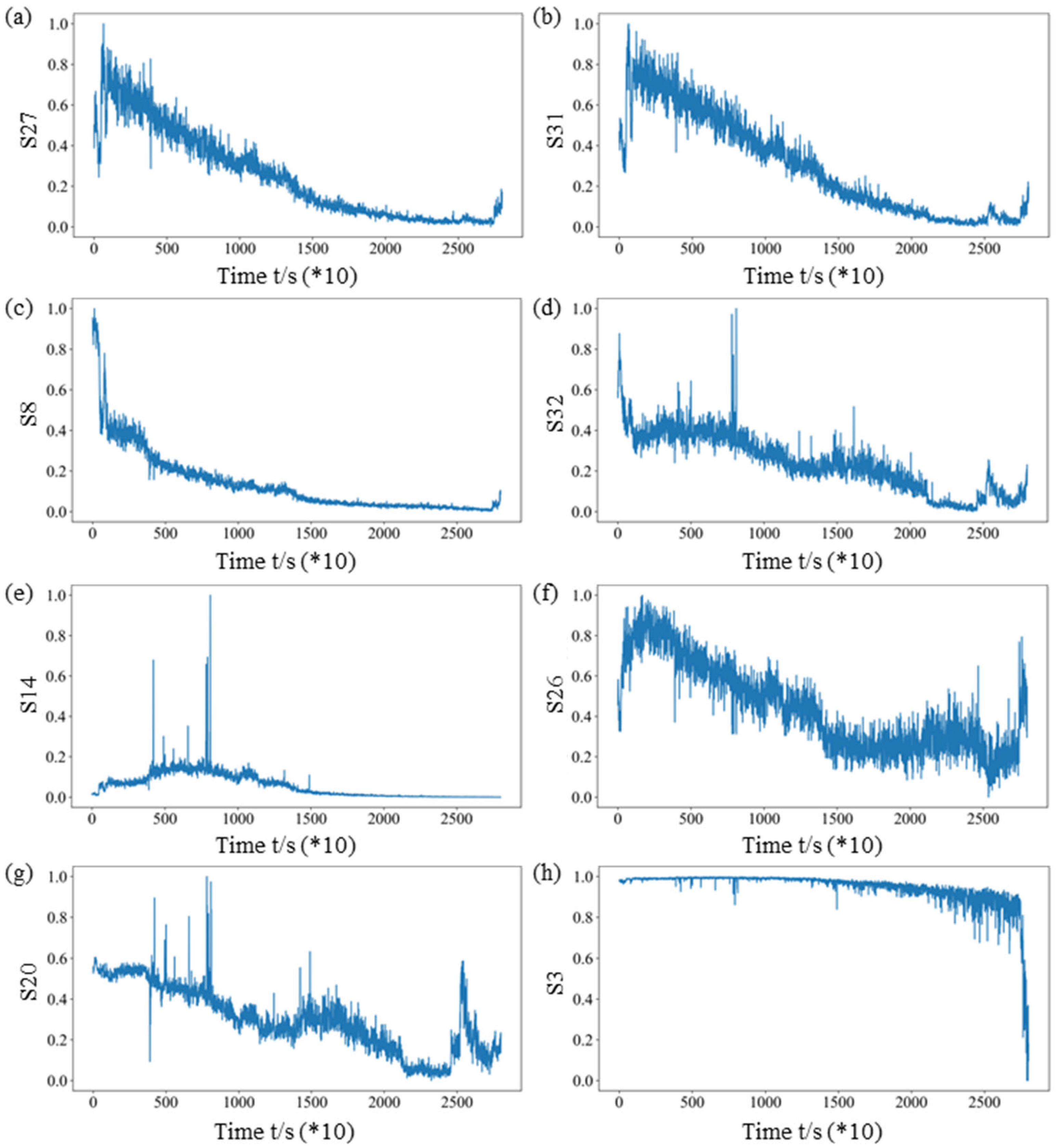
4.1. Verification of Feature Extraction and Health Index Construction
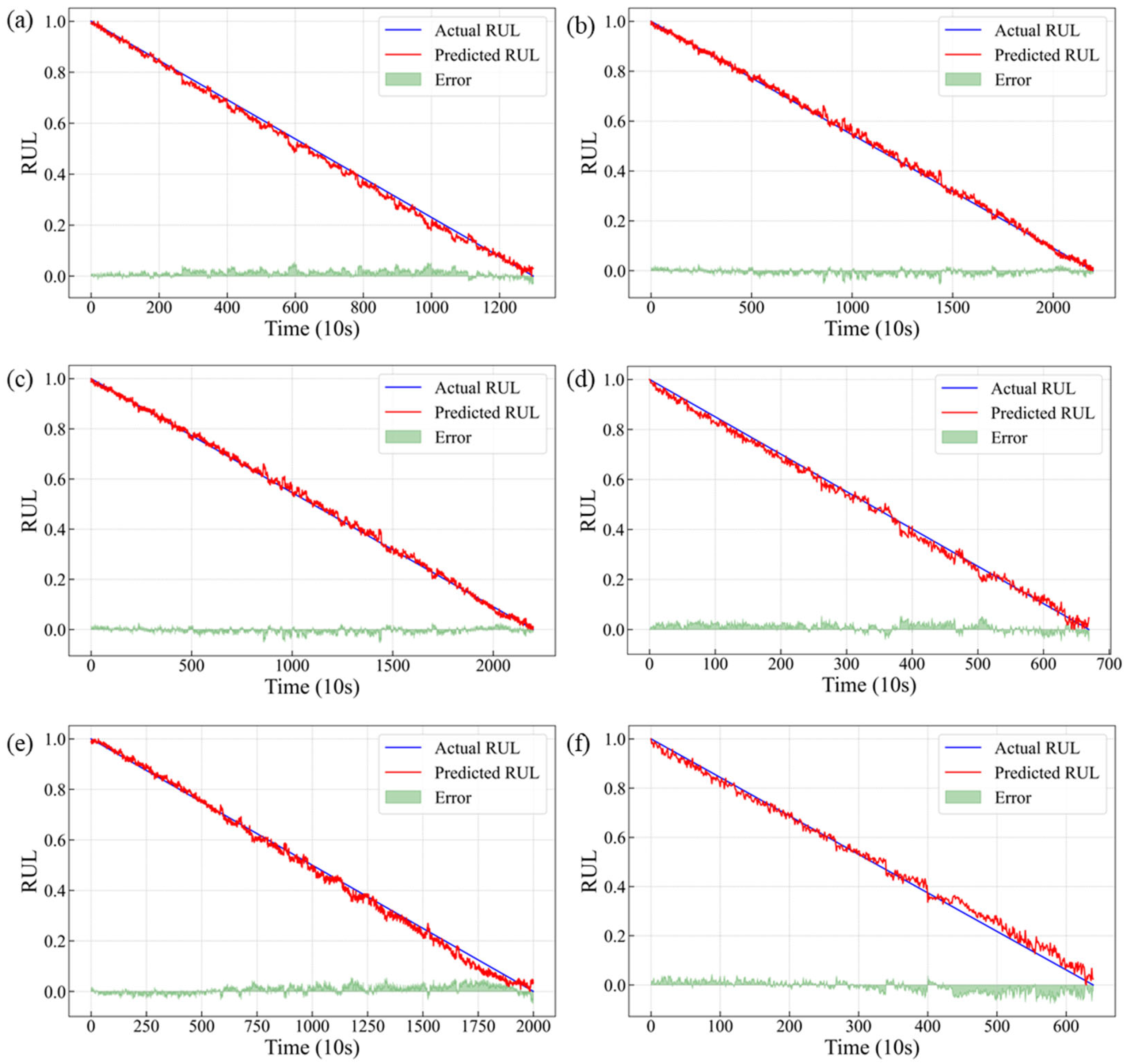
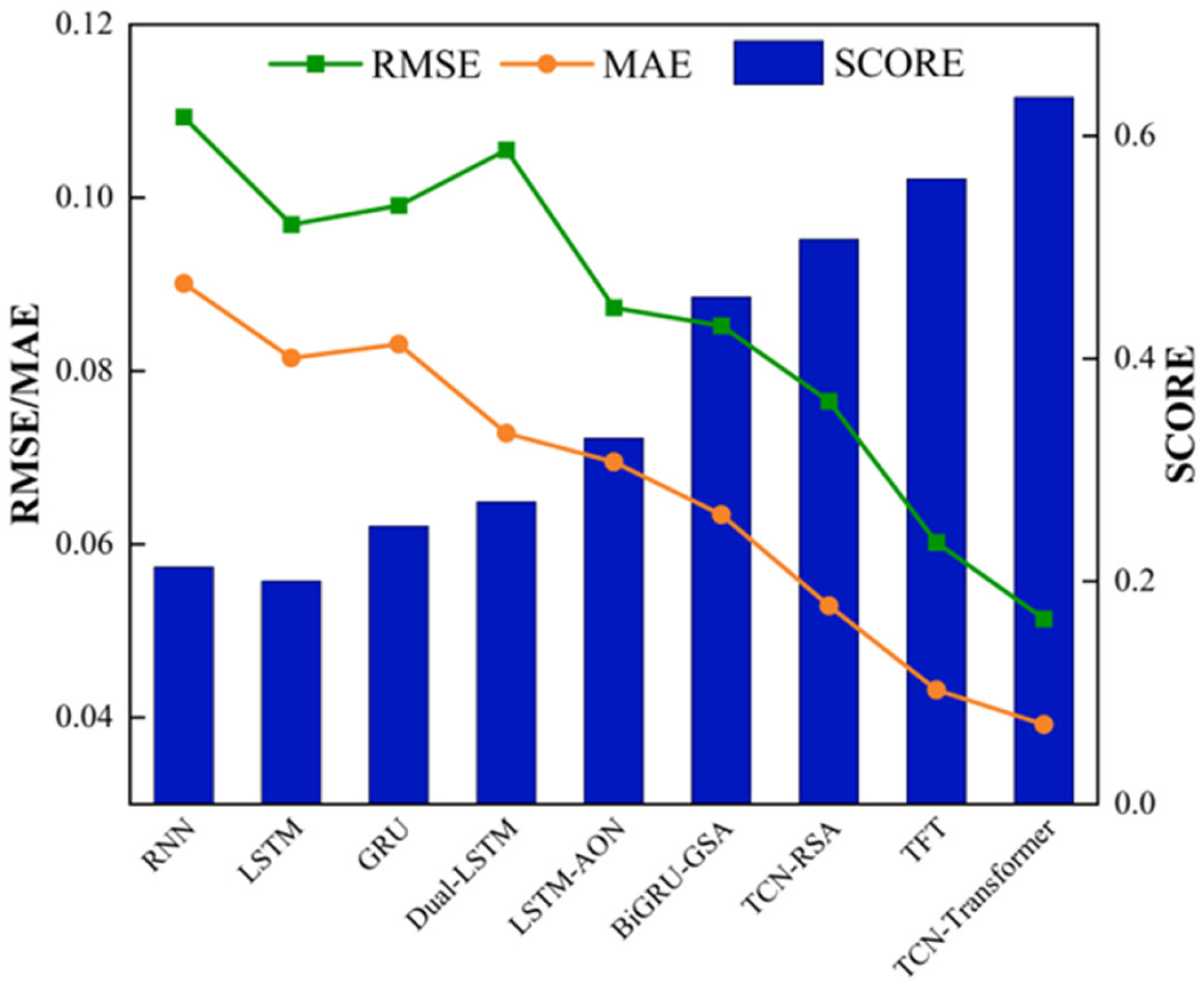
4.2. Experiment and Verification of the TCN–Transformer Networks
4.3. Ablation Experiment and Results of TCN–Transformer Networks
5. Conclusions
- The method for constructing a HIVS was developed to describe the performance features of rolling bearings. The eight sensitive feature indexes that can accurately reflect the performance of rolling bearings were selected from the 32 indexes to construct the feature set, and then the obtained sensitive feature index after dimensionality reduction was processed to remove outliers and then normalized to obtain the HI. The average comprehensive index of bearings improved by 8.69% on average.
- The TCN–Transformer employs a hierarchical parallel architecture combining TCN and Transformer modules, achieving higher computational efficiency and a more compact network scale. Compared with classical standalone TCN or Transformer networks, our approach significantly reduces the required number of channels through feature compression. The outputs from the TCN and Transformer modules interact through a novel multi-head feature fusion attention mechanism, enabling bidirectional integration of local temporal patterns (captured by TCN) and global dependencies (learned by Transformer). This specialized attention module dynamically prioritizes the most discriminative features extracted by both sub-networks, ensuring precise focus on performance-critical characteristics for RUL prediction.
