Abstract
In human activity recognition, accurate and timely fall detection is essential in healthcare, particularly for monitoring the elderly, where quick responses can prevent severe consequences. This study presents a new fall detection model built on a transformer architecture, which focuses on the movement speeds of key body points tracked using the MediaPipe library. By continuously monitoring these key points in video data, the model calculates real-time speed changes that signal potential falls. The transformer’s attention mechanism enables it to catch even slight shifts in movement, achieving an accuracy of 97.6% while significantly reducing false alarms compared to traditional methods. This approach has practical applications in settings like elderly care facilities and home monitoring systems, where reliable fall detection can support faster intervention. By homing in on the dynamics of movement, this model improves both accuracy and reliability, making it suitable for various real-world situations. Overall, it offers a promising solution for enhancing safety and care for vulnerable populations in diverse environments.
1. Introduction
As many countries transition into aging societies, the number of elderly people is increasing, many of whom live in one- or two-member households. In such family compositions, emergency situations such as sudden falls or heart attacks are particularly dangerous since it is difficult to receive immediate assistance from other family members. To address this issue, various technologies to monitor and assist elderly people have been developed. Activities of Daily Living (ADLs) are essential for assessments in fall detection studies, especially those involving balance. The Berg Balance Scale (BBS), commonly used for evaluating balance among older adults, includes tasks representative of daily life scenarios where falls may occur []. Among them, sudden fall detection is regarded as one of the most urgent technologies. Recent advancements in artificial intelligence and machine learning have raised the level of sudden fall detection []. They have enhanced the accuracy of detecting and tracing human poses in video footage, which can improve sudden fall detection. Some machine learning models can extract the locations of human body parts in the form of key points. These key points refer to specific points on the human body [], such as the body, face, hands, and feet. The study of key points [], especially in the context of body movement dynamics, becomes a fascinating aspect of this technology. These key points, acting as beacons of human body parts, provide intricate patterns according to human body movement []. This is particularly relevant when observing falls, which involve sudden and often unexpected changes in these patterns. Machine learning models, which have already revolutionized various sectors, offer significant promise in analyzing these key point dynamics relating to sudden falls. Although advanced machine learning models bring depth and sophistication, they also require a meticulous choice of architecture and approach. Among the numerous architectures available, transformers [] stand out for their high accuracy, especially with their powerful attention mechanisms.
Attention mechanisms enable models to focus on certain parts of the input more than others, discerning the salient features and relationships. This is especially crucial when analyzing key points [], where the inter-relationship and speed between certain key points can be the determining factor in detecting sudden falls. For example, an unexpected acceleration or deceleration between the nose and the center of the body could indicate a fall in progress. Incorporating the attention mechanism’s focus on the velocities of these key points can provide an unprecedented level of accuracy in detecting body motion. Each key point includes its own set of information, and when analyzed collectively, it can provide a comprehensive picture of human movement. A transformer, with its multiple layers of attention, can sift through this data, highlighting the anomalous pattern characteristic of a sudden fall. Moreover, the versatility of the transformer model makes it a suitable candidate for this endeavor. Although it was initially designed for tasks in language processing [], its adaptability has been proven across various domains, from image recognition to time-series data prediction []. In the context of fall detection, its ability to parse through sequential data [] and understand the inherent patterns and anomalies makes it a promising tool. In the proposed methodology in this study, the velocities of key points as well as their locations are integrated into the transformer’s attention mechanism. This was intended not only to enhance the reliability of fall detection but also to reduce the instances of false alarms, which has been a persistent challenge in earlier models. By emphasizing the dynamics of human body movement and leveraging the power of advanced machine learning architectures, the goal of supporting elderly people and rehabilitating patients [] can be reached, resulting in a new era of safety, assurance, and precision in fall detection.
2. Literature Review
In recent years, the application of machine learning in monitoring human activities and ensuring safety has garnered significant attention from industry and academics. The development of fall detection systems using various feature extraction [] and classification strategies [] has been the focus of several studies. These studies can be categorized into two main types: camera-based systems [] and wearable sensor-based systems []. However, there are only a few examples of sensor-based systems [] for individual monitoring. Many studies utilize sensors such as accelerometers [] and electromyography sensors (EMGs) [], and they record different signals in order to collect data.
2.1. Camera-Based Related Systems
Camera-based systems for fall detection collect video data using cameras [] so as to identify whether a fall has occurred. These systems gather information such as body posture, movement patterns, and the movement of critical parts of the human skeleton. Researchers such as Menacho et al. [] utilized a camera-based system that combines dense optical flow (OF) for global characterization with feature maps within convolutional neural networks (CNNs) for local characterization. This approach used red, green, and blue (RGB) signals as input and achieved an accuracy of 88.55% with the UR (University of Rzeszow) Fall Detection dataset. Xu et al. [] employed RGB signals and combined OpenPose with CNNs to characterize human key points for fall detection. Their approach was tested on three datasets, including the UR Fall Detection dataset [], the Multi-cam Fall Detection Dataset [], and the NTU RGB + D Dataset [], achieving an accuracy rate of 91.7%. Thummala et al. [] harnessed RGB signals as input and integrated foreground extraction via background subtraction, leveraging Gaussian Mixture Models (GMMs) for global characterization in fall detection. Applying their strategy to the LE2I dataset [], they registered an accuracy of 95.16%. Zhang et al. [] employed RGB signals as input and utilized CNNs for the identification of key points, specifically through convolutional pose machines and human body vector construction for local characterization. They incorporated a logistic regression classifier and considered both rotation energy sequences and generalized force sequences. While their method was evaluated on a proprietary video dataset, it achieved a fall detection rate of 98.7% and a low false-alarm rate of 1.05%.
2.2. Wearable Sensor-Based Systems
Wearable sensors, such as accelerometers, pressure sensors, gyroscopes, and magnetometers, are prevalently used in fall detection. Typically, the effectiveness of these wearable systems relies on specific datasets. Wearable sensors offer the benefit of being resilient across various environments and can directly record human activity data. However, they also come with a set of disadvantages, such as being bulky and invasive to wear continuously, particularly for the elderly. The obligation to wear these sensors throughout the day poses an inconvenience, compounded by limited battery life. Moreover, the precise placement of sensors plays a crucial role in the accuracy of fall detection and classification, which presents a notable challenge in the use of wearable sensors.
