
Screen-Shooting Resilient Watermarking Scheme via Learned Invariant Keypoints and QT



Abstract
:1. Introduction
- We apply a modified version of the keypoint detector SuperPoint. Specifically, we add a new model called Feature Regions Filtering model to SuperPoint (FRFS).
- We propose a screen-shooting watermarking scheme via learned invariant keypoints, which combines FRFS, QDFT, and TD (FRFSQT).
- The proposed scheme makes the most of the merits of a traditional watermarking algorithms and deep learning neural networks to build an efficient mechanism to protect proprietary information that is resilient to screen-shooting attacks.
2. Related Work
2.1. Local Feature Keypoint Detection
2.2. Watermarking Algorithm in Frequency Domain
2.3. SuperPoint
2.4. QDFT and TD Watermarking Algorithm
2.4.1. QDFT
2.4.2. TD
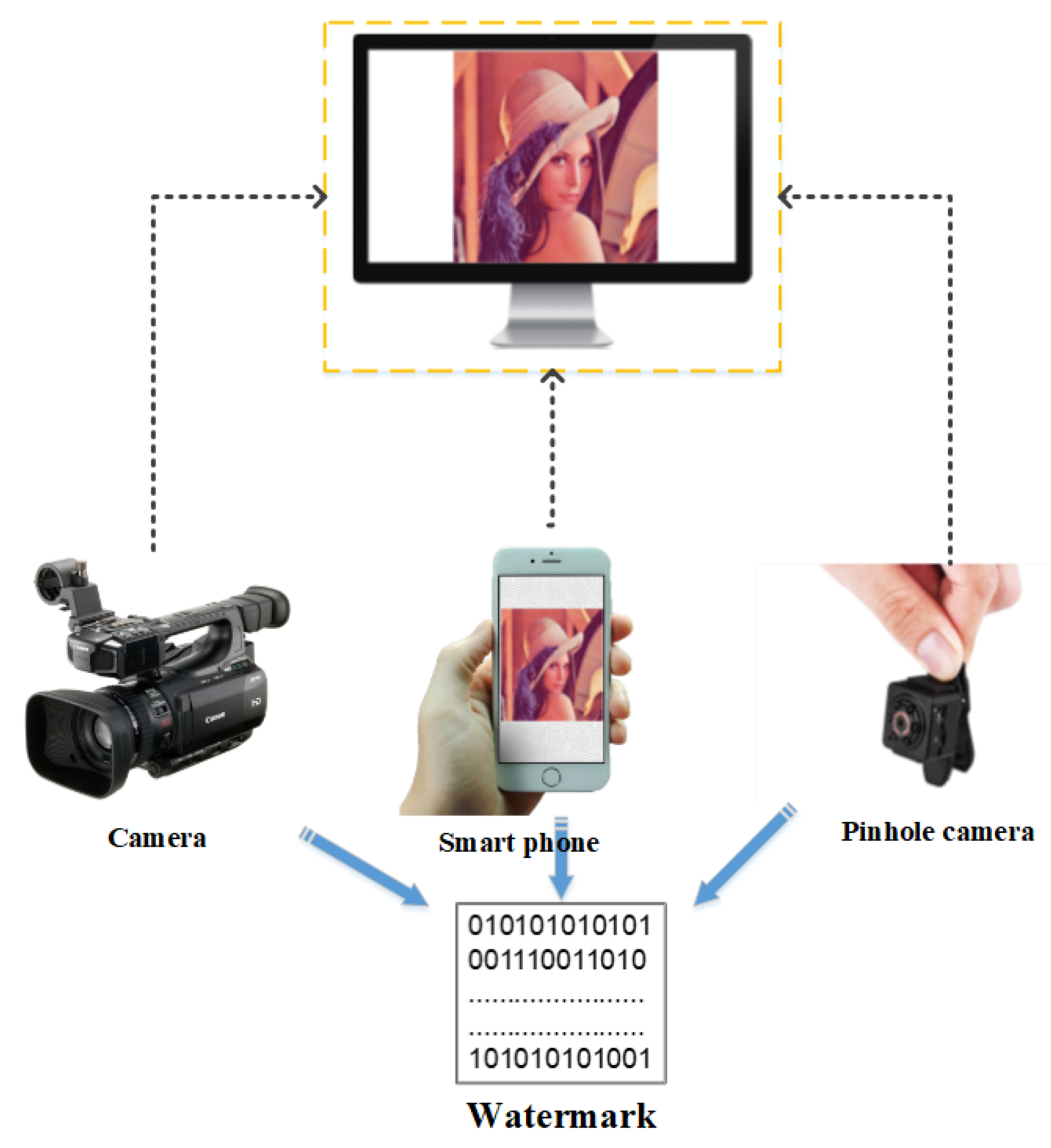
2.5. Screen-Shooting Attacks
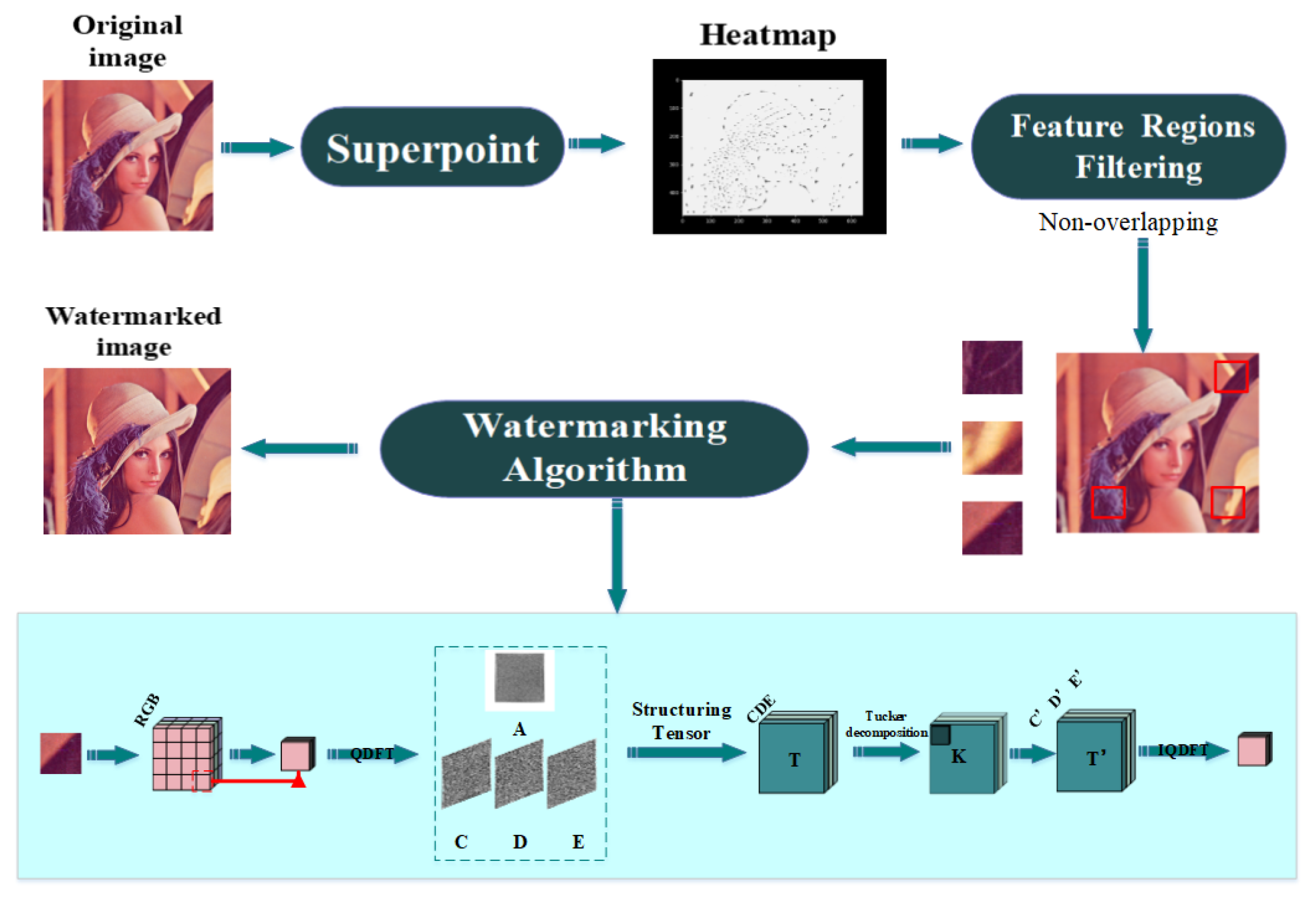
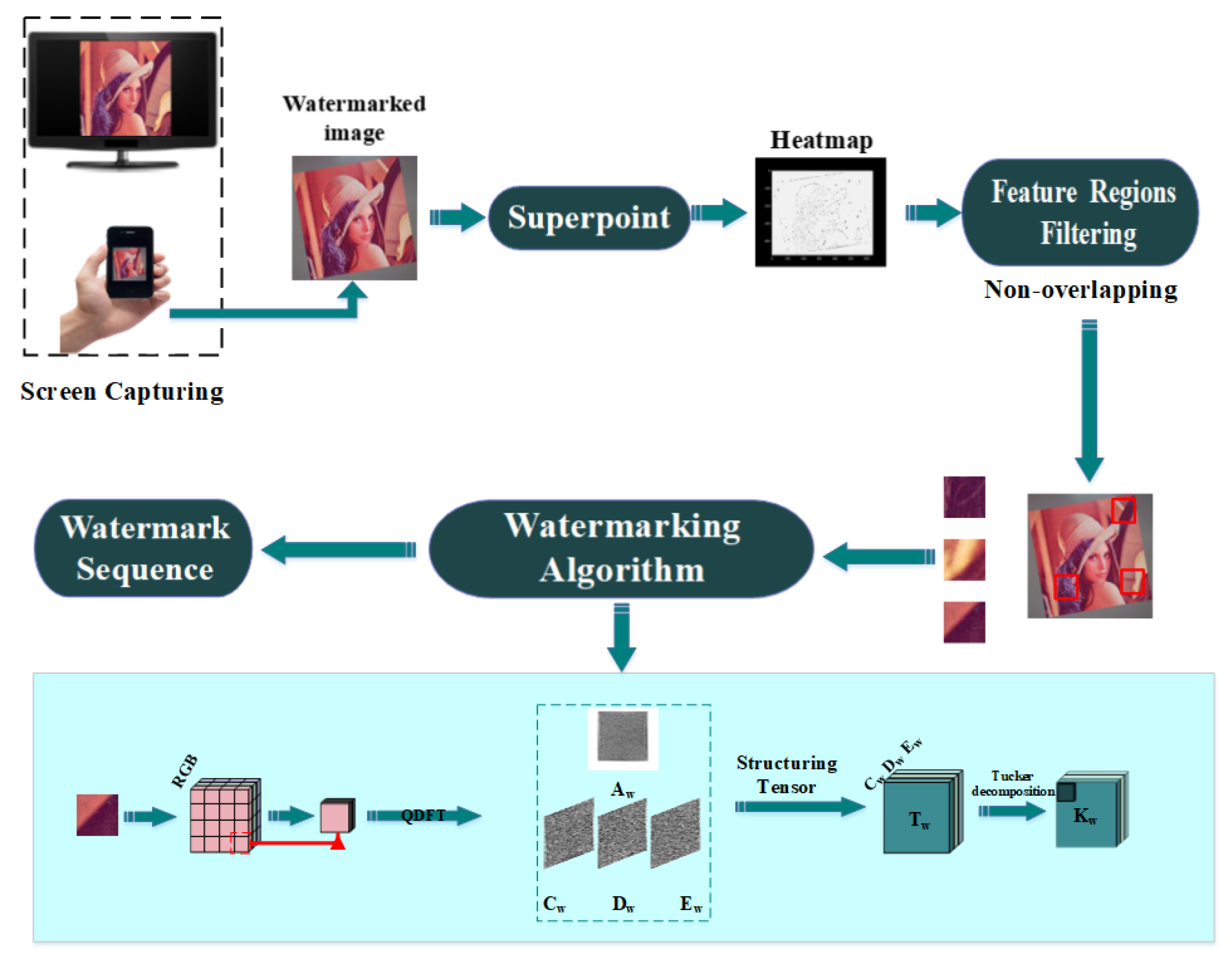
3. Proposed Scheme
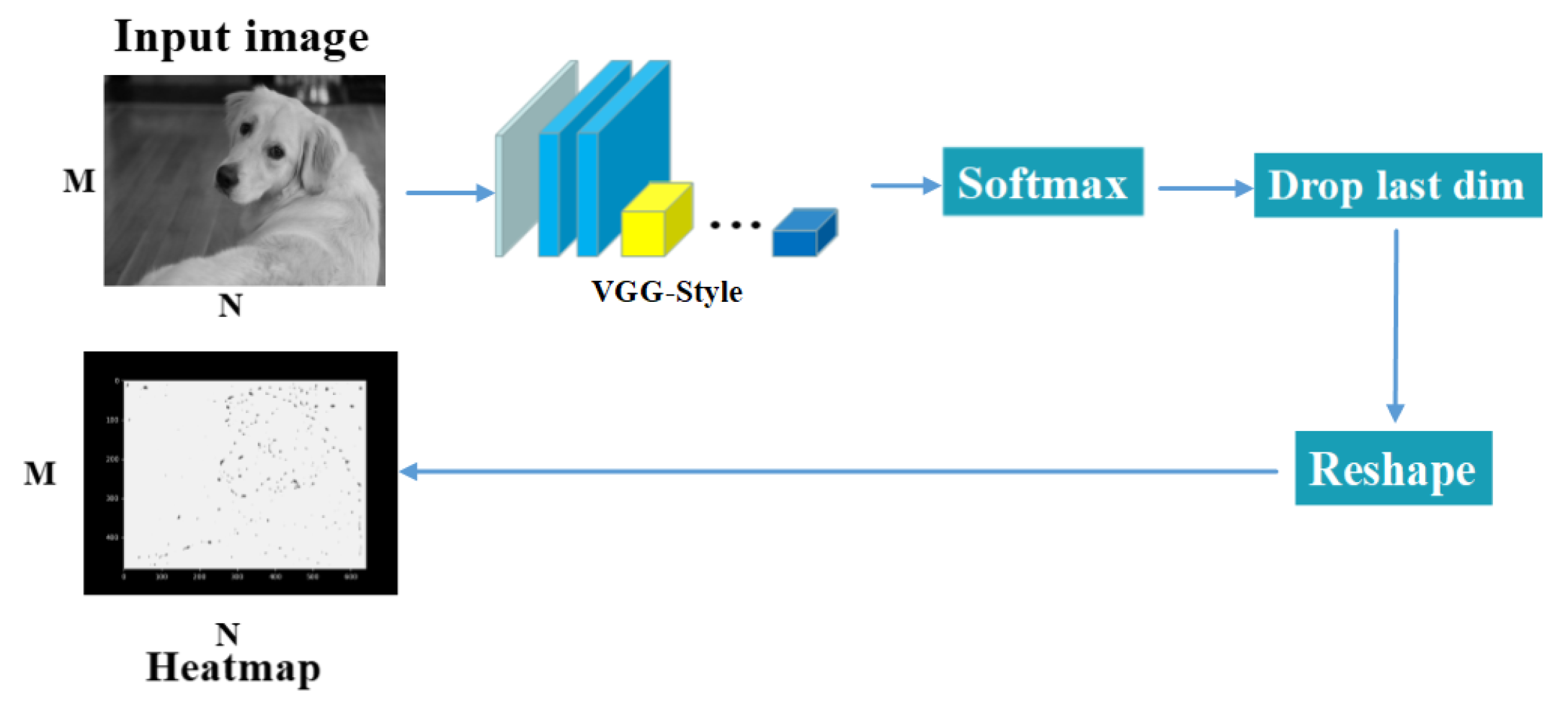
3.1. Feature Region Filtering Model
3.2. Embedding Procedure
3.3. Extraction Process
4. Experimental Results and Analysis
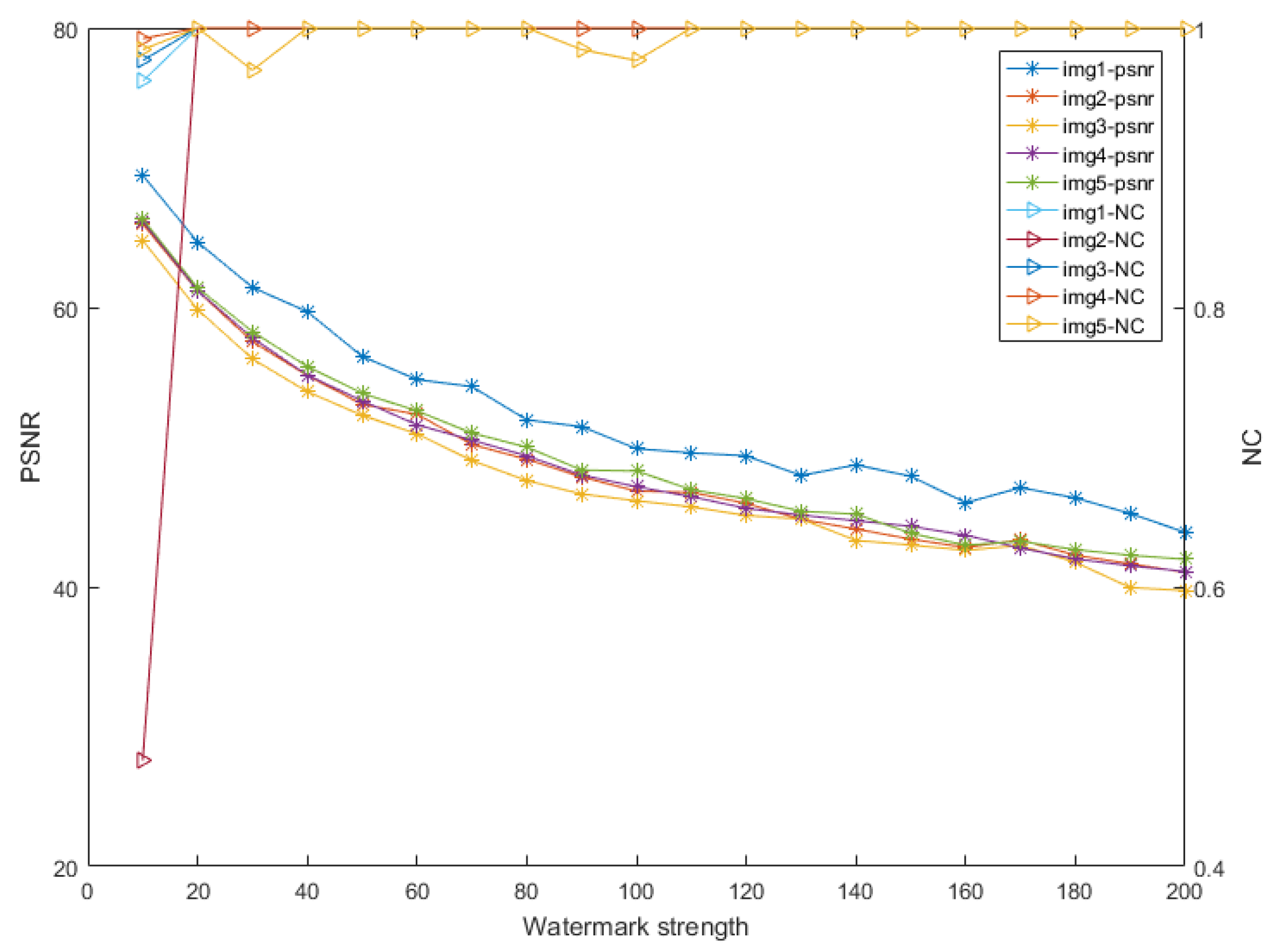
4.1. Choosing the Watermark Strength of the Watermarking Algorithm
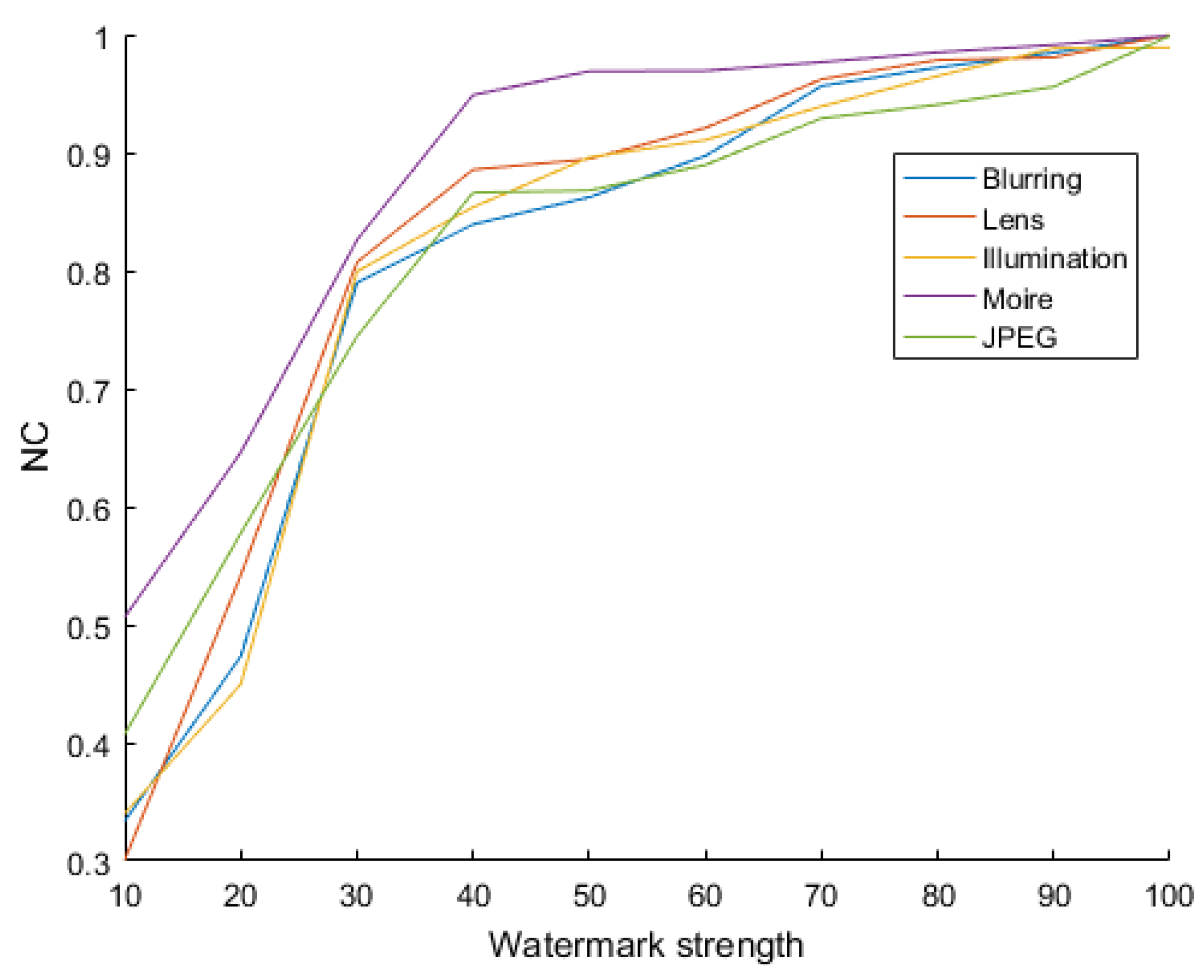
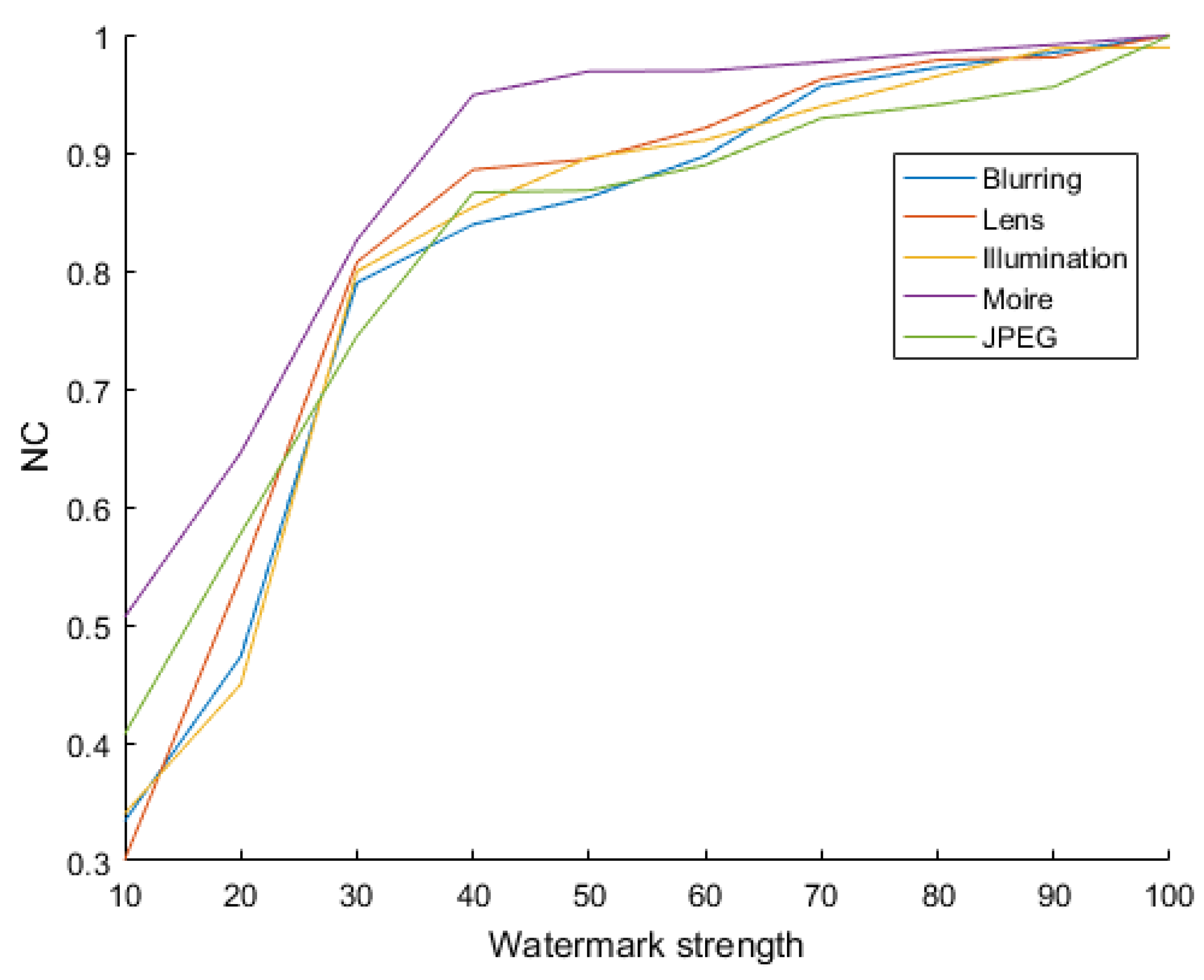
4.2. Robustness of the Watermarking Algorithm
