
Real-Time Closed-Loop Detection Method of vSLAM Based on a Dynamic Siamese Network



Abstract
:1. Introduction
- We design a real-time closed-loop detection method of vSLAM based on a dynamic Siamese network. Through a fast conversion learning model, the appearance change and background suppression of continuous key frames can be learned online using the first few frames of the images, which can effectively improve the closed-loop detection speed whilst retaining the online adaptive ability as much as possible.
- An elementwise fusion strategy is proposed to adaptively integrate the multi-layer depth features that truly reflects the complementary role of response mapping in the different layers and helps to obtain a better key frame positioning ability.
- The closed-loop detection training based on the labeled video sequence optimizes the traditional discriminant analysis method based on static image similarity so that the closed-loop detection model can fully consider the rich space–time information in the process of robot motion and then obtain a more accurate closed-loop detection effect.
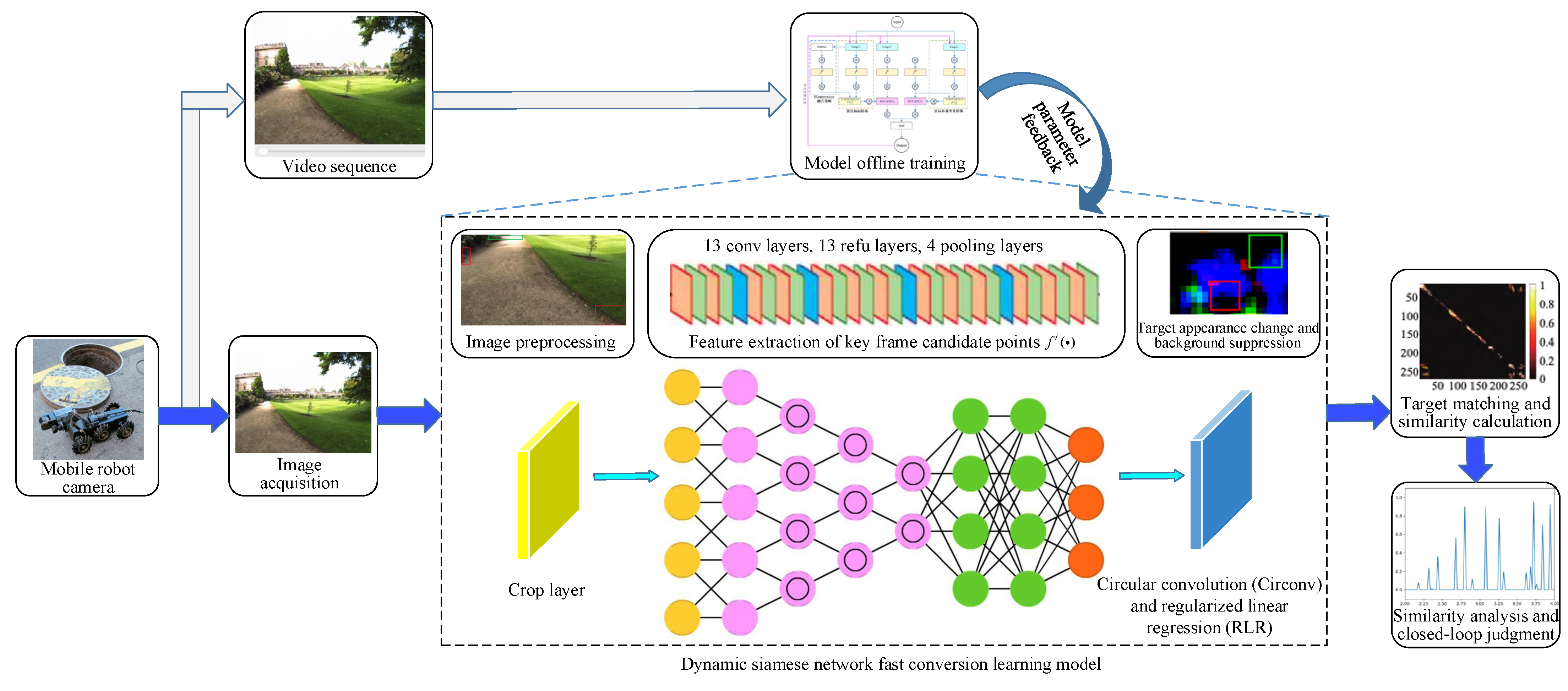
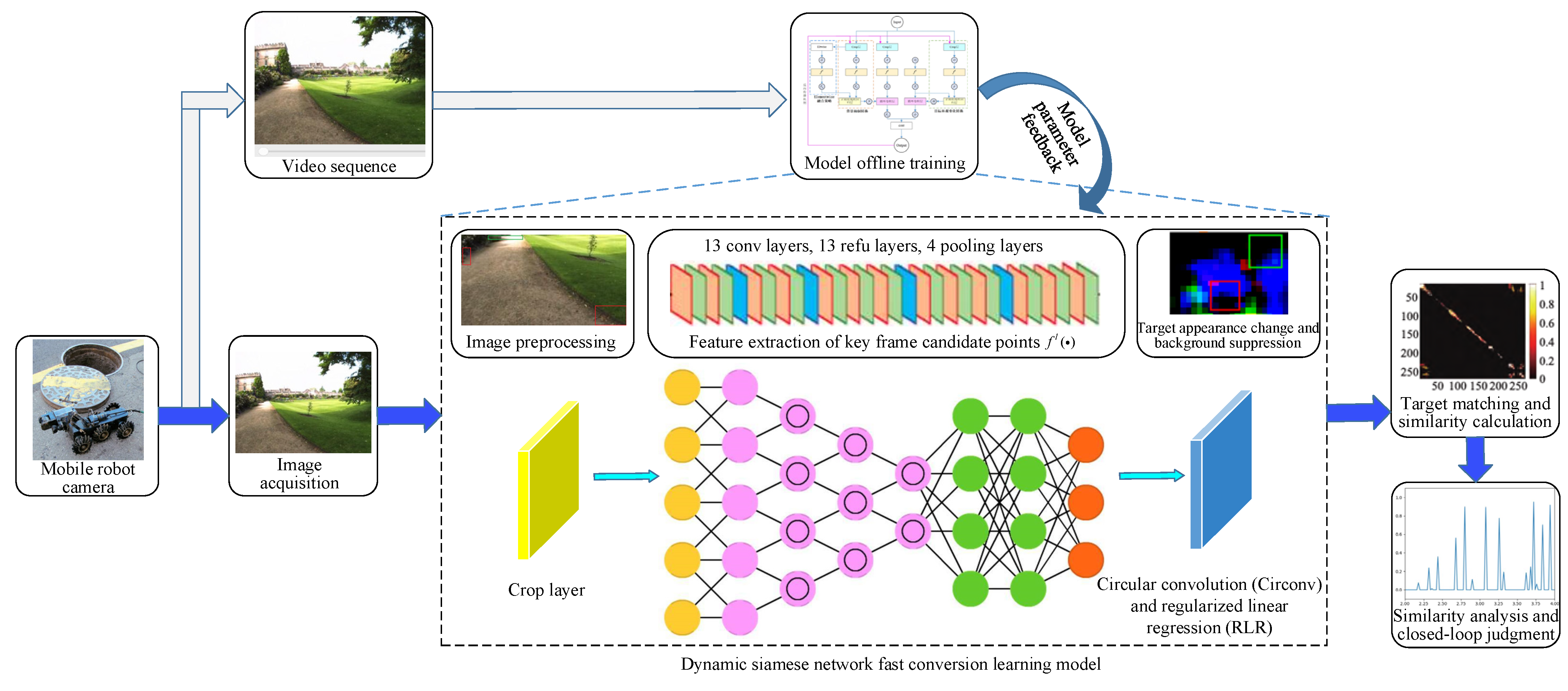
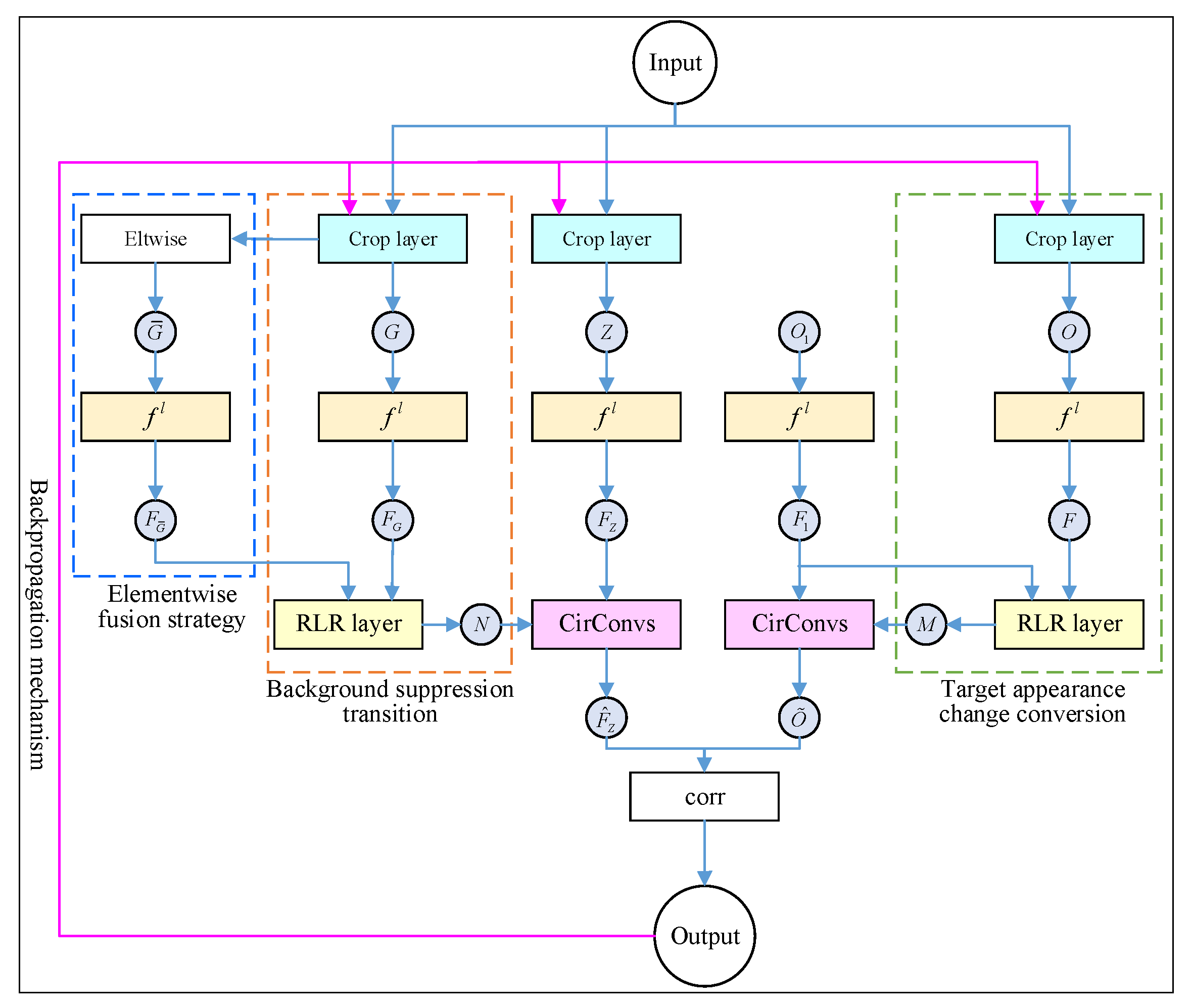
2. Fast Conversion Learning Model Based on a Dynamic Siamese Network
2.1. Fast Conversion Learning Model Idea
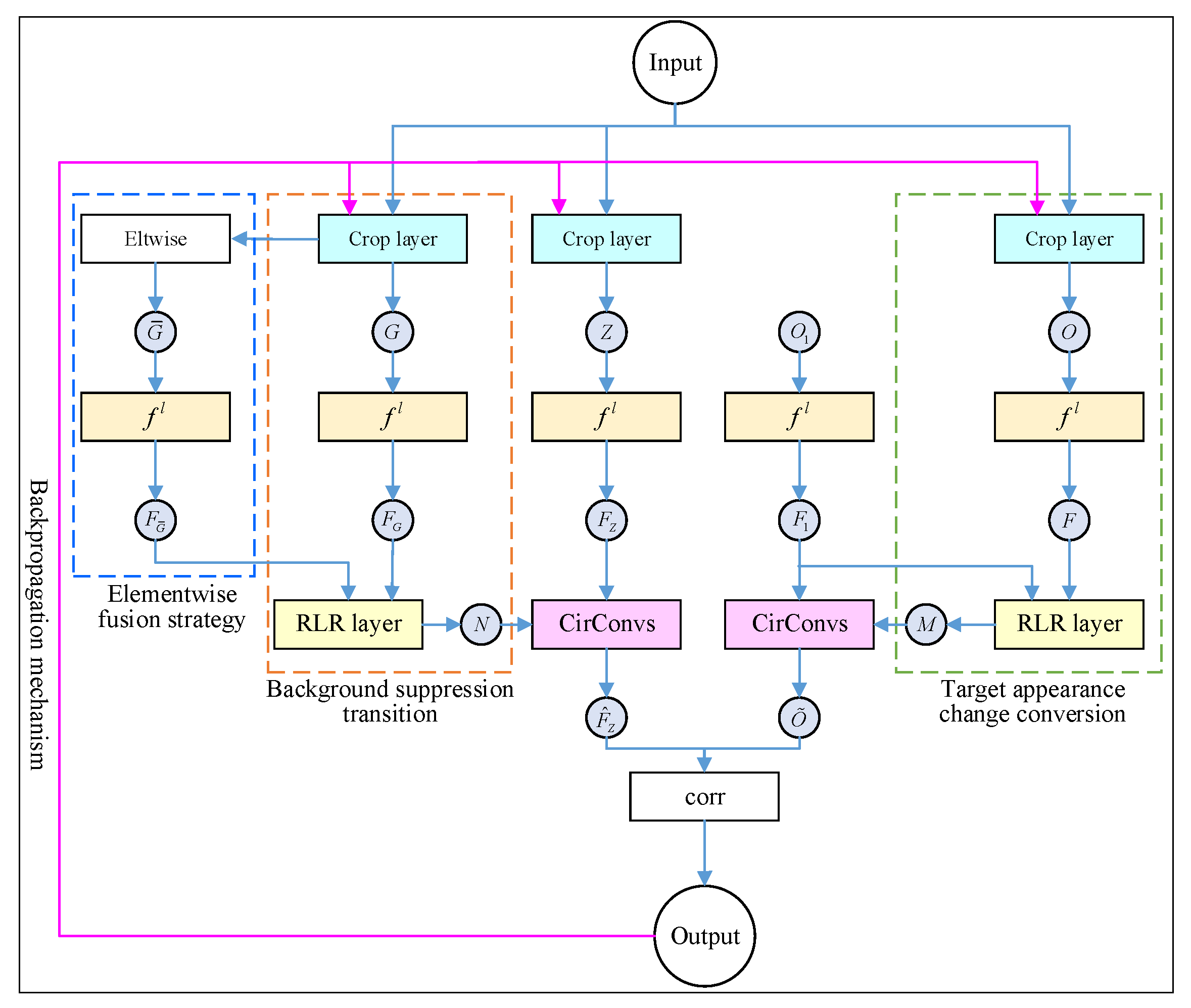
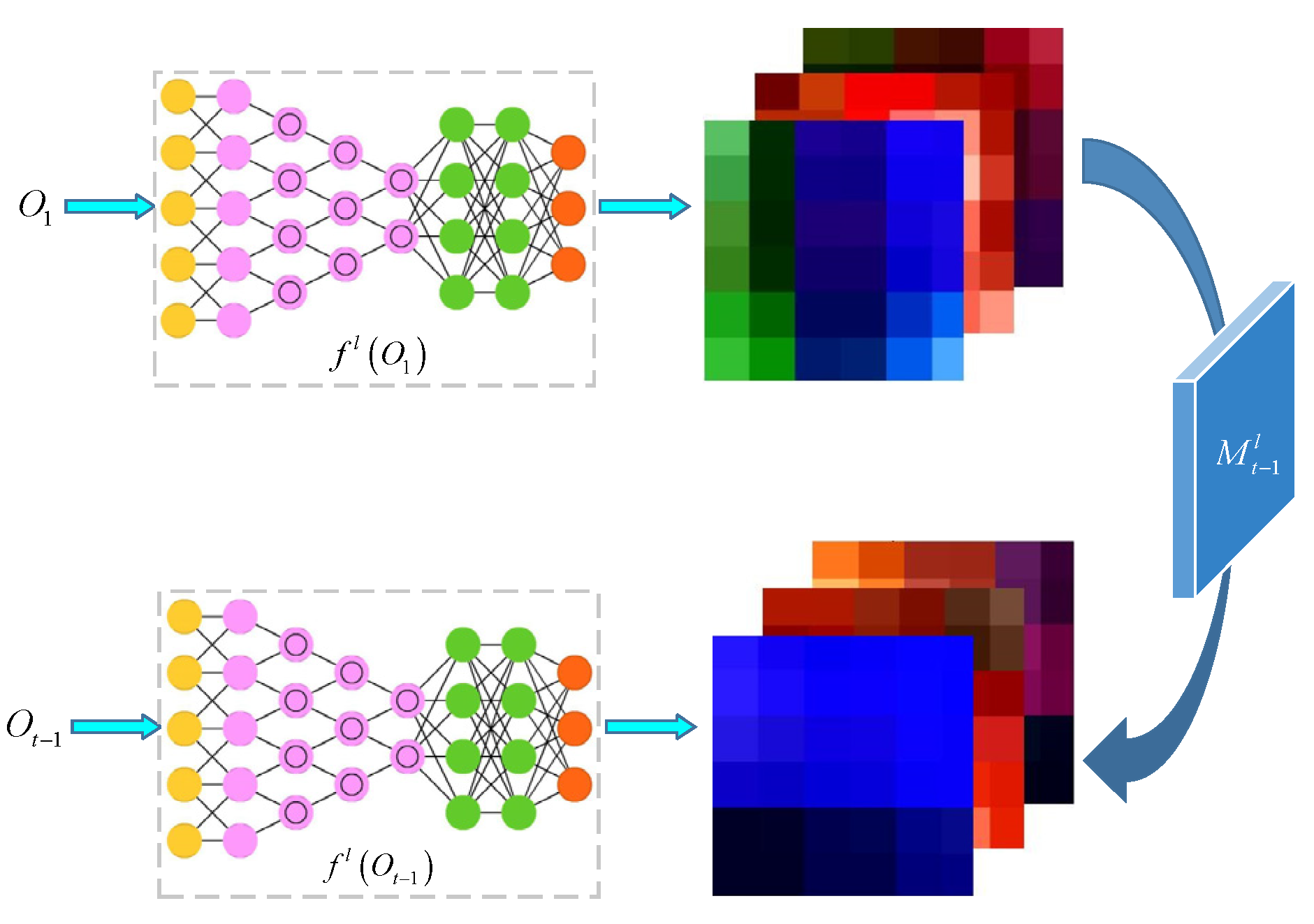
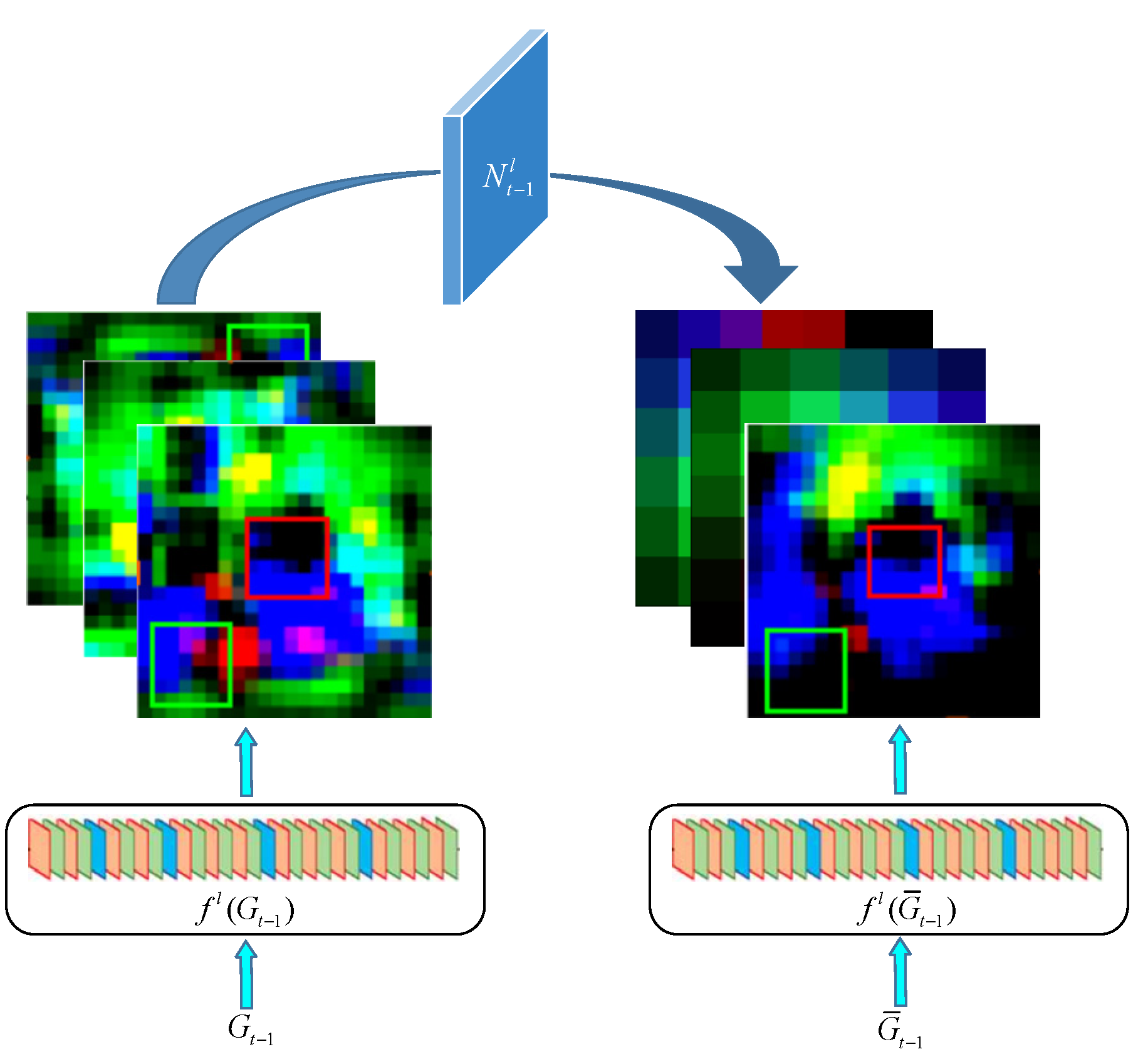
2.2. Online Learning of the Target Appearance Change and Background Suppression
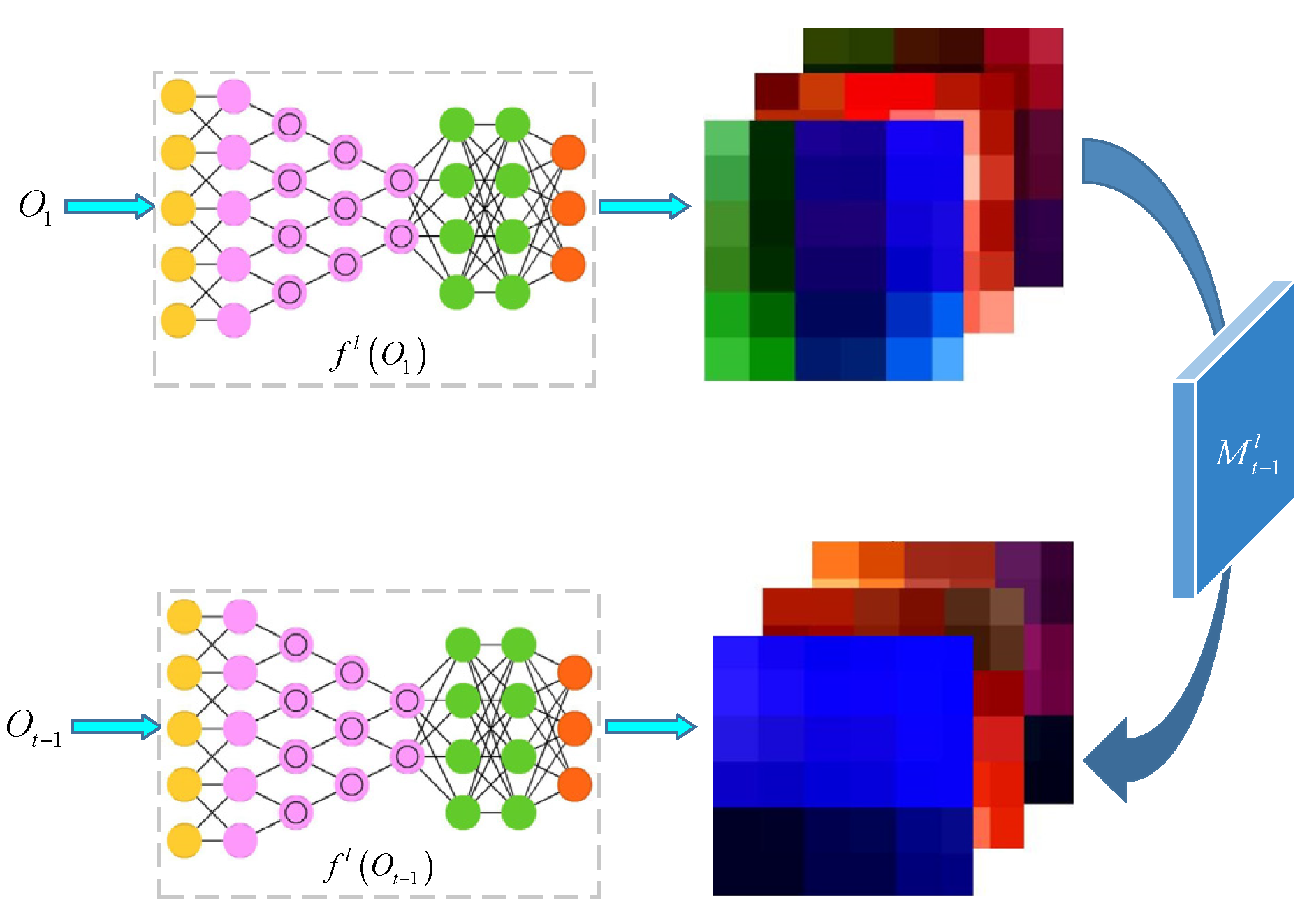
2.2.1. Solution of the Target Appearance Change Transformation
