
Multiresolution Aggregation Transformer UNet Based on Multiscale Input and Coordinate Attention for Medical Image Segmentation


Abstract
:1. Introduction
- A novel multiresolution aggregation transformer UNet (MRA-TUNet) based on multiscale input and coordinate attention for medical image segmentation is proposed. To the best of our knowledge, MRA-TUNet is the first transformer-based UNet method to study information aggregation of multiresolution input images.
- MRA-TUNet is the first method to introduce coordinate attention structure in medical image segmentation.
- MRA-TUNet outperforms the existing eight excellent medical image segmentation methods in dice score, precision, and recall, on the ACDC and the 2018 ASC.
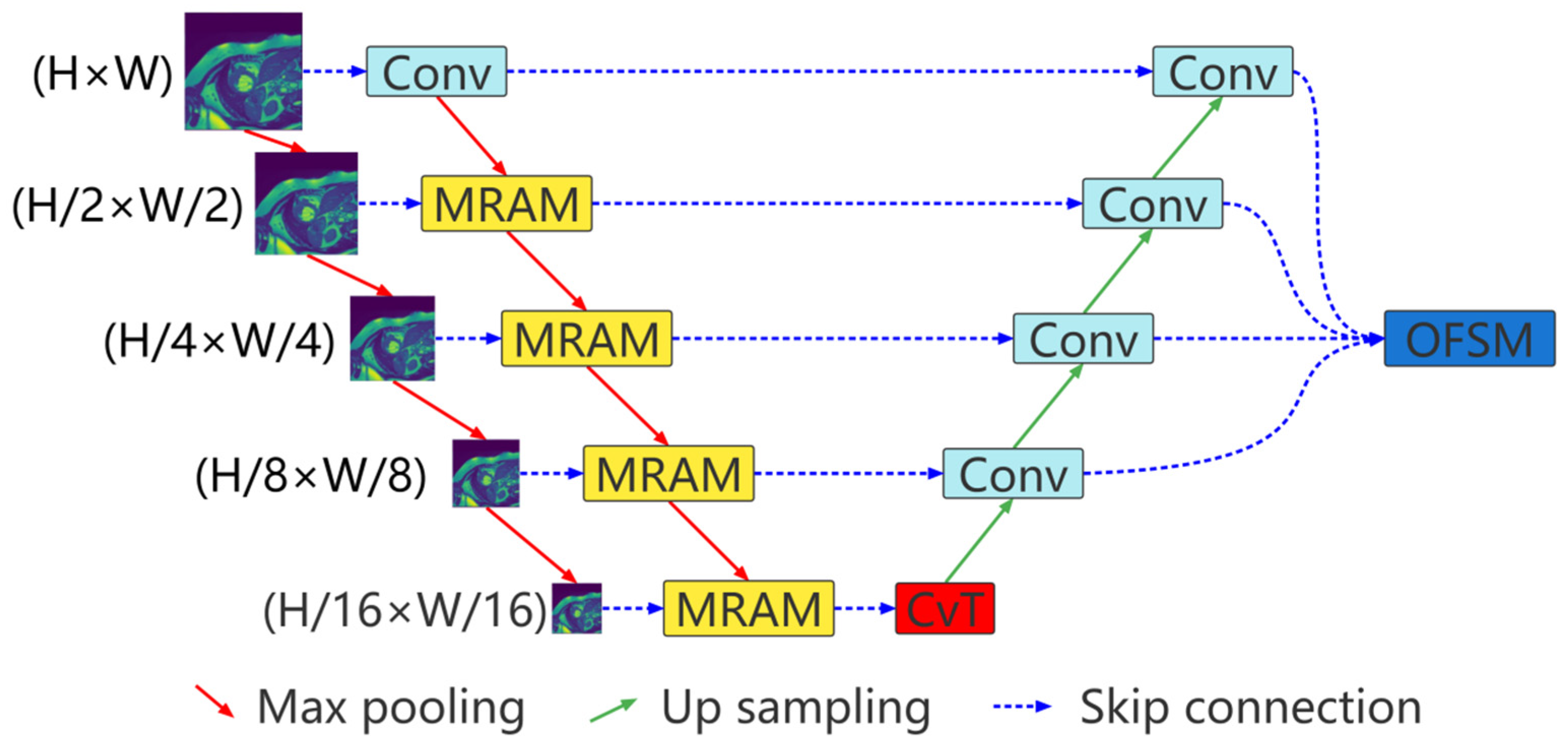
2. Approach
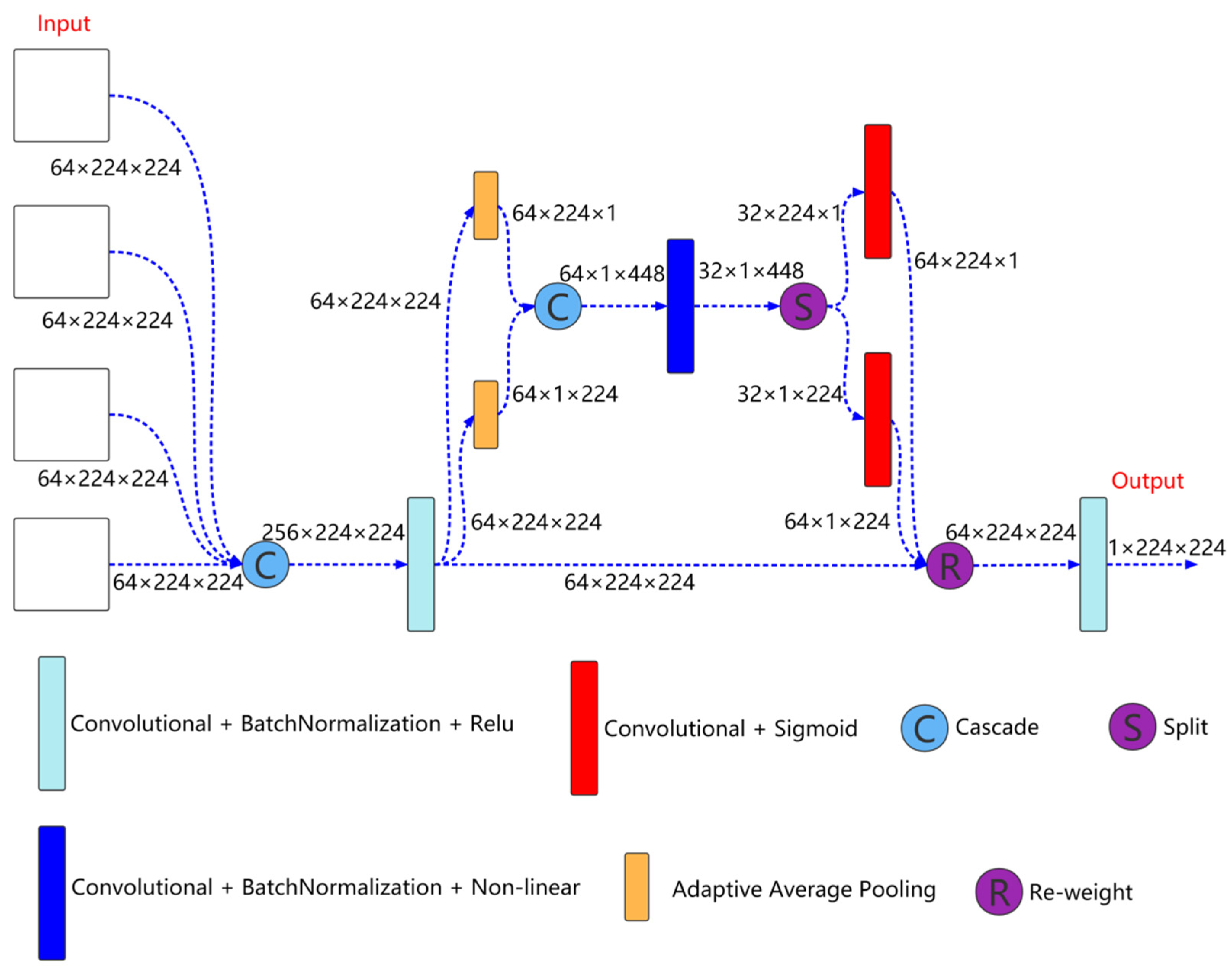
2.1. Multiresolution Aggregation Module
2.2. CvT as Encoder
2.3. Output Feature Selection Module
3. Experiments
3.1. Datasets, Implementation Details, and Evaluation Metrics
3.1.1. Datasets
3.1.2. Implementation Details
3.1.3. Evaluation Metrics
3.2. Ablation Experiments and Analyses
- (a)
- UNet + ViT as encoder (TransUNet),
- (b)
- UNet + CvT as encoder (U + CvT),
- (c)
- UNet + CvT as encoder + multiresolution aggregation module (U + CvT + MRAM),
- (d)
- UNet + CvT as encoder + multiresolution aggregation module + output feature selection module (U + CvT + MRAM + OFSM).
