
Image Generation for 2D-CNN Using Time-Series Signal Features from Foot Gesture Applied to Select Cobot Operating Mode

 ,
,  ,
,
Abstract
:1. Introduction
2. Related Work
2.1. Third-Hand Cobot
2.2. Use of Human Gesture as Command Center
2.3. Gesture Recognition Methods
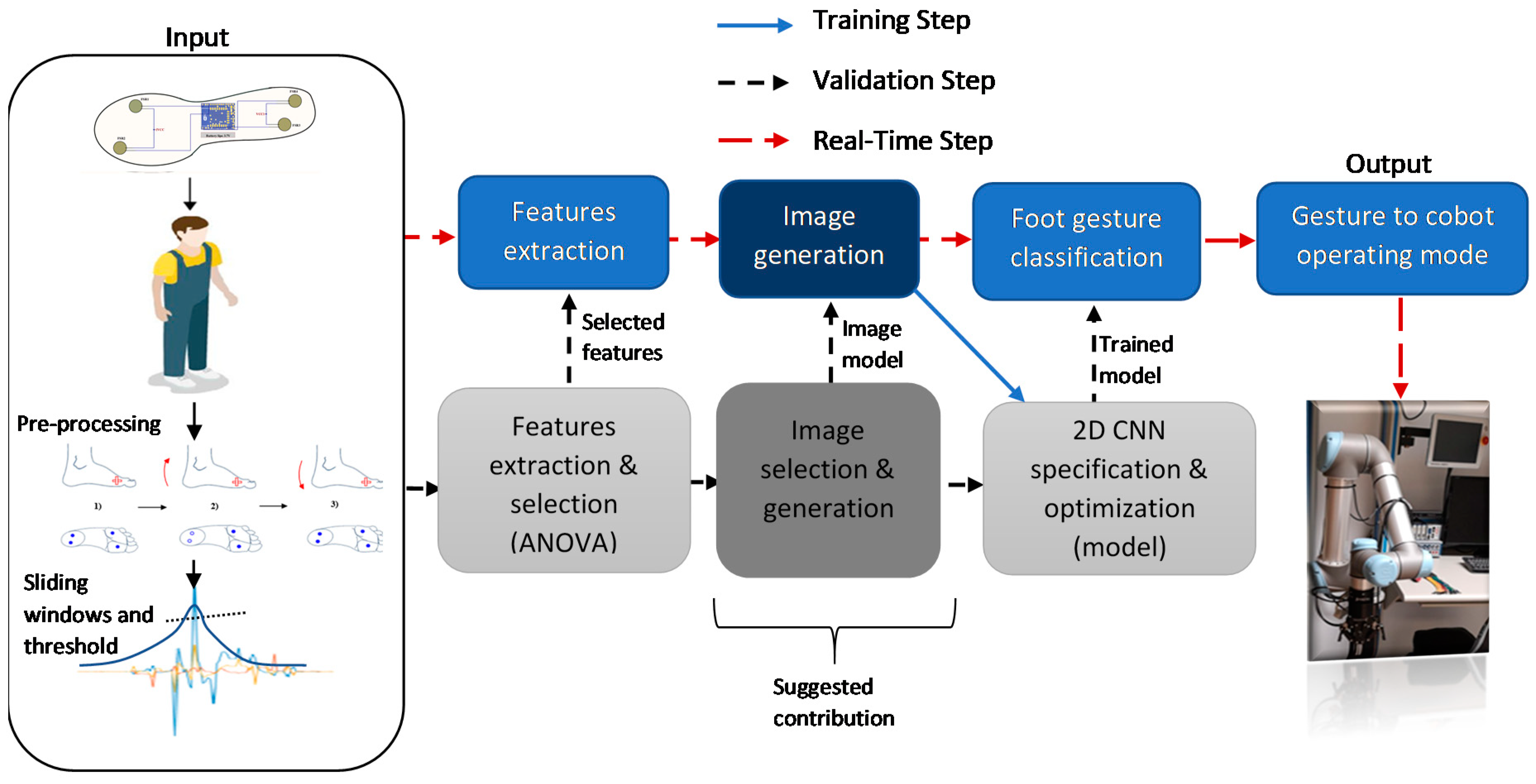
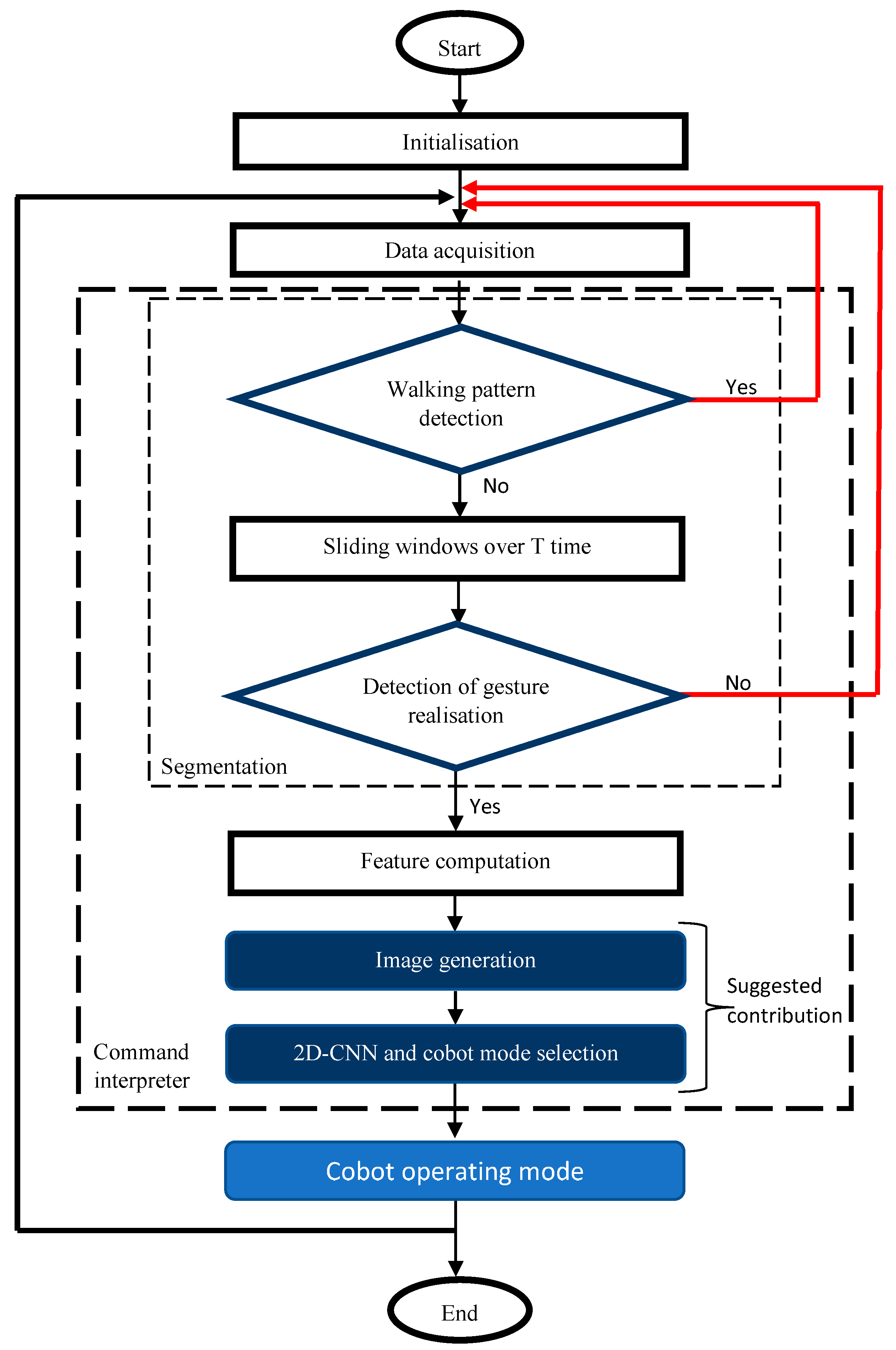
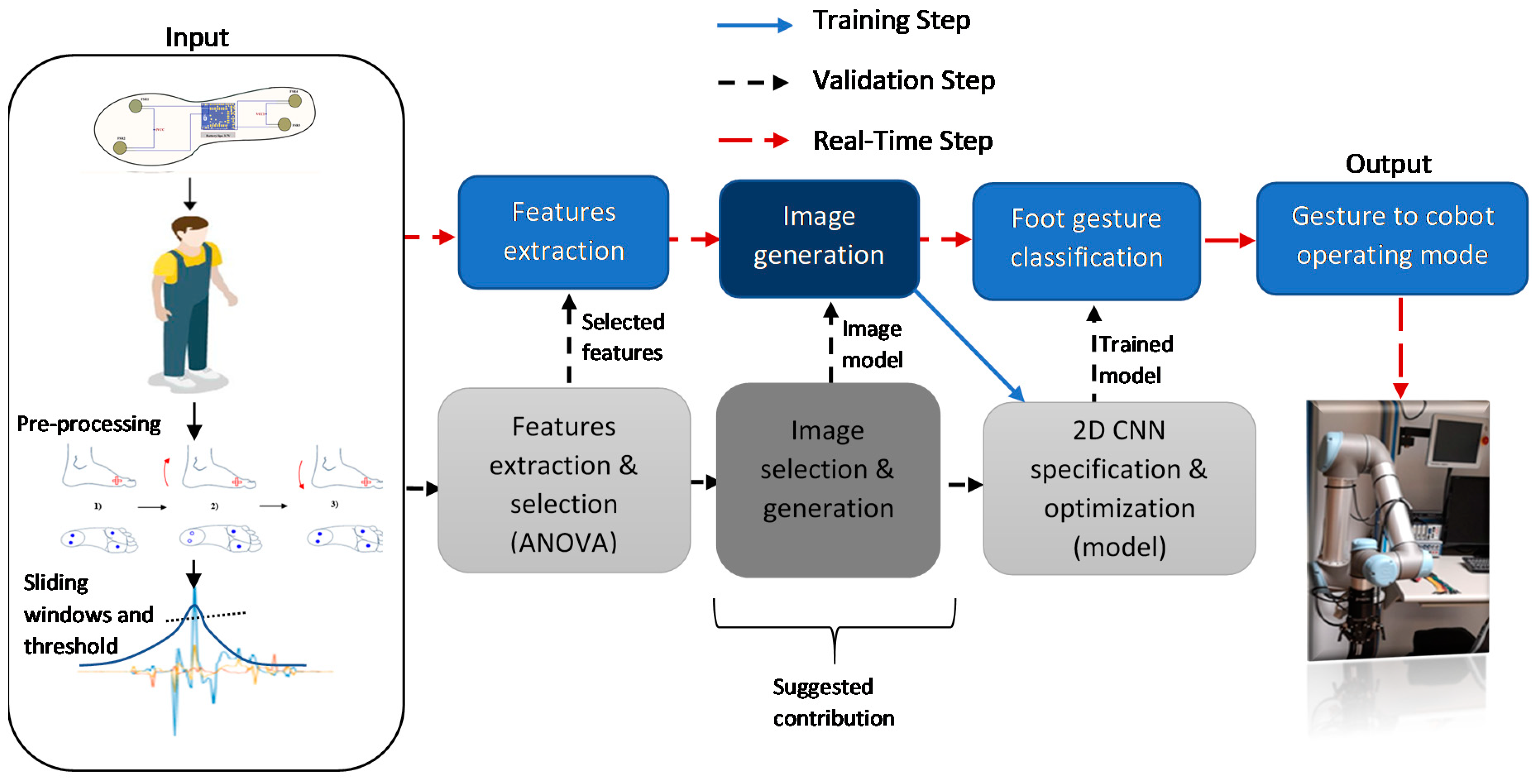
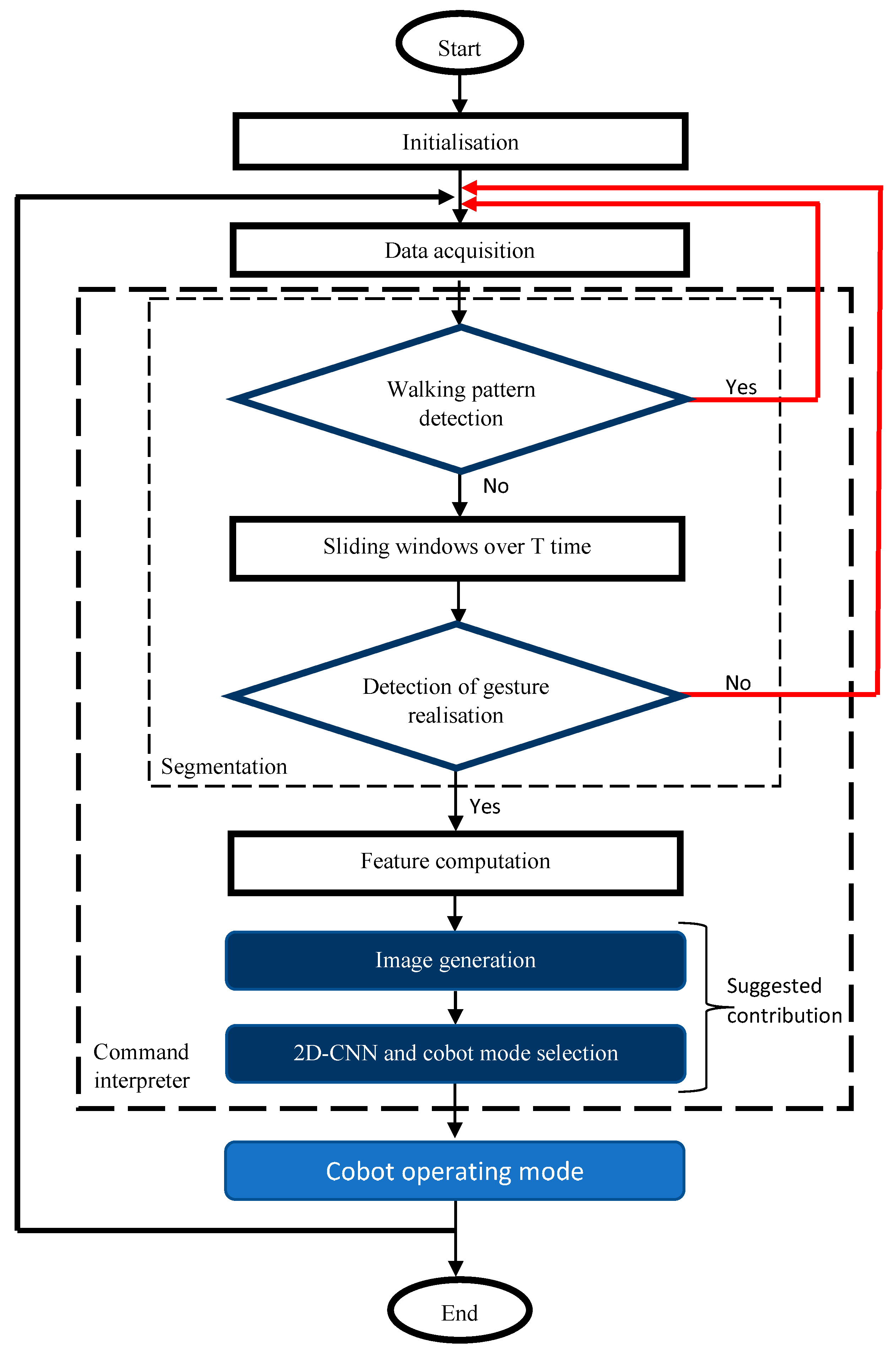
3. Materials and Methods
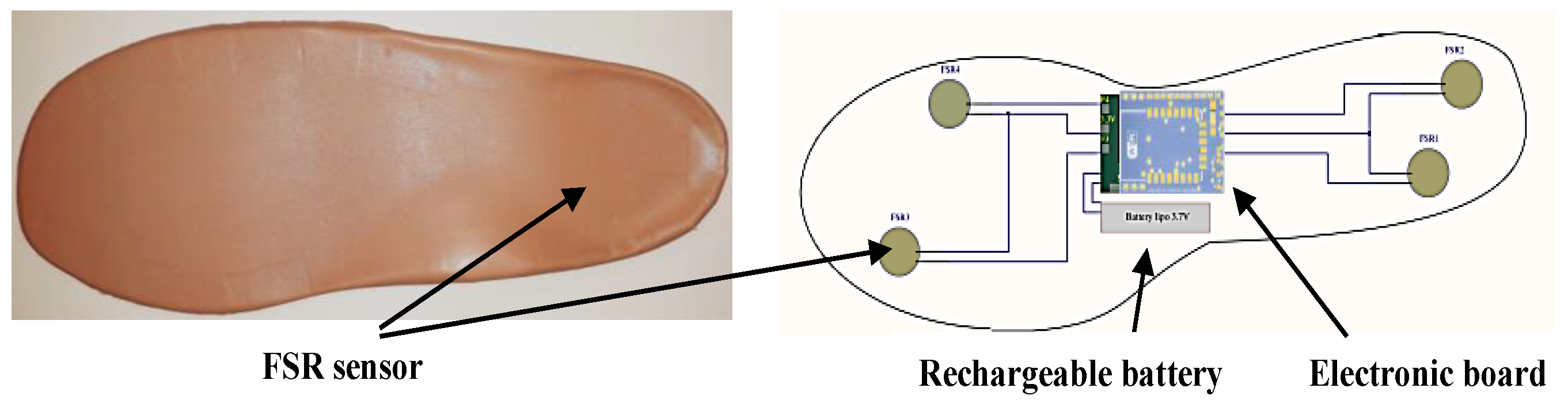
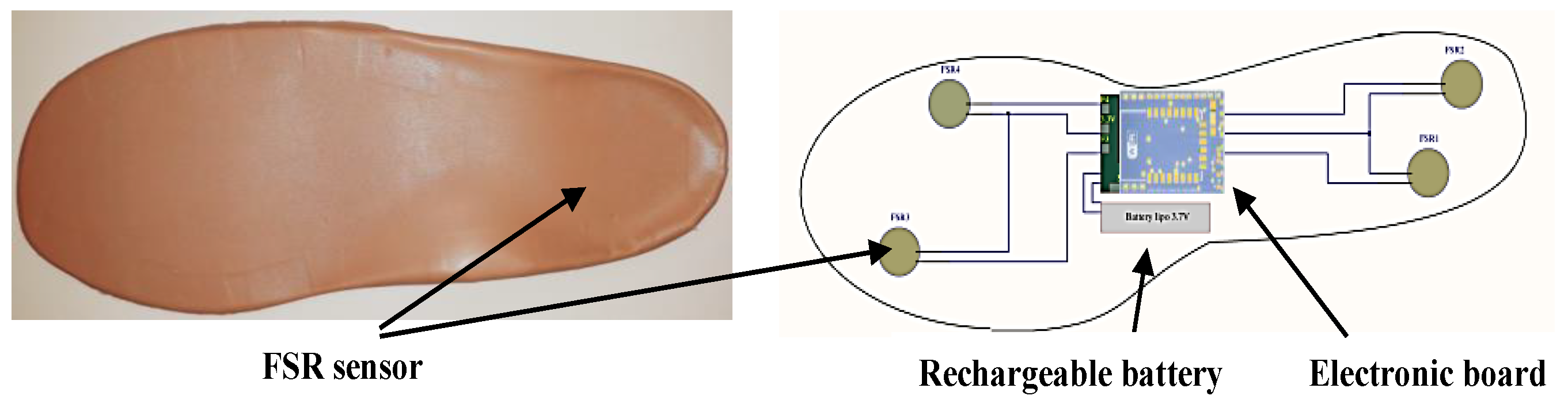
3.1. Instrumented Insole
3.2. Foot-Based Command: Gesture Dictionnaries
3.3. Data Acquisition and Features Selection
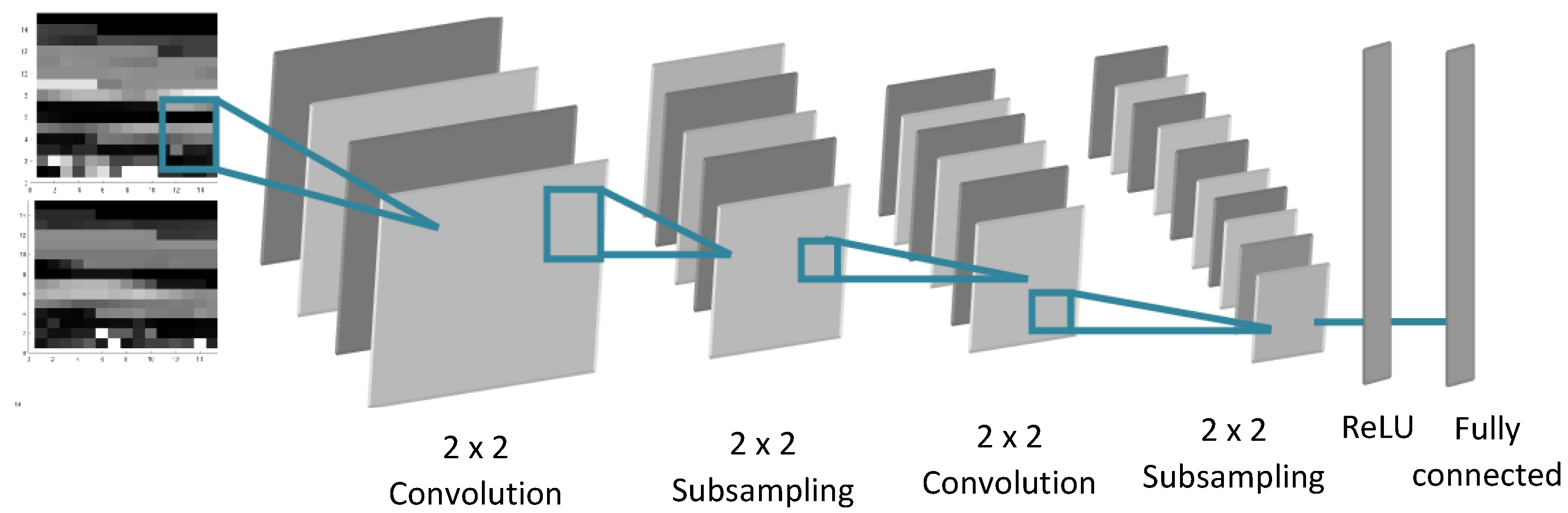
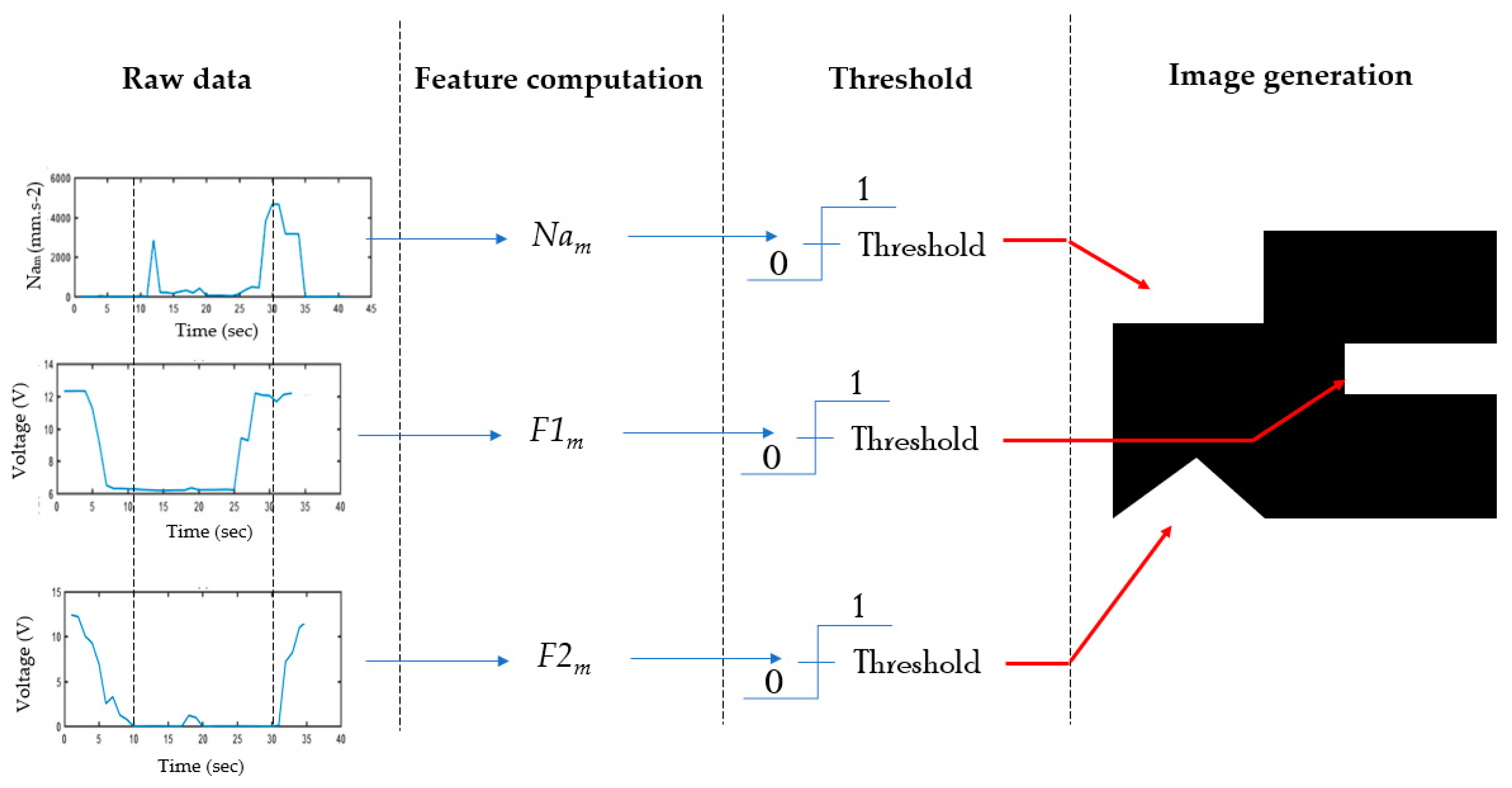
3.3.1. 2D-CNN Image Generation
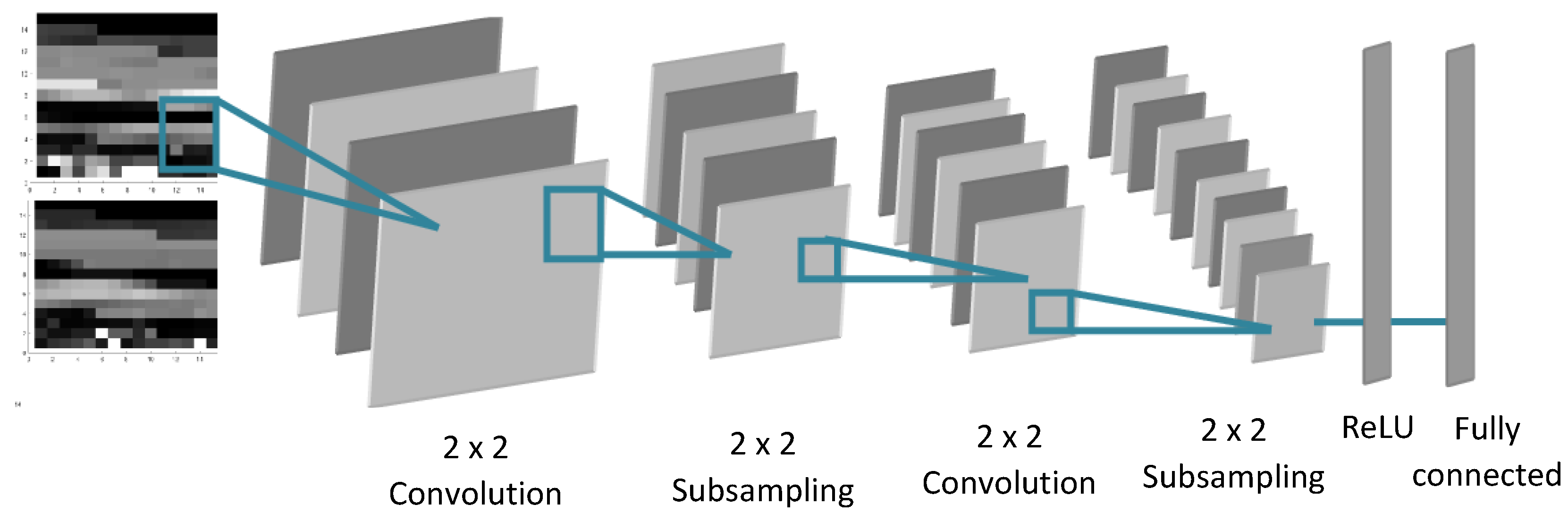
3.3.2. 2D-CNN Classification Method
4. Results
5. Limit of the Study
6. Conclusions and Future Works
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- ReferencesKrüger, J.; Lien, T.K.; Verl, A. Cooperation of human and machines in assembly lines. CIRP Ann. 2009, 58, 628–646. [Google Scholar]
- Matthias, B.; Kock, S.; Jerregard, H.; Källman, M.; Lundberg, I. Safety of collaborative industrial robots: Certification possibilities for a collaborative assembly robot concept. In Proceedings of the 2011 IEEE International Symposium on Assembly and Manufacturing (ISAM), Tampere, Finland, 25–27 May 2011; pp. 1–6. [Google Scholar]
- Safeea, M.; Neto, P.; Bearee, R. On-line collision avoidance for collaborative robot manipulators by adjusting off-line generated paths: An industrial use case. Robot. Auton. Syst. 2019, 119, 278–288. [Google Scholar] [CrossRef] [Green Version]
- Ende, T.; Haddadin, S.; Parusel, S.; Wüsthoff, T.; Hassenzahl, M.; Albu-Schäffer, A. A human-centered approach to robot gesture based communication within collaborative working processes. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Francisco, CA, USA, 25–30 September 2011; pp. 3367–3374. [Google Scholar]
- Juang, J.G.; Tsai, Y.J.; Fan, Y.W. Visual recognition and its application to robot arm control. Appl. Sci. 2015, 5, 851–880. [Google Scholar] [CrossRef]
- Jiang, W.; Ye, X.; Chen, R.; Su, F.; Lin, M.; Ma, Y.; Huang, S. Wearable on-device deep learning system for hand gesture recognition based on FPGA accelerator. Math. Biosci. Eng. 2020, 18, 132–153. [Google Scholar]
- Crossan, A.; Brewster, S.; Ng, A. Foot tapping for mobile interaction. In Proceedings of the 24th BCS Interaction Specialist Group Conference (HCI 2010 24), Dundee, UK, 6–10 September 2010; pp. 418–422. [Google Scholar]
- Valkov, D.; Steinicke, F.; Bruder, G.; Hinrichs, K.H. Traveling in 3d virtual environments with foot gestures and a multi-touch enabled wim. In Proceedings of the Virtual reality International Conference (VRIC 2010), Laval, France, 7–9 April 2010; pp. 171–180. [Google Scholar]