4.2.1. Proving the Robustness of the Watermarking Algorithm
4.2.2. Performance of the Robust Watermarking Algorithm
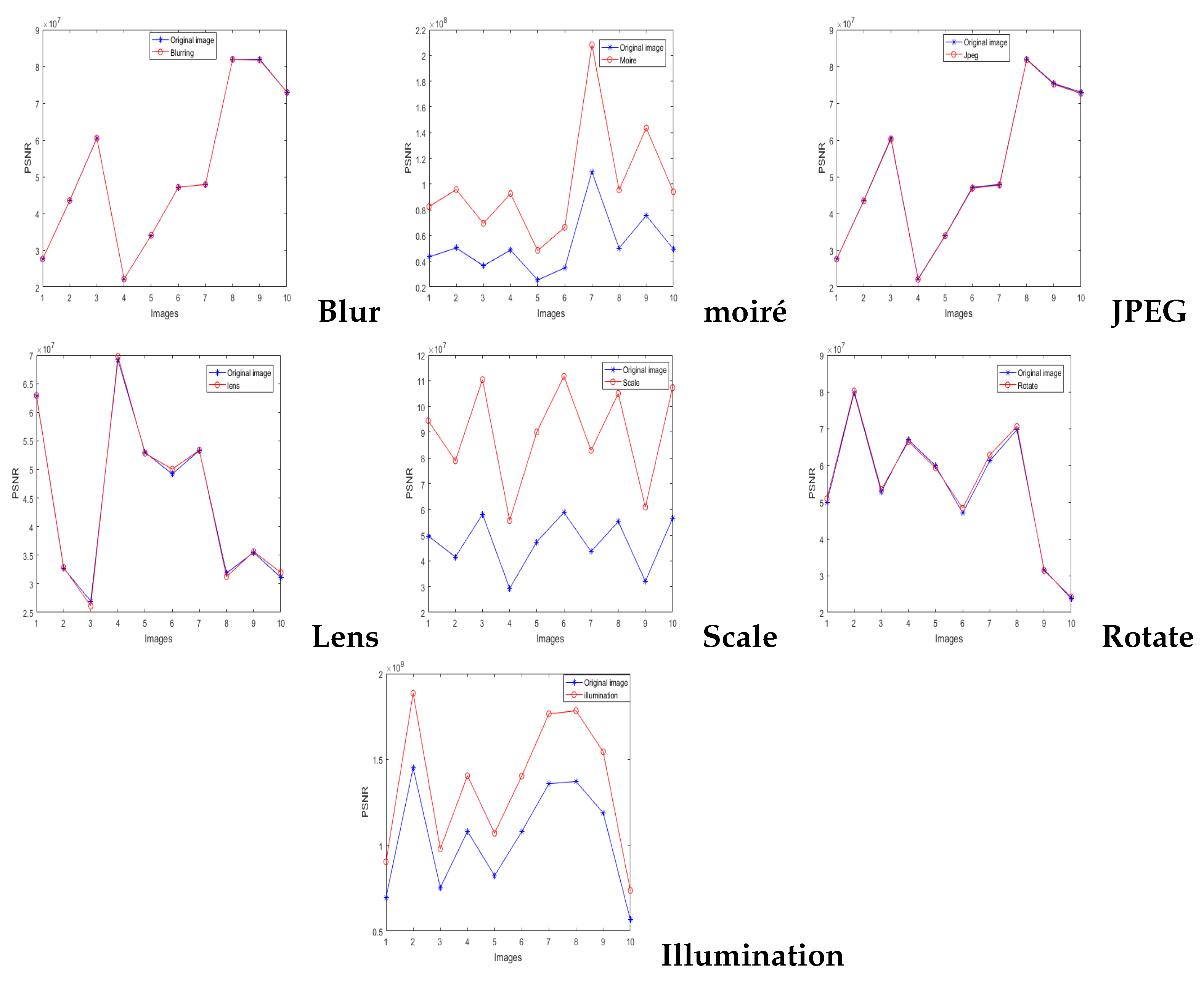
4.3. Fidelity of the Watermarking Algorithm
4.4. SuperPoint Heatmap
4.5. Estimated Keypoint Correspondences Detected by SuperPoint
4.6. Comparison with Other Papers
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| FRFS | Feature regions filtering model to superpoint |
| FRFSQT | Feature regions filtering model to superpoint, quaternion discrete Fourier transform, and Tensor decomposition |
| QDFT | Quaternion discrete Fourier transform |
| TD | Tensor decomposition |
| QT | Quaternion discrete Fourier transform and tensor decomposition |
| DCT | Discrete cosine transform |
| SVD | Singular value decomposition |
| DWT | Discrete Wavelet transformation |
| PSNR | Peak signal to noise ratio |
| NC | Normalized correlation coefficient |
| MSE | Mean square error |
| AR | Augmented reality |
| VR | Virtual reality |
| DFT | Discrete Fourier transform |
| SIFT | Scale invariant feature transform |
| SURF | Speeded up robust features |
| BRISK | Binary robust invariant scalable keypoints |
| FAST | Features from accelerated segment test |
| BRIEF | Binary robust independent elementary features |
| ORB | Oriented FAST and Rotated BRIEF |
| GIFT | Group invariant feature transform |
| TERA | Transparency, efficiency, robustness and adaptability |
