1. Introduction
With the advantages of large capacity, wide coverage, high cost-effectiveness, high safety, and good stability, railway transportation has always been an indispensable part of the transportation systems of countries around the world [
1,
2]. The safety and reliability of train operation are the basic guarantees for railway transportation safety; therefore, the fault diagnosis of key components of trains has always been a research focus for scholars. The train transmission system is the core component of the train power supply system, and its function is to transfer energy from electric machinery to wheelsets. Any unexpected failures of any component in the train transmission system may lead to serious safety accidents, resulting in unexpected casualties and significant economic losses. Therefore, developing effective fault diagnosis methods for reliability analysis and evaluation of train transmission systems and their key components has become an urgent problem to ensure the safe operation of trains [
3,
4].
Benefiting from the rapid development of advanced sensor technology and artificial intelligence algorithms, data-driven intelligent fault diagnosis methods have become effective and powerful tools for improving the safety and reliability of train operations [
5,
6,
7,
8,
9]. Some promising results have been achieved with data-driven intelligent fault diagnosis methods for the train transmission system. Wang et al. [
10] proposed a multi-attention one-dimensional convolutional neural network (MDCNN) for the diagnosis of wheel set faults by integrating the attention mechanism. Peng et al. [
11] proposed a novel deep one-dimensional convolutional neural network (Der-1DCNN) for the diagnosis of wheel set bearing faults under load, variable speeds, and strong ambient noise disturbances, and achieved a high diagnostic accuracy under a strong noise environment. Wang et al. [
12] proposed a novel multilayer wavelet integrated convolutional neural network (MWI-Net) for predicting wheel wear in high-speed trains and accurately predicted the wheel wear curve. Ding et al. [
13] also proposed an evolvable fault diagnosis framework for the train driveline system by combining the system-level fault diagnostic network with an evolutionary learning mechanism and achieved a joint diagnosis of the whole system.
However, for the train transmission system, there are two challenging problems that seriously limit the application of intelligent fault diagnosis methods in practical engineering. The first challenge is the noise corruption in vibration signals, which is ubiquitous in mechanical fault diagnosis. Trains usually operate under complicated working conditions such as high speeds, heavy loads, and uneven rail surfaces. Vibration signals collected by sensors not only contain useful fault information but also strong environmental noise. Furthermore, other vibration information generated during the operation of other components in the train system will also be reflected in the measured signals. This noise and irrelevant information mask the representative fault features, and the useful fault information can hardly be extracted from the collected signals as a result [
14,
15]. The second challenge is the multi-scale characteristics of fault features, which means various local patterns with different lengths of data segments. Under nonstationary working conditions, the speed and load of the train during operation will change dramatically. The fault impulsive response of the transmission system is a time-varying signal, and the feature frequencies caused by faults vary at different scales. Moreover, there are multiple components in the whole transmission system, and each component has various types of faults. The vibration signals generated by different components and faults will be coupled with each other. Ultimately, the collected vibration signals contain complex feature information across multiple time scales and exhibit multi-scale characteristics in the frequency domain. The multi-scale characteristic leads to a sharp decline in the feature extraction capability and robustness of network models [
16,
17].
For the first challenge, the attention mechanism has been proven to be an effective technique to enhance the ability of other models to process monitoring signals. The attention mechanism accomplishes adaptive denoising by learning the relative importance degrees of relevant and irrelevant information in different feature maps. For the irrelevant information, the vibration response of the mechanical system and noise, which is unrelated to the fault diagnosis task, will be assigned lower weights, and the information related to the fault diagnosis task is given larger weights. Research has shown that the attention mechanism has become an important technique in the field of mechanical fault diagnosis [
18,
19,
20]. For the second challenge, the multi-scale convolution model shows great potential. In the multi-scale convolution model, a multi-scale network structure is constructed by multiple convolutional layers with different convolution kernel sizes. Then, the features at different time scales and frequencies can be extracted automatically from vibration signals. Consequently, the performance and robustness of the deep network model are enhanced [
21].