- Hua, R.; Wang, Y. A Customized Convolutional Neural Network Model Integrated with Acceleration-Based Smart Insole Toward Personalized Foot Gesture Recognition. IEEE Sens. Lett. 2020, 4, 1–4. [Google Scholar] [CrossRef]
- Peshkin, M.A.; Colgate, J.E.; Wannasuphoprasit, W.; Moore, C.A.; Gillespie, R.B.; Akella, P. Cobot architecture. IEEE Trans. Robot. Autom. 2001, 17, 377–390. [Google Scholar] [CrossRef]
- Meziane, R.; Li, P.; Otis, M.J.-D.; Ezzaidi, H.; Cardou, P. Safer Hybrid Workspace Using Human-Robot Interaction While Sharing Production Activities. In Proceedings of the 2014 IEEE International Symposium on Robotic and Sensors Environments (ROSE), Timisoara, Romania, 16–18 October 2014; pp. 37–42. [Google Scholar]
- Neto, P.; Simão, M.; Mendes, N.; Safeea, M. Gesture-based human-robot interaction for human assistance in manufacturing. Int. J. Adv. Manuf. Technol. 2019, 101, 119–135. [Google Scholar] [CrossRef]
- Maeda, G.J.; Neumann, G.; Ewerton, M.; Lioutikov, R.; Kroemer, O.; Peters, J. Probabilistic movement primitives for coordination of multiple human–robot collaborative tasks. Auton. Robot. 2017, 41, 593–612. [Google Scholar] [CrossRef] [Green Version]
- Lopes, M.; Peters, J.; Piater, J.; Toussaint, M.; Baisero, A.; Busch, B.; Erkent, O.; Kroemer, O.; Lioutikov, R.; Maeda, G. Semi-Autonomous 3rd-Hand Robot. Robot. Future Manuf. Scenar. 2015, 3. [Google Scholar]
- Bischoff, R.; Kurth, J.; Schreiber, G.; Koeppe, R.; Albu-Schäffer, A.; Beyer, A.; Eiberger, O.; Haddadin, S.; Stemmer, A.; Grunwald, G. The KUKA-DLR Lightweight Robot arm-a new reference platform for robotics research and manufacturing. In Proceedings of the Robotics (ISR), 2010 41st International Symposium on and 2010 6th German Conference on Robotics (ROBOTIK), Munich, Germany, 7–9 June 2010; pp. 1–8. [Google Scholar]
- Sasaki, T.; Saraiji, M.; Fernando, C.L.; Minamizawa, K.; Inami, M. MetaLimbs: Multiple arms interaction metamorphism. In Proceedings of the ACM SIGGRAPH, Emerging Technologies, Los Angeles, CA, USA, 30 July–3 August 2017; p. 16. [Google Scholar]
- Fleming, I.; Balicki, M.; Koo, J.; Iordachita, I.; Mitchell, B.; Handa, J.; Hager, G.; Taylor, R. Cooperative robot assistant for retinal microsurgery. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, New York, NY, USA, 6–10 September 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 543–550. [Google Scholar]
- Faria, D.R.; Vieira, M.; Faria, F.C.; Premebida, C. Affective facial expressions recognition for human-robot interaction. In Proceedings of the 2017 26th IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN), Lisbon, Portugal, 28 August–1 September 2017; IEEE: New York, NY, USA, 2017; pp. 805–810. [Google Scholar]