| RST | Rotation, scaling, and translation |
| JPEG | Joint photographic experts group |
| CP | CANDECOMP/PARAFAC |
| FCNN | Fully convolutional neural network |
References
- Andalibi, M.; Chandler, D. Digital image watermarking via adaptive logo texturization. IEEE Trans. Image Process. 2015, 24, 5060–5073. [Google Scholar] [CrossRef]
- Zareian, M.; Tohidypour, H.R. A novel gain invariant quantization based watermarking approach. IEEE Trans. Inf. Forensics Secur. 2014, 9, 1804–1813. [Google Scholar] [CrossRef]
- Farid, H. Digital image forensics. Sci. Am. 2008, 298, 66–71. [Google Scholar] [CrossRef] [PubMed]
- Kang, X.; Huang, J.; Zeng, W. Efficient General Print-Scanning Resilient Data Hiding Based on Uniform Log-Polar Mapping. IEEE Trans. Inf. Forensics Secur. 2010, 5, 1–12. [Google Scholar] [CrossRef]
- Tang, Y.L.; Huang, Y.T. Print-and-Scan Resilient Watermarking for Authenticating Paper-Based Certificates. In Proceedings of the 2010 First International Conference on Pervasive Computing, Signal Processing and Applications, Harbin, China, 17–19 September 2010; pp. 357–361. [Google Scholar]
- Lee, S.H.; Kim, W.G.; Seo, Y.S. Image fingerprinting scheme for print-and-capture attacking model. In Advances in Multimedia Information Processing—PCM 2006; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2006; Volume 4261, pp. 733–734. [Google Scholar]