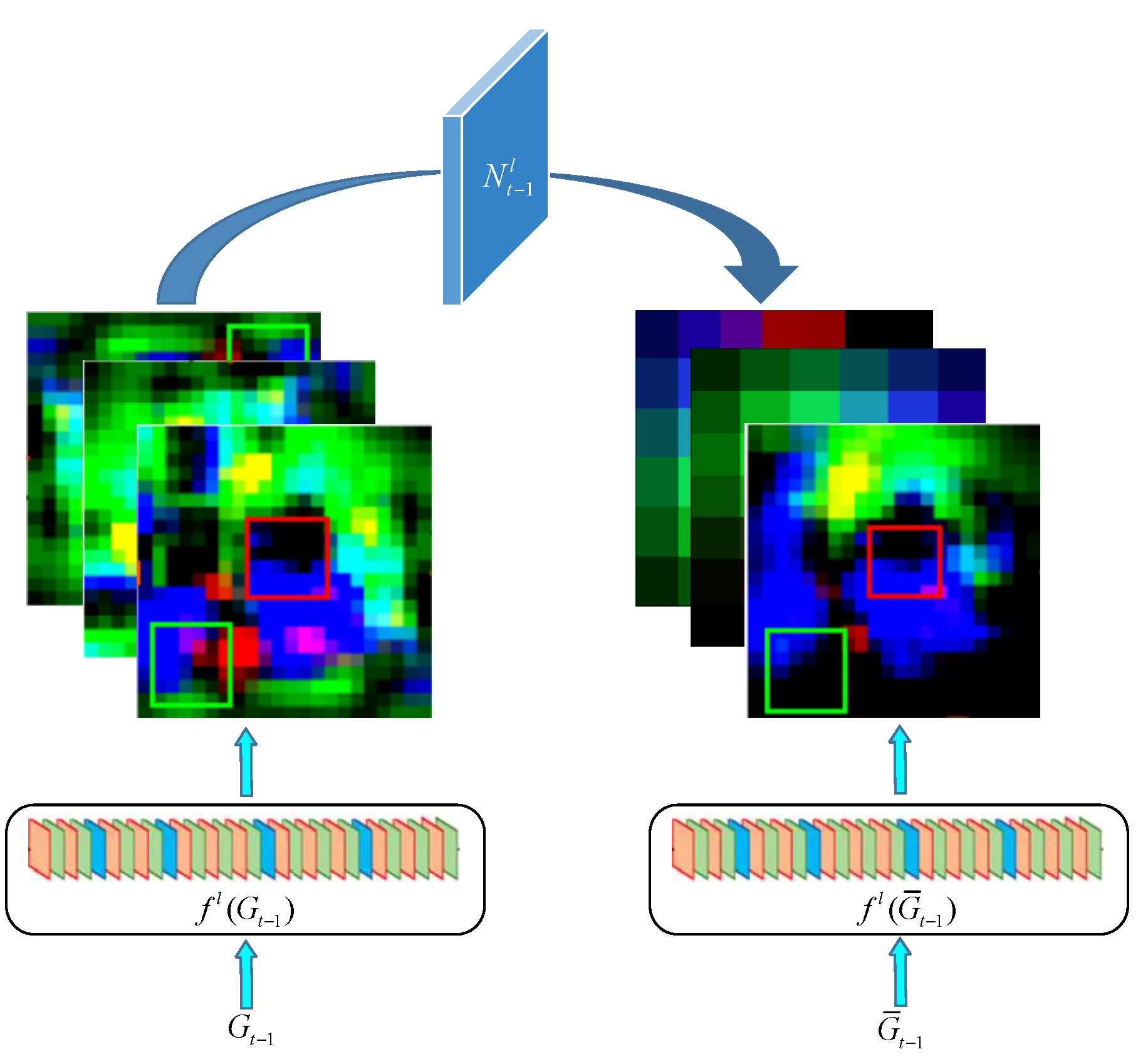
2.2.2. Solution of the Background Suppression Transformation
2.3. Adaptive Fusion of the Multi-Layer Depth Features
- The spatial variable integration of deep features realizes the effective integration of the element level.
- Weight mapping can be learned offline, replacing the traditional subjective manual setting.
2.4. Architecture of the Dynamic Siamese Network
3. Closed-Loop Detection Training Considering the Spatiotemporal Correlation
4. Experimental Results and Analysis
4.1. Dataset Analysis
4.2. Design of the Experiment
4.3. Experimental Results and Analysis
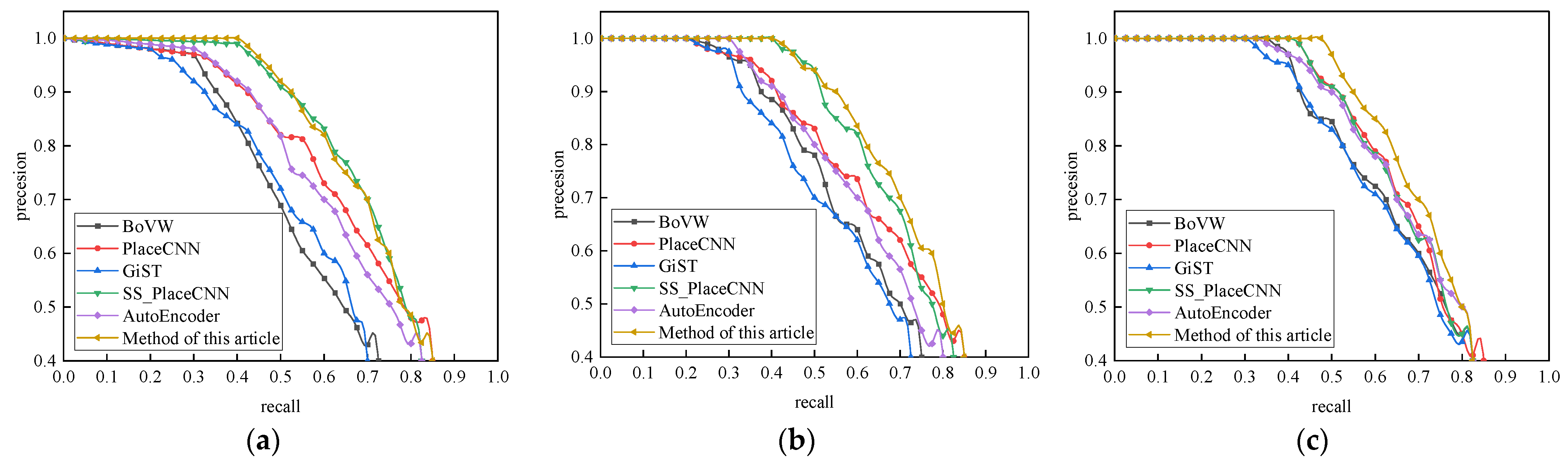
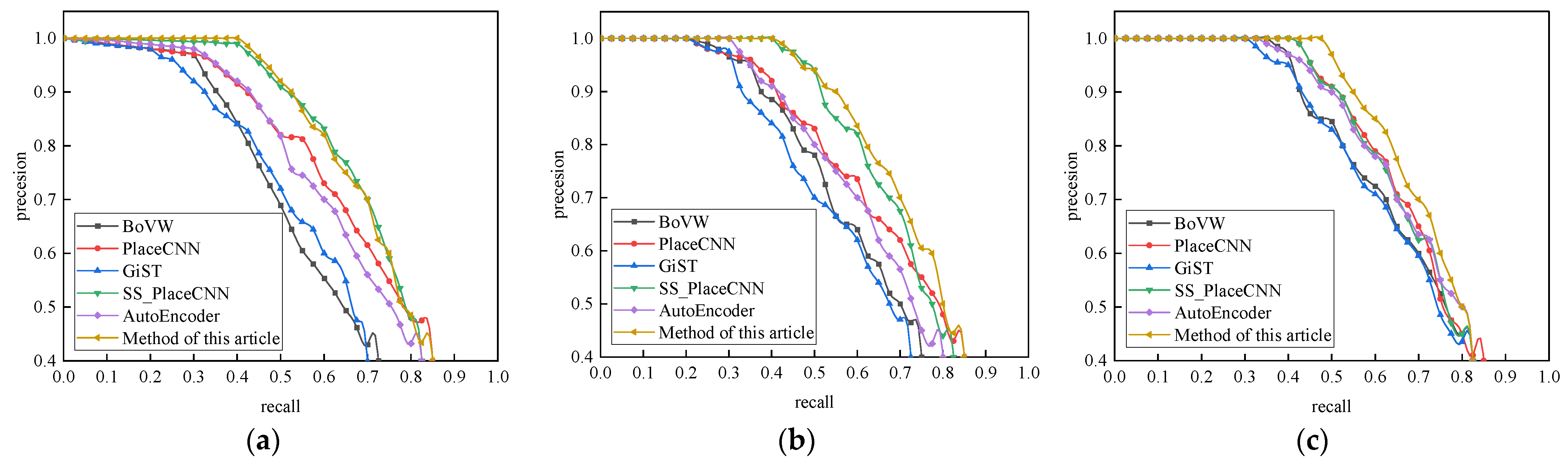
4.3.1. Robustness Analysis and a Comparison of the Closed-Loop Detection Algorithms
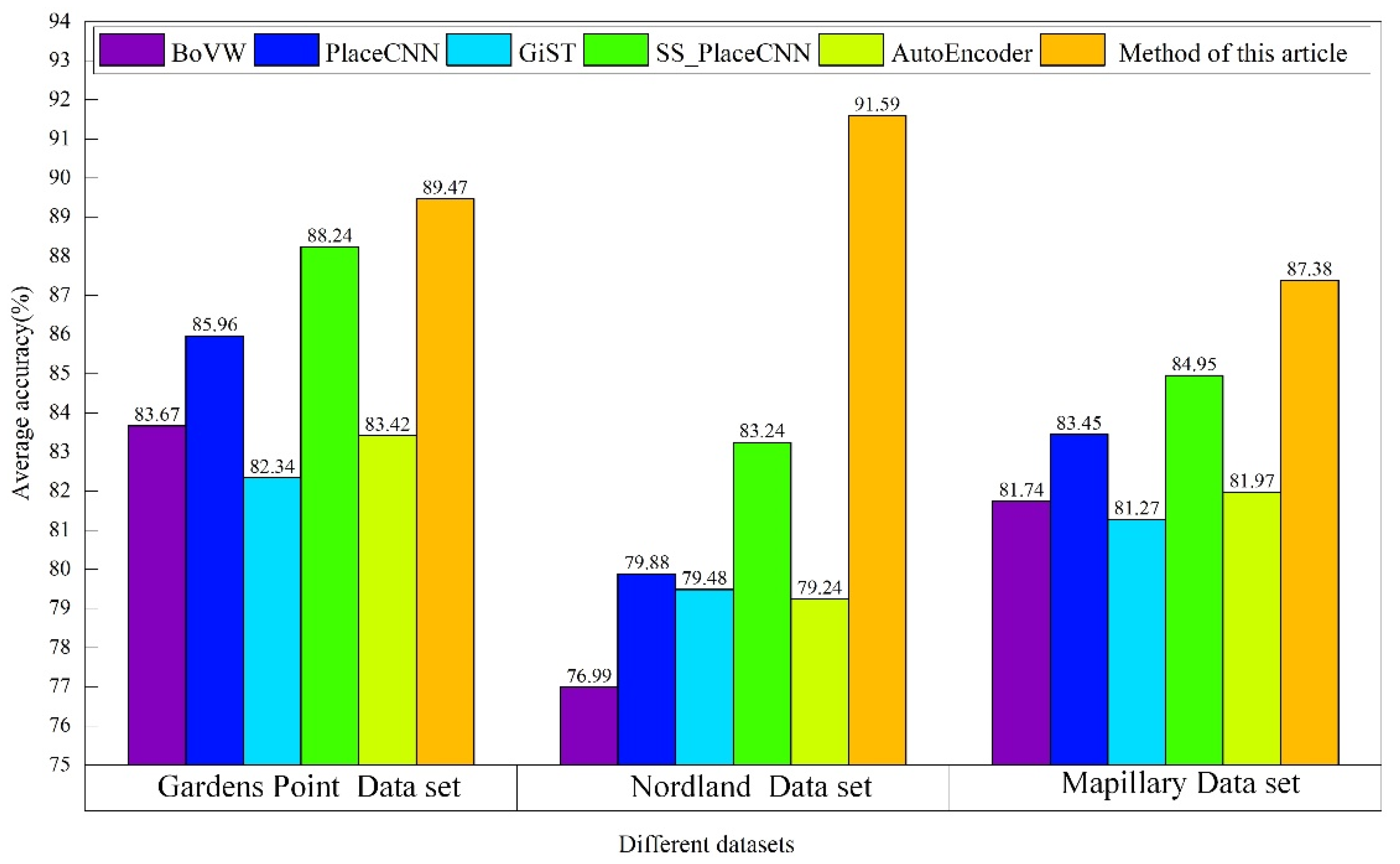
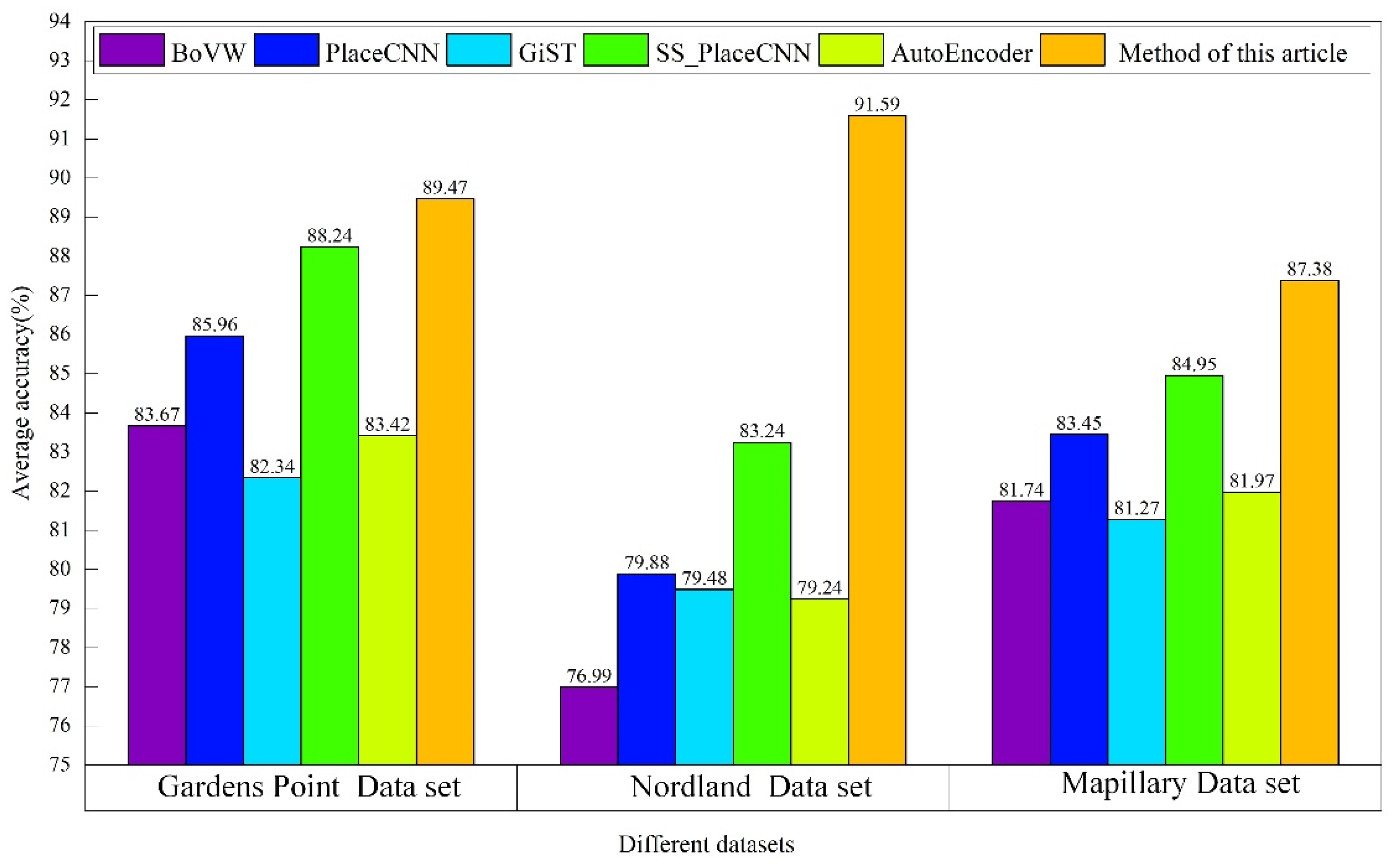
