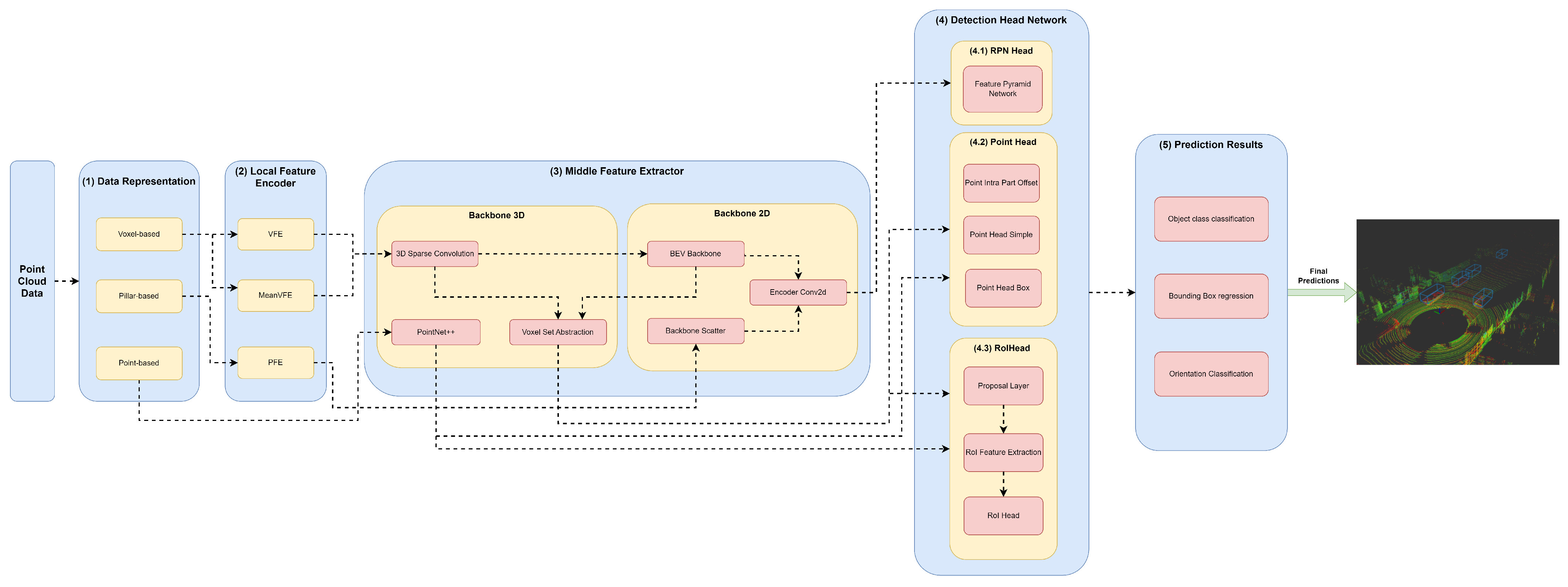
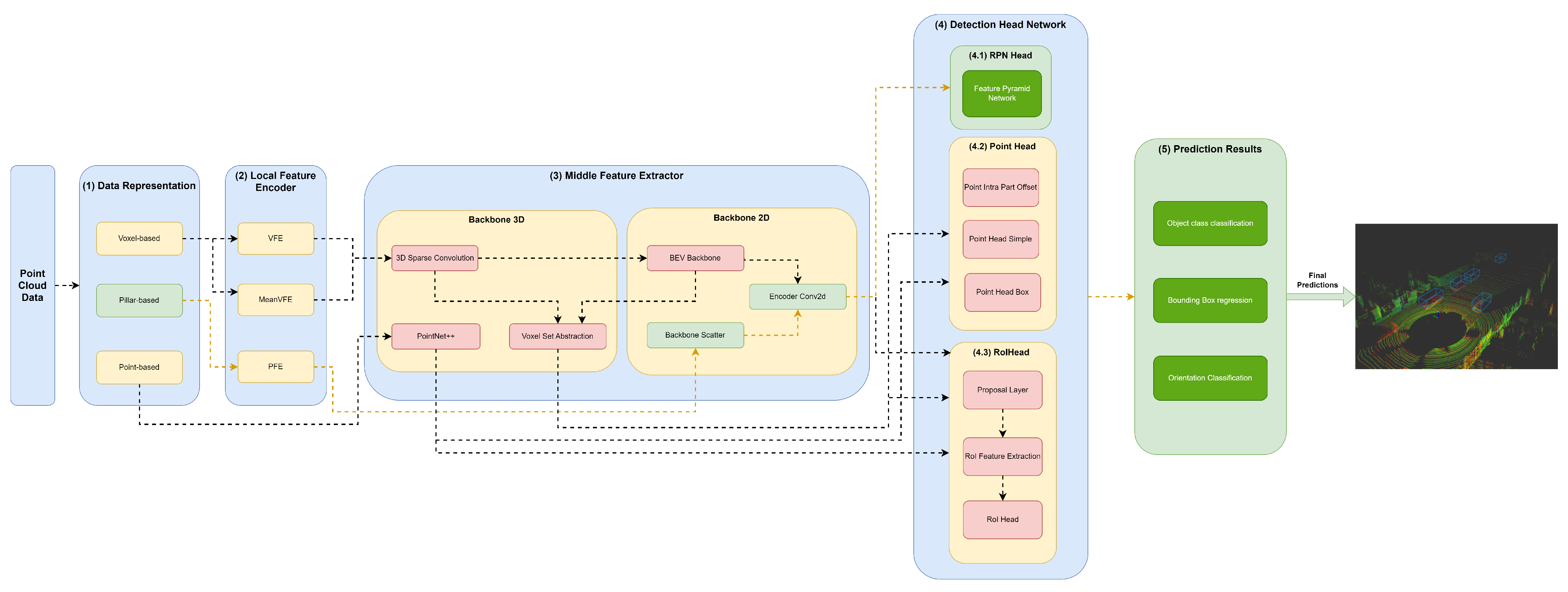
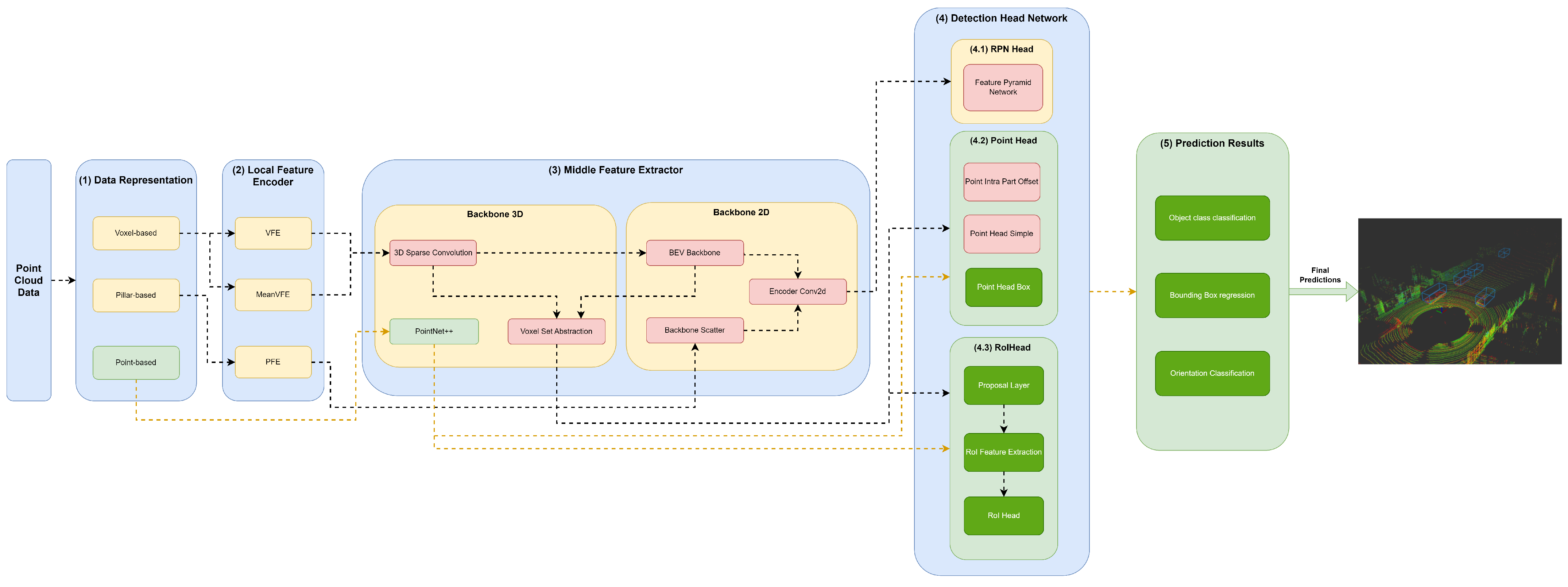
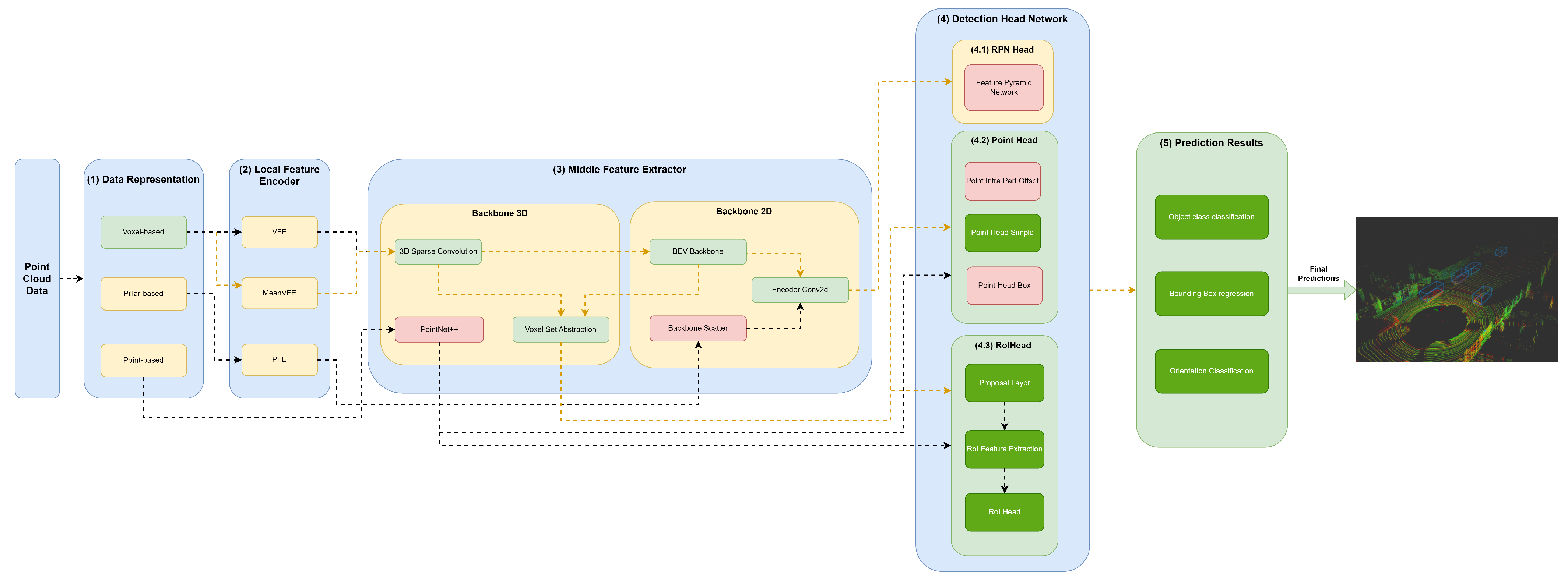
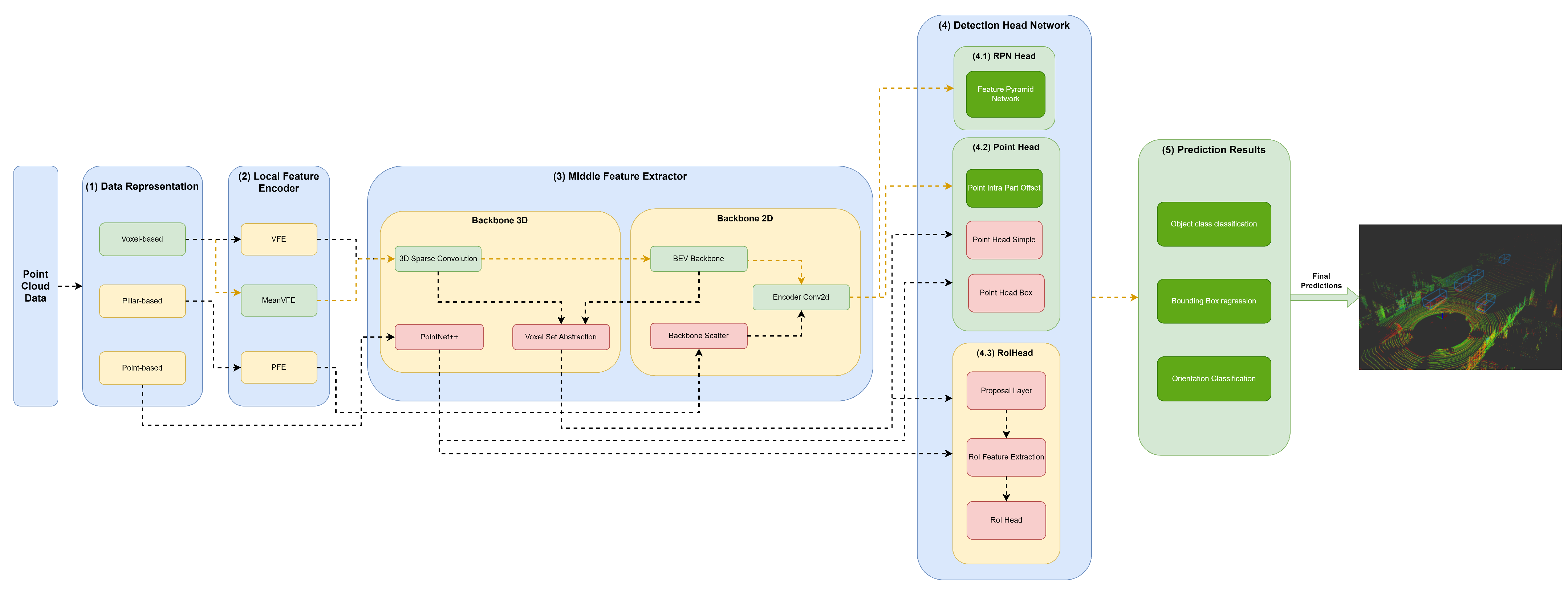
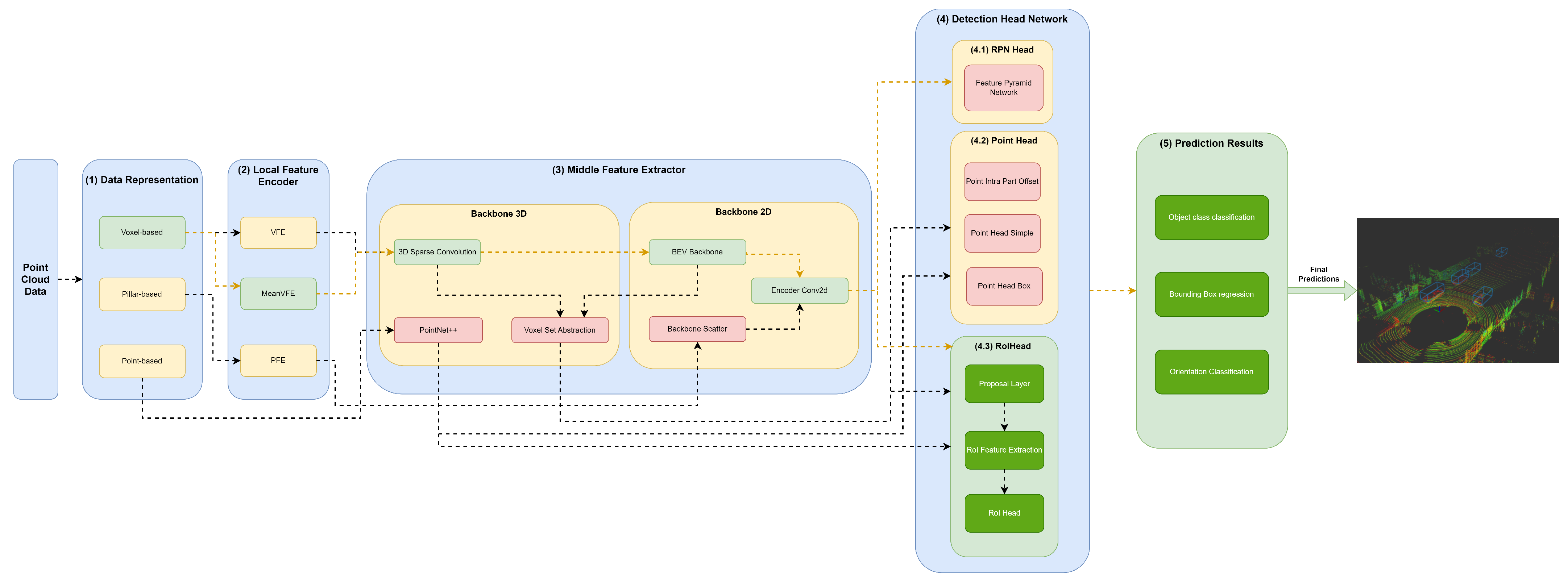
The (3) middle feature extractor is responsible for extracting more features from the (2) local feature encoders to provide more context for the shape description of objects for the networks of the detection head module. Various methods are used; herein, we separated them into 3D backbones and 2D backbones, which will be described in more detail below.
4.3.1. Backbone 3D
A variety of methods resort to 3D backbones using the sparse CNN component. Also, models can use a voxel set abstraction 3D backbone, aiming to encode the multiscale semantic features obtained by sparse CNN to keypoints. Others use PointNet++ with multiscale grouping for feature extraction and to obtain more context to the shape of objects, and then pass these features to the (4) detection head module.
3D Sparse Convolution
The 3D sparse convolution method receives the voxel-wise features of VFE, or mean VFE, .
This backbone is represented as a set of blocks
, in the form
, where
. Each block
can be defined by a set of sparse sequential operations denoted as
. Each
is described by
, where
means submanifold sparse convolution 3D [
18],
means spatially sparse convolution 3D [
19],
means 1D batch normalization operation and
represents the ReLU method. The last method assumes the standard procedure, as mentioned in [
20].
In our framework, the set of blocks assumes the following configurations:
The input block can be described by ;
The next block is represented in the form ;
The block 3 is represented as , ;
The block 4 is denoted as , ;
The block 5 is denoted as , ;
The last block is defined by .