- Tancik, M.; Mildenhall, B.; Ren, N. StegaStamp: Invisible Hyperlinks in Physical Photographs. In Proceedings of the Computer Vision and Pattern Recognition, Glasgow, UK, 23–28 August 2020; pp. 2114–2123. [Google Scholar]
- Piec, M.; Rauber, M. Real-time screen watermarking using overlaying layer. In Proceedings of the Ninth International Conference on Availability, Reliability and Security, Fribourg, Switzerland, 8–12 October 2014; pp. 561–570. [Google Scholar]
- Fang, H.; Zhang, W.; Zhou, H.; Cui, H.; Yu, N. Screen-Shooting Resilient Watermarking. IEEE Trans. Inf. Forensics Secur. 2019, 14, 1403–1418. [Google Scholar] [CrossRef]
- Gugelmann, D. Screen watermarking for data theft investigation and attribution. In Proceedings of the 10th International Conference on Cyber Conflict, Tallinn, Estonia, 30 May–1 June 2018. [Google Scholar]
- Cui, H.; Bian, H.; Zhang, W.; Yu, N. UnseenCode: Invisible On-screen Barcode with Image-based Extraction. In Proceedings of the IEEE Conference on Computer Communications Workshops, Paris, France, 29 April–2 May 2019; pp. 963–964. [Google Scholar]
- Nakamura, T.; Katayama, A.; Yamamuro, M. Fast Watermark Detection Scheme from Analog Image for Camera-Equipped Cellular Phone. IEICE Trans. Inf. Syst. Pt. 2004, 87, 2145–2155. [Google Scholar]