4.3.2. Analysis and Comparison of the Average Accuracy of the Closed-Loop Detection Algorithms
4.3.3. Analysis and Comparison of the Time Performance of the Closed-Loop Detection Algorithms
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yan, Y.P.; Wong, S.F. A navigation algorithm of the mobile robot in the indoor and dynamic environment based on the PF-SLAM algorithm. Clust. Comput. 2019, 22, 14207–14218. [Google Scholar] [CrossRef]
- Cadena, C.; Carlone, L.; Carrillo, H.; Latif, Y.; Scaramuzza, D.; Neira, J.; Reid, I.; Leonard, J.J. Past, present, and future of simultaneous localization and mapping: Toward the robust-perception age. IEEE Trans. Robot. 2016, 32, 1309–1332. [Google Scholar] [CrossRef] [Green Version]
- Cao, Y.; Beltrame, G. Vir-slam: Visual, inertial, and ranging slam for single and multi-robot systems. Auton. Robot. 2021, 45, 905–917. [Google Scholar] [CrossRef]
- Kuo, C.-Y.; Huang, C.-C.; Tsai, C.-H.; Shi, T.-S.; Smith, S. Development of an immersive SLAM-based VR system for teleoperation of a mobile manipulator in an unknown environment. Comput. Ind. 2021, 132, 103502. [Google Scholar] [CrossRef]
- Kim, U.H.; Kim, S.; Kim, J.H. Simvodis: Simultaneous visual odometry, object detection, and instance segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2020. [Google Scholar] [CrossRef]
- Chang, J.; Dong, N.; Li, D.; Qin, M. Triplet loss based metric learning for closed-loop detection in VSLAM system. Expert Syst. Appl. 2021, 185, 115646. [Google Scholar] [CrossRef]
- Liao, M.; He, G.; Zhang, L. Research on Closed-loop Detection Algorithm. Int. Core J. Eng. 2020, 6, 218–223. [Google Scholar]
