1.1. Main Problem
Reproduction is a cornerstone of life that aims to secure the prolongation of hereditary features or the gene pool [
1]. Problems in this aspect of life are associated with social, cultural, and medical issues [
2]. The problems can be described as extensive and comprehensive, and many variables should be considered when looking for a solution. One of the frequent problems in reproduction in recent years is infertility. This issue can be further categorized into two sub-categories: sub-fertility and infertility [
3]. Sub-fertility and infertility are closely related. However, the differences may be attributed to the duration of unwanted non-conception. Sub-fertility is defined as the prolonged duration of non-conception, while infertility can be considered sterility with sporadic conception moments. As mentioned, reproductive issues encompass many aspects of life, and choices in lifestyle have a significant role in fertility [
4]. Some lifestyle choices might negatively influence fertility, especially when made excessively.
Fat-rich diets, the use of recreational drugs, sexual activity, smoking, alcohol misuse, and mental conditions such as anxiety, stress, and depression are only some examples of lifestyle choices that promote infertility. With that said, around 10% of couples experience infertility [
5]. Delayed childbearing also drastically reduces the probability of conceiving [
4,
5]. To circumvent these problems and promote conception, assisted reproduction techniques (ART), such as IVF and ICSI, have been developed and are available [
5]. IVF stands for in vitro fertilization, while ICSI is the abbreviation for intracytoplasmic sperm injection [