- Nakamura, T.; Katayama, A.; Yamamuro, M. New high-speed frame detection method: Side Trace Algorithm (STA) for i-appli on cellular phones to detect watermarks. In Proceedings of the 3rd International Conference on Mobile and Ubiquitous Multimedia, College Park, MD, USA, 27–29 October 2004; pp. 109–116. [Google Scholar]
- Pramila, A.; Keskinarkaus, A.; SeppNen, T. Toward an interactive poster using digital watermarking and a mobile phone camera. Signal Image Video Process. 2012, 6, 211–222. [Google Scholar] [CrossRef]
- Delgado-Guillen, L.A.; Garcia-Hernandez, J.J.; Torres-Huitzil, C. Digital watermarking of color images utilizing mobile platforms. In Proceedings of the IEEE International Midwest Symposium on Circuits & Systems, Columbus, OH, USA, 4–7 August 2013. [Google Scholar]
- Zhang, L.; Chen, C.; Mow, W.H. Accurate Modeling and Efficient Estimation of the Print-Capture Channel with Application in Barcoding. IEEE Trans. Image Process. 2019, 28, 464–478. [Google Scholar] [CrossRef]
- Fang, H.; Chen, D.; Wang, F. TERA: Screen-to-Camera Image Code with Transparency, Efficiency, Robustness and Adaptability. IEEE Trans. Multimed. 2021, 99, 1. [Google Scholar]
- Low, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Se, S.; Lowe, D.; Little, J. Vision-based mobile robot localization and mapping using scale-invariant features. In Proceedings of the 2001 ICRA IEEE International Conference on Robotics and Automation, Taipei, Taiwan, 14–19 September 2003; Volume 