Wang et al. [] incorporated an attention mechanism into the traditional CNN model to analyze sensor data features more effectively. They employed the renowned UCI-HAR dataset to gauge the effectiveness of their enhanced CNN-based HAR model that achieved an accuracy of 90.18% on a weakly labeled dataset. Tufek et al. [] explored the proficiency of LSTM and CNN models in the classification of human activities using sensor data. Utilizing the UCI-HAR dataset for evaluation, their study discovered that the three-layer LSTM model surpassed the CNN model with 97.4% classification accuracy. Pernini et al. [] developed a fall detection system based on various phases such as start, impact, posture, and aftermath. The system is designed to trigger alarms for critical falls where recovery is not possible. The distinction between actual falls and other activities is achieved by setting specific thresholds for acceleration and orientation, which are determined by Support Vector Machines (SVMs). Santos et al. [] conducted a study utilizing a cloud technology platform based on the Internet of Things (IoT) in combination with a convolutional neural network, referred to as CNN-3B3 Conv, for fall detection. Rather than employing images for analysis, this study used sensors acting as accelerometers for end-users. These sensors were interconnected with a smartphone and a wristwatch affixed to the individual’s body. The model achieved an accuracy of 99.68% after data augmentation when using a smartwatch dataset. Chen et al. [] developed a CNN model specifically tailored for accelerometer data, consisting of three convolution and three pooling layers. Using a dataset of 31,688 samples covering eight distinct activities, including falling, running, jumping, and various modes of walking, this study utilized an accelerometer sensor embedded in an Android smartphone for data collection. Compared to SVM and Deep Belief Network (DBN) methods, the CNN model outperformed them and achieved an accuracy of 93.8%.
In sensor-based systems, the prominent trend is the use of smartphone-based sensors for data collection and the application of machine learning for data analysis []. Additionally, researchers have explored various fall detection methods, encompassing human activity levels [], shape characteristics (such as width-to-height ratio) [], and motion patterns []. While extensive reviews have covered vision-based systems, there is a notable gap in the literature regarding fall detection systems that rely on non-vision sensors, including wearables and ambient sensors. Chen et al. [] highlighted the significance of individual depth cameras and inertial sensors in vision- and non-vision-based systems, respectively. They emphasized that a fusion of both types of sensors can result in more robust fall detection systems compared to those relying on a single sensor modality. Xu et al. [] focused on vision-based systems but overlooked non-vision sensors like wearables and ambient sensors. Nyan et al. [] explored syncopes by employing a combination of a three-axis accelerometer and a two-axis gyroscope, which were attached to both the thigh and waist. Their approach involved utilizing distinctive body kinematic features to identify falls during the descending phase of body motion. With this system, Nyan achieved 100% sensitivity. However, 16% of Activities of Daily Living (ADLs) were undetected as falls, such as when shopping or using the toilet. Dai et al. [] introduced a novel approach involving the use of mobile phones. This approach relied on a 3D accelerometer within a mobile phone to develop a fall detection algorithm. The algorithm calculated the resultant acceleration vector and vertical acceleration magnitudes, using predefined thresholds for fall detection. However, the limitation of threshold-based methods, in general, is a challenge in adapting to different individuals. Several of the methods discussed above have not been validated for real-time applications and for outside controlled laboratory environments. Furthermore, the rapid advancement of electronics has led to the availability of smaller and more cost-effective components. For example, accelerometers and cameras integrated into smartphones have emerged as practical technological choices for conducting fall detection research, as noted by Igual et al. [].
This study introduces an application of a transformer-based model for fall detection, which significantly improves upon previous approaches that utilized traditional machine learning models like CNNs or LSTMs. By leveraging the self-attention mechanism, the transformer model captures complex dependencies in sequential data, thereby enhancing the accuracy of fall detection. Unlike earlier methods that often relied on wearable sensors or simpler key point analysis, this research utilizes key points extracted by MediaPipe, specifically targeting the body’s central point, nose, and knees to capture critical movement changes. By applying the Kalman Filter, key point data can be smoothed so as to reduce noise, resulting in more accurate velocity calculations. This approach also notably reduces false positives compared to traditional systems by effectively distinguishing falls from other movements, making it suitable for real-time applications in elderly care facilities.
3. Proposed Methodology
The proposed methodology in this study focuses on developing a transformer-based neural network model [] for classifying time-series or sequential data. This advanced approach leverages the self-attention mechanism [] intrinsic to the transformer, making it highly effective in understanding complex dependencies in sequential input data. The model architecture is designed to capture subtle patterns within the data, providing a nuanced understanding for accurate classification. Given the complexity and variability of time-series data, this methodology promises enhanced performance compared to traditional approaches, particularly in tasks where long-term dependencies or intricate patterns play a significant role.
In the context of real human pose data, this model can significantly contribute to fields such as motion analysis, activity recognition, and other areas where understanding sequential patterns is vital. Its capability to discern intricate relationships within sequential data makes it particularly suited for tasks requiring nuanced data interpretation. Looking ahead, this methodology has the potential for further enhancements, such as integrating more complex attention mechanisms or exploring different regularization techniques, to refine its predictive accuracy and utility across an even broader range of applications. Vision-based fall detection techniques often raise privacy concerns, particularly when deployed in private living spaces such as bathrooms or bedrooms. This study minimizes privacy risks by relying solely on human pose key points extracted through the MediaPipe framework, which abstracts human motion without capturing full visual information. Using only key points reduces identifiable details, making it a less intrusive method for fall detection.
3.1. Data Collection and Pre-Processing
Due to the challenge of finding existing datasets on fall incidents, this study creates its own experimental dataset. To ensure the data collection environment closely resembles real-life conditions, an indoor scenario similar to a CCTV surveillance setting was designed. In this experimental environment, the camera position and angle were fixed and maintained while recording the video.
The experiment was conducted by seven participants (four males and three females), providing a diversity of fall patterns across genders. Participants were recorded performing different postures (refer to Table 1), with each posture captured at roughly 10 s intervals. For the safety of participants during falls, a mattress was laid on the floor, and the participants fell onto the mattress. By installing the mattress, participants could perform posture more realistically while minimizing injury risk.

Table 1.
Posture types and corresponding data descriptions.
Table 1 summarizes the types of postures and their corresponding data counts. A total of 600 video clips was collected, with 100 samples per posture. To capture a diverse range of scenarios and environmental conditions, data collection was spread over several days rather than performing all postures at once.
In the initial phase of data preprocessing, where the collected video clips exhibited variability in length and frame numbers, a standardization of frame numbers was adopted to ensure data length uniformity, which is crucial in transformer models []. Among all recorded video clips, a video clip with the fewest frames was identified, and the frame number of this video clip was set to as standard frame number. This benchmark was important for randomized sampling in subsequent data extraction, ensuring dataset diversity []. Thereafter, for each video clip, an equal number of frames with the standard frame number was randomly chosen. This process was crucial for data balance and variety in enhancing model training. The selected frames were carefully arranged to ensure that the structure of the data was consistent, even though the original video clips varied in length and frame count. This means that after the frames were selected, they were placed in the correct order to preserve the sequence of actions in each video.