6]. The assisted reproduction technique unites gametes in vitro and bypasses the process of sexual intercourse [
5]. The resulting embryo can be stored, exchanged, designed, altered, and implanted in any womb. This method may be significant, as it is independent of sexual orientation, age, and gender.
1.2. Specific Problem
For the ART process to be lucrative, quality sperm need to be selected before being inserted into the ova [
7]. However, a universal parameter that defines the quality of sperm has not been developed, and selection has been made subjectively based on qualitative assessment. The ideal method for sperm selection should have two properties: namely, it should be non-invasive and cost-effective. One of the solutions is CASA, an acronym for computer-aided sperm analysis, which refers to the multi-image system of analyzing and extracting objective information related to sperm motion or morphology using computers. These systems project sperm images onto a detector, which will detect objects based on the pixel’s light intensity, extract desired information, and output them [
8]. This is similar to the principle behind computer vision models that use pixel brightness, color, and texture similarity to make inferences [
9]. CASA has been used extensively in clinical laboratories and hospitals worldwide for semen analysis procedures [
10].
There has been difficulty in applying this technology in human sperm samples due to several obstacles. Before the SVIA dataset, the lack of publicly available large-scale datasets that were suitable for training CASA systems was a major concern. Additionally, impurities, such as sperm clumping and background debris, have prevented accurate image analysis, which is required for a standalone routine clinical application [
