
A Music-Driven Dance Generation Method Based on a Spatial-Temporal Refinement Model to Optimize Abnormal Frames
Abstract
1. Introduction
2. Related Works
2.1. Cross-Modality Generation
2.2. Human Movement Prediction
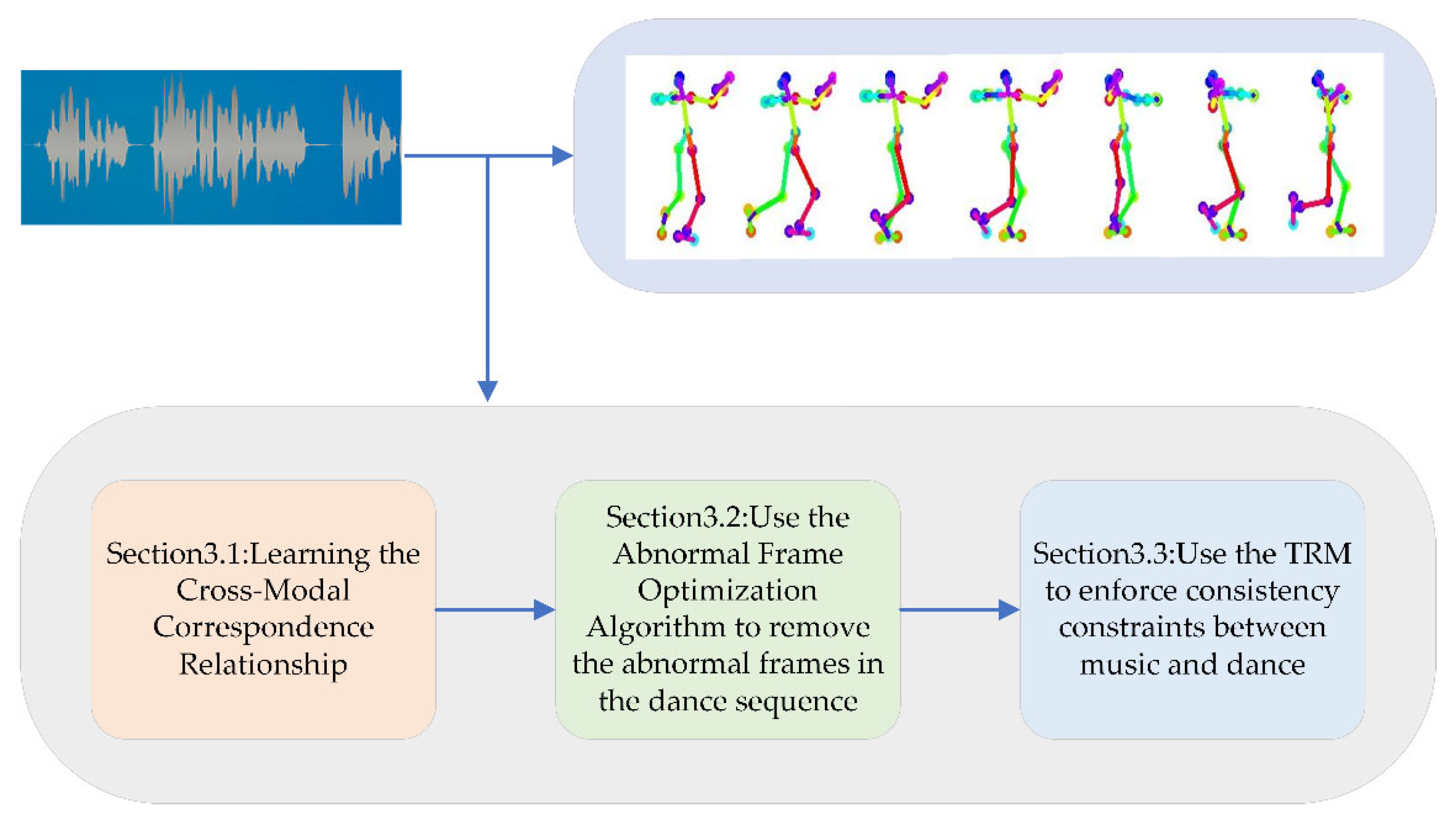
3. Methodology
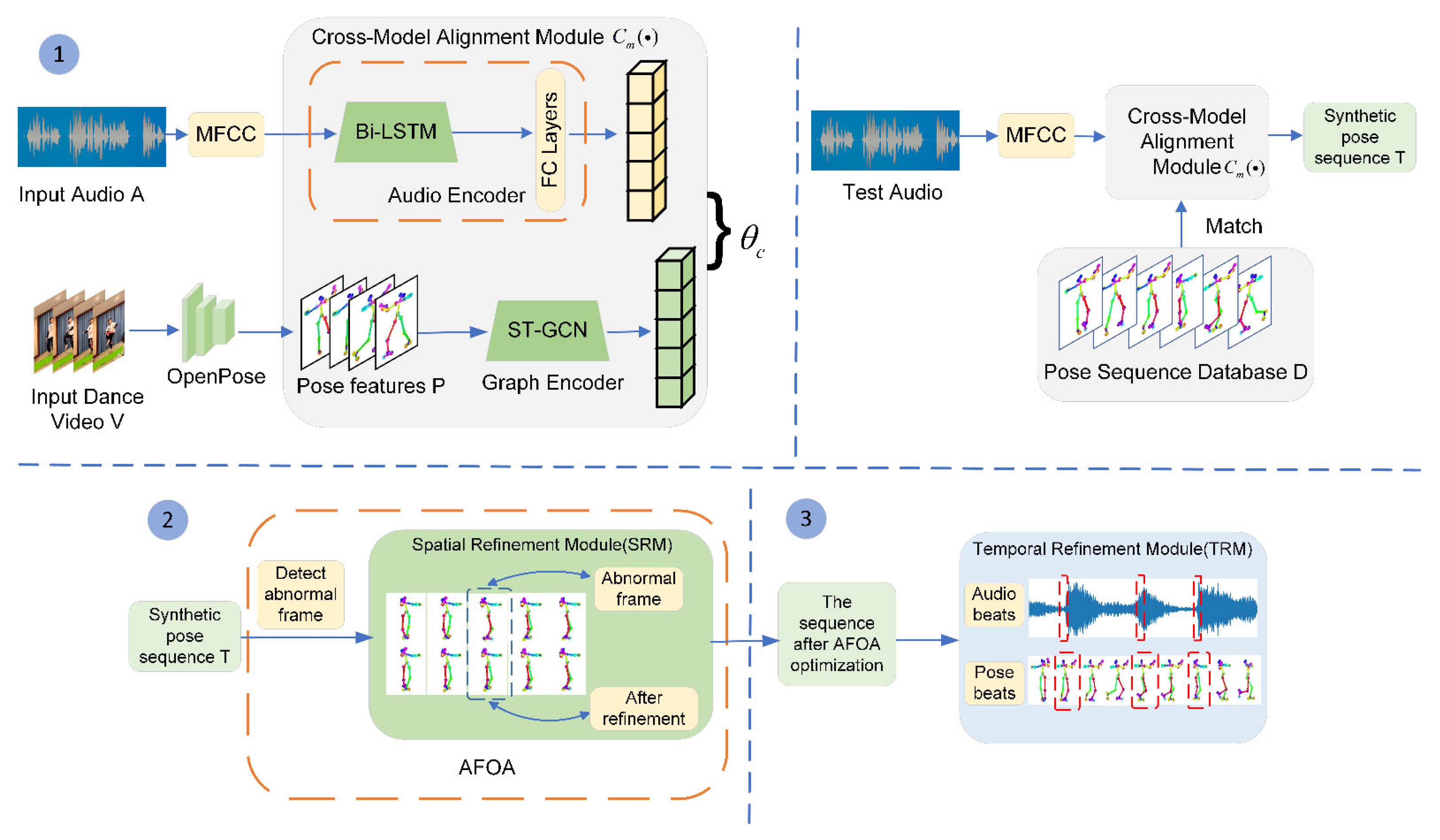
3.1. Learning the Cross-Modal Correspondence Relationship
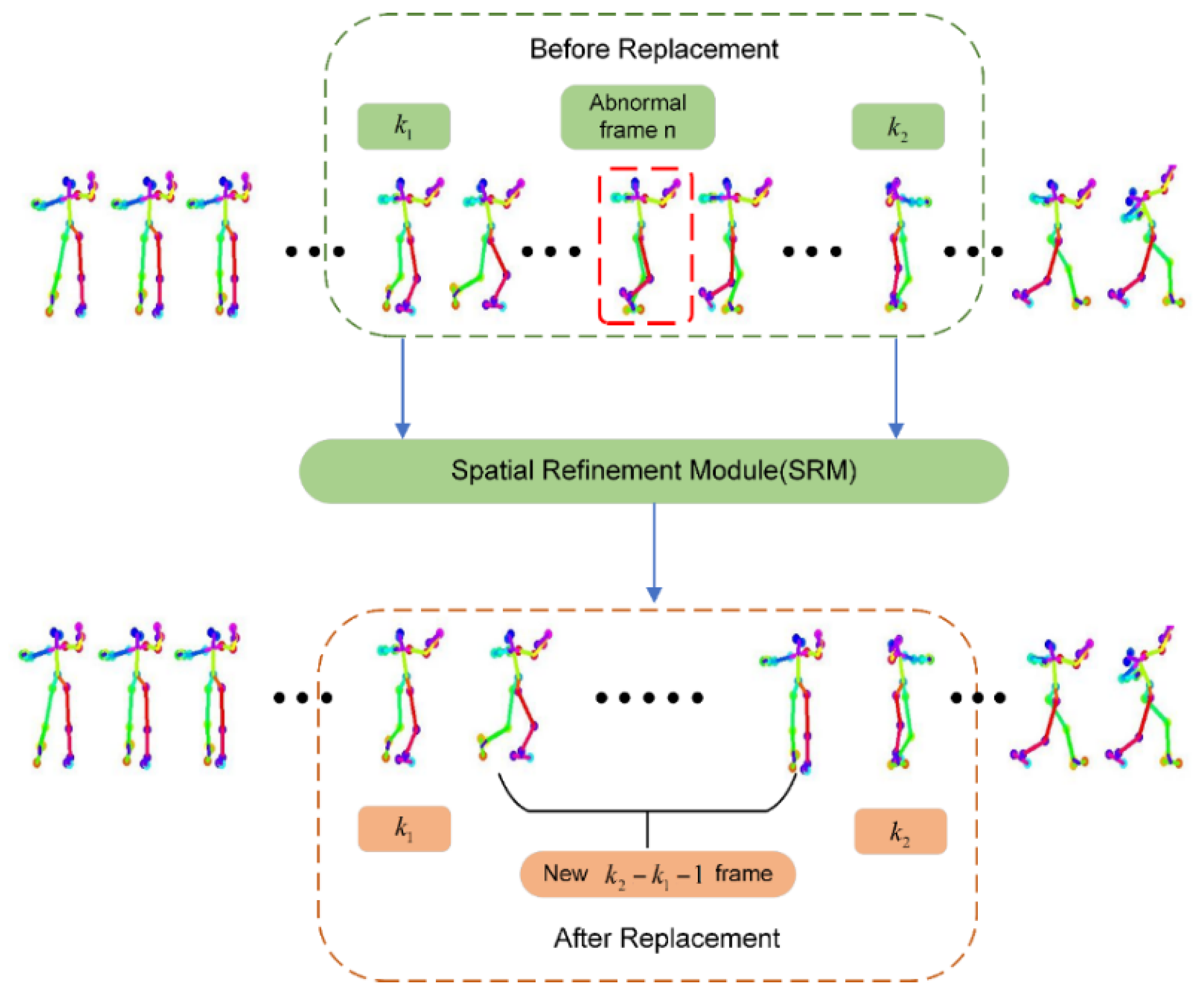
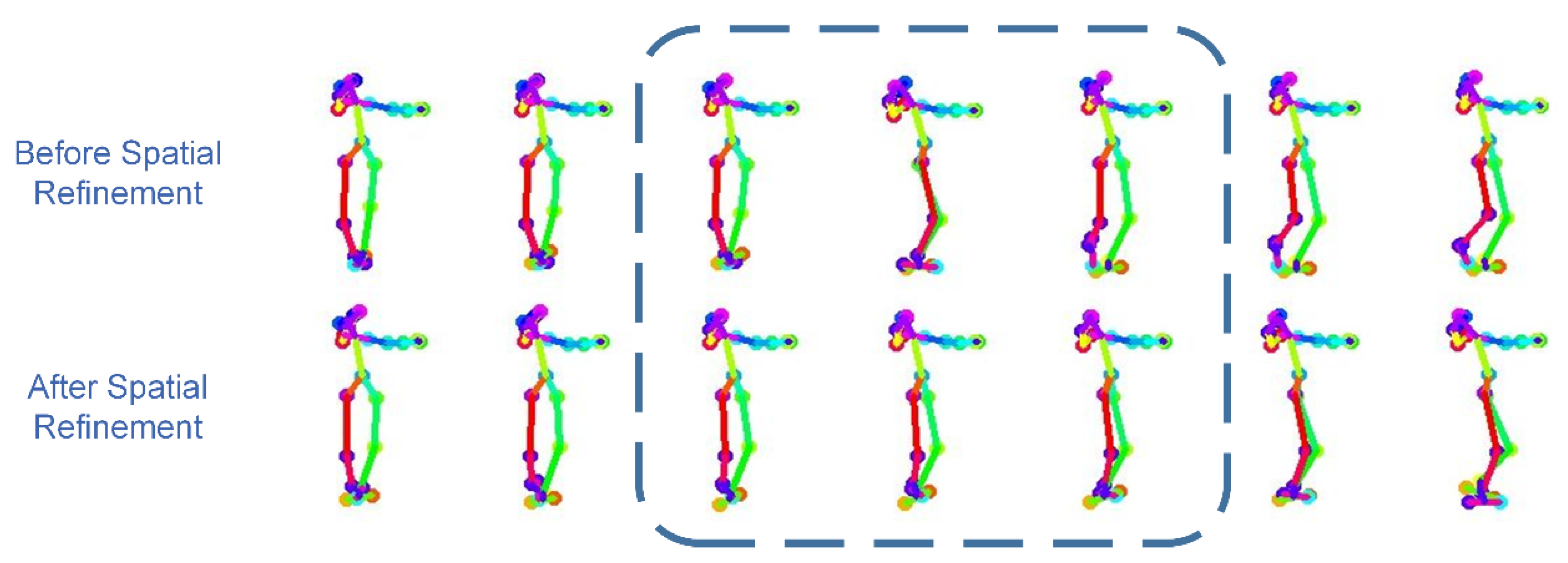
3.2. The Abnormal Frame Optimization Algorithm
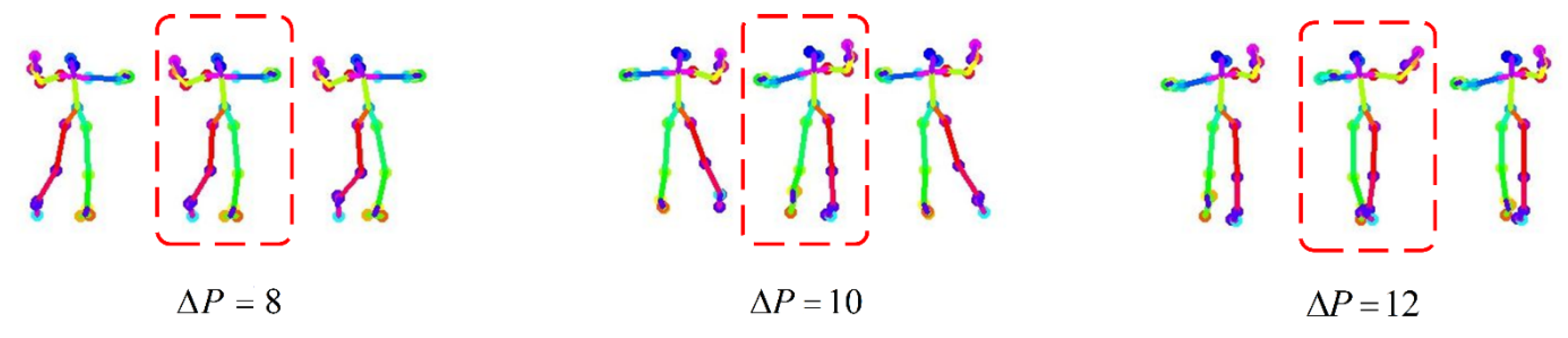
3.2.1. Detecting the Abnormal Frame
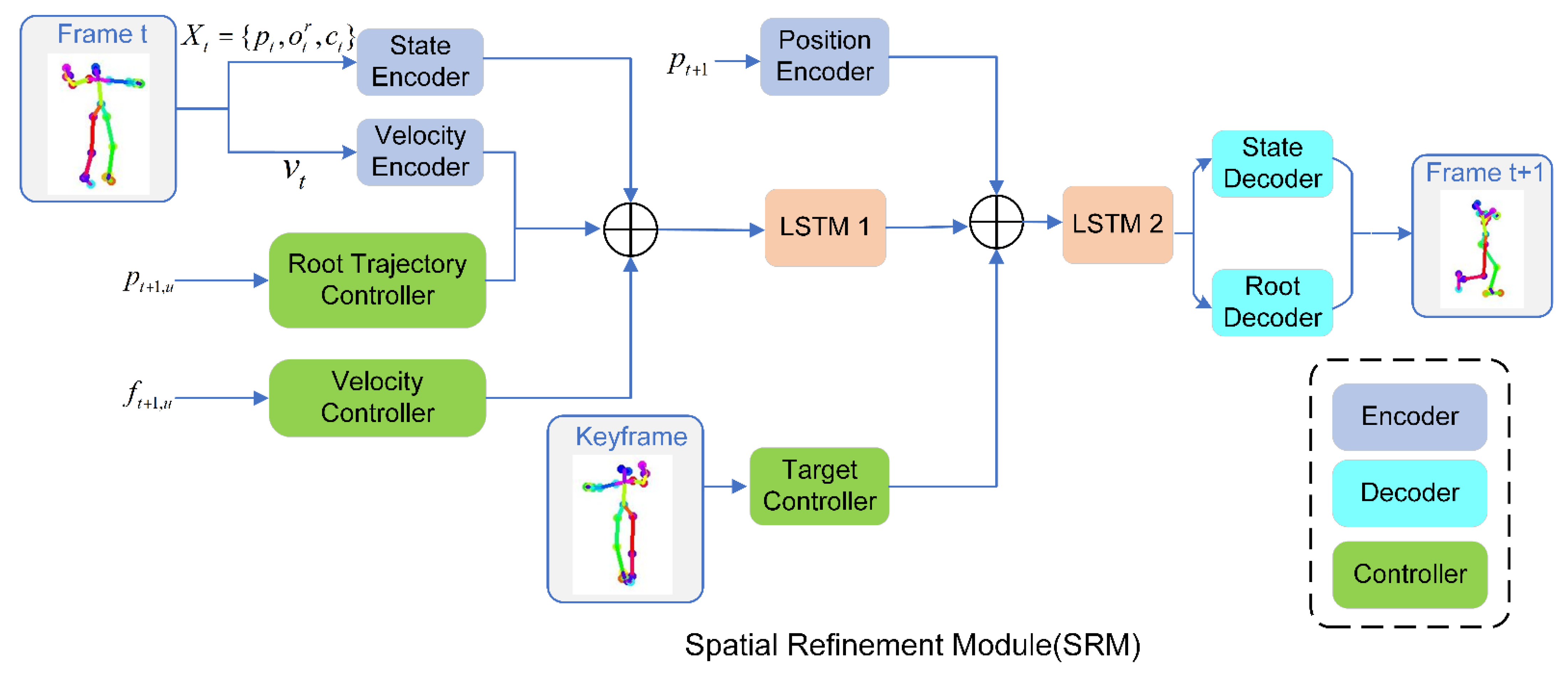
3.2.2. Spatial Refinement Model Network Structure
3.3. Music and Dance Consistency Constraints
4. Experiments
4.1. Dataset and Implementation Details
4.2. Evaluation Metrics
4.3. Comparison of the Results to Other Methods
4.4. Ablation Study
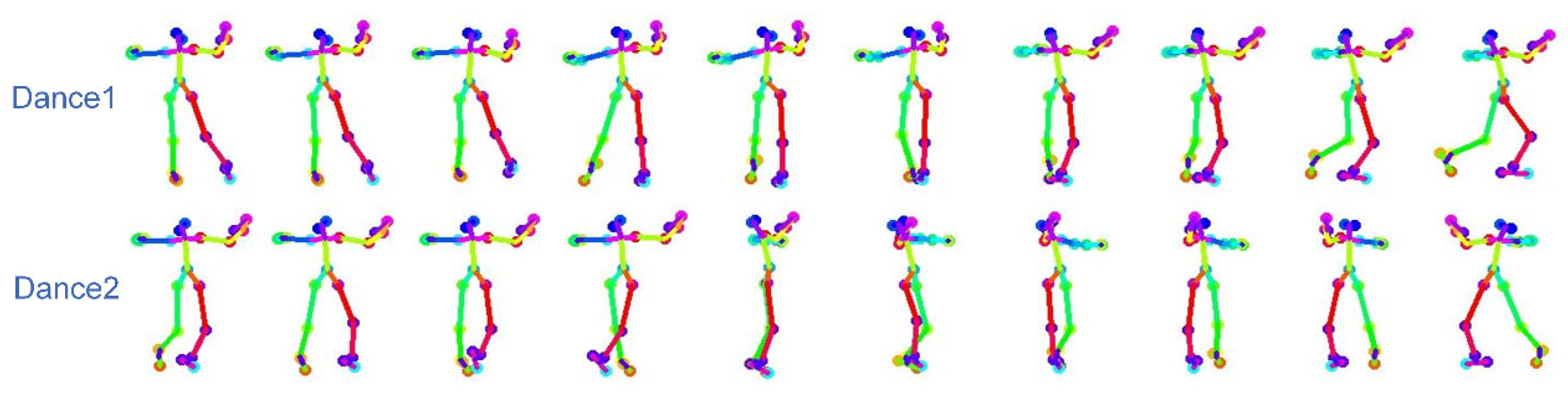
4.5. Visualization of the Generated Dance Sequence
5. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Xia, G.; Tay, J.; Dannenberg, R.; Veloso, M. Autonomous robot dancing driven by beats and emotions of music. In Proceedings of the 11th International Conference on Autonomous Agents and Multiagent Systems—Volume 1, Valencia, Spain, 4–8 June 2012; pp. 205–212. [Google Scholar]