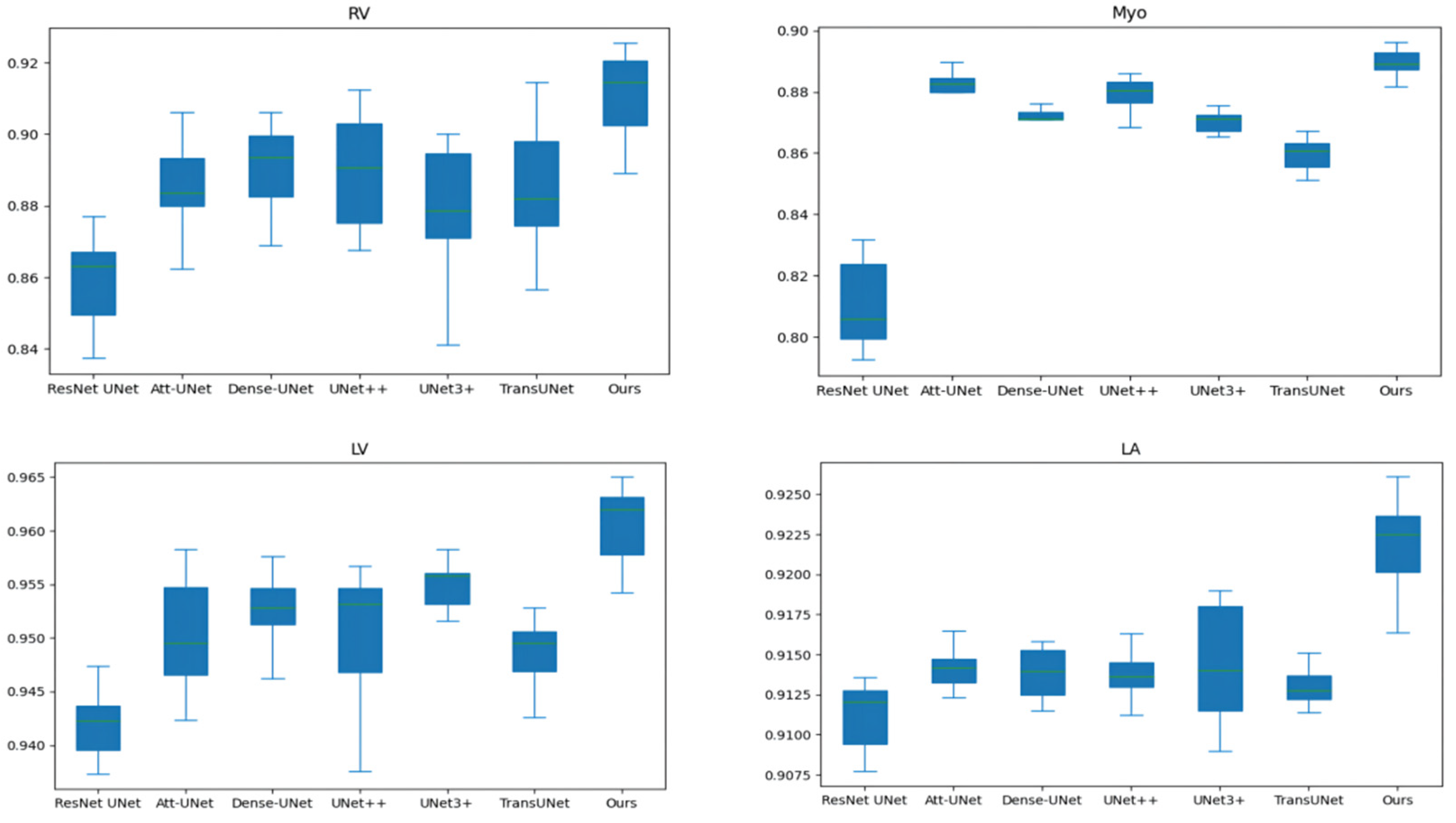
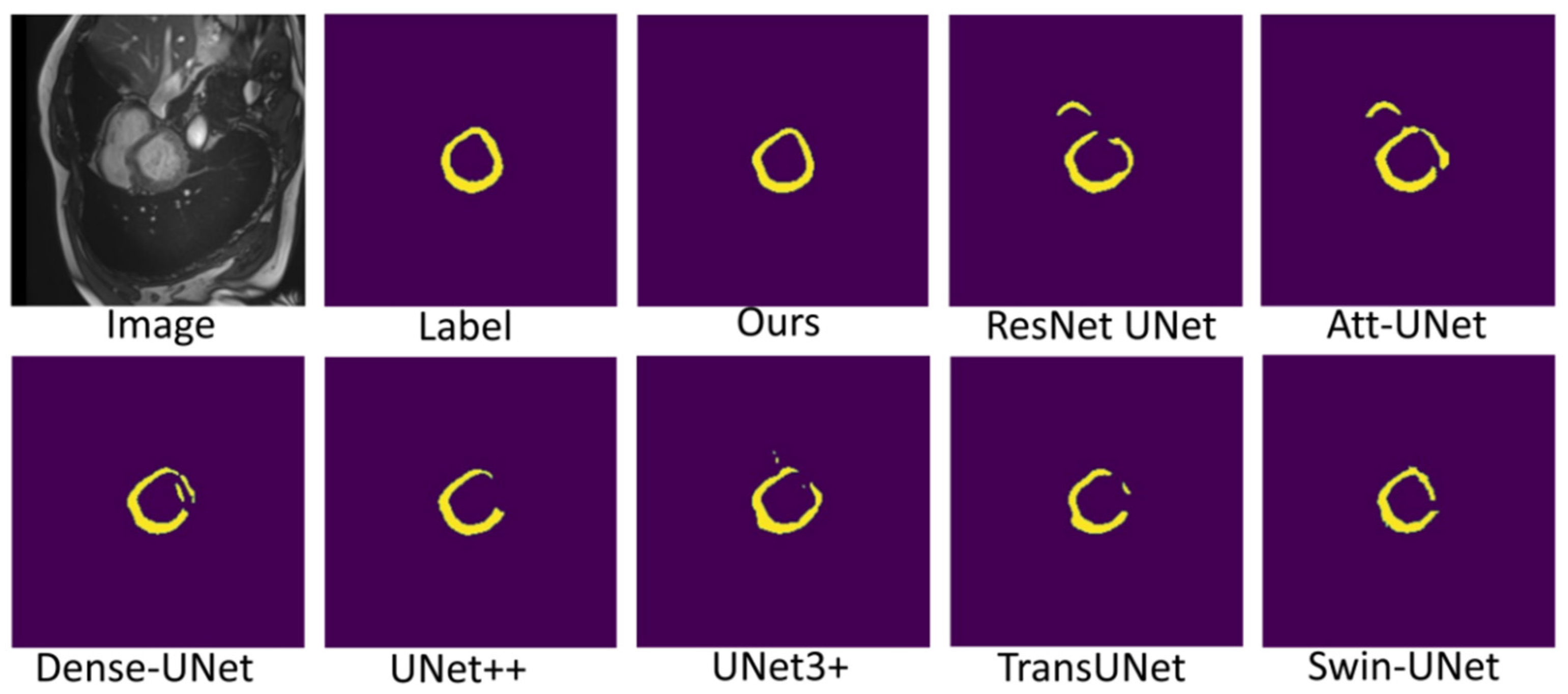
3.3. Comparison with State-Of-The-Art Works and Discussion
3.3.1. Comparison with State-Of-The-Art Works
3.3.2. Discussion
- (1)
- The multiresolution input image of our method shares the encoder, and the encoder may be difficult to balance the extraction of global and local features. Whether the multibranch encoding network is beneficial to improve feature extraction remains to be seen.