- Gao, X.; Zhang, T. Unsupervised learning to detect loops using deep neural networks for visual SLAM system. Auton. Robot. 2017, 41, 1–18. [Google Scholar] [CrossRef]
- Chen, L.; Jin, S.; Xia, Z. Towards a Robust Visual Place Recognition in Large-Scale vSLAM Scenarios Based on a Deep Distance Learning. Sensors 2021, 21, 310. [Google Scholar] [CrossRef]
- Bruno, H.M.S.; Colombini, E.L. LIFT-SLAM: A deep-learning feature-based monocular visual SLAM method. Neurocomputing 2021, 455, 97–110. [Google Scholar] [CrossRef]
- Luo, Y.; Xiao, Y.; Zhang, Y.; Zeng, N. Detection of loop closure in visual SLAM: A stacked assorted auto-encoder based approach. Optoelectron. Lett. 2021, 17, 354–360. [Google Scholar] [CrossRef]
- Wang, Z.; Peng, Z.; Guan, Y.; Wu, L. Manifold regularization graph structure auto-encoder to detect loop closure for visual SLAM. IEEE Access 2019, 7, 59524–59538. [Google Scholar] [CrossRef]
- Shamwell, E.J.; Lindgren, K.; Leung, S.; Nothwang, W.D. Unsupervised deep visual-inertial odometry with online error correction for RGB-D imagery. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2478–2493. [Google Scholar] [CrossRef] [PubMed]
- Geng, M.; Shang, S.; Ding, B.; Wang, H.; Zhang, P. Unsupervised learning-based depth estimation-aided visual slam approach. Circuits Syst. Signal Process. 2020, 39, 543–570. [Google Scholar] [CrossRef] [Green Version]
- Lan, E.S. A Novel Deep ML Architecture by Integrating Visual Simultaneous Localization and Mapping (vSLAM) into Mask R-CNN for Real-time Surgical Video Analysis. arXiv 2021, arXiv:2103.16847. Available online: https://arxiv.org/abs/2103.16847 (accessed on 23 September 2021).