- Putro, M.D.; Jo, K.H. Real-time face tracking for human-robot interaction. In Proceedings of the 2018 International Conference on Information and Communication Technology Robotics (ICT-ROBOT), Busan, Korea, 6–8 September 2018; IEEE: New York, NY, USA, 2018; pp. 1–4. [Google Scholar]
- Lakomkin, E.; Zamani, M.A.; Weber, C.; Magg, S.; Wermter, S. On the robustness of speech emotion recognition for human-robot interaction with deep neural networks. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; IEEE: New York, NY, USA, 2018; pp. 854–860. [Google Scholar]
- Fan, M.; Ding, Y.; Shen, F.; You, Y.; Yu, Z. An empirical study of foot gestures for hands-occupied mobile interaction. In Proceedings of the 2017 ACM International Symposium on Wearable Computers, Maui, HI, USA, 11–15 September 2017; pp. 172–173. [Google Scholar]
- Kim, T.; Blum, J.R.; Alirezaee, P.; Arnold, A.G.; Fortin, P.E.; Cooperstock, J.R. Usability of foot-based interaction techniques for mobile solutions. In Mobile Solutions and Their Usefulness in Everyday Life; Springer: Cham, Switzerland, 2019; pp. 309–329. [Google Scholar]
- Maragliulo, S.; LOPES, P.F.A.; Osório, L.B.; De Almeida, A.T.; Tavakoli, M. Foot gesture recognition through dual channel wearable EMG System. IEEE Sens. J. 2019, 19, 10187–10197. [Google Scholar] [CrossRef]
- CoupetÈ, E.; Moutarde, F.; Manitsaris, S. Gesture Recognition Using a Depth Camera for Human Robot Collaboration on Assembly Line. Procedia Manuf. 2015, 3, 518–525. [Google Scholar] [CrossRef]
- Calinon, S.; Billard, A. Stochastic gesture production and recognition model for a humanoid robot. In Proceedings of the 2004 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Sendai, Japan, 28 September–2 October 2004; pp. 2769–2774. [Google Scholar]
- Georgi, M.; Amma, C.; Schultz, T. Recognizing Hand and Finger Gestures with IMU based Motion and EMG based Muscle Activity Sensing. In Proceedings of the Biosignals 2015-International Conference on Bio-Inspired Systems and Signal Processing, Lisbon, Portugal, 12–15 January 2015; pp. 99–108. [Google Scholar]
- Zhu, C.; Sheng, W. Wearable sensor-based hand gesture and daily activity recognition for robot-assisted living. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2011, 41, 569–573. [Google Scholar] [CrossRef]
- Mitra, S.; Acharya, T. Gesture recognition: A survey. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2007, 37, 311–324. [Google Scholar] [CrossRef]
- Hartmann, B.; Link, N. Gesture recognition with inertial sensors and optimized DTW prototypes. In Proceedings of the 2010 IEEE International Conference on Systems, Man and Cybernetics, Istanbul, Turkey, 10–13 October 2010; pp. 2102–2109. [Google Scholar]
- Wu, H.; Deng, D.; Chen, X.; Li, G.; Wang, D. Localization and recognition of digit-writing hand gestures for smart TV systems. J. Inf. Comput. Sci. 2014, 11, 845–857. [Google Scholar] [CrossRef]
