
Sensor Fusion for the Robust Detection of Facial Regions of Neonates Using Neural Networks

 , ,
, ,  , , and
, , and
Abstract
1. Introduction
1.1. State of the Art
1.1.1. Thermal-RGB-Fusion
Direct Extrinsic Calibration
Indirect Extrinsic Calibration
Thermal-ToF-Fusion
RGB-ToF-Fusion
Fusion Using Neural Networks
1.1.2. Face Detection Using Neural Networks and Image Processing
1.1.3. Face Detection for Neonates
1.1.4. Face Detection Using Fused Images
1.1.5. Neural Networks Using Fused Image Data
2. Material and Methods
2.1. Concept and Theoretical Approach
2.1.1. Sensors
2.1.2. Intrinsic Calibration
2.1.3. Sensor Fusion
- Detect circles of the calibration target within the ToF mono image and calculate the corresponding depth points.
- Detect circles within RGB and thermal image.
- Calculate transformation between RGB and ToF camera using the circle centers.
- Calculate transformation between thermal and ToF camera using the circle centers.
- Project RGB points into the thermal image (at the position of the ToF points).
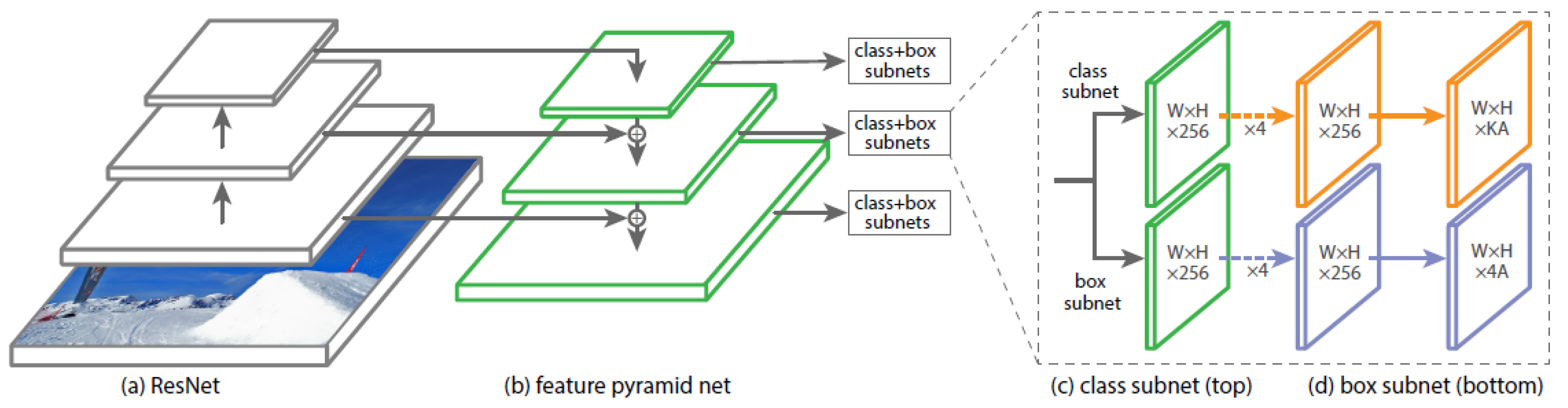
2.1.4. Neural Networks RetinaNet and YOLOv3
RetinaNet
YOLOv3

2.1.5. Data Augmentation
Mirroring
Rotation
Zooming
Random Crop
Erasing
Noise
Contrast and Saturation Changing
Blurring and Sharpening
Histogram Equalization
2.2. Hardware Setup
2.2.1. Thermal Camera
2.2.2. RGB Camera
2.2.3. 3D-Time-of-Flight Camera
2.2.4. Computer with GPU
2.3. Software Algorithms
2.3.1. Calibration
Thermal Camera
RGB Camera
2.3.2. Thermal-RGB-Fusion
Circle Detection
RGB-ToF and Thermal-ToF Fusion
2.3.3. Neural Networks RetinaNet and YOLOv3
RetinaNet
YOLOv3
2.4. Measurement Series
2.4.1. Subjects
2.4.2. Training, Validation and Test Datasets
3. Results
3.1. RGB Dataset
3.1.1. RetinaNet
3.1.2. YOLOv3
3.2. Thermal Dataset
3.2.1. RetinaNet
3.2.2. YOLOv3
3.3. Fusion Dataset
3.3.1. RetinaNet
3.3.2. YOLOv3
4. Discussion
4.1. Comparison of Theoretical Approach for the Sensor Fusion
4.2. Discussion of Training Results
4.2.1. RetinaNet
4.2.2. YOLOv3
4.2.3. Comparison between RetinaNet and YOLOv3
4.2.4. Summary
4.3. Comparison with State of the Art
4.3.1. Sensor Fusion
4.3.2. Neural Network for Face Detection
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AP | average precision |
| BPM | breaths per minute |
| CNN | Convolutional Neural Network |
| DLT | Direct Linear Transform |
| ECG | Electrocardiogram |
| FFT | Fast Fourier Transform |
| FoV | field of view |
| FPN | Feature Pyramid Network |
| fps | frames per second |
| GAN | Generative Adversial Network |
| GPU | graphical processing unit |
| IoU | Intersection over Union |
| IR | infrared |
| LIDAR | light detection and ranging |
| LSTM | Long Short-Term Memory |
| LWIR | long wave infrared |
| NCC | normalized cross correlation |
| NICU | Neonatal Intensive Care Unit |
| NIR | near infrared |
| PCA | Principal Component Analysis |
| PCL | Point Cloud Library |
| R-CNN | Region-Based Convolutional Neural Networks |
| ResNet | Residual Network |
| RGB | Red Green Blue |
| RGB-D | Red, Green, Blue -Depth |
| RMSE | root mean square error |
| ROI | region of interest |
| ROS | Robot Operating System |
| SGD | Stochastic Gradient Descent |
| SNR | Signal-to-noise ratio |
| T-ICP | thermal-guided iterative closest point |
| ToF | time-of-flight |
| UV | ultraviolet |