- LaViers, A.; Egerstedt, M. Style based robotic motion. In Proceedings of the 2012 American Control Conference (ACC), Montreal, QC, Canada, 27–29 June 2012; pp. 4327–4332. [Google Scholar]
- Kim, J.W.; Fouad, H.; Sibert, J.L.; Hahn, J.K. Perceptually motivated automatic dance motion generation for music. Comput. Animat. Virtual Worlds 2009, 20, 375–384. [Google Scholar] [CrossRef]
- Xu, J.; Takagi, K.; Sakazawa, S. Motion synthesis for synchronizing with streaming music by segment-based search on metadata motion graphs. In Proceedings of the 2011 IEEE International Conference on Multimedia and Expo, Barcelona, Spain, 11–15 July 2011; pp. 1–6. [Google Scholar]
- Fan, R.; Xu, S.; Geng, W. Example-based automatic music-driven conventional dance motion synthesis. IEEE Trans. Vis. Comput. Graph. 2012, 18, 501–515. [Google Scholar] [PubMed]
- Ofli, F.; Erzin, E.; Yemez, Y.; Tekalp, A.M. Learn2dance: Learning statistical music-to-dance mappings for choreography synthesis. IEEE Trans. Multimed. 2012, 14, 747–759. [Google Scholar] [CrossRef]
- Fukayama, S.; Goto, M. Music content driven automated choreography with beat-wise motion connectivity constraints. In Proc. Sound Music Comput. Proc. SMC 2015, 3, 177–183. [Google Scholar]