- Cascianelli, S.; Costante, G.; Bellocchio, E.; Valigi, P.; Fravolini, M.L.; Ciarfuglia, T.A. Robust visualsemi-semantic loop closure detection by a covisibility graph and CNN features. Robot. Auton. Syst. 2017, 92, 53–65. [Google Scholar] [CrossRef]
- Fan, Y.; Zhang, Q.; Liu, S.; Tang, Y.; Jing, X.; Yao, J.; Han, H. Semantic SLAM with more accurate point cloud map in dynamic environments. IEEE Access 2020, 8, 112237–112252. [Google Scholar] [CrossRef]
- Wang, N.; Zhou, W.; Song, Y.; Ma, C.; Liu, W.; Li, H. Unsupervised deep representation learning for real-time tracking. Int. J. Comput. Vis. 2021, 129, 400–418. [Google Scholar] [CrossRef]
- Ma, J.; Qian, K.; Ma, X.; Zhao, W. Reliable loop closure detection using 2-channel convolutional neural networks for visual slam. In Proceedings of the 2018 37th Chinese Control Conference, Wuhan, China, 8 October 2018; pp. 5347–5352. [Google Scholar]
- Zhou, H.; Ummenhofer, B.; Brox, T. DeepTAM: Deep tracking and mapping with convolutional neural networks. Int. J. Comput. Vis. 2020, 128, 756–769. [Google Scholar] [CrossRef]
- Zhong, Q.; Fang, X. A BigBiGAN-Based Loop Closure Detection Algorithm for Indoor Visual SLAM. J. Electr. Comput. Eng. 2021, 2021, 9978022. [Google Scholar] [CrossRef]
- He, A.; Luo, C.; Tian, X.; Zeng, W. A twofold siamese network for real-time object tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4834–4843. [Google Scholar]
- Zhao, J.; Li, T.; Yang, T.; Zhao, L.; Huang, S. 2D Laser SLAM With Closed Shape Features: Fourier Series Parameterization and Submap Joining. IEEE Robot. Autom. Lett. 2021, 6, 1527–1534. [Google Scholar] [CrossRef]
- Peršić, J.; Petrović, L.; Marković, I.; Petrovic, I. Spatiotemporal Multisensor Calibration via Gaussian Processes Moving Target Tracking. IEEE Trans. Robot. 2021, 37, 1401–1415. [Google Scholar] [CrossRef]
- Xu, G.; Zhang, Q.; Li, N.; Ouyang, L.; Zhao, T.; Chen, Q. Closed-loop detection and repositioning method based on bag of word. In Proceedings of the International Conference on Artificial Intelligence, Information Processing and Cloud Computing, New York, NY, USA, 19–21 December 2019; pp. 1–7. [Google Scholar]
- Li, L.; Kong, X.; Zhao, X.; Li, W.; Fen, F.; Zhang, H.; Liu, Y. SA-LOAM: Semantic-aided LiDAR SLAM with Loop Closure. arXiv 2021, arXiv:2106.11516. Available online: https://arxiv.org/abs/2106.11516v2 (accessed on 23 September 2021).
- Czarnowski, J.; Laidlow, T.; Clark, R.; Davison, A.J. Deepfactors: Real-time probabilistic dense monocular slam. IEEE Robot. Autom. Lett. 2020, 5, 721–728. [Google Scholar] [CrossRef] [Green Version]
- Tomiţă, M.A.; Zaffar, M.; Milford, M.; McDonald-Maier, K.D.; Ehsan, S. Convsequential-slam: A sequence-based, training-less visual place recognition technique for changing environments. IEEE Access 2021, 9, 118673–118683. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number | Type | Detailed Configuration | |
|---|---|---|---|
| 1 | Hardware resource configuration | CPU | Intel(R)Xeon(R)Gold5118 CPU @ 2.30 GHz |
| 2 | GPU | NVIDIA Quadro P5000 | |
| 3 | Memory | Physical memory 128 G, dedicated GPU memory 16 g | |
| 4 | Main software running environment and dependent environment | sys. platform | win32 |
| 5 | Python | 3.7.6 (MSC v.1916 64 bit (AMD64)) | |
| 6 | NumPy | 1.18.1 | |
| 7 | detectron2 | 0.1.1 | |
| 8 | CUDA | 10.1 | |
| 9 | PyTorch | 1.4.0 | |
| 10 | GPU 0 | Quadro P5000 | |
| 11 | Pillow | 7.0.0 | |
| 12 | torchvision | 0.5.0 | |
| 13 | cv2 | 4.2.0 | |
| Facts/Forecasts | Closed-Loop | Non-Closed-Loop |
|---|---|---|
| Closed-loop | True positive | False negative |
| Non-closed-loop | False positive | True negative |
| Dataset | Introduction to the Dataset | Dataset Characteristics |
|---|---|---|
| Gardens Point | The dataset was collected on the campus of the University of Queensland (QUT), including three subdatasets in two days and one night. | The dataset has two characteristics: viewing angle change and illumination change. Each subdataset has 200 images. |
| Mapillary | It has 25 K street view images (18 K train, 2 K Val, 5 K test) with a wide resolution. The dataset is densely annotated (covering 98% of pixels) and contains 28 stuff and 37 thing categories. | (1) Changes in weather conditions (sun, rain, snow, fog, haze) and photographing time (dawn, day, dusk, night); (2) A wide range of camera sensors, different focal lengths, image aspect ratios, and different types of camera noise; (3) Different camera angles (road, sidewalk, and off road). |
| Nordland | A documentary about the Nordland railway produced by NRK, a railway line connecting Trondheim and Bode city. | By erecting cameras at the front of the train, 729 km-long railway lines are photographed in different seasons of spring, summer, autumn, and winter. The length of each video is about 10 h. |
| Algorithm | BoVW | PlaceCNN | GiST | SS_PlaceCNN | AutoEncoder | Method Proposed |
|---|---|---|---|---|---|---|
| Dimension | 600 | 1000 | 1500 | 8614 | 256 | 512 |
| Time/s | 17.65 | 19.47 | 20.16 | 61.58 | 23.26 | 12.28 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuan, Q.; Zhang, Z.; Pi, Y.; Kou, L.; Zhang, F. Real-Time Closed-Loop Detection Method of vSLAM Based on a Dynamic Siamese Network. Sensors 2021, 21, 7612. https://doi.org/10.3390/s21227612
Yuan Q, Zhang Z, Pi Y, Kou L, Zhang F. Real-Time Closed-Loop Detection Method of vSLAM Based on a Dynamic Siamese Network. Sensors. 2021; 21(22):7612. https://doi.org/10.3390/s21227612
Chicago/Turabian StyleYuan, Quande, Zhenming Zhang, Yuzhen Pi, Lei Kou, and Fangfang Zhang. 2021. "Real-Time Closed-Loop Detection Method of vSLAM Based on a Dynamic Siamese Network" Sensors 21, no. 22: 7612. https://doi.org/10.3390/s21227612
APA StyleYuan, Q., Zhang, Z., Pi, Y., Kou, L., & Zhang, F. (2021). Real-Time Closed-Loop Detection Method of vSLAM Based on a Dynamic Siamese Network. Sensors, 21(22), 7612. https://doi.org/10.3390/s21227612