Aligning the length of video clips in this manner ensured that the model would be trained on a consistent and balanced set of data, enhancing the reliability and validity of the training outcomes. This meticulous standardization process not only addresses variability but also maximizes the dataset’s utility in developing the model.
Finally, each video frame, including positional and characteristic information (e.g., coordinates, visibility), was extracted into a new dataset for model development. This structured dataset became the foundation for further analysis and the training of machine learning models.
3.2. Selection of Key Points and Calculation of Key Point Change Speed
MediaPipe [] is a highly versatile framework developed by Google to build pipe-lines for processing perceptual data, such as video, audio, and sensor streams. When it is applied to human pose data, it offers a state-of-the-art solution for extracting key points [], specifically through its Pose module. MediaPipe Pose is designed to detect and track the human body through key points in real time, even in complex environments. It employs machine learning models that process images and video streams to identify and locate key points of the human body, such as the elbows, knees, shoulders, and hips. The model is efficient and lightweight, which makes it suitable for real-time applications on both CPU and mobile devices [].
MediaPipe Pose takes image or video frames, represented in, as input data. The model processes a frame to identify the region of interest that is typically where the human figure is located. The output is a set of coordinates (x, y, and z) for each detected key point. Notably, 33 distinct key points are extracted as landmarks [] (refer to Figure 1a and the images in Figure 1b). These coordinates can be used to understand posture, track movements, or serve as input data for further analysis such as activity recognition or biomechanical studies. MediaPipe Pose stands out for its ease of use, flexibility, and efficiency, so it is regarded as a go-to solution for developers and researchers work-ing with pose estimation and human movement analysis. Figure 2 shows video data with postures).

Figure 1.
(a) MediaPipe skeletal framework []; (b) Experimental environment and key points by MediaPipe Pose.

Figure 2.
Video clips for MediaPipe Pose on each posture class.
In this study, key points from both shoulders (11 and 12 in Figure 1a) and both hips (23 and 24 in Figure 1a) are used to generate the center of body named ‘central_point’. The purpose of defining ‘central_point’ is to trace the movement speed of the human body in detecting a sudden fall. The calculation of ‘central_point’ is performed by the following method: First, the midpoint () between the left shoulder () and the right hip () is calculated:
The subscripts , , and represent the three-dimensional coordinates of and are extracted from MediaPipe Pose. Then, the midpoint () between the right shoulder () and the left hip () is calculated:
Then, the ‘central_point’, , is calculated as the midpoint between two right and left midpoints ().
is used to track the movement speed and provides information on how quickly the upper body is moved. It provides a representative measure of the upper body’s overall motion and is particularly helpful when discriminating balance and fall likelihood. Moreover, after applying the Kalman Filter [] to smooth the 3D coordinate data of the human key points, the velocity of each key point is calculated. The Kalman Filter is an algorithm designed to estimate the state of a system based on observed data and allows for more accurate predictions by reducing the impact of noise. In this study, a Kalman Filter is employed to reduce noise in the coordinates of key points and to enhance the robustness and accuracy of velocity of key points. This filter combines previous states with current observations to compute the optimal estimates. To account for potential p in the key point data, a Kalman Filter was applied to smooth the extracted key point coordinates. This filtering approach helps estimate key point positions even during temporary occlusions, providing more reliable midpoint calculations. The application of Kalman Filter is computed as follows:
Here, represents the state variable. denotes the control input. is the observed value. is the state transition matrix and is the control matrix. indicates the observation matrix and is the Kalman Gain.
Using the smoothed 3D coordinate data after applying the Kalman Filter, the velocity of at each time step is calculated. Velocity is defined as the Euclidean distance between two consecutive points in time and is computed as follows:
Here, represents the unit velocity at time , and denotes the position at time . The velocity is initialized as 0, which assumes no movement at the initial state.
Using this calculation, the velocities of the ‘central_point’ as well as the head, left knee, and right knee are calculated. This velocity adds more information for detecting sudden fall so that location and movement are considered concurrently, which improves the performance of sudden fall detection. These four key points (central_point, left knee, and right knee) are chosen as they are expected to exhibit the most significant differences in movement patterns between daily activities and sudden falls for humans.
4. Experiments and Results
4.1. Definition of Normalization, Input Data and Output Data
The input layer of a transformer model is designed to handle sequential data, typically requiring data to be in a uniform format. Each input sequence is processed as a set of embeddings, which represent the data points in a multi-dimensional space. Transformers do not inherently preserve the order of input data; therefore, positional encodings are added to the input embeddings to maintain the sequence information. This allows the model to understand the relative positioning of each data point within the sequence, which is crucial for tasks like fall detection where the order of movement of key points matters. The input layer is the initial point of data entry, which refers to the process of feeding the model with standardized input data for fall detection. The input data consist of the normalized coordinates of key points extracted by MediaPipe, including the velocities of selected key points like the body’s central point, nose, and knees. This data entry is essential for the model to interpret sequential human body movements and detect falls based on the time-series data input. For this study, the input data consist of the coordinates of specific key points extracted using MediaPipe, such as the central point of the body, nose, left knee, and right knee. These key points are chosen as they are expected to exhibit the most significant movement changes of the human body during sudden falls. The data also include the instantaneous speeds of these key points, which are calculated to capture the dynamics of movement.
The key point coordinates are first smoothed using a Kalman Filter to reduce noise among video frames to ensure more reliable speed calculations. The resulting data are then normalized using Min-Max scaling to fit within a consistent range, which makes it suitable for model training. This normalized dataset is fed into the transformer as a series of time-ordered frames, and each represents the spatial and velocity data of key points at a given moment.
The output of the transformer model is a classification of the detected activity as a posture type (Table 2), specifically identifying whether the movement sequence corresponds to a fall or other actions (e.g., standing, sitting, lying down). The final output layer of the transformer uses a SoftMax activation function to assign probabilities to each possible action, with the highest probability indicating the detected posture. This setup allows the model to discern between different movement patterns and accurately classify sudden falls. Table 2 shows a structure and a sample from the original data collected.
Table 2.
Original data sample from MediaPipe.
Data normalization [] is performed to adjust each data point as a uniform range, which helps the model effectively learn from data with varying scales. This approach maintains consistent data distribution and prevents the learning process from being distorted by extreme values. To standardize the data, Min-Max normalization is employed so that all coordinate data are converted to values ranging between 0 and 1. Min-Max normalization is defined as follows:
where represents the original data value. is the minimum value in the dataset, and is the maximum value in the dataset. is the normalized data value.