- Sonnhammer, E.L.; Von Heijne, G.; Krogh, A. A hidden markov model for predicting transmembrane helices in protein sequences. Proc. Int. Conf. Intell. Syst. Mol. Biol. 1998, 6, 175–182. [Google Scholar] [PubMed]
- Manfrè, A.; Infantino, I.; Vella, F.; Gaglio, S. An automatic system for humanoid dance creation. Biol. Inspired Cogn. Archit. 2016, 15, 1–9. [Google Scholar] [CrossRef]
- Augello, A.; Infantino, I.; Manfré, A.; Pilato, G.; Vella, F.; Chella, A. Creation and cognition for humanoid live dancing. Robot. Auton. Syst. 2016, 86, 128–137. [Google Scholar] [CrossRef]
- Manfré, A.; Augello, A.; Pilato, G.; Vella, F.; Infantino, I. Exploiting interactive genetic algorithms for creative humanoid dancing. Biol. Inspired Cogn. Archit. 2016, 17, 12–21. [Google Scholar] [CrossRef]
- Qin, R.; Zhou, C.; Zhu, H.; Shi, M.; Chao, F.; Li, N. A music-driven dance system of humanoid robots. Int. J. Humanoid Robot. 2018, 15, 1850023. [Google Scholar] [CrossRef]
- Lee, H.; Yang, X.; Liu, M.; Wang, T.; Lu, Y.; Yang, M.; Kautz, J. Dancing to Music. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 3586–3596. [Google Scholar]
- Crnkovic-Friis, L.; Crnkovic-Friis, L. Generative Choreography using Deep Learning. In Proceedings of the International Conference on Innovative Computing and Cloud Computing, Paris, France; 2016; pp. 272–277. [Google Scholar] [CrossRef]