2, pp. 2051–2058. [Google Scholar]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the IEEE International Conference on Computer Vision, Corfu, Greece, 20–25 September 1999; Volume 2, pp. 1150–1157. [Google Scholar]
- Mikolajczyk, K.; Schmid, C. An affine invariant interest point detector. In Proceedings of the ECCV, Copenhagen, Denmark, 28–31 May 2002; Volume 1, p. E1973. [Google Scholar]
- Mikolajczyk, K.; Schmid, C. Scale & Affine Invariant Interest Point Detectors. Int. J. Comput. Vis. 2004, 60, 63–86. [Google Scholar]
- Brown, M.; Lowe, D. Recognising panoramas. In Proceedings of the IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003; pp. 1218–1227. [Google Scholar]
- Harris, C.; Stephens, M. A Combined Corner and Edge Detector. In Proceedings of the Alvey Vision Conference, Manchester, UK, 31 August–2 September 1988; pp. 147–151. [Google Scholar]
- Leutenegger, S.; Chli, M.; Siegwart, R.Y. BRISK: Binary Robust invariant scalable keypoints. In Proceedings of the International Conference on Computer Vision IEEE, Barcelona, Spain, 6–13 November 2011; pp. 2548–2555. [Google Scholar]
- Rosten, E. Machine learning for very high-speed corner detection. In Proceedings of the ECCV, Graz, Austria, 7–13 May 2006; pp. 430–443. [Google Scholar]
- Calonder, M.; Lepetit, V.; Strecha, C.; Fua, P. BRIEF: Binary Robust Independent Elementary Features. In Proceedings of the ECCV, Crete, Greece, 5–11 September 2010; pp. 778–792. [Google Scholar]
