3.1. The Overall Framework
Traditional CNN employs scalars to represent neurons and weights, then estimates the probability of various features. In this paper, the capsule network is employed to predict the probability of feature with vector norm, which effectively reduces the error caused by the change of face posture information, such as the change of direction and angle during the prediction process. As shown in the lower part in
Figure 2, the input images pass through the feature extraction module to obtain the feature maps. Then, they are input into the capsule network, which is divided into three main capsules and two output capsules. After the main capsules process the input features, the corresponding outputs are sent to two output capsules through the dynamic routing algorithm [
9].
However, the original capsule network has obvious defects. It only uses the first three layers of VGG19 [
29] as the feature extraction module, which weakens the detection accuracy. In order to optimize the feature extraction module in the original capsule network, the upper part of
Figure 2, namely, SMFAN, is introduced. Specifically, the face is first input into the SMFAN to extract features. Then, the features are input into the classifier, which are divided into two categories: natural or manipulated face. Moreover, the result of the classifier is compared with the correct label of the face. At the same time, the process will output an attention map which is used for optimizing the feature extraction module of the capsule network. With the continuous optimization of parameters during training process, the output attention map is more and more in line with the human visual mechanism, and the optimization result of the feature extraction module is getting better and better. In addition, focal loss, which is proposed to address examples imbalance by reshaping the standard cross entropy loss, is adopted to supervise the training of model to improve detection accuracy.
3.2. Supervised Multi-Feature Fusion Attention Network
The original capsule network makes up for the shortcomings of traditional CNN to a certain extent. However, its feature extraction module is too shallow. As a result, the insufficient details of extracted features are input into the main capsules, which limits detection accuracy.
In recent years, the attention mechanism has become an essential concept in deep learning, especially computer vision. The attention mechanism that conforms to the human visual mechanism can perform intuitive visual interpretation for images or videos. The attention structure can be straightforward, just like directly introducing a convolutional layer and activation function into the original network and multiplying the obtained attention map with the original feature map. At present, the attention mechanism in many works is a variant of the above mode, that is, operating on the convolutional layer and changing the way to obtain the attention maps. For example, Sitaula et al. [
30] concatenated the image after maximum pooling and average pooling, and then multiplied it with the feature map of the original VGG-16 after convolution. Dang et al. [
17] introduced the attention mechanism based on salient features of face, where a regression-based method was used to estimate the attention map and then multiplied it with the input feature maps to optimize. However, the attention maps obtained by the above methods are all unsupervised, so the perception of image details is poor. Therefore, this paper proposes the SMFAN, which is a separate network to estimate the attention map. Compared with the traditional attention network, the proposed attention network has supervision information, and the purpose is to estimate the attention map that is in line with the human visual mechanism. The attention map contains low-level, middle-level, and high-level features, which has detailed information owned by the shallow layer and semantic information owned by the deep layer. Furthermore, it will be continuously optimized during training process. Finally, the obtained attention map is introduced into the feature extraction module of the capsule network to optimize detailed features while retaining the structure of the capsule network.
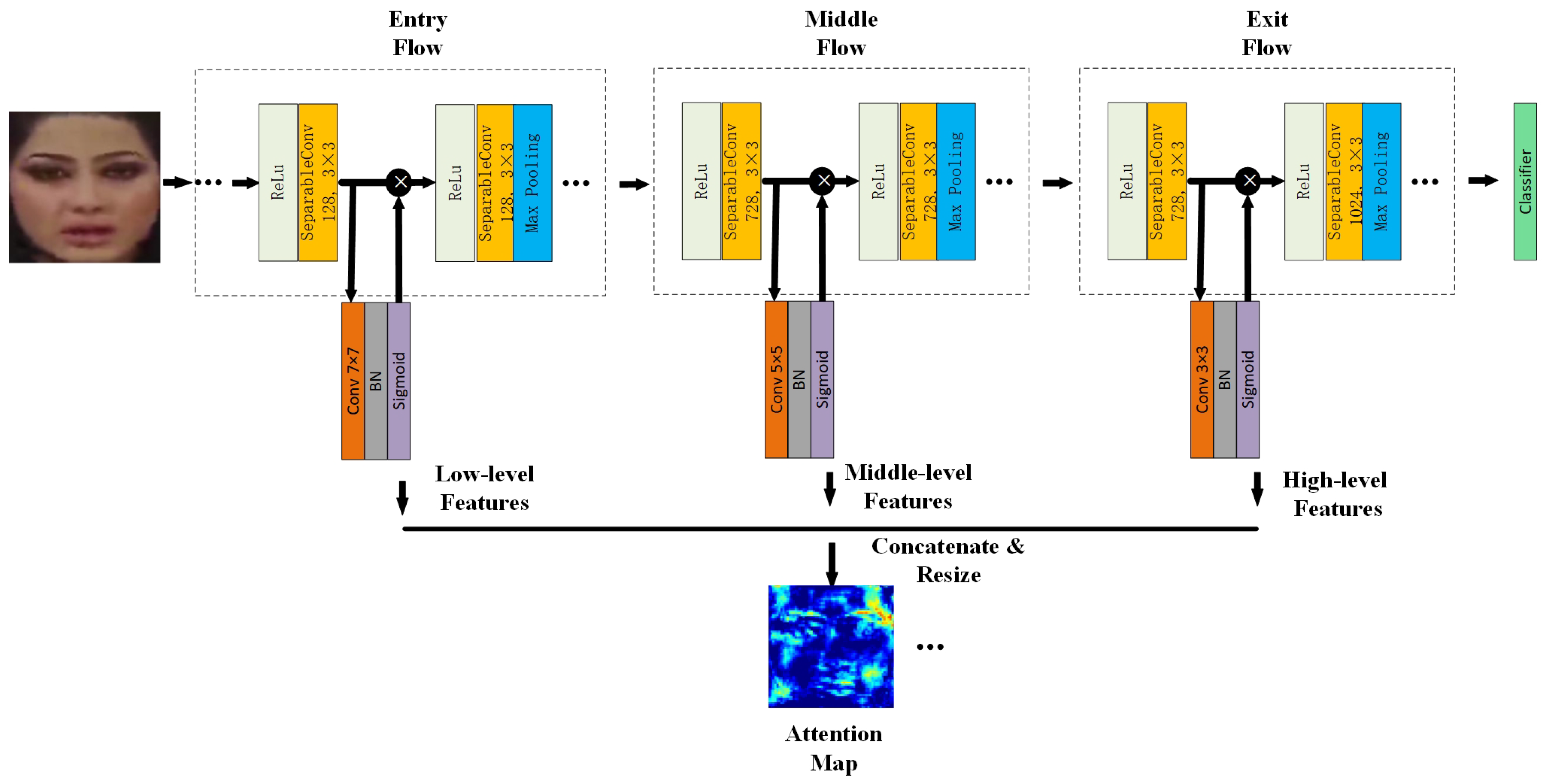
The process of obtaining the attention map is shown in
Figure 3. XceptionNet, pre-trained by Imagenet [
31], is adopted as the attention network. The reason why XceptionNet is used is that it serves as the baseline network in face manipulation detection, which is also one of the best performing CNNs within this field. In addition, we conducted comparative experiments in