- Compared with existing methods, the proposed TCN–Transformer demonstrates superior accuracy in predicting the RUL of rolling bearings across diverse operating conditions. Specifically, in ablation studies, TCN–Transformer outperforms both the standalone TCN and Transformer models, achieving consistent improvements across all evaluation tasks. When compared with state-of-the-art methods, TCN–Transformer reduces RMSE and MAE by 14.62% and 9.26%, respectively, while improving the SCORE metric by 13.04%. These results conclusively validate the superiority of our approach in RUL prediction.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhao, Z.; Liang, B.; Wang, X.; Lu, W. Remaining useful life prediction of aircraft engine based on degradation pattern learning. Reliab. Eng. Syst. Saf. 2017, 164, 74–83. [Google Scholar] [CrossRef]
- AlShorman, O.; Irfan, M.; Saad, N.; Zhen, D.; Haider, N.; Glowacz, A.; AlShorman, A. A review of artificial intelligence methods for condition monitoring and fault diagnosis of rolling element bearings for induction motor. Shock Vib. 2020, 2020, 1–20. [Google Scholar] [CrossRef]
- Li, Y.; Wang, S.; Li, N.; Deng, Z. Multiscale symbolic diversity entropy: A novel measurement approach for time-series analysis and its application in fault diagnosis of planetary gearboxes. IEEE Trans. Industr. Inform. 2022, 18, 1121–1131. [Google Scholar] [CrossRef]
- Ma, M.; Mao, Z. Deep wavelet sequence-based gated recurrent units for the prognosis of rotating machinery. Struct. Health Monit. 2021, 20, 1794–1804. [Google Scholar] [CrossRef]
- Zio, E. Prognostics and Health Management (PHM): Where are we and where do we (need to) go in theory and practice. Reliab. Eng. Syst. Saf. 2022, 218 Pt A, 108119. [Google Scholar] [CrossRef]
- Ahang, M.; Jalayer, M.; Shojaeinasab, A.; Ogunfowora, O.; Charter, T.; Najjaran, H. Synthesizing Rolling Bearing Fault Samples in New Conditions: A Framework Based on a Modified CGAN. Sensors 2022, 22, 5413. [Google Scholar] [CrossRef] [PubMed]
- Forest, F.; Fink, O. Calibrated Adaptive Teacher for Domain-Adaptive Intelligent Fault Diagnosis. Sensors 2024, 24, 7539. [Google Scholar] [CrossRef]
- Lv, K.L.; Jiang, H.N.; Fu, S.N.; Du, T.C.; Jin, X.C.; Fan, X.L. A predictive analytics framework for rolling bearing vibration signal using deep learning and time series techniques. Comput. Electr. Eng. 2024, 117, 109314. [Google Scholar] [CrossRef]
- Giraudo, L.; Di Maggio, L.G.; Giorio, L.; Delprete, C. Dynamic Multibody Modeling of Spherical Roller Bearings with Localized Defects for Large-Scale Rotating Machinery. Sensors 2025, 25, 2419. [Google Scholar] [CrossRef]
- Liu, X.R.; Yan, C.F.; Ming Lv Wu, L.X. Multi-rolling element faults diagnosis of rolling bearing based on time-frequency analysis and multi-curves extraction. Meas. Sci. Technol. 2024, 35, 106113. [Google Scholar] [CrossRef]
- Jiang, L.L.; Shi, C.Z.; Sheng, H.S.; Li, X.J.; Yang, T.G. Lightweight CNN architecture design for rolling bearing fault diagnosis. Meas. Sci. Technol. 2024, 35, 126142. [Google Scholar] [CrossRef]
- Wang, T.; Li, X.; Wang, W.; Du, J.; Yang, X. A spatiotemporal feature learning-based RUL estimation method for predictive maintenance. Measurement 2023, 214, 112824. [Google Scholar] [CrossRef]