- Brown, M.; Szeliski, R.; Winder, S. Multi-image matching using multi-scale oriented patches. In Proceedings of the CVPR, San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 510–517. [Google Scholar]
- Yi, K.M.; Trulls, E.; Lepetit, V.; Fua, P. LIFT: Learned Invariant Feature Transform. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Verdie, Y.; Yi, K.M.; Fua, P.; Lepetit, V. TILDE: A Temporally Invariant Learned DEtector. In Proceedings of the CVPR, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Han, X.; Leung, T.; Jia, Y.; Sukthankar, R.; Berg, A.C. MatchNet: Unifying Feature and Metric Learning for Patch-Based Matching. In Proceedings of the CVPR, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Learning to Compare Image Patches via Convolu-tional Neural Networks. In Proceedings of the CVPR, Boston, MA, USA, 7–12 June 2015; pp. 4353–4361. [Google Scholar]
- Yi, K.M.; Verdie, Y.; Fua, P.; Lepetit, V. Learning to Assign Orientations to FeaturePoints. In Proceedings of the CVPR, Las Vegas, NV, USA, 27–30 June 2016; pp. 107–116. [Google Scholar]
- Simo-Serra, E.; Trulls, E.; Ferraz, L.; Kokkinos, I.; Fua, P.; Moreno-Noguer, F. Discriminative Learning of Deep Convolutional Feature Point Descriptors. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), 7–13 December 2015. pp. 118–126.