- (2)
- Our method only fuses the features extracted from input images of different resolutions at the encoder side without considering the fusion at the decoder side.
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Eckstein, F.; Wirth, W.; Culvenor, A.G. Osteoarthritis year in review 2020: Imaging. Osteoarthr. Cartil. 2021, 29, 170–179. [Google Scholar] [CrossRef] [PubMed]
- Lories, R.J.; Luyten, F.P. The bone-cartilage unit in osteoarthritis. Nat. Rev. Rheumatol. 2010, 7, 43–49. [Google Scholar] [CrossRef] [PubMed]
- Chalian, M.; Li, X.J.; Guermazi, A.; Obuchowski, N.A.; Carrino, J.A.; Oei, E.H.; Link, T.M. The QIBA profile for MRI-based compositional imaging of knee cartilage. Radiology 2021, 301, 423–432. [Google Scholar] [CrossRef]
- Xue, Y.P.; Jang, H.; Byra, M.; Cai, Z.Y.; Wu, M.; Chang, E.Y.; Ma, Y.J.; Du, J. Automated cartilage segmentation and quantification using 3D ultrashort echo time (UTE) cones MR imaging with deep convolutional neural networks. Eur. Radiol. 2021, 31, 7653–7663. [Google Scholar] [CrossRef]
- Li, X.J.; Ma, B.C.; Bolbos, R.I.; Stahl, R.; Lozano, J.; Zuo, J.; Lin, K.; Link, T.M.; Safran, M.; Majumdar, S. Quantitative assessment of bone marrow edema-like lesion and overlying cartilage in knees with osteoarthritis and anterior cruciate ligament tear using MR imaging and spectroscopic imaging at 3 tesla. J. Magn. Reson. Imaging 2008, 28, 453–461. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Heimann, T.; Meinzer, H.P. Statistical shape models for 3d medical image segmentation: A review. Med. Image Anal. 2009, 13, 543–563. [Google Scholar] [CrossRef]
- Engstrom, C.M.; Fripp, J.; Jurcak, V.; Walker, D.G.; Salvado, O.; Crozier, S. Segmentation of the quadratus lumborum muscle using statistical shape modeling. J. Magn. Reson. Imaging 2011, 33, 1422–1429. [Google Scholar] [CrossRef]
- Castro-Mateos, I.; Pozo, J.M.; Pereanez, M.; Lekadir, K.; Lazary, A.; Frangi, A.F. Statistical interspace models (SIMs): Application to robust 3D spine segmentation. IEEE Trans. Med. Imaging 2015, 34, 1663–1675. [Google Scholar] [CrossRef]
- Candemir, S.; Jaeger, S.; Palaniappan, K.; Musco, J.P.; Singh, R.K.; Xue, Z.Y.; Karargyris, A.; Antani, S.; Thoma, G.; McDonald, C.J. Lung segmentation in chest radiographs using anatomical atlases with nonrigid registration. IEEE Trans. Med. Imaging 2014, 33, 577–590. [Google Scholar] [CrossRef]
- Dodin, P.; Martel-Pelletier, J.; Pelletier, J.P.; Abram, F. A fully automated human knee 3D MRI bone segmentation using the ray casting technique. Med. Biol. Eng. Comput. 2011, 49, 1413–1424. [Google Scholar] [CrossRef]
- Hwang, J.; Hwang, S. Exploiting global structure information to improve medical image segmentation. Sensors 2021, 21, 3249. [Google Scholar] [CrossRef]
- Li, Q.Y.; Yu, Z.B.; Wang, Y.B.; Zheng, H.Y. TumorGAN: A multi-modal data augmentation framework for brain tumor segmentation. Sensors 2020, 20, 4203. [Google Scholar] [CrossRef]
- Ullah, F.; Ansari, S.U.; Hanif, M.; Ayari, M.A.; Chowdhury, M.E.H.; Khandakar, A.A.; Khan, M.S. Brain MR image enhancement for tumor segmentation using 3D U-Net. Sensors 2021, 21, 7528. [Google Scholar] [CrossRef] [PubMed]
- Awan, M.J.; Rahim, M.S.M.; Salim, N.; Rehman, A.; Garcia-Zapirain, B. Automated knee MR images segmentation of anterior cruciate ligament tears. Sensors 2022, 22, 1552. [Google Scholar] [CrossRef] [PubMed]
- Jalali, Y.; Fateh, M.; Rezvani, M.; Abolghasemi, V.; Anisi, M.H. ResBCDU-Net: A deep learning framework for lung CT image segmentation. Sensors 2021, 21, 268. [Google Scholar] [CrossRef]
- Yin, P.S.; Wu, Q.Y.; Xu, Y.W.; Min, H.Q.; Yang, M.; Zhang, Y.B.; Tan, M.K. PM-Net: Pyramid multi-label network for joint optic disc and cup segmentation. Int. Conf. Med. Image Comput. Comput. Assist. Interv. 2019, 11764, 129–137. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. Int. Conf. Med. Image Comput. Comput. Assist. Interv. 2015, 9351, 234–241. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention U-Net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. Available online: https://arxiv.org/abs/1804.03999 (accessed on 2 May 2022).