Normalization is performed on the key points data obtained from the MediaPipe Pose pipeline, which is essential for preparing the data for a transformer model []. This process involves scaling the 33 landmarks, ensuring they fall within a consistent range, typically between 0 and 1. This is critical for the transformer model’s performance, as it relies on standardized input for accurate pattern recognition and learning. By normalizing the data, disparities caused by different scales or variations in the key points can be minimized, which leads to more reliable and effective model training and analysis. Normalized data are represented in Table 3.
Table 3.
Normalized data.
4.2. Transformer Encoder-Decoder Architecture with Attention Mechanism
The core of the transformer model is the encoder layers []. Each encoder consists of two main components: a multi-head self-attention mechanism [] and a position-wise fully connected feed-forward network []. The multi-head self-attention mechanism allows the model to weigh the importance of different parts of the input sequence differently, providing a dynamic aggregation of information. This is crucial for understanding the context of each posture within a sequence. Transformers do not inherently process sequential data as sequential; they treat inputs as sets. To account for the order of data, positional encodings are added to the input embeddings. These encodings give the model information about the position of each item (key point) in the sequence. This way, the model can distinguish between sequences with the same items and key points in different orders, which is vital for interpreting time-series data correctly. After passing through several transformer encoder layers, the output of the mode is a sequence of vectors representing the transformed input sequence. The final layer of the transformer model is typically a fully connected layer that maps these vectors to the desired output shape, which is a multi-class classification problem: falling, lie, lie down, sit down, sleeping, standing, and stand up. The activation function for this layer used in transformer is a SoftMax since it is a multi-class classification task.
The attention mechanism in deep learning imitates cognitive attention [] by allowing models to focus on specific parts of the input sequentially, rather than processing the entire dataset at once. This is particularly beneficial for sequential data where the relevance of a specific data point might depend on others in the sequence. The encoder processes the input sequence (a series of key points from pose data) and converts it into a context-rich representation. In the pose data, this would involve capturing the spatial relationships and dependencies between different key points at each frame in sequence.
The decoder [] then generates the output sequence as one element at a time. With an attention mechanism, the decoder can “attend” to different parts of the encoder’s output at each step. For instance, in pose-based activity recognition, the decoder might focus on the movement of arms in one step and the legs in another, depending on the activity being performed. The model calculates attention weights [], signifying the importance or relevance of each part of the encoder’s output to the current step of the decoder. These weights are then used to create a weighted combination of the encoder outputs, forming a context vector. This context vector is tailored to the decoder’s current step, ensuring that the model focuses on the most relevant information from the input sequence.
When analyzing pose data, the attention mechanism allows the model to focus on specific key points that are more relevant at different stages of an activity. For example, in swimming, the model might focus more on the arms’ position during the initial stages and more on the legs during the latter stages. The attention mechanism leads to better performance in tasks like sequence-to-sequence prediction, translation, or time-series analysis, as it enables the model to handle long-range dependencies and capture nuanced relationships in the data []. It offers the better interpretability of the model behavior, as one can analyze which parts of the input sequence the model is focusing on at each step. Figure 3 describes the structure of the transformer model.
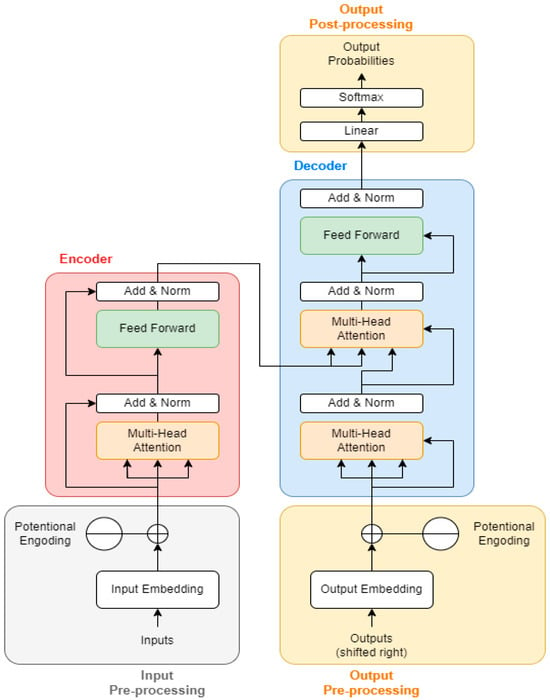
Figure 3.
Transformer model structure [].
4.3. Model Architecture and Training
Transformer-based neural network architecture is mainly used for sequential data analysis. The model begins with an input layer tailored to the preprocessed data’s dimensions. It then progresses through several transformer blocks, each composed of layer normalization, multi-head attention mechanisms (to capture diverse data aspects), dropout (for regularization), and residual connections (facilitating gradient flow during backpropagation). Following the transformer blocks, global average pooling reduces the data dimensionality, succeeded by a Multi-Layer Perceptron (MLP) [] with dense layers featuring ReLU activation and dropout []. The final layer, a dense SoftMax activation layer, classifies the input into predefined categories. Training involves the Adam optimizer with a learning rate that adjusts over time (Cosine Decay), and to mitigate overfitting, early stopping is strategically employed based on validation loss according to the proposed method.
The model’s efficacy is rigorously evaluated using the separated test dataset. Performance metrics such as accuracy and loss provide insights into the model’s classification capabilities. To enhance generalizability and curb overfitting, L2 regularization is integrated into the dense layers, imposing penalties on large weights to encourage the learning of more general patterns rather than overfitting to the training data. Then, the model’s detailed evaluation through a multi-classification report offers in-depth insights into its precision, recall, and F1-score across different classes, affirming its applicability and robustness in classifying falling, lie, lie down, sit down, sleeping, standing, and standup classes.
Moreover, various neural network configurations and training parameters were employed to evaluate the model’s performance under different conditions. Specifically, multiple architectures (LSTM [], GRU [], and transformer) and optimization methods (Adam, SGD, and AdamW) were tested to explore the robustness of the model. Each configuration provided insight into the model’s sensitivity to different hyperparameters and helped identify the optimal setup for fall detection tasks.
The selection of different optimization methods broadened the scope of analysis. For instance, AdamW [] was chosen for its ability to handle sparse gradients, which is advantageous when working with complex time-series data, while stochastic gradient descent (SGD) [] offered perspectives on model performance with traditional gradient descent techniques. This approach informed the selection of the final model configuration, which achieved a balance of accuracy and efficiency.
Although using multiple configurations introduced variability, it also yielded valuable insights into the model’s robustness and performance sensitivity. This systematic exploration underscores the effectiveness of the transformer model with attention mechanisms in fall detection applications.