- Martinez, J.; Black, M.J.; Romero, J. On Human Motion Prediction Using Recurrent Neural Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4674–4683. [Google Scholar]
- Komura, T.; Habibie, I.; Holden, D.; Schwarz, J.; Yearsley, J. A recurrent variational autoencoder for human motion synthesis. In Proceedings of the 28th British Machine Vision Conference, London, UK, 4–7 September 2017; pp. 1–12. [Google Scholar]
- Holden, D.; Saito, J.; Komura, T. A deep learning framework for character motion synthesis and editing. ACM Trans. Graph. 2016, 35, 138–145. [Google Scholar] [CrossRef]
- Li, Z.; Zhou, Y.; Xiao, S.; He, C.; Huang, Z.; Li, H. Auto-Conditioned Recurrent Networks for Extended Complex Human Motion Synthesis. arXiv 2018. [Google Scholar] [CrossRef]
- Ren, X.; Li, H.; Huang, Z.; Chen, Q. Music-oriented Dance Video Synthesis with Pose Perceptual Loss. arXiv 2019, arXiv:1912.06606v1. [Google Scholar]
- Yalta, N.; Watanabe, S.; Nakadai, K.; Ogata, T. Weakly-Supervised Deep Recurrent Neural Networks for Basic Dance Step Generation. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar]
- Sun, G.; Wong, Y.; Cheng, Z.; Kankanhalli, M.; Geng, W.; Li, X. DeepDance: Music-to-Dance Motion Choreography with Adversarial Learning. IEEE Trans. Multimed. 2020, 23, 497–509. [Google Scholar] [CrossRef]