Section 4.2.4 to prove that XceptionNet is a better choice.
Estimating the attention map is realized by a convolutional layer, batch normalization (BN), and sigmoid activation function. Specifically, the attention map is estimated after the first separable convolution of the entry stream, the middle stream, and the exit stream, respectively, and the size of the convolution kernel is
,
, and
, respectively. Then, we resize the three attention maps to
and concatenate them. Finally, after changing the dimension of the cascading attention maps, the multi-feature fusion attention map is obtained. The obtained attention map is multiplied with the feature maps extracted from the feature extraction module to enhance the representability ability. The optimized feature map is defined by Equation (
1):
where
is the low-level features,
is the middle-level features,
is the high-level features,
represents the concatenation operation, and
is the feature maps of the feature extraction module.
It can be seen from Equation (
1) that each pixel of the estimated attention map is added with a constant 1. The purpose is that the constant can highlight the feature maps at the peak of the attention map and prevent the low pixel values from falling to 0. Experiments in
Section 4.2.4 will evaluate the effect of adding the constant 1. As shown in
Figure 4, some attention maps are visualized. The first row is the cropped face images, and the second row is the attention maps corresponding to the face images of the first row. It can be seen that the attention mechanism can effectively pay attention to the critical parts of the face, such as the eyes, nose, mouth, and the face profile.
3.3. Loss Function
Traditional cross-entropy loss treats all examples equally and is utilized by most of the current methods, which causes that these methods to treat hard examples like easy examples. Using models trained by the cross-entropy loss, unpredictable errors may occur, especially in detecting hard examples.
Focal loss [
10] based on cross-entropy loss, by introducing a weighting factor
and a modulating factor
, addresses the scenario where there is an extreme imbalance between positive and negative classes during training. The loss reduces the weights of easy examples in training, so it can also be understood as a kind of hard example mining. Therefore, focal loss is adopted to improve the detection performance of hard examples in this paper, and the loss function
L is defined by Equation (2):
where
is the output,
is used to balance the imbalance in the number of positive and negative examples,
is used to reduce the loss contribution from easy examples and extends the range in which an example receives low loss, and
y is the label, where
represents positive examples and
represents negative examples.
The loss is used in the capsule network and the SMFAN, and the total loss
in the training process is shown in Equation (3):
where
is the focal loss of the SMFAN branch, and
is the focal loss of the capsule network. The definitions of the above two losses are defined by Equations (4) and (5):
where
and
are the output of the SMFAN branch and capsule network, respectively.
and
are used to balance the importance of positive and negative examples in the SMFAN branch and capsule network, respectively.
and
are used to reduce the loss contribution from well-classified examples in the SMFAN branch and capsule network, respectively.
y is the label.
In summary, the process of the SMFAN algorithm is shown in Algorithm 1.
| Algorithm 1 SMFAN |
| Input: The image I; |
| Output: The label: 0 (manipulated) or 1 (real); |
| for all training images do |
| | 1. Input the image I to the Xception network for classification (real or manipulated); |
| | 2. Estimate the attention maps , , after the first separable convolution of the entry stream, the middle stream, and the exit stream; |
| | 3. Resize the three attention maps to 64 × 64 and concatenate them to obtain the multi-feature fusion attention map ; |
| | 4. Obtain the feature maps via the feature extraction module of the capsule network; |
| | 5. The multi-feature fusion attention map is multiplied with , namely is obtained; |
| | 6. Through the dynamic routing algorithm of the capsule network, the results are output to two output capsules, 0 or 1 respectively; |
| | 7. Calculate the total focal loss L and back propagate to update network parameters. |
| end for |







{kind=link}
{kind=link}
{kind=link}
{kind=link}