- Buyssens, P.; Elmoataz, A. Réseaux de neurones convolutionnels multi-échelle pour la classification cellulaire. In Proceedings of the RFIA, Clermond-Ferand, France, 27 June–1 July 2016. [Google Scholar]
- Cho, H.; Yoon, S.M. Divide and conquer-based 1D CNN human activity recognition using test data sharpening. Sensors 2018, 18, 1055. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kiranyaz, S.; Ince, T.; Abdeljaber, O.; Avci, O.; Gabbouj, M. 1-d convolutional neural networks for signal processing applications. In Proceedings of the ICASSP 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; IEEE: New York, NY, USA, 2019; pp. 8360–8364. [Google Scholar]
- Fakhrulddin, A.H.; Fei, X.; Li, H. Convolutional neural networks (CNN) based human fall detection on Body Sensor Networks (BSN) sensor data. In Proceedings of the 2017 4th International Conference on Systems and Informatics (ICSAI), Hangzhou, China, 11–13 November 2017; IEEE: New York, NY, USA, 2017; pp. 1461–1465. [Google Scholar]
- Wang, L.; Peng, M.; Zhou, Q.F. Fall detection based on convolutional neural networks using smart insole. In Proceedings of the 2019 5th International Conference on Control, Automation and Robotics (ICCAR), Beijing, China, 19–22 April 2019; IEEE: New York, NY, USA, 2019. [Google Scholar]
- Li, G.; Tang, H.; Sun, Y.; Kong, J.; Jiang, G.; Jiang, D.; Tao, B.; Xu, S.; Liu, H. Hand gesture recognition based on convolution neural network. Clust. Comput. 2019, 22, 2719–2729. [Google Scholar] [CrossRef]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 221–231. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ha, S.; Choi, S. Convolutional neural networks for human activity recognition using multiple accelerometer and gyroscope sensors. In Proceedings of the 2016 International Joint Conference on Neural Networks, Vancouver, BC, Canada, 24–29 July 2016; pp. 381–388. [Google Scholar]
- Datasheet Mpu9250. Available online: https://www.invensense.com/wp-content/uploads/2015/02/PS-MPU-9250A-01-v1.1.pdf (accessed on 2 March 2017).
- Datasheet ADS1115. Available online: https://cdn-shop.adafruit.com/datasheets/ads1115.pdf (accessed on 11 March 2017).
- Datasheet ESP-12E. Available online: https://www.kloppenborg.net/images/blog/esp8266/esp8266-esp12e-specs.pdf (accessed on 11 March 2017).
- Barkallah, E.; Freulard, J.; Otis, M.J.D.; Ngomo, S.; Ayena, J.C.; Desrosiers, C. Wearable Devices for Classification of Inadequate Posture at Work Using Neural Networks. Sensors 2017, 17, 2003. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Johnson, K.J.; Synovec, R.E. Pattern recognition of jet fuels: Comprehensive GC × GC with ANOVA-based feature selection and principal component analysis. Chemom. Intell. Lab. Syst. 2002, 60, 225–237. [Google Scholar] [CrossRef]
- Wu, C.; Yan, Y.; Cao, Q.; Fei, F.; Yang, D. sEMG measurement position and feature optimization strategy for gesture recognition based on ANOVA and neural networks. IEEE Access 2020, 8, 56290–56299. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