11,
12,
13]. Background debris or impurities in sperm image analysis include dead or deformed sperm [
14]. Another consideration other than low accuracy is the need to obtain the analysis promptly with short inference time [
15,
16]. However, a fast inference time with low-accuracy performance would be meaningless. Determination of sperm from impurities can be considered one of the important factors in promoting CASA systems and having them even more widely implemented in clinical settings [
10].
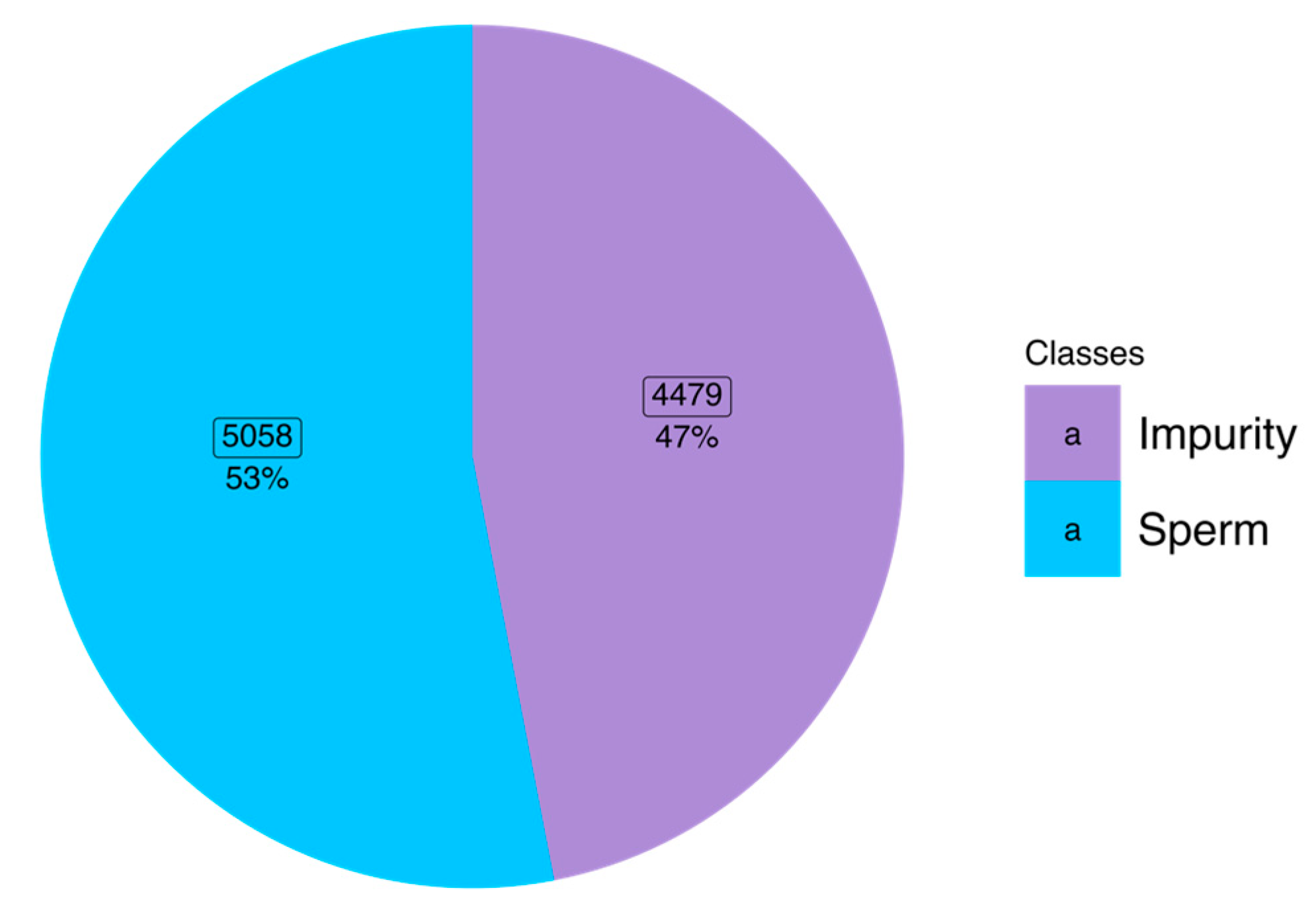
A recent dataset for sperm videos and image analysis called SVIA was collected and made publicly available. It consists of three subsets designed for different video and image analysis purposes. Subset-A is specific for object detection tasks, Subset-B is for image segmentation and tracking tasks, and Subset-C could be used for image classification tasks. This paper will focus on a classification task to clarify between impurities and sperm using Subset-C in the SVIA dataset. An impurity is a non-sperm object similar to sperm that can be bacteria, protein clumps, or bubbles, while the sperm class can contain a range of sperm morphological conditions including, normal, tapered, round, amorphous, pin or multi-nucleated heads. As of the writing of this paper, there has been no research that has classified the images in this SVIA Subset-C dataset.
1.3. Previous Studies
The HuSHeM and SCIAN datasets are the two most commonly used datasets for deep learning-based sperm classification [
13,
17,
18,
19,
20]. The HuSHeM [
13] dataset consists of 725 images, with only 216 of them containing sperm heads. In contrast, the SCIAN [