5. Results and Analysis
5.1. Performance Measure
In this study, precision and the F1-score are chosen as critical metrics to evaluate the performance of the transformer-based fall detection model. These metrics provide insight into the accuracy and reliability of AI model, which are crucial for real-world applications like monitoring human activity.
Precision measures the proportion of correctly identified fall events among all instances that the model predicted as falls. It is calculated using the following formula:
where (true positives) represents the correctly predicted falls and (false positives) indicates non-fall events that are incorrectly predicted as falls. A high precision value suggests that the model is effective at minimizing false alarms, which is important to avoid unnecessary interventions and reduce the burden on caregivers or monitoring systems. The F1-score provides a balanced measure of the model performance by combining precision and recall. Recall is the proportion of actual fall events that are correctly identified by the model and calculated as
where (false negatives) are actual falls that the model failed to detect. The F1-score is the harmonic mean of precision and recall, and is given by
The F1-score is particularly valuable in fall detection because it accounts for both false positives and false negatives, offering a comprehensive view of the model performance. A high F1-score indicates that the model not only accurately identifies falls but also does so consistently, balancing the need to detect true falls while avoiding missed detections.
Using these metrics allows for a robust evaluation of the effectiveness of model in distinguishing falls from other activities, which is essential in reducing both the number of missed falls and false alerts. This comprehensive assessment helps ensure that the model can be reliably deployed in practical environments, providing accurate and timely fall detection that enhances safety for elderly individuals.
5.2. Experimental Results
Table 4 provides a comparison of the three models—LSTM [], GRU [] and transformer—used for fall detection based on key points extracted by MediaPipe and normalized data.
Table 4.
Prediction results.
According to Table 4, various LSTM, GRU, and transformer models have been configured with distinct hyperparameters. LSTM1, utilizing the Adam optimizer [], with a learning rate of 0.01, 64 units, a dropout rate of 0.2, and a batch size of 32, shows an F1-score of 0.922 and a precision of 0.927. LSTM3, employing AdamW [], with an identical learning rate and units but a higher dropout rate of 0.4 and a larger batch size of 64, yields the highest accuracy among LSTM models, with an F1-score of 0.955 and a precision of 0.958. Similarly, GRU3, with AdamW, 128 units, and a 0.4 dropout rate, achieves an F1-score and a precision of 0.873 and 0.903, respectively. Among transformer models, Transformer 3, adopting AdamW, a higher dropout rate of 0.4, and a batch size of 64, achieves an F1-score of 0.974, with a precision score of 0.976, indicating superior performance with these settings. Notably, the models incorporate key layers such as Layer Normalization, Multi-Head Attention, Conv1D, GlobalAveragePooling1D, and Dense, as denoted by t1 to t5.
Transformer 2, which uses the Adam optimizer but with a higher dropout rate of 0.3 compared to Transformer 1, performs exceptionally well, with an accuracy of F1-score of 0.964 and a precision score of 0.962. These results are very close to those of Transformer 3, indicating that both configurations yielded strong performance in fall detection. However, Transformer 2 has a slightly lower accuracy compared to Transformer 3, which is the best-performing model according to Table 4. To further validate the prediction performance of the predictive model with the highest performance, a binary classification technique was used to measure classification performance through a fall-detection-class confusion matrix []. We also present an ROC (Receiver Operating Characteristic) curve [] in Figure 4 for the transformer.
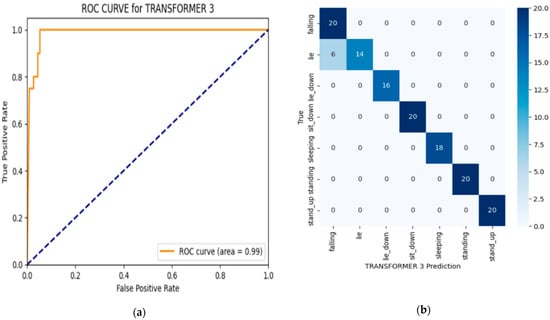
Figure 4.
(a) ROC; (b) confusion matrix.
The ROC (Receiver Operating Characteristic) curve evaluates the model’s performance by plotting the true-positive rate (sensitivity) against the false-positive rate across different classification thresholds. The area under the ROC curve (AUC) provides an overall measure of the model’s ability to distinguish between classes. In this case, the AUC of 0.99 indicates the model’s effectiveness in differentiating between fall and non-fall events, with high sensitivity and a low false-positive rate, as represented in Figure 4a. The confusion matrix provides a detailed view of the classification results for the transformer model. Each row represents the actual classes (true labels), while each column represents the predicted classes. The diagonal elements indicate the correct predictions for each class, such as the 20 correctly predicted instances of the “falling” class. Off-diagonal elements represent misclassifications—for example, the six instances where the model predicted “lie” instead of “falling”. This confusion matrix is useful for assessing the model’s accuracy by illustrating both correct classifications (true positives) and misclassifications (false positives and false negatives). It enables the calculation of key performance metrics, such as the precision, recall, and F1-score for each posture class. High values along the diagonal indicate accurate predictions, with minimal values in the off-diagonal cells reflecting fewer misclassifications, as represented in Figure 4b. Together, the ROC curve and confusion matrix help to demonstrate the model’s ability to classify posture types accurately, which is important for fall detection.
The evaluation of the proposed algorithm was conducted on an acquired dataset, with results compared to other studies in the field to contextualize its performance. This comparison demonstrates that the transformer-based model, leveraging attention mechanisms, offers improvements over conventional fall detection methods, particularly in terms of accuracy and the reduction of false positives. Additionally, an analysis of correctly and incorrectly classified instances was performed to provide further insights into the model’s reliability. This analysis revealed that misclassifications were predominantly due to subtle, complex movements that closely resemble fall patterns, highlighting areas for further refinement. Such an approach underscores the model’s contributions beyond dataset-specific performance, validating its applicability across a broader range of real-world scenarios.
6. Conclusions and Future Work
This study proposes a novel machine learning model utilizing a transformer architecture to predict sudden fall incidents by analyzing key points and movements derived from the human body. The primary focus of this paper is applying a new machine learning model for health monitoring, and it provides practical applications for elderly care facilities, where timely sudden fall detection is crucial. The model used analyzes video data using MediaPipe to track continuous positions of key points and calculate the instantaneous speed of key points. The unique aspect of an attention mechanism within the transformer model results in the effective recognition of critical patterns of position and speed shifts indicating sudden falls. The proposed method can be characterized by addressing the challenge of precise and timely fall detection by focusing on the dynamics of human body movement rather than static poses. Experimental tests on datasets established by this research demonstrated that this approach significantly enhances sudden fall detection accuracy and notably reduces false positives, which is a common issue in existing fall detection systems. By concentrating on the speed changes of key points, the proposed method offers a comprehensive understanding of human body movement, and it can improve the identification of potential fall events.