- Li, X.M.; Chen, H.; Qi, X.J.; Dou, Q.; Fu, C.W.; Heng, P.A. H-DenseUNet: Hybrid densely connected UNet for liver and tumor segmentation from CT volumes. IEEE Trans. Med. Imaging 2018, 37, 2663–2674. [Google Scholar] [CrossRef] [Green Version]
- Alom, M.Z.; Yakopcic, C.; Taha, T.M.; Asari, V.K. Nuclei segmentation with recurrent residual convolutional neural networks based U-Net (R2U-Net). In Proceedings of the IEEE National Aerospace and Electronics Conference (NAECON), Dayton, OH, USA, 23–26 July 2018; pp. 228–233. [Google Scholar]
- Zhou, Z.W.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J.M. UNet plus plus: Redesigning skip connections to exploit multiscale features in image segmentation. IEEE Trans. Med. Imaging 2020, 39, 1856–1867. [Google Scholar] [CrossRef] [Green Version]
- Zhang, S.H.; Fu, H.Z.; Yan, Y.G.; Zhang, Y.B.; Wu, Q.Y.; Yang, M.; Tan, M.K.; Xu, Y.W. Attention guided network for retinal image segmentation. Int. Conf. Med. Image Comput. Comput. Assist. Interv. 2019, 11764, 797–805. [Google Scholar]
- Huang, H.M.; Lin, L.F.; Tong, R.F.; Hu, H.J.; Zhang, Q.W.; Iwamoto, Y.; Han, X.H.; Chen, Y.W.; Wu, J. UNet 3+: A full-scale connected UNet for medical image segmentation. In Proceedings of the International Conference on Acoustics Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 1055–1059. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Processing Syst. 2017, 30, 5998–6008. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.H.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. Available online: https://arxiv.org/abs/2010.11929 (accessed on 2 May 2022).
- Zhou, D.Q.; Kang, B.Y.; Jin, X.J.; Yang, L.J.; Lian, X.C.; Jiang, Z.H.; Hou, Q.B.; Feng, J.S. DeepViT: Towards deeper vision transformer. arXiv 2021, arXiv:2103.11886. Available online: https://arxiv.org/abs/2103.11886 (accessed on 2 May 2022).
- Touvron, H.; Cord, M.; Sablayrolles, A.; Synnaeve, G.; Jégou, H. Going deeper with image transformers. arXiv 2021, arXiv:2103.17239. Available online: https://arxiv.org/abs/2103.17239 (accessed on 2 May 2022).
- Chen, C.F.; Fan, Q.F.; Panda, R. CrossViT: Cross-attention multi-scale vision transformer for image classification. arXiv 2021, arXiv:2103.14899. Available online: https://arxiv.org/abs/2103.14899 (accessed on 2 May 2022).
- Wu, H.P.; Xiao, B.; Codella, N.; Liu, M.C.; Dai, X.Y.; Yuan, L.; Zhang, L. CvT: Introducing convolutions to vision transformers. arXiv 2021, arXiv:2111.03940. Available online: https://arxiv.org/abs/2111.03940 (accessed on 2 May 2022).