20] dataset has 1854 sperm head images. A third sperm morphology dataset, SMIDS, compares three classes with a total of 3000 images recently available [
21]. Previous research has mostly used convolutional neural network (CNN) [
17,
18,
19], dictionary learning [
13], or machine learning (ML) [
20] models for classification. Research using a VGG16 transfer learning approach, called FT-VGG, achieved 94% accuracy on the HuSHeM dataset [
18]. Another CNN-based study obtained 63% and 77% on the partial and full expert agreement on the SCIAN dataset, beating the previous state-of-the-art [
18] method by an increase of 29% and 46%, respectively [
19]. It also achieved 95.7% accuracy. Using a late (decision level) fusion architecture, a study by [
21] achieved 90.87% accuracy on the SMIDS dataset. This particular research also investigated the model’s capability to replace rotation and cropping human intervention for automation purposes.
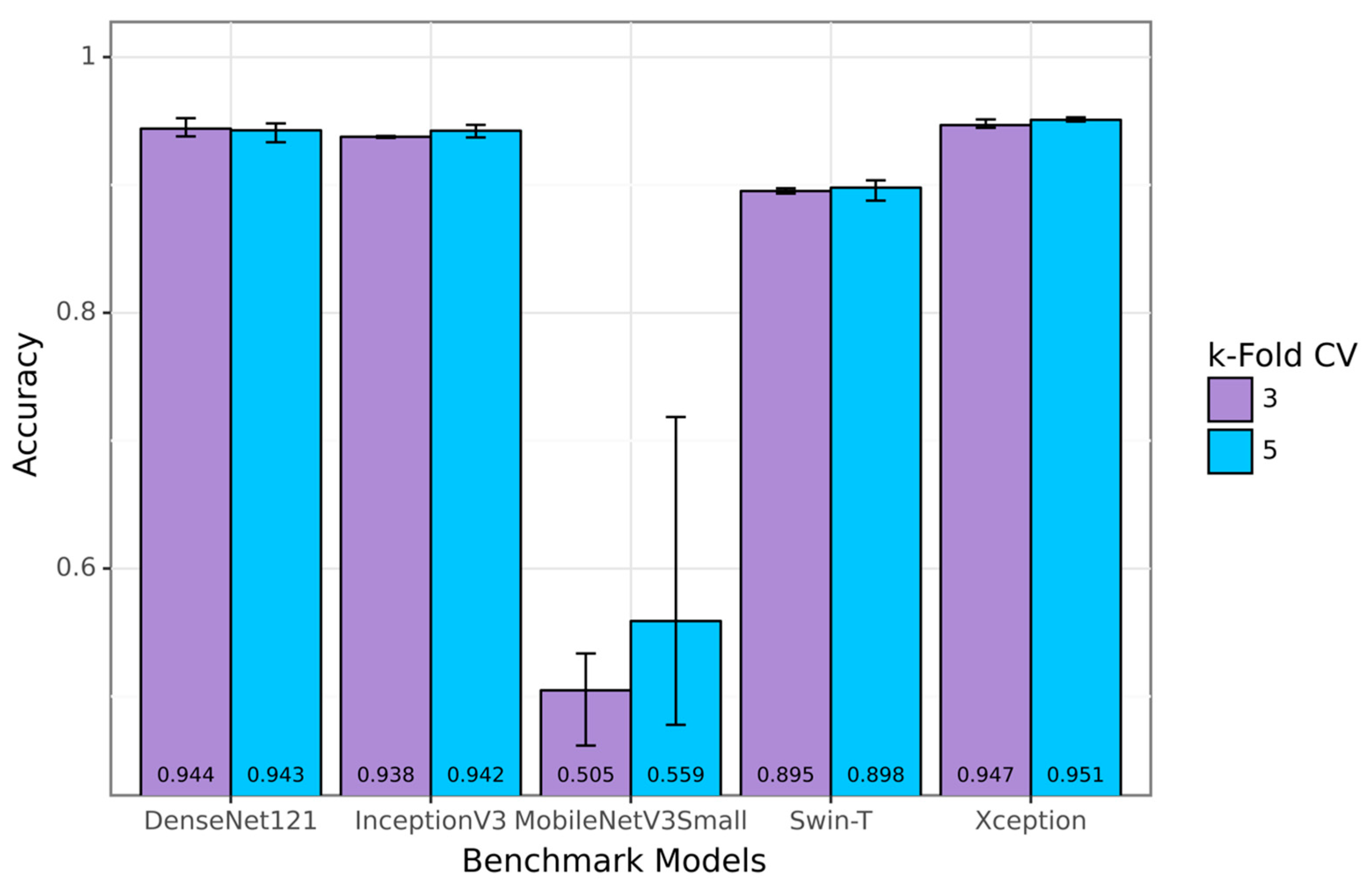
In addition to the SVIA dataset, several attempts at classification were made with the Subset-C dataset. In terms of accuracy, outstanding performers were the ImageNet pre-trained DenseNet121, InceptionV3, and Xception models. These models achieved 98.06%, 98.32%, and 98.43% on the accuracy metrics, respectively. Other pre-trained models attempted to classify the sperm images but obtained weaker results than the three mentioned above. In the research on sperm classification, the main problem associated with the low-performance scores is the lack of publicly available data, which was solved with the availability of the SVIA dataset. The works previously mentioned have shown their extraordinary abilities through machine learning because, although