| YOLO | you only look once |
References
- Larsen, R. Pädiatrische Intensivmedizin. In Anästhesie und Intensivmedizin für die Fachpflege; Springer: Berlin/Heidelberg, Germany, 2016; pp. 920–949. [Google Scholar] [CrossRef]
- Hausmann, J.; Salekin, M.S.; Zamzmi, G.; Goldgof, D.; Sun, Y. Robust Neonatal Face Detection in Real-world Clinical Settings. arXiv 2022, arXiv:2204.00655. [Google Scholar] [CrossRef]
- St-Laurent, L.; Prévost, D.; Maldague, X. Fast and accurate calibration-based thermal/colour sensors registration. In Proceedings of the 2010 International Conference on Quantitative InfraRed Thermography, Quebec, QC, Canada, 24–29 June 2010. [Google Scholar] [CrossRef]
- Shivakumar, S.S.; Rodrigues, N.; Zhou, A.; Miller, I.D.; Kumar, V.; Taylor, C.J. PST900: RGB-Thermal Calibration, Dataset and Segmentation Network. In Proceedings of the IEEE International Conference on Robotics and Automation, Paris, France, 31 May–31 August 2020; pp. 9441–9447. [Google Scholar] [CrossRef]
- Yang, M.D.; Su, T.C.; Lin, H.Y. Fusion of infrared thermal image and visible image for 3D thermal model reconstruction using smartphone sensors. Sensors 2018, 18, 2003. [Google Scholar] [CrossRef] [PubMed]
- Krishnan, A.K.; Saripalli, S. Cross-Calibration of RGB and Thermal Cameras with a LIDAR for RGB-Depth-Thermal Mapping. Unmanned Syst. 2017, 5, 59–78. [Google Scholar] [CrossRef]
- Gleichauf, J.; Vollet, J.; Pfitzner, C.; Koch, P.; May, S. Sensor Fusion Approach for an Autonomous Shunting Locomotive. In Proceedings of the Informatics in Control, Automation and Robotics, Paris, France, 7–9 July 2020; Gusikhin, O., Madani, K., Eds.; Springer: Cham, Switzerland, 2020; pp. 603–624. [Google Scholar]
- Tisha, S.M. LSU Digital Commons Thermal-Kinect Fusion Scanning System for Bodyshape Inpainting and Estimation under Clothing; Louisiana State University and Agricultural & Mechanical College: Baton Rouge, LA, USA, 2019. [Google Scholar]
- Yang, Q.; Yang, R.; Davis, J.; Nistér, D. Spatial-depth super resolution for range images. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007. [Google Scholar] [CrossRef]
- Van Baar, J.; Beardsley, P.; Pollefeys, M.; Gross, M. Sensor fusion for depth estimation, including TOF and thermal sensors. In Proceedings of the 2nd Joint 3DIM/3DPVT Conference: 3D Imaging, Modeling, Processing, Visualization and Transmission, 3DIMPVT 2012, Zurich, Switzerland, 13–15 October 2012; pp. 472–478. [Google Scholar] [CrossRef]
- Cao, Y.; Xu, B.; Ye, Z.; Yang, J.; Cao, Y.; Tisse, C.L.; Li, X. Depth and thermal sensor fusion to enhance 3D thermographic reconstruction. Opt. Express 2018, 26, 8179. [Google Scholar] [CrossRef] [PubMed]
- Pfitzner, C. Visual Human Body Weight Estimation with Focus on Medical Applications. Ph.D. Thesis, Universität Würzburg, Würzburg, Germany, 2018. [Google Scholar]
- Rocco Spremolla, I.; Antunes, M.; Aouada, D.; Ottersten, B. RGB-D and Thermal Sensor Fusion - Application in Person Tracking. VISIGRAPP 2016, 3, 610–617. [Google Scholar] [CrossRef]
- Salinas, C.; Fernández, R.; Montes, H.; Armada, M. A new approach for combining time-of-flight and RGB cameras based on depth-dependent planar projective transformations. Sensors 2015, 15, 24615–24643. [Google Scholar] [CrossRef]