- Guo, J.X.; Zhang, T.Y.; Xue, K.L.; Liu, J.H.; Wu, J.; Zhao, Y.D. Fault diagnosis of rolling bearing based on parameter-adaptive re-constraint VMD optimized by SABO. Meas. Sci. Technol. 2025, 36, 016174. [Google Scholar] [CrossRef]
- Kiakojouri, A.; Wang, L. A Generalized Convolutional Neural Network Model Trained on Simulated Data for Fault Diagnosis in a Wide Range of Bearing Designs. Sensors 2025, 25, 2378. [Google Scholar] [CrossRef]
- Wang, H.; An, J.; Yang, J.; Xu, S.; Wang, Z.M.; Cao, Y.; Yuan, W.Q. Remaining useful life prediction method of bearings based on the interactive learning strategy. Comput. Electr. Eng. 2025, 121, 109853. [Google Scholar] [CrossRef]
- Xu, Z.; Guo, Y.; Saleh, J.H. Accurate remaining useful life prediction with uncertainty quantification: A deep learning and nonstationary gaussian process approach. IEEE Trans. Reliab. 2021, 71, 443–456. [Google Scholar] [CrossRef]
- Hai, B.; Jiang, H.K.; Yao, P.; Wang, K.B.; Yao, R.H. Rolling bearing fault feature extraction using non-convex periodic group sparse method. Meas. Sci. Technol. 2021, 32, 105005. [Google Scholar] [CrossRef]
- Hu, C.F.; Liu, Z.J.; Xiao, X.W.; Jin, Y.F.; Wang, T.; Zhou, L.H.; Su, L. A degradation evaluation method with the convolutional neural network for the cyclic symmetry rolling bearing. Meas. Sci. Technol. 2025, 36, 016188. [Google Scholar] [CrossRef]
- Chang, Y.; Chen, Q.; Chen, J.; He, S.; Li, F.; Zhou, Z. Intelligent fault diagnosis scheme via multi-module supervised-learning network with essential features capture-regulation strategy. ISA Trans. 2022, 129, 459–475. [Google Scholar] [CrossRef]
- Zhu, J.; Chen, N.; Shen, C. A new data-driven transferable remaining useful life prediction approach for bearing under different working conditions. Mech. Syst. Signal Process. 2020, 139, 106602. [Google Scholar] [CrossRef]
- Shih, Y.S.; Chen, J.J. Analysis of fatigue crack growth on a cracked shaft. Int. J. Fatigue 1997, 19, 477–485. [Google Scholar] [CrossRef]
- Choi, Y.; Liu, C.R. Spall progression life model for rolling contact verified by finish hard machined surfaces. Wear 2007, 262, 24–35. [Google Scholar] [CrossRef]
- Chen, C.; Liu, Y.; Wang, S.; Sun, X.; Cairano-Gilfedder, C.; Titmus, S.; Syntetos, A.A. Predictive maintenance using cox proportional hazard deep learning. Adv. Eng. Inform. 2020, 44, 101054. [Google Scholar] [CrossRef]
- Aremu, O.O.; Hyland-Wood, D.; McAree, P.R. A Relative Entropy Weibull-SAX framework for health indices construction and health stage division in degradation modeling of multivariate time series asset data. Adv. Eng. Inform. 2019, 40, 121–134. [Google Scholar] [CrossRef]
- Caravaca, C.F.; Flamant, Q.; Anglada, M.; Gremillard, L.; Chevalier, J. Impact of sandblasting on the mechanical properties and aging resistance of alumina and zirconia based ceramics. J. Eur. Ceram. Soc. 2018, 38, 915–925. [Google Scholar] [CrossRef]
- Wu, R.T.; Jahanshahi, M.R. Data fusion approaches for structural health monitoring and system identification: Past, present, and future. Struct. Health Monit. 2020, 19, 552–586. [Google Scholar] [CrossRef]
- Ye, R.; Dai, Q. A novel transfer learning framework for time series forecasting. Knowl.-Based Syst. 2018, 156, 74–99. [Google Scholar] [CrossRef]
- Dang, D.Z.; Su, B.Y.; Wang, Y.W.; Ao, W.K.; Ni, Y.Q. A pencil lead break-triggered, adversarial autoencoder-based approach for rapid and robust rail damage detection. Eng. Appl. Artif. Intel. 2025, 150, 110637. [Google Scholar] [CrossRef]