The batch normalization
element is defined by
, which represents the formula in [
21].
represents the input features, which are the output features of submanifold sparse or spatially sparse convolutions 3D, so that
.
represents the eps, and
the momentum values. These values are defined in
Table 1.
The element
can be represented as
.
represents the input features of
, and it is denoted as
, where
represents the output features of submanifold sparse Conv3D. The element
represents the output features resulting from applying
.
means kernel size of a spatially sparse convolution 3D, and it is denoted as
, where
,
and
. The stride
can be described as a set
and
.
designates padding, and a set can define it
,
.
means dilation, and can be defined as a set
,
. The output padding
is represented as a in the form
and
. The configurations used in our framework are represented in
Table 2.
is represented by
[
18].
represents the input features passed by (2) the local feature encoder or by the last sparse sequential block
, and
represents the output features of
. Thus,
in the case of the local encoder being mean VFE, otherwise
, where
F represents the output features of the VFE network. Also,
can be represented by
and
, where
represents the output features of a
. The element
represents the kernel size, which can be defined as
, where
,
and
.
means stride, and can be defined as a set
,
and
.
represents padding, and a set can describe it in the form
.
means dilation, and can be described as a set
.
represents the output padding, and a set describes it in the form
,
and
. The configurations used in our framework are represented in
Table 3.
The hyperparameters used in each
are defined in
Table 7.
Finally, the output spatial features are defined by , where SP is defined by a tuple (B, C, D, H, W). B represents the batch size; C the output features of represented in as ; D depth; H height; and W width.
PointNet++
We use a modified version of PointNet++ [
9] based on [
13] to learn undiscretized raw point cloud data (herein denoted as
) features in multiscale grouping fashion. The objective is to learn to segment the foreground points and contextual information about them. For this purpose, a set abstraction module, herein denoted as
, is used to subsample points at a continuing increase rate, and a feature proposal module, described as
, is used to capture feature maps per point with the objective of point segmentation and proposal generation. A
is composed of
,
, where
means PointNet set abstraction module operations. Each
is represented by
, where
corresponds to query and grouping operations to learn multiscale patterns from points, and
is the set of specifications of the PointNet before the global pooling for each scale.
means ball query operation
followed by a grouping operation
. It can be defined by the set
, where
and
correspond to two query and group operations. A ball query
is represented as
, where
R means the radius within all points will be searched from the query point with an upper limit
, in a process called ball query;
P means the coordinates of the point features in the form
that are used to gather the point features;
represents the coordinates of the centers of the ball query in the form
, where
,
, and
are center coordinates of a ball query. Thus, this ball query algorithm searches for point features
P in a radius
R with an upper limit of
query points from the centroids (or ball query centers)
. This operation generates a list of indices
in the form
,
, where
corresponds to the number of
.
represents the indices of point features that form the query balls. Then, a grouping operation
is performed to group point features, and can be described by
, in which
and
correspond to point features and indices of the features to group with, respectively. In each
of a
, the number of centroids
will decrease, so that
, and due to the relation of the centroids in ball query search, the number of indices
and corresponding point features will also decrease. Thus, in each
, the number of points features is defined by
. The number of centroids defined in QGL during
operations is defined in
Table 4.
Afterwards, an
is performed, defined by a set of specifications of the PointNet before the
operations. The idea herein is to capture point-to-point relations of the point features in each
local region. The point feature coordinate translation to the local region relative to the centroid point is performed by the operation
.
,
and
are coordinates of point features
as mentioned before, and
,
and
are coordinates of the centroid center.
can be defined by a set
that represents two sequential methods. Each
is represented by the set of operations
,
, where
means convolution 2D,
2D batch normalization and
represents the ReLU method.
is defined by
.
, where
represents the input features that can be received by
or by the output features
of the
,
the kernel size, and
represents the stride of the convolution 2D. The kernel size
is defined by the set
and
. Also, the stride
is represented by a set
and
with
. The set of specifications used in our models regarding
are summarized in
Table 5.
can be defined as:
where
denotes max pooling,
denotes random sampling of
features and
denotes the multilayer perceptron network to encode features and relative locations.