This study tests various machine learning models, including conventional models, for comparative analysis. The transformer-based approach shows superior performance in detecting sudden falls, as evidenced by its high accuracy and the low rate of false positives. However, this study acknowledges certain limitations such as the dependency on the quality and variability of video data and challenges in real-time data processing. In future work, the authors will explore enhancements to the transformer model, including more complex attention mechanisms and different regularization techniques, to refine its predictive accuracy.
Additionally, integrating this model with real-time monitoring systems in healthcare and elderly care can vastly improve the timely detection and prevention of falls, which could potentially save lives and reduce healthcare costs. The next steps also involve adapting the proposed method for various environments and conditions, ensuring its effectiveness across diverse scenarios. However, a limitation of this study is the use of self-induced falls, which may not fully reflect the characteristics of accidental falls in older adults. Additionally, the study involved participants under sixty-five, which may differ from the target demographic of elderly populations. Future studies should aim to include participants aged sixty-five and older to increase the ecological validity of the results.
Author Contributions
Conceptualization, D.K., M.S.S. and J.-H.S.; methodology, Y.H., M.S.S., H.K., D.K. and J.-H.S.; software, M.S.S. and D.K.; validation, M.S.S. and H.K.; formal analysis, M.S.S. and J.-H.S.; investigation, M.S.S. and D.K.; resources, M.S.S.; data curation, H.K., Y.H., D.K.; writing—original draft preparation, M.S.S.; writing—review and editing, M.S.S., Y.H., D.K. and J.-H.S.; visualization, M.S.S. and D.K.; supervision, J.-H.S.; project administration, J.-H.S.; funding acquisition, J.-H.S. All authors have read and agreed to the published version of the manuscript.
Funding
This study was supported by a research fund from Chosun University (2023).
Institutional Review Board Statement
This study was conducted internally with volunteer lab students. Although formal IRB approval was not obtained, all participants were informed of the study’s purpose and procedures, and informed consent was obtained. The research was conducted under controlled conditions, ensuring participant safety and minimizing any potential risks.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
Dataset available on request from the authors.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Berg, K. Measuring Balance in the Elderly: Development and Validation of an Instrument. Ph.D. Thesis, McGill University, Montreal, QC, Canada, 1992. [Google Scholar]
- Kong, X.; Chen, L.; Wang, Z.; Chen, Y.; Meng, L.; Tomiyama, H. Robust Self-Adaptation Fall-Detection System Based on Camera Height. Sensors 2019, 19, 3768. [Google Scholar] [CrossRef]
- Singh, A.K.; Kumbhare, V.A.; Arthi, K. Real-Time Human Pose Detection and Recognition Using MediaPipe. In Soft Computing and Signal Processing; Reddy, V.S., Prasad, V.K., Wang, J., Reddy, K.T.V., Eds.; Advances in Intelligent Systems and Computing; Springer Nature: Singapore, 2022; Volume 1413, pp. 145–154. ISBN 9789811670879. [Google Scholar]
- Zhang, J.; Chen, Z.; Tao, D. Towards High Performance Human Keypoint Detection. Int. J. Comput. Vis. 2021, 129, 2639–2662. [Google Scholar] [CrossRef]
- Makris, A.; Argyros, A. Robust 3d Human Pose Estimation Guided by Filtered Subsets of Body Keypoints. In Proceedings of the 2019 16th International Conference on Machine Vision Applications (MVA), Tokyo, Japan, 27–31 May 2019; pp. 1–6. [Google Scholar]
- Duan, H.; Lin, K.-Y.; Jin, S.; Liu, W.; Qian, C.; Ouyang, W. Trb: A Novel Triplet Representation for Understanding 2d Human Body. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9479–9488. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M. Transformers: State-of-the-Art Natural Language Processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 16–20 November 2020; pp. 38–45. [Google Scholar]
- Suvitha, D.; Vijayalakshmi, M. Vehicle Density Prediction in Low Quality Videos with Transformer Timeseries Prediction Model (TTPM). Comput. Syst. Sci. Eng. 2023, 44, 873–894. [Google Scholar] [CrossRef]
- Sun, F.; Liu, J.; Wu, J.; Pei, C.; Lin, X.; Ou, W.; Jiang, P. BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 1441–1450. [Google Scholar]
- Suriani, N.S.; Rashid, F.N.; Yunos, N.Y. Optimal Accelerometer Placement for Fall Detection of Rehabilitation Patients. J. Telecommun. Electron. Comput. Eng. (JTEC) 2018, 10, 25–29. [Google Scholar]
- Xi, X.; Tang, M.; Miran, S.M.; Luo, Z. Evaluation of Feature Extraction and Recognition for Activity Monitoring and Fall Detection Based on Wearable sEMG Sensors. Sensors 2017, 17, 1229. [Google Scholar] [CrossRef]
- Kerdegari, H.; Samsudin, K.; Ramli, A.R.; Mokaram, S. Evaluation of Fall Detection Classification Approaches. In Proceedings of the 2012 4th International Conference on Intelligent and Advanced Systems (ICIAS2012), Kuala Lumpur, Malaysia, 12–14 June 2012; Volume 1, pp. 131–136. [Google Scholar]
- Debard, G.; Karsmakers, P.; Deschodt, M.; Vlaeyen, E.; Dejaeger, E.; Milisen, K.; Goedemé, T.; Vanrumste, B.; Tuytelaars, T. Camera-Based Fall Detection on Real World Data. In Outdoor and Large-Scale Real-World Scene Analysis; Dellaert, F., Frahm, J.-M., Pollefeys, M., Leal-Taixé, L., Rosenhahn, B., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7474, pp. 356–375. ISBN 978-3-642-34090-1. [Google Scholar]