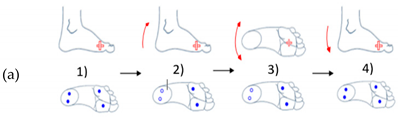
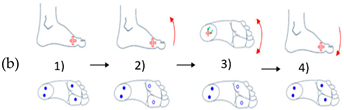
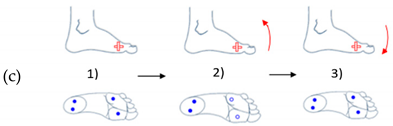
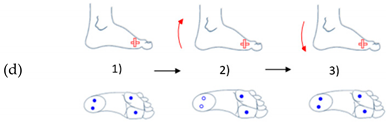
| Movements of Rotation and Translation with Ankle at Center | Movements of Rotation and Translation with Toes at Center | ||
|---|---|---|---|
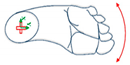 Horizontal movement rotation (with heel as center) |  Vertical movement rotation (with ankle as center) |  Vertical movement rotation (with ankle as center) | 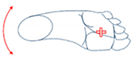 Horizontal movement of rotation (with toes as center) |
 Movement of translation (left/right) | 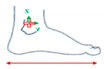 Movement of translation (front/back) | 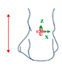 Movement of translation (up/down) |  Vertical movement of rotation (with toes as center) |
| Active or Inactive Force Sensors (FSR) during the Movements | |||
|---|---|---|---|
| 4 FSRs | 2 FSRs | 1 FSR | |
 The four sensors are inactive (foot is not touching the ground) | 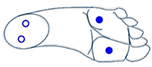 The two sensors at the front are active (foot is inclined forward) | 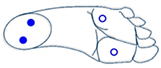 The two sensors at the back are active (foot is inclined backward) | 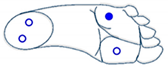 Only the sensor at the front outside is active (foot is inclined front-outward) |
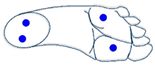 The four sensors are active (foot flat on the ground) | 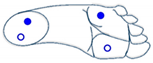 The two outside sensors are active (foot is inclined outwards) | 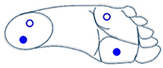 The two inside sensors are active (foot is inclined inwards) |  Only the sensor at the front inside is active (foot is inclined front-inward) |
 |  |
 |  |
 |
| Foot Gesture | Cobot Operating Mode |
|---|---|
| 1. Cigarette crush with the forefoot | Switching to the “third hand” mode |
| 2. Cigarette crush with the heel | Fast trajectory control |
| 3. Tap with the forefoot | Precise trajectory control (Slow) |
| 4. Tap with the heel | Motor-holding by the robot |
| 5. Kick | Stopping the robot |
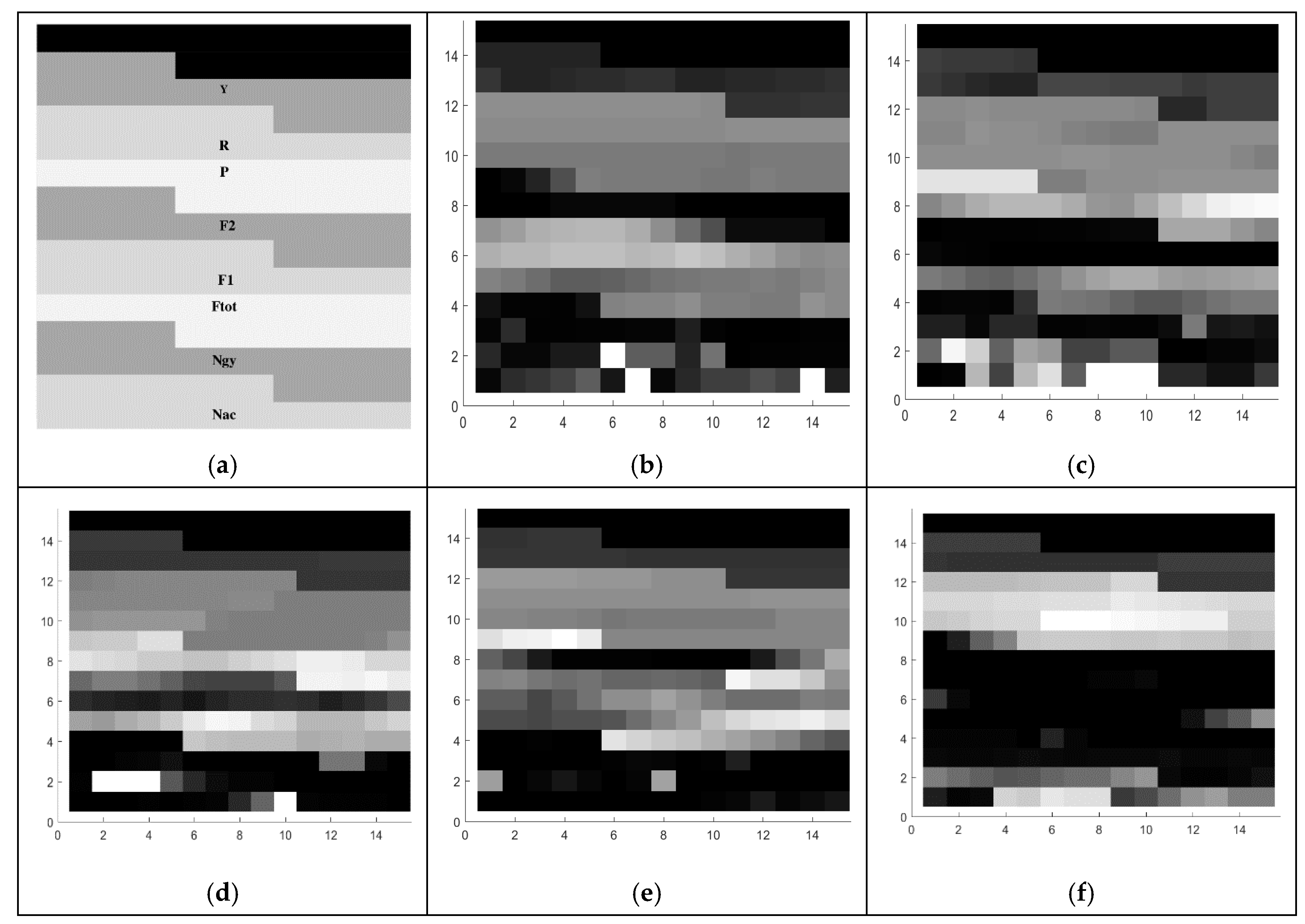
| Signal’s Name | Description | Signal’s Origin |
|---|---|---|
| AcX, AcY, AcZ | Acceleration in the 03 axis (X, Y, Z) | 3-axis accelerometer |
| VaX, VaY, VaZ | Angular velocity in the 03 axis (X, Y, Z) | 3 axis gyroscopes |
| P | Euler’s angle: P (Pitch) | DMP (Digital Motion Processor) |
| R | Euler’s angle: R (Roll) | |
| Y | Euler’s angle: Y (Yaw) | |
| q1, q2, q3, q4 | Quaternions | |
| F1 | Sum of two FSR sensors located at the forefoot | FSR sensors |
| F2 | Sum of two FSR sensors located in the heel | |
| Ftot | Sum of the four FSR sensors |
| Feature’s Name | Description | Signal’s Origin |