- Liu, Y.; Shen, Z.; Lin, Z.; Peng, S.; Bao, H.; Zhou, X. GIFT: Learning Transformation-Invariant Dense Visual Descriptors via Group CNNs. In Proceedings of the CVPR, Long Beach, CA, USA, 16 November 2019. [Google Scholar]
- Ono, Y.; Trulls, E.; Fua, P.; Yi, K.M. LF-Net: Learning Local Features from Images. arXiv 2018, arXiv:1805.09662. [Google Scholar]
- Detone, D.; Malisiewicz, T.; Rabinovich, A. SuperPoint: Self-Supervised Interest Point Detection and Description. In Proceedings of the CVPRW, Salt Lake City, UT, USA, 8–22 June 2018. [Google Scholar]
- Lai, C.C. Digital image watermarking using discrete wavelet transform and singular value decomposition. IEEE Trans. Instrum. Meas. 2010, 59, 3060–3063. [Google Scholar] [CrossRef]
- Tsui, T.K.; Zhang, X.P.; Androutsos, D. Color image watermarking using the spatio-chromatic fourier transform. In Proceedings of the IEEE International Conference on Acoustics Speech and Signal Processing Proceedings, Toulouse, France, 14–19 May 2006; Volume 2, p. II. [Google Scholar]
- Barni, M.; Bartolini, F.; Piva, A. Multichannel watermarking of color images. In Proceedings of the CVPR, Copenhagen, Denmark, 28–31 May 2002; Volume 12, pp. 142–156. [Google Scholar]
- Chen, B.; Coatrieux, G.; Chen, G.; Sun, X.; Coatrieux, J.L.; Shu, H. Full 4-D quaternion discrete Fourier transform based watermarking for color images. Digit. Signal Process. 2014, 28, 106–119. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.; Wang, X.; Zhang, C.; Xia, Z. Geometric correction based color image watermarking using fuzzy least squares support vector machine and Bessel K form distribution. Signal Process. 2017, 134, 197–208. [Google Scholar] [CrossRef]
- Xu, H.; Jiang, G.; Mei, Y.; Luo, T. A Color Image Watermarking Based on Tensor Analysis. IEEE Access 2018, 99, 1. [Google Scholar] [CrossRef]
- Li, L.; Boulware, D. High-order tensor decomposition for large-scale data analysis. In Proceedings of the IEEE International Congress on Big Data IEEE Computer Society, Santa Clara, CA, USA, 29 October–1 November 2015; pp. 665–668. [Google Scholar]
- Cao, X.; Wei, X.; Han, Y.; Lin, D. Robust face clustering via tensor decomposition. IEEE Trans. Cybern. 2015, 45, 2546–2557. [Google Scholar] [CrossRef]
- Fang, H.; Zhang, W.; Ma, Z.; Zhou, H.; Yu, N. A Camera Shooting Resilient Watermarking Scheme for Underpainting Documents. IEEE Trans. Circuits Syst. Video Technol. 2019, 99, 4075–4089. [Google Scholar] [CrossRef]
- Moxey, C.; Sangwine, S.; Ell, T. Color-grayscale image registration using hypercomplex phase correlation. In Proceedings of the 2002 IEEE International Conference on Image Processing, New York, NY, USA, 22–25 September 2002; Volume 3, pp. 247–250. [Google Scholar]
- Wang, X.; Wang, C.; Yang, H.; Niu, P. A robust blind color image watermarking in quaternion Fourier transform domain. J. Syst. Softw. 2013, 86, 255–277. [Google Scholar] [CrossRef]
- Tucker, L.R. Implications of factor analysis of three-way matrices for measurement of change. Probl. Meas. Chang. 1963, 15, 122–137. [Google Scholar]
- Kolda, T.G.; Bader, B.W. Tensor Decompositions and Applications. SIAM Rev. 2009, 51, 455–500. [Google Scholar] [CrossRef]
- Li, L.; Bai, R.; Lu, J.; Zhang, S.; Ching, C. A Watermarking Scheme for Color Image Using Quaternion Discrete Fourier Transform and Tensor Decomposition. Appl. Sci. 2021, 11, 5006. [Google Scholar] [CrossRef]
- Li, L.; Bai, R.; Zhang, S.; Zhou, Q. A Robust Watermarking Algorithm for Video Game Artwork Based on Pose Estimation Neural Network. Adv. Artif. Intell. Secur. 2021, 1424, 217–229. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Watermark Strength | Perception Rate (25) | ||||
|---|---|---|---|---|---|
| image 1 | image 2 | image 3 | image 4 | image 5 | |
| 10 | 0/25 | 0/25 | 0/25 | 0/25 | 0/25 |
| 30 | 0/25 | 0/25 | 0/25 | 0/25 | 0/25 |
| 60 | 0/25 | 0/25 | 0/25 | 0/25 | 0/25 |
| 100 | 0/25 | 0/25 | 0/25 | 0/25 | 0/25 |
| 120 | 6/25 | 9/25 | 8/25 | 8/25 | 12/25 |
| 150 | 15/25 | 14/25 | 12/25 | 14/25 | 15/25 |
| 180 | 25/25 | 25/25 | 25/25 | 25/25 | 25/25 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, L.; Bai, R.; Zhang, S.; Chang, C.-C.; Shi, M. Screen-Shooting Resilient Watermarking Scheme via Learned Invariant Keypoints and QT. Sensors 2021, 21, 6554. https://doi.org/10.3390/s21196554
Li L, Bai R, Zhang S, Chang C-C, Shi M. Screen-Shooting Resilient Watermarking Scheme via Learned Invariant Keypoints and QT. Sensors. 2021; 21(19):6554. https://doi.org/10.3390/s21196554
Chicago/Turabian StyleLi, Li, Rui Bai, Shanqing Zhang, Chin-Chen Chang, and Mengtao Shi. 2021. "Screen-Shooting Resilient Watermarking Scheme via Learned Invariant Keypoints and QT" Sensors 21, no. 19: 6554. https://doi.org/10.3390/s21196554
APA StyleLi, L., Bai, R., Zhang, S., Chang, C.-C., & Shi, M. (2021). Screen-Shooting Resilient Watermarking Scheme via Learned Invariant Keypoints and QT. Sensors, 21(19), 6554. https://doi.org/10.3390/s21196554