Inspired by the success of attention mechanisms and multi-scale convolutional models, researchers have proposed a variety of multi-scale networks incorporating attention mechanisms for the fault diagnosis of different mechanical systems [
22,
23]. For rolling bear fault diagnosis, the channel attention mechanism was introduced by Huang et al. [
24] into a multi-scale CNN network to enhance the diagnosis performance. The fault features of the bearing were extracted by the maximum and average pooling layers from multiple scales, and the convolutional layer’s feature-learning ability was increased by the channel attention mechanism. In [
25], a novel multiscale residual attention network model for bearing fault diagnosis was developed. In the proposed scheme, fault features at different scales were learned by an improved multiscale learning module, and a new residual attention learning strategy was developed to find the most informative features. Kim et al. [
26] presented a multi-scale path attention residual network to improve the feature representation ability of multi-scale structures for rotating machinery fault features. The important multi-scale fault features could be effectively extracted by three multi-scale attention residual blocks, and then the extracted features were fused into the next part of the network.
Although multi-scale networks combined with attention mechanisms have effectively improved the application effectiveness of intelligent models on various research objects, for the train transmission system, there are still two obvious shortcomings in the existing intelligent network models that need to be addressed. (1) The generalization ability of the network model is insufficient to meet the fault diagnosis task requirements of the entire train transmission system. At present, the research objects of network models mainly focus on the key components in mechanical systems, such as bearings, gears, rotating machinery, etc. The train transmission system is a comprehensive mechanical structure composed of multiple components such as traction motors, wheelsets, transmission gears, and axle boxes. The types of faults and diagnostic requirements for different components vary greatly. The existing network models for individual components cannot meet the diagnostic requirements of the transmission system. (2) Under non-stationary operating conditions, the robustness and accuracy of the network model need to be further improved. The existing attention methods have insufficient ability to extract relevant information within the sequence and at each position, resulting in a decrease in fault diagnosis accuracy and feature richness of multi-scale network models. In addition, traditional attention methods such as channel attention and spatial attention are implemented in a cascading manner, which makes the model design more complex.
To overcome the above shortcomings, a novel parallel multi-scale attention residual neural network (PMA-ResNet) for a train transmission system is proposed in this paper. The main contributions of this work can be summarized as follows.
- (1)
Three multi-scale learning modules (MLMods) with different structures and convolutional kernel sizes are constructed based on the Inception network and residual neural network (ResNet), which improve the representation ability and robustness of the captured fault features even under non-stationary conditions. The multi-scale fault features of different components are effectively learned from the vibration signal at different scales.
- (2)
A parallel network structure is designed to improve the generalization ability of the proposed method, thereby meeting the fault diagnosis task requirements of the entire train transmission system.
- (3)
The self-attention mechanism strategy is introduced to improve the performance of the neural network by adaptively learning the relative importance of different feature maps and increasing the weights of useful features. Then, the learned features are further enhanced, providing rich and reliable feature information for the final classification results of the network model.
- (4)
A multi-operating condition, multi-component, and strong noise interference train transmission system fault simulation platform has been constructed, covering nine non-steady state operating conditions and 16 typical fault types. In comparison with the extant literature, which focuses on a single component or steady state condition, this experiment is more aligned with the actual train-operating environment.
The rest of this paper is structured as follows.
Section 2 introduces the theoretical background of residual neural networks and inception networks. Then, the method of this paper is elaborated in
Section 3. Experiments are conducted in
Section 4 to evaluate the proposed method. Finally, conclusions are discussed in
Section 5.
3. Proposed Method
This section provides a detailed description of the proposed PMA-ResNet method, including the multi-scale learning module, the self-attention mechanism, and the parallel structure.