- Kim, Y.M.; Theobalt, C.; Diebel, J.; Kosecka, J.; Miscusik, B.; Thrun, S. Multi-view image and ToF sensor fusion for dense 3D reconstruction. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision Workshops, ICCV Workshops 2009, Kyoto, Japan, 27 September–4 October 2009; pp. 1542–1546. [Google Scholar] [CrossRef]
- Tang, L.; Yuan, J.; Zhang, H.; Jiang, X.; Ma, J. PIAFusion: A progressive infrared and visible image fusion network based on illumination aware. Inf. Fusion 2022, 83–84, 79–92. [Google Scholar] [CrossRef]
- Alexander, Q.G.; Hoskere, V.; Narazaki, Y.; Maxwell, A.; Spencer, B.F. Fusion of thermal and RGB images for automated deep learning based crack detection in civil infrastructure. AI Civ. Eng. 2022, 1, 3. [Google Scholar] [CrossRef]
- Jung, C.; Zhou, K.; Feng, J. Fusionnet: Multispectral fusion of RGB and NIR images using two stage convolutional neural networks. IEEE Access 2020, 8, 23912–23919. [Google Scholar] [CrossRef]
- Wang, H.; An, W.; Li, L.; Li, C.; Zhou, D. Infrared and visible image fusion based on multi-channel convolutional neural network. IET Image Process. 2022, 16, 1575–1584. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, F.; Wu, D.; Gao, G. Infrared and Visible Image Fusion Method Using Salience Detection and Convolutional Neural Network. Sensors 2022, 22, 5430. [Google Scholar] [CrossRef] [PubMed]
- Yang, S.; Luo, P.; Loy, C.C.; Tang, X. WIDER FACE: A Face Detection Benchmark. arXiv 2015, arXiv:1511.06523. [Google Scholar] [CrossRef]
- Qi, D.; Tan, W.; Yao, Q.; Liu, J. YOLO5Face: Why Reinventing a Face Detector. arXiv 2021, arXiv:2105.12931. [Google Scholar] [CrossRef]
- Deng, J.; Guo, J.; Zhou, Y.; Yu, J.; Kotsia, I.; Zafeiriou, S. RetinaFace: Single-stage Dense Face Localisation in the Wild. arXiv 2019, arXiv:1905.00641. [Google Scholar] [CrossRef]
- Kaipeng, Z.; Zhanpeng, Z.; Zhifeng, L.; Yu, Q. Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef]
- Yudin, D.; Ivanov, A.; Shchendrygin, M. Detection of a human head on a low-quality image and its software implementation. ISPRS—Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, XLII-2/W12, 237–241. [Google Scholar] [CrossRef]
- Jiang, H.; Learned-Miller, E. Face Detection with the Faster R-CNN. arXiv 2016, arXiv:1606.03473. [Google Scholar] [CrossRef]
- Cheong, Y.K.; Yap, V.V.; Nisar, H. A novel face detection algorithm using thermal imaging. In Proceedings of the 2014 IEEE Symposium on Computer Applications and Industrial Electronics (ISCAIE), Penang, Malaysia, 7–8 April 2014; pp. 208–213. [Google Scholar] [CrossRef]
- Kopaczka, M.; Nestler, J.; Merhof, D. Face Detection in Thermal Infrared Images: A Comparison of Algorithm- and Machine-Learning-Based Approaches. In Proceedings of the Advanced Concepts for Intelligent Vision Systems, Antwerp, Belgium, 18–21 September 2017; Blanc-Talon, J., Penne, R., Philips, W., Popescu, D., Scheunders, P., Eds.; Springer: Cham, Switzerland, 2017; pp. 518–529. [Google Scholar]