|---|---|---|
| Nam | Norm of acceleration | 3-axis accelerometer |
| Ngy | Norm of angular velocity | 3 axis gyroscopes |
| P | Euler’s angle: P (Pitch) | DMP (Digital Motion Processor) |
| R | Euler’s angle: R (Roll) | |
| Y | Euler’s angle: Y (Yaw) | |
| F1 | Sum of two FSR sensors located at the forefoot | FSR sensors |
| F2 | Sum of two FSR sensors located in the heel | |
| Ftot | Sum of the four FSR sensors |
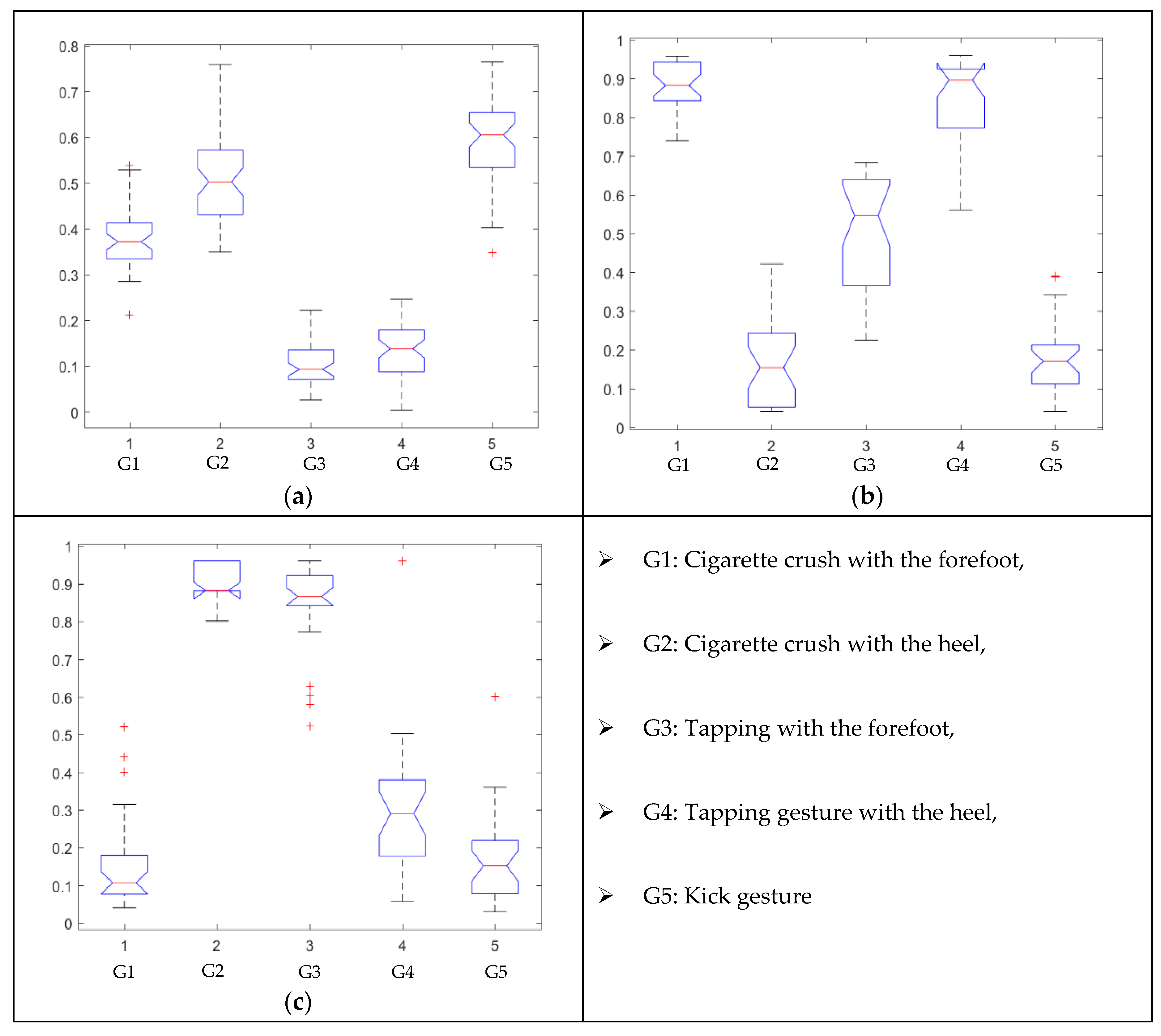
| Gestures | Norm of Acceleration Nam | Norm of Angular Velocity Ngy |
|---|---|---|
| G1 | 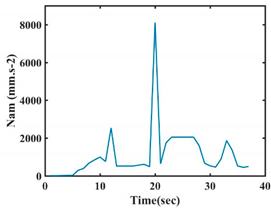 | 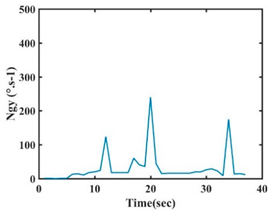 |
| G2 |  |  |
| G3 |  | 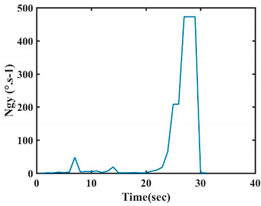 |
| G4 | 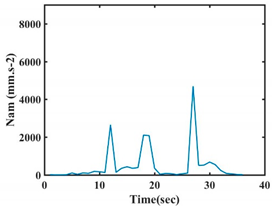 | 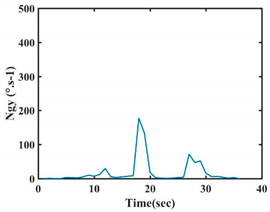 |
| G5 | 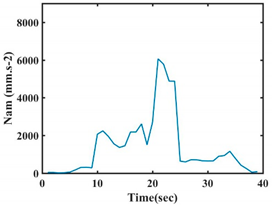 |  |
| Statistical Parameters (Abbreviation) | Mean (m) | Variance (var) | Standard Deviation (td) |
|---|---|---|---|
| Characteristics | AcXm, AcYm, AcZm, Nam | AcXvar, AcYvar, AcZvar | AcXstd, AcYstd, AcZstd |
| VaXm, VaYm, VaZm | VaXvar, VaYvar, VaZvar | VaXstd, VaYstd, VaZstd | |
| Pm, Rm, Ym | Pvar, Rvar, Yvar | Pstd, Rstd, Ystd | |
| q1m, q2m, q3m, q4m | q1var, q2var, q3var, q4var | q1std, q2std, q3std, q4std | |
| F1m, F2m | F1var, F2var | F1std, F2std |
| Statistical Parameters (Abbreviation) | Skewness (Skew) | Kurtosis (Kurt) | Root Mean Square (Rms) |
|---|---|---|---|
| Characteristics | AcXskew, AcYskew, AcZskew | AcXkurt, AcYkurt, AcZkurt | AcXrms, AcYrms, AcZrms |
| VaXskew, VaYskew, VaZskew | VaXkurt, VaYkurt, VaZkurt | VaXrms, VaYrms, VaZrms | |
| Pskew, Rskew, Yskew | Pkurt, Rkurt, Ykurt | Prms, Rrms, Yrms | |
| q1skew, q2skew, q3skew, q4skew | q1kurt, q2kurt, q3kurt, q4kurt | q1rms, q2 rms, q3 rms, q4 rms | |
| F1skew, F2skew | F1kurt, F2kurt | F1rms, F2rms |
| Characteristics | ANOVA (p-Value) | Characteristics | ANOVA (p-Value) | Characteristics | ANOVA (p-Value) |
|---|---|---|---|---|---|
| AcXm | 0.0362 | AcXvar | 9.82089 × 10−9 | AcXstd | 1.48053 × 10−12 |
| AcYm | 0.0037 | AcYvar | 7.0831 × 10−13 | AcYstd | 8.60749 × 10−14 |
| AcZm | 0.1522 | AcZvar | 1.11004 × 10−13 | AcZstd | 7.66846 × 10−15 |
| VaXm | 0.7163 | VaXvar | 0.0006 | VaXstd | 0.0004 |
| VaYm | 4.2743 × 10−5 | VaYvar | 0.0078 | VaYstd | 0.0001 |
| VaZm | 0.6465 | VaZvar | 0.9967 | VaZstd | 3.58713 × 10−6 |
| Pm | 4.70768 × 10−17 | Pvar | 0.0005 | Pstd | 1.15232 × 10−9 |
| Rm | 1.99492 × 10−35 | Rvar | 2.12177 × 10−16 | Rstd | 1.01984 × 10−5 |
| Ym | 0.0006 | Yvar | 0.0008 | Ystd | 2.06642 × 10−9 |
| q1m | 1.44179 × 10−16 | q1var | 6.40077 × 10−11 | q1std | 2.37864 × 10−6 |
| q2m | 2.29963 × 10−19 | q2var | 1.97067 × 10−10 | q2std | 2.38143 × 10−12 |
| q3m | 1.78075 × 10−9 | q3var | 0.048 | q3std | 9.1542 × 10−13 |
| q4m | 1.19374 × 10−7 | q4var | 7.41653 × 10−7 | q4std | 1.13254 × 10−10 |