3.1. Multi-Scale Learning Modules
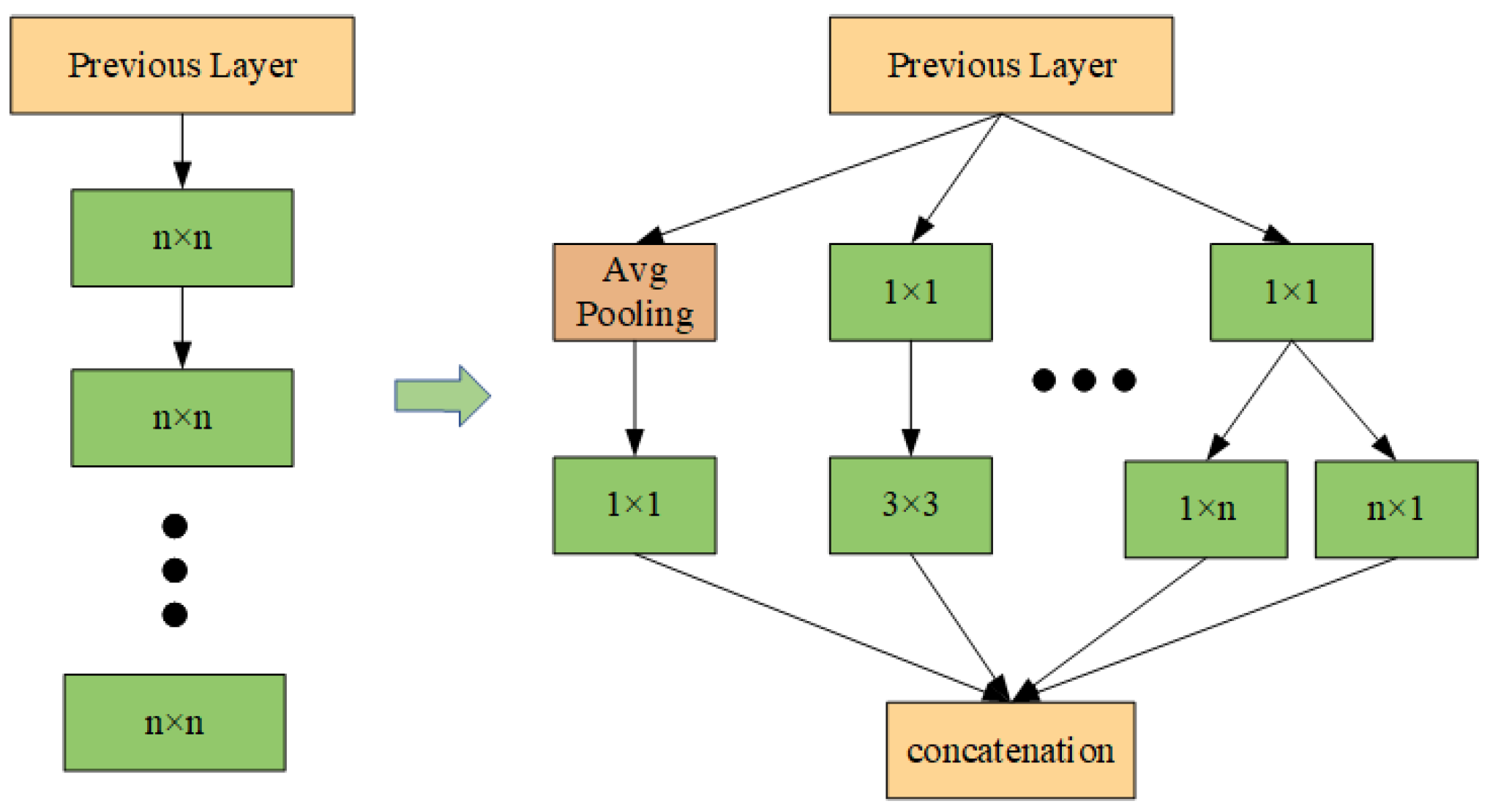
Inspired by the Inception network, multi-scale learning modules (MLMods) are designed in this paper. The designed MLMods are the layered structure comprising multiple convolutional layers and batch normalization (BN) layers, as illustrated in
Figure 2. Among the aforementioned modules, the
convolution reduces the dimensionality of the input channel and subsequently performs the convolution operation, thereby effectively enhancing the network’s width. The decomposition of the
convolution kernel into two convolutions,
and
, has the effect of reducing both the time and space complexities. Furthermore, the incorporation of a residual connection mitigates the issue of gradient vanishing due to network depth and enhances the overall generalization capability.
The convolutional layer of each module consists of multiple trainable convolutional kernels for extracting features of the input vibration signal, denoted as
where
is the output of the
lth layer,
denotes the activation function,
denotes the weight of the
ith convolutional kernel of the
lth layer,
is the input value of the
lth layer, and
is the bias vector of the convolutional layer.