- Chen, J.; Kwong, K.; Chang, D.; Luk, J.; Bajcsy, R. Wearable Sensors for Reliable Fall Detection. In Proceedings of the 2005 IEEE Engineering in Medicine and Biology 27th Annual Conference, Shanghai, China, 17–18 January 2006; pp. 3551–3554. [Google Scholar]
- Nooruddin, S.; Islam, M.M.; Sharna, F.A.; Alhetari, H.; Kabir, M.N. Sensor-Based Fall Detection Systems: A Review. J. Ambient. Intell. Hum. Comput. 2022, 13, 2735–2751. [Google Scholar] [CrossRef]
- Lindemann, U.; Hock, A.; Stuber, M.; Keck, W.; Becker, C. Evaluation of a Fall Detector Based on Accelerometers: A Pilot Study. Med. Biol. Eng. Comput. 2005, 43, 548–551. [Google Scholar] [CrossRef]
- Cheng, J.; Chen, X.; Shen, M. A Framework for Daily Activity Monitoring and Fall Detection Based on Surface Electromyography and Accelerometer Signals. IEEE J. Biomed. Health Inform. 2012, 17, 38–45. [Google Scholar] [CrossRef]
- Bian, Z.-P.; Hou, J.; Chau, L.-P.; Magnenat-Thalmann, N. Fall Detection Based on Body Part Tracking Using a Depth Camera. IEEE J. Biomed. Health Inform. 2014, 19, 430–439. [Google Scholar] [CrossRef] [PubMed]
- Menacho, C.; Ordoñez, J. Fall Detection Based on CNN Models Implemented on a Mobile Robot. In Proceedings of the 2020 17th International Conference on Ubiquitous Robots (UR), Kyoto, Japan, 22–26 June 2020; pp. 284–289. [Google Scholar]
- Xu, Q.; Huang, G.; Yu, M.; Guo, Y. Fall Prediction Based on Key Points of Human Bones. Phys. A Stat. Mech. Its Appl. 2020, 540, 123205. [Google Scholar] [CrossRef]
- Kwolek, B.; Kepski, M. Human Fall Detection on Embedded Platform Using Depth Maps and Wireless Accelerometer. Comput. Methods Programs Biomed. 2014, 117, 489–501. [Google Scholar] [CrossRef]
- Saurav, S.; Saini, R.; Singh, S. A Dual-Stream Fused Neural Network for Fall Detection in Multi-Camera and 360° Videos. Neural Comput. Applic 2022, 34, 1455–1482. [Google Scholar] [CrossRef]
- Chen, Z.; Wang, Y.; Yang, W. Video Based Fall Detection Using Human Poses. In Big Data; Liao, X., Zhao, W., Chen, E., Xiao, N., Wang, L., Gao, Y., Shi, Y., Wang, C., Huang, D., Eds.; Communications in Computer and Information Science; Springer: Singapore, 2022; Volume 1496, pp. 283–296. ISBN 9789811697081. [Google Scholar]
- Thummala, J.; Pumrin, S. Fall Detection Using Motion History Image and Shape Deformation. In Proceedings of the 2020 8th International Electrical Engineering Congress (iEECON), Chiang Mai, Thailand, 4–6 March 2020; pp. 1–4. [Google Scholar]
- Charfi, I.; Miteran, J.; Dubois, J.; Atri, M.; Tourki, R. Optimised Spatio-Temporal Descriptors for Real-Time Fall Detection: Comparison of SVM and Adaboost Based Classification. J. Electron. Imaging (JEI) 2013, 22, 17. [Google Scholar]
- Zhang, J.; Wu, C.; Wang, Y. Human Fall Detection Based on Body Posture Spatio-Temporal Evolution. Sensors 2020, 20, 946. [Google Scholar] [CrossRef]
- Wang, L.; Peng, M.; Zhou, Q. Pre-Impact Fall Detection Based on Multi-Source CNN Ensemble. IEEE Sens. J. 2020, 20, 5442–5451. [Google Scholar] [CrossRef]
- Tufek, N.; Yalcin, M.; Altintas, M.; Kalaoglu, F.; Li, Y.; Bahadir, S.K. Human Action Recognition Using Deep Learning Methods on Limited Sensory Data. IEEE Sens. J. 2019, 20, 3101–3112. [Google Scholar] [CrossRef]
- Pierleoni, P.; Belli, A.; Maurizi, L.; Palma, L.; Pernini, L.; Paniccia, M.; Valenti, S. A Wearable Fall Detector for Elderly People Based on AHRS and Barometric Sensor. IEEE Sens. J. 2016, 16, 6733–6744. [Google Scholar] [CrossRef]
- Santos, G.L.; Endo, P.T.; Monteiro, K.H.d.C.; Rocha, E.d.S.; Silva, I.; Lynn, T. Accelerometer-Based Human Fall Detection Using Convolutional Neural Networks. Sensors 2019, 19, 1644. [Google Scholar] [CrossRef]
- Chen, L.; Li, R.; Zhang, H.; Tian, L.; Chen, N. Intelligent Fall Detection Method Based on Accelerometer Data from a Wrist-Worn Smart Watch. Measurement 2019, 140, 215–226. [Google Scholar] [CrossRef]
- Santoyo-Ramón, J.A.; Casilari, E.; Cano-García, J.M. Analysis of a Smartphone-Based Architecture with Multiple Mobility Sensors for Fall Detection with Supervised Learning. Sensors 2018, 18, 1155. [Google Scholar] [CrossRef]
- Nizam, Y.; Mohd, M.N.H.; Jamil, M.M.A. A Study on Human Fall Detection Systems: Daily Activity Classification and Sensing Techniques. Int. J. Integr. Eng. 2016, 8, 35–43. [Google Scholar]
- Davari, A.; Aydin, T.; Erdem, T. Automatic Fall Detection for Elderly by Using Features Extracted from Skeletal Data. In Proceedings of the 2013 International Conference on Electronics, Computer and Computation (ICECCO), Ankara, Turkey, 7–9 November 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 127–130. [Google Scholar]
- Rezaee, K.; Haddadnia, J. Design of Fall Detection System: A Dynamic Pattern Approach with Fuzzy Logic and Motion Estimation. Inf. Syst. Telecommun. 2014, 3, 181. [Google Scholar]
- Xu, T.; Zhou, Y.; Zhu, J. New Advances and Challenges of Fall Detection Systems: A Survey. Appl. Sci. 2018, 8, 418. [Google Scholar] [CrossRef]
- Nyan, M.N.; Tay, F.E.; Tan, A.W.Y.; Seah, K.H.W. Distinguishing Fall Activities from Normal Activities by Angular Rate Characteristics and High-Speed Camera Characterization. Med. Eng. Phys. 2006, 28, 842–849. [Google Scholar] [CrossRef]
- Dai, J.; Bai, X.; Yang, Z.; Shen, Z.; Xuan, D. PerFallD: A Pervasive Fall Detection System Using Mobile Phones. In Proceedings of the 2010 8th IEEE International Conference on Pervasive Computing and Communications Workshops (PERCOM Workshops), Mannheim, Germany, 29 March–2 April 2010; pp. 292–297. [Google Scholar]
- Igual, R.; Medrano, C.; Plaza, I. A Comparison of Public Datasets for Acceleration-Based Fall Detection. Med. Eng. Phys. 2015, 37, 870–878. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.; Liu, Z.; Jia, W.; Lin, X.; Zhang, S. A Novel Transformer-Based Neural Network Model for Tool Wear Estimation. Meas. Sci. Technol. 2020, 31, 065106. [Google Scholar] [CrossRef]