- Silva, G.; Monteiro, R.; Ferreira, A.; Carvalho, P.; Corte-Real, L. Face Detection in Thermal Images with YOLOv3. In Proceedings of the Advances in Visual Computing, Lake Tahoe, NV, USA, 7–9 October 2019; Bebis, G., Boyle, R., Parvin, B., Koracin, D., Ushizima, D., Chai, S., Sueda, S., Lin, X., Lu, A., Thalmann, D., et al., Eds.; Springer: Cham, Switzerland, 2019; pp. 89–99. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Vuković, T.; Petrović, R.; Pavlović, M.; Stanković, S. Thermal Image Degradation Influence on R-CNN Face Detection Performance. In Proceedings of the 2019 27th Telecommunications Forum (TELFOR), Belgrade, Serbia, 26–27 November 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Mucha, W.; Kampel, M. Depth and thermal images in face detection—A detailed comparison between image modalities. In Proceedings of the 2022 the 5th International Conference on Machine Vision and Applications (ICMVA), New York, NY, USA, 18–20 February 2022. [Google Scholar]
- Jia, G.; Jiankang, D.; Alexandros, L.; Stefanos, Z. Sample and Computation Redistribution for Efficient Face Detection. arXiv 2021, arXiv:2105.04714. [Google Scholar]
- Chaichulee, S.; Villarroel, M.; Jorge, J.; Arteta, C.; Green, G.; McCormick, K.; Zisserman, A.; Tarassenko, L. Multi-Task Convolutional Neural Network for Patient Detection and Skin Segmentation in Continuous Non-Contact Vital Sign Monitoring. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017; pp. 266–272. [Google Scholar] [CrossRef]
- Green, G.; Chaichulee, S.; Villarroel, M.; Jorge, J.; Arteta, C.; Zisserman, A.; Tarassenko, L.; McCormick, K. Localised photoplethysmography imaging for heart rate estimation of pre-term infants in the clinic. In Proceedings of the Optical Diagnostics and Sensing XVIII: Toward Point-of-Care Diagnostics, San Francisco, CA, USA, 30 January–2 February 2018; Coté, G.L., Ed.; SPIE: Bellingham, WA USA, 2018; p. 26. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. arXiv 2017, arXiv:1708.02002. [Google Scholar]
- Kyrollos, D.G.; Tanner, J.B.; Greenwood, K.; Harrold, J.; Green, J.R. Noncontact Neonatal Respiration Rate Estimation Using Machine Vision. In Proceedings of the 2021 IEEE Sensors Applications Symposium (SAS), Sundsvall, Sweden, 23–25 August 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. arXiv 2014, arXiv:1409.0575. [Google Scholar] [CrossRef]
- Lu, G.; Wang, S.; Kong, K.; Yan, J.; Li, H.; Li, X. Learning Pyramidal Hierarchical Features for Neonatal Face Detection. In Proceedings of the 2018 14th International Conference on Natural Computation, Fuzzy Systems and Knowledge Discovery (ICNC-FSKD), Huangshan, China, 28–30 July 2018; pp. 8–13. [Google Scholar] [CrossRef]
- Jocher, G.; Stoken, A.; Borovec, J.; NanoCode012; ChristopherSTAN; Changyu, L.; Laughing; tkianai; Hogan, A.; lorenzomammana; et al. ultralytics/yolov5: V3.1—Bug Fixes and Performance Improvements; Zenodo: Genève, Switzerland, 2020. [Google Scholar] [CrossRef]
- Nagy, Á.; Földesy, P.; Jánoki, I.; Terbe, D.; Siket, M.; Szabó, M.; Varga, J.; Zarándy, Á. Continuous camera-based premature-infant monitoring algorithms for NICU. Appl. Sci. 2021, 11, 7215. [Google Scholar] [CrossRef]
- Khanam, F.T.Z.; Perera, A.G.; Al-Naji, A.; Gibson, K.; Chahl, J. Non-contact automatic vital signs monitoring of infants in a Neonatal Intensive Care Unit based on neural networks. J. Imaging 2021, 7, 122. [Google Scholar] [CrossRef]
- Salekin, M.S.; Zamzmi, G.; Hausmann, J.; Goldgof, D.; Kasturi, R.; Kneusel, M.; Ashmeade, T.; Ho, T.; Sun, Y. Multimodal neonatal procedural and postoperative pain assessment dataset. Data Brief 2021, 35, 106796. [Google Scholar] [CrossRef]