In order to obtain features at different scales and ensure the quality of these features, it is first necessary to extract the signal features through a multi-scale convolutional layer. These features are then fused.
Stacking convolutional layers can deepen the network structure, but an increase in the number of layers may cause the gradient to disappear during backpropagation. This problem can be solved effectively by introducing BN layers. The BN process is expressed as
where
is the batch size,
is the input element per batch,
is the batch mean,
is the batch variance, and
is the normalized value.
3.2. Self-Attention Mechanism
It is often the case that traditional convolutional neural networks fail to fully appreciate the significance and relevance of different features when engaged in the process of feature extraction. Furthermore, the constraints imposed by limited computational resources serve to restrict the extent of their processing capabilities. The incorporation of an attention mechanism into the network facilitates the prioritization of salient information within the input data, thereby enhancing the model’s accuracy and computational efficiency.
The self-attention mechanism [
31] is a process that enables the dynamic adjustment of the representation of each element by calculating the similarity between elements in the input sequence. This mechanism facilitates the capture of global dependencies by assigning a weight to each element based on its relationship with other elements during the computation of its representation. As illustrated in
Figure 3a, scaled dot product attention (SDPA) is demonstrated. The fundamental aspect of the methodology is the calculation of the correlation between each element in the input sequence and other elements, which can be conceptualized as attention weights. These weights are then employed to weight and sum the sequence, thereby obtaining a new representation. This representation not only preserves the information of all elements in the sequence but also identifies the salient portions relevant to the current element.
The computational process of the self-attention mechanism consists of the following steps:
(1) Vector representation: For an input vector of
X, each element in the sequence generates the corresponding query vector
Q, key vector
K, and value vector
V.
where
,
, and
are learnable weight matrices.
(2) Calculate relevance: For each query vector, calculate its similarity with all key vectors by the dot product to get the attention score.
To prevent the inner product value from becoming excessively large due to high dimensions, which can lead to vanishing or exploding gradients in the SoftMax function, the dot product result is typically scaled by a factor proportional to the dimensions of
Q and
K. This scaling factor helps control the magnitude of the inner product.
(3) Normalization: Weights: The attention scores are converted to attention weights by the SoftMax function such that they sum to one.
(4) Compute the attentional output: The attentional output is a weighted sum of the value vectors.
In contrast, the multi-head attention mechanism is founded upon the dot product attention mechanism, which employs a series of linear transformations to partition the input vector into multiple subspaces (i.e., ‘heads’). Each subspace then undergoes a calculation of the dot product attention independently, after which the outputs of the various subspaces are spliced together and subjected to a linear transformation. This design enables the model to concurrently attend to disparate information within distinct representation subspaces, thereby augmenting the model’s expressiveness and robustness. The structure of the multi-attention mechanism is illustrated in
Figure 3b.
The formula for the operation of the multi-attention mechanism with input
X is as follows:
where
h is the number of heads and
is the output projection matrix.
Each weight matrix is formed by concatenating the weight matrices of each header. The output of the result of each representation header operation is given by the following equation:
3.3. Parallel Network Structure
The traditional serial network structure relies on layer-by-stacked network layers for information transfer, but may face the following challenges during deep network training: (1) as the network depth increases, the gradient may gradually weaken during backpropagation, which affects the training effect of the model; (2) the computation of the serial structure relies on the outputs of the previous layer, which makes it difficult to make full use of the parallel computing capability of modern computing architectures; and (3) during the inter-layer transfer process, some local features may be lost, making the model limited in capturing global information. In contrast, the parallel structure can process multiple feature streams simultaneously, improve data throughput, reduce information loss, and alleviate the gradient-vanishing problem to a certain extent, thus improving the stability and computational efficiency of the deep network.
According to Ensemble Learning Theory, the collaborative work of multiple learners usually possesses stronger generalization ability than a single learner. The parallel network structure proposed in this paper (as in
Figure 4, the parallel network structure part) can be regarded as a special form of ensemble learning, which enhances the model’s ability to learn different feature dimensions through multi-branch feature extraction and improves the overall generalization ability through the fusion strategy.