- Guo, X.; Zhao, Y.; Li, J. DanceIt: Music-inspired dancing video synthesis. IEEE Trans. Image Process. 2021, 30, 5559–5572. [Google Scholar] [CrossRef] [PubMed]
- Karpathy, A.; Li, F.F. Deep visual-semantic alignments for generating image descriptions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Reed, S.; Akata, Z.; Yan, X.; Logeswaran, L.; Schiele, B.; Lee, H. Generative adversarial text to image synthesis. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016. [Google Scholar]
- Zhang, H.; Xu, T.; Li, H.; Zhang, S.; Huang, X.; Wang, X.; Metaxas, D. StackGAN: Text to photo-realistic image synthesis with stacked generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Owens, A.; Isola, P.; McDermott, J.; Torralba, A.; Adelson, E.; Freeman, W. Visually indicated sounds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Davis, A.; Rubinstein, M.; Wadhwa, N.; Mysore, G.; Durand, F.; Freeman, W. The visual microphone: Passive recovery of sound from video. In ACM Transactions on Graphics; Association for Computing Machinery: New York, NY, USA, 2014. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Herva, A.; Lehtinen, J. Audio-driven facial animation by joint end-to-end learning of pose and emotion. In ACM Transactions on Graphics; Association for Computing Machinery: New York, NY, USA, 2017. [Google Scholar]