the shape of sperm is very subtle, it can be detected quickly and precisely with deep learning. The ability of this deep learning is indeed difficult to find in traditional doctors, but its results should not be used as the primary basis for medical decisions. It would be wiser to use it as supporting evidence. Thus, a major challenge is to create a deep learning model that minimizes this problem. Steps can be taken to create a deep learning model that can approach the actual value of truth. In this case, the authors propose a deep learning model that can beat benchmarks from previous works. By leveraging the large SVIA dataset, we propose a model that provides a more representative capability for sperm classification than existing models. This research could provide more accurate and generalizable models than existing ones while also performing more reliably than embryologists in mass analyses. Furthermore, this could propel efforts to standardize infertility treatment in clinics worldwide, facilitating its progress.
1.4. Proposed Method
In response to the shortcomings that were found in previous studies related to sperm morphology classification, this study was conducted to develop a deep-learning model that improved on those used in previous studies. We considered several gaps found in previous studies that could be mitigated in this research. Moreover, those gaps had not been addressed by previous studies. Therefore, based on those gaps, in this study, we added three main ideas for developing a sperm morphology classification, including transformer-based models, fusion techniques, and an autoencoder. The first one employs a transformer-based model that utilizes an attention mechanism well-known to capture global feature dependencies more efficiently than the recurrent neural network (RNN) or LSTM model. Since there were also concerns about the lack of local inductive biases for transformers used in vision tasks, a lightweight CNN-based MobileNetV3 was incorporated. Hence, both global and local features could be utilized for classification. Second, using an early fusion technique involving the feature maps generated from two separate models, a large feature map could be generated, and this would enrich the features from the small sperm images to improve the accuracy of classification. Third, using autoencoders within the architecture would alleviate the effect of unwanted noise in the sperm images without prior human intervention in the images, thus further improving classification predictions. Therefore, this model architecture would also remove the need for excessive human intervention and automate sperm morphology classification using a more robust method than previous studies have attempted.
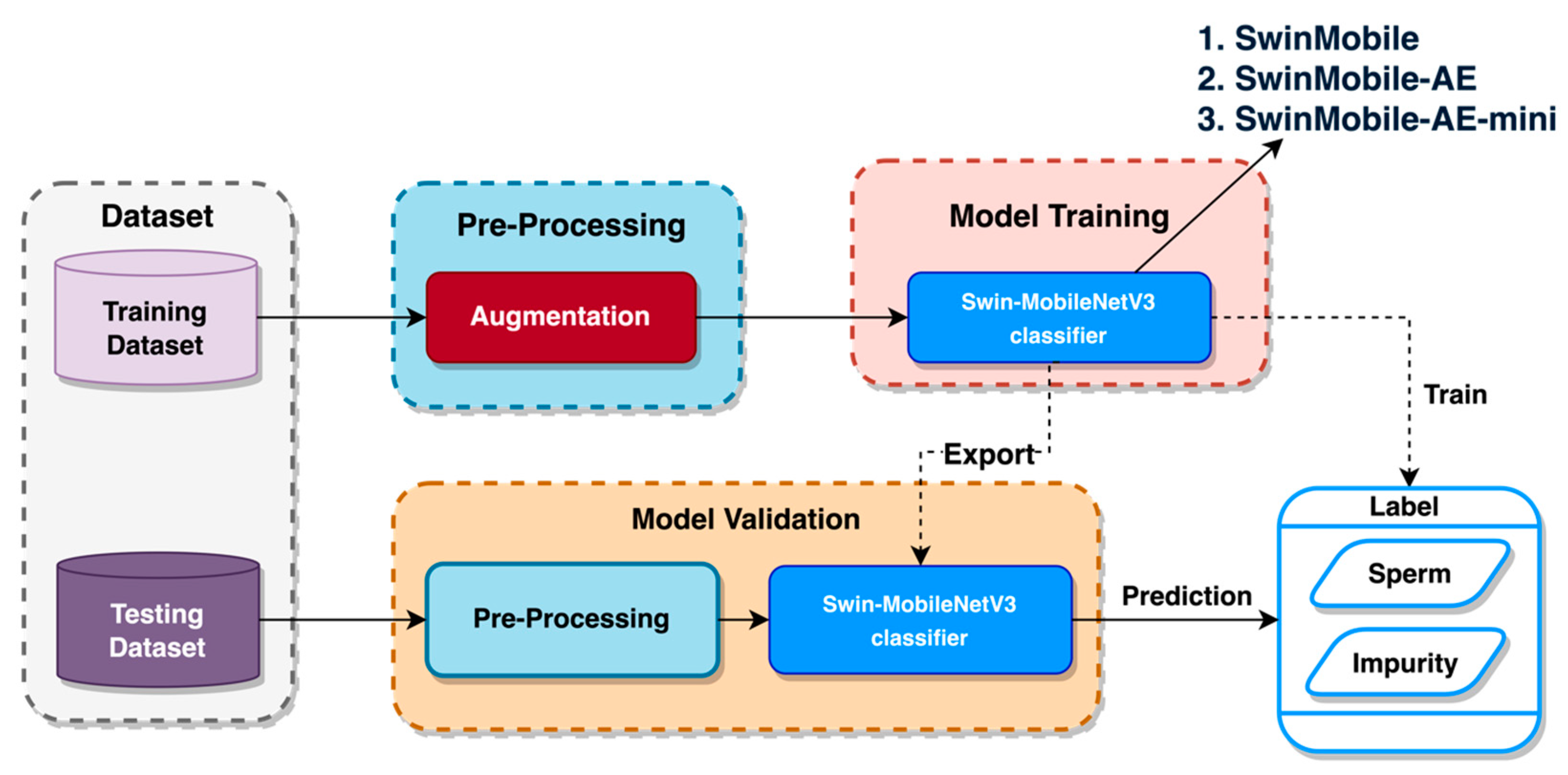
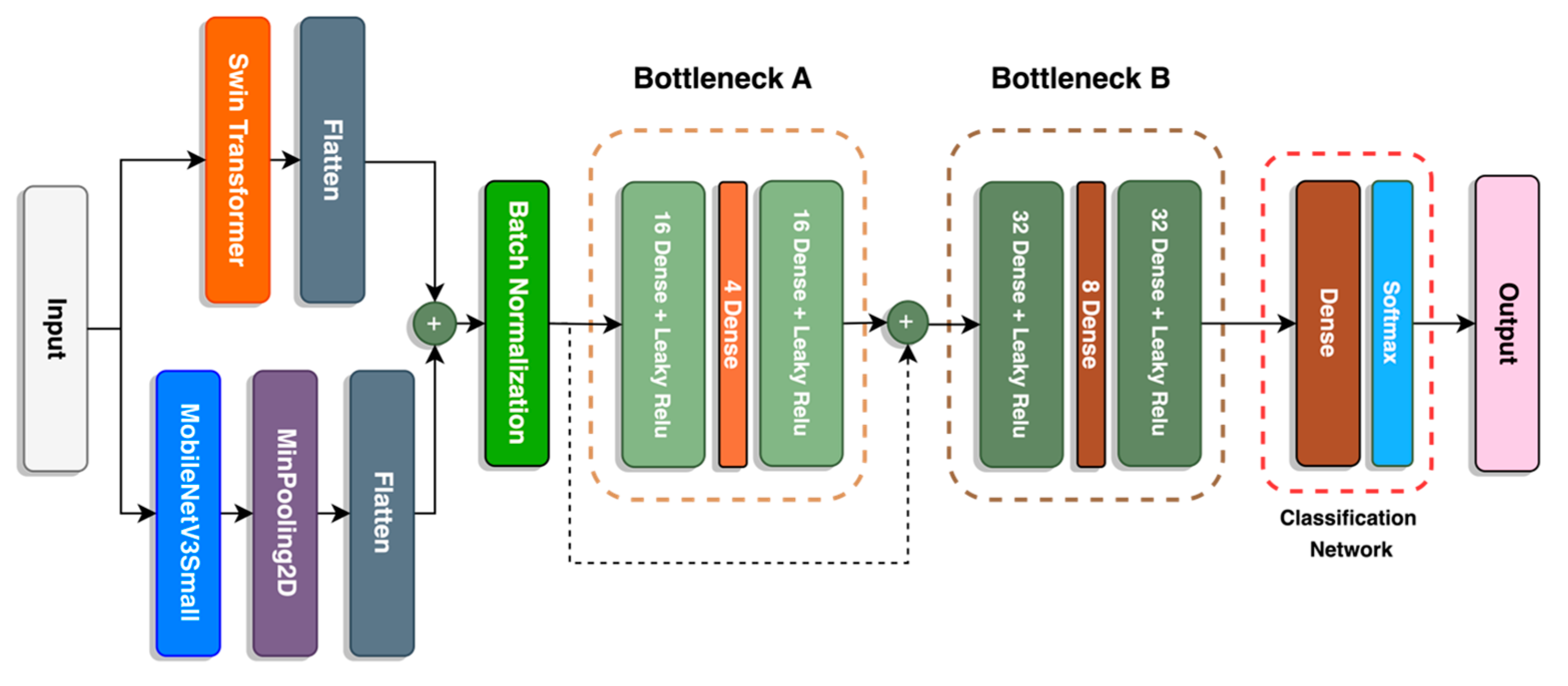
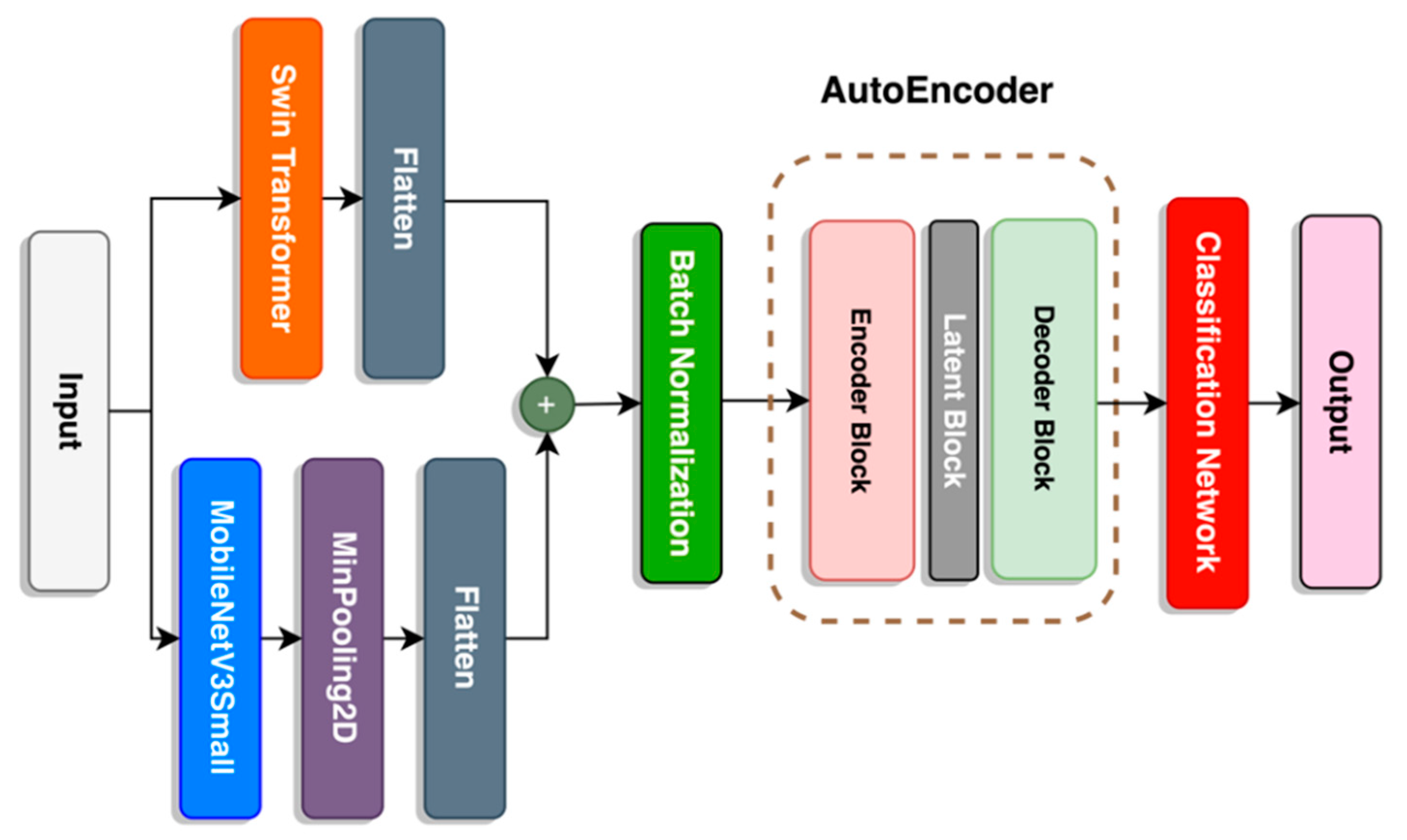
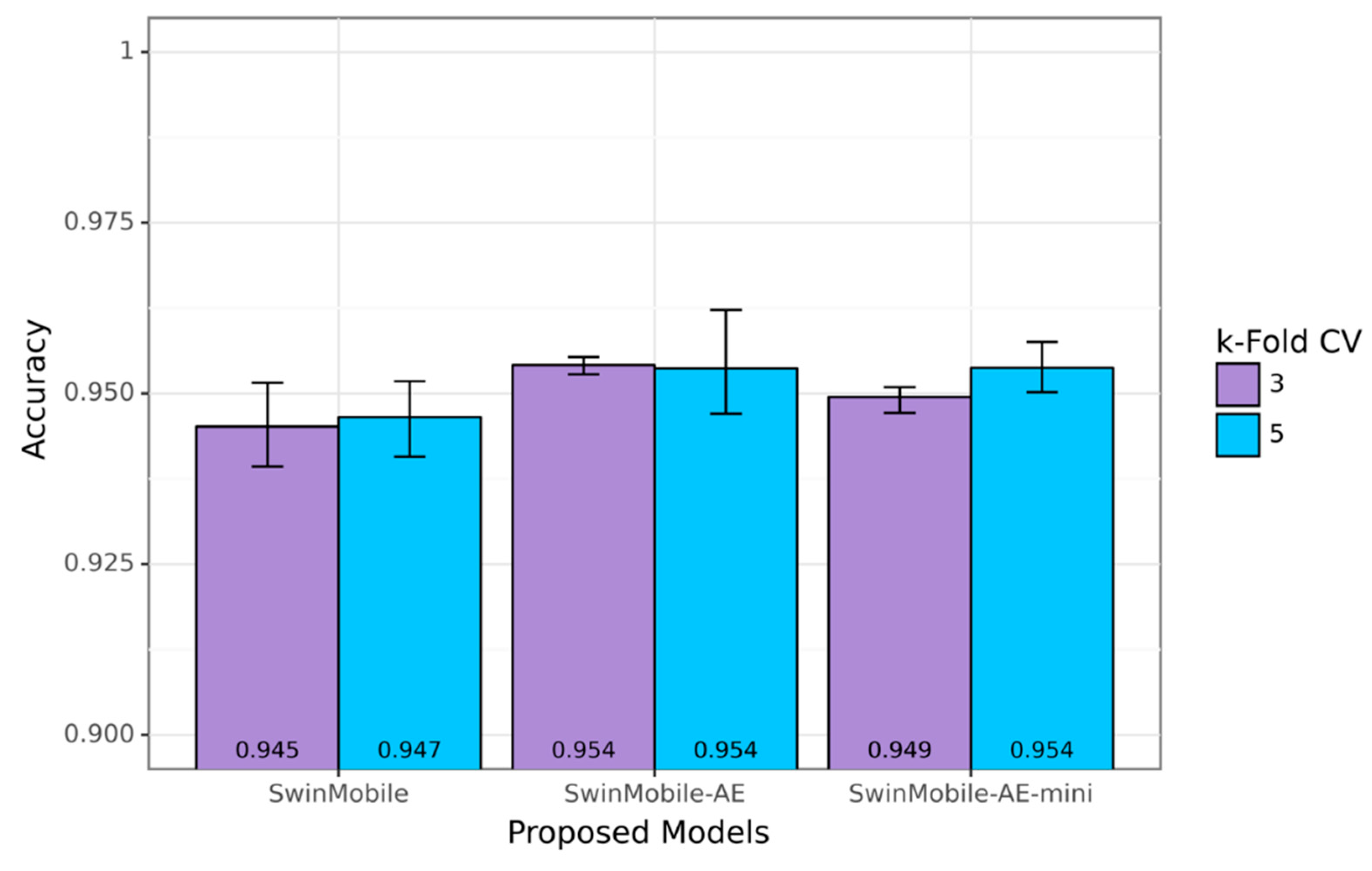
This paper proposes a deep learning fusion architecture, called SwinMobile, that combines the shifted windows vision transformer (Swin) and MobileNetV3 to classify sperm and impurities in SVIA Subset-C. Both the Swin and MobileNetV3 could resolve the problems associated with sperm classification, as they leverage the ability of Swin transformers to capture long-range feature dependencies in images and the mobile-sized architecture optimization algorithms in the MobileNetV3 to maximize accuracy. Another variant of SwinMobile was also