- Mao, W.; He, J.; Tang, J.; Li, Y. Predicting remaining useful life of rolling bearings based on deep feature representation and long short-term memory neural network. Adv. Mech. Eng. 2018, 10, 1–18. [Google Scholar] [CrossRef]
- Wang, Y.L.; Lu, Y.; Tan, Y.K.; Ao, W.K.; Ni, Y.-Q.; Tang, Q.-C. Bayesian optimization bidirectional LSTM approach for the condition assessment of underground-operating trains. J. Civ. Struct. Health Monit. 2025. [Google Scholar] [CrossRef]
- Silka, J.; Wieczorek, M.; Wozniak, M. Recurrent neural network model for high-speed train vibration prediction from time series. Neural Comput. Appl. 2022, 34, 13305–13318. [Google Scholar] [CrossRef]
- Caterini, A.L.; Chang, D.E. Recurrent neural networks. In Deep Neural Networks in a Mathematical Framework; SpringerBriefs in Computer Science; Springer: Cham, Switzerland, 2018. [Google Scholar] [CrossRef]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar] [CrossRef]
- Andrew, G.; Menglong, Z. Efficient convolutional neural networks for mobile vision applications, mobilenets. arXiv 2017, arXiv:1704.04861. [Google Scholar] [CrossRef]
- Van Den Oord, A.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. Wavenet: A generative model for raw audio. arXiv 2016, arXiv:1609.03499. [Google Scholar] [CrossRef]
- Bai, S.; Kolter, J.Z.; Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar] [CrossRef]
- Lin, L.; Xu, B.; Wu, W.; Richardson, T.W.; Bernal, E.A. Medical Time Series Classification with Hierarchical Attention-based Temporal Convolutional Networks: A Case Study of Myotonic Dystrophy Diagnosis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Long Beach, CA, USA, 15–20 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 83–86. [Google Scholar] [CrossRef]
- Zheng, X.; Qian, Y.; Wang, S. GRU prediction forperformance degradation of rolling bearings based on optimalwavelet packet and Mahalanobis distance. J. Vib. Shock 2020, 39, 9–46+63. (In Chinese) [Google Scholar] [CrossRef]
- Moradi, M.; Broer, A.; Chiachío, J.; Benedictus, R.; Loutas, T.H.; Zarouchas, D. Intelligent health indicator construction for prognostics of composite structures utilizing a semi-supervised deep neural network and SHM data. Eng. Appl. Artif. Intel. 2023, 117, 105502. [Google Scholar] [CrossRef]
- Wei, X.P. Deep Learning Based Health State Assessment and Remaining Life Prediction of Rolling Bearings. Master’s Thesis, Southwest Jiaotong University, Chengdu, China, 2021. (In Chinese). [Google Scholar] [CrossRef]
- Ao, W.K.; Hester, D.; O’Higgins, C.; Brownjohn, J. Tracking long-term modal behaviour of a footbridge and identifying potential SHM approaches. J. Civil Struct. Health Monit. 2025, 14, 1311–1337. [Google Scholar] [CrossRef]
- Liu, Y.; Wijewickrema, S.; Li, A.; Bester, C.; O’Leary, S.; Bailey, J. Time-transformer: Integrating local and global features for better time series generation. arXiv 2023, arXiv:2312.11714. [Google Scholar] [CrossRef]
- Nectoux, P.; Gouriveau, R.; Medjaher, K.; Ramasso, E.; Morello, B.; Zerhouni, N.; Varnier, C. PRONOSTIA: An experimental platform for bearings accelerated degradation tests. In Proceedings of the IEEE International Conference on Prognostics and Health Management, Denver, CO, USA, 18–21 June 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 1–8. Available online: https://hal.science/hal-00719503v1 (accessed on 2 June 2025).