- Suwajanakorn, S.; Seitz, S.M.; Kemelmacher-Shlizerman, I. Synthesizing Obama: Learning lip sync from audio. In ACM Transactions on Graphics; Association for Computing Machinery: New York, NY, USA, 2017. [Google Scholar]
- Chen, L.; Li, Z.; Maddox, R.K.; Duan, Z.; Xu, C. Lip Movements Generation at a Glance. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 16–28. [Google Scholar]
- Zhou, Y.; Wang, Z.; Fang, C.; Bui, T.; Berg, T. Visual to sound: Generating natural sound for videos in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Lebailly, T.; Kiciroglu, S.; Salzmann, M.; Fua, P.; Wang, W. Motion Prediction Using Temporal Inception Module. In Proceedings of the Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020. [Google Scholar]
- Li, M.; Chen, S.; Chen, X.; Zhang, Y.; Wang, Y.; Tian, Q. Actional-structural graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3595–3603. [Google Scholar]
- Wang, H.; Ho, E.S.L.; Shum, H.P.H.; Zhu, Z. Spatio-temporal manifold learning for human motions via long-horizon modeling. IEEE Trans. Vis. Comput. Graph. 2021, 27, 216–227. [Google Scholar] [CrossRef] [PubMed]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Two-stream adaptive graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 12026–12035. [Google Scholar]