- Dosso, Y.S.; Kyrollos, D.; Greenwood, K.J.; Harrold, J.; Green, J.R. NICUface: Robust neonatal face detection in complex NICU scenes. IEEE Access 2022, 10, 62893–62909. [Google Scholar] [CrossRef]
- Antink, C.H.; Ferreira, J.C.M.; Paul, M.; Lyra, S.; Heimann, K.; Karthik, S.; Joseph, J.; Jayaraman, K.; Orlikowsky, T.; Sivaprakasam, M.; et al. Fast body part segmentation and tracking of neonatal video data using deep learning. Med. Biol. Eng. Comput. 2020, 58, 3049–3061. [Google Scholar] [CrossRef]
- Voss, F.; Brechmann, N.; Lyra, S.; Rixen, J.; Leonhardt, S.; Hoog Antink, C. Multi-modal body part segmentation of infants using deep learning. Biomed. Eng. Online 2023, 22, 28. [Google Scholar] [CrossRef]
- Beppu, F.; Yoshikawa, H.; Uchiyama, A.; Higashino, T.; Hamada, K.; Hirakawa, E. Body part detection from neonatal thermal images using deep learning. In Lecture Notes of the Institute for Computer Sciences, Social Informatics and Telecommunications Engineering; Springer International Publishing: Cham, Switzerland, 2022; pp. 438–450. [Google Scholar]
- Awais, M.; Chen, C.; Long, X.; Yin, B.; Nawaz, A.; Abbasi Saadullah, F.; Akbarzadeh, S.; Tao, L.; Lu, C.; Wang, L.; et al. Novel Framework: Face Feature Selection Algorithm for Neonatal Facial and Related Attributes Recognition. IEEE Access 2020, 8, 59100–59113. [Google Scholar] [CrossRef]
- Neophytou, N.; Mueller, K. Color-Space CAD: Direct Gamut Editing in 3D. IEEE Comput. Graph. Appl. 2008, 28, 88–98. [Google Scholar] [CrossRef]
- Fairchild, M.D. Color Appearance Models, 3rd ed.; The Wiley-IS&T Series in Imaging Science and Technology; John Wiley & Sons: Nashville, TN, USA, 2013. [Google Scholar]
- Bebis, G.; Gyaourova, A.; Singh, S.; Pavlidis, I. Face recognition by fusing thermal infrared and visible imagery. Image Vis. Comput. 2006, 24, 727–742. [Google Scholar] [CrossRef]
- Selinger, A.; Socolinsky, D.A. Appearance-Based Facial Recognition Using Visible and Thermal Imagery: A Comparative Study; EQUINOX Corp.: New York, NY, USA, 2006. [Google Scholar]
- Chen, X.; Wang, H.; Liang, Y.; Meng, Y.; Wang, S. A novel infrared and visible image fusion approach based on adversarial neural network. Sensors 2022, 22, 304. [Google Scholar] [CrossRef] [PubMed]
- Vadidar, M.; Kariminezhad, A.; Mayr, C.; Kloeker, L.; Eckstein, L. Robust Environment Perception for Automated Driving: A Unified Learning Pipeline for Visual-Infrared Object Detection. In Proceedings of the 2022 IEEE Intelligent Vehicles Symposium, Aachen, Germany, 4–9 June 2022; pp. 367–374. [Google Scholar] [CrossRef]
- Shopovska, I.; Jovanov, L.; Philips, W. Deep visible and thermal image fusion for enhanced pedestrian visibility. Sensors 2019, 19, 3727. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Zhang, L.; Zhuo, L.; Zhang, J. Object tracking in RGB-T videos using modal-aware attention network and competitive learning. Sensors 2020, 20, 393. [Google Scholar] [CrossRef]
- Zhang, X.; Ye, P.; Peng, S.; Liu, J.; Gong, K.; Xiao, G. SiamFT: An RGB-Infrared Fusion Tracking Method via Fully Convolutional Siamese Networks. IEEE Access 2019, 7, 122122–122133. [Google Scholar] [CrossRef]
- What Is a Visible Imaging Sensor (RGB Color Camera)? Available online: https://www.infinitioptics.com/glossary/visible-imaging-sensor-400700nm-colour-cameras (accessed on 24 January 2023).