Finally, a feature proposal
is applied employing a set of feature proposal modules
. Each
is defined by the element
as defined above. Also, the element
assumes a set
, and each
has the same operations, with the only difference in the element
s that describes the number of operations, assuming
instead of
. The configurations used in our models are summarized in
Table 6.
Voxel Set Abstraction
This method aims to generate a set of keypoints from given point cloud and use a keypoint sampling strategy based on farthest point sampling. This method generates a small number of keypoints that can be represented by , , where is the number of points features that have the largest minimum distance, and B the batch size. The farthest point sampling method is defined according to a given subset , where M is the maximum number of features to sample, and subset , , where N is the total number of points features of ; the point distance metric is calculated based on . Based on D, an operation is performed, which calculates the smallest value distance between and . , and represent the list of the last known largest minimum distances of point features. Assuming , it returns the index . Based on , thus . Finally, this operation generates a set of indexes in the form , and , where B corresponds to the batch size and M represents the maximum number of features to sample. The keypoints K are given by .
These keypoints K are subject to an interpolation process utilizing the semantic features encoded by the 3D sparse convolution as . In this interpolation process, these semantic features are mapped with the keypoints to the voxel features that reside. Firstly, this process defines the local relative coordinates of keypoints with voxels by means . Then, a bilinear interpolation is carried out to map the point features from 3D sparse convolution in a radius R with the , the local relative coordinates of keypoints. This is perform . Afterwards, indexes of points are defined according to in the form and another . The expression that gives the features from the BEV perspective based on and is the following:
Thus, the weights between these indexes , and are calculated, as follows:
;
Finally, the bilinear expression that gives the features from the BEV perspective is , where , , , . Also, , , , , and .
The local features of
are indicated by
,
and aggregated using PointNet++ according with their specification defined above. They will generate
, which are voxel-wise features within the neighboring voxel set
of
, transforming using PointNet++ specifications. This generates
according to
, and each
is an aggregate feature of 3D sparse convolution
with
from different levels according to
Table 4.
4.3.2. Backbone 2D
Two-dimensional backbones are used to extract features from 2D feature maps resulting from a PFN component, such as those used by PointPillars, and to readjust the objects back to LiDAR’s Cartesian 3D system with minimal information loss utilizing a backbone scatter component. Also, models can compress the feature map of 3D backbones into a bird’s-eye view (BEV) feature map employing a BEV backbone and use an encoder Conv2D to perform feature encoding and concatenation. Such methodology is employed by models such as by SECOND, PV-RCNN, and Voxel-RCNN.
Backbone Scatter
The features resulting from the PFN are used by the PointPillars scatter component, which scatters them back to a 2D pseudoimage of size , where H and W denote height and width, respectively.
BEV Backbone
The BEV backbone module receives 3D feature maps from 3D sparse convolution and reshapes them to the BEV feature map. Admitting the given sparse features , the new sparse features are . The BEV backbone is represented as a set of blocks , in the form , where . Each block , is represented by . The element n represents the number of convolutional layers in . The set of convolutional layers C in is described as a set , where . F represents the number of filters of each , U is the number of upsample filters of . Each of the upsample filters has the same characteristics, and their outputs are combined through concatenation. S denotes the stride in . If , we have a downsampled convolutional layer (). There are a certain convolutional layers (, such that ) that follow this layer. batch-norm and ReLU layers are applied after each convolutional layer.
The input for this set of blocks is spatial features extracted by 3D sparse convolution or voxel set abstraction modules and reshaped to the BEV feature map.
Encoder Conv2D
Based on features extracted in each block and after upsampling based on , where D means the downsample factor of the convolution layer C, the upsample features , are concatenated, such that , where cat means .


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