- Hao, Y.; Dong, L.; Wei, F.; Xu, K. Self-Attention Attribution: Interpreting Information Interactions inside Transformer. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 12963–12971. [Google Scholar]
- Variš, D.; Bojar, O. Sequence Length Is a Domain: Length-Based Overfitting in Transformer Models. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 8246–8257. [Google Scholar]
- Wang, X.; Jin, Y.; Cen, Y.; Lang, C.; Li, Y. PST-NET: Point Cloud Sampling via Point-Based Transformer. In Image and Graphics; Peng, Y., Hu, S.-M., Gabbouj, M., Zhou, K., Elad, M., Xu, K., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2021; Volume 12890, pp. 57–69. ISBN 978-3-030-87360-8. [Google Scholar]
- Lugaresi, C.; Tang, J.; Nash, H.; McClanahan, C.; Uboweja, E.; Hays, M.; Zhang, F.; Chang, C.-L.; Yong, M.G.; Lee, J.; et al. MediaPipe: A Framework for Building Perception Pipelines. arXiv 2019, arXiv:1906.08172. [Google Scholar]
- Suherman, S.; Suhendra, A.; Ernastuti, E. Method Development Through Landmark Point Extraction for Gesture Classification with Computer Vision and MediaPipe. TEM J. 2023, 12, 1677–1686. [Google Scholar] [CrossRef]
- Shen, S.; Yao, Z.; Gholami, A.; Mahoney, M.; Keutzer, K. Powernorm: Rethinking Batch Normalization in Transformers. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 8741–8751. [Google Scholar]
- Nguyen, T.Q.; Salazar, J. Transformers without Tears: Improving the Normalization of Self-Attention. arXiv 2019. [Google Scholar] [CrossRef]
- Han, K.; Xiao, A.; Wu, E.; Guo, J.; Xu, C.; Wang, Y. Transformer in Transformer. Adv. Neural Inf. Process. Syst. 2021, 34, 15908–15919. [Google Scholar]
- Chang, Y.; Li, F.; Chen, J.; Liu, Y.; Li, Z. Efficient Temporal Flow Transformer Accompanied with Multi-Head Probsparse Self-Attention Mechanism for Remaining Useful Life Prognostics. Reliab. Eng. Syst. Saf. 2022, 226, 108701. [Google Scholar] [CrossRef]
- Lu, S.; Wang, M.; Liang, S.; Lin, J.; Wang, Z. Hardware Accelerator for Multi-Head Attention and Position-Wise Feed-Forward in the Transformer. In Proceedings of the 2020 IEEE 33rd International System-on-Chip Conference (SOCC), Virtual, 8–11 September 2020; pp. 84–89. [Google Scholar]
- Li, Y.; Lin, Y.; Xiao, T.; Zhu, J. An Efficient Transformer Decoder with Compressed Sub-Layers. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 13315–13323. [Google Scholar]
- Kobayashi, G.; Kuribayashi, T.; Yokoi, S.; Inui, K. Attention Is Not Only a Weight: Analyzing Transformers with Vector Norms. arXiv 2020, arXiv:2004.10102. [Google Scholar]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 11106–11115. [Google Scholar]
- Choi, S.R.; Lee, M. Transformer Architecture and Attention Mechanisms in Genome Data Analysis: A Comprehensive Review. Biology 2023, 12, 1033. [Google Scholar] [CrossRef] [PubMed]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H. Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6881–6890. [Google Scholar]
- Zhou, K.; Yu, H.; Zhao, W.X.; Wen, J.-R. Filter-Enhanced MLP Is All You Need for Sequential Recommendation. In Proceedings of the ACM Web Conference 2022, Virtual Event, Lyon, France, 25–29 April 2022; pp. 2388–2399. [Google Scholar]
- Butt, A.; Narejo, S.; Anjum, M.R.; Yonus, M.U.; Memon, M.; Samejo, A.A. Fall Detection Using LSTM and Transfer Learning. Wirel. Pers. Commun. 2022, 126, 1733–1750. [Google Scholar] [CrossRef]
- Lin, C.-B.; Dong, Z.; Kuan, W.-K.; Huang, Y.-F. A Framework for Fall Detection Based on OpenPose Skeleton and LSTM/GRU Models. Appl. Sci. 2020, 11, 329. [Google Scholar] [CrossRef]
- Benoit, A.; Escriba, C.; Gauchard, D.; Esteve, A.; Rossi, C. Analyzing and Comparing Deep Learning Models on a ARM 32 Bits Microcontroller for Pre-Impact Fall Detection. IEEE Sens. J. 2024, 24, 11829–11842. [Google Scholar] [CrossRef]
- Zeng, G.; Zeng, B.; Hu, H. Real-World Efficient Fall Detection: Balancing Performance and Complexity with FDGA Workflow. Comput. Vis. Image Underst. 2023, 237, 103832. [Google Scholar] [CrossRef]
- Siami-Namini, S.; Tavakoli, N.; Namin, A.S. The Performance of LSTM and BiLSTM in Forecasting Time Series. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 3285–3292. [Google Scholar]
- Zhang, X.; Shen, F.; Zhao, J.; Yang, G. Time Series Forecasting Using GRU Neural Network with Multi-Lag After Decomposition. In Neural Information Processing; Liu, D., Xie, S., Li, Y., Zhao, D., El-Alfy, E.-S.M., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2017; Volume 10638, pp. 523–532. ISBN 978-3-319-70138-7. [Google Scholar]
- Zhang, Z. Improved Adam Optimizer for Deep Neural Networks. In Proceedings of the 2018 IEEE/ACM 26th International Symposium on Quality of Service (IWQoS), Banff, AB, Canada, 4–6 June 2018; pp. 1–2. [Google Scholar]
- Llugsi, R.; El Yacoubi, S.; Fontaine, A.; Lupera, P. Comparison between Adam, AdaMax and Adam W Optimizers to Implement a Weather Forecast Based on Neural Networks for the Andean City of Quito. In Proceedings of the 2021 IEEE Fifth Ecuador Technical Chapters Meeting (ETCM), Cuenca, Ecuador, 12–15 October 2021; pp. 1–6. [Google Scholar]
- Deng, X.; Liu, Q.; Deng, Y.; Mahadevan, S. An Improved Method to Construct Basic Probability Assignment Based on the Confusion Matrix for Classification Problem. Inf. Sci. 2016, 340, 250–261. [Google Scholar] [CrossRef]
- Hand, D.J.; Anagnostopoulos, C. When Is the Area under the Receiver Operating Characteristic Curve an Appropriate Measure of Classifier Performance? Pattern Recognit. Lett. 2013, 34, 492–495. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).