- pmd FAQ. Available online: https://pmdtec.com/picofamily/faq/ (accessed on 19 November 2020).
- Gleichauf, J.; Herrmann, S.; Hennemann, L.; Krauss, H.; Nitschke, J.; Renner, P.; Niebler, C.; Koelpin, A. Automated Non-Contact Respiratory Rate Monitoring of Neonates Based on Synchronous Evaluation of a 3D Time-of-Flight Camera and a Microwave Interferometric Radar Sensor. Sensors 2021, 21, 2959. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. arXiv 2016, arXiv:1612.03144. [Google Scholar]
- Girshick, R. Fast R-CNN. arXiv 2015, arXiv:1504.08083. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. arXiv 2016, arXiv:1612.08242. [Google Scholar]
- Kathuria, A. Available online: https://towardsdatascience.com/yolo-v3-object-detection-53fb7d3bfe6b (accessed on 2 March 2023).
- Mikołajczyk, A.; Grochowski, M. Data augmentation for improving deep learning in image classification problem. In Proceedings of the 2018 International Interdisciplinary PhD Workshop (IIPhDW), Swinoujscie, Poland, 9–12 May 2018; pp. 117–122. [Google Scholar] [CrossRef]
- Hennemann, L. Realisierung und Optimierung der Detektion von Körperregionen Neugeborener zur Kontaktlosen und Robusten Überwachung der Vitalparameter mittels eines Neuronalen Netzes. Master’s Thesis, Nuremberg Institute of Technology, Nuremberg, Germany, 2023. [Google Scholar]
- May, S. optris_drivers. Available online: https://wiki.ros.org/optris_drivers (accessed on 24 January 2023).
- Hartmann, C.; Gleichauf, J. ros_cvb_camera_driver. Available online: http://wiki.ros.org/ros_cvb_camera_driver (accessed on 7 June 2019).
- For Artificial Intelligence University of Bremen, I. pico_flexx_driver. Available online: https://github.com/code-iai/pico_flexx_driver (accessed on 29 April 2020).
- camera_calibration. Available online: https://wiki.ros.org/camera_calibration (accessed on 14 January 2019).
- Ocana, D.T. image_pipeline. Available online: https://github.com/DavidTorresOcana/image_pipeline (accessed on 7 June 2019).
- openCV. How to Detect Ellipse and Get Centers of Ellipse. Available online: https://answers.opencv.org/question/38885/how-to-detect-ellipse-and-get-centers-of-ellipse/ (accessed on 12 May 2022).
- opencv 3, Blobdetection, The Function/Feature Is Not Implemented () in detectAndCompute. Available online: https://stackoverflow.com/questions/30622304/opencv-3-blobdetection-the-function-feature-is-not-implemented-in-detectand (accessed on 12 May 2022).
- openCV. solvePnP. Available online: https://docs.opencv.org/3.4/d9/d0c/group__calib3d.htmlga549c2075fac14829ff4a58bc931c033d (accessed on 12 May 2022).
- openCV. Rodrigues. Available online: https://docs.opencv.org/3.4/d9/d0c/group__calib3d.htmlga61585db663d9da06b68e70cfbf6a1eac (accessed on 12 May 2022).
- openCV. projectPoints. Available online: https://docs.opencv.org/3.4/d9/d0c/group__calib3d.htmlga1019495a2c8d1743ed5cc23fa0daff8c (accessed on 12 May 2022).