- Cao, Z.; Hidalgo, G.; Simon, T.; Wei, S.-E.; Sheikh, Y. OpenPose: Realtime multi-person 2D pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 7444–7452. [Google Scholar]
- Pan, J.; Wang, S.; Bai, J.; Dai, J. Diverse Dance Synthesis via Keyframes with Transformer Controllers. Comput. Graph. Forum 2021, 40, 71–83. [Google Scholar] [CrossRef]
- Banar, N.; Daelemans, W.; Kestemont, M. Character-level transformer-based neural machine translation. In Proceedings of the International Conference on Natural Language Processing and Information Retrieval, Seoul, Republic of Korea, 18–20 December 2020; pp. 149–156. [Google Scholar]
- Zhang, D.; Zhang, H.; Tang, J.; Wang, M.; Hua, X.; Sun, Q. Feature pyramid transformer. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 323–339. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kir-Illov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- McFee, B.; Raffel, C.; Liang, D.; Ellis, D.P.; McVicar, M.; Battenberg, E.; Nieto, O. Librosa: Audio and music signal analysis in Python. In Proceedings of the 14th Python in Science Conference, Austin, TX, USA, 6–12 July 2015; pp. 18–25. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | FID ↓ | Beat Hit Rate ↑ | Diversity ↑ | Multimodality ↑ |
|---|---|---|---|---|