- Chen, J.N.; Lu, Y.Y.; Yu, Q.H.; Luo, X.D.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y.Y. TransUNet: Transformers make strong encoders for medical image segmentation. arXiv 2021, arXiv:2102.04306. Available online: https://arxiv.org/abs/2102.04306 (accessed on 2 May 2022).
- Cao, H.; Wang, Y.Y.; Chen, J.; Jiang, D.S.; Zhang, X.P.; Tian, Q.; Wang, M.N. Swin-Unet: Unet-like pure transformer for medical image segmentation. arXiv 2021, arXiv:2105.05537. Available online: https://arxiv.org/abs/2105.05537 (accessed on 2 May 2022).
- Hatamizadeh, A.; Tang, Y.C.; Nath, V.; Yang, D.; Myronenko, A.; Landman, B.; Roth, H.; Xu, D.G. UNETR: Transformers for 3D medical image segmentation. arXiv 2021, arXiv:2201.01266. Available online: https://doi.org/10.48550/arXiv.2201.01266 (accessed on 2 May 2022).
- Wang, H.N.; Cao, P.; Wang, J.Q.; Zaiane, O.R. UCTransNet: Rethinking the skip connections in U-Net from a channel-wise perspective with transformer. arXiv 2021, arXiv:2109.04335. Available online: https://arxiv.org/abs/2109.04335 (accessed on 2 May 2022).
- Zhou, H.Y.; Guo, J.S.; Zhang, Y.H.; Yu, L.Q.; Wang, L.S.; Yu, Y.Z. nnFormer: Interleaved transformer for volumetric segmentation. arXiv 2021, arXiv:2109.03201. Available online: https://arxiv.org/abs/2109.03201 (accessed on 2 May 2022).
- Hou, Q.B.; Zhou, D.Q.; Feng, J.S. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13708–13717. [Google Scholar]
- Bernard, O.; Lalande, A.; Zotti, C.; Cervenansky, F.; Yang, X.; Heng, P.A.; Cetin, I.; Lekadir, K.; Camara, O.; Ballester, M.A.G.; et al. Deep learning techniques for automatic MRI cardiac multi-structures segmentation and diagnosis: Is the problem solved? IEEE Trans. Med. Imaging 2018, 37, 2514–2525. [Google Scholar] [CrossRef] [PubMed]
- Xiong, Z.H.; Xia, Q.; Hu, Z.Q.; Huang, N.; Bian, C.; Zheng, Y.F.; Vesal, S.; Ravikumar, N.; Maier, A.; Yang, X.; et al. A global benchmark of algorithms for segmenting the left atrium from late gadolinium-enhanced cardiac magnetic resonance imaging. Med. Image Anal. 2021, 67, 101832. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dice Average | Precision Average | Recall Average | |
|---|---|---|---|
| TransUNet | 0.898 | 0.885 | 0.923 |
| U + CvT | 0.909 | 0.901 | 0.926 |
| U + CvT + MRAM | 0.915 | 0.910 | 0.926 |
| U + CvT + MRAM + OFSM | 0.921 | 0.910 | 0.933 |
| Methods | Dice | Precision | Recall | ||||||
|---|---|---|---|---|---|---|---|---|---|
| RV | Myo | LV | RV | Myo | LV | RV | Myo | LV | |
| ResNet UNet [17] | 0.859 ± 0.012 | 0.810 ± 0.013 | 0.942 ± 0.003 | 0.843 ± 0.033 | 0.848 ± 0.016 | 0.940 ± 0.009 | 0.913 ± 0.019 | 0.812 ± 0.037 | 0.957 ± 0.009 |
| Att-UNet [18] | 0.885 ± 0.012 | 0.881 ± 0.007 | 0.949 ± 0.008 | 0.861 ± 0.019 | 0.876 ± 0.012 | 0.950 ± 0.012 | 0.929 ± 0.014 | 0.895 ± 0.010 | 0.957 ± 0.017 |