- Fizyr. Keras-Retinanet. Available online: https://github.com/fizyr/keras-retinanet (accessed on 10 May 2023).
- AlexeyAB. Darknet. Available online: https://github.com/AlexeyAB/darknet (accessed on 10 May 2023).























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Subject | Gestational Age | Age during Study | Sex | Weight |
|---|---|---|---|---|
| 01 | 34 + 0 | 2 days | male | 1745 g |
| 02 | term | 5 days | female | 3650 g |
| 03 | term | 4 days | female | 2330 g |
| 04 | term | 13 days | male | 3300 g |
| 05 | term | 2 days | female | 2750 g |
| Modality | Head | Nose | Torso | Intervention |
|---|---|---|---|---|
| RGB | 1193 | 575 | 1129 | 160 |
| Thermal | 1199 | 305 | 1183 | 123 |
| Fusion | 1190 | 8 | 1055 | 80 |
| Modality | Epoch | Average Precision | ||||
|---|---|---|---|---|---|---|
| Head | Nose | Torso | Intervention | |||
| RetinaNet | RGB | 25 | 1.0 | 0.9937 | 0.99 | 0.94 |
| Thermal | 28 | 0.9969 | 0.9864 | 0.9862 | 0.8695 | |
| Fusion | 38 | 0.9949 | 0.0 * | 0.9934 | 0.7683 | |
| YOLOv3 | RGB | 64 | 1.0 | 0.9885 | 0.9991 | 0.9821 |
| Thermal | 61 | 0.9983 | 0.9993 | 0.9963 | 0.9225 | |
| Fusion | 56 | 0.9949 | 0.3274 * | 0.9948 | 0.8390 | |
| Modality | Epoch | Average Precision | ||||
|---|---|---|---|---|---|---|
| Head | Nose | Torso | Intervention | |||
| RetinaNet | Fusion—RGB | 13 | −0.0051 | −0.9937 * | 0.0034 | −0.1717 |
| Fusion—Thermal | 10 | −0.002 | −0.9864 * | 0.0072 | −0.1012 | |
| Modality | Epoch | Average Precision | ||||
|---|---|---|---|---|---|---|
| Head | Nose | Torso | Intervention | |||
| YOLOv3 | Fusion—RGB | −8 | −0.0051 | −0.6611 * | −0.0043 | −0.1431 |
| Fusion—Thermal | −5 | −0.0034 | −0.6719 * | −0.0015 | −0.0835 | |
| Modality | Epoch | Average Precision | ||||
|---|---|---|---|---|---|---|
| Head | Nose | Torso | Intervention | |||
| RetinaNet—YOLOv3 | RGB | −39 | 0.0 | 0.0052 | −0.0091 | −0.0421 |
| Thermal | −33 | −0.0014 | −0.0066 | −0.0101 | −0.053 | |
| Fusion | −18 | 0.0 | −0.3274 * | −0.0014 | −0.0707 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gleichauf, J.; Hennemann, L.; Fahlbusch, F.B.; Hofmann, O.; Niebler, C.; Koelpin, A. Sensor Fusion for the Robust Detection of Facial Regions of Neonates Using Neural Networks. Sensors 2023, 23, 4910. https://doi.org/10.3390/s23104910
Gleichauf J, Hennemann L, Fahlbusch FB, Hofmann O, Niebler C, Koelpin A. Sensor Fusion for the Robust Detection of Facial Regions of Neonates Using Neural Networks. Sensors. 2023; 23(10):4910. https://doi.org/10.3390/s23104910
Chicago/Turabian StyleGleichauf, Johanna, Lukas Hennemann, Fabian B. Fahlbusch, Oliver Hofmann, Christine Niebler, and Alexander Koelpin. 2023. "Sensor Fusion for the Robust Detection of Facial Regions of Neonates Using Neural Networks" Sensors 23, no. 10: 4910. https://doi.org/10.3390/s23104910
APA StyleGleichauf, J., Hennemann, L., Fahlbusch, F. B., Hofmann, O., Niebler, C., & Koelpin, A. (2023). Sensor Fusion for the Robust Detection of Facial Regions of Neonates Using Neural Networks. Sensors, 23(10), 4910. https://doi.org/10.3390/s23104910