The introduction of parallel structure mainly optimizes the model performance in the following aspects:
- (1)
Feature diversity: Despite the same network structure in both branches, the parallel structure is able to learn different feature distributions due to the randomness of parameter initialization and differences in data flow, thus improving feature representation.
- (2)
Information redundancy: Feature extraction from multiple independent paths enables the model to characterize the data from different levels and perspectives, which helps to reduce the risk of underfitting or overfitting that a single path may bring.
- (3)
Feature fusion: In the final fusion stage, the features extracted from different paths are complemented and enhanced in the high-dimensional space, so as to obtain a more discriminative feature representation and improve the fault diagnosis performance of the model.
3.4. PMA-ResNet Overall Structure
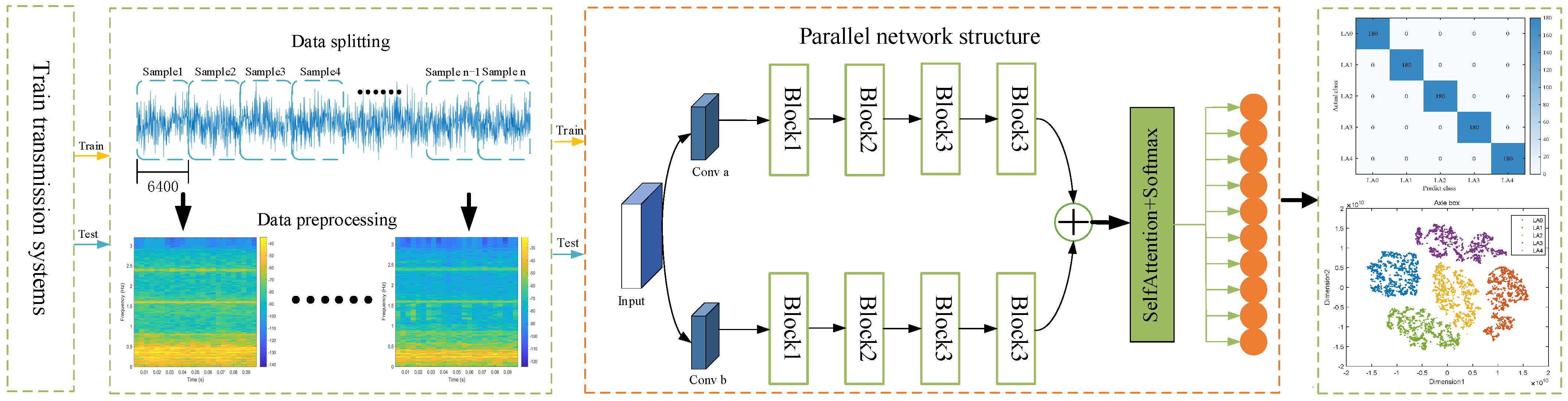
This paper introduces the multi-scale learning module and self-attention mechanism into the parallel network, leading to the proposal of the PMA-ResNet model for the diagnosis of faults in rotating machinery. The overall architecture of the proposed PMA-ResNet is illustrated in
Figure 4, and the parameter settings of the network are presented in
Table 1.
The steps involved in the diagnosis of faults using the PMA-ResNet method are as follows.
(1) Data preprocessing: The input data are intercepted for initial preprocessing through an equal-length sliding window, a process that can be referred to as data augmentation. Subsequently, the data are normalized to a specific range in order to ensure consistency, and the corresponding time–frequency maps are generated. These are then divided into a training set and a test set.
(2) Model training: The training set is employed as an input to train the network, and feature extraction is conducted by the multi-scale learning module, which acquires features from the attention layer and the fully connected layer. The Adam algorithm is utilized to update the network parameters by back propagation.
(3) Fault diagnosis: The input signals are introduced into a trained PMA-ResNet model, and the ultimate health of the part is determined by a classifier.