| F1m | 7.62104 × 10−67 | F1var | 1.52173 × 10−16 | F1std | 1.56796 × 10−12 |
| F2m | 1.64653 × 10−65 | F2var | 3.33183 × 10−17 | F2std | 3.23638 × 10−8 |
| AcXrms | 0.0104 | AcXkurt | 1.54661 × 10−9 | AcXskew | 1.48053 × 10−12 |
| AcYrms | 0.0024 | AcYkurt | 4.18682 × 10−21 | AcYskew | 8.60749 × 10−14 |
| AcZrms | 0.1614 | AcZkurt | 2.44817 × 10−17 | AcZskew | 7.66846 × 10−15 |
| VaXrms | 0.5866 | VaXkurt | 8.66958 × 10−7 | VaXskew | 0.0004 |
| VaYrms | 2.09045 × 10−5 | VaYkurt | 7.08042 × 10−14 | VaYskew | 0.0001 |
| VaZrms | 0.6497 | VaZkurt | 3.37356 × 10−6 | VaZskew | 3.58713 × 10−6 |
| Prms | 1.48031 × 10−13 | Pkurt | 0.0671 | Pskew | 1.15232 × 10−9 |
| Rrms | 0.0618 | Rkurt | 0.5788 | Rskew | 1.01984 × 10−5 |
| Yrms | 0.0003 | Ykurt | 0.1283 | Yskew | 2.06642 × 10−9 |
| q1rms | 3.92505 × 10−13 | q1kurt | 0.0284 | q1skew | 2.37864 × 10−6 |
| q2 rms | 0.1313 | q2kurt | 0.6328 | q2skew | 2.38143 × 10−12 |
| q3 rms | 0.091 | q3kurt | 0.0146 | q3skew | 9.1542 × 10−13 |
| q4 rms | 6.92425 × 10−11 | q4kurt | 0.0152 | q4skew | 1.13254 × 10−10 |
| F1rms | 6.59022 × 10−49 | F1kurt | 1.66156 × 10−7 | F1skew | 1.56796 × 10−12 |
| F2rms | 2.68932 × 10−38 | F2kurt | 5.70291 × 10−5 | F2skew | 3.23638 × 10−8 |
| Nam | 1.49825 × 10−115 |
| Nam | F2m | |
|---|---|---|
| G1 | 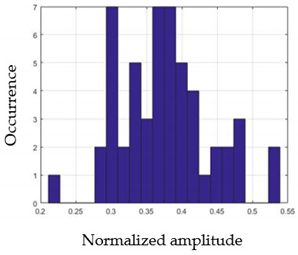 | 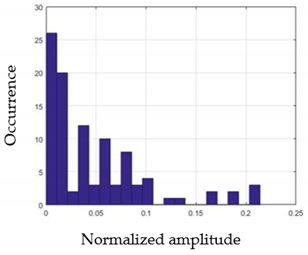 |
| G2 | 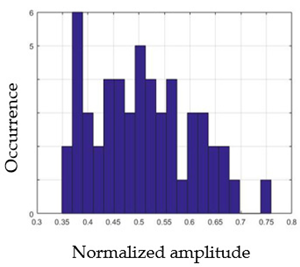 | 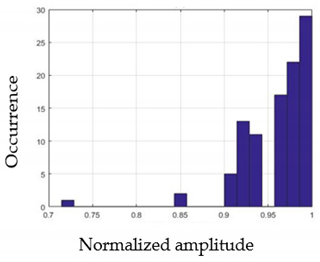 |
| G3 | 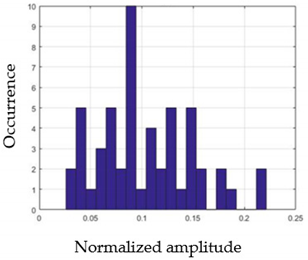 | 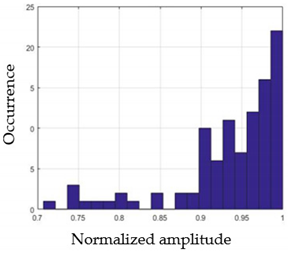 |
| G4 | 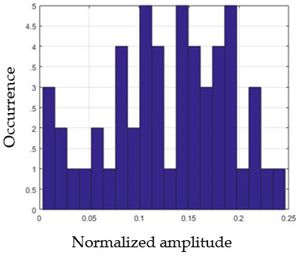 | 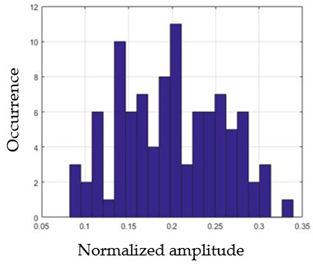 |
| G5 | 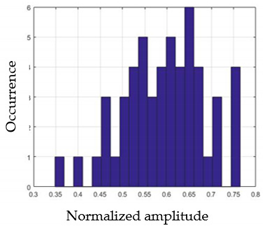 |  |
| G1 | G2 |
 | 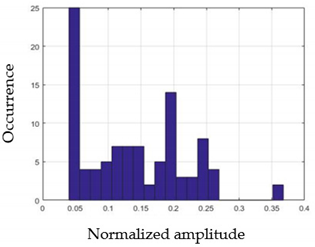 |
| G3 | G4 |
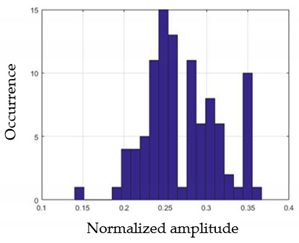 | 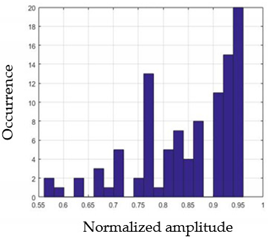 |
| G5 | |
 |
| Mean of the acceleration norm (Nam) | |
| Mean of the sum of two FSR sensors in the forefoot (F1m) | |
| Mean of the sum of two FSR sensors at the heel (F2m) |
| Convolution C1 | Pooling P1 | Convolution C2 | Pooling P2 | ||
|---|---|---|---|---|---|
 (10 neurons on the Fully connected Layer) | Number of convolution Kernel | 5 | / | 15 | / |
| Windows size | 2 × 2 | 2 × 2 | 2 × 2 | 2 × 2 | |
| Input | 15 × 15 | 14 × 14 | 7 × 7 | 6 × 6 | |
| Output | 14 × 14 | 7 × 7 | 6 × 6 | 3 × 3 | |
 (11 neurons on the Fully connected Layer) | Number of convolution Kernel | 7 | / | 17 | / |
| Windows size | 2 × 2 | 2 × 2 | 2 × 2 | 2 × 2 | |
| Input | 11 × 11 | 10 × 10 | 5 × 5 | 4 × 4 | |
| Output | 10 × 10 | 5 × 5 | 4 × 4 | 2 × 2 | |
 (100 neurons on the Fully connected Layer) | Number of convolution Kernel | 10 | / | 10 | / |
| Windows size | 4 × 4 | 2 × 2 | 2 × 2 | 2 × 2 | |
| Input | 9 × 9 | 6 × 6 | 3 × 3 | 2 × 2 | |
| Output | 6 × 6 | 3 × 3 | 2 × 2 | 1 × 1 | |
| Parameters |  |  |  |