developed with an autoencoder (AE) architecture before the classification network. Due to AE’s ability to denoise images and extract only the necessary features, classification accuracy should be improved, as it would only focus on the important aspects of the image [
22]. Essentially, it performs similarly to a PCA, whereby a PCA discovers the linear hyperplane, while an autoencoder unravels the hyperplane non-linearly.
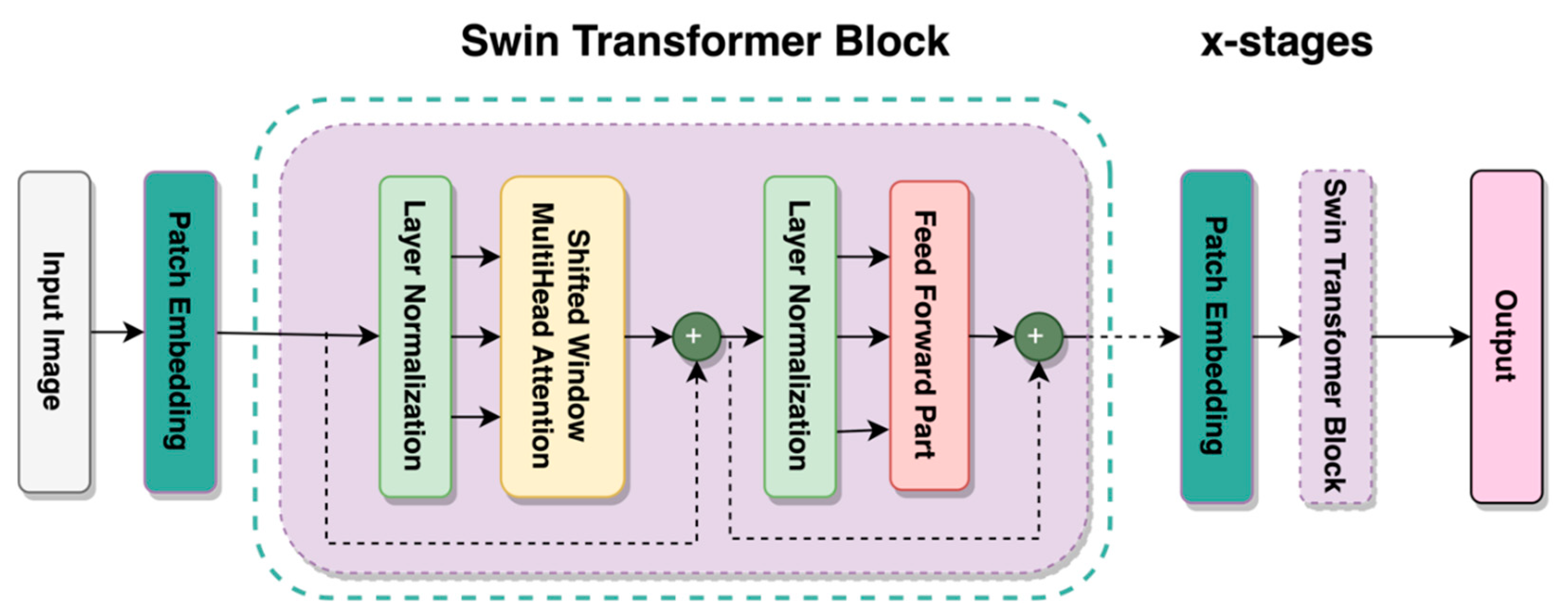
The Swin model improves on the vision transformer (ViT), which lacks the inductive bias possessed by CNN, such as translational equivariance and locality, when trained on insufficient data [
23,
24]. Benefiting from the small images of sperm, Swin also adds a linear computational complexity to the image size by performing self-attention computation locally in each non-overlapping window with a fixed number of patches, and partitions the whole image [
24]. Compared to sliding window-based transformers, Swin performs more than two times faster. It also outperforms other forms of vision transformers, ViT and DEiT, in terms of accuracy. On the other hand, MobileNetV3 is an improved version of MobileNetV2, with better accuracy and inference times [
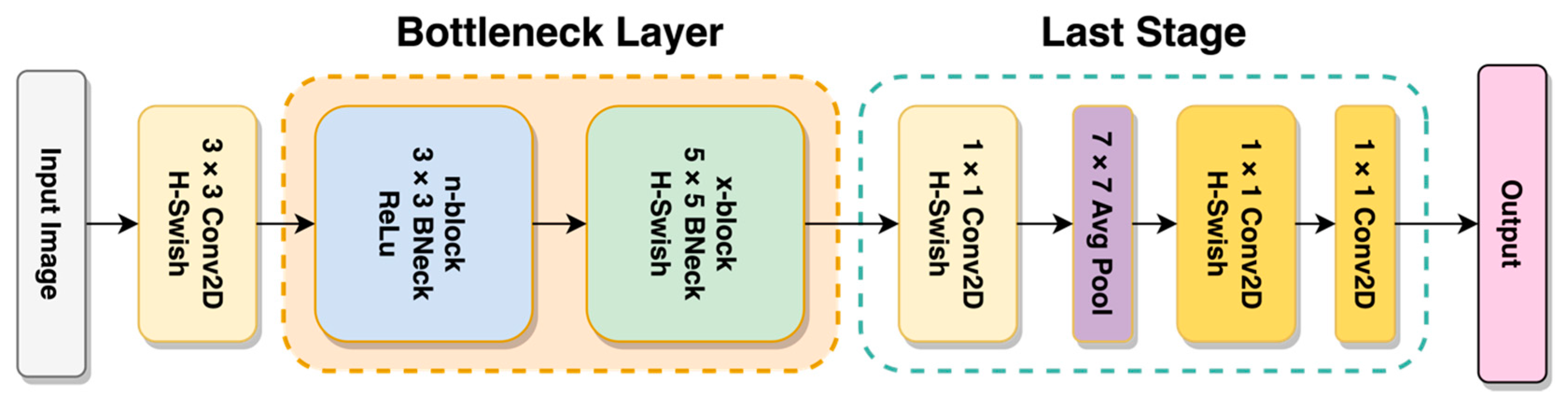
25]. It incorporates a platform-aware AutoML neural architecture search or NAS and NetAdapt algorithm that searches each layer’s optimal number of nodes. The resulting model would be optimized to provide maximum accuracy in short inference times for a given hardware platform.
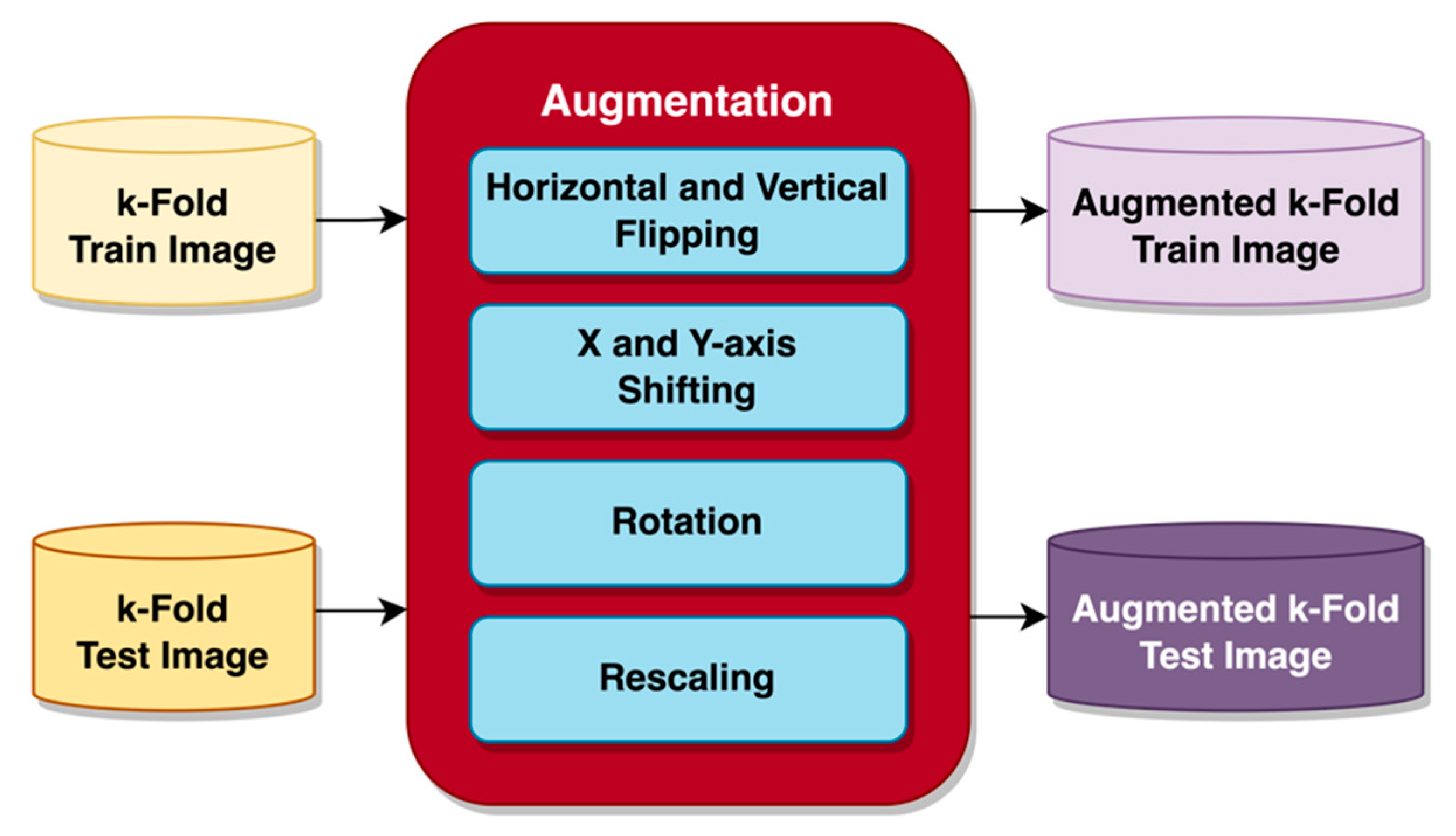
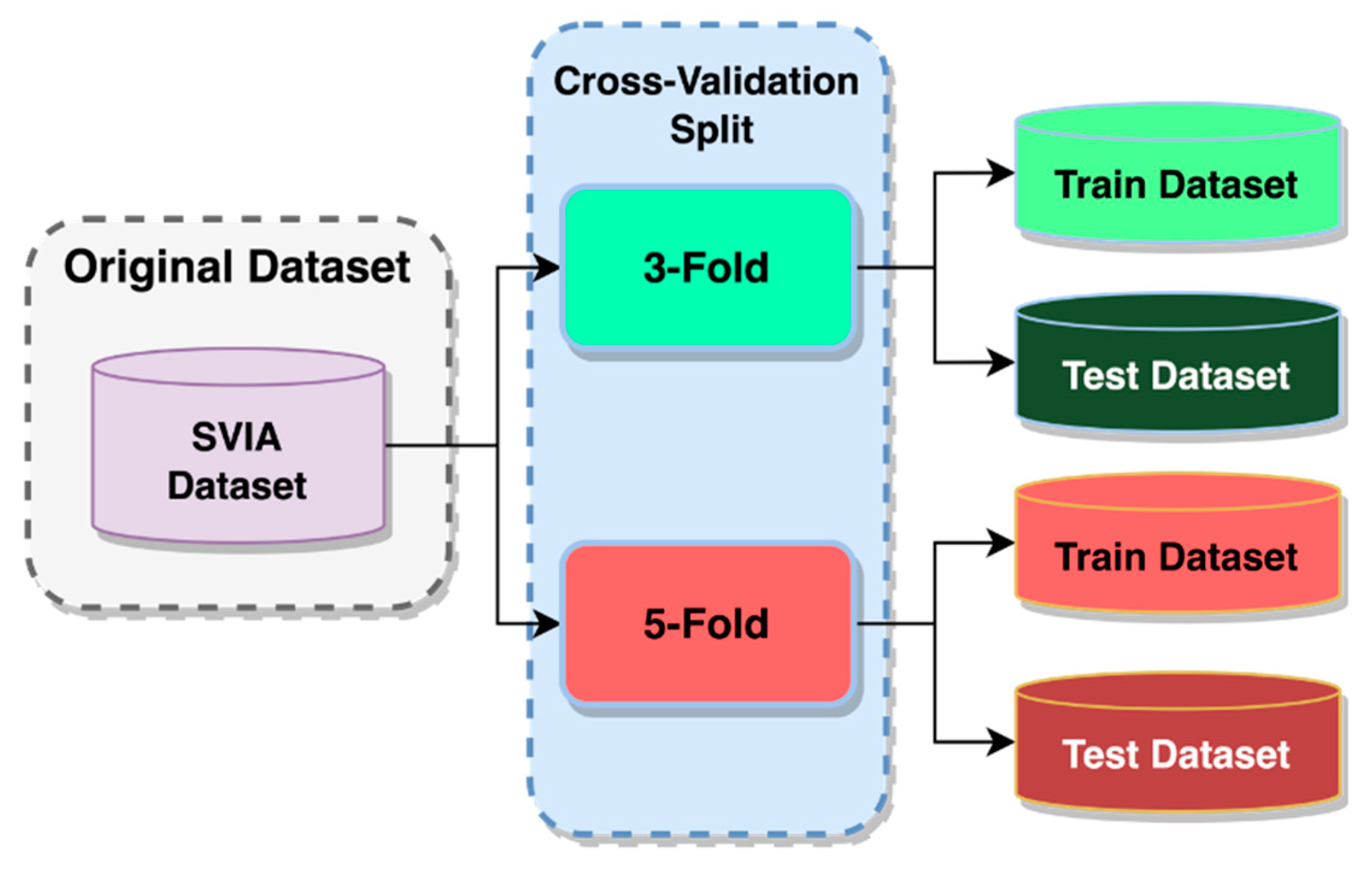