| Dense-UNet [19] | 0.891 ± 0.012 | 0.869 ± 0.007 | 0.953 ± 0.003 | 0.858 ± 0.014 | 0.869 ± 0.016 | 0.943 ± 0.009 | 0.939 ± 0.009 | 0.879 ± 0.015 | 0.969 ± 0.004 |
| UNet++ [21] | 0.885 ± 0.022 | 0.880 ± 0.005 | 0.951 ± 0.006 | 0.873 ± 0.038 | 0.870 ± 0.010 | 0.949 ± 0.011 | 0.914 ± 0.026 | 0.898 ± 0.013 | 0.964 ± 0.005 |
| UNet3+ [23] | 0.878 ± 0.019 | 0.870 ± 0.003 | 0.955 ± 0.003 | 0.847 ± 0.021 | 0.881 ± 0.008 | 0.951 ± 0.009 | 0.920 ± 0.024 | 0.867 ± 0.011 | 0.962 ± 0.008 |
| TransUNet [30] | 0.885 ± 0.016 | 0.860 ± 0.005 | 0.949 ± 0.003 | 0.849 ± 0.031 | 0.861 ± 0.016 | 0.946 ± 0.007 | 0.939 ± 0.008 | 0.870 ± 0.017 | 0.958 ± 0.006 |
| Swin-UNet [31] | 0.886 | 0.857 | 0.958 | - | - | - | - | - | - |
| nnFormer [34] | 0.902 | 0.895 | 0.956 | - | - | - | - | - | - |
| Ours | 0.911 ± 0.012 | 0.890 ± 0.004 | 0.961 ± 0.004 | 0.882 ± 0.026 | 0.889 ± 0.016 | 0.959 ± 0.008 | 0.944 ± 0.019 | 0.890 ± 0.019 | 0.964 ± 0.014 |
| Methods | Dice | Precision | Recall |
|---|---|---|---|
| LA | LA | LA | |
| ResNet UNet [17] | 0.911 ± 0.002 | 0.910 ± 0.010 | 0.921 ± 0.009 |
| Att-UNet [18] | 0.914 ± 0.002 | 0.911 ± 0.008 | 0.924 ± 0.008 |
| Dense-UNet [19] | 0.914 ± 0.002 | 0.909 ± 0.004 | 0.925 ± 0.004 |
| UNet++ [21] | 0.914 ± 0.002 | 0.914 ± 0.007 | 0.921 ± 0.007 |
| UNet3+ [23] | 0.915 ± 0.004 | 0.921 ± 0.007 | 0.916 ± 0.009 |
| TransUNet [30] | 0.913 ± 0.002 | 0.904 ± 0.008 | 0.928 ± 0.006 |
| Swin-UNet [31] | 0.909 | 0.901 | 0.924 |
| Ours | 0.923 ± 0.003 | 0.919 ± 0.007 | 0.927 ± 0.008 |
| Methods | Average Training Time (s) | Parameters (Million) | |
|---|---|---|---|
| ACDC | 2018 ASC | ||
| ResNet UNet [17] | 554 | 5308 | 82 |
| Att-UNet [18] | 609 | 6268 | 35 |
| Dense-UNet [19] | 544 | 4359 | 2 |
| UNet++ [21] | 1225 | 13,562 | 36 |
| UNet3+ [23] | 977 | 10,857 | 26 |
| TransUNet [30] | 448 | 5762 | 105 |
| Ours | 1175 | 12,891 | 56 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, S.; Qiu, C.; Yang, W.; Zhang, Z. Multiresolution Aggregation Transformer UNet Based on Multiscale Input and Coordinate Attention for Medical Image Segmentation. Sensors 2022, 22, 3820. https://doi.org/10.3390/s22103820
Chen S, Qiu C, Yang W, Zhang Z. Multiresolution Aggregation Transformer UNet Based on Multiscale Input and Coordinate Attention for Medical Image Segmentation. Sensors. 2022; 22(10):3820. https://doi.org/10.3390/s22103820
Chicago/Turabian StyleChen, Shaolong, Changzhen Qiu, Weiping Yang, and Zhiyong Zhang. 2022. "Multiresolution Aggregation Transformer UNet Based on Multiscale Input and Coordinate Attention for Medical Image Segmentation" Sensors 22, no. 10: 3820. https://doi.org/10.3390/s22103820
APA StyleChen, S., Qiu, C., Yang, W., & Zhang, Z. (2022). Multiresolution Aggregation Transformer UNet Based on Multiscale Input and Coordinate Attention for Medical Image Segmentation. Sensors, 22(10), 3820. https://doi.org/10.3390/s22103820