| Learning Rate | 0.01 | 0.00019 | 0.005 |
| Momentum Coefficient | 0.6 | 0.899 | 0.9 |
| Images Input | Recognition Rate | Comments |
|---|---|---|
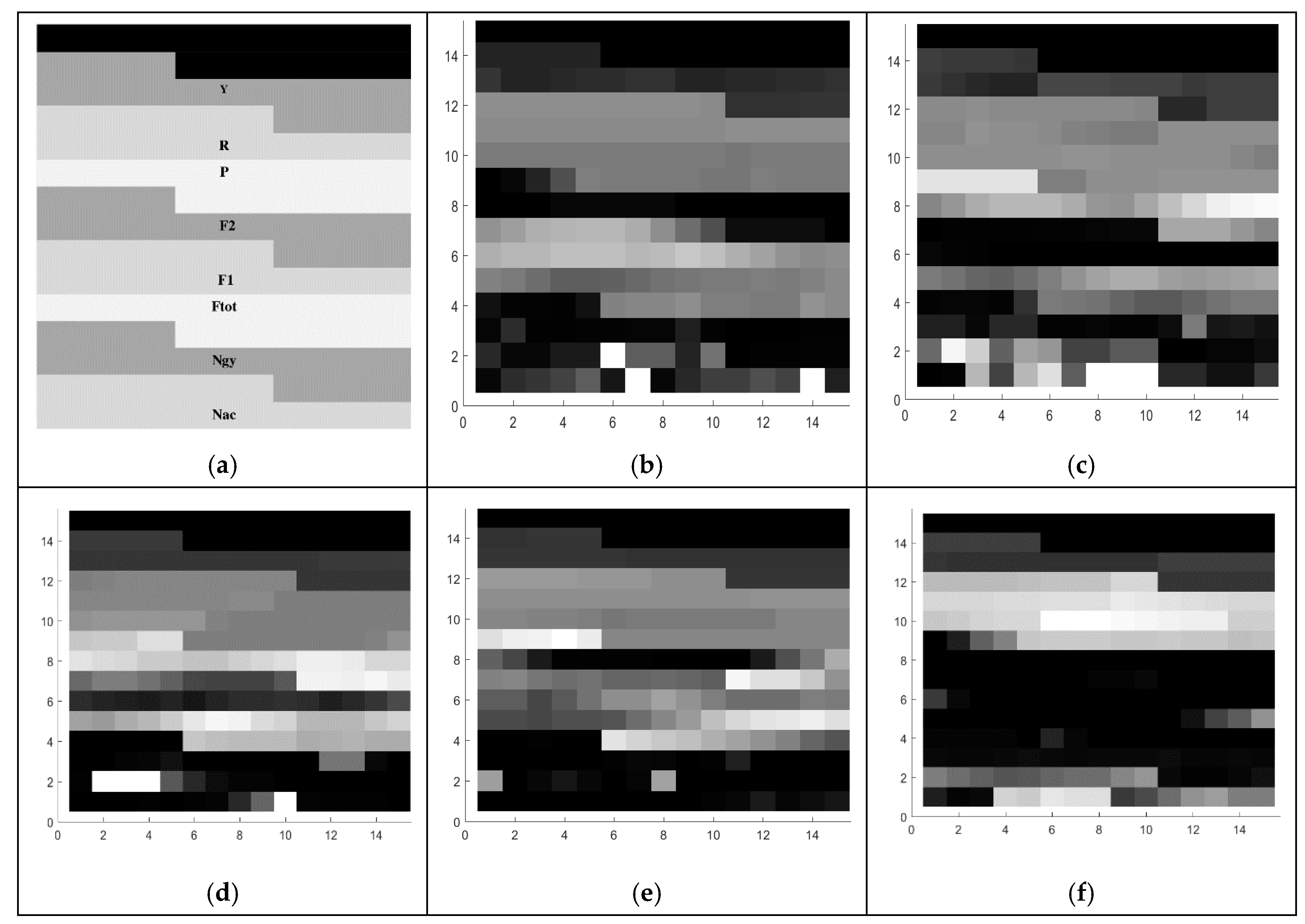
 Image based on temporal analysis | 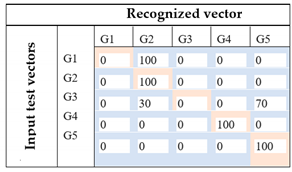 | The recognition rate is about 60%. By exploiting all the 8 features from human observation, only 3 foot gestures are correctly recognized (G2, G4, G5). For gesture recognition, G1 and G2 are recognized as the same gesture. Furthermore, the system could not accurately identify G3 because there is 30% of cases where G3 is classified as G2 and 70% where G3 is classified as G5. |
 Image based on ANOVA features First attempt: (Set of rectangles) | 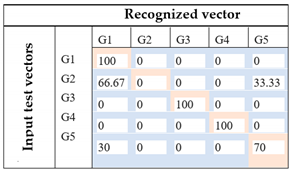 | By using statistical analysis based on ANOVA, the recognition rate appears to be greater than the previous one for about 14%. This set of images based on a spatial representation of selected features using a rectangular form could successfully recognize 3 foot gestures (G1, G3, G4). Furthermore, the system is able to make a clear distinction between G1 and G2. However, there is still some confusion of G2, between G1 and G5, and G5, between G1 and G5, with 66.6%, 33.3%, 30%, and 70%, respectively. |
 Image based on ANOVA features Image based on ANOVA featuresFinal proposition: (Set of rectangles and triangles) | 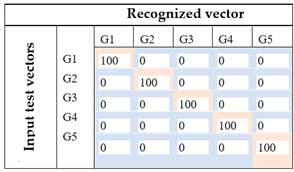 | With the enhancement of the images using ANOVA for selecting feature and the modification of the spatial representation of the features in the images using a set of forms (squares, rectangles, and triangles), the system achieves a 100% of recognition rate. Therefore, each foot gesture is correctly identified. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aswad, F.E.; Djogdom, G.V.T.; Otis, M.J.-D.; Ayena, J.C.; Meziane, R. Image Generation for 2D-CNN Using Time-Series Signal Features from Foot Gesture Applied to Select Cobot Operating Mode. Sensors 2021, 21, 5743. https://doi.org/10.3390/s21175743
Aswad FE, Djogdom GVT, Otis MJ-D, Ayena JC, Meziane R. Image Generation for 2D-CNN Using Time-Series Signal Features from Foot Gesture Applied to Select Cobot Operating Mode. Sensors. 2021; 21(17):5743. https://doi.org/10.3390/s21175743
Chicago/Turabian StyleAswad, Fadwa El, Gilde Vanel Tchane Djogdom, Martin J.-D. Otis, Johannes C. Ayena, and Ramy Meziane. 2021. "Image Generation for 2D-CNN Using Time-Series Signal Features from Foot Gesture Applied to Select Cobot Operating Mode" Sensors 21, no. 17: 5743. https://doi.org/10.3390/s21175743
APA StyleAswad, F. E., Djogdom, G. V. T., Otis, M. J.-D., Ayena, J. C., & Meziane, R. (2021). Image Generation for 2D-CNN Using Time-Series Signal Features from Foot Gesture Applied to Select Cobot Operating Mode. Sensors, 21(17), 5743. https://doi.org/10.3390/s21175743