| Real dances | 5.9 | 51.6% | 53.5 | - |
| Lee et al. [13] | 12.8 | 65.1% | 53.2 | 47.8 |
| Guo et al. [22] | 8.6 | 70.3% | 58.6 | 57.8 |
| Ours | 7.4 | 72.6% | 60.3 | 58.3 |
| Method | FID ↓ | Diversity ↑ |
|---|---|---|
| Real dances | 5.9 | 53.5 |
| No abnormal frame optimization process | 11.2 | 56.2 |
| Guo-TSD | 8.6 | 58.6 |
| Ours-AFOA algorithm | 7.4 | 60.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.; Song, Y.; Jiang, W.; Wang, T. A Music-Driven Dance Generation Method Based on a Spatial-Temporal Refinement Model to Optimize Abnormal Frames. Sensors 2024, 24, 588. https://doi.org/10.3390/s24020588
Wang H, Song Y, Jiang W, Wang T. A Music-Driven Dance Generation Method Based on a Spatial-Temporal Refinement Model to Optimize Abnormal Frames. Sensors. 2024; 24(2):588. https://doi.org/10.3390/s24020588
Chicago/Turabian StyleWang, Huaxin, Yang Song, Wei Jiang, and Tianhao Wang. 2024. "A Music-Driven Dance Generation Method Based on a Spatial-Temporal Refinement Model to Optimize Abnormal Frames" Sensors 24, no. 2: 588. https://doi.org/10.3390/s24020588
APA StyleWang, H., Song, Y., Jiang, W., & Wang, T. (2024). A Music-Driven Dance Generation Method Based on a Spatial-Temporal Refinement Model to Optimize Abnormal Frames. Sensors, 24(2), 588. https://doi.org/10.3390/s24020588