- Soualhi, A.; Medjaher, K.; Zerhouni, N. Bearing health monitoring based on hilbert-huang transform, support vector machine, and regression. IEEE Trans. Instrum. Meas. 2015, 64, 52–62. [Google Scholar] [CrossRef]
- Chang, Y.; Li, F.; Chen, J.; Liu, Y.; Li, Z. Efficient temporal flow Transformer accompanied with multi-head probsparse self-attention mechanism for remaining useful life prognostics. Reliab. Eng. Syst. Saf. 2022, 226, 108701. [Google Scholar] [CrossRef]
- Cao, Y.; Ding, Y.; Jia, M.; Tian, R. A novel temporal convolutional network with residual self-attention mechanism for remaining useful life prediction of rolling bearings. Reliab. Eng. Syst. Saf. 2021, 215, 107813. [Google Scholar] [CrossRef]
- Shi, Z.; Chehade, A. A dual-LSTM framework combining change point detection and remaining useful life prediction. Reliab. Eng. Syst. Saf. 2021, 205, 107257. [Google Scholar] [CrossRef]
- Xiang, S.; Qin, Y.; Zhu, C.; Wang, Y.; Chen, H. LSTM networks based on attention ordered neurons for gear remaining life prediction. ISA Trans. 2020, 106, 343–354. [Google Scholar] [CrossRef]
- Chang, Y.; Chen, J.; Lv, H.; Liu, S. Heterogeneous bi-directional recurrent neural network combining fusion health indicator for predictive analytics of rotating machinery. ISA Trans. 2022, 122, 409–423. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dimensional Index | Function | Dimensionless Index | Function |
|---|---|---|---|
| Mean absolute value (S1) | Skewness (S11) | ||
| Peak (S2) | Kurtosis (S12) | ||
| Minimum (S3) | Skewness factor (S13) | ||
| Mean value (S4) | Kurtosis factor (S14) | ||
| Maximum (S5) | Crest factor (S15) | ||
| Root mean square (S6) | Shape factor (S16) | ||
| Root amplitude (S7) | Impulse factor (S17) | ||
| Variance (S8) | Clearance factor (S18) | ||
| Standard deviation (S9) | Coefficient of variation (S19) | ||
| Maximum to minimum difference (S10) |
| Index | Function |
|---|---|
| Centroid frequency (S20) | |
| Average frequency (S21) | |
| Standard deviation of frequency (S22) | |
| Root mean square of frequency (S23) | |
| Variance of frequency (S24) |
| Bearing | Monotonicity Index | Correlation Index | Predictive Index | Robustness Index | Comprehensive Index | Original Maximum Comprehensive Index | Improvement |
|---|---|---|---|---|---|---|---|
| 1-1 | 0.9458 | 0.9654 | 0.9428 | 0.8943 | 0.9482 | 0.8904 | 6.5% |
| 1-2 | 0.8664 | 0.8628 | 0.9428 | 0.8805 | 0.8720 | 0.8173 | 6.7% |
| 1-3 | 0.9593 | 0.9573 | 0.9428 | 0.8801 | 0.9490 | 0.8524 | 11.3% |
| 1-4 | 0.8033 | 0.7707 | 0.9428 | 0.9097 | 0.8149 | 0.7518 | 8.4% |
| 1-5 | 0.8779 | 0.8952 | 0.9428 | 0.8893 | 0.8924 | 0.8218 | 8.6% |
| 1-6 | 0.9017 | 0.9132 | 0.9428 | 0.8982 | 0.9140 | 0.8096 | 12.9% |
| 1-7 | 0.9167 | 0.8978 | 0.9428 | 0.8587 | 0.9059 | 0.8512 | 6.4% |
| Dataset 1 Load (N) | Rotation Speed (rpm) | Dataset 2 Load (N) | Rotation Speed (rpm) |
|---|---|---|---|
| 4000 | 1800 | 4200 | 1650 |
| Bearing | Actual life | Bearing | Actual life |
| Bearing 1-1 | 7 h 47 min 00 s | Bearing 2-1 | 2 h 31 min 40 s |
| Bearing 1-2 | 2 h 25 min 00 s | Bearing 2-2 | 2 h 12 min 40 s |
| Bearing 1-3 | 5 h 00 min 10 s | Bearing 2-3 | 3 h 20 min 10 s |