5. Conclusions
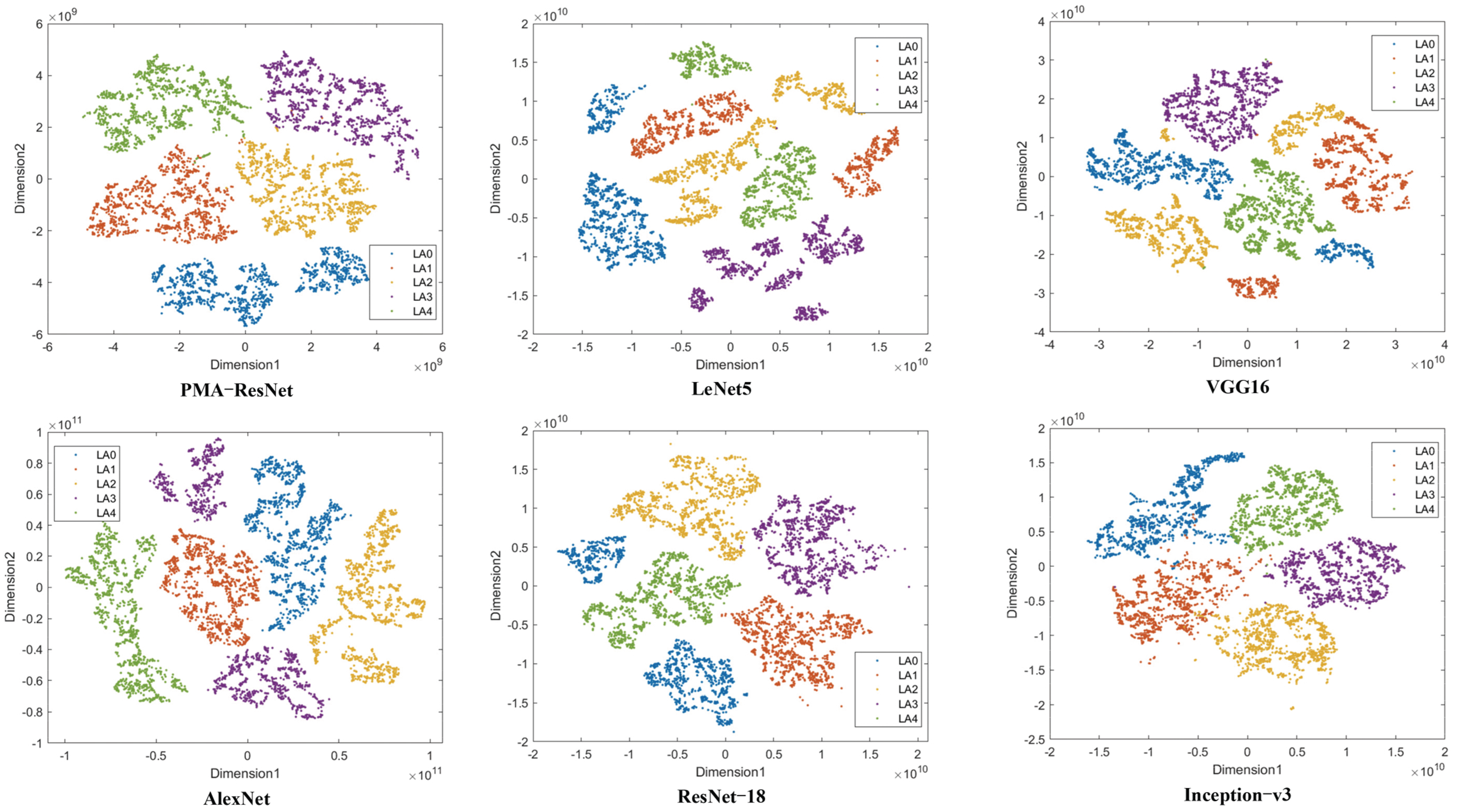
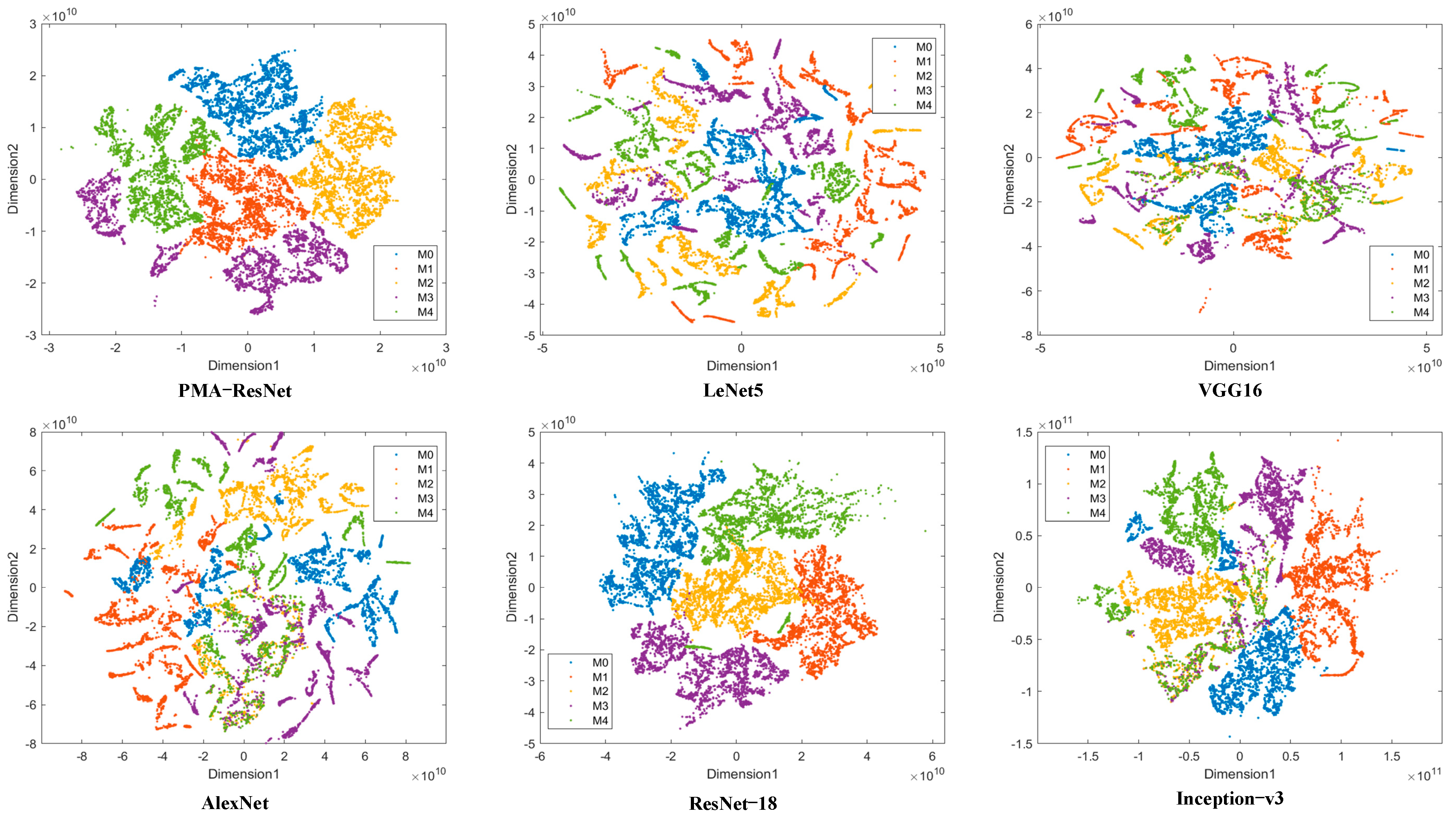
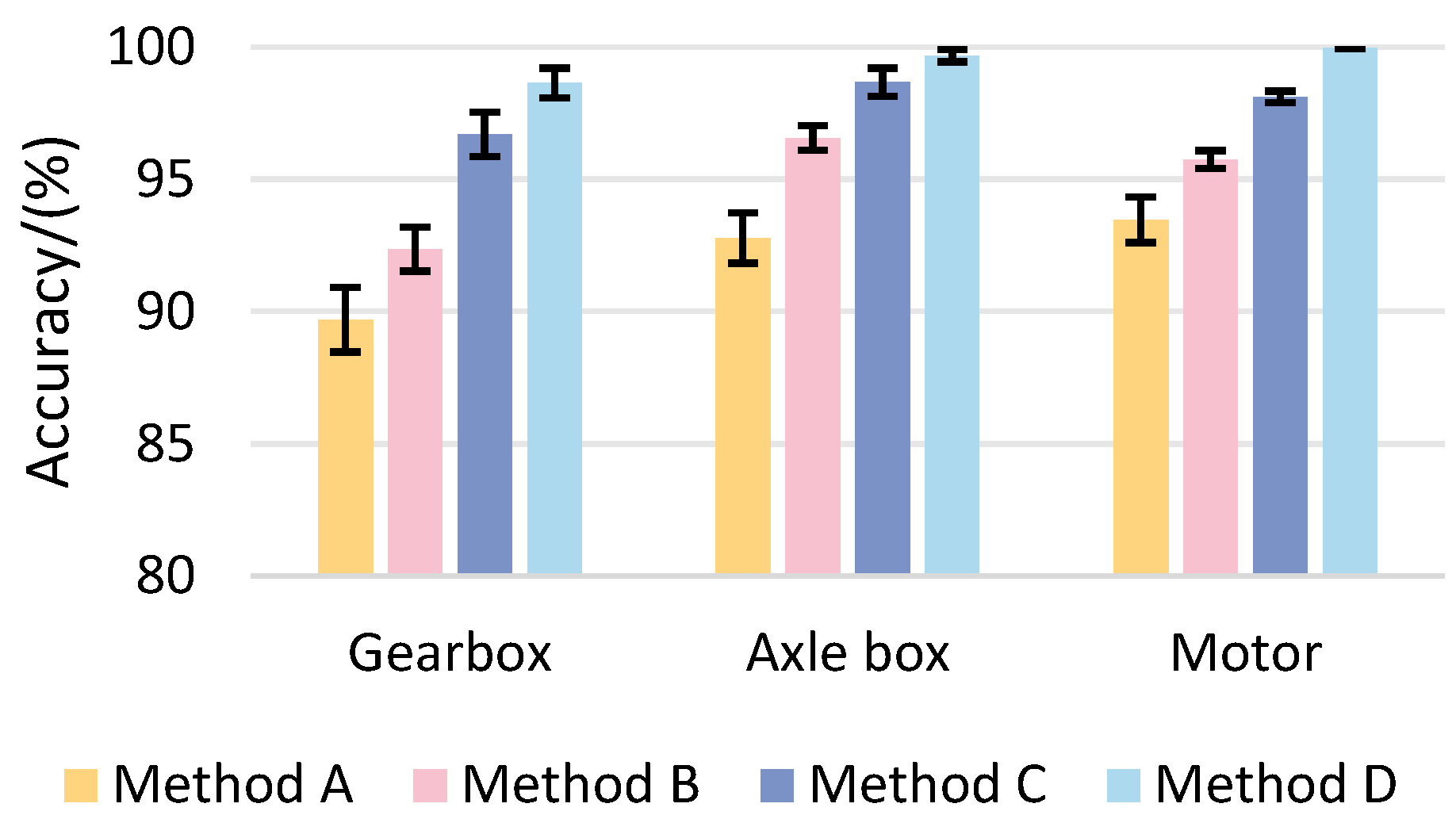
This paper proposes a PMA-ResNet model for the diagnosis of train driveline faults. This model combines multiscale learning and a self-attention mechanism, and is able to extract multiscale features from input signals and distinguish important features effectively. Specifically, a multi-scale learning module was designed to extract multi-scale features through convolutional kernels of different sizes; meanwhile, the self-attention mechanism assigns weights to the features and performs weighted summation, which effectively reduces the noise interference and enhances the useful information to improve the diagnostic accuracy of the network. In addition, the network adopts a parallel structure to enhance its generalization ability. The experimental part constructs a train transmission system fault experimental bench, and the collected experimental data are closer to the actual working conditions. The effectiveness of the proposed method is verified by the collected data. The experimental results show that PMA-ResNet exceeds the other five existing methods in terms of feature extraction capability and diagnostic accuracy, thus confirming the superiority of the model. The ablation experiments further validate the superiority of each module. By introducing the multi-scale learning module, self-attention mechanism, and parallel network structure, the average diagnostic accuracies of the model for each component increase by 2.91%, 2.94%, and 1.6%, respectively, which verifies the superiority of each module in improving the diagnostic performance of the model.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}