With the combination of these mentioned architectures, the problem of low accuracy could be solved for CASA systems on the SVIA dataset. In addition, compression on the best-performing proposed model was attempted to increase the inference time and reduce our model size while maintaining similar performances. This is essential, as CASA systems need high accuracy and a relatively high inference speed. DenseNet121, InceptionV3, and Xception models with outstanding accuracy scores on the SVIA dataset formed the benchmark against our proposed models. Due to the differences in pre-processing and other preparatory methods not explicitly described in the paper, the three models were rerun on our environment and dataset with the same pre-processing method as our models to ensure a fair comparison. The trained models were evaluated using a three-fold and five-fold cross-validation technique on several performance metrics, namely F1-score and accuracy. The proposed models were also tested on other sperm morphology datasets, such as the HuSHem [
13] and SMIDS [
21], to assess their generalization ability. Comparison to the state-of-the-art models was based on F1-score and accuracy. As part of this study, we developed an automated feature fusion model to improve the classification accuracy of sperm morphology by leveraging the abilities of the various model architectures. With this approach, the advantages of the various architectures were expected to be reaped, such as the global long-range feature dependence of Transformers, local inductive convolutional bias and small size of MobileNet, and the AutoEncoder’s denoising ability. Hence, our proposed models could achieve better automatic classification performance than previous models while being mobile-friendly.

 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}