| Bearing 1-4 | 3 h 09 min 40 s | Bearing 2-4 | 1 h 41 min 50 s |
| Bearing 1-5 | 6 h 23 min 29 s | Bearing 2-5 | 5 h 33 min 30 s |
| Bearing 1-6 | 4 h 10 min 11 s | Bearing 2-6 | 1 h 35 min 10 s |
| Task | Training Bearing | Test Bearing |
|---|---|---|
| A | Bearing 1-1, 1-2, 1-3 | Bearing 1-4 |
| B | Bearing 1-1, 1-2, 1-3 | Bearing 1-5 |
| C | Bearing 1-1, 1-2, 1-3 | Bearing 1-6 |
| D | Bearing 2-1, 2-2, 2-3 | Bearing 2-4 |
| E | Bearing 2-1, 2-2, 2-3 | Bearing 2-5 |
| F | Bearing 2-1, 2-2, 2-3 | Bearing 2-6 |
| Hyperparameter | Value | Hyperparamete | Value |
|---|---|---|---|
| Batch Size | 32 | Epochs | 10 |
| Activation Function | GELU | Learning Rate | 0.0001 |
| Embedding Dimension | 64 | Hidden Unit Dimension | 256 |
| Temporal Window Length | 30 | Loss Function | MSE |
| Model | Average RMSE | Average MAE | Average SCORE |
|---|---|---|---|
| RNN | 0.1093 | 0.0901 | 0.2129 |
| LSTM | 0.0969 | 0.0815 | 0.2004 |
| GRU | 0.0991 | 0.0831 | 0.2496 |
| Dual-LSTM | 0.1055 | 0.0728 | 0.2714 |
| LSTM-AON | 0.0873 | 0.0695 | 0.3286 |
| BiGRU-GSA | 0.0852 | 0.0634 | 0.4553 |
| TCN-RSA | 0.0765 | 0.0529 | 0.507 |
| TFT | 0.0602 | 0.0432 | 0.5614 |
| TCN–Transformer | 0.0514 | 0.0392 | 0.6346 |
| IMP | 14.62% | 9.26% | 13.04% |
| RMSE | MAE | SCORE | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Task | TCN- Transformer | Transformer | TCN | TCN- Transformer | Transformer | TCN | TCN- Transformer | Transformer | TCN |
| A | 0.0312 | 0.0177 | 0.6225 | 0.0227 | 0.0135 | 0.5131 | 0.6356 | 0.5290 | 0.1226 |
| B | 0.0660 | 0.0491 | 1.0182 | 0.0483 | 0.0406 | 0.8467 | 0.5673 | 0.5384 | 0.0724 |
| C | 0.0607 | 0.1208 | 0.9761 | 0.0530 | 0.1077 | 0.8184 | 0.5916 | 0.4122 | 0.0700 |
| D | 0.0275 | 0.1278 | 0.5127 | 0.0226 | 0.0624 | 0.4201 | 0.6764 | 0.5465 | 0.1961 |
| E | 0.0800 | 0.1257 | 1.0087 | 0.0436 | 0.0894 | 0.8567 | 0.6178 | 0.3828 | 0.0491 |
| F | 0.0430 | 0.0703 | 0.4298 | 0.0448 | 0.0662 | 0.3498 | 0.7188 | 0.5743 | 0.2675 |
| Average | 0.0514 | 0.0852 | 0.7613 | 0.0392 | 0.0633 | 0.6341 | 0.6346 | 0.4972 | 0.1296 |
| IMP | 39.67% | 38.07% | 26.63% | ||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jin, X.; Ji, Y.; Li, S.; Lv, K.; Xu, J.; Jiang, H.; Fu, S. Remaining Useful Life Prediction for Rolling Bearings Based on TCN–Transformer Networks Using Vibration Signals. Sensors 2025, 25, 3571. https://doi.org/10.3390/s25113571
Jin X, Ji Y, Li S, Lv K, Xu J, Jiang H, Fu S. Remaining Useful Life Prediction for Rolling Bearings Based on TCN–Transformer Networks Using Vibration Signals. Sensors. 2025; 25(11):3571. https://doi.org/10.3390/s25113571
Chicago/Turabian StyleJin, Xiaochao, Yaping Ji, Shiteng Li, Kailang Lv, Jianzheng Xu, Haonan Jiang, and Shengnan Fu. 2025. "Remaining Useful Life Prediction for Rolling Bearings Based on TCN–Transformer Networks Using Vibration Signals" Sensors 25, no. 11: 3571. https://doi.org/10.3390/s25113571
APA StyleJin, X., Ji, Y., Li, S., Lv, K., Xu, J., Jiang, H., & Fu, S. (2025). Remaining Useful Life Prediction for Rolling Bearings Based on TCN–Transformer Networks Using Vibration Signals. Sensors, 25(11), 3571. https://doi.org/10.3390/s25113571